Sparse dynamical system identification with simultaneous structural parameters and initial condition estimation
Abstract
Sparse Identification of Nonlinear Dynamics (SINDy) has been shown to successfully recover governing equations from data; however, this approach assumes the initial condition to be exactly known in advance and is sensitive to noise. In this work we propose an integral SINDy (ISINDy) method to simultaneously identify model structure and parameters of nonlinear ordinary differential equations (ODEs) from noisy time-series observations. First, the states are estimated via penalized spline smoothing and then substituted into the integral-form numerical discretization solver, leading to a sparse pseudo linear regression. Then, the sequential threshold least squares is performed to extract the fewest active terms from the overdetermined set of candidate features, thereby estimating structural parameters and initial condition simultaneously and meanwhile, making the identified dynamics parsimonious and interpretable. Simulations detail the method’s recovery accuracy and robustness to noise. Examples include a logistic equation, Lokta-Volterra system, and Lorenz system.
keywords:
nonlinear dynamics , penalized spline smoothing , integral matching , sparse regression , initial condition1 Introduction
There is a long and fruit history of modeling time-series data with dynamical systems, resulting in many powerful techniques for system identification [1, 2]. In practice, many branches of science and engineering represent dynamical systems as sets of ODEs, in which each equation describes the change of a single variable as a function of the other variables, and the structures of these ODEs are usually determined according to known physical laws (see e.g. Newton’s laws, conservation of mass and energy) that provide first principles from which it is possible to derive equations of motion [3]. However, it may be difficult or impossible for researchers to derive equations, especially in the emerging fields that are lacking of known physical laws. The problem of discovering governing equation from time-series observations is one of the challenges in modern dynamical system research [4].
There are a host of additional techniques for the discovery of governing equations from time-series data, including the state dependent parameter identification [2, 5], symbolic regression [6, 7, 8, 9], automated inference [10], empirical dynamic modelling [11], and deep learning [12, 13]; see [14] for an incomplete review. These approaches can be viewed as special cases of the fourth paradigm: data-intensive scientific discovery [15]. Inspired by the key observation that most dynamical systems only consist of a few terms, the recent breakthrough has resulted in a compressive sensing paradigm for the structure identification of underlying nonlinear dynamics [16, 17]. By using sparse regression to implement compressive sensing, the SINDy framework was proposed [18]. This approach has three principal procedures: (1) estimating the states together with derivatives from noisy time-series observations; (2) constructing a library of candidate features to approximate vector fields; (3) conducting sparse regression to generate parsimonious dynamics. At present, there exist a series of outputs about the extensions and applications of SINDy, such as the discovery of partial differential equations [19], the lasso-type sparse optimization [20], and the information criterion-based structure selection [21]. However, it should be noticed that SINDy has two limitations: (1) one needs to estimate the accurate derivatives of states from noisy time-series observations, but this may be hard in practice [22], and (2) the initial condition is assumed to be noise-free and exactly known in advance when simulating the fitted trajectory, which can not be satisfied in certain cases.
In a broad sense, the aforementioned SINDy framework can be considered as sparse parameter estimation of ODEs. The subproblem (i.e. estimating parameters of ODEs with known model structures under a measurement error framework) has been a hot topic in the statistical society, especially after Ramsay’s work [23]; see [24] for a comprehensive review. Integral matching [25] is an effective approach to this subproblem. The similar idea to integral matching was first introduced to SINDy by Schaeffer and McCalla [26] and lead to an integral variant of SINDy. In this variant, the derivative estimation of states is bypassed, one advantage over the standard SINDy. However, both this variant and standard SINDy have the drawbacks that they assume the initial condition to be precisely known in advance rather than estimating it from observations, and they also do not take measurement noise into account, which can lead to misspecified model structures. To this end, the present research improves SINDy framework by integrating integral matching as a parameter estimation approach. The principal contributions are as follows:
-
(i)
The penalised spline smoothing is introduced to estimate dynamical states from noisy observations. This provides a flexible data preprocessing approach to identify the underlying dynamical system from noisy observations.
-
(ii)
The matrix computation tricks are utilised to separate structural parameters from the initial condition, and a modified sequential threshold least squares is proposed to generate simultaneous estimates of sparse structural parameters and initial condition.
2 Integral SINDy
2.1 Problem formalization
Consider the structure identification and parameter estimation problem for homogeneous nonlinear ODE system
| (1) |
where is a -dimensional state vector, is an unknown vector function, and denotes the unknown structural parameters and initial condition, respectively.
In practice, the states are always observed with measurement errors, i.e. the observation equation is
| (2) |
where is an independent Gaussian noise with mean and finite variance matrix . Then, for simplicity of presentation, the -dimensional time-series observations are collectively denoted as , where each column , , corresponds to the time-series observations .
Note that the integral form of state equation (1) is
| (3) |
which allows for the simultaneous estimation of structural parameter and initial condition . That is, equation (3) offers an alternative integral SINDy (ISINDy) approach for sparse identification of nonlinear dynamical systems, as shown in Figure 1.
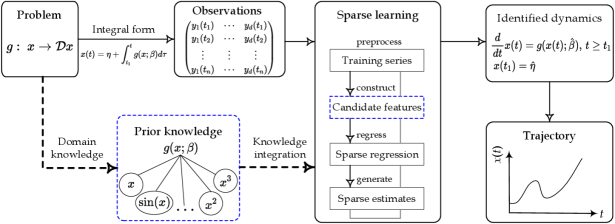
ISINDy depicts learning from a hybrid information source that consists of data and prior knowledge, also belonging to the emerging field known as informed machine learning [27, 28]. The prior knowledge comes from an independent source, such as domain information, empirical experience, and physical laws. The prior knowledge is converted to formal representations — a library of candidate features, which are used to induce an explicit, likely redundancy expression of vector fields. The following sparse learning consists of three steps: preprocessing the time-series observations to estimate noise-free states, determining the candidate features included in the library, and generating estimates from the sparse regression.
2.2 Penalized spline smoothing for states estimation
Since the observations are contaminated with noise, the penalized spline smoothing [29] is utilized to estimate the states without reference to the state equation. For simplicity of presentation, we treat a single-variable case due to that smoothing is applied to each variable in turn. By using a linear combination of basis functions to approximate , it follows that
| (4) |
where is the known basis function vector, and is the unknown coefficient to be estimated from the observations in equation (2). In order to balance the fitness and smoothness of the fitted curve, the objective function contains a penalized sum of squared errors
| (5) |
where is a hyper-parameter; at the right hand side, the first term is the squared error criterion measuring the fitness, and the second term is a smoothing penalty measuring the smoothness. The objective function is a trade-off expression between these two terms: when , it yields the least-square rough estimates; on the contrary, when , it yields very smooth estimates and thus nearly linear curve.
Since the basis functions together with their derivatives are known in advance, the penalty term can be reformulated as
| (6) |
where each element of is calculated as , and these definite integrals can be approximated using the Simpson’s rule. By substituting equation (6) into (5), partially differentiating the objective function with respect to all parameters, in turn, and setting these derivatives to zero, one obtains the estimates of the coefficients and states:
| (7) |
where is an matrix, and are both column vectors. To tune the hyper-parameter , the cross validation criterion [30] is used, i.e. minimizing the generalized cross validation error
| (8) |
where is a smoothing matrix. It is common to use the grid search strategy to find a reasonable value in the logit scale.
When implementing the penalised spline smoothing, it is vital to select appropriate basis functions. In practice, the basis functions are often chosen as the cubic B-spline basis functions because of their good properties [29, 31]. For example, the property called local compact support, ensures the efficient computation. See Appendix A for details of cubic B-spline basis functions.
2.3 Candidate features for vector field representation
From the prior knowledge that the underling dynamics have only a few terms, the vector field is sparse with respect to the candidate feature space , i.e.
| (9) |
where consists of all possible features and is a sparse matrix having zeros in each column. Subsequently, without loss of generality, each component of can be expressed as a linear combination of the candidate features
| (10) |
where , , is the th column of the sparse matrix .
By substituting the sparse expression (9) into state equation (3), it follows that
| (11) |
which, by combining equation (10), leads to separate integral equations
| (12) |
where is the th component of initial condition . By using the piecewise linear quadrature, the definite integral at each time instant can be approximated as
| (13) |
where is the time interval.
Note that the construction of candidate feature space, , is extremely important to guarantee the accuracy of system identification. Ideally, includes all terms in the underlying dynamic system; then, can be well represented as a linear combination of the candidate features. But this is not a simple task due to is not known in advance, even though the prior knowledge can provide some guidance. As a result, it is likely that the number of candidate features, , is large enough to include all possible terms appeared in the vector fields. An alternative strategy is the polynomial and trigonometric functions which has been commonly used in various literature [4].
To illustrate the construction process of , we give an example that has three state variables. Denoting the state variable as , the 3 linear features are ; the 6 quadratic features are and, the 10 cubic features are . Likewise, it is easy to show the trigonometric features; the cosine-based ones are where is a hyper-parameter. Finally, we obtain a library of candidate features , .
Here, if there exists no specific priori knowledge of candidate features, the polynomial functions are suggested because of the following reasons: (1) it is hard to obtain the priori coefficients in the trigonometric functions (see e.g. the hyper-parameter, , in ) and (2) in a finite time interval, there always exists a truncated Taylor series to approximate the vector filed globally.
2.4 Sparse identification by sequential threshold least squares
In the following context, the candidate features are set to polynomial functions unless otherwise stated, that is, , , , and is the largest degree of polynomials and traditionally set to be less than 3 for the sake of numerical stability.
Denoting the smoothed time series as a matrix form
and, by using the element-wise product (denoted by ), we can obtain the data vectors corresponding to the candidate features. For example, if , then and subsequently, the data matrix is and for ease of notation, denoted by .
Substituting data matrices into equation (12) gives a pseudo linear regression whose estimates can be obtained by minimizing the least-square objective function
| (14) |
where selects the last rows, denotes the cumulative operation, is an identity matrix and is a special left triangular with all the entries above the main diagonal are zero and ones elsewhere. It is easy to show the simultaneous least-square estimates of structural parameters and initial condition are
| (15) |
then, according to the inverse formula of block matrix [32], the inverse matrix can be rewritten as
| (16) |
where
By plugging equation (16) back into (15), we can separate the estimates of structural parameters and initial condition, respectively expressed as
| (17) |
and
| (18) |
Note that all of the the resultant least-square estimates of structural parameters are not equal to zero and thus cannot select the correct model structure, that is, equation (17) always results in a full model including all candidate features. In order to perform structure selection, the objective function (14) is constrained to generate sparse estimates, that is
| (19) |
where is a hyper-parameter that measures the sparsity of the parameter vector .
By selecting an appropriate hyper-parameter , equation (19) leads to a parsimonious model structure that balances model complexity with descriptive capability. Equation (19) can be solved by many algorithms, such as the least absolute shrinkage and selection operator (LASSO) [33] and least square approximation (LSA) [34]. Here, we select the sequential threshold least squares (STLS) [35] to generate sparse structural estimates, as shown in Algorithm 1.
3 Simulations
In this section the finite sample performance of ISINDy is investigated via Monte Carlo simulations; three nonlinear ODEs, namely Logistic, Lokta-Volterra, and Lorenz dynamics, are used as examples. The underlying time series is approximated with Runge-Kutta numerically. For each component of state variable, the noise level is measured by the noise-variance ratio
| (20) |
where and .
The proposed ISINDy is compared to the benchmark methods: the standard SINDy [18] and its integral variant presented in [26] (which is referred as to InSINDy hereafter). Note that these two benchmark methods do not consider measurement noises of the observations and also cannot produce estimations of initial condition.
3.1 Logistic equation
Consider the logistic growth equation
with initial condition .
The trajectories are generated under the configuration: with , and the noise level . When implementing Algorithm 1, the threshold value is set to . In each noisy scenario, the estimates of sparse structural parameters and initial condition are summarised in Table 1 (Appendix B), and the results show that only the proposed ISINDy identifies the correct active terms together with high-accuracy estimates. By substituting the ISINDy-based estimates and running the ode45 routine, one has the identified trajectories in Figure 2.
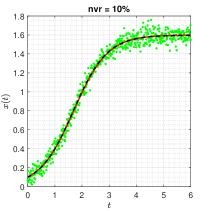
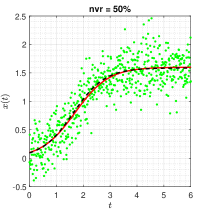
Figure 2 shows that the identified trajectories is very close to the true ones, even though the noise level is as high as , indicating that ISINDy is robust to measurement noises. Moreover, both InSINDy and ISINDy can identify the correct active terms when the noise level is , but ISINDy produces more accurate estimates and as the noise level increases, InSINDy fails to generate correct active terms. For example, when the noise level is , the identified equations of ISINDy and InSINDy are
and
respectively. It is obvious that the InSINDy-based equation includes a redundant active term in the vector field.
3.2 Lokta-Volterra system
Consider the Lokta–Volterra system
with initial condition .
The true trajectory are generated under the configuration: with , and the noise level . Setting the threshold value to , the estimates of sparse structural parameters and initial conditions are summarised in Table 2 (Appendix B). The results show that in all three noisy scenarios, only the proposed ISINDy identifies the correct active terms and generates high-accuracy parameter estimates. By substituting these ISINDy-based estimates and running the ode23 routine, one obtains the identified trajectories in Figure 3.
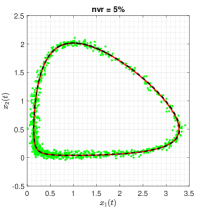
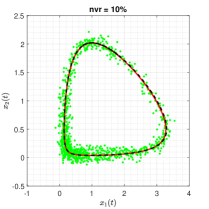
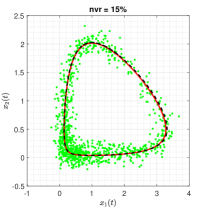
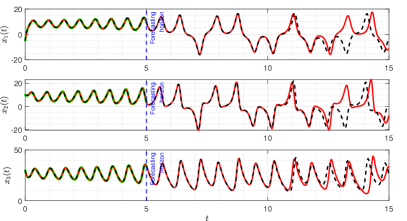
Figure 3 shows that the proposed ISINDy captures the correct active terms in all three noisy scenarios, even though the noise level is up to . Increasing the noise level leads to larger errors in the estimation of structural parameters and initial condition, resulting in more biased trajectories. Besides, to compare the identified and true dynamic systems in the presence of measurement noises on the observations, we simulate the true and identified trajectories at the time range . Figure 4 shows that the trajectory of the identified dynamical system almost coincides with the true one, indicating that ISINDy can also generate accurate long-term forecasts.
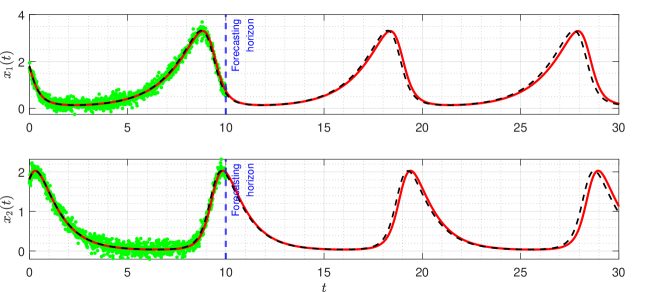
3.3 Lorenz system
Consider the chaotic Lorenz system
with initial condition .
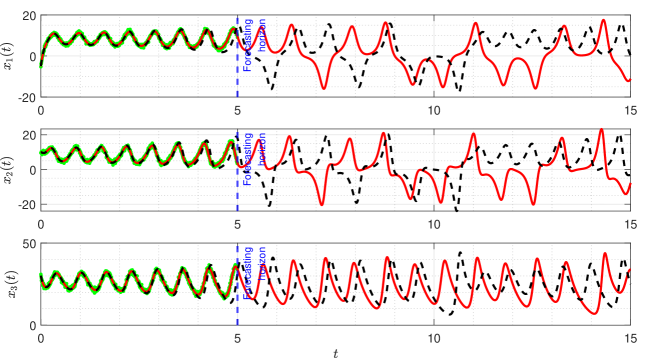
The true trajectories are generated under the configuration: , , and . The threshold value is set to , and the estimates of sparse structural parameters and initial conditions are summarised in Table 3 (Appendix C). The results show that SINDy, InSINDy, and ISINDy correctly identify the active terms in all three noisy scenarios for the first component, but SINDy and InSINDy fail to identify the correct active terms in the second and third components, letting alone the accurate estimates of parameters. Only ISINDy picks out the correct active terms and generates high-accuracy estimates in all three noisy scenarios. By substituting the ISINDy-based estimates and running the ode45 routine, one obtains the identified trajectories in Figure 5.
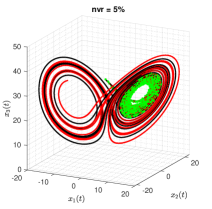
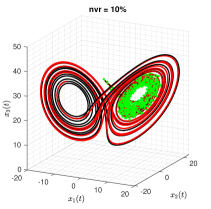
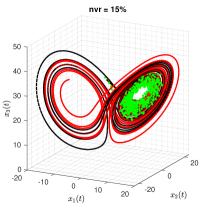
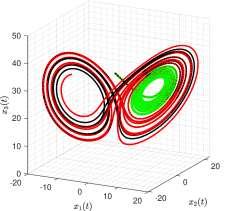
It is worth noting, however, that although the identified equation has correct model structure and also high-accuracy estimates, the identified trajectories may still stray off the true one quickly. For instance, in the scenario, the trajectories of three state variables are plotted in Figure 6. It is clear that the identified trajectories almost coincides with the true ones for a short time from to about and then stray from about on. The reason for this phenomenon is that Lorenz system has chaotic solutions for certain structural parameters and initial conditions. The identified trajectory is very sensitive to the estimates of structural parameters and initial condition. A small bias on the estimates results in large offsets in the trajectory. Specifically, assuming the observations are noise-free, i.e. , the identified attractor associated with the trajectories of three states are shown in Figure 7. The identified trajectories starts to fast stray off the true ones from about on, indicating unreliable long-term forecasts even under a noise-free environment.
3.4 Short discussions
The results of three cases show that the proposed ISINDy outperforms the standard SINDy and its integral variant InSINDy, in both structure identification and parameter estimation terms. When observations are noise-free, i.e. , all three methods can identify the correct model structure, but the parameter estimates obtained from ISINDy are much closer to their true values than those obtained form SINDy and InSINDy (see Tables 1–3 in Appendix B). To be specific, SINDy and ISINDy outperform InSINDy due to that the formers use a trapezoid formula rather than the Euler’s formula, but this does not hold in noisy scenarios due to that the derivative approximation-based SINDy is sensitive to measurement noises and thus generates poor results, especially in the Lorenz system case (see Table 3 in Appendix B).
It is worth noting, however, that the aforementioned simulations are conducted under two conditions: (1) the time range is fixed in a specified interval, and (2) the candidate features include all possible terms appearing in vector fields. Actually, these two factors have important effects on the performance of ISINDy.
-
(i)
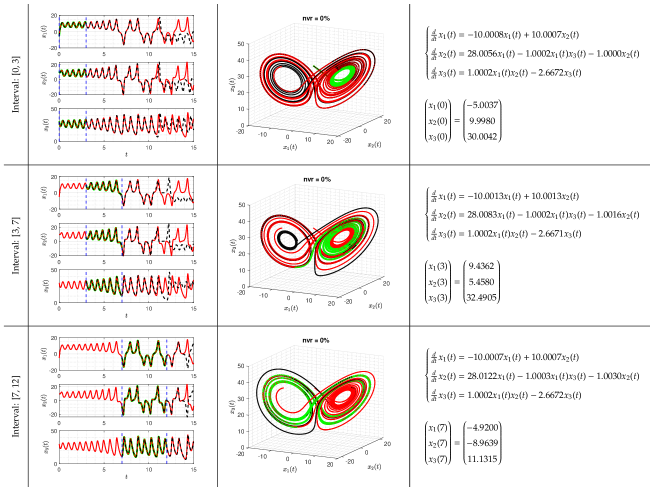
For factor (1), taking the Lorenz system as an example, the fixed time interval is set to , , and , respectively. When the observations are noise-free, ISINDy identifies the correct model structure in all three time interval settings (see Figure 9 in Appendix C). But, when the observations are contaminated by noises, the noise robustness of ISINDy in each interval is different. Figure 10 in Appendix C shows that ISINDy generates wrong model structure when , indicating that in the noise tolerance is less than 2%. Similarly, in the noise tolerance is less than 5% and in the noise tolerance is less than 10%. An alternative strategy to improve robustness is guaranteeing the quality of smoothing, which is inferred from the noise-free observations cases.
-
(ii)
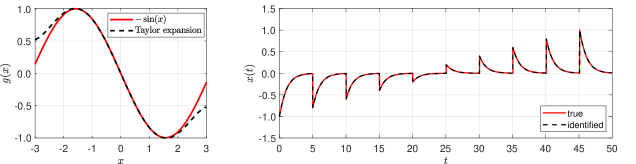
For factor (2), a simple ODE is employed to explore the effect of candidate features on identification accuracy. Note that the Taylor expansion of the vector field is
On this test problem, ISINDy with different candidate features is investigated, including polynomial, trigonometric, and a combination of both, shown in Table 4 (Appendix D). In the case of polynomial features, the degree of polynomial is set to 3 and 5 in turn, and in both settings ISINDy identifies the correct active terms together with high-accuracy parameters in the Taylor expansion of . In both of the other cases of trigonometric features or a combination of polynomial and trigonometric features, the correct active term is identified.
Furthermore, the time interval and the design of candidate features always interact. Taking the simple ODE as an example, in the time range of , the resulting trajectories lie in the range of . This guarantees that the Taylor series expansion can approximate the vector filed, thereby generating the excellent dynamic reconstruction, as shown in Figure 11 (Appendix D).
4 Conclusion
In this work, an integral SINDy approach that leverages penalized spline smoothing is proposed for simultaneously (1) denoising time-series observations, (2) generating accurate estimates of structural parameters and initial condition, and (3) identifying parsimonious systems of differential equations responsible for generating time series. Using the integral formulation, noisy time-series observations are handled in a stable and robust way; even for high noise levels, the algorithm can produce correct model structure, high-accuracy estimates of structural parameters and initial condition, showing the improvement of proposed approach with respect to robustness to noise with less training data in comparison with the previous integral variant of SINDy [26]. Simulations show that this approach is accurate and robust to noise when dynamic behavior is included in the observations, suggesting its ability to extract interpretable equations from data.
The current research assumes that all terms appeared in the vector field are included in the candidate features. We must acknowledge that the proposed approach has several limitations, e.g., (1) time-consuming of penalized spline smoothing process, especially for large-sample observations, and (2) incorrect identification of vector fields if the candidate features are improperly designed. In practice, how to design an appropriate library of candidate features is still a challenging problem [36], although physical intuition or domain knowledge may be leveraged in many systems. Besides, note that this work does not relate to the identifiability of structural parameters and initial condition [37, 38, 39], and the uncertainty quantification of model structure inference [40], which are the centre topic of our future theoretical research.
Data availability
All scripts to reproduce the results are available at https://github.com/weibl9/integralSINDy.
Declaration of competing interest
The author declares no competing interests.
References
- Lennart [1999] L. Lennart, System identification: Theory for the user, Prentice Hall PTR, 1999.
- Young [2012] P. C. Young, Recursive estimation and time-series analysis: an introduction for the student and practitioner, 2nd ed., Springer Science & Business Media, 2012.
- Ahsan [2016] Z. Ahsan, Differential equations and their applications, PHI Learning Pvt. Ltd., 2016.
- Brunton and Kutz [2019] S. L. Brunton, J. N. Kutz, Data-driven science and engineering: Machine learning, dynamical systems, and control, Cambridge University Press, 2019.
- Young [2013] P. C. Young, Hypothetico-inductive data-based mechanistic modeling of hydrological systems, Water Resources Research 49 (2013) 915–935.
- Chen et al. [2011] Y. Chen, B. Yang, Q. Meng, Y. Zhao, A. Abraham, Time-series forecasting using a system of ordinary differential equations, Information Sciences 181 (2011) 106–114.
- Bongard and Lipson [2007] J. Bongard, H. Lipson, Automated reverse engineering of nonlinear dynamical systems, Proceedings of the National Academy of Sciences 104 (2007) 9943–9948.
- Schmidt and Lipson [2009] M. Schmidt, H. Lipson, Distilling free-form natural laws from experimental data, Science 324 (2009) 81–85.
- Quade et al. [2016] M. Quade, M. Abel, K. Shafi, R. K. Niven, B. R. Noack, Prediction of dynamical systems by symbolic regression, Physical Review E 94 (2016) 012214.
- Daniels and Nemenman [2015] B. C. Daniels, I. Nemenman, Automated adaptive inference of phenomenological dynamical models, Nature Communications 6 (2015) 1–8.
- Ye et al. [2015] H. Ye, R. J. Beamish, S. M. Glaser, S. C. Grant, C.-h. Hsieh, L. J. Richards, J. T. Schnute, G. Sugihara, Equation-free mechanistic ecosystem forecasting using empirical dynamic modeling, Proceedings of the National Academy of Sciences 112 (2015) E1569–E1576.
- Raissi [2018] M. Raissi, Deep hidden physics models: Deep learning of nonlinear partial differential equations, Journal of Machine Learning Research 19 (2018) 932–955.
- Qin et al. [2019] T. Qin, K. Wu, D. Xiu, Data driven governing equations approximation using deep neural networks, Journal of Computational Physics 395 (2019) 620–635.
- Wang et al. [2016] W.-X. Wang, Y.-C. Lai, C. Grebogi, Data based identification and prediction of nonlinear and complex dynamical systems, Physics Reports 644 (2016) 1–76.
- Tolle et al. [2011] K. M. Tolle, D. S. W. Tansley, A. J. Hey, The fourth paradigm: Data-intensive scientific discovery [point of view], Proceedings of the IEEE 99 (2011) 1334–1337.
- Wang et al. [2011] W.-X. Wang, R. Yang, Y.-C. Lai, V. Kovanis, C. Grebogi, Predicting catastrophes in nonlinear dynamical systems by compressive sensing, Physical Review Letters 106 (2011) 154101.
- Schaeffer et al. [2013] H. Schaeffer, R. Caflisch, C. D. Hauck, S. Osher, Sparse dynamics for partial differential equations, Proceedings of the National Academy of Sciences 110 (2013) 6634–6639.
- Brunton et al. [2016] S. L. Brunton, J. L. Proctor, J. N. Kutz, Discovering governing equations from data by sparse identification of nonlinear dynamical systems, Proceedings of the National Academy of Sciences 113 (2016) 3932–3937.
- Rudy et al. [2017] S. H. Rudy, S. L. Brunton, J. L. Proctor, J. N. Kutz, Data-driven discovery of partial differential equations, Science Advances 3 (2017) e1602614.
- Rudy et al. [2019] S. Rudy, A. Alla, S. L. Brunton, J. N. Kutz, Data-driven identification of parametric partial differential equations, SIAM Journal on Applied Dynamical Systems 18 (2019) 643–660.
- Mangan et al. [2017] N. M. Mangan, J. N. Kutz, S. L. Brunton, J. L. Proctor, Model selection for dynamical systems via sparse regression and information criteria, Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 473 (2017) 20170009.
- Chou and Voit [2009] I.-C. Chou, E. O. Voit, Recent developments in parameter estimation and structure identification of biochemical and genomic systems, Mathematical biosciences 219 (2009) 57–83.
- Ramsay et al. [2007] J. O. Ramsay, G. Hooker, D. Campbell, J. Cao, Parameter estimation for differential equations: a generalized smoothing approach, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 69 (2007) 741–796.
- Ramsay and Hooker [2017] J. Ramsay, G. Hooker, Dynamic data analysis: modeling data with differential equations, Springer Science & Business Media, 2017.
- Dattner and Klaassen [2015] I. Dattner, C. A. J. Klaassen, Optimal rate of direct estimators in systems of ordinary differential equations linear in functions of the parameters, Electronic Journal of Statistics 9 (2015) 1939–1973.
- Schaeffer and McCalla [2017] H. Schaeffer, S. G. McCalla, Sparse model selection via integral terms, Physical Review E 96 (2017) 023302.
- von Rueden et al. [2021] L. von Rueden, S. Mayer, K. Beckh, B. Georgiev, S. Giesselbach, R. Heese, B. Kirsch, J. Pfrommer, A. Pick, R. Ramamurthy, M. Walczak, J. Garcke, C. Bauckhage, J. Schuecker, Informed Machine Learning – A taxonomy and survey of integrating prior knowledge into learning systems, IEEE Transactions on Knowledge and Data Engineering (2021) 1–20.
- Karniadakis et al. [2021] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, Physics-informed machine learning, Nature Reviews Physics 3 (2021) 422–440.
- Cao et al. [2012] J. Cao, J. Cai, L. Wang, Estimating curves and derivatives with parametric penalized spline smoothing, Statistics and Computing 22 (2012) 1059–1067.
- Wahba [1990] G. Wahba, Spline models for observational data, Siam, 1990.
- Patrikalakis and Maekawa [2002] N. M. Patrikalakis, T. Maekawa, Representation of curves and surfaces, in: N. M. Patrikalakis, T. Maekawa (Eds.), Shape Interrogation for Computer Aided Design and Manufacturing, Springer, Berlin, Heidelberg, 2002, pp. 1–33. doi:10.1007/978-3-642-04074-0_1.
- Lu and Shiou [2002] T.-T. Lu, S.-H. Shiou, Inverses of 2 2 block matrices, Computers and Mathematics with Applications 43 (2002) 119–129.
- Tibshirani [2011] R. Tibshirani, Regression shrinkage and selection via the lasso: a retrospective, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 73 (2011) 273–282.
- Wang and Leng [2007] H. Wang, C. Leng, Unified LASSO estimation by least squares approximation, Journal of the American Statistical Association 102 (2007) 1039–1048.
- Zhang and Schaeffer [2019] L. Zhang, H. Schaeffer, On the convergence of the SINDy algorithm, Multiscale Modeling and Simulation 17 (2019) 948–972.
- Delahunt and Kutz [2022] C. B. Delahunt, J. N. Kutz, A toolkit for data-driven discovery of governing equations in high-noise regimes, IEEE Access 10 (2022) 31210–31234.
- Pia Saccomani et al. [2003] M. Pia Saccomani, S. Audoly, L. D’Angiò, Parameter identifiability of nonlinear systems: The role of initial conditions, Automatica 39 (2003) 619–632.
- Miao et al. [2011] H. Miao, X. Xia, A. S. Perelson, H. Wu, On identifiability of nonlinear ODE models and applications in viral dynamics, SIAM Review 53 (2011) 3–39.
- Peng et al. [2011] H. Peng, L. Li, Y. Yang, F. Sun, Conditions of parameter identification from time series, Physical Review E 83 (2011) 036202.
- DeGennaro et al. [2019] A. M. DeGennaro, N. M. Urban, B. T. Nadiga, T. Haut, Model structural inference using local dynamic operators, International Journal for Uncertainty Quantification 9 (2019) 59–83.
Appendix A. The cubic B-spline basis functions
A cubic B-spline function is formed by jointing piece-wise polynomials of degree 3 with at most continuity at the knots. The basis functions between two knots are defined by the Cox-de Boor recursion formula [31]:
where denotes knots and denotes degree of polynomial.
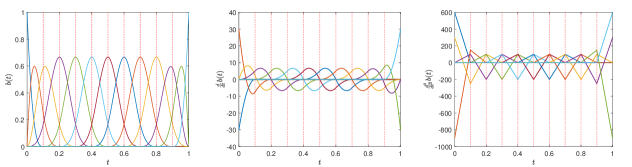
For example, let the knots be . Then, 13 basis functions are defined over the interval , and at each knot the polynomial values and their first two derivatives match, as show in Figure 8.
Appendix B. The estimates of structural parameters and initial condition under varying noise levels
| Terms | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| — | — | 0.1000 | — | — | 0.0985 | — | — | 0.0962 | — | — | 0.0935 | |
| 1.6000 | 1.5975 | 1.6000 | 1.8604 | 1.6831 | 1.6203 | 3.7477 | 2.3752 | 1.6609 | 5.1682 | 3.4485 | 1.7047 | |
| 1.0000 | 0.9980 | 1.0000 | 1.4848 | 1.0551 | 1.0145 | 5.0504 | 2.1302 | 1.0434 | 7.4255 | 3.5429 | 1.0744 | |
| 0 | 0 | 0 | 0.2016 | 0 | 0 | 1.6942 | 0.4054 | 0 | 2.5584 | 0.8550 | 0 | |
| Terms | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| First | — | — | 1.8000 | — | — | 1.8017 | — | — | 1.8030 | — | — | 1.8032 | |
| Comp. | 0.6667 | 0.6692 | 0.6667 | 0.6664 | 0.6698 | 0.6720 | 0.6589 | 0.6702 | 0.6774 | 0.6425 | 0.5575 | 0.6825 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.7683 | 0 | ||
| 1.3334 | 1.3430 | 1.3333 | 1.3292 | 1.3277 | 1.3388 | 1.3114 | 1.3122 | 1.3444 | 1.2771 | 2.7419 | 1.3488 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.9956 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.7534 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.9186 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.4481 | 0 | ||
| Second | — | — | 1.8000 | — | — | 1.8037 | — | — | 1.8077 | — | — | 1.8121 | |
| Comp. | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0.9999 | 0.9968 | 1.0000 | 1.1301 | 1.0956 | 0.9954 | 0.9973 | 0.9677 | 0.9908 | 0.8007 | 1.0828 | 0.9863 | ||
| 0.9990 | 0.9978 | 1.0000 | 1.7761 | 0 | 0.9956 | 1.8408 | 0.9851 | 0.9911 | 1.9741 | 0 | 0.9865 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5601 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0.7589 | 0 | 0 | 0 | 0 | 0.4198 | 0.7636 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| Terms | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | SINDy | InSINDy | ISINDy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| First | — | — | 5.0046 | — | — | 4.9798 | — | — | 4.9215 | — | — | 4.8467 | |
| Comp. | 10.0013 | 10.2411 | 10.0013 | 10.0200 | 10.3430 | 10.0180 | 9.9638 | 10.4420 | 10.0100 | 9.8377 | 10.5390 | 9.9915 | |
| 10.0012 | 10.2435 | 10.0013 | 10.0000 | 10.3270 | 9.9987 | 9.9286 | 10.4070 | 9.9728 | 9.7906 | 10.4840 | 9.9353 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| Second | — | — | 9.9983 | — | — | 9.9822 | — | — | 9.9451 | — | — | 9.8771 | |
| Comp. | 27.9523 | 27.9406 | 28.0061 | 59.9790 | 25.8860 | 28.0770 | 52.5500 | 26.0150 | 28.0720 | 66.2880 | 26.1250 | 27.9900 | |
| 0 | 0 | 0 | 5.1065 | 0 | 0 | 1.8500 | 0 | 0 | 2.4958 | 0 | 0 | ||
| 0.9820 | 0.9683 | 1.0002 | 7.9855 | 0 | 0.9592 | 47.4620 | 0 | 0.8955 | 68.9500 | 0 | 0.8065 | ||
| 0 | 0 | 0 | 3.5886 | 0 | 0 | 5.3775 | 0 | 0 | 12.8470 | 0 | 0 | ||
| 0 | 0 | 0 | 1.0011 | 0 | 0 | 5.1637 | 0 | 0 | 7.4029 | 0 | 0 | ||
| 0 | 0 | 0 | 12.214 | 0 | 0 | 27.9080 | 0 | 0 | 44.8650 | 0 | 0 | ||
| 0.9970 | 0.9990 | 1.0002 | 5.5552 | 0.96061 | 1.0047 | 7.0064 | 0.9654 | 1.0073 | 9.1726 | 0.9695 | 1.0079 | ||
| 0 | 0 | 0 | 1.0570 | 0 | 0 | 1.4457 | 0 | 0 | 3.2327 | 0 | 0 | ||
| 0 | 0 | 0 | 0.9825 | 0 | 0 | 2.4698 | 0 | 0 | 4.0385 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| Third | — | — | 30.0043 | — | — | 30.0420 | — | — | 30.0700 | — | — | 30.0950 | |
| Comp. | 0 | 0 | 0 | 50.8140 | 0 | 0 | 96.1630 | 1.8294 | 0 | 130.3000 | 10.6670 | 0 | |
| 0 | 0 | 0 | 5.3069 | 0 | 0 | 12.2670 | 0 | 0 | 17.3530 | 0 | 0 | ||
| 0 | 0 | 0 | 58.8090 | 0 | 0 | 121.9800 | 0 | 0 | 157.9900 | 0 | 0 | ||
| 0.9949 | 1.0088 | 1.0002 | 8.3655 | 1.0142 | 0.9964 | 21.4980 | 0.9183 | 0.9923 | 29.0380 | 1.1835 | 0.9879 | ||
| 0 | 0 | 0 | 4.5377 | 0 | 0 | 9.6943 | 0 | 0 | 12.2090 | 0 | 0 | ||
| 2.6710 | 2.6934 | 2.6672 | 6.1171 | 2.7172 | 2.6625 | 15.8890 | 3.0193 | 2.6572 | 17.9310 | 0 | 2.6507 | ||
| 0 | 0 | 0 | 3.5181 | 0 | 0 | 6.5122 | 0 | 0 | 9.5474 | 0 | 0 | ||
| 0 | 0 | 0 | 4.0361 | 0 | 0 | 9.3839 | 0 | 0 | 12.7760 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.1170 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 1.5798 | 0 | 0 | 1.7850 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
Appendix C. The identified trajectories of Lorenz system under varying time intervals
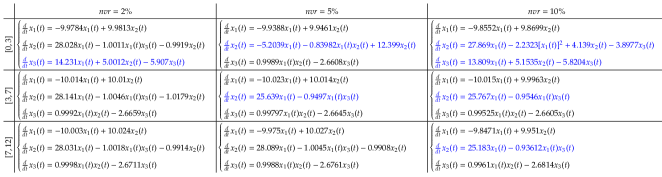
Appendix D. The effect of candidate features on structure identification
| initial condition | 1.00 | 0.80 | 0.60 | 0.40 | 0.20 | 0.20 | 0.40 | 0.60 | 0.80 | 1.00 |
|---|---|---|---|---|---|---|---|---|---|---|
| polynomial features: degree 3 | ||||||||||
| 0.9997 | 0.7999 | 0.6000 | 0.4000 | 0.2000 | 0.2000 | 0.4000 | 0.6000 | 0.7999 | 0.9997 | |
| 0.9996 | 0.9998 | 0.9999 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9999 | 0.9998 | 0.9996 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.1612 | 0.1632 | 0.1647 | 0.1658 | 0.1664 | 0.1664 | 0.1658 | 0.1647 | 0.1632 | 0.1612 | |
| polynomial features: degree 5 | ||||||||||
| 1.0000 | 0.8000 | 0.6000 | 0.4000 | 0.2000 | 0.2000 | 0.4000 | 0.6000 | 0.8000 | 1.0000 | |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | 0.1666 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.0081 | 0.0082 | 0.0082 | 0.0083 | 0.0083 | 0.0083 | 0.0083 | 0.0082 | 0.0082 | 0.0081 | |
| trigonometric features | ||||||||||
| 1.0000 | 0.8000 | 0.6000 | 0.4000 | 0.2000 | 0.2000 | 0.4000 | 0.6000 | 0.8000 | 1.0000 | |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| combination of polynomial and trigonometric features | ||||||||||
| 1.0000 | 0.8000 | 0.6000 | 0.4000 | 0.2000 | 0.2000 | 0.4000 | 0.6000 | 0.8000 | 1.0000 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |