Single-Frame based Deep View Synchronization for Unsynchronized Multi-Camera Surveillance
Abstract
Multi-camera surveillance has been an active research topic for understanding and modeling scenes. Compared to a single camera, multi-cameras provide larger field-of-view and more object cues, and the related applications are multi-view counting, multi-view tracking, 3D pose estimation or 3D reconstruction, etc. It is usually assumed that the cameras are all temporally synchronized when designing models for these multi-camera based tasks. However, this assumption is not always valid, especially for multi-camera systems with network transmission delay and low frame-rates due to limited network bandwidth, resulting in desynchronization of the captured frames across cameras. To handle the issue of unsynchronized multi-cameras, in this paper, we propose a synchronization model that works in conjunction with existing DNN-based multi-view models, thus avoiding the redesign of the whole model. We consider two variants of the model, based on where in the pipeline the synchronization occurs, scene-level synchronization and camera-level synchronization. The view synchronization step and the task-specific view fusion and prediction step are unified in the same framework and trained in an end-to-end fashion. Our view synchronization models are applied to different DNNs-based multi-camera vision tasks under the unsynchronized setting, including multi-view counting and 3D pose estimation, and achieve good performance compared to baselines.
I Introduction
Compared to single cameras, multi-camera networks allow better understanding and modeling of the 3D world through more dense sampling of information in a 3D scene [1]. Multi-camera based vision tasks have been a popular research field, especially deep learning related tasks, such as 3D pose estimation from multiple 2D observations [2, 3], 3D reconstruction [4, 5], multi-view tracking [6, 7, 8], multi-view crowd counting [9], and ReID [10, 11, 12, 13, 14]. Usually, it is assumed that the multi-cameras are temporally synchronized when designing DNNs models, i.e., all cameras capture images at the same time point. However, the synchronization assumption for multi-camera systems may not always be valid in practical applications due to a variety of reasons, such as dropped camera frames due to limited network bandwidth or system resources, network transmission delays, etc. Other examples of situations where camera synchronization is not possible include: 1) using images captured from different camera systems; 2) using images from social media to reconstruct the crowd at an event; 3) performing 3D reconstruction of a dynamic scene using video from a drone. Thus, handling unsynchronized multi-cameras is an important issue in the adoption and practical usage of multi-view computer vision.
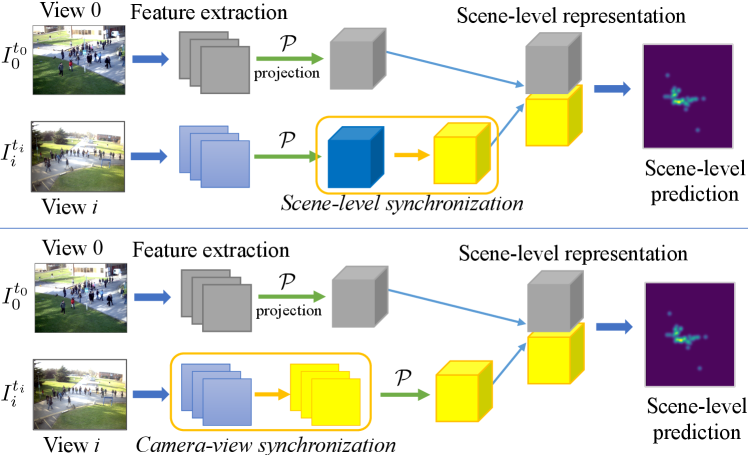
There are several possible methods to fix the problem of unsynchronized cameras. The first method is using hardware-based solutions to synchronize the capture times, such as improving network bandwidth, or by using a central clock to synchronize capture of all cameras in the multi-camera network. However, this will increase the cost and overhead of the system, and is not possible when there is limited bandwidth. The second method is to capture image sequences from each camera, and then synchronize the images afterwards by determining the frame offset between cameras. The fineness of the synchronization depends on the frame rate of the image sequences. However, this method is not effective when acquiring high frame-rate image sequences is not possible due to limited the bandwidth and storage space, or the frame latency between multi-cameras is random. The final method is to modify the multi-view model to handle unsynchronized images, especially for low-frame-rate multi-camera systems or random frame latency between multi-cameras, such as introducing new assumptions or relaxing the original constraints under the unsynchronized setting. Existing approaches for handling unsynchronized multi-cameras are largely based on optimization frameworks [15, 16], but are not directly applicable to DNNs-based multi-view methods, which have seen recent successes in tracking [6, 7], 3D pose estimation [2], and crowd counting [9, 17].
In this paper, we propose a synchronization model that operates in conjunction with existing DNN-based multi-view models by using single frames from each camera to deal with low-frame-rate unsynchronized multi-camera systems or random frame latency between multi-cameras. Our proposed model first synchronizes other views to a reference view using a differentiable module, and then the synchronized multi-views features are fused and decoded to obtain the task-oriented output. As illustrated in Fig. 1, the synchronization can either occur after the camera-to-scene (2D-to-3D) projection (Fig. 1 top) or before the projection (Fig. 1 bottom). Thus, to fully explore these options, we consider two variants of our model that perform synchronization at different stages in the pipeline (see Fig. 2): 1) scene-level synchronization performs the synchronization after projecting the camera features to their 3D scene representation; 2) camera-level synchronization performs the synchronization between camera views first, and then projects the synchronized 2D feature maps to their 3D representations. In both cases, motion flow between the cameras’ feature maps are estimated and then used to warp the feature maps to align with the reference view (either at the scene-level or the camera-level). With both variants, the view synchronization and the multi-view fusion are unified in the same framework and trained in an end-to-end fashion. In this way, the original DNN-based multi-view model can be adapted to work in the unsynchronized setting by adding the view synchronization module, thus avoiding the need to design a new model. Furthermore, the synchronization module only relies on content-based image matching and camera geometry, and thus is widely applicable to many DNNs-based multi-view tasks, such as crowd counting, tracking, 3D pose estimation, and 3D reconstruction.
In summary, the contributions of this paper are 3-fold:
-
•
We propose an end-to-end trainable framework to handle the issue of unsynchronized multi-camera images in DNNs-based multi-camera vision tasks. To the best of our knowledge, this is the first study on DNNs-based single-frame synchronization of multi-view cameras.
-
•
We propose two synchronization modules, scene-level synchronization and camera-view level synchronization, which are based on image-based content matching that is guided by epipolar geometry. The synchronization modules can be applied to many different DNNs-based multi-view tasks.
-
•
We conduct experiments on multi-view counting and 3D pose estimation from unsynchronized images, demonstrating the efficacy of our approach.
The remainder of this paper is organized as follows. We review related works in Section II. In Section III, we propose our single-frame multi-camera synchronization methods, and in Section IV we present experiments on two applications, multi-view crowd counting and multi-view 3d human pose estimation. Finally, Section V concludes the paper.
II Related Work
In this section, we review DNN-based methods on synchronized multi-view images and unsynchronized multi-view video tasks, as well as traditional multi-view video synchronization methods. We then review DNN-based image matching and flow estimation methods.
II-A DNN-based synchronized multi-camera tasks
Multi-camera surveillance based on DNNs has been an active research area. By utilizing multi-view cues and the strong mapping power of DNNs, many DNNs models have been proposed to solve multi-view surveillance tasks, such as multi-view tracking and detection [18, 6, 7], crowd counting [9], 3D reconstruction [4, 5, 19, 20] and 3D human pose estimation [2, 21, 22, 23, 24]. [4] proposed a deep learning 3D reconstruction framework with differentiable feature projection and unprojection steps. [10] proposed the collaboration ensemble learning for ReID with middle-level sharable two-stream network. [2] proposed volumetric aggregation of feature maps for 3D pose estimation. The DNN pipelines used for these multi-camera tasks can be generally divided into three stages: the single-view feature extraction stage, the multi-view fusion stage to obtain a scene-level representation, and prediction stage. Furthermore, all these DNN-based methods assume that the input multi-views are synchronized, which is not always possible in real multi-camera surveillance systems, or in multi-view data from disparate sources (e.g., crowd sourced images). Therefore, relaxing the synchronization assumption can allow more practical applications of multi-camera vision tasks in real world.
II-B Tasks on unsynchronized multi-camera video
Only a few works have considered computer vision tasks on unsynchronized multi-camera video. [15] posed the estimation of 3D structure observed by multiple unsynchronized video cameras as the problem of dictionary learning. [16] proposed a multi-camera motion segmentation method using unsynchronized videos by combining shape and dynamical information. [25] proposed a method of estimating 3D human pose from multi-view videos captured by unsynchronized and uncalibrated cameras by utilizing the projections of joint as the corresponding points. [26] presented a method for simultaneously estimating camera geometry and time shift from video sequences from multiple unsynchronized cameras using minimal correspondence sets. [27] addressed the problem of aligning unsynchronized camera views by low and/or variable frame rates using the intersections of corresponding object trajectories to match views.
Note that all these methods assume that videos or image sequences are available to perform the synchronization. In contrast, our framework, which is motivated by practical low-fps systems, is solving a harder problem, where only a single image is available from each camera view, i.e., there is no temporal information available. Furthermore, these methods pose frame synchronization as optimization problems that are applicable only to the particular multi-view task, and cannot be directly applied to DNN-based multi-view models. In contrast, we propose a synchronization module that can be broadly applied to many DNN-based multi-camera models, enabling their use with unsynchronized inputs.
II-C Traditional methods for multi-view video synchronization
Traditional synchronization methods usually serve as a preprocessing step for multi-camera surveillance tasks. Except audio-based synchronization like [28], most traditional camera synchronization methods rely on videos or image sequences and hand-crafted features for camera alignment/synchronization [29, 30, 31, 32, 33]. Typical approaches recover the temporal offset by matching features extracted from the videos, e.g., space-time feature trajectories [34, 35, 36], image features [37], low-level temporal signals based on fundamental matrices [38], silhouette motion [39], and relative object motion [40]. The accuracy of feature matching is improved using epipolar geometry [37, 39] and rank constraints [35]. [34] proposed to use the space-time feature trajectories matching instead of feature-points matching to reduce the search space. [29] proposed an iterative procedure to achieve the alignment in space and time with the homography assumption in spatial domain. [37] utilized image feature correspondences and epipolar geometry to find the corresponding frame indices and computes the relative frame rate and offset by fitting a 2D line to the index correspondences. [36] estimated the frame accurate offset by analysing the trajectories and matching their characteristic time patterns. [38] presented a method for online synchronization that relied on the video sequences with known fundamental matrix to compute low level temporal signals for matching. [35] proposed the rank constraint of corresponding points in two views to measure the similarity between trajectories to avoid the noise sensitivity of the fundamental matrix. [39] proposed a RANSAC-based algorithm that computed the epipolar geometry and synchronization of a pair of cameras from the motion of silhouettes in videos. [32] estimated possible synchronization parameters via the Hough transform and refined these parameters using non-linear optimization methods. [33] relied on correlating space-time interest point distribution in time between videos which represented events in video that had high variation in both space and time. [40] synchronized two independently moving cameras via the relative motion between objects and known camera intrinsic.
The main disadvantages for these traditional camera synchronization methods are: 1) Videos and image-sequences are required, which might not be available in practical multi-camera systems with limited network bandwidth and storage; 2) A fixed frame rate of the multi-cameras are usually assumed, which means random frame dropping cannot be handled (except [38]); 3) Feature matching is based on hand-crafted features, which lack representation ability, or known image correspondences, which requires extra manual annotations and may not always be available. Compared with these methods, we consider a more practical and difficult setting: only single-frames and no videos (no temporal information) are available, which means that these traditional video-based methods are not suitable solutions. These traditional methods perform image content matching using hand-crafted features and traditional matching algorithms, while in contrast our method uses DNN-based image matching. Because we also assume that only single-frames are available, our method also requires DNN-based motion estimation to estimate a frame’s features after synchronization. Finally, our synchronization module is end-to-end trainable with existing multi-view DNNs and thus avoids the redesign of the whole DNNs models to handle unsynchronized multi-cameras.
II-D DNN-based image matching and flow estimation
Image matching and optical flow estimation both involve estimating image-to-image correspondences, which is related to frame synchronization of multi-views. We mainly review the DNN-based image matching [41, 42, 43] or optical flow estimation methods [44, 45, 46], which inspire us to solve the unsynchronized multi-camera based problems in a DNN-based fashion. DNN flow [47] proposed an image matching method based on a DNN feature pyramid in a coarse-to-fine optimization manner. FlowNet [48] predicted the optical flow from DNNs with feature concatenation and correlation. SpyNet [49] combined a classical spatial-pyramid formulation with deep learning and estimated large motions in a coarse-to-fine approach by warping one image to the other at each pyramid level by the current flow estimate and computing an update to the flow. [41] addressed image correspondence problem using a convolutional neural network architecture that mimics classic image matching algorithms. PWC-Net [50] uses a feature pyramid and one image feature map is warped to the other at each scale, which is guided by the upsampled optical flow estimated from the previous scale. [51] proposed a single network to jointly learn spatiotemporal correspondence for stereo matching and flow estimation.
Our method is related to the DNN-based image matching and optical flow estimation, but the difference is still significant: 1) Typical image/geometric matching only involves either a camera view angle transformation (e.g., camera relative pose estimation, stereo matching) or a small time change in the same view (optical flow estimation), while both factors appear in our problem, which makes our problem harder; 2) Image/geometric matching is directly supervised by the correspondence of two images, while the multi-view fusion ground-truth in the 3D world is used as supervisory signal in our problem; 3) The 2D-to-3D projection causes ambiguity for multi-view feature fusion, which also causes difficulties for view synchronization.
III Single-Frame DNNs Multi-Camera Synchronization
In this section we propose our single-frame synchronization model for DNN-based multi-view models. The temporal offset between cameras can either be constant latency for each camera (the same offset over time), or random latency (random offsets over time). Similar to most multi-view methods [7, 17, 20, 2], we assume that the cameras are static and the cameras’ intrinsic and extrinsic parameters are known. The main idea of our method is to choose a camera view as the reference view, and then use the view synchronization model to warp the other camera views to be synchronized with the reference view. The synchronization model should be general enough to handle both constant and random latencies between cameras, in order to work under various conditions causing de-synchronization.
DNNs models for the multi-camera surveillance tasks typically consist of 3 stages (see in Fig. 1): Single-view feature extraction, which extracts single-view features of the input camera views. Multi-view feature projection and fusion, where a fixed differentiable projection layer is first adopted to project the single-view features to the 3D coordinate map and then the projected multi-view features are fused together to form the scene-level representation. The projection layer depends the application task, and our framework can generally handle any differentiable projection layer. For example, for multi-view counting [9], the projection maps the 2D camera view to the 3D scene plane at the average person height (assuming all camera pixels fall on the same height plane), while for 3D pose estimation [2], the projection copies features along a view-ray in the 3D grid, assuming an unknown height of each camera-view pixel. Prediction, where the decoder predicts the final result in the 3D coordinate map, such as ground-plane density maps [9] or 3D reconstruction [4].
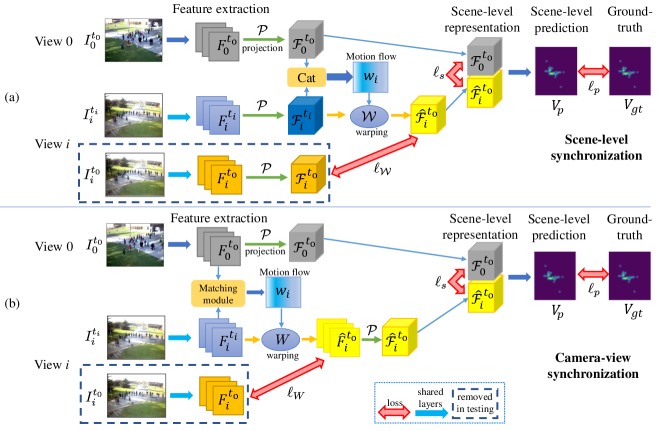
In Fig. 2, we take multi-view crowd counting [9] as an example to show the pipeline of the proposed single-frame based view synchronization model. In the multi-view fusion model, we denote the input multi-view frames as , where denotes the camera view id and is the input camera view number, and superscript indicates that the frames are all captured at the same time point , corresponding to the synchronized multi-camera setup. After being fed into the single-view feature extractor , the extracted features are denoted as
| (1) |
For multi-view counting [9], the projection maps the 2D camera view to the 3D scene plane at the average person height. After projection layer , the projected multi-view features are
| (2) |
We use to denote the fusion operation (e.g., concatenation, max-pooling) of the projected multi-view features, thus the fused feature is . Finally, the decoder is applied to obtain the final prediction ,
| (3) | ||||
However, when the input multi-cameras frames are not synchronized, denoted as , the capture time for the -th view . Thus, we need to synchronize the camera views first by utilizing the view synchronization model.
The view synchronization model can be embedded into one of the first two stages, synchronizing the extracted single-view features or projected features , without the need to redesign a new architecture. Thus, we propose two variants of the synchronization model: 1) scene-level synchronization, where the projected features from different camera views are synchronized during multi-camera feature fusion; and 2) camera-level synchronization, where the camera view features are synchronized before projection and fusion. We present the details of the two synchronization models next. Note that we first consider the case when both synchronized and unsynchronized multi-view images are available for training (but not available in the testing stage). We then extend this to the case when only unsynchronized training images are available.
III-A Scene-level synchronization
Scene-level synchronization works by synchronizing the multi-camera features after the projection stage in the multi-view pipeline. The pipeline for scene-level synchronization is shown in the Fig. 2 (a).
III-A1 Synchronization module
Without loss in generality, we choose one view (denoted as view ) as the reference view, and other views are to be synchronized to this reference view. We first assume that synchronized frame pairs are available in the training stage. The frames are from reference view captured at reference time , and and from view () taken at times and . Note that frames are synchronized, while are not.
The synchronization module consists of the following stages. First, camera frame feature maps (both synchronized and unsynchronized frames) are extracted and projected to the 3D world space, resulting in the projected feature maps . Second, synchronization is performed between the reference view and each other view . The projected feature map from the reference view is concatenated with the projected feature map from view , and then fed into a motion flow estimation network to predict the scene-level motion flow between view at time and the reference view at time :
| (4) |
where is the concatenation operation. The from view is then synchronized with the reference view at time using a warping transformation guided by , ,
| (5) |
where are the warped projected features of the -th view synchronized to time . Note that the warping only applies spatial shifting to the feature map , i.e., it only changes the feature locations and does not change the feature values. Finally, the reference view features and estimated warped features of the other views are fused and decoded to obtain the final scene-level prediction :
| (6) | ||||
| (7) |
In the testing stage, only unsynchronized frames are available and the forward operations related to frame are removed from the network.
III-A2 Training loss
Two losses are used in the training stage. The first loss is a task-specific prediction loss between the scene-level prediction and the ground-truth . For example, for multi-view crowd counting is the mean-square error, and are the predicted and ground-truth scene-level density maps. The second loss is on the multi-view feature synchronization in the multi-view fusion stage. Since the synced frame pairs are available during training, the feature warping loss encourages the warped features to be similar to the features of the original synced frame of view ,
| (8) | ||||
where is the mean-square error loss. Note that the warping only applies spatial shifting, and thus the minimization of the warping loss in (8) will be based on the feature alignment via scene-level motion flow and not global feature value changes (e.g., color correction). Finally, the training loss combines the task loss and the warping loss summed over all non-reference views,
| (9) |
where is a hyperparameter.
III-B Camera view-level synchronization
Each image pixels’ height in 3D space is unknown, and thus the projection operation of multi-camera DNNs models [9, 17, 2] will either project each pixel to the same assumed height level [9] (causing distortion when the true pixel height is different), or to multiple height levels [17], [2] (duplicating features along the view ray). These projection cause the features to stretch along the view ray in the 3D scene, which makes their synchronization more difficult due to their imprecise (stretched) and ambiguous (duplicated) nature. Therefore, we also consider synchronization between camera view features before the projection. The pipeline for camera-level synchronization is presented in Fig. 2 (b).
III-B1 Synchronization model
The view synchronization model is applied to each view separately. The camera view features from the unsynchronized reference view and view are first passed through a matching module (see below) and then fed into the motion flow estimation network to predict the camera-view motion flow for view . The warping transformation guided by then warps the camera-view features from view to be synchronized with the reference view at time ,
| (10) |
where is the warped camera-view features of view captured at time , which is synchronized to reference view captured at time . Finally, the reference and warped camera views are projected
| (11) |
and then fused and decoded to obtain the scene-level prediction :
| (12) | ||||
| (13) |
In the testing stage, only unsynchronized frames are available and the forward operations related to frame are removed from the network.
III-B2 Matching module
We propose 3 methods to match features to predict the view-level motion flow. The first method concatenates the features and then feeds them into the motion flow estimation network to predict the motion flow :
| (14) |
The second method builds a correlation map between features from each pair of spatial locations in and ,
| (15) |
which is then fed into the motion flow estimation network to predict the motion flow :
| (16) |
The third method incorporates camera geometry information into the correlation map to suppress false matches. If both cameras are synchronized at , then according the multi-view geometry, each spatial location in view must match a location in view on its corresponding epipolar line (Fig. 3a). Thus in the synchronized setting, detected matches that are not on the epipolar line can be rejected as false matches. For our unsynchronized setting, the matched location in view remains on the epipolar line only when its corresponding feature/object does not move between times and . To handle the case where the feature moves, we assume that a matched feature in view moves according to a Gaussian motion model with standard deviation (Fig. 3b). With the epipolar line and motion model, we then build a weighting mask, with high weights on locations with high probability of containing the matched features, and vice versa. Specifically, we set the mask if is on the epipolar line induced by , and 0 otherwise, and then convolve it with a 2D Gaussian with standard deviation (Fig. 3c). We then apply the weight mask on the correlation map , which will suppress false matches that are not consistent with the scene and motion model. Thus, the motion flow is
| (17) |

III-B3 Multi-scale architecture
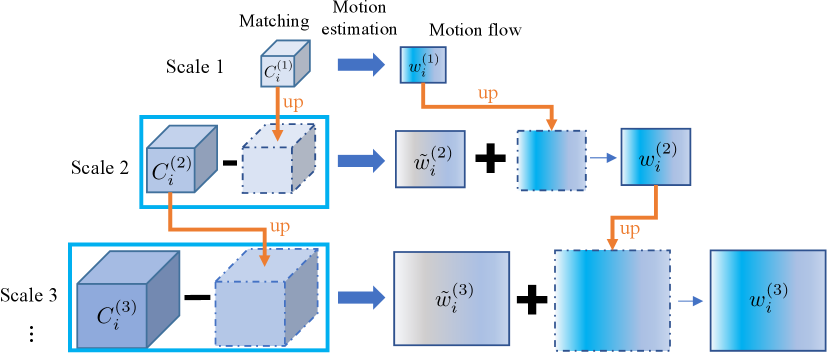
Multi-scale feature extractors are used in multi-camera tasks like crowd counting [9] or to refine the final prediction via multi-scale prediction fusion [51, 50]. Therefore, we next show how to incorporate multi-scale feature extractors with our camera-level synchronization model.111No extra steps are needed to incorporate multi-scale features with scene-level synchronization because the synchronization occurs after the feature projection. Instead of performing the view synchronization in each scale separately, the motion flow estimate of neighbor scales is fused to refine the current scale’s estimate (see Fig. 4). In particular, let there be scales in the multi-scale architecture and denotes one scale in the scale range , with the largest scale. The multi-scale predicted motion flow are fused as follows.
-
•
When (the smallest scale), the correlation map of scale is fed into the motion flow estimation net to predict the motion flow for scale .
-
•
For scales , first the difference between the correlation map and the upsampled correlation map of the previous scale is fed into the motion flow estimation net to predict the residual of the motion flow between two scales, denoted as .
-
•
The refined motion flow of scale is
(18)
III-B4 Training loss
Similar to scene-level synchronization, a combination of two losses (scene-level prediction and feature synchronization) is used in the training stage. The scene-level prediction loss is the same as before. The feature synchronization loss encourages the warped camera-view features at each scale to match the features of the original synchronized frame,
| (19) | ||||
| (20) |
Similar to scene-level synchronization, the warping function only applies spatial shifting, and thus the minimization of in (20) will be based on feature alignment rather than feature value changes. Finally, the training loss is the combination of the prediction loss and the synchronization loss summed over all non-reference views and scales,
| (21) |
where is a hyperparameter.
III-C Training with only unsynchronized frames
In the previous models, we assume that both synchronized and unsynchronized multi-camera frames are available during training. For more practical applications, we also consider the case when only unsynchronized multi-view frames are available for training. In this case, for the scene-level synchronization, the warping feature loss is replaced with a similarity loss on the projected features, to indirectly encourage synchronization of the projected multi-view features,
| (22) |
where “” is the cosine similarity between feature maps (along the channel dimension), and “” is the mean over all spatial locations. Similarly, for camera-level synchronization, the warping feature loss is replaced by the similarity loss of the projected features . Note that the similarity loss is applied after the projection – thus the warping function only needs to predict the residual motion in the camera view, which is the object motion in time, so as to align the projected features.
IV Experiments
We validate the effectiveness of the proposed view synchronization model on two unsynchronized multi-view tasks: multi-view crowd counting and multi-view 3d human pose estimation.
IV-A Implementation details
The synchronization model consists of two parts: motion estimation network and feature warping layer. The input of the motion estimation network is the unsynchronized multi-view features (the concatenation of the projected features) for scene-level synchronization or the matching result of the 2D camera-view features for camera-level synchronization, and the output is a 2-channel motion flow. The layer setting of the motion estimation network is shown in Table I. The feature warping layer warps the features from other views to align with the reference views, guided by the estimated motion flow. The feature warping layer is based on the image resampler from the Spatial Transformation layer in [52].
The synchronized multi-view model consists of feature extraction module, projection module and multi-view prediction module. For the multi-view counting model [9], Table II shows the model setting of the feature extraction and multi-view prediction module. For the 3D pose estimation model [2], the feature extraction module consists of a ResNet-152 network, a series of transposed convolution layers and a 1 by 1 convolution layer to predict joint heatmaps [53], and the V2V-PoseNet [54] is used for multi-view prediction, which is based on hour-glass network [55].
| Layer | Filter |
|---|---|
| conv 1 | |
| conv 2 | |
| conv 3 | |
| conv 4 | |
| conv 5 | |
| conv 6 |
|
|
||||||||||||||||||||||||||||||||||
IV-B Experiment setup
We test four versions of our synchronization model: scene-level synchronization (denoted as SLS), and camera-level synchronization using concatenation, correlation, or correlation with epipolar-guided weights (denoted as CLS-cat, CLS-cor, CLS-epi) for the matching module (Section III-B2). The synchronization models are trained with the multi-view DNNs introduced in each application later.
We consider two training scenarios: 1) both synchronized and unsynchronized training data is available; 2) only unsynchronized training data is available, which is the more difficult setting. For the first training scenario, we compare against two comparison methods: BaseS trains the DNN only on the synchronized data; BaseSU fine-tunes the BaseS model using the unsynchronized training data (using the full training set). For the second training scenario, BaseU trains the DNN directly from the unsynchronized data. Note that traditional synchronization methods [29, 30, 31, 32, 33] are based on videos (temporal information) and assume high-fps cameras with fixed frame rates, which are unavailable in our problem setting. Thus, traditional and video-based synchronization methods are not suitable for comparison.
To test the proposed method, we first create an unsynchonized multi-view dataset from the existing multi-view datasets (the specific datasets are introduced in each application later). In particular, suppose the frame sequence in the reference view is captured at times , where is the time offset between neighbor frames, and is the number of frames. For view , the unsynchronized frames are captured at times , where is the desynchronization time offset between view and the reference view. We consider two settings of the desynchronization offset. The first is a constant latency for each view, , for some constant value . The second is random latency, where the offset for each frame and view is randomly sampled from a uniform distribution, . Finally, since the synchronization is with the reference view, the ground-truth labels for the multi-view task correspond to the times of the reference view, .
| PETS2009 | CityStreet | ||||||||
| constant | random | constant | random | ||||||
| loss | model | MAE | NAE | MAE | NAE | MAE | NAE | MAE | NAE |
| BaseS | 7.21 | 0.200 | 4.58 | 0.139 | 9.07 | 0.108 | 8.86 | 0.107 | |
| BaseSU | 4.36 | 0.137 | 4.30 | 0.140 | 9.02 | 0.106 | 8.82 | 0.108 | |
| SLS | 4.49 | 0.145 | 4.91 | 0.154 | 8.23 | 0.102 | 8.02 | 0.101 | |
| CLS-cat | 4.18 | 0.130 | 4.85 | 0.150 | 8.82 | 0.111 | 8.57 | 0.108 | |
| CLS-cor | 4.13 | 0.135 | 4.03 | 0.128 | 8.03 | 0.099 | 7.99 | 0.098 | |
| CLS-epi | 3.95 | 0.130 | 4.09 | 0.129 | 8.05 | 0.100 | 7.93 | 0.096 | |
| PETS2009 | CityStreet | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| constant | random | constant | random | ||||||
| loss | model | MAE | NAE | MAE | NAE | MAE | NAE | MAE | NAE |
| BaseU | 6.18 | 0.187 | 6.22 | 0.192 | 10.22 | 0.134 | 9.35 | 0.121 | |
| SLS | 5.37 | 0.178 | 4.82 | 0.150 | 8.50 | 0.105 | 8.33 | 0.100 | |
| CLS-cat | 6.00 | 0.186 | 6.08 | 0.189 | 8.48 | 0.102 | 9.17 | 0.110 | |
| CLS-cor | 4.18 | 0.136 | 4.34 | 0.136 | 8.02 | 0.098 | 7.77 | 0.093 | |
| CLS-epi | 4.25 | 0.135 | 4.77 | 0.144 | 8.04 | 0.095 | 7.70 | 0.094 | |
| SLS | 7.13 | 0.226 | 5.30 | 0.162 | 8.77 | 0.107 | 8.45 | 0.107 | |
| CLS-cat | 6.30 | 0.194 | 5.98 | 0.184 | 8.28 | 0.098 | 9.15 | 0.108 | |
| CLS-cor | 4.25 | 0.138 | 4.49 | 0.141 | 8.20 | 0.099 | 8.10 | 0.102 | |
| CLS-epi | 4.27 | 0.135 | 4.53 | 0.143 | 8.16 | 0.097 | 7.86 | 0.096 | |
| PETS2009 | CityStreet | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| constant | random | constant | random | ||||||
| loss | model | MAE | NAE | MAE | NAE | MAE | NAE | MAE | NAE |
| BaseU | 14.89 | 0.458 | 10.95 | 0.484 | 10.96 | 0.146 | 11.30 | 0.149 | |
| SLS | 6.80 | 0.229 | 6.58 | 0.283 | 9.18 | 0.111 | 9.49 | 0.117 | |
| CLS-cat | 7.41 | 0.237 | 6.10 | 0.237 | 9.72 | 0.130 | 9.69 | 0.129 | |
| CLS-cor | 5.91 | 0.201 | 5.93 | 0.240 | 8.55 | 0.106 | 8.31 | 0.107 | |
| CLS-epi | 5.72 | 0.184 | 4.80 | 0.187 | 8.32 | 0.104 | 8.05 | 0.102 | |
| SLS | 7.85 | 0.274 | 7.22 | 0.313 | 9.31 | 0.109 | 8.91 | 0.108 | |
| CLS-cat | 7.52 | 0.240 | 6.20 | 0.243 | 8.48 | 0.107 | 9.85 | 0.121 | |
| CLS-cor | 6.98 | 0.244 | 6.26 | 0.282 | 8.03 | 0.099 | 8.24 | 0.107 | |
| CLS-epi | 6.80 | 0.229 | 5.18 | 0.200 | 8.23 | 0.102 | 8.16 | 0.103 | |
IV-C Unsynchronized multi-view counting
We first apply our synchronization model to unsynchronized multi-view counting system, whose bandwidth is assumed to be limited and the frame latency between cameras can be fixed or random. Here we adopt the multi-view multi-scale fusion model (MVMS) from [9], which is the state-of-the-art model for multi-view counting DNNs. We embed the synchronization models in the MVMS model to handle the unsynchronized multi-view frames for crowd counting.
IV-C1 Datasets and metric
Two multi-view counting datasets used in [9], PETS2009 [56] and CityStreet [9], are selected and desynchronized for the experiments.
PETS2009 contains 3 views (camera 1, 2 and 3), and the first camera view is chosen as the reference view. The input image resolution () is and the ground-truth scene-level density map resolution is . There are 825 multi-view frames for training and 514 frames for testing. The frame rate of PETS2009 is 7 fps (). For constant frame latency, is used for cameras 2 and 3, and for random latency.
CityStreet proposed in [9] consists of 3 views (camera 1, 3 and 4), and camera 1 is chosen as the reference view. The input image resolution is and the ground-truth density map resolution is . There are 500 multi-view frames, and the first 300 are used for training and the remaining 200 for testing. The frame rate of CityStreet is 1 fps ()222We obtained the higher fps version from the dataset authors.. For constant latency, for cameras 3 and 4, and for random latency.
Following [9], the mean absolute error (MAE) and normalized absolute error (NAE) of the predicted counts on the test set are used as the evaluation metric:
| (23) |
| (24) |
where is the ground truth count and is the predicted count, and is the number of testing images.
IV-C2 Results for training with synced and unsynced frames
The experiment results using training with synchronized and unsynchronized frames are shown in Table III. The hyperparameter is used for feature warping loss. On both datasets, our camera-level synchronization methods, CLS-cor and CLS-epi, perform better than other methods, including the baselines, demonstrating the efficicacy of our approach. Scene-level synchronization (SLS) performs worse than camera-level synchronization methods (CLS), due to the ambiguity of the projected features from multi-views. Furthermore after projection to the ground-plane, the crowd movement between frames and on the ground-plane is less salient due to the low resolution of the ground-plane feature map. CLS-cat performs worse among the CLS methods because simple concatenation of features cannot capture the image correspondence between different views to estimate the motion flow. Finally, the two baselines (BaseS and BaseSU) perform badly on CityStreet because of the larger scene with larger crowd movement between neighboring frames (due to lower frame rate).
IV-C3 Results for training with only unsynchronized frames
The experiment results by training with only unsynchronized frames (which is a more practical real-world case) are shown in Table IV. Since the synchronized frames are not available, the MVMS model weights are trained from scratch using only unsynchronized data. Our models are trained with the similarity loss (with hyperparameter ), which encourages alignment of the projected multi-view features. Generally, without the synchronized frames in the training stage, the counting error increases for each method. Nonetheless, the proposed camera-level synchronization models CLS-cor and CLS-epi performs much better than the baseline BaseU. CLS-cor and CLS-epi trained on only unsynchronized data also performs better (on CityStreet) or on par with (on PETS2009) the baseline BaseSU, which uses both synchronized and unsynchronized training data. These two results demonstrate the efficacy of our synchronization model when only unsynchronized training data is available. Finally, the error for almost all synchronization models increases on both datasets when training without the similarity loss ( in Table IV). This demonstrates the effectiveness of using to align the multi-view features in training.
| Loss/Training data | Method | Multi-scale | Single-scale | ||
|---|---|---|---|---|---|
| MAE | NAE | MAE | NAE | ||
| SLS | 8.02 | 0.101 | 8.31 | 0.100 | |
| / | CLS-cat | 8.57 | 0.108 | 8.77 | 0.102 |
| sync and unsync | CLS-cor | 7.99 | 0.098 | 8.25 | 0.099 |
| CLS-epi | 7.93 | 0.096 | 8.12 | 0.098 | |
| SLS | 8.33 | 0.100 | 8.95 | 0.112 | |
| CLS-cat | 9.17 | 0.110 | 9.54 | 0.116 | |
| unsync | CLS-cor | 7.77 | 0.093 | 8.62 | 0.111 |
| CLS-epi | 7.70 | 0.094 | 8.59 | 0.110 | |
IV-C4 Results for using ground-truth from unsynchronized multi-view images
In the previous experiments (training with only unsynchronized frames, see Sec. IV-C3), the ground-truth is corresponded (synchronized) to the frames of the reference view. We also perform experiments when the ground-truth scene-level density maps are calculated from the unsynchronized multi-view images. Specifically, we project the same person’s image coordinates of each unsynchronized view to the world plane and the average of the projection results is used as the ground-truth person location on the ground. Then, we use the obtained person location map to generate the scene-level density map.
The results for training with ground-truth from unsynchronized multi-view images and only unsynchronized frames can be seen in Table V. From the table, we can also find that the proposed method CLS-cor / CLS-epi can achieve better performance than other methods and CLS-epi achieves the best performance, and the performance can be further improved by adding similarity loss .
| Method | view 2 | view 3 |
|---|---|---|
| before warping | ||
| after warping |
IV-C5 Ablation study on the multi-scale architecture
We next present an ablation study on the multi-scale architecture for the multi-view counting in Table VI. Generally, the multi-scale architecture performs better than single-scale architecture models, and the proposed CLS-cor/CLS-epi can perform better than SLS or CLS-cat under both single-scale or multi-scale architecture, and under both training paradigms (sync and unsynced, or only unsynced).
| Method | constant | random |
|---|---|---|
| Color correction | 8.90/0.108 | 8.64/0.100 |
| SLS | 8.50/0.105 | 8.33/0.100 |
| CLS-cat | 8.48/0.102 | 9.17/0.110 |
| CLS-cor | 8.02/0.098 | 7.77/0.093 |
| CLS-epi | 8.04/0.095 | 7.70/0.094 |
IV-C6 Ablation study on color correlation
The feature warping module only applies spatial shifting on the features of the unsynced views, i.e., it does not change the values (e.g., color) of the unsynced features (see Eqs. 5 and 10). To demonstrate this, we calculate the average statistics (mean and variance) of the feature maps before and after feature warping of Views 2 and 3 of CityStreet, and present the results in Table VII. The statistics of the feature maps do not change much after performing feature warping, and thus the performance improvement of the feature warping module is not due to color correction (feature value changes).
We further perform an ablation study to show that image color correction by itself cannot solve the frame desychronization problem. On the CityStreet dataset, in the baseline model (MVMS [9]), we add a learnable “color correction” layer, comprising an extra 11 convolution layer (32 channels) in the branches of the other camera views before the projection and fusion step. The results are denoted as “color correction” in Table VIII. The error for using “color correction” is worse than the proposed SLS, CLS-cor and CLS-epi. The reason is that the desychronization issue comes from the capture time difference between camera views, which is better solved by spatial shifting of features rather than color correction (changing feature values).
IV-C7 Model size and running speed comparison
| Method | Paras. Num | FPS |
|---|---|---|
| BaseS/BaseSU/BaseU | 853.4K | 21.9 |
| SLS | 3.7M | 8.3 |
| CLS-cat | 3.7M | 8.9 |
| CLS-cor | 37.3M | 7.2 |
| CLS-epi | 37.3M | 3.6 |
We present the model size (number of parameters) and running speed of the baseline methods and the proposed SLS, CLS-cat, CLS-cor and CLS-epi in Table IX. The input resolution for the correlation step of the camera-view synchronization module is . All models are tested on the CityStreet dataset with a Nvidia 1080Ti GPU. The baseline methods (BaseS, BaseSU and BaseU) do not use view synchronization modules, so their model sizes are smaller and running speeds are faster. The proposed CLS-cor and CLS-epi methods have the correlation module, and thus have more parameters than SLS or CLS-cat. CLS-epi is slower than CLS-cor due to the extra multiplication step with the epipolar weights.

IV-C8 Visualization results
Example results are shown in Fig. 5. Generally, the proposed synchronization methods CLS-epi and CLS-cor can predict better quality density maps, such as in the red box regions in the figure, where comparison methods tend to over-count these regions due to the same person being counted multiple times in unsynchronized frames. Furthermore, we also observe that the predicted density map is with better quality when synchronized frames are available compared to training with only unsynchronized frames. Finally, the prediction results are improved if similarity loss is enforced when training with only unsynchronized frames, such as the methods CLS-epi and CLS-cor on PETS2009.
IV-D Unsynchronized 3D human pose estimation
We next apply our synchronization model to the unsynchronized 3D human pose estimation task. The DNNs model for 3D human pose estimation is adopted from [2], which proposed two learnable triangulation methods for multi-view 3D human pose from multiple 2D views: algebraic triangulation and volumetric aggregation. Here we use volumetric aggregation (softmax aggregation) as the multi-view fusion DNN in the experiments.
| Latency | |||
|---|---|---|---|
| BaseS | 62.8/59.2 | 78.6/78.2 | 151.1/151.5 |
| BaseSU | 26.5/27.8 | 49.9/50.1 | 69.4/69.2 |
| BaseU | 37.3/38.9 | 50.9/50.6 | 71.0/70.7 |
| CLS-cor(=0) | 25.8/26.9 | 36.5/36.7 | 56.6/56.9 |
| CLS-cor | 25.8/27.0 | 38.2/38.7 | 46.8/47.1 |
| CLS-epi | 25.7/26.8 | 37.6/37.8 | 45.7/45.6 |
| Pose | BaseS | BaseSU | BaseU | CLS-cor(=0) | CLS-cor | CLS-epi |
|---|---|---|---|---|---|---|
| Directions | 42.8 | 29.3 | 34.3 | 26.1 | 25.8 | 26.1 |
| Discussion | 60.7 | 28.4 | 38.8 | 27.3 | 26.7 | 27.0 |
| Eating | 60.7 | 26.4 | 28.8 | 23.9 | 24.0 | 23.4 |
| Greeting | 63.8 | 19.7 | 32.3 | 25.3 | 24.3 | 25.1 |
| PhoneCall | 52.2 | 25.7 | 31.0 | 24.7 | 24.5 | 24.4 |
| Posing | 49.7 | 22.0 | 27.6 | 24.1 | 24.0 | 24.0 |
| Purchases | 67.5 | 24.4 | 52.5 | 28.7 | 27.4 | 28.8 |
| Sitting | 33.2 | 22.6 | 36.6 | 23.8 | 24.0 | 24.0 |
| SittingDown | 37.4 | 25.7 | 66.6 | 25.9 | 26.8 | 27.2 |
| Smoking | 42.2 | 25.7 | 31.2 | 24.8 | 24.3 | 24.4 |
| TakingPhoto | 59.9 | 24.3 | 44.2 | 28.2 | 27.9 | 27.2 |
| Waiting | 44.3 | 19.5 | 35.8 | 23.2 | 23.8 | 24.2 |
| Walking | 161.1 | 31.9 | 32.1 | 27.0 | 30.2 | 27.8 |
| WalkingDogs | 91.5 | 34.2 | 54.8 | 30.1 | 30.1 | 29.8 |
| WalkingTogether | 126.8 | 33.9 | 31.8 | 25.5 | 26.8 | 25.5 |
| Average | 62.8 | 26.5 | 37.3 | 25.8 | 25.8 | 25.7 |
| Pose | BaseS | BaseSU | BaseU | CLS-cor(=0) | CLS-cor | CLS-epi |
|---|---|---|---|---|---|---|
| Directions | 46.2 | 48.7 | 65.1 | 42.9 | 42.5 | 43.9 |
| Discussion | 75.6 | 53.6 | 55.2 | 38.9 | 41.0 | 41.6 |
| Eating | 64.5 | 39.1 | 40.2 | 32.5 | 32.7 | 30.8 |
| Greeting | 71.5 | 48.5 | 55.4 | 35.7 | 38.1 | 36.8 |
| PhoneCall | 64.5 | 43.6 | 43.0 | 33.9 | 35.2 | 35.1 |
| Posing | 49.3 | 42.1 | 43.3 | 32.7 | 33.3 | 30.8 |
| Purchases | 111.5 | 50.9 | 48.7 | 35.9 | 42.4 | 40.4 |
| Sitting | 55.2 | 46.0 | 43.7 | 33.6 | 33.8 | 34.7 |
| SittingDown | 108.3 | 79.3 | 64.9 | 36.8 | 41.8 | 42.8 |
| Smoking | 54.5 | 44.3 | 44.0 | 35.5 | 35.9 | 35.7 |
| TakingPhoto | 87.9 | 57.0 | 58.6 | 39.3 | 43.0 | 41.3 |
| Waiting | 64.3 | 45.6 | 47.3 | 35.5 | 33.7 | 35.0 |
| Walking | 150.6 | 47.6 | 48.1 | 34.2 | 37.1 | 34.2 |
| WalkingDogs | 123.1 | 66.2 | 67.5 | 44.5 | 49.2 | 49.1 |
| WalkingTogether | 125.5 | 50.3 | 52.7 | 36.9 | 38.5 | 34.9 |
| Average | 78.6 | 49.9 | 50.9 | 36.5 | 38.2 | 37.6 |
| Pose | BaseS | BaseSU | BaseU | CLS-cor(=0) | CLS-cor | CLS-epi |
|---|---|---|---|---|---|---|
| Directions | 99.2 | 83.2 | 76.3 | 70.3 | 64.8 | 66.5 |
| Discussion | 144.1 | 72.0 | 67.5 | 57.3 | 48.2 | 48.4 |
| Eating | 138.2 | 55.3 | 63.2 | 44.7 | 40.4 | 37.9 |
| Greeting | 181.3 | 68.0 | 74.1 | 54.8 | 46.9 | 46.3 |
| PhoneCall | 138.1 | 58.8 | 61.1 | 49.2 | 40.7 | 40.5 |
| Posing | 121.7 | 53.5 | 50.2 | 42.1 | 36.6 | 36.3 |
| Purchases | 155.7 | 69.0 | 62.4 | 58.1 | 47.0 | 50.6 |
| Sitting | 74.0 | 64.2 | 67.8 | 55.2 | 41.1 | 39.6 |
| SittingDown | 103.8 | 112.3 | 140.7 | 89.8 | 54.6 | 50.6 |
| Smoking | 112.7 | 58.7 | 60.3 | 49.2 | 41.7 | 41.7 |
| TakingPhoto | 166.8 | 76.8 | 79.6 | 64.5 | 57.7 | 53.5 |
| Waiting | 120.2 | 62.7 | 61.1 | 51.1 | 42.0 | 42.6 |
| Walking | 301.1 | 66.3 | 69.2 | 49.7 | 44.0 | 41.7 |
| WalkingDogs | 219.2 | 95.9 | 91.6 | 77.0 | 62.7 | 55.5 |
| WalkingTogether | 302.7 | 67.2 | 68.9 | 54.5 | 43.5 | 42.5 |
| Average | 151.1 | 69.4 | 71.0 | 56.6 | 46.8 | 45.7 |
| 0.005 | 0.01 | 0.02 | |
|---|---|---|---|
| 25.6 | 25.7 | 26.0 | |
| 38.3 | 37.6 | 37.9 | |
| 51.7 | 45.7 | 46.8 |
IV-D1 Datasets and Metrics
We use the Human3.6M [57] dataset, which consists of 3.6 million frames from 4 synchronized 50 Hz digital cameras along with the 3D pose annotations. We follow the preprocessing step333https://github.com/anibali/h36m-fetch. Accessed: Oct. 10, 2019. recommended in [57], and sample one of every 64 frames () for the testing set, and sample one of every 4 frames () as the training set. The first camera view is always used as the reference view (if the first camera view is missing, the second one is used). We test desynchronization via random frame latency, with seconds, and only use unsynchronized data for training. Following [2], Mean Per Point Position Error (MPJPE) and absolute position MPJPE are used as the metric for evaluation. In training, the single-view backbone uses the pretrained weights from the original 3D pose estimation model. Baseline methods BaseS, BaseSU and BaseU are compared with our proposed camera-view synchronization models CLS-cor and CLS-epi.


IV-D2 Experiment results
The experiments results are presented in Table X. The original 3D pose estimation method (BaseS, BaseSU and BaseU) cannot perform well under the unsynchronized test condition, especially under large latencies (e.g., 64/50s). Our camera-view synchronization methods performs better than the baseline methods, with the performance gap increasing as the latency increases. Using similarity loss improves the performance of our models, and adding epipolar-guided weights can suppress false matches and further reduces the error. The detailed performance for each pose type under different frame latency settings is shown in Table XI, Table XII and Table XIII. From the tables, we can find that the proposed methods can perform especially better on the poses with larger movement between unsynchronized frames, e.g., Walking, WalkingDogs and WalkingTogether.
IV-D3 Ablation study on for 3D pose estimation
The ablation study on hyperparameter for the method CLS-epi for 3D pose estimation is presented in Table XIV. In general, achieves better performance than other weights.
IV-D4 Model size and running speed comparison
We present the model sizes and running speed comparisons of our proposed models and the baselines for 3D pose estimation in Table XV. The input resolution for the correlation step of the camera-view synchronization module is . As the original synchronized 3D pose estimation model [2] is already very large, the running speed of the proposed models CLS-cor and CLS-epi is similar to the baseline methods BaseS/BaseSU/BaseU.
| Method | Paras. Num | FPS |
|---|---|---|
| BaseS/BaseSU/BaseU | 80.6M | 3.7 |
| CLS-cor | 86.3M | 3.4 |
| CLS-epi | 86.3M | 3.0 |
IV-D5 Visualization results
Visualization results of unsynchronized 3D pose estimation are presented in Figs. 6 and 7. In the figures, the first row shows the input unsynchronized multi-view frames, and the top labels indicate the unsynchronized frame latency. Rows 2-8 show the 2D key-joints projected from 3D poses of Ground-truth, BaseS, BaseSU, BaseU, CLS-cor (), CLS-cor and CLS-epi, respectively, where synchronized frames are displayed for better visualization effect. In Fig. 6, BaseU fails on the unsynchronized input, and CLS-epi achieves the best performance among all methods, especially the prediction of the arms in view 1. In Fig. 7, the CLS-epi also achieves the best performance among all comparison methods.
V Conclusion
In this paper, we focus on the issue of unsynchronized cameras in DNNs-based multi-view computer vision tasks. We propose two view synchronization models based on single frames (not videos) from each view, scene-level synchronization and camera-level synchronization. The two models are trained and evaluated under two training settings (with or without synchronized frame pairs), and a similarity loss of the projected multi-view features is proposed to boost the performance when synchronized training pairs are not available. Furthermore, to show its generality to different conditions of desynchronization, the proposed models are tested with desynchronization based on both constant and random latency. Finally, the proposed models are applied to unsynchronized multi-view counting and unsynchronized 3D human pose estimation, and achieve better performance compared to the baseline methods. Overall, camera-level synchronization model using correlation and epipolar weights (CLS-epi) performs best among the proposed models.
In addition to unsynchronized multi-camera crowd counting and 3D pose estimation, the proposed method can also be applied to other multi-camera vision tasks, such as multi-camera detection [7], multi-camera tracking [18]. In these tasks, multi-cameras may also be unsynchronized due to no synchronization clock or limited network bandwidth. As these DNN models [7, 18] generally follow the 3 stage pipeline (single-view feature extraction, multi-view projection and fusion, and prediction), our proposed synchronization modules can be inserted to adapt them to unsynchronized frames.
In our current model, image content matching is used for view synchronization, while the 2D-to-3D projection for multi-view fusion relies on known camera parameters. The multi-camera surveillance tasks themselves require known calibration for better multi-view fusion. Note that our proposed view synchronization module based on correlation maps (CLS-cor) does not require camera calibrations due to the single-frame basis, and still achieves good performance. When the calibrations are provided, epipolar constraint can be utilized to achieve better results (CLS-epi). In future work, the 2D-3D projection in the original multiview models could be replaced with camera self-calibration modules, which can allow the model to handle unsynchronized and uncalibrated multi-cameras.
VI Acknowledgements
This work was supported by grants from the Research Grants Council of the Hong Kong Special Administrative Region, China (Project No. [T32-101/15-R] and CityU 11212518).
References
- [1] H. Aghajan and A. Cavallaro, Multi-camera networks: principles and applications. Academic press, 2009.
- [2] K. Iskakov, E. Burkov, V. Lempitsky, and Y. Malkov, “Learnable triangulation of human pose,” in ICCV, 2019.
- [3] E. Remelli, S. Han, S. Honari, P. Fua, and R. Wang, “Lightweight multi-view 3d pose estimation through camera-disentangled representation,” in CVPR.
- [4] A. Kar, C. Háne, and J. Malik, “Learning a multi-view stereo machine,” in NIPS, 2017, pp. 365–376.
- [5] P.-H. Huang, K. Matzen, and et al., “Deepmvs: Learning multi-view stereopsis,” in CVPR, 2018, pp. 2821–2830.
- [6] P. Baqué, F. Fleuret, and P. Fua, “Deep occlusion reasoning for multi-camera multi-target detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 271–279.
- [7] T. Chavdarova, P. Baqué, S. Bouquet, A. Maksai, C. Jose, T. Bagautdinov, L. Lettry, P. Fua, L. Van Gool, and F. Fleuret, “Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5030–5039.
- [8] L. Chen, H. Ai, R. Chen, Z. Zhuang, and S. Liu, “Cross-view tracking for multi-human 3d pose estimation at over 100 fps,” in CVPR.
- [9] Q. Zhang and A. B. Chan, “Wide-area crowd counting via ground-plane density maps and multi-view fusion cnns,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 8297–8306.
- [10] M. Ye, X. Lan, Q. Leng, and J. Shen, “Cross-modality person re-identification via modality-aware collaborative ensemble learning,” IEEE Transactions on Image Processing, vol. 29, pp. 9387–9399, 2020.
- [11] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 3702–3712.
- [12] M. Ye and P. C. Yuen, “Purifynet: A robust person re-identification model with noisy labels,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 2655–2666, 2020.
- [13] M. Ye, J. Shen, X. Zhang, P. C. Yuen, and S.-F. Chang, “Augmentation invariant and instance spreading feature for softmax embedding,” IEEE transactions on pattern analysis and machine intelligence, 2020.
- [14] L. Song, C. Wang, L. Zhang, B. Du, Q. Zhang, C. Huang, and X. Wang, “Unsupervised domain adaptive re-identification: Theory and practice,” Pattern Recognition, 2018.
- [15] E. Zheng, D. Ji, E. Dunn, and J.-M. Frahm, “Sparse dynamic 3d reconstruction from unsynchronized videos,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 4435–4443.
- [16] X. Zhang, B. Ozbay, M. Sznaier, and O. Camps, “Dynamics enhanced multi-camera motion segmentation from unsynchronized videos,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 4668–4676.
- [17] Q. Zhang and A. B. Chan, “3d crowd counting via multi-view fusion with 3d gaussian kernels,” in AAAI Conference on Artificial Intelligence, 2020.
- [18] Y. He, J. Han, W. Yu, X. Hong, and Y. Gong, “City-scale multi-camera vehicle tracking by semantic attribute parsing and cross-camera tracklet matching,” in In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020.
- [19] C. B. Choy, D. Xu, J. Gwak, K. Chen, and S. Savarese, “3d-r2n2: A unified approach for single and multi-view 3d object reconstruction,” in ECCV. Springer, 2016, pp. 628–644.
- [20] H. Xie, H. Yao, X. Sun, S. Zhou, and S. Zhang, “Pix2vox: Context-aware 3d reconstruction from single and multi-view images,” in The IEEE International Conference on Computer Vision (ICCV), October 2019.
- [21] M. Kocabas, S. Karagoz, and E. Akbas, “Self-supervised learning of 3d human pose using multi-view geometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 1077–1086.
- [22] C.-H. Chen, A. Tyagi, A. Agrawal, D. Drover, S. Stojanov, and J. M. Rehg, “Unsupervised 3d pose estimation with geometric self-supervision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 5714–5724.
- [23] H. Joo, H. Liu, L. Tan, L. Gui, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, and Y. Sheikh, “Panoptic studio: A massively multiview system for social motion capture,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3334–3342.
- [24] G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis, “Harvesting multiple views for marker-less 3d human pose annotations,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6988–6997.
- [25] K. Takahashi, D. Mikami, M. Isogawa, and H. Kimata, “Human pose as calibration pattern; 3d human pose estimation with multiple unsynchronized and uncalibrated cameras,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018, pp. 1775–1782.
- [26] C. Albl, Z. Kukelova, A. Fitzgibbon, J. Heller, M. Smid, and T. Pajdla, “On the two-view geometry of unsynchronized cameras,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4847–4856.
- [27] T. Kuo, S. Sunderrajan, and B. Manjunath, “Camera alignment using trajectory intersections in unsynchronized videos,” in Proceedings of the IEEE International Conference on Computer Vision, 2013, pp. 1121–1128.
- [28] N. Hasler, B. Rosenhahn, T. Thormahlen, M. Wand, and H. P. Seidel, “Markerless motion capture with unsynchronized moving cameras,” in Computer Vision and Pattern Recognition, 2009.
- [29] C. Dai, Y. Zheng, and L. Xin, “Subframe video synchronization via 3d phase correlation,” in ICIP, 2006.
- [30] F. Padua, R. Carceroni, G. Santos, and K. Kutulakos, “Linear sequence-to-sequence alignment,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 2, pp. 304–320, 2008.
- [31] C. Lei and Y.-H. Yang, “Tri-focal tensor-based multiple video synchronization with subframe optimization,” IEEE Transactions on Image Processing, vol. 15, no. 9, pp. 2473–2480, 2006.
- [32] P. A. Tresadern and I. D. Reid, “Video synchronization from human motion using rank constraints,” Computer Vision and Image Understanding, vol. 113, no. 8, pp. 891–906, 2009.
- [33] J. Yan and M. Pollefeys, “Video synchronization via space-time interest point distribution,” in Advanced Concepts for Intelligent Vision Systems, vol. 1, 2004, pp. 12–21.
- [34] Y. Caspi, D. Simakov, and M. Irani, “Feature-based sequence-to-sequence matching,” International Journal of Computer Vision, vol. 68, no. 1, pp. 53–64, 2006.
- [35] Rao, Gritai, Shah, and Syeda-Mahmood, “View-invariant alignment and matching of video sequences,” in Proceedings Ninth IEEE International Conference on Computer Vision, 2003, pp. 939–945.
- [36] B. Meyer, T. Stich, M. A. Magnor, and M. Pollefeys, “Subframe temporal alignment of non-stationary cameras.” in BMVC, 2008, pp. 1–10.
- [37] E. Imre and A. Hilton, “Through-the-lens synchronisation for heterogeneous camera networks.” in BMVC, 2012, pp. 1–11.
- [38] D. Pundik and Y. Moses, “Video synchronization using temporal signals from epipolar lines,” in ECCV, 2010.
- [39] S. N. Sinha and M. Pollefeys, “Synchronization and calibration of camera networks from silhouettes,” in Pattern Recognition, 2004. ICPR 2004. Proceedings of the 17th International Conference on, 2004.
- [40] T. Gaspar, P. Oliveira, Favaro, and Paolo, Synchronization of Two Independently Moving Cameras without Feature Correspondences, 2014.
- [41] I. Rocco, R. Arandjelovic, and J. Sivic, “Convolutional neural network architecture for geometric matching,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6148–6157.
- [42] S. Phillips and K. Daniilidis, “All graphs lead to rome: Learning geometric and cycle-consistent representations with graph convolutional networks,” arXiv preprint arXiv:1901.02078, 2019.
- [43] H. Altwaijry, E. Trulls, J. Hays, P. Fua, and S. Belongie, “Learning to match aerial images with deep attentive architectures,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3539–3547.
- [44] T.-W. Hui, X. Tang, and C. Change Loy, “Liteflownet: A lightweight convolutional neural network for optical flow estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8981–8989.
- [45] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox, “Flownet 2.0: Evolution of optical flow estimation with deep networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2462–2470.
- [46] M. Bai, W. Luo, K. Kundu, and R. Urtasun, “Exploiting semantic information and deep matching for optical flow,” in European Conference on Computer Vision. Springer, 2016, pp. 154–170.
- [47] W. Yu, K. Yang, Y. Bai, H. Yao, and Y. Rui, “Dnn flow: Dnn feature pyramid based image matching.” in BMVC, 2014.
- [48] A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V. Golkov, P. Van Der Smagt, D. Cremers, and T. Brox, “Flownet: Learning optical flow with convolutional networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2758–2766.
- [49] A. Ranjan and M. J. Black, “Optical flow estimation using a spatial pyramid network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4161–4170.
- [50] D. Sun, X. Yang, M.-Y. Liu, and J. Kautz, “Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8934–8943.
- [51] H.-Y. Lai, Y.-H. Tsai, and W.-C. Chiu, “Bridging stereo matching and optical flow via spatiotemporal correspondence,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 1890–1899.
- [52] M. Jaderberg, K. Simonyan, A. Zisserman et al., “Spatial transformer networks,” in Advances in neural information processing systems, 2015, pp. 2017–2025.
- [53] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in ECCV, 2018.
- [54] G. Moon, J. Y. Chang, and K. M. Lee, “V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map,” pp. 5079–5088, 2018.
- [55] A. Newell, K. Yang, and D. Jia, “Stacked hourglass networks for human pose estimation,” in European Conference on Computer Vision, 2016, pp. 483 C–499.
- [56] J. Ferryman and A. Shahrokni, “Pets2009: Dataset and challenge,” in IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, 2009, pp. 1–6.
- [57] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,” IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 7, pp. 1325–1339, 2013.