Solution for Large-scale Long-tailed Recognition with Noisy Labels
Abstract
This is a technical report for CVPR 2021 AliProducts Challenge 111https://tianchi.aliyun.com/competition/entrance/531884/introduction. AliProducts Challenge is a competition proposed for studying the large-scale and fine-grained commodity image recognition problem encountered by world-leading e-commerce companies. The large-scale product recognition simultaneously meets the challenge of noisy annotations, imbalanced (long-tailed) data distribution and fine-grained classification. In our solution, we adopt state-of-the-art model architectures of both CNNs and Transformer, including ResNeSt, EfficientNetV2, and DeiT. We found that iterative data cleaning, classifier weight normalization, high-resolution finetuning, and test time augmentation are key components to improve the performance of training with the noisy and imbalanced dataset. Finally, we obtain 6.4365% mean class error rate in the leaderboard with our ensemble model. 222This work is finished when Yuqiao Xian and Jia-Xin Zhuang were interns at Tencent Youtu Lab.
1 Introduction
Recently, deep learning has shown its impressive performance in computer vision with large well-annotated image datasets such as ImageNet [7], MS-COCO [5]. However, clean and well-annotated image datasets are hard to obtain and, thus not really in a real-world scenario most time. Datasets like AliProducts [2], a noisy and fine-grained product dataset containing 2.5 million web images from the 50,030 fine-grained semantic classes in Stock Keeping Unit (SKU) level, is more challenging and closer to the real-world applications.
There are several challenges for deep models to achieve high performance in product recognition tasks like AliProducts. Firstly, AliProducts present a long-tail data distribution, whose portions of the distribution haves many occurrences far from the head and central part of the distribution. Secondly, data in AliProducts is very imbalanced and the least number of the category is one of 16 millionths of the largest category. Without any specific strategies for data imbalance, the model would degrade its performance dramatically. Lastly, labels are collected from the internet and are very noisy and data a cleaning algorithm has to be proposed to deal with it [2].
To alleviate problems brought by the noisy labels and long-tail distribution in AliProducts, we adopt several strategies to re-balance samples from each class, and then select clean labels in an automatic manner for training models, and train the model with a progressive training scheme. Finally we ensemble CNNs and transformer models to obtain higher accuracy.
2 Our Solution
2.1 Model Architectures
In our solution, we ensemble three different network architectures with ImageNet pretrained weights, including ResNeSt-101, DeiT-small and EfficientNevV2-m.
ResNeSt [12]. ResNeSt is a strong CNN backbone and was adopted by many solutions in last year’s competition. We find that ResNeSt-101 can obtain the best performance.
DeiT [9]. Deit [9] is selected as transformer branch, which is a kind of vision transformer. We modified DeiT based on official implementation 333https://github.com/facebookresearch/deit. Consider trade-off between accuracy and efficiency, we use deit-S without distillation from [9] in our implementation. We train DeiT with cosine learning for 300 epochs (about 9 days with 8 Tesla V100) to get better performance. We find that training DeiT with fewer epochs will result in inferior performance.
EfficientNetV2 [8]. We find that the EfficientNetV2-m backbone can achieve better validation performance with fewer training epochs. Results of 4 EfficientNetV2-m models with different training settings are included in the final submission.
BNNeck [6]. We add a BN layer before the linear classifier to normalize the global features, which slightly improve the performance.
Embedding layer. Since the number of classes in AliProduct is massvie (50K+), we insert a fully connected layer with 512 output dimensions before the linear classifier to reduce the ites input feature dimensions. It will reduce the parameters of classifier layer training time, and will not result in noticable performance drop.
2.2 Iterative Data Cleaning
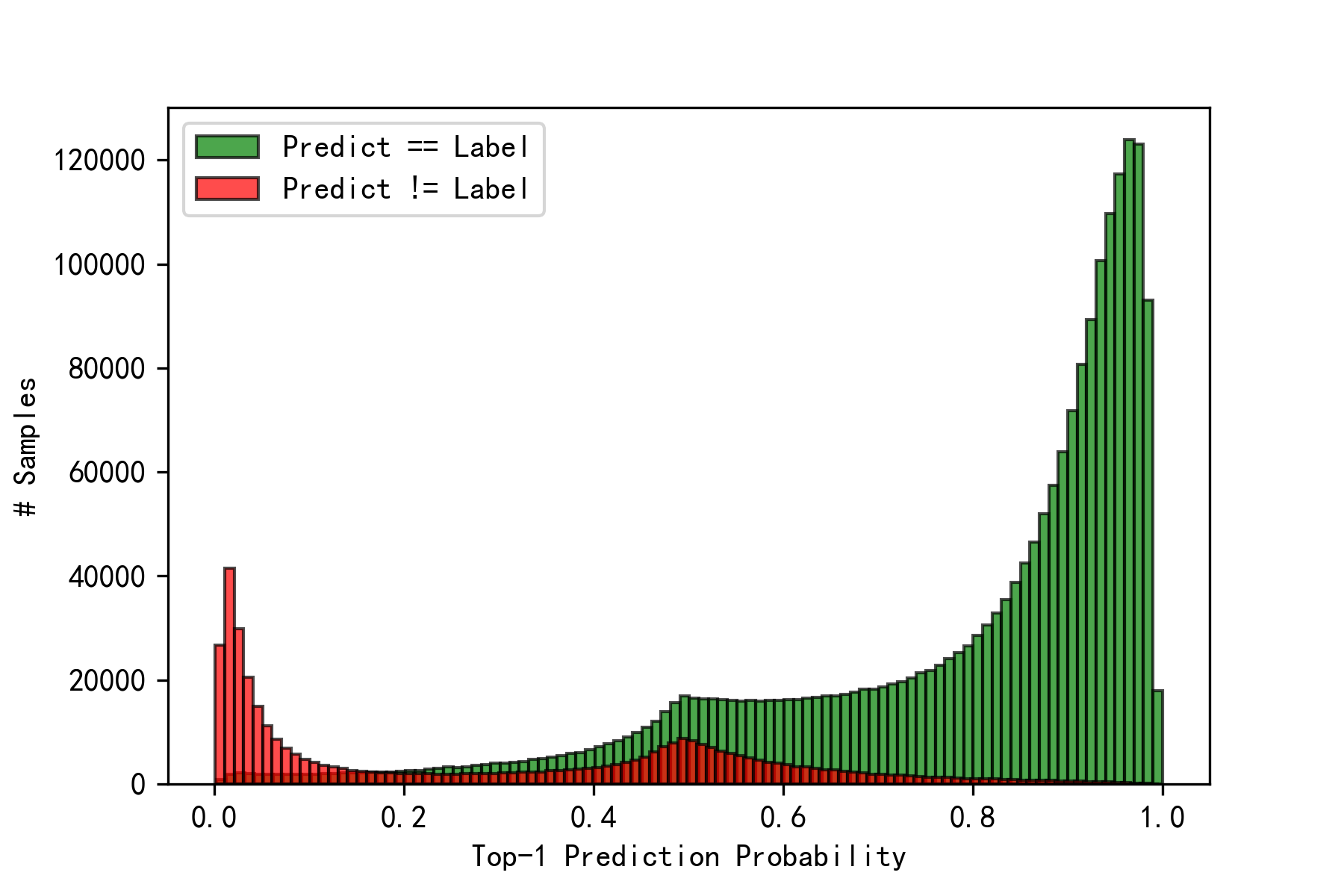
To tackle the severe label noise problem in the non-manually labeled training dataset, we iteratively cleaning the training based on model predictions and re-train the model in a self-learning manner. We firstly train the model with the whole training set and use the model to predict the label of training samples. Then, we rank the samples according to the top-1 prediction probability. As shown in Fig. 1, we observe that many samples’ predictions are not equal to their labels and also have low prediction probability (confidence). We consider these samples are with noisy labels and abandon them in the next iteration of model training. After 3 - 4 iterations of data cleaning and model re-training, the training dataset will be much cleaner and the model performance can improve about 3% - 5% in top-1 accuracy.
2.3 Training Strategy
We train all the models using standard cross entropy loss for the classification task, with some strategies to alleviate the negative effect of data imbalance.
Retraining or Finetuning the Classifier [4]. We found that retraining or finetuning the classifier with class-balanced sampling (CBS) is more effective when the training data is noisy, which improve about 3% - 5% of the average classification accuracy. After several iterations of data cleaning, the model performance will be higher with instance-balanced sampling (IBS), and finetuning the classifier with CBS improves about 1% ACC on validation set. Fine-tuning with a balanced training subset is an alternative approach to acquire balanced classifier. We use a trained model to select top 30 images of each class with highest classification probabilities to construct a clean and balance subset and use it to finetune the classifier (or the whole network). We also found these way can improe about 1% average classification accuray.
High Resolution Finetuning. Following the idea of progressive training [8], we train the ResNeSt-101 and EfficientV2 backbone with input size in the first 40 epochs and finetune them with input size for about 5-10 epochs, which can improve about 1% top-1 accuracy.
2.4 Test Time Augmentation
-Normalization. [4] We use -normalization to re-balance the decision boundaries of by normalizing the clasifier weights. We found that this method significantly improve the accuracy of tail classes. We found that the optimal value of is different with different model architecture. We choose the value of as 0.5-0.7 based on the validation performance.
Fixing Test Resolution. Following [10], we scale the resolution of test image by 1.5x of training image. Then, we use ten crop augmentation to crop the enlarged test image to the size of training input. (e.g., .) This augmentation is quite effective and can improve 1% - 2% performance in the most cases.
Model Prediction Ensemble. To acquire a more robust classification performance, we adaptively ensemble multiple CNN (ResNeSt) and Transformer (DeiT) models with different training settings, such as different dataset versions, different sampling strategies, and different regularizations. We preserve the top-10 predictions of each model for each sample and average the predicting probabilities.
| Method | Top-1 ACC |
|---|---|
| Baseline (EfficientNetV2-m) | |
| + Data Cleaning | + |
| + Iterative Cleaning | + |
| + Retraining Classifier | + |
| + -Normalization | + |
| + TTA (Enlarge + Ten Crop) | + |
| + High Resolution Finetuning | + |
| + 3 Model Ensemble | + |
| + 8 Model Ensemble | + |
2.5 Other Techniques
We also use the following techniques to train some of our models, which may slightly improve the performance on the validation set. These models are included in the final ensemble model. However, due to the limited chances of submission, we are not able to provide a comprehensive ablation study and evaluate each component on test set: 1. HAR [1]; 2. Large weight decay rate (0.0005); 3. Mixup; 4. Relabeling the filtered training Wimages with model prediction.
3 Implementation Settings
Most of our models are trained on a node with 8 NVIDIA Tesla V100 GPUs on Tencent Jizhi Computation Platform. A typical EfficientV2-m model is trained with 30 epochs with IBS and other 10 epochs with CBS using standard SGD optimizer with momentum, which needs about 30 hours. The settings are as following:
-
•
Data Augementation: Resize to with random crop, random hue saturation shift, random brightness contrast shift, random gaussian blur, random horizontal flip, random vertical flip and coarse dropout.
-
•
Step learning rate decay at 14 and 20 epoch (ratio 0.1).
-
•
Warmup training at the first 2 epochs.
-
•
Initial learning rate of
-
•
Label smoothing: 0, 0.1 and 0.2.
-
•
Batch size: 1024.
-
•
Dimensions of embedding layer: 512.
-
•
Weight decay: .
For transformer, a typical training of 300 epochs takes 9 days with 8 V100 for the deit-S. We follow the default settings [9] in most time. Learning rate is 5e-4 with cosine scheduler with AdamW. A batch contains 2048 images. Images are resized to and random cropped by . Many data augmentations methods such as random augment, repeated augmentation is used to train our model. Note that, we follow the default strategies to train deit [9] and use repeated augmentations with 3 repetitions.
4 Conclusion
Since AliProducts presents noisy labels and long-tail distribution, we select clean images based on confidence score from the model prediction and then adopt several effective strategies to re-balance samples from each class and train the model with strong regularization terms in a progressive way. Ensemble of strong yet diverse backbones like CNNs and Transformer would further improve generalization and boost the performance. Finally, we achieve 0.064365 mean class error rate in the leaderboard with our solution.
Acknowledgement
Gratitude to CVPR 2021 organizing Committee and Alibaba TianChi platform for organizing this competition. Tencent Youtu Lab and Tencent Jizhi Computation Platform provide the technical and computation support for our solution. Thanks to Enwei Zhang and Xing Sun from Tencent Youtu Lab to provide precious opinions to our solution.
References
- [1] Kaidi Cao, Yining Chen, Junwei Lu, Nikos Arechiga, Adrien Gaidon, and Tengyu Ma. Heteroskedastic and imbalanced deep learning with adaptive regularization. In Int. Conf. Learn. Represent., 2021.
- [2] Lele Cheng, Xiangzeng Zhou, Liming Zhao, Dangwei Li, Hong Shang, Yun Zheng, Pan Pan, and Yinghui Xu. Weakly supervised learning with side information for noisy labeled images. In Eur. Conf. Comput. Vis., 2020.
- [3] Jiankang Deng, Jia Guo, Xue Niannan, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [4] Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In Int. Conf. Learn. Represent., 2020.
- [5] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Eur. Conf. Comput. Vis., pages 740–755.
- [6] H. Luo, W. Jiang, Y. Gu, F. Liu, X. Liao, S. Lai, and J. Gu. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimedia, 2019.
- [7] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. In Int. J. Comput. Vis., 2015.
- [8] Mingxing Tan and Quoc V. Le. Efficientnetv2: Smaller models and faster training. 2021.
- [9] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.
- [10] Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Hervé Jégou. Fixing the train-test resolution discrepancy. In Adv. Neural Inform. Process. Syst., 2019.
- [11] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Int. Conf. Comput. Vis., 2019.
- [12] Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Zhi Zhang, Haibin Lin, Yue Sun, Tong He, Jonas Muller, R. Manmatha, Mu Li, and Alexander Smola. Resnest: Split-attention networks. arXiv preprint arXiv:2004.08955, 2020.