SpeechColab Leaderboard: An Open-Source Platform for Automatic Speech Recognition Evaluation
Abstract
In the wake of the surging tide of deep learning over the past decade, Automatic Speech Recognition (ASR) has garnered substantial attention, leading to the emergence of numerous publicly accessible ASR systems that are actively being integrated into our daily lives. Nonetheless, the impartial and replicable evaluation of these ASR systems encounters challenges due to various crucial subtleties. In this paper we introduce the SpeechColab Leaderboard, a general-purpose, open-source platform designed for ASR evaluation. With this platform: (i) We report a comprehensive benchmark, unveiling the current state-of-the-art panorama for ASR systems, covering both open-source models and industrial commercial services. (ii) We quantize how distinct nuances in the scoring pipeline influence the final benchmark outcomes. These include nuances related to capitalization, punctuation, interjection, contraction, synonym usage, compound words, etc. These issues have gained prominence in the context of the transition towards an End-to-End future. (iii) We propose a practical modification to the conventional Token-Error-Rate (TER) evaluation metric, with inspirations from Kolmogorov complexity and Normalized Information Distance (NID). This adaptation, called modified-TER (mTER), achieves proper normalization and symmetrical treatment of reference and hypothesis. By leveraging this platform as a large-scale testing ground, this study demonstrates the robustness and backward compatibility of mTER when compared to TER. The SpeechColab Leaderboard is accessible at https://github.com/SpeechColab/Leaderboard.
Index Terms:
Automatic Speech Recognition (ASR), Benchmark, Evaluation Metrics, Word Error Rate, Kolmogorov ComplexityI Introduction
Automatic Speech Recognition (ASR) has been an active research topic for many years. Traditional ASR combines Hidden Markov Models (HMM) and Gaussian Mixture Models (GMM) to capture the dynamics of speech signal and the hierarchical knowledge behind human languages [1]. In recent years, deep neural networks (DNN) have started to emerge with superior accuracy [2], and have quickly become the mainstream for ASR. For instance, chain model [3] incorporates Convolutional Neural Networks (CNNs) and Time Delay Neural Network (TDNNs), while DeepSpeech [4] model utilizes Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs). Modern systems are leaning to even more sophisticated architectures such as Transformer [5] and Conformer [6], coupled with sequence losses like Connectionist Temporal Classification (CTC) [7] and Recurrent Neural Network Transducer (RNN-T) [8]. From a system perspective, driven by the scaling law from language modeling research, large speech models have been developed such as OpenAI-Whisper [9], and Google-USM [10], pushing up the scale of ASR training by orders of magnitude. In the meantime, self-supervised training, as a paradigm shift, is also gaining popularity to leverage abundant unlabeled data in the world. Notable examples are wav2vec 2.0 [11], HuBERT [12], WavLM [13], and data2vec [14].
Given the swift evolution of ASR technology, a variety of speech toolkits have been developed and open-sourced, such as HTK [15], Kaldi [16], ESPnet [17], NeMo [18], SpeechBrain [19], WeNet [20], and K2111https://github.com/k2-fsa, offering comprehensive libraries and recipes to facilitate ASR research and development. However, the evaluation of ASR still remains challenging [21] [22], because there exist various crucial subtleties and pitfalls that require non-trivial efforts to do right in practice, such as text normalization [23]. The divergent ecosystem struggles to reach a clear and consistent understanding on the performance of modern ASR systems.
To address the problem, we present SpeechColab Leaderboard, an open-source benchmark platform, so that speech researchers and developers can reliably reproduce, examine, and compare all kinds of ASR systems. The platform is designed to be: (i) Simple: consistent data formats and unified interfaces minimize accidental complexity. (ii) Open: leaderboard users should be able to easily share and exchange resources (e.g. test sets, models, configurations). (iii) Reproducible: ASR systems, including all their dependencies and environment details, should be reproducible as a whole.
In Section 2, we describe the proposed platform, including three major components: a dataset zoo, a model zoo, and an evaluation pipeline. In Section 3, we report a large-scale benchmark for English ASR on the platform. In Section 4, the traditional evaluation metric TER (Token Error Rate) is briefly revisited, and a simple and practical modification is proposed to make TER more robust.
| Dataset | Number of sentences | Total duration | Source | Style | Release Date |
| LibriSpeech.test-clean [24] | 2620 | 5.403 hours | the LibriVox project | narrated audio-books | 2015 |
| LibriSpeech.test-other [24] | 2939 | 5.342 hours | the LibriVox project | narrated audio-books | 2015 |
| TEDLIUM3.dev [25] | 507 | 1.598 hours | TED talks | oratory | 2018 |
| TEDLIUM3.test [25] | 1155 | 2.617 hours | TED talks | oratory | 2018 |
| GigaSpeech.dev [26] | 5715 | 11.366 hours | Podcast and YouTube | spontaneous | 2021 |
| GigaSpeech.test [26] | 19930 | 35.358 hours | Podcast and YouTube | spontaneous | 2021 |
| VoxPopuli.dev [27] | 1753 | 4.946 hours | European Parliament | spontaneous | 2021 |
| VoxPopuli.test [27] | 1841 | 4.864 hours | European Parliament | spontaneous | 2021 |
| VoxPopuli.test-accented [27] | 8357 | 26.174 hours | European Parliament | spontaneous | 2022 |
| CommonVoice11.0.dev [28] | 16352 | 27.245 hours | crowd sourcing | narrated prompts | 2022 |
| CommonVoice11.0.test [28] | 16351 | 26.950 hours | crowd sourcing | narrated prompts | 2022 |
| Type | Model | Architecture | Size in bytes | Date of Evaluation |
| Commercial API | aliyun_api_en | – | – | 2022.10 |
| amazon_api_en | 2022.10 | |||
| baidu_api_en | 2022.10 | |||
| google_api_en | 2022.10 | |||
| google_USM_en [10] | 2023.03 | |||
| microsoft_sdk_en | 2022.10 | |||
| tencent_api_en | 2022.10 | |||
| Open-Source (Supervised) | vosk_model_en_large | Kaldi chain model | 2.7G | 2022.10 |
| deepspeech_model_en [4] | RNN + N-gram | 1.1G | 2022.10 | |
| coqui_model_en | RNN + N-gram | 979M | 2022.10 | |
| nemo_conformer_ctc_large_en [18] | Conformer-CTC | 465M | 2022.10 | |
| nemo_conformer_transducer_xlarge_en [18] | Conformer-Transducer | 2.5G | 2022.10 | |
| k2_gigaspeech [29] | Pruned stateless RNN-T | 320M | 2022.10 | |
| whisper_large_v1 [9] | Transformer Encoder-Decoder | 2.9G | 2022.10 | |
| whisper_large_v2 [9] | Transformer Encoder-Decoder | 2.9G | 2023.03 | |
| Open-Source (Unsupervise + Fine-tuned) | data2vec_audio_large_ft_libri_960h | data2vec [14] | 1.2G | 2022.10 |
| hubert_xlarge_ft_libri_960h | HuBERT [12] | 3.6G | 2022.10 | |
| wav2vec2_large_robust_ft_libri_960h | wav2vec 2.0 [11] | 2.4G | 2022.10 | |
| wavlm_base_plus_ft_libri_clean_100h | WavLM [13] | 361M | 2022.10 |
* Some models do not provide interfaces to query the total number of parameters, so we list model sizes in bytes in the table for consistency.
II The Platform
II-A Overview
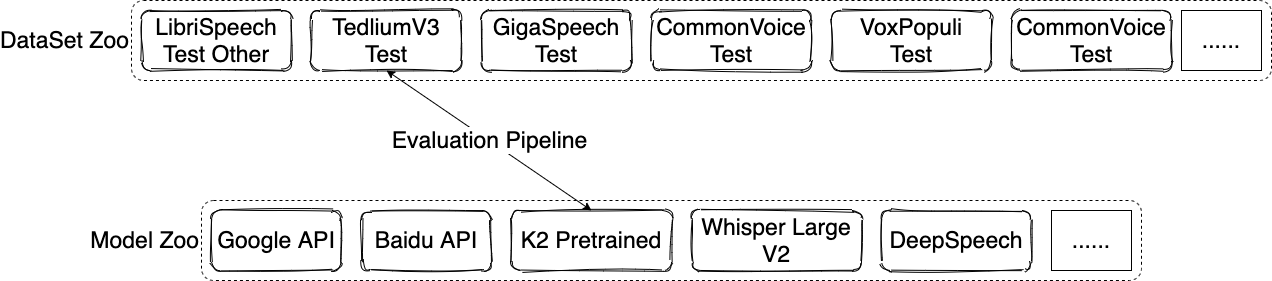
The overall platform is shown in Figure 1. We implement the dataset zoo and the model zoo on top of commercial cloud-storage services, so that the platform can serve as a reliable and high-speed disk for our users to exchange data and models. Evaluation sets and models are associated with globally unique identifiers. Within our repository, to initiate a benchmark:
ops/benchmark -m <MODEL_ID> -d <DATASET_ID>
II-B Dataset Zoo
In the dataset zoo: (i) All utterances, if necessary, are extracted from raw long audio, and stored consistently in short222The utterances longer than 60s are removed. WAV format. (ii) The metadata is organized in tab-separated-values (.tsv) format with 4 columns, as shown in Table III.
| ID | AUDIO | DURATION | TEXT |
| POD0000051 | audio/POD0000051.wav | 2.100 | But what kind of business? |
| POD0000094 | audio/POD0000094.wav | 2.727 | So we’re gonna make it … |
| … | … | … | … |
As of the writing of this paper, 11 well-known ASR evaluation sets are processed and integrated into the dataset zoo, summarized in Table I. We provide simple operational utilities for dataset management. For example, to share a local test set to the zoo:
ops/push -d <DATASET_ID>
And to retrieve a test set from the zoo:
ops/pull -d <DATASET_ID>
II-C Model Zoo
We define a simple and unified interface for model zoo: all models should be built within a Docker container along with an ASR program that takes a list of WAV files as input. By design, we support both open-source models and commercial API services. Similar to the dataset zoo, leaderboard users can easily publish or reproduce ASR systems by using:
ops/push -m <MODEL_ID>
ops/pull -m <MODEL_ID>
Table II provides a detailed list of 19 integrated models.
II-D Evaluation Pipeline
| Pipeline components | Description | Raw text | New text |
| CASE | unify cases | And then there was Broad Street. | AND THEN THERE WAS BROAD STREET. |
| PUNC | remove punctuations (, . ? ! ” - and single quote) | ”’He doesn’t say exactly what it is,’ said Ruth, a little dubiously. ” | He doesn’t say exactly what it is said Ruth a little dubiously |
| ITJ | remove interjections | uh yeah um that’s good | yeah that’s good |
| UK-US | unify UK & US spelling conventions | 1. she went to the theatre 2. such a humour 3. I apologise | 1. she went to the theater 2. such a humor 3. I apologize |
| NSW | normalize Non-Standard-Word (number, quantity, date, time, address etc) | 1. gave him $100. 2. Just before 8.30 a.m. 3. grew up in the 1980s 4. the baggage is 12.7kg 5. in the 21st century 6. 1/3 of the population 7. 13,000 people 8. 1998/2/30 | 1. gave him one hundred dollars. 2. Just before eight thirty AM 3. grew up in the nineteen eighties 4. the baggage is twelve point seven kilograms 5. in the twenty first century 6. one third of the population 7. thirteen thousand people 8. february thirtieth nineteen ninety eight |
II-D1 Preprocessing
In practice, references and hypotheses are usually in different forms, therefore pre-processing is needed to remove the discrepancy. As listed in table IV, we deal with case, punctuation, common interjections, US/UK spelling convention333http://www.tysto.com/uk-us-spelling-list.html etc. For Non-Standard-Word (NSW) normalization, we leverage the context-dependent rewriting rules from NeMo toolkit [30]. 444We currently do not have reliable solution for stutter and dis-fluency detection, this could be one of our future works.
| Pipeline components | Description | Alternative Set | Raw hyp | hyp after DAE |
| DAE | contractions, abbreviations, compounds etc… | We’re = We are I’m = I am, gonna = going to, OK = O K = Okey storyteller = story-teller = story teller | 1.We’re here early 2.I’m gonna be OK 3.He is an excellent storyteller | 1.(We’re|We are) here early 2.(I’m|I am) (gonna|going to) be (OK|O K|Okay) 3.He is an excellent (storyteller|story teller|story-teller) |
II-D2 Metric
Token Error Rate is used to evaluate the accuracy of ASR systems:
| (1) |
where denotes the Levenshtein Distance, and refers to the number of words (for English ASR) in the reference.
II-D3 Scoring
The scoring module is implemented in Weighted Finite State Transducer (WFST) framework, in particular via OpenFST [31] and Pynini [32]. The pre-processed references and hypotheses are first tokenized as word sequences, then transformed to linear FSTs. The Levenshtein transducer is constructed with the standard operations and costs: insertion (INS:1.0), deletion (DEL:1.0), substitution (SUB:1.0), and correct-match (COR:0.0). Hence the Levenshtein distance in the numerator can be calculated as:
where denotes FST composition. Note that in large vocabulary continuous speech recognition (LVCSR), the static size of could explode because the substitution requires space, where refers to the vocabulary size. We follow the optimization practice in [33] by leveraging auxiliary symbols, so that is factored as the product of two smaller FSTs.
II-D4 Dynamic Alternative Expansion (DAE)
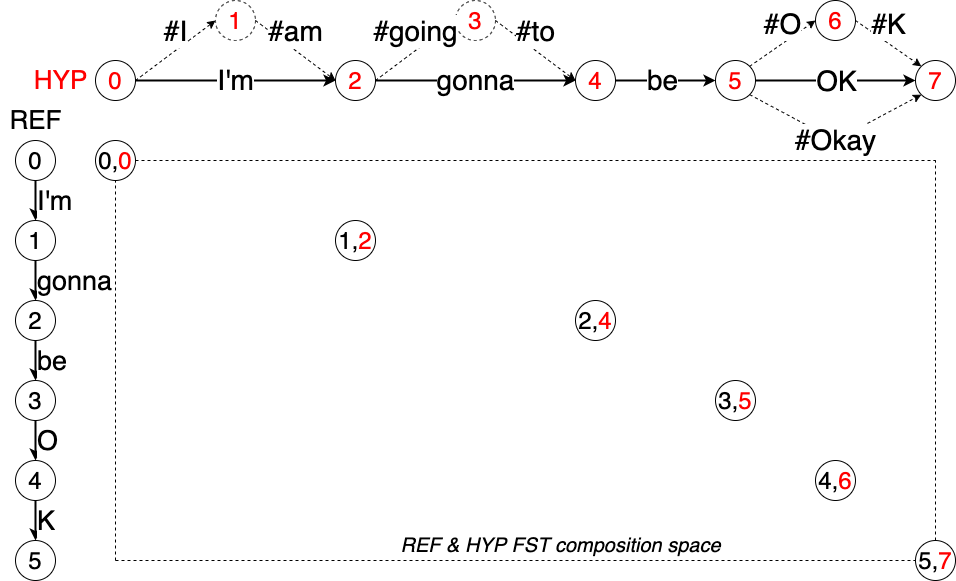
Similar to NIST’s GLM machnism555https://github.com/usnistgov/SCTK/blob/master/doc/GLMRules.txt, we enhance standard Levenshtein distance algorithm to support customizable alternative sets to deal with synonyms, contractions, abbreviations, compound words, etc on-the-fly.
As illustrated in Figure 2. is transformed from the original linear structure to a sausage-like FST, so that no matter which alternative appears in , the expanded can correctly match up with it. Note that we mark the expanded alternative paths with auxiliary hash tags, and Levenshtein transducer is modified accordingly to disallow partial matches of these expanded segments. Also note that dynamic alternative expansion (DAE) is only applied to the , whereas the remains intact.
| Model |
LibriSpeech.test-clean |
LibriSpeech.test-other |
TEDLIUM3.dev |
TEDLIUM3.test |
GigaSpeech.dev |
GigaSpeech.test |
VoxPopuli.dev |
VoxPopuli.test |
VoxPopuli.test-accented |
CommonVoice11.0.dev |
CommonVoice11.0.test |
| aliyun_api_en | 4.34 (12) | 10.01 (12) | 5.79 (12) | 5.53 (12) | 12.63 (11) | 12.83 (11) | 11.93 (9) | 11.50 (9) | 15.61 (5) | 15.67 (9) | 17.86 (9) |
| amazon_api_en | 6.42 (16) | 13.20 (15) | 5.11 (8) | 4.74 (9) | 11.31 (8) | 11.71 (8) | 12.14 (11) | 11.84 (11) | 14.56 (4) | 22.66 (15) | 26.25 (16) |
| baidu_api_en | 6.61 (17) | 14.69 (16) | 8.65 (14) | 7.93 (14) | 16.94 (13) | 16.80 (13) | 14.55 (15) | 14.08 (15) | 19.98 (11) | 22.74 (16) | 25.97 (15) |
| google_api_en | 5.63 (15) | 12.56 (14) | 5.54 (10) | 5.26 (10) | 11.70 (9) | 11.78 (9) | 11.95 (10) | 11.77 (10) | 15.72 (6) | 17.49 (10) | 20.60 (10) |
| google_USM_en | 2.13 (5) | 4.35 (5) | 3.69 (3) | 3.05 (1) | 8.67 (2) | 9.23 (3) | 9.89 (8) | 9.50 (8) | 14.18 (3) | 8.69 (5) | 10.19 (4) |
| microsoft_sdk_en | 3.03 (10) | 6.65 (10) | 3.65 (2) | 3.14 (2) | 8.74 (3) | 9.02 (1) | 9.04 (5) | 8.88 (5) | 12.17 (1) | 8.86 (6) | 10.46 (5) |
| tencent_api_en | 3.54 (11) | 7.26 (11) | 4.94 (7) | 4.20 (5) | 10.19 (6) | 10.37 (6) | 9.21 (6) | 8.90 (6) | 15.81 (7) | 11.59 (7) | 12.91 (7) |
| vosk_model_en_large | 5.17 (14) | 12.36 (13) | 5.74 (11) | 5.41 (11) | 13.84 (12) | 14.08 (12) | 13.22 (12) | 12.52 (12) | 20.27 (12) | 21.66 (14) | 25.46 (14) |
| deepspeech_model_en | 6.95 (18) | 21.23 (19) | 17.71 (18) | 18.31 (18) | 32.68 (17) | 31.21 (17) | 28.46 (19) | 29.10 (19) | 38.23 (19) | 43.34 (19) | 47.80 (19) |
| coqui_model_en | 4.94 (13) | 15.92 (18) | 17.48 (17) | 18.66 (19) | 34.62 (18) | 32.45 (18) | 27.60 (18) | 27.66 (18) | 37.85 (18) | 35.52 (17) | 40.10 (17) |
| nemo_conformer_ctc_large_en | 1.95 (4) | 4.26 (4) | 5.11 (8) | 4.69 (8) | 11.70 (9) | 12.01 (10) | 6.68 (2) | 6.61 (2) | 18.24 (8) | 8.44 (3) | 9.23 (2) |
| nemo_conformer_transducer_xlarge_en | 1.36 (1) | 2.76 (1) | 4.61 (5) | 4.31 (6) | 10.85 (7) | 11.53 (7) | 6.05 (1) | 5.97 (1) | 20.80 (14) | 5.20 (1) | 5.82 (1) |
| k2_gigaspeech | 2.18 (7) | 5.30 (8) | 3.42 (1) | 3.40 (3) | 8.90 (4) | 9.71 (5) | 9.80 (7) | 9.48 (7) | 12.46 (2) | 14.05 (8) | 17.04 (8) |
| whisper_large_v1 | 2.66 (9) | 5.81 (9) | 4.90 (6) | 4.31 (6) | 9.11 (5) | 9.68 (4) | 8.31 (4) | 7.88 (4) | 20.80 (14) | 8.68 (4) | 10.89 (6) |
| whisper_large_v2 | 2.14 (6) | 4.65 (6) | 3.70 (4) | 3.55 (4) | 8.53 (1) | 9.19 (2) | 7.82 (3) | 7.17 (3) | 18.83 (9) | 7.88 (2) | 10.01 (3) |
| data2vec_audio_large_ft_libri_960h | 1.64 (2) | 3.85 (3) | 8.31 (13) | 7.66 (13) | 18.43 (14) | 17.92 (14) | 13.73 (13) | 13.42 (13) | 19.45 (10) | 18.25 (12) | 21.75 (11) |
| hubert_xlarge_ft_libri_960h | 1.79 (3) | 3.48 (2) | 8.94 (15) | 8.14 (15) | 18.87 (15) | 18.43 (15) | 14.47 (14) | 13.62 (14) | 20.58 (13) | 18.05 (11) | 21.79 (12) |
| wav2vec2_large_robust_ft_libri_960h | 2.46 (8) | 5.18 (7) | 9.66 (16) | 9.02 (16) | 19.80 (16) | 18.81 (16) | 14.99 (16) | 14.76 (16) | 21.00 (16) | 18.93 (13) | 22.35 (13) |
| wavlm_base_plus_ft_libri_clean_100h | 7.00 (19) | 15.68 (17) | 18.75 (19) | 18.21 (17) | 34.78 (19) | 33.02 (19) | 21.55 (17) | 21.16 (17) | 27.94 (17) | 40.17 (18) | 44.96 (18) |
There are two reasons for dynamic alternative expansion instead of processing them directly in the text normalization stage. Firstly, specifying a canonical form out of these alternatives is controversial, and we as platform developers are more interested in providing DAE as a flexible mechanism rather than ironing out some specific TN (Text Normalization) policies. Secondly, with -only expansion, the algorithm will always honor the raw form of human labels (i.e. ), so that alternative sets can evolve without mutating the denominator of TER (i.e. ), which is a desirable property for comparison purpose over time.
III The Benchmark
III-A Results
Table VI shows Word Error Rates (WER) and the ranking covering all models and test sets on the platform:
1) Given DeepSpeech being the SOTA back in 2014, OpenAI-Whisper model now has achieved remarkable relative WER reductions over DeepSpeech: 78% on LibriSpeech-test-other, 81% on TedLium3-test, 71% on GigaSpeech-test, 75% on VoxPopuli-test, 50% on VoxPopuli-accented, 79% on CommonVoice-test. These numbers reflect the overall progress of ASR over the last decade.
2) Open-source models tend to beat commercial services on LibriSpeech by a large margin, which reveals some weird situations relating to the highly influential LibriSpeech dataset: (i) The LibriSpeech benchmark may not be a preferable indicator for real-life ASR, therefore commercial services assign little efforts to the task in their productions. (ii) On the other hand, open-source models apparently prioritize LibriSpeech since it is the de facto standard in ASR research, but these systems often generalize poorly to other tasks. The effort in pushing the LibriSpeech SOTA may turn out to be an overfitting game. (iii) Similarly, even strong self-supervised pretrained models (such as data2vec, hubert, wav2vec and wavlm) fail to show strong generalization ability if finetuned on LibriSpeech only.
3) As another manifestation of the scaling law, large speech models, such as Whisper, USM, and xlarge NeMo transducer, are shown to be highly competitive even compared with the best commercial services. More importantly, some of these large ASR systems are open-sourced. Therefore in a foreseeable future, as these large models getting better and hardware getting cheaper, some of the traditional ASR providers need to seek compelling reasons for customers to pay.
III-B Scoring subtleties
There are various subtleties in the scoring pipeline that can affect benchmark results, such as punctuation, interjection, non-standard word normalization, US/UK spellings, etc. To study the importance of these subtleties, an ablation experiment is conducted by turning off each component respectively, as shown in columns (A1-A5) from table VII. 666 Note that we use GigaSpeech test set for this study rather than LibriSpeech, since GigaSpeech is curated mainly from real-world scenarios (YouTube and podcasts) on daily topics in spontaneous conversations.
| A0 (baseline) | A1 | A2 | A3 | A4 | A5 | ||
| Evaluation Pipeline Component (crossed = turned off) | CASE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PUNC | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | |
| ITJ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | |
| UK-US | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | |
| NSW | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | |
| DAE | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | |
| WER(%) (Rank) | microsoft_sdk_en | 9.02 (1) | 9.81 (1) | 9.68 (1) | 9.05 (1) | 9.02 (1) | 10.46 (1) |
| whisper_large_v2 | 9.19 (2) | 22.43 (14) | 9.91 (3) | 9.22 (2) | 10.88 (4) | 10.57 (2) | |
| google_USM_en | 9.23 (3) | 9.85 (2) | 9.85 (2) | 9.26 (3) | 10.77 (3) | 10.75 (3) | |
| whisper_large_v1 | 9.68 (4) | 22.62 (15) | 10.39 (5) | 9.71 (4) | 11.34 (5) | 11.12 (5) | |
| k2_gigaspeech | 9.71 (5) | 10.34 (3) | 10.36 (4) | 9.74 (5) | 9.72 (2) | 11.06 (4) | |
| tencent_api_en | 10.37 (6) | 20.88 (13) | 10.94 (6) | 10.39 (6) | 11.42 (6) | 11.70 (6) | |
| nemo_conformer_transducer_xlarge_en | 11.53 (7) | 12.35 (4) | 12.22 (7) | 11.57 (7) | 11.53 (7) | 12.78 (7) | |
| amazon_api_en | 11.71 (8) | 23.78 (16) | 12.30 (8) | 11.73 (8) | 13.30 (11) | 13.05 (8) | |
| google_api_en | 11.78 (9) | 12.41 (5) | 12.48 (9) | 11.80 (9) | 13.29 (10) | 13.32 (10) | |
| nemo_conformer_ctc_large_en | 12.01 (10) | 12.81 (6) | 12.62 (10) | 12.04 (10) | 12.01 (8) | 13.27 (9) | |
| aliyun_api_en | 12.83 (11) | 13.71 (7) | 13.44 (11) | 12.86 (11) | 12.83 (9) | 13.98 (11) | |
| vosk_model_en_large | 14.08 (12) | 14.84 (8) | 14.68 (12) | 14.10 (12) | 14.08 (12) | 15.47 (12) | |
| baidu_api_en | 16.80 (13) | 17.56 (9) | 17.43 (13) | 16.83 (13) | 16.81 (13) | 17.98 (13) | |
| data2vec_audio_large_ft_libri_960h | 17.92 (14) | 18.68 (10) | 18.13 (14) | 17.99 (14) | 17.92 (14) | 18.85 (14) | |
| hubert_xlarge_ft_libri_960h | 18.43 (15) | 19.19 (11) | 18.61 (15) | 18.50 (15) | 18.43 (15) | 19.33 (15) | |
| wav2vec2_large_robust_ft_libri_960h | 18.81 (16) | 19.56 (12) | 18.93 (16) | 18.89 (16) | 18.81 (16) | 19.73 (16) | |
| deepspeech_model_en | 31.21 (17) | 31.70 (17) | 31.73 (17) | 31.24 (17) | 31.21 (17) | 32.04 (17) | |
| coqui_model_en | 32.45 (18) | 33.12 (18) | 32.72 (18) | 32.49 (18) | 32.45 (18) | 33.27 (18) | |
| wavlm_base_plus_ft_libri_clean_100h | 33.02 (19) | 33.74 (19) | 33.06 (19) | 33.07 (19) | 33.02 (19) | 33.42 (19) |
* Microsoft API provides a switch to disable Inverse Text Normalization(ITN), so its number in A4 (turning off NSW normalization in our pipeline) is basically the same as the baseline.
III-B1 PUNC
The comparison between A1 and A0 reminds us that the processing of punctuation is vital. By turning off the punctuation removal component, we see a dramatic increase of WER for Whisper, tencent, amazon. This is because different ASR systems do have quite distinctive policies for punctuation. Therefore it requires serious and careful treatment, otherwise the whole evaluation can be completely biased and dominated by punctuation-related errors. Also note that proper processing of punctuation is non-trivial: consider things like single quotes mixed with apostrophe in contraction, comma and period in numbers, hyphen in compound words, etc.
III-B2 ITJ
Comparing A2 and A0, we see the processing of interjections can result in absolute WER changes around 0.5% 1.0%. The difference seems to be mild, until we realize these numbers translate to a relative ~10% WER increase. Therefore the removal of interjections is by no means a factor that we can ignore in ASR research and evaluation on conversational ASR tasks. The implementation is trivial though, given a list of common interjections such as ’uh’, ’eh’, ’um’. 777Our platform maintains common interjections at: https://github.com/SpeechColab/Leaderboard/blob/master/utils/interjections_en.csv
III-B3 UK-US
Comparing A3 and A0, we can see that the unification of US-UK spelling convention has minor effects.
III-B4 NSW and DAE
Comparing A4, A5 with A0, it is apparent that NSW normalization and DAE are both crucial 888NSW component deals with the normalization of numbers, quantities, date, money, and times, etc, and DAE module is responsible for contractions, abbreviations, and compound words.. Traditional ASR systems tend to generate spoken-form recognition results, whereas commercial services and modern end-to-end systems (such as Whisper) normally yield the written-form as default. The discrepancy between spoken and written forms is so significant, that any serious benchmark should dive into these details to make sure the normalized hypotheses and references are consistent, otherwise the benchmark can become pointless. However, robust text normalization (TN) is challenging and immensely tedious due to numerous rules and long-tail exceptions. Therefore, we highly suggest other benchmark developers to leverage and improve existing tools instead of building new TN from scratch.
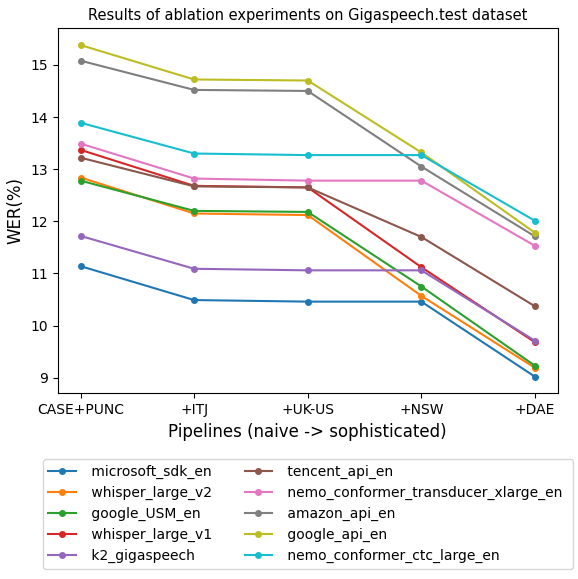
In Figure 3, we show how these individual components are stacked together. As can be seen: i) The ranking can vary from the left (a barely working naive pipeline) to the right (a sophisticated pipeline). ii) The sophisticated pipeline can have a relative 20% 30% WER reduction over the naive pipeline. These observations raise a concerning revelation that technological progress can be easily shadowed by implementation details of the scoring pipeline. For this reason, when we are discussing the absolute number of WER and the rankings of different systems, the specific toolkit and pipeline in use should be deliberately brought into the context, to avoid misunderstanding and misinformation.
IV Modified Token Error Rate (mTER)
For decades, Token Error Rate (TER) has been the standard evaluation metric of Automatic Speech Recognition (ASR). In this section, we propose a new metric to address some fundamental issues of TER.
IV-A Problems with TER
IV-A1 TER violates the metric-space axioms
In mathematics, a metric space needs to satisfy a small set of requirements called the metric (in)equalities999 Consisting of following axioms: 1) positivity: ; 2) identity: if and only if ; 3) symmetry: ; 4) triangle-inequality: . Obviously, TER violates the symmetry axiom, because:
This has broad impacts in practice: For industry, tools and pipelines need to implement asymmetric interfaces and options, so as documentations; For education, instructors need to emphasis the denominator calculation to their students, as well as the relativity of insertion (INS) versus deletion (DEL).
IV-A2 TER is ill-normalized
TER picks as the normalizer, which makes it numerically unbounded (can easily exceed 100%). This becomes more confusing since it is literally called error rate.
These problems have been identified and reported in the prior literature, and new metrics are proposed in [34, 35]. Besides fixing above issues, these new metrics tend to incorporate some sort of informational/cognitive measure into ASR evaluation, which is generally the right call. Unfortunately, a new metric needs to fight against strong inertia since the main purpose of a metric is to serve comparisons over time. As a result, these backward-incompatible metrics never receive widespread adoptions.
| Model |
LibriSpeech.test-clean |
LibriSpeech.test-other |
TEDLIUM3.dev |
TEDLIUM3.test |
GigaSpeech.dev |
GigaSpeech.test |
VoxPopuli.dev |
VoxPopuli.test |
VoxPopuli.test-accented |
CommonVoice11.0.dev |
CommonVoice11.0.test |
| aliyun_api_en | |||||||||||
| amazon_api_en | |||||||||||
| baidu_api_en | |||||||||||
| google_api_en | |||||||||||
| google_USM_en | |||||||||||
| microsoft_sdk_en | |||||||||||
| tencent_api_en | |||||||||||
| vosk_model_en_large | |||||||||||
| deepspeech_model_en | |||||||||||
| coqui_model_en | |||||||||||
| nemo_conformer_ctc_large_en | |||||||||||
| nemo_conformer_transducer_xlarge_en | |||||||||||
| k2_gigaspeech | |||||||||||
| whisper_large_v1 | |||||||||||
| whisper_large_v2 | |||||||||||
| data2vec_audio_large_ft_libri_960h | |||||||||||
| hubert_xlarge_ft_libri_960h | |||||||||||
| wav2vec2_large_robust_ft_libri_960h | |||||||||||
| wavlm_base_plus_ft_libri_clean_100h |
----------------------------------------------------- an example -----------------------------------------------------
{"uid":YOU1000000117_S0000168, "TER":76.92, "mTER":43.48, "cor":13,"sub":0, "ins":10, "del":0}
REF : FOR OLDER KIDS THAT CAN BE THE SAME * WE DO IT AS ADULTS * * * * * * * * *
HYP : FOR OLDER KIDS THAT CAN BE THE SAME WAY WE DO IT AS ADULTS FOR MORE INFORMATION VISIT WWW DOT FEMA DOT GOV
EDIT : I I I I I I I I I I
----------------------------------------------------------------------------------------------------------------------
IV-B mTER
In [36], Paul M. B. Vitányi et al proposed a universal similarity metric based on Kolmogorov complexity, called Normalized Information Distance (NID):
| (2) |
Due to the incomputability of Kolmogorov complexity (subjected to Turing’s halting problem), NID can only serve as a theoretical framework. Some practical approximations of NID, such as Normalized Compression Distance (NCD) [37], Normalized Web Distance (NWD) have been investigated for wide range of tasks including genome phylogeny [38], plagiarism detection [39] and information retrieval [40], etc.
The similarity between Conditional Kolmogorov complexity and Levenshtein distance is striking. Since depicts the theoretical minimal program length to generate output given input (both encoded in bit-sequences) within a Universal Turing Machine, whereas takes a more pragmatic approach by counting the minimal edit instructions required to transform into (both encoded as token sequences) within a heavily constrained instruction set {INS, DEL, SUB}. In the scope of this paper, it is not necessary to establish more formal connection between and though 101010 Actually, the algorithmic information framework can provide deeper insights. For instance: The “INS” and “DEL” instructions should by no means be equally weighted from an information perspective, because it requires immensely more complexity for DaVinci to create the “Mona Lisa” than someone to erase it, i.e.: . So in principle, more cognitive-aware metrics can be designed following the algorithmic information theory. , we denote it as a simple heuristic:
| (3) |
Given this heuristic, now observing the definition of NID (especially pay attention to the form of the denominator as the metric normalizer), we propose modified Token Error Rate:
| (4) |
Note that the above numerator simplification is based on the fact that is symmetric with regard to and .
Compared to the vanilla TER in equation (1), it is merely a modification to the denominator: . However, the resulting mTER is symmetric, gracefully normalized and bounded between , and perfectly conforms to the aforementioned metric-space axioms.
IV-C Empirical study on mTER and TER
IV-C1 Dataset-Level comparison
Table VIII compares TER and mTER on all models and test sets on the platform. About 66% of the mTER numbers are exact same as TER. And for the rest, WER discrepancies are minor (<4% relatively). That basically means mTER is backward-compatible, researchers will still be able to compare with TER from prior works.
IV-C2 Utterence-Level comparison
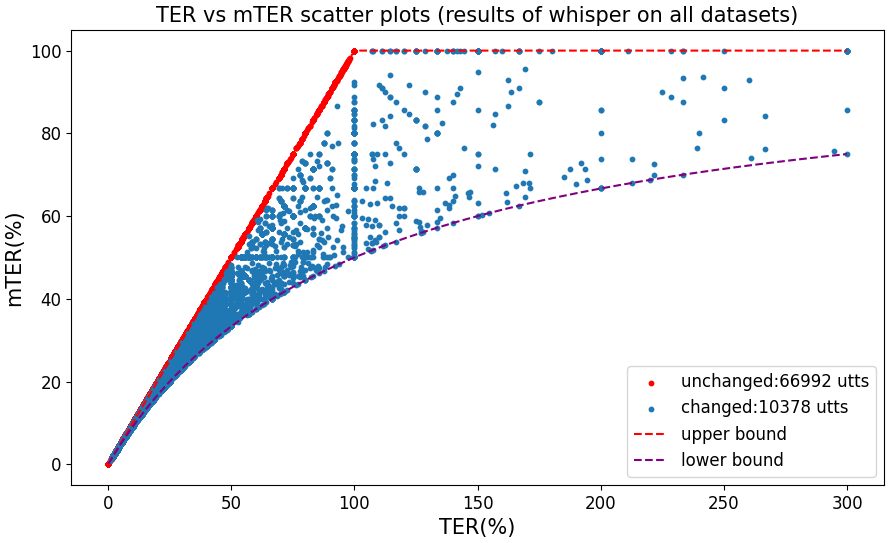
Figure 5 shows mTER vs TER of all testing utterances on whisper_large_v1 model. The samples on the red diagonal line represent utterances whose mTER is precisely consistent with TER, accounting to 87% of the total samples. The remaining 13% samples illustrated how mTER and TER are correlated, and how mTER wrapped overflowed TER (i.e. TER 100%) into [0%, 100%].
Figure 4 provides an utterance from our benchmark on Whisper, showing a closer look at the discrepancy between TER and mTER. The recognition result contains 23 words in total, among which 9 words are hallucinated. In this case, mTER (43.38%) is intuitively better than TER (76.92%) because it reflects the valid portion of the ASR output more precisely. TER is vulnerable to overflow, especially in short utterances and for insertion errors like model hallucination.
To sum up, through large-scale empirical experiments, we found the proposed mTER is robust. i) It is no longer necessary for scoring tools, pipelines, and documentation to differentiate and , since mTER is symmetric. ii) The numbers of evaluation results are guaranteed to be normalized, with no more confusing overflowed error rate. In practice, the adoption of mTER is demonstrated to be backward-compatible the with the existing TER in dataset level evaluations.
V Conclusion
This paper introduces SpeechColab Leaderboard, an open-source evaluation platform for Automatic Speech Recognition (ASR). Base on the proposed platform, we conduct and report an extensive benchmark, revealing the landscape of state-of-the-art ASR systems from both research and industry. In addition, our study quantitatively investigates the relevance of different components within the evaluation pipeline, which presents a valuable reference for the community to build serious ASR benchmarks in the future. Furthermore, by leveraging our platform and the benchmark results, we propose a new metric, modified Token Error Rate (mTER), which is more robust and elegant than the traditional Token Error Rate (TER). In the future, we intend to incorporate more datasets and models into the platform.
Acknowledgments
We would like to thank Yong LIU for his help to integrate the TEDLIUM-3 evaluation sets.
References
- [1] L. Deng, P. Kenny, M. Lennig, V. Gupta, F. Seitz, and P. Mermelstein, “Phonemic hidden Markov models with continuous mixture output densities for large vocabulary word recognition,” IEEE Transactions on Signal Processing, vol. 39, no. 7, pp. 1677–1681, 1991.
- [2] G. E. Dahl, D. Yu, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition,” IEEE Transactions on audio, speech, and language processing, vol. 20, no. 1, pp. 30–42, 2011.
- [3] D. Povey, V. Peddinti, D. Galvez, P. Ghahremani, V. Manohar, X. Na, Y. Wang, and S. Khudanpur, “Purely sequence-trained neural networks for ASR based on lattice-free MMI.” in Interspeech, 2016, pp. 2751–2755.
- [4] A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates et al., “Deep speech: Scaling up end-to-end speech recognition,” arXiv preprint arXiv:1412.5567, 2014.
- [5] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [6] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented transformer for speech recognition,” Interspeech 2020, 2020.
- [7] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in Proc. ICML, 2006.
- [8] A. Graves, “Sequence transduction with recurrent neural networks,” Computer Science, vol. 58, no. 3, pp. 235–242, 2012.
- [9] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518.
- [10] Y. Zhang, W. Han, J. Qin, Y. Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V. Axelrod, G. Wang et al., “Google USM: Scaling automatic speech recognition beyond 100 languages,” arXiv preprint arXiv:2303.01037, 2023.
- [11] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [12] W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
- [13] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- [14] A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “Data2vec: A general framework for self-supervised learning in speech, vision and language,” in International Conference on Machine Learning. PMLR, 2022, pp. 1298–1312.
- [15] S. Young, G. Evermann, M. Gales, T. Hain, D. Kershaw, X. Liu, G. Moore, J. Odell, D. Ollason, D. Povey et al., “The HTK book,” Cambridge university engineering department, vol. 3, no. 175, p. 12, 2002.
- [16] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., “The Kaldi speech recognition toolkit,” in IEEE 2011 workshop on automatic speech recognition and understanding, no. CONF. IEEE Signal Processing Society, 2011.
- [17] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” in Proceedings of Interspeech, 2018, pp. 2207–2211.
- [18] O. Kuchaiev, J. Li, H. Nguyen, O. Hrinchuk, R. Leary, B. Ginsburg, S. Kriman, S. Beliaev, V. Lavrukhin, J. Cook et al., “Nemo: A toolkit for building ai applications using neural modules,” arXiv preprint arXiv:1909.09577, 2019.
- [19] M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong et al., “SpeechBrain: A general-purpose speech toolkit,” arXiv preprint arXiv:2106.04624, 2021.
- [20] Z. Yao, D. Wu, X. Wang, B. Zhang, F. Yu, C. Yang, Z. Peng, X. Chen, L. Xie, and X. Lei, “WeNet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit,” in Proc. Interspeech. Brno, Czech Republic: IEEE, 2021.
- [21] M. Del Rio, N. Delworth, R. Westerman, M. Huang, N. Bhandari, J. Palakapilly, Q. McNamara, J. Dong, P. Zelasko, and M. Jetté, “Earnings-21: A practical benchmark for ASR in the wild,” arXiv preprint arXiv:2104.11348, 2021.
- [22] S. Gandhi, P. Von Platen, and A. M. Rush, “ESB: A benchmark for multi-domain end-to-end speech recognition,” arXiv preprint arXiv:2210.13352, 2022.
- [23] A. Faria, A. Janin, K. Riedhammer, and S. Adkoli, “Toward zero oracle word error rate on the switchboard benchmark,” arXiv preprint arXiv:2206.06192, 2022.
- [24] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- [25] F. Hernandez, V. Nguyen, S. Ghannay, N. Tomashenko, and Y. Esteve, “TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation,” in Speech and Computer: 20th International Conference, SPECOM 2018, Leipzig, Germany, September 18–22, 2018, Proceedings 20. Springer, 2018, pp. 198–208.
- [26] G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhang et al., “GigaSpeech: An evolving, multi-domain ASR corpus with 10,000 hours of transcribed audio,” in 22nd Annual Conference of the International Speech Communication Association, INTERSPEECH 2021. International Speech Communication Association, 2021, pp. 4376–4380.
- [27] C. Wang, M. Rivière, A. Lee, A. Wu, C. Talnikar, D. Haziza, M. Williamson, J. Pino, and E. Dupoux, “VoxPopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” in ACL 2021-59th Annual Meeting of the Association for Computational Linguistics, 2021.
- [28] R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common Voice: A massively-multilingual speech corpus,” in Proceedings of the 12th Language Resources and Evaluation Conference, 2020, pp. 4218–4222.
- [29] F. Kuang, L. Guo, W. Kang, L. Lin, M. Luo, Z. Yao, and D. Povey, “Pruned RNN-T for fast, memory-efficient ASR training,” arXiv preprint arXiv:2206.13236, 2022.
- [30] E. Bakhturina, Y. Zhang, and B. Ginsburg, “Shallow fusion of weighted finite-state transducer and language model for text normalization,” arXiv preprint arXiv:2203.15917, 2022.
- [31] C. Allauzen, M. Riley, J. Schalkwyk, W. Skut, and M. Mohri, “OpenFst: A general and efficient weighted finite-state transducer library: (extended abstract of an invited talk),” in Implementation and Application of Automata: 12th International Conference, CIAA 2007, Praque, Czech Republic, July 16-18, 2007, Revised Selected Papers 12. Springer, 2007, pp. 11–23.
- [32] K. Gorman, “Pynini: A python library for weighted finite-state grammar compilation,” in Proceedings of the SIGFSM Workshop on Statistical NLP and Weighted Automata, 2016, pp. 75–80.
- [33] K. Gorman and R. Sproat, “Finite-state text processing,” Synthesis Lectures onSynthesis Lectures on Human Language Technologies, vol. 14, no. 2, pp. 1–158, 2021.
- [34] V. Maier, “Evaluating RIL as basis of automatic speech recognition devices and the consequences of using probabilistic string edit distance as input,” Univ. of Sheffield, third year project, 2002.
- [35] A. C. Morris, V. Maier, and P. Green, “From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition,” in Eighth International Conference on Spoken Language Processing, 2004.
- [36] P. M. B. Vitányi, F. J. Balbach, R. L. Cilibrasi, and M. Li, Normalized Information Distance. Boston, MA: Springer US, 2009, pp. 45–82. [Online]. Available: https://doi.org/10.1007/978-0-387-84816-7_3
- [37] R. Cilibrasi and P. M. Vitányi, “Clustering by compression,” IEEE Transactions on Information theory, vol. 51, no. 4, pp. 1523–1545, 2005.
- [38] M. Li, J. H. Badger, X. Chen, S. Kwong, P. Kearney, and H. Zhang, “An information-based sequence distance and its application to whole mitochondrial genome phylogeny,” Bioinformatics, vol. 17, no. 2, pp. 149–154, 2001.
- [39] X. Chen, B. Francia, M. Li, B. Mckinnon, and A. Seker, “Shared information and program plagiarism detection,” IEEE Transactions on Information Theory, vol. 50, no. 7, pp. 1545–1551, 2004.
- [40] R. L. Cilibrasi and P. M. B. Vitanyi, “Normalized web distance and word similarity,” Computer Science, pp. 293–314, 2009.