Situation-Aware Deep Reinforcement Learning for Autonomous Nonlinear Mobility Control in Cyber-Physical Loitering Munition Systems
Abstract
According to the rapid development of drone technologies, drones are widely used in many applications including military domains. In this paper, a novel situation-aware DRL-based autonomous nonlinear drone mobility control algorithm in cyber-physical loitering munition applications. On the battlefield, the design of DRL-based autonomous control algorithm is not straightforward because real-world data gathering is generally not available. Therefore, the approach in this paper is that cyber-physical virtual environment is constructed with Unity environment. Based on the virtual cyber-physical battlefield scenarios, a DRL-based automated nonlinear drone mobility control algorithm can be designed, evaluated, and visualized. Moreover, many obstacles exist which is harmful for linear trajectory control in real-world battlefield scenarios. Thus, our proposed autonomous nonlinear drone mobility control algorithm utilizes situation-aware components those are implemented with a Raycast function in Unity virtual scenarios. Based on the gathered situation-aware information, the drone can autonomously and nonlinearly adjust its trajectory during flight. Therefore, this approach is obviously beneficial for avoiding obstacles in obstacle-deployed battlefields. Our visualization-based performance evaluation shows that the proposed algorithm is superior from the other linear mobility control algorithms.
Index Terms:
Drone, Loitering Munition, Sensing, Deep Reinforcement Learning, Drone mobility Control, Unity.I Introduction
I-A Background and Motivation
With the Internet of Things (IoT) revolution in modern communications and network applications, drones for autonomous aerial ad-hoc on-demand three-dimensional (3D) networking have encountered a rapid change in their applications, from professional toys to professional application-specific complex IoT devices [2, 3, 4]. In modern embedded drone design and implementation, drones are integrated with several sensors, including cameras and global positioning system (GPS), and thus, they are actively and widely used in various fields. It means the drones are not only used for live broadcasts, agriculture, and weather forecasting but also have potentials to be used in global logistics or future mobility to bring dramatic convenience to human life. For more details, when drones are utilized in agriculture applications, multi-drone networking platform can manage vast farms, diagnose crop conditions, and provide appropriate solutions to increase productivity [5]. In the field of logistics, enterprises like Amazon have launched drone delivery pilot services, delivering packages safely and on time through fully autonomous driving systems. Kong et al. [6] also conducted a research project to optimize the drone path/trajectory using attention-based pointer networks for future mobility applications. In future mobility, when vertiports are built in smart cities, drone taxis are expected to transport passengers [7].
In order to fully utilize the drone-related technologies in many emerging applications, research to control the drone mobility in an autonomous way is essentially required. To design and implement the algorithms for the autonomous drone mobility control, the use of deep reinforcement learning (DRL) is one of the promising deep learning algorithms because DRL is formally defined as a discrete-time stochastic decision-making control process for maximizing the expected return/utility. Furthermore, during drone trajectory control in various applications, many obstacles (such as buildings and structures) can exist. Therefore, nonlinear autonomous drone mobility control under the consideration of near-field situation sensing is essentially desired for avoiding the obstacles in physical worlds. Although major studies have been conducted on how drones avoid obstacles via situation-aware DRL algorithms, this research contribution is inappropriate for military usage (such as loitering munition) as it has been studied in terms of multi-drone swarm flight for attacking target areas via autonomous nonlinear drone mobility control [8, 9].
In considering multi-drone autonomous networks, the use of cyber-physical systems for interacting/mapping between the actions in the virtual environment and the ones in the real world environment is getting a lot of attention in industry and academia [10, 11, 12, 13]. The CPS technologies are based on the integration of communications, networking, sensing, mechatronics, and data analytics. Therefore, CPS is widely used in many industrial applications such as smart production, smart electric grids, smart logistics, and smart health care [13, 14]. In order to realize the interaction/mapping between the actions in the virtual environment and the ones in the physical environment, visualization tools (such as Unity) can be definitely helpful because the algorithm designers can intuitively and immediately understand and validate the algorithm functionalities, as well-studied in [12, 15, 16, 17].
I-B Use Cases
In this paper, among various promising applications and use cases in order to utilize DRL algorithms in multi-drone networks, military applications are considered because it is one of the promising topics nowadays based on the big success in modern wars, especially in urban areas. In the military field, the application-specific drones can take on a variety of roles, such as monitoring the enemy, providing supplies, and executing combat missions, as illustrated in Fig. 1. Despite the short operation time due to the limitations of batteries (approximately a few tens of minutes), military drones have a significant advantage in swiftly navigating areas that infantry cannot observe, with avoiding pursuit. In December 2022, the South Korean military failed to track five North Korean drones that invaded South Korean airspace, sending them all back to North Korea [18]. In modern warfare, drone attacks while operating loitering munitions have become an inevitable strategy to gain the upper hand in wars. As one example of the use of drones in wars, military-purpose drones are also used in the current war between Ukraine and Russia. The SwitchBlade 300 loitering munition, made by AeroVironment of the United States, is being used successfully to attack the Russian garrison and tanks [19]. According to the Russian defense ministry, the drone attack on Russian bases fatally wounded three technical Russian staff [20]. Furthermore, dogfights between reconnaissance drones have also occurred [21]. There have also been some cases of massive damage caused by drone attacks. Saudi Arabia’s state-owned oil refinery enterprise, Aramco, was hit by more than 17 loitering munition trials at its two refineries in 2019 [22]. More than 20 drones each carried more than three kilograms of explosives and suffered massive damage, disrupting supplies of 5.7 million barrels of petroleum. It was a situation caused by the lack of defense measures and an opportunity to remind people of the need to build defense systems.
I-C Algorithm Design Rationale
According to the modern trends in the usage scenarios of drone networks, we can observe that drones can be effective and efficient in battlefield autonomous unmanned defense system design based on autonomous multi-drone UAV mobility control cooperation and coordination. For the purpose, deep reinforcement learning (DRL) algorithms can be the best solution due to the nature of discrete-time stochastic control and sequential decision-making processes. Among various DRL algorithms, our proposed algorithm is fundamentally designed based on deep deterministic policy gradient (DDPG) for utilizing continuous action space in order to realize nonlinear drone mobility control [23, 24, 25]. Furthermore, for dealing with unexpected blockage and real-time environment changes dynamically in the physical worlds, situation-aware mechanisms are additionally considered on top of DDPG-based DRL design. In previous research results, drones fly over slight-line trajectories, thus it is not possible to consider nonlinear drone mobility control for avoiding blockages [24, 26, 27, 28, 29].
I-D Contributions
The major contributions of this research in situation-aware DDPG-based nonlinear drone mobility control can be summarized as follows.
-
•
First of all, our proposed DRL-based algorithm fundamentally aims at autonomous nonlinear drone mobility control based on near-field situation sensing for taking care of obstacles. In the literature, many approaches are using pure DRL algorithms without situation-awareness, which can be harmful in an urban battlefield environment where the locations are with many obstacles (blockages, buildings, and structures). This situation-aware nonlinear mobility control is definitely beneficial in our considering applications, i.e., autonomous drone mobility control for loitering munition.
-
•
Moreover, the proposed situation-aware DRL-based autonomous nonlinear drone mobility control algorithm is also implemented with Unity 3D Environment for loitering munition mobility control. This implementation with Unity 3D Environment is the essential part for the realization of CPS for interacting and matting the actions in the virtual environment and the ones in the real world for better intuitive and efficient understanding to the algorithm designers and system users (military officers and soldiers).
-
•
Lastly, compared to our previous work [1], this paper mathematically specified the algorithm and the performances are evaluated in various ways.
I-E Organization
The rest of this paper is organized as follows. Sec. II presents the related work of drone technologies and reinforcement learning. Sec. III explains our proposed situation-aware autonomous nonlinear drone mobility control algorithm with mathematical analysis, and Sec. IV includes simulation-based performance evaluation results with corresponding discussions. Finally, Sec. V concludes this paper and presents future research directions.
II Related Work
There are a lot of research results in terms of drone trajectory optimization and mobility control. In order to design the drone mobility control algorithms, each research contribution is with its own objective for the mobility control. In [30], DRL-based multi-drone mobility control algorithms are designed and implemented under the considerations of weights and batteries which can restrict the drone’s flight time and mobility. This type of research results is to optimize the trajectories of drones to move efficiently within a limited time [31]. In addition, free-space optical communication (FSOC) is employed to deal with the trajectory optimization of a fixed-wing UAV over various atmospheric conditions, as well-presented in [31].
The autonomous drone mobility control algorithms can be also designed under the consideration of the drone’s specific applications and objectives. In [32], the drone mobility control algorithms are designed using multi-agent DRL for CCTV-based surveillance systems in smart city applications. In addition, autonomous drone mobility control algorithms can be designed for cooperative and coordinated mobile access points and base-stations positioning [33, 34, 35, 36]. Furthermore, the proposed DRL-based algorithm in [7] aims at optimal passenger delivery in urban air mobility (UAM) applications (i.e., drone-taxi) while avoiding accidents. The algorithm in [7] is distributed DRL-based mobility control to electric vertical takeoff and landing (eVTOL) drone platforms for UAM passenger delivery applications. The eVTOL vehicles search for the optimal passenger transport routes under the consideration of passengers’ behaviors, collision potentials, and battery status levels through QMIX-based multi-agent DRL.
According to the fact that it is essential to develop power-charging algorithms in power-hungry drones, the proposed multi-agent DRL algorithm in [37] studied an outdoor environment ad-hoc battery charging method for multiple drone environment. For the sake of overcoming the lack of charging platform and the pressing of charging time, an auction-based resource allocation using deep learning framework is employed to perform the charging schedule. The main reason why auction-based algorithms should be used in this problem is that it is fully distributed (i.e., also working with only neighbor information under uncertainty) and truthful [37]. The proposed Myerson auction with a deep learning framework is to ensure dominant strategy incentive compatibility (DSIC) and individual rationality (IR) for truthful operations. According to the data-intensive performance evaluation for the proposed algorithm, it ensures optimal revenue under the considerations of DSIC and IR while achieving revenue-optimality. Lastly, the proposed multi-agent DRL-based drone mobility control algorithm in [38] is for joint cooperative power-charging control and drone charging scheduling under the support of built-in infrastructure, i.e., charging towers. The proposed algorithm in the paper determines scheduling between drones and charging towers at first. During this phase, it has been confirmed that the proposed scheduling optimization framework is non-convex; thus, it is converted to convex with some mathematical theories. After that, the amounts of power-charging in the scheduled drone-tower pairs are determined based on multi-agent DRL.
III Situation-Aware and DRL-based Autonomous Nonlinear Drone Mobility Control for Loitering Munition
Our proposed autonomous nonlinear drone mobility control algorithm is fundamentally designed on top of the deep deterministic policy gradient (DDPG) algorithm, which is one of the well-known policy-gradient (PG) DRL frameworks. By utilizing the PG-based DRL algorithms, the shortcomings of the existing value-based deep Q-network (DQN) algorithms can be compensated [39]. Unlike the value-based algorithms, which can only be applied to the environments with discrete actions, DDPG-based DRL algorithms can handle the continuous movements of drones [23]. To conduct action inference computation in A2C, an function should be used after passing through the actor network, which is infeasible for continuous action spaces. To take care of this issue, our proposed autonomous nonlinear drone mobility control algorithm is designed based on DDPG because it aims at continuous action control. There are also differences in how the network is updated for training via gradient descent. A2C updates its own actor network by evaluating actions, using the estimation of its own Q-function. On the other hand, our considering DDPG-based algorithm updates the critic network by temporal difference (TD) target to improve the stability.
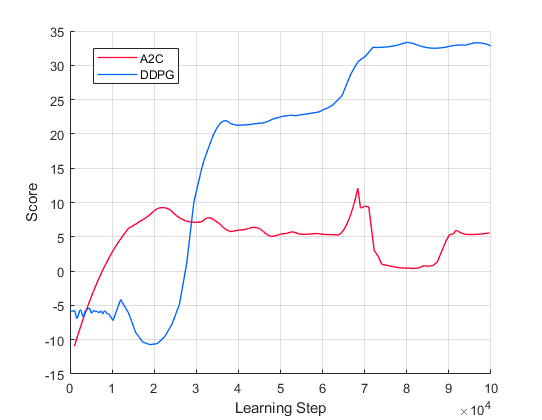
When the action control and experiments are conducted for drone aerial movements using conventional PG-based DRL algorithms such as actor-critic (A2C)-based algorithms, the corresponding modeling can increase (+) and decrease (-) the movements in 3D , , and directions, e.g., , , , , , and , respectively. However, according to the simulation-based verification as shown in Fig. 2, we can observe that the performance of A2C-based algorithms is significantly lower than that of DDPG-based algorithms because DDPG-based algorithms can control the mobility via continuous action control which is easily tractable for nonlinear continuous behavior modeling and computation.
Note that the parameters of the actor neural network and the critic neural network as denoted as and in our desired DDPG-based DRL algorithm computation. In addition, the objectives of actor and critic network are for our actor network to maximize action-value derived from critic network, as well as for our critic network to follow Bellman’s equation which consists of the target critic network and reward function, respectively. For this purpose, our proposed DDPG-based DRL algorithm adopts a greedy policy that the actor network approximates the action which maximizes action-value function (i.e., critic network) for given state , which can be expressed as,
| (1) |
The parameter of the actor neural network should meet the following optimization criteria,
| (2) |
and the parameter can be calculated by maximizing based on following stochastic gradient ascent computation,
| (3) |
Now, the gradient for in can be expressed as follows,
| (4) | ||||
| (5) | ||||
| (6) |
according to a chain rule.
We can now calculate TD error using the target critic neural network as follows,
| (7) | ||||
| (8) | ||||
| (9) |
where and stand for the next state and the action given state-action , respectively. The loss function of actor neural network is defined as follows,
| (10) |
where
| (11) |
is the gradient obtained by stochastic gradient descent methods, and thus, (10) indicates that the neural network updates its parameters for the direction of loss function minimization.
In addition, the loss function of the critic neural network is calculated with a TD target as follows,
| (12) |
where
| (13) |
as described in (7). Note that the action is calculated by applying target actor neural network parameterized to . Our proposed DDPG-based DRL algorithm applies soft target update method, which means the parameter of the target neural network follows the actor neural network slowly, setting with a very small value, i.e.,
| (14) |
According to the fact that our proposed DDPG-based DRL algorithm is a deterministic policy based algorithm, it is required to provide randomness to the action. Therefore, a noise factor is added to the action as shown in (15),
| (15) |
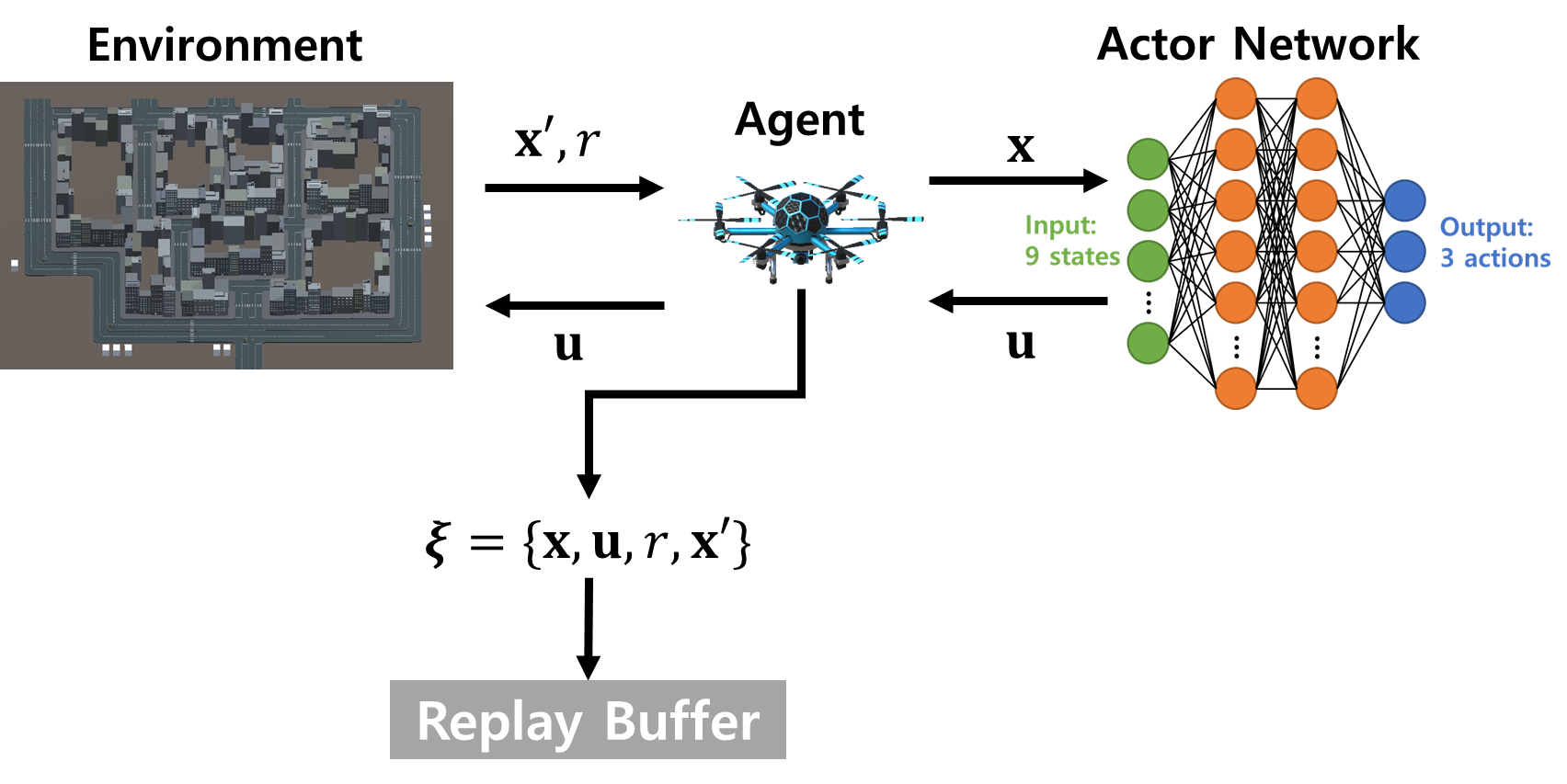
Our proposed algorithm’s state space contains information about the agent and the environment. The difference between the coordinate vector of the drone and the target, and the vector represents the drone’s flight speed and angular speeds are included in the state space. For realizing the obstacle factors in drone mobility control, a Raycast function is provided by Unity in the state space. Note that the Raycast is a function that shoots a virtual laser, and it can detect the direction and distance between the agent and the obstacle by shooting lasers in vertical or horizontal directions. In addition, the actions are defined as the moves over , , and directions, respectively. Finally, we can confirm that situation-awareness can be realized by the Raycast function for utilizing virtual laser functionalities.

The proposed algorithm is different from the existing conventional DDPG because it can recognize surrounding objects, i.e., situation-awareness. As explained, we added the Raycast function provided by Unity to identify nearby obstacles, where the Raycast is a function that casts virtual rays from the moving object to measure the distance to another object or determine whether the laser reaches an object. Fig. 3 represents the Raycast shot from the agent. In Fig. 3, the drone/agent can know that there are no obstacles at the 12 o’clock, 1 o’clock, and 9 o’clock directions through the Raycast. In addition, considering the previously acquired location information of the target, the drone/agent will act to fly in the direction of 1 o’clock. A ray in the vertical direction measures the distance to the ground and is used to avoid colliding with the ground. In order to induce the drone/agent to avoid surrounding obstacles, when the launched ray collides with an obstacle, the drone/agent gets a negative reward that is inversely proportional to the distance to the obstacle. By recognizing obstacles through Raycast, our proposed situation-aware autonomous nonlinear drone mobility control algorithm is designed.
The pseudo-code of our proposed situation-aware DDPG-based algorithm is described in Algorithm 1. First of all, the weights and of actor/critic networks and the weights and of target network are initialized. After that, a replay buffer is also initialized in the last part of the episode. For each minibatch, states are randomly generated and get the appropriate set of actions for each state . After that, the drone/agent recognizes obstacles around itself through Raycast observation for situation-aware DRL computation, and stores the information in state space , in (line 7). Then we input the and pairs to predesigned drone environments and obtain the set of reward for each pair, and observe the next state . The actor network uses the state obtained from the drone as an input, and calculates an appropriate action as an output through two fully connected layers. The drone agent that receives the action performs the corresponding action in the environment and gets the next state . The observed transition pairs from the drone/agent are saved as a minibatch , as shown in Fig. 4.
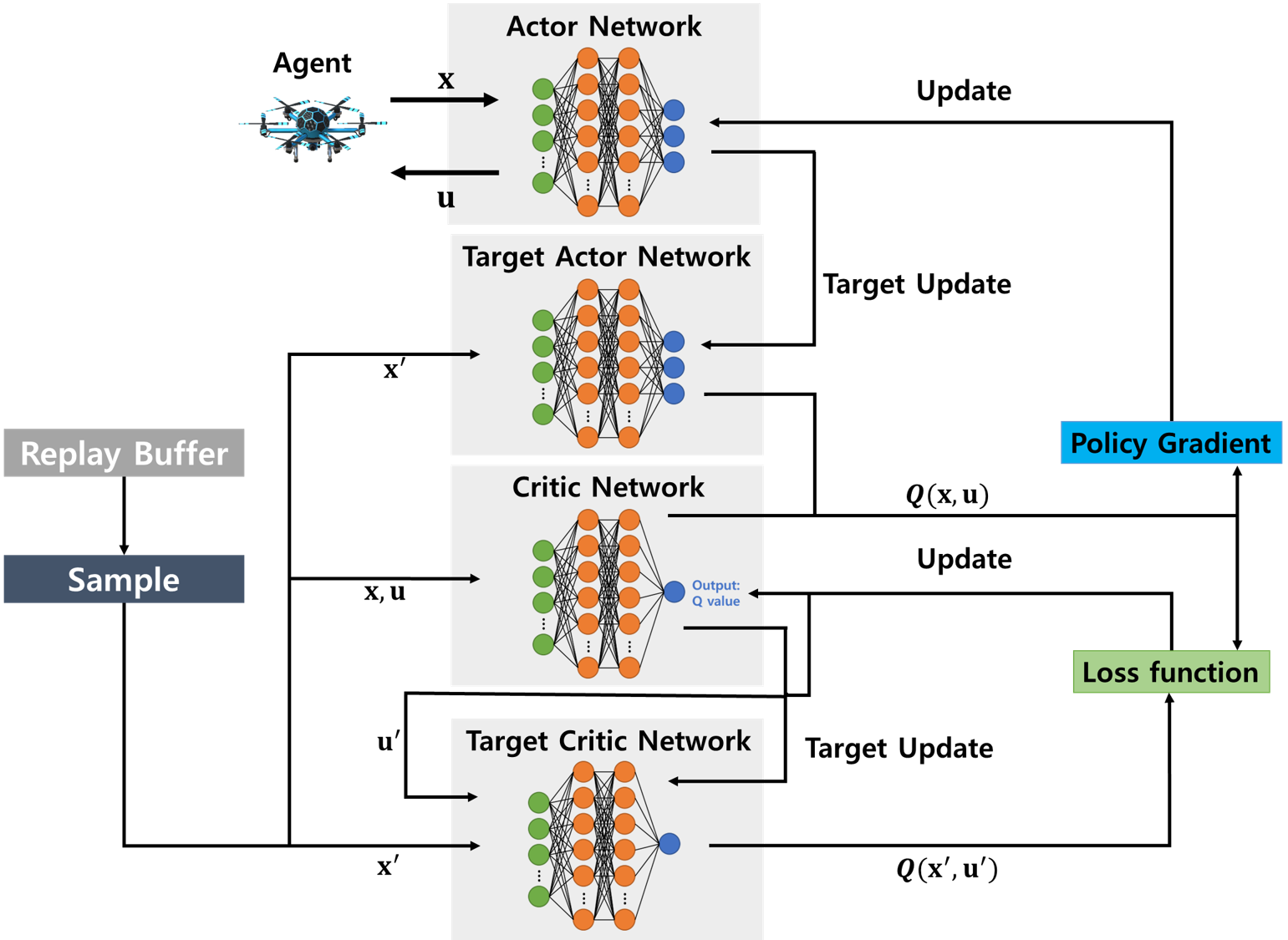
During the next phase, we should update the networks regularly. For each time step, if the time step is in the update period, we sample a random minibatch without replacement from the replay buffer . In the successive policy decision process, in order to solve the correlation problem between samples, the learning outcome can be increased by performing learning in the replay buffer in the unit of samples. To obtain the network’s TD target, this algorithm calculates the equation in (line 17) of Algorithm 1. The random sample extracted from the tuple delivered to the replay buffer by the drone/agent in Fig. 4 becomes the input of the target actor network, critic network, and target critic network, as shown in Fig. 5. Finally, this algorithm updates the target critic and the target actor network for time steps and ends the algorithm computation procedure. The stability of learning can be increased through the usage of target networks. The update of the critic network and the two target networks using the loss function and the policy gradient method is a series of processes for maximizing the expected reward by eventually deriving more appropriate actions for the actor network.
IV Performance Evaluation
IV-A Unity Environment
Unity is a 3D tool-creating platform that utilizes Unity Machine Learning Agents (ML-Agents), an API to support artificial intelligence for training agents through Unity. The ML-Agents basically support various functions for DRL learning computation. In real world scenarios, the use of DRL algorithms to multi-drone mobility control takes much longer time and can lead to costs, tens of times or more. Therefore, the use of DRL algorithms in a simulation environment is suitable, whereas it is not suitable in the physical/real world. The software architecture for RL/DRL trainers and Unity environment is illustrated in Fig. 6. We build the environment using the assets furnished by Unity 3D and set it by applying the ML-Agent to the environment [40]. Then the drone/agent is trained by employing a PyTorch-based reinforcement learning trainer. When the learning is completed, it is embedded into the Unity environment through the communicator. Finally, the Unity environment with the trained agent is created.
IV-B Evaluation Settings

We build the city environment (for emulating urban military battlefield scenarios) through the Unity Asset Store. In addition, we add drone and tank assets to the environment scene. The drone is set as an agent, and the target with the tank shape is set as a game object. The batch size of each neural network is set to 128, and the discount factor from the previous step is set to 0.9. The learning computation is carried out for a total of 100,000 steps, and the test step is performed 10,000 times. The critic network updates the Q-function in the direction of reducing the difference between the predicted value and target value. Moreover, the policy of the actor network is updated to maximize the objective function through two fully connected layers, which have the size of 128. The agents and targets are generated randomly within a designated area, respectively, and the target moves forward at a constant speed. To ensure that the agent does not consider staying in place as optimal, we start with the addition of the reward of -0.01 by default. In order to induce the drone to approach the target gradually, a value obtained by subtracting the current distance from the previous distance is reflected in the compensation function. When the drone reaches the target, it receives a reward of +1; if it is too far from the target or collides with the obstacle, it receives a reward of -1 and ends the episode. If an obstacle is recognized nearby through the Raycast (i.e., situation-awareness), a negative reward is given so that the agent learns to avoid the obstacle. By acquiring information about surrounding obstacles, the proposed situation-aware autonomous nonlinear drone mobility control algorithm can obtain better results compared to the conventional DDPG-based DRL algorithm.
In order to evaluate the algorithm in various ways and more difficult environments, the cyber environment that can be harsher (i.e., more obstacles) than the physical situation is constructed. By setting different densities of obstacles in the cyber environment with no obstacles at all to environments where it is harsh for the agent to pass through, the robustness of the algorithm can be evaluated, especially in environments with densely distributed obstacles. Fig. 7 depicts the top-down view of the environment where the obstacle density is set to 20%, 50%, 80%, and 100%, respectively. Note that the obstacles are created in random sizes in random locations between the agent and the target in each episode. The agent and the target are also produced at random positions within a designated space.
IV-C Evaluation Results

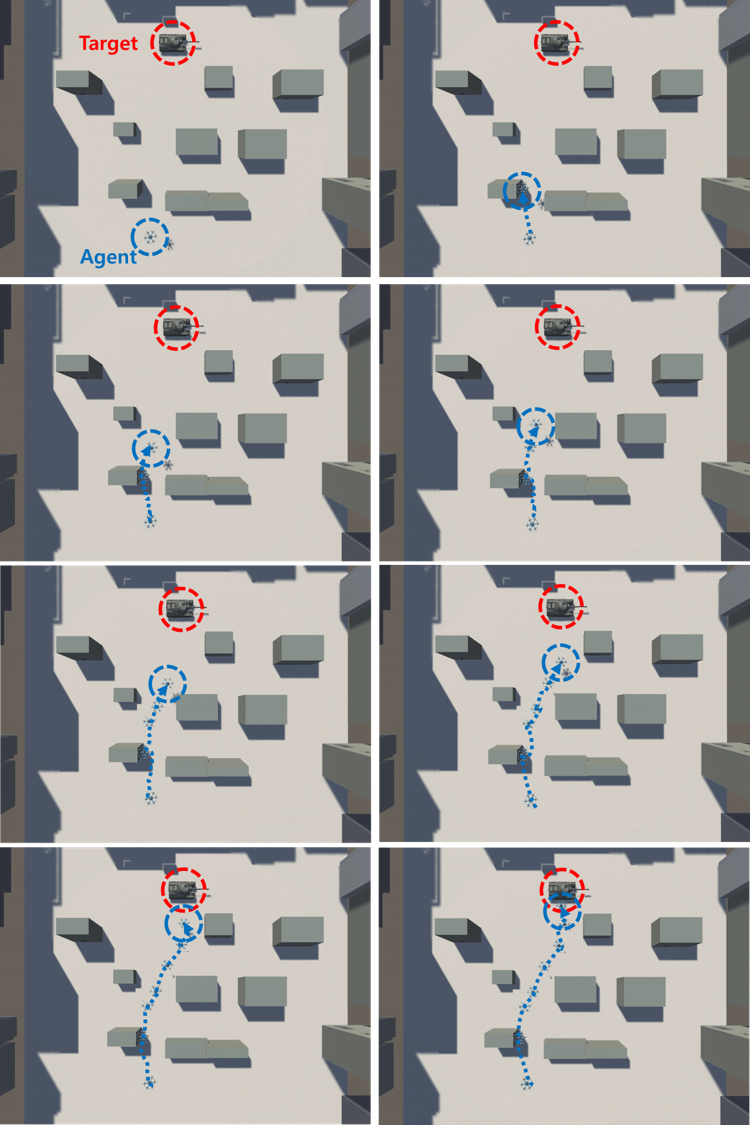
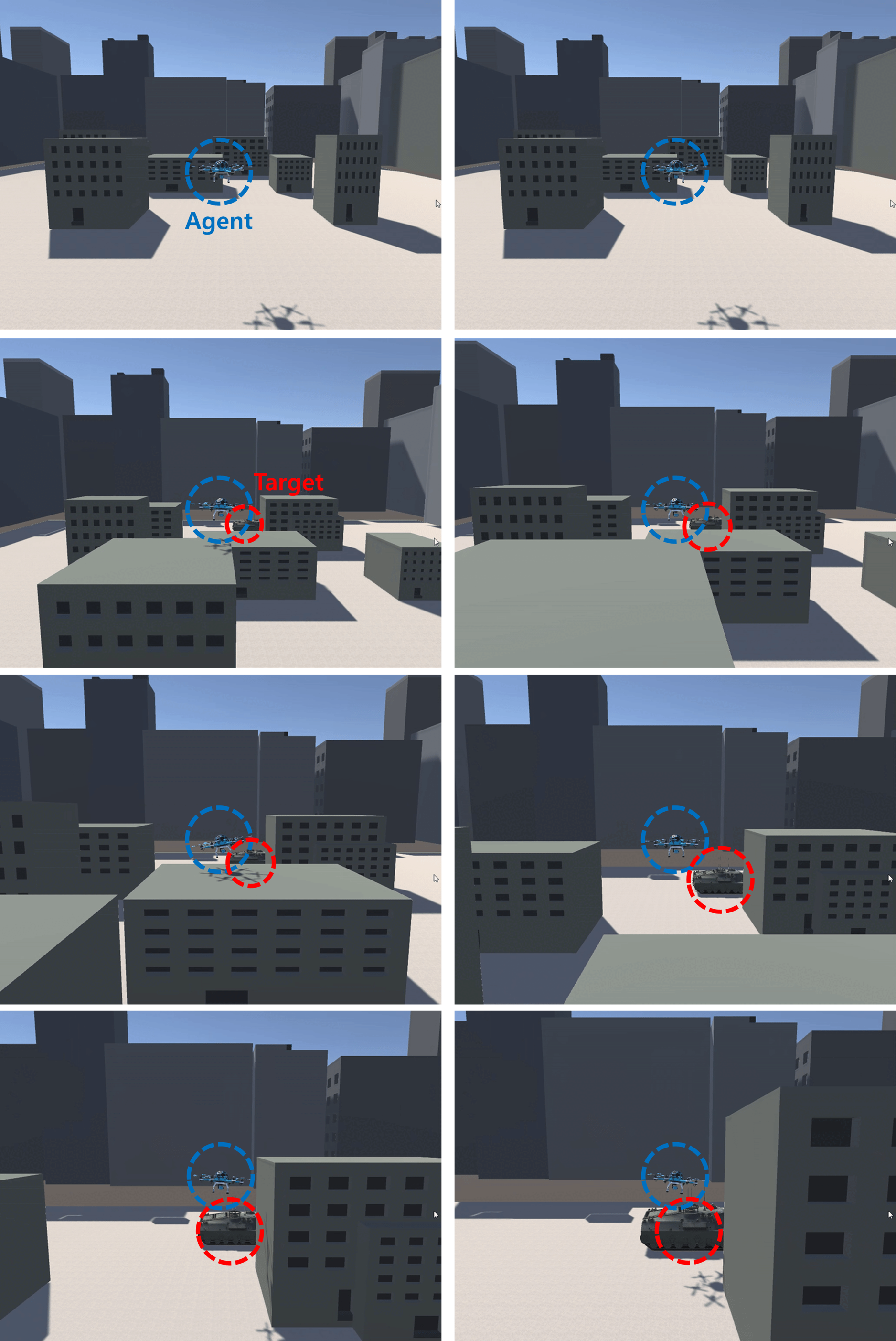
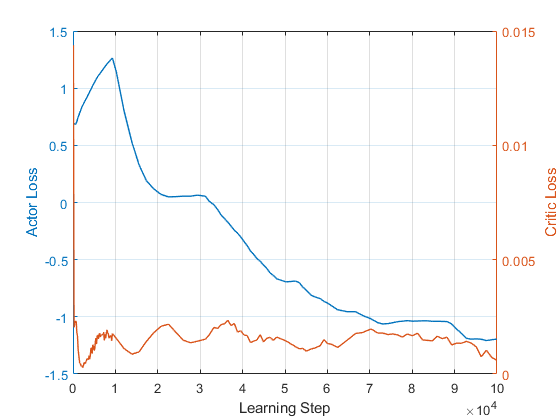
Fig. 8 shows the actor loss and critic loss, which indicates the convergence of the proposed actor/critic-enabled DDPG-based DRL algorithm. The actor loss and critic loss values also decreased as learning data were accumulated, as described in Fig. 8. A decrease in actor loss means that the action value is maximized, and thus the cumulative reward is maximized. In addition, the reduction in the critical loss indicates that the actor network approaches the optimal Q-network according to Bellman’s expectation equation, as described in (7). Fig. 9 depicts the case where a drone reaches a target (tank) while avoiding obstacles in six frames, in a physical urban environment. As shown in Fig. 9, a trained drone/agent can accurately reach a target (tank). The white arrow is a predicted trajectory of the conventional linear mobility control (LMC), which may not be able to reach the target. It can be seen that the learning was performed smoothly in both the visualized simulations and the corresponding numerical values.
In order to show the robustness of the algorithm, the experimental results in the cyber-physical space with many obstacles are shown in Fig. 10 and Fig. 11. According to the benefits of the nature of autonomous nonlinear drone mobility control, the drone/agent found its destination well, even in the cyber CPS systems with dense obstacles. In Fig. 10, we can find out that the drone/agent controls its altitude autonomously, as displayed through the drone/agent’s shadow. We can check the trajectory drawn by the drone/agent through the top-down view, but we cannot confirm the height difference of the buildings. For more details, in Fig. 11, we can see that the drone/agent is controlling its altitude autonomously, as depicted in a third-person view avoiding obstacles and reaching the target/tank. In the top-down view, it may seem to fly very close to the building, but in the third-person view expressed in Fig 11, you can confirm that the drone is flying while adjusting the altitude and distance from the building.
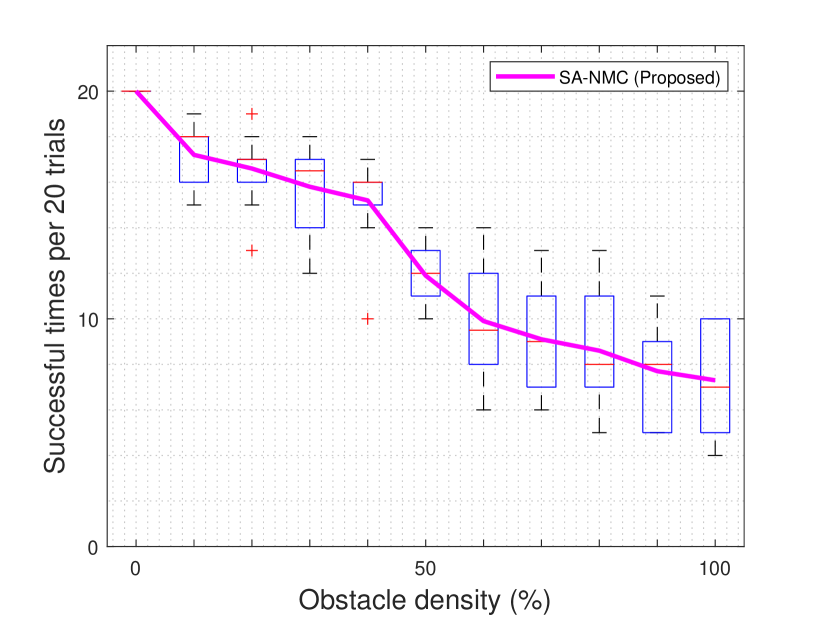
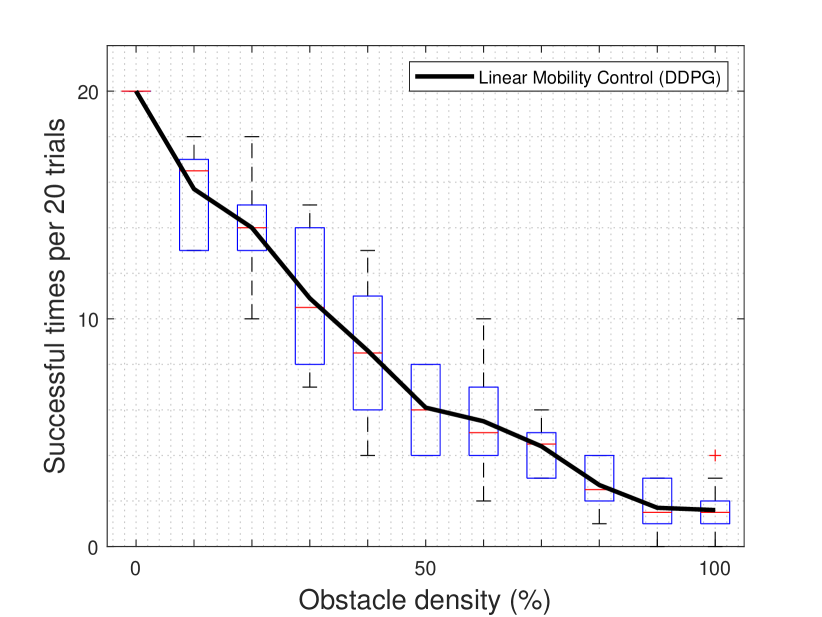
Fig. 12 shows the number of successful attacks according to the density of obstacles. In the cyber-physical visualization environment, each experiment was performed for 10 rounds, 20 times in one environment, and the number of times that the target was successfully reached/destroyed was measured in each round. If there are no obstacles, the drone/agent successfully reaches the target/tank in all trials, however the accuracy decreases as the density of the obstacles increases. Notice that the comparison between Fig. 12(a) and Fig. 12(b) is presented in Appendix A. Moreover, this results are numerically presented in Table I and Table II. When the obstacle density becomes 50%, our comparing LMC algorithm shows about 48% less performance than our proposed situation-aware autonomous nonlinear drone mobility control algorithm. In addition, even with the maximum number of obstacles deployed, our proposed algorithm succeeded in attacking at least four times. This matches the maximum number of successful attacks of conventional DDPG algorithms in the same environment and shows a maximum attack success rate of 2.5 times better than the rate of conventional DDPG algorithm. In particular, in an environment with high obstacle density, our comparing LMC algorithm is almost impossible to use, whereas our proposed situation-aware autonomous nonlinear drone mobility control algorithm can be operated in the same environment. In Table III, the performance difference between the two algorithms is compared and summarized. Overall, the higher density of obstacles introduces better performance improvements. When the obstacle density exceeds 70%, the performance improvement becomes at least 100%, as presented in Table III.
| Nonlinear Mobility Control (Proposed) | 0% | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Round 1 | 20/20 | 18/20 | 16/20 | 14/20 | 14/20 | 12/20 | 10/20 | 13/20 | 10/20 | 8/20 | 7/20 |
| Round 2 | 20/20 | 15/20 | 17/20 | 17/20 | 15/20 | 10/20 | 7/20 | 9/20 | 8/20 | 7/20 | 7/20 |
| Round 3 | 20/20 | 18/20 | 13/20 | 12/20 | 17/20 | 13/20 | 8/20 | 9/20 | 11/20 | 5/20 | 5/20 |
| Round 4 | 20/20 | 16/20 | 18/20 | 17/20 | 16/20 | 11/20 | 9/20 | 6/20 | 7/20 | 8/20 | 7/20 |
| Round 5 | 20/20 | 17/20 | 17/20 | 14/20 | 16/20 | 12/20 | 14/20 | 11/20 | 5/20 | 10/20 | 10/20 |
| Round 6 | 20/20 | 18/20 | 17/20 | 18/20 | 15/20 | 12/20 | 6/20 | 6/20 | 11/20 | 9/20 | 8/20 |
| Round 7 | 20/20 | 18/20 | 17/20 | 17/20 | 16/20 | 12/20 | 14/20 | 13/20 | 6/20 | 11/20 | 10/20 |
| Round 8 | 20/20 | 15/20 | 19/20 | 17/20 | 17/20 | 14/20 | 8/20 | 9/20 | 13/20 | 5/20 | 4/20 |
| Round 9 | 20/20 | 19/20 | 15/20 | 16/20 | 16/20 | 13/20 | 12/20 | 7/20 | 7/20 | 5/20 | 5/20 |
| Round 10 | 20/20 | 18/20 | 17/20 | 16/20 | 10/20 | 10/20 | 11/20 | 8/20 | 8/20 | 9/20 | 10/20 |
| Maximum | 20 | 19 | 19 | 18 | 17 | 14 | 14 | 13 | 13 | 11 | 10 |
| Average | 20 | 17.2 | 16.6 | 15.8 | 15.2 | 11.9 | 9.9 | 9.1 | 8.6 | 7.7 | 7.3 |
| Median | 20 | 18 | 17 | 16.5 | 16 | 12 | 9.5 | 9 | 8 | 8 | 7 |
| Minimum | 20 | 15 | 13 | 12 | 10 | 10 | 6 | 6 | 5 | 5 | 4 |
| Linear Mobility Control (DDPG) | 0% | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Round 1 | 20/20 | 13/20 | 17/20 | 15/20 | 9/20 | 4/20 | 5/20 | 6/20 | 4/20 | 2/20 | 2/20 |
| Round 2 | 20/20 | 17/20 | 13/20 | 13/20 | 10/20 | 8/20 | 4/20 | 4/20 | 2/20 | 1/20 | 1/20 |
| Round 3 | 20/20 | 17/20 | 15/20 | 14/20 | 6/20 | 6/20 | 4/20 | 5/20 | 2/20 | 3/20 | 1/20 |
| Round 4 | 20/20 | 13/20 | 14/20 | 9/20 | 11/20 | 8/20 | 2/20 | 6/20 | 3/20 | 2/20 | 2/20 |
| Round 5 | 20/20 | 18/20 | 18/20 | 10/20 | 12/20 | 6/20 | 9/20 | 3/20 | 1/20 | 3/20 | 1/20 |
| Round 6 | 20/20 | 15/20 | 13/20 | 14/20 | 7/20 | 8/20 | 10/20 | 4/20 | 4/20 | 3/20 | 0/20 |
| Round 7 | 20/20 | 13/20 | 11/20 | 8/20 | 8/20 | 4/20 | 5/20 | 5/20 | 3/20 | 1/20 | 2/20 |
| Round 8 | 20/20 | 17/20 | 15/20 | 11/20 | 6/20 | 4/20 | 5/20 | 5/20 | 2/20 | 1/20 | 3/20 |
| Round 9 | 20/20 | 18/20 | 10/20 | 7/20 | 4/20 | 7/20 | 4/20 | 3/20 | 2/20 | 0/20 | 0/20 |
| Round 10 | 20/20 | 16/20 | 14/20 | 8/20 | 13/20 | 6/20 | 7/20 | 3/20 | 4/20 | 1/20 | 4/20 |
| Maximum | 20 | 18 | 18 | 15 | 13 | 8 | 10 | 6 | 4 | 3 | 4 |
| Average | 20 | 15.7 | 14 | 10.9 | 8.6 | 6.1 | 5.5 | 4.4 | 2.7 | 1.7 | 1.6 |
| Median | 20 | 16.5 | 14 | 10.5 | 8.5 | 6 | 5 | 4.5 | 2.5 | 1.5 | 1.5 |
| Minimum | 20 | 13 | 10 | 7 | 4 | 4 | 2 | 3 | 1 | 0 | 0 |
| Performance Improvement(%) | 0% | 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Maximum | 0 | 5.5 | 5.5 | 20 | 30.77 | 75 | 40 | 116.67 | 225 | 266.67 | 150 |
| Average | 0 | 9.55 | 18.57 | 44.95 | 76.74 | 95.08 | 80 | 106.82 | 218.52 | 352.94 | 356.25 |
| Median | 0 | 9.09 | 21.43 | 57.14 | 88.24 | 100 | 90 | 100 | 220 | 433.33 | 366.67 |
| Minimum | 0 | 15.38 | 30 | 71.43 | 150 | 150 | 200 | 100 | 400 | - | - |
V Concluding Remarks and Future Work
This paper proposes a novel situation-aware autonomous nonlinear drone mobility control DRL-based algorithm in cyber-physical loitering munition applications. On the battlefield, the design and implementation of a DRL-based algorithm are not straightforward because real-world data gathering is not easy at all. Therefore, the cyber-physical virtual environment is constructed with Unity in this paper. Based on that, a DRL-based automated drone mobility control algorithm can be designed, evaluated, and visualized. In real world battlefield scenarios, many obstacles exist which is harmful to linear trajectory control. Therefore, this paper proposes a novel nonlinear drone mobility control using situation-aware components (e.g., Raycast function in Unity for the virtual environment). Based on the sensed situation-aware information, the drone can adjust its trajectory during flight. Therefore, this approach can be definitely beneficial for avoiding obstacles on the battlefield. Our visualization-based performance evaluation shows that the proposed algorithm is superior to the other conventional linear mobility control algorithms.
As future research directions, the proposed algorithm can be implemented on top of embedded drone platforms where the platforms are equipped with multiple sensors for situation-awareness functionalities.
References
- [1] H. Lee, W. J. Yun, S. Jung, J.-H. Kim, and J. Kim, “DDPG-based deep reinforcement learning for loitering munition mobility control: Algorithm design and visualization,” in Proc. IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), Seoul, Korea, August 2022.
- [2] S. Anokye, D. Ayepah-Mensah, A. M. Seid, G. O. Boateng, and G. Sun, “Deep reinforcement learning-based mobility-aware UAV content caching and placement in mobile edge networks,” IEEE Systems Journal, vol. 16, no. 1, pp. 275–286, 2022. [Online]. Available: https://doi.org/10.1109/JSYST.2021.3082837
- [3] W. Na, N. Dao, and S. Cho, “Reinforcement-learning-based spatial resource identification for IoT D2D communications,” IEEE Systems Journal, vol. 16, no. 1, pp. 1068–1079, 2022. [Online]. Available: https://doi.org/10.1109/JSYST.2021.3087167
- [4] Y. Shi, E. Alsusa, and M. W. Baidas, “Energy-efficient decoupled access scheme for cellular-enabled UAV communication systems,” IEEE Systems Journal, vol. 16, no. 1, pp. 701–712, 2022. [Online]. Available: https://doi.org/10.1109/JSYST.2020.3046689
- [5] C. Singh, R. Mishra, H. P. Gupta, and P. Kumari, “The Internet of drones in precision agriculture: Challenges, solutions, and research opportunities,” IEEE Internet of Things Magazine, vol. 5, no. 1, pp. 180–184, March 2022.
- [6] F. Kong, J. Li, B. Jiang, H. Wang, and H. Song, “Trajectory optimization for drone logistics delivery via attention-based pointer network,” IEEE Transactions on Intelligent Transportation Systems (Early Access), pp. 1–13, May 2022.
- [7] W. J. Yun, S. Jung, J. Kim, and J.-H. Kim, “Distributed deep reinforcement learning for autonomous aerial eVTOL mobility in drone taxi applications,” ICT Express, vol. 7, no. 1, pp. 1–4, March 2021.
- [8] J. Hu, X. Yang, W. Wang, P. Wei, L. Ying, and Y. Liu, “Obstacle avoidance for UAS in continuous action space using deep reinforcement learning,” IEEE Access, vol. 10, pp. 90 623–90 634, August 2022.
- [9] S. Qamar, S. H. Khan, M. A. Arshad, M. Qamar, J. Gwak, and A. Khan, “Autonomous drone swarm navigation and multi-target tracking with island policy-based optimization framework,” IEEE Access, pp. 1–1, August 2022.
- [10] U. Bodkhe, D. Mehta, S. Tanwar, P. Bhattacharya, P. K. Singh, and W.-C. Hong, “A survey on decentralized consensus mechanisms for cyber physical systems,” IEEE Access, vol. 8, pp. 54 371–54 401, 2020.
- [11] R. Atat, L. Liu, J. Wu, G. Li, C. Ye, and Y. Yang, “Big data meet cyber-physical systems: A panoramic survey,” IEEE Access, vol. 6, pp. 73 603–73 636, 2018.
- [12] H.-D. Tran, F. Cai, M. L. Diego, P. Musau, T. T. Johnson, and X. Koutsoukos, “Safety verification of cyber-physical systems with reinforcement learning control,” ACM Transactions on Embedded Computing Systems (TECS), vol. 18, no. 5s, pp. 1–22, 2019.
- [13] C. Sun, G. Cembrano, V. Puig, and J. Meseguer, “Cyber-physical systems for real-time management in the urban water cycle,” in Proc. IEEE International Workshop on Cyber-physical Systems for Smart Water Networks (CySWater), 2018, pp. 5–8.
- [14] Z. Wang, H. Song, D. W. Watkins, K. G. Ong, P. Xue, Q. Yang, and X. Shi, “Cyber-physical systems for water sustainability: Challenges and opportunities,” IEEE Communications Magazine, vol. 53, no. 5, pp. 216–222, 2015.
- [15] W.-T. Wang, C.-H. Chang, and R.-N. Sheng, “The study on the implementation of multi-axis cutting & cyber-physical system on unity 3D platform,” in Proc. IEEE International Conference on Industrial Engineering and Applications (ICIEA), 2019, pp. 77–80.
- [16] W.-Y. Chang, B.-Y. Hsu, and J.-W. Hsu, “Real-time collision avoidance for five-axis CNC machine tool based on cyber-physical system,” in Proc. IEEE International Conference on Advanced Manufacturing (ICAM), 2018, pp. 284–287.
- [17] C. Villacís, W. Fuertes, L. Escobar, F. Romero, and S. Chamorro, “A new real-time flight simulator for military training using mechatronics and cyber-physical system methods,” Military Engineering, pp. 73–90, 2020.
- [18] K. Armstrong, “North Korea drones: South’s military apologises for pursuit failure,” BBC, December 2022, last accessed 30 December 2022. [Online]. Available: https://www.bbc.com/news/world-asia-64100974
- [19] D. Hambling, “Failure Or Savior? Busting Myths About Switchblade Loitering Munitions In Ukraine,” Forbes, June 2022, last accessed 16 November 2022. [Online]. Available: https://www.forbes.com/sites/davidhambling/2022/06/08/failure-or-savior-busting-myths-about-switchblade-loitering-munitions-in-ukraine
- [20] S. Rosenberg and J. Lukiv, “Ukraine war: Drone attack on Russian bomber base leaves three dead,” BBC, December 2022, last accessed 27 December 2022. [Online]. Available: https://www.bbc.com/news/world-europe-64092183
- [21] D. Hambling, “Ukraine Wins First Drone Vs. Drone Dogfight Against Russia, Opening A New Era Of Warfare,” Forbes, October 2022, last accessed 16 November 2022. [Online]. Available: https://www.forbes.com/sites/davidhambling/2022/10/14/ukraine-wins-first-drone-vs-drone-dogfight-against-russia-opening-a-new-era-of-warfare
- [22] P. K. Ben Hubbard and S. Reed, “Two Major Saudi Oil Installations Hit by Drone Strike, and U.S. Blames Iran,” The New York Times, September 2019, last accessed 16 November 2022. [Online]. Available: https://www.nytimes.com/2019/09/14/world/middleeast/saudi-arabia-refineries-drone-attack.html
- [23] D. Kwon, J. Jeon, S. Park, J. Kim, and S. Cho, “Multiagent DDPG-based deep learning for smart ocean federated learning IoT networks,” IEEE Internet of Things Journal, vol. 7, no. 10, pp. 9895–9903, 2020.
- [24] T. M. Ho, K.-K. Nguyen, and M. Cheriet, “Energy-aware control of UAV-based wireless service provisioning,” in Proc. IEEE Global Communications Conference (GLOBECOM), 2021, pp. 1–6.
- [25] D. Kwon and J. Kim, “Multi-agent deep reinforcement learning for cooperative connected vehicles,” in Proc. IEEE Global Communications Conference (GLOBECOM), December 2019, pp. 1–6.
- [26] T. M. Ho, K.-K. Nguyen, and M. Cheriet, “UAV control for wireless service provisioning in critical demand areas: A deep reinforcement learning approach,” IEEE Transactions on Vehicular Technology, vol. 70, no. 7, pp. 7138–7152, 2021.
- [27] G. Lee, W. J. Yun, S. Jung, J. Kim, and J.-H. Kim, “Visualization of deep reinforcement autonomous aerial mobility learning simulations,” in Proc. IEEE Conference on Computer Communications Demo (INFOCOM Demo), Virtual, May 2021, pp. 1–2.
- [28] Q. Wang, A. Gao, and Y. Hu, “Joint power and QoE optimization scheme for multi-UAV assisted offloading in mobile computing,” IEEE Access, vol. 9, pp. 21 206–21 217, 2021.
- [29] X. Luo, Y. Zhang, Z. He, G. Yang, and Z. Ji, “A two-step environment-learning-based method for optimal UAV deployment,” IEEE Access, vol. 7, pp. 149 328–149 340, 2019.
- [30] S. Jung, W. J. Yun, J. Kim, and J.-H. Kim, “Infrastructure-assisted cooperative multi-UAV deep reinforcement energy trading learning for big-data processing,” in Proc. International Conference on Information Networking (ICOIN), Jeju Island, Korea (South), January 2021, pp. 159–162.
- [31] J.-H. Lee, K.-H. Park, Y.-C. Ko, and M.-S. Alouini, “A UAV-mounted free space optical communication: Trajectory optimization for flight time,” IEEE Transactions on Wireless Communications, vol. 19, no. 3, pp. 1610–1621, March 2020.
- [32] W. J. Yun, S. Park, J. Kim, M. Shin, S. Jung, D. A. Mohaisen, and J.-H. Kim, “Cooperative multiagent deep reinforcement learning for reliable surveillance via autonomous Multi-UAV control,” IEEE Transactions on Industrial Informatics, vol. 18, no. 10, pp. 7086–7096, October 2022.
- [33] Y. Dang, C. Benzaïd, B. Yang, T. Taleb, and Y. Shen, “Deep-ensemble-learning-based GPS spoofing detection for cellular-connected UAVs,” IEEE Internet of Things Journal, vol. 9, no. 24, pp. 25 068–25 085, 2022.
- [34] A. Soliman, M. Bahri, D. Izham, and A. Mohamed, “AirEye: UAV-based intelligent DRL mobile target visitation,” in 2022 International Wireless Communications and Mobile Computing (IWCMC), 2022, pp. 554–559.
- [35] M. Mozaffari, W. Saad, M. Bennis, Y.-H. Nam, and M. Debbah, “A tutorial on UAVs for wireless networks: Applications, challenges, and open problems,” IEEE Communications Surveys and Tutorials, vol. 21, no. 3, pp. 2334–2360, 2019.
- [36] B. Jiang, S. N. Givigi, and J.-A. Delamer, “A marl approach for optimizing positions of VANET aerial base-stations on a sparse highway,” IEEE Access, vol. 9, pp. 133 989–134 004, 2021.
- [37] M. Shin, J. Kim, and M. Levorato, “Auction-based charging scheduling with deep learning framework for multi-drone networks,” IEEE Transactions on Vehicular Technology, vol. 68, no. 5, pp. 4235–4248, May 2019.
- [38] S. Jung, W. J. Yun, M. Shin, J. Kim, and J.-H. Kim, “Orchestrated scheduling and multi-agent deep reinforcement learning for cloud-assisted multi-UAV charging systems,” IEEE Transactions on Vehicular Technology, vol. 70, no. 6, pp. 5362–5377, June 2021.
- [39] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” in Proc. 4th International Conference on Learning Representations (ICLR), May 2016.
- [40] A. Juliani, V.-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, M. Mattar, and D. Lange, “Unity: A general platform for intelligent agents,” arXiv preprint arXiv:1809.02627, 2018.
Appendix A Performance Comparison
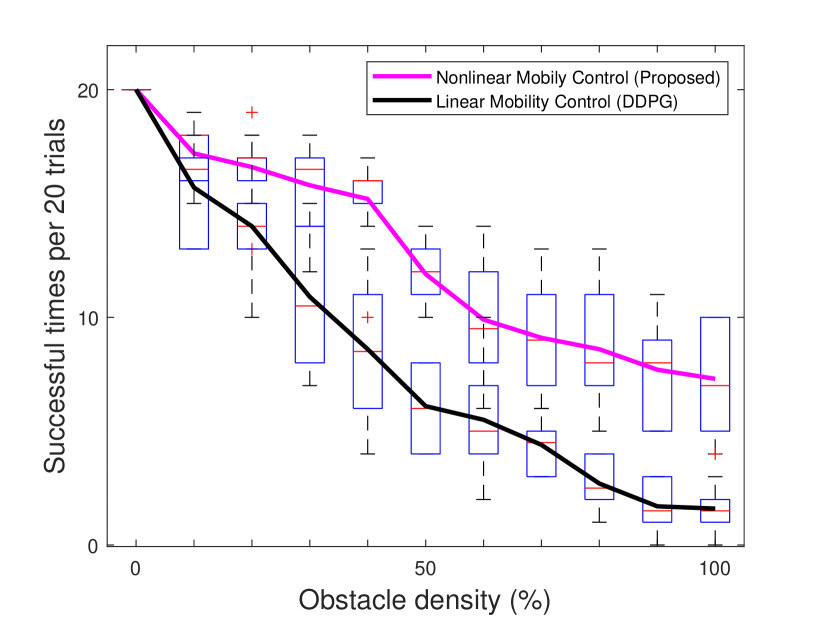
In Fig. 13, we can compare the performance of the two algorithms, i.e., our proposed nonlinear drone mobility control and the comparing linear drone mobility control at a glance. As the obstacle density increases, performance degradation occurs in both algorithms. Therefore, we can confirm that our proposed nonlinear mobility control has much less performance degradation. Furthermore, we can also confirm that our proposed algorithm becomes getting better when the density of obstacles increases, i.e., the performance gap between the proposed nonlinear mobility control algorithm and the comparing linear mobility control becomes larger when the density of obstacles increases.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9081c8c1-c52f-4b3a-be70-c21b75759550/people_hyunsoo.png) |
Hyunsoo Lee is currently pursuing the Ph.D. degree in electrical and computer engineering at Korea University, Seoul, Republic of Korea. He received the B.E. degree in electronic engineering from Soongsil University, Seoul, Republic of Korea, in 2021. His research focuses include deep learning algorithms and their applications to mobility and networking. He was a recipient of the IEEE Vehicular Technology Society (VTS) Seoul Chapter Award in 2022. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9081c8c1-c52f-4b3a-be70-c21b75759550/people_soohyun.png) |
Soohyun Park is currently pursuing the Ph.D. degree in electrical and computer engineering at Korea University, Seoul, Republic of Korea. She received the B.S. degree in computer science and engineering from Chung-Ang University, Seoul, Republic of Korea, in 2019. Her research focuses include deep learning algorithms and their applications to autonomous mobility and connected vehicles. She was a recipient of the IEEE Vehicular Technology Society (VTS) Seoul Chapter Award in 2019. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9081c8c1-c52f-4b3a-be70-c21b75759550/people_wonjoonyun.jpg) |
Won Joon Yun is currently a Ph.D. student in electrical and computer engineering at Korea University, Seoul, Republic of Korea, since March 2021, where he received his B.S. in electrical engineering. He was a visiting researcher at Cipherome Inc., San Jose, CA, USA (Summer 2022),; and also a visiting researcher at the University of Southern California (USC), Los Angeles, CA, USA (Spring 2023) for a joint project with Prof. Andreas F. Molisch at the Ming Hsieh Department of Electrical and Computer Engineering, USC Viterbi School of Engineering. He was a recipient of IEEE ICOIN Best Paper Award (2021). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9081c8c1-c52f-4b3a-be70-c21b75759550/people_jungsoyi.png) |
Soyi Jung has been an assistant professor at the Department of Electrical of Computer Engineering, Ajou University, Suwon, Republic of Korea, since September 2022. Before joining Ajou University, she was an assistant professor at Hallym University, Chuncheon, Republic of Korea, from 2021 to 2022; a visiting scholar at Donald Bren School of Information and Computer Sciences, University of California, Irvine, CA, USA, from 2021 to 2022; a research professor at Korea University, Seoul, Republic of Korea, in 2021; and a researcher at Korea Testing and Research (KTR) Institute, Gwacheon, Republic of Korea, from 2015 to 2016. She received her B.S., M.S., and Ph.D. degrees in electrical and computer engineering from Ajou University, Suwon, Republic of Korea, in 2013, 2015, and 2021, respectively. Her current research interests include network optimization for autonomous vehicles communications, distributed system analysis, big-data processing platforms, and probabilistic access analysis. She was a recipient of Best Paper Award by KICS (2015), Young Women Researcher Award by WISET and KICS (2015), Bronze Paper Award from IEEE Seoul Section Student Paper Contest (2018), ICT Paper Contest Award by Electronic Times (2019), and IEEE ICOIN Best Paper Award (2021). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9081c8c1-c52f-4b3a-be70-c21b75759550/people_joongheon.png) |
Joongheon Kim (M’06–SM’18) has been with Korea University, Seoul, Korea, since 2019, where he is currently an associate professor at the School of Electrical Engineering and also an adjunct professor at the Department of Communications Engineering (established/sponsored by Samsung Electronics) and the Department of Semiconductor Engineering (established/sponsored by SK Hynix). He received the B.S. and M.S. degrees in computer science and engineering from Korea University, Seoul, Korea, in 2004 and 2006; and the Ph.D. degree in computer science from the University of Southern California (USC), Los Angeles, CA, USA, in 2014. Before joining Korea University, he was a research engineer with LG Electronics (Seoul, Korea, 2006–2009), a systems engineer with Intel Corporation (Santa Clara, CA, USA, 2013–2016), and an assistant professor of computer science and engineering with Chung-Ang University (Seoul, Korea, 2016–2019). He serves as an editor for IEEE Transactions on Vehicular Technology, IEEE Transactions on Machine Learning in Communications and Networking, and IEEE Communications Standards Magazine. He is also a distinguished lecturer for IEEE Communications Society (ComSoc) and IEEE Systems Council. He was a recipient of Annenberg Graduate Fellowship with his Ph.D. admission from USC (2009), Intel Corporation Next Generation and Standards (NGS) Division Recognition Award (2015), IEEE Systems Journal Best Paper Award (2020), IEEE ComSoc Multimedia Communications Technical Committee (MMTC) Outstanding Young Researcher Award (2020), IEEE ComSoc MMTC Best Journal Paper Award (2021), and Best Special Issue Guest Editor Award by ICT Express (Elsevier) (2022). He also received several awards from IEEE conferences including IEEE ICOIN Best Paper Award (2021), IEEE Vehicular Technology Society (VTS) Seoul Chapter Awards (2019, 2021, and 2022), and IEEE ICTC Best Paper Award (2022). |