SPATL: Salient Parameter Aggregation and Transfer Learning for Heterogeneous Federated Learning
Abstract
Federated learning (FL) facilitates the training and deploying AI models on edge devices. Preserving user data privacy in FL introduces several challenges, including expensive communication costs, limited resources, and data heterogeneity. In this paper, we propose SPATL, an FL method that addresses these issues by: (a) introducing a salient parameter selection agent and communicating selected parameters only; (b) splitting a model into a shared encoder and a local predictor, and transferring its knowledge to heterogeneous clients via the locally customized predictor. Additionally, we leverage a gradient control mechanism to further speed up model convergence and increase robustness of training processes. Experiments demonstrate that SPATL reduces communication overhead, accelerates model inference, and enables stable training processes with better results compared to state-of-the-art methods. Our approach reduces communication cost by up to , accelerates local inference by reducing up to FLOPs on VGG-11, and requires less communication overhead when training ResNet-20. 111Code is available at: https://github.com/yusx-swapp/SPATL
I Introduction
Distributed machine learning (ML) is extensively used to solve real-world problems in high performance computing (HPC) environments. Typically, training data is first collected at a central location like a data center or HPC cluster. Afterwards, the data is carefully distributed across the cluster nodes based on the availability of resources. Training is conducted in a distributed manner and a resource and data aware fashion. However, new legislation such as General Data Protection Regulation (GDPR) [1] and Health Insurance Portability and Accountability Act (HIPAA) [2] prohibit user data collection. In response to user privacy concerns, federated learning (FL) [3] was proposed to train ML models while maintaining local data privacy (restricting direct access to private user data).
FL trains a shared model on edge devices (e.g., mobile phones) by aggregating locally trained models on a cloud/central server. This setting, however, presents three key challenges: First, the imbalance/non-independent identically distributed (non-IID) local data easily causes training failure in the decentralized environment. Second, frequent sharing of model weights between edge devices and the server incurs excessive communication overhead. Lastly, the increasing demand of computing, memory, and storage for AI models (e.g., deep neural networks – DNNs) makes it hard to deploy on resource-limited edge devices. These challenges suggest that designing efficient FL models and deploying them effectively will be critical in achieving higher performance on future systems. Recent works in FL and its variants [4, 5, 6] predominantly focus on learning efficiency, i.e., improving training stability and using the minimum training rounds to reach the target accuracy. However, these solutions further induce extra communication costs. As such, there is no superior solution to address the three key issues jointly. Furthermore, the above methods aim to learn a uniform shared model for all the heterogeneous clients. But this provides no guarantees of model performance on every non-IID local data.
Deep learning models are generally over-parameterized and can easily overfit during local FL updates; in which case, only a subset of salient parameters decide the final prediction outputs. It is therefore unnecessary to aggregate all the parameters of the model. Additionally, existing work [7, 8] demonstrate that a well-trained deep learning model can be easily transferred to non-IID datasets. Therefore, we propose to use transfer learning to address the data heterogeneity issue of Federated Learning. As such, we train a shared model and transfer its knowledge to heterogeneous clients by keeping its output layers customized on each client. For instance, computer vision models (e.g., CNNs) usually consist of an encoder part (embed the input instance) and a predictor head (output layers). In this case, we only share the encoder part in the FL communication process and transfer the encoder’s knowledge to local Non-IID data using a customized local predictor.
Although we use the encoder-predictor based model as an example, our idea can be extend to all AI models whose knowledge is transferable (i.e., we can transfer deep learning model by keeping the output layers heterogeneous on local clients).
Based on these observations, we propose an efficient FL method through Salient Parameter Aggregation and Transfer Learning (SPATL). Specifically, we train the model’s encoder in a distributed manner through federated learning and transfer its knowledge to each heterogeneous client via locally deployed predictor heads. Additionally, we deploy a pre-trained local salient parameter selection agent to select the encoder’s salient parameters based on its topology. Then, we customize the pre-trained agent on each local client by slightly fine-tuning its weights through online reinforcement learning. We reduce communication overhead by only uploading the selected salient parameters to the aggregating server. Finally, we leverage a gradient control mechanism to correct the encoder’s gradient heterogeneity and guide the gradient towards a generic global direction that suits all clients. This further stabilizes the training process and speeds up model convergence.
In summary, the contributions of SPATL are:
-
•
SPATL reduces communication overhead in federated learning by introducing salient parameter selection and aggregation for over-parameterized models. This also results in accelerating the model’s local inference.
-
•
SPATL addresses data heterogeneity in federated learning via knowledge transfer of the trained model to heterogeneous clients.
-
•
SPATL utilizes a salient parameter selection agent by leveraging online reinforcement learning for fine-tuning.
-
•
SPATL enables scalable federated learning to allow large-scale decentralized training.
-
•
We evaluate SPATL on a medium-scale, 100 clients setup using Non-IID Benchmark [9]. Our results show that compared to state-of-the-art FL solutions, when optimizing a model, SPATL reduces communication cost by up to , improves model performance by up to 19.86%, and reduces inference time by up to 39.7% FLOPs.
II Motivation – Use Cases
With advancements in the performance of mobile and embedded devices, more and more applications are moving to decentralized learning on the edge. Improved ML models and advanced weight pruning techniques mean a significant amount of future ML workload will come from decentralized training and inference on edge devices [10]. Edge devices operate under strict performance, power, and privacy constraints, which are affected by factors such as model size and accuracy, training and inference time, and privacy requirements. Many edge applications, such as self-driving cars, could not be developed and validated without HPC simulations, in which HPC accelerates data analysis and the design process of these systems to ensure safety and efficiency.
Therefore, the prevailing edge computing trend alongside FL requirements and edge constraints motivate SPATL to address challenges in HPC. Firstly, frequent sharing of model weights between edge devices and the central server incurs a hefty communication cost [11, 12]. Thus, reducing communication overhead is imperative. Secondly, the increasing demand for computing, memory, and storage for AI models (e.g., deep neural networks – DNNs) makes it hard to deploy them on resource-constrained Internet-of-Things (IoT) and edge devices [13, 14]. Transfer learning can be a viable solution to address this problem. Thirdly, latency-sensitive applications with privacy constraints (e.g., self-driving cars [15], augmented reality [16]) in particular, are better suited for fast edge computing [17]. Hence, cutting back on inference time is quite important. Tech giants like Google, Apple, and NVIDIA are already using FL for their applications (e.g., Google Keyboard [18, 19], Apple Siri [20, 21], NVIDIA medical imaging [22]) thanks to their large number of edge devices. Hence, scalability is important in FL and HPC settings. Lastly, training data on client edge devices depends on the user’s unique usage causing an overall non-IID [3, 23] user dataset. Data heterogeneity is a major problem in decentralized model training [11, 24, 23, 25, 26, 27, 6, 28, 4, 5, 29]. Thus designing efficient decentralized learning models and deploying them effectively will be crucial to improve performance of future edge computing and HPC.
III Related work
III-A Federated Learning
With increasing concerns over user data privacy, federated learning was proposed in [3], to train a shared model in a distributed manner without direct access to private data. The algorithm FedAvg [3] is simple and quite robust in many practical settings. However, the local updates may lead to divergence due to heterogeneity in the network, as demonstrated in previous works [30, 4, 26]. To tackle these issues, numerous variants have been proposed [6, 5, 4]. For example, FedProx [6] adds a proximal term to the local loss, which helps restrict deviations between the current local model and the global model. FedNova [5] introduces weight modification to avoid gradient biases by normalizing and scaling the local updates. SCAFFOLD [4] corrects update direction by maintaining drift variates, which are used to estimate the overall update direction of the server model. Nevertheless, these variants incur extra communication overhead to maintain stable training. Notably, in FedNova and SCAFFOLD, the average communication cost in each communication round is approximately compared to FedAvg.
Numerous research papers have addressed data heterogeneity (i.e. non-IID data among local clients) in FL [23, 25, 27, 31, 32, 33, 34, 35], such as adjusting classifier [36], improving client sampling fairness [24], adapting optimization [29, 37, 28, 38], correcting local updates [4, 39, 5], using a tiering mechanism to synchronously update local model parameters within tiers and asynchronously update the global model [40], generating client models from a central hypernetwork model [41], dynamically measuring local model divergence and adaptively adjusting to optimize hyper-parameters [42], and using data-free knowledge distillation approach to address heterogeneous FL [43].
Further more, federated learning has been extended in real life applications [44, 45]. One promising solution is personalized federated learning [46, 47, 48, 49, 50, 51], which tries to learn personalized local models among clients to address data heterogeneity. These works, however, fail to address the extra communication overhead. However, very few works, such as [52, 53] focus on addressing communication overhead in FL. They either use knowledge distillation, or aggregation protocol, the communication overhead reduction is not significant.
Additionally, benchmark federated learning settings have been introduced to better evaluate the FL algorithms. FL benchmark LEAF [54] provides benchmark settings for learning in FL, with applications including federated learning, multi-task learning, meta-learning, and on-device learning. Non-IID benchmark [9] is an experimental benchmark that provides us with Non-IID splitting of CIFAR-10 and standard implementation of SOTAs. Framework Flower [55] provides FL SOTA baselines and is a collection of organized scripts used to reproduce results from well-known publications or benchmarks. IBM Federated Learning [56] provides a basic fabric for FL on which advanced features can be added. It is not dependent on any specific machine learning framework and supports different learning topologies, e.g., a shared aggregator and protocols. It is meant to provide a solid basis for federated learning that enables a large variety of federated learning models, topologies, learning models, etc., particularly in enterprise and hybrid-Cloud settings.
III-B Salient Parameter Selection
Since modern AI models are typically over-parameterized, only a subset of parameters determine practical performance. Several network pruning methods have been proposed to address this issue. These methods have achieved outstanding results and are proven techniques to drastically shrink model sizes. However, traditional pruning methods [57, 58, 59] require time-consuming re-training and re-evaluating to produce a potential salient parameter selection policy. Recently, AutoML pruning algorithms [60, 61] offered state-of-the-art (SoTA) results with higher versatility. In particular, reinforcement learning (RL)-based methods [62, 63, 64, 65], which model the neural network as graphs and use GNN-based RL agent to search for pruning policy present impressive results. However, AutoML methods need costly computation to train a smart agent, which is impractical to deploy on resource-limited edge FL devices.
The enormous computational cost and effort of network pruning makes it difficult to directly apply in federated learning. To overcome challenges of previous salient parameter selection methods and inspired by the RL-based AutoML pruning methods, we utilize a salient parameter selection RL agent pre-trained on the network pruning task. Then with minimal fine-tuning, we implemented an efficient salient parameter selector with negligible computational burden.
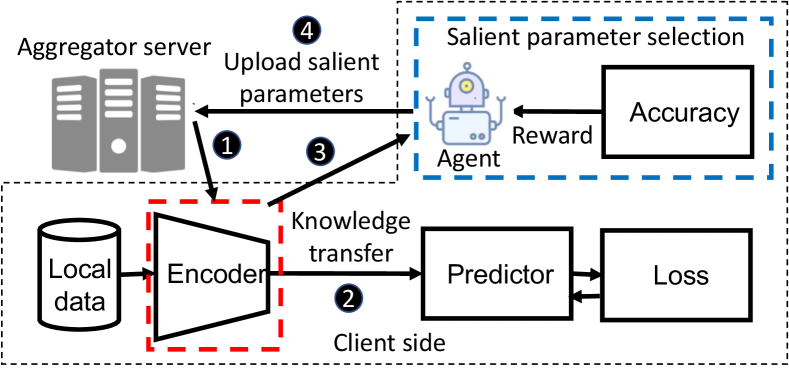
IV Methodology
SPATL consists of three main components: knowledge transfer learning, salient parameter selection agent, and gradient control federated learning. Figure 1 shows the SPATL overview. Unlike mainstream FL solutions, which attempt to train the entire deep learning model, SPATL only trains the encoder part of the model in a distributed manner and transfers the knowledge to heterogeneous clients. In each round of federated learning, the client first downloads the encoder from the cloud aggregator (➊ in Figure 1) and transfers its knowledge using a local predictor through local updates (➋ in Figure 1). After local updates, the salient parameter selection agent will evaluate the training results of the current model based on the model performance (➌ in Figure 1), and finally selected clients send the salient parameters to the server (➍ in Figure 1). Additionally, both clients and the server maintain a gradient control variate to correct the heterogeneous gradients, in order to stabilize and smoothen the training process.
IV-A Heterogeneous Knowledge Transfer Learning
Inspired by transfer learning [7], SPATL aims to train an encoder in FL setting and address the heterogeneity issue through transferring the encoder’s knowledge to heterogeneous clients. Formally, we formulate our deep learning model as an encoder and a predictor , where and are encoder and predictor parameters respectively, is an input instance to the encoder and is an input instance to the predictor (or embedding).
SPATL shares the encoder with the cloud aggregator, while the predictor for the client is kept private on the client. The forward propagation of the model in the local client is formulated as follows:
| (1) |
| (2) |
During local updates, the selected client first downloads the shared encoder parameter, , from the cloud server and optimizes it with the local predictor head, , through back propagation. Equation 3 shows the optimization function.
| (3) |
Here, refers to the loss when fitting the label for data , and is the constant coefficient.
In federated learning, not all clients are involved in communication during each round. In fact, there is a possibility a client might never be selected for any communication round. Before deploying the trained encoder on such a client, the client will download the encoder from the aggregator and apply local updates to its local predictor only. After that, both encoder and predictor can be used for that client. Equation 4 shows the optimization function.
| (4) |
IV-B RL-based Topology-Aware Salient Parameter Selection
One key issue of FL is the high communication overhead caused by the frequent sharing of parameters between clients and the cloud aggregator server. Additionally, we observed that deep learning models (e.g., VGG [66] and ResNet [67]) are usually bulky and over-parameterized. As such, only a subset of salient parameters decide the final output. Therefore, in order to reduce the communication cost, we implemented a local salient parameter selection agent for selecting salient parameters for communication.
Figure 2 shows the idea of a salient parameter agent. Specifically, inspired by topology-aware network pruning task [65, 62], we model the neural network (NN) as a simplified computational graph and use it to represent the NN’s states. Since NNs are essentially computational graphs, their parameters and operations correspond to nodes and edges of the computational graph. We then introduced the graph neural network (GNN)-based reinforcement learning (RL) agent, which takes the graph as input (RL’s environment states) and produces a parameter selection policy from the topology through GNN embedding. Additionally, the RL agent uses the selected sub-model’s accuracy as reward to guide its search for the optimal pruning policy. Training a smart agent directly through RL, however, is costly and impractical to deploy on the edge. To address this issue, we first pre-train the salient parameter agent in the network pruning task, and then customize the pre-trained agent on each local client by slightly fine-tuning its weights through online reinforcement learning (detailed hyper-parameter setting in section V).

IV-B1 Reinforcement Learning Task Definition
Defining environment states, action space, reward function, and RL policy are essential for specifying an RL task. In this section, we will discuss these components in more detail. Algorithm LABEL:alg:ppo shows the RL search process. For search step, we first initialize the target encoder with the input encoder , and convert it to a graph. If the size of does not satisfy the constraints, the proximal policy optimization (PPO) [68] RL agent will produce a parameter selection policy (i.e., the action of the RL), to update . If satisfies the size constraint, the RL agent will use its accuracy as reward to update the policy. Finally, the parameter and corresponding parameter index of the target encoder with the best reward will be uploaded to the cloud server.
Environment States. We use a simplified computational graph to represent the NN model [65]. In a computational graph, nodes represent hidden features (feature maps), and edges represent primitive operations (such as ‘add’, ‘minus’, and ‘product’). Since the NN model involves billions of operations, it’s unrealistic to use primitive operations. Instead, we simplified the computational graph by replacing the primitive operations with machine learning operations (e.g., conv 3x3, Relu, etc.).
Action Space. The actions are the sparsity ratios for encoder’s hidden layers. The action space is defined as , where is the number of encoder’s hidden layers. The actor network in the RL agent projects the NN’s computational graph to an action vector, as shown in equations 5 and 6.
| (5) |
| (6) |
Here, is the environment state, is the graph representation, and MLP is a multi-layer perceptron neural network. The graph encoder learns the topology embedding, and the MLP projects the embedding into hidden layers’ sparsity ratios.
Reward Function. The reward function is the accuracy of selected sub-network on validation dataset.
| (7) |
IV-B2 Policy Updating
The RL agent is updated end-to-end through the PPO algorithm. The RL agent trains on the local clients through continual online-learning over each FL round. Equation 8 shows the objective function we used for the PPO update policy.
| (8) |
Here, is the policy parameter (the actor-critic network’s parameter), denotes the empirical expectation over time steps, is the ratio of the probability under the new and old policies, respectively, is the estimated advantage at time t, and is a clip hyper-parameter, usually 0.1 or 0.2.
IV-C Generic Parameter Gradient Controlled Federated Learning
Inspired by stochastic controlled averaging federated learning [4], we propose a generic parameter gradient controlled federated learning to correct the heterogeneous gradient. Due to client heterogeneity, local gradient update directions will move towards local optima and may diverge across all clients. To correct overall gradient divergence by estimating gradient update directions, we maintain control variates both on clients and the cloud aggregator. However, controlling the entire model’s gradients will hurt the local model’s performance on non-IID data. In order to compensate for performance loss, SPATL only corrects the generic parameter’s gradients (i.e., the encoder’s gradients) while maintaining a heterogeneous predictor. Specifically in equation 9, during local updates of the encoder, we correct gradient drift by adding the estimate gradient difference .
| (9) |
Here, control variate is the estimate of the global gradient direction maintained on the server side, and is the estimate of the update direction for local heterogeneous data maintained on each client. In each round of communication, the is updated as equation 10:
| (10) |
Here, is the number of local epochs, and is the local learning rate, while is updated by equation 11:
| (11) |
Here, is the difference between new and old local control variates of client , is the set of clients, and is the set of selected clients.
Algorithm LABEL:alg:aggregate shows SPATL with gradient controlled FL. In each update round, the client downloads the global encoder’s parameter and update direction from server, and performs local updates. When updating the local encoder parameter , is applied to correct the gradient drift. The predictor head’s gradient remains heterogeneous. Before uploading, the local control variate is updated by estimating the gradient drift.
IV-C1 Aggregation with Salient Parameters
Due to the non-IID local training data in heterogeneous clients, salient parameter selection policy varies among the heterogeneous clients after local updates. Since the selected salient parameters have different matrix sizes and/or dimensions, directly aggregating them will cause a matrix dimension mismatch. To prevent this, as Figure LABEL:fig:pram_aggre shows, we only aggregate partial parameters according to the current client’s salient parameter index on the server side. Equation 12 shows the mathematical representation of this process.
| (12) |
Here, is the global parameter, is the client’s salient parameter, is the ’s index corresponding to the original weights, and is the update step size. By only aggregating the salient parameter and its corresponding index (negligible burdens), we can significantly reduce the communication overhead and avoid matrix dimension mismatches.
V Experiment
We conducted extensive experiments to examine SPATL’s performance. Overall, we divided our experiments into three categories: learning efficiency, communication cost, and inference acceleration. We also performed an ablation study and compared SPATL with state-of-the-art FL algorithms.
V-A Implementation and Hyper-parameter Setting
Datasets and Models. The experiments are conducted with FEMNIST [54] and CIFAR-10 [69]. In FEMNIST, we follow the LEAF benchmark federated learning setting [54]. In CIFAR-10, we use the Non-IID benchmark federated learning setting [9]. Each client is allocated a proportion of the samples of each label according to Dirichlet distribution (with concentration ). Specifically, we sample and allocate a proportion of the instances to client . Here we choose the . The deep learning models we use in the experiment are VGG-11 [66] and ResNet-20/32 [67].
Federated Learning Setting. We follow the Non-IID benchmark federated learning setting and implementation [9]. In SPATL, the models in each client are different. Thus, we evaluate the average performance of models in heterogeneous clients. We experiment on different clients and sample ratio (percentage of participating clients in each round) setting, from 10 clients to 100 clients, and the sample ratio from 0.4 to 1. During local updates, each client updates 10 rounds locally. The detailed setting can be found in supplementary materials.
RL Agent Settings. The RL agent is pre-trained on ResNet-56 by a network pruning task. Fine-tuning the RL agent in the first 10 communication rounds with 20 epochs in each updating round. We only update the MLP’s (i.e., output layers of RL policy network) parameter when fine-tuning. We use the PPO [68] RL policy, the discount factor is , the clip parameter is , and the standard deviation of actions is . Adam optimizer is applied to update the RL agent, where the learning rate is and the .
Baseline. We compare SPATL with the state-of-the-art FL algorithms, such as FedNova [5], FedAvg [3], FedProx [6], and SCAFFOLD [4].
Experimental Setup. Our experimental setup ranges from 10 clients to 100 clients, and our experimental scale is on par with existing state-of-the-art works. To better compare and fully investigate the optimization ability, some of our experiments (e.g., communication efficiency) scales are set to be larger than many SOTA method experiments (such as FedNova [5], FedAvg [3], FedProx [6], and SCAFFOLD [4]). Recent FL works, such as FedAT [40], pFedHN [41], QuPeD [51], FedEMA [42], and FedGen [43], their evaluations are within the same scale as our experiments. Since the FL is an optimization algorithm, we mainly investigate the training stability and robustness. The larger experiment scale will show a similar trend.
FL Benchmark. We use two standard FL benchmark settings: LEAF [54] and Non-IID benchmark [9]. LEAF [54] provides benchmark settings for learning in FL, with applications including federated learning, multi-task learning, meta-learning, and on-device learning. We use the LEAF to split the FEMNIST into Non-IID distributions. Non-IID benchmark [9] is an experimental benchmark that provides us with Non-IID splitting of CIFAR-10 and standard implementation of SOTAs. Our implementation of FedAvg, FedProx, SCAFFOLD, and FedNova are based on the Non-IID benchmark.
V-B Learning Efficiency
In this section, we evaluate the learning efficiency of SPATL by investigating the relationship between communication rounds and the average accuracy of the model. Since SPATL learns a shared encoder, each local client has a heterogeneous predictor, and the model’s performance is different among clients. Instead of evaluating a global test accuracy on the server side, we allocate each client a local non-IID training dataset and a validation dataset to evaluate the top-1 accuracy, i.e., the highest probability prediction must be exactly the expected answer, of the model among heterogeneous clients. We train VGG-11 [66] and ResNet-20/32 [67] on CIFAR-10 [69], and 2-layer CNN on FEMNIST [54] separately until the models converge. We then compare model performance results of SPATL with state-of-the-arts (SoTAs) (i.e., FedNova [5], FedAvg [3], FedProx [6], and SCAFFOLD [4]).
Figure LABEL:fig:vgg_cifar experiments show 10 clients setting where we sample all 10 clients for aggregation. The effect of heterogeneity is not significant compared to a real-world scale. SPATL moderately outperforms the SoTAs on CIFAR-10. Results on the 2-layer CNN model trained on FEMNIST however, is an exception; in this case the model trained by SPATL has a slightly lower accuracy than SoTAs. We suspect that it has to do with the small size of the 2-layer CNN and the large data quantity. Particularly, in this case, our “model over-parameterization” assumption no longer holds, making it hard for the salient parameter selection to fit the training data. To verify our analysis, we increase the complexity of our experiments and conduct further experiments on larger scale FL settings. We increase the number of clients to 30, 50, and 100 with different sample ratios.
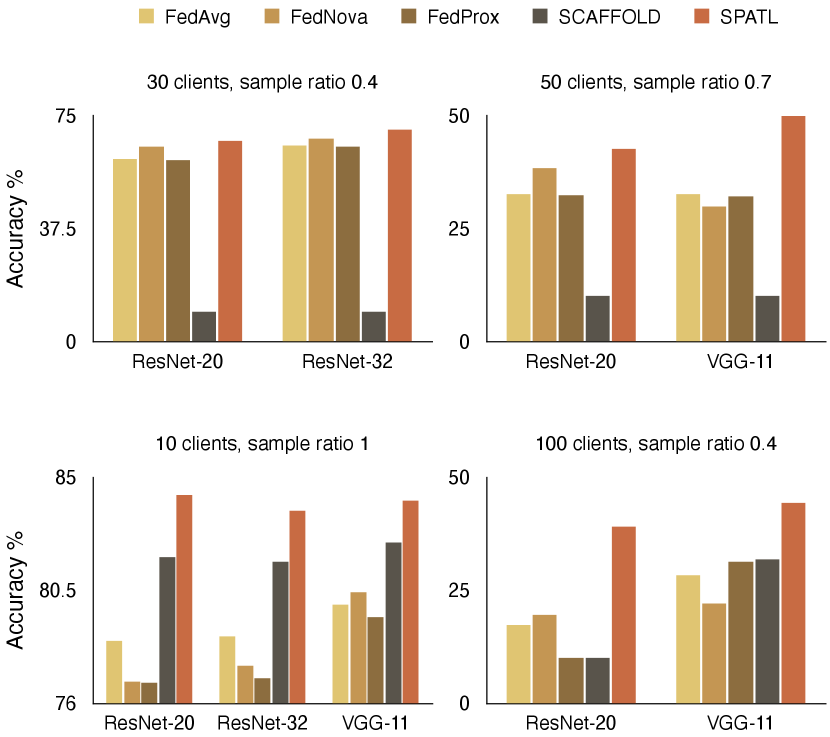
As heterogeneity rises with the increase in number of clients, SPATL demonstrates superiority in coping with data heterogeneity. Experiment results in Figure LABEL:fig:vgg_cifar show that for more complex FL settings, SPATL outperforms SoTAs with larger margins. In the 30 clients FL setting222In Fig. LABEL:fig:vgg_cifar SCAFFOLD[4] diverges with gradient explosion in Non-IID benchmark settings [9] when there are more than 10 clients., for ResNet-20, ResNet-32, and VGG-11, SPTAL outperforms the SoTA FL methods. Notably, SPATL yields a better convergence accuracy and a substantially more stable training process. In the 50 clients and 100 clients settings, the experiment improvements become more significant, as SPATL outperforms the SoTAs by a larger margin. Moreover, we noticed that the gradient control based method SCAFFOLD [4] suffers from gradient explosion issues when the number of clients increases. Even though we set a tiny learning rate, the explosion problem persists. Other researchers are facing the same issues when reproducing SCAFFOLD, and our results satisfy finding 6 in [9].
Intuitively, we investigate the model’s accuracy overhead. Figure 3 shows the converge accuracy comparison with SoTAs. SPATL surpasses SoTAs in all the FL settings and achieves higher converge accuracy than SoTAs. Again, the superiority of SPATL grows progressively with the heterogeneity of FL settings. For instance, in ResNet-20 with 30 clients, SPATL outperforms SoTAs only in terms of final convergence accuracy. However, when we increase to 50 heterogeneous clients, SPATL achieves 42.54 % final accuracy, that is around 10% higher than FedAvg and FedProx (they achieve 32.71% and 32.43% accuracy, respectively). Additionally, it is worth mentioning that, in the 100 clients experiment setting, we compare the accuracy within 200 rounds since all the baselines diverge in 200 rounds except SPATL. This further demonstrates that SPATL optimizes and improves the quality of the model progressively and stably.
Trained model performance on heterogeneous local clients is also an essential indicator when evaluating FL algorithms with regards to deploying AI models on the edge. Since edge devices have various application scenarios and heterogeneous input data, models will likely exhibit divergence on such devices. We further evaluate the robustness and feasibility of FL methods on distributed AI by testing local model accuracies on all clients. Figure LABEL:fig:local_acc shows ResNet-20 on each client’s accuracy after the training is complete for CIFAR-10 (total 10 clients trained by SPATL and SCAFFOLD with 100 rounds). The model trained by SPATL produces better performance across all clients. In particular, the edge model trained by SPATL produces more stable performance among each client, whereas models trained by baselines exhibit more variance. For instance, all the edge models trained by SPATL have similar accuracy performance. Since SPATL uses heterogeneous predictors to transfer the encoder’s knowledge, the model is more robust when dealing with non-IID data. However, our baseline methods (such as SCAFFOLD [4]) share the entire model when training on non-IID clients, leading to a variance in model performance on non-IID clients and causing poor performance on some clients.
V-C Communication Efficiency
| Method | Model | Target Accuracy | Clients | Communication Rounds | Communication Cost | |||
|---|---|---|---|---|---|---|---|---|
| Round/Client | Total | Cost | Speed Up | |||||
| FedAvg [3] | ResNet-20 | 80% | 10 | 203 | 2.1MB | 4.16GB | 0GB | (1 ) |
| ResNet-32 | 192 | 3.2MB | 6.00GB | 0GB | (1 ) | |||
| VGG-11 | 181 | 42MB | 74.24GB | 0GB | (1 ) | |||
| FedNova [5] | ResNet-20 | 80% | 10 | 198 | 4.2MB | 8.12GB | +3.96GB | (0.51 ) |
| ResNet-32 | 197 | 6.4MB | 12.31GB | +6.31GB | (0.48 ) | |||
| VGG-11 | 159 | 84MB | 130.43GB | +56.19 | (0.57 ) | |||
| FedProx [6] | ResNet-20 | 80% | 10 | 288 | 2.1MB | 5.91GB | +1.75GB | (0.70 ) |
| ResNet-32 | 400 | 3.2MB | 12.80GB | +6.80GB | (0.47 ) | |||
| VGG-11 | 296 | 42MB | 121.41GB | +47.17GB | (0.61 ) | |||
| SCAFFOLD [4] | ResNet-20 | 80% | 10 | 49 | 4.3MB | 2.10GB | -2.06GB | (1.98 ) |
| ResNet-32 | 55 | 6.5MB | 3.60GB | -2.40GB | (1.67 ) | |||
| VGG-11 | 54 | 84MB | 45.00GB | -29.24GB | (1.65 ) | |||
| SPATL (Ours) | ResNet-20 | 80% | 10 | 52 | 2.1MB | 1.10GB | -3.06GB | (3.78 ) |
| ResNet-32 | 50 | 3.6MB | 1.80GB | -4.20GB | (3.33 ) | |||
| VGG-11 | 46 | 61.3MB | 28.00GB | -46.24GB | (2.65 ) | |||
A key contribution of SPATL that makes it stand out among SoTAs is its significant reduction of communication overhead due to salient parameter selection. Although SoTAs, like FedNova [5] and SCAFFOLD [4], achieve stable training via gradient control or gradient normalization variates, their average communication cost doubles compared to FedAvg [3] as a result of sharing the extra gradient information. We present two experiment settings to evaluate model communication efficiencies. First, we trained all models to a target accuracy and calculated communication cost. Second, we trained all models to converge and calculated the communication cost of each FL algorithm. The communication cost is calculated as:
| (13) |
Table I shows the detailed information of communication cost (FedAvg [3] as benchmark) when we train models to a target accuracy. SPATL remarkably outperforms SoTAs. In ResNet-20, SPATL reduced communication cost by up to (FedNova costs 8.12GB while SPATL only costs 1.1GB). Moreover, SPATL reduced communication by up to 102GB when training VGG-11 compared to FedNova.
There are two main benefits of SPATL in reducing communication overhead. First, training in SPATL is much more efficient and stable. Our experiments show that SPATL requires fewer communication rounds to achieve target accuracy. For example, in VGG-11, FedProx uses 296 training rounds while SPATL uses 250 less rounds to achieve the same target accuracy. This significantly reduces the communication cost. We provide a more comprehensive comparison to show the number of rounds different models take to achieve target accuracy. As Figure LABEL:fig:train_rounds shows, we try different FL settings, and SPATL consistently requires fewer rounds than SoTAs in most of the FL settings (except in ResNet-20 with 10 clients and 80% target accuracy, SPATL requires 3 rounds more than SCAFFOLD. However, as shown in Table I), the total communication cost of SPATL is significant less than all others. Second, since the salient parameter selection agent selectively uploads partial parameters, SPATL significantly reduces communication cost. As shown in Table I, compared to the gradient control based methods, such as SCAFFOLD [4] and FedNova [5], SPATL remarkably reduces per round communication cost. For instance, SPATL uses less round costs in ResNet-20 compared to the traditional FL, such as FedAvg [3]. Even when factoring in gradient control information, salient parameter selection enables SPATL to drop unnecessary communication burdens, which makes its round costs comparable to FedAvg.
Furthermore, we investigated the convergence accuracy of models using SoTAs and SPATL optimizations. We consider a performance upper bound by creating a hypothetical centralized case where images are heterogeneously distributed across 30, 50, and 100 clients. Table II shows the results of training the models to convergence. Compared to FedAvg [3], gradient control based FL algorithms have higher accuracy at the expense of communication efficiency. For instance, FedNova [5] achieves slightly higher accuracy. However, their communication budget increases by more than . Models optimized by SPATL achieve significantly higher accuracy than all other baselines. Especially on VGG-11 with 50 clients, SPATL achieves 17.8%, 19.86%, and 17.62% higher accuracy than FedAvg, FedNova, and FedProx respectively. Particularly, unlike FedNova, which sacrifices communication cost for higher accuracy, SPATL takes advantage of salient parameter selection to achieve higher accuracy with relatively negligible communication overhead. For instance, when training the ResNet-20 for 30 and 50 clients, SPATL achieves the best accuracy with the lowest communication cost. The results further show that SPATL remarkably reduces the communication cost and has a higher capacity to train models for better performance.
| Method | Model | Clients | Sample Ratio | Converge Rounds | Communication Cost | Avg. Converge Acc. | Acc. | ||
|---|---|---|---|---|---|---|---|---|---|
| Round/Client | Total | Speedup | |||||||
| FedAvg [3] | ResNet-20 | 30 | 0.4 | 170 | 2.1MB | 4.18GB | (1 ) | 60.58% | 0% |
| 50 | 0.7 | 184 | 13.21GB | (1 ) | 32.71% | 0% | |||
| ResNet-32 | 30 | 0.4 | 140 | 3.2MB | 5.25GB | (1 ) | 64.92% | 0% | |
| VGG-11 | 50 | 0.7 | 171 | 42MB | 246GB | (1 ) | 32.68% | 0% | |
| 100 | 0.4 | 322 | 528GB | (1 ) | 28.33% | 0% | |||
| FedNova [5] | ResNet-20 | 30 | 0.4 | 159 | 4.2MB | 7.83GB | (0.54 ) | 64.50% | +3.92% |
| 50 | 0.7 | 200 | 28.71GB | (0.46 ) | 38.35% | +5.64% | |||
| ResNet-32 | 30 | 0.4 | 149 | 6.4MB | 11.18GB | (0.47 ) | 67.48% | +2.56% | |
| VGG-11 | 50 | 0.7 | 193 | 84MB | 554GB | (0.44 ) | 29.90% | -2.78% | |
| 100 | 0.4 | 287 | 941GB | (0.56 ) | 22.12% | -6.21% | |||
| FedProx [6] | ResNet-20 | 30 | 0.4 | 157 | 2.1MB | 3.86GB | (1.08 ) | 60.20% | -0.38% |
| 50 | 0.7 | 193 | 13.85GB | (0.95 ) | 32.43% | -0.28% | |||
| ResNet-32 | 30 | 0.4 | 151 | 3.2MB | 5.66GB | (0.93 ) | 64.75% | -0.17% | |
| VGG-11 | 50 | 0.7 | 195 | 42MB | 280GB | (0.88 ) | 32.14% | -0.54% | |
| 100 | 0.4 | 123 | 201GB | (2.63 ) | 31.21% | +2.88% | |||
| SCAFFOLD [4] | ResNet-20 | 30 | 0.4 | 400 | 4.3MB | 20.16GB | (0.20 ) | 10.00% | -50.58% |
| 50 | 0.7 | 400 | 58.79GB | (0.22 ) | 10.00% | -22.71% | |||
| ResNet-32 | 30 | 0.4 | 400 | 6.5MB | 30.47GB | (0.17 ) | 10.00% | -54.92% | |
| VGG-11 | 50 | 0.7 | 400 | 84MB | 1148GB | (0.21 ) | 10.00% | -22.68% | |
| 100 | 0.4 | 400 | 1312GB | (0.40 ) | 31.78% | +3.45% | |||
| SPATL (Ours) | ResNet-20 | 30 | 0.4 | 140 | 2.1MB | 3.44GB | (1.21 ) | 66.49% | +5.91% |
| 50 | 0.7 | 171 | 12.27GB | (1.08 ) | 42.54% | +9.83% | |||
| ResNet-32 | 30 | 0.4 | 117 | 3.6MB | 4.93GB | (1.06 ) | 70.23% | +5.31% | |
| VGG-11 | 50 | 0.7 | 156 | 61.3MB | 324GB | (0.76 ) | 49.76% | +17.08% | |
| 100 | 0.4 | 86 | 205GB | (2.58 ) | 44.23% | +15.90% | |||
V-D Inference Acceleration
In this section, we evaluate the inference acceleration of SPATL. Local inference is a crucial measure for deploying AI models on the edge since edge devices have limited computing power, and edge applications (e.g., self-driving car) are inference sensitive. In SPATL, when the salient parameter selection agent selects salient parameters, it prunes the model as well. For a fair evaluation of inference, instead of recording the actual run time (run time may vary on different platforms) of pruned models, we calculated the FLOPs (floating point operations per second).
Table LABEL:tab:inference shows the inference acceleration status after training is complete. SPATL notably reduced the FLOPs in all the evaluated models. For instance, in ResNet-32, the average FLOPs reduction among 10 clients is , and the client with the highest FLOPs reduction achieves fewer FLOPs than the original model, while the client models have a relatively low sparsity ratio (the sparsity ratio represents the ratio of salient parameters compared to the entire model parameters). The low sparsity ratio can further benefit by accelerating the models on parallel platforms, such as GPUs. Additionally, we evaluate the salient parameter selection agents’ pruning ability and compare it with SoTA pruning methods. As shown in Table IV, our agent achieves outstanding results in pruning task and outperforms popular AutoML pruning baselines. The results indicate that SPATL can significantly accelerate model inference with acceptably small accuracy loss.
V-E Transferbility of Learned Model
In SPATL, since only the partial model (i.e., knowledge encoder) is trained in a distributed manner, we conducted a transferability comparison experiment to test for successful transfer of knowledge among heterogeneous edge clients. Specifically, we transfer the neural network trained by SPATL and SoTAs (e.g., FedAvg, FedNova, SCAFFOLD, etc.) separately to a new portion of data and compare the performance of transferred models. The experimental settings are as follows: we split the CIFAR-10 [69] into two separate datasets, one with 50K images (for federated learning) and another with 10K images (for transfer learning after FL is finished). We use ResNet-20 and set 10 clients for federated learning, where each client has 4k image local training data and 1k validation set. Transfer learning was conducted in a regular manner without involving training distribution.
Table III shows the results. The model trained by SPATL achieves comparable transfer learning results with the SoTAs. This further shows that SPATL, which only trains a shared encoder in a distributed manner (i.e., as opposed to training the entire model), can successfully learn and transfer the knowledge of a heterogeneous dataset.
V-F Ablation Study
V-F1 Salient Parameter Selection vs. No Parameter Selection
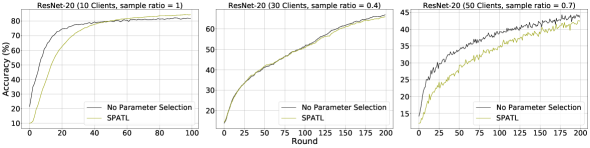
Modern AI models are huge (involving billions of parameters) and often over-parameterized. Thus, only a subset of salient parameters can significantly affect the model’s final performance. As such, a reasonable pruning of redundant parameters might not negatively impact model training. This section investigates the impact of salient parameter selection on federated learning. Specifically, we compare SPATL with and without salient parameter selection.
Figure 4 shows the results. We conducted the experiment on ResNet-20 with various FL settings. All of the results indicate that properly pruning some unimportant weights of over-parameterized networks will not harm training stability in federated learning. Instead, it might produce better results in some cases. Especially in the 10 clients setting, SPATL optimized a higher quality model after applying the parameter selection. We further evaluate the salient parameter agent by applying it to network pruning task and comparing it with popular pruning methods. Table IV shows the pruning results. SPATL’s parameter selection agent achieves competitive results with SoTA pruning methods, which means that it can prune redundant parameters and significantly reduce the FLOPs or pruned model with negligible accuracy loss. Moreover, state-of-the-art salient parameter selection methods, such as SFP [70], DSA [72], and FPGM [71], are usually non-transferable for a given model. They require time-consuming search and re-training to find a target model architecture and salient parameters. For instance, as shown in [73] (table 2), a combined model compression method needs 85.08 lbs of emissions to find a target model architecture. This makes it expensive to deploy on edge devices. In SPATL, the RL agent is a tiny GNN followed by an MLP. The cost to compute target salient parameters within one-shot inference (0.36 ms on NVIDIA V100) and the memory consumption is 26 KB, which is acceptable on edge devices.
V-F2 Transfer Learning vs. No Transfer Learning
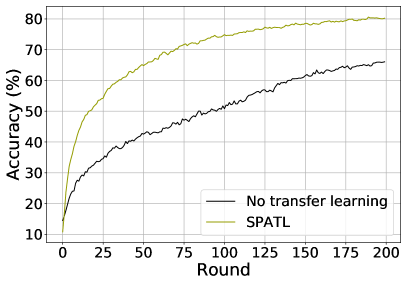
SPATL transfers the shared encoder to local non-IID datasets and addresses the heterogeneous issue of FL. To investigate the effects of transfer learning on SPATL, in this section, we disable SPATL’s transfer learning. Figure 5 (a) shows the results. We train the ResNet-20 [67] on CIFAR-10 [69] with 10 clients and sample all the clients in communication. SPATL without transfer learning has a poor performance when optimizing the model. Combining the results present in Figure LABEL:fig:local_acc, we can infer that a uniform model deployed on heterogeneous clients can cause performance diversity (i.e., the model performs well on some clients but poor on others). Intuitively, clients with data distribution similar to global data distribution usually perform better; nevertheless, clients far away from global data distribution are hard to converge. It is adequate to show that by introducing transfer learning, SPATL can better deal with heterogeneous issues in FL. Transfer learning enables every client to customize the model on its non-IID data and produces significantly better performance than without transfer learning.
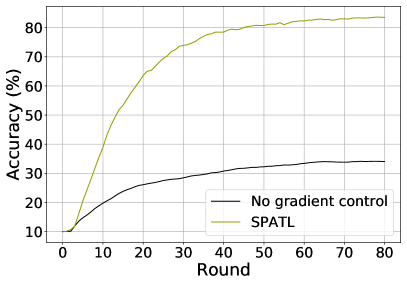
V-F3 Impact of Gradient Control
SPATL maintains control variates both in the local and cloud environment to help correct the local update directions and guide the encoder’s local gradient towards the global gradient direction. Figure 5 (b) shows the results of SPATL with and without gradient control. We train VGG-11 [66] on CIFAR-10 [69] with 10 clients. Training the model in the heterogeneous non-IID local dataset typically causes high variants of local gradients leading to poor convergence. The gradient control variates in SPATL maintain the global gradient direction and correct the gradient drift, thus producing a stable training process. The results are in line with our expectations that gradient control remarkably improves the training performance of SPATL.
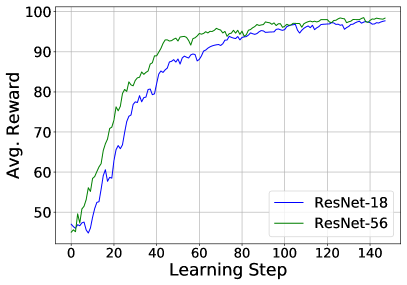
V-F4 Fine-tuning Reinforcement Learning Agent
This section discusses the cost of pre-training a reinforcement learning agent and the cost of customization by slightly fine-tuning the agent’s weights through online reinforcement learning. We pre-train the RL-agent and perform network pruning on ResNet-56, then transfer the agent to ResNet-18 by fine-tuning, and only update the predictor of RL-agent’s policy network. Figure 6 shows the average reward the RL agent gets on network pruning task and the agent’s corresponding update round. In both ResNet-18 and ResNet-56, the RL agent converges rapidly around 40 rounds of RL policy updating. Particularly, in ResNet-18, by slightly fine-tuning the RL-agent, it achieves comparable rewards to ResNet-56. That means the agent can be successfully transferred to a newly deployed model. This further shows the feasibility of fine-tuning the pre-trained salient parameter selection agent.
VI Conclusion and Discussion
In this paper, we presented SPATL, a method for efficient federated learning using salient parameter aggregation and transfer learning. To address data heterogeneity in federated learning, we introduced a knowledge transfer local predictor that transfers the shared encoder to each client. We proposed a salient parameter selection agent to filter salient parameters of the over-parameterized model before communicating it with the server. As a result, the proposed method significantly decreases the communication overhead. We further leveraged a gradient control mechanism to stabilize the training process and make it more robust. Our experiments show that SPATL has a stable training process and achieves promising results. Moreover, SPATL significantly reduces the communication cost and accelerates the model inference time. The proposed approach may have poor performance on simple models. As Figure LABEL:fig:vgg_cifar shows, our approach works well on over-parameterized neural networks, such as ResNet [67] and VGG [66] net. However, when it turns to less-parameterized models, such as 2-layer CNNs, the salient parameter selection may degrade in performance, making the model converge slower than baselines. In practice, less-parameterized models are rarely used in real-world applications. Second, not all AI models are transferable. In our future work, we will continuously improve the universality of our method.
References
- [1] E. R. Jefferson and E. Trucco, “Chapter 20 - the challenges of assembling, maintaining and making available large data sets of clinical data for research,” in Computational Retinal Image Analysis, ser. The Elsevier and MICCAI Society Book Series, E. Trucco, T. MacGillivray, and Y. Xu, Eds. Academic Press, 2019, pp. 429–444. [Online]. Available: https://www.sciencedirect.com/science/article/pii/B9780081028162000216
- [2] S. Gerke, T. Minssen, and G. Cohen, “Chapter 12 - ethical and legal challenges of artificial intelligence-driven healthcare,” in Artificial Intelligence in Healthcare, A. Bohr and K. Memarzadeh, Eds. Academic Press, 2020, pp. 295–336. [Online]. Available: https://www.sciencedirect.com/science/article/pii/B9780128184387000125
- [3] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proc. of International Conference on Artificial Intelligence and Statistics (AISTATS), 2017.
- [4] S. P. Karimireddy, S. Kale, M. Mohri, S. J. Reddi, S. U. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” in Proc. of International Conference on Machine Learning (ICML), 2020.
- [5] J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [6] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” in Proc. of Conference on Machine Learning and Systems (MLSys), 2020.
- [7] L. Torrey and J. Shavlik, “Transfer learning,” in Handbook of research on machine learning applications and trends: algorithms, methods, and techniques. IGI global, 2010, pp. 242–264.
- [8] K. Weiss, T. M. Khoshgoftaar, and D. Wang, “A survey of transfer learning,” Journal of Big data, vol. 3, no. 1, pp. 1–40, 2016.
- [9] Q. Li, Y. Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: An experimental study,” in IEEE International Conference on Data Engineering (ICDE), 2022.
- [10] J. Park, M. Naumov, P. Basu, S. Deng, A. Kalaiah, D. Khudia, J. Law, P. Malani, A. Malevich, S. Nadathur, J. Pino, M. Schatz, A. Sidorov, V. Sivakumar, A. Tulloch, X. Wang, Y. Wu, H. Yuen, U. Diril, D. Dzhulgakov, K. Hazelwood, B. Jia, Y. Jia, L. Qiao, V. Rao, N. Rotem, S. Yoo, and M. Smelyanskiy, “Deep learning inference in facebook data centers: Characterization, performance optimizations and hardware implications,” arXiv preprint arXiv:1811.09886, 2018.
- [11] P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, R. G. L. D’Oliveira, H. Eichner, S. E. Rouayheb, D. Evans, J. Gardner, Z. Garrett, A. Gascón, B. Ghazi, P. B. Gibbons, M. Gruteser, Z. Harchaoui, C. He, L. He, Z. Huo, B. Hutchinson, J. Hsu, M. Jaggi, T. Javidi, G. Joshi, M. Khodak, J. Konečný, A. Korolova, F. Koushanfar, S. Koyejo, T. Lepoint, Y. Liu, P. Mittal, M. Mohri, R. Nock, A. Özgür, R. Pagh, H. Qi, D. Ramage, R. Raskar, M. Raykova, D. Song, W. Song, S. U. Stich, Z. Sun, A. T. Suresh, F. Tramèr, P. Vepakomma, J. Wang, L. Xiong, Z. Xu, Q. Yang, F. X. Yu, H. Yu, and S. Zhao, “Advances and open problems in federated learning,” Foundations and Trends® in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021. [Online]. Available: http://dx.doi.org/10.1561/2200000083
- [12] M. J. Sheller, G. A. Reina, B. Edwards, J. Martin, and S. Bakas, “Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation,” in Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries - 4th International Workshop, BrainLes 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 16, 2018, Revised Selected Papers, Part I, ser. Lecture Notes in Computer Science, vol. 11383. Springer, 2018, pp. 92–104. [Online]. Available: https://doi.org/10.1007/978-3-030-11723-8_9
- [13] A. Imteaj, U. Thakker, S. Wang, J. Li, and M. H. Amini, “A survey on federated learning for resource-constrained iot devices,” IEEE Internet of Things Journal, vol. 9, no. 1, pp. 1–24, 2022.
- [14] D. C. Nguyen, M. Ding, P. N. Pathirana, A. Seneviratne, J. Li, and H. V. Poor, “Federated learning for internet of things: A comprehensive survey,” IEEE Communications Surveys Tutorials, vol. 23, no. 3, pp. 1622–1658, 2021.
- [15] S. Kato, S. Tokunaga, Y. Maruyama, S. Maeda, M. Hirabayashi, Y. Kitsukawa, A. Monrroy, T. Ando, Y. Fujii, and T. Azumi, “Autoware on board: Enabling autonomous vehicles with embedded systems,” in Proc. of International Conference on Cyber-Physical Systems (ICCPS), 2018.
- [16] S. Mangiante, G. Klas, A. Navon, Z. GuanHua, J. Ran, and M. D. Silva, “VR is on the edge: How to deliver 360° videos in mobile networks,” in Proc. of Workshop on Virtual Reality and Augmented Reality Network, 2017.
- [17] C.-J. Wu, D. Brooks, K. Chen, D. Chen, S. Choudhury, M. Dukhan, K. Hazelwood, E. Isaac, Y. Jia, B. Jia, T. Leyvand, H. Lu, Y. Lu, L. Qiao, B. Reagen, J. Spisak, F. Sun, A. Tulloch, P. Vajda, X. Wang, Y. Wang, B. Wasti, Y. Wu, R. Xian, S. Yoo, and P. Zhang, “Machine learning at Facebook: Understanding inference at the edge,” in Proc. of IEEE International Symposium on High Performance Computer Architecture (HPCA), 2019.
- [18] T. Yang, G. Andrew, H. Eichner, H. Sun, W. Li, N. Kong, D. Ramage, and F. Beaufays, “Applied federated learning: Improving Google Keyboard query suggestions,” arXiv preprint arXiv:1812.02903, 2018.
- [19] M. Chen, R. Mathews, T. Ouyang, and F. Beaufays, “Federated learning of Out-Of-Vocabulary words,” arXiv preprint arXiv:1903.10635, 2019.
- [20] J. Freudiger, “Private federated learning,” in NeurIPS Expo Talk, 2019.
- [21] M. Paulik, M. Seigel, H. Mason, D. Telaar, J. Kluivers, R. van Dalen, C. W. Lau, L. Carlson, F. Granqvist, C. Vandevelde, S. Agarwal, J. Freudiger, A. Byde, A. Bhowmick, G. Kapoor, S. Beaumont, Áine Cahill, D. Hughes, O. Javidbakht, F. Dong, R. Rishi, and S. Hung, “Federated evaluation and tuning for On-Device personalization: System design & applications,” arXiv preprint arXiv:2102.08503, 2021.
- [22] W. Li, F. Milletarì, D. Xu, N. Rieke, J. Hancox, W. Zhu, M. Baust, Y. Cheng, S. Ourselin, M. J. Cardoso, and A. Feng, “Privacy-preserving federated brain tumour segmentation,” in Proc. of MICCAI Workshop on Machine Learning in Medical Imaging (MLMI), 2019.
- [23] Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with Non-IID data,” arXiv preprint arXiv:1806.00582, 2018.
- [24] T. Nishio and R. Yonetani, “Client selection for federated learning with heterogeneous resources in mobile edge,” in Proc. of IEEE International Conference on Communications (ICC), 2019.
- [25] K. Hsieh, A. Phanishayee, O. Mutlu, and P. B. Gibbons, “The Non-IID data quagmire of decentralized machine learning,” in Proc. of International Conference on Machine Learning (ICML), 2020.
- [26] X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of FedAvg on Non-IID data,” in Proc, of International Conference on Learning Representations (ICML), 2020.
- [27] W. Y. B. Lim, N. C. Luong, D. T. Hoang, Y. Jiao, Y. Liang, Q. Yang, D. Niyato, and C. Miao, “Federated learning in mobile edge networks: A comprehensive survey,” IEEE Communications Surveys & Tutorials, vol. 22, no. 3, pp. 2031–2063, 2020.
- [28] S. J. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Konečný, S. Kumar, and H. B. McMahan, “Adaptive federated optimization,” in Proc. of International Conference on Learning Representations (ICLR), 2021.
- [29] J. Zhang, S. Guo, Z. Qu, D. Zeng, Y. Zhan, Q. Liu, and R. A. Akerkar, “Adaptive federated learning on Non-IID data with resource constraint,” in Proc. of IEEE Transactions on Computers, 2021.
- [30] T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,” arXiv preprint arXiv:1909.06335, 2019.
- [31] L. Zhang, Y. Luo, Y. Bai, B. Du, and L.-Y. Duan, “Federated learning for Non-IID data via Unified Feature learning and Optimization objective alignment,” in Proc. of International Conference on Computer Vision (ICCV), 2021.
- [32] X. Gong, A. Sharma, S. Karanam, Z. Wu, T. Chen, D. Doermann, and A. Innanje, “Ensemble Attention Distillation for Privacy-Preserving Federated Learning,” in Proc. of International Conference on Computer Vision (ICCV), 2021.
- [33] D. Caldarola, M. Mancini, F. Galasso, M. Ciccone, E. Rodola, and B. Caputo, “Cluster-driven Graph Federated Learning over Multiple Domains,” in Proc. of Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2021.
- [34] J. Sun, A. Li, B. Wang, H. Yang, H. Li, and Y. Chen, “Soteria: Provable Defense Against Privacy Leakage in Federated Learning From Representation Perspective,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [35] S. Horváth, S. Laskaridis, M. Almeida, I. Leontiadis, S. Venieris, and N. D. Lane, “FjORD: Fair and accurate federated learning under heterogeneous targets with ordered dropout,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [36] M. Luo, F. Chen, D. Hu, Y. Zhang, J. Liang, and J. Feng, “No fear of heterogeneity: Classifier calibration for federated learning with non-IID data,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [37] P. Han, S. Wang, and K. K. Leung, “Adaptive gradient sparsification for efficient federated learning: An online learning approach,” in Proc. of IEEE International Conference on Distributed Computing Systems (ICDCS), 2020.
- [38] S. Yu, P. Nguyen, A. Anwar, and A. Jannesari, “Adaptive dynamic pruning for non-iid federated learning,” arXiv preprint arXiv:2106.06921, 2021.
- [39] Q. Li, B. He, and D. Song, “Model-Contrastive Federated Learning,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [40] Z. Chai, Y. Chen, A. Anwar, L. Zhao, Y. Cheng, and H. Rangwala, “Fedat: a high-performance and communication-efficient federated learning system with asynchronous tiers,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–16.
- [41] A. Shamsian, A. Navon, E. Fetaya, and G. Chechik, “Personalized federated learning using hypernetworks,” in Proc. of International Conference on Machine Learning (ICML), 2021.
- [42] W. Zhuang, Y. Wen, and S. Zhang, “Divergence-aware federated self-supervised learning,” in Proc. of International Conference on Learning Representations (ICLR), 2022.
- [43] Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for heterogeneous federated learning,” in Proc. of International Conference on Machine Learning (ICML), 2021.
- [44] Q. Liu, C. Chen, J. Qin, Q. Dou, and P.-A. Heng, “FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [45] P. Guo, P. Wang, J. Zhou, S. Jiang, and V. M. Patel, “Multi-Institutional Collaborations for Improving Deep Learning-Based Magnetic Resonance Image Reconstruction Using Federated Learning,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [46] C. T. Dinh, N. H. Tran, and T. D. Nguyen, “Personalized federated learning with moreau envelopes,” arXiv preprint arXiv:2006.08848, 2021.
- [47] Y. Huang, L. Chu, Z. Zhou, L. Wang, J. Liu, J. Pei, and Y. Zhang, “Personalized cross-silo federated learning on non-iid data,” in Proc. of AAAI Conference on Artificial Intelligence (AAAI), 2021.
- [48] M. Zhang, K. Sapra, S. Fidler, S. Yeung, and J. M. Alvarez, “Personalized federated learning with first order model optimization,” in Proc. of International Conference on Learning Representations (ICLR), 2021.
- [49] A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning: A meta-learning approach,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [50] F. Hanzely, S. Hanzely, S. Horváth, and P. Richtárik, “Lower bounds and optimal algorithms for personalized federated learning,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [51] K. Ozkara, N. Singh, D. Data, and S. Diggavi, “Quped: Quantized personalization via distillation with applications to federated learning,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [52] X. Guo, Z. Liu, J. Li, J. Gao, B. Hou, C. Dong, and T. Baker, “Verifl: Communication-efficient and fast verifiable aggregation for federated learning,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1736–1751, 2020.
- [53] C. Wu, F. Wu, L. Lyu, Y. Huang, and X. Xie, “Communication-efficient federated learning via knowledge distillation,” Nature communications, vol. 13, no. 1, pp. 1–8, 2022.
- [54] S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Konečnỳ, H. B. McMahan, V. Smith, and A. Talwalkar, “LEAF: A benchmark for federated settings,” in Proc. of Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [55] D. J. Beutel, T. Topal, A. Mathur, X. Qiu, T. Parcollet, and N. D. Lane, “Flower: A friendly federated learning research framework,” arXiv preprint arXiv:2007.14390, 2020.
- [56] H. Ludwig, N. Baracaldo, G. Thomas, Y. Zhou, A. Anwar, S. Rajamoni, Y. Ong, J. Radhakrishnan, A. Verma, M. Sinn et al., “Ibm federated learning: an enterprise framework white paper v0.1,” arXiv preprint arXiv:2007.10987, 2020.
- [57] S. Gao, F. Huang, W. Cai, and H. Huang, “Network Pruning via Performance Maximization,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [58] Y. Liu, L. Liu, C. Lin, Z. Dong, and W. Wang, “Learnable Motion Coherence for Correspondence Pruning,” in Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2021.
- [59] Z. Wang, C. Li, and X. Wang, “Convolutional Neural Network Pruning With Structural Redundancy Reduction,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [60] B. Li, B. Wu, J. Su, and G. Wang, “EagleEye: Fast sub-net evaluation for efficient neural network pruning,” in Proc. of the European Conference on Computer Vision (ECCV), 2020.
- [61] T.-W. Chin, R. Ding, C. Zhang, and D. Marculescu, “Towards efficient model compression via learned global ranking,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [62] S. Yu, A. Mazaheri, and A. Jannesari, “Topology-aware network pruning using multi-stage graph embedding and reinforcement learning,” in Proc. of the International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 17–23 Jul 2022, pp. 25 656–25 667.
- [63] ——, “GNN-RL compression: Topology-aware network pruning using multi-stage graph embedding and reinforcement learning,” arXiv preprint arXiv:2102.03214, 2021.
- [64] Y. He, J. Lin, Z. Liu, H. Wang, L.-J. Li, and S. Han, “AMC: AutoML for model compression and acceleration on mobile devices,” in Proc. of European Conference on Computer Vision (ECCV), 2018.
- [65] S. Yu, A. Mazaheri, and A. Jannesari, “Auto graph encoder-decoder for neural network pruning,” in Proc. of International Conference on Computer Vision (ICCV), 2021.
- [66] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. of International Conference on Learning Representations (ICLR), 2015.
- [67] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [68] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [69] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Master’s thesis, Department of Computer Science, University of Toronto, 2009.
- [70] Y. He, G. Kang, X. Dong, Y. Fu, and Y. Yang, “Soft filter pruning for accelerating deep convolutional neural networks,” in International Joint Conference on Artificial Intelligence (IJCAI), 2018, pp. 2234–2240.
- [71] Y. He, P. Liu, Z. Wang, Z. Hu, and Y. Yang, “Filter pruning via geometric median for deep convolutional neural networks acceleration,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [72] X. Ning, T. Zhao, W. Li, P. Lei, Y. Wang, and H. Yang, “DSA: More efficient budgeted pruning via differentiable sparsity allocation,” in Proc. of European Conference on Computer Vision (ECCV), 2020.
- [73] T. Wang, K. Wang, H. Cai, J. Lin, Z. Liu, H. Wang, Y. Lin, and S. Han, “Apq: Joint search for network architecture, pruning and quantization policy,” in Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2078–2087.