Splitting Gaussian Process Regression for
Streaming Data
Abstract
Gaussian processes offer a flexible kernel method for regression. While Gaussian processes have many useful theoretical properties and have proven practically useful, they suffer from poor scaling in the number of observations. In particular, the cubic time complexity of updating standard Gaussian process models make them generally unsuitable for application to streaming data. We propose an algorithm for sequentially partitioning the input space and fitting a localized Gaussian process to each disjoint region. The algorithm is shown to have superior time and space complexity to existing methods, and its sequential nature permits application to streaming data. The algorithm constructs a model for which the time complexity of updating is tightly bounded above by a pre-specified parameter. To the best of our knowledge, the model is the first local Gaussian process regression model to achieve linear memory complexity. Theoretical continuity properties of the model are proven. We demonstrate the efficacy of the resulting model on multi-dimensional regression tasks for streaming data.
1 Introduction
Gaussian process (GP) regression is a flexible kernel method for approximating smooth functions from data. Assuming there is a latent function which describes the relationship between predictors and a response, from a Bayesian perspective a GP defines a prior over latent functions. When conditioned on the observed data, the GP then gives a posterior distribution of the latent function. In practice, GP models are fit to training data by optimizing the marginal log likelihood with respect to hyperparameters of the kernel function, .
A notable shortcoming of GP regression is its poor scaling both in memory and computational complexity. In what we will hereafter refer to as full GP regression, the posterior mean and variance can be directly computed at any finite number of points using linear algebra [24]. However, a computational bottleneck is caused by the necessary matrix inversion of the kernel matrix , which is well-known to have a time complexity of , where is the number of observations. The memory complexity of storing may also pose issues for massive data sets.
GP regression may also struggle to well-approximate latent functions which are non-stationary [7, 9]. Non-stationary latent function’s mean or covariance may vary over its domain. Non-stationarity may be induced in more subtle ways as well, such as heteroscedastic additive noise in the observed response.
Local GP regression is a class of models which address both of these problems, to varying extents. The commonality of these models is the assignment of observations to one of many local GPs during training, and the aggregation of the local models’ individual predictions. As a result of observations being assigned to a single local model, effectively only a block-diagonal approximation of the full kernel matrix is maintained [20, 3], easing the time and memory complexity. The price of this flexibility and computational advantage is a potential decrease in predictive ability, relative to full GP regression, on tasks for which a full GP is well-suited.
A successful method for assigning observations to local GPs is partitioning the input space, the domain of the latent function, and creating a local GP model for each cell of the partition. Existing local GP models may encounter various difficulties during the partitioning process, as detailed in Section 2, and/or neglect a setting where only a sequential data source is available and partitioning must be performed sequentially.
This sequential setting is important since it encompasses tasks with changing dynamics. For example, in applications such as process quality monitoring [29, 13] and motion tracking [11], a sequential approach allows for the model to adapt to regimes which are yet-unobserved.
The primary contribution of this paper is an algorithm which recursively partitions the input space to construct local GPs using sequential observations. The resulting model is dubbed the splitting GP. The algorithm is shown to have superior asymptotic time and memory complexity relative to other state-of-the-art local GP methods which can be used in this problem setting. By design of the algorithm, we also ensure an exact upper bound on the time complexity of updating the splitting GP model. We also prove theoretical properties of the model related to continuity of the predictions and empirically demonstrate the efficacy of the model. Additionally, a software implementation of the algorithm is provided, which leverages the computational advantages of the GPyTorch library [6], to facilitate the use of the algorithm by others.
2 Related work
It appears that the first exploration of local GP regression is due to Rasmussen and Ghahramani [23], as a special case of their mixture of GP experts model, where prediction at a point is performed by one designated “expert” GP. Snelson and Ghahramani [26] further developed this idea, but only as a supplementary method to sparse GP regression.
An adjacent line of research on treed GP models was begun by Gramacy [7]. Treed GP models perform domain decomposition in the same manner as classification and regression trees [2], and fit distinct GP models to each resulting partition. Predictions are then formed using -nearest neighbors. Gramacy [7] found that local GP regression methods, such as treed GP models, were well-suited to non-stationary regression tasks since each leaf GP model in the tree could specialize to local phenomena in the data. Since the inception of this method, further advances have been made by Gramacy and collaborators [9, 8], particularly with respect to large scale computer experiments and surrogate modeling. It is acknowlegded by Gramacy [7] and Gramacy and Lee [9] that predictions by the treed GP model are not continuous in the input space. Additionally, the construction of the tree is performed probabilistically, and does not make use of the intrinsic structure of the data for domain decomposition.
Since the original proposal of local GP regression, several methods have been proposed which are adapted to the sequential setting. Shen et al. [25] reduced the prediction time and kernel matrix storage for isotropic kernels by building a kd-tree from the training data set. Nguyen-Tuong et al. [18] proposed a method of local GP regression for online learning, which assigns incoming data to local models by similarity in the feature space and forms mean predictions by weighting local predictions. This local GP model was among the first to consider a fully sequential setting. This model has two notable drawbacks: it suffers from discontinuities in its predictive mean, and depends on a hyperparameter which is difficult to tune in practice and strongly affects prediction performance. Another local GP method which may be used in the sequential setting is the robust Bayesian committee machine (rBCM) by Deisenroth and Ng [4], which can be seen as a product of GP experts [10]. The rBCM emphasizes rapid, distributed computation over model flexibility. This is demonstrated by a) its assumption that the latent function is well-modeled by a single GP and b) consequent random assignment of observations to GP experts, rather than a partitioning-based approach. This modeling approach does not address potential non-stationarity of the latent function.
More recently, Park and collaborators have done significant work in this area, applying mesh generating procedures from finite element analysis [21, 22] and the recursive Principal Direction Divisive Partitioning algorithm [20, 1] to partition the input space for fitting local models. However, in these papers it is assumed that a substantial number of observations are available during the initial model construction to perform the partitioning procedure, particularly when using mesh generation methods. These models also suffer from discontinuities at the boundaries of partition cells, an issue which the authors have creatively addressed by adding constraints to the hyperparameter optimization which force equality at finitely many boundary points, or by adding “pseudo-inputs” at the boundaries to induce continuity.
3 Recursive splitting of local Gaussian processes
As previous works have shown, there is a trade-off between the predictive ability of the aggregate model, the number of local models, and computation speed. Given this fact, we aim to construct a model which maintains strong predictive capability while keeping its computational demands below a pre-specified upper bound. We show that this can be accomplished in a straightforward manner by recursively splitting GP models once they surpass a presupposed threshold in the number of observations. Splitting the model amounts to performing a clustering subroutine which divides the observations associated with the model into two subsets, and then fitting a new local model to each subset.
We consider streaming data that requires the model to permit sequential updating and prediction. A natural quantity of interest is the time required for a single update; since is a function of the size, , of the kernel matrix of a local model indexed by , is then an interpretable parameter describing the period of splitting. The parameter may be interpreted as the splitting limit, the maximum number of observations which may be assigned to a local model before it is split. For the remainder of the paper, we will describe the splitting GP model, which is characterized almost entirely by this intuitive parameterization. Additionally, the full specification of the splitting GP algorithm may be found as pseudo-code in the appendix.
3.1 Notation
In preparation for the proceeding material, we define some notation. We assume some familiarity of readers with the theory of GPs and kernel methods [24].
The input data matrix and the response vector associated with the local model are denoted by
and , respectively, where is a column vector and is the number of observations associated with the local model. We call the input space.
When creating the local GP, its center is defined to be the centroid of as follows:
Centers are critical to the assignment of observations to local GPs, as well as prediction, in the splitting GP model. Each time a new observation is assigned to a local model, its center is recomputed.
The kernel function is a positive-definite, symmetric function. A vector parameterizes the kernel, and is called the hyperparameter of the GP model. For simplicity, we omit from our notation. We use the term feature space to refer to the reproducing kernel Hilbert space in which implicitly computes an inner product.
We write to say that the function is distributed as a GP with mean and kernel function , and implicitly assume that the domain of is . The notation denotes that is conditioned on the data . We use to denote a test input at which a prediction is to be made and to be a GP conditioned on the test input, i.e. the posterior distribution.
3.2 The splitting procedure
To address modeling a potentially non-stationary latent function, each local GP model is split in a manner which centers the resulting child GPs on regions of different means. This is done by performing principal component analysis (PCA) on the training inputs associated with the parent model. The first principal component gives the direction of most variance of the training inputs, which implies that the corresponding orthogonal hyperplane is the minimizer of within-cluster variance among all linear bisections, leading to Principal Direction Divisive Partitioning (PDDP) [1].
Two new GPs, which we call child GPs, are then created, each of which is assigned the data of the parent model from one side of the hyperplane, as in Fig. 1(a). This heuristic is based on the idea that, by fitting separate GPs to the subsets of training inputs which are maximally different, the model may best adapt to non-stationary behavior of the latent function. We utilize PDDP since the splitting procedure is computed efficiently in closed form, i.e. without the use of a convergent algorithm such as k-means. It also allows for different choices in how the principal direction is computed. For example, in a setting where observations are fully sequential, the principal direction can be efficiently approximated using Oja’s rule [19] to avoid a singular value decomposition of the data matrix.
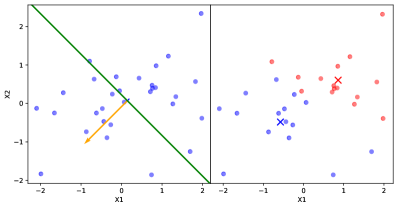
Critically, the prior of each child GP is taken to be the posterior of the parent model when conditioned on the training observations, reflecting the Bayesian belief that the latent function’s local covariance structure is not too dissimilar from its covariance structure in the larger subspace prior to splitting.
Formally, in the function space inference view of GP regression,
| (1) |
where is the prior of the child and is the posterior of the parent given the training data . This assumption of local similarity is implicit in the use of many smooth kernel functions, particularly the radial basis function family, which are infinitely differentiable.
3.3 Aggregating predictions of local models
A new data point is assigned to a child GP whose center is most similar to the predictor in the feature space, as determined by the kernel function. That is, for child GPs, the data point is assigned to the child GP indexed by
Similarly, the posterior mean at the test input is computed by weighting the prediction of each child GP by the relative similarity of its center to the test input in the feature space. This idea is based upon an interpretation of the predictive mean as weighting observations by their similarity to the point of prediction in the feature space, according to Shen et al. [25]. The same idea was also used by Nguyen-Tuong et al. [18].
Unlike these previous works, we take a weighted average of all predictions of child GPs, rather than only a subset, as follows:
| (2) |
where This may be interpreted as weighting each child GP’s mean prediction by the similarity of its local region to the test input . In the next section, we will show that using predictions from all child GPs has important consequences on the theoretical properties of the resulting model.
4 Theoretical properties of the splitting GP model
4.1 Continuity of the splitting GP
As a consequence of this weighting procedure and the choice of priors for the child GPs, the splitting GP model has some convenient properties. The proofs of the following propositions may be found in the appendix.
Proposition 1.
Let be the full GP prior to splitting and let be a test input. The child GPs from the first split have the property that, prior to being updated with any new observations, . That is, the predictive distribution is preserved by the splitting procedure.
This result is somewhat intuitive, since no additional evidence has been obtained which might alter our Bayesian beliefs about the latent function; we have simply altered the model structure. In agreement with this idea, the equality of the parent and childrens’ predictive distribution no longer holds after any new data is assigned to one of the child GPs. Note that, in general, this relationship does not hold for any split after the first.
An important property of the splitting GP model is the preservation of continuity properties of the child GPs. We provide a result which shows the necessary and sufficient condition for continuity of the splitting GP model’s predictions.
Proposition 2.
Suppose is a kernel function and . Then the random field given by
is mean square continuous in the input space if and only if the kernel function, , is continuous. Under the same condition, the mean prediction is also continuous in the input space.
While it may seem obvious that the mean prediction is continuous in the input space, it is reassuring to know that the random field created by the splitting model has the same sufficient condition for mean square continuity as the underlying child GPs. Intuitively, we are computing a continuously weighted average of smooth random fields, so the resulting random field should also be smooth.
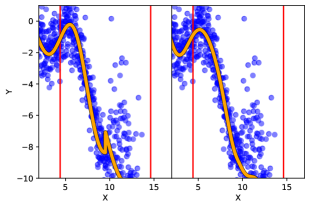
Note that it is not necessary to aggregate the predictions of each local model. Instead, one may elicit predictions only from the local models most similar to the point of prediction, as measured by the kernel. This variation of the prediction method, as used in [18], may result in faster computation of predictions. However, we caution against this practice without careful consideration. This prediction method will result in a loss of continuity of the mean prediction , and consequently the mean square continuity of the random field , since the mean prediction is computed using a maximum function, which is not continuous. The discontinuity will manifest as sharp jumps in the mean predictions, as illustrated in Fig. 1(b).
4.2 Complexity analysis of the algorithm
The algorithm for the splitting GP model has improved complexity in both memory and training/prediction time compared to the full GP regression. Additionally, it maintains some benefit in asymptotic complexity relative to other local GP methods.
The complexity of updating the splitting GP model with a single datum is bounded above by , corresponding to a matrix inversion of one child GP. The contribution of the PCA-based splitting procedure to the time complexity is negligible. Assuming the PCA is performed via naive singular value decomposition, the procedure would have complexity amortized over sequential observations, which yields a linear additive term .
While each child GP has at most observations, the average case will clearly be lower. It should be noted that we explicitly chose to not utilize a rank-one update of the Cholesky decomposition of the kernel matrix during the update procedure, a method which is used in other local GP methods such as in [18]. We made this choice to permit updating the model with a batch of observations, in addition to fully sequential updating, which would require an update of rank greater than one. We also observed empirically that repeatedly updating a single child GP using rank-one updates would cause numerical issues if the kernel length-scale parameter is small.
Since the time complexity of the algorithm is characterized primarily by the parameter , the largest number of observations which may be associated with a single child model, it is straightforward to select an appropriate parameter value for applications requiring rapid sequential updating. After empirically determining the necessary wall-clock time needed for an update, the parameter may be adjusted appropriately.
The splitting algorithm also imposes a lower memory complexity in terms of the number of observations, . It is well known that local GP methods effectively store only a block-diagonal approximation of the full covariance matrix [20, 3]. In particular, when the splitting algorithm has observations, child GPs have been created, each of which will store a kernel matrix with up to entries. The resulting memory complexity of the algorithm is then , where is the memory complexity of a full GP regression. In contrast, the rBCM by [4] has an asymptotic memory complexity of , where is the (constant) number of experts specified as a parameter. Nguyen-Tuong et al. [18] did not present the memory complexity of their local GP model but, under the mild assumption that the input space is bounded, it can be shown that the asymptotic memory complexity is . Notably, the splitting GP model is, to the best of our knowledge, the only local GP model to achieve a linear memory complexity.
5 Experiments
The efficacy of the splitting GP model was experimentally evaluated on one synthetic and two real-world data sets. For each experiment, all models used the radial basis function kernel, with automatic relevance determination [15] enabled. We compared the performance of the splitting GP model to the local GP regression of Nguyen-Tuong et al. [18], the robust Bayesian committee machine (rBCM) of Deisenroth and Ng [4], and full GP regression as a baseline comparison. Each of these models was chosen since they may be updated using sequential data, and make no use of a “complete” training data set to inform the model. This is in contrast to, for example, the patchwork kriging method of Park and Apley [20], which utilizes information from the entirety of data for domain decomposition.
5.1 Synthetic data with a non-stationary latent function
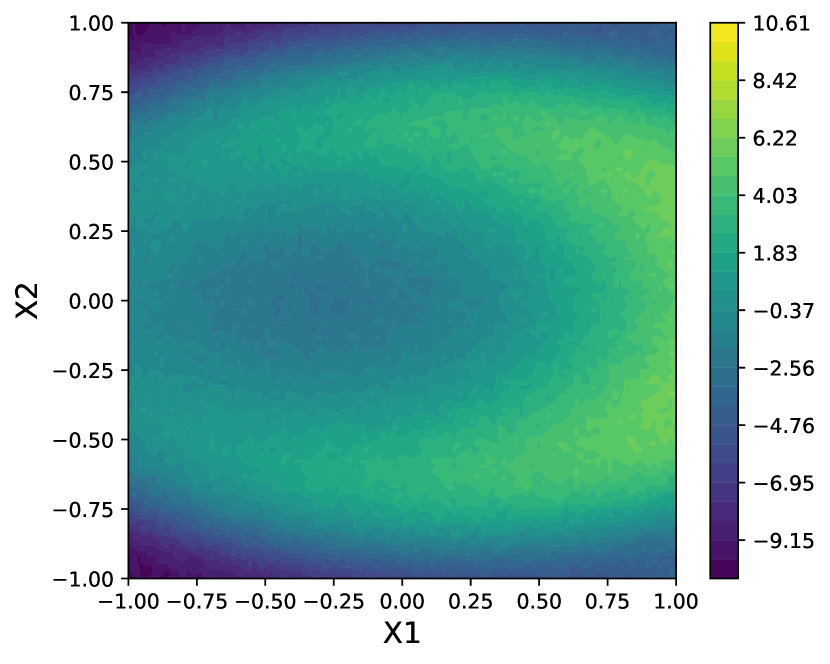
The synthetic data set (see Fig. 2) was constructed to have a non-stationary latent function of a two-dimensional predictor . The response function is defined as
| (3) |
where with . To construct the synthetic data set, a grid of 10,000 points was constructed in the - plane and the latent function evaluated at each point. A subset of 2500 observations were sampled uniformly, without replacement, from the resulting grid for each replicate of the experiment. This sampling over the grid ensured that no two observations are too close to one another, which may cause numerical issues during training.
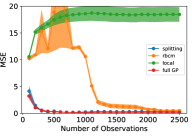
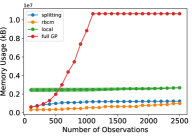
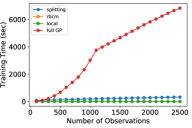
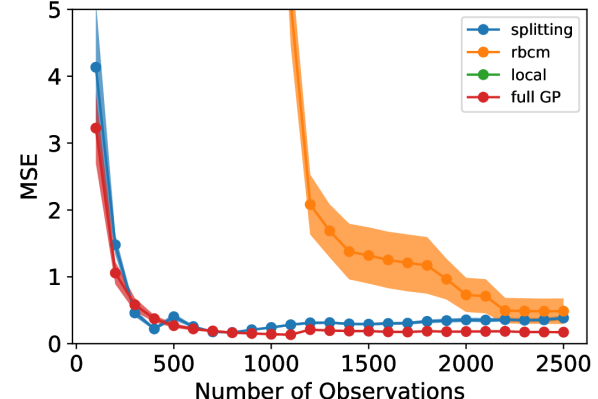
For this experiment, we compared three metrics of the models’ performance: prediction error (in mean squared error, or MSE), memory usage (in kilobytes, or kB), and training time (in seconds). Each metric was estimated using a 5-fold cross validation procedure. We utilized common random numbers [28] as a variance reduction technique. Each experiment was replicated 10 times to reduce variability of results. In Fig. 3, the shaded region shows the 95% pointwise confidence region for the mean metric. The experiment was performed with different numbers of observations, ranging from 100 to 2500 in increments of 100, to demonstrate the relative data requirements for each model to converge. Each model was updated sequentially with single observations to simulate a streaming data setting.
For each alternative model compared, the experiment was replicated for a range of parameter values and the most favorable, in terms of MSE, results for each model are reported. For the splitting GP model, we used a splitting limit of . For the rBCM, local experts were used. We found the parameter of the local GP model difficult to tune and eventually used based on an extensive grid search (detailed in the appendix).
In Fig. 3, one can see that the splitting model and full GP required relatively few observations to achieve strong predictive power. The rBCM was much slower to converge, and exhibited high variability in its MSE across replicates of the experiment. We attribute the greater variability in MSE to the rBCM’s random assignment of data to GP experts. On the other hand, the splitting GP model exhibited remarkably low variability in MSE between replicates. It is worth noting that the splitting model’s MSE slowly increased as it splits at intervals of 500 observations (see Fig. 4).
The memory usage of the splitting GP model proved to be significantly lower than the full GP model, and marginally higher than that of the rBCM. However, for ~2500 observations, it can be seen that the memory usage of the rBCM model began to surpass that of the splitting GP model. This is to be expected, since the asymptotic memory complexity of the rBCM is quadratic, as opposed to the linear complexity of the splitting GP model.
The training time of the rBCM and local GP models were found to be comparable, and the splitting GP model took slightly longer. The full GP took significantly longer to train. The change in regime of the training time of the full GP at ~1100 observations is due to specialized numerical methods in the GPyTorch library [6].
5.2 Real-world data in robotic control application
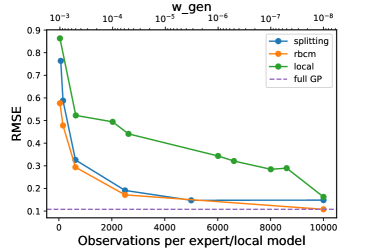
The first real-world data set, kin40k, consists of 40,000 records describing the location of a robotic arm as a function of an 8-dimensional control input [17]. This data set was chosen since it exemplifies a task where the fast sequential updating and low memory profile offered by the splitting GP model are desirable. Furthermore, kin40k is a popular benchmark for other GP regression methods [4, 16, 14], and thus facilitates direct comparison.
We used the same training/test split of 10,000/30,000 points as in the previous work [4, 16, 14]. Observations were added to the models in batches, with each batch having a number of observations equal to the number of observations per local model. The results can be seen in Fig. 5(a). The splitting model’s root-mean-square error (RMSE) is comparable with that of the rBCM, which is designed under a stronger assumption (that the latent function is well-modeled by a single GP), which is satisfied in this stationary regression task. In contrast, the local GP model struggled to achieve the same RMSE in this experiment (see the appendix for more detail on the difficulty tuning the parameter ).
5.3 Real-world data in power plant control application
The second real-world data set is powergen, which consists of four predictors describing control inputs of a combined cycle power plant, and a response of the net electrical energy production. This data set is due to Kaya et al. [12] and Tüfekci [27] and is publicly available [5]. We pre-processed the data to remove duplicate observations, leaving a total of 7622 observations.
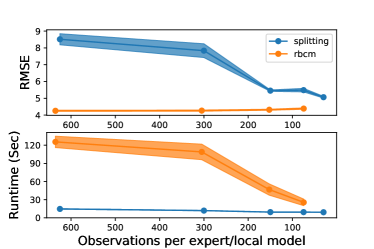
In the powergen experiment, we compared both the predictive error (in RMSE) and the combined training and prediction time (in seconds) of the splitting GP model and rBCM. We compared only these two models, since they proved to be the most competitive local GP methods in earlier experiments. The data set was randomly divided into a 80%/20% train/test split, and each model evaluated for several different parameter values. Observations were added to the models in batches, with each batch having a number of observations equal to the number of observations per local model. The experiment was replicated 10 times, and common random numbers were used for splitting the data set and training the models for sharper comparisons between the models. The results can be seen in Fig. 5(b).
The splitting GP model’s RMSE decreased with the number of observations per local model, achieving a comparable performance with the rBCM. In terms of runtime, the splitting GP model was significantly faster, while having little variability between replicates. While the rBCM’s runtime decreased with the number of observations per expert, its average runtime was 2.5-6 times longer than that of the splitting GP model, depending on the choice of parameters.
6 Conclusion
In this paper, we have developed an algorithm for constructing splitting GP regression models for potentially non-stationary latent functions using streaming data. We have shown that splitting GP models attain comparable predictive performance, while addressing critical shortcomings of other local GP models, such as discontinuity of predictions, lack of flexibility for modeling non-stationary latent functions, and opaque parameters which may be challenging to tune. Furthermore, splitting GP models are shown to enjoy linear memory complexity which, to the best of our knowledge, is the best among existing local GP methods, which typically have quadratic memory complexity. An implementation of the splitting GP model is available in the supplementary material to this article.
References
- Boley [1998] Daniel Boley. Principal Direction Divisive Partitioning. Data Mining and Knowledge Discovery, 2(4):325–344, December 1998. ISSN 1573-756X. doi: 10.1023/A:1009740529316.
- Breiman [1984] L. Breiman. Classification and Regression Trees. Routledge, 1984. doi: 10.1201/9781315139470.
- Das and Srivastava [2010] K. Das and A. N. Srivastava. Block-gp: Scalable gaussian process regression for multimodal data. In 2010 IEEE International Conference on Data Mining, pages 791–796, 2010. doi: 10.1109/ICDM.2010.38.
- Deisenroth and Ng [2015] Marc Peter Deisenroth and Jun Wei Ng. Distributed gaussian processes. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, page 1481–1490. JMLR.org, 2015. doi: 10.5555/3045118.3045276.
- Dua and Graff [2019] Dheeru Dua and Casey Graff. UCI machine learning repository, 2019. URL http://archive.ics.uci.edu/ml.
- Gardner et al. [2018] Jacob R. Gardner, Geoff Pleiss, David Bindel, Kilian Q. Weinberger, and Andrew Gordon Wilson. GPyTorch: blackbox matrix-matrix Gaussian process inference with GPU acceleration. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pages 7587–7597, Montréal, Canada, December 2018. doi: 10.5555/3327757.3327857.
- Gramacy [2005] Robert B. Gramacy. Bayesian Treed Gaussian Process Models. Doctoral thesis, University of California, Santa Cruz, 2005. URL https://bobby.gramacy.com/prepo/gra2005-02.pdf.
- Gramacy and Apley [2015] Robert B. Gramacy and Daniel W. Apley. Local Gaussian Process Approximation for Large Computer Experiments. Journal of Computational and Graphical Statistics, 24(2):561–578, April 2015. ISSN 1061-8600. doi: 10.1080/10618600.2014.914442.
- Gramacy and Lee [2008] Robert B. Gramacy and Herbert K. H Lee. Bayesian Treed Gaussian Process Models With an Application to Computer Modeling. Journal of the American Statistical Association, 103(483):1119–1130, September 2008. ISSN 0162-1459. doi: 10.1198/016214508000000689.
- Hinton [2002] Geoffrey E. Hinton. Training Products of Experts by Minimizing Contrastive Divergence. Neural Computation, 14(8):1771–1800, 2002. doi: 10.1162/089976602760128018.
- Jixu Chen et al. [2009] Jixu Chen, Minyoung Kim, Y. Wang, and Q. Ji. Switching Gaussian process dynamic models for simultaneous composite motion tracking and recognition. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 2655–2662, 2009. doi: 10.1109/CVPR.2009.5206580.
- Kaya et al. [2012] Heysem Kaya, Pinar Tüfekci, and Fikret S. Gürgen. Local and global learning methods for predicting power of a combined gas & steam turbine. In Proceedings of the international conference on emerging trends in computer and electronics engineering ICETCEE, pages 13–18, 2012. URL http://psrcentre.org/images/extraimages/70.20312595.pdf.
- Liu et al. [2015] Yi Liu, Tao Chen, and Junghui Chen. Auto-Switch Gaussian Process Regression-Based Probabilistic Soft Sensors for Industrial Multigrade Processes with Transitions. Industrial & Engineering Chemistry Research, 54(18):5037–5047, May 2015. ISSN 0888-5885. doi: 10.1021/ie504185j. Publisher: American Chemical Society.
- Lázaro-Gredilla et al. [2010] Miguel Lázaro-Gredilla, Joaquin Quiñonero-Candela, Carl Edward Rasmussen, and Aníbal R. Figueiras-Vidal. Sparse Spectrum Gaussian Process Regression. Journal of Machine Learning Research, 11(63):1865–1881, 2010. URL http://www.jmlr.org/papers/v11/lazaro-gredilla10a.html.
- Neal [1996] Radford M. Neal. Bayesian Learning for Neural Networks. Springer-Verlag, Berlin, Heidelberg, 1996. ISBN 0387947248. doi: 10.1007/978-1-4612-0745-0.
- Nguyen and Bonilla [2014] Trung Nguyen and Edwin Bonilla. Fast allocation of gaussian process experts. In Eric P. Xing and Tony Jebara, editors, Proceedings of the 31st International Conference on Machine Learning, volume 32 of Proceedings of Machine Learning Research, pages 145–153, Bejing, China, 22–24 Jun 2014. PMLR. URL http://proceedings.mlr.press/v32/nguyena14.html.
- Nguyen [2019] V. Nguyen. trungngv/fgp, November 2019. URL https://github.com/trungngv/fgp. original-date: 2013-06-03T01:51:19Z.
- Nguyen-Tuong et al. [2009] Duy Nguyen-Tuong, Jan Peters, and Matthias Seeger. Local Gaussian Process Regression for Real Time Online Model Learning. Advances in Neural Information ProcessingSystems, pages 1193–1200, 2009.
- Oja [1997] Erkki Oja. The nonlinear PCA learning rule in independent component analysis. Neurocomputing, 17(1):25–45, 1997. doi: 10.1016/S0925-2312(97)00045-3.
- Park and Apley [2018] Chiwoo Park and Daniel Apley. Patchwork Kriging for Large-scale Gaussian Process Regression. Journal of Machine Learning Research, 19(7):1–43, 2018. URL http://jmlr.org/papers/v19/17-042.html.
- Park and Huang [2016] Chiwoo Park and Jianhua Z. Huang. Efficient Computation of Gaussian Process Regression for Large Spatial Data Sets by Patching Local Gaussian Processes. Journal of Machine Learning Research, 17(174):1–29, 2016. URL http://jmlr.org/papers/v17/15-327.html.
- Park et al. [2011] Chiwoo Park, Jianhua Z. Huang, and Yu Ding. Domain Decomposition Approach for Fast Gaussian Process Regression of Large Spatial Data Sets. Journal of Machine Learning Research, 12(47):1697–1728, 2011. URL http://jmlr.org/papers/v12/park11a.html.
- Rasmussen and Ghahramani [2002] Carl E Rasmussen and Zoubin Ghahramani. Infinite Mixtures of Gaussian Process Experts. Advances in Neural Information Processing Systems, 14:881–888, 2002. URL http://papers.nips.cc/paper/2055-infinite-mixtures-of-gaussian-process-experts.pdf.
- Rasmussen and Williams [2005] Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning). The MIT Press, 2005. ISBN 026218253X.
- Shen et al. [2006] Yirong Shen, Matthias Seeger, and Andrew Y. Ng. Fast Gaussian process regression using KD-trees. In Advances in Neural Information Processing Systems, pages 1225–1232, 2006. URL https://papers.nips.cc/paper/2835-fast-gaussian-process-regression-using-kd-trees.pdf.
- Snelson and Ghahramani [2007] Edward Snelson and Zoubin Ghahramani. Local and global sparse Gaussian process approximations. In Artificial Intelligence and Statistics, pages 524–531, March 2007. URL http://proceedings.mlr.press/v2/snelson07a.html. ISSN: 1938-7228 Section: Machine Learning.
- Tüfekci [2014] Pınar Tüfekci. Prediction of full load electrical power output of a base load operated combined cycle power plant using machine learning methods. International Journal of Electrical Power & Energy Systems, 60:126–140, 2014. doi: 10.1016/j.ijepes.2014.02.027.
- Wright and Ramsay [1979] R. D. Wright and T. E. Ramsay. On the effectiveness of common random numbers. Management Science, 25(7):649–656, 1979. doi: 10.1287/mnsc.25.7.649.
- Yu [2012] Jie Yu. Online quality prediction of nonlinear and non-Gaussian chemical processes with shifting dynamics using finite mixture model based Gaussian process regression approach. Chemical Engineering Science, 82:22–30, September 2012. ISSN 0009-2509. doi: 10.1016/j.ces.2012.07.018.