SMDP-Based Dynamic Batching for Improving Responsiveness and Energy Efficiency of Batch Services
Abstract
For servers incorporating parallel computing resources, batching is a pivotal technique for providing efficient and economical services at scale. Parallel computing resources exhibit heightened computational and energy efficiency when operating with larger batch sizes. However, in the realm of online services, the adoption of a larger batch size may lead to longer response times. This paper aims to provide a dynamic batching scheme that delicately balances latency and efficiency. The system is modeled as a batch service queue with size-dependent service times. Then, the design of dynamic batching is formulated as a semi-Markov decision process (SMDP) problem, with the objective of minimizing the weighted sum of average response time and average power consumption. A method is proposed to derive an approximate optimal SMDP solution, representing the chosen dynamic batching policy. By introducing an abstract cost to reflect the impact of “tail” states, the space complexity and the time complexity of the procedure can decrease by 63.5% and 98%, respectively. Numerical results showcase the superiority of SMDP-based batching policies across various parameter setups. Additionally, the proposed scheme exhibits noteworthy flexibility in balancing power consumption and latency.
Index Terms:
Dynamic batching, SMDP, latency, power consumption, GPUs.I Introduction
To meet the escalating demands for powerful computing capabilities, processors have undergone significant advancements in recent decades. The processors of today, including multi-core processors, graphics processing units (GPUs) and tensor processing units (TPUs), are equipped to better support parallel computing. This enhancement is crucial for efficiently managing large-scale data and executing complex tasks. For instance, GPUs have played a prominent role in accelerating the training and inference of neural networks due to their advantage in parallel computing[2]. These computing resources are now widely deployed across various levels—locally, on edge servers, and on cloud servers, providing computing services that facilitate ubiquitous access to intelligence at any time and from anywhere.
For servers equipped with processors capable of parallel operations, an important factor that affects both performance and cost of computing services is batch processing, or batching[3, 4]. Specifically, batching is usually employed for homogeneous tasks that share common operations, allowing the grouping of data into a unified batch for simultaneous processing on the server. The number of standard units of data or tasks gathered in a batch is referred to as the batch size. It is noteworthy that batching helps to better utilize computing and energy resources due to parallelism. This batching effect has been examined across different hardware platforms for various tasks, including basic matrix computations[5] and diverse machine learning (ML) inference models[6, 7, 8, 9, 10, 11].
However, opting for a larger batch size is not always the preferred approach, especially for online service provisioning where requests arrive in a random pattern, and expect responsive feedback. This gives rise to two main challenges in determining the batch size: (1) Larger batch sizes enhance energy efficiency and throughput by improving resource utilization and reducing per-sample I/O overhead. However, this benefit may come at the cost of decreased responsiveness, as batching can increase request response time due to potential waiting time needed to form a batch and extended processing time for handling multiple requests simultaneously[12, 4, 13]. This creates a tradeoff between efficiency and responsiveness[12]. (2) The use of statically configured batching proves inadequate in realistic scenarios[14], exhibiting poor responsiveness under low load conditions and limited throughput under high load[15]. To address these issues, a dynamic batching scheme is essential, allowing for judicious batch size adjustments to well balance the performance and cost.
In this paper, we study the dynamic batching scheme on batch processing-capable servers, aiming to strike a delicate balance between responsiveness and energy efficiency. This issue has gained increasing significance with the emergence of ML-as-a-Service (MLaaS) platforms like Google Cloud Prediction[16], where trained ML models are published on the platforms to provide inference (prediction) services for massive end users. As illustrated in Fig. 1, batch processing the inference requests becomes a natural strategy, for efficiency and economical concerns.
We commence our exploration with intra-processor parallelism, considering a scenario with a single server equipped with a single parallel computing processor. We leverage the theoretical framework of sequential decision-making to address the sequential batch size decisions. In our context, where we assume Poisson request arrivals and an arbitrary service time distribution, the problem is formulated as a semi-Markov decision process (SMDP). The objective is a weighted sum of the long-term average request response time and average power consumption. Notably, to the best of our knowledge, the optimal control problem for batch service queues with size-dependent service times remains unexplored in the literature. Moreover, the inherent complexities of the formulated SMDP problem—characterized by an infinite state space, an average (non-discounted) objective, and unbounded costs—pose challenges for efficient resolution using traditional methods. To address these challenges, we propose a procedure to solve the SMDP problem and derive an approximate optimal policy, which manifests as the selected dynamic batching scheme. Our main contributions are summarized as follows:
-
1.
To the best of our knowledge, our work is the first to rigorously formulate and optimally solve the dynamic batching problem for online computing services. The batching decision is formulated as an infinite-state SMDP, with the objective of minimizing the weighted sum of average response time and average power consumption.
-
2.
A new method is proposed, composed of finite state approximation, model “discretization” and relative value iteration, to obtain an approximate optimal policy. The demanding problem of state space explosion is tackled by a novel abstract cost, which reflects the impact of costs in “tail” states.
-
3.
We also conclude the theoretical results regarding the optimal policy structure in special cases. The SMDP solutions obtained through the proposed general method are visualized under different parameter settings. On one hand, the computed policies align with the theoretical results in special cases, affirming the effectiveness of the proposed method and the correctness of the theoretical results. On the other hand, certain instances reveal that the theoretical results might not extend to more general scenarios, underscoring the necessity of the general solving approach.
-
4.
Extensive numerical results demonstrate that the SMDP-based policies achieve the lowest average cost compared to benchmarks. The latency-energy tradeoff curves show that when having the same average response time, the SMDP-based policies never consume more energy than any other benchmark policy, and vice versa. Moreover, the proposed scheme can adapt to different traffic intensities and flexibly balance the response time and power consumption.
The rest of this paper is organized as follows. We begin by presenting related works in Section II. The system model is introduced in Section III, followed by the SMDP formulation in Section IV. A procedure for solving the SMDP problem is proposed in Section V. Theoretical analyses regarding the optimal policy in special cases of the problem are detailed in Section VI. Numerical results are showcased in Section VII. Finally, Section VIII provides the concluding remarks for the paper.
II Related Works
Dynamic Batching. Some works have explored dynamic batching for systems such as data centers[18] and Spark Streaming[19]. Recently, there has been a notable increase in attention towards dynamic batching, particularly in the context of ML applications. While works like DBS[20] and Zeus[21] explore batching for ML training, they fall outside the scope of our focus. Our exclusive attention is on online services. For example, in applications such as smart healthcare monitoring, data generated by devices can be efficiently processed through cloud, edge, or hybrid computing solutions to ensure timely responses[22, 23, 24]. Plenty of research has been conducted on dynamic batching for ML inference serving on GPU-based platforms[4, 3, 15, 14, 12, 8, 25, 26, 27]. There are also studies addressing the batching issue on a multi-core central processing unit (CPU)[10]. Nevertheless, progress in theoretical analysis remains very limited. For example, SERF[25] models inference serving as an M/D/c queue. However, it does not explicitly account for batching in the model. Another work, BATCH[12], characterizes request arrivals as a Poisson process or a Markov-modulated Poisson process with two phases (MMPP(2))[28], allowing for the estimation of the number of requests that arrive before a timeout. However, this analysis overlooks the cases where requests arrive during processing times. In contrast, the author of [29] presents a closed-form queueing analysis of dynamic batching under the greedy batching policy. Nonetheless, this policy is suboptimal as it does not leverage the potential benefits of larger batches. Additionally, the analysis in [29] assumes an infinite batching capacity, which is generally impractical.
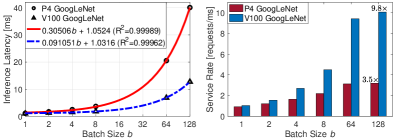
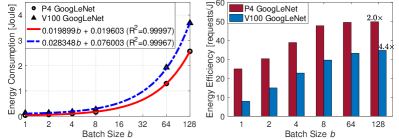
Parallel Batch Processing. Parallel batch processing, or parallel batching, is a classical issue in operational research that finds applications in numerous fields such as manufacturing, transportation, and healthcare[30, 31, 32]. However, the batch processing problem studied in this paper exhibits two distinctive deviations from classical scenarios in the existing literature. Firstly, unlike the ideal parallelism with batch-size independent service times[33, 34], the batch processing time can increase with the batch size[35, 36]. Secondly, the energy efficiency can directly benefit from an increased batch size, rather than remaining unchanged. For instance, as illustrated in Fig. 2LABEL:sub@fig:latency and Fig. 2LABEL:sub@fig:energy, which are based on the statistics from NIVIDIA[7], the processing time and energy consumption for batch ML inference services appear to be affine functions of the batch size. Consequently, the average processing time and energy consumption per batch decrease as the batch size increases, leading to improvements in both computational and energy efficiency, as shown in Fig. 2. For GoogLeNet inference on a TESLA V100, using a batch size of 128 can achieve a speedup of 9.8 times compared to inference without batching (batch size of 1). Additionally, the energy efficiency is improved by 4.4 times.
Queueing analyses for batch servers with size-dependent service times have been conducted in the literature, but they only focus on certain structured policies that are suboptimal[37, 38, 39, 40]. Following the line of optimal control, existing research[33, 41, 32] primarily addresses problems where batch processing times are independent of the batch size. In [42], the author models the load-balancing problem in multiple batch service queues with size-dependent processing times as a Markov decision process and identifies it as an open problem. In fact, optimal batching in one such batch service queue, as the simplest sub-problem of [42], still remains unsolved.
SMDP. Continuous-time Markov decision processes (CTMDPs) and SMDPs are the common formulations for sequential decision-making in continuous-time systems[43]. Given that the processing times of computation tasks often exhibit limited randomness[12], deviating from the characteristics of an exponential distribution, SMDPs appear as more fitting choices for the studied problem. In this work, we need to address an infinite-horizon and infinite-state SMDP problem with unbounded costs, where the objective is expressed in a long-term average form. Analytical results regarding optimal policies for this SMDP are available only in specific cases[33]. An alternative approach is to utilize iteration-based numerical methods, which require finite state approximation due to the intractable infinite state space. In prior research, the authors in [44] demonstrated the convergence of several finite state approximation algorithms for average cost SMDP models, but only with bounded costs. In [45], proofs were provided for the convergence of finite state approximation algorithms for models with unbounded costs, but with a discounted objective. Nevertheless, none of the existing finite state approximation algorithms has been proven effective for the considered SMDP problem.
In summary, the lack of theoretical guarantees in existing dynamic batching schemes necessitates a rigorous formulation. The extracted system model distinguishes from classical batch service queues in its size-dependent service times, a feature that remains unexplored in the literature. The design of dynamic batching can be formulated into an SMDP problem with an infinite state space. Regrettably, none of the existing finite state approximation algorithms has been proven effective in addressing the studied SMDP, highlighting the need for the development of novel methods.
In our prior work[1], we proposed an SMDP-based dynamic batching scheme for ML inference serving on GPU-based platforms. This paper extends the research to encompass general online computing service scenarios. The batch service time and energy consumption take more general forms with respect to the batch size, unlike the deterministic and linear functions considered in [1]. Moreover, additional insights are gained through both theoretical induction and extensive numerical results.
III System Model
We consider a single server with a single parallel computing processor in the continuous-time setting. Batch processing is implemented on the same type of computing requests, and it cannot be interrupted once the processing is started. The system is modeled as a single service queue, where computing requests (tasks) are assumed to arrive according to a Poisson process with an arrival rate of . The requests awaiting processing are stored in a buffer, which is assumed to have an infinite capacity. This assumption of an infinite buffer is based on the fact that the storage capacity of a computing server, which functions as the buffer in the queuing model, is significantly larger than the memory size. The total number of requests in the buffer as well as being processed at time is denoted by .
Let denote the batch size, where and . (or ) is the maximum (or minimum) batch size allowed by the system. The cumulative distribution function (CDF) of the processing (service) time for a batch of size is with mean . Assume that for every , has a finite second moment. Moreover, the mean processing time should be finite and larger than zero, i.e., and . Let represent the function of the mean batch processing time with respect to the batch size, where for , and . The time required for processing a larger batch should be no less than that for a smaller batch. Therefore, we assume that is monotonically non-decreasing in terms of . Let denote the Laplace transform of the service time distribution , defined by
| (1) |
with .
When operating with a batch size of , define the batch processing computational efficiency, or batch service rate, as the average number of requests processed per unit of time, denoted as . Since parallelism can enhance computational efficiency, it is assumed that is monotonically non-decreasing with the batch size . Noting that is also a non-decreasing function with respect to , it follows that the mean batch processing time should exhibit linear or sublinear growth as increases, if is dependent on .
Remark 1.
(i) When exhibits sublinear growth as increases, the computational efficiency monotonically increases with . (ii) When exhibits linear growth as increases, there are two cases: If is proportional to , i.e., with , the computational efficiency is constant and independent of ; If is affine to , i.e., with and , the computational efficiency monotonically increases with .
Thus, the maximum service rate is . Let denote the ratio of the arrival rate over the maximum service rate. Assume that , or equivalently , then satisfies , which is a necessary condition for the system stability.
The energy consumption of processing a batch of requests is denoted by , . Let denote the batch processing energy efficiency, which is defined as the average number of requests served with one unit of energy consumption. Given the potential for parallelism to improve energy efficiency, we assume that is monotonically non-decreasing with the batch size . Similarly, , the function of the batch processing energy consumption, should exhibit linear or sublinear growth as increases, if is not independent of .
Given the server configurations and the specific computing task, the parameters and can be profiled and determined. Additionally, the exact forms of , and are established by fitting the latency and energy consumption statistics obtained from prior profiling[12, 29].
We consider two main factors in the objective: One is the request response time (or latency), which includes both waiting and processing time, as the performance metric. The other is the power consumption of the server, as the running cost metric. Our objective is to minimize the weighted sum of average request response time, denoted by , and average power consumption, denoted by :
| (2) |
where and are the weights.
The serving process consists of sequential service rounds. Define as the start time of the th service round and as the batch size in the th service round. Let denote the total number of service rounds until time . The objective can then be expressed as
| (3) |
Note that here the average request response time is equivalently transformed to the average queue length through Little’s Law [46], where .
Remark 2.
The energy cost considered in this model can also be replaced with other types of costs, such as the monetary cost[12].
IV SMDP Formulation
The decision-making process for batching in the continuous-time system, as introduced in Section III, naturally lends itself to the formulation as an SMDP[43]. In SMDP, we are only concerned with the states at decision epochs, upon which the decisions are made. Let be the timeline of the SMDP model. The decision epochs are set as the moments when either the server completes a batch of service, or a request arrives while the server is idle. The th () decision epoch is denoted as . Let the state be the number of requests in the system. The state at the th decision epoch is denoted by , taking values from the state space .
At each epoch , the server takes an action from the action space . The action is the size of batch to be processed. Note that means that no requests are served in the th epoch. Let be the set of feasible actions for a given state . The number of requests to be batched should be no more than the available requests, which means , and thus .
The state transition is associated with the current state and action. Let denote the probability that the semi-Markov decision process occupies state at the next decision epoch when action is chosen at the current state . Let denote the probability that requests arrive during the period of processing a batch of requests. With the assumption that the arrival of requests follows a Poisson process, we have
| (4) |
A useful method to generate the probabilities is by using , which is the Laplace transform of the service time distribution. Denote the probability generating function (PGF) that corresponds to as , which can be simplified to
| (5) | ||||
Then the required probabilities can be computed by
| (6) |
The transition probability for is expressed as
| (7) |
Let a random variable denote the sojourn time between the th and the th epoch. The random variables , are conditionally independent given the state and action . Let denote the CDF of when action is chosen at the state , given by
| (8) |
Define as the expected sojourn time until the next decision epoch, given by
| (9) |
Costs are incurred for serving the requests as well as holding them. The cost of serving a batch of requests is denoted by , and the cost of holding requests in the system per unit time is denoted by . Let denote the expected cost until the next decision epoch when action is taken in state . We have , and for ,
| (10) |
The cost functions corresponding to the objective in (3) are , and . This leads to a detailed description of , which is
| (11) | ||||
where denotes a generic random variable that follows the CDF , and .
We can also generalize in the form
| (12) |
where , referred to as the cost rate, represents the holding cost averaged over the sojourn time:
| (13) |
The formulated SMDP can be fully described by the set of objects , and we will use the symbol to represent this SMDP model in the subsequent text.
Remark 3.
This formulation assumes Poisson arrivals but does not restrict the distribution of the processing time.
To extend the SMDP method to more general arrival processes, fictitious decision epochs and additional state variables are required to maintain the semi-Markov property. For example, with MMPP arrivals, phase shifts must be included as decision epochs. For non-memoryless renewal arrivals, such as deterministic processes, the arrival points should be incorporated as decision epochs, and the remaining time of the arrival interval must be included in the state. Because of the decision epochs occurring during processing times, the remaining processing time must also be part of the state for both cases. Moreover, an extra state variable is needed to distinguish the exact event of the decision epoch.
Handling continuous state variables and addressing the curse of dimensionality caused by the enlarged state space are significant challenges. Therefore, utilizing SMDP with both general arrival intervals and processing times is quite difficult.
Let denote the set of probability distributions on Borel subsets of . A Markovian decision rule specifies the probabilities of taking each action at epoch . It is called Markovian since it relies solely on the current state for its decision-making. The decision rule is deterministic if it selects an action with probability 1. A policy is a sequence of decision rules. Furthermore, is called stationary if .
Our goal is to find a policy that minimizes the long term average expected cost , given at , which is
| (14) |
The objective (14) and the SMDP model together constitute the SMDP problem. The objective focuses on the long-term average, and for every history-dependent policy, there exists an equivalent Markovian policy with the same objective value (referred to Theorem 8.1.2 in [43]). This implies that only Markovian policies need to be considered. Moreover, in this paper, we restrict our consideration to stationary deterministic policies. A stationary deterministic policy is a function that maps the state space to the action space . This type of policy is concise and clear, helping to reduce the solution space. For instance, the static batching policy and the greedy batching policy are both stationary deterministic policies.
Definition 1.
A static batching policy with a parameter is denoted as , and is defined as follows:
| (15) |
Under such a policy , the served batches have a constant batch size of .
The greedy batching policy is a representative dynamic batching policy, defined as follows:
Definition 2.
Define a greedy batching policy as
| (16) |
Under such a policy , the system greedily serves batches with the current maximum allowable sizes.
The considered model is an infinite state SMDP with non-negative, unbounded costs and finite action sets. The existence of an optimal stationary deterministic policy for such a model requires further discussions.
Proposition 1.
An average expected optimal stationary deterministic policy exists for the SMDP model .
Proof:
See Appendix A. ∎
The equations corresponding to the optimal stationary deterministic policies are provided as follows.
Proposition 2.
Let denote a value function, and let represent a scalar. Given the SMDP model , the constant and functions such that
| (17) | ||||
are exactly the optimal average expected cost per unit time, and the corresponding relative value functions. The function is referred to as the relative value function since is exactly the relative expected total cost when starting with state .
Consequently, the optimal stationary deterministic policy for the SMDP problem is given by
Equations (17) are referred to as the optimality equations for the SMDP problem with and the average objective.
Proof:
See Appendix B. ∎
V Solving the Infinite State SMDP Problem
Iteration-based algorithms, such as value iteration and policy iteration, are widely used to solve the optimality equations for most common discrete-time, finite-state and discounted Markov decision process (MDP) problems. However, the standard procedure is not readily applied to our problem, which is a continuous-time SMDP with an infinite state space and a long-term average objective.
We solve this problem in three steps. In Section V-A, we approximate the infinite state space by a finite state space through “tail” state aggregation. In Section V-B, we transform the finite state SMDP to an equivalent discrete time MDP. Finally in Section V-C, we use the relative value iteration (RVI) algorithm to solve the average-cost MDP problem.
V-A Finite State Approximation
The SMDP problem has infinite states in , and is impractical to be solved by numerical methods. Hence, we truncate the infinite state space to a finite state space , which replaces the states larger than by an “overflow” state . In other words, the “overflow” state is an aggregation of the “tail” states . The dimension of the finite state space is , where needs to be no less than . The rationale of the state space truncation is that the tail probability, defined as the probability of being in the “tail” states , decreases with . When is large enough, the “tail” states are negligible.
In the truncated model, the action space , the sojourn time distribution , and the expected sojourn time are the same as before, while the feasible action space at state is since . Original transitions to the “tail” states are aggregated to , and we assume the number of requests at is . The adapted transition probability for is
| (18) | ||||
The unbounded holding cost induced by the infinite states in the primal problem is also erased by the truncation. Therefore, we introduce an abstract cost to the “overflow” state , working as an estimation of the difference between the expected holding cost at “tail” states and the holding cost at . The adapted cost is
| (19) |
Since , the optimal policy must stabilize the system. The abstract cost can also be interpreted as an overflow punishment, which pushes the optimal policy away from causing overflow. Note that the abstract cost in (19) is rarely mentioned in the literature, without which the problem can be solved as well, but leading to a larger satisfactory and higher computational complexity in iteration algorithms (which will be discussed in Section VII-D).
Let denote the finite state SMDP model, and the optimality equations for the finite-state average-cost SMDP problem are
| (20) |
for . Denote as the optimal average expected cost.
Given a stationary deterministic policy as a function , the corresponding state transition matrix is . Suppose that the Markov chain with has a unique stationary distribution , where is the stationary probability at state . Then the average expected cost per unit time is
| (21) |
We establish a criterion for assessing the approximation based on the difference in average cost under stabilizing policies: Let represent the average expected cost contributed by per unit time under policy :
| (22) |
It is important to note that for a policy that stabilizes the system, the average cost contributed by the “tail” states should asymptotically decrease to zero as increases. Therefore, given a predefined constant , if , we consider the approximation acceptable with tolerance . If , we conclude that the approximation is not acceptable with tolerance , and a larger should be selected.
V-B Associated Discrete-Time MDP
The finite state continuous-time SMDP is associated with a discrete-time MDP through a “discretization” transformation (see Section 11.4 of [43]). The time slots are denoted by . The state space , the action space and the feasible action space for any keep unchanged in the transformed model. The transformed cost and the transformed transition probability for are
| (23) | ||||
where satisfies
| (24) |
for all and for which .
By (9) and (18), should satisfy
| (25) |
And from experiments we find that the larger the is, the faster the value-based iteration algorithm converges.
The discrete-time MDP model can be denoted by . The transformation (23) serves to standardize costs to a unit time basis, and then adjust the transition structure to align the long-run average cost of the discrete model with that of the SMDP model (refer to Section 11.5.1 in [43] for additional insights into this conversion).
For the average cost MDP problem with , the optimality equations are
| (26) |
According to Proposition 11.4.5 in [43], if satisfies the discrete-time optimality equations in (26), then satisfies (20). Let represent the optimal average expected cost in the MDP problem. Then, is equivalent to the optimal average expected cost per unit time in the continuous-time SMDP problem. Therefore, the optimal stationary policy for the MDP problem, given by
is also optimal for the finite state SMDP problem (in section V-A). The existence of a solution to (26) is established through Theorem 8.4.3 in [43].
V-C Relative Value Iteration
We utilize the value-based iteration algorithm to solve the optimality equations (26) of the discrete-time MDP problem. Specifically, for average-cost MDP problems, the standard value iteration is numerically unstable, so we use the relative value iteration algorithm instead[43].
Let denote the space of value functions. For any value function , the exact Bellman operator is , defined as
| (27) |
The span of a value function is defined as
| (28) |
Let and be value functions that iterate with , and we describe the relative value iteration algorithm in Algorithm 1.
| (29) |
Note that in each iteration, is the renormalized form of by subtracting a common from each . This helps prevent the divergence of value functions in ordinary value iteration, but it does not affect the minimizing actions or the value of . The termination of iteration is triggered when becomes smaller than a predefined constant . According to Proposition 6.6.1 in [43], the Bellman operator is a contraction operator over the span of (28). Therefore, the iteration algorithm is guaranteed to terminate. Moreover, it can be proven that within Algorithm 1, the value function asymptotically converges to the optimal value function as . The resulting policy is an -optimal policy. In other words, the average expected cost associated with policy , denoted as , satisfies . Detailed proof for this can be found in Section 8.5.5 of [43].
The computational complexity of Algorithm 1 is discussed as follows. Suppose the total number of iterations is . It is important to note that , and in most cases, is significantly larger than . Also, please note that for , the feasible action space can be represented as . Now, we break down the computational complexity: The number of multiplications per iteration is approximately . The number of additions per iteration is approximately . As for space complexity, it is primarily determined by and . The storage required for contributes to a space complexity of approximately . Referring to (18), the storage needed for simplifies to the storage of , resulting in a space complexity of approximately . Consequently, the overall space complexity is , and the time complexity is .
It should be noted that the state space of the computed policy is , but the ultimate goal is to derive a policy that maps from the infinite state space to the action space . Therefore, given the policy , we can define its corresponding policy in the original infinite state space as , using the following equation:
| (30) |
Here, the actions for “tail” states are assigned the same action as for the state .
In summary, the RVI algorithm guarantees the derivation of a stationary deterministic policy , which is -optimal for the discrete-time MDP problem discussed in Section V-B. Additionally, thanks to the benefits of the “discretization” transformation, maintains its -optimality for the finite state SMDP problem introduced in Section V-A. When considering the performance of in the original infinite state SMDP problem (as presented in Section IV), it is closely tied to the impact of finite state approximation. On one hand, with a larger the approximation to the original infinite state SMDP becomes more accurate, enhancing the performance of in the original problem. On the other hand, a larger increases the computational complexity of RVI. Therefore, as defined in Section V-A, we can set a tolerance value for approximation. Choosing an as small as possible is preferred in terms of complexity, as long as the resulting satisfies .
VI Optimal Policy in Special Cases
In the previous section, we introduced a general approach to address the formulated SMDP problem. However, in existing literature, specific properties of optimal policies have been discussed for certain special cases. Research studies[33, 47] have shown that in scenarios with size-independent service times, optimal policies exhibit a threshold-based structure known as a Q-policy or control limit policy, given certain assumptions.
The concept of the control limit policy is explained as follows:
Definition 3.
Define a stationary deterministic policy as
| (31) |
with a parameter . Under such a policy , a batch service of requests will be initiated if and only if the number of awaiting requests at a review point, , exceeds the threshold .
The necessary assumptions for the specific cases discussed in this section are listed as follows:
Assumption 1.
Service times are independent and identically distributed (i.i.d.), irrespective of the batch size. In other words, with independent of , and is independent of as well.
Assumption 2.
The minimum batch size is , i.e., .
Assumption 3.
The energy consumed in a batch service is a linear function of , i.e., , with and .
The conclusion regarding the structure of the optimal policy for the specific scenario is as follows.
Proposition 3.
If Assumptions 1-3 hold, then there exists a positive integer , , such that the associated control limit policy is an average expected optimal policy for the SMDP model .
Proof:
See Appendix C. ∎
Assumption 4.
Service times follow an exponential distribution, i.e., .
In a more special case with exponential service time, the optimal value can be computed in the following way:
Proposition 4 (Refer to Section 6 in [33]).
Assume that Assumptions 1-4 hold. Combining Assumption 1 and Assumption 4, we have , with mean . Let , and let denote the unique solution of
Let , , and
| (32) |
Then, the optimal is the smallest positive integer for which . If there is no positive such that , the optimal is .
Collary 1.
Assuming that Assumptions 1-4 are satisfied, if either or , the optimal value of is only influenced by and .
Proof:
See Appendix D. ∎
It is important to note that the general case under Assumptions 1-3 is intractable, which means that the optimal threshold cannot be obtained through explicit computation. In such cases, a linear search approach can be employed to assess the policy performance of various potential values, thereby allowing us to identify the optimal threshold .

VII Numerical Results
In numerical experiments, we take the GoogLeNet inference on a TESLA P4 as the basic scenario[7]. As depicted in Fig. 2, the latency and energy functions, which were fitted from the empirical data[7], are ms and mJ, respectively. Since the processing time for such image recognition tasks is almost deterministic[12], the Laplace transform of the service time is . The minimum batch size for the ML inference task is , and the maximum batch size is set to by default. This basic scenario with deterministic processing times and linear latency and energy functions is acknowledged as a representative case for ML inference serving[12, 29, 8].
We conduct experiments under varying values of and . It is important to note that represents the “normalized” traffic intensity, calculated as the ratio of the absolute traffic intensity (arrival rate) to the maximum service rate . This ratio serves as a measure of the system load. The weight reflects the importance of power consumption in the overall objective, with fixed at .
VII-A SMDP Solution
In this subsection, we visualize the SMDP solutions under various parameter sets, as illustrated in Fig. 3. We construct three scenarios with processing times independent of the batch size, named Cases 1-3, based on the basic scenario. The maximum batch size is set as 8, for convenience of visualization. The depicted solutions are the converged results (which remain consistent with increased ) obtained using the procedure in Section V. Each horizontal block in Fig. 3 corresponds to one scenario, and solutions are obtained under different and . The charts of policies are placed from left to right for increasing . Each row in the chart is a stationary deterministic policy under a certain , where each element denotes the action taken at the state corresponding to the column.
From Fig.3, it can be observed that for Cases 1-3, where Assumptions 1-3 hold true, all SMDP solutions exhibit a control limit structure, with the control limits highlighted by pink boxes. This finding concurs with the conclusions in Proposition 3. Under control limit policies, the system does not serve until the state exceeds a threshold, known as a “control limit”. Once the state exceeds this control limit, the system serves a maximum available batch of requests. It can be seen that the control limit increases with . When is as large as , the control limits under different traffic intensities are all . This is reasonable because the importance of power consumption grows with , and the energy is better saved with a larger batch size.
For Case 2 and Case 3 that satisfy Assumptions 1-4, the optimal control limits can be explicitly calculated using Proposition 4. We observe that the control limits of the obtained SMDP solutions are in alignment with the directly calculated results, which also validates the effectiveness of the proposed general solving procedure. It is further observed that when , the SMDP solutions in Case 3 are exactly the same as those in Case 2. This can be explained by Collary 1: when , the control limits are solely influenced by and , which means that they are only influenced by values and . Moreover, when , it can be seen that the control limits in Case 3 are equal to or larger than those in Case 2. Note that the batch service rate in Case 2 is , while in Case 3 it is . As a result, Case 3 offers a greater marginal benefit from increasing the batch size compared to Case 2, leading to its control limits no less than those of Case 2.
Furthermore, upon examining the solutions in a broader set of cases (see Appendix E), we have observed that in more general situations with characteristics such as size-dependent batch service time, a minimum batch size greater than 1, or a nonlinear energy consumption function, the control limit structure may not be applicable or maintained.
VII-B Performance Comparisons
In this subsection, we compare the performance of the obtained SMDP solutions with other benchmark batching policies. The benchmark policies encompass the greedy batching policy, as well as static batching policies with batch sizes of . Under the greedy batching policy, the server processes the largest feasible batch of current requests. In static batching policies, the server consistently processes batches in a fixed batch size and waits for new incoming requests if there are insufficient requests. The static batching policy with represents a special case known as the maximum batching policy in this context, where .
In what follows, we first showcase that the SMDP-based policies always yield the lowest average cost compared to other benchmark policies. Then, we present the two-dimensional figures illustrating latency and energy measurements, highlighting the superior performance of SMDP solutions from a Pareto perspective.
Furthermore, we demonstrate that the SMDP-based policy can enhance the satisfaction of delay requirements, as it produces a lighter-tailed distribution.
VII-B1 Overall Objective
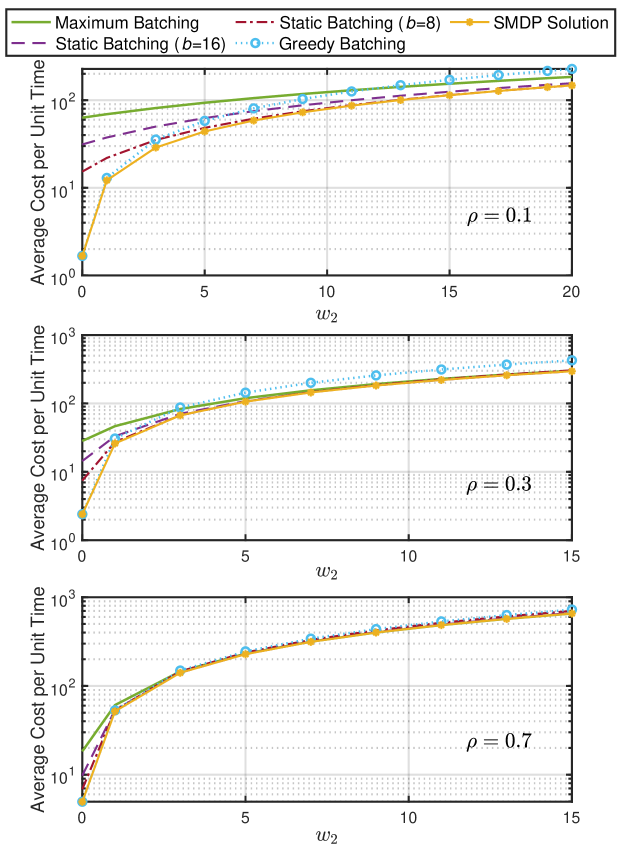
We first compare the overall objective, namely the average cost per unit time, under three levels of traffic intensities, and , as shown in Fig. 4. The weight for the latency term, , is fixed at , while the weight for the power consumption term, , ranges from to . The objectives are computed using Eq.(21). It is observed that the SMDP solutions always achieve the lowest (best) average cost per unit time among all policies under various parameter settings.
When is close to zero, the objective primarily focuses on latency. In such cases, we observe that the cost of the greedy batching policy is close to that of the SMDP-based policy. Meanwhile, the costs associated with static batching policies are higher and increase with the batch size , with the maximum batching policy incurring the highest (worst) cost. This suggests that the latency introduced by serving with larger batches is comparable or even greater than the latency saved by increased batch service rate. When reaches a large value, the objective is primarily influenced by power consumption. In such cases, it is observed that the maximum batching policy yields nearly the lowest cost, approaching that of the SMDP solution. (Unfortunately, for , a value of is not large enough to observe this phenomenon.) This observation is consistent with the results in Fig. 3. Meanwhile, in such cases, the greedy batching policy works poorly and incurs a much higher cost than other policies, due to its limited parallelism. In most common scenarios, the weighted average cost is not dominated by a single term, and the other two static batching policies () can achieve a proper balance between latency and energy, thus approaching the SMDP solution under certain parameter scales.
The comparison of the overall objective has two main limitations: (1) The overall objective lacks a unified metric and is not sufficiently informative, as it combines power consumption and latency through a weighted sum. (2) The value of the overall objective can become infinitely large as increases, resulting in a wide range that is difficult to visualize, especially under high load conditions. Therefore, we will analyze the objective factors separately in what follows.
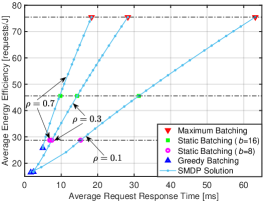
VII-B2 Objective Pairs
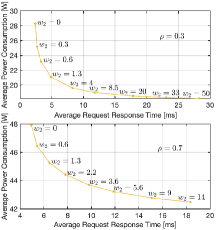
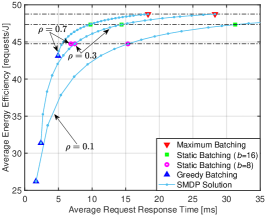
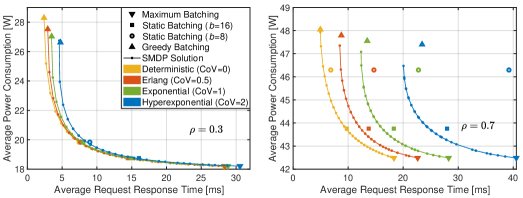
We now focus on the two factors in the multi-objective optimization (as formulated in Eq.(2)): (a) Average request response time, or long-term average latency, denoted as ; (b) Average power consumption, denoted as , calculated by dividing the long-term energy consumption by the time period. The unit of average power consumption is measured in Watt (W). Additionally, we introduce average energy efficiency, representing the average number of requests processed per Joule of energy (calculated by ), as an alternative measure of power consumption.
By fixing and varying , different SMDP solutions can be obtained through the proposed scheme. Accordingly, a set of pairs is acquired. The latency-power consumption tradeoff curves for these pairs under and are illustrated in Fig. 5LABEL:sub@fig:data_3_tradeoff. It can be seen that as the weight for power consumption, , increases, the average power consumption decreases while the average request response time increases, thus forming the latency-energy tradeoff. After acquiring this curve, an appropriate weight can be selected according to the requirements. For example, if the average request response time is required to be less than 5 ms when , the maximum weight whose corresponding SMDP solution meets this requirement should be selected, which is in this case. By selecting the weight and batching policy in this manner, the least power consumption is achieved while satisfying the latency requirement. The method for choosing an appropriate under a power constraint is similar.
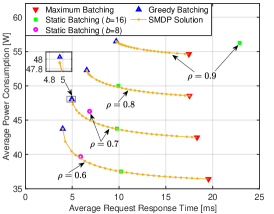
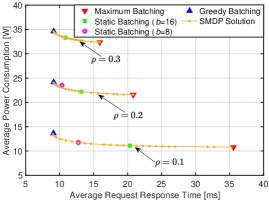
Fig. 5LABEL:sub@fig:case6_tradeoff illustrates the pairs of different policies under various load conditions. Furthermore, Fig. 5LABEL:sub@fig:case6_tradeoff_ee depicts the interplay between latency and energy efficiency. By varying the values of , the solutions obtained from the weighted-objective SMDP demonstrate a flexible balance between latency and energy, forming the tradeoff curves. In contrast, the objective pairs of benchmark policies are represented as separate points that remain unchanged with the weights. Moreover, it can be seen from Fig. 5LABEL:sub@fig:case6_tradeoff (or Fig. 5LABEL:sub@fig:case6_tradeoff_ee) that the SMDP objective pairs are positioned to the lower (or upper) left of those of the benchmark policies, indicating that the SMDP solutions consistently outperform other benchmark policies in a Pareto-optimal sense.
The latency-power consumption pairs associated with the maximum batching policy precisely correspond to the right endpoints of the SMDP’s tradeoff curves. This observation aligns with our findings in Fig. 3 and Fig. 4 under conditions where is large. This is reasonable, given that the maximum batching policy exhibits the highest energy efficiency among all policies. There is no alternative policy that can achieve equal or lower power consumption with a smaller latency. The latency-power consumption pairs associated with the greedy batching policy are situated near the left endpoints of SMDP’s tradeoff curves. It is essential to highlight that, although not evident, the greedy batching policy is at a slight disadvantage compared to the SMDP solution. For instance, when , magnifying the plot around the left corner of the SMDP’s tradeoff reveals that the objective pair of the greedy batching policy (the blue triangle) is in the upper right relative to the objective pair of an SMDP solution (an orange dot).
Several points of static batching policies with and are close to the SMDP’s tradeoff curve, indicating that these policies can effectively approximate SMDP solutions under specific parameters. This observation aligns with the findings in Fig. 4. However, in certain cases, the superiority of the SMDP-based policy over static batching becomes evident. For example, when , the latency-power consumption (or energy efficiency) pair of static batching with is positioned above (or below) the SMDP curve, implying higher power consumption (or lower energy efficiency) compared to an SMDP-based policy with equal latency. Furthermore, the static batching policy with fails to stabilize the system when . Similarly, when , static batching with results in significantly longer latency compared to the SMDP solutions.
VII-B3 Latency Distribution and Percentile Analysis
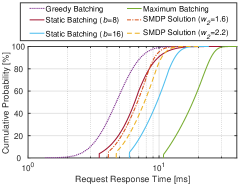
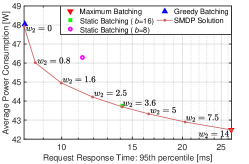
In real applications, the average request response time studied in our formulated framework may not be the primary concern. Instead, the service level objective (SLO) usually specifies that the request response time at a certain percentile must meet some latency bound. Therefore, we conduct simulations and subsequently analyze the distribution and percentiles of latency.
Fig. 6LABEL:sub@cdf_case6_rho7 demonstrates the empirical CDFs of request response time for different batching policies under a load condition of , with each CDF based on latency data points. A CDF positioned further to the left represents a better policy, as it achieves lower latency for a higher proportion of requests. Therefore, the latency performance of the benchmark policies, from best to worst, is ranked as follows: greedy batching, static batching with , static batching with , and maximum batching. The CDFs of the selected SMDP solutions with and intersect the CDF of static batching with with an upward crossing at the intersection points. This indicates that the CDFs of these SMDP solutions are lighter-tailed, and at percentiles beyond the intersection points, the request response times are shorter than that of static batching with .
| Policy | Static Batching () | SMDP Solution () | SMDP Solution () |
|---|---|---|---|
| [W] | |||
| [ms] | |||
| : 50th percentile [ms] | |||
| : 90th percentile [ms] | |||
| : 95th percentile [ms] |
Table I presents more comprehensive data including average power consumption, average request response time, and request response times at the 50th, 90th, and 95th percentiles for static batching with , as well as SMDP solutions with and . While both SMDP solutions achieve lower power consumption, they result in longer average response times compared to static batching with . However, the SMDP solution with improves the request response times at the 90th and 95th percentiles compared to static batching with . Similarly, the SMDP solution with provides a shorter request response time at the 95th percentile compared to static batching with .
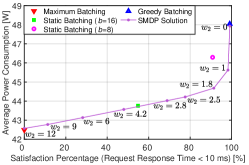
Suppose the SLO specifies that the 95th percentile of request response time must be less than 10 ms. Then, we can either obtain and plot the data pairs of latency at the 95th percentile under various weights, as illustrated in Fig. 6LABEL:sub@L95_case6_rho7, or plot the data pairs of satisfaction percentage for the 10 ms constraint, as shown in Fig. 6LABEL:sub@Lless10_case6_rho7. Both exhibit tradeoff trends similar to those in Fig. 5LABEL:sub@fig:data_3_tradeoff. Therefore, the maximum (or minimum) weight should be selected such that the corresponding SMDP solution results in a 95th percentile request response time of less than 10 ms (or a satisfaction percentage for the 10 ms constraint greater than 95%). This ensures that the SLO constraint is met while minimizing the power consumption.
VII-C Performance Comparisons in Other Settings
All experiments in Section VII-B are conducted in the default configuration. Therefore, in this subsection, we study some other typical cases and demonstrate the comparison results in these settings.
VII-C1 Stronger Batching Effect in Batch Service Rate
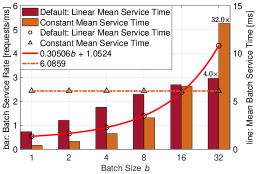
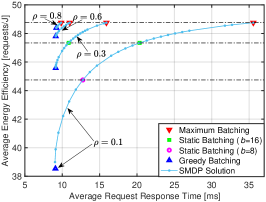
In this part, we modify the mean batch service time function of the default scenario to a constant value of ms, representing ideal parallelism. Scenarios involving running inference models on powerful processors can approximate this ideal batching, such as the inference of InceptionV2 with float16 on a Titan V with batch sizes up to fifty[36]. As shown in Fig. 7LABEL:sub@case1_setting, whereas the default batch service rate increases sub-linearly with the batch size , the constant service time leads to a linear increase in the batch service rate with . Consequently, at , the batch service rate achieves a speedup of 32 times compared to service without batching (), whereas it is only 4 times in the default setting.
The latency-power consumption pairs for different policies under various load conditions are illustrated in Fig. 7LABEL:sub@fig:case1_tradeoff, and the latency-energy efficiency pairs are shown in Fig. 7LABEL:sub@fig:case1_tradeoff_ee. It is observed that the SMDP-based policies consistently outperform other benchmarks. Additionally, a few notable observations for this special case include: (1) The latency of the greedy batching policy shows minor growth with increasing load, compared to the significant growth in the default setting (see Fig. 5LABEL:sub@fig:case6_tradeoff). The reason is that, in the default setting, the experienced service time grows with the average batch size as increases, and the service rate does not increase as quickly as with constant service time, worsening the situation. (2) The latency of the maximum batching policy is much lower than that in the default case and decreases rapidly with increasing . This is because the batch service rate of maximum batching is significantly higher than that in the default case, and an increased traffic load reduces the waiting time for forming a batch. (3) When is 0.6 or higher, the latency of the maximum batching policy is very close to that of the work-conserving policy. This follows the previous observation, as a sufficiently high load can effectively activate the power of the maximum batching policy. This insight suggests that under high load conditions, if the latency of maximum batching is acceptable, there is no need to compute or select an SMDP policy.
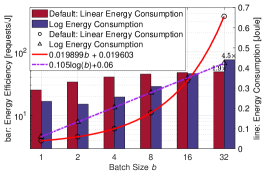
VII-C2 Stronger Batching Effect in Energy Efficiency
In this part, we modify the energy consumption function of the default scenario to mJ, which is a logarithmic function of . As illustrated in Fig. 8LABEL:sub@case7o_setting, the default energy consumption function increases linearly with the batch size , resulting in energy efficiency that grows sub-linearly with . In contrast, with the logarithmic energy function, the energy efficiency increases super-linearly with the batch size . Notably, the energy efficiency continues to improve significantly after exceeds 8, while in the default setting, it remains relatively stable.
The latency-power consumption pairs for different policies under various load conditions are illustrated in Fig. 8LABEL:sub@fig:case7o_tradeoff, and the latency-energy efficiency pairs are demonstrated in Fig. 8LABEL:sub@fig:case7o_tradeoff_ee. It is observed that the SMDP-based policies consistently perform as well as or better than other benchmarks. Notable observations for this case include: (1) The power consumption of the work-conserving policy decreases as increases from 0.6 to 0.8, unlike in the default setting where power consumption rises with higher load. This is due to the significant increase in energy efficiency with larger batch sizes. (2) The latency-power consumption tradeoff curve is much steeper compared to the default setting. This is because the wider power consumption range and consistent latency range result in a larger absolute value of the tradeoff derivative. Furthermore, compared to the default setting, the energy efficiency increases more rapidly at relatively large latency values. Therefore, a small increase in latency can lead to substantial power savings in this scenario.
VII-C3 Impact of the Distribution of Service Time
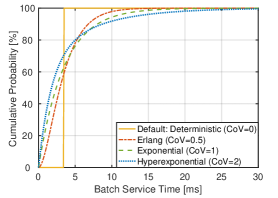
In the default setting, the service time follows a deterministic distribution with a coefficient of variation (CoV) of 0. However, in scenarios such as inference running with interference from other tasks, the service time is typically stochastic, and a larger CoV represents more complex and severe interference. Therefore, in this part, we conduct experiments with three additional types of service time distributions while keeping the same . (a) Erlang distribution with a Laplace transform given by , which has a CoV of 0.5. (b) Exponential distribution with a Laplace transform given by , which has a CoV of 1. (c) Hyperexponential distribution with a Laplace transform given by , which has a CoV of 2.
The CDFs of these service time distributions for are illustrated in Fig. 9LABEL:sub@cdf_covs. It can be seen that the tail of the service time distribution becomes heavier as the CoV increases. Furthermore, as shown in the latency-power consumption curves in Fig. 9LABEL:sub@results_covs, the average latency for a given power consumption increases with the CoV. This effect is more pronounced under high load conditions (e.g., ) compared to low load conditions (e.g., ). This observation aligns with our expectations, as the average latency increases with the CoV due to its corresponding increase in the second moment, as shown in Eq.(11). Additionally, the average power consumption under the greedy batching policy decreases with increasing CoV, reflecting the increase in the average batch size.
VII-D Efficiency of the Solving Procedure
| Iterations | |||||
|---|---|---|---|---|---|
| Space Complexity | |||||
| Time Complexity | |||||
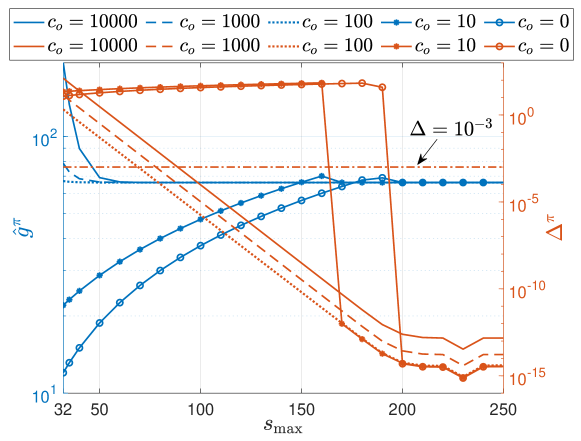
We want to evaluate the accuracy and complexity under different abstract costs in the finite state approximation. As mentioned in Section V-A, there are two parameters in the approximation: and , which determine the dimension of the state space and the abstract cost, respectively. Given a specific approximate model with certain and , a policy is calculated following the procedure outlined in Sections V-B and V-C, and it serves as an approximation to the optimal policy. The corresponding average cost per unit time , evaluated in the state space , can be obtained by Eq.(21). The accuracy of the approximation is assessed using , as detailed in Eq.(22), representing the average cost contributed by per unit time. For simplicity, we use and to denote these metrics in the following text. We conduct experiments in the basic scenario, with and . The stopping parameter in RVI is set to . Additionally, we impose a maximum iteration value in the RVI process as .
In Fig. 10, we illustrate the evolution of and with ranging from 32 to 250. The with decreases and converges around , while with increases and converges around . We can infer that the abstract cost with (or ) overestimates (or underestimates) the impact of “tail” states, leading to the mostly larger (or smaller) than the convergence value. From the orange curves, we observe that decreases with , and almost converges when exceeds 200. A sharp drop is observed for under . This is due to the underestimated impact of “tail” states with , resulting in a lower estimated value for (“wait”) in the RHS of Eq.(29). Consequently, the computed policy is to always wait, until is large enough for the cost of waiting to be comparable to the cost of serving. Although the converged values of are no more than , we only need an approximation acceptable with tolerance , and we choose . In Table II, we list the minimum values of that satisfy the approximation requirement. The and , the number of RVI iterations, as well as the space and time complexity corresponding to the minimum are also recorded. It can be seen that all are less than , and the differences among are also no greater than . The least required is , observed in the approximation with . Compared to the ordinary finite state approximation with , the minimum decreases from to . Consequently, the space complexity reduces by , and the time complexity decreases by . Furthermore, approximations with larger (or smaller) than exhibit an increasing trend in complexity due to the growing overestimation (or underestimation).
In addition to the state aggregation method used for finite state approximation in our work, the literature also explores approximate iteration algorithms to implement finite state approximation within iteration algorithms[44, 45]. A comparison between our proposed scheme and two representative approximate iteration algorithms (detailed in Appendix F) shows that our approximation procedure outperforms these algorithms in both convergence speed and result accuracy, especially when the abstract cost is included.
VIII Conclusion
In this paper, we have studied the dynamic batching problem for online serving, where the batch service time is dependent on the batch size. The problem is formulated as an SMDP with the objective of minimizing the weighted sum of average response time and average power consumption. The inherent complexities of this SMDP problem, characterized by an infinite state space, an average (non-discounted) objective, and unbounded costs, make it challenging to efficiently solve using traditional methods. To overcome these challenges, we have introduced a solution procedure consisting of finite state approximation, “discretization” transformation, and relative value iteration. The computational complexity is largely reduced owning to the introduction of an abstract cost. Then, we have conducted comprehensive numerical experiments across various parameter settings. The overall average cost and the tradeoff between average latency and average power consumption are depicted under different parameter setups. Comparisons with benchmark batching policies further showcase the superiority of the SMDP solutions.
Compared to many existing dynamic batching schemes, our proposed solution is theoretically derived, rather than relying on repeated trials. As a result, our scheme can be computed offline, alleviating the system from the burden of additional complex modules. Despite focusing on average objectives, statistics related to the SLO requirements, such as the satisfaction percentage for a certain latency constraint, can be obtained through offline simulations. When running in real time, it then becomes easy to find the most suitable weight and its corresponding batching policy that minimizes power consumption while satisfying the SLO requirement. For bursty or non-stationary traffic arrival processes, which are common in real systems, they can be approximated as temporal compositions of Poisson process periods. Specifically, in the case of MMPPs, they are exact temporal compositions of Poisson process periods. By detecting phases and applying the proposed method to each period, such traffic can be effectively managed. We also plan to explore dynamic batching schemes for multiple processors, incorporating both inter- and intra-processor parallelism in future work.
Appendix A Proof of Proposition 1
To prove the proposition, we first introduce Lemma 1, which extends Theorem 3 from [50] to our specific context.
Lemma 1 (Extended from Theorem 3 in [50]).
Let . Assume and for every , assume and . Assume there exist a service parameter and nonnegative integer such that , a nonnegative polynomial of degree , has finite st moment and satisfies . Then there exists an expected average cost optimal stationary deterministic policy.
Then, we validate these assumptions within our framework.
In we have , and for , . Thus, . For every , and hold, according to Section III.
When , there is , where is a nonnegative polynomial of degree one. Furthermore, is assumed to have finite second moment, and also holds (see Section III). That is to say, there exist a service parameter and nonnegative integer that satisfy the assumptions in Lemma 1.
Therefore, by Lemma 1, there exisits an average expected optimal stationary deterministic policy for the SMDP model .
Appendix B Proof of Proposition 2
The state process induced by a stationary deterministic policy , defined as with representing a stochastic evolution, is a Markov chain. To get the equations corresponding to the optimal stationary deterministic policies, we need to first discuss the chain structure of the transition matrices of Markov chains generated by stationary policies[43].
Definition 4.
The SMDP model is unichain if the Markov chain corresponding to every deterministic stationary policy has a single recurrent class and a possibly empty set of transient states.
Lemma 2.
The SMDP model is unichain.
Proof:
Note that under any policy, each state can reach its neighboring state in one step, since . This is valid because and , for . Since state is accessible from state , we know that if state is a recurrent state, should also be recurrent. Therefore, the Markov chain of some stationary policy never contains more than one closed irreducible recurrent class, which concludes the proof. ∎
Appendix C Proof of Proposition 3
The holding cost function is . Then, for each value of , it can be observed that . Additionally, as stated in Section III, the assumption holds that . Combined with Assumption 1, we have . Consequently, the conditions of Theorem 5.3 in [33] are satisfied. Thus, applying Theorem 5.3 from [33] completes the proof.
Appendix D Proof of Collary 1
In Proposition 4, when or , we observe that is solely affected by , , and . Here, is influenced by and . It is also worth noting that is determined by . As a result, is determined by , and , when or . Therefore, the optimal , which is the smallest positive integer such that , is only influenced by and . It remains unaffected by the absolute values of and , when is given.
Appendix E SMDP Solution Visualization for Broader Cases
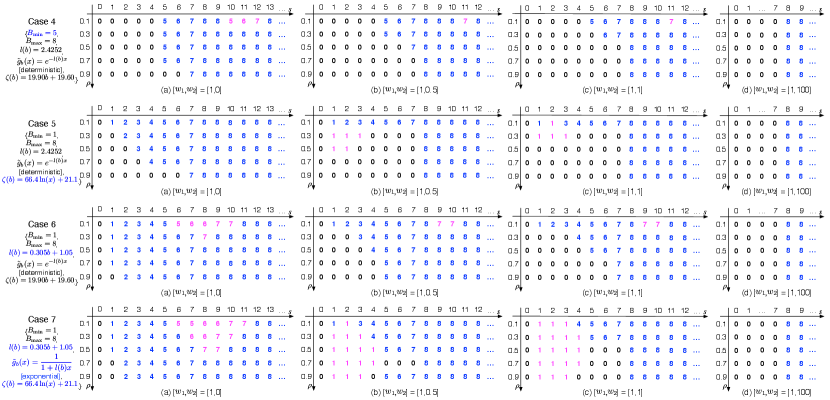
We construct four scenarios named Cases 4-7, based on the basic scenario. The maximum batch size is set as 8. The converged SMDP solutions under Cases 4-7 are demonstrated in Fig. 11. In Cases 4-6, which violate Assumptions 2, 3, and 1, respectively, it is observed that not all SMDP solutions adhere to the control limit structure. The elements that disrupt the control limit structure are highlighted in magenta. In Case 4, where the minimum batch size is set to 5, the SMDP solutions do not merely adjust the control limits of Case 1 to . For example, when and and , there are states that exceed with corresponding actions smaller than , which contradicts the definition of control limit policies. In Case 5, some solutions feature more than one threshold dividing the actions between “wait” () and “serve” (). In Case 6, there are actions involving serving a batch smaller than the maximum available size. This can be attributed to the possibility of forming a larger batch when the newly initiated service is completed, with some requests remaining in the buffer. In the more general scenario, Case 7, there are even more instances where the solutions deviate from the control limit structure.
Appendix F Comparison with Approximate Iteration Algorithms
| RVI | RVI | AVI | API | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| () | () | (Scheme I in [44]) | (Scheme IV in [44]) | ||||||||
| CPU time [s] | CPU time [s] | CPU time [s] | CPU time [s] | ||||||||
We compare the proposed finite state approximation scheme with two classical approximate iteration algorithms. Scheme I in [44] (also Scheme II in [45]) is a typical approximate value iteration algorithm (abbreviated as AVI in this paper). Scheme IV in [44] is an approximate policy iteration algorithm (abbreviated as API in this paper) that incorporates the aforementioned AVI algorithm in its inner loop. AVI and API algorithms are applied to solve the infinite state discrete-time MDP directly associated with the original SMDP.
The experiments are conducted in the basic scenario, with and . In our proposed schemes, we set to and to and , respectively. For all value iterations, we initialize the value functions to zero. The API algorithm has an initial policy set as for all . The number of inner iterations is set to in the th () outer iteration loop. The algorithms are implemented in MATLAB_R2021b and executed on a MacBook Air (M2, 2022). The Apple M2 chip is equipped with an 8-core CPU comprising four performance cores and four efficiency cores.
In Table III, we demonstrate the change in the evaluated average cost with the exact CPU execution time (averaged over 11 runs) under different schemes. We also record the evolution of under the proposed scheme (referred to as RVI in Table III). In both AVI and API, the state space consistently expands with each iteration, while the exact number of iterations used for computing the policy on a state decreases with the increasing value of . Consequently, the latter part of the computed policy (the policy computed for relatively large states) does not converge very effectively. Therefore, we introduce to truncate and only maintain the policy on the state space , whose cardinality is the same as the state space of the proposed scheme. We use to denote the average cost of evaluated on .
Table III shows that the proposed methods with and start converging at approximately seconds and seconds, respectively. The converged values are on the order of , ensuring high approximation accuracy. In contrast, AVI and API do not achieve convergence for the entire computed policy within the demonstrated CPU times, but their truncated policies converge around seconds and seconds, respectively. Both RVI schemes demonstrate faster convergence than AVI and API, with RVI () exhibiting a notable advantage over other schemes. Furthermore, the converged average cost in RVI is , which is lower than the converged average cost in AVI and API algorithms. This suggests that the converged policies obtained through the proposed schemes provide better approximations to optimal policies than those obtained from AVI and API algorithms. Moreover, approximate iteration algorithms may encompass a very large state space as the number of iterations increases, which raises challenges in complexity and numerical stability.
References
- [1] Y. Xu, J. Sun, S. Zhou, and Z. Niu, “SMDP-Based Dynamic Batching for Efficient Inference on GPU-Based Platforms,” in Proc. IEEE Int. Conf. Commun. (ICC), Rome, Italy, May 2023.
- [2] K.-S. Oh and K. Jung, “GPU Implementation of Neural Networks,” Pattern Recognition, vol. 37, no. 6, pp. 1311–1314, Jun. 2004.
- [3] C. Zhang, M. Yu, W. Wang, and F. Yan, “MArk: Exploiting Cloud Services for Cost-Effective, SLO-Aware Machine Learning Inference Serving,” in Proc. USENIX Annu. Tech. Conf. (ATC), Renton, WA, USA, Jul. 2019.
- [4] D. Crankshaw, X. Wang, G. Zhou, M. J. Franklin, J. E. Gonzalez, and I. Stoica, “Clipper: A Low-Latency Online Prediction Serving System,” in Proc. USENIX Symp. Netw. Syst. Des. Implement. (NSDI), Boston, MA, USA, Mar. 2017.
- [5] H. Shin, D. Kim, E. Park, S. Park, Y. Park, and S. Yoo, “McDRAM: Low Latency and Energy-Efficient Matrix Computations in DRAM,” IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst., vol. 37, no. 11, pp. 2613–2622, Nov. 2018.
- [6] Y. E. Wang, G.-Y. Wei, and D. Brooks, “Benchmarking TPU, GPU, and CPU Platforms for Deep Learning,” [Online]. Available: https://arxiv.org/abs/1907.10701, 2019.
- [7] NVIDIA, “NVIDIA AI inference platform technical overview,” [Online]. Available: https://www.nvidia.com/en-us/data-center/resources/inference-technical-overview/, 2018, (accessed 23-Nov-2019).
- [8] C. Yao, W. Liu, W. Tang, and S. Hu, “EAIS: Energy-Aware Adaptive Scheduling for CNN Inference on High-Performance GPUs,” Future Gener. Comp. Syst., vol. 130, pp. 253–268, May 2022.
- [9] Y. Wang, Q. Wang, and X. Chu, “Energy-Efficient Online Scheduling of Transformer Inference Services on GPU Servers,” IEEE Trans. Green Commun. Netw., vol. 6, no. 3, pp. 1649–1659, Sep. 2022.
- [10] A. Bhardwaj, A. Phanishayee, D. Narayanan, M. Tarta, and R. Stutsman, “Packrat: Automatic Reconfiguration for Latency Minimization in CPU-Based DNN Serving,” [Online]. Available: http://arxiv.org/abs/2311.18174, 2023.
- [11] S. M. Nabavinejad, S. Reda, and M. Ebrahimi, “Coordinated Batching and DVFS for DNN Inference on GPU Accelerators,” IEEE Trans. Parallel Distrib. Syst., vol. 33, no. 10, pp. 2496–2508, Oct. 2022.
- [12] A. Ali, R. Pinciroli, F. Yan, and E. Smirni, “BATCH: Machine Learning Inference Serving on Serverless Platforms with Adaptive Batching,” in Proc. Int. Conf. High Perform. Comput. Netw. Storage Anal. (SC), Atlanta, GA, USA, Nov. 2020.
- [13] Q. Zhang, Y. Liu, T. Liu, and D. Qian, “CoFB: Latency-Constrained Co-Scheduling of Flows and Batches for Deep Learning Inference Service on the CPU–GPU System,” J. Supercomput., vol. 79, pp. 14 172–14 199, Apr. 2023.
- [14] Y. Choi, Y. Kim, and M. Rhu, “Lazy Batching: An SLA-Aware Batching System for Cloud Machine Learning Inference,” in Proc. IEEE Int. Symp. High Perform. Comput. Archit. (HPCA), Seoul, Korea (South), Feb. 2021.
- [15] W. Cui, Q. Chen, H. Zhao, M. Wei, X. Tang, and M. Guo, “E2Bird: Enhanced Elastic Batch for Improving Responsiveness and Throughput of Deep Learning Services,” IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 6, pp. 1307–1321, Jun. 2021.
- [16] GoogleCloud, “Google cloud prediction API documentation,” [Online]. Available: https://cloud.google.com/prediction/docs/, 2017, (accessed 19-Oct-2022).
- [17] C. Szegedy et al., “Going Deeper with Convolutions,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Boston, MA, USA, Jun. 2015.
- [18] Y. Wang and X. Wang, “Virtual Batching: Request Batching for Server Energy Conservation in Virtualized Data Centers,” IEEE Trans. Parallel Distrib. Syst., vol. 24, no. 8, pp. 1695–1705, Aug. 2012.
- [19] D. Cheng, X. Zhou, Y. Wang, and C. Jiang, “Adaptive Scheduling Parallel Jobs with Dynamic Batching in Spark Streaming,” IEEE Trans. Parallel Distrib. Syst., vol. 29, no. 12, pp. 2672–2685, Dec. 2018.
- [20] Q. Ye, Y. Zhou, M. Shi, Y. Sun, and J. Lv, “DBS: Dynamic Batch Size for Distributed Deep Neural Network Training,” [Online]. Available: https://arxiv.org/abs/2007.11831, 2020.
- [21] J. You, J.-W. Chung, and M. Chowdhury, “Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training,” in Proc. USENIX Symp. Netw. Syst. Des. Implement. (NSDI), Boston, MA, USA, Apr. 2023.
- [22] R. Yadav, W. Zhang, O. Kaiwartya, H. Song, and S. Yu, “Energy-Latency Tradeoff for Dynamic Computation Offloading in Vehicular Fog Computing,” IEEE Trans. Veh. Technol., vol. 69, no. 12, pp. 14 198–14 211, Dec. 2020.
- [23] C. Ling, W. Zhang, H. He, R. Yadav, J. Wang, and D. Wang, “QoS and Fairness Oriented Dynamic Computation Offloading in the Internet of Vehicles based on Estimate Time of Arrival,” IEEE Trans. Veh. Technol., vol. 73, no. 7, pp. 10 554–10 571, Jul. 2024.
- [24] R. Yadav et al., “Smart Healthcare: RL-Based Task Offloading Scheme for Edge-Enable Sensor Networks,” IEEE Sens. J., vol. 21, no. 22, pp. 24 910–24 918, Nov. 2021.
- [25] F. Yan, O. Ruwase, Y. He, and E. Smirni, “SERF: Efficient Scheduling for Fast Deep Neural Network Serving via Judicious Parallelism,” in Proc. Int. Conf. High Perform. Comput. Netw. Storage Anal. (SC), Salt Lake City, UT, USA, Nov. 2016.
- [26] Z. Li et al., “AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving,” in Proc. USENIX Symp. Oper. Syst. Des. Implement. (OSDI), Boston, MA, USA, Jul. 2023.
- [27] H. Qin, S. Zawad, Y. Zhou, L. Yang, D. Zhao, and F. Yan, “Swift Machine Learning Model Serving Scheduling: A Region Based Reinforcement Learning Approach,” in Proc. Int. Conf. High Perform. Comput. Netw. Storage Anal. (SC), Denver, CO, USA, Nov. 2019.
- [28] W. Fischer and K. Meier-Hellstern, “The Markov-Modulated Poisson Process (MMPP) Cookbook,” Performance Evaluation, vol. 18, no. 2, pp. 149–171, Sep. 1993.
- [29] Y. Inoue, “Queueing Analysis of GPU-Based Inference Servers with Dynamic Batching: A Closed-Form Characterization,” Performance Evaluation, vol. 147, p. 102183, May 2021.
- [30] D. Bonvin, “Control and Optimization of Batch Processes,” IEEE Control Syst. Mag., vol. 6, no. 26, pp. 34–45, Dec. 2006.
- [31] S. Sasikala and K. Indhira, “Bulk Service Queueing Models-A Survey,” Int. J. Pure Appl. Math, vol. 106, no. 6, pp. 43–56, Apr. 2016.
- [32] J. W. Fowler and L. Mönch, “A Survey of Scheduling with Parallel Batch (p-Batch) Processing,” Eur. J. Oper. Res., vol. 298, no. 1, pp. 1–24, Apr. 2022.
- [33] R. K. Deb and R. F. Serfozo, “Optimal Control of Batch Service Queues,” Adv. Appl. Probability, vol. 5, no. 2, pp. 340–361, Aug. 1973.
- [34] Y. Zeng and C. H. Xia, “Optimal bulking threshold of batch service queues,” J. Appl. Probability, vol. 54, no. 2, pp. 409–423, Jun. 2017.
- [35] W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Multiuser Co-Inference With Batch Processing Capable Edge Server,” IEEE Trans. Wireless Commun., vol. 22, no. 1, pp. 286–300, Jul. 2022.
- [36] J. Hanhirova, T. Kämäräinen, S. Seppälä, M. Siekkinen, V. Hirvisalo, and A. Ylä-Jääski, “Latency and Throughput Characterization of Convolutional Neural Networks for Mobile Computer Vision,” in Proc. ACM Multimedia Syst. Conf. (MMSys), Amsterdam, Netherlands, Jun. 2018.
- [37] M. F. Neuts, “A General Class of Bulk Queues with Poisson Input,” Ann. Math. Statist., vol. 38, no. 3, pp. 759–770, Jun. 1967.
- [38] A. Maity and U. C. Gupta, “Analysis and Optimal Control of a Queue with Infinite Buffer Under Batch-Size Dependent Versatile Bulk-Service Rule,” OPSEARCH, vol. 52, no. 3, pp. 472–489, Sep. 2015.
- [39] S. Pradhan, “On the Distribution of an Infinite-Buffer Queueing System with Versatile Bulk-Service Rule Under Batch-Size-Dependent Service Policy: ,” Int. J. Math. Oper. Res., vol. 16, no. 3, p. 407, Apr. 2020.
- [40] G. K. Gupta and A. Banerjee, “Analysis of Infinite Buffer General Bulk Service Queue with State Dependent Balking,” Int. J. Oper. Res., vol. 40, no. 2, pp. 137–161, Mar. 2021.
- [41] K. P. Papadaki and W. B. Powell, “Exploiting Structure in Adaptive Dynamic Programming Algorithms for a Stochastic Batch Service Problem,” Eur. J. Oper. Res., vol. 142, no. 1, pp. 108–127, Oct. 2002.
- [42] Y. Inoue, “A Load-Balancing Problem for Distributed Bulk-Service Queues with Size-Dependent Batch Processing Times,” Queueing Systems, vol. 100, no. 3-4, pp. 449–451, Apr. 2022.
- [43] M. L. Puterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, 1994.
- [44] L. C. Thomas and D. Stengos, “Finite State Approximation Algorithms for Average Cost Denumerable State Markov Decision Processes,” Oper. Res. Spectr., vol. 7, no. 1, pp. 27–37, Mar. 1985.
- [45] D. White, “Finite State Approximations for Denumerable State Infinite Horizon Discounted Markov Decision Processes with Unbounded Rewards,” J. Math. Anal. Appl., vol. 86, no. 1, pp. 292–306, Mar. 1982.
- [46] J. D. C. Little, “A Proof for the Queuing Formula: L = W,” Operations Research, vol. 9, no. 3, pp. 383–387, Jun. 1961.
- [47] S. Aalto, “Optimal Control of Batch Service Queues with Finite Service Capacity and Linear Holding Costs,” Math. Method Oper. Res., vol. 51, no. 2, pp. 263–285, Apr. 2000.
- [48] H. J. Weiss, “The Computation of Optimal Control Limits for a Queue with Batch Services,” Management Science, vol. 25, no. 4, pp. 320–328, Apr. 1979.
- [49] E. Ignall and P. Kolesar, “Optimal Dispatching of an Infinite-Capacity Shuttle: Control at a Single Terminal,” Operations Research, vol. 22, no. 5, pp. 1008–1024, Oct. 1974.
- [50] L. I. Sennott, “Average Cost Semi-Markov Decision Processes and the Control of Queueing Systems,” Probability Eng. Inf. Sci., vol. 3, no. 2, pp. 247–272, Apr. 1989.