Institute of Informatics, University of Warsaw, Polandbenjamin.bergougnoux@mimuw.edu.pl Humboldt-Universität zu Berlin, Germanyvera.chekan@informatik.hu-berlin.dehttps://orcid.org/0000-0002-6165-1566Supported by the DFG Research Training Group 2434 “Facets of Complexity.” Algorithms and Complexity Group, TU Wien, Vienna, Austriarganian@gmail.comhttps://orcid.org/0000-0002-7762-8045Project No. Y1329 of the Austrian Science Fund (FWF), WWTF Project ICT22-029. Université Clermont Auvergne, Clermont Auvergne INP, LIMOS, CNRS, Clermont-Ferrand, Francemamadou.kante@uca.frhttps://orcid.org/0000-0003-1838-7744Supported by the French National Research Agency (ANR-18-CE40-0025-01 and ANR-20-CE48-0002). Hamburg University of Technology, Institute for Algorithms and Complexity, Hamburg, Germanymatthias.mnich@tuhh.dehttps://orcid.org/0000-0002-4721-5354 Discrete Mathematics Group, Institute for Basic Science (IBS), Daejeon, Korea and Department of Mathematical Sciences, KAIST, Daejeon, Koreasangil@ibs.re.krhttps://orcid.org/0000-0002-6889-7286Supported by the Institute for Basic Science (IBS-R029-C1). Institute of Informatics, University of Warsaw, Polandmichal.pilipczuk@mimuw.edu.pl\flag[0.17]flags.jpgThis work is a part of project BOBR that has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 948057). Dept. Information and Computing Sciences, Utrecht University, The Netherlandse.j.vanleeuwen@uu.nlhttps://orcid.org/0000-0001-5240-7257 \CopyrightBenjamin Bergougnoux, Vera Chekan, Robert Ganian, Mamadou M. Kanté, Matthias Mnich, Sang-il Oum, Michał Pilipczuk, and Eric Jan van Leeuwen
Acknowledgements.
This work was initiated at the Graph Decompositions: Small Width, Big Challenges workshop held at the Lorentz Center in Leiden, The Netherlands, in 2022. \ccsdesc[300]Theory of computation Parameterized complexity and exact algorithmsSpace-Efficient Parameterized Algorithms on Graphs of Low Shrubdepth
Abstract
Dynamic programming on various graph decompositions is one of the most fundamental techniques used in parameterized complexity. Unfortunately, even if we consider concepts as simple as path or tree decompositions, such dynamic programming uses space that is exponential in the decomposition’s width, and there are good reasons to believe that this is necessary. However, it has been shown that in graphs of low treedepth it is possible to design algorithms which achieve polynomial space complexity without requiring worse time complexity than their counterparts working on tree decompositions of bounded width. Here, treedepth is a graph parameter that, intuitively speaking, takes into account both the depth and the width of a tree decomposition of the graph, rather than the width alone.
Motivated by the above, we consider graphs that admit clique expressions with bounded depth and label count, or equivalently, graphs of low shrubdepth. Here, shrubdepth is a bounded-depth analogue of cliquewidth, in the same way as treedepth is a bounded-depth analogue of treewidth. We show that also in this setting, bounding the depth of the decomposition is a deciding factor for improving the space complexity. More precisely, we prove that on -vertex graphs equipped with a tree-model (a decomposition notion underlying shrubdepth) of depth and using labels,
-
•
Independent Set can be solved in time using space;
-
•
Max Cut can be solved in time using space; and
-
•
Dominating Set can be solved in time using space via a randomized algorithm.
We also establish a lower bound, conditional on a certain assumption about the complexity of Longest Common Subsequence, which shows that at least in the case of Independent Set the exponent of the parametric factor in the time complexity has to grow with if one wishes to keep the space complexity polynomial.
keywords:
Parameterized complexity, shrubdepth, space complexity, algebraic methods1 Introduction
Treewidth and Treedepth. Dynamic programming on graph decompositions is a fundamental method in the design of parameterized algorithms. Among various decomposition notions, tree decompositions, which underly the parameter treewidth, are perhaps the most widely used; see e.g. [14, 18] for an introduction. A tree decomposition of a graph of width provides a way to “sweep” while keeping track of at most “interface vertices” at a time. This can be used for dynamic programming: during the sweep, the algorithm maintains a set of representative partial solutions within the part already swept, one for each possible behavior of a partial solution on the interface vertices. Thus, the width of the decomposition is the key factor influencing the number of partial solutions that need to be stored.
In a vast majority of applications, this number of different partial solutions depends (at least) exponentially on the width of the decomposition, which often leads to time complexity of the form for an exponential function . This should not be surprising, as most problems where this technique is used are -hard. Unfortunately, the space complexity—which often appears to be the true bottleneck in practice —is also exponential. There is a simple tradeoff trick, first observed by Lokshtanov et al. [38], which can often be used to reduce the space complexity to polynomial at the cost of increasing the time complexity. For instance, Independent Set can be solved in time and using space on an -vertex graph equipped with a width- tree decomposition via dynamic programming [26]; combining this algorithm with a simple recursive Divide&Conquer scheme yields an algorithm with running time and space complexity .
Allender et al. [2] and then Pilipczuk and Wrochna [45] studied the question whether the loss on the time complexity is necessary if one wants to achieve polynomial space complexity in the context of dynamic programming on tree decompositions. While the formal formulation of their results is somewhat technical and complicated, the take-away message is the following: there are good complexity-theoretical reasons to believe that even in the simpler setting of path decompositions, one cannot achieve algorithms with polynomial space complexity whose running times asymptotically match the running times of their exponential-space counterparts. We refer to the works [2, 45] for further details.
However, starting with the work of Fürer and Yu [27], a long line of advances [33, 40, 41, 45] showed that bounding the depth, rather than the width, of a decomposition leads to the possibility of designing algorithms that are both time- and space-efficient. To this end, we consider the treedepth of a graph , which is the least possible depth of an elimination forest: a forest on the vertex set of such that every two vertices adjacent in are in the ancestor/descendant relation in . An elimination forest of depth can be regarded as a tree decomposition of depth , and thus treedepth is the bounded-depth analogue of treewidth. As shown in [27, 33, 41, 45], for many classic problems, including 3-Coloring, Independent Set, Dominating Set, and Hamiltonicity, it is possible to design algorithms with running time and polynomial space complexity, assuming the graph is supplied with an elimination forest of depth . In certain cases, the space complexity can even be as low as or [45]. Typically, the main idea is to reformulate the classic bottom-up dynamic programming approach so that it can be replaced by a simple top-down recursion. This reformulation is by no means easy—it often involves a highly non-trivial use of algebraic transforms or other tools of algebraic flavor, such as inclusion-exclusion branching.
Cliquewidth and Shrubdepth. In this work, we are interested in the parameter cliquewidth and its low-depth counterpart: shrubdepth. While treewidth applies only to sparse graphs, cliquewidth is a notion of tree-likeness suited for dense graphs as well. The decompositions underlying cliquewidth are called clique expressions [13]. A clique expression is a term operating over -labelled graphs—graphs where every vertex is assigned one of labels—and the allowed operations are: (i) apply any renaming function to the labels; (ii) make a complete bipartite graph between two given labels; and (iii) take the disjoint union of two -labelled graphs. Then the cliquewidth of is the least number of labels using which (some labelling of) can be constructed. Similarly to treewidth, dynamic programming over clique expressions can be used to solve a wide range of problems, in particular all problems expressible in logic, in time when parameterized by cliquewidth. Furthermore, while several problems involving edge selection or edge counting, such as Hamiltonicity or Max Cut, remain -hard under the cliquewidth parameterization [23, 24], standard dynamic programming still allows us to solve them in time. In this sense, clique-width can be seen as the “least restrictive” general-purpose graph parameter which allows for efficient dynamic programming algorithms where the decompositions can also be computed efficiently [25]. Nevertheless, since the cliquewidth of a graph is at least as large as its linear cliquewidth, which in turn is as large as its pathwidth, the lower bounds of Allender et al. [2] and of Pilipczuk and Wrochna [45] carry over to the cliquewidth setting. Hence, reducing the space complexity to polynomial requires a sacrifice in the time complexity.
Shrubdepth, introduced by Ganian et al. [30], is a variant of cliquewidth where we stipulate the decomposition to have bounded depth. This necessitates altering the set of operations used in clique expressions in order to allow taking disjoint unions of multiple graphs as a single operation. In this context, we call the decompositions used for shrubdepth -tree-models, where stands for the depth and for the number of labels used; a formal definition is provided in Section 2. Shrubdepth appears to be a notion of depth that is sound from the model-theoretic perspective, is -time computable [28], and has become an important concept in the logic-based theory of well-structured dense graphs [19, 20, 29, 30, 42, 43].
Since shrubdepth is a bounded-depth analogue of cliquewidth in the same way as treedepth is a bounded-depth analogue of treewidth, it is natural to ask whether for graphs from classes of bounded shrubdepth, or more concretely, for graphs admitting -tree-models where both and are considered parameters, one can design space-efficient algorithms. Exploring this question is the topic of this work.
Our contribution. We consider three example problems: Independent Set, Max Cut, and Dominating Set. For each of them we show that on graphs supplied with -tree-models where , one can design space-efficient fixed-parameter algorithms whose running times asymptotically match the running times of their exponential-space counterparts working on general clique expressions. While we focus on the three problems mentioned above for concreteness, we in fact provide a more general algebraic framework, inspired by the work on the treedepth parameterization [27, 33, 40, 41, 45], that can be applied to a wider range of problems. Once the depth is not considered a constant, the running times of our algorithms increase with . To mitigate this concern, we give a conditional lower bound showing that this is likely to be necessary if one wishes to keep the space complexity polynomial.
Recall that standard dynamic programming solves the Independent Set problem in time and space on a graph constructed by a clique expression of width [26]. Our first contribution is to show that on graphs with -tree-models, the space complexity can be reduced to as low as at the cost of allowing time complexity . In fact, we tackle the more general problem of computing the independent set polynomial.
Theorem 1.1.
There is an algorithm which takes as input an -vertex graph along with a -tree model of , runs in time and uses at most space, and computes the independent set polynomial of .
The idea of the proof of Theorem 1.1 is to reorganize the computation of the standard bottom-up dynamic programming by applying the zeta-transform to the computed tables. This allows a radical simplification of the way a dynamic programming table for a node is computed from the tables of its children, so that the whole dynamic programming can be replaced by top-down recursion. Applying just this yields an algorithm with space polynomial in . We reduce space to by computing the result modulo several small primes, and using space-efficient Chinese remaindering. This is inspired by the algorithm for Dominating Set on graphs of small treedepth of Pilipczuk and Wrochna [45].
In fact, the technique used to prove Theorem 1.1 is much more general and can be used to tackle all coloring-like problems of local character. We formalize those under a single umbrella by solving the problem of counting List -homomorphisms (for an arbitrary but fixed pattern graph ), for which we provide an algorithm with the same complexity guarantees as those of Theorem 1.1. The concrete problems captured by this framework include, e.g., Odd Cycle Transveral and -Coloring for a fixed constant ; details are provided in Section 3.2.
Next, we turn our attention to the Max Cut problem. This problem is -hard when parameterized by cliquewidth, but it admits a simple -time algorithm on -vertex graphs provided with clique expressions of width [24]. Our second contribution is a space-efficient counterpart of this result for graphs equipped with bounded-depth tree-models.
Theorem 1.2.
There is an algorithm which takes as input an -vertex graph along with a -tree model of , runs in time and uses at most space, and solves the Max Cut problem in .
Upon closer inspection, the standard dynamic programming for Max Cut on clique expressions solves a Subset Sum-like problem whenever aggregating the dynamic programming tables of children to compute the table of their parent. We apply the approach of Kane [36] that was used to solve Unary Subset Sum in logarithmic space: we encode the aforementioned Subset Sum-like problem as computing the product of polynomials, and use Chinese remaindering to compute this product in a space-efficient way.
Finally, we consider the Dominating Set problem, for which we prove the following.
Theorem 1.3.
There is a randomized algorithm which takes as input an -vertex graph along with a -tree model of , runs in time and uses at most space, and reports the minimum size of a dominating set in that is correct with probability at least .
Note that the algorithm of Theorem 1.3 is randomized and uses much more space than our previous algorithms: more than . The reason for this is that we use the inclusion-exclusion approach proposed very recently by Hegerfeld and Kratsch [34], which is able to count dominating sets only modulo . Consequently, while the parity of the number of dominating sets of certain size can be computed in space , to determine the existence of such dominating sets we use the Isolation Lemma and count the parity of the number of dominating sets of all possible weights. This introduces randomization and necessitates sampling—and storing—a weight function. At this point we do not know how to remove neither the randomization nor the super-linear space complexity in Theorem 1.3; we believe this is an excellent open problem.
Note that in all the algorithms presented above, the running times contain a factor in the exponent compared to the standard (exponential-space) dynamic programming on clique expressions. The following conditional lower bound shows that some additional dependency on the depth is indeed necessary; the relevant precise definitions are provided in Section 4.
Theorem 1.4.
Suppose Longest Common Subsequence cannot be solved in time and space for any computable function , even if the length of the sought subsequence is bounded by for any unbounded computable function ; here is the number of strings on input, is the common length of each string, and is the total bitsize of the instance. Then for every unbounded computable function , there is no algorithm that solves the Independent Set problem in graphs supplied with -tree-models satisfying that would run in time and simultaneously use space.
The possibility of achieving time- and space-efficient algorithms for Longest Common Subsequence was also the base of conjectures formulated by Pilipczuk and Wrochna [45] for their lower bounds against time- and space-efficient algorithms on graphs of bounded pathwidth. The supposition made in Theorem 1.4 is a refined version of those conjectures that takes also the length of the sought subsequence into account. The reduction underlying Theorem 1.4 is loosely inspired by the constructions of [45], but requires new ideas due to the different setting of tree-models of low depth.
Finally, given that the above results point to a fundamental role of shrubdepth in terms of space complexity, it is natural to ask whether shrubdepth can also be used to obtain meaningful tractability results with respect to the “usual” notion of fixed-parameter tractability. We conclude our exposition by highlighting two examples of problems which are -hard on graphs of bounded cliquewidth (and even of bounded pathwidth) [12, 37], and yet which admit fixed-parameter algorithms when parameterized by the shrubdepth.
Theorem 1.5.
Metric Dimension and Firefighter can be solved in fixed-parameter time on graphs supplied with -tree-models, where and are considered the parameters.
2 Preliminaries
For a positive integer , we denote by and . For a function and elements (not necessarily from ), the function is given by for and . We use standard graph terminology [17].
We use the same computational model as Pilipczuk and Wrochna [45], namely the RAM model where each operation takes time polynomially proportional to the number of bits of the input, and the space is measured in terms of bits. We say that an algorithm runs in time and space if, for every input of size , the number of operations of is bounded by and the auxiliary used space of has size bounded by bits.
Shrubdepth.
We first introduce the decomposition notion for shrubdepth: tree-models.
Definition 2.1.
For , a -tree-model of a graph is a rooted tree of depth together with a family of symmetric Boolean -matrices , a labeling function , and a family of renaming functions with for all such that:
-
•
The leaves of are identified with vertices of . For each node of , we denote by the leaves of that are descendants of , and with we denote the subgraph induced by these vertices.
-
•
With each node of we associate a labeling function defined as follows. If is a leaf, then . If is a non-leaf node, then for every child of and every vertex , we have .
-
•
For every pair of vertices of , let denote their least common ancestor in . Then we have if and only if .
We introduce some notation. If is a -tree model of a graph , then for every node of and every , let be the set of vertices labeled at . Given a subset of and , let be the vertices of labeled at .
A -tree-model can be understood as a term of depth that constructs a -labelled graph from single-vertex graphs by means of the following operations: renaming of the labels, and joining several labelled graphs while introducing edges between vertices originating from different parts based on their labels. This makes tree-models much closer to the NLC-decompositions which underly the parameter NLC-width than to clique expressions. NLC-width is a graph parameter introduced by Wanke [46] that can be seen as an alternative, functionally equivalent variant of cliquewidth.
We say that a class of graphs has shrubdepth if there exists such that every graph in admits a -tree-model. Thus, shrubdepth is a parameter of a graph class, rather than of a single graph; though there are functionally equivalent notions, such as SC-depth [30] or rank-depth [16], that are suited for the treatment of single graphs.
We remark that in the original definition proposed by Ganian et al. [30], there is no renaming of the labels: for every vertex , is always the same label for all relevant nodes . This boils down to all the renaming functions equal to the identify function on . Clearly, a -tree-model in the sense of Ganian et al. is also a -tree-model in our sense, while a -tree-model in our sense can be easily turned into a -model in the sense of Ganian et al. by setting to be the tuple of consisting of labels , for ranging over the ancestors of in . Thus, using either definition yields the same notion of shrubdepth for graph classes. We choose to use the definition with renaming, as it provides more flexibility in the construction of tree-models that can result in a smaller number of labels and, consequently, better running times. It is also closer to the original definitions of clique expressions or NLC-decompositions.
Within this work we will always assume that a -tree-model of the considered graph is provided on input. Thus, we abstract away the complexity of computing tree-models, but let us briefly discuss this problem. Gajarský and Kreutzer [28] gave an algorithm that given a graph and parameters and , computes a -tree-model of (in the sense of Ganian et al. [30]), if there exists one, in time for a computable function . The approach of Gajarský and Kreutzer is essentially kernelization: they iteratively “peel off” isomorphic parts of the graph until the problem is reduced to a kernel of size bounded only in terms of and . This kernel is then treated by any brute-force method. Consequently, a straightforward inspection of the algorithm of [28] shows that it can be implemented so that it uses polynomial space; but not space of the form , due to the necessity of storing all the intermediate graphs in the kernelization process.
Cover products and transforms.
We now recall the algebraic tools we are going to use. Let be a finite set and be a ring. Let be set functions, for some integer . For every , the zeta-transform of is defined by
and similarly, the Möbius-transform of is given by
The cover product of is defined by
We emphasize that unlike another well-known concept of subset convolution, here the sets are not required to be pairwise disjoint. The following result of Björklund et al. [6] will be relevant for us:
Lemma 2.2 ([6]).
Let be a finite set, be a ring, and be set functions for a positive integer . Then for every , it holds that
Also for every , we have .
3 Space-Efficient Algorithms on Tree-Models
3.1 Independent Set
In this section, we provide a fixed-parameter algorithm computing the independent set polynomial of a graph in time and using space, when given a -tree model. In particular, given a -tree model of an -vertex graph , our algorithm will allow to compute the number of independent sets of size for each . For simplicity of representation, we start by describing an algorithm that uses space and then show how a result by Pilipczuk and Wrochna [45] can be applied to decrease the space complexity to .
In order to simplify forthcoming definitions/statements, let be an internal node of with as children. For , we denote by the number of independent sets of size of such that . Let us define the polynomial
For the root of , the number of independent sets of of size is then given by
and the independent set polynomial of is
Therefore, the problem boils down to the computation of and its coefficients . A usual way to obtain a polynomial or logarithmic space algorithm is a top-down traversal of a rooted tree-like representation of the input—in our case, this will be the tree model. In this top-down traversal, the computation of coefficients of makes some requests to the coefficients of for each , for some integer , and some set of labels of so that and . Since there are exponentially many (in ) possible partitions of into integers and can be , we must avoid running over all such integer partitions, and this will be done by the fast computation of a certain subset cover.
We will later show that if some independent set of contains vertices of labels and with , then all these vertices come from the same child of . In particular, the vertices of label (rsp. ) cannot come from multiple children of . To implement this observation, after fixing a set of labels, for each label class in we “guess” (i.e., branch on) whether it will come from a single child of or from many. Such a guess is denoted by . So, the assignment will allow us to control the absence of edges in the sought-after independent set. For a fixed , naively branching over all possibilities of assigning the labels of to the children of with respect to would take time exponential in , which could be as large as . We will use inclusion-exclusion branching to speed-up the computations while retaining the space complexity. In some sense, we will first allow less restricted assignments of labels to the children of , and then filter out the ones that result in non-independent sets using the construction of a certain auxiliary graph. The former will be implemented by using “less restricted” guesses where reflects that vertices of the corresponding label come from at least one child of . Note that if the vertices of some label come from exactly one child of , then such an independent set satisfies both and . Although it might seem counterintuitive, this type of guesses will enable a fast computation of a certain subset cover. After that, we will be able to compute the number of independent sets satisfying guesses of type by observing that independent sets where some label occurs in at least two children of can be obtained by counting those where label occurs in at least one child and subtracting those where this label occurs in exactly one child.
We now proceed to a formalization of the above. Let and be fixed. Let be an arbitrary linear ordering of . To compute the number of independent sets that match our choice of , we proceed by iterating over , and we count independent sets where the labels in occur exactly once, and the number of such sets where the labels occur at least once. Later, we will obtain the desired number of independent sets via carefully subtracting these two values. In particular, let , and we denote by the number of independent sets of size of such that
-
•
for every label , we have ;
-
•
for every label with , there exists a unique child of such that ;
-
•
for every label with , there exists at least one child of such that ;
-
•
for every label with , there exists a unique child of such that ;
-
•
and for every label with , there exist at least two children and of such that and .
Then for we define the polynomial as
We now proceed with some observations that directly follow from the definitions.
For every and integer , we have
and hence,
| (1) |
Moreover, for every , every and every , we have
and hence
| (2) |
It remains then to show how to compute, for every and every , the polynomial . It is worth mentioning that if is such that and , then is exactly the number of independent sets of size of satisfying the following:
-
1.
For every , we have .
-
2.
For every , there exists a unique index such that .
-
3.
For every , there exists a (not necessarily unique) index such that .
We will therefore write instead of and we define the polynomial (where “T” stands for “transformed”) as Recall that because we are computing and in a top-down manner, some queries for will be made during the computation. Before continuing in the computation of , let us first explain how to request the polynomials from each child of . If is not the root, let be its parent in , and we use (where “P” stands for “parent”) to denote the polynomial
| where | |||
is the number of independent sets of of size that contain a vertex with label (i.e., ) if and only if holds, where the labels are treated with respect to . Then it holds that
| (3) |
As our next step, we make some observations that will not only allow to restrict the ’s we will need in computing the polynomial from the polynomials , but will also motivate the forthcoming definitions. Recall that we have fixed and , and in and we are only counting independent sets such that if and only if .
If there exist such that , then for any independent set counted in , there exists a unique such that .
Proof 3.1.
Both and are non-empty. So if there are at least two distinct and in such that and are non-empty, then implies that there is a complete bipartite graph between and . Hence the graph induced on would contain an edge, which is a contradiction.
Recall that for every label , each independent set contributing to the value has the property that there are distinct children and such that and are both non-empty. Then by Section˜3.1 for every it holds that if , then for all . So if does not satisfy this, the request can be directly answered with . Otherwise, since we use Section˜3.1 for recursive requests, the requests made all have the property that for each the following holds: if , then for all . We call such ’s conflict-free and we restrict ourselves to only conflict-free ’s. In other words, we may assume that if and , then we have . Observation 3.1 implies that for such and , each independent set counted in is such that for some child of . Now, to capture this observation, we define an auxiliary graph as follows. The vertex set of is and there is an edge between vertices if and only if . Thus, by the above observation, if we consider a connected component of , then in each independent set counted in , all the vertices of with labels from come from a single child of .
Let be a connected component of . For every independent set counted in , there exists a unique such that .
We proceed with some intuition on how we compute by requesting some . Let be some independent set counted in . This set contains vertices with labels from the set , and the assignment determines whether there is exactly one or at least one child from which the vertices of a certain label come from. Moreover, by Section˜3.1, for two labels from the same connected component of , the vertices with labels and in come from the same child of . Hence, to count such independent sets, we have to consider all ways to assign labels from to subsets of children of such that the above properties are satisfied—namely, each connected component of is assigned to exactly one child while every label from is assigned to at least one child. Since the number of such assignments can be exponential in , we employ the fast computation of a certain subset cover.
We now formalize this step. Let we denote the set of connected components of . The universe (i.e., the set of objects we assign to the children of ) is defined as . For every , we define a mapping (i.e., to polynomials over and ) as follows: where intuitively performs a union over all the present labels—formally:
So if we fix the set of labels coming from the child , then the (unique) coefficient in reflects the number of independent sets of using exactly these labels (with respect to ). The exponent of the formal variable is intended to store the number of connected components of assigned to . This will later allow us to exclude from the computation those assignments of labels from to children of where the elements of some connected component of are assigned to multiple children of . For every , we define a similar function as follows:
Observe that the function is injective and hence is well-defined. The mapping filters out those assignments where some connected component of is “split”. For simplicity of notation, when and are clear from the context, we omit the superscript .
Crucially for our algorithm, we claim that the following holds:
where for a polynomial the polynomial is defined as . In simple words, the operator first removes all terms where the degree of is not equal to and then “forgets” about . Before we provide a formal proof, let us sketch the idea behind it. On the left side of the equality, we have the polynomial keeping track of the independent sets of that “respect” . First, for every label , some vertex of this label must occur in at least one child of : this is handled by considering all covers where for every , the set represents the labels assigned to the child . Next, if some “splits” a connected component, i.e., takes only a proper non-empty subset of this component, then such an assignment would not yield an independent set by Section˜3.1 and the function ensures that the corresponding cover contributes zero to the result. Hence, for every cover with a non-zero contribution to the sum, every connected component of is completely contained in at least one . In particular, this implies that for every non-zero term on the right side, the degree of the formal variable in this term is at least . On the other hand, if some connected component of is contained in several sets , then the degree of the corresponding monomial is strictly larger than the total number of connected components and such covers are excluded from the consideration by applying . We formalize this intuition below:
Lemma 3.2.
Let be a -tree model of an -vertex graph . Let be a non-leaf node of and let be the children of . For every , and every conflict-free , it holds that
Proof 3.3.
First, we bring the right-hand side of the equality into a more suitable form.
We recall that is injective so the sum above is well-defined. So we have to prove that
i.e.,
| (4) |
To prove that these two polynomials are equal, we show that for every power of , the coefficients at in both polynomials are equal. So let us fix an arbitrary integer .
For one direction, let be an independent set counted in the coefficient at the term on the left-hand side ; in particular, we then have . For every , let , , and . Clearly, we have and . Now consider some . The set is an independent set of that contains vertices with labels from exactly (with respect to ). So is counted in . Let and . Note that , , and . Then by Section˜3.1, for every connected component of and every , we either have or . Therefore, for every , we have . and hence, where . Finally, by the definition of objects counted in , since the labels from occur in exactly one child of , it holds that for any . Together with this implies that for every connected component of , there exists exactly one index with , i.e., . So we obtain Altogether, the tuple is counted in the product and the properties shown above imply that this product contributes to the coefficient at the monomial . Also note that the mapping of to is injective so we indeed obtain that the coefficient at on the left-hand side of (4) is at most as large as one the right-hand side.
Now we show that the other inequality holds as well. Let , , , and be such that the following properties hold:
-
•
,
-
•
,
-
•
for every , it holds that ,
-
•
,
-
•
and for every , the set is an independent set of of size such that for every , holds iff , i.e., is counted in .
Let . Since for every , we have , the sets are pairwise disjoint and we have . We also have and for every , we have iff , i.e., contains vertices with labels from exactly with respect to . We claim that is an independent set of . Since are independent sets of , respectively, and are induced subgraphs of , it suffices to show that there are no edges between and for any . For this, suppose there is an edge of with and for some . Also let and . Since is the lowest common ancestor of and , it holds that . By the assumption of the lemma, the mapping is conflict-free so we have . Then, the property implies that and belong to the same connected component, say , of . Recall that we have , , , and . Hence, it holds that and . On the other hand, let be an arbitrary connected component of and let be some label. The property implies that there exists an index with . Due to we then have . I.e., every connected component of is contained in at least one of the sets while is contained in at least two such sets so we get – a contradiction.
Hence, the set is indeed an independent set of of size such that it contains vertices with labels from exactly with respect to . So it is counted in the coefficient of the term in . Finally, first note that is uniquely mapped to the tuple so it is counted only once on the right-hand side. And second, the mapping of to is injective (since are pairwise disjoint). Therefore, the coefficient at the term on the right-hand side of (4) is at most as large as on the left-hand side. Altogether, we conclude that the two polynomials in (4) are equal, as desired.
The above lemma implies that:
| (5) |
We now have the equalities required for our algorithm to solve Independent Set parameterized by shrubdepth. By using these equalities directly, we would obtain an algorithm running in time and space . However, the latter can be substantially improved by using a result of Pilipczuk and Wrochna [45] based on the Chinese remainder theorem:
Theorem 3.4 ([45]).
Let be a polynomial in one variable of degree at most with integer coefficients satisfying for . Suppose that given a prime number and , the value can be computed in time and space . Then given , the value can be computed in time and space .
With this, we can finally prove:
See 1.1
Proof 3.5.
The independent set polynomial of the graph is exactly where is the root of . Let us denote this polynomial . To apply Theorem˜3.4, we use . Let be a prime number. The bound on implies that any number from can be encoded using bits, this will bound the space complexity. There are at most independent sets of so every coefficient of lies between and , and therefore the prerequisites stated in the first sentence of Theorem˜3.4 are satisfied. Let . We will now show that the value can be evaluated in time and space . At that point, the result will follow by Theorem˜3.4.
Since we are interested in the evaluation of at modulo , instead of querying and storing all coefficients, as a result of the recursion, we return the evaluation of a certain polynomial (e.g., ) at modulo . For this, the formal variable is always substituted by and then arithmetic operations in are carried out. In the following, when computing a sum (resp. product) of certain values, these values are computed recursively one after another and we store the counter (e.g., current subset ) as well as the current value of the sum (resp. product). Our algorithm relies on the equalities provided above and we now provide more details to achieve the desired time and space complexity. Let us denote for simplicity.
First, if is a leaf of , then can be computed directly via
| (6) |
and this is our base case. Otherwise, the queries are answered recursively and five types of queries occur, namely , , , , and . Let be an inner node with children . To answer a query for , we recurse via (1). If , then we first construct given by and and then query . Then, to answer a query , we recurse via (5). And finally, to answer a query , we recurse using (3).
Each of the above recurrences is given by a combination of sums and products of the results of recursive calls and these values are from . To keep the space complexity of the algorithm bounded, for such recursion, the result is computed “from inside to outside” by keeping track of the current sums (resp. products) as well as the next value to be queried. For example, for (5), we iterate through all , store the current value of the outer sum (modulo ), then for fixed , we iterate over and store and the current value of the product (modulo ), and then for fixed and , iterate through and store the current value of and the current inner sum. After the complete iteration over (resp. ) we update the current value of the product (resp. outer sum) and move on to the next (resp. ).
Now we analyze the time and space complexity of the algorithm. We start with the running time. For this, we analyze how often every query is answered. Namely, for all relevant values of , , , , , and , for each query , , , , resp. , we use , , , , , respectively, to denote the number of times the query is answered by the algorithm and we call this value the multiplicity of the query. Then, for , we define the value to be the maximum multiplicity of a query over all nodes at height in and all reasonable . Similarly, we define the values , , , and where we maximize over all nodes at height and all reasonable values of , , , and . We now upper bound these values.
Let be a node at height for some . If , then a query is not asked at all. Otherwise, let be the parent of , and let be such that is the -th child of . Then can be asked when answering some query of the form to compute some value such that . Therefore, for fixed and , the value is queried at most times, so we obtain and hence,
Next, we consider a query of form . Observe that for every when recursing via (1) to answer , we branch on the values and for one after another. Thus, after steps every branch results in its own , and hence, in its own . Therefore, if we fix , then every is queried at most once when answering . Hence, we have
and therefore, . Every query is also asked at most once while answering a query of , i.e., and .
Further, for each fixed , a query is asked exactly once for every query of , i.e., and . Finally, a query of the form is queried at most once for every query of the form , so we have and .
By induction over , we obtain that
and
for every , i.e., any fixed query is asked times.
There are nodes in and there are at most reasonable values of ; for any , there are at most choices for , , and ; and there are at most reasonable values of . Hence, there are at most
different forms of queries and so there are at most recursive calls.
Next, we bound the time spent on each query additionally to the recursive calls. For each query, this additional time is mostly determined by arithmetic operations. For a query of the form , arithmetic operations are carried out over polynomials in a formal variable where the coefficients are from . It is crucial to observe that since in the end of the computation we apply the operation and the auxiliary graph has at most connected components, we can safely discard coefficients at terms for any . Therefore, it suffices to keep track of at most coefficients from . For the remaining queries, the arithmetic operations are carried out over . So in any case, there are at most relevant values from to store as a partial sum resp. product and a single arithmetic operation can be therefore carried out in time. Further, when answering a query of the form and computing a value of the form for this, we can check whether for there is with as follows. First, we compute the connected components of : we start with a partition of into singletons and then iterate over all pairs of vertices and and if , then we merge the sets containing and . As a result of this process, we obtain the set of connected components of . Then for each connected component , we check if holds. If this does not hold for at least one connected component, then we conclude that . Otherwise, the desired set exists and we have where is the number of connected components with . This process then runs in time and space . Although this can be accelerated, this step is not a bottleneck so this time and space complexity suffices for our purposes. Also, when answering a query of the form , we need to check whether there exist labels with and : this can be done in time and space by considering all pairs and looking up these properties. So for any query, the time spent on this query apart from the recursive calls is bounded by . And the total running time of the algorithm is bounded by , i.e., the number of queries times the complexity of a single query.
Finally, we bound the space complexity. The space used by a single query is to store the partial sums and/or products modulo as well as the counters that store the information about the next recursive call (e.g., current ). For any query other than , the partial result is in . For a query of the form , we are working with a polynomial in the formal variable . Above we have argued why the coefficients at for can be discarded. Therefore, it suffices to keep track of at most coefficients from . Recall that so any value from can be encoded with bits. When answering a query of the form , we also need to consider the connected components of : as argued above, this can be accomplished in space. So the space complexity of a single query can be bounded by . The depth of the recursion is bounded by : the depth of is and for each node, there are at most recursive calls queried at this node (namely, , , , , , ). Finally, during the algorithm we need to keep track of the node we are currently at. Therefore, the space complexity of the algorithm is .
3.2 Counting List-Homomorphisms
We now explain how to apply the techniques from Section˜3.1 to a broader class of problems, namely all problems expressible as instantiations of the #-List--Homomorphism problem for a fixed pattern graph (which we will introduce in a moment). In this way, we cover problems such as Odd Cycle Transversal and -Coloring, for a fixed . Furthermore, the techniques will be useful for solving Dominating Set later.
Let be a fixed undirected graph (possibly with loops) and let be a designated set of vertices. An instance of the -Weighted #-List--Homomorphism problem consists of a graph , a weight function , a list function , a cardinality and a total weight . The goal is to count the number of list -homomorphisms of such that exactly vertices of are mapped to and their total weight in is . More formally, we seek the value
We say that such has cardinality and weight . For the “standard” #-List -Homomorphism problem we would use , , and unit weights. We also have the following special cases of the -Weighted #-List--Homomorphism problem. In all cases, we consider unit weights.
-
•
To model Independent Set, the pattern graph consists of two vertices and and the edge set contains a loop at and the edge . The set consists of only. Then Independent Set is equivalent to finding the largest for which we have a positive number of solutions in the constructed instance of -Weighted #-List--Homomorphism.
-
•
Similarly, to model Odd Cycle Transversal, the pattern graph is a triangle on vertex set with a loop added on . Again, we take .
-
•
To model -Coloring, we take to be the loopless clique on vertices, and .
While in all the cases described above we only use unit weights, we need to work with any weight function in our application to Dominating Set.
Theorem 3.6.
Fix a graph (possibly with loops) and . There is an algorithm which takes as input an -vertex graph together with a weight function and a -tree-model, runs in time and uses space , and solves the -Weighted #-List--Homomorphism in , where denotes the maximum weight in .
Using the argumentation above, from Theorem˜3.6 we can derive the following corollaries.
Corollary A.
Fix a graph (possibly with loops). Then given an -vertex graph together with a -tree-model, #-List--Homomorphism in can be solved in time and space .
Corollary B.
Fix . Then given an -vertex graph together with a -tree-model, -Coloring and Odd Cycle Transversal in can be solved in time and space .
The remainder of this section is devoted to the proof of Theorem˜3.6. We assume that the reader is familiar with the approach presented in Section˜3.1, as we will build upon it.
Let now and be fixed and let be the maximum weight in . Now we show how to adapt our techniques from Section˜3.1 to the -Weighted #-List--Homomorphism problem. We assume that the graph is provided with a -model . There are two main changes: first, we adapt the dynamic programming formulas and second, we show how to apply Theorem˜3.4 to polynomials in two variables that will appear in the proof.
We start with dynamic programming. Let be a node of . For Maximum Independent Set, our guess was the set of labels occurring in an independent set of the current subgraph . Now, instead, we guess a subset of . For each label , the set is intended to reflect to which vertices of the set is mapped by a homomorphism. The set has size , i.e., for fixed . So as in Section˜3.1, there are still possibilities for and this will be the reason for the running time of as in that section. As before, we then employ guesses of the form and to compute the polynomials reflecting the number of -homomorphisms of certain cardinality via inclusion-exclusion. Further, we need to forbid that edges of are mapped to non-edges of . For this, the auxiliary graph again has vertex set but now there is an edge between two vertices and whenever and is not an edge of . Then, if a homomoprhism maps a vertex with label to and a vertex with label to , our approach from Section˜3.1 ensures that and come from the same child of so that no edge between and is created at .
In Section˜3.1, all polynomials had only one variable whose degree reflected the size of an independent set. Here, additionally to cardinality we are interested in the weight of vertices mapped to . So instead of univariate polynomials from , we use polynomials in two variables and where the degree of keeps track of the weight. The weights of partial solutions are initialized in the leaves of the tree-model, there we also take care of lists : the polynomial for a guess and a leaf is given by provided for some and , and otherwise this polynomial is the zero polynomial.
With this adaptations in hand, by a straightforward implementation of the recursion we can already obtain a -time algorithm that uses only polynomial space and computes the polynomial where is the number of list -homomorphisms of of cardinality and weight . The answer to the problem is then the value . To obtain logarithmic dependency on the graph size in space complexity, in Section˜3.1 we relied on Theorem˜3.4. However, Theorem˜3.4 concerns univariate polynomials, while has two variables. We now explain how to model as a univariate polynomial in order to apply the theorem.
Let
First, observe that and form a base representation of the degree of the corresponding monomial. So the coefficient standing by in is exactly , i.e., the value we seek. Further, it holds
so evaluating at some value modulo a prime number is equivalent to computing the value .
It remains to choose suitable values to apply Theorem˜3.4. The degree of is bounded by . The number of -homomorphisms of , and hence each coefficient of as well, is bounded by . Since is a problem-specific constant, there is a value of magnitude satisfying the prerequisities of Theorem˜3.4. Then for a prime number , any value from is bits long. Now to compute the value for some , we proceed similarly to Section˜3.1: during the recursion, instead of storing all coefficients of the polynomials, as a partial result we only store the current result of the evaluation at and modulo .
Let us now summarize the time and space complexity of this evaluation similarly to Section˜3.1. The depth of is and per node of , there are at most recursive calls where reflects that the transformation from to is carried out for every element of a guess (recall the tables in Section˜3.1). Due to , the recursion depth is then . The number of possible guesses as well as reasonable and is bounded by . Also, for a node and a reasonable , the auxiliary graph has at most vertices. Recall that in Section˜3.1, at some point of the computation we work with a polynomial using a variable . For this variable, only coefficients at monomials for are relevant. Hence, for each query we need to keep only coefficients from and such a coefficient uses bits. The addition and multiplication of two such coefficients can be done in time . These properties imply that following the argument from Section˜3.1 we obtain the running time of and space complexity of .
With that, Theorem˜3.4 implies that the coefficients of , and in particular the sought value , can be reconstructed in time and using space. This concludes the proof of Theorem˜3.6.
We remark that the result of Theorem˜3.6 can be combined with the Cut&Count technique of Cygan et al. [15] in order to incorporate also connectivity constraints to List -Homomorphism and solve problems like Connected Vertex Cover and Connected Odd Cycle Transversal. In essence Cut&Count provides a randomized reduction from List -Homomorphism with connectivity constraints to #-List -Homomorphism for a new pattern graph with at most twice as many vertices as . Since in the reduction only the parity of the number of solutions is preserved, in Cut&Count one typically uses the Isolation Lemma [35] to sample a weight function so that with high probability, there is exactly one (and thus, an odd number) solution of minimum possible weight; then counting the number of solutions mod for all possible weights reveals the existence of a solution. Note here that the algorithm of Theorem˜3.6 is already prepared to count weighted solutions. In our setting, the usage of Isolation Lemma necessitates allowing randomization and adds an factor to the space complexity for storing the sampled weights. We leave the details to the reader.
3.3 Max-Cut
In the classical Max Cut problem, we are given a graph and the task is to output . Towards solving the problem, let us fix a graph and a -tree model of . Recall that for every node of , and , we denote by the set of vertices in labeled at , i.e., . Given a child of , we let and we denote by the set of vertices in labeled at , i.e., . By we denote the set . Given , we define the -signature of — denoted by — as the vector . We let be the set of -signatures of all the subsets of , i.e., . Observe that holds. Also, for the children of , we define as the set of all tuples with for each . Given , we define as the maximum of over all the subsets with -signature . To solve Max Cut on , it suffices to compute where is the root of .
Let be a child of . We start explaining how to compute by making at most calls to the function . Given , we define as the vector such that, for each , we have . Observe that for every , we have . Consequently, for every , is the maximum of over the -signatures such that . It follows that we can compute with at most calls to the function .
Given a node of with a child and , we can compute in space and time with oracle access to the function .
In order to simplify forthcoming statements, we fix a node of with children . Now, we explain how to compute by making at most calls to the functions . The first step is to express in terms of . We first describe in terms of . We denote by the set of edges of whose endpoints lie in different ’s, i.e. . Given , we denote by the intersection of and . In simple words, is the set of all cut-edges (i.e., between and ) running between distinct children of . For , we denote by the subset of consisting of the edges whose endpoints are labeled and . We capture the size of with the following notion. For every , and , we define
It is not hard to check that, for every subset with -signature , is the size of being the set of pairs of distinct vertices in labeled and at such that exactly one of them is in . Observe that when , then is the number of pairs in whose endpoints belong to different sets among . Moreover, given a child of , the number of pairs in whose both endpoints belong to is exactly . Thus when , we have
| (7) |
We capture the size of with the following notion. For every , and -matrix , we define
Note that . Hence, by Equation 7, we deduce that . Since is the disjoint union of and the sets , we deduce:
For every we have
We are ready to express in terms of and .
Lemma 3.7.
For every , we have
Proof 3.8.
Let . By Section˜3.3 we know that
where is a shorthand for . Observe that for every , we have iff . Since is the maximum over all with -signature while only depends on and not on the concrete choice of , we conclude that equals plus
To compute we use a twist of Kane’s algorithm [36] for solving the -dimensional Unary Subset Sum in Logspace. The twist relies on using a polynomial, slightly different from the original work of Kane [36], defined in the following lemma.
Given a vector and , we denote by the vector . We denote by the number and, given a vector , we denote by the sum .
Lemma C.
Let and . Let be the number of tuples such that and
For every prime number , we have (mod ) where
Proof 3.9.
First, note that
| (8) |
where
As in [36], the idea of this proof is to change the order of summation, show that the terms where cancel out, and prove that the sum of the terms where is . The latter is implied by the following claim.
Claim D.
For every , the absolute value of is at most . Moreover, iff and .
By definition of , we have
I.e.,
with
We claim that the absolute value of each is at most . For every , by definition, and are at least and at most . Hence, for each the absolute value of is at most . Both and are upper bounded by . Moreover, from the definition of the functions , we deduce that both and are upper bounded by . It follows that the absolute value of is at most . Thus, the absolute value of is at most .
It remains to prove that that iff for every . One direction is trivial. For the other direction, observe that if , then the absolute value of is at least . But the absolute value of is at most . Hence, if , then . By induction, it follows that is equivalent to for every .
By using Equation˜8 on and interchanging the sums, we deduce that
It was proven in the proof of Lemma 1 in [36] that
We infer from the above formula that
Observe that, for every , we have iff because and the absolute value of is at most by ˜D. From the equivalence given by ˜D, we deduce that there are tuples such that , i.e.,
With this, we can prove Theorem 1.2 via Algorithm˜1. As a subroutine, we use the function NextPrime(), which computes the smallest prime larger than .
Lemma E.
Let . Algorithm˜1 computes in space and time with oracle access to the functions .
Proof 3.10.
The correctness of Algorithm˜1 follows from the following claims. Let be an integer between 0 and , and let be the integer defined in ˜C.
Claim F.
If the algorithm returns , then .
Suppose there exists a prime number such that (mod ). As (mod ) by ˜C, we have and thus there exists such that and From Section˜3.3, we deduce that there exists such that and .
Claim G.
If (mod ) for every value taken by the variable , then .
Let be the product of the values taken by . Then is a product of distinct primes such that (mod ). By ˜C, we have (mod ) for every prime . Therefore, is a multiple of . Observe that and . Hence, we have . Since corresponds to the number of tuples that satisfy some properties, we have . As divides and , we conclude that .
Complexity.
We adapt the arguments used in [36] to prove the complexity of our algorithm.
-
•
First, the variable is never more than . Indeed, standard facts about prime numbers imply that there are prime numbers between and . Each of these primes causes to increase by at least 1. Thus, each value of can be encoded with bits.
-
•
Secondly, observe that we can compute in space . Recall that
To compute , it is sufficient to keep track of the current value of , the current running total (modulo ) and enough information to compute the next term, i.e. or . For that, we need only the current values of (at most bits) and (at most bits) and the current running total to compute (or ) modulo .
-
•
Finally, primality testing of numbers between and can be done in space via divisions, and thus each call to can be computed in time and space.
We are now ready to prove that one can solve Max-Cut in time using space.
See 1.2
Proof 3.11.
Given the root of , we solve Max-Cut by computing . For every internal node of of with children , we use Algorithm˜1 to compute each call of from calls to . For every internal node with child , we use Section˜3.3 to compute each call of from calls to . Finally, for every leaf of , we simply have for every because is a singleton.
First, we prove the running time. By ˜E, for each node with children and , we compute by calling at most times the functions . By Section˜3.3, for each node with parent and , we compute by calling at most times the function . Consequently, we call each of these functions at most times in total. Since has nodes, we conclude that computing this way takes time.
Finally, observe that the stack storing the calls to these functions is of size at most . Our algorithm solves Max Cut in space .
3.4 Dominating Set
In this section we prove Theorem˜1.3, which we recall for convenience.
See 1.3
The remainder of this section is devoted to the proof of Theorem˜1.3. Note that Dominating Set cannot be directly stated in terms of -homomorphisms for roughly the following reason. For -homomorphisms, the constraints are universal: every neighbor of a vertex with a certain state must have one of allowed states. For Dominating Set, there is an existential constraint: a vertex in state “dominated” must have at least one neighbor in the dominating set. Also, the state of a vertex might change from “undominated” to “dominated” during the algorithm. The techniques we used for -homomorphisms cannot capture such properties.
The problem occurs for other parameters as well. One approach that circumvents the issue is informally called inclusion-exclusion branching, and was used by Pilipczuk and Wrochna [45] in the context of Dominating Set on graphs of low treedepth. Their dynamic programming uses the states Taken (i.e., in a dominating set), Allowed (i.e., possibly dominated), and Forbidden (i.e., not dominated). These states reflect that we are interested in vertex partitions into three groups such that there are no edges between Taken vertices and Forbidden vertices; these are constraints that can be modelled using -homomorphisms for a three-vertex pattern graph . Crucially, for a single vertex , if we fix the states of the remaining vertices, the number of partitions in which is dominated is given by the number of partitions where is possibly dominated minus the number of partitions where it is not dominated, i.e., informally “Dominated = Allowed - Forbidden”. We will come back to this state transformation later to provide more details. We also remark that the transformed formulation of dynamic programming is exactly what one gets by applying the zeta-transform to the standard dynamic programming for Dominating Set.
For technical reasons explained later, our algorithm uses the classic Isolation Lemma:
Theorem 3.12 (Isolation lemma, [39]).
Let be a non-empty set family over the universe . For each , choose a weight uniformly and independently at random. Then with probability at least there exists a unique set of minimum weight in .
Consequently, we pick a weight function that assigns every vertex a weight from uniformly and independently at random. Storing takes space. By Theorem˜3.12, with probability at least among dominating sets with the smallest possible cardinality there will be a unique one of minimum possible weight.
To implement the above idea, we let the graph have vertex set standing for Taken, Allowed, and Forbidden. This graph has a loop at each vertex as well as the edges and . Further, let . Following our approach for -homomorphisms, for every set with , every cardinality , and every weight , in time and space (recall that here for the maximum weight we have ) we can compute the value being the number of ordered partitions of satisfying the following properties:
-
1.
there are no edges between and ;
-
2.
and ; and
-
3.
for every and , we have iff .
Note that we do not care whether vertices of some label are mapped to or not.
After that, we aim to obtain the number of dominating sets of cardinality and weight from values . For this we need to transform the “states” Allowed and Forbidden into Dominated. Above we have explained how this transformation works if we know the state of a single vertex. However, now the set only captures for every label , which states occur on the vertices of label . First, the vertices of this label might be mapped to different vertices of . And even if we take the partitions where all vertices of label are possibly dominated and subtract the partitions where all these vertices are not dominated, then we obtain the partitions where at least one vertex with label is dominated. However, our goal is that all vertices of label are dominated. So the Dominated = Allowed - Forbidden equality is not directly applicable here.
Recently, Hegerfeld and Kratsch [34] showed that when working with label sets, this equality is in some sense still true modulo . On a high level, they show that if we fix a part of a partition satisfying the above properties, then any undominated vertex might be put to any of the sides and . Thus, if is not a dominating set of , then there is an even number of such partitions and they cancel out modulo .
Now we follow their ideas to formalize this approach and conclude the construction of the algorithm. For and we define the value as the number of ordered partitions of with the following properties:
-
1.
there are no edges between and ;
-
2.
and ;
-
3.
for every and , we have iff ; and
-
4.
is dominated by .
The following observation is obvious.
Claim H.
For every , we have .
Next, we observe that it suffices to compute values for and .
Claim I.
is the number of dominating sets of size and total weight .
Proof 3.13.
Consider a partition counted in . Recall that . So the fourth property implies that is dominated by , i.e., is a dominating set of . The first property then implies that is empty and . Finally, by definition of , we know that the size of is and its weight is . On the other hand, every dominating set of cardinality and weight defines a partition counted in .
Finally, we prove that modulo , can be computed from .
Claim J.
For every and every , it holds that
Proof 3.14.
We follow the proof idea of Hegerfeld and Kratsch. For , let be the set of partitions counted in (see the definition above). Note that we have for any . So
Let be the set of partitions counted in and let . The goal is to prove .
By definition of these values we have . We claim that the size of is even. To see this, consider some fixed partition . This is exactly the case if the following properties hold:
-
1.
there are no edges between and ;
-
2.
and ;
-
3.
for every and , we have iff ; and
-
4.
the set is dominated by while the set is not dominated by ,
Let . The last property implies that is non-empty. Also let and . Observe that due to the first property. We claim that if we fix the first set of the partition as well as the partition of (by fixing and ), then the extensions of to a partition in are exactly the partitions of form
| (9) |
for . So informally speaking, if we fix , every vertex of can be put to either or thus giving rise to an even number of such extensions.
Now we prove this claim following the idea of Hegerfeld and Kratsch. First, consider a partition of form (9) for an arbitrary . Since is fixed and the partition on is fixed as well, the last three properties defining trivially hold. Next, due to , there are no edges between and . And since is not dominated by , there are no edges between and as well, so the first property holds too.
For the other direction, if we consider an extension of , then by the first property we know that has no edges to and hence, it is a subset of .
So, for any fixed , either there is no extension to a partition from at all or there are of them where is a non-empty set. So the size of is even and this concludes the proof.
The application of ˜J for implies
By ˜H, the parity of the number of dominating sets of size and weight can be expressed as
Recall that every can be computed in time and space , hence this is also the case for their sum modulo 2. We compute the value for all cardinalities and all weights and output the smallest value such that for some the value is non-zero (or it outputs if no such value exists).
Now we argue the correctness of our algorithm. Let denote the size of the smallest dominating set of . First, this implies that for any and any , the value is zero. And second, Isolation Lemma (Theorem˜3.12) implies that with probability at least , the weight function isolates the family of dominating sets of of size , i.e., there exists a weight such that there is exactly one dominating set of size and weight , and therefore . In this case, the algorithm outputs . So with probability at least our algorithm outputs the minimum size of a dominating set of .
The iteration over all and increases the space complexity by an additive and it increases the running time by a factor of . Recall that in the beginning, to sample the weight function we have used space . So all in all, the running time of the algorithm is and the space complexity is . This concludes the proof of Theorem˜1.3.
Note that in our algorithm, the only reason for super-logarithmic dependency on in the space complexity is the need to sample and store a weight function in order to isolate a minimum-weight dominating set. We conjecture that this can be avoided and ask:
Question 3.15.
Is there an algorithm for Dominating Set of -vertex graphs provided with a -tree-model that runs in time and uses space?
4 The Lower Bound
In this section, we prove Theorem˜1.4. This lower bound is based on a reasonable conjecture on the complexity of the problem Longest Common Subsequence (LCS).
An instance of LCS is a tuple where and are positive integers, is an alphabet and are strings over of length . The goal is to decide whether there exists a string of length appearing as a subsequence in each . There is a standard dynamic programming algorithm for LCS that has time and space complexity . From the point of view of parameterized complexity, LCS is -hard for every level when parameterized by [7]. It remains -hard when the size of the alphabet is constant [44], and it is -complete when parameterized by [32].Abboud et al. [1] proved that the existence of an algorithm with running time for any would contradict the Strong Exponential-Time Hypothesis. As observed by Elberfeld et al. [21], LCS parameterized by is complete for the class : parameterized problems solvable by a nondeterministic Turing machine using time and space, for a computable function . See also [7, 8, 9, 10, 11] for further research on and related complexity classes.The only known progress on the space complexity is due to Barsky et al. with an algorithm running in space [4]. This motivated Pilipczuk and Wrochna to formulate the following conjecture [45].
Conjecture 4.1 ([45]).
There is no algorithm that solves the LCS problem in time and using space for any computable function , where is the total bitsize of the instance and is the number of input strings.
Note that in particular, the existence of an algorithm with time and space complexity as in ˜4.1 implies the existence of such algorithms for all problems in the class .
Our lower bound is based on the following stronger variant of ˜4.1, in which we additionally assume that the sought substring is short.
Conjecture 4.2.
For any unbounded and computable function , ˜4.1 holds even when .
Thus, we may rephrase Theorem˜1.4 as follows.
Theorem 4.3.
Unless ˜4.2 fails, for any unbounded and computable function , there is no algorithm that solves the Independent Set problem in graphs supplied with -tree-models satisfying that would run in time and use space.
The remainder of this section is devoted to the proof of Theorem˜4.3. Not surprisingly, we provide a reduction from LCS to Independent Set on graphs provided with suitable tree-models.
Let be an instance of LCS. For the sake of clarity, we assume without loss of generality that is a power of . Indeed, we can always obtain an equivalent instance where , is obtained from by adding a new letter and each is obtained by adding times at the end of .
For every , we denote the -th letter of by . In the following, we present our reduction from to an equivalent instance of Independent Set consisting of a graph with vertices and a -tree-model where and . This implies Theorem˜4.3 since for every unbounded and computable function there exists an unbounded and computable function such that if , then (we explain this in more details at the end of this section).
In the intuitions along the construction, we denote by a potential common substring of of length . The main idea is to use matchings to represent the binary encoding of the positions of the letters of in each string.
For every string and , we define the selection gadget which contains, for every , an edge called the -edge of . One endpoint of this edge is called the 0-endpoint and the other is called the 1-endpoint; i.e., a selection gadget induces a matching on edges. This results in the following natural bijection between and the maximal independent sets of . For every , we denote by the independent set that contains, for each , the -endpoint of the -edge of where is the value of the -th bit of the binary representation of (we consider the first bit to be the most significant one and the -th one the least significant). Then the vertices selected in encode the position of the -th letter of in .
We need to guarantee that the selected positions in the gadgets are coherent, namely, for every , the position selected in is strictly smaller than the one selected in . For this, we construct an inferiority gadget denoted by for every string and every . The idea behind it is to ensure that the only possibility for an independent set to contain at least vertices from , and their inferiority gadget, is the following: there exist such that the independent set contains . The maximum solution size in the constructed instance of Independent Set—which is the sum of the independence number of each gadget—will guarantee that only such selections are possible.
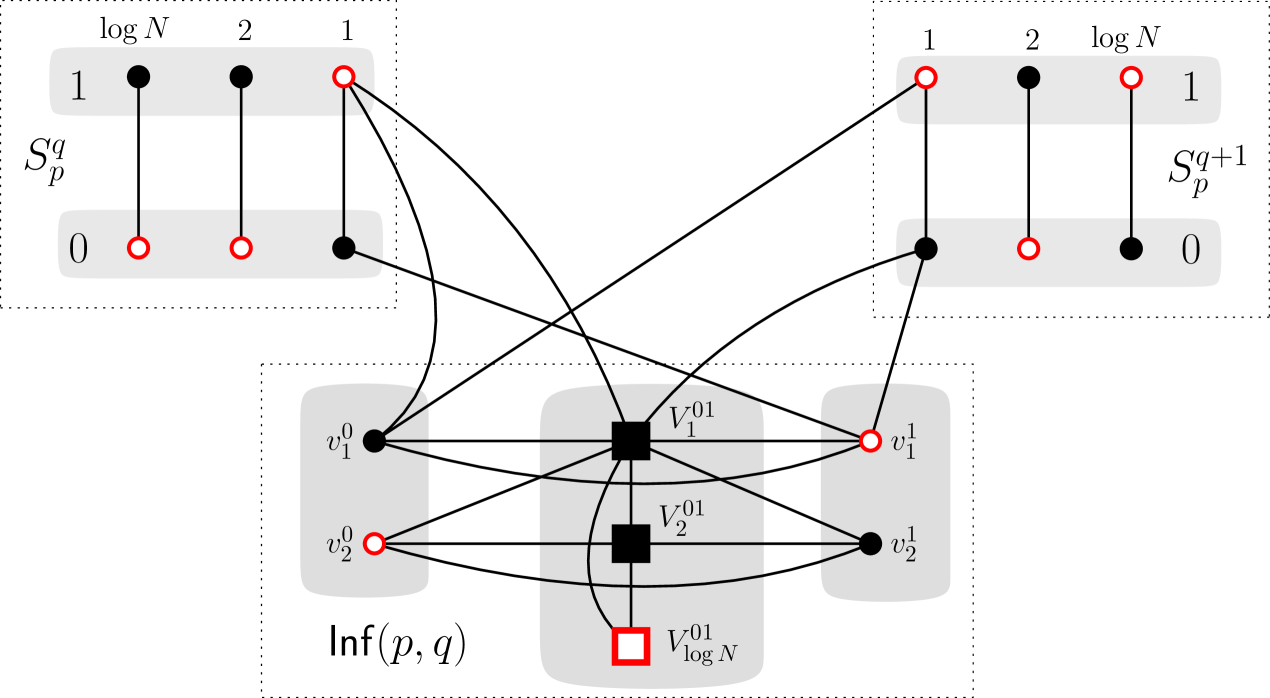
Figure˜1 provides an example of the following construction. The vertex set of consists of the following vertices: for each , there are two vertices and . Moreover, for each , there is a set of vertices (we drop from the notation when they are clear from the context). We now describe the edges incident to the inferiority gadget:
-
•
For every , and are adjacent and for each , is adjacent to the -endpoints of the -edges from and .
-
•
For every , all the vertices in are adjacent to (1) the -endpoint of the -edge from , (2) the -endpoint from the -edge of , (3) all the vertices for every and (4) all the vertices in for every .
On a high level, an inferiority gadget reflects that for values , if we go from high-order to low-order bits, then the binary encodings of and first contains the same bits and then there is an index, where has a zero-bit and has a one-bit. If such a difference first occurs at some position , then the corresponding independent set first takes vertices of the form or (for ) and then takes vertices from – this results in vertices taken in the inferiority gadget. The following statement follows from
Let and . The independence number of is and for every , we have iff there exists a set of vertices from such that the union of , and induces an independent set.
Next, we need to ensure that the positions chosen in indeed correspond to a common subsequence, i.e., for every , the -th chosen letter must be the same in every . For , let denote the set of all ordered pairs such that the -th letter of and the -th of are identical. For each and , we create the matching gadget as follows:
-
•
For every pair and for each , we create a copy of and for every and , we add an edge between the -endpoint of the -edge of and the -endpoint of the -edge of .
-
•
For every pair , we add a new vertex adjacent to (1) all the vertices from that are not in and (2) all the vertices from that are not in .
Finally, we turn into a clique. Observe that, for each , an independent set contains vertices from and its copies if and only if there exists a value such that contains and for each copy. This leads to the following observation.
Let and . The independence number of is and for every , we have iff there exists an independent set of with vertices such that the union of , and is an independent set.
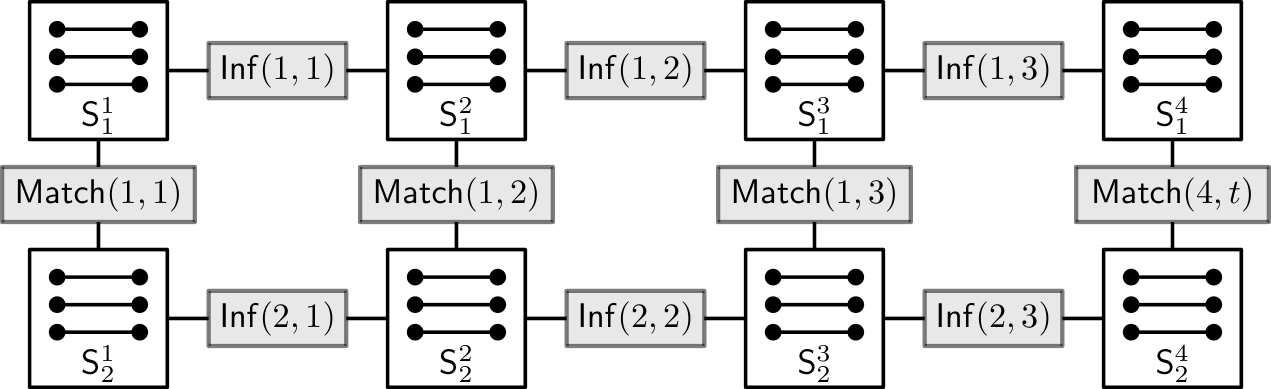
This concludes the construction of the graph . See Figure˜2 below for an overview.
We prove the correctness of the reduction in the following lemma.
Lemma 4.4.
There exists an integer such that admits an independent set of size at least iff the strings admit a common subsequence of length .
Proof 4.5.
Let .
()
Assume that admit a common subsequence of length . Then, for every string , there exist such that and for every . We construct an independent set as follows. For every selection gadget , we add to . Note that, at this point, is an independent set because there is no edge between the selection gadgets in . For every inferiority gadget , since , we can use Section˜4 and add a set of vertices from to . Note that remains an independent set because the added vertices are not adjacent to and by Section˜4 and the only edges going out of are incident to and . At this point, we have vertices in .
Observe that for every and , we have . Thus, we have and by Section˜4, there exists an independent set of with vertices such that the union of , and is an independent set. We add to and note that remains an independent set since the only edges going out of are incident to and . As we do this for every and , the union of the ’s contains vertices. We conclude that admits an independent set of size .
()
Assume admits an independent set of size at least . The independence number of each selection gadget is and, by Section˜4, this is also the case for each inferiority gadget . Hence, contains at most vertices from selection and inferiority gadgets. By Section˜4, the independence number of each matching gadget is , thus contains at most vertices from the matching gadgets. From the definition of , we obtain that contains exactly vertices from each selection and inferiority gadget, and it contains exactly vertices from each matching gadget. We make the following deductions:
-
•
For each , there exist such that contains for every .
-
•
For each and , the independent set contains the vertices in and as well as vertices from . Section˜4 implies that . Thus, is a subsequence of .
-
•
For every and , the independent set contains and as well as vertices from . We deduce from Section˜4 that and consequently, . Hence, for every , we have .
We conclude that is a common subsequence of .
The next step is to construct a tree-model of .
Lemma 4.6.
We can compute in polynomial time a -tree-model of where and .
Proof 4.7.
Let and be disjoint subsets of such that each set among has size and has size . First, we prove that the union of the gadgets associated with a position admits a simple tree-model. For every , we denote by the union of the selection gadgets with and the matching gadgets with .
Claim 1.
For every , we can construct in polynomial time a -tree-model for .
Let . We create the root of and we attach all the vertices in the selection gadgets with as leaves adjacent to . Then, for every , we create a node adjacent to and for every , we create a node adjacent to . For each , we make adjacent to the vertex and all the vertices in , . Note that all the vertices in are the leaves of the subtree rooted at , and the leaves of are exactly the vertices in . See Figure˜3 for an illustration of .
We define as follows:
-
•
maps each vertex in to a unique label in .
-
•
For every , maps all the -endpoints of the -edges from the different copies of to a unique label in .
-
•
We have for every and .
We define such that is the identity function for every . It follows that for every node of . We finish the construction of the tree-model of by proving that there exists a family of matrices such that is a -tree-model of . For doing so, we simply prove that the property holds for every label and internal node of with children , where is true if:
-
•
For every and with , we have .
Observe that trivially holds when there is at most one vertex labeled in . Consequently, is true for every node and . Moreover, is true for every internal node and every . Recall that for every node of . For every pair of distinct vertices in , if then either:
-
•
There exists such that and are the -endpoints of the -edges in respectively and for some , and . Observe that the parent of is and the neighbors of in are all children of . Indeed, the only neighbors of in are the -endpoint of the -edge of and potentially . Symmetrically, belongs to , its parent is and the only neighbors of in are children of . Moreover, observe that and have both only one neighbor in which is the -endpoint of the -edge of . We deduce that and and are true for every .
-
•
We have and . In that case, is a child of and a child of . The only neighbors of and that are not children of nor are all the other vertices of label . Thus, holds for every internal node of .
We conclude that holds for every internal node of and every . Hence, there exists a family of matrices such that is a -tree model of for every .
For every , we denote by the union of . Moreover, for every interval , we denote by , the union of the graphs over and the inferiority gadgets in over such that . We prove by induction that for every interval , there exists a -tree-model of such that given the root of , the following properties are satisfied:
-
(A)
maps each vertex from to a unique label in .
-
(B)
maps each vertex from to a unique label in .
When , we only require that exactly one property among (A) and (B) is satisfied (we can choose which one as it is symmetric). The induction is on . The base case is when , in which case and we simply modify the -tree-model for as follows. We add to a new root adjacent to the former root . We add to the function that bijectively maps to (or if we want to satisfy (B) rather than (A)) and every label not in to . Finally, we add the zero -matrix to . After these modifications, it is easy to see that is a -tree model of that satisfies (A) or (B).
Now assume that and that admits the desired tree-model for every strictly included in . Let . By induction hypothesis, there exist:
-
•
A -tree model for with the desired properties (if , we require (A) to be satisfied).
-
•
A -tree-model for with the desired properties (if , we require (B) to be satisfied).
For the sake of legibility, we assume that is different from , which implies that is not empty graph (note that is not empty as and ). We lose some generality with this assumption, but we can easily deal with the case with some simple modifications on the following construction (i.e. removing some nodes and changing some renaming functions).
In the following, we construct a -tree-model of from the above tree-models of , but also the -tree-model of given by ˜1. To obtain , we create the root of and we make it adjacent to the root of and two new vertices: and . We make adjacent to the root of and to all the vertices in . Symmetrically, we make adjacent to the root of and to all the vertices in . See Figure˜3 for an illustration of .
We define as follows:
where maps the vertices in from and to such that for each label of , there exists and such that is associated with either: (1) for some and or (2) all the vertices in for some . Since , we have enough labels for doing so. The family of renaming function is obtained from the union of by adding for every edge in that is not in or a function defined as follows:
-
•
is the identify function when is an edge adjacent to a leaf from or .
-
•
maps every label in to itself and every other label to , when is the edge between and the root of for .
-
•
maps every label in to itself and every other label to when .
-
•
maps every label in to itself and every other label to , when .
-
•
maps every label in to itself and every other label to , when .
Observe that satisfies Properties (A) and (B). As satisfies (A), this function maps every vertex from to a unique label in . The above renaming functions guarantee that the only vertices mapped to a label in by are from . We deduce that Property (A) holds and symmetrically, Property (B) holds too.
Now we prove that a family of matrices exists such that is a tree model of . As before, we prove that holds for every internal node of and every label . Since our construction is based on tree-models for and , we only need to prove that holds for every and .
We first deal with . Let us describe the labeling function . Remember that satisfies Properties (A) and (B), or just (A) when . Moreover, the renaming function associated with the edge between and preserves the labels in and maps the other labels to . Thus, assign every vertex in to a unique label in . We deduce that for every a pair of distinct vertices in , if assigns and to the same label , then either:
-
•
for some and . In this case, and are false twins by construction of —i.e. —and we deduce that holds.
-
•
and are in and not from . Then, all the neighbors of and are in and thus . We deduce that holds in this case too.
We conclude that holds for every and with symmetric arguments, we can prove that holds also for every .
For , notice that for every , the vertices in labeled by have neighbors only in , hence holds. Furthermore, every label in is mapped by to a unique vertex in , so holds. Finally, each label in is mapped by to a unique vertex or to all the vertices in for some and . Since the vertices in are false twins, we deduce that holds for every . We conclude that holds for every and thus there exists a family of matrices such that is a tree-model of .
It remains to prove that the depth of is at most . By definition of , both and are smaller than . Thus, and are smaller than . Now observe that the depth of is the maximum between (i) the depth of plus 1 which is 4, (ii) the depth of plus 2, and (iii) the depth of plus 2. The depth of is at most . Since , the depth of plus 2 is at most . Symmetrically, the depth of plus 2 is also upper bounded by . It follows that the depth of is at most .
We conclude that for every interval , admits a -tree-model. In particular, it implies that admits a -tree-model. It is easy to see from our proof that this -tree-model is computable in polynomial time.
We are now ready to prove Theorem˜4.3.
Proof 4.8 (Proof of Theorem˜4.3).
Let be an unbounded and computable function. Assume towards a contradiction that there exists an algorithm that solves the Independent Set problem in graphs supplied with -tree-models satisfying that runs in time and uses space.
Since is unbounded and computable and is monotone, there exists an unbounded and computable function such that for all sufficiently large , we have
Let be an instance of LCS such that . Our reduction provides us with a graph and an integer such that the following holds:
-
•
has vertices and thus it can be constructed in time where is the total bitsize of . Indeed, the selection gadgets are made of vertices, the inferiority gadgets have exactly vertices and the matching gadgets consist of vertices.
-
•
By Lemma˜4.4, admits an independent set of size at least iff admits a common subsequence of size .
-
•
By Lemma˜4.6, we can construct in polynomial time a -tree-model of with and .
Observe that we have
Consequently, we can run to check whether admits an independent set of size at least in time and space . Since and , it follows that we can solve in time and space . As this can be done for every instance where , it contradicts ˜4.2.
5 Fixed-Parameter Algorithms for Metric Dimension and Firefighting
The Firefighter problem on a graph is the following. At time , a vertex catches fire. Then at each time step , first a firefighter is permanently placed on a vertex that is not currently on fire. This vertex is now permanently protected. Then the fire spreads to all unprotected neighbors of all vertices currently on fire. This process ends in the time step when the fire no longer spreads to new vertices. All vertices that do not catch fire during this process (including the protected vertices) are called saved; the rest are called burned. The goal is to maximize the number of saved vertices.
Bazgan et al. [5] showed that the Firefighter problem is fixed-parameter tractable when parameterized by the treewidth of the input graph and the number of vertices that may be protected during the process. In this result, one first writes an formula that expresses that a set of vertices can be saved assuming that vertices can be protected, and then applies the optimization variant of Courcelle’s Theorem, due to Arnborg et al. [3], to find the largest vertex subset for which is satisfied. By inspection of the formula, we can see that it does not quantify over edge sets, hence is in fact an formula. Then, by replacing the usage of the algorithm of Arnborg et al. with the algorithm of Courcelle et al. [13], we conclude that the Firefighter problem is fixed-parameter tractable when parameterized by the cliquewidth of the input graph and the number of vertices that may be protected.
We now recall that in graphs with a -tree model, any induced path has length at most (this follows from [30, Theorem 3.7]; the bound accounts for our slightly different definition of a tree model). This implies that the firefighting game has at most time steps and the same amount of vertices can be protected. Hence, recalling that a graph with a -tree model has bounded cliquewidth [30, Proposition 3.4], we immediately obtain the following result.
Theorem 5.1.
The Firefighter problem is fixed-parameter tractable when parameterized by and on graphs provided with a -tree-model.
We observe that this is in contrast to the complexity of the Firefighter problem on graphs of bounded treewidth. The Firefighter problem is in fact already NP-hard on trees of maximum degree (which are graphs of treewidth ) [22] and trees of pathwidth [12].
A similar situation arises for the Metric Dimension problem. In Metric Dimension, given a graph , we are asked to find a smallest set such that for any pair , there is a vertex such that the distance between and and the distance between and are distinct. Gima et al. [31] observed that Metric Dimension is fixed-parameter tractable when parameterized by the cliquewidth and the diameter of the input. Since in graphs with a -tree model, any induced path has length at most (the bound accounts for our slightly different definition of a tree model), and any such graph has bounded cliquewidth [30], we immediately obtain the following.
Theorem 5.2.
The Metric Dimension problem is fixed-parameter tractable when parameterized by and on graphs provided with a -tree-model.
This is again in contrast to the complexity of the Metric Dimension problem on graphs of bounded treewidth. The Metric Dimension problem is in fact already -hard on graphs of pathwidth [37].
References
- [1] Amir Abboud, Arturs Backurs, and Virginia Vassilevska Williams. Tight hardness results for LCS and other sequence similarity measures. In Proc. FOCS 2015, pages 59–78, 2015.
- [2] Eric Allender, Shiteng Chen, Tiancheng Lou, Periklis A. Papakonstantinou, and Bangsheng Tang. Width-parametrized SAT: Time–space tradeoffs. Theory Comput., 10(12):297–339, 2014.
- [3] Stefan Arnborg, Jens Lagergren, and Detlef Seese. Easy problems for tree-decomposable graphs. J. Algorithms, 12(2):308–340, 1991.
- [4] Marina Barsky, Ulrike Stege, Alex Thomo, and Chris Upton. Shortest path approaches for the longest common subsequence of a set of strings. In Proc. BIBE 2007, pages 327–333, 2007.
- [5] Cristina Bazgan, Morgan Chopin, Marek Cygan, Michael R. Fellows, Fedor V. Fomin, and Erik Jan van Leeuwen. Parameterized complexity of firefighting. J. Comput. System Sci., 80(7):1285–1297, 2014.
- [6] Andreas Björklund, Thore Husfeldt, Petteri Kaski, and Mikko Koivisto. Fourier meets Möbius: fast subset convolution. In Proc. STOC 2007, pages 67–74, 2007.
- [7] Hans L. Bodlaender, Rodney G. Downey, Michael R. Fellows, and Harold T. Wareham. The parameterized complexity of sequence alignment and consensus. Theoret. Comput. Sci., 147(1&2):31–54, 1995.
- [8] Hans L. Bodlaender, Carla Groenland, Hugo Jacob, Lars Jaffke, and Paloma T. Lima. Xnlp-completeness for parameterized problems on graphs with a linear structure. In 17th International Symposium on Parameterized and Exact Computation, IPEC 2022, volume 249 of LIPIcs, pages 8:1–8:18. Schloss Dagstuhl — Leibniz-Zentrum für Informatik, 2022.
- [9] Hans L. Bodlaender, Carla Groenland, Hugo Jacob, Marcin Pilipczuk, and Michał Pilipczuk. On the complexity of problems on tree-structured graphs. In 17th International Symposium on Parameterized and Exact Computation, IPEC 2022, volume 249 of LIPIcs, pages 6:1–6:17. Schloss Dagstuhl — Leibniz-Zentrum für Informatik, 2022.
- [10] Hans L. Bodlaender, Carla Groenland, Jesper Nederlof, and Céline M. F. Swennenhuis. Parameterized problems complete for nondeterministic FPT time and logarithmic space. In 62nd IEEE Annual Symposium on Foundations of Computer Science, FOCS 2021, pages 193–204. IEEE, 2021.
- [11] Hans L. Bodlaender, Carla Groenland, and Michał Pilipczuk. Parameterized complexity of binary CSP: Vertex cover, treedepth, and related parameters. CoRR, abs/2208.12543, 2022.
- [12] Janka Chlebíková and Morgan Chopin. The firefighter problem: further steps in understanding its complexity. Theoret. Comput. Sci., 676:42–51, 2017.
- [13] Bruno Courcelle, Johann A. Makowsky, and Udi Rotics. Linear time solvable optimization problems on graphs of bounded clique-width. Theory Comput. Syst., 33(2):125–150, 2000.
- [14] Marek Cygan, Fedor V Fomin, Łukasz Kowalik, Daniel Lokshtanov, Dániel Marx, Marcin Pilipczuk, Michał Pilipczuk, and Saket Saurabh. Parameterized Algorithms. Springer, 2015.
- [15] Marek Cygan, Jesper Nederlof, Marcin Pilipczuk, Michał Pilipczuk, Johan M. M. van Rooij, and Jakub Onufry Wojtaszczyk. Solving connectivity problems parameterized by treewidth in single exponential time. ACM Trans. Algorithms, 18(2):17:1–17:31, 2022.
- [16] Matt DeVos, O-joung Kwon, and Sang-il Oum. Branch-depth: Generalizing tree-depth of graphs. European J. Combin., 90:Article 103186, 2020.
- [17] Reinhard Diestel. Graph Theory, volume 173 of Graduate texts in mathematics. Springer, 4th edition, 2012.
- [18] Rodney G. Downey and Michael R. Fellows. Fundamentals of Parameterized Complexity. Texts in Computer Science. Springer, 2013.
- [19] Jan Dreier. Lacon- and shrub-decompositions: A new characterization of first-order transductions of bounded expansion classes. In Proc. LICS 2021, pages 1–13, 2021.
- [20] Jan Dreier, Jakub Gajarský, Sandra Kiefer, Michał Pilipczuk, and Szymon Toruńczyk. Treelike decompositions for transductions of sparse graphs. In Proc. LICS 2022, pages 31:1–31:14, 2022.
- [21] Michael Elberfeld, Christoph Stockhusen, and Till Tantau. On the space and circuit complexity of parameterized problems: Classes and completeness. Algorithmica, 71(3):661–701, 2015.
- [22] Stephen Finbow, Andrew D. King, Gary MacGillivray, and Romeo Rizzi. The firefighter problem for graphs of maximum degree three. Discret. Math., 307(16):2094–2105, 2007.
- [23] Fedor V. Fomin, Petr A. Golovach, Daniel Lokshtanov, and Saket Saurabh. Intractability of clique-width parameterizations. SIAM J. Comput., 39(5):1941–1956, 2010.
- [24] Fedor V. Fomin, Petr A. Golovach, Daniel Lokshtanov, and Saket Saurabh. Almost optimal lower bounds for problems parameterized by clique-width. SIAM J. Comput., 43(5):1541–1563, 2014.
- [25] Fedor V. Fomin and Tuukka Korhonen. Fast FPT-approximation of branchwidth. In Proc. STOC 2022, pages 886–899, 2022.
- [26] Martin Fürer. Multi-clique-width. In Proc. ITCS 2017, volume 67 of Leibniz Int. Proc. Inform., pages 14:1–14:13, 2017.
- [27] Martin Fürer and Huiwen Yu. Space saving by dynamic algebraization based on tree-depth. Theory Comput. Syst., 61(2):283–304, 2017.
- [28] Jakub Gajarský and Stephan Kreutzer. Computing shrub-depth decompositions. In Proc. STACS 2020, volume 154 of Leibniz Int. Proc. Inform., pages 56:1–56:17, 2020.
- [29] Jakub Gajarský, Stephan Kreutzer, Jaroslav Nešetřil, Patrice Ossona de Mendez, Michał Pilipczuk, Sebastian Siebertz, and Szymon Toruńczyk. First-order interpretations of bounded expansion classes. ACM Trans. Comput. Log., 21(4):Art. 29, 41, 2020.
- [30] Robert Ganian, Petr Hliněný, Jaroslav Nešetřil, Jan Obdržálek, and Patrice Ossona de Mendez. Shrub-depth: Capturing height of dense graphs. Log. Methods Comput. Sci., 15(1):7:1–7:25, 2019.
- [31] Tatsuya Gima, Tesshu Hanaka, Masashi Kiyomi, Yasuaki Kobayashi, and Yota Otachi. Exploring the gap between treedepth and vertex cover through vertex integrity. Theoret. Comput. Sci., 918:60–76, 2022.
- [32] Sylvain Guillemot. Parameterized complexity and approximability of the longest compatible sequence problem. Discret. Optim., 8(1):50–60, 2011.
- [33] Falko Hegerfeld and Stefan Kratsch. Solving connectivity problems parameterized by treedepth in single-exponential time and polynomial space. In Proc. STACS 2020, volume 154 of Leibniz Int. Proc. Inform., 2020.
- [34] Falko Hegerfeld and Stefan Kratsch. Tight algorithms for connectivity problems parameterized by clique-width. Technical report, 2023. https://arxiv.org/abs/2302.03627.
- [35] Russell Impagliazzo, Ramamohan Paturi, and Francis Zane. Which problems have strongly exponential complexity? J. Comput. Syst. Sci., 63(4):512–530, 2001.
- [36] Daniel M. Kane. Unary subset-sum is in logspace. Technical report, 2010. https://arxiv.org/abs/1012.1336.
- [37] Shaohua Li and Marcin Pilipczuk. Hardness of metric dimension in graphs of constant treewidth. Algorithmica, 84(11):3110–3155, 2022.
- [38] Daniel Lokshtanov, Matthias Mnich, and Saket Saurabh. Planar -path in subexponential time and polynomial space. In Proc. WG 2011, volume 6986 of Lecture Notes Comput. Sci., pages 262–270, 2011.
- [39] Ketan Mulmuley, Umesh V. Vazirani, and Vijay V. Vazirani. Matching is as easy as matrix inversion. Combinatorica, 7(1):105–113, 1987.
- [40] Wojciech Nadara, Michał Pilipczuk, and Marcin Smulewicz. Computing treedepth in polynomial space and linear FPT time. In Proc. ESA 2022, volume 244 of Leibniz Int. Proc. Inform., pages 79:1–79:14, 2022.
- [41] Jesper Nederlof, Michał Pilipczuk, Céline M. F. Swennenhuis, and Karol Węgrzycki. Hamiltonian cycle parameterized by treedepth in single exponential time and polynomial space. In Proc. WG 2020, volume 12301 of Lecture Notes Comput. Sci., pages 27–39, 2020.
- [42] Pierre Ohlmann, Michał Pilipczuk, Wojciech Przybyszewski, and Szymon Toruńczyk. Canonical decompositions in monadically stable and bounded shrubdepth graph classes. Technical report, 2023. https://arxiv.org/abs/2303.01473.
- [43] Patrice Ossona de Mendez, Michał Pilipczuk, and Sebastian Siebertz. Transducing paths in graph classes with unbounded shrubdepth. European J. Combin., page 103660, 2022.
- [44] Krzysztof Pietrzak. On the parameterized complexity of the fixed alphabet shortest common supersequence and longest common subsequence problems. J. Comput. Syst. Sci., 67(4):757–771, 2003.
- [45] Michał Pilipczuk and Marcin Wrochna. On space efficiency of algorithms working on structural decompositions of graphs. ACM Trans. Comput. Theory, 9(4):18:1–18:36, 2018.
- [46] Egon Wanke. -NLC graphs and polynomial algorithms. Discret. Appl. Math., 54(2-3):251–266, 1994.