Sparse Bayesian Learning-Based 3D Spectrum Environment Map Construction —— Sampling Optimization, Scenario-Dependent Dictionary Construction and Sparse Recovery
Abstract
The spectrum environment map (SEM), which can visualize the information of invisible electromagnetic spectrum, is vital for monitoring, management, and security of spectrum resources in cognitive radio (CR) networks. In view of a limited number of spectrum sensors and constrained sampling time, this paper presents a new three-dimensional (3D) SEM construction scheme based on sparse Bayesian learning (SBL). Firstly, we construct a scenario-dependent channel dictionary matrix by considering the propagation characteristic of the interested scenario. To improve sampling efficiency, a maximum mutual information (MMI)-based optimization algorithm is developed for the layout of sampling sensors. Then, a maximum and minimum distance (MMD) clustering-based SBL algorithm is proposed to recover the spectrum data at the unsampled positions and construct the whole 3D SEM. We finally use the simulation data of the campus scenario to construct the 3D SEMs and compare the proposed method with the state-of-the-art. The recovery performance and the impact of different sparsity on the constructed SEMs are also analyzed. Numerical results show that the proposed scheme can reduce the required spectrum sensor number and has higher accuracy under the low sampling rate.
Index Terms:
3D spectrum environment map, sparse Bayesian learning, mutual information, propagation channel model, clustering algorithm.I Introduction
With the increase of various electronic devices, i.e., radio, radar, navigation and so on, the electromagnetic environment becomes significantly complex [1, 2, 3]. The Spectrum Environment Map (SEM) visualizes the spectrum related information, including the time, frequency and the received signal strength (RSS) of signals, and the locations of the sensor devices, on a geographical map [4, 5]. It is useful for the abnormal spectral activity detection, radiation source localization, radio frequency (RF) resource management, and so on. However, constructing an accurate SEM for the scenario with lots of buildings is still difficult. This is because the sensor device number and sampling time are limited in practice. Besides, with the development of space-air-ground integrated communication networks, electronic devices are distributed in the three-dimensional (3D) space.
Many SEM reconstruction methods have been proposed recently [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]. They can be divided into two major categories, i.e., the direct construction methods driven by massive measured data and the indirect construction methods driven by channel propagation characteristics.
The direct construction methods typically employ interpolation algorithms to recovery the missing data by mining the correlation between the given measured data. In [17], the authors utilized the Kriging interpolation to construct the two-dimensional (2D) SEM at different frequencies. A tensor completion method was used in [9] to recovery the missing data in both the spatial domain and temporal domain. Machine learning techniques have also been adopted for the data-driven REM construction. For example, from the perspective of image processing, the authors in [11] developed a generative adversarial network (GAN) to obtain the SEM based on the sampling data. Deep neural networks were used in [10] to ”learn” the intricate underlying structure from the given data and constructed the SEM. Nevertheless, the aforementioned methods mainly focus on the 2D SEM re-construction and can only achieve satisfactory performance by using a large amount of sampling data.
The indirect construction methods can greatly reduce the number of sampling data by using the rule of wireless signal propagation [18]. In [12, 13], the limited sampling data was used to estimate the transmitters’ information, and then the missing data was recovered by using the ideal propagation model. Considering the realistic propagation model, the authors in [19] modeled the spectrum data as the tomographic accumulation of spatial loss field.
However, in many practical cases, the number of sampling sensors is very limited and the spatial sampling rate may be much lower than the Nyquist rate. To tackle this issue, the compressed sensing (CS) technique is applied, which decomposes the measurement into the linear superposition of the sensing matrix and the sparse signal to realize data recovery under sparse sampling. For example, the authors in [20] constructed the SEM based on least absolute shrinkage and selection operator (LASSO) with random sparse sensing data. In [15], the authors proposed an improved orthogonal matching pursuit algorithm (OMP) to build compressed SEM with right-triangular (QR) pivoting based sampling locations optimization. However, the traditional CS approaches, such as LASSO [21], OMP [22] and linear programming [23], are point estimation for sparse signals. Besides, the SEM sensing matrix usually has high spatial correlation, which would greatly deteriorate the recovery performance from the noisy measurements. The sparse Bayesian learning (SBL) [24, 25, 26] can recover the exact sparse signal under the high correlated sensing matrix. A SBL-based SEM construction algorithm was proposed in [27]. The authors used a Laplacian function to describe the signal propagation model for sparse dictionary construction, which does not consider the realistic propagation scenario, especially the impact of buildings. Furthermore, the authors arranged the sampling sensors randomly without considering the sampling location (SL) optimization for different scenarios.
To fill these gaps, we propose a novel 3D SBL-based SEM construction scheme with optimized sampling positions of sensors and a scenario-dependent dictionary with full consideration of scenario characteristics. The main novelties and contributions of this paper are summarized as follows:
-
•
A channel propagation dictionary design method for SEM construction under sparse sampling is proposed. Combined with the ray tracing (RT) simulation technology and the spatial interpolation algorithm, the scenario-dependent SEM construction dictionary is obtained.
-
•
A maximum mutual information (MMI)-based measurement matrix optimization architecture is proposed. By modeling the construction problem as a communication channel model, the objective function is derived from the SBL framework and solved by the greedy algorithm, which improving the efficiency of spectrum data acquisition.
-
•
An improved SBL algorithm based on cluster analysis is developed for 3D compressed spectrum recovery. The maximum and minimum distance (MMD) clustering and dynamic threshold pruning are combined with the SBL, which can recover sparse signals and achieve accurate SEM construction.
The rest of this paper is organized as follows. Section II gives the 3D SEM construction model and the sparse sampling model. In Section III, the details of proposed 3D SEM construction scheme is given and demonstrated. Then, Section IV presents the simulation and comparison results and Section V gives some conclusions.
II System Model
II-A 3D SEM Model
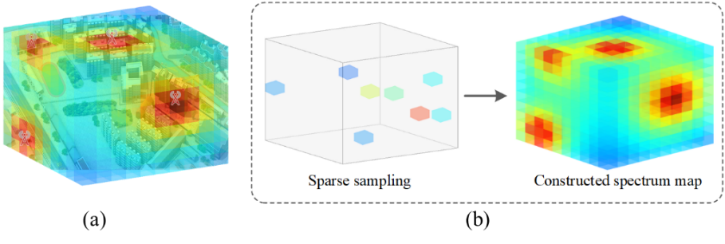
As shown in Fig.1, the region of interest (ROI) is discretized into several small cubes. Each cube is colored according to its RSS, where red cubes represent high RSS values and blue cubes represent low RSS values. The ROI constitutes a spectrum tensor in the 3D space, where , , indicate the grid number along , , dimensions, respectively. Technically, 3D SEM construction in this paper aims to recovery RSS values of all cubes based on the known RSS values of sampling cubes.
A sparse signal vector can be defined as
| (1) |
where is the transmitting power of the th RF transmitter. is a -sparse signal vector with . That is if there are stationary RF transmitters denoted as , where is the location of th RF transmitter, we have nonzero elements in .
Suppose that we select SLs from all cubes denoted by and . The sampling rate is . The Euclidean distance from the th transmitter to the th SL can be written as
| (2) |
Under the line-of-sight (LOS) condition, the RSS from the th transmitter to the th SL can be approximated by using the free space propagation model as
| (3) |
where and are the antenna gain of transceivers, denotes the transmitting power, is the wavelength of carrier, and is the path loss exponent. Since the RSS sensed at each SL may include the receiving power of several RF transmitters [15], the total RSS can be approximately expressed as
| (4) |
It should be mentioned that the realistic propagation model is very complex due to reflection, diffraction and other propagation phenomena. The above data recovery method for the unsampled cubes is only suitable for the LOS propagation scenarios.
II-B Sparse Sampling Model
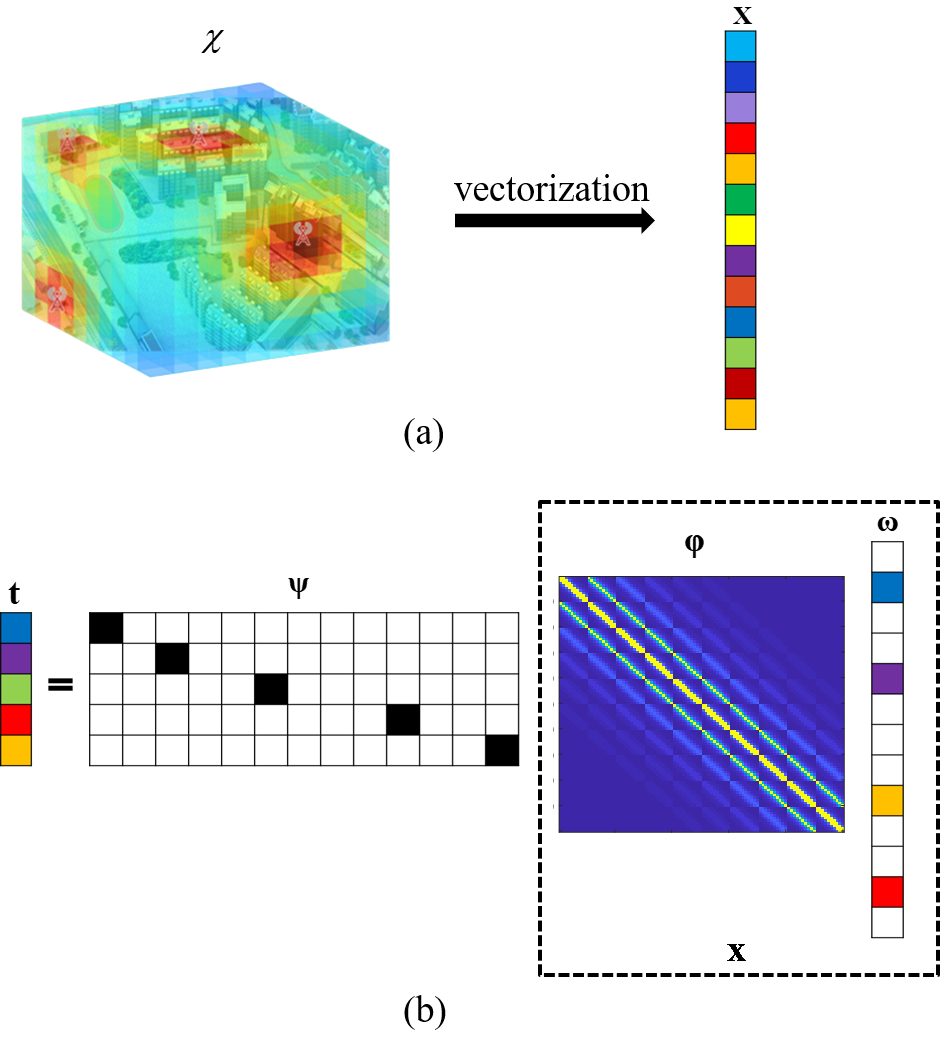
As shown in Fig.2 (a), the spectrum tensor is firstly vectorized into . Compared with the total number of discretized cubes in the ROI, the number of stationary RF transmitters is much small (). Since the spectrum vector has high spatial correlation, it can be represented by the product of a sparse dictionary and the sparse signal as
| (5) |
where the element of sparse dictionary is defined as the channel gain or propagation path loss between the th and the th cubes. Let us set the RSS vector of SLs as . The measurement matrix can be defined as
| (6) |
where each row of has an element of 1 denoting the SL’s position in the ROI. Then, we can have
| (7) |
where is the measurement noise that obeys the zero-mean Gaussian distribution with variance , and is a sensing matrix.
This paper recovers the spectrum data by two steps. Firstly, the sparse signal is recovered by the noisy measurement vector and the sensing matrix . Then, the spectrum vector is constructed according to (5). The sparse signal recovery (SSR) is equivalent to solving the following -minimization problem as
| (8) |
The -minimization problem of (8) is NP-hard, and can be equivalent to a -minimization problem as [28]
| (9) |
The authors in [29] have proved that if satisfies the condition of restricted isometry property, can be recovered by applying CS algorithms. In this paper, we focus on using the sparse Bayesian theory to solve the recovery problem of the SEM construction.
III 3D SEM Construction based on SBL
III-A An Overview of the Proposed 3D SEM Construction Scheme
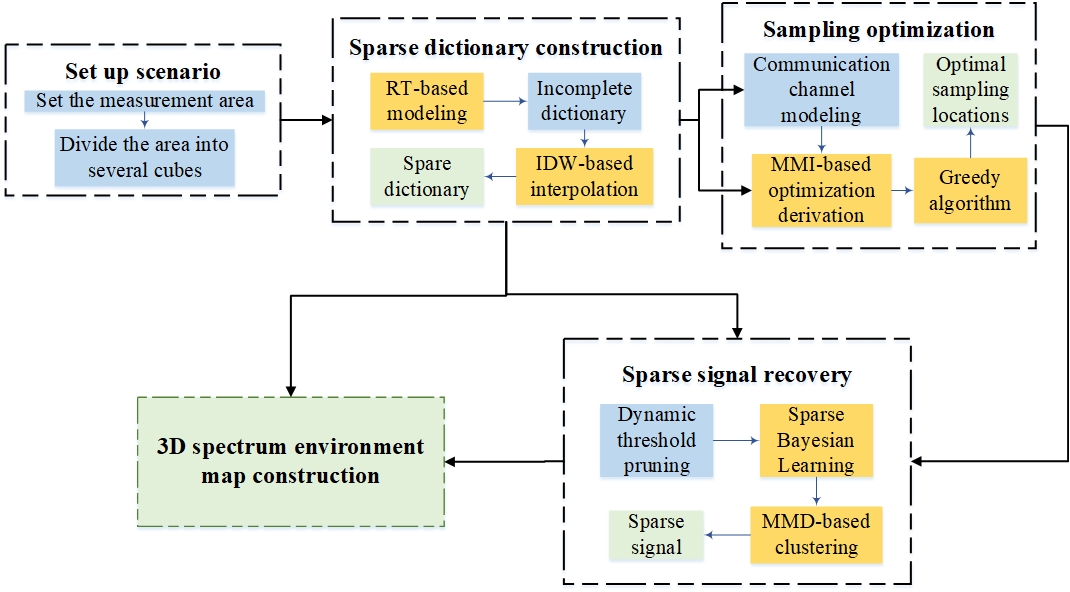
The proposed 3D SEM construction scheme is illustrated in Fig. 3, which mainly contains the scenario-dependent dictionary construction, the measurement matrix optimization and the 3D SEM construction. Firstly, combined with RT technology and interpolation algorithm, we take the factor of scenario into account and build a scenario-dependent sparse dictionary . According to the maximum mutual information criterion, we design the selection scheme of SLs and obtain the measurement matrix . Then, based on the sparse dictionary and measurement matrix, the sparse signal can be recovered based on the SBL algorithm. Finally, we utilize the sparse dictionary and sparse signal to construct the full SEM.
In order to recover the sparse signal for the SEM construction, we adopt the SBL theory and hierarchical sparse probabilistic model as follows.
1) Noise Model: The sparse regression model (7) is defined in a zero-mean Gaussian noise with unknown variance , and then the Gaussian likelihood of can be written as
| (10) |
A Gamma distribution is then posed on , which is a conjugate prior to the Gaussian distribution and can greatly simplifies the analysis [30], as
| (11) |
with
| (12) |
where is the shape parameter, and is the scale parameter, .
2) Hierarchical Sparse Prior Model: To induce the sparsity of , we deploy a sparseness-promoting prior on it. In the Relevance Vector Machine, is a two-layer hierarchical sparse prior, which shares the same properties with Laplace prior while enabling convenient computation [24]. Specifically, each element of is first posed a zero-mean Gaussian prior
| (13) |
where . Then, to complete the specification of this hierarchical prior, we consider the Gamma hyperpriors over as
| (14) |
The graphical model is shown in Fig.4. The overall prior can be obtained by computing the marginal integral of hyper-parameters in as
| (15) |

Since the integral is computable for Gamma , the true prior is a Student-t distribution which can promote sparsity on [31].
3) Sparse Bayesian Inference: Following the Bayesian inference, the posterior distribution over all unknowns is desired as
| (16) |
with the decomposition of the ‘weight posterior’ and the ‘hyper-parameter posterior’. It can be inferred that the weight posterior of is Gaussian
| (17) |
with
| (18) |
where . The SBL considers the signal recovery from the perspective of statistics. With sparse prior of and compressive samples , the posteriori probability density function of sparse vector can be inferred. We further estimate the with the mean and evaluate the accuracy of the recovery by the variance . To calculate and , we estimate probabilistic model hyperparameters and , the details of estimation will be discussed in the Section III-D.
III-B Scenario-dependent Sparse Dictionary Construction
The traditional sparse dictionary usually adopts the free-space propagation model without considering the scene information, which is not suitable for urban environments with a lot of buildings. The propagation occurs direct, reflection, and diffraction phenomena in the actual environment. Accordingly, a scenario-dependent dictionary is constructed here by analyzing the characteristics of propagation channel. The RT technique is based on Geometrical Optics and the Uniform Theory of Diffraction. It has been used to predict all the possible propagation path parameters in a given geographic map [32].
Assume that the position of th transmitting cube and th receiving cube are and , respectively. The propagation distance of direct path is obtained as
| (19) |
For the indirect path, we define the intersection coordinates of scatterers as . Thus, the Euclidean distance of th path ray between and the scatterer, and the Euclidean distance of th ray between the scatterer and can be respectively calculated as
| (20) |
| (21) |
The proposed RT-based dictionary construction method includes three steps, i.e., decomposition of ray source, tracking rays, and superposition of the filed strength. Firstly, the ray source is decomposed with direct ray, reflection ray and diffraction ray. If the ray arrives at the receiving field position in LOS propagation, the field intensity of arriving at is
| (22) |
where is the wave number. is the electric field intensity of away from , and is the propagation distance of the direct path in (19). For the reflected ray, the electric field intensity can be expressed as
| (23) |
where is the reflection coefficient. The electric field intensity of the diffraction path can be expressed as
| (24) |
where is the diffraction coefficient.
Then, according to (22)-(24), the final received field strength of can be obtained by vector superposition of all the field strengths
| (25) |
where is the total number of effective rays. is the electric field intensity of direct path, reflection path or diffraction path. It should be mentioned that the direct ray disappears when the link between and is blocked. Then the parameter calculation of direct ray can be ignored [32]. Therefore, the total average RSS of is
| (26) |
where is the wavelength. and are the antenna gains of the transmitter at and receiver at respectively. Thus, the channel gain in dB between and can be calculated, i.e., the element in the th row and the th column of matrix , as
| (27) |
where is transmitting power of the th transmitting cube.
Finally, we can predict the channel gain between any two cubes in the ROI and construct a scenario-dependent dictionary matrix. In this paper, we only calculate a small part of dictionary matrix and achieve the whole matrix by interpolation. The inverse distance weighted interpolation is adopted [33]. It assumes that each known value has a local influence with respect to the distance, which is consistent with the radio propagation principle.
Let us set the data obtained by RT as , corresponding to the element in the th row and the th column of matrix . The unknown value in the th row and the th column can be obtained by
| (28) |
where is the distance between interpolation point and the known point, and is the distance exponent.
III-C MMI-based Sampling Optimization
The layout of sampling sensors, i.e., the measurement matrix , has a significant effect on the SEM construction accuracy. In [34, 35], the authors used the mutual information between the predicted sensors’ observation and the current target location distribution to optimize the layout.
Different from traditional methods using the random selection, we model the sparse signal reconstruction problem as an information theory problem in communication channel, where sparse signal is the input to the channel and the SLs’ RSS samples is the output. The SLs are tasked to observe in order to increase the information (or to reduce the uncertainty) about the ’s state. We select SLs based on the MMI criterion.
We define the index set of candidate SLs for selection is . The subset of indices for the determined SLs is expressed as . When the SLs have different observation angles and perceptual uncertainties, the information gain attributable to different SLs can be quite different [36, 37]. Then, the SLs set is chosen when their observations minimizes the expected conditional entropy of the posterior distribution of , as given by
| (29) |
which is equivalent to maximize the entropy reduction of . We maximize mutual information
| (30) | ||||
| (31) | ||||
The derivation of formula (31) is given in AppendexA. In the initialization stage, there is no prior information related to the sparse signal . According to SBL, we assign the same variance , i.e., 1. Then, the formula (31) can be further converted to
| (32) | ||||
with
| (33) | ||||
where is a sufficiently small number denoted the ratio of noise variance to sparse signal variance [36]. Therefore, by ignoring the constant terms, the final objective function of MMI-based sampling is asymptotically approaches to
| (34) | ||||
where . is consisted of the rows indexed by set in . Accordingly, the problem can be further expressed as
| (35) |
We solve the above problem by the greedy algorithm. Let denote the sensing matrix after the th SL’s selection as
| (36) |
where is the index of the th selected SL and is the th row vector of the sparse dictionary matrix . The step-by-step maximization process is considered by the greedy method. The matrix can be expanded as
| (37) | ||||
Therefore, the th row of is determined according to the following formula,
| (38) | ||||
After recursive iterations, the optimal SLs can be finally selected. The measurement matrix is obtained.
III-D SEM Construction with Improved SBL
In Section II-B, we recover with the mean and evaluate the recovery accuracy by the variance . The hyperparameters are estimated by maximum a posterior (MAP) probability [24] as
| (39) | ||||
which is equivalent to maximize the product of marginal likelihood and the priors over hyperparameters in the logarithmic case. By ignoring the irrelevant terms, we can obtain the objective equation
| (40) |
We exploit expectation-maximization (EM) to solve and . For , the update procedure is equivalent to maximize , and then the update rule can be derived through differentiation
| (41) |
where represents the th diagonal element of . We maximize to update as
| (42) |
The derivation of (41) and (42) are given in AppendixB. Continue the above iterations between (18), (41) and (42) until the convergence condition is satisfied, and then we can obtain the solution of by .
Furthermore, in the traditional SBL algorithm, a fix threshold is set to prune the small values of the recovered sparse signal in each iteration. The equals to zero when , and thus the corresponding th column in can be pruned out. The recovery algorithm based on the traditional SBL is unable to accurately restore the locations of all sources in the 3D SEM. Besides, it is difficult to determine the value of under different scenarios. However, the positions of the recovered signal sources are usually adjacent or close to the real signal sources in Cartesian coordinate. Therefore, we develop the clustering-based SBL (CSBL) algorithm and use adaptive threshold to improve the recovery accuracy.
Firstly, we define an adaptive dynamic threshold truncation in the pruning step of algorithm iterations, which is
| (43) |
Through the adaptive dynamic threshold truncation, the near the source points are selected to the most extent and the cube whose power is below threshold can be abandoned. The pruning rule is
| (44) |
Then, we propose to combine clustering algorithm with the SBL. Considering the number of transmitters is unknown, we employ the MMD clustering algorithm. It can adaptively determine the cluster seeds when the number of clusters is unknown and improve the efficiency of partitioning the dataset. The MMD clustering is a trial-based clustering algorithm in pattern recognition. It takes the furthest object as the clustering center based on Euclidean distance, and can avoid the situation that the cluster seeds may be too close when the initial value is selected by k-means method.
At the end of the SBL iteration process, the solution may only have a small number of significant coefficients. The rest of small coefficients, which contribute very little to the sparse signal, is negligible. Therefore, we first approximate by neglecting the small coefficients as
| (45) |
where is a negative sparsity threshold. Accordingly, the non-zero item set of estimated preliminarily is obtained, which represents the cubes in 3D space. Due to the characteristics of clusters they are distributed in space, the candidate set will be divided into clusters denoted by adaptively by MMD clustering. Then, by weighting the items in with the averaging rule, the cluster centers are obtained as
| (46) |
where , and are the , , coordinates of the th cube of set in 3D space. , and are the , , coordinates of the cluster center of set , which is also the re-estimated non-zero position in the updated sparse signal . Simultaneously, we update the sparse coefficient as
| (47) |
Eventually, the updated sparse signal is obtained. According to the recovered sparse signal, the SEM construction model is
| (48) |
where is the spectrum vector we constructed.
| Parameters | Value | ||||
|---|---|---|---|---|---|
| Region of interest | |||||
| SEM tensor size | |||||
| Granularity of SEM tensor | |||||
| Number of RF transmitters () | 4, 8, 12, 16 | ||||
| Transmitting frequency () | 1 GHz | ||||
| Transmitting power () | 2 W | ||||
| Positions of RF transmitters | Random generated in the ROI | ||||
|
|
||||
| Algorithms for comparison |
|
IV Simulation Results And Validations
IV-A Experiment Setup
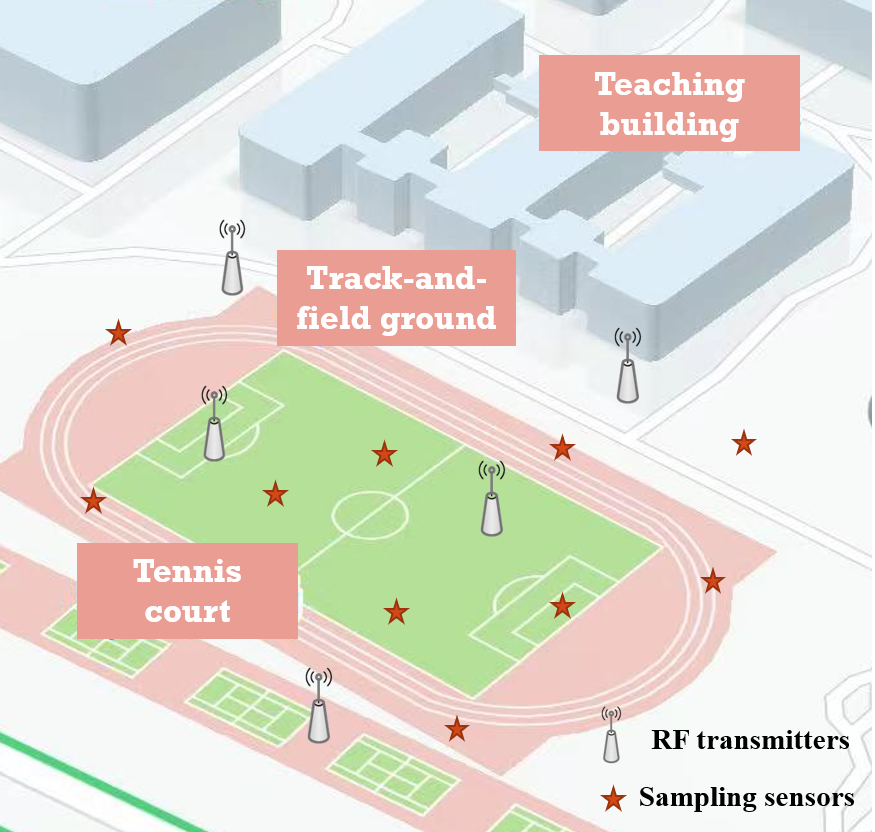
In this section, the performance of proposed 3D SEM construction method is analyzed and verified by simulations under the campus scenario, as shown in Fig. 5. The ROI is . We firstly discretize the ROI into cubes and each cube is . Then we construct a spectrum tensor . We denote the proposed algorithm as MMI-CMSBL. Six SEM construction algorithms, i.e., Random-SBL, Random-CSBL, Random-MSBL, MMI-SBL, MMI-CMSBL and random stagewise weak orthogonal matching pursuit (Random-SWOMP) [38] are used to construct the 3D SEM. The main simulation parameters are shown in the Table 1, where the random means that SLs are selected randomly from the ROI.
IV-B Sparse Signal Recovery Performance
We compare the proposed MMI-CMSBL with Random-SBL, Random-CSBL, Random-MSBL, MMI-SBL, and Random-SWOMP in terms of the SSR performance. The Mean Squared Error (MSE) of sparse signal recovery is defined as
| (49) |
where and are the estimated sparse signal and true sparse signal.
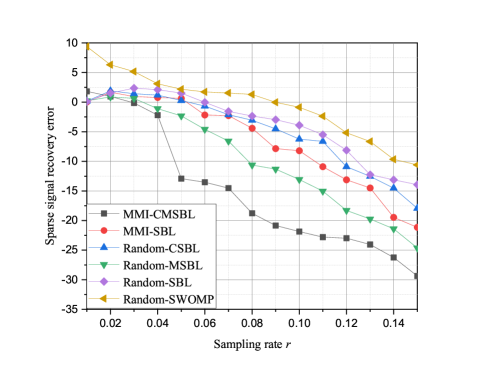
It can be seen from the simulation results in the Fig. 6 that the MSE of sparse signal recovery decreases as the sampling rates increases. The proposed MMI-CSBL outperforms other algorithms in terms of the convergence speed. The performance of Random-MSBL algorithm is better than that of the Random-CSBL, MMI-SBL and Random-SBL, which reveals that the propagation model-based SBL algorithm brings more performance improvement than traditional SBL in SSR by considering scenario to construct the sparse dictionary. Besides, the SBL has better performance than other CS algorithms when recovering sparse signals if the sensing matrix has high correlation.
IV-C SEM Construction Performance
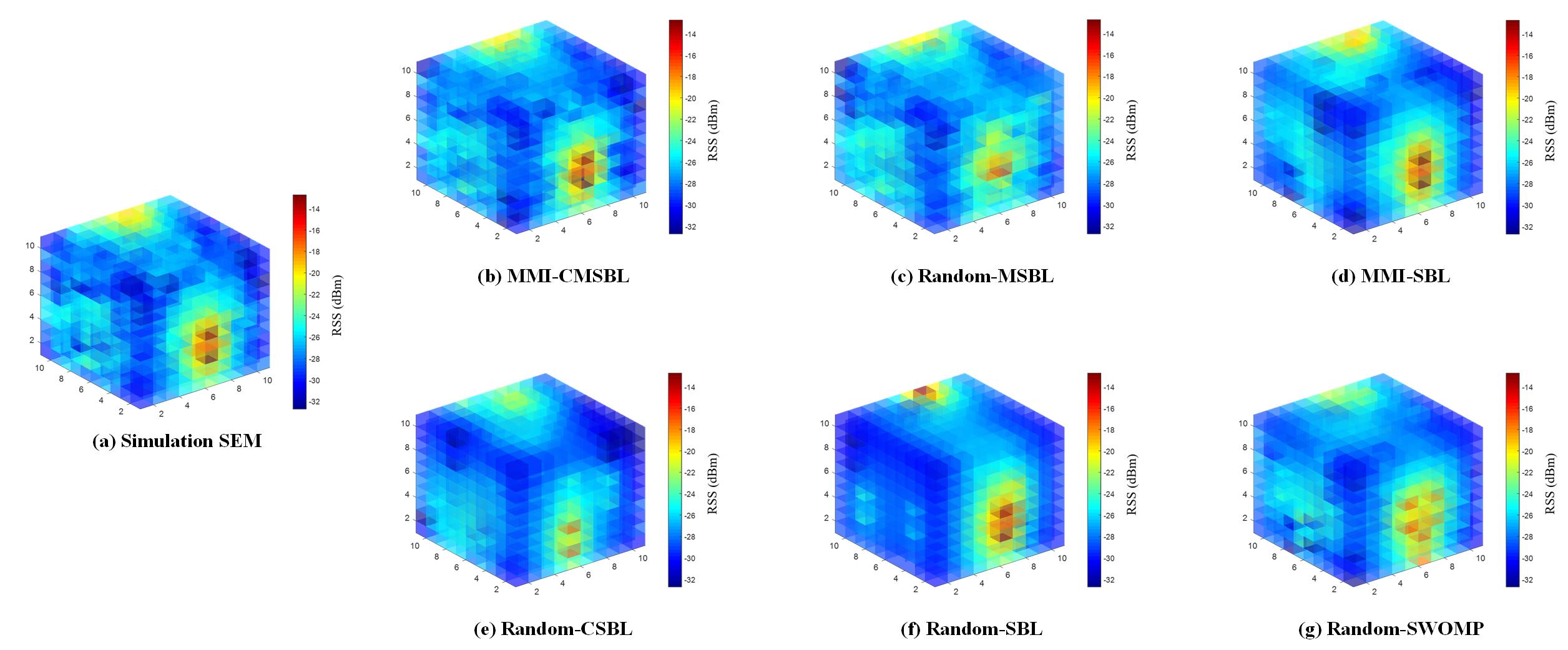
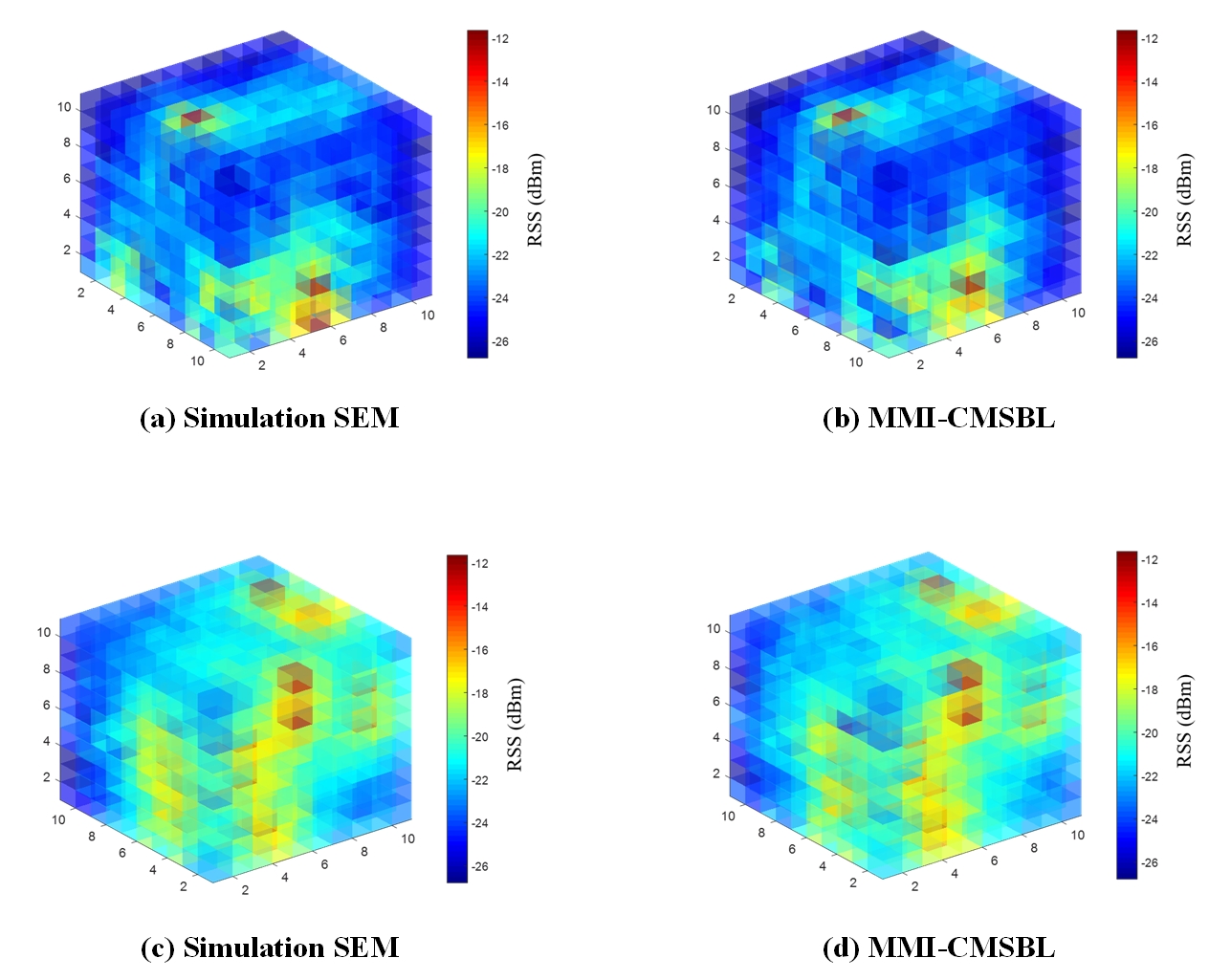
Fig. 7 presents the SEM construction results of Random-SBL, Random-CSBL, Random-MSBL, MMI-SBL, MMI-CMSBL and Random-SWOMP. We can also see that the sparse signal recovery accuracy of MMI-CMSBL is higher than other algorithms, and the minimal components in Fig. 7 (b) are reduced obviously through clustering and dynamic threshold operations.
The Root Mean Square Error (RMSE) is used to evaluate the RSS recovery performance. The RMSE is defined as the difference of each cube in RSS between the estimated REM and the real REM, given by
| (50) |
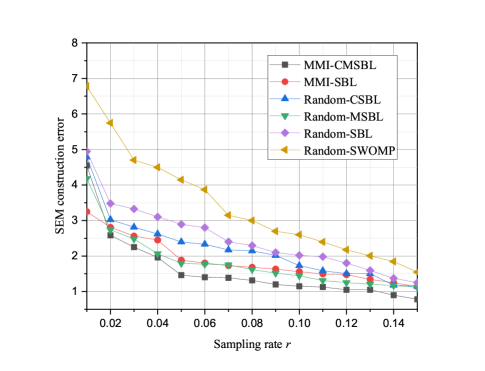
where and are the estimated and the actual RSS values at the th cube respectively. It can be seen from Fig. 8 that MMI-CMSBL achieves the best performance compared with other methods even at a very low sampling rate. SWOMP performs worse than other SBL-based algorithms, due to the highly correlation of the sparse dictionary. Furthermore, based on the sparse dictionary constructed by RT technology, the MMI-CMSBL and Random-MSBL algorithm can rapidly converge and accurately recover the spectrum map at a low sampling rate. Comparing Fig. 6 and Fig. 8, we can see that when the MSE of sparse signal is large, the SEM construction performance is unsatisfactory.
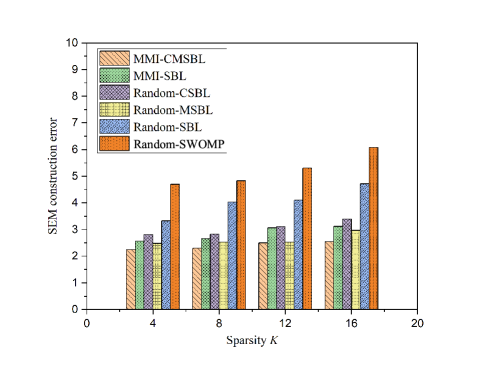
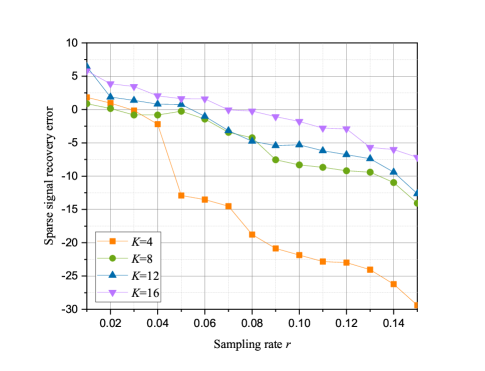
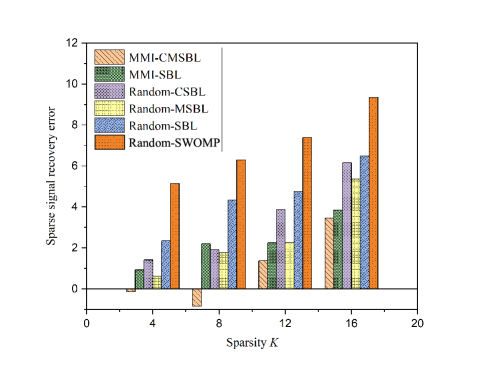
IV-D Impact of Sparsity
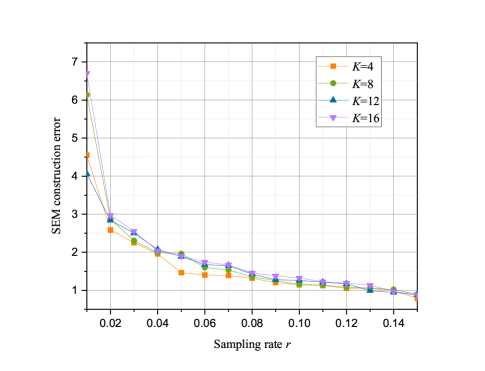
The impact of on the performance of SEM construction and sparse signal recovery are shown in Figs. 9 - 12. In Fig. 9 and 11 show that as the sparsity increases, the SEM construction error and the MSE of sparse signal recovery with MMI-CMSBL increase. Meanwhile, as shown in Fig. 9, when sampling rate is small, the SEM construction error first increases and then decreases with the increasing of . Fig. 11 shows that the MSE of sparse signal recovery increases as increases, and we can successfully recover the signal at least when . In addition, the convergence rate of sparse support distortion improves with the decrease of sparsity .
In Fig. 10 and 12, it can be seen that with the increase of sparsity the MMI-CMSBL can still maintain excellent performance on SEM recovery and sparse signal recovery compared with other algorithms at a fixed low sampling rate. MMI-CMSBL and Random-MSBL are less influenced by the sparsity than Random-SBL. Due to the increase of RF transmitters, their interference with each other also increases. Additionally, CSBL can achieve better performance than the traditional SBL. The visualization of SEM construction with different sparsity is shown in Fig. 13.
V Conclusion
In this paper, we have investigated the issue of 3D SEM construction based on SBL, which offers high value for efficient application of CR. We have first formulated 3D SEM construction as a sparse sampling problem by exploiting the underlying sparse nature of 3D spectrum situation. Then, we have proposed a 3D scenario-dependent SEM construction scheme, which is composed of three components: sparse dictionary construction, sampling optimization and spectrum situation recovery. Firstly, considering the complexity of electromagnetic propagation environment in the actual scenario, we have designed a scenario-dependent sparse dictionary for SEM construction based on the channel model. Secondly, we have developed MMI-based sampling architecture to obtain optimized measurement matrix. Based on SBL framework, we have derived the optimization function of MMI sampling and have solved it by greedy algorithm. Finally, due to the ineffectiveness of traditional SBL recovery algorithm in 3D SEM construction, a tailored MMD-clustering based SBL algorithm has been proposed. The sparse signal recovered can achieve high precision by dynamic threshold pruning. We have also compared the sparse signal recovery performance and SEM construction performance among six methods, i.e., Random-SBL, Random-CSBL, Random-MSBL, MMI-SBL, MMI-CMSBL and Random-SWOMP. The impact of sparsity on situation recovery precision has been studied. Simulations have demonstrated the superiority of the proposed 3D SEM construction scheme.
Appendix A Proof of the equation (31)
In this part, we present the derivation of (31) in the text. Firstly, we introduce the Mahalanobis transformation lemma,
Lemma 1. An arbitrary dimension Gaussian distribution , we call the Mahalanobis transformation, where
| (51) |
which means that is the standard Gaussian distribution .
Proof: We have
| (52) |
| (53) |
we compute the Jacobian determinant
| (54) |
According to Lemma of substitution of variables
| (55) |
where and inverse function . is the absolute value of the Jacobian determinant. Then the distribution of is
| (56) |
The lemma has been proven. Then, for continuous random variables , we have its conditional entropy
| (57) |
The posterior distribution of obeys the multidimensional Gaussian distribution with mean and covariance given by (18). Therefore, we use a posterior distribution to approximate the distribution of , as SBL use a posterior mean to estimate , so we have
| (58) | ||||
By using Lemma 1, we then have
| (59) | ||||
Accordingly, we can obtain the conditional entropy term in the formula (31), as given by
| (60) | ||||
The derivation of can be obtained by analogy.
Appendix B Proofs of the equations (41) and (42)
To obtain Eq. (41), we first define
| (61) | ||||
with being the item constant to . Then, we let to find the stationary point of , as
| (62) | ||||
And we obtain
| (63) |
To obtain Eq. (42), we define
| (64) | ||||
Then, we let to find the stationary point of , and we obtain
| (65) |
where
| (66) | ||||
References
- [1] G. Ding, Q. Wu, L. Zhang, Y. Lin, T. A. Tsiftsis, and Y.-D. Yao, “An amateur drone surveillance system based on the cognitive internet of things,” IEEE Communications Magazine, vol. 56, no. 1, pp. 29–35, 2018.
- [2] A. Ahmad, S. Ahmad, M. H. Rehmani, and N. U. Hassan, “A survey on radio resource allocation in cognitive radio sensor networks,” IEEE Communications Surveys & Tutorials, vol. 17, no. 2, pp. 888–917, 2015.
- [3] B. Wang and K. R. Liu, “Advances in cognitive radio networks: A survey,” IEEE Journal of Selected Topics in Signal Processing, vol. 5, no. 1, pp. 5–23, 2011.
- [4] H. B. Yilmaz, T. Tugcu, F. Alagöz, and S. Bayhan, “Radio environment map as enabler for practical cognitive radio networks,” IEEE Communications Magazine, vol. 51, no. 12, pp. 162–169, 2013.
- [5] M. Höyhtyä, A. Mämmelä, M. Eskola, M. Matinmikko, J. Kalliovaara, J. Ojaniemi, J. Suutala, R. Ekman, R. Bacchus, and D. Roberson, “Spectrum occupancy measurements: A survey and use of interference maps,” IEEE Communications Surveys & Tutorials, vol. 18, no. 4, pp. 2386–2414, 2016.
- [6] K. Sato and T. Fujii, “Kriging-based interference power constraint: Integrated design of the radio environment map and transmission power,” IEEE Transactions on Cognitive Communications and Networking, vol. 3, no. 1, pp. 13–25, 2017.
- [7] Y. Hu and R. Zhang, “A spatiotemporal approach for secure crowdsourced radio environment map construction,” IEEE/ACM Transactions on Networking, vol. 28, no. 4, pp. 1790–1803, 2020.
- [8] E. Dall’Anese, S.-J. Kim, and G. B. Giannakis, “Channel gain map tracking via distributed kriging,” IEEE Transactions on Vehicular Technology, vol. 60, no. 3, pp. 1205–1211, 2011.
- [9] M. Tang, G. Ding, Q. Wu, Z. Xue, and T. A. Tsiftsis, “A joint tensor completion and prediction scheme for multi-dimensional spectrum map construction,” IEEE Access, vol. 4, pp. 8044–8052, 2016.
- [10] S. Shrestha, X. Fu, and M. Hong, “Deep spectrum cartography: Completing radio map tensors using learned neural models,” IEEE Transactions on Signal Processing, vol. 70, pp. 1170–1184, 2022.
- [11] X. Han, L. Xue, Y. Xu, and Z. Liu, “A radio environment maps estimation algorithm based on the pixel regression framework for underlay cognitive radio networks using incomplete training data,” Sensors, vol. 20, no. 8, p. 2245, 1 2020.
- [12] H. B. Yilmaz and T. Tugcu, “Location estimation-based radio environment map construction in fading channels,” Wireless communications & mobile computing, vol. 15, no. 3, pp. 561–570, 1 2015.
- [13] M. Pesko, T. Javornik, L. Vidmar, A. Kosir, M. Stular, and M. Mohorcic, “The indirect self-tuning method for constructing radio environment map using omnidirectional or directional transmitter antenna,” Eurasip Journal on Wireless Communications and Networking, vol. 2015, pp. 50–1–50–12, 1 2015.
- [14] F. Shen, G. Ding, Z. Wang, and Q. Wu, “Uav-based 3d spectrum sensing in spectrum-heterogeneous networks,” IEEE Transactions on Vehicular Technology, vol. 68, no. 6, pp. 5711–5722, 2019.
- [15] F. Shen, Z. Wang, G. Ding, K. Li, and Q. Wu, “3d compressed spectrum mapping with sampling locations optimization in spectrum-heterogeneous environment,” IEEE Transactions on Wireless Communications, vol. 21, no. 1, pp. 326–338, 2022.
- [16] Q. Zhu, Y. Zhao, Y. Huang, Z. Lin, L. H. Wang, Y. Bai, T. Lan, F. Zhou, and Q. Wu, “Demo abstract: An uav-based 3d spectrum real-time mapping system,” in IEEE INFOCOM 2022 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), 2022, pp. 1–2.
- [17] K. Sato, K. Suto, K. Inage, K. Adachi, and T. Fujii, “Space-frequency-interpolated radio map,” IEEE Transactions on Vehicular Technology, vol. 70, no. 1, pp. 714–725, 2021.
- [18] K. Mao, Q. Zhu, M. Song, H. Li, B. Ning, G. F. Pedersen, and W. Fan, “Machine-learning-based 3-d channel modeling for u2v mmwave communications,” IEEE Internet of Things Journal, vol. 9, no. 18, pp. 17 592–17 607, 2022.
- [19] D. Lee, S.-J. Kim, and G. B. Giannakis, “Channel gain cartography for cognitive radios leveraging low rank and sparsity,” IEEE Transactions on Wireless Communications, vol. 16, no. 9, pp. 5953–5966, 2017.
- [20] J. A. Bazerque and G. B. Giannakis, “Distributed spectrum sensing for cognitive radio networks by exploiting sparsity,” IEEE Transactions on Signal Processing, vol. 58, no. 3, pp. 1847–1862, 2010.
- [21] R. Tibshirani, “Regression shrinkage and selection via the lasso: a retrospective,” Journal of the Royal Statistical Society, Series B. Statistical Methodology, vol. 73, no. 3, pp. 273–282, 1 2011.
- [22] S. K. Sahoo and A. Makur, “Signal recovery from random measurements via extended orthogonal matching pursuit,” IEEE Transactions on Signal Processing, vol. 63, no. 10, pp. 2572–2581, 2015.
- [23] R. Tichatschke, “Ciarlet, p. g., introduction to numerical linear algebra and optimization. cambridge etc., cambridge university press 1989. xiv, 436 pp., 15.‐pb. isbn 0–521–32788–1/0–521–33984‐7 (cambridge texts in applied mathematics),” ZAMM ‐ Journal of Applied Mathematics and Mechanics / Zeitschrift für Angewandte Mathematik und Mechanik, vol. 71, no. 3, p. 202, 1 1991.
- [24] M. E. Tipping, “Sparse bayesian learning and the relevance vector machine,” J. Mach. Learn. Res., vol. 1, pp. 211–244, 2001.
- [25] C. M. Bishop and M. E. Tipping, “Variational relevance vector machines,” ArXiv, vol. abs/1301.3838, 2000.
- [26] F. Kiaee, H. Sheikhzadeh, and S. Eftekhari Mahabadi, “Relevance vector machine for survival analysis,” IEEE Transactions on Neural Networks and Learning Systems, vol. 27, no. 3, pp. 648–660, 2016.
- [27] D.-H. Huang, S.-H. Wu, W.-R. Wu, and P.-H. Wang, “Cooperative radio source positioning and power map reconstruction: A sparse bayesian learning approach,” IEEE Transactions on Vehicular Technology, vol. 64, no. 6, pp. 2318–2332, 2015.
- [28] M. Fornasier and H. Rauhut, Compressive Sensing. New York, NY: Springer New York, 2011, pp. 187–228. [Online]. Available: https://doi.org/10.1007/978-0-387-92920-0_6
- [29] M. A. Herman and T. Strohmer, “General deviants: An analysis of perturbations in compressed sensing,” IEEE Journal of Selected Topics in Signal Processing, vol. 4, no. 2, pp. 342–349, 2010.
- [30] S. D. Babacan, R. Molina, and A. K. Katsaggelos, “Bayesian compressive sensing using laplace priors,” IEEE Transactions on Image Processing, vol. 19, no. 1, pp. 53–63, 2010.
- [31] M. E. Tipping, “Bayesian inference: An introduction to principles and practice in machine learning,” in Advanced Lectures on Machine Learning, 2003.
- [32] Q. Zhu, K. Mao, M. Song, X. Chen, B. Hua, W. Zhong, and X. Ye, “Map-based channel modeling and generation for u2v mmwave communication,” IEEE Transactions on Vehicular Technology, vol. 71, no. 8, pp. 8004–8015, 2022.
- [33] D. Denkovski, V. Atanasovski, L. Gavrilovska, J. Riihijärvi, and P. Mähönen, “Reliability of a radio environment map: Case of spatial interpolation techniques,” in 2012 7th International ICST Conference on Cognitive Radio Oriented Wireless Networks and Communications (CROWNCOM), 2012, pp. 248–253.
- [34] H. Wang, G. Pottie, K. Yao, and D. Estrin, “Entropy-based sensor selection heuristic for target localization,” in Third International Symposium on Information Processing in Sensor Networks, 2004. IPSN 2004, 2004, pp. 36–45.
- [35] F. Zhao, J. Shin, and J. Reich, “Information-driven dynamic sensor collaboration,” IEEE Signal Processing Magazine, vol. 19, no. 2, pp. 61–72, 2002.
- [36] Y. Saito, T. Nonomura, K. Yamada, K. Nakai, T. Nagata, K. Asai, Y. Sasaki, and D. Tsubakino, “Determinant-based fast greedy sensor selection algorithm,” IEEE Access, vol. 9, pp. 68 535–68 551, 2021.
- [37] K. Hintz, “A measure of the information gain attributable to cueing,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 21, no. 2, pp. 434–442, 1991.
- [38] T. Blumensath and M. E. Davies, “Stagewise weak gradient pursuits,” IEEE Transactions on Signal Processing, vol. 57, no. 11, pp. 4333–4346, 2009.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x7.png) |
Jie Wang received the B.S. degree in internet of things engineering from the College of Information Science and Technology, Nanjing Forestry University of China, Nanjing, China, in 2021. She is currently pursuing the Ph.D. degree in communications and information systems with the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics. Her current research interests conclude spectrum mapping. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x8.png) |
Qiuming Zhu received the B.S. degree in electronic engineering and the M.S. and Ph.D. degrees in communication and information system from the Nanjing University of Aeronautics and Astronautics (NUAA), Nanjing, China, in 2002, 2005, and 2012, respectively. He is currently a Professor in the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, China. His current research interests include channel sounding, modeling, and emulation for the fifth/sixth generation (5G/6G) mobile communication, vehicle-to-vehicle (V2V) communication, and unmanned aerial vehicles (UAV) communication systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x9.png) |
Zhipeng Lin received the Ph.D. degrees from the School of Information and Communication Engineering, Beijing University of Posts and Telecommunications, Beijing, China, and the School of Electrical and Data Engineering, University of Technology of Sydney, NSW, Australia, in 2021. Currently, He is an Associate Researcher in the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, China. His current research interests include signal processing, massive MIMO, spectrum sensing, and UAV communications. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x10.png) |
Qihui Wu received the B.S. degree in communications engineering and the M.S. and Ph.D. degrees in communications and information system from the PLA University of Science and Technology, Nanjing, China, in 1994, 1997, and 2000, respectively. He is currently a Professor with the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics. His current research interests include algorithms and optimization for cognitive wireless networks, soft-defined radio, and wireless communication systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x11.png) |
Yang Huang received the B.S. and M. S. degrees from Northeastern University, China, in 2011 and 2013, respectively, and the Ph.D. degree from Imperial College London in 2017. He is currently an Associate Professor with College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, China. His research interests include wireless communications, MIMO systems, convex optimization, machine learning and signal processing for communications. He has served as Technical Program Committee (TPC) members for many International conferences, such as IEEE GLOBECOM, etc. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/caixuezhao.jpg) |
Xuezhao Cai received the B.S. degree in information engineering from the School of Artificial Intelligence, Nanjing University of Information Science and Technology, Nanjing, China , in 2022. He is currently pursuing the M.S. degree in electronic information with the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics. His current research direction is related to spectrum.. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x12.png) |
Weizhi Zhong received the B.S. degree in communications engineering and the M.S. and Ph.D. degrees in communications and information system from the PLA University of Science and Technology, Nanjing, China, in 1994, 1997, and 2000, respectively. He is currently a Professor with the College of Electronic and Information Engineering, Nanjing University of Aeronautics and Astronautics. His current research interests include algorithms and optimization for cognitive wireless networks, soft-defined radio, and wireless communication systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/6f1d6411-2acb-4ce7-a73d-37efc468b77f/x13.png) |
Yi Zhao received the B.S. degree in information engineering from Nanjing University of Aeronautics and Astronautics (NUAA) in 2021. He is currently working towards the master degree in electronic information engineering, NUAA. His current research is temporal and spatial prediction and reconstruction of spectrum situation. |