Skewed Bernstein–von Mises theorem
and skew–modal approximations
Abstract
Gaussian deterministic approximations are routinely employed in Bayesian statistics to ease inference when the target posterior of direct interest is intractable. Although these approximations are justified, in asymptotic regimes, by Bernstein–von Mises type results, in practice the expected Gaussian behavior may poorly represent the actual shape of the target posterior, thereby affecting approximation accuracy. Motivated by these considerations, we derive an improved class of closed–form and valid deterministic approximations of posterior distributions which arise from a novel treatment of a third–order version of the Laplace method yielding approximations within a tractable family of skew–symmetric distributions. Under general assumptions which also account for misspecified models and non–i.i.d. settings, this novel family of approximations is shown to have a total variation distance from the target posterior whose rate of convergence improves by at least one order of magnitude the one achieved by the Gaussian from the classical Bernstein–von Mises theorem. Specializing such a general result to the case of regular parametric models shows that the same improvement in approximation accuracy can be also established for polynomially bounded posterior functionals, including moments. Unlike other higher–order approximations based on, e.g., Edgeworth expansions, our results prove that it is possible to derive closed–form and valid densities which are expected to provide, in practice, a more accurate, yet similarly–tractable, alternative to Gaussian approximations of the target posterior of direct interest, while inheriting its limiting frequentist properties. We strengthen these arguments by developing a practical skew–modal approximation for both joint and marginal posteriors which achieves the same theoretical guarantees of its theoretical counterpart by replacing the unknown model parameters with the corresponding maximum a posteriori estimate. Simulation studies and real–data applications confirm that our theoretical results closely match the remarkable empirical performance observed in practice, even in finite, possibly small, sample regimes.
keywords:
[class=MSC2020]keywords:
14pt \startlocaldefs \endlocaldefs
, and
t1Co–funded by the European Union (ERC, BigBayesUQ, project number: 101041064). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them.
t2Funded by the European Union (ERC, PrSc-HDBayLe, project number: 101076564). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them.
1 Introduction
Modern Bayesian statistics relies extensively on deterministic approximations to facilitate inference in those challenging, yet routine, situations when the target posterior of direct interest is intractable (e.g., Tierney and Kadane, 1986; Minka, 2001; Rue, Martino and Chopin, 2009; Blei, Kucukelbir and McAuliffe, 2017). A natural option to enforce the desired tractability is to constrain the approximating distribution within a suitable family which facilitates the evaluation of functionals of interest for inference. To this end, both classical solutions, such as the approximation of posterior distributions induced by the Laplace method (e.g., Bishop, 2006, Ch. 4.4), and state–of–the–art strategies, including, for example, Gaussian variational Bayes (Opper and Archambeau, 2009) and standard implementations of expectation–propagation (Minka, 2001), employ Gaussian approximations. These further appear, either as the final solution or as a recurring building–block, also within several routinely–implemented alternatives, such as mean–field variational Bayes (Blei, Kucukelbir and McAuliffe, 2017) and integrated nested Laplace approximation (inla) (Rue, Martino and Chopin, 2009). See also Wang and Blei (2013), Chopin and Ridgway (2017), Durante and Rigon (2019), Ray and Szabó (2022) and Vehtari et al. (2020), among others, for further examples illustrating the relevance of Gaussian approximations.
From a theoretical perspective, the choice of the Gaussian family to approximate the posterior distribution is justified, in asymptotic regimes, by Bernstein–von Mises type results. In its classical formulation (Laplace, 1810; Bernstein, 1917; Von Mises, 1931; Le Cam, 1953; Le Cam and Yang, 1990; Van der Vaart, 2000), the Bernstein–von Mises theorem states that, in sufficiently regular parametric models, the posterior distribution converges in total variation (tv) distance, with probability tending to one under the law of the data, to a Gaussian distribution. The mean of such a limiting Gaussian is a known function of the true data–generative parameter, or any efficient estimator of this quantity, such as the maximum likelihood estimator, while the variance is the inverse of the Fisher information. Extensions of the Bernstein–von Mises theorem to more complex settings have also been made in recent years. Relevant contributions along these directions include, among others, generalizations to high-dimensional regimes (Boucheron and Gassiat, 2009; Spokoiny and Panov, 2021), along with in–depth treatments of misspecified (Kleijn and van der Vaart, 2012) and irregular (Bochkina and Green, 2014) models. Semiparametric settings have also been addressed (Bickel and Kleijn, 2012; Castillo and Rousseau, 2015). In the nonparametric context, Bernstein–von Mises type results do not hold in general, but the asymptotic Gaussianity can be still proved for weak Sobolev spaces via a multiscale analysis (Castillo and Nickl, 2014).
Besides providing crucial advances in the understanding of the limiting frequentist properties of posterior distributions, the above Bernstein–von Mises type results have also substantial implications in the design and in the theoretical justification of practical Gaussian deterministic approximations for intractable posterior distributions from, e.g., the Laplace method (Kasprzak, Giordano and Broderick, 2022), variational Bayes (vb) (Wang and Blei, 2019) and expectation–propagation (ep) (Dehaene and Barthelmé, 2018). Such a direction has led to important results. Nonetheless, in practical situations the Gaussian approximation may lack the required flexibility to closely match the actual shape of the posterior distribution of direct interest, thereby undermining accuracy when inference is based on such an approximation. In fact, as illustrated via two representative real–data clinical applications in Sections 5.2–5.3, the error in posterior mean estimation of the Gaussian approximation supported by the classical Bernstein–von Mises theorem is non–negligible not only in a study with low sample size and parameters, but also in a higher–dimensional application with and . Both regimes often occur in routine implementations. The results in Sections 5.2–5.3 further clarify that the issues encountered by the Gaussian approximation are mainly due to the inability of capturing the non–negligible skewness often displayed by the actual posterior in these settings. Such an asymmetric shape is inherent to routinely–studied posterior distributions. For example, Durante (2019), Fasano and Durante (2022) and Anceschi et al. (2023) have recently proved that, under a broad class of priors which includes multivariate normals, the posterior distribution induced by probit, multinomial probit and tobit models belongs to a skewed generalization of the Gaussian distribution known as unified skew–normal (sun) (Arellano-Valle and Azzalini, 2006). More generally, available extensions of Gaussian deterministic approximations which account, either explicitly or implicitly, for skewness (see e.g., Rue, Martino and Chopin, 2009; Challis and Barber, 2012; Fasano, Durante and Zanella, 2022) have shown evidence of improved empirical accuracy relative to their Gaussian counterparts. Nonetheless, these approximations are often model–specific and general justifications relying on Bernstein–von Mises type results are not available yet. In fact, in–depth theory and methods for skewed approximations are either lacking or are tailored to specific models and priors (Fasano, Durante and Zanella, 2022).
In this article, we cover the aforementioned gaps by deriving an improved class of closed–form, valid and theoretically–supported skewed approximations of generic posterior distributions. Such a class arises from a novel treatment of a higher–order version of the Laplace method which replaces the third–order term with a suitable univariate cumulative distribution function (cdf) satisfying mild regularity conditions. As clarified in Section 2.1, this new perspective yields tractable approximations that crucially belong to the broad and known skew–symmetric family (see e.g., Ma and Genton, 2004). More specifically, these approximations can be readily obtained by direct perturbation of the density of a multivariate Gaussian via a suitably–defined univariate cdf evaluated at a cubic function of the parameter. This implies that the proposed class of approximations admits straightforward i.i.d. sampling schemes facilitating direct Monte Carlo evaluation of any functional of interest for posterior inference. These are crucial advancements relative to other higher–order studies relying on Edgeworth or other types of representations (see e.g., Johnson, 1970; Weng, 2010; Kolassa and Kuffner, 2020, and references therein), which consider arbitrarily truncated versions of infinite expansions that do not necessarily correspond to closed–form valid densities, even after normalization — e.g., the density approximation is not guaranteed to be non–negative (e.g., Kolassa and Kuffner, 2020, Remark 11). This undermines the methodological and practical impact of current higher–order results which still fail to provide a natural, valid and general alternative to Gaussian deterministic approximations that can be readily employed in practice. In contrast, our novel results prove that a previously–unexplored treatment of specific higher–order expansions can actually yield valid, practical and theoretically–supported approximations, thereby opening the avenues to extend such a perspective to orders even higher than the third one; see also our final discussion in Section 6.
Section 2.2 clarifies that the proposed class of skew–symmetric approximations has also strong theoretical support in terms of accuracy improvements relative to its Gaussian counterpart. More specifically, in Theorem 2.1 we prove that the newly–proposed class of skew–symmetric approximations has a total variation distance from the target posterior distribution whose rate of convergence improves by at least one order of magnitude the one attained by the Gaussian from the classical Bernstein–von Mises theorem. Crucially, this result is derived under general assumptions which account for both misspecified models and non–i.i.d. settings. This yields an important refinement of standard Bernstein–von Mises type results clarifying that it is possible to derive closed–form and valid densities which are expected to provide, in practice, a more accurate, yet similarly–tractable, alternative to Gaussian approximations of the target posterior of direct interest, while inheriting its limiting frequentist properties. In Section 2.3 these general results are further specialized to, possibly non–i.i.d. and misspecified, regular parametric models, where and the dimension of the parametric space is fixed. Under such a practically–relevant setting, we show that the proposed skew–symmetric approximation can be explicitly derived as a function of the log–prior and log–likelihood derivatives. Moreover, we prove that by replacing the classical Gaussian approximation from the Bernstein–von Mises theorem with such a newly–derived alternative yields a remarkable improvement in the rates of order , up to a poly–log term. This gain is shown to hold not only for the tv distance from the target posterior, but also for the error in approximating polynomially bounded posterior functionals (e.g., moments).
The methodological impact of the theory in Section 2 is further strengthened in Section 4 through the development of a readily–applicable plug–in version for the proposed class of skew–symmetric approximations derived in Section 2.1. This is obtained by replacing the unknown true data–generating parameter in the theoretical construction with the corresponding maximum a posteriori estimate, or any other efficient estimator. The resulting solution is named skew–modal approximation and, under mild conditions, is shown to achieve the same improved rates of its theoretical counterpart, both in terms of the tv distance from the target posterior distribution and with respect to the approximation error for polynomially bounded posterior functionals. In such a practically–relevant setting, we further refine the theoretical analysis through the derivation of non–asymptotic bounds for the tv distance among the skew–modal approximation and the target posterior. These bounds are guaranteed to vanish also when the dimension grows with , as long as up to a poly–log term. Interestingly, this condition is related to those required either for (see e.g., Panov and Spokoiny, 2015) or for the notion of effective dimension (see Spokoiny and Panov, 2021; Spokoiny, 2023) in recent high–dimensional studies of the Gaussian Laplace approximation. However, unlike these studies, the bounds we derive vanish with , up to a poly–log term, rather than , for any given dimensions. These advancements enable also the derivation of a novel lower bound for the tv distance among the Gaussian Laplace approximation and the target posterior, which is shown to still vanish with . This result strengthens the proposed skew–modal solution whose associated upper bound vanishes with , up to a poly–log term. When the focus of inference is not on the joint posterior but rather on its marginals, we further derive in Section 4.2 accurate skew–modal approximations for such marginals that inherit the same theory guarantees while scaling up computation.
The superior empirical performance of the newly–proposed class of skew–symmetric approximations and the practical consequences of our theoretical results on the improved rates are illustrated through both simulation studies and two real–data applications in Sections 3 and 5. All these numerical analyses demonstrate that the remarkable theoretical improvements encoded within the rates we derive closely match the empirical behavior observed in practice even in finite, possibly small, sample regimes. This translates into noticeable empirical accuracy gains relative to the classical Gaussian–modal approximation from the Laplace method. Even more, in the real–data application the proposed skew–modal approximation also displays a highly competitive performance with respect to more sophisticated state–of–the–art Gaussian and non–Gaussian approximations from mean–field vb and expectation–propagation (ep) (Minka, 2001; Blei, Kucukelbir and McAuliffe, 2017; Chopin and Ridgway, 2017; Durante and Rigon, 2019; Fasano, Durante and Zanella, 2022).
As discussed in the concluding remarks in Section 6, the above results stimulate future advancements aimed at refining the accuracy of other Gaussian approximations from, e.g., vb and ep, via the inclusion of skewness. To this end, our contribution provides the foundations to achieve this goal, and suggests that a natural and tractable class where to seek these improved approximations would be still the skew–symmetric family. Extensions to higher–order expansions beyond the third term are also discussed as directions of future research. Finally, notice that although the non–asymptotic bounds we derive for the skew–modal approximation in Section 4 yield refined theoretical results that can be readily proved for the general skew–symmetric class in Section 2, the practical consequences of non–asymptotic bounds and the associated constants is an ongoing area of research even for basic Gaussian approximations (see e.g., Kasprzak, Giordano and Broderick, 2022, and references therein). In this sense, it shall be emphasized that, in our case, even the asymptotic theoretical support encoded in the rates we derive finds empirical evidence in the finite–sample studies considered in Sections 3 and 5.
1.1 Notation
We denote with , , a sequence of random variables with unknown true distribution . Moreover, let , with , be a parametric family of distributions. In the following, we assume that there exists a common –finite measure which dominates as well as all measures , and we denote by and the corresponding density functions. The Kullback–Leibler projection of on is defined as where denotes the Kullback–Leibler divergence between and . The log–likelihood of the, possibly misspecified, model is . Prior and posterior distributions are denoted by and , whereas the corresponding densities are indicated with and , respectively.
As mentioned in Section 1, our results rely on higher–order expansions and derivatives. To this end, we characterize operations among vectors, matrices and arrays in a compact manner by adopting the index notation along with the Einstein’s summation convention (see e.g., Pace and Salvan, 1997, p. 335). More specifically, the inner product between the generic random vector with components for , and the vector of coefficients having elements for is expressed as , with the sum being implicit in the repetition of the indexes. Similarly, if is a matrix with entries for the quadratic form is expressed as The generalization to operations involving arrays with higher dimensions is obtained under the same reasoning.
Leveraging the above notation, the score vector evaluated at is defined as
whereas, the second, third and fourth order derivatives of , still evaluated at , are
where all the indexes in the above definitions and in the subsequent ones go from to . The observed and expected Fisher information are denoted by and , respectively, where is the expectation with respect to . In addition,
represent the first two derivatives of the log–prior density, evaluated at
The Euclidean norm of a vector is denoted by , whereas, for a generic matrix , the notation indicates its determinant, while and its minimum and maximum eigenvalue, respectively. Furthermore, and correspond to and . For two positive sequences we employ if there exists a universal positive constant such that . When and are satisfied simultaneously, we write .
2 A skewed Bernstein–von Mises theorem
This section presents our first important contribution. In particular, Section 2.1 shows that, for Bayesian models satisfying a refined version of the local asymptotic normality (lan) condition (see e.g., Van der Vaart, 2000; Kleijn and van der Vaart, 2012), a previously–unexplored treatment of a third–order version of the Laplace method can yield a novel, closed–form and valid approximation of the posterior distribution. Crucially, this approximation is further shown to belong to the tractable skew–symmetric (sks) family (e.g., Ma and Genton, 2004). Focusing on this newly–derived class of sks approximations, we then prove in Section 2.2 that the –indexed sequence of tv distances between such a class and the target posterior has a rate which improves by at least one order of magnitude the one achieved under the classical Bernstein–von Mises theorem based on Gaussian approximations. Such a skewed Bernstein–von Mises type result is proved under general assumptions which account for misspecified models in non–i.i.d. settings. Section 2.3 then specializes this result to the practically–relevant context of regular parametric models with and fixed . In this setting we prove that the improvement in rates over the Bernstein–von Mises theorem is by a multiplicative factor of order , up to a poly–log term. This result is shown to hold not only for the tv distance from the posterior, but also for the error in approximating polynomially bounded posterior functionals.
Let be a generic norming rate governing the posterior contraction toward . Consistent with standard Bernstein–von Mises type theory (see e.g., Van der Vaart, 2000; Kleijn and van der Vaart, 2012), consider the re–parametrization . Moreover, let denote any univariate cumulative distribution function which satisfies and , for some . Then, the class of sks approximating densities we derive and study has the general form
| (1) |
with denoting the associated cumulative distribution function. In (1), is the density of a –variate Gaussian with mean vector and covariance matrix , while the function is responsible for inducing skewness, and takes the form , where denotes a third order odd polynomial depending on the parameter that regulates the expansion of , i.e., .
Crucially, Equation (1) not only ensures that is a valid and closed–form density, but also that such a density belongs to the tractable and known skew–symmetric class (Azzalini and Capitanio, 2003; Ma and Genton, 2004). This follows directly by the definition of sks densities, provided that is an odd function, and is symmetric about (see e.g., Azzalini and Capitanio, 2003, Proposition 1). Therefore, in contrast to available higher–order studies of posterior distributions based on Edgeworth or other type of expansions (see e.g., Johnson, 1970; Weng, 2010; Kolassa and Kuffner, 2020), our theoretical and methodological results focus on a family of closed–form and valid approximating densities which are essentially as tractable as multivariate Gaussians, both in terms of evaluation of the corresponding density, and i.i.d. sampling. More specifically, let and denote samples from a –variate Gaussian having density and from a uniform with support , respectively. Then, adapting results in, e.g., Wang, Boyer and Genton (2004), a sample from the sks distribution with density as in (1) can be readily obtained via
Therefore, sampling from the proposed sks approximation simply reduces to drawing values from a –variate Gaussian and then changing or not the sign of the sampled value via a straightforward perturbation scheme.
As clarified within Sections 2.3 and 4, the general sks approximation in (1) is not only interesting from a theoretical perspective, but has also relevant methodological consequences and direct applicability. This is because, when specializing the general theory in Section 2.2 to, possibly misspecified and non–i.i.d., regular parametric models where , is fixed and , we can show that the quantities defining in (1) can be expressed as closed–form functions of the log–prior and log–likelihood derivatives at . In particular, let for , then, as clarified in Section 2.3, we have
| (2) |
Interestingly, in this case, the first factor on the right hand side of (1) closely resembles the limiting Gaussian density with mean vector and covariance matrix from the classical Bernstein–von Mises theorem which, however, fails to incorporate skewness. To this end, the symmetric component in (1) is perturbed via a skewness–inducing mechanism regulated by to obtain a valid asymmetric density with tractable normalizing constant. As shown in Section 4, this solution admits a directly–applicable practical counterpart, which can be obtained by replacing and in (1)–(2), with routine–use univariate cdfs such as, e.g., , and with the maximum a posteriori estimate of , respectively. This results in a practical and novel skew–modal approximation that can be shown to have the same theoretical guarantees of improved accuracy of its theoretical counterpart.
2.1 Derivation of the skew–symmetric approximating density
Prior to stating and proving within Section 2.2 the general skewed Bernstein–von Mises theorem which supports the proposed class of sks approximations, let us focus on providing a constructive derivation of such a class via a novel treatment of a third–order extension of the Laplace method. To simplify notation, we consider the simple univariate case with and . The extension of these derivations to and to the general setting we consider in Theorem 2.1 follow as a direct adaptation of the reasoning for the univariate case; see Sections 2.2–2.3.
As a first step towards deriving the approximating density , notice that the posterior for can be expressed as
| (3) |
since and do not depend on , and .
Under suitable regularity conditions discussed in Sections 2.2–2.3 below, the third–order Taylor’s expansion for the logarithm of the likelihood ratio in Equation (3) is
| (4) |
whereas the first order Taylor’s expansion of the log–prior ratio is
| (5) |
Combining (4) and (5) it is possible to reformulate the right–hand–side of Equation (3) as
| (6) |
where
Notice that, up to a multiplicative constant, the Gaussian density arising from the classical Bernstein–von Mises theorem can be obtained by neglecting all terms in (4)–(5) which converge to zero in probability. These correspond to the contribution of the prior, the difference between the observed and expected Fisher information, and the term associated to the third–order log–likelihood derivative. Maintaining these quantities would surely yield improved accuracy, but it is unclear whether a valid and similarly–tractable density can be still identified. In fact, current solutions (e.g., Johnson, 1970) consider approximations based on the sum among a Gaussian density and additional terms in the Taylor’s expansion. However, as for related alternatives arising from Edgeworth–type expansions (e.g., Weng, 2010; Kolassa and Kuffner, 2020), there is no guarantee that such constructions provide valid densities.
As a first key contribution we prove below that a valid and tractable approximating density can be, in fact, derived from the above expansions and belongs to the sks class. To this end, let with and , and note that, by replacing in the right hand side of Equation (6) with , the exponential term in (6) can be rewritten as proportional to
| (7) |
At this point, recall that, for , we can write and , for some , where is the univariate cumulative distribution function introduced in Equation (1). Therefore, leveraging the similarity among these two expansions and the fact that the exponent in Equation (7) is an odd function of about , of order , it follows that (7) is equal to
with defined as in Equation (2), for a univariate setting. The above expression coincides with the univariate case of the skew–symmetric density in Equation (1), up to an additive term. The direct extension of the above derivations to the multivariate case provides the general form of in Equation (1) with parameters as in (2). Section 2.2 further extends, and supports theoretically, such a construction in more general settings.
2.2 The general theorem
The core message of Section 2.1 is that a suitable treatment of the cubic terms in the Taylor expansion of the log–posterior can yield a higher–order, yet valid, sks approximating density. This solution is expected to improve the accuracy of the classical second–order Gaussian approximation, while avoiding known issues of polynomial approximations, such as regions with negative mass (e.g., McCullagh, 2018, p. 154).
In this section, we provide theoretical support to the above arguments. More specifically, we clarify that the derivations in Section 2.1 can be applied generally to obtain sks approximations in a variety of different settings, provided that the posterior contraction is governed by a generic norming rate , and that some general, yet reasonable, regularity conditions are met. In particular, Theorem 2.1 requires Assumptions 1–4 below. For convenience, let us introduce the notation , with a constant to be specified later.
Assumption 1.
The Kullback–Leibler projection is unique.
Assumption 2.
There exists a sequence of -dimensional random vectors , a sequence of random matrices with , and also a sequence of random arrays with , so that
with , for some positive constant , where . In addition, there are two positive constants and such that the event holds with .
Assumption 3.
There exists a –dimensional vector such that
with and for some constant .
Assumption 4.
It holds
Albeit general, Assumptions 1–4 provide reasonable conditions that extend those commonly considered to derive classical Bernstein–von Mises type results. Moreover, as clarified in Section 2.3, these assumptions directly translate, under regular parametric models, into natural and explicit conditions on the behavior of the log–likelihood and log–prior. In particular, Assumption 1 is mild and can be found, for example, in Kleijn and van der Vaart (2012). Together with Assumption 4, it guarantees that asymptotically the posterior distribution concentrates in the region where the two expansions in Assumptions 2–3 hold with negligible remainders. Notice that, Assumptions 2 and 4 naturally extend those found in general theoretical studies of Bernstein–von Mises type results (e.g., Kleijn and van der Vaart, 2012) to a third–order construction, which further requires quantification of rates. Assumption 3 provides, instead, an additional condition relative to those found in the classical theory. This is because, unlike for second–order Gaussian approximations, the log–prior enters the sks construction through its first derivative; see Section 2.1. To this end, Assumption 3 imposes suitable and natural smoothness conditions on the prior. Interestingly, such a need to include a careful study for the behavior of the prior density is also useful in forming the bases to naturally extend our proofs and theory to the general high–dimensional settings considered in Spokoiny and Panov (2021) and Spokoiny (2023) for the classical Gaussian Laplace approximation, where the prior effect has a critical role in controlling the behavior of the third and fourth–order components of the log–posterior. Motivated by these results, Section 4 further derives non–asymptotic bounds for the practical skew–modal approximation, which are guaranteed to vanish also when grows with , as long as this growth in the dimension is such that up to a poly–log term. See Remark 4.2 for a detailed discussion and Section 6 for future research directions in high dimensions motivated by such a result.
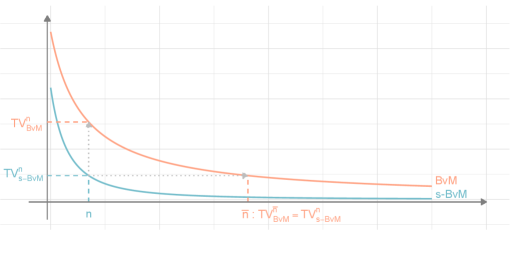
Under the above assumptions, Theorem 2.1 below provides theoretical support to the proposed sks approximation by stating a novel skewed Bernstein–von Mises type result. More specifically, this result establishes that in general contexts, covering also misspecified models and non–i.i.d. settings, it is possible to derive a sks approximation, with density as in (1), whose tv distance from the target posterior has a rate which improves by at least one order of magnitude the one achieved by the classical Gaussian counterpart from the Bernstein–von Mises theorem. By approaching the target posterior at a provably–faster rate, the proposed solution is therefore expected to provide, in practice, a more accurate alternative to Gaussian approximations of the target posterior, while inheriting the corresponding limiting frequentist properties. To this end, Theorem 2.1 shall not be interpreted as a theoretical result aimed at providing novel or alternative frequentist support to Bayesian inference. Rather, it represents an important refinement of the classical Bernstein–von Mises theorem which guides and supports the derivation of improved deterministic approximations to be used in practice as tractable, yet accurate, alternatives to the intractable posterior of direct interest. Figure 1 provides a graphical intuition for such an argument. The practical impact of these results is illustrated in the empirical studies within Sections 3 and 5. Such studies clarify that the theoretical improvements encoded in the rates we derive directly translate into the remarkable accuracy gains of the proposed class of sks approximations observed in finite–sample studies.
Theorem 2.1.
Remark 2.2.
Under related conditions and a simpler proof, it is possible to show that the order of convergence for the Bernstein–von Mises theorem based on limiting Gaussians is , for some . Thus, Theorem 2.1 guarantees that by relying on suitably–derived sks approximations with density as in (1), it is possible to improve the rates of the classical Bernstein–von Mises result by a multiplicative factor of . This follows directly from the fact that the sks approximation is able to include terms of order that are present in the Taylor expansion of the log–posterior but are neglected in the Gaussian limit. This allows an improved redistribution of the mass in the high posterior probability region, thereby yielding increased accuracy in characterizing the shape of the target posterior. As illustrated in Sections 3 and 5, this correction yields remarkable accuracy improvements in practice.
Remark 2.3.
Theorem 2.1 holds for a broad class of sks approximating distributions as long as the univariate cdf which enters the skewing factor in (1) satisfies and for some when . These conditions are mild and add flexibility in the selection of . Relevant and practical examples of possibile choices for are the cdf of the standard Gaussian distribution, , and the inverse logit function, . Both satisfy , and the associated Taylor expansions are and , respectively, for . Interestingly, when , the resulting skew–symmetric approximation belongs to the well–studied sub–class of generalized skew–normal (gsn) distributions (Ma and Genton, 2004), which provide the most natural extension of multivariate skew–normals (Azzalini and Capitanio, 2003) to more flexible skew–symmetric representations. Due to this, Sections 3 and 5 focus on assessing the empirical performance of such a noticeable example.
Before entering the details of the proof of Theorem 2.1, let us highlight an interesting aspect regarding the interplay between skew–symmetric and Gaussian approximations that can be deduced from our theoretical studies. In particular, notice that Theorem 2.1 states results in terms of approximation of the whole posterior distribution under the tv distance. This implies, as a direct consequence of the definition of such a distance, that the same rates hold also for the absolute error in approximating the posterior expectation of any bounded function. As shown later in Corollary 2.5, such an improvement can also be proved, under mild additional conditions, for the approximation of the posterior expectation of any function bounded by a polynomial (e.g., posterior moments). According to Remark 2.2 these rates cannot be achieved in general under a Gaussian approximation. Nonetheless, as stated in Lemma 2.4, for some specific functionals the classical Gaussian approximation can actually attain the same rates of its skewed version. This result follows from the skew–symmetric distributional invariance with respect to even functions (Wang, Boyer and Genton, 2004). Such a property implies that the sks approximation and its Gaussian component yield the same level of accuracy in estimating the posterior expected value of functions that are symmetric with respect to the location parameter . Thus, our results provide also a novel explanation of the phenomenon observed in Spokoiny and Panov (2021) and Spokoiny (2023), where the quality of the Gaussian approximation, within high–dimensional models, increases by an order of magnitude when evaluated on Borel sets which are centrally symmetric with respect to the location (e.g., Spokoiny, 2023, Theorem 3.4). Nonetheless, as clarified in Theorem 2.1 and Remark 2.2, Gaussian approximations remain still unable to attain the same rates of the sks counterparts in the estimation of generic functionals. Relevant examples are highest posterior density intervals which are often studied in practice and will be non–symmetric by definition whenever the posterior is skewed.
Lemma 2.4.
Let with and , be a skew-symmetric approximation of and let be an even function. If both and are finite, it holds
As clarified in the Supplementary Materials, Lemma 2.4 follows as a direct consequence of Proposition 6 in Wang, Boyer and Genton (2004).
The proof of Theorem 2.1 is reported below and extends to sks approximating distributions the reasoning behind the derivation of general Bernstein–von Mises type results (Kleijn and van der Vaart, 2012). Nonetheless, as mentioned before, the need to derive sharper rates which establish a higher approximation accuracy, relative to Gaussian limiting distributions, requires a number of additional technical lemmas and refined arguments ensuring a tighter control of the error terms in the expansions behind Theorem 2.1. Note also that, in addressing these aspects, it is not sufficient to rely on standard theory for higher–order approximations. In fact, unlike for current results, Theorem 2.1 establishes improved rates for a valid class of approximating densities. This means that, beside replacing the second–order expansion of the log–posterior with a third–order one, it is also necessary to carefully control the difference between such an expansion and the class of sks distributions.
Proof.
Let denote the sks density in (1) with parameters derived in Lemma B.1 under Assumptions 2 and 3 (see the Supplementary Materials). In addition, let and be the constrained versions of and to the set , i.e, and . Using triangle inequality
| (9) |
the proof of Theorem 2.1 reduces to study the behavior of the three above summands.
As for the first term, Assumption 4 and a standard inequality of the tv norm yield
| (10) |
Let us now deal with the third term via a similar reasoning. More specifically, leveraging the same tv inequality as above and the fact that within the expression for in (1) is a univariate cdf meeting the condition , we have
Define and let for some sequence going to infinity arbitrary slowly and some . Moreover, notice that has entries of order . As a consequence, in view of Assumptions 2–3 and Lemma B.2 in the Supplementary Materials, it follows that . Conditioned on , the eigenvalues of lay on a positive bounded range. This, together with , imply
| (11) |
for every , where is a sufficiently small positive constant and the last inequality follows from the tail behavior of the multivariate Gaussian for a sufficiently large choice of in . This gives
| (12) |
We are left to study the last summand . To this end, let us consider the event Notice that
by Assumption 4. Moreover, in view of (11), it follows that implying, in turn, . As a consequence, we can restrict our attention to
| (13) |
Now, note that, by the definition of , we have . This fact, together with an application of Jensen’s inequality, implies that the quantity on the right hand side of Equation (13) can be upper bounded by
At this point, it is sufficient to recall Lemma B.1 within the Supplementary Materials and the fact that , for some , to obtain
| (14) | |||||
where , and is some constant defined in Lemma B.1. We conclude the proof by noticing that the combination of (9), (10), (12) and (14), yields Equation (8) in Theorem 2.1. ∎
2.3 Skew–symmetric approximations in regular parametric models
Theorem 2.1 states a general result under broad assumptions. In this section, we strengthen the methodological and practical impact of such a result by specializing the analysis to the context of, possibly misspecified and non–i.i.d., regular parametric models with fixed and . The focus on this practically–relevant setting crucially clarifies that Assumptions 1–4 can be readily verified under standard explicit conditions on the log–likelihood and log–prior derivatives, which in turn enter the definition of the sks parameters , and . This allows direct and closed–form derivation of in routine implementations of deterministic approximations for intractable posteriors induced by broad classes of parametric models. As stated in Corollary 2.5, in this setting the resulting sks approximating density achieves a remarkable improvement in the rates by a factor, up to a poly–log term, relative to the classical Gaussian approximation. This accuracy gain can be proved both for the tv distance from the target posterior and also for the absolute error in the approximation for the posterior expectation of general polynomially bounded functions, with finite prior expectation.
Prior to stating Corollary 2.5, let us introduce a number of explicit assumptions which allow to specialize the general theory in Section 2.2 to the setting with fixed and . As discussed in the following, Assumptions 5–6 provide natural and verifiable conditions which ensure that the general Assumptions 2–4 are met, thereby allowing Theorem 2.1 to be applied, and specialized, to the regular parametric models setting.
Assumption 5.
Define . Then, the log–likelihood of the, possibly misspecified, model is four times differentiable at with
and , for .
Assumption 6.
The entries of the expected Fisher information matrix satisfy while , for Moreover, there exist two positive constants and such that and .
Assumption 7.
The log–prior density is two times continuously differentiable in a neighborhood of , and .
Assumption 8.
For every sequence there exists a constant such that
Assumptions 5–6 are mild and considered standard in classical frequentist theory (see e.g., Pace and Salvan, 1997, p. 347). In Lemma 2.8 we show that these conditions allow to control with precision the error in the Taylor approximation of the log–likelihood. Assumption 7 is also mild and is satisfied by several priors that are commonly used in practice. Such a condition allows to consider a first order Taylor expansion for the log–prior of the form
| (15) |
with . Finally, Assumption 8 is required to control the the rate of contraction of the, possibly misspecified, posterior distribution into . In other modern versions of Berstein–Von Mises type results, such an assumption is usually replaced by conditions on the existence of a suitable sequence of tests. Sufficient conditions for the correctly–specified case can be found, for example, in Van der Vaart (2000). In the misspecified setting, assumptions ensuring the existence of these tests have been derived by Kleijn and van der Vaart (2012). Another possible option is to assume, for every , the presence of a positive constant such that
| (16) |
In the misspecified setting, condition (16) is considered by, e.g., Koers, Szabo and van der Vaart (2023). Assumption 8 is a slightly more restrictive version of (16). In fact, Lemma 2.10 below shows that it is implied by mild and readily–verifiable sufficient conditions.
Under Assumption 1 and 5–8, Corollary 2.5 below clarifies that Theorem 2.1 holds for a general class of sks distributions yielding tv rates in approximating the exact posterior of order , with and . Furthermore, the sks parameters are defined as explicit functions of the log–prior and log–likelihood derivatives. As stated in Equation (18) of Corollary 2.5, the same rates can be derived also for the absolute error in approximating the posterior expectation of general polynomially bounded functions.
Corollary 2.5.
Let and define , with . Then, under Assumptions 1 and 5–8 it holds
| (17) |
where , and is the cdf of the sks density in (1) with parameters
where for . The function entering the definition of in (1) denotes any univariate cdf which satisfies and , for some , when . In addition, let be a function satisfying . If the prior is such that then
| (18) |
with denoting the skew–symmetric approximating density defined above.
Remark 2.6.
As for Theorem 2.1, under conditions similar to those required by Corollary 2.5, it is possible to show that the tv distance between the posterior and the Gaussian approximation dictated by the classical Bernstein–von Mises theorem is for some fixed . Therefore, the improvement in rates achieved by the proposed sks approximation is by a remarkable factor, up to a poly–log term. As illustrated in Figure 1, this implies that the sks solution is expected to substantially improve, in practice, the accuracy of the classical Gaussian in approximating the target posterior, while inheriting its limiting frequentist properties. Intuitively, the rates we derive suggest that the proposed sks approximation can possibly attain with a sample size the same accuracy obtained by its Gaussian counterpart with a sample size of . The empirical studies in Sections 3 and 5 confirm this intuition, which is further strengthened in Section 4 through the derivation of non–asymptotic upper bounds for the practical skew–modal approximation, along with novel lower bounds for the classical Gaussian from the Laplace method.
Remark 2.7.
Equation (18) confirms that the improved rates hold also when the focus is on the error in approximating the posterior expectation of generic polynomially bounded functions. More specifically, notice that, by direct application of standard properties of integrals, the proof of Equation (18) in the Supplementary Materials, implies
| (19) |
This clarifies that the skewed Bernstein–von Mises type result in (17) has important methodological and practical consequences that point toward remarkable improvements in the approximation of posterior functionals of direct interest for inference (e.g., moments).
The proof of Equation (18) can be found in the Supplementary Materials. As for the main result in Equation (17), it is sufficient to apply Theorem 2.1, after ensuring that its Assumptions 1–4 are implied by 1 and 5–8. Section 2.3.1 presents two key results (see Lemma 2.8 and Lemma 2.9) which address this point. Section 2.3.2 introduces instead simple and verifiable conditions which ensure the validity of Assumption 8.
2.3.1 Log–posterior asymptotics and posterior contraction
In order to move from the general theory within Theorem 2.1 to the specialized setting considered in Corollary 2.5, two key points are the rate at which the target posterior concentrates in and the behavior of the Taylor expansion of the log–likelihood within . Here we show that Assumptions 1 and 5–8 are indeed sufficient to obtain the required guarantees. Lemma 2.8 below establishes that, under Assumptions 5–6, the error introduced by replacing the log–likelihood with its third–order Taylor approximation is uniformly of order on .
Lemma 2.9 shows that under the above conditions it is then possible to select in , and hence , such that the posterior distribution concentrates its mass in , at any polynomial rate, with probability tending to 1 as . This in turn implies that Assumption 4 in Section 2.2 is satisfied.
Lemma 2.9 (Posterior contraction).
2.3.2 Sufficient conditions for Assumption 8
Lemma 2.9 requires the fulfillment of Assumption 8 which allows precise control on the behavior of the log–likelihood ratio outside the set . In addition, Assumption 8 further plays a crucial role in the development of the practical skew–modal approximation presented in Section 4. Given the relevance of such an assumption, Lemma 2.10 provides a set of natural and verifiable sufficient conditions that guarantee its validity; see the Supplementary Materials for the proof of Lemma 2.10.
Lemma 2.10.
Suppose that Assumptions 1 and 6 hold, and that for every there exists a positive constant such that
| (21) |
If there exist and such that, for all , it holds
-
•
R1) is concave in , two times differentiable at with negative Hessian equal to the expected Fisher information matrix
-
•
R2) and
then there is a constant such that , for any .
As highlighted at the beginning of Section 2.3, condition (21) is mild and can be found both in classical (e.g., Lehmann and Casella, 2006) and modern (Koers, Szabo and van der Vaart, 2023) Bernstein–von Mises type results. Condition R1 requires the expected log–likelihood to be sufficiently regular within a neighborhood of and is closely related to standard assumptions on M–estimators (e.g., Van der Vaart, 2000, Ch. 5). Finally, among the assumptions of Lemma 2.10, R2 is arguably the most specific. It requires that, for all such that , the quantity converges uniformly to zero in probability with rate . This type of behavior is common in several routinely–implemented statistical models, such as generalized linear models.
3 Empirical results
Sections 3.1–3.2 provide empirical evidence of the improved accuracy achieved by the sks approximation in Corollary 2.5 (s–BvM), relative to its Gaussian counterpart (BvM) arising from the classical Bernstein–von Mises theorem in regular parametric models. We study both correctly–specified and misspecified settings, and focus not only on assessing the superior performance of the sks approximation, with , but also on quantifying whether the remarkable improvements encoded in the rates we derived under asymptotic arguments find empirical evidence also in finite–sample studies. To this end, s–BvM and BvM are compared both in terms of tv distance from the target posterior and also with respect to the absolute error in approximating the posterior mean. These two measures illustrate the practical implications of the rates derived in Equation (17) and (18), respectively. Since for the illustrative studies in Sections 3.1 and 3.2 the target posterior can be derived in closed form, the tv distances and can be evaluated numerically, for every , via standard routines in R. The same holds for the errors in posterior mean approximation and .
Note that, as for other versions of the classical Bernstein–von Mises theorem, also our theoretical results in Sections 2.2 and 2.3 require knowledge of the Kullback–Leibler minimizer between the true data–generating process and the parametric family . Since is clearly unknown in practice, in Section 4 we address this aspect via a practical plug–in version of the sks approximation in Corollary 2.5, which replaces with its maximum a posteriori estimate. This yields a readily–applicable skew–modal approximation with similar theoretical and empirical support; see the additional simulations and real–data applications in Section 5.
3.1 Exponential model
Let , for , where denotes the exponential distribution with rate parameter In the following, we consider a correctly specified model having exponential likelihood and a prior for . To obtain the skew–symmetric approximation for the posterior distribution induced by such a Bayesian model, let us first verify that all conditions of Corollary 2.5 hold.
To address this goal first note that, as the model is correctly specified, Assumption 1 holds with . The first four derivates of the log–likelihood at are , and , respectively. Hence, Assumptions 5–6 are both satisfied, even around a small neighborhood of . Assumption 7 is met by a broad class of routinely–implemented priors. For example, can be considered in such a case. Finally, we need to check Assumption 8. To this end, note that which, by the law of large number, converges in probability to a negative constant for every fixed implying (21). Additionally, is concave in and, therefore, it fulfills condition R1 of Lemma 2.10. Since also condition R2 in Lemma 2.10 is satisfied and, as a consequence, also Assumption 8.
| 55 | 120 | 250 | 350 | 820 | 1690 | 2470 | |
| 15 | 25 | 70 | 110 | 380 | 1050 | 2280 |
The above results ensure that Corollary 2.5 holds and can be leveraged to derive the parameters of the sks approximation in (1) under this exponential example. To this end, first notice that, since the prior distribution is an , then . As a consequence, and . For what concerns the skewing factor, we choose which implies a cubic function equal to .
Table 1 compares the accuracy of the skew–symmetric (s–BvM) and the Gaussian (BvM) approximations corresponding to the newly–derived and classical Bernstein–von Mises theorems, respectively, under growing sample size and replicated experiments. More specifically, we consider 50 different simulated datasets with and sample size . Then, within each of these 50 experiments, we derive the target posterior under several subsets of data with a growing sample size , and then compare the accuracy of the two approximations under the tv and fmae measures discussed at the beginning of Section 3. The first part of Table 1 displays, for each , these two measures averaged across the 50 replicated experiments under both s–BvM and BvM. The empirical results confirm that the sks approximation yields remarkable accuracy improvements over the Gaussian counterpart for any . Such an empirical finding clarifies that the improvement encoded in the rates we derive, is visible also in finite, even small, sample size settings. This suggests that the theory in Sections 2.2–2.3 is informative also in practice, while motivating the adoption of the sks approximation in place of the Gaussian one. Such a result is further strengthened in the second part of Table 1, which shows that to attain the same accuracy achieved by the proposed sks approximation with a given , the classical Gaussian counterpart requires a sample size higher by approximately one order of magnitude.
3.2 Misspecified exponential model
Section 3.2 deals with a correctly–specified model where . Since Corollary 2.5 holds even when the model is misspecified, it is of interest to compare the accuracy of the proposed sks approximation and the Gaussian one also within this context. To this end, let us consider the case , for , where denotes the log–normal distribution with parameters and . As in Section 3.1, an exponential likelihood is assumed, parameterized by the rate parameter , and the prior is . In this misspecified context, the minimizer of the Kullback–Leibler divergence between the log–normal distribution and the family of exponential distributions is unique and equal to . Similarly to Section 3.1 one can show that the conditions of Corollary 2.5 are still satisfied, thus allowing the derivation of the same sks approximating density with parameters evaluated at instead of .
4 Skew–modal approximation
As for standard theoretical derivations of Bernstein–von Mises type results, also our theory in Section 2 studies approximating densities whose parameters depend on the minimizer of for , which coincides with when the model is correctly–specified. Such a quantity is unknown in practice. Hence, to provide an effective alternative to the classical Gaussian–modal approximation, which can be implemented in practical contexts, it is necessary to replace with a suitable estimate. To this end, in Section 4.1 we consider a simple, yet effective, plug–in version of the sks density in Corollary 2.5 which replaces with its maximum a posteriori (map) estimator, without losing the theoretical accuracy guarantees. Note that, in general, can be replaced by any efficient estimator. However, by relying on the map several quantities simplify, giving raise to a highly tractable and accurate solution, which is named skew–modal approximation. When the focus is on approximating posterior marginals, Section 4.2 further derives a theoretically supported, yet more scalable, skew–modal approximation for such quantities.
4.1 Skew–modal approximation and theoretical guarantees
Consistent with the above discussion, we consider the plug–in version of in Equation (1), where the unknown is replaced by the map . This yields the skew–symmetric density, for the rescaled parameter , defined as
| (22) |
where with while the skewing function entering the univariate cdf is defined as .
Relative to the expression for in Equation (1), the location parameter is zero in (22), since is a function of the quantity which is zero by definition when is the map. For the same reason, unlike its population version defined below (17), in the expression for the precision matrix of the Gaussian density factor in (22) the additional term including the third order derivative disappears. Therefore, approximation (22) does not introduce additional complications in terms of positive–definiteness and non–negativity of the precision matrix relative to those of the classical Gaussian–modal approximation.
Equation (22) provides a practical skewed approximation of the exact posterior centered at the mode. For this reason, such a solution is referred to as skew–modal approximation. In order to provide theoretical guarantees for this practical version, similar to those in Corollary 2.5, while further refining these guarantees through novel non–asymptotic bounds, let us introduce two mild assumptions in addition to those outlined in Section 2.3.
Assumption 9.
For every , the event satisfies for some sequence converging to zero.
Assumption 10.
There exist two positive constants such that the event holds with a probability for a suitable sequence converging to zero as . Moreover, there exist positive constants and , , such that, for , the joint event holds with a probability , for some suitable sequence converging to zero, where represents the spectral norm.
Assumption 9 is mild and holds generally in regular parametric problems. This assumption ensures us that the map is in a suitably–small neighborhood of , where the centering took place in Corollary 2.5. Condition 10 is a similar and arguably not stronger version of the analytical assumptions for the Laplace method described in Kass, Tierney and Kadane (1990). Notice also that under Assumption 9, condition 10 replaces Assumptions 5–6, and requires the upper bound to hold in a neighborhood of These conditions ensure uniform control on the difference between the log–likelihood ratio and its third order Taylor’s expansion. Based on these additional conditions we provide an asymptotic result for the skew–modal approximation in (22), similar to Corollary 2.5. The proof can be found in the Supplementary Materials and follows as a direct consequence of a more refined non–asymptotic bound we derive for ; see Remark 4.2.
Theorem 4.1.
Remark 4.2.
As discussed above, Theorem 4.1 follows directly from a more refined non–asymptotic upper bound that we derive for in Section C of the Supplementary Materials. In particular, as in recently–derived non–asymptotic results for the Gaussian Laplace approximation (e.g., Spokoiny and Panov, 2021; Spokoiny, 2023), it is possible to keep track of the constants and the dimension dependence also within our derivations, to show that on an event with high probability (approaching ), it holds
| (25) |
for some constant not depending on and , see Theorem C.1. As a consequence, the rates in (23) follow directly from (25), when keeping fixed and letting . More importantly, the above bound vanishes also when the dimension grows with , as long as up to a poly–log term. Although our original focus is not specific to these high–dimensional regimes, it shall be emphasized that such a growth for is interestingly in line with those required either for (e.g., Panov and Spokoiny, 2015) or for the notion of effective dimension (Spokoiny and Panov, 2021; Spokoiny, 2023) in recent high–dimensional studies of the Gaussian Bernstein–von Mises theorem and the Laplace approximation. However, unlike the bounds derived in these studies, the one in (25) decays to zero with , up to a poly–log term, rather than , for any given dimensions.
Remark 4.3.
Similarly to Remark 2.6 our proofs can be easily modified to show that the tv distance between the posterior and the classical Gaussian Laplace approximation is, up to a poly–log term, of order . This is a substantially worse upper bound than those derived for the skew–modal approximation. Theorem C.6 in the Supplementary Materials further refines such a result by proving that, up to a poly–log term, this upper bound is sharp, whenever the posterior displays local asymmetries; see condition (C.30). More specifically, under (C.30), we prove that, on an event with high probability (approaching ), the tv distance between the posterior and the classical Laplace approximation (gm) is bounded from below by , for some constant , possibly depending on . Crucially, the proof of this lower bound implies that is also bounded from below by . This result strengthens (23)–(25).
Remark 4.4.
Since the tv distance is invariant with respect to scale and location transformations, the above results can be stated also for the original parametrization of interest. Focusing, in particular, on the choice , this yields the density
| (26) |
which coincides with that of the well–studied sub–class of generalized skew–normal (gsn) distributions (Ma and Genton, 2004) and is guaranteed to approximate the posterior density for with the rate derived in Theorem 4.1.
Our novel skew–modal approximation provides, therefore, a similarly tractable, yet substantially more accurate, alternative to the classical Gaussian from the Laplace method. This is because, as discussed in Section 2, the closed–form skew–modal density can be evaluated at a similar computational cost as the Gaussian one, when is not too large. Furthermore, it admits a straightforward i.i.d. sampling scheme that facilitates Monte Carlo estimation of any functional of interest. Recalling Section 2, such a scheme simply relies on sign perturbations of samples from a –variate Gaussian and, hence, can be implemented via standard R packages for simulating from these variables. Note that, although the non–asymptotic bound in (25) can be also derived for the theoretical skew–symmetric approximations in Section 2, the focus on the skew–modal is motivated by the fact that such an approximation provides the solution implemented in practice. Section 4.2 derives and studies an even more scalable, yet similarly–accurate, approximation when the focus is on posterior marginals.
4.2 Marginal skew–modal approximation and theoretical guarantees
The skew–modal approximation in Section 4.1 targets the joint posterior. In practice, the marginals of such a posterior are often the main object of interest (Rue, Martino and Chopin, 2009). For studying these quantities, it is possible to simulate i.i.d. values from the joint skew–modal approximation in (22), leveraging the sampling strategy discussed in Section 2, and then retain only samples from the marginals of direct interest. This requires, however, multiple evaluations of the cubic function in the skewness–inducing factor. In the following, we derive a closed–form skew–modal approximation for posterior marginals that mitigates this scalability issue.
To address the above goal, denote with the set containing the indexes for the elements of on which we are interested in. Let be the cardinality of , and the complement of . Finally, write . Accordingly, the corresponding matrix can be partitioned in two diagonal blocks , , and an off–diagonal one .
Under the regularity conditions stated in Section 4.1, it is possible to write, for ,
The second order term in the above expression is proportional to the kernel of a Gaussian and, therefore, can be decomposed as
where and .
To obtain a marginal skew–modal approximation, let us leverage again the fact that the third order term converges to zero in probability, and that for . With these results, an approximation for the posterior marginal of is, therefore, proportional to
| (27) |
where denotes the expectation with respect to . Leveraging basic properties of the expected value, the term can be further decomposed as
| (28) |
with and . Therefore, the above expected values simply require the first three non–central moments of the multivariate Gaussian having density . These are , and . Hence, letting
| (29) |
the summation in (28) can be written as , with . Replacing this quantity in (LABEL:taylor:marginal), yields , with
| (30) |
Therefore, by leveraging the reasoning as in Section 2.1, we can write where , and is a univariate cdf satisfying , and As a result, the posterior marginal density of can be approximated by
| (31) |
Note that in (30) is an odd polynomial of , and that .
Equation (31) shows that, once the quantities defining are pre–computed, then the cost of inference under such an approximating density scales with , and no more with . As a consequence, when the focus is on the univariate marginals, i.e., , the computational gains over the joint approximation in (22) can be substantial, and calculation of functionals can be readily performed via one–dimensional numerical integration methods.
Theorem 4.5 below clarifies that, besides being effective from a computational perspective, the above solution preserves the same theoretical accuracy guarantees in approximating the target marginal posterior density .
Theorem 4.5.
5 Empirical analysis of skew–modal approximations
Sections 5.1–5.2 demonstrate on both synthetic datasets and real–data applications that the join and marginal skew–modal approximations (skew–m) in Section 4 achieve remarkable accuracy improvements relative to the Gaussian–modal counterpart (gm) from the Laplace method. These improvements are again in line with the rates we derived theoretically. Comparisons against other state–of–the–art approximations from mean–field vb (e.g., Blei, Kucukelbir and McAuliffe, 2017) and ep (e.g., Vehtari et al., 2020) are also discussed. In the following, we focus, in particular, on assessing performance of the generalized skew–normal approximations in Remarks 4.4–4.6.
5.1 Exponential model revisited
Let us first replicate the simulation studies in Sections 3.1–3.2 with focus on the practical skew–modal approximation in Section 4.1, rather than its population version which assumes knowledge of . Consistent with this focus, the performance of the skew–m approximation in Equation (26) is compared against the gm solution arising from the Laplace method (see e.g., Gelman et al., 2013, p. 318). Note that both the correctly–specified and misspecified models satisfy the additional Assumptions 9–10 required by Theorem 4.1 and Remark 4.4. In fact, is asymptotically equivalent to the maximum likelihood estimator which implies that condition 9 is fulfilled. Moreover, in view of the expressions for the first three log–likelihood derivatives in Section 3.1 also 10 holds.
| 150 | 260 | 470 | 730 | ||
| 190 | 390 | 650 | 1030 |
Table 2 reports the same summaries as in the second part of Table 1, but now with a focus on comparing the skew–m approximation in (26) and the gm . Results are in line with those in Section 3.1, and show, for example, that to achieve the same accuracy attained by the skew–modal with , the Gaussian from the Laplace method requires a sample size of . These results are strengthened in Tables D.2–D.3 in the Supplementary Materials which confirm the findings of Sections 3.1–3.2. Also in this context, the asymptotic theory in Theorem 4.1 closely matches the empirical behavior observed in practice.
5.2 Probit and logistic regression model
We consider now a real–data application on the Cushings dataset (Venables and Ripley, 2002), openly–available in the R library Mass. In this case the true data–generative model is not known and, therefore, this analysis is useful to evaluate again performance in possibly misspecified contexts.
The data are obtained from a medical study on individuals, aimed at investigating the relationship between four different sub–types of Cushing’s syndrome and two steroid metabolites, Tetrahydrocortisone and Pregnanetriol respectively. To simplify the analysis, we consider here the binary response variable which takes value if patient is affected by bilateral hyperplasia, and otherwise, for The observed covariates are = “urinary excretion rate of Tetrahydrocortisone for patient ” and = “urinary excretion rate of Pregnanetriol for patient ”. In the following, we focus on the two most widely–implemented regression models for binary data, namely the probit regression , and the logistic one with the inverse logit function defined in Remark 2.3.
Under both models, Bayesian inference proceeds via standard weakly informative Gaussian priors for the three regression coefficients within . Such priors, combined with the likelihood of each model, yield a posterior for which we approximate under both the joint and the marginal skew–modal approximations (skew–m). Table 3 compares, via different measures, the accuracy of these solutions relative to the one obtained under the classical Gaussian–modal approximation from the Laplace methods (gm) (Gelman et al., 2013, pp. 318). Notice that, all these approximations can be readily derived from the closed–form derivatives of the log–likelihood and log–prior for both the probit and logistic regression. Moreover, since the prior is Gaussian, the map under both models coincides with the ridge–regression estimator and hence can be computed via basic R functions.
ave–pr Probit skew–m gm Logit skew–m gm
Table 3 displays Monte Carlo estimates of tv distances from the target posterior distribution and its marginals, along with errors in approximating the posterior means for the three regression parameters and the posterior probabilities of being affected by a bilateral hyperplasia. Under probit, the latter quantity is defined as with and , for each , where is any generic approximation for . The logistic case follows by replacing with . The Monte Carlo estimate of such a measure and of all those reported within Table 3 rely on i.i.d. samples from both skew–m and gm, and on chains of length of Hamiltonian Monte Carlo realizations from the target posterior obtained with the R function stan_glm from the rstanarm package.
As illustrated in Table 3, the proposed skew–m solutions generally yield remarkable accuracy improvements relative to gm, under both models. More specifically, skew–m almost halves, on average, the tv distance associated with gm, while providing a much more accurate approximation for the posterior means and posterior probabilities. This is an important accuracy gain provided that the ratio between the absolute error made by gm in posterior means approximation and the actual value of these posterior means is, on average, .
As discussed in the Supplementary Materials, skew–m outperforms also state–of–the–art mean–field vb (Consonni and Marin, 2007; Durante and Rigon, 2019; Fasano, Durante and Zanella, 2022), and is competitive with ep (Chopin and Ridgway, 2017). The latter result is particularly remarkable since our proposed approximation only leverages the local behavior of the posterior distribution in a neighborhood of its mode, whereas ep is known to provide an accurate global solution aimed at matching the first two moments of the target posterior.
5.3 High–dimensional logistic regression
We conclude with a final real–data application which is useful to assess more in detail the marginal skew–modal approximation from Section 4.2, while studying the performance of the proposed class of skewed approximations in a high–dimensional context that partially departs from the regimes we have studied from a theoretical perspective. To this end, we consider a clinical study that investigates whether biological measurements from cerebrospinal fluid collected on subjects can be used to diagnose the Alzheimer’s disease (Craig-Schapiro et al., 2011). The dataset is available in the R package AppliedPredictiveModeling and comprises explanatory variables along with a response , which takes the value 1 if patient is affected by the Alzheimer’s disease, and 0 otherwise.
Bayesian inference relies on logistic regression with independent Gaussian priors for the coefficients. Here we consider a lower variance than in the previous application to induce shrinkage in this higher–dimensional context. The inclusion of the intercept and the presence of a categorical variable with 6 levels imply that the number of parameters in the model is . As a consequence, although the sample size is not small in absolute terms, since and the behavior of the posterior in this example is not necessarily closely described by the asymptotic and non–asymptotic theory developed in Section 4.
| err (mean) | err (median) | tv (mean) | tv (median) | |
|---|---|---|---|---|
| skew–m | 0.139 | 0.068 | 0.104 | 0.078 |
| gm | 0.425 | 0.347 | 0.145 | 0.120 |
Nonetheless, as clarified in Table 4, skew–m still yields remarkable improvements relative to gm also in this challenging regime. These gains are visible both in the absolute difference between the exact posterior mean and its approximation (err), and also in the tv distances between each marginal posterior density and its approximation (tv). Such quantities are computed via Monte Carlo as in Section 5.2 for each of the coefficients. Table 4 reports the means and medians over these different values. As for the results in Section 5.2, also these improvements are particularly relevant provided that the absolute error of gm is not negligible when compared with the actual posterior means ( of these means are between and ). These findings provide further empirical evidence in favor of the proposed skew–m, and clarify that it can yield substantial accuracy improvements whenever the shape of the posterior departs from Gaussianity, either because of low sample size, or also in situations where is large in absolute terms, but not in relation to .
6 Discussion
Through a novel treatment of a third order version of the Laplace method, this article shows that it is possible to derive valid, closed–form and tractable skew symmetric approximations of posterior distributions. Under general assumptions which also account for both misspecified models and non–i.i.d. settings, such a novel family of approximations is shown to admit a Bernstein–von Mises type result that establishes remarkable improvements in convergence rates to the target posterior relative to those of the classical Gaussian limiting approximation. The specialization of this general theory to regular parametric models yields skew–symmetric approximations with a direct methodological impact and immediate applicability under a novel skew–modal solution which is obtained by replacing the unknown entering the theoretical version with its map estimate . The empirical studies on both simulated data and real applications confirm that the remarkable accuracy improvements dictated by our asymptotic and non–asymptotic theory are visible also in practice, even for small–sample regimes. This provides further support to the superior theoretical, methodological and practical performance of the proposed class of approximations.
The above advancements open new avenues that stimulate research in the field of Bayesian inference based on skewed deterministic approximations. As shown in a number of contributions appeared after our article and referencing to our theoretical results, interesting directions include the introduction of skewness in other deterministic approximations, such as vb (e.g., Tan, 2023), and further refinements of the high–dimensional results implied by the non–asymptotic bounds we derive for the proposed skew–modal approximation. Katsevich (2023) provides an interesting contribution along such a latter direction, which leverages a novel theoretical approach based on Hermit polynomial expansions to show that can possibly grow faster than , under suitable models. However, unlike for our results, the focus is on studying non–valid skewed approximating densities. The notion of effective dimension introduced by Spokoiny and Panov (2021) and Spokoiny (2023) for the study of the classical Gaussian Laplace approximation in high dimensions is also worth further investigations under our skewed extension provided that can be possibly .
Semiparametric settings (e.g., Bickel and Kleijn, 2012; Castillo and Rousseau, 2015) are also of interest. Moreover, although the inclusion of skewness is arguably sufficient to yield an accurate approximation of posterior distributions, accounting for kurtosis might provide additional improvements both in theory and in practice. To this end, a relevant research direction is to seek for an alternative to the Gaussian density in the symmetric part, possibly obtained from an extension to the fourth order of our novel treatment of the Laplace method. Our conjecture is that this generalization would provide an additional order–of–magnitude improvement in the rates, while yielding an approximation still within the sks class.
References
- Anceschi et al. (2023) {barticle}[author] \bauthor\bsnmAnceschi, \bfnmNiccolo’\binitsN., \bauthor\bsnmFasano, \bfnmAugusto\binitsA., \bauthor\bsnmDurante, \bfnmDaniele\binitsD. and \bauthor\bsnmZanella, \bfnmGiacomo\binitsG. (\byear2023). \btitleBayesian conjugacy in probit, tobit, multinomial probit and extensions: A review and new results. \bjournalJournal of the American Statistical Association \bvolume118 \bpages1451–1469. \endbibitem
- Arellano-Valle and Azzalini (2006) {barticle}[author] \bauthor\bsnmArellano-Valle, \bfnmReinaldo B\binitsR. B. and \bauthor\bsnmAzzalini, \bfnmAdelchi\binitsA. (\byear2006). \btitleOn the unification of families of skew-normal distributions. \bjournalScandinavian Journal of Statistics \bvolume33 \bpages561–574. \endbibitem
- Azzalini and Capitanio (2003) {barticle}[author] \bauthor\bsnmAzzalini, \bfnmAdelchi\binitsA. and \bauthor\bsnmCapitanio, \bfnmAntonella\binitsA. (\byear2003). \btitleDistributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume65 \bpages367–389. \endbibitem
- Bernstein (1917) {bbook}[author] \bauthor\bsnmBernstein, \bfnmS\binitsS. (\byear1917). \btitleTheory of Probability. \bpublisherMoskow. \endbibitem
- Bickel and Kleijn (2012) {barticle}[author] \bauthor\bsnmBickel, \bfnmPeter J\binitsP. J. and \bauthor\bsnmKleijn, \bfnmBas JK\binitsB. J. (\byear2012). \btitleThe semiparametric Bernstein–von Mises theorem. \bjournalThe Annals of Statistics \bvolume40 \bpages206–237. \endbibitem
- Bishop (2006) {bbook}[author] \bauthor\bsnmBishop, \bfnmC.\binitsC. (\byear2006). \btitlePattern Recognition and Machine Learning. \bpublisherSpringer. \endbibitem
- Blei, Kucukelbir and McAuliffe (2017) {barticle}[author] \bauthor\bsnmBlei, \bfnmDavid M\binitsD. M., \bauthor\bsnmKucukelbir, \bfnmAlp\binitsA. and \bauthor\bsnmMcAuliffe, \bfnmJon D\binitsJ. D. (\byear2017). \btitleVariational inference: A review for statisticians. \bjournalJournal of the American Statistical Association \bvolume112 \bpages859–877. \endbibitem
- Bochkina and Green (2014) {barticle}[author] \bauthor\bsnmBochkina, \bfnmNatalia A\binitsN. A. and \bauthor\bsnmGreen, \bfnmPeter J\binitsP. J. (\byear2014). \btitleThe Bernstein–von Mises theorem and nonregular models. \bjournalThe Annals of Statistics \bvolume42 \bpages1850–1878. \endbibitem
- Boucheron and Gassiat (2009) {barticle}[author] \bauthor\bsnmBoucheron, \bfnmStéphane\binitsS. and \bauthor\bsnmGassiat, \bfnmElisabeth\binitsE. (\byear2009). \btitleA Bernstein-von Mises theorem for discrete probability distributions. \bjournalElectronic Journal of Statistics \bvolume3 \bpages114–148. \endbibitem
- Castillo and Nickl (2014) {barticle}[author] \bauthor\bsnmCastillo, \bfnmIsmaël\binitsI. and \bauthor\bsnmNickl, \bfnmRichard\binitsR. (\byear2014). \btitleOn the Bernstein–von Mises phenomenon for nonparametric Bayes procedures. \bjournalThe Annals of Statistics \bvolume42 \bpages1941–1969. \endbibitem
- Castillo and Rousseau (2015) {barticle}[author] \bauthor\bsnmCastillo, \bfnmIsmaël\binitsI. and \bauthor\bsnmRousseau, \bfnmJudith\binitsJ. (\byear2015). \btitleA Bernstein–von Mises theorem for smooth functionals in semiparametric models. \bjournalThe Annals of Statistics \bvolume43 \bpages2353–2383. \endbibitem
- Challis and Barber (2012) {barticle}[author] \bauthor\bsnmChallis, \bfnmEdward\binitsE. and \bauthor\bsnmBarber, \bfnmDavid\binitsD. (\byear2012). \btitleAffine independent variational inference. \bjournalAdvances in Neural Information Processing Systems \bvolume25 \bpages1–9. \endbibitem
- Chopin and Ridgway (2017) {barticle}[author] \bauthor\bsnmChopin, \bfnmNicolas\binitsN. and \bauthor\bsnmRidgway, \bfnmJames\binitsJ. (\byear2017). \btitleLeave Pima Indians alone: Binary regression as a benchmark for Bayesian computation. \bjournalStatistical Science \bvolume32 \bpages64–87. \endbibitem
- Consonni and Marin (2007) {barticle}[author] \bauthor\bsnmConsonni, \bfnmGuido\binitsG. and \bauthor\bsnmMarin, \bfnmJean-Michel\binitsJ.-M. (\byear2007). \btitleMean-field variational approximate Bayesian inference for latent variable models. \bjournalComputational Statistics & Data Analysis \bvolume52 \bpages790–798. \endbibitem
- Craig-Schapiro et al. (2011) {barticle}[author] \bauthor\bsnmCraig-Schapiro, \bfnmRebecca\binitsR., \bauthor\bsnmKuhn, \bfnmMax\binitsM., \bauthor\bsnmXiong, \bfnmChengjie\binitsC., \bauthor\bsnmPickering, \bfnmEve H\binitsE. H., \bauthor\bsnmLiu, \bfnmJingxia\binitsJ., \bauthor\bsnmMisko, \bfnmThomas P\binitsT. P., \bauthor\bsnmPerrin, \bfnmRichard J\binitsR. J., \bauthor\bsnmBales, \bfnmKelly R\binitsK. R., \bauthor\bsnmSoares, \bfnmHolly\binitsH., \bauthor\bsnmFagan, \bfnmAnne M\binitsA. M. \betalet al. (\byear2011). \btitleMultiplexed immunoassay panel identifies novel CSF biomarkers for Alzheimer’s disease diagnosis and prognosis. \bjournalPloS one \bvolume6 \bpagese18850. \endbibitem
- Dehaene and Barthelmé (2018) {barticle}[author] \bauthor\bsnmDehaene, \bfnmGuillaume\binitsG. and \bauthor\bsnmBarthelmé, \bfnmSimon\binitsS. (\byear2018). \btitleExpectation propagation in the large data limit. \bjournalJournal of the Royal Statistical Society: Series B (Statistical Methodology) \bvolume80 \bpages199–217. \endbibitem
- Durante (2019) {barticle}[author] \bauthor\bsnmDurante, \bfnmDaniele\binitsD. (\byear2019). \btitleConjugate Bayes for probit regression via unified skew-normal distributions. \bjournalBiometrika \bvolume106 \bpages765–779. \endbibitem
- Durante and Rigon (2019) {barticle}[author] \bauthor\bsnmDurante, \bfnmDaniele\binitsD. and \bauthor\bsnmRigon, \bfnmTommaso\binitsT. (\byear2019). \btitleConditionally conjugate mean-field variational Bayes for logistic models. \bjournalStatistical Science \bvolume34 \bpages472–485. \endbibitem
- Fasano and Durante (2022) {barticle}[author] \bauthor\bsnmFasano, \bfnmAugusto\binitsA. and \bauthor\bsnmDurante, \bfnmDaniele\binitsD. (\byear2022). \btitleA class of conjugate priors for multinomial probit models which includes the multivariate normal one. \bjournalJournal of Machine Learning Research \bvolume23 \bpages1–26. \endbibitem
- Fasano, Durante and Zanella (2022) {barticle}[author] \bauthor\bsnmFasano, \bfnmAugusto\binitsA., \bauthor\bsnmDurante, \bfnmDaniele\binitsD. and \bauthor\bsnmZanella, \bfnmGiacomo\binitsG. (\byear2022). \btitleScalable and accurate variational Bayes for high-dimensional binary regression models. \bjournalBiometrika \bvolume109 \bpages901–919. \endbibitem
- Frobenius (1912) {barticle}[author] \bauthor\bsnmFrobenius, \bfnmGeorg\binitsG. (\byear1912). \btitleÜber Matrizen aus nicht negativen Elementen. \bjournalSitzungsberichte der Königlich Preussischen Akademie der Wissenschaften \bvolume26 \bpages456–477. \endbibitem
- Gelman et al. (2013) {bbook}[author] \bauthor\bsnmGelman, \bfnmAndrew\binitsA., \bauthor\bsnmCarlin, \bfnmJohn B\binitsJ. B., \bauthor\bsnmStern, \bfnmHal S\binitsH. S., \bauthor\bsnmDunson, \bfnmDavid B\binitsD. B., \bauthor\bsnmVehtari, \bfnmAki\binitsA. and \bauthor\bsnmRubin, \bfnmDonald B\binitsD. B. (\byear2013). \btitleBayesian Data Analysis. \bpublisherChapman and Hall/CRC. \endbibitem
- Johnson (1970) {barticle}[author] \bauthor\bsnmJohnson, \bfnmRichard A\binitsR. A. (\byear1970). \btitleAsymptotic expansions associated with posterior distributions. \bjournalThe Annals of Mathematical Statistics \bpages851–864. \endbibitem
- Kasprzak, Giordano and Broderick (2022) {barticle}[author] \bauthor\bsnmKasprzak, \bfnmMikołaj J\binitsM. J., \bauthor\bsnmGiordano, \bfnmRyan\binitsR. and \bauthor\bsnmBroderick, \bfnmTamara\binitsT. (\byear2022). \btitleHow good is your Gaussian approximation of the posterior? Finite-sample computable error bounds for a variety of useful divergences. \bjournalarXiv:2209.14992. \endbibitem
- Kass, Tierney and Kadane (1990) {barticle}[author] \bauthor\bsnmKass, \bfnmR. E.\binitsR. E., \bauthor\bsnmTierney, \bfnmL.\binitsL. and \bauthor\bsnmKadane, \bfnmJ. B.\binitsJ. B. (\byear1990). \btitleThe validity of posterior expansions based on Laplace’s method. \bjournalBayesian and Likelihood Methods in Statistics and Econometrics: Essays in Honor of George A. Barnard \bpages473–-487. \endbibitem
- Katsevich (2023) {barticle}[author] \bauthor\bsnmKatsevich, \bfnmAnya\binitsA. (\byear2023). \btitleTight skew adjustment to the Laplace approximation in high dimensions. \bjournalarXiv:2306.07262. \endbibitem
- Kleijn and van der Vaart (2012) {barticle}[author] \bauthor\bsnmKleijn, \bfnmBas JK\binitsB. J. and \bauthor\bparticlevan der \bsnmVaart, \bfnmAad W\binitsA. W. (\byear2012). \btitleThe Bernstein-von-Mises theorem under misspecification. \bjournalElectronic Journal of Statistics \bvolume6 \bpages354–381. \endbibitem
- Koers, Szabo and van der Vaart (2023) {barticle}[author] \bauthor\bsnmKoers, \bfnmGeerten\binitsG., \bauthor\bsnmSzabo, \bfnmBotond\binitsB. and \bauthor\bparticlevan der \bsnmVaart, \bfnmAad\binitsA. (\byear2023). \btitleMisspecified Bernstein-Von Mises theorem for hierarchical models. \bjournalarXiv:2308.07803. \endbibitem
- Kolassa and Kuffner (2020) {barticle}[author] \bauthor\bsnmKolassa, \bfnmJohn E\binitsJ. E. and \bauthor\bsnmKuffner, \bfnmTodd A\binitsT. A. (\byear2020). \btitleOn the validity of the formal Edgeworth expansion for posterior densities. \bjournalThe Annals of Statistics \bvolume48 \bpages1940–1958. \endbibitem
- Laplace (1810) {bbook}[author] \bauthor\bsnmLaplace, \bfnmPierre Simon\binitsP. S. (\byear1810). \btitleThéorie Analytique des Probabilités, \bedition3rd ed. \bpublisherCourcier. \endbibitem
- Le Cam (1953) {barticle}[author] \bauthor\bsnmLe Cam, \bfnmLucien\binitsL. (\byear1953). \btitleOn some asymptotic properties of maximum likelihood estimates and related Bayes’ estimates. \bjournalUniversity of California Publications in Statistics \bvolume1 \bpages277–330. \endbibitem
- Le Cam and Yang (1990) {bbook}[author] \bauthor\bsnmLe Cam, \bfnmLucien\binitsL. and \bauthor\bsnmYang, \bfnmGrace Lo\binitsG. L. (\byear1990). \btitleAsymptotics in Statistics. \bpublisherSpringer. \endbibitem
- Lehmann and Casella (2006) {bbook}[author] \bauthor\bsnmLehmann, \bfnmErich L\binitsE. L. and \bauthor\bsnmCasella, \bfnmGeorge\binitsG. (\byear2006). \btitleTheory of Point Estimation. \bpublisherSpringer Science & Business Media. \endbibitem
- Ma and Genton (2004) {barticle}[author] \bauthor\bsnmMa, \bfnmYanyuan\binitsY. and \bauthor\bsnmGenton, \bfnmMarc G\binitsM. G. (\byear2004). \btitleFlexible class of skew-symmetric distributions. \bjournalScandinavian Journal of Statistics \bvolume31 \bpages459–468. \endbibitem
- McCullagh (2018) {bbook}[author] \bauthor\bsnmMcCullagh, \bfnmPeter\binitsP. (\byear2018). \btitleTensor Methods in Statistics. \bpublisherCourier Dover Publications. \endbibitem
- Minka (2001) {barticle}[author] \bauthor\bsnmMinka, \bfnmT. P.\binitsT. P. (\byear2001). \btitleExpectation propagation for approximate Bayesian inference. \bjournalProceedings of Uncertainty in Artificial Intelligence \bvolume17 \bpages362–369. \endbibitem
- Opper and Archambeau (2009) {barticle}[author] \bauthor\bsnmOpper, \bfnmManfred\binitsM. and \bauthor\bsnmArchambeau, \bfnmCédric\binitsC. (\byear2009). \btitleThe variational Gaussian approximation revisited. \bjournalNeural Computation \bvolume21 \bpages786–792. \endbibitem
- Pace and Salvan (1997) {bbook}[author] \bauthor\bsnmPace, \bfnmLuigi\binitsL. and \bauthor\bsnmSalvan, \bfnmAlessandra\binitsA. (\byear1997). \btitlePrinciples of Statistical inference: From a Neo-Fisherian Perspective. \bpublisherWorld Scientific. \endbibitem
- Panov and Spokoiny (2015) {barticle}[author] \bauthor\bsnmPanov, \bfnmMaxim\binitsM. and \bauthor\bsnmSpokoiny, \bfnmVladimir\binitsV. (\byear2015). \btitleFinite sample Bernstein–von Mises theorem for semiparametric problems. \bjournalBayesian Analysis \bvolume10 \bpages665–710. \endbibitem
- Perron (1907) {barticle}[author] \bauthor\bsnmPerron, \bfnmOskar\binitsO. (\byear1907). \btitleZur theorie der matrices. \bjournalMathematische Annalen \bvolume64 \bpages248–263. \endbibitem
- Ray and Szabó (2022) {barticle}[author] \bauthor\bsnmRay, \bfnmKolyan\binitsK. and \bauthor\bsnmSzabó, \bfnmBotond\binitsB. (\byear2022). \btitleVariational Bayes for high-dimensional linear regression with sparse priors. \bjournalJournal of the American Statistical Association \bvolume117 \bpages1270–1281. \endbibitem
- Rue, Martino and Chopin (2009) {barticle}[author] \bauthor\bsnmRue, \bfnmH.\binitsH., \bauthor\bsnmMartino, \bfnmS.\binitsS. and \bauthor\bsnmChopin, \bfnmN.\binitsN. (\byear2009). \btitleApproximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. \bjournalJournal of the Royal Statistical Society: Series B \bvolume71 \bpages319-392. \endbibitem
- Spokoiny (2023) {barticle}[author] \bauthor\bsnmSpokoiny, \bfnmVladimir\binitsV. (\byear2023). \btitleInexact Laplace approximation and the use of posterior mean in Bayesian inference. \bjournalBayesian Analysis \bvolume1 \bpages1–28. \endbibitem
- Spokoiny and Panov (2021) {barticle}[author] \bauthor\bsnmSpokoiny, \bfnmVladimir\binitsV. and \bauthor\bsnmPanov, \bfnmMaxim\binitsM. (\byear2021). \btitleAccuracy of Gaussian approximation for high-dimensional posterior distribution. \bjournalBernoulli \bvolume(in print). \endbibitem
- Tan (2023) {barticle}[author] \bauthor\bsnmTan, \bfnmLinda SL\binitsL. S. (\byear2023). \btitleVariational inference based on a subclass of closed skew normals. \bjournalarXiv:2306.02813. \endbibitem
- Tao (2011) {barticle}[author] \bauthor\bsnmTao, \bfnmTerence\binitsT. (\byear2011). \btitleTopics in random matrix theory. \bjournalGraduate Studies in Mathematics \bvolume132. \endbibitem
- Tierney and Kadane (1986) {barticle}[author] \bauthor\bsnmTierney, \bfnmLuke\binitsL. and \bauthor\bsnmKadane, \bfnmJoseph B\binitsJ. B. (\byear1986). \btitleAccurate approximations for posterior moments and marginal densities. \bjournalJournal of the American Statistical Association \bvolume81 \bpages82–86. \endbibitem
- Van der Vaart (2000) {bbook}[author] \bauthor\bparticleVan der \bsnmVaart, \bfnmAad W\binitsA. W. (\byear2000). \btitleAsymptotic Statistics \bvolume3. \bpublisherCambridge University Press. \endbibitem
- Vehtari et al. (2020) {barticle}[author] \bauthor\bsnmVehtari, \bfnmAki\binitsA., \bauthor\bsnmGelman, \bfnmAndrew\binitsA., \bauthor\bsnmSivula, \bfnmTuomas\binitsT., \bauthor\bsnmJylänki, \bfnmPasi\binitsP., \bauthor\bsnmTran, \bfnmDustin\binitsD., \bauthor\bsnmSahai, \bfnmSwupnil\binitsS., \bauthor\bsnmBlomstedt, \bfnmPaul\binitsP., \bauthor\bsnmCunningham, \bfnmJohn P\binitsJ. P., \bauthor\bsnmSchiminovich, \bfnmDavid\binitsD. and \bauthor\bsnmRobert, \bfnmChristian P\binitsC. P. (\byear2020). \btitleExpectation propagation as a way of life: A framework for Bayesian inference on partitioned data. \bjournalJournal of Machine Learning Research \bvolume21 \bpages1–53. \endbibitem
- Venables and Ripley (2002) {bbook}[author] \bauthor\bsnmVenables, \bfnmW. N.\binitsW. N. and \bauthor\bsnmRipley, \bfnmB. D.\binitsB. D. (\byear2002). \btitleModern Applied Statistics with S, \bedition4 ed. \bpublisherSpringer, \baddressNew York. \endbibitem
- Von Mises (1931) {bbook}[author] \bauthor\bsnmVon Mises, \bfnmR\binitsR. (\byear1931). \btitleWahrscheinlichkeitsrechnung. \bpublisherSpringer Verlagr. \endbibitem
- Wang and Blei (2013) {barticle}[author] \bauthor\bsnmWang, \bfnmChong\binitsC. and \bauthor\bsnmBlei, \bfnmDavid M\binitsD. M. (\byear2013). \btitleVariational inference in nonconjugate models. \bjournalJournal of Machine Learning Research \bvolume14 \bpages1005–1031. \endbibitem
- Wang and Blei (2019) {barticle}[author] \bauthor\bsnmWang, \bfnmYixin\binitsY. and \bauthor\bsnmBlei, \bfnmDavid M\binitsD. M. (\byear2019). \btitleFrequentist consistency of variational Bayes. \bjournalJournal of the American Statistical Association \bvolume114 \bpages1147–1161. \endbibitem
- Wang, Boyer and Genton (2004) {barticle}[author] \bauthor\bsnmWang, \bfnmJiuzhou\binitsJ., \bauthor\bsnmBoyer, \bfnmJoseph\binitsJ. and \bauthor\bsnmGenton, \bfnmMarc G\binitsM. G. (\byear2004). \btitleA skew-symmetric representation of multivariate distributions. \bjournalStatistica Sinica \bpages1259–1270. \endbibitem
- Weng (2010) {barticle}[author] \bauthor\bsnmWeng, \bfnmRuby C\binitsR. C. (\byear2010). \btitleA Bayesian Edgeworth expansion by Stein’s identity. \bjournalBayesian Analysis \bvolume5 \bpages741–763. \endbibitem
- Zwillinger and Jeffrey (2007) {bbook}[author] \bauthor\bsnmZwillinger, \bfnmDaniel\binitsD. and \bauthor\bsnmJeffrey, \bfnmAlan\binitsA. (\byear2007). \btitleTable of Integrals, Series, and Products. \bpublisherElsevier. \endbibitem
Supplementary Materials
Appendix A Proofs of Lemmas, Theorems and Corollaries
Section A contains the proofs of the Lemmas, Theorems and Corollaries stated in the main article. The proof of Theorem 4.1 is discussed in Section C, and follows as a direct consequence of the non–asymptotic bound we derive for the tv distance among the skew–modal approximation and the target posterior.
proof of Lemma 2.4.
proof of Corollary 2.5.
To prove (17) notice that the general Assumptions 1–2 and 4, introduced in Section 2.2, are implied by Assumptions 1 and 5–8 together with Lemma 2.8 and Lemma 2.9 in Section 2.3.1. In addition, Assumption 7 implies that Assumption 3 is verified with . Hence, all the conditions of Theorem 2.1 are satisfied with , proving the validity of the statement in Equation (17).
To prove (18), recall that . In addition, since , it is sufficient to prove the statement for . Leveraging the triangle inequality we have
| (A.1) | ||||
Recall that, , for some positive constants , and for some going to infinity arbitrary slow. Now, note that from Assumptions 5–6, Lemma 2.8 and Lemma B.2 it follows .
To bound the element in (A.1) we use the fact that, from Assumptions 7–8 and Equation (A.7) of Lemma 2.9, the event with denoting an arbitrary small and fixed positive constant, satisfies . By combining this result with and Jensen’s inequality we obtain
for a sufficiently large choice of in . Since , this implies
| (A.2) |
Similarly, the boundedness of and the tail behavior of the Gaussian distribution ensure
for a sufficiently large choice of . In turn, this implies
| (A.3) |
Finally, Equation (17) gives
| (A.4) |
Combining (A.1), (A.2), (A.3) and (A.4) proves Equation (18). ∎
proof of Lemma 2.8.
The proof of the lemma follows directly from Assumptions 5–6. Such assumptions allow to take, in , the following Taylor expansion
with , , and
for some . To conclude, we only need to check that the first term can be written as with . To this end, note that, in view of Assumption 6, Lemma B.2 implies that and are bounded from above and below, respectively, with probability tending to 1 as . Since, by the eigendecomposition (we assume the eigenvectors are normalized) it follows that the entries of are bounded, in absolute value, by we get , which implies, in turn, .
∎
proof of Lemma 2.9.
Let us start by writing
| (A.5) |
Recall that under Assumption 8 it holds
As a consequence, for every ,
| (A.6) |
given a sufficiently large constant in and the boundedness condition within Assumption 7. For the denominator of the right–hand–side of (A.5), we use Assumptions 5–6–7 to consider the Taylor expansions reported in (15) and (20). Recall that from Assumption 6 and Lemma B.2 there exist two positive constants and such that holds with probability . As a consequence, if we collect the third order term in (20) and the prior effect in the remainder, it follows
| , |
with since is positive definite when conditioned on ,
and . Notice that we consider instead of since we are currently studying the quantity at the denominator of (A.5).
Define now the event for some going to infinity arbitrary slow and a fixed positive constant. Since and , we can equivalently study the asymptotic behavior of the following lower bound
| (A.7) | ||||
proof of Lemma 2.10.
To prove Lemma 2.10, let us deal with the cases and separately. For the claim trivially follows from (21). We are left to deal with the case . To this end, let us write
where and . Note that Assumption R1 implies that is concave in with Hessian . Since is positive definite from Assumption 6, for sufficiently small choice of it follows
In addition, define the event for a sufficiently large constant , and a sequence going to infinity arbitrary slow. Notice that from Assumption R2. As a consequence, conditioned on , we have for every which meets , that
Since can be chosen such that , the first component in the right–hand–side of the last display becomes always negative for large enough and the whole expression is asymptotically maximized when is at its minimum. This implies
for some , with –probability tending to one. This concludes the proof. ∎
Proof of Theorem 4.5.
Define . The tv distance among and is Adding and subtracting , and by exploiting Jensen’s and triangle inequality, we obtain the following upper bound
It follows from Theorem 4.1 that
| (A.8) |
for some . Therefore, it is sufficient to study Note that, as a direct consequence of Equation (31), we have
Let for some fixed . From Assumption 10 and Lemma B.3 it follows . Hence, let us condition on , and split the integral
between and . From the tail behavior of the Gaussian distribution and the boundedness of if follows that
for some constant , which in turn implies
|
|
(A.9) |
for a sufficiently large constant in . In addition, from Lemma B.4 it follows that
for some , which implies
| (A.10) |
The combination of (A.8), (A.9) and (A.10) concludes the proof with . ∎
Appendix B Technical lemmas
In the following, we state and prove the technical lemmas required for the proofs of the theoretical results in the article.
Lemma B.1.
Proof.
We start by noting that Assumptions 2 and 3 imply
| (B.3) | ||||
Furthermore, note that
| (B.4) |
where and is a quantity not depending on .
Let us now add and subtract from in the three dimensional array part, obtaining
| (B.5) | ||||
where does not depend on . Combining (B.4) and (B.5) it is possible to rewrite (B.3) as
| (B.6) | ||||
with , , , .
To conclude the proof of the lemma note that, Assumption 2, the fact that the parameter dimension is fixed, and the Cauchy–Schwarz inequality imply
By exploiting the conditions imposed on , let us write
since the argument of converges to zero in probability. An additional Taylor expansion, this time for gives
| (B.7) | ||||
where the remainder term is . Note that, when restricted on , . This fact combined with (B.6) and (B.7) gives
where Then, Assumptions 2–3 imply that
| (B.8) |
for some constant , concluding the proof. ∎
Lemma B.2.
Let and denote two real symmetric matrices. Suppose that is random with entries , whereas is non–random and has elements . Moreover, assume
| (B.9) |
for some norming rate and . If there exist two positive constants and such that and then, with –probability tending to , there exist two positive constants and such that and .
Proof.
Leveraging (B.9), let us first notice that with having entries of order As a consequence, there exist constants and such that
for every . Define now the matrix having entries for . From Wielandt’s theorem (Zwillinger and Jeffrey, 2007), with probability the spectral radius of is an upper bound of the spectral radius of Moreover, since is a non–negative matrix, the Perron–Frobenius theorem (Perron, 1907; Frobenius, 1912) implies that the largest eigenvalue in absolute value is bounded by constant times Since both and are real symmetric matrices, in view of the Weyl’s inequalities (e.g., Tao, 2011, equation (1.54)), the eigenvalues of and can differ at most by constant times with probability As a consequence, since the lemma assumes the existence of two positive constants and such that and , it follows that there exist such that, with probability and . ∎
Lemma B.3.
Let be a symmetric positive definite matrix satisfying and . Let be a set of indexes having cardinality , and be the submatrix obtained by keeping only rows and columns of whose position is in . Then it holds that and .
Proof.
Without loss of generality assume that the elements of are in increasing order. Note, also, that where is a matrix having entries if , where denotes the -th element of , and otherwise. Recall that, from the relation between minimum and maximum eigenvalues and the Rayleigh quotient it follows that
Similarly, leveraging , it holds for that
with the inequality that follows from the fact that Following the same line of reasoning it is possible to prove . This concludes the proof. ∎
Lemma B.4.
Proof.
Recall that the covariance matrix , associated to the Gaussian measure , is the Schur complement of the block of the matrix . This implies that, in view of Assumption 10, Lemma B.3 and the properties of the Schur complement, there exist constants such that the eigenvalues of are bounded from below by and above by with probability tending to one.
As a consequence, there exists a large enough constant such that the complement of the set has negligible mass, i.e., the event has probability . This fact and the boundedness of imply
| (B.10) | ||||
We further decompose the first term on the right–hand–side of the last display by adding and subtracting the first order Taylor expansion of . Moreover, recall that under the assumptions of Theorem 4.5, there exists such that holds with probability . Since it follows also that, conditioned on , both and are of order , while for some . This, together with , implies for sufficiently large
As a consequence,
| (B.11) |
To conclude, note that for sufficiently large,
|
|
with the first inequality that follows from the Taylor expansion of at 0, the equality from and the last line from the Cauchy–Schwarz inequality. Finally, note that while
for some large enough. From the previous display it follows
| (B.12) |
for a large enough. Combining (B.10), (B.11) and (B.12) concludes the proof. ∎
Appendix C Non–Asymptotic bounds and proof of Theorem 4.1
The proof of Theorem 4.1 follows as a direct consequence of a non–asymptotic version of this result, which we derive in Theorem C.1 below. More precisely, we show that, for a large enough , the tv distance between the skew–modal approximation and the target posterior is upper bounded by a constant times , on an event with . When is fixed and , this result implies the rate stated in Theorem 4.1, with . Similarly, we provide also a non–asymptotic upper bound for the approximation error of functionals of the posterior that implies the asymptotic rate stated in (24).
To prove the above result, let us introduce some additional notations. For , define
| (C.1) |
along with the event
| (C.2) |
providing bound on the logarithm of the likelihood–ratio outside of the –radius ball centered around the map. Then, for convenience, let us denote the intersection of the events in Assumptions 9–10 and the one above by
| (C.3) |
Finally, recall that in the definition of the skew–symmetric approximation in (1), we consider a univariate cdf satisfying and , while admitting a suitable expansion. By making more explicit such an expansion, let us assume that for some and a sufficiently small it holds
| (C.4) |
for .
Theorem C.1.
Suppose that Assumptions 1, 7–8–9–10 hold and that there exists small enough such that (C.1) and (C.4) are satisfied. Then . Furthermore, let and , with satisfying
| (C.5) |
where is defined as
| (C.6) |
Then, conditioned on , for large enough satisfying
| (C.7) |
with
| (C.8) |
and given in (C.1), we have that
| (C.9) |
where for with denoting the skew–modal approximating density defined in (22), while
| (C.10) |
In addition, let be a function satisfying , for some constant . Then for satisfying also , it holds, conditioned on , that
| (C.11) |
Remark C.2.
Let us discuss briefly the conditions and results of the previous theorem. The condition (C.7) on is needed in order to provide a finite sample control for the total variation distance. Under such a condition, for large enough, all the summands within the expression for in (C.10), except , can be always bounded by an arbitrarily small constant not depending on and . As such, the term in (C.9) can be itself upper bounded by , thereby yielding the constant in Remark 4.2 within the article. In addition, investigating the proof reveals that could be replaced in the limit by . Similarly, can be replaced asymptotically by . Then the derived upper bound on the total variation distance in fact extends our results to the high dimensional setting in which grows with at a rate that is, up to a poly–log term, slower than . Leveraging this discussion, it can also be noticed that the upper bound for the functional in (C.11) is asymptotically equal to Finally, as already discussed, by fixing and letting , Theorem C.1 yields directly to Theorem 4.1.
proof of Theorem C.1.
First note that, in view of Assumption 8,
hold with -probability , where . Note also that under , in view of maximizing the posterior, for any , we have
Therefore, . Hence by the union bound
To finish the proof we follow a similar lines of reasoning as in Theorem 2.1 and Corollary 2.5 with the main additional difference of restricting ourselves to the event and tracking the constant terms and dimension dependence explicitly in the rest of the proof.
Let us first split the problem into three parts using triangle inequality
|
|
(C.12) |
where and are the versions of and restricted to
| (C.13) |
A standard inequality of the tv norm together with Lemma C.5 implies that, on , for a large enough choice of , satisfying (C.5),
| (C.14) |
We deal now with the third term in a similar manner. The same tv inequality as above, together with the invariance of sks with respect to even functions (leveraged in the proof of Lemma 2.4), and Lemma C.4 give
We are left to deal with the second term on the right side of (C.12). To this end, define
| (C.15) |
where with , while the skewing function is defined as , with . Furthermore, note that, conditioned on , it follows from Lemmas C.4 and C.5 that and . Hence, similarly as in the proof of Theorem 2.1, using Lemma C.3 and we obtain for large enough satisfying that
|
|
Let us now combine the above results to obtain (C.9).
In particular, as a direct consequence of the above derivations, an upper bound for the tv distance among and is
It remains to deal with the upper bound in Equation (C.11). Similarly to Corollary 2.5, it is sufficient to prove the statement for . Using the triangle inequality we can again split the problem into three parts
|
|
(C.16) |
For the first term above note that as in Lemma C.5, we have on the event that
| (C.17) |
Similarly, conditioned on , the boundedness of and Lemma C.4 imply
Let us introduce the notation . Then by noting that for , the preceding display can be further bounded by
| (C.18) |
Lemma C.3.
Proof.
First note that since is the map, the first derivative of the log–posterior is zero by definition when evaluated at . As a consequence using Assumption 10, together with the combination of a third order Taylor expansion of the log–likelihood with a first order Taylor expansion of the log–prior gives
| (C.21) | ||||
for some . As a consequence, conditioned on , by the Cauchy–Schwarz inequality and the upper bounds on the spectral norms of , and (see Assumption 10), we have, for satisfying , that
| (C.22) |
Furthermore, in view of condition (C.4), we also have that
| (C.23) |
where in the remainder part the additional term is incorporated within the function .
By combining the above displays we get the following upper bound for ,
|
|
(C.24) |
Notice that, by (C.22) the last two summands in the above display can be upper–bounded by and , respectively. As for the first summand, note that for large enough satisfying with , we have, in view of the inequalities if and , Assumption (C.4), and Cauchy–Schwarz inequality, that such a summand can be upper–bounded by
Combining the above upper bound with those for the last two summands in (C.24) yields, for large enough satisfying ,
thereby concluding the proof. ∎
Lemma C.4 (Concentration Gaussian modal approximation).
Let and denote with the centered Gaussian distribution for with covariance matrix . Conditioned on the event it holds that
| (C.25) |
Proof.
Let us write the covariance matrix in the form , where comprises the eigenvectors of as columns, whereas is the diagonal matrix of eigenvalues. Then, we have that , with . Note that for every fixed , Cauchy–Schwarz inequality gives
where denotes the Frobenius norm, while the last inequality follows from and the conditioning on . Finally, an application of Hoeffding’s inequality provides
concluding the proof of the lemma. ∎
Lemma C.5 (Posterior contraction about map).
proof of Lemma C.5.
First note that
| (C.26) |
Then, in view of , on the event ,
| (C.27) |
For the denominator of the right–hand–side of (C.26), we use part of the results in the proof of Lemma C.3 and the fact that, conditioned on , In particular, it follows from (C.21) and (C.22) that
where
with is defined in (C.6), for . As a consequence, conditioned on ,
| (C.28) | ||||
Then using (C.27) and (C.28), the inequalities and for and , Lemma C.4, Assumptions 7 and (C.1), we get for large enough, satisfying , and large enough satisfying (C.5), that
|
|
(C.29) |
concluding the proof of the lemma. ∎
Theorem C.6.
Let us consider the assumptions and notations of Theorem C.1. Furthermore, assume that there exists a such that, for all , it holds for a positive constant and for every . Moreover, let
and assume that
| (C.30) |
Then, conditioned on the event , for large enough satisfying , the total variation distance between the posterior distribution and the Gaussian Laplace approximation has the following lower bound
where is a constant possibly depending on , whereas for measurable .
Proof.
We start by noting that, conditioned on the event and in view of Theorem C.1, an application of triangle inequality gives
Next, notice that for satisfying (C.7), Assumption (C.4) on the cdf and by triangle inequality, we have that
| (C.31) | ||||
Note also that, since by assumption is Lipschitz continuous in a –neighborhood of and, conditioned on and , the quantity in the last line of (C.31) can be lower bounded by
| (C.32) |
It remains to show that the first term above is lower bounded by a positive constant. Let us introduce the notation
Then, on the event , the Cauchy–Schwartz and triangle inequalities together with Assumption 10 and the fact that and imply, for every with , that
Since and is lower bounded by a positive constant (depending on ), the first term in (C.32) is also lower bounded by a positive constant times . Including such a lower bound in (C.32) concludes the proof. ∎
Appendix D Empirical studies
In the following, we provide additional results related to the empirical studies considered in Sections 3 and 5 of the main article.
D.1 Misspecified exponential model from Section 3.2
Table D.1 reproduces the same analyses reported within Table 1 of the main article, but now with a focus on the misspecified exponential model described in detail in Section 3.2. The focus is again on comparing the accuracy of the approximations arising from the classical (BvM) and the skewed (s–BvM) Bernstein–von Mises theorem, respectively.
As discussed in Section 3.2, Table D.1 yields the same conclusions as those obtained for the correctly–specified setting in Table 1. These results further stress that the proposed sks class of approximating distributions outperforms remarkably the classical Gaussian arising from Bernstein–von Mises theorem, also in misspecified settings. The magnitude of these improvements is again in line with the expected gains encoded within the rates we derived in Section 2.3 from a theoretical perspective.
| 75 | 140 | 210 | 250 | 980 | 1560 | ||
| 35 | 65 | 140 | 150 | 830 | 1560 |
D.2 Gamma–Poisson model
Below we study in detail an additional important example that meets the conditions required to guarantee the validity of Corollary 2.5 and Theorem 4.1. Let , be independent and identically distributed realizations of a Poisson random variable with mean , and consider the case in which a Gamma prior on is assumed. In this framework, the log–likelihood of the model is while for .
Let us verify that the conditions of Corollary 2.5 and Theorem 4.1 are fulfilled by starting from Assumptions 5–6–7 and 8 (since we are in a correctly–specified setting, Assumption 1 holds with ). The first four log–likelihood derivatives are
where . Since , it immediately follows that . In addition, in view of , we have that , and for any fixed , and also for any sufficiently small and . This implies that both Assumptions 5 and 6 are satisfied. Similarly, also Assumption 7 is easily seen to hold in view of the fact that, for every , the Gamma density is bounded in a neighborhood of . To ensure the validity of Corollary 2.5 the last condition to be checked is Assumption 8. We prove it leveraging Lemma 2.10. First note that
| (D.1) |
and
| (D.2) |
The right–hand–side of Equation (D.1) is a non–positive function, having maximum at , which is two times differentiable and concave. This implies that Assumption of Lemma 2.10 is fulfilled. Similarly, since is bounded for every ,
implying that also Assumption of Lemma 2.10 is fulfilled. Note that these results for the quantities in the right–hand–side of (D.1) and (D.2) imply also that, for every , there exists such that as . Therefore, Lemma 2.10 holds for the model under consideration. This concludes the part regarding Corollary 2.5.
To demonstrate the validity of Theorem 4.1, note that in view of the conjugacy between Gamma prior and Poisson likelihood the map estimator takes the form
for . Thus, and, as a direct consequence, Assumption 9 is fulfilled. Finally note that, for every , the event has probability converging to one as . Conditioned on , in view of and of the previously–derived results for the log–likelihoods derivatives, it follows that , and are bounded by positive constants in a sufficiently small neighborhood of . This last observation implies Assumption 10 and, therefore, the validity of Theorem 4.1 for the Gamma–Poisson model.
D.3 Exponential model revisited from Section 5.1
Tables D.2 and D.3, together with Table 2 in the article, reproduce the same outputs reported in Tables 1 and D.1, but now with focus on the practical skew–modal (skew–m) approximation in Section 4.1, rather than its population version which assumes knowledge of . Consistent with this focus, the performance of the skew–modal approximation in Equation (26) is compared against the Gaussian arising from the Laplace method (gm) (see e.g., Gelman et al., 2013, p. 318).
As discussed in detail within Section 5.1, the remarkable improvements of skew–m in Tables D.2–D.3 are in line with those reported for its theoretical s–BvM counterpart in Section 3. Interestingly, by comparing the results in Tables D.2 and D.3 with those in Tables 1 and D.1 it is possible to notice that skew–m approximates even more accurately the target posterior than its theoretical s–BvM counterpart. This is because the practical skew–modal approximation is located, by definition, at the actual map of the target posterior, whereas its theoretical counterpart relies on . Therefore, in practical implementations, skew–m is expected to be closer to the actual posterior of interest than its theoretical version, since, in finite samples, there might be a non–negligible difference between and the map of the target posterior to be approximated.
Correctly–specified Misspecified
| 150 | 260 | 470 | 730 | ||
| 220 | 450 | 760 | 1120 |
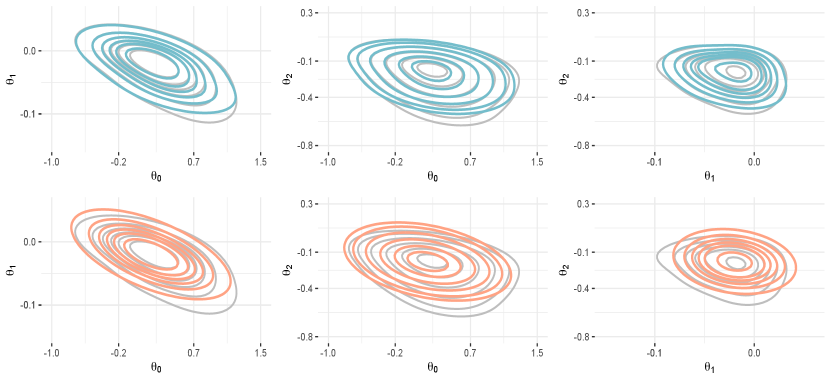
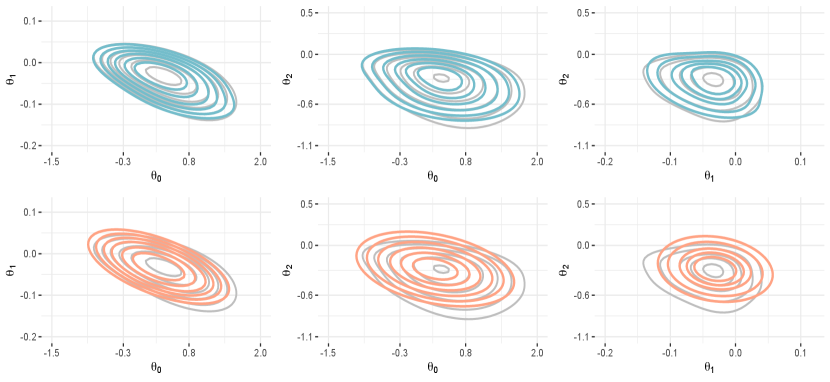
D.4 Probit and logistic regression model from Section 5.2
This section reports some additional results for the real–data analysis described in Section 5.2. Figures D.1 and D.2 strengthen the results within Table 3 in the main article by providing a graphical comparison between the accuracy of the newly–developed skew–modal approximation for the bivariate posteriors in the Cushings dataset, and the one obtained under the classical Gaussian–modal solution. Results confirm again the improved ability of the proposed skew–modal in approximating the target posterior through an accurate characterization of its skewness.
Probit skew–m gm ep mf–vb pfm–vb Logit skew–m gm ep mf–vb
Table D.4 concludes the analysis by assessing the behavior of the newly–proposed skew–m solution when compared against other advanced techniques within the class of deterministic approximations for binary regression models, beyond the classical Gaussian–modal (gm) alternative. State–of–the–art methods under this framework are mean–field variational Bayes (mf–vb) (Consonni and Marin, 2007; Durante and Rigon, 2019) and expectation–propagation (ep) (Chopin and Ridgway, 2017), while partially–factorized variational Bayes (pfm–vb) (Fasano, Durante and Zanella, 2022) is available only for probit regression. mf–vb and pfm–vb for probit regression leverage the implementation in the GitHub repository Probit-PFMVB (Fasano, Durante and Zanella, 2022), while in the logistic setting we rely on the codes in the repository logisticVB (Durante and Rigon, 2019). Note that pfm–vb is designed for probit regression only. Finally, ep is implemented under both models using the code in the GitHub repository GaussianEP.jl by Simon Barthelmé; see also the R library EPGLM (Chopin and Ridgway, 2017) for a previous implementation.
The results in Table D.4 highlight how the use of skew–m ensures noticeable improvements relative to mf–vb and pfm–vb. The advantages over pfm–vb in the probit model are remarkable since also such a strategy leverages a skewed approximation of the target posterior distribution. This yields a higher accuracy than mf–vb, but the improvements are not as noticeable as skew–m. A reason for this result is that pfm–vb has been originally developed to provide high accuracy in high–dimensional settings (Fasano, Durante and Zanella, 2022), whereas in this study and . Remarkably, skew–m yields results competitive also with ep. This fact is noteworthy for at least two reasons. First, Gaussian ep methods are aimed at matching the first two posterior moments. Being global characteristics of the target posterior, these objectives lead to approximations that, albeit symmetric, are often difficult to improve in practice. On the contrary, the proposed skew–m focuses on the local behavior of the posterior distribution in a neighborhood of its mode. It is therefore interesting to notice how inclusion of skewness can dramatically improve the global quality of an approximation, even when targeting its local behavior at the mode. For the Cushing application, this translates into an average for the tv distances in Table D.4 of , lower than the average of achieved by ep. Second, ep techniques typically rely on a convenient factorization of the target density (e.g., Gelman et al., 2013, p. 338). Such a condition is not required for the adoption of skew–m, making it applicable to a wider range of models.