Spatial Applications of Topological Data Analysis: Cities, Snowflakes, Random Structures, and Spiders Spinning Under the Influence
Abstract
Spatial networks are ubiquitous in social, geographical, physical, and biological applications. To understand the large-scale structure of networks, it is important to develop methods that allow one to directly probe the effects of space on structure and dynamics. Historically, algebraic topology has provided one framework for rigorously and quantitatively describing the global structure of a space, and recent advances in topological data analysis (TDA) have given scholars a new lens for analyzing network data. In this paper, we study a variety of spatial networks — including both synthetic and natural ones — using novel topological methods that we recently developed for analyzing spatial networks. We demonstrate that our methods are able to capture meaningful quantities, with specifics that depend on context, in spatial networks and thereby provide useful insights into the structure of those networks, including a novel approach for characterizing them based on their topological structures. We illustrate these ideas with examples of synthetic networks and dynamics on them, street networks in cities, snowflakes, and webs spun by spiders under the influence of various psychotropic substances.
I Introduction
Many complex systems have a natural embedding in a low-dimensional space or are otherwise influenced by space, and it is often insightful to study such spatial complex systems using the formalism of networks [1, 2]. In a spatial network, the location of nodes and edges in space can heavily inform both the structure of the network and the behavior of dynamical processes on it. Indeed, obtaining a meaningful understanding of power grids [3, 4, 5], granular systems [6], rabbit warrens [7], and many other systems is impossible without considering the physical relationships between nodes in a network. For example, to examine traffic patterns on a transportation network in a meaningful way, it is important to include information about the physical distances between points and about the locations and directions of paths between heavily trafficked areas [8].
There are a variety of existing perspectives for studying spatial networks [1, 9]. Many of these perspectives hail from quantitative geography [10, 11]. In the 1970s, geographers were already studying the role of space in the formation of networks and in the activities of individuals and goods over geographical networks. As data have become richer and more readily available, it has become possible to take increasingly intricate computational approaches to the study of spatial networks, and a variety of complex-systems approaches have contributed greatly to the literature on spatial networks [1]. Researchers have also proposed various random models for spatial networks, and studying them yields baseline examples to compare to empirical networks [12, 13, 14, 15]. There have also been investigations of the effects of certain spatial network properties on the behaviors of several well-known dynamical processes, including the Ising model [16], coupled oscillators [17], and random walks [18].
Although there is much existing work on the properties of spatial networks (e.g., degree distributions, shortest paths, and so on), there are relatively few network tools that leverage “global” structure in the traditional topological sense of the word. Current tools for studying global network structure tend to rely on aggregating local information in some way to paint a global picture of a network. By contrast, methods for understanding the global structure of a topological space rely intrinsically on information about the entire space. To illustrate the difference, consider a sphere. If we sample a neighborhood of any point on a sphere, we obtain a surface with the same properties as a plane. If we take a collection of a sphere’s neighborhoods (which each resemble a plane) and stitch them together, we are able to obtain a lot of information about the sphere, but we are unable to describe the void in the center of the sphere. (For example, a stereographic projection of a sphere covers the sphere’s entire surface, but it fails to capture the void.) To fully understand the structure of a sphere, we must consider the entire sphere at once. Over the last few decades, algebraic topology has been very useful for characterizing the global structure of mathematical spaces [19, 20] through its use of mathematical tools that consider spaces as global objects. By reframing spatial networks using the language of topological spaces, we can leverage existing topological tools to better understand their structures. For a case study with voting data, see our recent paper [21].
Homology groups, which were defined originally in algebraic topology and have been applied insightfully to a broad range of mathematical topics, provide one way to distinguish between mathematical spaces based on their numbers and types of “holes” [19]. Moreover, the extension of homology to so-called “persistent homology” (PH) allows one to quantify holes in data in a meaningful way and has made it possible to apply homological ideas to a wide variety of empirical data sets [22, 23]. PH is helpful for characterizing the “shape” of data, and the myriad applications of it include protein structure [24, 25, 26, 27], DNA structure [28], neuronal structure [29], computer vision [30], diurnal cycles in hurricanes [31], inferring symbolic dynamics in chaotic systems [32], spatial percolation problems [33], and many others. Additionally, combining machine-learning approaches with PH has also been very useful for several classification problems [34, 35, 36, 37].
Because it is so natural to apply PH to the study of the shape of data, many successful applications of it have been to spatial networks. One particular area of interest has been the study of granular materials, because PH is able to effectively capture geometric properties of granular substances [6, 38, 39]. In addition to analyzing geometric information, PH methods are also able to describe multiscale spatial relationships. Many biological applications to proteins and DNA rely on the ability of PH to illuminate features at multiple scales, as multiscale structures and compositions of these molecules are extremely important to their functionality. PH has also been applied to larger-scale biological systems, including leaf-venation patterns [40], aggregation models [41], human migration [42], networks of blood vessels [43], and the effects of psychoactive substances on brain activity [44]. The recent review article [45] includes an extensive discussion of applications of PH to networks.
One confounding factor in the use of PH to study spatial networks is that although PH is able to capture information across scales, traditional distance-based PH constructions can have difficulty with applications in which differences in scale may not be meaningful. For example, in most applications to human geographical data, the difference in population density between urban and rural areas can dominate analyses that employ traditional PH constructions, and they thereby miss signals that do not rely on this variation in density. In a recent paper [21], we examined the shape of voting patterns in the state of California and found that traditional methods for computing PH are more likely to capture disparities in population than to detect the presence of interesting voting patterns. To address this issue, we developed two novel PH constructions — one based on network adjacency and one based on the physical geometry of a map — that were more successful at capturing these voting patterns. For a recent analysis of the difficulty of interpreting signal and noise in PH results, see [46]. For approaches other than PH for analyzing maps while accounting for density variation, see [47, 48].
In the present paper, we apply our new PH constructions to a variety of spatial complex systems to demonstrate their usefulness across many domains. We show that these methods are well-adapted to capturing interesting structural properties of spatial networks and can thereby yield new insights into such networks, especially with respect to their global structure. Our examples include several synthetic graph models and dynamics on them, city street networks (which we compare both within a city and across different cities), snowflakes, and webs spun by spiders under the influence of various psychotropic substances.
Our paper proceeds as follows. In Section II, we give technical background on PH and on our particular constructions. In Section III, we discuss computational results from computing the PH of (1) several well-known models of synthetic networks and (2) a variety of empirical data sets from diverse applications. We conclude in Section IV. A public repository of the code that we use for our computations is available at https://bitbucket.org/mhfeng/spatialtda/src/master/.
II Methods
II.1 Computing Persistent Homology
We now give a brief introduction to PH and tools for computing it. See [22, 49, 50] for more details. We begin by defining -simplices and simplicial complexes. A -simplex is -dimensional polytope that is a convex hull of nodes. A face of a -simplex is any subset (of dimension smaller than ) of the -simplex that is itself a simplex. A simplicial complex is a set of simplices that satisfy the following requirements: (1) if is a -simplex, then every face of is in ; and (2) if and are simplices in , then is a face of both and .
Given a data set , we construct a sequence of simplicial complexes of some fixed maximum dimension. We call the sequence a “filtered simplicial complex”, and we call each a “subcomplex” of the filtered simplicial complex. We equip each relation with an inclusion map. The filtered simplicial complex, along with its inclusion maps and the chain and boundary maps of each subcomplex, constitutes a “persistence complex”. The inclusion maps induce a map between homology groups. The map allows us to track an element of (the th homology group of the subcomplex ) to an element of . The th homologies of the persistence complex are given by the pair
| (1) |
and we call them the “th persistent homology” of . We refer to the collection of all th persistent homologies as the “persistent homology” (PH) of .
Consider a generator for some and . If is not in the image of , we say that is “born” at time . Correspondingly, if and , we say that “dies” at time . If for every , we have that , then we say that never dies, and we assign a death time of to the element . For each element of the PH of , there is a birth time and a death time , and the collection of intervals is the “barcode” of . Generators with longer associated half-open intervals are more persistent. It is traditional to construe more-persistent intervals as better indicators of a signal and construe less-persistent intervals as noise, although recent work (including our own [21, 51]) indicates that it is not always possible to interpret persistence in this way.
The collection of features in each describes the topological properties of the filtration . Intuitively, each feature in corresponds to some -dimensional void. In , features are connected components; in , features are loops. By considering the PHs of , we can examine how the connectedness of changes for each step of the filtration in each dimension. For example, a short-persistence feature in is a connected component that appears and combines quickly with another component. PH records all features and their persistences, allowing us to take a global view of topological changes in each filtration step of .
II.2 Adjacency Construction of PH
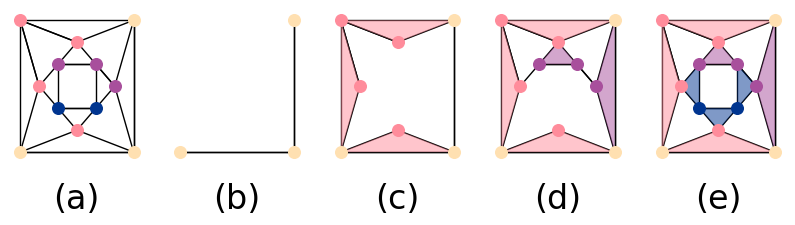
We now describe a way to construct a filtered simplicial complex based on network adjacencies. We consider a network in the form of a graph , with numerical data associated with each node . For a given filtration step , let the -simplices of be given by such that for some value . For any edge , if and , we add to . Finally, to , we add all triangles such that , , and are in . We repeat this process for , but now we use a larger value of . By construction, each , and we have a valid filtered simplicial complex. See Fig. 1 for an illustration of such a filtered simplicial complex.
This adjacency construction tracks topological changes in a network as it grows. The homology group characterizes the topology of the first filtration step. As one adds more nodes, edges, and faces to the simplicial complex, the topology changes and is recorded in . By choosing carefully, we can control which subset of a network exists in the first filtration step, and we can also control how the network expands. For example, in [21], by attaching voting data to a network of precincts of a county, we used the adjacency construction to examine how the topology of a county changes as one considers precincts with an increasingly wide range of voting preferences.
In some of our applications, we use an alternate adjacency construction in which we associate data to each edge , instead of to the nodes. This construction differs from the one above only in that we define the function . We then proceed with the above adjacency construction, but we substitute for . We recently introduced our main adjacency construction in [21], and we introduce this adaptation of it to edge-based data in the present work.
II.3 Level-Set Construction of PH
The other PH construction that we use (again see [21] for details) involves describing data as a manifold, rather than as a graph. Let denote a two-dimensional (2D) manifold, such as data in an image format. We consider the boundary of and construct a sequence
of manifolds, where at each time step, we evolve the boundary of outward according to the level-set equation. (See [54] for a thorough exposition of the level-set equation and level-set dynamics.) That is, for a manifold that is embedded in , we define a function , where is the signed distance function from to at time . We propagate outward at velocity using the equation
| (2) |
until all homological features have died. Because this evolution gives a signed distance function at each time step , we take to be the set of points such that . (This corresponds to points inside the boundary .) We show an example of this evolution in Fig. 2. Throughout this paper, we use . Different values of cause the level set to evolve faster (if ) or slower (if ), resulting in a different number of time steps (and hence a different number of filtration steps) in our evolution. However, we obtain the same homological features, although with different birth times and death times. If is sufficiently large, it is possible that all features would have the same birth and death time, such that no features would occur after the first filtration step. When , there is no evolution.



By imposing over a triangular grid of points, as described in [21], we obtain a corresponding simplicial complex for each . In Fig. 3, we give a visualization of this simplicial complex. We construct this level-set complex using a polygon whose points we choose uniformly at random from as an initial synthetic image. Because the level-set equation (2) evolves continually outward, we automatically satisfy that condition that , so is a filtered simplicial complex. Our implementation of the level-set method works with any black-and-white image (or any image that one formulate as a piecewise-constant function ). We expect our level-set approach to capture information about and for any such image. The level-set approach also captures geometric information, which can be useful for some applications; however, this may make it difficult to capture information about holes that are visually irregular. Throughout this paper, we compare images that have roughly the same resolutions, where we take the image resolution from raw image data. Because image size should primarily affect the computation time of our level-set approach — but not the order in which features appear and disappear as an image evolves — we expect that it is possible to adapt our level-set construction when comparing images of different resolutions. Possible approaches for such an adaptation include normalizing image sizes or adjusting the resolution of the triangular grid that one uses for each image.



III Applications
We now discuss applications of PH to both synthetic networks and empirical spatial networks from a diverse variety of applications.
III.1 Synthetic Networks
In this subsection, we discuss applications of our adjacency PH construction to a dynamical process on synthetic networks in which space plays an important role. For each network , we run the Watts threshold model (WTM) [55] on it. Given a graph, we select a fraction of its nodes uniformly at random to be “infected” at time . At each time step, we then we compute the fraction of each node’s neighbors that are infected. (That is, we synchronously update the states of the nodes [56].) If the fraction of a node’s neighbors that are infected meets or exceeds a threshold (in our case, the threshold is for all nodes), the node becomes infected. We take this implementation of the WTM to be the generator of a function 111We use the convention that includes ., where is the time at which node becomes infected. We say that infected nodes are in the set . If never becomes infected, we set , so that we eventually add all nodes to a filtered simplicial complex. The resulting filtered simplicial complex consists of the subgraphs that are generated by at each time step. See [58, 59, 60] for studies of the WTM on spatial networks.
We use parameter values of and throughout this section. We expect changes in and to affect the birth times and death times of features in a filtered simplicial complex. Using a different value of entails considering a different fraction of initially infected notes. Therefore, a larger value of yields a larger simplicial complex at the first filtration step, and smaller value of yields a smaller simplicial complex. Using a larger value of results in fewer nodes becoming infected at each time step, and it thus takes more filtration steps before the simplicial complex stops growing. Because our underlying graph is the same for any choice of values of and , we do not expect changes in the homology of the last filtration step, unless or are sufficiently small such that some nodes in a graph never become infected. However, one can certainly obtain a different PH for different values of or , as nodes and edges can join the filtered simplicial complex at different times and (more importantly) in different orders.
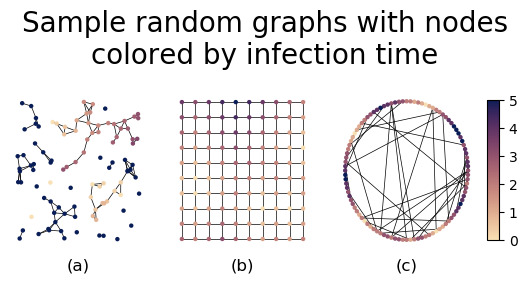
We examine topological changes in the infected subgraph of three different types of synthetic networks (see Fig. 4). We first examine random geometric graphics (RGGs) [61]. For each instance of an RGG, we pick nodes uniformly at random from the unit square. If the Euclidean distance between two nodes is less than or equal to , we add an edge between them [see Fig. 4(a)]. Our second type of synthetic network is a square lattice with nodes. We arrange the nodes in a grid on the unit square, and we then connect the nodes along the grid lines [see Fig. 4(b)]. Our third type of synthetic network is a Watts–Strogatz (WS) small-world network [62, 63]. We begin with a ring of nodes, and we then connect each node to its nearest neighbors on each side. We then rewire each edge uniformly at random with a probability of using the implementation of the WS model in NetworkX [64]. In this version of the WS model, one removes each rewired edge before replacing it with a new edge. We show an example of a WS graph in Fig.. 4(c).
For each type of synthetic network, we consider instances, which we generate using NetworkX. For the RGG and WS networks, each instance is a different graph; the square lattice network is deterministic. For all three types of networks, each instance has a different initial set of infected nodes. We show visualizations of each of these types of networks (with WTM dynamics on it) in Fig. 4.
Our adjacency construction begins by selecting the initially infected nodes and the edges between them of a network to create an infected subgraph that we call an “infection network”. As an infection spreads, we add more nodes and edges to the infection network until eventually we have added all nodes and edges to it.
Examining the PHs of the RGGs (see Fig. 5), we see for our parameter values that an infection network tends to have several connected components, resulting in a large number of features in . However, because of the spreading behavior of the WTM, new nodes can become infected only via their infected neighbors. Because features in record connected components of a graph, new infected nodes join existing connected components. Therefore, features can only be born at time or in the last step, which is when we add all remaining uninfected nodes to our filtered simplicial complex. By contrast, features in are relatively rare, as most cycles that occur in an RGG are filled because of the uniform probability distribution of the node locations.
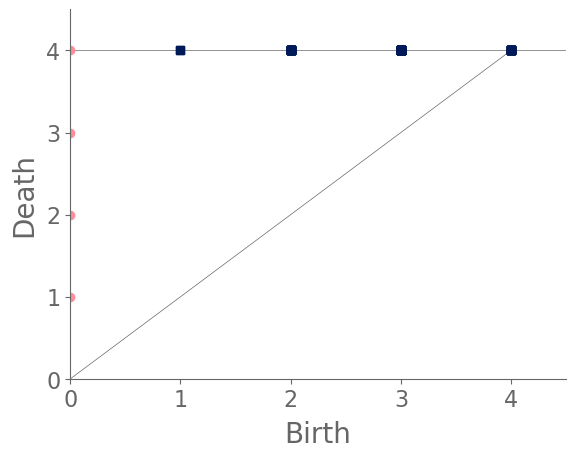
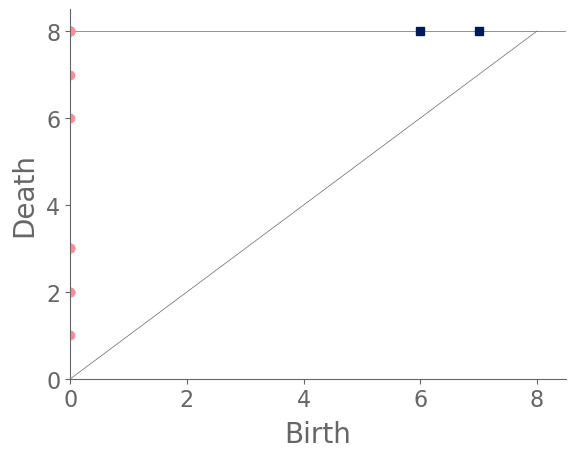
For a square lattice network (see Fig. 6 for a PD of the WTM on such a network), we first note that there is only a single infinite-length feature in , as the final infection network necessarily consists of a single connected component. Consequently, consists of a set of features that are born at time and eventually merge (and therefore die), resulting in a single infinite-length feature. Additionally, there are a constant number (81, to be precise) of features in , because when we construct a simplicial complex, every grid cell of the lattice is a feature in at the last filtration step. However, these features can be born at a variety of times, as the filtration does not include every lattice cell until every node of the graph has entered the filtration.
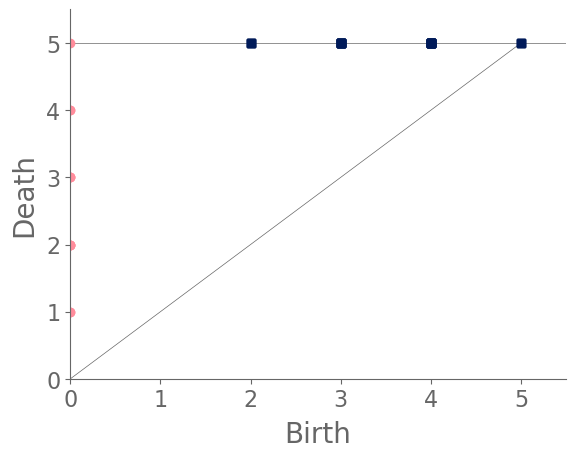
From Fig. 7, we see that a WS small-world network also eventually has an infection network that consists of a single connected component. However, the WS networks consistently have more features in than the RGG networks, because the former’s (non-geometric) shortcut edges usually result in splitting an existing cycle (and hence a feature in ) into two cycles.
We summarize our observations about the various synthetic networks in Table 1, in which we give the means and standard deviations of the number of features during the temporal evolution of the WTM in each type of synthetic graph. Our counts include features that appear at any time during the WTM dynamics.
| Mean () | STD () | Mean () | STD () | |
|---|---|---|---|---|
| RGG | 23.16 | 3.1897 | 1.2 | 1.0 |
| Square lattice | 4.56 | 0.5886 | 81 | 0 |
| WS | 8.29 | 2.0214 | 26.95 | 5.2314 |
III.2 Street Networks in Cities
The field of urban analytics has grown rapidly in the last several years [1, 65, 11], Increasingly powerful computational tools have allowed researchers to characterize cities in terms of their street networks [66], and a variety of approaches from network analysis have been applied to the study of urban street networks [67, 68, 69, 8, 70, 71, 72]. In the present subsection, we use city street networks as base manifolds in our level-set construction, and we thereby characterize cities based on their PHs. We use these PHs to compare city morphologies both within a single city and across a variety of cities.
We use our level-set construction to obtain topological descriptors in the form of persistence for city street networks. We then use these city persistences to compare (1) different regions of the same city and (2) different cities to each other. We obtain all of our city street networks with the software package OSMnx [73] using latitude–longitude coordinates and taking a km block that is centered at specified coordinates. In each example, we indicate how we choose these coordinates.
The first filtration step of a filtered simplicial complex that results from our PH construction consists only of the streets in a network. As we increase the filtration time, we slowly add city blocks to the complex, and the topology changes as those blocks are filled in. More regular city blocks are more likely to be filled in without creating any new homological features, and larger blocks take longer to be filled in. Our construction is thereby able to capture information about the size and regularity of city blocks. The existence of dead ends tends to lead to the “pinching” of blocks into multiple homological features — as dead ends expand, they lengthen and eventually meet with nearby streets, cutting through blocks in the process — so our approach also yields information about dead ends.
III.2.1 Comparing Different Regions of the Same City
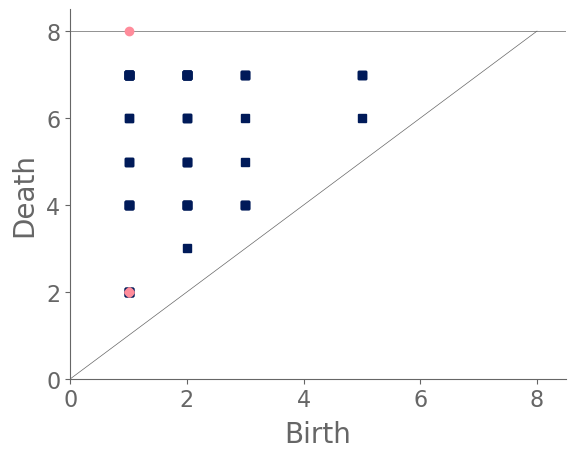
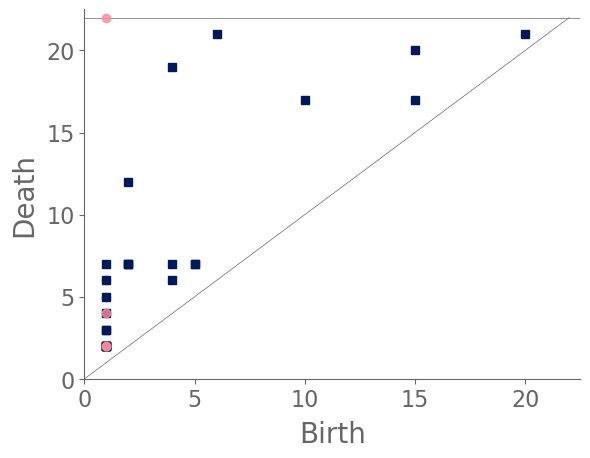
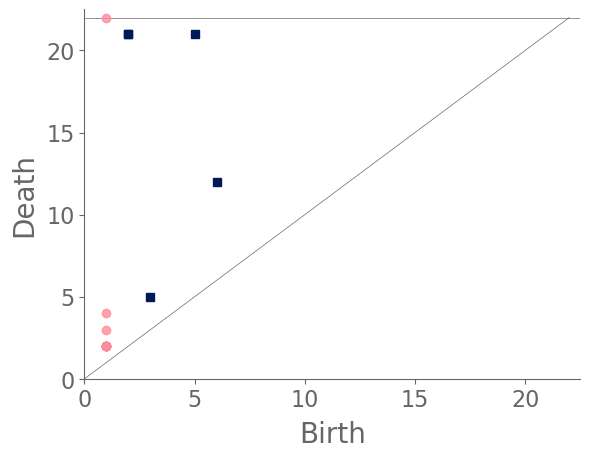
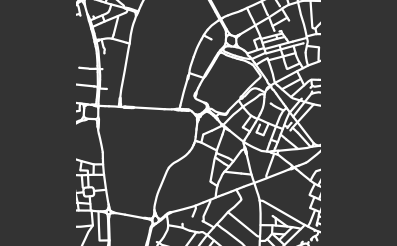
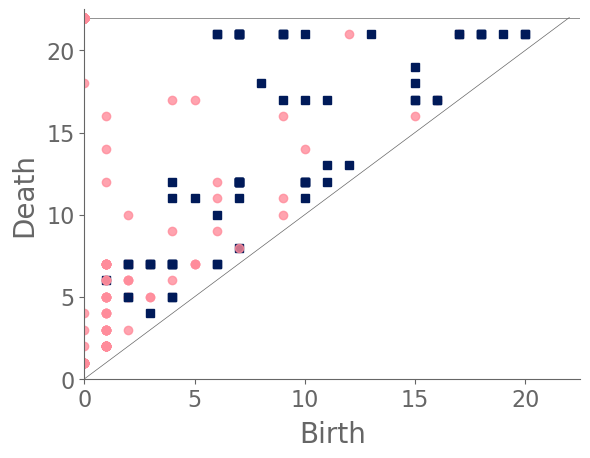
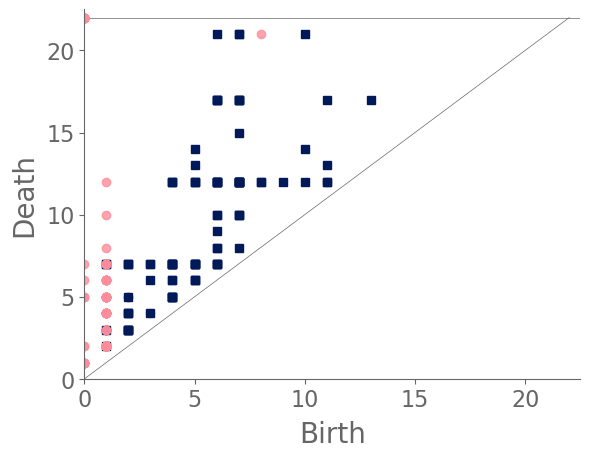
We sample 169 points from the city of Shanghai using a shapefile of Shanghai’s administrative-district boundaries that we downloaded from ArcGIS [74]. From the shapefile, we obtain a bounding box for each point. We sample uniformly within this bounding box, discarding points that do not lie within the polygonal district geometry that is defined in the shapefile. We stop sampling when we reach the desired number of points. In total, we sample ten points from each administrative district, and we also include nine historical landmarks with coordinates from Google Maps [75]. In Fig. 8, we show maps and their associated PDs for two examples.

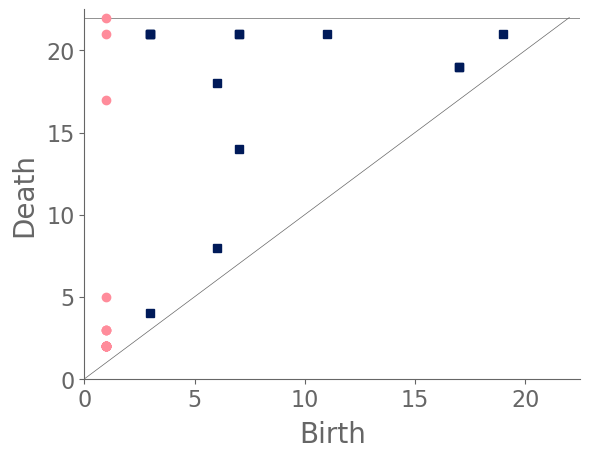

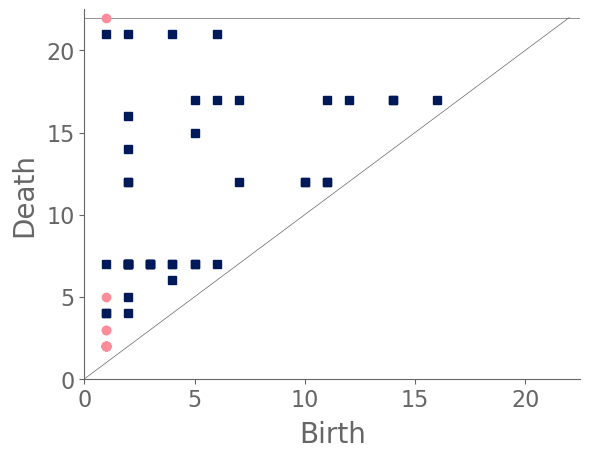
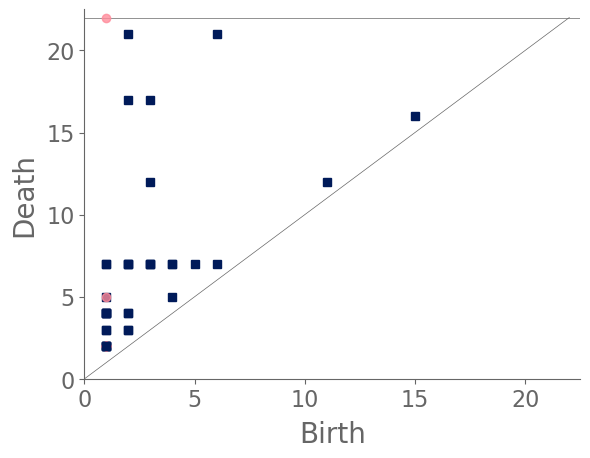
After computing PH (in the form of a PD) for each map, we compute the bottleneck distance between each pair of maps. Bottleneck distance is a metric that is defined on the space of PDs. It gives the shortest distance for which there exists a perfect matching between the points of the two PDs (along with all diagonal points), such that any pair of matched points are at most a distance from each other, where we use the supremum norm in to compute the distance between points. Once we have pairwise bottleneck distances between PDs, we perform average-linkage hierarchical clustering into three clusters. (We chose to have three clusters based on looking at the dendrogram.) We can replace our metric with a different metric (such as a Wasserstein distance [76]) on PDs or cluster our PDs using a different clustering algorithm. We do not discuss the impact that such choices may have on our results, although we note in passing that we performed -medoids clustering [77] for our case study of Shanghai and obtained qualitatively similar results.
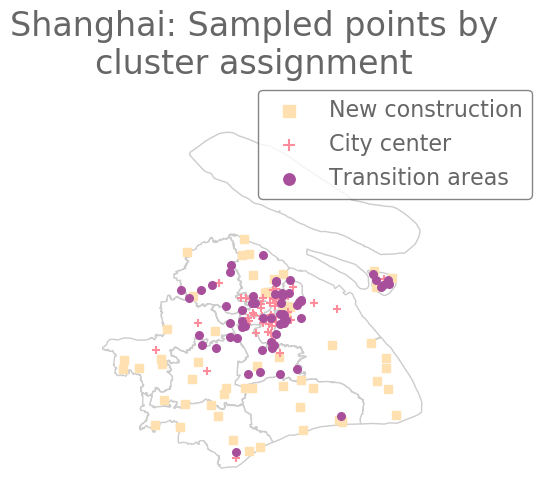
In Fig. 9, we show the sampled points (which we color according to their cluster assignment). We observe that the three clusters consist largely of historical areas (“City center”), concession-era areas (“Transition areas”), and modern areas (“New construction”). In Fig. 10, we show administrative districts along with the year that they were constructed. We break them down by the percentage of the sample points that are in each cluster.
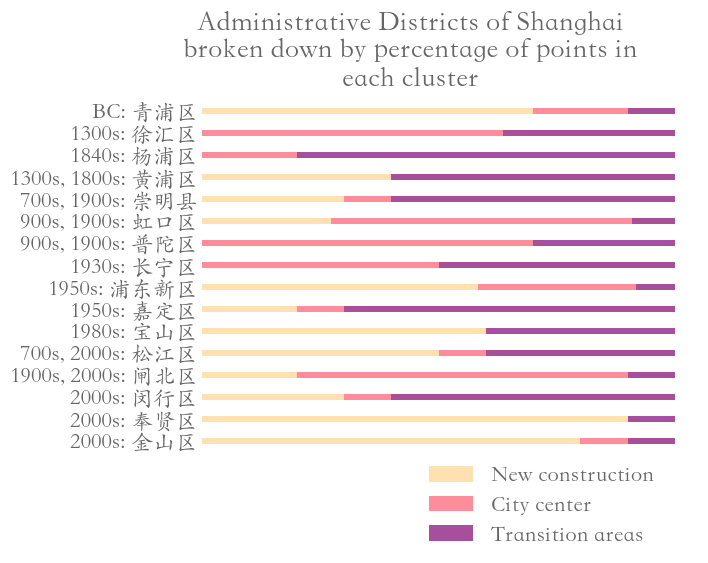
III.2.2 Comparing Street Networks from Different Cities
We continue our analysis of cities by characterizing and comparing the structures of street networks of 306 cities across the globe. We downloaded latitude and longitude coordinates from SimpleMaps [78] and selected all cities with a population of at least million people. Given these latitude and longitude coordinates, we use OSMnx [73] to obtain street networks. We then compute PH for each city and cluster their PDs using average-linkage hierarchical clustering with three clusters. We sometimes refer to a city in a given cluster as a city of a certain “type”. Our results depend on the specific latitude and longitude coordinates in our downloaded data set. Accordingly, our results are influenced by the particular location of a city’s coordinates, which are the standard ones in SimpleMaps.
In the following paragraphs, we describe our clusters of cities. We define “blocks” to be the cells of a planar street graph. Although our level-set construction for computing PH is not designed explicitly to characterize blocks, we take advantage of the fact that our level-set construction takes the set of streets as its initial manifold. As the streets expand outward according to the level-set equation (2), they fill in the blocks. Larger blocks take longer to fill in, and blocks fill in more evenly when they are closer to circular in shape. Roughly, we characterize block sizes based on the death times of features in : small sizes correspond to early death times (specifically, less than 10), medium sizes correspond to death times between 10 and 15, and large sizes correspond to late death times (specifically, more than 15). We also designate blocks as “regular” (when they are close to a regular convex polygon) or “irregular” (for blocks that do not resemble a rectangle or some other regular convex polygon). If a block is very irregular, then as its streets expand, it is possible that narrow parts of the block will shrink and close off, such that the block segments into smaller blocks. We refer to this phenomenon as “pinching”. Our three main clusters are dominated by (1) gridlike cities; (2) cities with gridlike patches that are interspersed with larger, non-gridlike blocks; and (3) cities that have a large number of non-gridlike structures (specifically, dead ends or large holes) that interrupt other structures. We use the term “interrupted grid” for cities that are either (1) mostly gridlike with some patches that are not gridlike or (2) consist of patches of disparate grids that are stitched together (with other features between them).
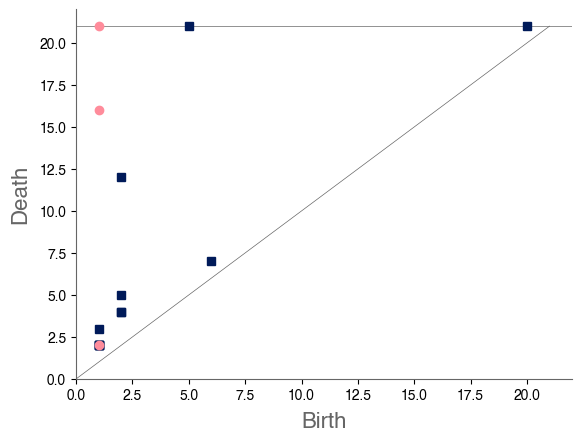
Our first major cluster has 99 cities and is dominated by cities with small, gridlike blocks. All regions of the world have some cities of this type, but North America has the largest percentage (relative to all of the cities that we sample from that continent) of these gridlike cities and Europe has the smallest percentage of them. The block sizes in this cluster tend to be small or of medium size, resulting in filtrations whose maximum filtration value tends to be small in comparison to cities in the other two clusters. In the PDs, we also observe that the distributions of death times of features in tends to be close to uniform and over a small range. Such distributions occur because these gridlike cities tend to have even distributions of block sizes, even though they include some areas with slightly smaller and/or slightly larger grid sizes. They do not have large blocks, so they do not have features in with late death times.

Our second major cluster has cities with patches of grids that are interspersed with structures that are not gridlike. This cluster, with 149 cities, is the largest of our three clusters. The PDs in this cluster tend to have larger maximum death times than the PDs for the cities in our first cluster. In the PDs, gridlike blocks yield collections of features in with early death times; and the larger, non-gridlike structures yield features in with late death times. The non-gridlike areas in these cities tend to have fairly regular shapes, resulting in a relatively small number of features in with late birth times. Such late-birth-time features usually correspond to the pinching of blocks, which can occur either via dead ends or via shape irregularities. By examining the dendrogram from our hierarchical clustering, we can further separate the second cluster into two subclusters, which we show in Fig. 12. The first of these subclusters consists mostly of cities that have large patches of gridlike structure, with a small number of large blocks that interrupt the grids. The PDs for cities in this subcluster tend to have a large number of features in with early death times, and they tend to have only a small number of isolated features in with late death times. The second subcluster of our second major cluster consists mostly of cities with small patches of grids that are mixed with large irregular blocks. The PDs for cities in this subcluster tend to have a larger number of features in with late death times than is the case for the cities in the other subcluster of cluster two.
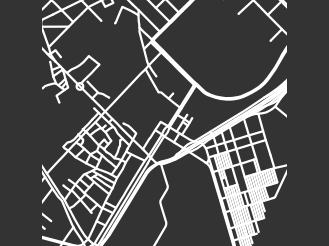
Our third major cluster, with 58 cities, consists of cities with a large number of non-gridlike structures. In particular, many of these cities include a large number of dead ends, rectangular blocks that are not arranged in a grid, or both. We observe streets that do not continue through particular blocks (e.g., there is a street, it is obstructed, but then it continues after the obstruction), which leads to a mixture of block sizes even in areas of a city that tend to have regular blocks. We refer to these situations as “obstructions”. The PDs of the cities in this cluster have a larger number of features in with medium death times (specifically, in the range 10–15), and many of these features are close to the diagonal. This is common when large blocks are pinched into several regions, as the smaller regions are born at the pinching time, rather than near the beginning of the filtration. Therefore, they do not survive long enough to have a late death time. By examining the dendrogram from our hierarchical clustering, we see two clear subclusters. However, one of these subclusters consists of only two cities (Beirut and Nanyang). The PDs of both of these cities are dominated by two features in with late death times, and they also have several features in with medium death times. In Fig. 13, we show examples of cities in cluster three.
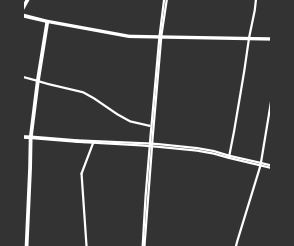
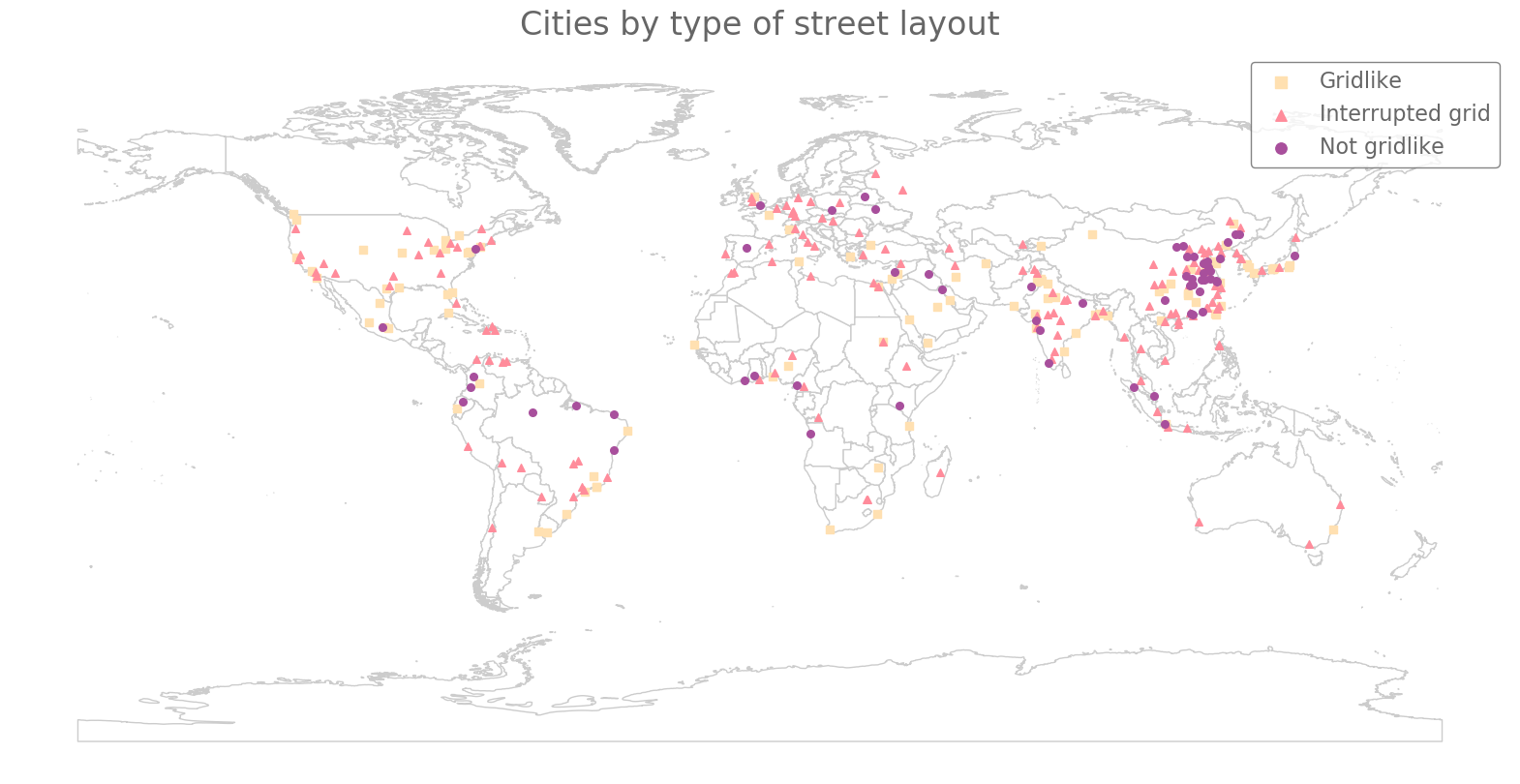
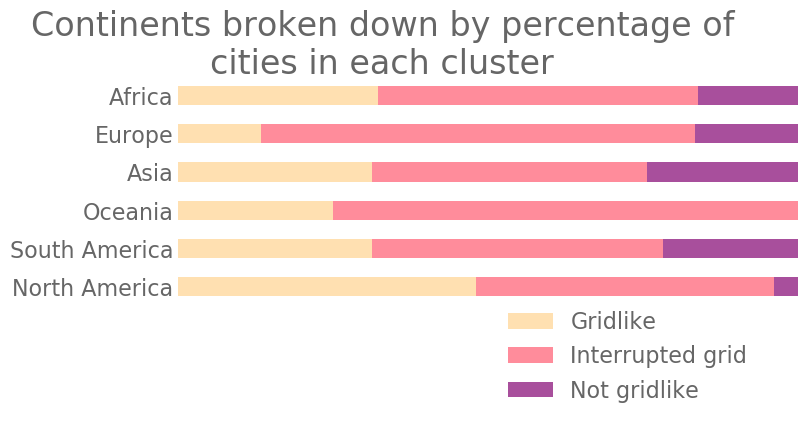
We color our cities according to their major cluster and show them on a world map in Fig. 14. In Fig. 15, we show the breakdown of cities from each continent into the various clusters. We calculate PH for only four major cities in Oceania, so we cannot draw strong conclusions from the cluster assignments of those cities. Among the other regions, we observe that North America has the largest proportion of cities with gridlike street layouts and the smallest proportion of cities with non-gridlike layouts. By contrast, Europe has the smallest proportion of cities with gridlike street layouts. This is consistent with the common perception that North American cities are much more gridlike than European cities. In all regions, we also observe that a large fraction of the cities are interrupted grids. Additionally, we observe that South America, Africa, and Asia have similar distributions of city types.
Interestingly, from the map in Fig. 14, South America, Asia, and Africa appear to have areas that are dominated by specific major clusters. We observe non-gridlike cities in the northern part of South America, whereas we see gridlike cities along its east coast. In Africa, most of the non-gridlike cities occur along the western coastline. In Asia, most of the gridlike and non-gridlike cities occur in East Asia, whereas Southeast Asia is dominated by interrupted grids. Across the map, there appears to be a potential equatorial band of non-gridlike cities. We do not have an explanation for these patterns, but they are fascinating and seem worthy of future research efforts.
III.2.3 Comparison of Our Classification of Cities to that of Louf and Barthelemy [80]
We compare our results to the city classification of Louf and Barthelemy [80], who associated each city with a conditional probability distribution that captures the area and shape of its blocks. We choose their method as a point of comparison because they studied a wide range of cities and (like us) codified cities from a block-based perspective. They used the word “fingerprint” as a monicker for their block-based representation of cities. In our method, we codify cities according to their PHs, which we generate using the level-set construction of Section II.3. Both the approach of [80] and our approach capture information that is based on city blocks, although our PH representation differs substantially from the fingerprints of [80].
Louf and Barthelemy clustered cities into four groups, whereas we have chosen to cluster our cities into three groups. In [80], European and North American cities largely inhabit the same cluster (group three in [80]), but they appear in distinct subclusters, demonstrating that there is a substantive difference between cities from the two regions. Our method finds that North America has the largest proportion of cities with gridlike streets among all of the regions and that Europe has the smallest proportion of such cities.
In contrast to the above situation, Africa, Asia, and South America have a fairly balanced composition of city types, with a potential equatorial band of non-gridlike cities. Louf and Barthelemy observed several clusters (groups one, two, and four in [80]) that occur predominantly in Africa, Asia and Oceania (which they combined into one entity), and South America. Notably, none of our clusters are as dominant as group three (which they described as having heterogeneous block sizes and shapes) of [80], although we do observe that our cluster of cities with interrupted grids (such cities are characterized in part by their heterogeneous block sizes) is also our largest cluster.
Now that we have compared our results to those of [80], we briefly compare and contrast the types of information that the two methods can capture. Recall that our level-set construction for PH generates filtered simplicial complexes that first consist of streets and then expand outward to absorb the blocks between them. The PH of such a filtered simplicial complex thereby gives a low-dimensional representation of the original image of a city street network. Because irregularly shaped blocks are absorbed into the surrounding streets at a different pace than regular blocks, we capture information about the regularity of each block. Louf and Barthelemy’s method also uses information about the regularity of block shape. See Eq. (3.2) in [80] for a precise mathematical statement of how they measured the regularity of blocks. It is related to a subset of so-called “compactness measures” [81] (which are used in the study of gerrymandering [82, 83]) that compare the area of a shape to the area of a circle in which the shape is circumscribed.
Because the original image of a city street network includes information about the spatial relationships between blocks, the PH that results from our approach also encodes some of this information. By contrast, Louf and Barthelemy’s fingerprints do not encode information about the spatial relationships of blocks to each other. Additionally, our method captures information from dead ends, which Louf and Barthelemy discarded.
Overall, although both our approach and that of [80] use a block-based representation to characterize cities, there are subtle differences in the way that the two approaches encode block information. Nevertheless, the commonality of a block-based perspective results in some similarities. For example, the clusters that result from the two approaches seem to be based heavily on block size and regularity. However, our approach appears to prioritize spatial relationships between different clusters of blocks (specifically, whether blocks are arranged in a grid); such information is not captured in the approach of [80]. Consequently, the two approaches capture different city morphologies, and we expect them to be useful as complementary techniques for studying structures in spatial complex systems.
III.3 Snowflakes



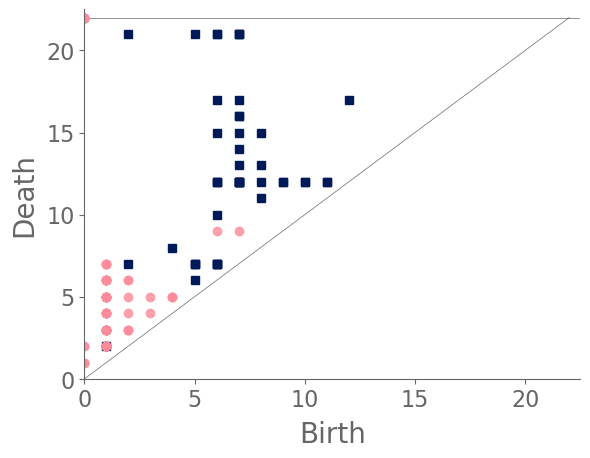
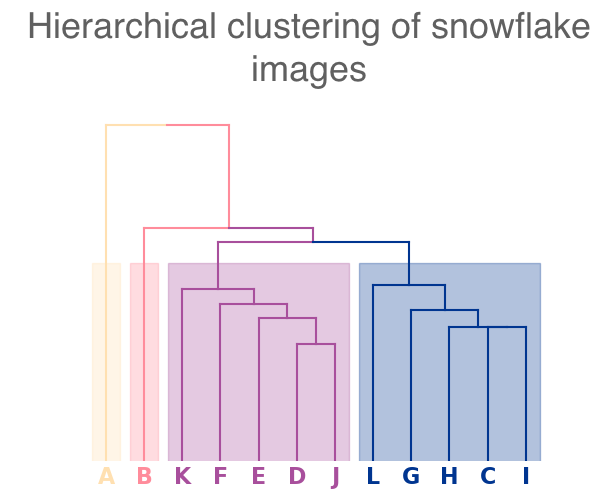
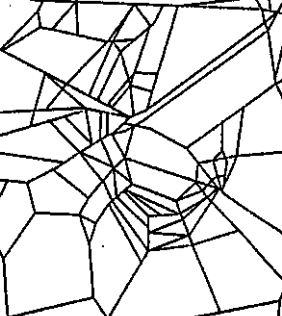
As a second application that uses empirical data, we consider snowflake crystals [84]. We start with twelve different images (from [84]) of snowflakes with different crystalline structures. (See Fig. 20 in Appendix A.) Using the GNU Image Manipulation Program [85], we threshold these grayscale images (using a thresholding setting of 205) to create black-and-white images. From the black-and-white images, we compute level-set complexes and PHs, and we then perform average-linkage hierarchical clustering on the PDs to produce the dendrogram in Fig. 17.
The images of snowflakes consist of edges (the black lines in our images) and cells (the white spaces that are bounded by the edges). We refer to the outer areas that extend from the center of the snowflakes as their “points”. The twelve snowflakes have fairly regular crystalline structures, so our computation of PH predominantly records information about the distribution of cell sizes in a snowflake. The inherent hexagonal nature of snowflakes and the regularity of their crystalline structures largely overwhelms our ability to use PH to glean information about their spatial relationships and irregularities. Constructing a simplicial complex that is better suited to capturing information about images with a large number of regular structures may yield better results.
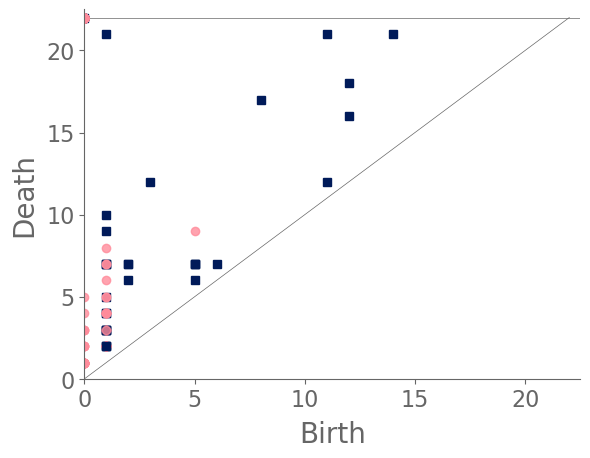
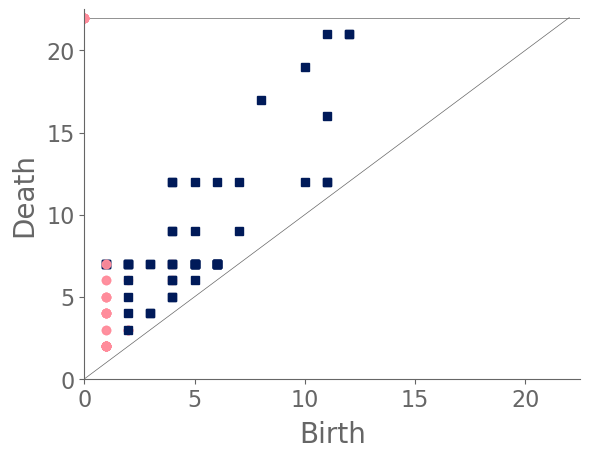
Examining the clusters (see Fig. 17) reveals that snowflake A and snowflake B each reside in their own cluster, and the remaining snowflakes split into two clusters. Snowflake A’s PD [see Fig. 16(a)] is dominated by a feature in with an early birth and a late death. (See the blue square in the top-left corner of the diagram. This arises from the large feature that is formed by the bold ring near the center of the snowflake. None of the other snowflakes have a bold central ring. More generally, we observe few features in the PD for snowflake A. By contrast, snowflake B’s features are largely close to the diagonal [see Fig. 16(b)] because the initial manifold of the snowflake does not have large holes. Notably, we do not observe any points in the top-left region of its PD. The cell sizes in snowflake B are smaller than those in most of the other snowflakes, and even its central ring structure includes a large number of small holes. The remaining snowflakes either have more large holes than snowflake B, or they do not have a bold central ring like the one in snowflake A. We also note the PD of snowflake B is much closer than that of snowflake A to those of the other snowflakes.
III.4 Spiderwebs
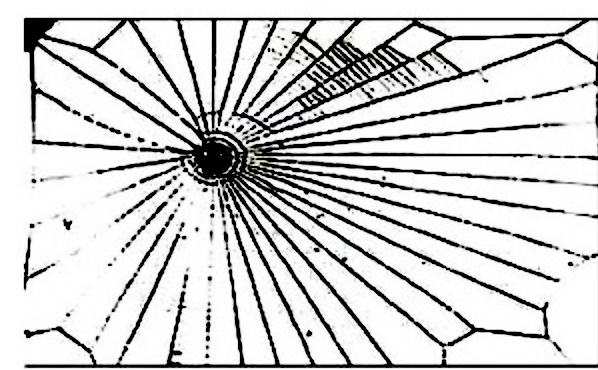
Our final application is to the topology of spiderwebs. In 1948, Peter Witt began research on the effects of drugs on spiders to test whether garden spiders would shift their web-building hours if they were administered drugs. Witt found that drugs affect the size and shape of the webs that are produced by spiders 222Interestingly, whiskey itself produces webs [90].. He also found that higher doses of most drugs (e.g., 100 g per spider, as opposed to 10 g per spider) tend to lead to larger changes in the shapes of webs, including yielding more irregular webs. Witt eventually published more than papers and several books on the behavior of spiders and spider webs. For more information on his experiments with psychotropic substances and spiders, see his 1971 review article [87]. In a 1995 technical briefing [88], NASA (which was inspired by Witt’s research) proposed that spiders who were administered more toxic substances produce webs that are more deformed (in comparison to a web that is spun by a drug-free spider) than less toxic substances. Additionally, using techniques from statistical crystallography, they concluded that spiders fail to complete more sides of their webs when they are under the influence of more toxic substances.
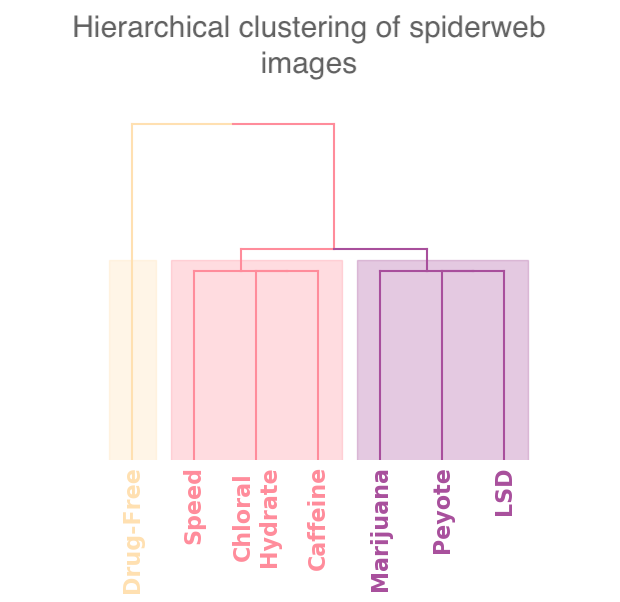
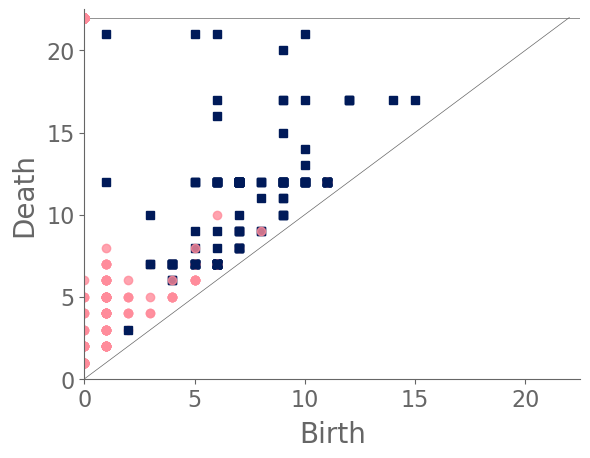
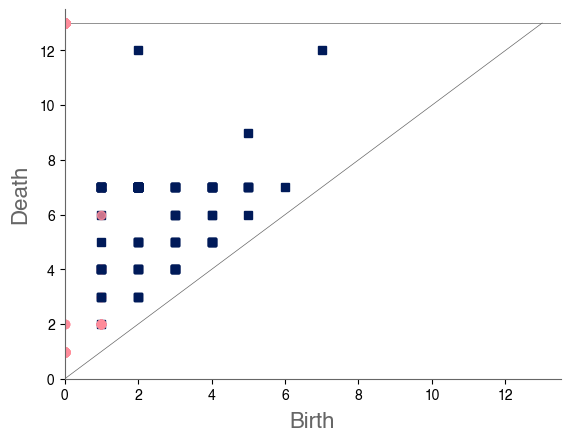
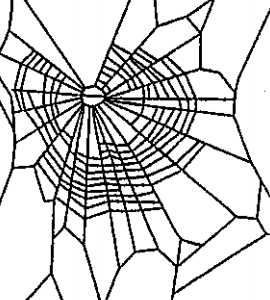
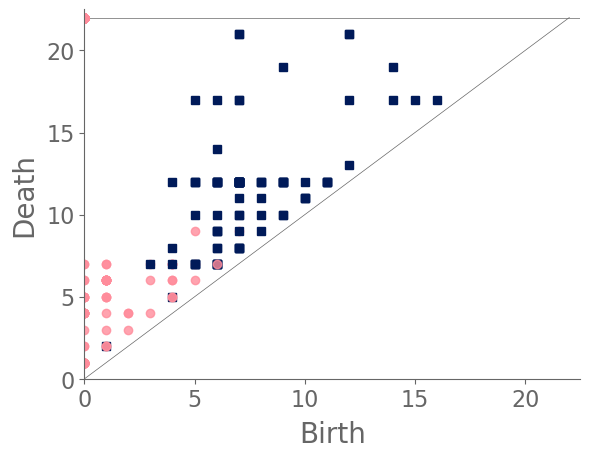
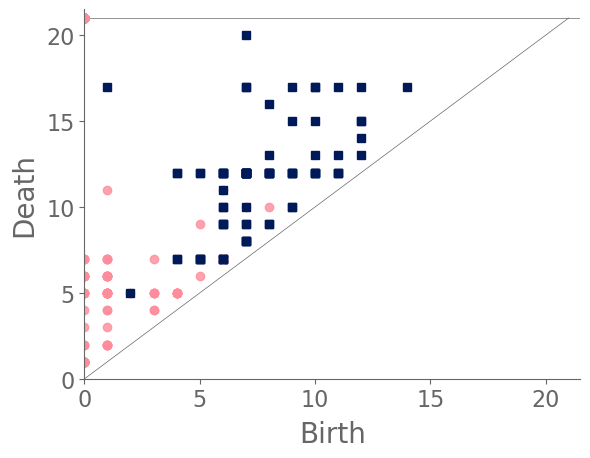
In our case study of PH in spiderwebs, we use five images from the NASA technical briefing [88] and two images from Witt [87] of webs that were spun by spiders under the influence of a variety of psychotropic substances, threshold grayscale images to turn them into black-and-white images (using a thresholding setting of 205 in the GNU Image Manipulation Program), apply our level-set construction to compute PH, and perform average-linkage hierarchical clustering to yield the dendrogram in Fig. 18. We show the images of the spiderwebs and their associated PDs in Fig. 19.
Our classification places the drug-free spider into its own cluster. The spiderweb of the drug-free spider is characterized by a clear central hole, threads radiating outward at approximately even intervals, and completed rings of threads that surround the center. We place the webs that were spun by spiders under the influence of marijuana, peyote, and LSD into the same cluster. In these webs, there is a clearly identifiable center; and most of the radial threads are evenly-spaced, straight, and radiate outward directly from the center. However, for the webs in this cluster, rings of threads are either difficult to see or are incomplete. The final cluster consists of webs that were spun by spiders under the influence of chloral hydrate, caffeine, and speed. In the caffeinated spider’s web, one cannot even clearly identify a center 333The web that was produced by the caffeinated spider is always fun to point out when giving presentations.. One can locate a center in the webs of the spiders that were under the influence of speed or chloral hydrate (a sedative that is used in sleeping pills), but many of the radial threads do not join the center and some of the radial threads are not straight. Almost no complete rings of thread are visible in any of the three webs in this cluster.


IV Conclusions
It is important to exploit spatial information in the study of spatial complex systems. In this paper, by using new methods of computing persistent homology that take spatial information into account, we presented several applications of topological data analysis to spatial networks. We showed that topological methods are capable of characterizing network structures and detecting structural differences from images of various spatial networks. We also demonstrated, using both synthetic examples and networks from empirical data, that such methods are able to provide insights into large-scale network structures that complement those from traditional techniques of network analysis. As an extended case study, we examined the morphology of street networks in cities, and we used spatial TDA to compare and contrast (1) different regions of the same city and (2) different cities. We hope that our examples help illustrate some ways in which topological methods, especially ones that directly incorporate spatial information in their formulation, can be useful for the analysis of spatial complex systems.
Appendix A Additional Snowflake Images
In Fig. 20, we show the images of all twelve snowflakes that we examined.









Acknowledgements.
We thank Marc Barthelemy, Heather Zinn Brooks, Hanbaek Lyu, Elizabeth Munch, Stan Osher, Nina Otter, Giovanni Petri, Bernadette Stolz, and an anonymous referee for helpful comments. We are particularly grateful to Joshua Gensler for his many helpful comments on both our paper and our code. We also acknowledge support from the National Science Foundation (grant number 1922952) through the Algorithms for Threat Detection (ATD) program.References
- Barthelemy [2018] M. Barthelemy, Morphogenesis of Spatial Networks (Springer International Publishing, Cham, Switzerland, 2018).
- Newman [2018] M. E. J. Newman, Networks, 2nd ed. (Oxford University Press, Oxford, UK, 2018).
- Solé et al. [2008] R. V. Solé, M. Rosas-Casals, B. Corominas-Murtra, and S. Valverde, Physical Review E 77, 026102 (2008).
- Kim et al. [2018] H. Kim, D. Olave-Rojas, E. Álvarez-Miranda, and S.-W. Son, Scientific Data 5, 180209 (2018).
- Albert et al. [2004] R. Albert, I. Albert, and G. L. Nakarado, Physical Review E 69, 025103 (2004).
- Papadopoulos et al. [2018] L. Papadopoulos, M. A. Porter, K. E. Daniels, and D. S. Bassett, Journal of Complex Networks 6, 485 (2018).
- Lee et al. [2014] S. H. Lee, M. Cucuringu, and M. A. Porter, Physical Review E 89, 032810 (2014).
- [8] M. Batty, The New Science of Cities (MIT Press, Cambridge, MA, USA).
- Barthelemy [2011] M. Barthelemy, Physics Reports 499, 1 (2011).
- Haggett and Chorley [1969] P. Haggett and R. J. Chorley, Network Analysis in Geography (Edward Arnold Publishers Ltd., London, UK, 1969).
- Pumain [2020] D. Pumain, ed., Theories and Models of Urbanization: Geography, Economics and Computing Sciences (Springer International Publishing, Cham, Switzerland, 2020).
- Liu and Porter [2020] A. Liu and M. A. Porter, Physical Review E 101, 062305 (2020).
- Nauer et al. [2019] S. Nauer, L. Böttcher, and M. A. Porter, Journal of Complex Networks advanced access (available at doi:10.1093/comnet/cnz037) (2019).
- Sarzynska et al. [2016] M. Sarzynska, E. A. Leicht, G. Chowell, and M. A. Porter, Journal of Complex Networks 4, 363 (2016).
- Expert et al. [2011] P. Expert, T. S. Evans, V. D. Blondel, and R. Lambiotte, Proceedings of the National Academy of Sciences of the United States of America 108, 7663 (2011).
- Boulatov and Kazakov [1987] D. V. Boulatov and V. A. Kazakov, Physics Letters B 186, 379 (1987).
- Arenas et al. [2008] A. Arenas, A. Díaz-Guilera, J. Kurths, Y. Moreno, and C. Zhou, Physics Reports 469, 93 (2008).
- Ying et al. [2019] F. Ying, A. O. G. Wallis, M. Beguerisse-Díaz, M. A. Porter, and S. D. Howison, Physical Review E 100, 062304 (2019).
- Hatcher [2002] A. Hatcher, Algebraic Topology (Cambridge University Press, Cambridge, UK, 2002).
- Edelsbrunner and Harer [2010] H. Edelsbrunner and J. Harer, Computational Topology: An Introduction (American Mathematical Society, Providence, RI, USA, 2010).
- Feng and Porter [2020] M. Feng and M. A. Porter, SIAM Review, in press (arXiv:1902.05911) (2020).
- Otter et al. [2017] N. Otter, M. A. Porter, U. Tillmann, P. Grindrod, and H. A. Harrington, European Physical Journal — Data Science 6, 17 (2017).
- Kaczynski et al. [2004] T. Kaczynski, K. M. Mischaikow, and M. Mrozek, Computational Homology (Springer-Verlag, Heidelberg, Germany, 2004).
- Gameiro et al. [2015] M. Gameiro, Y. Hiraoka, S. Izumi, M. Kramar, K. Mischaikow, and V. Nanda, Japan Journal of Industrial and Applied Mathematics 32, 1 (2015).
- Xia and Wei [2014] K. Xia and G.-W. Wei, International Journal for Numerical Methods in Biomedical Engineering 30, 814 (2014).
- Kovacev-Nikolic et al. [2016] V. Kovacev-Nikolic, P. Bubenik, D. Nikolic, and G. Heo, Statistical Applications in Genetics and Molecular Biology 15, 19 (2016).
- Zhou and Yan [2014] W. Zhou and H. Yan, Briefings in Bioinformatics 15, 54 (2014).
- Emmett et al. [2016] K. Emmett, B. Schweinhart, and R. Rabadan, in Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (Formerly BIONETICS), BICT’15 (ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), ICST, Brussels, Belgium, Belgium, 2016) pp. 177–180.
- Kanari et al. [2018] L. Kanari, P. Dłotko, M. Scolamiero, R. Levi, J. Shillcock, K. Hess, and H. Markram, Neuroinformatics 16, 3 (2018).
- Carlsson et al. [2008] G. Carlsson, T. Ishkhanov, V. de Silva, and A. Zomorodian, International Journal of Computer Vision 76, 1 (2008).
- Tymochko et al. [2019] S. Tymochko, E. Munch, J. Dunion, K. Corbosiero, and R. Torn, arXiv:1902.06202 (2019).
- Yalnız and Budanur [2020] G. Yalnız and N. B. Budanur, Chaos 30, 033109 (2020).
- Speidel et al. [2018] L. Speidel, H. A. Harrington, S. J. Chapman, and M. A. Porter, Physical Review E 98, 012318 (2018).
- Adams et al. [2017] H. Adams, T. Emerson, M. Kirby, R. Neville, C. Peterson, P. Shipman, S. Chepushtanova, E. Hanson, F. Motta, and L. Ziegelmeier, Journal of Machine Learning Research 18, 218 (2017).
- Khasawneh et al. [2018] F. A. Khasawneh, E. Munch, and J. A. Perea, IFAC-PapersOnLine 51-14, 195 (2018), part of the special issue of the 14th IFAC Workshop on Time Delay Systems TDS 2018 (Budapest, Hungary, 28–30 June 2018).
- Yesilli et al. [2019] M. C. Yesilli, S. Tymochko, F. A. Khasawneh, and E. Munch, in 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA) (2019) pp. 1211–1218.
- Cai and Wang [2020] C. Cai and Y. Wang, arXiv:2001.06058 (2020).
- Kraár et al. [2013] M. Kraár, A. Goullet, L. Kondic, and K. Mischaikow, Physical Review E 87 (2013).
- Buchet et al. [2018] M. Buchet, Y. Hiraoka, and I. Obayashi, in Nanoinformatics (Springer-Verlag, Heidelberg, Germany, 2018) pp. 75–95.
- Ronellenfitsch and Katifori [2016] H. Ronellenfitsch and E. Katifori, Physical Review Letters 117, 138301 (2016).
- Topaz et al. [2015] C. M. Topaz, L. Ziegelmeier, and T. Halverson, PLOS ONE 10, e0126383 (2015).
- Ignacio and Darcy [2019] P. S. P. Ignacio and I. K. Darcy, European Physical Journal — Data Science 8, 1 (2019).
- Byrne et al. [2019] H. M. Byrne, H. A. Harrington, R. Muschel, G. Reinert, B. J. Stolz, and U. Tillmann, Mathematics Today 55, 206 (2019).
- Petri et al. [2014] G. Petri, P. Expert, F. Turkheimer, R. Carhart-Harris, D. Nutt, P. J. Hellyer, and F. Vaccarino, Journal of the Royal Society Interface 11 (2014).
- Battiston et al. [2020] F. Battiston, G. Cencetti, I. Iacopini, V. Latora, M. Lucas, A. Patania, J.-G. Young, and G. Petri, arXiv:2006.01764 (2020).
- Bubenik et al. [2020] P. Bubenik, M. Hull, D. Patel, and B. Whittle, Inverse Problems 36, 025008 (2020).
- Tobler [1963] W. R. Tobler, Geographical Review 53, 59 (1963).
- Gastner and Newman [2004] M. T. Gastner and M. E. J. Newman, Proceedings of the National Academy of Sciences of the United States of America 101, 7499 (2004), arXiv:0401102 [physics] .
- Zomorodian and Carlsson [2005] A. Zomorodian and G. Carlsson, Discrete & Computational Geometry 33, 249 (2005).
- Ghrist [2008] R. Ghrist, Bulletin of the American Mathematical Society 45, 61 (2008).
- Stolz et al. [2017] B. J. Stolz, H. A. Harrington, and M. A. Porter, Chaos 27, 047410 (2017).
- The Gudhi Project [2015] The Gudhi Project, Gudhi User and Reference Manual (Gudhi Editorial Board, 2015).
- Maria [2015] C. Maria, in Gudhi User and Reference Manual (Gudhi Editorial Board, 2015).
- Osher and Fedkiw [2003] S. Osher and R. Fedkiw, Level Set Methods and Dynamic Implicit Surfaces, Vol. 153 (Springer-Verlag, Heidelberg, Germany, 2003).
- Watts [2002] D. J. Watts, Proceedings of the National Academy of Sciences of the United States of America 99, 5766 (2002).
- Porter and Gleeson [2016] M. A. Porter and J. P. Gleeson, Dynamical Systems on Networks: A Tutorial, Vol. 4 (Springer International Publishing, Cham, Switzerland, 2016).
- Note [1] We use the convention that includes .
- Taylor et al. [2015] D. Taylor, F. Klimm, H. A. Harrington, M. Kramár, K. Mischaikow, M. A. Porter, and P. J. Mucha, Nature Communications 6, 7723 (2015).
- Mahler et al. [2018] B. I. Mahler, U. Tillmann, and M. A. Porter, arXiv:1812.09806 (2018).
- Ying [2013] F. M. Ying, Dynamical processes on random geometric graphs (2013), available at https://www.math.ucla.edu/~mason/research/fabian-report-092913.pdf.
- Penrose [2003] M. Penrose, Random Geometric Graphs (Oxford University Press, Oxford, UK, 2003).
- Watts and Strogatz [1998] D. J. Watts and S. H. Strogatz, Nature 393, 440 (1998).
- Porter [2012] M. A. Porter, Scholarpedia 7, 1739 (2012).
- Hagberg et al. [2008] A. A. Hagberg, D. A. Schult, and P. J. Swart, in Proceedings of the 7th Python in Science Conference, edited by G. Varoquaux, T. Vaught, and J. Millman (Pasadena, CA USA, 2008) pp. 11 – 15.
- Barthelemy [2019] M. Barthelemy, Nature Reviews Physics 1, 406 (2019).
- Boeing [2019] G. Boeing, International Journal of Information Management (2019), available at doi:10.1016/j.ijinfomgt.2019.09.009.
- Boeing [2020] G. Boeing, Environment and Planning B: Urban Analytics and City Science 47, 590 (2020).
- Barthelemy [2017] M. Barthelemy, Environment and Planning B: Urban Analytics and City Science 44, 256 (2017).
- Cardillo et al. [2006] A. Cardillo, S. Scellato, V. Latora, and S. Porta, Physical Review E 73, 066107 (2006).
- Ahmed et al. [2014] M. Ahmed, B. T. Fasy, and C. Wenk, in Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, SIGSPATIAL ’14 (Association for Computing Machinery, New York, NY, USA, 2014) pp. 43–52.
- Wu et al. [2018] Y. Wu, G. Shindnes, V. Karve, D. Yager, D. B. Work, A. Chakraborty, and R. B. Sowers, in IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, Vol. 2018-March (Institute of Electrical and Electronics Engineers Inc., 2018) pp. 1–6.
- Thompson et al. [2020] J. Thompson, M. Stevenson, J. S. Wijnands, K. A. Nice, G. D. P. A. Aschwanden, J. Silver, M. Nieuwenhuijsen, P. Rayner, R. Schofield, R. Hariharan, and C. N. Morrison, The Lancet: Planetary Health 4, E32 (2020).
- Boeing [2017] G. Boeing, Computers, Environment, and Urban Systems 65, 126 (2017).
- Song [2017] E. Song, Administrative district boundaries of city of Shanghai, People’s Republic of China, 2017, ArcGIS (2017).
- [75] Google, Google Maps search for Shanghai, available at https://www.google.com/maps/place/Shanghai,+China/data=!4m2!3m1!1s0x35b27040b1f53c33:0x295129423c364a1?sa=X&ved=2ahUKEwjSmom9nevmAhXNuZ4KHangDhIQ8gEwK3oECBkQBA.
- Kerber et al. [2017] M. Kerber, D. Morozov, and A. Nigmetov, Journal of Experimental Algorithmics 22, 1.4 (2017).
- Park and Jun [2009] H.-S. Park and C.-H. Jun, Expert Systems with Applications 36, 3336 (2009).
- SimpleMaps [2019] SimpleMaps, World cities database (2019), available at https://simplemaps.com/data/world-cities.
- Belgiu [2015] M. Belgiu, UIA_Latitude/Longitude Graticules and World Countries Boundaries, ArcGIS (2015), available at https://www.arcgis.com/home/item.html?id=a21fdb46d23e4ef896f31475217cbb08.
- Louf and Barthelemy [2014] R. Louf and M. Barthelemy, Journal of the Royal Society Interface 11, 20140924 (2014).
- Gillman [2002] R. Gillman, Math Horizons 10, 10 (2002).
- Barnes and Solomon [2018] R. Barnes and J. Solomon, arXiv:1803.02857 (2018).
- Duchin and Tenner [2018] M. Duchin and B. E. Tenner, arXiv:1808.05860 (2018).
- Libbrecht [2019] K. G. Libbrecht, arXiv:1910.06389 (2019).
- [85] The GIMP Development Team, GIMP.
- Note [2] Interestingly, whiskey itself produces webs [90].
- Witt [1971] P. N. Witt, Behavioral Science 16, 98 (1971).
- Noever et al. [1995] D. A. Noever, R. J. Cronise, and R. A. Relwani, NASA Tech Briefs 19, 82 (1995).
- Note [3] The web that was produced by the caffeinated spider is always fun to point out when giving presentations.
- Williams et al. [2019] S. J. Williams, M. J. Brown, and A. D. Carrithers, Physical Review Fluids 4, 100511 (2019).