Spatial Heterogeneity Automatic Detection and Estimation
Abstract
Spatial regression is widely used for modeling the relationship between a dependent variable and explanatory covariates. Oftentimes, the linear relationships vary across space, when some covariates have location-specific effects on the response. One fundamental question is how to detect the systematic variation in the model and identify which locations share common regression coefficients and which do not. Only a correct model structure can assure unbiased estimation of coefficients and valid inferences. In this work, we propose a new procedure, called Spatial Heterogeneity Automatic Detection and Estimation (SHADE), for automatically and simultaneously subgrouping and estimating covariate effects for spatial regression models. The SHADE employs a class of spatially-weighted fusion type penalty on all pairs of observations, with location-specific weight adaptively constructed using spatial information, to cluster coefficients into subgroups. Under certain regularity conditions, the SHADE is shown to be able to identify the true model structure with probability approaching one and estimate regression coefficients consistently. We develop an alternating direction method of multiplier algorithm (ADMM) to compute the SHAD efficiently. In numerical studies, we demonstrate empirical performance of the SHADE by using different choices of weights and compare their accuracy. The results suggest that spatial information can enhance subgroup structure analysis in challenging situations when the spatial variation among regression coefficients is small or the number of repeated measures is small. Finally, the SHADE is applied to find the relationship between a natural resource survey and a land cover data layer to identify spatially interpretable groups.
key words: Areal data; Structure Selection; Penalization; Repeated measures; Spatial heterogeneity; Subgroup analysis
1 Introduction
Spatial regression is commonly used to model the relationship between a response and explanatory variables. For complex problems, some covariates (we call them global covariates) may have constant effects across space, while other covariates (we call them local covariates) may have location-specific effects, i.e, their effects on the response variable vary across space. This has received wide attention in many fields such as environmental sciences (Hu and Bradley,, 2018), biology (Zhang and Lawson,, 2011), social science (Bradley et al.,, 2018), economics (Brunsdon et al.,, 1996), and biostatistics (Xu et al.,, 2019).
A motivating example is about studying the relationship between two landcover data sources, one is the National Resources Inventory (NRI, Nusser and Goebel, 1997) survey conducted by the USDA Natural Resources Conservation Service (NRCS), the other one is the Cropland data layer (CDL, Han et al., 2012) produced by the USDA National Agricultural Statistics Service (NASS). Accurate estimate on local landcover information from NRI is essential for developing conservation policies and land management plans. However, direct estimates in small geographical areas such as at the county level may not be accurate due to small sample sizes. Auxiliary information such as CDL can be used to improve the small area estimator in NRI (Wang et al.,, 2018). Traditional regression models used in the small area estimation problems typically assume common regression coefficients over all domains, which may not be appropriate. For example, when we looked at the linear relationship between the NRI and CDL estimates of different types of land covers at county level, the regression coefficients in the Mountain states are quite different from the west coast and the vast areas in the east. This is reflected in Figure 9 (a) in Section 5. One reason for that difference is due to the scope of the NRI survey, which only include non-federal land in the US. Another contributing reason is that CDL is created by training separate machine learning models at the state level using only ground observations from that state, which creates variations among states. A common regression assumption would be too simple to capture the regional differences and will lead to biases in the estimators. This type of spatial heterogeneity is also known as structural instability. For linear models, this implies that the linear relationship changes geographically over space, and the linear regression coefficients may form subgroups. It is an important and challenging problem to identify the correct grouping structure of the regression coefficients, as only a correct model structure can lead to unbiased estimation of the regression coefficients and their valid inference. In practice, ad hoc grouping of states as regions defined by tradition or for federal administrative purposes are sometimes used to address this issue. However, such grouping is not driven by the data in specific problems, and may not be appropriate or efficient. For example, the central region in Figure 9 (a) includes not only all the Mountain states, but also the North and South Dakotas which are not traditionally considered Mountain states. Figure 9 (b) suggests further division of the east to sub-regions, which does not align to any well known administrative regions. One natural approach is to assume that regression coefficients of states nearby are more likely to belong to the same subgroup than states which are further apart, and use both the estimated regression coefficients and the spatial structure to guide the clustering of states into subregions, which is what we propose to do in this paper.
The problem of taking into account spatial dependence structure in linear regression has been studied for a long time in literature. Classical works include spatial expansion methods (Casetti,, 1972; Casetti and Jones,, 1987), which treat the spatially varying regression coefficients as a function of expansion variables, typically using longitude and latitude coordinates as location variables. One popular approach to accounting for spatial variations in the model is by introducing an additive spatial random effect for each location, as done for linear models by Cressie, (2015) and generalized linear models by Diggle et al., (1998). Another class of models in wide use are spatial varying coefficient models, including the geographically weighted regression (GWR; Brunsdon et al., 1996) and its extensions to generalized linear models (Nakaya et al.,, 2005) and the Cox model for survival analysis (Xue et al.,, 2020; Hu and Huffer,, 2020). There has been also development in the Bayesian framework, such as Gelfand et al., (2003).
The methods mentioned above typically assume that the regression parameters are smooth functions of location variables, which is reasonable in certain practice, but may not be appropriate for applications where the covariate effects are constant over subregions defined by some unobserved hidden factors. In this work, we take a different perspective by grouping the covariate effects into spatially-interpretable subgroups or clusters. As in the motivating example, different clusters have different patterns, which can be used to build more flexible estimators to improve the original direct estimates. A majority of existing work in the literature on spatial cluster detection are based on hypothesis tests, including the scan statistic methods based on the likelihood ratio (Kulldorff and Nagarwalla,, 1995; Jung et al.,, 2007; Cook et al.,, 2007) and the two-step spatial test methods under the GWR framework (Lee et al.,, 2017, 2020). Test-based methods are intuitive and useful in practice, but proper test statistics are often difficulty to construct and the tests may have low power when the number of locations is large. In addition, these methods handle the cluster detection problem and the model estimation separately, making it difficult to study inferential properties of the final estimator. The main purpose of this article is to fill this gap by developing a unified framework to detect clusters of regression coefficients, estimate them consistently, and make valid inferences.
In the context of non-spatial data analysis, a variety of clustering methods have been proposed to identify homogeneous groups for either observations or regression coefficients. Chi and Lange, (2015) developed a method for the convex clustering problem through the alternating direction method of multiplier algorithm (ADMM) (Boyd et al.,, 2011) with pairwise penalty. Nonnegative weights are considered to reduce bias for pairwise penalties. Fan et al., (2018) considered a clustering problem with penalty on graphs. For clustering the regression coefficients, Ma and Huang, (2017) and Ma et al., (2019) proposed a concave fusion approach for estimating the group structure and estimating subgroup-specific effects, where smoothly clipped absolute deviation (SCAD) penalty (Fan and Li,, 2001) and the minimax concave penalty (MCP) (Zhang,, 2010) are considered.
For spatial analysis, some interesting work are recently proposed for grouping regression coefficients in the spatial regression. Ma et al., (2020) proposed the Bayesian heterogeneity pursuit regression models to detect clusters in the covariate effects based on the Dirichlet process. Hu et al., (2020) proposed a Bayesian method for clustering coefficients with auxiliary covariates random effects, based on a mixture of finite mixtures (MFM). Li and Sang, (2019) proposed a penalized approach based on the minimum spanning tree. In the area of spatial boundaries detection, Lu and Carlin, (2005) and Lu et al., (2007) considered the areal boundary detection using a Bayesian hierarchical model based on the conditional autoregressive model (Banerjee et al.,, 2014). The boundaries were determined by the posterior distribution of the corresponding spatial process or spatial weights. These boundary detection methods focused on clustering of observations instead of regression coefficients.
The main difficulty in clustering spacial covariate effects is how to estimate the number of clusters and cluster memberships consistently, by taking into account spatial neighborhood information properly. To our knowledge, none of the existing methods can address this challenge. In this work, we fill the gap by proposing a new procedure, called Spatial Heterogeneity Automatic Detection and Estimation (SHADE), for automatically grouping and estimating local covariate effects simultaneously. The SHADE employs a class of spatially-weighted fusion type penalty on all pairs of observations, with location-specific weight adaptively constructed using geographical proximity of locations, and achieves spatial clustering consistency for spatial linear regression. In theory, we show that the oracle estimator based on weighted least squares is a local minimizer of the objective function with probability approaching 1 under certain regular conditions, which indicates that the the number of clusters can be estimated consistently. We believe that this result is the first of its kind in the contest of spatial data analysis. To implement the SHADE, an alternating direction method of multiplier algorithm (ADMM) algorithm is developed. To make the best choices of spatial weights and understand their roles in practical applications, we consider a number of different schemes to choose pairwise weights and compare them numerically and theoretically. Our numerical examples suggest that, the number of clusters and the group structure can be recovered with high probability, and the spatial information can help in spatial clustering analysis when the minimal group difference is small or the number of repeated measures is small.
The article is organized as follows. In Section 2, we describe the Spatial Heterogeneity Automatic Detection and Estimation (SHADE) model and the corresponding ADMM algorithm. In Section 3, we establish theoretical properties of the SHADE estimator. The simulation study is conducted in Section 4 under several scenarios to show performances of the proposed estimator. The proposed method is applied to an NRI small area estimation problem to illustrate the use of SHADE in real-data applications in Section 5. Finally, some discussions are given in Section 6.
2 Methodology and Algorithm
2.1 Methodology: SHADE
Assume our spatial data consist of multiple measurements at each location or subject. Let be the th response for the th subject observed at location , where . Based on their effects on the response variable, the covariates can be divided into two categories: “global” covariates which have common effects on the response across all the locations, and “local” covariates which have location-specific effects on the response. To reflect this, let and be the corresponding covariate vectors with dimension and respectively, where ’s are “global” covariates which have common linear effects to the response across all the locations, while ’s are “local” covariates which have location-specific linear effects on the response. We consider the following linear regression model
| (1) |
where represents the vector of common regression coefficients shared by global effects, ’s are location-specific regression coefficients, and ’s are i.i.d random errors with and . Furthermore, some locations may have same or similar location-specific effects, grouping locations of same location-specific effects can help to achieve dimension reduction and improve model prediction accuracy. Assume the location-specific effects belong to mutually exclusive subgroups: the locations with a common belong to the same group. Denote the corresponding partition of as , where the index set contains all the locations belonging to the group for . For convenience, denote the regression coefficients associated with as . In practice, since neither nor the partition ’s are known, the goal is to use the observed data to construct the estimator and the partition , where .
To achieve this goal, we use the following optimization problem: minimize the weighted least squares objective function subject to a spatially-weighted pairwise penalty
| (2) |
where , , denotes the Euclidean norm, is a penalty function imposed on all distinct pairs. In the penalty function, is a tuning parameter, is a built-in constant in the penalty function, and different weights ’s are assigned to different pairs of locations and for any . One popular choice of penalty is the penalty (lasso) (Tibshirani,, 1996) with the form . Since penalty tends to produce too many groups as shown in Ma and Huang, (2017), we consider the SCAD penalty, which is defined as
| (3) |
Here we treat as a fixed value as in Fan and Li, (2001), Zhang, (2010) and Ma et al., (2019).
2.2 Choices of Spatial Weights
In (2), the values weights are crucial, as they control the number of subgroups and grouping results. The pairs with larger weights are shrunk together more than those pairs with smaller weights. For spatial data, reasonable choices of should take into account two factors: locations with closer values are more grouped together, and locations closer to each other are more likely to form a subgroup as they typically have similar trends. Since the true values of are not available, we use their estimators as the surrogates. For example, we can define the weights as
where is an initial estimate of , and is a scale parameter to control magnitudes of the weights. In areal data, we suggest three different ways of taking into spatial information in the data to construct the weights.
(i) using both spatial and regression coefficients information:
| (4) |
where is the neighbor order between location and location , which means that if and are neighbors, . If and are not neighbors, but they have at least one same neighbor, . Similarly, we can have all the neighborhood order for all subjects or locations.
(ii) using regression coefficients information only:
| (5) |
(iii) using spatial information only:
| (6) |
Weights in (4) and (5) both includes the regression coefficients, which would depend on the accuracy of . If the number of repeated measures is not large, the values of will not show the real relationship between different locations, which would lead to very bad weights. The phenomenon can be observed in the simulation study. The weights we use here are three special cases which use the information of either regression coefficients or the spatial neighborhood orders. Definitely, there are other ways to construct weights, such as using distance to borrow the spatial information. At least the weights satisfy condition (C4) in Section 3, the theoretical results will hold under other conditions. For example, the weights in (5) will satisfy (C4) automatically if ’s are consistent estimators. That is, besides the condition (C4), there are no other conditions about the format of the weight function.
2.3 Algorithm for SHADE
In this section, we describe the ADMM algorithm to solve (2) in Section 2.1. The algorithm shares the same spirit as Ma and Huang,’s (2017), where a non-weighted penalty is used in non-spatial settings without repeated measures.
There are two tuning parameters, and , in the proposed method. We choose them adaptively using some tuning procedures discussed at the end of this section. For now, we fix them and present the computational algorithm for solving (2). Denote the solution as
| (7) |
First, we introduce the slack variables for all the pairs () , for . Then the problem is equivalent to minimizing the following objective function with regard to ,
where . To handle the equation constraints in the optimization problem, we introduce the augmented Lagrangian
where are Lagrange multipliers and is the penalty parameter.
To solve the problem, we use an iterative algorithm which updates sequentially, one at a time. At the th iteration, given their current values , the updates of are
| (8) |
To update and , we minimize the following objective function
where , , with , and with an matrix , where is an vector with th element 1 and other elements 0. Then the solutions for and are
| (9) |
| (10) |
where , and
To update ’s componentwisely, it is equivalent to minimize the following objective function
where . The solution based on SCAD penalty has a closed-form solution as
| (11) |
where and , and if , 0 otherwise.
In summary, the computational algorithm can be described as follows.
If the size of is reasonable, such as 10 or larger, we construct the initial values by fitting a linear regression model for each . Then, set and . If or small, the initial values can be set using the procedure in Ma et al., (2019). They used a ridge fusion criterion with a small value of the tuning parameter, then the initial group structure was obtained by assigning objects into (a given value) groups by ranking the estimated .
If , then the location and belong to the same group. Thus, we can obtain the corresponding estimated partition and the estimated number of groups . For each group, its group-specific parameter vector is estimated as for .
Remark 1.
If there are no global covariates, the model is simplified as . The algorithm will be simplified, that is, will become . The model we use in the application is the simplified model.
Remark 2.
The convergence criterion used is the same as Ma and Huang, (2017), which is based on the primal residual . The algorithm is stopped if , where is a small positive value.
We need to select two tuning parameters, and , in the SaSa algorithm. In this paper, we use the modified Bayes Information Criterion (BIC) (Wang et al.,, 2007) to determine the best tuning parameters adaptively from the data. In particular, we have
| (12) |
where is a positive number which can depend on . Here we use following Ma and Huang, (2017) with . To select , we select the best value from a set of candidate values, such as 0.1, 0.5, 1, 3. For each given , we use the warm start and continuation strategy as in Ma et al., (2019) to select tuning parameter . A grid of is predefined within . For each , the initial values are the estimated values from the previous estimation. Denote the selected tuning parameters as and . Correspondingly, the estimated group number is , and the estimated regression coefficients are and .
3 Theoretical Properties of SHADE
In this section, we study theoretical properties of the proposed SHADE estimator. Assume ’s are the true partition of location-specific regression coefficients. Let be the number of subjects in group for , and be the minimum and maximum group sizes, respectively. Let be an matrix with element and if , , otherwise. Denote , which is an matrix and . Define . Using these notations, we can then express as if , where . For any positive numbers, and , means that . Define the scaled penalty function by
| (13) |
Below are our assumptions, where (C1) and (C3) follow those in Ma et al., (2019).
-
(C1)
The function is symmetric, non-decreasing, and concave on . It is constant for for some constant , and . Also, exists and is continuous except for a finite number values of and .
-
(C2)
There exist finite positive constants such that , for and and . Also, assume that , for some constants and , where and are the corresponding minimum and maximum eigenvalues respectively. In addition, assume that and for some constants and .
-
(C3)
The random error vector has sub-Gaussian tails such that for any vector and , where and .
-
(C4)
The pairwise weights ’s are bounded away from zero if and are in the same group.
Conditions (C1) and (C3) are common used in high-dimensional penalized regression problems, which are also used in Ma et al., (2019). Condition (C2) is also similar to the condition mentioned in Ma et al., (2019), also includes the bounded conditions for covariates, which are used in Huang et al., (2004). In general, if the weights functions are not only defined on a finite support, ’s will satisfy condition (C4).
First, we establish the properties of the oracle estimator, which is defined as the weighted least squares estimator assuming that the underlying group structure is known. Specifically, the oracle estimator of is
| (14) |
And the corresponding oracle estimator of is . Let be the true coefficient vector for group , and , and let be the true common coefficient vector. The following theorem shows the properties of the oracle estimator.
Theorem 1.
Suppose
Under conditions (C1)-(C3), and , we have with probability at least ,
and
where
Furthermore, for any vector , we have as
| (15) |
where
| (16) |
Remark 3.
We don’t have any specific assumptions about . If , or , we have . If , we have . In this case, if , and are fixed values, what we need is only .
Remark 4.
The model considered in Ma et al., (2019) is a special case of our model, and their condition is a special case of our condition, that is when .
Remark 5.
If let for some constant , then
Moreover, if , and are fixed values, then for some constant .
Next, we study the properties of our proposed estimator. Let
| (17) |
be the minimal difference among different groups.
Theorem 2.
Remark 6.
Theorem 2 implies that true group structure can be recovered with probability approaching 1. It also implies that the estimated number of groups satisfies
Let be the distinct group vectors of . According to Theorem 1 and Theorem 2, we have the following result.
Corollary 1.
Suppose the conditions in Theorem 2 hold, for any vector , we have as
| (19) |
Remark 7.
The variance parameter can be estimated by
| (20) |
The algorithm can be implemented through package Spgr in https://github.com/wangx23/Spgr.
4 Simulation Studies
In this section, we evaluate and compare performance of the proposed SHADE estimator with different weight choices: equal weights (denoted as “equal”), weights defined in (4) (denoted as “reg-sp”), weights defined in (5) (denoted by “reg”), and weights defined in (6) (denoted by “sp”).
The simulations are carried as follows. Let with and are generated a multivariate normal distribution with mean 0, variance 1, and pairwise correlation . Define , where is simulated from a standard normal distribution and is simulated from a centered and standardized binomial . Let , where ’s are simulated from Uniform and standard deviation of the error term is . We set and and use the SCAD penalty function. The tuning parameters are chosen by the modified BIC defined by (12). We consider the simulations in several scenarios. The results are based on 100 simulations.
To evaluate subgrouping performance of the proposed method, we report the estimated group number , adjusted Rand index (ARI) (Rand,, 1971; Hubert and Arabie,, 1985; Vinh et al.,, 2010), and the root mean square error (RMSE) for estimating . For the estimated over 100 simulations, we report its average (denoted by “mean”), standard error in the parenthesis, and the occurrence percentage of (denoted by “per”). The quantity ARI is used to measure the degree of agreement between two partitions, taking a value between 0 and 1: the larger ARI value, the more agreement. We report the average ARI across 100 simulations along with the standard error in the parentheses. To evaluate estimation accuracy of , we also report the average RMSE
| (21) |
4.1 Balanced group
We assume that there are true groups and . Consider the two spatial settings, for which the group parameters are respectively given by:
Setting 1: if ; if ; if .
Setting 2: if ; if ; if .
Under each setting, we simulate the data on two sizes of regular lattice, a grid (left) and a grid (right), as shown in Figure 1. Furthermore, for the grid with , we use a 10-fold cross validation to select the tuning parameters. The repeated measures of location are divided into 10 parts; the th part of each location is combined as the validation data set, the remaining observations form the training data set. The spatial weights (6) are considered. The results are labeled as “cv” in all the tables. Note that “reg_sp” and “reg” were not computed for the grid.

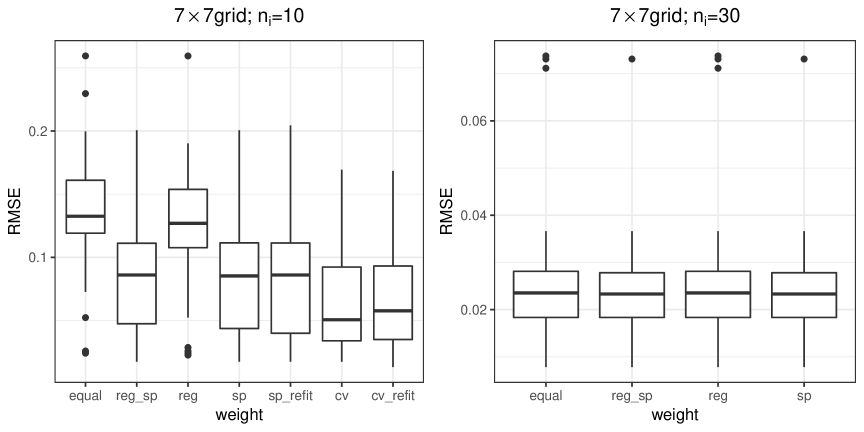
Results for Setting 1: Tables 1 , 2 and 3 show the estimated number of groups and ARI. Figures 2 and 3 plot the RMSE of the estimates obtained using different weight choices. After estimating the group structure, one can also estimate parameters and again by assuming that the group information is known; the results are denoted as “refit”. Based on the numerical results, we make the following observations.
First, we summarize the results for the grid. In all the considered scenarios, the spatially weighted penalty outperforms the non-weighed penalty ( “equal”). The upper panels in Tables 1 and 2, the left plot in Figure 2 suggest that, if the number of repeated measurements is relatively small (say, ), the weights “reg_sp” and “sp” perform similarly and they are the best in terms of estimating , recovering the true subgroup structure (large ARI), and estimating regression coefficients (small RMSE); the weights “equal” and “reg” are much worse. The lower panels of Tables 1 and 2 and the right plot in Figure 2 show that, when the number of repeated measurements gets larger (say, ), all the methods improve and there is not much difference among them. Cross validation works well in terms of ARI and RMSE, but it tends to over-estimate the number of groups . This is because that cross validation focuses more on the prediction accuracy; the coefficient estimates of some groups are close to the true coefficients, but they are not shrank together. In addition, refitting the model does not appear to further improve the accuracy of estimating .
| equal | reg_sp | reg | sp | cv | ||
|---|---|---|---|---|---|---|
| mean | 3.34(0.054) | 3.15(0.039) | 3.33(0.051) | 3.13(0.034) | 3.82(0.13) | |
| per | 0.69 | 0.86 | 0.69 | 0.87 | 0.56 | |
| mean | 3.00(0) | 3.00(0) | 3.00(0) | 3.00(0) | ||
| per | 1.00 | 1.00 | 1.00 | 1.00 |
| equal | reg_sp | reg | sp | cv | |
|---|---|---|---|---|---|
| 0.80(0.011) | 0.92(0.008) | 0.82(0.01) | 0.92(0.007) | 0.95(0.007) | |
| 0.998(0.001) | 0.999(0.0006) | 0.998(0.001) | 0.999(0.0006) |
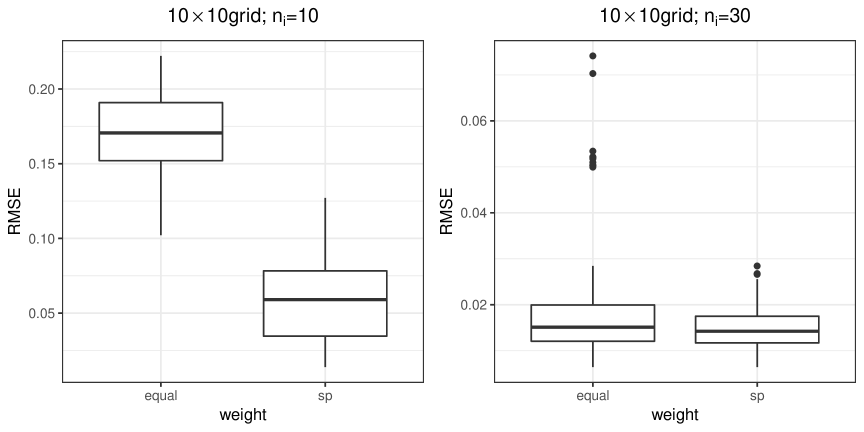
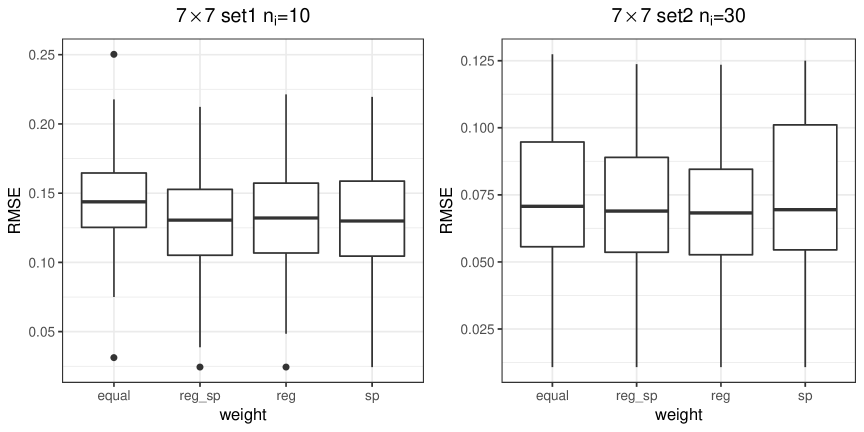
Next, we summarize the results for the grid. In this case, we consider equal weights and spatial weights only. Again, the spatially-weighted penalty outperforms the non-weighed penalty ( “equal”). Table 3 and Figure 3 suggest that, if the number of repeated measurements is relatively small (say, ), “sp” performs much better in terms of grouping and estimating regression coefficients than “equal”; for a larger number of repeated measurements (say, ), they perform similarly.
| ARI | |||||
|---|---|---|---|---|---|
| equal | sp | equal | sp | ||
| mean | 3.59(0.073) | 3.37(0.065) | 0.70(0.009) | 0.97(0.003) | |
| per | 0.53 | 0.71 | - | - | |
| mean | 3(0) | 3(0) | 0.996(0.001) | 1.00(0) | |
| per | 1.00 | 1.00 | - | - | |
Results for Setting 2: In this setting, the group difference becomes smaller. Tables 4, 5 and Figure 4 summarize the results for the grid. For both values of , the weights “sp” performs best in terms of estimating the number of groups (), recovering the true group structure (ARI), and estimating regression coefficients. In contrast to Setting 1, when the difference among groups becomes smaller, even with , the model with the spatial weight is superior to other models.
| equal | reg_sp | reg | sp | ||
|---|---|---|---|---|---|
| mean | 3.25(0.119) | 3.01(0.093) | 3.14(0.107) | 2.88(0.067) | |
| per | 0.34 | 0.45 | 0.33 | 0.60 | |
| mean | 2.70(0.046) | 2.90(0.030) | 2.76(0.043) | 2.95(0.022) | |
| per | 0.70 | 0.90 | 0.76 | 0.95 |
| equal | reg_sp | reg | sp | |
|---|---|---|---|---|
| 0.32(0.011) | 0.50(0.023) | 0.33(0.01) | 0.61(0.026) | |
| 0.72(0.018) | 0.86(0.015) | 0.75(0.017) | 0.90(0.012) |
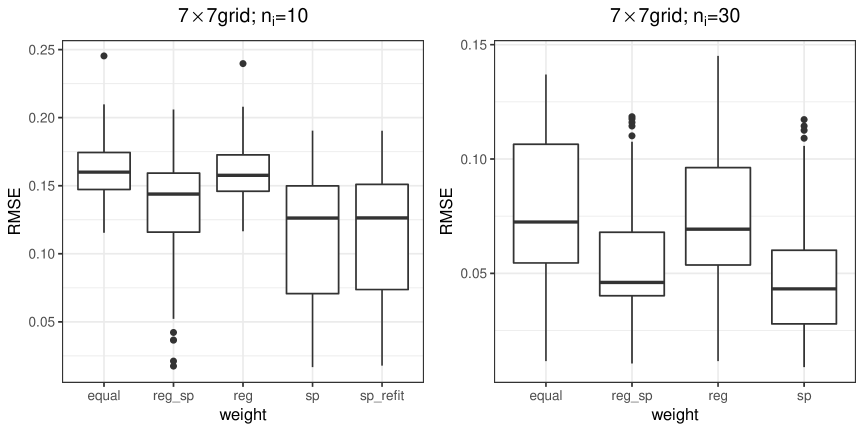
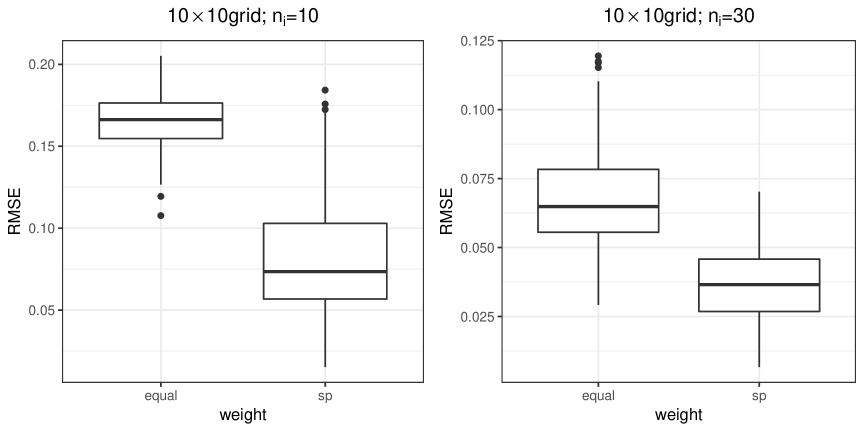
Table 6 and Figure 5 show the results for the grid. Again, we only compare “equal” weights and “sp” weights. The results suggest similar conclusions to those for the grid: the model with the spatial weight is superior even with a large number of repeated measurements () by producing larger ARI and smaller RMSE.
| ARI | |||||
|---|---|---|---|---|---|
| equal | sp | equal | sp | ||
| mean | 3.82(0.146) | 3.35(0.078) | 0.32(0.009) | 0.81(0.022) | |
| per | 0.32 | 0.620 | - | - | |
| mean | 3.10(0.060) | 3.00(0.0) | 0.79(0.012) | 0.94(0.005) | |
| per | 0.64 | 1.0 | - | - | |
4.2 Unbalanced group setting
Here we consider an unbalanced group setting as shown in Figure 6. In this setting, there are four groups, denoted as and , and two groups have 9 subjects and the other two groups have 41 subjects. The group parameters are if , if , if and if .
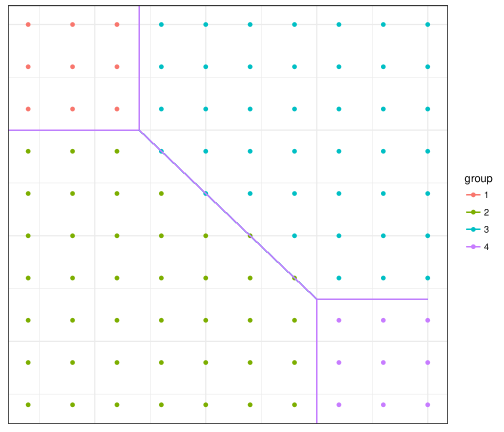
Table 7 and Figure 7 show the summaries of , ARI and RMSE for when the number of repeated measurements is . Overall speaking, “reg_sp” and “sp” perform better than the other two types of weights. Especially, “sp” performs a slightly better than “reg_sp” . The results are consistent with those under balanced cases. We expect that, when the group difference becomes smaller, “sp” would still perform better than other weights even when the number of repeated measurements is large.
| equal | reg_sp | reg | sp | ||
|---|---|---|---|---|---|
| mean | 4.58(0.093) | 4.23(0.049) | 5.17(0.011) | 4.35(0.059) | |
| per | 0.570 | 0.800 | 0.300 | 0.710 | |
| ARI | mean | 0.62(0.010) | 0.94(0.061) | 0.67(0.009) | 0.96(0.004) |
4.3 Random group setting
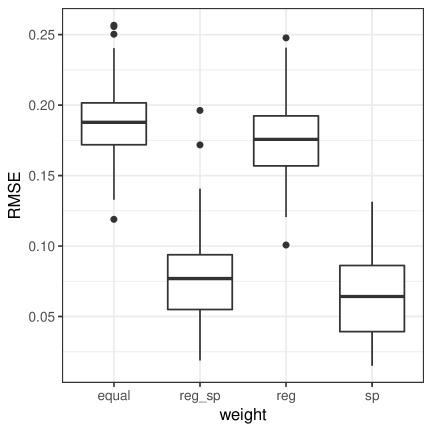
We consider a setting without specified location group information. For each location, it has equal probability to three groups. Tables 8 shows the summary of and ARI for Setting 1 under the grid with 10 repeated measures. Table 9 shows the summary of and ARI for Setting 2 under the grid with 30 repeated measures. Figure 8 shows the RMSE results for both cases. We can see that different weights have similar performances. The results suggest that even without prior information on the existence of spatial groups, “sp” weights can still produce comparable results as equal weights.
| equal | reg_sp | reg | sp | ||
|---|---|---|---|---|---|
| mean | 3.42(0.064) | 3.45(0.063) | 3.40(0.059) | 3.45(0.063) | |
| per | 0.66 | 0.62 | 0.65 | 0.62 | |
| ARI | mean | 0.78(0.011) | 0.82(0.010) | 0.81(0.010) | 0.82(0.011) |
| equal | reg_sp | reg | sp | ||
|---|---|---|---|---|---|
| mean | 2.77(0.045) | 2.77(0.045) | 2.83(0.040) | 2.73(0.047) | |
| per | 0.75 | 0.75 | 0.81 | 0.71 | |
| ARI | mean | 0.74(0.015) | 0.76(0.016) | 0.77(0.014) | 0.74(0.017) |
5 Application
In this section, we apply our SHADE method to the modeling of the National Resources Inventory survey (NRI) data 111https://www.nrcs.usda.gov/wps/portal/nrcs/main/national/technical/nra/nri/ for the purpose of small area estimation. The NRI survey is one of the largest longitudinal natural resource surveys in the U.S., and its national and state level estimates of the status and change of land cover and use and soil erosion have been used by numerous federal, state, and local agencies in the past few decades. In recent years, there is an increasing demand for NRI to provide various county level estimates. These include estimates of different land covers, such as cropland, pasture land, urban and forest. Due to the limitation of sample size, the uncertainty of the NRI direct county level estimates are usually too large for local stakeholders for making policy decisions. To make the county level estimates more useful, it is necessarily to include some auxiliary information and appropriate model to reduce the uncertainty of the estimates. One such set of auxiliary covariates is Cropland Data Layer (CDL), which is based on classification of satelliate image pixels into several mutually exclusive and exhaustive land cover categories. In this section, we model the relationship between the NRI forest proportion and the CDL forest proportion among 48 states. In NRI, forests belonging to federal land, such as national parks, are not included in the forest category. For states with more forest federal land, NRI estimates can be substantially smaller than CDL estimates. Therefore, different states could have different relationship between these two proportions.
The model we consider is,
| (22) |
where is the NRI forest proportion of the th county in the th state, is the corresponding CDL forest proportion of the th county in the th state, and and are the unknown coefficients. Both and are standardized. Instead of using the estimated linear regression coefficients as initial values directly, we use five sets of initial values which are simulated from a multivariate normal distribution with estimated coefficients as the mean vector and estimated covariance matrix as the covariance matrix. The models with the smallest modified BIC values are selected for equal weights and spatial weights respectively.
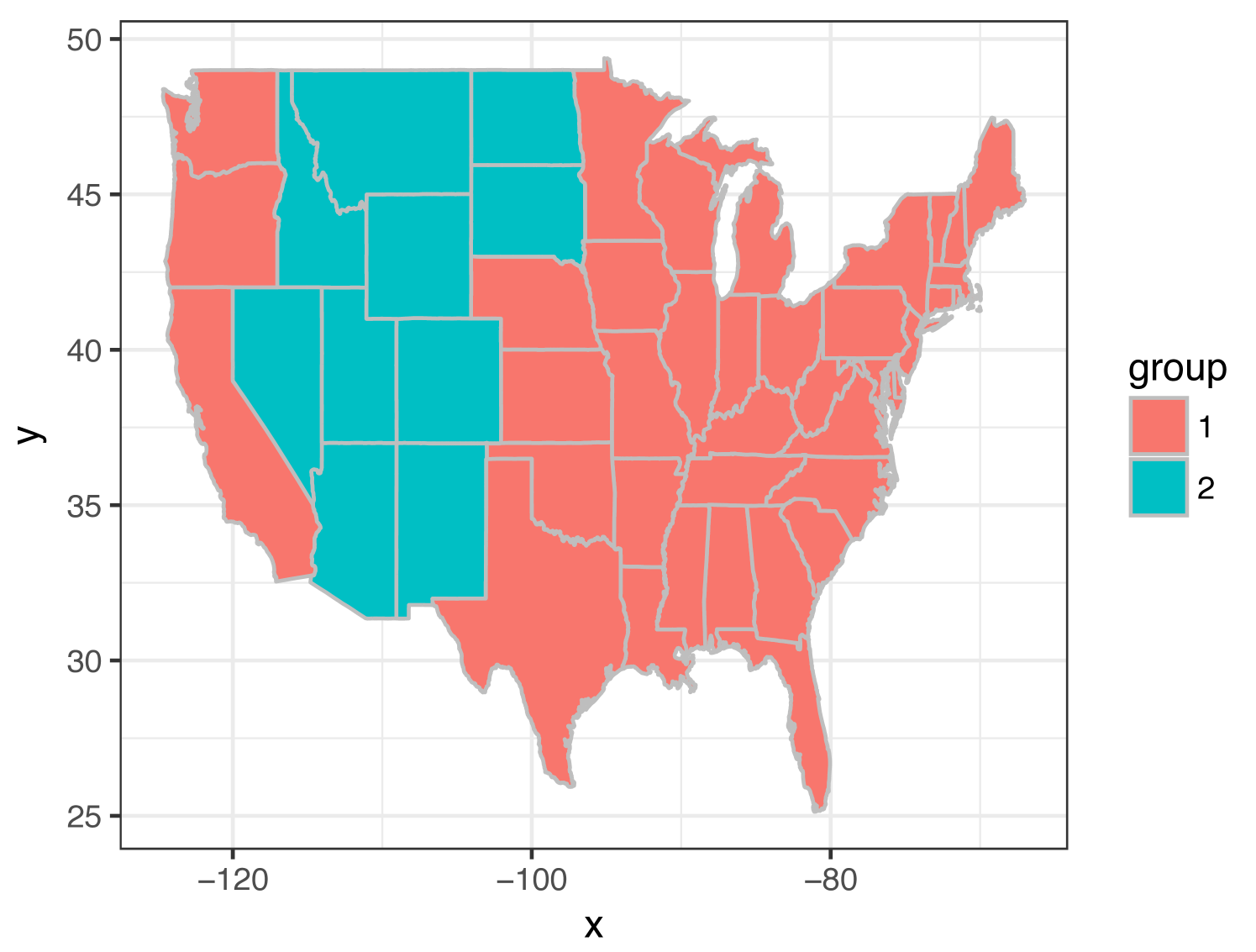
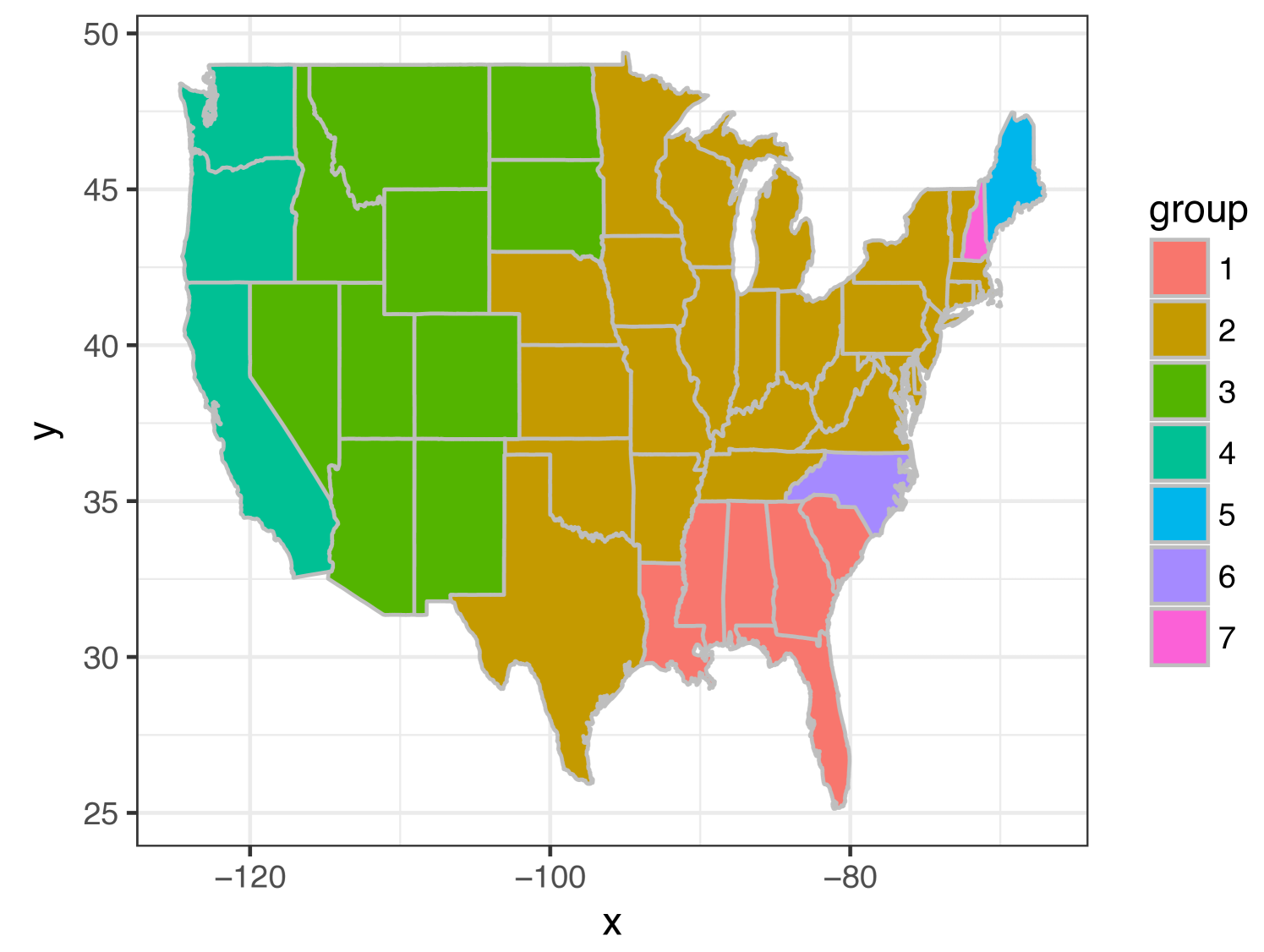
Figure 9 shows the estimated groups based on 2011 NRI data sets. The left figure plots the estimated groups based on equal weights, and the right one is for the estimated groups based on spatial weights in (6). We find that the two different weights give different estimated groups. Tables 10 and 11 are the corresponding estimates of regression coefficients in different groups.
| group | 1 | 2 |
|---|---|---|
| -0.029(0.006) | 0.003(0.008) | |
| 0.885(0.011) | 0.241(0.026) |
| group | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| -0.041(0.016) | -0.032(0.006) | 0.003(0.007) | 0.023(0.015) | -0.108(0.293) | 0.275(0.038) | 0.376 (0.309) | |
| 1.018(0.028) | 0.867(0.012) | 0.241(0.024) | 0.608(0.033) | 1.148 (0.377) | 0.332(0.064) | 0.341(0.384) |
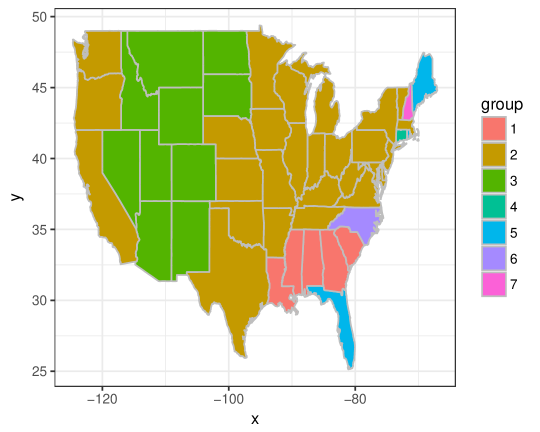
When considering equal weights, is the only tuning parameter in the algorithm. By changing the value of , we can have different number of groups. We consider to change the value in the algorithm based on equal weights such that the number of groups is the same as what we have selected based on the spatial weights, that is 7 groups. Figure 10 shows the group structure with 7 groups based on equal weights. In both Figure 10 and the left figure of Figure 9, “WA”, “OR” and “CA” are not separated from the majority group (the group with the largest group size) when considering equal weights. These three states are in group 4, which are separated from the majority group (group 2) when considering spatial weights, which is more reasonable and intuitive based on the estimates of regression coefficients as shown in Table 11. Besides that, these three states have more national parks than those states in group 2.
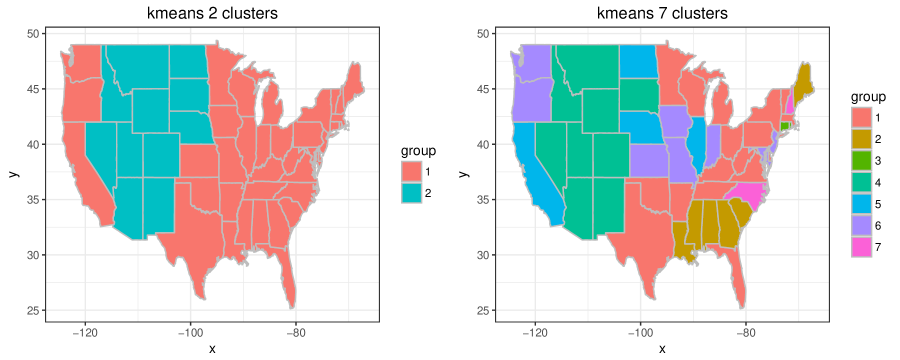
Alternatively, we also implement -means clustering based on the initial estimates to identify similar behaviors among the states. Figure 11 shows the maps based on 2-means clustering and 7-means clustering, respectively. We notice that the 2-cluster map is almost the same as the map based on equal weights. However, the 7-cluster map is not interpretable compared to the result based on spatial weights. This suggests that the proposed procedure can produce more interpretable subgroup structures than -means clustering methods.
6 Discussion
In this article, we consider the problem of spatial clustering of local covariate effects and develop a general framework called Spatial Heterogeneity Automatic Detection and Estimation (SHADE) for spatial areal data with repeated measures. In spatial data, since locations near each other usually have similar patterns, we propose to take into account spatial information in the pairwise penalty, where closer locations are assigned with larger weights to encourage stronger shrinkage. In the simulation study, we use several examples to investigate and compare performance of the procedure using different weights and have found that spatial information helps to improve the accuracy of grouping, especially when the minimal group difference is small or the number of repeated measures is small. We also establish theoretical properties of the proposed estimator in terms of its consistency in estimating the number of groups.
In the real data example, we have treated states as locations and counties as repeated measures. Alternatively, one can treat counties as individual units, since one state could have counties with two different features. Then, the algorithm will involve a matrix inverse with dimension more than 3000, which will require higher computational burden. A further study is needed to compare these two models for the application.
The proposed method does not consider the spatial dependence in the regression error when constructing the objective function. The basic idea of this algorithm can be extended to a general spatial clustering setup with consideration of the spatially dependent error. More specifically, the weighted least squared term in the objective function needs to be replaced by a generalized least squares term, which includes an estimated covariance matrix. The new algorithm should have two iterative steps. The first step is to update regression coefficients to find clusters and the second step is to update covariance parameters. More simulation studies are needed to explore the performance of the two-step algorithm. And the theoretical properties needs to be established to support the new algorithm. Both theoretical and computational aspect of such extension are nontrivial and will be considered in a follow up work.
Appendices
A Proof of Theorem 1
In this section, we prove Theorem 1. When proving the central limit theorem (CLT) we use the technique in Huang et al., (2004).
The oracle estimator is define in (14), which has the following form
Thus, we have
where with . Therefore,
| (23) |
where is matrix norm, which is defined as, for a matrix , .
We know that
| (24) |
where is a finite positive constant and is defined as, for a vector , . By condition (C2), we have
Since
from condition (C3), it follows that
Similarly, . Again, by condition (C3), we have
Thus, (24) can be bounded by
Since ,
Let , thus
| (25) |
Also, according to condition (C2), we have
| (26) |
Next, we consider the central limit theorem. Let with for . Consider
where . By the assumption of in the model (1), we have
The variance of can be written as
We use the technique of Huang et al., (2004) in the proof of their Theorem 3. That is,
can be written as with
where ’s are independent with mean zero and variance one. If
then is asymptotically .
For any , we have
where the last inequality is by condition (C2). So,
| (27) |
by assumption.
B Proof of Theorem 2
In this section, we prove Theorem 2. As in Ma et al., (2019) and Ma and Huang, (2017), we define to be the mapping that and to be the mapping that .
Consider the following neighborhood of ,
According to Theorem 1, there exists an event where and such that .
Recall that the objective function to minimize is given in (2), which has the following form
| (28) |
Here we show that is a strict local minimizer of the above objective function with probability approaching 1 by two steps as in Ma et al., (2019). The first step is to show that in event , for any and , where and . The proof of this step is almost the same as the first step in Ma et al., (2019) , which is omitted here.
Here we show the second step, that is, there exists an event such that . In the event , there is a neighborhood of , such that for any for sufficiently large .
Let , where is a positive sequence with . By Taylor’s expansion, for ,
| (29) |
where
with for some constant .
We have as follows,
For , and , then
Since , for , ,,
Thus, by assumption (C1). Therefore,
| (30) |
Also, for , , so by assumption (C1). Thus, we have
Let with
We have,
| (31) |
Moreover,
so
where with . According to Condition (C3),
Thus, there exists an event such that and
Thus,
| (32) |
Combining (30), (B) and (32), (29) follows that
As , . Since , and , then and . Thus, , and . Therefore, for sufficiently large by the assumption (C4) that ’s are bounded if and are in the same group.
Therefore, combining the two steps, we will have that for any and . This shows that is a strict local minimizer of the objective function (2) on with probability at least for sufficiently large .
References
- Banerjee et al., (2014) Banerjee, S., Carlin, B. P., and Gelfand, A. E. (2014). Hierarchical modeling and analysis for spatial data. Crc Press.
- Boyd et al., (2011) Boyd, S., Parikh, N., Chu, E., Peleato, B., and Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3(1):1–122.
- Bradley et al., (2018) Bradley, J. R., Holan, S. H., and Wikle, C. K. (2018). Computationally efficient multivariate spatio-temporal models for high-dimensional count-valued data (with discussion). Bayesian Analysis, 13(1):253–310.
- Brunsdon et al., (1996) Brunsdon, C., Fotheringham, A. S., and Charlton, M. E. (1996). Geographically weighted regression: a method for exploring spatial nonstationarity. Geographical analysis, 28(4):281–298.
- Casetti, (1972) Casetti, E. (1972). Generating models by the expansion method: applications to geographical research. Geographical analysis, 4(1):81–91.
- Casetti and Jones, (1987) Casetti, E. and Jones, J. P. (1987). Spatial aspects of the productivity slowdown: an analysis of us manufacturing data. Annals of the Association of American Geographers, 77(1):76–88.
- Chi and Lange, (2015) Chi, E. C. and Lange, K. (2015). Splitting methods for convex clustering. Journal of Computational and Graphical Statistics, 24(4):994–1013.
- Cook et al., (2007) Cook, A. J., Gold, D. R., and Li, Y. (2007). Spatial cluster detection for censored outcome data. Biometrics, 63(2):540–549.
- Cressie, (2015) Cressie, N. (2015). Statistics for spatial data. John Wiley & Sons.
- Diggle et al., (1998) Diggle, P. J., Tawn, J. A., and Moyeed, R. A. (1998). Model-based geostatistics. Journal of the Royal Statistical Society: Series C (Applied Statistics), 47(3):299–350.
- Fan and Li, (2001) Fan, J. and Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American statistical Association, 96(456):1348–1360.
- Fan et al., (2018) Fan, Z., Guan, L., et al. (2018). Approximate -penalized estimation of piecewise-constant signals on graphs. The Annals of Statistics, 46(6B):3217–3245.
- Gelfand et al., (2003) Gelfand, A. E., Kim, H.-J., Sirmans, C., and Banerjee, S. (2003). Spatial modeling with spatially varying coefficient processes. Journal of the American Statistical Association, 98(462):387–396.
- Han et al., (2012) Han, W., Yang, Z., Di, L., and Mueller, R. (2012). Cropscape: A Web service based application for exploring and disseminating US conterminous geospatial cropland data products for decision support. Computers and Electronics in Agriculture, 84:111–123.
- Hu and Bradley, (2018) Hu, G. and Bradley, J. (2018). A bayesian spatial–temporal model with latent multivariate log-gamma random effects with application to earthquake magnitudes. Stat, 7(1):e179.
- Hu and Huffer, (2020) Hu, G. and Huffer, F. (2020). Modified Kaplan–Meier estimator and Nelson–Aalen estimator with geographical weighting for survival data. Geographical Analysis, 52(1):28–48.
- Hu et al., (2020) Hu, G., Xue, Y., and Ma, Z. (2020). Bayesian clustered coefficients regression with auxiliary covariates assistant random effects. arXiv preprint arXiv:2004.12022.
- Huang et al., (2004) Huang, J. Z., Wu, C. O., and Zhou, L. (2004). Polynomial spline estimation and inference for varying coefficient models with longitudinal data. Statistica Sinica, 14(3):763–788.
- Hubert and Arabie, (1985) Hubert, L. and Arabie, P. (1985). Comparing partitions. Journal of classification, 2(1):193–218.
- Jung et al., (2007) Jung, I., Kulldorff, M., and Klassen, A. C. (2007). A spatial scan statistic for ordinal data. Statistics in medicine, 26(7):1594–1607.
- Kulldorff and Nagarwalla, (1995) Kulldorff, M. and Nagarwalla, N. (1995). Spatial disease clusters: detection and inference. Statistics in medicine, 14(8):799–810.
- Lee et al., (2017) Lee, J., Gangnon, R. E., and Zhu, J. (2017). Cluster detection of spatial regression coefficients. Statistics in medicine, 36(7):1118–1133.
- Lee et al., (2020) Lee, J., Sun, Y., and Chang, H. H. (2020). Spatial cluster detection of regression coefficients in a mixed-effects model. Environmetrics, 31(2):e2578.
- Li and Sang, (2019) Li, F. and Sang, H. (2019). Spatial homogeneity pursuit of regression coefficients for large datasets. Journal of the American Statistical Association, 114(527):1050–1062.
- Lu and Carlin, (2005) Lu, H. and Carlin, B. P. (2005). Bayesian areal wombling for geographical boundary analysis. Geographical Analysis, 37(3):265–285.
- Lu et al., (2007) Lu, H., Reilly, C. S., Banerjee, S., and Carlin, B. P. (2007). Bayesian areal wombling via adjacency modeling. Environmental and Ecological Statistics, 14(4):433–452.
- Ma and Huang, (2017) Ma, S. and Huang, J. (2017). A concave pairwise fusion approach to subgroup analysis. Journal of the American Statistical Association, 112(517):410–423.
- Ma et al., (2019) Ma, S., Huang, J., Zhang, Z., and Liu, M. (2019). Exploration of heterogeneous treatment effects via concave fusion. The international journal of biostatistics.
- Ma et al., (2020) Ma, Z., Xue, Y., and Hu, G. (2020). Heterogeneous regression models for clusters of spatial dependent data. Spatial Economic Analysis, pages 1–17.
- Nakaya et al., (2005) Nakaya, T., Fotheringham, A. S., Brunsdon, C., and Charlton, M. (2005). Geographically weighted Poisson regression for disease association mapping. Statistics in medicine, 24(17):2695–2717.
- Nusser and Goebel, (1997) Nusser, S. M. and Goebel, J. J. (1997). The National Resources Inventory: a long-term multi-resource monitoring programme. Environmental and Ecological Statistics, 4(3):181–204.
- Rand, (1971) Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical association, 66(336):846–850.
- Tibshirani, (1996) Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 58(1):267–288.
- Vinh et al., (2010) Vinh, N. X., Epps, J., and Bailey, J. (2010). Information theoretic measures for clusterings comparison: variants, properties, normalization and correction for chance. Journal of Machine Learning Research, 11:2837–2854.
- Wang et al., (2007) Wang, H., Li, R., and Tsai, C.-L. (2007). Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika, 94(3):553–568.
- Wang et al., (2018) Wang, X., Berg, E., Zhu, Z., Sun, D., and Demuth, G. (2018). Small area estimation of proportions with constraint for National Resources Inventory survey. Journal of Agricultural, Biological and Environmental Statistics, 23(4):509–528.
- Xu et al., (2019) Xu, Z., Bradley, J. R., and Sinha, D. (2019). Latent multivariate log-gamma models for high-dimensional multi-type responses with application to daily fine particulate matter and mortality counts. arXiv preprint arXiv:1909.02528.
- Xue et al., (2020) Xue, Y., Schifano, E. D., and Hu, G. (2020). Geographically weighted Cox regression for prostate cancer survival data in louisiana. Geographical Analysis, 52(4):570–587.
- Zhang, (2010) Zhang, C.-H. (2010). Nearly unbiased variable selection under minimax concave penalty. The Annals of statistics, 38(2):894–942.
- Zhang and Lawson, (2011) Zhang, J. and Lawson, A. B. (2011). Bayesian parametric accelerated failure time spatial model and its application to prostate cancer. Journal of applied statistics, 38(3):591–603.