Smart Speech Segmentation using acousto-linguistic features
with look-ahead
Abstract
Segmentation for continuous Automatic Speech Recognition (ASR) has traditionally used silence timeouts or voice activity detectors (VADs), which are both limited to acoustic features. This segmentation is often overly aggressive, given that people naturally pause to think as they speak. Consequently, segmentation happens mid-sentence, hindering both punctuation and downstream tasks like machine translation for which high-quality segmentation is critical. Model-based segmentation methods that leverage acoustic features are powerful, but without an understanding of the language itself, these approaches are limited. We present a hybrid approach that leverages both acoustic and language information to improve segmentation. Furthermore, we show that including one word as a look-ahead boosts segmentation quality. On average, our models improve segmentation-F0.5 score by 9.8% over baseline. We show that this approach works for multiple languages. For the downstream task of machine translation, it improves the translation BLEU score by an average of 1.05 points.
Index Terms— Speech recognition, audio segmentation, decoder segmentation, continuous recognition
1 Introduction
As Automatic Speech Recognition (ASR) quality has improved, the focus has gradually shifted from short utterance scenarios such as Voice Search and Voice Assistants to long utterance scenarios such as Voice Typing and Meeting Transcription. In the short utterance scenarios, speech end-pointing is important for user perceived latency and user experience. Voice Search and Voice Assistants are scenarios where the primary goal is task completion and elements of written form language such as punctuation are not as critical. The output of ASR is rarely revisited after task completion. For long-form scenarios, the primary goal is to generate highly readable well formatted transcription. Voice Typing aims to replace typing with keyboard for important tasks such as typing e-mails or documents, which are more “permanent” than search queries. Punctuation and capitalization become as important as recognition errors.
Recent research has demonstrated that ASR models suffer from several problems in the context of long-form utterances, such as lack of generalization from short to long utterances [1] and high WER and deletion errors [2, 3, 4]. The common practice in the context of long-form ASR is to segment the input stream. Segmentation quality is critical for optimal WER and punctuation, which is in turn critical for readability [5]. Furthermore, segmentation directly impacts downstream tasks such as machine translation. Prior works have demonstrated that improvements in segmentation and punctuation lead to significant BLEU gains in machine translation [6, 7].
Conventionally, simple silence timeouts or voice activity detectors (VADs) have been used to determine segment boundaries [8, 9]. Over the years, researchers have taken more complex and model-based approaches to predicting end-of-segment boundaries [10, 11, 12]. However, a clear drawback of VAD and many such model-based approaches is that they leverage only acoustic information, foregoing potential gains from incorporating semantic information from text [13]. Many works have addressed this issue in end-of-query prediction, combining the prediction task with ASR via end-to-end models [14, 15, 16, 17, 18]. Similarly, [19] leveraged both acoustic and textual features via an end-to-end segmenter for long-form ASR.
Our main contributions are as follows:
-
•
We demonstrate that linguistic features improve decoder segmentation decisions
-
•
We use look-ahead to further improve segmentation decisions by leveraging more surrounding context
-
•
We extend our approach to other languages and establish BLEU score gains on the downstream task of machine translation
2 Methods
2.1 Models
We describe three end-pointing techniques, each progressively improving upon the previous. A key contribution of this paper is introducing an RNN-LM in the segmentation decision-making process, which becomes even more powerful when using a look-ahead. Once segments are produced, they continue through a punctuation stage, where a transformer-based punctuation model punctuates each segment. This punctuation model is fixed for all following setups.
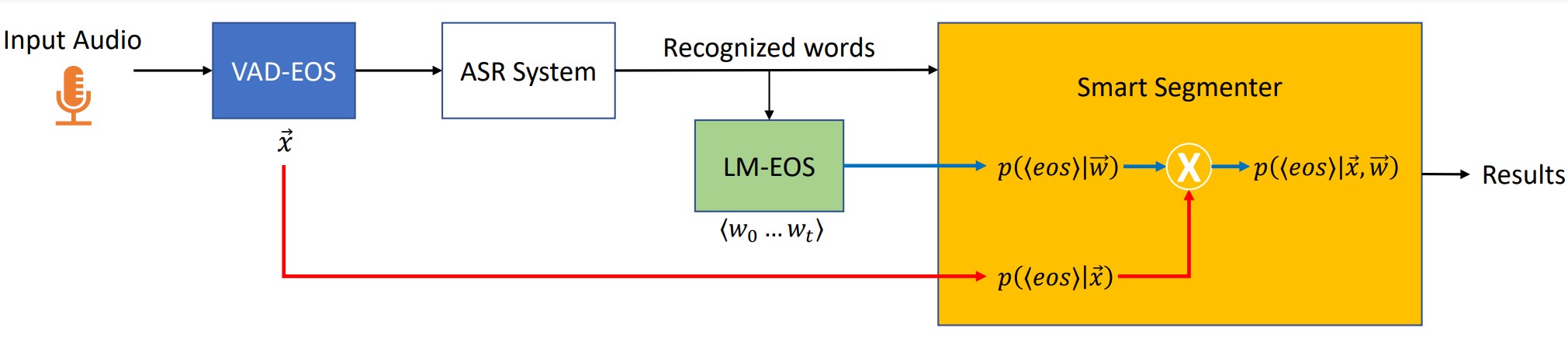
2.1.1 Acoustic/prosodic-only signals (v1)
In this baseline system, the segmentation decisions are based on a pre-defined threshold for silence. Typically, the default threshold used in such systems is 500ms. This threshold may vary by locale, given that speech rate as well as the frequency and duration of pauses may vary from language to language. This threshold may also vary by scenario. For instance, people tend to speak faster in conversations compared to dictation, so the optimal silence-based timeout threshold may be higher for dictation compared to conversational scenarios like meeting transcription. In addition to silence threshold, the system uses VAD models, which produces better speech end-pointing compared to a simple silence-based timeout approach [8, 9].
2.1.2 Acousto-linguistic signals (v2)
In natural speech, people often pause disproportionately. Thus, an aggressive v1 setup would result in overly aggressive end-pointing. In the v2 setup, we introduce a language model to offer a second opinion based on linguistic features. We call this an LM-EOS (Language Model – End of Segment predictor) model, as shown in Fig 1. Since the v2 setup incorporates both acoustic and linguistic features in decision-making, it avoids obvious error cases from v1.
2.1.3 Acousto-linguistic signals with look-ahead (v3)
In v2, LM-EOS only has access to left context when predicting end-of-segment boundaries. As prior work has established, this setup is severely limiting for punctuation tasks, where the right context is important for optimal punctuation quality [7]. Therefore, in the v3 setup we incorporate the right context in LM-EOS predictions.
2.2 Model Training
Our VAD follows prior works which have extensively covered VAD implementation details [8]. Here, we describe LM-EOS training in detail. First, let us establish the goal for these models.
2.2.1 LM-EOS model with no look-ahead
This model used in v2 is trained to predict whether the input sequence is a valid end of a sentence or not, only looking at the past. As illustrated in the examples below, only looking at the left context to predict can be quite limiting. To train this model, we use the Open Web Text corpus [20], and splitting the data into rows with one sentence per row. Each sentence must end in a period or a question mark. We discard any sentences containing punctuation other than periods, commas, and question marks. We then normalize the rows into the spoken form using a WFST (Weighted Finite State Transducers)-based text normalization tool. The LM-EOS model should predict end-of-segment () for every one of the rows, as each row is a sentence. To balance this set of sentences with countercases, we take each sentence and delete the last word. For each of these modified sequences, the model will be trained to predict non-EOS. Examples of the resulting training sequences are illustrated in 1.
| Id | Input | Output |
|---|---|---|
| A1 | how is the weather in seattle | O O O O O eos |
| A2 | how is the weather in | O O O O O |
| B1 | i’m new in town | O O O eos |
| B2 | i’m new in | O O O |
| C1 | wake me up at noon tomorrow | O O O O O eos |
| C2 | wake me up at noon | O O O O O |
| Id | Input | Output |
|---|---|---|
| A3 | how is the weather in seattle i’m | O O O O O eos O |
| B3 | i’m new in town wake | O O O eos O |
| C3 | wake me up at noon how | O O O O O eos O |
We include examples C1 and C2 to highlight an important shortcoming in our v2 training data preparation. The v2 model would not predict for example C2, even though C2 is a perfectly valid sentence. However, we observe that with enough training data, the model still learns that C2 is a valid sentence on its own.
2.2.2 LM-EOS model with 1-word look-ahead
The previous training setup can be extended to predict output tags with a one-word delay. This ensures that the model takes the next word into account when making its segmentation decision. To generate the training data for this model, in addition to the data in Table 1, we add corresponding variants with one word picked from the beginning of the next sentence, as shown in Table 2.
This model can be further extended to explore 2-word, 3-word, 4-word look-ahead. As we incorporate more right context, the LM-EOS accuracy increases, but so does the decoder latency. Because latency is critical for real-time ASR scenarios, we focus on the 1-word look-ahead setup in our experiments.
2.3 Experiments
Our VAD-EOS model is a 3-layer LSTM model with 64 hidden units. All the LM-EOS models are one-layer LSTMs with 1024 hidden units, an embedding size of 256, and a vocabulary size of 250k. These models are trained per locale, with and without the one-word look-ahead. They are trained until convergence.
| Test Set | Model | Segmentation | |||
|---|---|---|---|---|---|
| P | R | F0.5 | F0.5-gain | ||
| Dictation-100 | v1 | 0.60 | 0.81 | 0.63 | |
| v2 | 0.70 | 0.78 | 0.71 | 12.7% | |
| v3 | 0.71 | 0.81 | 0.73 | 15.9% | |
| NPR-76 | v1 | 0.76 | 0.81 | 0.77 | |
| v2 | 0.79 | 0.83 | 0.80 | 3.9% | |
| v3 | 0.82 | 0.82 | 0.82 | 6.5% | |
| EP-100 | v1 | 0.59 | 0.74 | 0.61 | |
| v2 | 0.63 | 0.74 | 0.65 | 6.6% | |
| v3 | 0.64 | 0.77 | 0.66 | 8.2% | |
| Earnings-10 | v1 | 0.69 | 0.77 | 0.70 | |
| v2 | 0.73 | 0.78 | 0.74 | 5.7% | |
| v3 | 0.75 | 0.79 | 0.76 | 8.5% | |
2.3.1 Test sets
We evaluate performance across various scenarios using both public and internal test sets.
NPR-76 [21]: 20 hours of test data from 76 transcribed NPR Podcast episodes.
EP-100 [22]: This dataset contains 100 English sessions scraped from European Parliament Plenary videos. It also contains human-labeled translations into German.
EP-locale [22]: This collection of datasets also contains sessions scraped from European Parliament Plenary videos, but across different locales. The collection has 5 locale-specific sets and their corresponding human-labeled translation into English.
Earnings-10: 10 hours of earnings call transcription data from the MAEC corpus [23]
Dictation-100: This internal set consists of 100 utterances with human transcriptions.
2.3.2 Metrics
We compute segmentation-F0.5 as the primary metric, with a higher weight given to precision than recall. This is in line with our users preferring under-segmentation over over-segmentation. For the European Parliament sets, we also compute source-BLEU as well as translation-BLEU scores against the corresponding human-transcribed ground truth sets.
3 Results
Our baseline system suffers from over-segmentation problem as indicated by recall being much higher than precision. Our user studies indicate that precision is much more important than recall; users prefer the system only punctuating when it is confident. Thus, we focus on F0.5, weighing precision higher than recall.
Table 3 presents the segmentation-F0.5 scores across the four test sets. Firstly, the v2 model (LM-EOS model with no look ahead) improves over the baseline across all the datasets. This supports our hypothesis that introducing linguistic features can help segmentation decisions. Furthermore, v3 (LM-EOS model with one-word look ahead) brings additional gains over v2, indicating that using look-ahead to leverage right context is important for LM-EOS to perform well.
It is worth noting that the impact of linguistic features varies across the datasets. The problem of over-segmentation is especially apparent in the dictation task compared to the others. This is as expected, because dictation or voice typing generally involves much more pausing and thinking compared to more natural or prepared speech as in NPR podcasts or earnings calls. For the NPR-76 set, v3 achieves a complete balance between precision and recall.
Table 4 presents results from the translation task for 6 locales. Each locale indicates the language of the original source audio file. The non-English audio files are transcribed and then translated into English. English source files are translated into German. Finally, BLEU scores are computed, matching the machine translation outputs against corresponding human-translated reference texts. The results demonstrate that not only is our hybrid approach effective across locales, but it also significantly boosts performance on the downstream task of machine translation.
| Locale | Model | BLEU | Gain |
|---|---|---|---|
| en-GB | v1 | 35.5 | |
| v2 | 36 | +0.5 | |
| v3 | 36.9 | +1.4 | |
| es-ES | v1 | 41.4 | |
| v2 | 41.6 | +0.2 | |
| v3 | 41.8 | +0.4 | |
| el-GR | v1 | 34.5 | |
| v2 | 35.1 | +0.7 | |
| v3 | 35.3 | +0.8 | |
| fr-FR | v1 | 38.4 | |
| v2 | 39.1 | +0.7 | |
| v3 | 39.6 | +1.2 | |
| it-IT | v1 | 44.7 | |
| v2 | 45.7 | +1.0 | |
| v3 | 46 | +1.3 | |
| ro-RO | v1 | 40.3 | |
| v2 | 40.9 | +0.6 | |
| v3 | 41.5 | +1.2 |
en-GB translated to de-DE, other locales translated to en-GB.
4 Discussion
We establish that introducing the linguistic features significantly improves decoder segmentation decisions. Our preliminary work on LM-EOS models with look-ahead demonstrates that leveraging limited right context is a powerful way to maximize the gains from incorporating linguistic features. We focused on LSTMs due to latency constraints of the system. In the future, we plan to explore transformer-based LM-EOS with much larger look-ahead values to capture even more right context. While this has latency implications, it is possible that with a more powerful LM-EOS, we may be able to rely a lot more on this model even in the absence of VAD signals to endpoint sooner. At the very least, it could benefit near-real-time or non-real-time use cases like Voicemail Transcriptions.
Our current approach combines the decisions from two separate models. The VAD-EOS model is language independent, while the LM-EOS model is trained per language. This allows us to train and improve them separately, which is critical considering the sparsity of publicly available audio and corresponding human-punctuated transcriptions. This allows for easier insertion of custom vocabulary into LM-EOS or early end-pointing based on detection of certain keywords or commands.
5 Conclusion
In this paper, we explored techniques that can improve speech segmentation. We demonstrated that linguistic features improve decoder segmentation decisions and look-ahead is a good way to leverage surrounding context in this decision making. We demonstrated its effectiveness on a wide range of scenarios. The method is most effective for human2machine scenarios like Dictation where users pause and think a lot. We see a segmentation-F0.5 gain of 15.9% for this. The technique nevertheless proves effective for other human2human scenarios as well. We prove that the technique can work well for other languages. We establish the benefit of improved segmentation for the downstream task of machine translation, measured by BLEU score gains of 0.4-1.4 across languages. In the future, we will explore transformer-based LM-EOS with longer look-ahead particularly targeting non-real-time use cases.
References
- [1] Arun Narayanan, Rohit Prabhavalkar, Chung-Cheng Chiu, David Rybach, Tara N Sainath, and Trevor Strohman, “Recognizing long-form speech using streaming end-to-end models,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 920–927.
- [2] Chung-Cheng Chiu, Arun Narayanan, Wei Han, Rohit Prabhavalkar, Yu Zhang, Navdeep Jaitly, Ruoming Pang, Tara N Sainath, Patrick Nguyen, Liangliang Cao, et al., “Rnn-t models fail to generalize to out-of-domain audio: Causes and solutions,” in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 873–880.
- [3] Zhiyun Lu, Yanwei Pan, Thibault Doutre, Liangliang Cao, Rohit Prabhavalkar, Chao Zhang, and Trevor Strohman, “Input length matters: An empirical study of rnn-t and mwer training for long-form telephony speech recognition,” arXiv preprint arXiv:2110.03841, 2021.
- [4] Jinhan Wang, Xiaosu Tong, Jinxi Guo, Di He, and Roland Maas, “Vadoi: Voice-activity-detection overlapping inference for end-to-end long-form speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6977–6981.
- [5] Maria Shugrina, “Formatting time-aligned asr transcripts for readability,” in Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2010, pp. 198–206.
- [6] Eunah Cho, Jan Niehues, and Alex Waibel, “Nmt-based segmentation and punctuation insertion for real-time spoken language translation.,” in Interspeech, 2017, pp. 2645–2649.
- [7] Piyush Behre, Sharman Tan, Padma Varadharajan, and Shuangyu Chang, “Streaming punctuation for long-form dictation with transformers,” arXiv preprint arXiv:2210.05756, 2022.
- [8] Javier Ramirez, Juan Manuel Górriz, and José Carlos Segura, “Voice activity detection. fundamentals and speech recognition system robustness,” Robust speech recognition and understanding, vol. 6, no. 9, pp. 1–22, 2007.
- [9] Takenori Yoshimura, Tomoki Hayashi, Kazuya Takeda, and Shinji Watanabe, “End-to-end automatic speech recognition integrated with ctc-based voice activity detection,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6999–7003.
- [10] Elizabeth Shriberg, Andreas Stolcke, Dilek Hakkani-Tür, and Gökhan Tür, “Prosody-based automatic segmentation of speech into sentences and topics,” Speech communication, vol. 32, no. 1-2, pp. 127–154, 2000.
- [11] Zulfiqar Ali and Muhammad Talha, “Innovative method for unsupervised voice activity detection and classification of audio segments,” Ieee Access, vol. 6, pp. 15494–15504, 2018.
- [12] Junfeng Hou, Wu Guo, Yan Song, and Li-Rong Dai, “Segment boundary detection directed attention for online end-to-end speech recognition,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2020, no. 1, pp. 1–16, 2020.
- [13] Meng Li, Shiyu Zhou, and Bo Xu, “Long-running speech recognizer: An end-to-end multi-task learning framework for online asr and vad,” arXiv preprint arXiv:2103.01661, 2021.
- [14] Roland Maas, Ariya Rastrow, Chengyuan Ma, Guitang Lan, Kyle Goehner, Gautam Tiwari, Shaun Joseph, and Björn Hoffmeister, “Combining acoustic embeddings and decoding features for end-of-utterance detection in real-time far-field speech recognition systems,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5544–5548.
- [15] Shuo-Yiin Chang, Rohit Prabhavalkar, Yanzhang He, Tara N Sainath, and Gabor Simko, “Joint endpointing and decoding with end-to-end models,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 5626–5630.
- [16] Bo Li, Shuo-yiin Chang, Tara N Sainath, Ruoming Pang, Yanzhang He, Trevor Strohman, and Yonghui Wu, “Towards fast and accurate streaming end-to-end asr,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6069–6073.
- [17] Inyoung Hwang and Joon-Hyuk Chang, “End-to-end speech endpoint detection utilizing acoustic and language modeling knowledge for online low-latency speech recognition,” IEEE Access, vol. 8, pp. 161109–161123, 2020.
- [18] Liang Lu, Jinyu Li, and Yifan Gong, “Endpoint detection for streaming end-to-end multi-talker asr,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7312–7316.
- [19] W Ronny Huang, Shuo-yiin Chang, David Rybach, Rohit Prabhavalkar, Tara N Sainath, Cyril Allauzen, Cal Peyser, and Zhiyun Lu, “E2e segmenter: Joint segmenting and decoding for long-form asr,” arXiv preprint arXiv:2204.10749, 2022.
- [20] Aaron Gokaslan and Vanya Cohen, “Openwebtext corpus,” 2019.
- [21] “Home page top stories,” https://www.npr.org/, Accessed: 2022-05-30.
- [22] “Debates and videos: Plenary: European parliament,” https://www.europarl.europa.eu/plenary/en/debates-video.html, Accessed: 2022-05-30.
- [23] Jiazheng Li, Linyi Yang, Barry Smyth, and Ruihai Dong, “Maec: A multimodal aligned earnings conference call dataset for financial risk prediction,” in Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 2020, pp. 3063–3070.