Solving sparse linear systems with approximate inverse preconditioners on analog devices
Abstract
Sparse linear system solvers are computationally expensive kernels that lie at the heart of numerous applications. This paper proposes a preconditioning framework that combines approximate inverses with stationary iterations to substantially reduce the time and energy requirements of this task by utilizing a hybrid architecture that combines conventional digital microprocessors with analog crossbar array accelerators. Our analysis and experiments with a simulator for analog hardware demonstrate that an order of magnitude speedup is readily attainable without much impact on convergence, despite the noise in analog computations.
Index Terms:
Richardson iteration, approximate inverse preconditioners, analog crossbar arraysI Introduction
The iterative solution of sparse linear systems [1] is a fundamental task across many applications in science, engineering, and optimization. For decades, progress in speeding up preconditioned iterative solvers was primarily driven by constructing more effective preconditioning algorithms and via steady microprocessor performance gains. The last decade saw the advent of fast power-efficient low-precision hardware, such as Graphics Processing Units (GPUs), which gave rise to new opportunities to accelerate sparse iterative solvers [2, 3, 4, 5, 6, 7, 8]. While these advances have led to remarkable gains in the performance of sparse iterative solvers, conventional CMOS-based digital microprocessors possess inherent scaling and power dissipation limitations. It is therefore imperative that we explore alternative hardware architectures to address current and future challenges of sparse iterative solvers. One such alternative paradigm is based on analog devices configured as crossbar arrays of non-volatile memory. Such arrays can achieve high degrees of parallelism with low energy consumption by mapping matrices onto arrays of memristive elements capable of storing information and executing simple operations such as a multiply-and-add. In particular, these devices can perform Matrix-Vector Multiplication (MVM) in near constant time independent of the number of nonzero entries in the operand matrices [9, 10]. Indeed, considerable computational speed-ups have been achieved with analog crossbar arrays [11, 12, 13, 14, 15, 16, 17, 18, 19], mostly for machine learning applications that can tolerate the noise and lower precision of these devices.
Analog designs with enhanced precision have been proposed [20, 21] to meet the accuracy demands of scientific applications, but the improvement in precision comes at the cost of increased hardware complexity and energy consumption. Memristive hardware with precision enhancement has been exploited in the context of Jacobi iterations to solve linear systems stemming from partial differential equations (PDEs) [22], and as an autonomous linear system solver [23] for small dense systems. The latter approach was used to apply overlapping block-Jacobi preconditioners in the Generalized Minimal RESidual (GMRES) iterative solver [20] with bit-slicing for increasing precision. Inner-outer iterations [24, 25, 26] have been considered for dense systems, where analog arrays were used for the inner solver while iterative refinement was used as an outer solver in the digital space.
The main contribution of this paper is a flexible preconditioning framework for inexpensively solving a large class of sparse linear systems by effectively utilizing simple analog crossbar arrays without precision-enhancing extensions. Our approach combines flexible iterative solvers and approximate inverse preconditioners on a hybrid architecture consisting of a conventional digital processor and an analog crossbar array accelerator. We analytically and experimentally show that this combination can solve certain sparse linear systems at a fraction of the cost of solving them on digital processors. While the relative advantage of analog hardware grows with the size of the linear systems, we demonstrate the potential for an order of magnitude speedup even for systems with just a few hundred equations.
While our method can be used to provide a fast stand-alone sparse solver, it also has exciting applications in the context of the upcoming exascale platforms [27]. Extreme-scale solvers are likely to be highly composable [28] and hierarchical [29] with multiple levels of nested algorithmic components. A solver like the one proposed in this paper, running on analog accelerator-equipped nodes of a massively parallel platform, is an ideal fast and low-power candidate for a local subdomain or coarse-grid solver to tackle the local components of a much larger sparse linear system.
II Linear Algebra on Analog Hardware
We begin by briefly describing our architecture model and its key properties. Figure 1 illustrates a hybrid digital-analog architecture that combines a conventional microprocessor system with an analog crossbar array for performing MVM. The crossbar consists of rows and columns of conductors with a memristive element at each row-column intersection [30]. The conductance of these elements can be set, reset, or updated in a non-volatile manner. Matrix operations are performed by mapping the operand matrix onto the crossbar array, where the conductance at the intersection of row and column represents the value (i.e., the -th entry of the matrix ) after a suitable scaling.
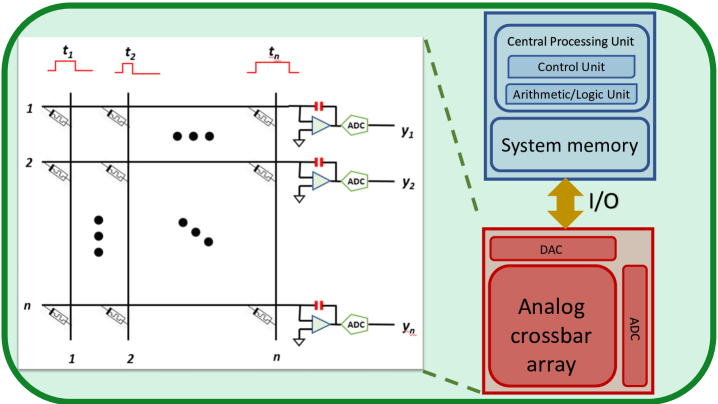
The MVM operation can be emulated by sending pulses of volts along the columns of the crossbar such that the length of the pulse along column is proportional to the th entry of vector , with suitable normalization. Following Ohm’s Law, this contributes a current equal to on the conductor corresponding to row for a duration . Following Kirchoff’s Current Law, the currents along each row accumulate and can be integrated over the time period equivalent to the maximum pulse length using capacitors, yielding a charge proportional to , which in turn is proportional to . This integrated value can be recovered as a digital quantity via an analog-to-digital converter (ADC), and yields an approximation to .
The above procedure involves multiple sources of nondeterministic noise so that the output is equivalent to a low precision approximation of . Writing to the crossbar array incurs multiplicative and additive write noises and , respectively, and the actual conductance values at the crosspoints of the array reflect , where denotes element-wise multiplication. Similarly, digital-to-analog conversion (DAC) of the vector into voltage pulses suffers from multiplicative and additive input noises and , respectively. As a result, the matrix is effectively multiplied by a perturbed version of given by , where is a vector of all ones.
A characteristic equation to describe the output of an analog MVM can be written as
| (1) |
where and denote the multiplicative and additive components of the output noise, respectively. These components reflect the inherent inexactness in the multiplication based on circuit laws and current integration, as well as the loss of precision in the ADC conversion of the result vector. Equation (1) can be simplified as
| (2) |
where is the overall effective additive noise that captures all the lower order noise terms from Equation (1) and the nondetermistic error matrix is given by
| (3) |
here denotes outer product. We provide additional technical details in Appendix A.
The exact characteristics and magnitudes of the noises depend on the physical implementation [12, 25] of the analog array and the materials used therein, the details of which are beyond the scope of this paper but they are generally captured by our model. Regardless of the implementation, the noises are always device dependent and stochastic.
Once the matrix is written to the crossbar array, analog MVMs involving the matrix can be performed in time, resulting in an speedup over the equivalent digital computation if is dense. Therefore, a linear system solver that can overcome the analog MVM error, even if it requires many more MVM operations than its digital counterpart, can substantially reduce the cost of the solution.
III An iterative solver based on memristive approximate inverse preconditioning
The goal of preconditioning is to transform an system of linear equations to enable an iterative procedure to compute a sufficient approximation of in fewer steps. Algebraically, preconditioning results in solving the system , where is an approximation of . Since is dense in general, most popular general-purpose preconditioners are applied implicitly; e.g., the ILU preconditioner generates a lower (upper) triangular matrix () such that . The preconditioner is then applied by forward/backward substitution [1].
III-A Approximate inverse matrices as preconditioners
Although the inverse of a sparse matrix is dense in general, a significant fraction of the entries in the inverse matrix often have small magnitudes [31, 32]. Approximate inverse preconditioners [33, 34, 35] exploit this fact and seek to compute an approximation to that can be applied via an MVM operation. Computing can be framed as an optimization problem that seeks to minimize . One popular method for computing is by the Sparse Approximate Inverse (SPAI) technique [35], which updates the sparsity pattern of dynamically by repeatedly choosing new profitable indices for each column of that lead to an improved approximation of . The quality of the approximation is controlled by computing the norm of the residual after each column update. The th column of has at most nonzero entries and satisfies , for a given threshold tolerance .
An effective approximate inverse preconditioner can still be considerably denser than the coefficient matrix . Therefore, preconditioning must lead to a drastic convergence improvement for a reduction in the overall wall-clock time. Applying approximate inverse preconditioners as proposed in this paper has the advantage that the computation time and energy consumption of preconditioning would be much lower on an analog crossbar array than on digital hardware, even at low precisions. Since MVM with can be performed in time on an analog array regardless of the number of nonzeros in , denser approximate inverses may be utilized without increasing the associated costs.
While analog crossbar arrays can speed up the application of the approximate inverse preconditioner, the accuracy of the application step is constrained by the various nondeterministic noises in the analog hardware discussed in Section II. This restricts the use of popular Krylov subspace approaches such as GMRES [36], which require a deterministic preconditioner. Although flexible variants [37] exist, in which the preconditioner can vary from one step to another, these variants generally require the orthonormalization of large subspaces and perform a relatively larger number of Floating Point Operations (FLOPs) outside the preconditioning step. Therefore, in this paper, we consider a stationary iterative scheme.
III-B Preconditioned Richardson iteration
Stationary methods approximate the solution of a linear system by iteratively applying an update of the form , where and are fixed. Preconditioned Richardson iteration can be defined as
which is identical to the form , with and [38]. The approximate solution produced by preconditioned Richardson iteration during the th iteration satisfies
where the latter inequality holds for any vector norm and the corresponding induced matrix norm. A similar bound can also be shown for the residual vector ; i.e.,
The above inequalities show that the sequence will converge to the true solution as long as the preconditioner and scaling scalar are chosen such that . In fact, the limit of the iterative process will converge to as long as the spectral radius of the matrix is strictly less than one. Nonetheless, we use the spectral norm since . If we denote the eigenvalues of the matrix by , then we need to pick such that , i.e., we need . We use in the remainder of the paper.
III-C Preconditioning through memristive hardware
Algorithm 1 summarizes our hybrid Richardson iterations preconditioned by applying an approximate inverse through analog crossbar hardware. The iterative procedure terminates when either the maximum number of iterations is reached or the relative residual norm drops below a given threshold tolerance . Each iteration of Algorithm 1 requires a sparse MVM with the coefficient matrix (Line 5), two “scalar alpha times x plus y” (AXPY) [39] operations (Lines 5 and 7), a vector norm computation (Line 6), and an MVM with the approximate inverse preconditioner (Line 7) computed in analog hardware. Therefore, of the total FLOPs per iteration, can be performed in time on the analog hardware.
The ideal per-iteration speedup that the hybrid implementation can achieve over its digital counterpart is , which increases with the density of the preconditioner. In reality, the hybrid implementation is likely to require more iterations to reach the same residual norm as the digital implementation because the noise introduced by the analog hardware leads to a less accurate application of the preconditioner . More specifically, excluding the time spent on constructing , the overall computational speedup achieved by the hybrid implementation is
where and denote the number of digital and hybrid preconditioned Richardson iterations, respectively.
III-D The effects of device noise
Since the MVM between the preconditioner and the residual vector of the th iteration is computed through an analog crossbar array, the inherent inaccuracies of the analog device lead to an update of the form
from Equation (2). Note that and stochastically and nondeterministically vary between iterations. The error norm then satisfies the relationships
and
The additive noise has a direct impact on the lower bound of the error that can be achieved. Additionally, the norm of the error will be smaller than as long as , for which we have the upper bound
Under the assumption that the spectral norm of the matrix is less than one, i.e., , a sufficient condition for the spectral norm of the matrix to be less than one is
Additionally, for to hold under the condition , .
Consistent with the original deterministic analysis for iterative refinement by Moler [40] from a digital perspective, but adapted to Richardson iteration with noisy analog devices, a sufficiently small in a stochastic sense guarantees the convergence of the preconditioned Richardson iteration process. In particular, we need to have hold in a sufficiently large number of iterations. To understand and ensure when these conditions will hold, we establish explicit bounds for in terms of the statistical characteristics of the elements of the matrix . We omit the details here and refer the interested reader to Appendix A.
IV Simulation Experiments
Our experiments were conducted in a Matlab environment (version R2020b) with 64-bit arithmetic on a single core of a 2.3 GHz 8-Core Intel i9 machine with 64 GB of system memory. We used a Matlab version of the publicly available simulator [41] with a PyTorch interface for emulating the noise, timing, and energy characteristics of an analog crossbar array. The simulator models all sources of analog noise outlined in Section II as scaled Gaussian processes. Using Matlab notation, the components of the matrix write noise were modeled as , and those of the input and output noises were both modeled as ; these are the default settings in the simulator based on currently realizable analog hardware [16]. The number of bits used in the ADC and DAC was set to and , respectively. Table I shows the default parameters used throughout our experiments to simulate the analog device and to construct the approximate inverse preconditioner.
| Module | Parameter | Value |
|---|---|---|
| Analog device | ||
| Analog device | ||
| Analog device | ||
| Richardson it. | ||
| Richardson it. | ||
| Approximate inverse | ||
| Approximate inverse |
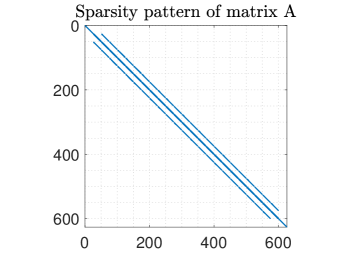
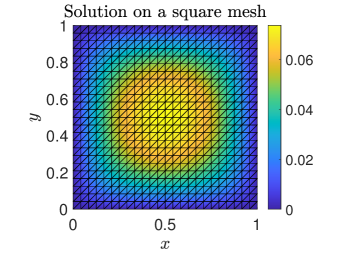
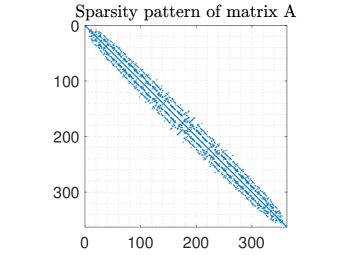
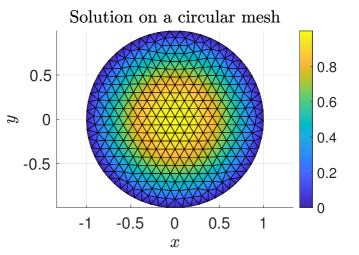
Our test problems originate from discretizations of model PDEs. The first two matrices are derived from a Finite Element (FE) discretization of Poisson’s equation on with homogeneous Dirichlet boundary conditions
| (4) |
where denotes the partial derivative with respect to an independent variable and denotes the load (or source) vector. We consider two different domains: a square domain and a circular domain of radius one centered at the origin. The Laplace operator is discretized by linear finite elements while the load vector is set equal to the constant source function . Figure 2 plots the sparsity patterns of the discretized Laplacian matrices and the surfaces of the solutions for the square () and circular () meshes. Our third test matrix stems from a Finite Difference (FD) discretization of the Laplace operator in the unit cube with homogeneous Dirichlet boundary conditions and . The average number of nonzero entries per row in the discretized sparse matrices and in the corresponding preconditioners are listed in Table II, which shows that the fill-in factor (i.e., the ratio ) ranges from to . Our test matrices are relatively small because we are limited by the speed of the Matlab version of the simulator for the analog crossbar arrays; however, our results are meaningful because the relative advantage of analog hardware, in general, only increases with larger matrices.
| Problem | FLOPs() | FLOPs() | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FE Square | 625 | 4.4 | 93.5 | 0.99 | 0.75 | 0.75 | Failed | 41 | 44 | |||
| FE Circular | 362 | 5.6 | 86.6 | 0.97 | 0.55 | 0.55 | Failed | 21 | 23 | |||
| FD 3D | 512 | 6.2 | 81.1 | 0.75 | 0.17 | 0.54 | Failed | 7 | 16 |
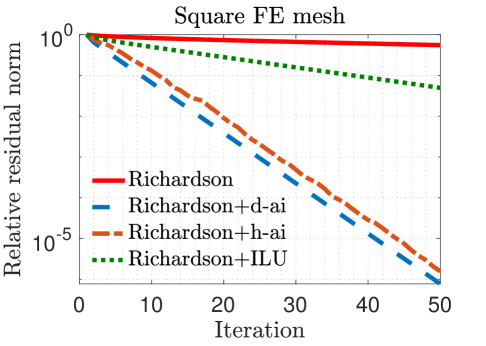
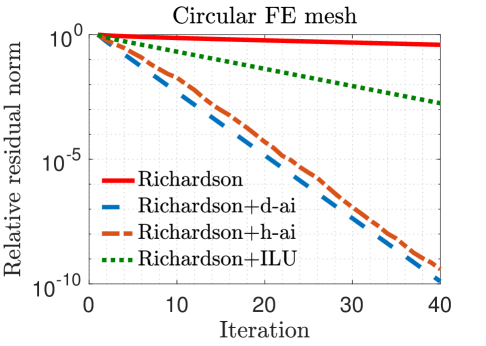
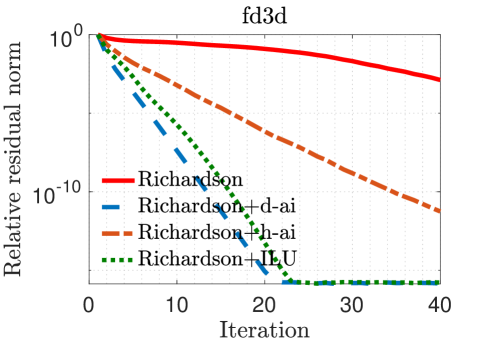
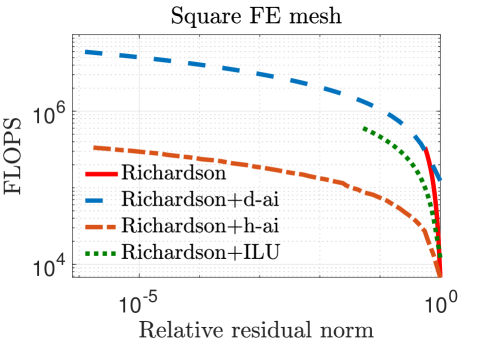
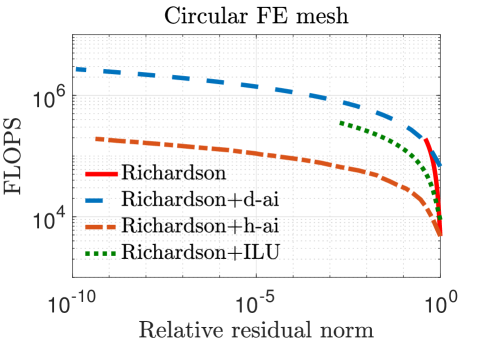
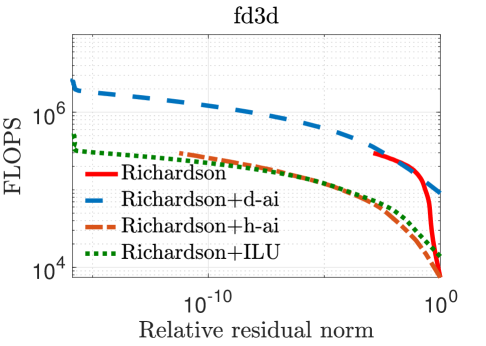
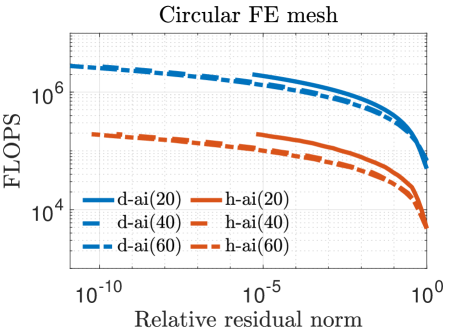
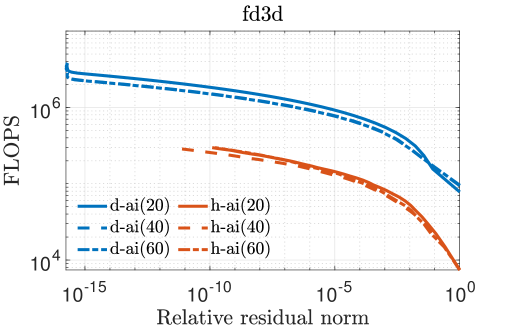
In our experiments, we mainly compare the following iterative solvers: () Richardson iterations without preconditioning; () Richardson iterations with approximate inverse preconditioning applied in the IEEE 754 standard (denoted by “Richardson+d-ai”); and () Richardson iterations with approximate inverse preconditioning applied through simulated analog hardware (denoted by “Richardson+h-ai”). We observe from the results in Table II that standard Richardson iterations fail to converge within iterations for all three test problems, but converge rapidly with approximate inverse preconditioning. This is not surprising since the spectral radius of the matrix , i.e., , is very close to one in all cases. The convergence behavior of the two preconditioned variants is almost identical for the FE matrices, but hybrid preconditioned Richardson iteration requires more than twice the number iterations compared to the digital variant for the FD matrix. Overall, the hybrid preconditioned Richardson requires to fewer digital FLOPs compared to the purely digital version.
Figure 3 plots the relative residual norm after each Richardson iteration both without preconditioning and with the various preconditioners considered in this paper. As expected, hybrid preconditioning requires more iterations; however, this trade-off is highly beneficial because analog hardware allows for a rapid application of the preconditioner. This is evident in Figure 4 which shows that, on an average, hybrid preconditioning requires substantially fewer digital FLOPs to converge. For reference, we have also included Richardson iterations with an ILU(0) preconditioner [1] applied in the IEEE 754 standard.
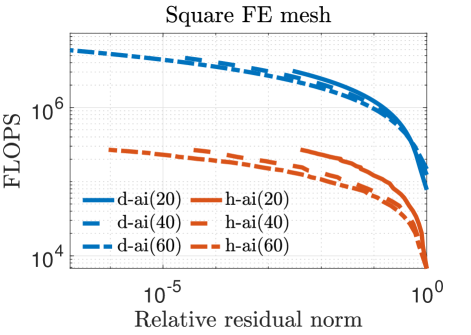
Figure 5 plots the number of digital FLOPs versus the relative residual norm for values of , , and . A denser preconditioner speeds up the convergence rate at the cost of additional FLOPs per iteration in the digital implementation. For the square FE mesh, the hybrid implementation yields a greater improvement in FLOPs compared to its digital counterpart as the preconditioner is made denser because the time to apply on the analog device does not increase with nnz(). However, this trend is not observed for the other matrices and diminishes with increasing preconditioner density because the analog noises limit the accuracy of the MVM operation even if is highly accurate. As a result, the number of iterations does not always decline as nnz() increases.
Figures 3–5 show that Richardson iterations preconditioned with approximate inverses on the hybrid architecture outperform preconditioned Richardson iterations on the digital architecture by greater margins as the condition number (listed in Table II) of grows larger. Figure 5 also shows that our method can use denser preconditioners more effectively for matrices with higher condition numbers. These trends bode well for the potential use of our proposed preconditioning framework on a hybrid architecture in real-life problems that are likely to be larger and more ill-conditioned.
Figure 6 plots the impact of varying the fill-in factor for the FE square matrix on the time required by the key operations of Algorithm 1, such as constructing , writing it to the analog crossbar, performing an MVM with it in both the digital and hybrid settings, and performing a digital MVM with the coefficient matrix . The sequential time for the construction of the preconditioner in MATLAB is reported for academic purposes only; in practice, this step would utilize compiler optimizations and the ample availability of parallelism [34, 35] to finish much faster. The time for writing is roughly equivalent to that of performing seven digital MVMs with it, implying that the benefits of the hybrid architecture start accruing after seven iterations. Note that the size of this matrix is only . The current state of analog hardware technology is capable of realizing crossbar arrays of sizes up to [16]. These can accommodate much larger preconditoner matrices for which the analog MVM times would still be similar to those in Figure 6 and the write times will increase as , but the digital MVM times would be much higher, growing as .
Some hardware parameters, such as the number of DAC and ADC bits, can have a profound impact on the time and energy consumption of the analog device, and therefore on its overall performance. We vary the number of DAC and ADC bits and plot the results in Figure 7 to justify our choice of 7 DAC bits and 9 ADC bits. Fewer bits tend to lead to divergence, while more bits result in increased time and energy consumption with little or no improvement in convergence, as the accuracy of the analog computations is limited by other sources of noise.
V Concluding remarks
With the slowing of Moore’s law [42] for digital microprocessors, there has been considerable interest in exploring alternatives, such as analog computing, for speeding up computationally expensive kernels. While simple analog crossbar arrays have been shown to be effective in many applications involving dense matrices, it has been challenging to address sparse matrix problems, such as solving sparse linear systems, because they do not naturally map to dense crossbar arrays and generally have a low tolerance for the stochastic errors pervasive in analog computing. This paper proposes, analyzes, and experimentally evaluates a preconditioning framework that exploits inexpensive MVM on analog arrays to substantially reduce the time and energy required for solving an important practical class of sparse linear systems. These and similar efforts are critical for meeting the continually growing computational demands of various applications of sparse solvers and for preparing these solvers for the fast but energy-constrained embedded and exascale [27] systems of the future.
Acknowledgments
We would like to thank Tayfun Gokmen, Malte Rasch, and Shashanka Ubaru for helpful discussions and input that substantially contributed to the content of this paper.
References
- [1] Y. Saad, Iterative methods for sparse linear systems. SIAM, 2003.
- [2] D. Bertaccini and S. Filippone, “Sparse approximate inverse preconditioners on high performance GPU platforms,” Computers & Mathematics with Applications, vol. 71, no. 3, pp. 693–711, 2016.
- [3] A. Abdelfattah, H. Anzt, E. G. Boman, E. Carson, T. Cojean, J. Dongarra, M. Gates, T. Grützmacher, N. J. Higham, S. Li et al., “A survey of numerical methods utilizing mixed precision arithmetic,” arXiv preprint arXiv:2007.06674, 2020.
- [4] K. L. Oo and A. Vogel, “Accelerating geometric multigrid preconditioning with half-precision arithmetic on GPUs,” arXiv preprint arXiv:2007.07539, 2020.
- [5] M. Baboulin, A. Buttari, J. Dongarra, J. Kurzak, J. Langou, J. Langou, P. Luszczek, and S. Tomov, “Accelerating scientific computations with mixed precision algorithms,” Computer Physics Communications, vol. 180, no. 12, pp. 2526–2533, 2009.
- [6] A. Haidar, S. Tomov, J. Dongarra, and N. J. Higham, “Harnessing GPU tensor cores for fast fp16 arithmetic to speed up mixed-precision iterative refinement solvers,” in SC18: Int. Conf. for High Perf. Computing, Networking, Storage and Analysis. IEEE, 2018, pp. 603–613.
- [7] H. Anzt, M. Gates, J. Dongarra, M. Kreutzer, G. Wellein, and M. Köhler, “Preconditioned krylov solvers on GPUs,” Parallel Computing, vol. 68, pp. 32–44, 2017.
- [8] A. Haidar, H. Bayraktar, S. Tomov, J. Dongarra, and N. J. Higham, “Mixed-precision iterative refinement using tensor cores on GPUs to accelerate solution of linear systems,” Proceedings of the Royal Society A, vol. 476, no. 2243, p. 20200110, 2020.
- [9] M. Hu et al., “Dot-product engine for neuromorphic computing: Programming 1t1m crossbar to accelerate matrix-vector multiplication,” in 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC). IEEE, 2016, pp. 1–6.
- [10] L. Xia, P. Gu, B. Li, T. Tang, X. Yin, W. Huangfu, S. Yu, Y. Cao, Y. Wang, and H. Yang, “Technological exploration of rram crossbar array for matrix-vector multiplication,” Journal of Computer Science and Technology, vol. 31, no. 1, pp. 3–19, 2016.
- [11] A. Sebastian, M. L. G. Le Gallo, R. Khaddam-Aljameh, and E. Eleftheriou, “Memory devices and applications for in-memory computing,” Nature Nanotechnology, vol. 15, pp. 529–544, 2020.
- [12] W. Haensch, T. Gokmen, and R. Puri, “The next generation of deep learning hardware: Analog computing,” Proceedings of the IEEE, vol. 107, pp. 108–122, 2019.
- [13] M. J. Rasch, T. Gokmen, M. Rigotti, and W. Haensch, “RAPA-ConvNets: Modified convolutional networks for accelerated training on architectures with analog arrays,” Frontiers in Neuroscience, vol. 13, p. 753, 2019.
- [14] S. Ambrogio et al., “Equivalent-accuracy accelerated neural-network training using analogue memory,” Nature, vol. 558, pp. 60–67, 2018.
- [15] A. Fumarola, P. Narayanan, L. L. Sanches, S. Sidler, J. Jang, and K. Moon, “Accelerating machine learning with non-volatile memory: exploring device and circuit tradeoffs,” in IEEE International Conference on Rebooting Computing (ICRC), 2016, pp. 1–8.
- [16] T. Gokmen and Y. Vlasov, “Acceleration of deep neural network training with resistive cross-point devices: Design considerations,” Frontiers in Neuroscience, vol. 10, 2016.
- [17] G. W. Burr, R. M. Shelby, A. Sebastian, S. Kim, and S. Sidler, “Neuromorphic computing using non-volatile memory,” Advances in Physics, vol. 2, pp. 89–124, 2016.
- [18] M. N. Bojnordi and E. Ipek, “Memristive Boltzmann machine: A hardware accelerator for combined optimization and deep learning,” in Int. Symp. on High Performance Computer Architecture (HPCA), 2016.
- [19] A. Shafice et al., “ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,” in International Symposium on Computer Architecture (ISCA), 2016.
- [20] B. Feinberg, R. Wong, T. P. Xiao, C. H. Bennett, J. N. Rohan, E. G. Boman, M. J. Marinella, S. Agarwal, and E. Ipek, “An analog preconditioner for solving linear systems,” in 2021 IEEE Int. Symp. on High-Performance Computer Architecture (HPCA). IEEE, pp. 761–774.
- [21] B. Feinberg, U. K. R. Vengalam, N. Whitehair, S. Wang, and E. Ipek, “Enabling scientific computing on memristive accelerators,” in International Symposium on Computer Architecture (ISCA), 2018, pp. 367–382.
- [22] M. A. Zidan, Y. Jeong, J. Lee, B. Chen, S. Huang, M. J. Kushner, and W. D. Lu, “A general memristor-based partial differential equation solver,” Nature Electronics, vol. 1, no. 7, pp. 411–420, 2018.
- [23] Z. Sun, G. Pedretti, E. Ambrosi, A. Bricalli, W. Wang, and D. Ielmini, “Solving matrix equations in one step with cross-point resistive arrays,” Proceedings of the National Academy of Sciences, vol. 116, no. 10, pp. 4123–4128, 2019.
- [24] I. Richter, K. Pas, X. Guo, R. Patel, J. Liu, E. Ipek, and E. G. Friedman, “Memristive accelerator for extreme scale linear solvers,” in Government Microcircuit Applications & Critical Technology Conference (GOMACTech), 2015.
- [25] M. Le Gallo, A. Sebastian, R. Mathis, M. Manica, H. Giefers, T. Tuma, C. Bekas, A. Curioni, and E. Eleftheriou, “Mixed-precision in-memory computing,” Nature Electronics, vol. 1, no. 4, pp. 246–253, 2018.
- [26] Z. Zhu, A. B. Klein, G. Li, and S. Pang, “Fixed-point iterative linear inverse solver with extended precision,” arXiv preprint arXiv:2105.02106, 2021.
- [27] H. Antz et al., “Preparing sparse solvers for exascale computing,” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 378, no. 20190053, 2020.
- [28] J. Brown, M. G. Knepley, D. A. May, L. C. McInnes, and B. Smith, “Composable linear solvers for multiphysics,” in 11th International Symposium on Parallel and Distributed Computing, 2012, pp. 55–62.
- [29] L. C. McInnes, B. Smith, H. Zhang, and R. T. Mills, “Hierarchical and nested Krylov methods for extreme-scale computing,” Parallel Computing, vol. 40, no. 1, pp. 17–31, 2014.
- [30] L. Chua, “Memristor-the missing circuit element,” IEEE Transactions on Circuit Theory, vol. 18, no. 5, pp. 507–519, 1971.
- [31] M. Benzi and G. H. Golub, “Bounds for the entries of matrix functions with applications to preconditioning,” BIT Numerical Mathematics, vol. 39, no. 3, pp. 417–438, 1999.
- [32] S. Demko, W. F. Moss, and P. W. Smith, “Decay rates for inverses of band matrices,” Mathematics of computation, vol. 43, no. 168, pp. 491–499, 1984.
- [33] M. Benzi and M. Tuma, “A comparative study of sparse approximate inverse preconditioners,” Applied Numerical Mathematics, vol. 30, no. 2-3, pp. 305–340, 1999.
- [34] E. Chow, “Parallel implementation and practical use of sparse approximate inverse preconditioners with a priori sparsity patterns,” The International Journal of High Performance Computing Applications, vol. 15, no. 1, pp. 56–74, 2001.
- [35] M. J. Grote and T. Huckle, “Parallel preconditioning with sparse approximate inverses,” SIAM Journal on Scientific Computing, vol. 18, no. 3, pp. 838–853, 1997.
- [36] Y. Saad and M. H. Schultz, “GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems,” SIAM J. on scientific and statistical computing, vol. 7, no. 3, pp. 856–869, 1986.
- [37] Y. Saad, “A flexible inner-outer preconditioned GMRES algorithm,” SIAM J. on Scientific Computing, vol. 14, no. 2, pp. 461–469, 1993.
- [38] L. F. Richardson, “IX. The approximate arithmetical solution by finite differences of physical problems involving differential equations, with an application to the stresses in a masonry dam,” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 210, no. 459-470, pp. 307–357, 1911.
- [39] C. L. Lawson, R. J. Hanson, D. R. Kincaid, and F. T. Krogh, “Basic Linear Algebra Subprograms for Fortran usage,” ACM Transactions on Mathematical Software, vol. 5, no. 3, pp. 308–323, 1979.
- [40] C. Moler, “Iterative refinement in floating point,” Annals of the ACM, vol. 14, no. 2, pp. 316–321, 1967.
- [41] M. J. Rasch, D. Moreda, T. Gokmen, M. L. Gallo, F. Carta, C. Goldberg, K. E. Maghraoui, A. Sebastian, and V. Narayanan, “A flexible and fast pytorch toolkit for simulating training and inference on analog crossbar arrays,” 2021.
- [42] J. Shalf, “The future of computing beyond Moore’s law,” Phil. Trans. R. Soc. A., vol. 378, no. 20190061, 2020.
- [43] J. Wilkinson, Rounding Errors in Algebraic Processes. Prentice Hall, 1963.
- [44] J. Merikoski and R. Kumar, “Lower bounds for the spectral norm,” Journal of Inequalities in Pure and Applied Mathematics, vol. 6, no. 4, 2005, article 124.
- [45] P. Billingsley, Probability and Measure, 3rd ed. John Wiley & Sons, 1995.
Appendix A Error and Convergence Analysis
A-A Error in MVM Due to Device Noise
Performing the MVM operation with a matrix and vector on an analog crossbar array involves multiple sources of nondeterministic noise so that the output is equivalent to a low precision approximation of . Writing to the crossbar array incurs multiplicative and additive write noises and , respectively, and the actual conductance values at the crosspoints of the array are given by , where denotes element-wise multiplication. Similarly, digital-to-analog conversion (DAC) of the vector into voltage pulses suffers from multiplicative and additive input noises and , respectively. As a result, the matrix is effectively multiplied by a perturbed version of given by , where is a vector of all ones.
A characteristic equation to describe the output of an analog MVM is given by
| (5) |
where and denote the multiplicative and additive components of the output noise, respectively, which reflects the inherent inexactness of the multiplication based on circuit laws and current integration, as well as the loss of precision in the ADC conversion of the result vector.
Equation (5) can be rearranged as
or more concisely
| (6) |
where is the overall effective additive noise and captures the lower order noise terms. The th entry of in Equation (6) is given by
and upon ignoring the products of components of , and , we then have
| (7) |
Rewriting Equation (7) in matrix form yields
where denotes outer product, or more concisely
| (8) |
where the nondeterministic error matrix is given by
| (9) |
A-B Wilkinson and Moler’s Deterministic Analysis of Iterative Refinement from a Digital Perspective
The iterative refinement (IR) scheme, proposed by Wilkinson in 1948 [43], is often used to reduce errors in solving linear systems , especially when the matrix is ill-conditioned. This IR approach consists of the use of an inaccurate solver for the most expensive operations, namely solving the residual equation (with time complexity ), and then updating the estimate and computing the next residual (both with time complexity ) using forms of higher precision arithmetic. Error bounds for the IR algorithm were subsequently analyzed by Moler in 1967 [40]. In particular, it was shown by Wilkinson and Moler that if the condition number of the matrix is not too large and the residual is computed at double the working precision, then the IR algorithm will converge to the true solution within working precision.
More precisely, the IR algorithm comprises the following steps:
-
1.
Solve ;
-
2.
Compute residual ;
-
3.
Solve using a basic (inaccurate computation) method;
-
4.
Update ;
-
5.
Repeat until stopping criteria satisfied.
Although there are many variants of the above IR algorithm, our primary focus here is on the use of analog hardware to compute the solution of the linear system in step , rendering the benefits of greater efficiency and/or lower power consumption, but at the expense of lower and noisier precision. All other steps in the above algorithm are assumed to be computed on a digital computer at some form of higher precision.
We end this brief summary of previous work by providing a high-level overview of the original error and convergence analysis due to Moler [40]. Consider the IR algorithm and focus on the following three steps for each iteration :
-
1.
;
-
2.
;
-
3.
.
Here, , and are corrections that allow for the above equations to hold exactly, since the actual computations are performed on hardware that is inexact. For now, to simplify the exposition of our analysis, let us assume , i.e., steps and are computed with perfect precision; positive instances of these precision constants can be readily incorporated subsequently in our analysis.
Suppose it can be shown that , and hence the matrices are nonsingular. Furthermore, we have
which implies
| (10) |
Then, letting be the true solution, it is possible to algebraically establish that
from which it follows
This therefore leads to a contraction when is sufficiently small (in particular, ), thus guaranteeing convergence with a rate corresponding to the above equation.
A-C Analysis of Iterative Refinement from an Analog Perspective
Adapting the above error and convergence analysis due to Moler [40] for our objectives herein, we start by modeling the writing of the matrix into the analog hardware before beginning the -step iterative process. This results in a one-time write error that we model as
| (11) |
where is a matrix whose elements are independent and identically distributed (i.i.d.) according to a general distribution (not necessarily Gaussian) having finite mean and finite variance . For the analog devices under consideration [41], .
Next, we consider step of the -step iterative process in Appendix A-B as being the only one performed on inaccurate (analog) hardware. We want to model in a general fashion the overall noise that is incurred when solving the linear system in step of each iteration . To this end, let us assume that the computation of in step of iteration satisfies
| (12) |
where are matrices whose elements are i.i.d. according to a general distribution (not necessarily Gaussian) having finite mean and finite variance .
We seek to establish bounds on . Even though all matrix norms are equivalent in a topological sense, it is convenient and prudent for our purposes to choose matrix norms with which it is easy to work. Let us consider the norm , the Euclidean distance operator norm and the Frobenius matrix norm , taking advantage of the known bounds
where are the row sums of ; refer to [44] for this lower bound. Focusing on the norm being either or , we then derive
| (13) |
where the first inequality follows from the above matrix-norm upper bound, the first equality is by definition of the Frobenius matrix norm, the second inequality is due to Jensen’s inequality, the second equality is a basic property of the expectation operator, the third equality is due to the i.i.d. assumption, the fourth equality is by definition of the second moment, the th element of the matrix is denoted by , and expectation is with respect to .
Let us next consider the variance of , more specifically . To this end, we focus initially on the second moment and follow along the lines of the derivation of Equation (13) above, to obtain
| (14) |
where expectation is again with respect to . Now we turn to a lower bound on , for which we exploit the above matrix-norm lower bound to conclude
Then we derive for the numerator on the right hand side
from which we obtain
| (15) |
Upon combining Equations (14) and (15), this yields
| (16) |
Hence, under the assumption that the elements of are i.i.d. random variables with general distribution , it follows from the above analysis that
| (17) |
Next we turn to complete the error and convergence analysis that covers the iterative process with per-iteration errors modeled via . From step of the original -step IR algorithm together with Equation (12), we have
Letting denote an upper bound on , together with Equation (17) and recalling that and are independent by definition, we then derive
| (18) |
and
| (19) |
which also renders
Recall from the original analysis above due to Moler that
| (20) |
from which we have by definition for our purposes
where denotes the solution to . We further obtain from Equation (20)
which then leads to
| (21) | ||||
| (22) |
where the second inequality follows from the triangle inequality and the third inequality is by definition of the logarithm applied to both sides. Let denote the asymptotic limit for , namely as . Then, taking the limit as , it follows from the above that
| (23) |
where the second inequality is due to Equation (10) and is a finite constant.
Taking the expectation of both sides of Equation (A-C) yields
| (24) |
Consistent with the original analysis of Moler, we assume that the support for is between and , i.e., the distribution of is such that . Further assume that the distribution of is symmetric around its mean with bounded away from . Then, due to the symmetry of for , it follows that the second term in the expectation of Equation (A-C) is greater than the first term, and therefore the expectation is negative and the summation tends to since . To see this, note that is monotonically increasing in and, for , . Let be the probability distribution of the random variable that is symmetric around its mean . Then, and is in fact bounded away from . We therefore have established convergence in expectation of the iterative process under the assumptions above which implies that .
Lastly, we establish a related result that exploits an important characteristic of analog computing devices [41], namely that the random variables have different means whose average is asymptotically equal to zero; i.e., in the limit as . Consider the sequence of independent random variables and assume that all of the random variables have the same variance, i.e., . Define and thus . Let us now consider
| (25) |
Assuming that at a rate faster than and taking the limit as on both sides of Equation (A-C), we obtain
| (26) |
Further suppose that, for some , the following (Lyapunov) condition is satisfied:
Then, from the Lyapunov central limit theorem [45] and Equation (26), we have that the sum of converges in distribution to a standard normal random variable as goes to infinity, namely
| (27) |
where denotes the standard normal distribution.
We have therefore established convergence in expectation of the iterative refinement process such that , as long as the distribution of is symmetric around its mean with taking values in and . From Equation (18), this implies the requirement that
| (28) |
to ensure convergence in expectation of the iterative process. Our asymptotic result in Equation (27) suggests that we can drop as part of the overall iterative process, and thus this requirement can be further simplified over many iterations as
| (29) |
It is important to note, however, that Equations (28) and (29) only represent upper bounds on the parameters associated with , which can be (and are likely to be) quite loose. Mathematically speaking, we really only need or infinitely often. In practice, we simply need to have hold a sufficiently large number of times such that for large .
A-D Analysis of Preconditioned Richardson Iteration from an Analog Perrspective
We next apply our error and convergence analysis above to the case of preconditioned Richardson iteration. In particular, analogous to the analysis in Appendix A-C for , we have that as long as . With defined as in Section III-D to be
we then seek to establish bounds on such that
Analogous again to the analysis in Appendix A-C for , we assume to be a matrix whose elements are i.i.d. according to a general distribution (not necessarily Gaussian) having finite mean and finite variance . Even though all matrix norms are equivalent in a topological sense, it is convenient and prudent for our purposes to choose matrix norms with which it is easy to work. As in Appendix A-C, we shall continue to consider the norm , the Euclidean distance operator norm and the Frobenius matrix norm .
Focusing on the norm being either or , we follow our derivation above that leads to Equation (13) and obtain
| (30) |
Similarly, from our analysis above leading to Equations (14) and (16), we respectively have
| (31) |
and
| (32) |
Our asymptotic result in Equation (27) applied to suggests that we can drop as part of the overall preconditioned Richardson iteration process, and thus Equations (30) and (31) can be further simplified over many iterations as
| (33) |
Summing everything together, and assuming that write errors are the dominant source of noise, we can guarantee from Equation (30) that the hybrid preconditioned Richardson iteration process will make progress in expectation during each iteration as long as
whereas Equation (33) suggests that such progress will be guaranteed in expectation over many iterations as long as
Observe that, in both cases, the upper bound becomes larger when: () ; () the spectral norm of the matrix becomes smaller; and/or () the size of matrix decreases. The first component () is the only part that we can control by constructing a more accurate approximate inverse, while the second component () and third component () depend on the given matrix . Hence, depending upon the properties of the problem and the quality of the approximate inverse, we have from the above analysis an understanding of the suitability of the device properties.
At the same time, it is important to note that Equations (30) – (33) only represent upper bounds on the parameters associated with , which can be (and are likely to be) quite loose. Mathematically speaking, we really only need infinitely often, and thus in practice we simply need to have hold a sufficiently large number of times to realize convergence.
Similarly, for the bound on under the condition , we have from the above analysis that a sufficient condition for convergence in expectation is given by