SODA: Detecting Covid-19 in Chest X-rays with Semi-supervised Open Set Domain Adaptation
Abstract.
Due to the shortage of COVID-19 viral testing kits and the long waiting time, radiology imaging is used to complement the screening process and triage patients into different risk levels. Deep learning based methods have taken an active role in automatically detecting COVID-19 disease in chest x-ray images, as witnessed in many recent works in early 2020. Most of these works first train a Convolutional Neural Network (CNN) on an existing large-scale chest x-ray image dataset and then fine-tune it with a COVID-19 dataset at a much smaller scale. However, direct transfer across datasets from different domains may lead to poor performance for CNN due to two issues, the large domain shift present in the biomedical imaging datasets and the extremely small scale of the COVID-19 chest x-ray dataset. In an attempt to address these two important issues, we formulate the problem of COVID-19 chest x-ray image classification in a semi-supervised open set domain adaptation setting and propose a novel domain adaptation method, Semi-supervised Open set Domain Adversarial network (SODA). SODA is able to align the data distributions across different domains in a general domain space and also in a common subspace of source and target data. In our experiments, SODA achieves a leading classification performance compared with recent state-of-the-art models in separating COVID-19 with common pneumonia. We also present initial results showing that SODA can produce better pathology localizations in the chest x-rays.
1. Introduction
Since the Coronavirus disease 2019 (COVID-19) was first declared as a Public Emergency of International Concern (PHEIC) on January 30, 2020111https://www.statnews.com/2020/01/30/who-declares-coronavirus-outbreak-a-global-health-emergency/, it has quickly evolved from a local outbreak in Wuhan, China to a global pandemic, taking away hundreds of thousands of lives and causing dire economic loss worldwide. In the US, the total COVID-19 cases grew from just one confirmed on Jan 21, 2020 to over 1 million on April 28, 2020 in a span of 3 months. Despite drastic actions like shelter-in-place and contact tracing, the total cases in US kept increasing at an alarming daily rate of 20,000 - 30,000 throughout April, 2020. A key challenge for preventing and controlling COVID-19 right now is the ability to quickly, widely and effectively test for the disease, since testing is usually the first step in a series of actions to break the chains of transmission and curb the spread of the disease.
COVID-19 is caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) 222https://www.who.int/emergencies/diseases/novel-coronavirus-2019/technical-guidance/naming-the-coronavirus-disease-(covid-2019)-and-the-virus-that-causes-it By far, the most reliable diagnosis is through Reverse Transcription Polymerase Chain Reaction (RT-PCR) 333https://spectrum.ieee.org/the-human-os/biomedical/diagnostics/how-do-coronavirus-tests-work in which a sample is taken from the back of throat or nose of the patients and tested for viral RNA. While taking samples from the patients, aerosol pathogens could be released and would put the healthcare workers at risk. Furthermore, once the sample is collected, the testing process usually takes several hours and recent study reports that the sensitivity of RT-PCR is around 60-70% (Ai et al., 2020), which suggests that many people tested negative for the virus may actually carry it thus could infect more people without knowing it. On the other hand, the sensitivity of chest radiology imaging for COVID-19 was much higher at 97% as reported by (Ai et al., 2020; Fang et al., 2020).
Due to the shortage of viral testing kits, the long period of waiting for results, and low sensitivity rate of RT-PCR, radiology imaging has been used as a complementary screening process to assist the diagnosis of COVID-19. Unlike RT-PCR, imaging is readily available in most healthcare facilities around the world, and the whole process can be done rapidly. Additionally, one of the key step in reducing mortality rate is early patient triage, since the health level of patients in severe conditions could quickly deteriorate while waiting for the viral testing result. Radiology imaging can provide more detailed information about the patients, e.g. pathology location, lesion size, the severity of lung involvement (Zhang et al., 2020). These insights can help doctors to timely triage patients into different risk levels, bring patients in severe conditions to ICU earlier, and saving more lives.
In recent years, with the rapid advancement in deep learning and computer vision, many breakthroughs have been developed in using Artificial Intelligence (AI) for medical imaging analysis, especially disease detection (Wang et al., 2017; Irvin et al., 2019; Wang et al., 2018) and report generation (Jing et al., 2017; Li et al., 2018; Jing et al., 2019; Biswal et al., 2020), and some AI models achieve expert radiologist-level performance (Lakhani and Sundaram, 2017). Right now, with most healthcare workers busy at front lines saving lives, the scalability advantage of AI-based medical imaging systems stand out more than ever. Some AI-based chest imaging systems have already been deployed in hospitals to quickly inform healthcare workers to take actions accordingly444https://spectrum.ieee.org/the-human-os/biomedical/imaging/hospitals-deploy-ai-tools-detect-covid19-chest-scans.
Annotated datasets are required for training AI-based methods, and a small chest x-ray dataset with COVID-19 is collected recently: COVID-ChestXray (Cohen et al., 2020). In the last few weeks, several works (Linda Wang and Wong, 2020; Li et al., 2020; Apostolopoulos and Mpesiana, 2020; Minaee et al., 2020) apply Convolutional Neural Networks (CNN) and transfer learning to detect COVID-19 cases from chest x-ray images. They first train a CNN on a large dataset like Chexpert (Irvin et al., 2019) and ChestXray14 (Wang et al., 2017), and then fine-tune the model on the small COVID-19 dataset. By far, due to the lack of large-scale open COVID-19 chest x-ray imaging datasets, most works only used a very small amount of positive COVID-19 imaging samples (Cohen et al., 2020). While the reported performance metrics like accuracy and AUC-ROC are high, it is likely that these models overfit on this small dataset and may not achieve the reported performance on a different and larger COVID-19 x-ray dataset. Besides, these methods suffer a lot from label domain shift: these newly trained models lose the ability to detect common thoracic diseases like “Effusion” and “Nodule” since these labels do not appear in the new dataset. Moreover, they also ignored the visual domain shift between the two datasets. On the one hand, the large-scale datasets like ChestXray14 (Wang et al., 2017) and Chexpert (Irvin et al., 2019) are collected from top U.S. health institutes like National Institutes of Health (NIH) clinical center and Stanford University, which are well-annotated and carefully processed. On the other hand, COVID-ChestXray (Cohen et al., 2020) is collected from a very diverse set of hospitals around the world and they are of very different qualities and follow different standards, such as the viewpoints, aspect ratios and lighting, etc. In addition, COVID-ChestXray contains not only chest x-ray images but also CT scan images.
In order to fully exploit the limited but valuable annotated COVID-19 chest x-ray images and the large-scale chest x-ray image dataset at hand, as well as to prevent the above-mentioned drawbacks of those fine-tuning based methods, we define the problem of learning a x-ray classifier for COVID-19 from the perspective of open set domain adaptation (Definition 2.1) (Panareda Busto and Gall, 2017). Different from traditional unsupervised domain adaptation which requires the label set of both source and target domain to be the same, the open set domain adaptation allows different domains to have different label sets. This is more suitable for our problem because COVID-19 is a new disease which is not included in the ChestXray14 or Chexpert dataset. However, since our task is to train a new classifier for COVID-19 dataset, we have to use some annotated samples. Therefore, we further propose to view the problem as a Semi-Supervised Open Set Domain Adaptation problem (Definition 2.2).
Under the given problem setting, we propose a novel Semi-supervised Open set Domain Adversarial network (SODA) comprised of four major components: a feature extractor , a multi-label classifier , domain discriminators and , as well as common label recognizer . SODA learns the domain-invariant features by a two-level alignment, namely, domain level and common label level. The general domain discriminator is responsible for guiding the feature extractor to extract domain-invariant features. However, it has been argued that the general domain discriminator might lead to false alignment and even negative transfer (Pei et al., 2018; Wang et al., 2019). For example, it is possible that the feature extractor maps images with “Pneumonia” in the target domain and images with “Cardiomegaly” in the source domain into similar positions, which might result in the miss-classification of . In order to solve this problem, we propose a novel common label discriminator to guide the model to align images with common labels across domains. For labeled images, only activates when the input image is associated with a common label. For unlabeled images, we propose a common label recognizer to predict their probabilities of having a common label.
The main contributions of the paper are summarized as follows:
-
•
To the best of our knowledge, we are the first to tackle the problem of COVID-19 chest x-ray image classification from the perspective of domain adaptation.
-
•
We formulate the problem in a novel semi-supervised open set domain adaptation setting.
-
•
We propose a novel two-level alignment model: Semi-supervised Open set Domain Adversarial network (SODA).
-
•
We present a comprehensive evaluation to demonstrate the effectiveness of the proposed SODA.
2. Preliminary
2.1. Problem Definition
Definition 0.
Unsupervised Open Set Domain Adaptation
Let x be the input chest x-ray image, y be the ground-truth disease label. We define as a source domain with labeled samples, and as a target domain with unlabeled samples, where the underlying label set of the target domain might be different from the label set of the source domain. Define as the set of common labels shared across different domains, and be sets of domain-specific labels which only appear in the source and the target domain respectively.
The task of Unsupervised Open Set Domain Adaptation is to build a model which could accurately assign common labels in to samples in the target domain, as well as distinguish those belonging to .
Definition 0.
Semi-supervised Open Set Domain Adaptation
Given a source domain with labeled samples, and a target domain consisting of with unlabeled samples and with labeled samples.
The task of Semi-supervised Open Set Domain Adaptation is to build a model to assign labels from to unlabeled samples in .
2.2. Notations
We summarize the symbols used in the paper and their descriptions in Table 1.
| Symbols | Description |
|---|---|
| set of labeled samples in the source domain | |
| set of unlabeled samples in the target domain | |
| set of labeled samples in the target domain | |
| set of labels for the source domain | |
| set of labels for the target domain | |
| set of common labels across domains | |
| set of domain-specific labels in the source domain | |
| set of domain-specific labels in the target domain | |
| set of all labels from all domains | |
| number of labeled samples in the source domain | |
| number of unlabeled samples in the target domain | |
| number of labeled samples in the target domain | |
| feature extractor | |
| multi-label classifier for | |
| binary classifier for label (part of ) | |
| common label recognizer | |
| domain discriminator for common labels | |
| general domain discriminator | |
| loss of multi-label classification over the entire dataset | |
| loss of over the entire dataset | |
| loss of over the entire dataset | |
| loss of over the entire dataset | |
| the coefficient of losses | |
| input image | |
| hidden features | |
| ground-truth label | |
| predicted probability | |
| predicted probability that belongs to source domain | |
| predicted probability that has common labels |
3. Methodology
3.1. Overview
An overview of the proposed Semi-supervised Open Set Domain Adversarial network (SODA) is shown in Fig. 1. Given an input image , it will be first fed into a feature extractor , which is a Convolutional Neural Network (CNN), to obtain its hidden feature (green part). The binary classifier (part of the multi-label classifier ) takes as input, and will predict the probability for the label (blue part).
We propose a novel two-level alignment strategy for extracting the domain invariant features across the source and target domain. On the one hand, we perform domain alignment (Section 3.2), which leverages a general domain discriminator to minimize the domain-level feature discrepancy. On the other hand, we emphasize the alignment of common labels (Section 3.3) by introducing another domain discriminator for images associated with common labels. For labeled images in and , we compute loss for and conduct back-propagation during training only if the input image is associated with a common label . As for unlabeled data in , we propose a common label recognizer to predict the probability that an image has a common label, and use as a weight in the losses of and .
3.2. Domain Alignment
Domain adversarial training (Ganin et al., 2016) is the most popular method for helping feature extractor learn domain-invariant features such that the model trained on the source domain can be easily applied to the target domain. The objective function of the domain discriminator can be written as:
| (1) |
where denotes the predicted probability that the input image belongs to the source domain.
In SODA, we use a Multi-Layer Perceptron (MLP) as the general domain discriminator .
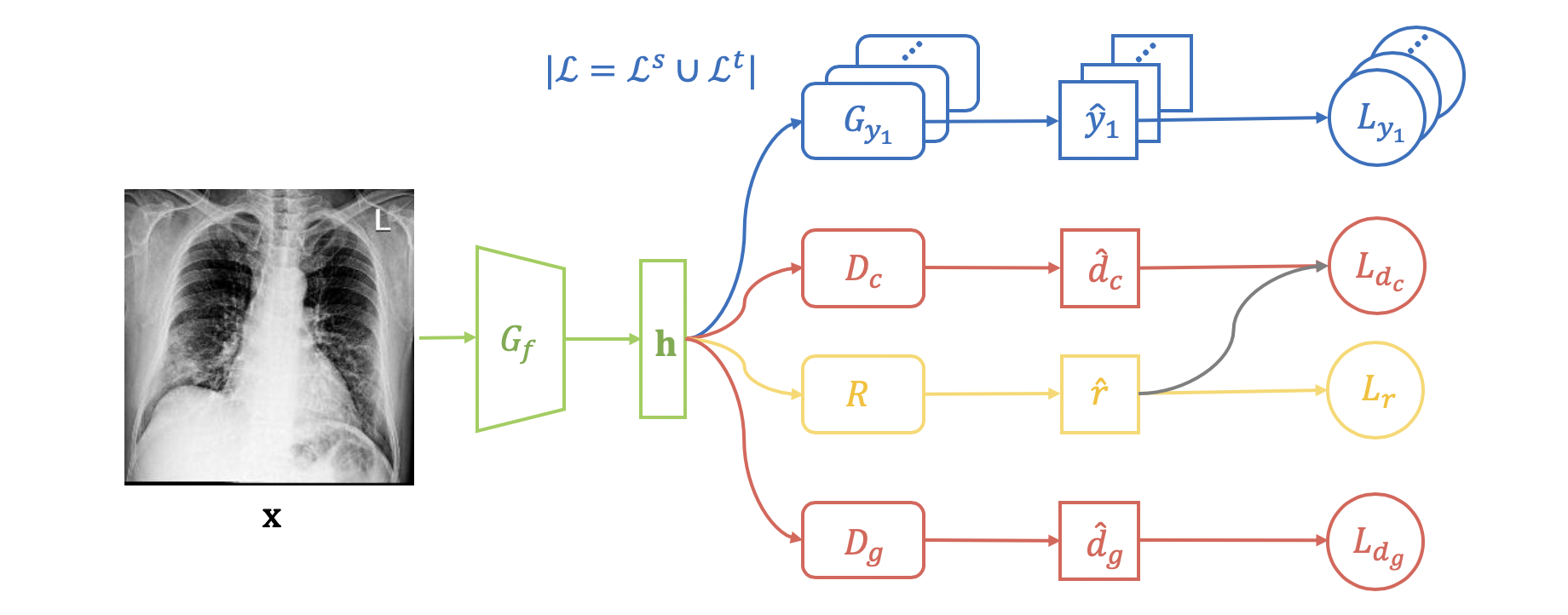
3.3. Common Label Alignment
In the field of adversarial domain adaptation, most of the existing methods only leverage a general domain discriminator to minimize the discrepancy between the source and target domain. Such a practice ignores the label structure across domains, which will result in false alignment and even negative transfer (Pei et al., 2018; Wang et al., 2019). If we only use a general domain discriminator in the open set domain adaptation setting (Definition 2.1 and Definition 2.2), it is possible that the feature extractor will map the target domain images with a common label , “Pneumonia”, and the source domain images with a specific label , e.g., “Cardiomegaly”, to similar positions in the hidden space, which might lead to the classifier miss-classifying a “Pneumonia” image in the target domain as “Cardiomegaly”.
To address the problem of the miss-matching between the common and specific label sets, we propose a domain discriminator to distinguish the domains for the images with a common label. For the labeled data from the source domain and the target domain , we know whether an image has a common label or not, and we only calculate the loss for on the samples with common labels:
| (2) |
where denotes the predicted probability that the input images is associated with a common label.
However, a large number of images in the target domain are unlabeled, and thus extra effort is required for determining whether an unlabeled image is associated with a common label. To address this problem, we propose a novel common label recognizer to predict the probability whether an unlabeled image has at least one common label. The probability will be used as a weight in the loss function of 555Note that gradients stop at in the training period.:
| (3) |
In addition, we also use to re-weigh unlabeled samples in (Equation 1) to further emphasize the alignment of common labels:
| (4) |
Finally, the recognizer is trained on the labeled set via cross-entropy loss:
| (5) |
3.4. Overall Objective Function
The overall objective function of SODA can be written as a min-max game between classifiers , and discriminators , :
| (6) |
4. Experiments
4.1. Experiment Setup
4.1.1. Datasets
Source Domain
We use ChestXray-14 (Wang et al., 2017) as the source domain dataset. This dataset is comprised of 112,120 anonymized chest x-ray images from the National Institutes of Health (NIH) clinical center. The dataset contains 14 common thoracic disease labels: “Atelectasis”, “Consolidation”, “Infiltration”, “Pneumothorax”, “Edema”, “Emphysema”, “Fibrosis”, “Effusion”, “Pneumonia”, “Pleural thickening”, “Cardiomegaly”, “Nodule”, “Mass” and “Hernia”.
Target Domain
The newly collected COVID-ChestXray (Cohen et al., 2020) is adopted as the target domain dataset. This dataset contains images collected from various public sources and different hospitals around the world. This dataset (by the time of this writing) contains 328 chest x-ray images in which 253 are labeled positive as the new disease “COVID-19”, whereas 61 are labeled as other well-studied “Pneumonia”.
4.1.2. Evaluation Metrics
We evaluate our model from four different perspectives. First, to test the classification performance, following the semi-supervised protocol, we randomly split the 328 x-ray images in COVID-ChestXray into 40% labeled set, and 60% unlabeled set. We run each model 3 times and report the average AUC-ROC score. Second, we compute the Proxy- Distance (PAD) (Ben-David et al., 2007) to evaluate models’ ability for minimizing the feature discrepancy across domains. Thirdly, we use t-SNE to visualize the feature distributions of the target domain. Finally, we also qualitatively evaluate the models by visualizing their saliency maps.
4.1.3. Baseline Methods
We compare the proposed SODA with two types of baselines methods: fine-tuning based transfer learning models and domain adaptation models. For fine-tuning based models, we select the two most popular CNN models DenseNet121 (Huang et al., 2017) and ResNet50 (He et al., 2016) as our baselines. These models are first trained on the ChestXray-14 dataset and then fine-tuned on the COVID-ChestXray dataset. As for the domain adaptation models, we compare our model with two classic models, Domain Adversarial Neural Networks (DANN) (Ganin et al., 2016) and Partial Adversarial Domain Adaptation (PADA) (Cao et al., 2018). Note that DANN and PADA were designed for unsupervised domain adaptation, and we implement a semi-supervised version of them.
4.1.4. Implementation Details
We use DenseNet121 (Huang et al., 2017), which is pretrained on the ChestXray-14 dataset (Wang et al., 2017), as the feature extractor for SODA. The multi-label classifier is a one layer neural network and its activation is the sigmoid function. We use the same architecture for , and : a MLP containing two hidden layers with ReLU (Nair and Hinton, 2010) activation and an output layer. The hidden dimension for all of the modules: , , and is 1024. For fair comparison, we use the same setting of , and for DANN (Ganin et al., 2016) and PADA (Cao et al., 2018). All of the models are trained by Adam optimizer (Kingma and Ba, 2014), and the learning rate is .
4.2. Classification Results
To investigate the effects of domain adaptation and demonstrate the performance improvement of the proposed SODA, we present the average AUC-ROC scores for all models in Table 2. Comparing the results for ResNet50 and DenseNet121, we observe that deeper and more complex models achieve better classification performance. For the effects of domain adaptation, it is obvious that the domain adaptation methods (DANN, PADA, and SODA) outperform those fine-tuning based transfer learning methods (ResNet50 and DenseNet121). Furthermore, the proposed SODA achieves higher AUC scores on both COVID-19 and Pneumonia than DANN and PADA, demonstrating the effectiveness of the proposed two-level alignment.
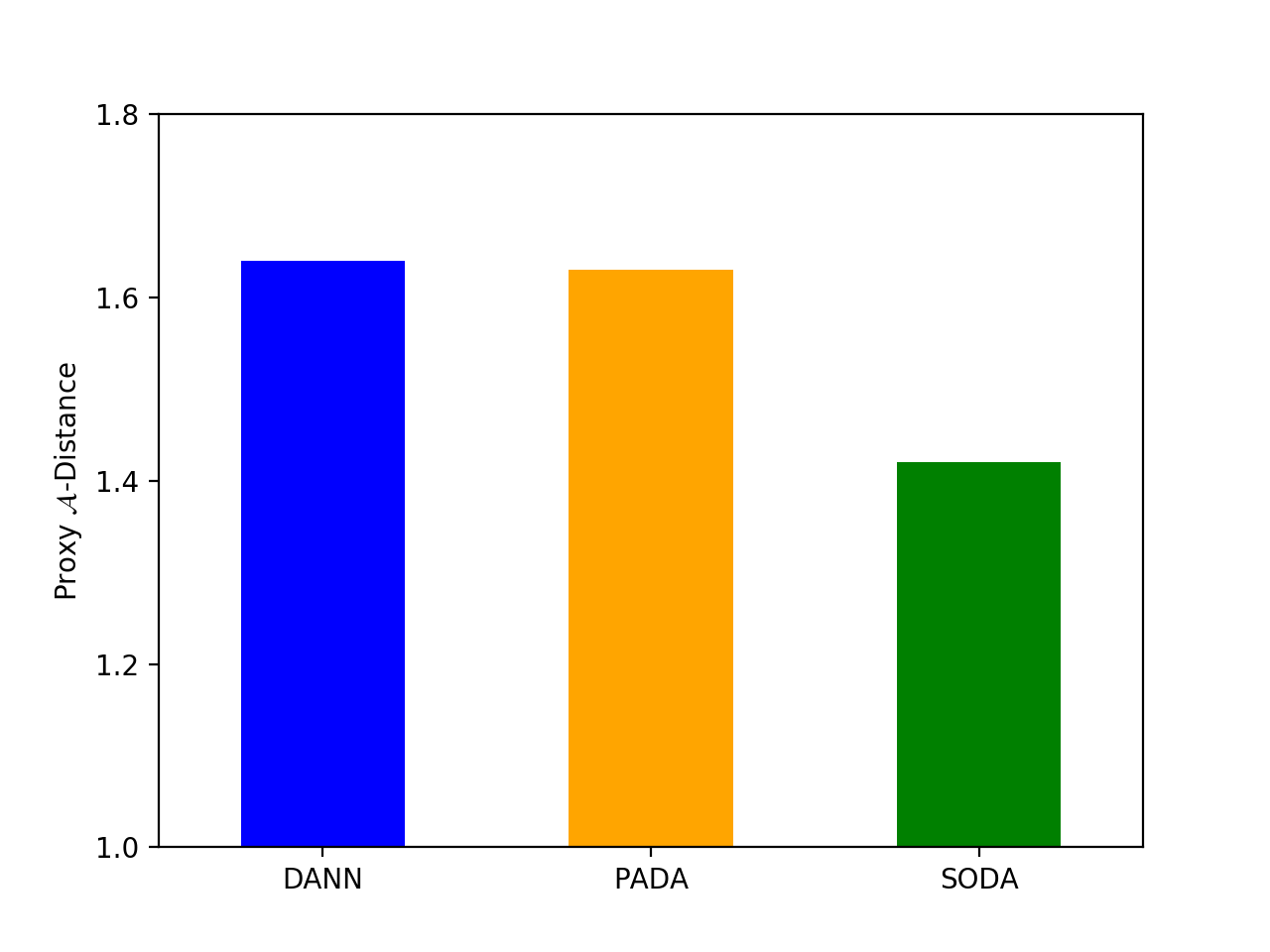
4.3. Proxy -Distance
Proxy -Distance (Ben-David et al., 2007) has been widely used in domain adaptation for measuring the feature distribution discrepancy between the source and target domains. PAD is defined by
| (7) |
where is the domain classification error (e.g. mean absolute error) of a classifier (e.g. linear SVM (Cortes and Vapnik, 1995)).
Following (Ganin et al., 2016), we train SVM models with different and use the minimum error to calculate PAD. In general, a lower means a better ability for extracting domain invariant features. As shown in Fig. 2, SODA has a lower PAD compared with the baseline methods, which indicates the effectiveness of the proposed two-level alignment strategy.
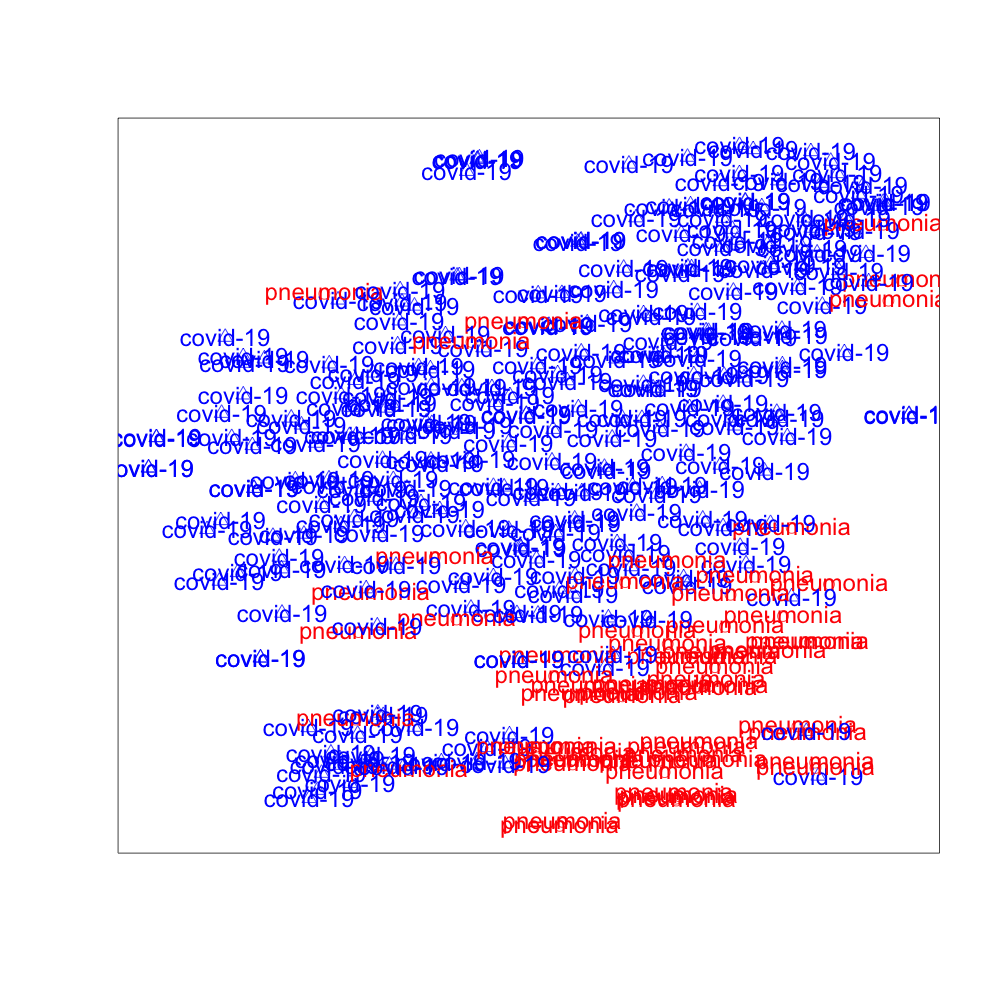
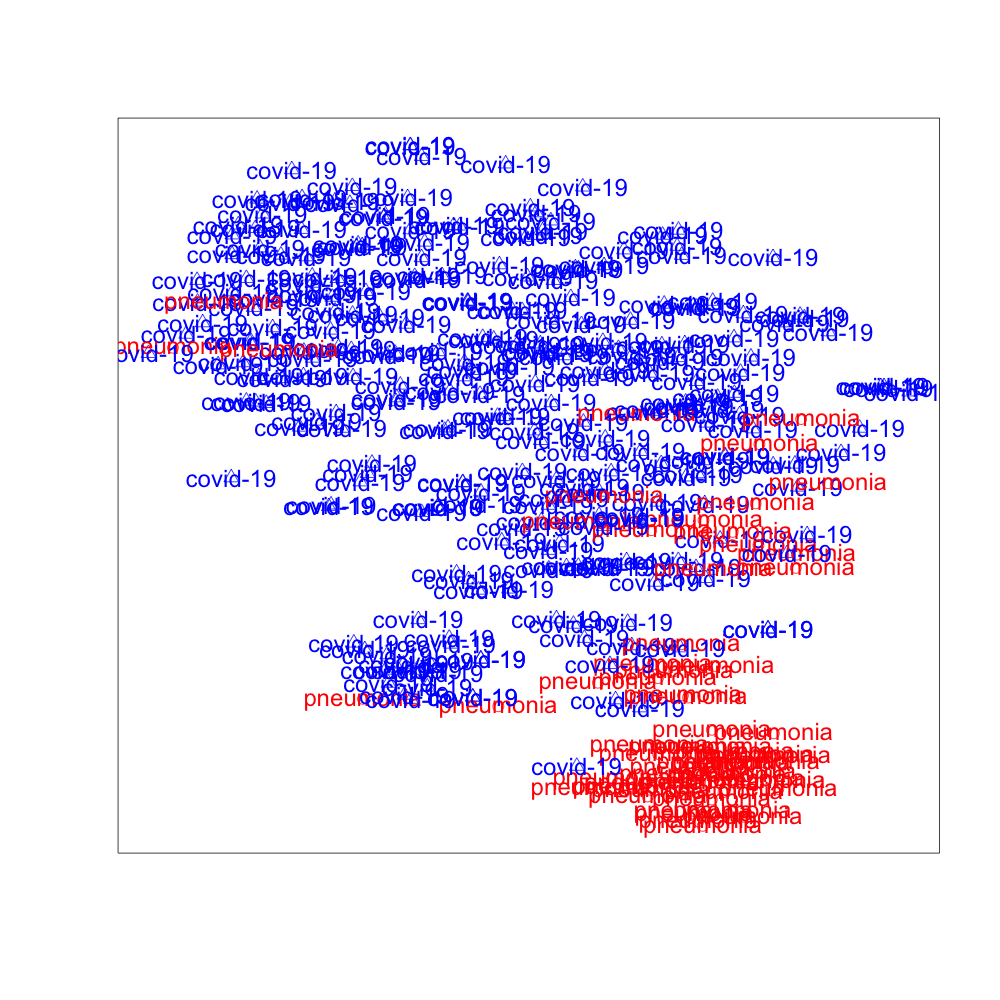

4.4. Feature Visualization
We use t-SNE to project the high dimensional hidden features extracted by DANN, PADA, and SODA to low dimensional space. The 2-dimensional visualization of the features in the target domain is presented in Fig. 3, where the red data points are image features of “Pneumonia” and the blue data points are image features of “COVID-19”. It can be observed from Fig. 3 that SODA performs the best for separating “COVID-19” from “Pneumonia”, which demonstrates the effectiveness of the proposed common label recognizer as well as the domain discriminator for common labels .
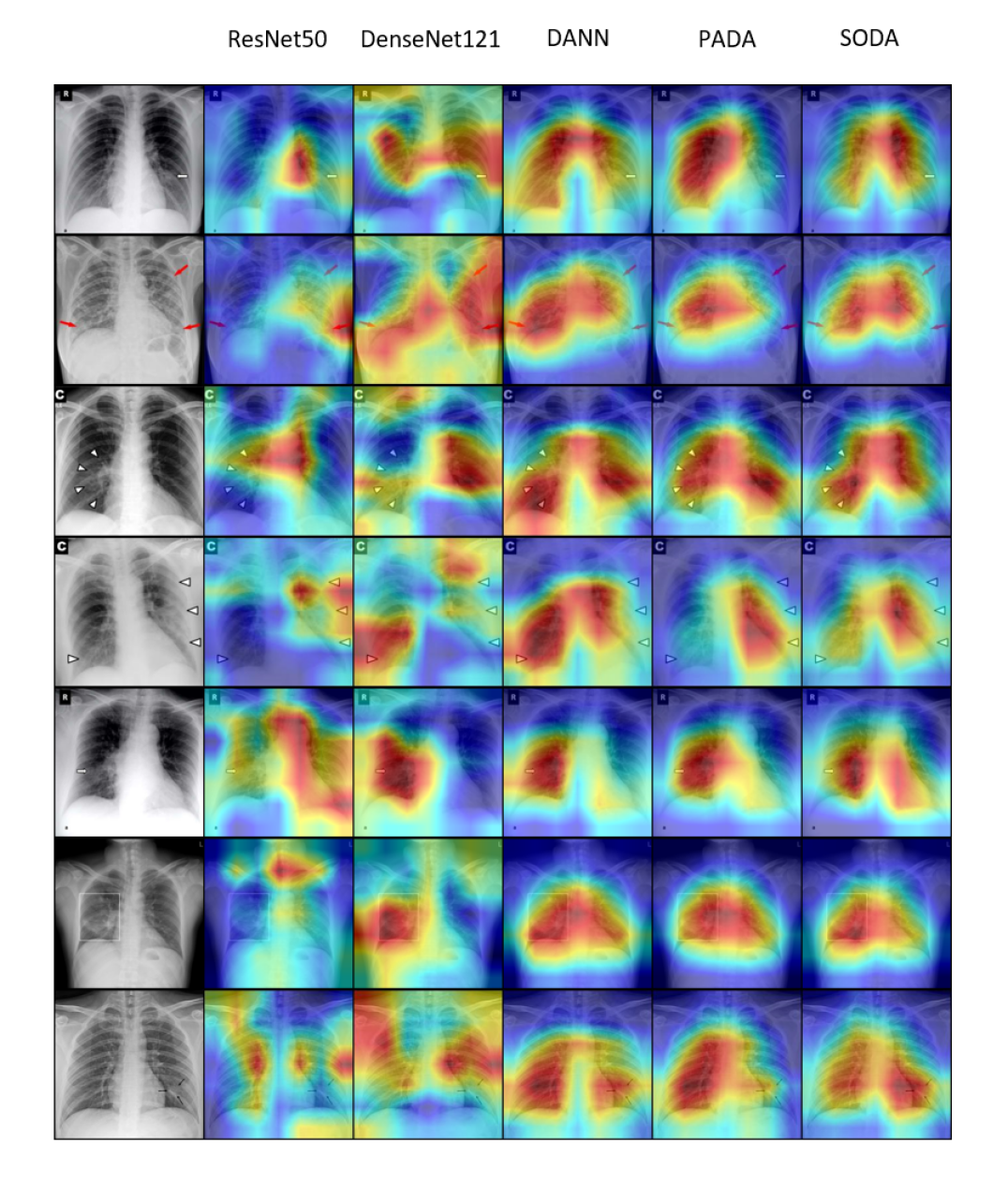
4.5. Grad-CAM
Grad-CAM (Selvaraju et al., 2017) is used to visualize the features extracted from all compared models. Fig. 4 shows the Grad-CAM results on seven different COVID-19 positive chest x-rays. These seven images have annotations (small arrows and box) indicating the pathology locations. We observe that ResNet50 and DenseNet121 can focus wrongly on irrelevant locations like the dark corners and edges. In contrast, domain adaptation models have better localization in general, and our SODA model gives more focused and accurate pathological locations than other models compared. In addition, we consult a professional radiologist with over 15 years of clinical experience from Wuxi People’s Hospital and received positive feedback on the pathological locations as indicated by the Grad-CAM of SODA. In the future, we plan to do a more rigorous evaluation study with more inputs from radiologists. We believe the features extracted from SODA can assist radiologists to pinpoint the suspect COVID-19 pathological locations faster and more accurately.
5. Related Work
5.1. Domain Adaptation
Domain adaptation is an important application of transfer learning that attempts to generalize the models from source domains to unseen target domains (Ganin and Lempitsky, 2015; Ganin et al., 2016; Tzeng et al., 2017; Tzeng et al., 2014; You et al., 2019; Jing et al., 2018; Wang et al., 2020). Deep domain adaptation approaches are usually implemented through discrepancy minimization (Tzeng et al., 2014) or adversarial training (Ganin and Lempitsky, 2015; Ganin et al., 2016; Tzeng et al., 2017). Adversarial training, inspired by the success of generative adversarial modeling (Goodfellow et al., 2014), has been widely applied for promoting the learning of transfer features in image classification. It takes advantage of a domain discriminator to classify whether an image is from the source or target domains. On top of these methods, a couple of works have been presented for exploring the high-level structure in the label space, which aim at further improving the domain adaptation performance for multi-class image classification (Wang et al., 2019) or fundamentally solving the application problem when the label sets from source domains and target domains are different (You et al., 2019). In order to meet the latter target, more and more researchers have started to study the open set domain adaptation problem, in which case the target domain has images that do not come from the classes in the source domain (You et al., 2019; Panareda Busto and Gall, 2017). Universal domain adaptation is the latest method that is proposed through using an adversarial domain discriminator and a non-adversarial domain discriminator to successfully solve this problem. (You et al., 2019). Although domain adaptation has been well explored, its application in medical imaging analysis, such as domain adaptation for chest x-ray images, is still under-explored.
5.2. Semi-supervised Learning
Semi-supervised learning is a very important task for image classification, which can make use of both labeled and unlabeled data at the same time (Saito et al., 2019). Recently it has been used to solve image classification problems on a very large (1 billion) set of unlabelled images (Yalniz et al., 2019). In spite of many progresses that have been made with unsupervised domain adaptation methods, the domain adaptation with semi-supervised learning has not yet been fully explored.
5.3. Chest X-Ray Image Analysis
There has been substantial progress in constructing publicly available databases for chest x-ray images as well as a related line of works to identify lung diseases using these images. The largest public datasets of chest x-ray images are Chexpert (Irvin et al., 2019) and ChestXray14 (Wang et al., 2017), which respectively include more than 200,000 and 100,000 chest x-ray images collected by Stanford University and National Institute of Healthcare. The creation of these datasets have also motivated and promoted the multi-label chest x-ray classification for helping the screening and diagnosis of various lung diseases. The problems of disease detection (Wang et al., 2017; Irvin et al., 2019; Wang et al., 2018) and report generation using chest x-rays (Jing et al., 2017; Li et al., 2018; Jing et al., 2019; Biswal et al., 2020) are fully investigated and have achieved much-improved results upon recently. However, there have been very few attempts for studying the domain adaptation problems with the multi-label image classification problem using chest x-rays.
6. Conclusion
In this paper, in order to assist and complement the screening and diagnosing of COVID-19, we formulate the problem of COVID-19 chest x-ray image classification in a semi-supervised open set domain adaptation framework. Accordingly, we propose a novel deep domain adversarial neural network, Semi-supervised Open set Domain Adversarial network (SODA), which is able to align the data distributions across different domains at both domain level and common label level. Through evaluations of the classification accuracy, we show that SODA achieves better AUC-ROC scores than the recent state-of-the-art models. We further demonstrate that the features extracted by SODA is more tightly related to the lung pathology locations, and get initial positive feedback from an experienced radiologist. In practice, SODA can be generalized to any semi-supervised open set domain adaptation settings where there are a large well-annotated dataset and a small newly available dataset. In conclusion, SODA can serve as a pilot study in using techniques and methods from domain adaptation to radiology imaging classification problems.
References
- (1)
- Ai et al. (2020) Tao Ai, Zhenlu Yang, Hongyan Hou, Chenao Zhan, Chong Chen, Wenzhi Lv, Qian Tao, Ziyong Sun, and Liming Xia. 2020. Correlation of chest CT and RT-PCR testing in coronavirus disease 2019 (COVID-19) in China: a report of 1014 cases. Radiology (2020), 200642.
- Apostolopoulos and Mpesiana (2020) Ioannis D Apostolopoulos and Tzani A Mpesiana. 2020. Covid-19: automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Physical and Engineering Sciences in Medicine (2020), 1.
- Ben-David et al. (2007) Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. 2007. Analysis of representations for domain adaptation. In Advances in neural information processing systems. 137–144.
- Biswal et al. (2020) Siddharth Biswal, Cao Xiao, Lucas Glass, Brandon Westover, and Jimeng Sun. 2020. Clinical Report Auto-completion. In Proceedings of The Web Conference 2020. 541–550.
- Cao et al. (2018) Zhangjie Cao, Lijia Ma, Mingsheng Long, and Jianmin Wang. 2018. Partial adversarial domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV). 135–150.
- Cohen et al. (2020) Joseph Paul Cohen, Paul Morrison, and Lan Dao. 2020. COVID-19 image data collection. arXiv 2003.11597 (2020). https://github.com/ieee8023/covid-chestxray-dataset
- Cortes and Vapnik (1995) Corinna Cortes and Vladimir Vapnik. 1995. Support-vector networks. Machine learning 20, 3 (1995), 273–297.
- Fang et al. (2020) Yicheng Fang, Huangqi Zhang, Jicheng Xie, Minjie Lin, Lingjun Ying, Peipei Pang, and Wenbin Ji. 2020. Sensitivity of chest CT for COVID-19: comparison to RT-PCR. Radiology (2020), 200432.
- Ganin and Lempitsky (2015) Yaroslav Ganin and Victor Lempitsky. 2015. Unsupervised Domain Adaptation by Backpropagation. In International Conference on Machine Learning. 1180–1189.
- Ganin et al. (2016) Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. 2016. Domain-adversarial training of neural networks. Journal of Machine Learning Research 17, 1 (2016), 2096–2030.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In NIPS. 2672–2680.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Huang et al. (2017) Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. 2017. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4700–4708.
- Irvin et al. (2019) Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. 2019. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 590–597.
- Jing et al. (2018) Baoyu Jing, Chenwei Lu, Deqing Wang, Fuzhen Zhuang, and Cheng Niu. 2018. Cross-Domain Labeled LDA for Cross-Domain Text Classification. In 2018 IEEE International Conference on Data Mining (ICDM). IEEE, 187–196.
- Jing et al. (2019) Baoyu Jing, Zeya Wang, and Eric Xing. 2019. Show, Describe and Conclude: On Exploiting the Structure Information of Chest X-ray Reports. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 6570–6580.
- Jing et al. (2017) Baoyu Jing, Pengtao Xie, and Eric Xing. 2017. On the automatic generation of medical imaging reports. arXiv preprint arXiv:1711.08195 (2017).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Lakhani and Sundaram (2017) Paras Lakhani and Baskaran Sundaram. 2017. Deep learning at chest radiography: automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology 284, 2 (2017), 574–582.
- Li et al. (2020) Lin Li, Lixin Qin, Zeguo Xu, Youbing Yin, Xin Wang, Bin Kong, Junjie Bai, Yi Lu, Zhenghan Fang, Qi Song, et al. 2020. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology (2020), 200905.
- Li et al. (2018) Yuan Li, Xiaodan Liang, Zhiting Hu, and Eric P Xing. 2018. Hybrid retrieval-generation reinforced agent for medical image report generation. In Advances in neural information processing systems. 1530–1540.
- Linda Wang and Wong (2020) Zhong Qiu Lin Linda Wang and Alexander Wong. 2020. COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest Radiography Images. arXiv:cs.CV/2003.09871
- Minaee et al. (2020) Shervin Minaee, Rahele Kafieh, Milan Sonka, Shakib Yazdani, and Ghazaleh Jamalipour Soufi. 2020. Deep-covid: Predicting covid-19 from chest x-ray images using deep transfer learning. arXiv preprint arXiv:2004.09363 (2020).
- Nair and Hinton (2010) Vinod Nair and Geoffrey E Hinton. 2010. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10). 807–814.
- Panareda Busto and Gall (2017) Pau Panareda Busto and Juergen Gall. 2017. Open set domain adaptation. In Proceedings of the IEEE International Conference on Computer Vision. 754–763.
- Pei et al. (2018) Zhongyi Pei, Zhangjie Cao, Mingsheng Long, and Jianmin Wang. 2018. Multi-adversarial domain adaptation. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Saito et al. (2019) Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, and Kate Saenko. 2019. Semi-supervised domain adaptation via minimax entropy. In Proceedings of the IEEE International Conference on Computer Vision. 8050–8058.
- Selvaraju et al. (2017) Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision. 618–626.
- Tzeng et al. (2017) Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. 2017. Adversarial Discriminative Domain Adaptation. In CVPR. IEEE, 2962–2971.
- Tzeng et al. (2014) Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. 2014. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474 (2014).
- Wang et al. (2020) Deqing Wang, Baoyu Jing, Chenwei Lu, Junjie Wu, Guannan Liu, Chenguang Du, and Fuzhen Zhuang. 2020. Coarse Alignment of Topic and Sentiment: A Unified Model for Cross-Lingual Sentiment Classification. IEEE Transactions on Neural Networks and Learning Systems (2020).
- Wang et al. (2017) Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. 2017. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2097–2106.
- Wang et al. (2018) Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, and Ronald M Summers. 2018. Tienet: Text-image embedding network for common thorax disease classification and reporting in chest x-rays. In Proceedings of the IEEE conference on computer vision and pattern recognition. 9049–9058.
- Wang et al. (2019) Zeya Wang, Baoyu Jing, Yang Ni, Nanqing Dong, Pengtao Xie, and Eric P Xing. 2019. Adversarial Domain Adaptation Being Aware of Class Relationships. arXiv preprint arXiv:1905.11931 (2019).
- Yalniz et al. (2019) I Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, and Dhruv Mahajan. 2019. Billion-scale semi-supervised learning for image classification. arXiv preprint arXiv:1905.00546 (2019).
- You et al. (2019) Kaichao You, Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I Jordan. 2019. Universal domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2720–2729.
- Zhang et al. (2020) Kang Zhang, Xiaohong Liu, Jun Shen, Zhihuan Li, Ye Sang, Xingwang Wu, Yunfei Zha, Wenhua Liang, Chengdi Wang, Ke Wang, et al. 2020. Clinically applicable AI system for accurate diagnosis, quantitative measurements, and prognosis of covid-19 pneumonia using computed tomography. Cell (2020).