Source Printer Identification using Printer Specific Pooling of Letter Descriptors
Abstract
The digital revolution has replaced the use of printed documents with their digital counterparts. However, many applications require the use of both due to several factors, including challenges of digital security, installation costs, ease of use, and lack of digital expertise. Technological developments in the digital domain have also resulted in the easy availability of high-quality scanners, printers, and image editing software at lower prices. Miscreants leverage such technology to develop forged documents that may go undetected in vast volumes of printed documents. These developments mandate the research on creating fast and accurate digital systems for source printer identification of printed documents. We extensively analyze and propose a printer-specific pooling that improves the performance of printer-specific local texture descriptor on two datasets. The proposed pooling performs well using a simple correlation-based prediction instead of a complex machine learning-based classifier achieving improved performance under cross-font scenarios. The proposed system achieves an average classification accuracy of 93.5%, 94.3%, and 60.3% on documents printed in Arial, Times New Roman, and Comic Sans font types respectively, when documents printed in only Cambria font are available for training.
keywords:
Printer Classification , Printer Forensics, Source Identification, Multimedia Forensics, Local Binary Pattern , Local Texture Descriptor1 Introduction
Printed documents have been used traditionally for record-keeping, certification, and communication purposes. The digital revolution has propelled the use of digital documents in place of printed documents. However, many critical applications use printed documents like financial dealings, judicial process, administrative record keeping and communication, and certifications. The frameworks for many such applications require a combination of printed documents, scanned versions, and digital documents. This co-existence of printed and digital documents results from multiple reasons, including ease of use, operating cost, lack of digital expertise, and open digital security challenges. Technological developments have allowed the easy availability of good quality printers, scanners, and image-editing software. These are routinely misused by potential miscreants to create forged documents. The vast volume of printed documents and the evolving forging technology makes it challenging to analyze and detect forged documents and warrants the use of fast and accurate digital systems to analyze the authenticity of printed documents. The source printer’s information can provide important clues for forensic analysis of printed documents [1, 2, 3, 4].
Traditional methods use chemical techniques to investigate the chemical composition of toner spread on a paper. Chemical processes use spectroscopy [5] and x-ray [6] to discover a connection in seized documents. These methods require laboratory equipment and an expert to examine the samples. Also, these techniques require a significant amount of time and can damage the printed document in question. In sharp contrast, digital methods convert the printed documents into their digital counterpart using a reference scanner. Source printer identification with digital techniques has been gaining much attention. All the analysis is carried out in the digital domain; thus, it is faster and automatic. Two major digital approaches for source printer identification are discussed in the literature, namely, extrinsic (active) and intrinsic (passive) [1]. An extrinsic signature approach is an active approach in which a user embeds an extrinsic signal in the printed document before or during the printing process. However, they require active access to the printer, and a sophisticated signal embedding mechanism needs to be integrated with the printer [7]. Such methods are complicated and costly for the large volume of text documents printed by general-purpose consumer-grade printers. On the contrary, passive approaches rely on visually imperceptible printer artifacts induced intrinsically during the printing process [8].
In this paper, we work on source printer identification for text documents using an intrinsically induced printer signature. The existing methods process all the printed letters uniformly during the computation of the printer signature model for source printer identification in a close-set scenario (i.e., the user needs to know the set of all possible printers in advance). Our proposed method is based on the hypothesis that the printed letters exhibit location-specific variations due to the electrophotographic printing process’s characteristics [9]. We introduced the printer-specific local texture descriptor (PSLTD) in [4], a state-of-the-art handcrafted method for identifying the source printer using scanned images of printed documents. Most existing methods (including deep learning-based [2, 10]) do not perform well when the font type of letters in printed documents under test is not available in training. We term this as the cross-font scenario [4]. PSLTD outperforms all existing methods under a cross-font scenario.
We analyze the variation of PSLTD-based printer signature concerning the location of printed letters across the document. We show that the distribution of printer artifacts correlates strongly with printed letters’ location on the document (Figures 4). We introduce a printer-specific pooling technique that allows the prediction of source printer. We further improve the performance of PSLTD under a cross-font scenario using the proposed pooling technique. We show the efficacy of the proposed method using a correlation technique (Figure 2). The significant highlights of this work are as follows:
-
1.
We provide an extensive analysis of printer signature variations across a printed document.
-
2.
We introduce a location-based pooling technique that improves the performance of PSLTD for source printer identification.
-
3.
We show the efficacy of the proposed pooling technique using a correlation-based prediction method instead of a complex classifier, thus paving classifier-independent prediction.
-
4.
The proposed method performs better than state-of-the-art methods under the cross-font scenario achieving an average classification accuracy of 93.5%, 94.3%, and 60.3% on documents printed in Arial, Times New Roman, and Comic Sans font types when documents printed in only Cambria font are available for training.
The paper consists of the following sections. Section 2 briefly describes the related literature of intrinsic signature-based techniques for classifying the source printer of printed text documents. The details of our proposed pooling have been specified in Section 4. An extensive set of experiments are used to examine the effectiveness of the proposed method. The description and results of the proposed approach have been discussed in Section 5. Finally, we draw out conclusions from this work and the directions for future work in Section 6.
2 Related Works
The problem of Source printer classification has gained much attention in the past decade [1]. This work is based on an intrinsic signature, so we focus only on them. Our method also extracts printer signature from images of printed letters, so we only discuss methods related to text documents. One of the early reliable printer signatures was based on the banding phenomenon, i.e., the appearance of light and dark lines perpendicular to the direction of the paper movement inside the printer [1]. It is a promising approach but requires documents images scanned at a very high resolution (2400 dpi).
From banding, the researchers moved towards texture-based methods. These methods are suitable for documents scanned at lower resolutions (300-600 dpi). The texture patterns created by the distribution of intensity values observed in the scanned document image form the basis for these methods. These variations are visually imperceptible to human eyes at commonly used font sizes. Nevertheless, their zoomed versions depict texture variations. These methods follow the traditional pattern recognition pipeline in which features are extracted from letter images followed by learning a suitable classifier model. The learned model is capable of predicting the source printer labels for each letter image. The majority voting over all the predicted letter labels provides the prediction for the whole document under test. The early methods in this category were developed for a specific letter type like ‘e’, which is the most frequently occurring letter in the English language. The features include gray-level co-occurrence matrices (GLCM) [11], GLCM extended in multiple directions, and scales [12], convolutional texture gradient filter (CTGF) based on filtering textures with a specific gradient [12], a combination of the discrete wavelet transform (DWT) and GLCM based features [13], a combination of features obtained after applying a spatial filter, Wiener filter, and Gabor filter [14], and GLTrP-based features [3]. A recent method proposes a decision-fusion model-based approach for source printer classification [15]. All these methods extract features that learn a model for a specific letter type except [3], which introduces a single-classifier approach that learns a single model for all letter types printed on a document. The use of all letters increases training samples, thus lowering the requirement on the number of training documents and also increasing predicted labels for a document under test to achieve good performance.
Elkasrawi and Shafait [16] and the authors in [10] proposed noise residual-based features. Kee and Farid [17] followed a different strategy and proposed a method based on the estimation of a printer profile. They create the profile using a mean character image (of letter type ‘e’), and top p eigenvectors (obtained by PCA) is generated for each printer. The mean character image is obtained from all occurrences of letter ‘e’ extracted by convolving each character image with a user-selected reference character image. Zhou et al. [18] proposed an interesting text-independent approach to identify source printer based on a piece of patented equipment to scan fine textures on printed pages. More recent work proposed a method for source printer identification using document images acquired using a reference smartphone camera [19].
Two methods have also been proposed using convolutional neural networks (CNN) [2, 10]. They replace the task of handcrafted feature extraction with a model learned by letter images. Both methods work using specific letter types (‘e’ and ‘a’). None of the techniques discussed so far have been evaluated for cross-font scenario (i.e., font type of documents in testing is not available during training.) This is crucial as there are so many font types available, and it is increasingly difficult to expect that all font types are available during training. A recent method based on printer-specific local texture descriptor (PSLTD) [4] tries to address this challenge. A completely different category is characterized by geometric distortion-based approaches [20, 21], which rely on features from translational and rotational distortions of printed text relative to its reference soft copy [22, 23, 24]. A detailed literature review has been covered in [12, 2, 3].
3 Printer Specific Local Texture Descriptor
Printer specific local texture descriptor [4] is one of the most state-of-the-art digital systems for source identification of printed documents. The significant advantage of the PSLTD-based method is its performance under a cross-font scenario in which it outperforms existing methods by huge margins. PSLTD is a novel handcrafted feature extracted from each letter image capable of learning a single discriminative classifier model for all letter types. It belongs to the family of local binary patterns [25]. The design of our PSLTD emphasizes on preprocessing, thresholding and quantization, and encoding and regrouping stages of local binary feature extraction. It introduces a novel encoding and regrouping strategy built upon small linear structures of 3 1 shaped structures. The main hypothesis of PSLTD is that the distribution of such linear structures in small overlapping 3 3 patches can effectively encode and group local binary patterns. The method observes linear-shaped groups of pixels that exist around the center pixel at all possible orientations, i.e., horizontal (0∘), vertical (90∘), forward slant (45∘), and backward slant (135∘). Each 3 3 patch is assigned one or more line orientations based on intensity and gradient direction similarity. A pent-pattern vector is calculated from contiguous 3 3 sized patches, which is converted into five binary pattern vectors (BPVs). These BPVs from a local patch are mapped to multiple normalized pattern occurrence histograms based on uniformity [25] by encoding and regrouping them by their line orientations. The detailed mathematical description of PSLTD is beyond the scope of this paper. For more details, please refer [4]. The final PSLTD is a feature vector of 10502 dimensions comprising of four major components. The first group comprises normalized histograms obtained using intensity and gradient direction similarities as encoding and regrouping strategies. It is denoted by and is of 4425 dimensions. Similarly, the second and third groups are formed by considering only intensity similarity and only gradient direction similarity to encode and regroup the BPVs. They are denoted by and and are of 1475 and 4425 dimensions, respectively. The last component is formed by binary magnitude pattern vector (BMPV) denoted by and of 177 dimensions.
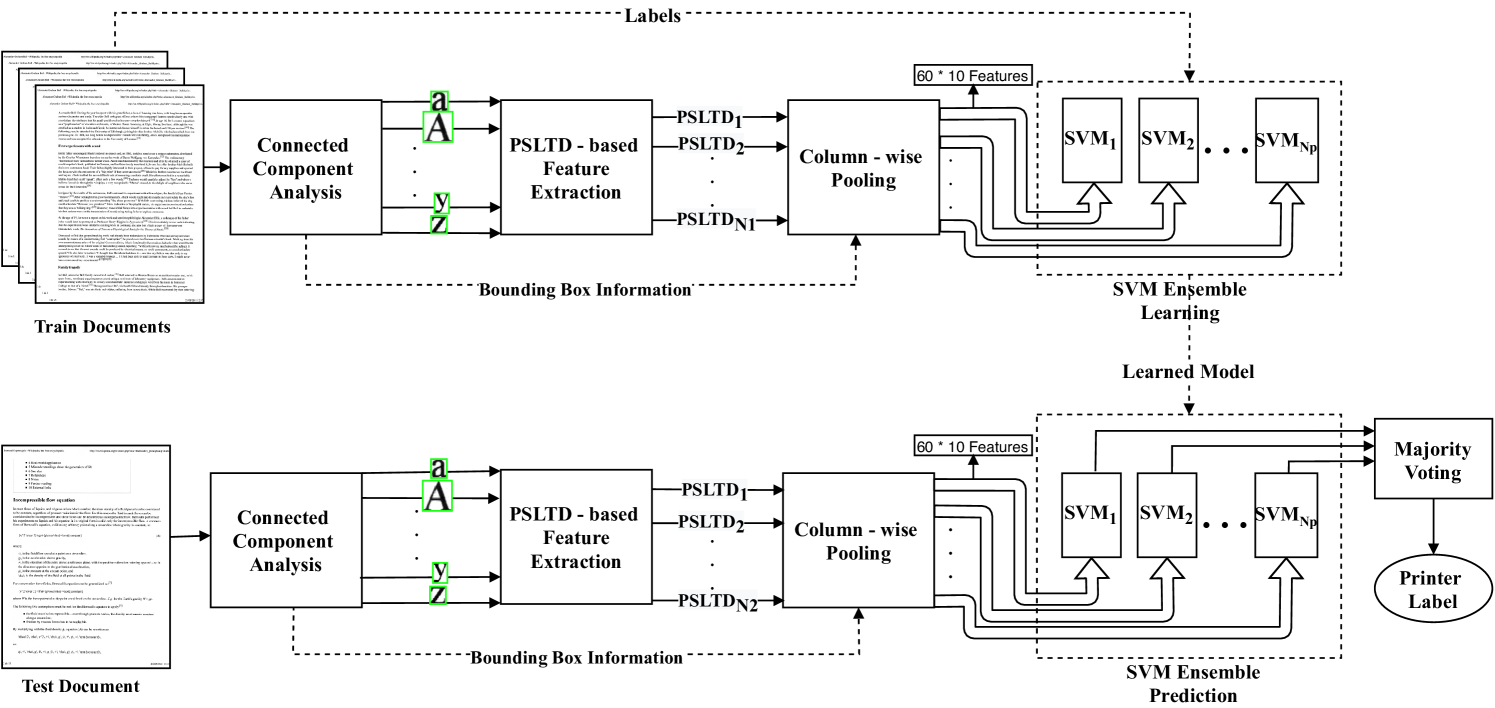
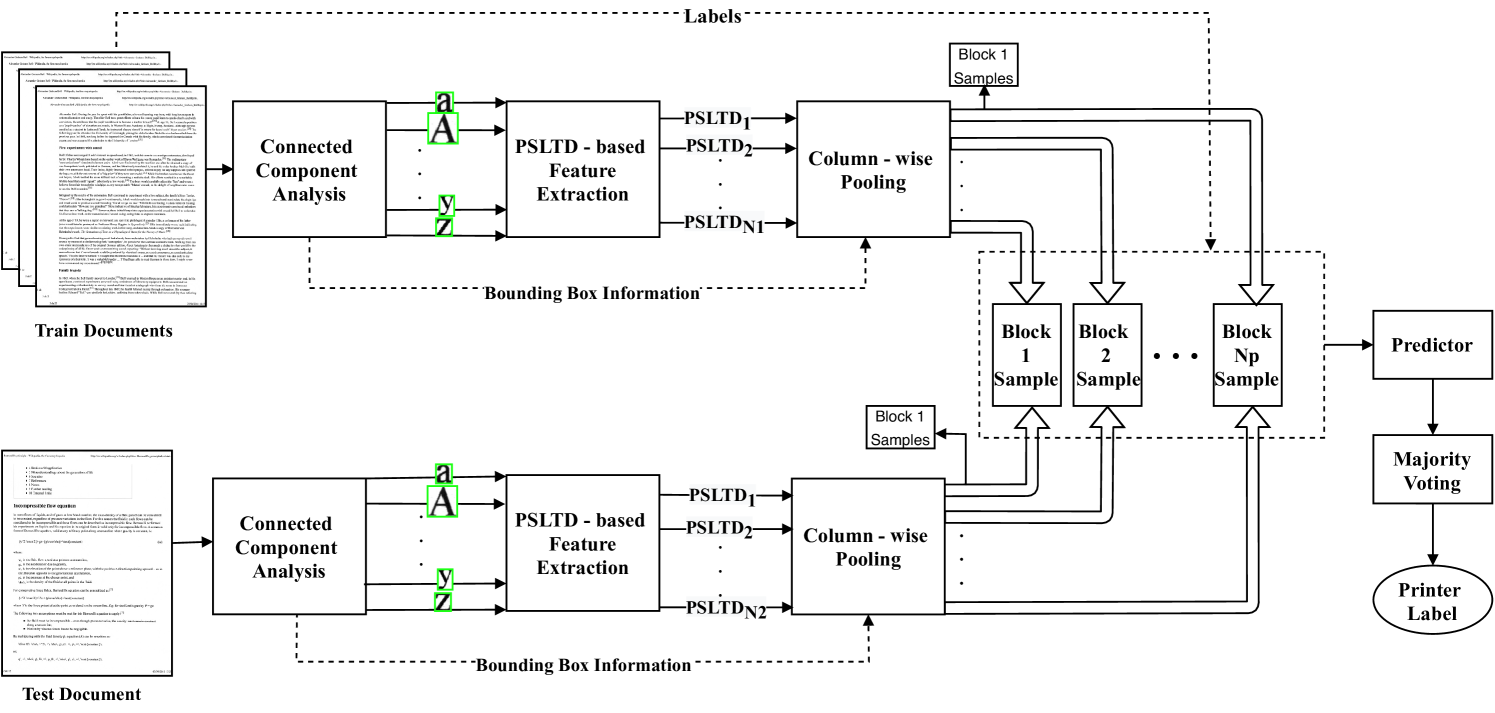
4 Proposed Method
In this work, we analyze the change in PSLTD-based printer signature [4] concerning the location of printed letters across the document. Based on the analysis, we introduce a printer-specific pooling technique that enhances source printer classification accuracy. We try two types of pooling-topology, i.e., columns and grids. Our proposed system’s input is document images of hard copy printed documents acquired using a reference scanner. The choice of reference scanner does not impact the system performance as long as it is kept constant for all the documents. The proposed system comprises of four significant steps: 1) connected component extraction, 2) PSLTD-based feature extraction, 3) and printer-specific pooling, and 4) classification. The general pipeline remains the same as in [4]. The novel step is our proposed pooling strategy, which enhances classification performance. Figure 1 depicts an overall pipeline of the proposed system using classifier-based prediction. For images scanned and saved using 16-bit intensity values (our dataset [3]), the proposed method also allows prediction of source printer using a correlation technique instead of a complex classifier-based prediction. as shown in Figure 2.
4.1 Connected Component Extraction
The first step is the extraction of individual letter images using connected component analysis from a printed document [3]. We binarize the document image followed by bounding box detection around each connected component following the procedure in [3]. Our interest lies in letter images. However, the system also finds some spurious components due to punctuation and noise. We selectively filter and remove bounding boxes that are too small or large in area and dimension. Such filtering parameters are empirically selected, depending on the text’s characteristics printed in the document. Specifically, for our dataset [3], we remove all components larger than four times the median of areas of all components or smaller than 0.5 times the median of areas of all components on a document. For the publicly available dataset [12], we also need to remove components with a width smaller than 15 and larger than 90 pixels and components of height smaller than 30 and larger than 100 pixels. This technique also removes the dots occurring in letter types ‘i’ and ‘j’. Our method performs this step on all train and test documents.
4.2 Feature Extraction
The feature extractor stage input is the letter images extracted using the bounding boxes obtained by connected components analysis. A PSLTD is extracted from each connected component (C), i.e., letter images of train and test document. However, instead of using the full length PSLTD, we show that its approximated smaller length version is sufficient. In particular, we use the and components. This approximation reduces the feature vector dimension to 4602 dimensions, reducing complexity and time to run so many experiments.
4.3 Printer Specific Pooling
The feature pooling step is usually inserted in modern visual classification techniques. Pooling aggregates local features into a static value via some pooling operation [26]. Our work’s primary hypothesis is that the artifacts induced by a printer are not identical for the entire printed document. It is a well-established observation that the occurrences of the same letter on a document printed in one go by a single printer may have different intensity distribution [10]. One possible reason for this observation is the complex electro-mechanical parts and circuitry involved in the printing process. The electrophotographic printing process follows a line by line approach from top to bottom [9]. The various steps in the printing process occur in the same fashion. So, we expect that the combined artifacts induced by all these steps will contain particular variation while moving perpendicular to the printer process direction (i.e., horizontal row-wise fashion for the document image of a printed document). In contrast, we expect that the variation along the process direction must be smaller. However, some other sources may also introduce variations that may not occur identically in a horizontal row-wise fashion. We analyze our hypothesis using two techniques, namely, column pooling and grid pooling.
4.3.1 Column Pooling
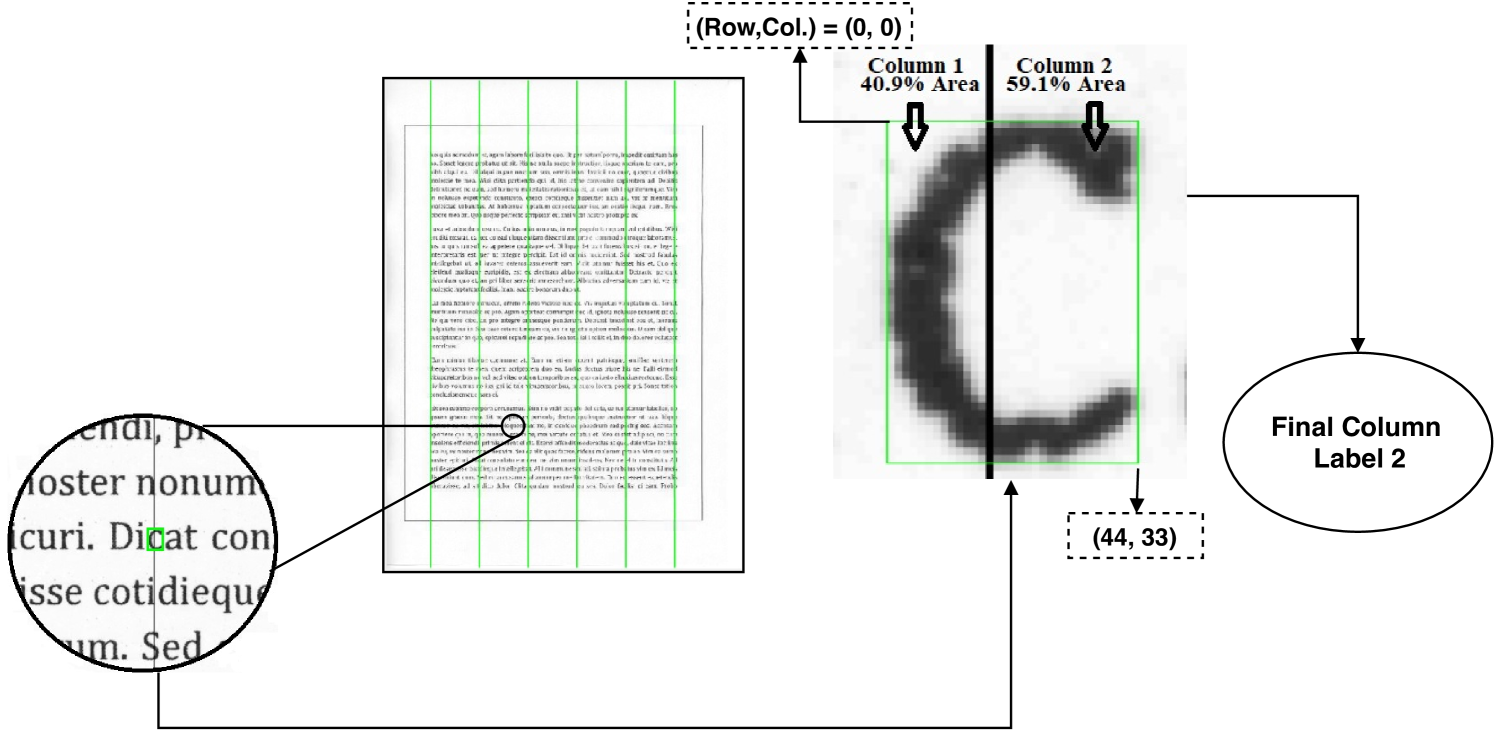
In this pooling strategy, we divide each printed document into a specific number of vertical columns (i.e., along the printer process direction) using some fixed rules. At first, we estimate the empty horizontal margin space on both the right and left sides of the printed text as it does not contain any printed letters. We estimate the start and endpoints of printed text using the minimum and maximum value of horizontal coordinates, i.e., row-coordinates. Specifically, for each document, we sort the bounding boxes of connected components based on their row-coordinates. Then, we calculate the median values of 1% of the smallest (i.e., left-most) and largest (i.e., right-most) coordinates of the bounding boxes of connected components. These two median values establish the start and endpoints of printed text denoted by and , respectively. We chose the median operator to avoid the effect of any spurious components that may still pass the filtering process of the connected component extraction stage (Section 4.1). The first column’s start is a 1-pixel wide boundary passing through and parallel to the document image’s vertical boundary. Similarly, the last column’s end is a 1-pixel wide boundary passing through and parallel to the document image’s vertical boundary. The printed text area’s start and endpoints allow the horizontal margin space to be removed as it does not contain any data of interest. The boundaries of all columns are equispaced and parallel to the vertical boundary of the document image. The spacing between them is termed as column-width (CW), which is defined as the ratio of horizontal space covered by printed text to the number of columns (Nc) as follows.
| (1) |
Here, denote the set of row coordinates of all connected components. and denote the functions to compute maximum and minimum values. Each column’s width depends upon the size of the document and side margins (i.e., left and right margin). For example, in our dataset [3], the average size of a scanned document image is 70192 5100 pixels with right and left margin of 887 and 638 pixels, respectively. So, for = 15, the width of each column would be 238 pixels. We assign a column to each connected component in a document image using the following rules.
-
1.
If a connected component (characterized by its bounding box) is printed entirely inside a column, it is assigned to that column.
-
2.
If a connected component occurs at the intersection of two columns, we compute the area covered by each column’s component. The column containing the larger area of that component is assigned to that component, as described in Figure 3.
-
3.
If a connected component occurs at the intersection of two columns with an equal area in both columns, we assign the left-most column number.
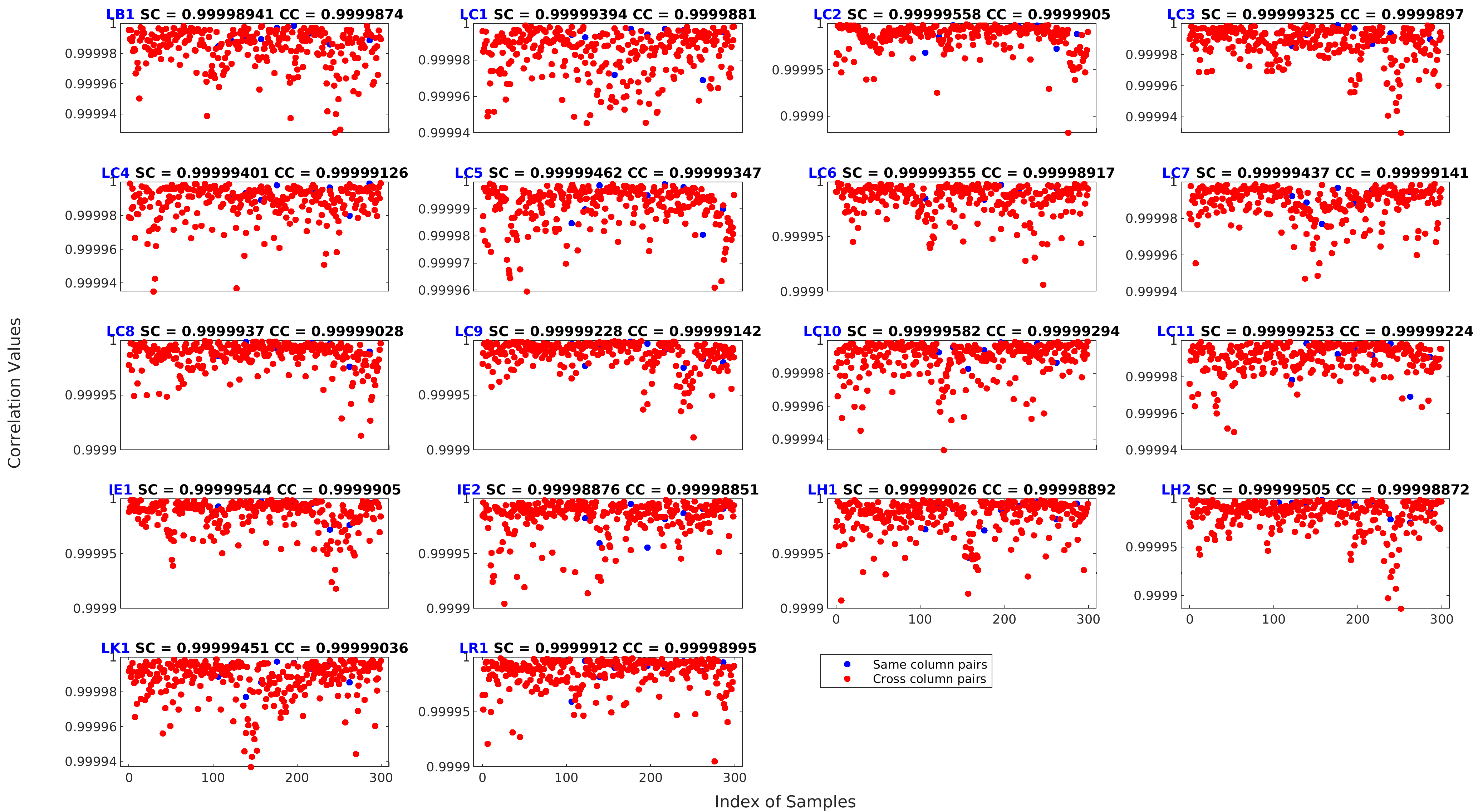
We pool the PSLTD of a group of Np letters assigned to a column by average pooling resulting in Np feature vectors. Here, Np is termed as the pooling parameter. The hypothesis behind post-extraction pooling (PoEP) is that it reduces the variance among PSLTDs extracted from the same page [4]. We expect PoEP to eliminate undesired noise as the pooled feature vectors represent all samples of a column. We visualize the comparison of correlation values obtained by the same column and cross column pairs in Figure 4. The median correlation values of the same column (SC) pairs are consistently higher than those for cross column (CC) pairs across all printers.
4.3.2 Grid Pooling
We further analyze the variation of our PSLTD printer signature across the document by dividing the document into Nw Nh grids. We hypothesize that the printer signature may also vary within each column. The general procedure of estimating the empty margin space and removing it remains the same as in column pooling. In addition to removing horizontal space, we also need to remove the space at the top and bottom of the printed text area (vertical margin) to determine the top-most grids’ horizontal boundary. Each grid has a 1-pixel wide boundary determined using the estimated printed text area. The dimensions of each grid (GW GH) are calculated from the horizontal and vertical space covered by the printed text area.
| (2) |
| (3) |
ccol denote the set of column coordinates of all connected components. For an 8 8 grid, each grid consists of approximately 665 446 pixels, and there are approximately 39 letters in one grid. We assign a grid to each connected component (i.e., printed letter) similar to column pooling. The PSLTDs of all letters in a grid are average pooled into a single feature vector.
4.4 Prediction
The prediction stage uses the pooled feature vectors to predict the source printer label corresponding to each feature vector. We hypothesize a similarity in the printer signature for each block, i.e., either a column or a grid. This hypothesis allows us to train and test letter samples separately for each block.
4.4.1 Using SVM
The PSLTDs of all letters in a block for all training documents are used to learn a single classifier model. For column pooling, we train Np SVM classifier models, one for each column. SVM is a standard classifier used by most existing methods for source printer identification [12, 3, 4]. During testing, the pth classifier model is used to predict the source printer labels of Np pooled feature vectors corresponding to a group of letters in the pth column (p {1,2,…,Np}) as shown in Figure 1. Finally, a majority vote on predicted labels of all groups of letters in the document provides the printer label for the printed document under test. Grid pooling uses a similar strategy. The major difference is that there is only a single pooled PSLTD for each block in a document with grid pooling.
4.4.2 Using Correlation
Pearson correlation coefficient, also referred to as Pearson’s r, is a statistic that estimate the linear correlation between two variables as follows [27].
| (4) |
Here, and represent the values of two variables. and denote the mean of all observed values in and , respectively. The value of Pearson’s r is between and , where a value of denotes a total positive linear correlation, is no linear correlation, and is a total negative linear correlation. We also analyze the effectiveness of features independent of a complex classifier. For this, we calculate the Pearson correlation coefficient (termed as correlation value from here on) between pooled PSLTDs from train and test documents for each block. A PSLTD pooled from a bock (i.e., a column or grid) in the test document is correlated with all PSLTDs pooled from that block in training documents printed by all the printers. Note that there is only a single pooled PSLTD for each block in a document for grid pooling. The printer corresponding to the largest correlation value between pooled PSLTDs in train and test is predicted as the pooled feature vector’s source printer label. We repeat this process for all pooled samples in the test. Similar to the SVM method, a majority vote is taken over all predicted printer labels corresponding to groups of letters to obtain the printer label for the document under test.
5 Experimental Evaluation
We evaluate The performance of the proposed method on two datasets: a publicly available dataset [12], termed as DB1 from here on and another dataset [3] containing documents printed by 18 printers in four font types (termed as DB2). We do an extensive parameter search for both column and grid pooling to analyze printer signature variations. We chose DB2 as our baseline dataset for this purpose as it allows analysis under cross font scenario. The dataset DB2 is a higher precision dataset consisting of 16-bit depth intensity values compared to 8-bit depth in DB1. So, we analyze the impact of the correlation-based prediction technique on the DB2 dataset. The full-length PSLTD is a feature vector of 10502 dimensions [4]. We also compare the full-length feature vector’s performance and the approximated feature vector of a smaller length. In the remainder of this paper, we use PSLTD4k and PSLTD10k to denote the methods based on approximated smaller length feature vector and the original full-length feature vector, respectively. Also, we use the general term PSLTD has been used to denote PSLTD4k to explain the experiments as we use PSLTD4k for all experiments except in Section 5.3. The performance of our technique is compared with hand-crafted methods including GLCM [11], multi-directional GLCM (GLCM_MD) [12], multi-directional multi-scale GLCM (GLCM_MD_MS) [12], [12] and CC-RS-LTrP-PoEP [3]. We also compare with data-driven methods of [2] denoted by CNN- and [10] denoted as CNN-.
| S. No. |
|
|
|
|
|
||||||||||
| 1 | LB1 | Brothers | DCP 7065DN | Laser | |||||||||||
| 2 | LC1 | Canon | D520 | Laser | |||||||||||
| 3 | LC2 | Canon | 16570 | Laser | |||||||||||
| 4 | LC3 | Canon | IR 5000 | Laser | |||||||||||
| 5 | LC4 | Canon | IR 7095 | Laser | |||||||||||
| 6 | LC5 | Canon | IR 8500 | Laser | |||||||||||
| 7 | LC6 | Canon | LBP 2900B | Laser | |||||||||||
| 8 | LC7 | Canon | LBP 5050 | Laser | |||||||||||
| 9 | LC8 | Canon | MF 4320 | Laser | |||||||||||
| 10 | LC9 | Canon | MF 4820d | Laser | |||||||||||
| 11 | LC10 | Canon | MF 4820d | Laser | |||||||||||
| 12 | LC11 | Canon | MF 4820d | Laser | |||||||||||
| 13 | IE1 | Epson | L800 | Inkjet | |||||||||||
| 14 | IE2 | Epson | EL 360 | Inkjet | |||||||||||
| 15 | LH1 | HP | 1020 | Laser | |||||||||||
| 16 | LH2 | HP | M1005 | Laser | |||||||||||
| 17 | LK1 | Konica Minolta | Bizhub 215 | Laser | |||||||||||
| 18 | LR1 | Ricoh | MP 5002 | Laser |
5.1 Dataset and Experimental Setup:
We used the publicly available dataset DB1 [12] and our dataset, DB2 [3], to evaluate our method’s performance. DB1 contains 1184 Wikipedia pages (documents) in English and Portuguese language. These pages are printed from 10 printers, including two of the same brand and same model. This dataset consists of document images scanned at 600 dpi via the Plustek SO PL2546 scanner. The image is available in an 8-bit format. The documents comprise letters printed in mixed font types and sizes distributed randomly. Some documents contain bold and italic font styles also.
We created a dataset (Table 1) consisting of 720 pages printed from 18 laser and inkjet printers to examine the effect of font types. These include three printers of the same brand and model. The documents contain random text in the English language printed using four different font types. However, in contrast with the DB1 dataset, a single document contains only a specific font type. For each printer, there are twenty-five pages (documents) in Cambria (EC) font, while five pages each are in Arial (EA), Comic Sans (ES), and Times New Roman (ET) fonts. Pages in Arial font have font size 11, while pages in the other three fonts have font size 12 as per the general settings used in most legal documents. The dataset includes Cambria, Arial, and Times New Roman, as most legal documents widely use them. In contrast, comic Sans is included because it looks considerably different from the rest of the fonts. A single reference scanner (Epson Perfection V600 Photo Scanner) scanned all printed pages at 600 dpi and 300 dpi resolutions. The image is available in a 16-bit format. Three printers are of the same brand and model (LC9, LC10, and LC11).
For all the experiments, we fix the train and test sets in a disjoint manner. The intensity and gradient threshold is kept fixed at = 20, = 80, = 90 for DB1 as it is scanned using 256 grayscale levels while and are set to 13000 and 50000, respectively for DB2 as it is scanned using 65536 grayscale levels. All experiments have been performed using Matlab 2018b software. The C - SVM with the radial basis function kernel of LIBSVM [28] is used for classification. Parameters (c and gamma) of SVM are chosen individually for each experiment using the search option available in LIBSVM with c [-5, 15], and g [-15, 3]. The step size of the grid search is fixed at 2. The validation set is a subset of training data. The experimental settings are consistent with the earlier works [3, 4, 2, 10].
5.2 Parameter Search
|
|
C | A | T | S | ||||||
| 11 | all | 98.94 | 78 | 91.5 | 47.5 | ||||||
| 12 | all | 98.94 | 79.5 | 90.25 | 51.75 | ||||||
| 13 | all | 98.94 | 81.5 | 90.75 | 48.5 | ||||||
| 14 | all | 98.94 | 80.25 | 89.75 | 48.5 | ||||||
| 15 | all | 98.94 | 80.25 | 91.5 | 49.25 | ||||||
| 16 | all | 98.94 | 81.25 | 89.75 | 48.5 | ||||||
| 17 | all | 98.94 | 79.5 | 89.5 | 49 | ||||||
| 18 | all | 98.94 | 83.5 | 89.75 | 48.75 | ||||||
| 19 | all | 98.94 | 83.5 | 89.5 | 47.5 | ||||||
| 20 | all | 98.94 | 80.25 | 89.25 | 47.75 |
| Printer ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| LB1 | 190 | 177 | 175 | 170 | 167 | 175 | 172 | 172 | 168 | 169 | 167 | 167 | 169 | 162 | 185 |
| LC1 | 188 | 179 | 174 | 170 | 168 | 172 | 172 | 173 | 167 | 165 | 166 | 166 | 166 | 159 | 179 |
| LC2 | 191 | 175 | 174 | 170 | 168 | 174 | 173 | 170 | 167 | 167 | 166 | 165 | 166 | 158 | 184 |
| LC3 | 189 | 177 | 175 | 170 | 168 | 175 | 172 | 172 | 167 | 168 | 168 | 167 | 169 | 161 | 187 |
| LC4 | 189 | 178 | 173 | 170 | 169 | 172 | 171 | 171 | 167 | 166 | 167 | 165 | 168 | 159 | 184 |
| LC5 | 166 | 152 | 152 | 149 | 147 | 151 | 151 | 150 | 149 | 144 | 146 | 147 | 147 | 139 | 162 |
| LC6 | 190 | 179 | 175 | 169 | 168 | 173 | 171 | 172 | 169 | 168 | 166 | 166 | 168 | 163 | 187 |
| LC7 | 190 | 178 | 175 | 171 | 168 | 174 | 172 | 173 | 169 | 168 | 167 | 167 | 168 | 161 | 187 |
| LC8 | 189 | 179 | 175 | 170 | 167 | 174 | 172 | 173 | 169 | 168 | 165 | 166 | 167 | 163 | 186 |
| LC9 | 173 | 170 | 169 | 163 | 162 | 166 | 162 | 159 | 155 | 150 | 148 | 147 | 141 | 140 | 161 |
| LC10 | 165 | 162 | 157 | 153 | 159 | 159 | 156 | 156 | 152 | 152 | 152 | 149 | 152 | 146 | 165 |
| LC11 | 186 | 177 | 171 | 169 | 164 | 168 | 166 | 167 | 161 | 158 | 161 | 156 | 157 | 149 | 171 |
| IE1 | 173 | 164 | 164 | 160 | 156 | 163 | 158 | 159 | 154 | 157 | 154 | 157 | 157 | 151 | 172 |
| IE2 | 187 | 175 | 173 | 170 | 166 | 172 | 171 | 170 | 167 | 166 | 166 | 165 | 168 | 161 | 185 |
| LH1 | 190 | 180 | 174 | 170 | 167 | 174 | 173 | 174 | 168 | 168 | 166 | 166 | 167 | 163 | 187 |
| LH2 | 190 | 180 | 175 | 169 | 167 | 173 | 174 | 173 | 168 | 167 | 166 | 166 | 167 | 164 | 187 |
| LK1 | 190 | 177 | 174 | 172 | 167 | 174 | 173 | 172 | 169 | 168 | 167 | 166 | 169 | 162 | 186 |
| LR1 | 190 | 177 | 176 | 171 | 168 | 175 | 172 | 173 | 167 | 169 | 167 | 166 | 169 | 161 | 186 |
We conduct a complete parameter search for both column and grid pooling approaches of the proposed method. DB2 allows the comparison under both the same and cross-font scenarios. All experiments have been conducted using five pages containing text printed in Cambria font for training. There are 20 pages in testing: Cambria font and 5 pages each of Arial, Times New Roman, and Comic Sans fonts. All experimental results have been reported over five iterations, i.e., five unique and disjoint combinations of train and test set fixed for all parameter variations.
5.2.1 Column Pooling
For column pooling, we analyze the effect of a different number of columns (Nc) as well as the pooling parameter (Np) on the classification accuracies. Expressly, the value of Nc is varied from 11 to 20 whereas, the value of Np is fixed at maximum possible value, i.e., all letters in a column are pooled into a single pooled feature vector (Table 2). Preliminary experimental results with varying values of Np showed that the values do not make much of an impact as long as the number of samples is sufficient to train an SVM model. We ensure this by choosing sufficiently smaller values of Nc but large enough to capture the variation in printer signature. The classification accuracy remains constant for the same font experiments. For cross font experiments, the classification accuracy does not vary monotonically, and there is no single parameter pair that provides the highest classification accuracy for all three fonts. For rest of the experiments, we chose Nc = 15 and Np = ‘all’ as this setting provides a significant number of samples (Table 3) to learn a separate classifier model for each column. The average number of letters per column (using Nc = 15) for all printers has been reported in Table 3. The Table shows that the proposed column pooling strategy evenly distributes letters across all printers in our dataset.
| Nw | Nh | C | A | T | S |
| 2 | 2 | 98.94 | 72.50 | 90.50 | 52.75 |
| 2 | 4 | 98.94 | 77.25 | 90.75 | 53.00 |
| 2 | 6 | 98.94 | 78.50 | 91.75 | 50.75 |
| 2 | 8 | 98.94 | 80.25 | 91.00 | 49.75 |
| 4 | 2 | 98.94 | 78.25 | 89.75 | 50.75 |
| 4 | 4 | 98.94 | 82.75 | 92.00 | 51.25 |
| 4 | 6 | 98.94 | 85.75 | 92.75 | 52.25 |
| 4 | 8 | 98.94 | 86.00 | 91.00 | 50.75 |
| 6 | 2 | 98.94 | 82.75 | 90.00 | 48.75 |
| 6 | 4 | 98.94 | 87.75 | 92.50 | 50.25 |
| 6 | 6 | 98.94 | 87.00 | 92.75 | 51.00 |
| 6 | 8 | 98.94 | 88.75 | 92.00 | 49.50 |
| 8 | 2 | 98.94 | 83.00 | 90.00 | 50.00 |
| 8 | 4 | 98.94 | 89.50 | 92.25 | 49.50 |
| 8 | 6 | 98.94 | 89.50 | 91.25 | 52.75 |
| 8 | 8 | 98.94 | 90.00 | 92.25 | 49.50 |
5.2.2 Grid Pooling
For grid pooling, we analyze the effect of a different number of grids (Nw Nh) on the classification accuracies. The number of grids is varied from 2 to 8 while also varying the number of grid blocks Nw and Nh with respect to each other (Table 4). The classification accuracy remains constant for all varying values of parameters. The cross font accuracies with Arial font in general increases with the number of grid blocks. The results with Nw > 8 (not reported in the paper) showed that the average cross font accuracy does not increase significantly. There is no specific trend observed in the other two fonts. Like column pooling, there is no single parameter setting that provides the highest classification accuracy for all three fonts. However, 8 8 grid configuration provides reasonably high accuracies for all three font types. So we chose this setting for the remaining experiments.
5.3 Full Length PSLTD vs. Approximated PSLTD
| C | A | T | S | ||||||
| Nc | Np | 10k | 4k | 10k | 4k | 10k | 4k | 10k | 4k |
| 15 | all | 98.94 | 98.94 | 78.00 | 80.25 | 90.25 | 91.50 | 50.00 | 49.25 |
| Grid 8 8 | 98.94 | 98.94 | 84.75 | 90.00 | 91.00 | 92.25 | 50.25 | 49.50 | |
The performance of proposed method using approximated PSLTD (i.e., PSLTD4k) is compared with that using the full length PSLTD (i.e., PSLTD10k) in Table 5. The approximated PSLTD of reduced dimensions performs similar to their full-length counterpart for both same and cross font experiments. Thus to reduce complexity and save time, we use the approximated PSLTD4k as feature vectors with our proposed method for the remaining experiments.
5.4 Block Pooling vs. Consecutive Pooling
For comparison between proposed block pooling and consecutive pooling [3], we first visualize the feature vector in a reduced dimension using linear discriminant analysis (LDA). Secondly, Pearson’s r correlation is used for comparison. We choose the same training data (i.e., five printed documents per printer containing the same font type) of dataset DB2 [3] for both pooling methods.
5.4.1 Comparison using LDA
To visualize the distribution of features in a lower-dimensional space, we extracted PSLTDs from training samples of DB2. We pool PSLTDs using Np equals 20 via consecutive pooling, column pooling for fifteen columns (i.e,, Nc = 15) and grid pooling using 8 8 grid. Then we apply linear discriminant analysis (LDA) to reduce the feature’s dimension. The first two dimensions corresponding to the largest eigenvalues of projected data are plotted in figure 5. These plots indicate that both column and grid pooling method reduces intra-class separation and increases inter-class separation. The figure depicts that different clusters corresponding to various printers have more discrimination in column pooling than consecutive pooling. As expected, the improvement in class-wise cluster separation is drastically better with column pooling than grid pooling. It provides visual clues that column pooling offers us a better representation with less overlapping of different class samples.
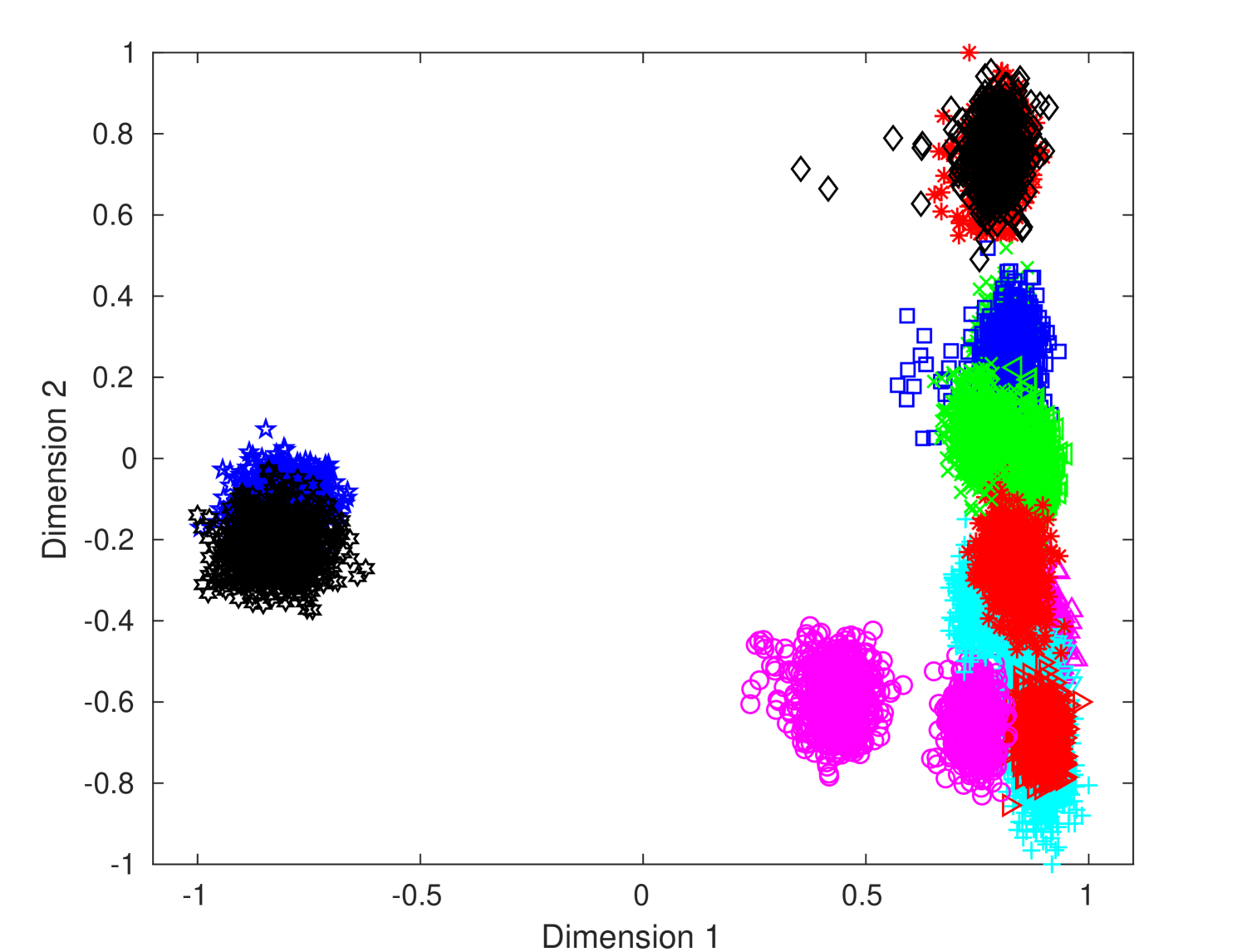
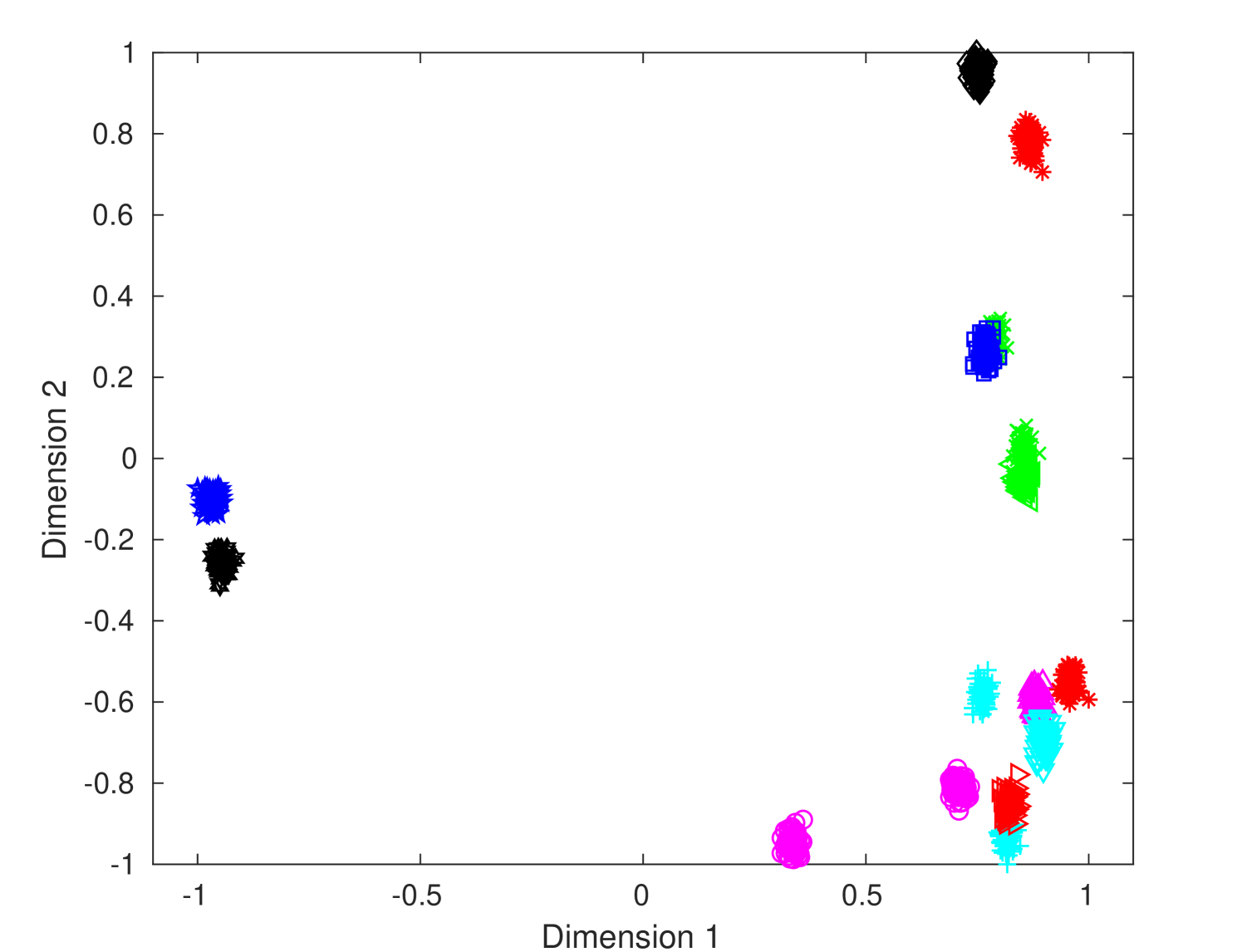
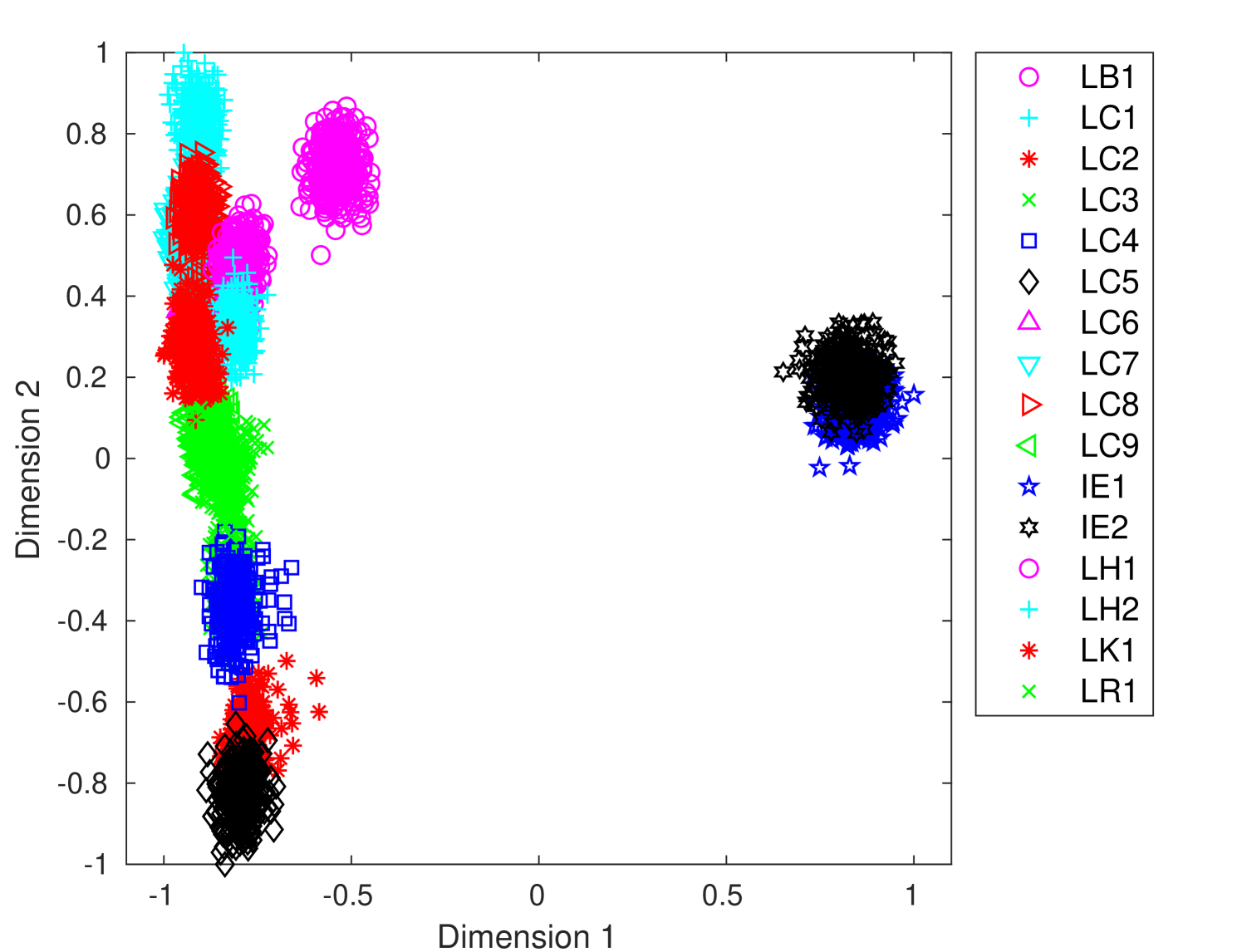
| Printer ID | Consecutive Pooling | Column Pooling | Grid Pooling |
| LB1 | 0.9999403786 | 0.9999894087 | 0.9999932251 |
| LC1 | 0.9999417235 | 0.9999939426 | 0.9999928397 |
| LC2 | 0.9999496627 | 0.9999955784 | 0.9999918113 |
| LC3 | 0.9999536711 | 0.9999932549 | 0.9999933009 |
| LC4 | 0.9999521655 | 0.9999940128 | 0.9999921736 |
| LC5 | 0.9999686467 | 0.9999946214 | 0.9999937096 |
| LC6 | 0.9999703351 | 0.9999935464 | 0.9999952785 |
| LC7 | 0.9999716916 | 0.9999943718 | 0.9999941307 |
| LC8 | 0.9999756106 | 0.9999937039 | 0.9999948721 |
| LC9 | 0.9999789123 | 0.9999922834 | 0.99999445 |
| LC10 | 0.9999812282 | 0.9999958219 | 0.9999927177 |
| LC11 | 0.9999814061 | 0.9999925254 | 0.9999929945 |
| IE1 | 0.9999829966 | 0.9999954384 | 0.9999886172 |
| IE2 | 0.9999834864 | 0.9999887612 | 0.9999882253 |
| LH1 | 0.9999884284 | 0.9999902606 | 0.9999933383 |
| LH2 | 0.9999898499 | 0.9999950545 | 0.9999945381 |
| LK1 | 0.999989456 | 0.9999945135 | 0.999990502 |
| LR1 | 0.9999909281 | 0.999991202 | 0.9999940467 |
5.4.2 Comparison using Correlation
Following our method’s primary hypothesis, we consider that sample from the same column of a printer’s pages has more similarity than cross columns. We compute the correlation values between pooled PSLTDs using consecutive pooling, column pooling, and grid pooling to observe this phenomenon. For consecutive pooling, the correlation values are calculated between all pooled PSLTDs of a printer for all 18 printers in DB2. On the other hand, for column and grid pooling, correlation values are calculated between pooled PSLTDs belonging to a printer’s training documents but belonging to the same block (column or grid). The median of correlation values obtained by the same block correlation is consistently higher than that of consecutive pooling for all printers (Table 6). This observation establishes the validity of our primary hypothesis about the variation of printer signature across a document image and its effectiveness compared to consecutive pooling. However, the difference between correlation values obtained using consecutive and block pooling is seen only after 4th or 5th digit after the decimal point. So, the document images need to be scanned using a high precision of 16-bit depth images.
5.5 Comparison with State-of-the-art
| Method |
|
||
| GLCMe [11] | 77.87 | ||
| GLCM_MDe [12] | 91.08 | ||
| GLCM_MD_MSe [12] | 94.30 | ||
| CTGF-GLCM-MD-MSe [2] | 96.26 | ||
| CNN- [2] | 96.13 | ||
| CNN- [2] | 97.33 | ||
| CC-RS-LTrP-PoEPe [3] | 97.12 | ||
| PSLTDe [4] | 98.92 | ||
| Proposedcol5,e | 98.61 | ||
| Proposedcol15,e | 97.76 | ||
| Proposedgrid,e | 92.93 |
| Method |
|
||
| PSLTD [4] | 99.27 | ||
| Proposedcol5 | 99.37 | ||
| Proposedcol15 | 99.16 | ||
| Proposedgrid | 96.77 |
We compare the performance of the proposed method with existing state-of-the-art methods using a combination of datasets DB1 and DB2. For DB1, the proposed method’s efficacy is analyzed using an ensemble of SVMs, while the higher precision of DB2 allows us to use correlation-based prediction.
5.5.1 Experiment on Dataset DB1
First, we evaluated the performance of our method on dataset DB1. As only 8-bit document images available in DB1, we use our SVM-based approach. We analyzed the performance using only letter type ‘e’ (the most frequently occurring letter in the English language) and all connected components printed on a document. We use the same train and test folds used in previous works [12, 2, 3, 4] for their result based on a 5 2 cross-validation method for a fair comparison. Each fold has around 592 pages each for training and testing. The performance of the proposed method has been compared with various state-of-the-art methods using all occurrences of letter type ‘e’. This approach allows a fair comparison consistently with many other baseline methods developed for a specific letter type. The proposed method achieves an accuracy of 97.76% and 92.93% using column (Nc=15) and grid (8 8) pooling, respectively (Table 7). Our proposed method using column pooling is denoted by Proposedcol5 and Proposedcol15 for Nc=5 and 15, respectively. Whereas, our proposed grid pooling-based method is denoted by Proposedgrid. Results show that grid pooling does not perform well. A possible reason could be that the number of samples per SVM is insufficient to learn a discriminative model. Note that the proposed method using 8 8 grid pooling has an ensemble of 64 SVMS. We also try other pooling parameters and find that the proposed method performs slightly better with =5 as compared to consecutive pooling. PSLTDe and proposed method (PSLTD4k,e) outperforms all other existing methods. We further compare PSLTDe and proposed method using all printed letters as reported in Table 8. We observe that the proposed method performs similarly to the PSLTD method. Nonetheless, the font type and size characteristics of train and test data in DB1 are not well defined. So, we also carry out experiments on the DB2 dataset, which allows analysis in an ideal cross-font scenario.
5.6 Experiments on dataset DB2
We evaluated the performance of the proposed method on DB2 (having approximately 2300 connected components per document) for (a) inter-model scenario (i.e., no two printers are of the same brand and model) and (b) intra-model scenario (i.e., multiple printers of same brand and model). We extract all connected components for experiments on DB2. Dataset DB2 consists of documents scanned at 16 - bit (65536 - scale). So, unlike DB1, on DB2 we use correlation-based prediction in our proposed method.
| Train Font | Cambria (C) | |||
| Test Font | C | A | T | S |
| PSLTD [4] | 100 | 80.00 | 98.75 | 54.25 |
| Proposedcol15 | 100 | 85.25 | 96.25 | 54.75 |
| Proposedgrid | 99.50 | 93.50 | 94.25 | 60.25 |
5.6.1 Intermodel scenario
For the inter-model scenario, we analyzed the proposed method’s performance on 16 printers (except LC10, LC11 in table 1). There are 20 Cambria font documents per printer in training and five Cambria font documents in testing. We also test on all five documents containing text printed in Arial (A), Times New Roman (T), and Comic Sans font (S) types. The results are reported over five iterations, i.e., five unique combinations of train and test data. In this setting, PSLTD [4] and column pooling variants of proposed method achieve 100% classification accuracy in the same font scenario as reported in Table 9. The grid pooling variant of the proposed method achieves 99.50% accuracy. Note that, in original PSLTD [4], we need to learn an SVM model, but the proposed method predicts using a simple correlation-based prediction technique without the requirement of learning a complex classifier model. Moreover, the proposed method surpasses the performance of state-of-the-art PSLTD-based method [4] under the cross-font scenario. Specifically, the grid pooling variant (i.e., 88 grid) of the proposed method achieves average classification accuracies of 93.50%, 94.25%, and 60.25% when trained using documents containing Cambria font and tested using documents containing A, T, and S font types, respectively. The column pooling variant (i.e., Nc=15) of the proposed method achieves average classification accuracies of 85.25%, 96.25%, and 54.75%, respectively with A, T, and S. The results show that neither variant of the proposed method is consistently better than the other on all font types. However, it can be seen that the overall performance of grid column pooling is better than column pooling under the cross-font scenario on DB2.
|
LC9 | LC10 | LC11 | ||
| LC9 | 100 [100] | 0 | 0 | ||
| LC10 | 0 | 100 [97.1] | 0 [2.9] | ||
| LC11 | 0 | 0 [1.2] | 100 [98.8] |
5.6.2 Intra-model scenario
The intra-model scenario analyzes the performance of the proposed method on printers of the same brand and model. For the Intra model scenario, DB2 consists of three printers of the same brand and model. We choose the same folds of 20 and 5 documents in training and testing, respectively, over five iterations. Under these settings, The proposed method achieves 100% classification accuracy, as shown in Table 10 whereas, there is some confusion between printers using PSLTD-based method [4]. The proposed method correctly classifies documents printed from printers of the same brand and model without learning a complex classifier. We further analyze the proposed method’s performance using all 18 printers of DB2, achieving an average classification accuracy of 100% under the same font scenario for both column and grid polling variants. The experimental setting remains the same as in the inter-model scenario, i.e., 20 documents of Cambria in train and rest five documents in the test. The column pooling methods achieve 84.89%, 91.33%, and 52.67% accuracies under the cross-font scenario, and grid pooling achieves 92.67%, 89.11%, and 56.89%, respectively on A, T, and S font types. Similar to the intra-model scenario, grid pooling performs better than the inter-model scenario. The confusion matrices corresponding to grid pooling have been depicted in Tables 11 and 12. For font type A, the proposed method correctly classifies 15 out of 18 printers for all test documents, whereas, for font type T, all documents printed by 16 out of 18 printers are correctly classified. As expected, there is some confusion between the printer of the same brand and model for font types A and T. There is a lot of confusion among many printers for font type S. The results show that block pooling achieves significant performance under cross font scenarios when font types in train and test are not drastically different. The discriminative power of block pooling is highlighted by a simple correlation-based prediction instead of a complex classifier.
| Arial (A) | ||||||||||||||||||
| LB1 | LC1 | LC2 | LC3 | LC4 | LC5 | LC6 | LC7 | LC8 | LC9 | LC10 | LC11 | IE1 | IE2 | LH1 | LH2 | LK1 | LR1 | |
| LB1 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC1 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC2 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC3 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC4 | 0 | 0 | 0 | 4 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC5 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC6 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 28 | 72 | 0 | 0 | 0 | 0 | 0 | 0 |
| IE1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 |
| IE2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 |
| LH1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 |
| LH2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 |
| LK1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LR1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Times New Roman (T) | ||||||||||||||||||
| LB1 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC1 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC2 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC3 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC4 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC5 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC6 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| IE1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 |
| IE2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 |
| LH1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 |
| LH2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 96 | 4 | 0 | 0 |
| LK1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 |
| LR1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Comic Sans (S) | ||||||||||||||||||
| LB1 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC1 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 |
| LC3 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 72 | 0 | 0 |
| LC4 | 0 | 0 | 0 | 0 | 0 | 0 | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 80 | 0 | 0 | 0 |
| LC5 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 |
| LC7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 96 | 0 | 0 | 0 |
| LC9 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 20 | 0 | 56 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LC11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 52 | 48 | 0 | 0 | 0 | 0 | 0 | 0 |
| IE1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 |
| IE2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 96 | 0 | 0 | 0 | 0 |
| LH1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 |
| LH2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 80 | 20 | 0 | 0 |
| LK1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 88 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 |
| LR1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
6 Conclusion
We have proposed a new printer-specific pooling based system for source printer identification. We use an extensive set of visual analysis and experimental results to show that a printer’s signature varies across a printed document, and this variation can be captured by dividing the document image into non-overlapping blocks. We analyzed two variants for block pooling, i.e., column and grid pooling. For document images scanned at lower precision (i.e., 8-bit depth), we use SVM-based prediction (as used in most state-of-the-art methods). The proposed method performs better than most methods on the publicly available dataset and performs similar to the PSLTD-based method. Results show that column pooling performs better than grid pooling using an ensemble of SVMs as the number of samples available for each SVM (corresponding to each block) is insufficient to learn a discriminative model. However, for document images scanned at higher precision (i.e., 16-bit depth), the proposed method’s discriminative power is highlighted by a correlation-based prediction instead of a complex classifier. Both grid and column variants of the proposed method performs better than state-of-the-art methods when evaluated under cross font scenario. An extensive set of experiments reveal that the grid pooling variant performs better than column pooling using a correlation-based technique. The proposed method’s grid pooling variant achieves more than 93.5% and 94.3%accuracies when tested on documents containing Arial and Times New Roman font types and trained using documents containing only Cambria font type. Classification with Pearson correlation provides promising results that could pave the way for classifier independent detection approach with a high precision image acquisition process.
The proposed method and the existing state-of-the-art combination of PSLTD and consecutive pooling does not perform well on Comic Sans font as it is drastically different from the other three font types in our dataset DB2. The proposed method requires that the test document contains a sufficient number of letters printed in a block to estimate a good quality printer signature. The proposed method is less useful for intra-page forgery locations, as its localization ability is reduced if the prediction of source printer is carried out on fewer pooled feature vectors. There are other open challenges that need to be analyzed in detail, including toner variation, paper quality and type, and printer age. Future work will include improving the printer signature model to address cross-font type, cross-font size, and cross-language scenarios. It would allow the scaling of source printer identification systems to a larger number of printers.
Acknowledgment
This material is based upon work partially supported by the [http://www.serb.gov.in]Department of Science and Technology (DST), Government of India under the Award Number ECR/2015/000583 and supported by Visvesvaraya PhD Scheme, MeitY, Govt. of India MEITY-PHD-951. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding agencies.
References
- [1] P.-J. Chiang, N. Khanna, A. K. Mikkilineni, M. V. O. Segovia, S. Suh, J. P. Allebach, G. T.-C. Chiu, E. J. Delp, Printer And Scanner Forensics, IEEE Signal Process. Mag. 26 (2) (2009) 72–83.
- [2] A. Ferreira, L. Bondi, L. Baroffio, P. Bestagini, J. Huang, J. dos Santos, S. Tubaro, A. Rocha, Data-Driven Feature Characterization Techniques for Laser Printer Attribution, IEEE Trans. Inf. Forensics Security 12 (8) (2017) 1860–1873.
- [3] S. Joshi, N. Khanna, Single Classifier-based Passive System for Source Printer Classification Using Local Texture Features, IEEE Transactions on Information Forensics and Security 13 (7) (2018) 1603–1614.
- [4] S. Joshi, N. Khanna, Source printer classification using printer specific local texture descriptor, IEEE Transactions on Information Forensics and Security.
- [5] A. Braz, M. López-López, C. García-Ruiz, Raman spectroscopy for forensic analysis of inks in questioned documents, Forensic science international 232 (1-3) (2013) 206–212.
- [6] P.-C. Chu, B. Y. Cai, Y. K. Tsoi, R. Yuen, K. S. Leung, N.-H. Cheung, Forensic analysis of laser printed ink by x-ray fluorescence and laser-excited plume fluorescence, Analytical chemistry 85 (9) (2013) 4311–4315.
- [7] P.-J. Chiang, J. P. Allebach, G. T. C. Chiu, Extrinsic Signature Embedding And Detection In Electrophotographic Halftoned Images Through Exposure Modulation, IEEE Trans. Inf. Forensics Security 6 (3) (2011) 946–959.
- [8] A. K. Mikkilineni, O. Arslan, P.-J. Chiang, R. M. Kumontoy, J. P. Allebach, G. T.-C. Chiu, E. J. Delp, Printer Forensics Using SVM Techniques, in: NIP & Digital Fabrication Conf., Vol. 2005, 2005, pp. 223–226.
- [9] G. N. Ali, A. K. Mikkilineni, J. P. Allebach, E. J. Delp, P.-J. Chiang, G. T. Chiu, Intrinsic and extrinsic signatures for information hiding and secure printing with electrophotographic devices, in: NIP & Digital Fabrication Conference, Vol. 2003, Society for Imaging Science and Technology, 2003, pp. 511–515.
- [10] S. Joshi, M. Lamba, V. Goyal, N. Khanna, Augmented data and improved noise residual-based CNN for printer source identification, in: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2002–2006.
- [11] A. K. Mikkilineni, P.-J. Chiang, G. N. Ali, G. T. C. Chiu, J. P. Allebach, E. J. Delp, Printer Identification Based On Graylevel Co-occurrence Features For Security And Forensic Applications, in: Proc. SPIE Int. Conf. on Security, Steganography, and Watermarking of Multimedia Contents VII, Vol. 5681, San Jose, CA, 2005, pp. 430–440.
- [12] A. Ferreira, L. C. Navarro, G. Pinheiro, J. A. dos Santos, A. Rocha, Laser Printer Attribution: Exploring New Features And Beyond, Forensic Science International 247 (2015) 105–125.
- [13] M. J. Tsai, J. S. Yin, I. Yuadi, J. Liu, Digital Forensics of Printed Source Identification for Chinese Characters, Multimedia Tools and Applications 73 (3) (2014) 2129–2155.
- [14] M.-J. Tsai, C.-L. Hsu, J.-S. Yin, I. Yuadi, Japanese character based printed source identification, in: Proc. IEEE Int. Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 2015, pp. 2800–2803.
- [15] M.-J. Tsai, I. Yuadi, Y.-H. Tao, Decision-theoretic Model to Identify Printed Sources, Multimedia Tools and Applications (2018) 1–45.
- [16] S. Elkasrawi, F. Shafait, Printer Identification Using Supervised Learning for Document Forgery Detection, in: Proc. 11th IAPR Int. Workshop on Document Analysis Systems (DAS), France, 2014, pp. 146–150.
- [17] E. Kee, H. Farid, Printer Profiling For Forensics And Ballistics, in: Proc. 10th ACM Workshop Multimedia and Security, Oxford, United Kingdom, 2008, pp. 3–10.
- [18] Q. Zhou, Y. Yan, T. Fang, X. Luo, Q. Chen, Text-Independent Printer Identification Based On Texture Synthesis, Multimedia Tools and Applications 75 (10) (2016) 5557–5580.
- [19] S. Joshi, S. Saxena, N. Khanna, Source printer identification from document images acquired using smartphone, arXiv preprint arXiv:2003.12602.
- [20] O. Bulan, J. Mao, G. Sharma, Geometric Distortion Signatures For Printer Identification, in: Proc. IEEE Int. Conf. Acoustics, Speech and Signal Process., Taipei, Taiwan, 2009, pp. 1401–1404.
- [21] Y. Wu, X. Kong, X. You, Y. Guo, Printer Forensics Based on Page Document’s Geometric Distortion, in: Proc. IEEE International Conference on Image Processing (ICIP), IEEE, 2009, pp. 2909–2912.
- [22] J. Hao, X. Kong, S. Shang, Printer Identification Using Page Geometric Distortion On Text Lines, in: Proc. IEEE China Summit and Int. Conf. Signal and Inform. Process., Chengdu, China, 2015, pp. 856–860.
- [23] S. Shang, X. Kong, X. You, Document Forgery Detection Using Distortion Mutation Of Geometric Parameters In Characters, Journal of Electronic Imaging 24 (2) (2015) 023008.
- [24] H. Jain, G. Gupta, S. Joshi, N. Khanna, Passive Classification of Source Printer Using Text-Line-Level Geometric Distortion Signatures From Scanned Images of Printed Documents, arXiv preprint arXiv:1706.06651.
- [25] T. Ojala, M. Pietikäinen, M. Mäenpää, Multiresolution Gray-scale And Rotation Invariant Texture Classification With Local Binary Patterns, IEEE Trans. Pattern Anal. Mach. Intell. 24 (7) (2002) 971–987.
- [26] J. Feng, B. Ni, Q. Tian, S. Yan, Geometric lp-norm feature pooling for image classification, in: CVPR 2011, 2011, pp. 2609–2704.
- [27] T. D. V. Swinscow, M. J. Campbell, et al., Statistics at square one, Bmj London, 2002.
- [28] C.-C. Chang, C.-J. Lin, LIBSVM: A Library for Support Vector Machines, ACM Trans. on Intelligent Systems and Technology 2 (3) (2011) 1–27.