Sparse Quadratic Optimisation over the
Stiefel Manifold with Application to
Permutation Synchronisation
Abstract
We address the non-convex optimisation problem of finding a sparse matrix on the Stiefel manifold (matrices with mutually orthogonal columns of unit length) that maximises (or minimises) a quadratic objective function. Optimisation problems on the Stiefel manifold occur for example in spectral relaxations of various combinatorial problems, such as graph matching, clustering, or permutation synchronisation. Although sparsity is a desirable property in such settings, it is mostly neglected in spectral formulations since existing solvers, e.g. based on eigenvalue decomposition, are unable to account for sparsity while at the same time maintaining global optimality guarantees. We fill this gap and propose a simple yet effective sparsity-promoting modification of the Orthogonal Iteration algorithm for finding the dominant eigenspace of a matrix. By doing so, we can guarantee that our method finds a Stiefel matrix that is globally optimal with respect to the quadratic objective function, while in addition being sparse. As a motivating application we consider the task of permutation synchronisation, which can be understood as a constrained clustering problem that has particular relevance for matching multiple images or 3D shapes in computer vision, computer graphics, and beyond. We demonstrate that the proposed approach outperforms previous methods in this domain.
1 Introduction
We are interested in optimisation problems of the form
| (1) |
where is the identity matrix of dimension , and the set denotes the Stiefel manifold (). Throughout the paper, w.l.o.g. we consider a maximisation formulation and we assume that is a symmetric and positive semidefinite matrix (see Lemma 1 in Sec. 2). Despite the non-convexity of Problem (1), problems of this form can be solved to global optimality based on the eigenvalue decomposition, i.e. by setting , where denotes an orthogonal basis of eigenvectors corresponding to the largest eigenvalues of , see Lemma 2. The fact that we can efficiently find global optima of Problem (1) makes it a popular relaxation formulation of various difficult combinatorial problems. This includes spectral relaxations [43, 26, 17] of the NP-hard quadratic assignment problem (QAP) [35], spectral clustering [33, 44], or spectral permutation synchronisation [34, 39, 31]. Yet, a major difficulty of such approaches is to discretise the (relaxed) continuous solution in order to obtain a feasible solution of the original (discrete) problem. For example, in the QAP one optimises over the set of permutation matrices, in clustering one optimises over the set of matrices with rows comprising canonical basis vectors, and in permutation synchronisation one optimises over multiple permutation matrices that are stacked into a large block matrix. Often such combinatorial sets can be characterised by Stiefel matrices that are sparse – for example, the set of (signed) permutation matrices can be characterised by matrices in that have exactly non-zero elements, whereas any other element in that has more than non-zero elements is not a signed permutation matrix.
The most common approach to obtain sparse solutions in an optimisation problem is to integrate an explicit sparsity-promoting regulariser. However, a major hurdle when considering quadratic optimisation problems over the Stiefel manifold is that the incorporation of sparsity-promoting terms is not compatible with solutions based on eigenvalue decomposition, so that desirable global optimality guarantees are generally no longer maintained.
Instead, we depart from the common path of integrating explicit regularisers and instead exploit the orthogonal-invariance present in Problem (1) to assure sparsity. To be more specific, for any orthogonal matrix it holds that . Hence, if is a solution to Problem (1), so is for any . The subspace that is spanned by for a given (and arbitrary ) is equal to the subspace . Motivated by this observation we utilise orthogonal-invariance in order to find a solution such that is sparse. To this end, we build upon the additional degrees of freedom due to , which allows to rotate a given solution to a sparser representation – most notably, while remaining a globally optimal solution to Problem (1).
Main contributions. We summarise our main contributions as follows: (i) For the first time we propose an algorithm that exploits the orthogonal-invariance in quadratic optimisation problems over the Stiefel manifold while simultaneously accounting for sparsity in the solution. (ii) Despite its simplicity, our algorithm is effective as it builds on a modification of the well-established Orthogonal Iteration algorithm for finding the most dominant eigenspace of a given matrix. (iii) Our algorithm is guaranteed to converge to the dominant subspace with the same convergence rate as the original Orthogonal Iteration algorithm, and our solution constitutes a global optimiser of Problem (1). (iv) We experimentally confirm the efficacy of our approach in the context of the permutation synchronisation problem.
2 Preliminaries & Related Work
In this section we clarify our assumptions, introduce additional preliminaries, and provide reference to related work. Let be the eigenvalues of ordered decreasingly. We impose the following assumption on :
Assumption 1 (Separated eigenspace).
We assume that .
Throughout the paper we also assume that is symmetric and positive semidefinite (p.s.d.), which, however, is not a restriction as the following straightforward result indicates:
Lemma 1 (Symmetry and positive semidefiniteness).
In Problem (1), if is not symmetric and not p.s.d. there is an equivalent optimisation problem (i.e. with the same optimisers) where has been replaced by a symmetric p.s.d. matrix .
Proof.
See Appendix. ∎
Next, we define the notion of a dominant subspace and convergence of matrix sequences to such a subspace.
Definition 1 (Dominant invariant subspace).
The -dimensional dominant invariant subspace (or dominant subspace in short) of the matrix is defined as the subspace , where is the matrix whose columns are formed by the eigenvectors corresponding to the largest eigenvalues of .
Definition 2 (Convergence).
We say that a sequence of matrices converges to the dominant subspace of if .
There exists a close relation between the dominant subspace of and solutions of Problem (1):
Lemma 2 (Solution to Problem (1)).
Problem (1) is solved for any matrix that forms an orthogonal basis for the -dimensional dominant subspace of , i.e. .
Proof.
See Appendix. ∎
Basic algorithms for computing eigenvectors. In order to find the dominant subspace of we can use algorithms for finding eigenvectors. The Power method [21] is an efficient way for finding the single most dominant eigenvector of a given matrix, i.e. it considers the case . It proceeds by iteratively updating a given initial based on the update . In order to find the most dominant eigenvectors, one can consider the Orthogonal Iteration algorithm [21], which generalises the Power method to the case . The algorithm proceeds by repeatedly computing based on the (thin) QR-decomposition of , where and is upper triangular. For the sequence converges (under mild conditions on the intial ) to the dominant invariant subspace as long as , see Thm. 8.2.2 in [21].
Sparse Stiefel optimisation. There are numerous approaches for addressing general optimisation problems over the Stiefel manifold, including generic manifold optimisation techniques (e.g. [3, 14]), or Stiefel-specific approaches (e.g. [30, 46]). In the following we will focus on works that consider sparse optimisation over the Stiefel manifold that are most relevant to our approach. In order to promote sparse solutions, sparsity-inducing regularisers can be utilised, for example via the minimisation of the (non-convex) -‘norm’ for , or the (convex) -norm [36]. However, the non-smoothness of such regularisers often constitutes a computational obstacle.
The optimisation of non-smooth functions over the Stiefel manifold has been considered in [16], where the sum of a non-convex smooth and a convex non-smooth function is optimised via a proximal gradient method. In [27], the authors consider the optimisation of a sum of non-smooth weakly convex functions over the Stiefel manifold using Riemannian subgradient-type methods. Yet, in practice often differentiable surrogates of non-smooth sparsity-promoting terms are considered [40, 29, 38, 15]. Instead of minimising -‘norms’ with , on the Stiefel manifold one may instead choose the maximisation of -norms with , such as the -norm [47], or the -norm [49]. Further motivation for sparsity promoting higher-order norms in this context can be found in [37, 50, 28].
Optimisation over the Stiefel manifold has a close connection to optimisation over the Grassmannian manifold [3]. There are numerous approaches for Grassmannian manifold optimisation (e.g. [19, 18]), including sparse optimisation via an -norm regulariser [45] and the optimisation of non-convex and non-smooth objective functions via a projected Riemannian subgradient method [52]. In our case, due to the rotation-invariance of the objective for any in Problem (1), finding the dominant subspace of could also be posed as an optimisation problem over the Grassmannian manifold. However, we are not only interested in identifying this subspace (which can for example be done via the Orthogonal Iterations algorithm [21], or via Grassmann-Rayleigh Quotient Iterations [4]), but we want to find a specific choice of coordinates for which the representation of the subspace is sparse.
3 Proposed Method for Sparse Quadratic Optimisation over the Stiefel
In this section we introduce our Algorithm 1 that can be seen as a modification of the popular Orthogonal Iteration algorithm. The main difference is that we iteratively weigh the matrix by a matrix , where the matrix function maps onto the set of full rank matrices. The purpose of the matrix (see Sec. 3.2 for our specific choice) is to promote sparsity. Intuitively, we characterise sparsity as having few elements that are large, whereas most elements are close to zero, which is formally expressed in (4).
First, we focus on the overall interpretation of our approach: We want to ensure that we retrieve a that is a global maximiser of Problem (1), which, in some relaxed sense, is also sparse. However, we cannot in general augment the objective function in Problem (1) with an explicit sparsity regulariser and expect that the respective solution is still a maximiser of the original objective. Instead we steer the solution towards being more sparse by weighing our matrix of interest with the matrix .
3.1 Convergence
We start by ensuring that, under the assumption that is full rank, the sequence generated by Algorithm 1 converges to the dominant subspace of . This can straightforwardly be shown by using the following result.
Lemma 3.
Consider the two algorithms:
Algorithm A: ,
Algorithm B: ,
where is full rank, and for each of the two left-hand sides above the two matrices in the product are obtained by the unique (thin) QR-factorisation of the corresponding right-hand side, where and are upper triangular with positive diagonal. Now, if up to a rotation from the right, then is equal to up to rotation from the right for all .
Proof.
Suppose , where . It holds that , where and are the two matrices in the QR-factorisation of the matrix . This means that . This is due to the uniqueness of the QR-factorisation, so that also . Now the results follows readily by using induction. ∎
Thus, if is full rank for each , we can identify our Algorithm 1 with Algorithm A in Lemma 3, and conclude that the sequence converges to the dominant subspace of as . This is because Algorithm B in Lemma 3 corresponds to the Orthogonal Iteration algorithm, which is known to converge to the dominant subspace of [21].
We continue by investigating the behaviour at the limit where the columns of are in the dominant subspace of . Let us consider the update of Algorithm 1, and further assume that the largest eigenvalues of are equal, which is for example the case for synchronisation problems assuming cycle consistency (cf. Sec. 4).
Lemma 4.
Assume that the largest eigenvalues of the p.s.d. matrix are all equal to one111If they are all equal to a value , we can w.l.o.g. consider in place of , since the optimiser of Problem (1) is invariant to scaling . and strictly larger than the other eigenvalues, and assume that the columns of are contained in the dominant subspace of . Provided is full rank, it holds that
where is the unique QR-factorisation of and is the unique QR-factorisation of .
Proof.
Since all the largest eigenvalues of are equal to one and the columns of are in the dominant subspace it holds that , which explains the first equality. While the second equality follows by definition, the third equality remains to be proven. Let be the unique QR-decomposition of . We want to show that and . From the QR-decomposition of it follows that , while from the QR-decomposition of it follows that . The uniqueness of the QR-decomposition implies and . ∎
3.2 Choosing to Promote Sparsity
We now turn our attention to the choice of in Algorithm 1. We know that, as long as is full rank in each iteration , the columns of converge to the dominant subspace of . In addition to our objective function in Problem (1), we now introduce the secondary objective
| (4) |
where for being a positive integer the notation means to raise each element in to the power . For and larger than , the maximisation of promotes sparsity in a relaxed sense. To be specific, if is odd, a few larger elements (with value close to 1) lead to a larger value of compared to many smaller elements (with value close to 0), so that sparsity and non-negativity are simultaneously promoted. Analogously, if is even, a few elements with value closer to lead to a larger value of compared to many smaller elements close to .
Let us consider the maximisation of
| (5) |
with respect to , where , and . This means that we want to rotate by in such a way that the secondary objective is maximised after the rotation. By applying the rotation from the right, we ensure that the columns span the same space after the rotation, but a higher objective value is achieved for the secondary objective in (4).
The extrinsic gradient with respect to (for relaxed to be in ) of at is . Thus the (manifold) gradient of at is given by the projection of the extrinsic gradient at onto the tangent space, which reads
| (6) |
For a small step size , we can perform a first-order approximation of gradient ascent if we choose , and then update in terms of the Q-matrix of the QR-factorisation of . Now, let us assume that we investigate the behaviour at the limit under the assumptions in Lemma 4, i.e. that the largest eigenvalues of are equal. In this context the Q-matrix of the QR-factorisation is a retraction [3] and serves as a first-order approximation of the exponential map. With that, the updates become
| (7) | ||||
| (8) |
This choice of the matrix ensures that it is full rank, since adding the identity matrix and a skew-symmetric matrix results in a full rank matrix. Hence, for sufficiently small step size , we iteratively move in an ascent direction on by utilising the QR-retraction.
4 Application to Permutation Synchronisation
4.1 Permutation Synchronisation in a Nutshell
Permutation synchronisation is a procedure to improve matchings between multiple objects [23, 34], and related concepts have been utilised to address diverse tasks, such as multi-alignment [7, 5, 25], multi-shape matching [22, 24, 20], multi-image matching [51, 42, 9, 13, 12], or multi-graph matching [48, 6, 41], among many others. Permutation synchronisation refers to the process of establishing cycle consistency in the set of pairwise permutation matrices that encode correspondences between points in multiple objects. In computer vision there is a typical application where the points are feature descriptors or key-points, and the objects are images, as shown in Fig. 2.
Let denote the number of objects, where each object contains points. For being a -dimensional vector of all ones, and vector inequalities being understood in an element-wise sense, let be the partial permutation matrix that represents the correspondence between the points in object and the points in object . In the case of bijective permutations, the set of pairwise permutations is said to be cycle-consistent if for all it holds that .
We define the set of partial permutation matrices with full row-rank as , where denotes the total number of distinct points across all objects. Cycle consistency is known to be equivalent to the existence of so-called object-to-universe matchings such that for all we can write (see [23, 34] for details). The object-to-universe characterisation of cycle consistency is also valid for the case of non-bijective (i.e. partial) permutations (see [42, 8] for details).
Given the noisy (i.e. not cycle-consistent) set of pairwise permutations , permutation synchronisation can be phrased as the optimisation problem
| (9) |
where for we define the set , the -dimensional block matrix , and the block matrix in order to allow for a compact matrix representation of the objective.
4.2 Proposed Permutation Synchronisation Approach
The core idea of existing spectral permutation synchronisation approaches [34, 39, 31] is to replace the feasible set in Problem (9) with the Stiefel manifold , so that we obtain an instance of Problem (1). We utilise Algorithm 1 to obtain a (globally optimal) solution of this spectral formulation. In our algorithm we choose to promote sparsity and non-negativity in the resulting via the function . With that, in addition to being an orthogonal matrix, it contains few large elements that are close to 1 and many smaller elements that are close to 0. As such, we can readily project the matrix onto the set in terms of a Euclidean projection. The Euclidean projection is given by projecting each of the blocks of individually onto the set of partial permutations, i.e. , see e.g. [8], which amounts to a (partial) linear assignment problem [32, 11] that we solve based on the efficient implementation in [10].
4.3 Experimental Results
We experimentally compare our proposed approach with various methods for permutation synchronisation and perform an evaluation on both real and synthetic datasets. In particular, our comparison includes two existing spectral approaches, namely MatchEig [31] and Spectral [34], where for the latter we use the efficient implementation from the authors of [51]. In addition, we also compare against the alternating minimisation method MatchALS [51], and against the non-negative matrix factorisation approach NmfSync [8]. To emphasise that the methods MatchEig and MatchALS do not guarantee cycle consistency (but instead aim to improve the initial matchings), in all plots we show results of respective methods as dashed lines. We use the fscore to measure the quality of obtained multi-matchings, which is defined as the fraction , where and denote the precision and recall, respectively. All experiments are run on a Macbook Pro (2.8 GHz quad core i7, 16 GB RAM), where for we use as convergence criterion in Algorithm 1, and a step size of in (7).
Real data. In this experiment we use the CMU house image sequence [1] comprising frames within the experimental protocol of [34]. We generate a sequence of permutation synchronisation problem instances with a gradually increasing number of objects by extracting respective pairwise matchings for objects. To this end, we vary from to and sample the pairwise matchings evenly-spaced from the pairwise matchings. Quantitative results in terms of the fscore, the objective value of Problem (9), and the runtimes are shown in Fig. 1, in which the individual problem instances vary along the horizontal axis. We can see that our proposed method dominates other approaches in terms of the fscore and the objective value (the reported objective values are divided by to normalise the scale in problems of different sizes), while being among the fastest. Note that we do not report the objective value for MatchEig and MatchALS, since they do not lead to cycle-consistent matchings so that the obtained solution does not lie in the feasible set of Problem (9). Qualitative results of the matching between one pair of images for are shown in Fig. 2. As expected, our proposed approach clearly outperforms the Spectral baseline, since our method is guaranteed to converge to the same same subspace that is spanned by the spectral solution, while at the same time providing a sparser and less negative solution that is thereby closer to the feasible set .




| Input | MatchEig |
 |
 |
| MatchALS | Spectral |
 |
 |
| NmfSync | Ours |
 |
 |
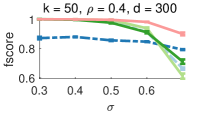
Synthetic data. We reproduce the procedure described in [8] for generating synthetic instances for the synchronisation of partial permutations. Four different parameters are considered for generating a problem instance: the universe size , the number of objects that are to be matched, the observation rate , and the error rate (see [8] for details). One of these parameters varies in each experimental setting, while the others are kept fixed. Each individual experiment is repeated times with different random seeds. In Fig. 3 we compare the performance of MatchEig [31], MatchALS [51], Spectral [34], NmfSync [8] and Ours. The first row shows the fscore, and the second row the respective runtimes. Note that we did not run MatchALS on the larger instances since the runtime is prohibitively long. The methods MatchEig and MatchALS do not guarantee cycle consistency, and are thus shown as dashed lines. It can be seen that in most settings our method obtains superior performance in terms of the fscore, while being almost as fast as the most efficient methods that are also based on a spectral relaxation (MatchEig and Spectral).








5 Discussion and Limitations
Our algorithm has several favourable properties: it finds a globally optimal solution to Problem (1), it is computationally efficient, it has the same convergence behaviour as the Orthogonal Iteration algorithm [21], and promotes (approximately) sparse solutions. Naturally, since our solution is globally optimal (with respect to Problem (1)) and thus converges to , the amount of sparsity that we can achieve is limited by the sparsest orthogonal basis that spans . In turn, we rather interpret sparsity in some looser sense, meaning that there are few elements that are large, whereas most elements are close to zero. Furthermore, since the secondary sparsity-promoting problem (with objective in (4)) is generally non-convex, we cannot guarantee that we attain its global optimum.
Since permutation synchronisation was our primary motivation it is the main focus of this paper. In the case of permutations, the assumption that the eigenvalues corresponding to the are equal (as we explain in Sec. 3.2) is reasonable, since this must hold for cycle-consistent bijective matchings. However, broadening the scope of our approach to other problems in which this assumption may not be valid will require further theoretical analysis and possibly a different strategy for choosing the matrix . Studying the universality of the proposed method, as well as analysing different convergence criteria and different matrix functions are open problems that we leave for future work.
The proposed method comprises a variation of a well-known iterative procedure for computing the dominant subspace of a matrix. The key component in this procedure is the QR-factorisation, which is differentiable almost everywhere and is therefore well-suited to be applied within a differentiable programming context (e.g. for end-to-end training of neural networks).
6 Conclusion
We propose an efficient algorithm to find a matrix that forms an orthogonal basis of the dominant subspace of a given matrix while additionally promoting sparsity and non-negativity. Our procedure inherits favourable properties from the Orthogonal Iteration algorithm, namely it is simple to implement, converges almost everywhere, and is computationally efficient. Moreover, our method is designed to generate sparser solutions compared to the Orthogonal Iteration algorithm. This is achieved by rotating our matrix of interest in each iteration by a matrix corresponding to the gradient of a secondary objective that promotes sparsity (and optionally non-negativity).
The considered problem setting is relevant for various spectral formulations of difficult combinatorial problems, such as they occur in applications like multi-matching, permutation synchronisation or assignment problems. Here, the combination of orthogonality, sparsity and non-negativity is desirable, since these are properties that characterise binary matrices such as permutation matrices. Experimentally we show that our proposed method outperforms existing methods in the context of partial permutation synchronisation, while at the same time having favourable a runtime.
Broader Impact
The key contribution of this paper is an effective and efficient optimisation algorithm for addressing sparse optimisation problems over the Stiefel manifold. Given the fundamental nature of our contribution, we do not see any direct ethical concerns or negative societal impacts related to our work.
Overall, there are numerous opportunities to use the proposed method for various types of multi-matching problems over networks and graphs. The problem addressed is highly relevant within the fields of machine learning (e.g. for data canonicalisation to faciliate efficient learning with non-Euclidean data), computer vision (e.g. for 3D reconstruction in structure from motion, or image alignment), computer graphics (e.g. for bringing 3D shapes into correspondence) and other related areas.
The true power of permutation synchronisation methods appears when the number of objects to synchronise is large. With large quantities of data becoming increasingly available, the introduction of our scalable optimisation procedure that can account for orthogonality – while promoting sparsity and non-negativity – is an important contribution to the synchronisation community on the one hand. Moreover, on the other hand, it has the potential to have an impact on more general non-convex optimisation problems, particularly in the context of spectral relaxations of difficult and large combinatorial problems.
Acknowledgement
JT was supported by the Swedish Research Council (2019-04769).
References
- [1] CMU/VASC image database. http://www.cs.cmu.edu/afs/cs/project/vision/vasc/idb/www/html/motion/.
- [2] P.-A. Absil, C. G. Baker, and K. A. Gallivan. Trust-region methods on riemannian manifolds. Foundations of Computational Mathematics, 7(3):303–330, 2007.
- [3] P.-A. Absil, R. Mahony, and R. Sepulchre. Optimization algorithms on matrix manifolds. Princeton University Press, 2009.
- [4] P.-A. Absil, R. Mahony, R. Sepulchre, and P. Van Dooren. A grassmann–rayleigh quotient iteration for computing invariant subspaces. SIAM review, 44(1):57–73, 2002.
- [5] F. Arrigoni, B. Rossi, and A. Fusiello. Spectral synchronization of multiple views in se (3). SIAM Journal on Imaging Sciences, 9(4):1963–1990, 2016.
- [6] F. Bernard, C. Theobalt, and M. Moeller. DS*: Tighter Lifting-Free Convex Relaxations for Quadratic Matching Problems. In CVPR, 2018.
- [7] F. Bernard, J. Thunberg, P. Gemmar, F. Hertel, A. Husch, and J. Goncalves. A solution for multi-alignment by transformation synchronisation. In CVPR, 2015.
- [8] F. Bernard, J. Thunberg, J. Goncalves, and C. Theobalt. Synchronisation of partial multi-matchings via non-negative factorisations. Pattern Recognition, 92:146–155, 2019.
- [9] F. Bernard, J. Thunberg, P. Swoboda, and C. Theobalt. Hippi: Higher-order projected power iterations for scalable multi-matching. In CVPR, 2019.
- [10] F. Bernard, N. Vlassis, P. Gemmar, A. Husch, J. Thunberg, J. Goncalves, and F. Hertel. Fast correspondences for statistical shape models of brain structures. In Medical Imaging 2016: Image Processing, volume 9784, page 97840R. International Society for Optics and Photonics, 2016.
- [11] D. P. Bertsekas. Network Optimization: Continuous and Discrete Models. Athena Scientific, 1998.
- [12] T. Birdal, V. Golyanik, C. Theobalt, and L. J. Guibas. Quantum permutation synchronization. In CVPR, 2021.
- [13] T. Birdal and U. Simsekli. Probabilistic permutation synchronization using the riemannian structure of the birkhoff polytope. In CVPR, 2019.
- [14] N. Boumal, B. Mishra, P.-A. Absil, and R. Sepulchre. Manopt, a Matlab toolbox for optimization on manifolds. Journal of Machine Learning Research, 15(42):1455–1459, 2014.
- [15] A. Breloy, S. Kumar, Y. Sun, and D. P. Palomar. Majorization-minimization on the stiefel manifold with application to robust sparse pca. IEEE Transactions on Signal Processing, 69:1507–1520, 2021.
- [16] S. Chen, S. Ma, A. Man-Cho So, and T. Zhang. Proximal gradient method for nonsmooth optimization over the stiefel manifold. SIAM Journal on Optimization, 30(1):210–239, 2020.
- [17] T. Cour, P. Srinivasan, and J. Shi. Balanced graph matching. NIPS, 2006.
- [18] L. De Lathauwer, L. Hoegaerts, and J. Vandewalle. A grassmann-rayleigh quotient iteration for dimensionality reduction in ica. In International Conference on Independent Component Analysis and Signal Separation, pages 335–342. Springer, 2004.
- [19] A. Edelman, T. A. Arias, and S. T. Smith. The geometry of algorithms with orthogonality constraints. SIAM journal on Matrix Analysis and Applications, 20(2):303–353, 1998.
- [20] M. Gao, Z. Lähner, J. Thunberg, D. Cremers, and F. Bernard. Isometric multi-shape matching. In CVPR, 2021.
- [21] G. H. Golub and C. F. Van Loan. Matrix computations, volume 4. JHU press, 2013.
- [22] Q. Huang, Z. Liang, H. Wang, S. Zuo, and C. Bajaj. Tensor maps for synchronizing heterogeneous shape collections. ACM Transactions on Graphics (TOG), 38(4):1–18, 2019.
- [23] Q.-X. Huang and L. Guibas. Consistent shape maps via semidefinite programming. In Symposium on Geometry Processing, 2013.
- [24] R. Huang, J. Ren, P. Wonka, and M. Ovsjanikov. Consistent zoomout: Efficient spectral map synchronization. In Computer Graphics Forum, volume 39, pages 265–278. Wiley Online Library, 2020.
- [25] X. Huang, Z. Liang, X. Zhou, Y. Xie, L. J. Guibas, and Q. Huang. Learning transformation synchronization. In CVPR, 2019.
- [26] M. Leordeanu and M. Hebert. A Spectral Technique for Correspondence Problems Using Pairwise Constraints. In ICCV, 2005.
- [27] X. Li, S. Chen, Z. Deng, Q. Qu, Z. Zhu, and A. Man-Cho So. Weakly convex optimization over stiefel manifold using riemannian subgradient-type methods. SIAM Journal on Optimization, 31(3):1605–1634, 2021.
- [28] Y. Li and Y. Bresler. Global geometry of multichannel sparse blind deconvolution on the sphere. In NeurIPS, pages 1132–1143, 2018.
- [29] C. Lu, S. Yan, and Z. Lin. Convex sparse spectral clustering: Single-view to multi-view. IEEE Transactions on Image Processing, 25(6):2833–2843, 2016.
- [30] J. H. Manton. Optimization algorithms exploiting unitary constraints. IEEE Transactions on Signal Processing, 50(3):635–650, 2002.
- [31] E. Maset, F. Arrigoni, and A. Fusiello. Practical and Efficient Multi-View Matching. In ICCV, 2017.
- [32] J. Munkres. Algorithms for the Assignment and Transportation Problems. Journal of the Society for Industrial and Applied Mathematics, 5(1):32–38, Mar. 1957.
- [33] A. Ng, M. Jordan, and Y. Weiss. On spectral clustering: Analysis and an algorithm. NIPS, 14:849–856, 2001.
- [34] D. Pachauri, R. Kondor, and V. Singh. Solving the multi-way matching problem by permutation synchronization. In NIPS, 2013.
- [35] P. M. Pardalos, F. Rendl, and H. Wolkowicz. The Quadratic Assignment Problem - A Survey and Recent Developments. DIMACS Series in Discrete Mathematics, 1993.
- [36] Q. Qu, J. Sun, and J. Wright. Finding a sparse vector in a subspace: Linear sparsity using alternating directions. IEEE Transactions on Information Theory, 62(10):5855–5880, 2016.
- [37] Q. Qu, Y. Zhai, X. Li, Y. Zhang, and Z. Zhu. Geometric analysis of nonconvex optimization landscapes for overcomplete learning. In International Conference on Learning Representations, 2019.
- [38] Q. Qu, Z. Zhu, X. Li, M. C. Tsakiris, J. Wright, and R. Vidal. Finding the sparsest vectors in a subspace: Theory, algorithms, and applications. arXiv preprint arXiv:2001.06970, 2020.
- [39] Y. Shen, Q. Huang, N. Srebro, and S. Sanghavi. Normalized spectral map synchronization. NIPS, 29:4925–4933, 2016.
- [40] J. Song, P. Babu, and D. P. Palomar. Sparse generalized eigenvalue problem via smooth optimization. IEEE Transactions on Signal Processing, 63(7):1627–1642, 2015.
- [41] P. Swoboda, D. Kainmüller, A. Mokarian, C. Theobalt, and F. Bernard. A convex relaxation for multi-graph matching. In CVPR, 2019.
- [42] R. Tron, X. Zhou, C. Esteves, and K. Daniilidis. Fast multi-image matching via density-based clustering. In CVPR, 2017.
- [43] S. Umeyama. An eigendecomposition approach to weighted graph matching problems. IEEE transactions on pattern analysis and machine intelligence, 10(5):695–703, 1988.
- [44] U. Von Luxburg. A tutorial on spectral clustering. Statistics and computing, 17(4):395–416, 2007.
- [45] Q. Wang, J. Gao, and H. Li. Grassmannian manifold optimization assisted sparse spectral clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5258–5266, 2017.
- [46] Z. Wen and W. Yin. A feasible method for optimization with orthogonality constraints. Mathematical Programming, 142(1):397–434, 2013.
- [47] Y. Xue, Y. Shen, V. Lau, J. Zhang, and K. B. Letaief. Blind data detection in massive mimo via -norm maximization over the stiefel manifold. IEEE Transactions on Wireless Communications, 2020.
- [48] J. Yan, X.-C. Yin, W. Lin, C. Deng, H. Zha, and X. Yang. A short survey of recent advances in graph matching. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, pages 167–174, 2016.
- [49] Y. Zhai, Z. Yang, Z. Liao, J. Wright, and Y. Ma. Complete dictionary learning via l4-norm maximization over the orthogonal group. Journal of Machine Learning Research, 21(165):1–68, 2020.
- [50] Y. Zhang, H.-W. Kuo, and J. Wright. Structured local optima in sparse blind deconvolution. IEEE Transactions on Information Theory, 66(1):419–452, 2019.
- [51] X. Zhou, M. Zhu, and K. Daniilidis. Multi-image matching via fast alternating minimization. In ICCV, 2015.
- [52] Z. Zhu, T. Ding, D. Robinson, M. Tsakiris, and R. Vidal. A linearly convergent method for non-smooth non-convex optimization on the grassmannian with applications to robust subspace and dictionary learning. NeurIPS, 32:9442–9452, 2019.
Appendix A Proofs
Proof of Lemma 1
Proof.
If the matrix is not symmetric, we can split into the sum of a symmetric part and skew-symmetric part . It holds that . Further, if is not positive semidefinite, we can shift its eigenvalues via to make it p.s.d. Since is constant for any scalar , the term does not affect the optimisers of Problem (1). Thus, we can replace in (1) by the p.s.d. matrix without affecting the optimisers. ∎
Proof of Lemma 2
Proof.
Consider the eigenvalue decomposition of , i.e. , where contains the decreasingly ordered (nonnegative) eigenvalues on its diagonal and . For , this matrix can be written as the product of and another matrix , i.e., . So, instead of optimising over , we can optimise over . Let the -th row of be denoted as for . It holds that . Thus, an equivalent formulation of Problem (1) is the optimisation problem
| (A10) |
We observe that , and that . Hence, a relaxation to (A10) is given by
| (A11) | ||||
| (A12) | ||||
| (A13) |
This is a linear programming problem for which an optimal solution is given by and (since the ’s are provided in decreasing order). Now we choose , so that
| (A14) |
where is the unit vector with element equal to at the -th place. We observe that for this choice , and that the objective value for (A10) is the same as the optimal value for the problem defined by (A11)-(A13). Since the latter problem was a relaxation of the former problem, is an optimal solution to Problem (A10). The corresponding optimal for Problem (1) is . The observation that for any with we have that concludes the proof. ∎
Appendix B Additional Experiments
In the following we provide further evaluations of our proposed algorithm.
B.1 Step Size and Comparison to Two-Stage Approaches
In this section, on the one hand we experimentally confirm that our approach of choosing the step size (see Sec. 4.3) is valid and that in practice it is not necessary to perform line search. On the other hand, we verify that our proposed algorithm leads to results that are comparable to two-stage approaches derived from Lemma 4. Such two-stage approaches first determine the matrix that spans the -dimensional dominant subspace of , and subsequently utilise the updates in equations (2) and (3) in order to make sparser. As explained, this corresponds to finding a matrix that maximises our secondary objective
| (A15) |
We compare our proposed algorithm to two different settings of two-stage approaches:
-
1.
Our algorithm as stage two. Our proposed algorithm forms the second stage of a two-stage approach. To this end, in the first stage we use the Orthogonal Iteration algorithm [21] to find the matrix that spans the -dimensional dominant subspace of . Subsequently in the second stage, we initialise , and according to Lemma 4 we make use of the updates in equations (2) and (3) in order to make iteratively sparser. We consider two variants for the second stage:
-
(a)
In the variant denoted Ours/2-stage we run the second-stage updates exactly for the number of iterations that the Orthogonal Iteration required in the first stage to find (with convergence threshold ). We use the step size as described in Sec. 4.3.
-
(b)
In the variant denoted Ours/2-stage/bt we utilise backtracking line search (as implemented in the ManOpt toolbox [14]) in order to find a suitable step size in each iteration. Here, we run the algorithm until convergence w.r.t. to , i.e. until for .
-
(a)
-
2.
Manifold optimisation as stage two. Further, we consider the trust regions method [2] to find a (local) maximiser of (A15) in the second stage. Here, the optimisation over the Riemannian manifold is performed using the ManOpt toolbox [14]. For the first stage, we consider three different initialisations for finding the matrix that spans the -dimensional dominant subspace of : the Matlab functions eig() and eigs(), as well as our implementation of the Orthogonal Iteration algorithm [21]. We call these methods Eig+ManOpt, Eigs+ManOpt and OrthIt+ManOpt, respectively.
Results are shown in Figs. 4 and 5 for the CMU house sequence and the synthetic dataset, respectively. We observe the following:
-
•
In terms of solution quality (fscore and objective), all considered methods are comparable in most cases. For the real dataset (Fig. 4) Eigs+ManOpt performs worse due to numerical reasons. For the largest considered permutation synchronisation problems (the right-most column in the synthetic data setting shown in Fig. 5) Ours leads to the best results on average.
-
•
In terms of runtime, in overall Ours is among the fastest, considering both the real and the synthetic data experiments. In the real dataset, where is relatively small, Eigs+ManOpt is the fastest (but with poor solution quality), while Eig+ManOpt is the slowest (with comparable solution quality to Ours). Methods that utilise the Orthogonal Iteration have comparable runtimes in the real data experiments.
Most notably, in the largest considered synthetic data setting (right-most column in Fig. 5) Ours is among the fastest (together with Ours/2-stage), while Ours has the largest fscore on average (as mentioned above) – this indicates that Ours is particularly well-suited for permutation synchronisation problems with increasing size.
-
•
Overall Ours is the simplest method, see Algorithm 1: the solution is computed in one single stage rather than in two consecutive stages, and it does not require line search, as can be seen by comparing Ours with Ours/2-stage/bt across all experiments.













B.2 Comparison to Riemannian Subgradient and Evaluation of Different
In Fig. 6 we compare Ours with and to the Riemannian subgradient-type method (with QR-retraction) by Li et al. [27] with -norm as sparsity-inducing penalty. In the qualitative results (bottom) we can observe that the Riemannian subgradient-type method and Ours () obtain sparse solutions with few elements with large absolute values (both positive and negative), whereas Ours () obtains a sparse and (mostly) nonnegative solution. Since for permutation synchronisation we are interested in nonnegative solutions, Ours with thus outperforms the two alternatives quantitatively (top).







B.3 Effect of Sparsity-Promoting Secondary Objective
In Fig. 7 we illustrate the effect of our sparsity-promoting secondary objective. It can clearly be seen that our method (right) results in a significantly sparser solution compared to the Orthogonal Iteration algorithm (left).

