Speed-up of Data Analysis with Kernel Trick
in Encrypted Domain
Abstract
Homomorphic encryption (HE) is pivotal for secure computation on encrypted data, crucial in privacy-preserving data analysis. However, efficiently processing high-dimensional data in HE, especially for machine learning and statistical (ML/STAT) algorithms, poses a challenge. In this paper, we present an effective acceleration method using the kernel method for HE schemes, enhancing time performance in ML/STAT algorithms within encrypted domains. This technique, independent of underlying HE mechanisms and complementing existing optimizations, notably reduces costly HE multiplications, offering near constant time complexity relative to data dimension. Aimed at accessibility, this method is tailored for data scientists and developers with limited cryptography background, facilitating advanced data analysis in secure environments.
Index Terms:
Homomorphic Encryption, Kernel Method, Privacy-Preserving Machine Learning, Privacy-Preserving Statistical Analysis, High-dimensional Data AnalysisI Introduction
Homomorphic encryption (HE) enables computations on encrypted data, providing quantum-resistant security in client-server models. Since its introduction by Gentry in 2009 [1], HE has rapidly evolved towards practical applications, offering privacy-preserving solutions in various data-intensive fields such as healthcare and finance.
Despite these advancements, applying HE to complex nonlinear data analysis poses significant challenges due to the computational demands of internal nonlinear functions. Although basic models such as linear regression are well-suited for HE, extending this to more complex algorithms, like those seen in logistic regression models [2, 3, 4, 5], often results in oversimplified linear or quasi-linear approaches. This limitation narrows the scope of HE’s applicability to more intricate models.
Furthermore, advanced data analysis algorithms resist simple linearization, shifting the focus of research to secure inference rather than encrypted training. Prominent models like nGraph-HE2 [6], LoLa [7], and CryptoNets [8] exemplify this trend, emphasizing inference over training, with reported latencies on benchmarks like the MNIST dataset of 2.05 seconds for nGraph-HE2, 2.2 seconds for LoLa, and 250 seconds for CryptoNets. It should be noted that these models are only used for testing and do not encrypt trained parameters, relying instead on relatively inexpensive plaintext-ciphertext multiplications, which contributes to their reported time performance.
Since all of these problems arise from the time-consuming nature of operations performed in HE schemes, much literature focuses on optimizing the performance level of FHE by hardware acceleration or adding new functionality in the internal primitive. Jung et al. [9] propose a memory-centric optimization technique that reorders primary functions in bootstrapping to apply massive parallelism; they use GPUs for parallel computation and achieve 100 times faster bootstrapping in one of the state-of-the-art FHE schemes, CKKS [10]. Likewise, [11] illustrates the extraction of a similar structure of crucial functions in HE multiplication; they use GPUs to improve time performance by 4.05 for CKKS multiplication. Chillotti et al. [12] introduces the new concept of programmable bootstrapping (PBS) in TFHE library [13, 14] which can accelerate neural networks by performing PBS in non-linear activation function.
Our approach to optimization is fundamentally different from existing techniques, which primarily focus on hardware acceleration or improving cryptographic algorithms within specific schemes or libraries. Unlike these approaches, our optimizer operates independently of underlying cryptographic schemes or libraries, and works at a higher software (SW) level. As a result, it does not compete with other optimization techniques and can synergistically amplify their effects to improve time performance.
Moreover, our approach does not necessitate extensive knowledge of cryptographic design. By utilizing our technique, significant speed-ups in homomorphic circuits, particularly for machine learning and statistical algorithms, can be achieved with relative ease by data scientists and developers. Our approach requires only a beginner-level understanding of cryptography, yet yields remarkable improvements in performance that are difficult to match, especially for high-dimensional ML/STAT analysis.
Furthermore, our approach holds great promise for enabling training in the encrypted domain, where traditional most advanced machine learning methods struggle to perform. We demonstrate the effectiveness of our technique by applying it to various machine learning algorithms, including support vector machine (SVM), -means clustering, and -nearest neighbor algorithms. In classical implementations of these algorithms in the encrypted domain, the practical execution time is often prohibitive due to the high-dimensional data requiring significant computation. However, our approach provides a nearly dimensionless property, where the required computation for high-dimensional data remains nearly the same as that for low-dimensional data, allowing for efficient training even in the encrypted domain.
Our optimizer is based on the kernel method [15], a widely-used technique in machine learning for identifying nonlinear relationships between attributes. The kernel method involves applying a function that maps the original input space to a higher-dimensional inner product space. This enables the use of modified versions of machine learning algorithms expressed solely in terms of kernel elements or inner products of data points. By leveraging this approach, our optimizer enables the efficient training of machine learning algorithms even in the presence of high-dimensional data, providing a powerful tool for encrypted machine learning.
Our findings suggest that the kernel trick can have a significant impact on HE regarding execution time. This is due to the substantial time performance gap between addition and multiplication operations in HE. In HE schemes, the design of multiplication is much more complex. For example, in TFHE, the multiplication to addition is about 21, given the 16-bit input size for Boolean evaluation. In addition, BGV-like schemes (BGV, BFV, CKKS) require additional steps followed by multiplication of ciphertexts such as relinearization and modulus-switching. On contrary, the latency of plain multiplication is approximately the same as that of plain addition [16].
The kernel method can effectively reduce the number of heavy multiplication operations required, as it transforms the original input space to an inner product space where kernel elements are used for algorithm evaluation. Since the inner product between data points is pre-evaluated in the preprocessing stage, and since the inner product involves the calculation of (dimension size) multiplications, much of the multiplication in the algorithm is reduced in this process. This structure can lead to significant performance improvements for some ML/STAT algorithms, such as -means and total variance.
To showcase the applicability of the kernel method to encrypted data, we performed SVM classification as a preliminary example on a subset of the MNIST dataset [17] using the CKKS encryption scheme, which is implemented in the open-source OpenFHE library [18]. Specifically, we obtained an estimation111 represents the security parameter, signifies the dimension of the polynomial ring, is the scaling factor, and stands for the circuit depth (Check [10].) of 38.18 hours and 509.91 seconds for SVM’s general and kernel methods, respectively. This demonstrates a performance increase of approximately 269 times for the kernel method compared to the classical approach.
We summarize our contributions as follows:
-
•
Universal Applicability. Introduced the linear kernel trick to the HE domain, where our proposed method works independently, regardless of underlying HE schemes or libraries. The kernel method can synergistically combine with any of the underlying optimization techniques to boost performance.
-
•
Dimensionless Efficiency. Demonstrated near-constant time complexity across ML/STAT algorithms (classification, clustering, dimension reduction), leading to significant execution time reductions, especially for high-dimensional data.
-
•
Enhanced Training Potential. Shown potential for significantly improved ML training in the HE domain where current HE training models struggle.
-
•
User-Friendly Approach. Easily accessible for data scientists and developers with limited knowledge of cryptography.
II Preliminaries
II-A Homomorphic Encryption (HE)
Homomorphic encryption (HE) is a quantum-resistant encryption scheme that includes a unique evaluation step, allowing computations on encrypted data. The main steps for a general two-party (client-server model) symmetric HE scheme are as follows, with the client performing:
-
•
KeyGen(): Given a security parameter , the algorithm outputs a secret key and an evaluation key .
-
•
Enc(, ): Given a message from the message space , the encryption algorithm uses the secret key to generate a ciphertext .
-
•
Dec(, ): Given a ciphertext encrypted under the secret key , the decryption algorithm outputs the original message .
A distinguishing feature of HE, compared to other encryption schemes, is the evaluation step, Eval, which computes on encrypted messages and is performed by the server.
-
•
Eval(, ; ): Suppose a function is to be performed over messages . The evaluation algorithm takes as input the ciphertexts , each corresponding to encrypted under the same , and uses to generate a new ciphertext such that .
Fully or Leveled HE. The most promising HE schemes rely on lattice-based problem—learning with errors (LWE) which Regev [19] proposed in 2005, followed by its ring variants by Stehlé [20] in 2009. LWE-based HE uses noise for security; however, the noise is accumulated for each evaluation of ciphertext. When the noise of ciphertext exceeds a certain limit, the decryption of ciphertext does not guarantee the correct result. Gentry [1] introduces a bootstrapping technique that periodically reduces the noise of the ciphertext for an unlimited number of evaluations, i.e., fully homomorphic. However, such bootstrapping is a costly operation. Thus many practical algorithms bypass bootstrapping and instead use leveled homomorphic encryption, or LHE—the depth of the circuit is pre-determined; it uses just enough parameter size for the circuit to evaluate without bootstrapping.
Arithmetic or Boolean. There are two primary branches of FHE: arithmetic and Boolean-based. (1) The arithmetic HE—BGV [21] family—uses only addition and multiplication. Thus, it has to approximate nonlinear operations with addition and multiplication. Also, it generally uses the LHE scheme and has a faster evaluation. B/FV [22] and CKKS [10] are representative examples. (2) Boolean-based HE is the GSW [23] family—FHEW [24] and TFHE [14], which provides fast-bootstrapping gates such as XOR and AND gates. Typically, it is slower than arithmetic HE; however, it has more functionalities other than the usual arithmetics.
II-B Kernel Method
In data analysis, the kernel method is a technique that facilitates the transformation from the input space to a high-dimensional feature space , enabling the separation of data in that is not linearly separable in the original space . The kernel function computes the inner product of and in without explicitly mapping the data to the high-dimensional space . The kernel matrix is a square symmetric matrix of size that contains all pair-wise inner products of and , i.e., , where the data matrix contains data points each with dimension . For more details, refer to [25].
III Kernel Effect in Homomorphic Encryption
III-A Why is Kernel More Effective in HE than Plain Domain?
The kernel method can greatly benefit from the structural difference in HE between addition and multiplication operations. Specifically, the main reason is that the kernel method avoids complex-designed HE multiplication and uses almost-zero cost additions.
Time-consuming HE Multiplication. Homomorphic multiplication is significantly more complex than addition, unlike plain multiplication, which has a similar time performance to addition. For example, in the BGV family of the homomorphic encryption scheme, the multiplication of two ciphertexts and is defined as:
where is the polynomial ring. The size of the ciphertext grows after multiplication, requiring an additional process called relinearization to reduce the ciphertext to its normal form. In the CKKS scheme, a rescaling procedure is used to maintain a constant scale. On the other hand, HE addition is merely vector addition of polynomial ring elements . Thus, the performance disparity between addition and multiplication in HE is substantial compared to that in plain operations (see Table I).
| Plain222We obtained the average execution time of plaintext additions and multiplications by measuring their runtime 1000 times each. | TFHE333 | CKKS444 | B/FV555 | |
| Addition | ||||
| Multiplication | ||||
| Ratio |
III-B Two Kernel Properties for Acceleration
P1: Parallel Computation of Kernel Function. One property of kernel evaluation is the ability to induce parallel structures in the algorithm, such as computing kernel elements . Since evaluating kernel elements involves performing the same dot product structure over input vectors of the same size, HE can benefit from parallel computation of these kernel elements. For instance, in the basic HE model, (1) the server can perform concurrent computation of kernel elements during the pre-processing stage. (2) Alternatively, the client can compute the kernel elements and send the encrypted kernels to the server as alternative inputs, replacing the original encrypted data for further computation. Either way, the server can bypass the heavy multiplication in the pre-processing stage, thereby accelerating the overall kernel evaluation process (see Fig. 1).
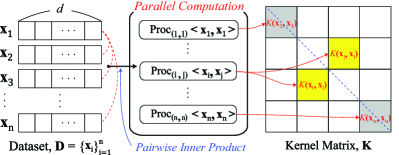
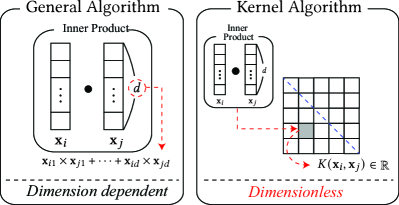
P2: Dimensionless—Constant Time Complexity with respect to Dimension. A key feature of the kernel method in HE schemes is its dimensionless property. Generally, evaluating certain ML/STAT algorithms requires numerous inner products of vectors, each involving multiplications. Given the high computational cost of HE multiplications, this results in significant performance degradation. However, by employing the kernel method, we can circumvent the need for these dot products. Consequently, dimension-dependent computations are avoided during kernel evaluation, leading to a total time complexity that is constant with respect to the data dimension , unlike general algorithms, which have a linear dependency on (see Fig. 2).
III-C Example: -means Algorithm
The means algorithm is an iterative process for finding optimal clusters. The algorithm deals with (1) cluster reassignment and (2) centroid update (see Fig. 3). The bottleneck is the cluster reassignment process that computes the distance from each centroid . Since evaluating the distance requires a dot product of the deviation from the centroid, multiplications are required for calculating each distance. Assuming that the algorithm converges in iteration, the total number of multiplications is .

Using the kernel method and its properties, we can significantly improve the time performance of the circuit. First, we express the distance in terms of the kernel elements:
| (1) |
where is the number of elements in the cluster . We verify that only one multiplication is performed in Eq. (1), which reduces the multiplications by a factor of from the general distance calculation. Therefore, the total number of multiplications in the kernel means is (P2, dimensionless property), whereas in the general method. Note that we can evaluate the kernel elements in parallel at the algorithm’s beginning, compensating for the multiplication time (P1, parallel structure).
Kernel Method—More Effective in the Encrypted Domain: means Simulation. Based on algorithms in Fig. 3, we simulate the -means algorithm within different types of domains—plain, TFHE, CKKS, and B/FV—to demonstrate the effectiveness of the kernel method in the encrypted domain (see Fig. 4). We count the total number of additions and multiplications in means; based on the HE parameter set and execution time in Table I, we compute the total simulation time with fixed parameters .
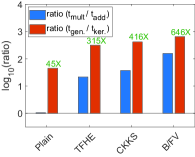
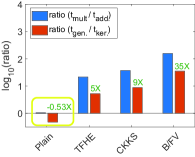
The result indicates that the kernel method is more effective in the encrypted domain. Fig. 4a shows that the kernel method has a significant speed-up when the time ratio of addition and multiplication is large. For instance, B/FV has a maximum speed-up of times, whereas plain kernel has times (CKKS: times, TFHE: times). Moreover, Fig. 4b demonstrates that depending on the parameter set, the kernel effect on the time performance can differ. For instance, B/FV has a speed-up of times in Fig. 4b.
Furthermore, the kernel can even have a negative impact on the execution time. For example, the plain kernel in Fig. 4b conversely decreases the total execution time by percent. This highlights the sensitivity of the plain kernel’s performance to variations. We provide actual experimental results regarding the kernel effect in Section VI.
III-D Benefits of the Kernel Method
Software-Level Optimization—Synergistic with Any HE Schemes or Libraries. The kernel method is synergistic with any HE scheme, amplifying the speed-up achieved by HE hardware accelerators since it operates at the software level. For instance, [11] uses GPUs at the hardware level to accelerate HE multiplication by 4.05 times in the CKKS scheme. When the kernel method is applied to evaluate the SVM of dimension 784 (single usage: 269), it can increase acceleration by more than 1,076 times. Most current literature focuses on the hardware acceleration of each HE scheme. However, the kernel method does not compete with each accelerator; instead, it enhances the time performance of HE circuits.
Reusability of the Kernel Matrix. The kernel method enables the reusability of the kernel matrix, which can be employed in other kernel algorithms. The server can store both the dataset and the kernel matrix , eliminating the need to reconstruct inner products of data points. This results in faster computations and efficient resource utilization.
IV Kernel Trick and Asymptotic Complexities
This section analyzes the time complexities of general and kernel evaluations for ML/STAT algorithms. We first present a summary of the theoretical time complexities in Table II, followed by an illustration of how these complexities are derived. Note that the -means and -NN algorithms use a Boolean-based approach, while the remaining algorithms are implemented with an arithmetic HE scheme.
| Algorithm | General TC | Kernel TC |
|---|---|---|
| SVM | ||
| PCA | ||
| -NN | ||
| -means | ||
| Total Variance | ||
| Distance | ||
| Norm | ||
| Similarity |
IV-A Arithmetic HE Construction
Matrix Multiplication and Linear Transformation. Halevi et al. [26] demonstrate efficient matrix and matrix-vector multiplication within HE schemes. Specifically, the time complexity for multiplying two matrices is optimized to , while linear transformations are improved to .
Dominant Eigenvalue: Power Iteration. The power iteration method [28] recursively multiplies a matrix by an initial vector until convergence. For a square matrix of degree , assuming iterations, the time complexity is .
Square Root and Inverse Operation of Real Numbers. Wilkes’s iterative algorithm [29] approximates the square root operation with a complexity of . Goldschmidt’s division algorithm approximates the inverse operation with a complexity of .
IV-A1 SVM
Kernel Trick. The main computation part of SVM is to find the optimal parameter to construct the optimal hyperplane . For optimization, we use SGD algorithm that iterates over the following gradient update rule: .
The kernel trick for SVM is a replacement of with a linear kernel element . Thus, we compute for the kernel evaluation.
(1) General Method. The gradient update rule for requires multiplications. For the complete set of and assuming that the worst-case of convergence happens in iterations, the total time complexity is .
(2) Kernel Method. The kernel trick bypasses inner products, which requires multiplications. Hence, it requires multiplications for updating ( for ). Therefore, the total time complexity is .
IV-A2 PCA
Kernel Trick. Suppose is the dominant eigenvalue with the corresponding eigenvector of the covariance matrix . Then, the eigenpair satisfies . Since , we can express where . Plugging in the formulae for and and multiplying on both sides yield: for all . By substituting inner products with the corresponding kernel elements , we derive the following equation expressed in terms of the kernel elements:
Further simplification yields , where is an eigenvector of the kernel matrix . Thus, a reduced basis element is derived by scaling with .
Comparison of Complexities. Both general and kernel methods require the computation of eigenvalues and eigenvectors using the power iteration method for the covariance matrix and kernel matrix .
(1) General Method. This algorithm involves one matrix multiplication, power iteration, and matrix-vector multiplications. The time complexity is , where .
(2) Kernel Method. This algorithm involves power iteration, normalizations (square root), and inner-products. The time complexity is .
IV-A3 Total Variance
Kernel Trick. The linear kernel trick simplifies the normal variance formula by expressing it in terms of dot products:
where the second equality holds by substituting .
(1) General Method. This requires dot products of deviations; the time complexity is .
(2) Kernel Method. The kernel trick for total variance bypasses dot products, resulting in a time complexity of .
IV-A4 Distance / Norm
Kernel trick. We can apply the linear kernel trick on distance :
(1) General Method. The general distance formula requires for evaluating a dot product. Moreover, norm operation entails additional square root operation; hence, .
(2) Kernel Method. The kernel method necessitates only addition and subtraction requiring . Likewise, kernelized norm involves the square root operation; thus, .
IV-A5 Similarity
Kernel Trick. Applying the linear kernel trick to cosine similarity formula, we have
(1) General Method. We compute three dot products, one multiplication, one inverse of a scalar, and two square root operations for computing the general cosine similarity. Hence, it requires .
(2) Kernel Method. We can bypass the evaluation of the three inner products using the kernel method. Thus, the total time complexity is .
IV-B Boolean-based HE Construction
-means and -NN Boolean Construction. Performing -means and -NN in the encrypted domain requires functionalities beyond addition and multiplication, such as comparison operations. In the -means algorithm, it is essential to evaluate the minimum encrypted distance to label data based on proximity to each cluster’s encrypted mean. Similarly, -NN necessitates evaluating the maximum encrypted labels given the encrypted distances to all data points. Detailed algorithms for -means and -NN are provided in the Appendix.
Time Complexity for TFHE Circuit Evaluation. We measure the algorithms’ performance by counting the total number of binary gates for exact calculation. Boolean gates such as XOR, AND, and OR take twice the time of a single MUX gate [14]. We assume that the TFHE ciphertext is an encryption of an -bit fixed-point number, with bits for decimals, bits for integers, and bit for the sign bit. Table III presents the time complexity of fundamental TFHE operations used throughout the paper.
| TFHE Basic Operation | |||||||
| Comparison | argmin / argmax | Add / Subt. | Multiplication | Absolute Value | Two’s Complement | Division | |
| (Binary Gate) | |||||||
IV-B1 -means
Kernel Trick. Let denote the distance from data point to the mean of cluster .
where is the number of elements in cluster . Applying the linear kernel trick, we can compute using kernel elements:
Further simplification yields the objective function:
| (2) |
where the common factor and divisions are omitted for efficiency.
(1) General Method. The -means algorithm involves four steps: computing distances , labeling , forming labeled dataset , and calculating cluster means . The total complexity of -means is asymptotically , assuming iterations until convergence.
(2) Kernel Method. The kernel -means algorithm involves four steps: computing the labeled kernel matrix , counting the number of elements in each cluster, computing distances , and labeling . The total complexity of kernel -means is asymptotically , assuming iterations until convergence.
IV-B2 -NN
Kernel Trick. The linear kernel trick can be applied to the distance in -NN:
For computational efficiency, we simplify by removing the common kernel element :
| (3) |
Comparison of Complexities. Both -NN algorithms share the same processes: sorting, counting, and finding the majority label. Specifically, sorting requires swaps, with each swap involving 4 MUX gates and one comparison circuit, resulting in a complexity of . Counting elements in each class requires comparisons and additions, with a complexity of . Finding the majority index among labels has a complexity of . Thus, the shared complexity is , denoted as .
(1) General Method. Computing involves subtractions, multiplications, and additions, resulting in a total complexity of . Including the shared process, the total complexity is .
(2) Kernel Method. Using Eq. (3), is computed with one addition and two subtractions per element, totaling additions. Including the shared process, the total complexity is .
V Experiment
V-A Evaluation Metric
We aim to evaluate the effectiveness of the kernel method in various ML/STAT algorithms using the following metrics.
(1) Kernel Effect in HE. Let and denote the execution times for the general and kernel methods, respectively. The kernel effectiveness or speed-up is evaluated by the ratio:
(2) Kernel Effect Comparison: Plain and HE. Let and represent the execution times for the general and kernel methods in the plain domain. Similarly, let and represent the execution times in the HE domain. The effectiveness of the kernel methods in both domains can be compared by their respective ratios: and .
V-B Experiment Setting
Environment. Experiments were conducted on an Intel Core i7-7700 8-Core 3.60 GHz, 23.4 GiB RAM, running Ubuntu 20.04.5 LTS. We used TFHE version 1.1 for Boolean-based HE and CKKS from OpenFHE [18] for arithmetic HE.
Dataset and Implementation Strategy. We used a randomly generated dataset of data points with dimensions in . The dataset is intentionally small due to the computational time required for logic-gates in TFHE. For example, -means with parameters () under the TFHE scheme takes 8,071 seconds. Despite the small dataset, this work aligns with on-going efforts like Google’s Transpiler [27] and its extension HEIR, which use TFHE for practical HE circuit construction. Employing the kernel method can significantly enhance scalability and efficiency.
Parameter Setting. Consistent parameters were used for both the general and kernel methods across all algorithms.
(1) TFHE Construction. TFHE constructions were set to a 110-bit security level666Initial tests at 128-bit security were revised due to recent attacks demonstrating a lower effective security level., with 16-bit message precision.
(2) CKKS Construction. CKKS constructions used a 128-bit security level and a leveled approach to avoid bootstrapping. Parameters () were pre-determined to minimize computation time (see Table IV).
(3) -means and -NN. For the experiments, and were used for -means, and for -NN.
| RingDim | ScalingMod | MultDepth | ||
|---|---|---|---|---|
| SVM | ||||
| PCA | ||||
| Variance | ||||
| Distance | ||||
| Norm | ||||
| Similarity |
VI Results and Analysis
VI-A Kernel Effect in the Encrypted Domain
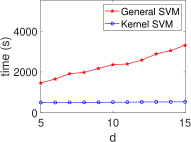
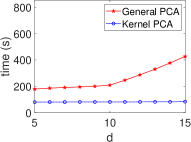
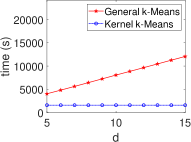
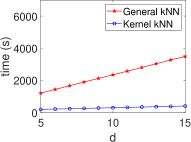
Kernel Method in ML/STAT: Acceleration in HE Schemes. Fig. 5 demonstrates the stable execution times of kernel methods in ML algorithms within encrypted domains, contrasting with the linear increase observed in general methods. This consistency in both CKKS and TFHE settings aligns with our complexity analysis in Table II, improving computational efficiency for algorithms such as SVM, PCA, -means, and -NN. Notably, for general PCA, we observe a linear time increase for and a rapid rise as for due to the quadratic complexity of evaluating the covariance matrix .
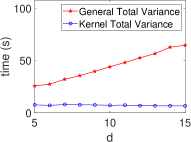
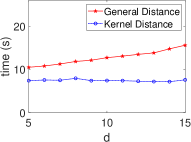
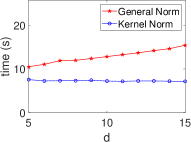
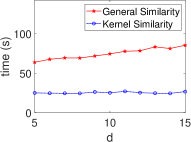
Fig. 6 shows that the kernel method consistently outperforms general approaches in STAT algorithms within HE schemes. The kernel method maintains stable execution times across various statistical algorithms, unlike the linearly increasing times of general methods as data dimension grows. This aligns with our complexity calculations (Table II), highlighting the kernel method’s efficiency in encrypted data analysis. The dimensionless property of the kernel method makes it a powerful tool for high-dimensional encrypted data analysis, enabling efficient computations in complex settings.
Kernelization Time (Pre-Processing Stage). Kernelization occurs during preprocessing, with kernel elements computed in parallel. Although not included in the main evaluation duration, kernelization time is minimal, constituting less than 0.05 of the total evaluation time. For instance, in SVM, kernel generation accounts for only 0.02 of the total evaluation time (10.82 seconds of 509.91 seconds). Additionally, the reusability of kernel elements in subsequent applications further reduces the need for repeated computations.
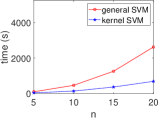
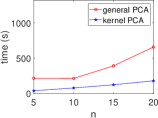
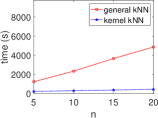
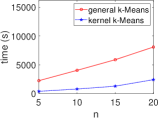
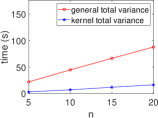
Kernel Method Outperforms with Increasing Data. We present the execution time of four ML algorithms (SVM, PCA, -NN, -means) and the total variance in the STAT algorithm, with respect to varying numbers of data () at a fixed dimension (), as shown in Fig. 7. Our results demonstrate that the kernel method consistently outperforms the general method in terms of execution time, even as the number of data increases. This aligns with our complexity table (see Table 3), where general SVM and PCA show a quadratic increase, while -NN, -means, and total variance increase linearly.
VI-B Kernel Effect Comparison: Plain vs HE
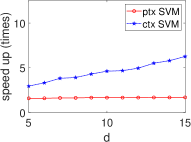
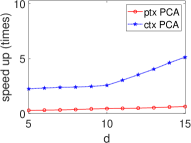
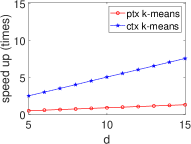
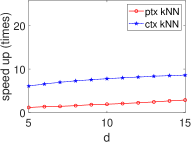
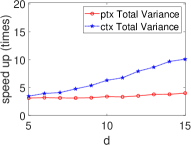
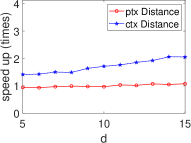
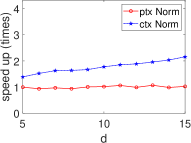
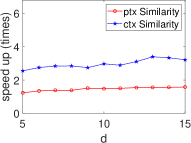
Significant Kernel Effect in the HE Domain. Our experiments demonstrate a more substantial kernel effect in the HE domain compared to the plain domain for both ML and STAT algorithms. This effect is consistently observed across algorithms (see Fig. 8 and Fig. 9). For example, the kernel effect in SVM within HE amplifies performance by 2.95-6.26 times, compared to 1.58-1.69 times in the plain domain, across dimensions 5-15. This enhanced performance is due to the kernel method’s ability to reduce heavy multiplicative operations, a significant advantage in HE where multiplication is more time-consuming than addition (see Section III).
VII Conclusion
This paper introduces the kernel method as an effective optimizer for homomorphic circuits in ML/STAT applications, applicable across various HE schemes. We systematically analyze the kernel optimization and demonstrate its effectiveness through complexity analysis and experiments. Our results show significant performance improvements in the HE domain, highlighting the potential for widespread use in secure ML/STAT applications.
References
- [1] C. Gentry, ”Fully homomorphic encryption using ideal lattices,” in Proc. 41st Annu. ACM Symp. Theory Comput., 2009, pp. 169–178.
- [2] A. Kim, Y. Song, M. Kim, K. Lee, and J. H. Cheon, ”Logistic regression model training based on the approximate homomorphic encryption,” BMC Med. Genomics, vol. 11, no. 4, pp. 23–31, 2018.
- [3] H. Chen, R. Gilad-Bachrach, K. Han, Z. Huang, A. Jalali, K. Laine, and K. Lauter, ”Logistic regression over encrypted data from fully homomorphic encryption,” BMC Med. Genomics, vol. 11, no. 4, pp. 3–12, 2018.
- [4] Y. Aono, T. Hayashi, L. T. Phong, and L. Wang, ”Scalable and secure logistic regression via homomorphic encryption,” in Proc. Sixth ACM Conf. Data Appl. Secur. Priv., 2016, pp. 142–144.
- [5] E. Crockett, ”A low-depth homomorphic circuit for logistic regression model training,” Cryptology ePrint Archive, 2020.
- [6] F. Boemer, A. Costache, R. Cammarota, and C. Wierzynski, ”nGraph-HE2: A high-throughput framework for neural network inference on encrypted data,” in Proc. 7th ACM Workshop Encrypted Comput. & Appl. Homomorphic Cryptogr., 2019, pp. 45–56.
- [7] A. Brutzkus, R. Gilad-Bachrach, and O. Elisha, ”Low latency privacy preserving inference,” in Int. Conf. Mach. Learn., 2019, pp. 812–821.
- [8] R. Gilad-Bachrach, N. Dowlin, K. Laine, K. Lauter, M. Naehrig, and J. Wernsing, ”Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy,” in Int. Conf. Mach. Learn., 2016, pp. 201–210.
- [9] W. Jung, S. Kim, J. H. Ahn, J. H. Cheon, and Y. Lee, ”Over 100x faster bootstrapping in fully homomorphic encryption through memory-centric optimization with GPUs,” IACR Trans. Cryptogr. Hardw. Embed. Syst., pp. 114–148, 2021.
- [10] J. H. Cheon, A. Kim, M. Kim, and Y. Song, ”Homomorphic encryption for arithmetic of approximate numbers,” in Int. Conf. Theory Appl. Cryptol. Inf. Secur., Springer, 2017, pp. 409–437.
- [11] W. Jung, E. Lee, S. Kim, J. Kim, N. Kim, K. Lee, C. Min, J. H. Cheon, and J. H. Ahn, ”Accelerating fully homomorphic encryption through architecture-centric analysis and optimization,” IEEE Access, vol. 9, pp. 98772–98789, 2021.
- [12] I. Chillotti, M. Joye, and P. Paillier, ”Programmable bootstrapping enables efficient homomorphic inference of deep neural networks,” in Int. Symp. Cyber Secur. Cryptogr. Mach. Learn., Springer, 2021, pp. 1–19.
- [13] I. Chillotti, N. Gama, M. Georgieva, and M. Izabachene, ”Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds,” in Adv. Cryptol.–ASIACRYPT, 2016, pp. 3–33.
- [14] I. Chillotti, N. Gama, M. Georgieva, and M. Izabachène, ”TFHE: Fast Fully Homomorphic Encryption over the Torus,” J. Cryptol., vol. 33, no. 1, pp. 34–91, 2020.
- [15] M. J. Zaki and W. Meira, Data Mining and Analysis: Fundamental Concepts and Algorithms. Cambridge University Press, 2014.
- [16] Part Guide, ”Intel® 64 and ia-32 architectures software developer’s manual,” Vol. 3B: System Programming Guide, Part, vol. 2, no. 11, 2011.
- [17] L. Deng, ”The MNIST database of handwritten digit images for machine learning research,” IEEE Signal Process. Mag., vol. 29, no. 6, pp. 141–142, 2012.
- [18] A. Al Badawi et al., ”OpenFHE: Open-Source Fully Homomorphic Encryption Library,” in Proc. 10th Workshop Encrypted Comput. & Appl. Homomorphic Cryptogr., 2022, pp. 53–63.
- [19] O. Regev, ”On lattices, learning with errors, random linear codes, and cryptography,” J. ACM, vol. 56, no. 6, pp. 1–40, 2009.
- [20] D. Stehlé, R. Steinfeld, K. Tanaka, and K. Xagawa, ”Efficient public key encryption based on ideal lattices,” in ASIACRYPT, 2009, pp. 617–640.
- [21] Z. Brakerski, C. Gentry, and V. Vaikuntanathan, ”(Leveled) fully homomorphic encryption without bootstrapping,” ACM Trans. Comput. Theory, vol. 6, no. 3, pp. 1–36, 2014.
- [22] J. Fan and F. Vercauteren, ”Somewhat practical fully homomorphic encryption,” Cryptology ePrint Archive, 2012.
- [23] C. Gentry, A. Sahai, and B. Waters, ”Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based,” in Annu. Cryptol. Conf., 2013, pp. 75–92.
- [24] L. Ducas and D. Micciancio, ”FHEW: bootstrapping homomorphic encryption in less than a second,” in Annu. Int. Conf. Theory Appl. Cryptogr. Tech., 2015, pp. 617–640.
- [25] B. Schölkopf, A. J. Smola, and F. Bach, Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press, 2002.
- [26] S. Halevi and V. Shoup, ”Faster homomorphic linear transformations in HElib,” in Annu. Int. Cryptol. Conf., 2018, pp. 93–120.
- [27] S. Gorantala, R. Springer, S. Purser-Haskell, W. Lam, R. Wilson, A. Ali, E. P. Astor, I. Zukerman, S. Ruth, C. Dibak, et al., ”A general purpose transpiler for fully homomorphic encryption,” arXiv preprint arXiv:2106.07893, 2021.
- [28] G. H. Golub and H. A. Van der Vorst, ”Eigenvalue computation in the 20th century,” J. Comput. Appl. Math., vol. 123, no. 1–2, pp. 35–65, 2000.
- [29] M. V. Wilkes, D. J. Wheeler, and S. Gill, The Preparation of Programs for an Electronic Digital Computer: With special reference to the EDSAC and the Use of a Library of Subroutines. Addison-Wesley Press, 1951.
Appendix A ML / STAT
Appendix B means and NN: Boolean Construction
B-A Boolean-based HE Construction: -means
(1) General Method. Constructing the -means circuit in the encrypted domain presents a primary challenge: the iterative update of encrypted labels in each iteration.
| (4) |
This involves two key tasks: 1) labeling data using Eq. (4), and 2) computing the average value for each cluster based on the encrypted labels.
Issue 1: Labeling Data. We solve Eq. (4) using the TFHE.LEQ comparison operation. This operation returns if is less than or equal to , and otherwise. Algorithm 1 determines the index of the minimum value from a set of encrypted ciphertexts . The output is a binary ciphertext , where a non-zero indicates the label corresponding to .
Issue 2: Computing Average Value. Identifying the data in a specific group using encrypted labels is challenging. We address this by extracting cluster data , setting non-belonging data to zero through an AND operation between each label and its respective data (see Algorithm 2).
With identified, the mean for each cluster is computed by summing all elements in and dividing by the number of elements in the class . The number of elements in each class is obtained by summing the encrypted label for all (see Algorithm 3).
(2) Kernel Method. Kernel -means reduces to solving Eq. (2). Directly solving partial sums from the kernel matrix is infeasible due to encrypted labels. Therefore, we proceed as follows (see Algorithm 4 for the complete kernel evaluation):
-
•
Obtain cluster-specific kernel , where equals if both ; otherwise, it is zero.
-
•
Compute the partial sums from Eq. (2) using the cluster-specific kernel .
Proc. 1: Cluster-specific Kernel. We obtain using and AND gates:
where is if both and belong to .
Proc. 2: Partial Sum Evaluation. We compute over elements in :
B-B Boolean-based HE construction: NN
(1) General Method: The -NN algorithm involves 1) sorting, 2) counting, and 3) finding the majority label among encrypted data. We address the issues as follows.
Issue 1: Sorting. We use the TFHE.minMax function, detailed in Algorithm 5, to arrange a pair of ciphertexts in ascending order using the TFHE.LEQ operation. By using and its negation as selectors in a MUX gate, we obtain the ordered pair .
By employing the TFHE.minMax function, Algorithm 6 executes the Bubblesort algorithm, yielding a sorted sequence in ascending order, with their respective labels .
Issue 2: Counting. From the sorted distances and respective labels , we count the number of elements in each class among the nearest neighbors. We repeatedly use the TFHE.EQ comparison, which outputs if two input ciphertexts are equal (see Algorithm 7).
Issue 3: Majority Label. Finally, we use the TFHE.argmax operation on to determine the majority label.
(2) Kernel Method. Kernel evaluation of -NN replaces distance calculations with kernel elements (see Algorithm 8).