11email: {jsbaik, inyoungyoon}@spa.hanyang.ac.kr, 11email: junwchoi@hanyang.ac.kr
ST-CoNAL: Consistency-Based Acquisition Criterion Using Temporal Self-Ensemble for Active Learning
Abstract
Modern deep learning has achieved great success in various fields. However, it requires the labeling of huge amounts of data, which is expensive and labor-intensive. Active learning (AL), which identifies the most informative samples to be labeled, is becoming increasingly important to maximize the efficiency of the training process. The existing AL methods mostly use only a single final fixed model for acquiring the samples to be labeled. This strategy may not be good enough in that the structural uncertainty of a model for given training data is not considered to acquire the samples. In this study, we propose a novel acquisition criterion based on temporal self-ensemble generated by conventional stochastic gradient descent (SGD) optimization. These self-ensemble models are obtained by capturing the intermediate network weights obtained through SGD iterations. Our acquisition function relies on a consistency measure between the student and teacher models. The student models are given a fixed number of temporal self-ensemble models, and the teacher model is constructed by averaging the weights of the student models. Using the proposed acquisition criterion, we present an AL algorithm, namely student-teacher consistency-based AL (ST-CoNAL). Experiments conducted for image classification tasks on CIFAR-10, CIFAR-100, Caltech-256, and Tiny ImageNet datasets demonstrate that the proposed ST-CoNAL achieves significantly better performance than the existing acquisition methods. Furthermore, extensive experiments show the robustness and effectiveness of our methods.
Keywords:
Active Learning Consistency Temporal Self-Ensemble Image Classification .1 Introduction
Deep neural networks (DNNs) require a large amount of training data to optimize millions of weights. In particular, for supervised-learning tasks, labeling of training data by human annotators is expensive and time-consuming. The labeling cost can be a major concern for machine learning applications, which requires a collection of real-world data on a massive scale (e.g., autonomous driving) or the knowledge of highly trained experts for annotation (e.g., automatic medical diagnosis). Active learning (AL) is a promising machine learning framework that maximizes the efficiency of labeling tasks within a fixed labeling budget [35].
This study focuses on the pool-based AL problem, where the data instances to be labeled are selected from a pool of unlabeled data. In a pool-based AL method, the decision to label a data instance is based on a sample acquisition function. The acquisition function, , takes the input instance and the currently trained model and produces a score to decide if should be labeled. Till date, various types of AL methods have been proposed [36, 9, 10, 35, 46, 38, 47, 20, 11]. The predictive uncertainty-based methods [36, 9, 10, 46] used well-studied theoretic measures such as entropy and mutual information. Recently, representation-based methods [38, 34, 20, 47] have been widely used as a promising AL approach to exploit high-quality representation of DNNs. However, the acquisition used for these methods rely on a single trained model , failing to account for model uncertainty arising given a limited labeled dataset. To solve this problem, several AL methods [2, 35] attempted to utilize an ensemble of DNNs and design acquisition functions based on them. However, these methods require significant computational costs to train multiple networks.
When the amount of labeled data is limited, semi-supervised learning (SSL) is another promising machine learning approach to improve performance with low labeling costs. SSL improves the model performance by leveraging a large number of unlabeled examples [31]. Consistency regularization is one of the most successful approach to SSL [11, 22, 30, 40]. In a typical semi-supervised learning, the model is trained using the consistency-regularized loss function , where denotes the cross-entropy loss and denotes the consistency-regularized loss. Minimization of regularizes the model to produce consistent predictions over the training process, improving the performance for a given task. model [22] applied a random perturbation to the input of the DNN and measured the consistency between the model outputs. Mean Teacher (MT) [40] produced the temporal self-ensemble through SGD iterations and measured the consistency between the model being trained and the teacher model obtained by taking the exponential moving average (EMA) of the self-ensemble. These methods successfully regularized the model to produce consistent predictions while using perturbed predictions on unlabeled samples.
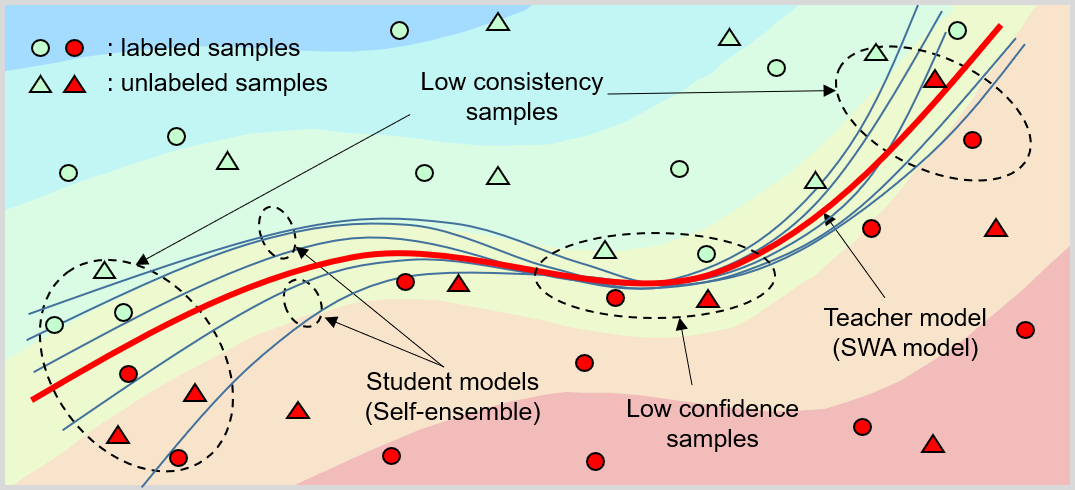
The objective of this study is to improve the sample acquisition criterion for pool-based AL methods. Inspired by the consistency regularization for SSL, we build a new sample acquisition criterion that measures consistency between multiple ensemble models obtained during the training phase. The proposed acquisition function generates the temporal self-ensemble by sampling the models at the intermediate check-points of the weight trajectory formed by the SGD optimization. This provides a better acquisition performance and eliminates the additional computational cost required by previous ensemble-based AL methods. In [1, 17, 27], the aforementioned method has shown to produce good and diverse self-ensembles, which were used to improve the inference model via stochastic weight averaging (SWA) [1, 17, 27]. We derive the acquisition criterion based on the temporal self-ensemble models used in SWA. We present the AL method, referred to as student-teacher consistency-based AL (ST-CoNAL), which measures the consistency between the student and teacher models. The self-ensemble model constitutes a student model, and a teacher model is formed by taking an equally-weighted average (EWA) of the parameters of the student models. Treating the output of the teacher model as a desired supervisory signal, ST-CoNAL measures the Kullback–Leibler (KL) divergence of each teacher-student output pairs. The acquisition function of ST-CoNAL acquires the samples to be labeled that yield the highest inconsistency.
Though ST-CoNAL was inspired by the consistency regularization between student and teacher models of the MT, these two methods are quite different in the following aspects. MT constructs the teacher model by assigning larger weights to more recent model weights obtained through SGD iterations. Due to this constraint, as training progresses, the teacher model in MT tends to be correlated with the student models, making it difficult to measure good enough consistency measure for AL acquisition. To address this problem, ST-CoNAL generates a better teacher model by taking an equally-weighted averaging (EWA) of the weights of the student models instead of EMA used in MT. Similar to previous AL methods [9, 10] that utilize ensemble models to capture the posterior distribution of model weights for a given data set, the use of student model weights allows our acquisition criterion to account for model uncertainty.
We further improve our ST-CoNAL method by adopting the principle of entropy minimization used for SSL [12, 24, 39, 3, 4, 44]. We apply one of the entropy minimization methods, sharpening to the output of the teacher model. When the sharpened output is used for our KL divergence, our acquisition criterion can measure the uncertainty of the prediction for the given sample. Our evaluation shows that the ST-CoNAL is superior to other AL methods on various image classification benchmark datasets.
Fig.1 illustrates that these low consistency samples lie in the region of the feature space where the student models produce the predictions of a larger variation. Note that these samples are not necessarily identical to the low confidence samples located near the decision boundary specified by the teacher model. The proposed ST-CoNAL prefers the acquisition of the inconsistent samples rather than the low-confidence samples.
The main contributions of our study are summarized as follows:
-
•
We propose a new acquisition criterion based on the temporal self-ensemble. Temporal self-ensemble models are generated by sampling DNN weights through SGD optimization. ST-CoNAL measures the consistency between these self-ensemble models and acquires the most inconsistent samples for labeling. We evaluated the performance of ST-CoNAL on four different public datasets for multi-class image classification tasks. We observe that the proposed ST-CoNAL method achieves the significant performance gains over other AL methods.
-
•
We identified a work relevant to ours [11]. While both ours and their work aim to exploit consistency regularization for AL, our work differs from theirs in the following aspects. While CSSAL [11] relies on the input perturbation to a single fixed model, ST-CoNAL utilizes the self-ensemble models to measure the consistency. Note that the benefits of using model ensembles for AL have been demonstrated in [2] and our findings about the superior performance of ST-CoNAL over CSSAL are consistent with the results of these studies.
2 Related Work
2.1 Acquisition for AL
The acquisition methods for pool-based AL can be roughly categorized into three classes: 1) uncertainty-based, 2) representation-based and 3) consistency-based methods. The uncertainty-based methods [2, 9, 10, 19, 26, 42] estimate the prediction uncertainty for the given data instances. Max-entropy [26, 36], least confidence [26] and variation ratio [18] are the widely used criteria. Recently, the representation-based method [38, 47, 20, 34] significantly improved the acquisition performance. VAAL [38] performed adversarial learning to find informative unlabeled data in the task-agnostic latent representation of the data. TA-VAAL [20] is the latest state-of-the-art method, which incorporated a task-aware uncertainty-based approach to the VAAL baseline. The consistency-based methods measure the disagreement among the predictions of the ensemble models [9, 10, 15, 11]. TOD-Semi [16], Query-by-committee [35], and DBAL [10] are the well known criteria used in these methods.
2.2 Consistency Regularization for SSL
One of the most successful approaches to SSL is consistency regularization. The model [22, 33] enforces consistency for model by minimizing , where denotes the data perturbed by noise and augmentation, and measures the distance between and . While model uses the predictions as a target, the consistency loss for regularizing the consistent behavior between an ensemble prediction and the model prediction was shown to be effective. Mean teacher method [40] generates the weights of the teacher model with EMA of the student weights over SGD iterations. ICT [43] and MixMatch [4] enforce consistency between linearly interpolated inputs and model predictions.
2.3 Temporal Self-Ensemble via Stochastic Weight Averaging
Several studies have attempted to use temporal self-ensemble obtained through model optimization to improve the inference performance [22, 6, 25, 17]. Izmailov et al. [17] proposed SWA method, which determines an improved inference model using the equally weighted average of the intermediate model weights traversed via SGD iterates. Using cyclical learning rate scheduling [27], SGD can yield the weights in the flat regions in the loss surface. By averaging the weights found at SGD trajectory, SWA can find the weight solution that can generalize well. In [1], consistency regularization and modified cyclical learning rate scheduling assisted in finding the improved weights through SWA.
2.4 Combining AL and SSL
The combination of SSL and AL was discussed in several works [8, 10, 11, 32, 41, 48]. However, most works considered applying SSL and AL independently. Only a few works considered the joint design of SSL and AL. Zhu et al. [48] used a Gaussian random field on a weighted graph to combine SSL and AL. Additionally, the authors of [11] proposed an enhanced acquisition function by adopting the variance over the data augmentation of the input image.
3 Proposed Active Learning
In this section, we present the details of the ST-CoNAL algorithm.
3.1 Consistency Measure-Based Acquisition
The proposed algorithm follows the setup of a pool-based AL for the -image class classification task. Suppose that the labeling budget is fixed to data samples. In the th sample acquisition step, we are given the dataset , which consists of a set of labeled data and a set of unlabeled data . is the model trained with dataset . We consider two cases; 1) is trained with only via supervised learning and 2) is trained with via SSL. The AL algorithm aims to acquire the set of data samples from the pool of unlabeled data . To select the data samples to be labeled, the acquisition function is used to score the given data instance with the currently trained model . The samples that yield the highest score are selected as
| (1) |
The selected samples are then labeled, i.e., and , and the model is retrained using the newly labeled dataset . This procedure is repeated until a labeled dataset is obtained as large as required within the limited budget.
Suppose that we have student models and one teacher model trained with the dataset . Each model produces the dimensional output through the softmax output layer. The method for obtaining these models will be discussed in the next section. We first apply sharpening [4, 3, 44] to the output of the teacher model as
| (2) |
where denotes the th element of the output produced by the function and denotes the temperature hyper-parameter. Then, the acquisition function of the ST-CoNAL is obtained by accumulating the KL divergence between the predictions produced by each student model and the teacher model, i.e.,
| (3) |
where . The KL divergence in this acquisition function measures the inconsistency between the student and teacher models. As the sharpening makes the prediction of teacher model to have low-entropy, the high KL divergence value reflects the uncertainty in the prediction of the student models.
3.2 Generation of Student and Teacher Models via Optimization Path
The ST-CoNAL computes the student and teacher models using the temporal self-ensemble networks. The parameters of these self-ensemble networks are obtained by capturing the network weights at the intermediate check points of the weight trajectory. The study in [1] revealed that the average of the weights obtained through the SGD iterates can yield the weights corresponding to the flat minima of the loss surface, which are known to generalize well [29, 45]. In ST-CoNAL, the average of these weights forms a teacher model. To obtain the diverse student models, we adopt the learning rate (LR) schedule used for SWA [17, 29, 45]. The learning rate used for our method is given by
| (4) |
where denotes the initial learning rate, denotes the parameter for learning rate decay, is the current training epoch, and denotes the training epoch at which the learning rate will be switched to a smaller value. After running epochs (i.e., ), the intermediate network weights are stored every epoch, which constitute the weights of the student networks. We obtain self-ensemble networks and these models are treated as the student models. The teacher model is then obtained by taking the equally weighted average of the parameters of . Note that this learning rate schedule does not require any additional training cost for obtaining the temporal self-ensemble.
3.3 Summary of Proposed ST-CoNAL
Algorithm 1 presents the summary of the ST-CoNAL algorithm.
4 Experiments
In this section, we evaluate the performance of ST-CoNAL via experiments conducted on four public datasets, CIFAR-10 [21], CIFAR-100 [21], Caltech-256 [13] and Tiny ImageNet [23].
4.1 Experiment Setup
Datasets. We evaluated ST-CoNAL on four benchmarks: CIFAR-10 [21], CIFAR-100 [21], Caltech-256 [13] and Tiny ImageNet [23]. CIFAR-10 contains training examples with 10 categories and CIFAR-100 contains training examples with 100 categories. Caltech-256 has training examples with 256 categories and Tiny ImageNet has training examples with 200 categories.
To see how ST-CoNAL performed on class-imbalanced scenarios, we additionally used the synthetically imbalanced CIFAR-10 datasets; the step imbalanced CIFAR-10 [20, 7] and the long-tailed CIFAR-10 [5, 7]. The step imbalance CIFAR-10 has 50 samples for the first five smallest classes and 5,000 samples for the last five largest classes. Long-tailed CIFAR-10 followed the configuration used in [5], where 12,406 training images were generated with 5,000 samples from the largest class and 50 samples from the smallest class. The imbalance ratio of 100 is the widely used setting adopted in the literature [20, 5].
Implementation Details. In all experiments, an 18-layer residual network (ResNet-18) was used as the backbone network. The detailed structure of this network was provided in [14]. For CIFAR-10 and CIFAR-100 datasets, models were trained with standard data augmentation operations including random translation and random horizontal flipping [14]. For Caltech-256 and Tiny-ImageNet datasets, we applied the data augmentation operations including resizing to 256256, random cropping to 224224, and horizontal flipping. In the inference phase, we applied the image resizing method followed by the center cropping to generate 224224 input images [14]. We also applied our ST-CoNAL method to SSL setup. We used the mean teacher method using the detailed configurations described in [40]. We conducted all experiments with a TITAN XP GPU for training.
Configurations for AL. According to [34, 35], selection of samples from a large pool of unlabeled samples requires computation of the acquisition function for all unlabeled samples in the pool, yielding considerable computational overhead. To mitigate this issue, the subset of unlabeled samples was randomly drawn from the unlabeled pool [2, 46, 20]. Then, acquisition functions were used to acquire the best samples from .
In all experiments, the temperature parameter was set to , which was determined through empirical optimization. For CIFAR-10, we set and , and for CIFAR-100, we set and . For Tiny ImageNet, we set and . For Caltech-256, we set and . These configurations followed the convention adopted in the existing methods. The parameter used for the learning rate scheduling was set to 160 epochs for all datasets except Tiny ImageNet. We used of 60 epochs for Tiny ImageNet.
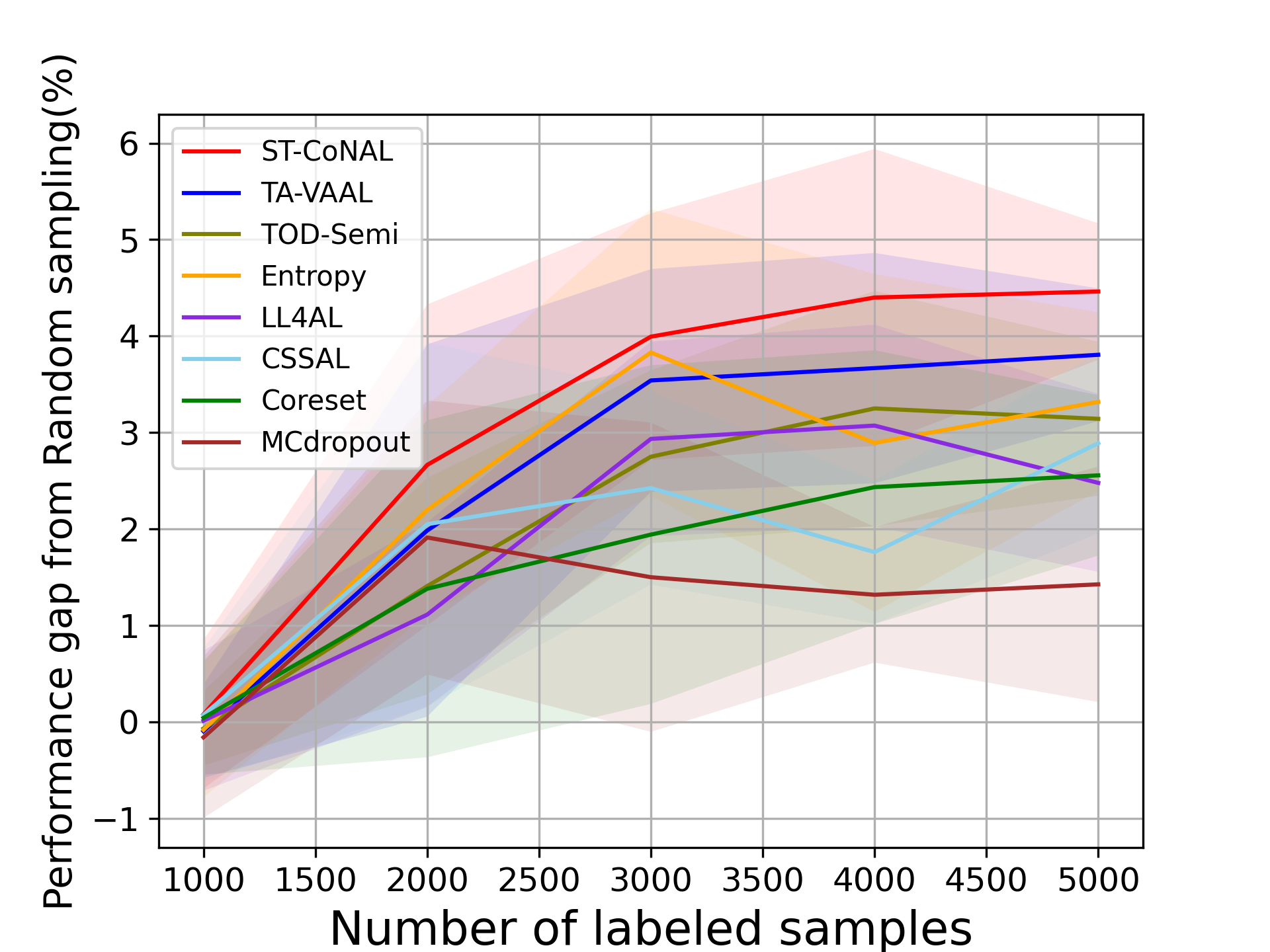
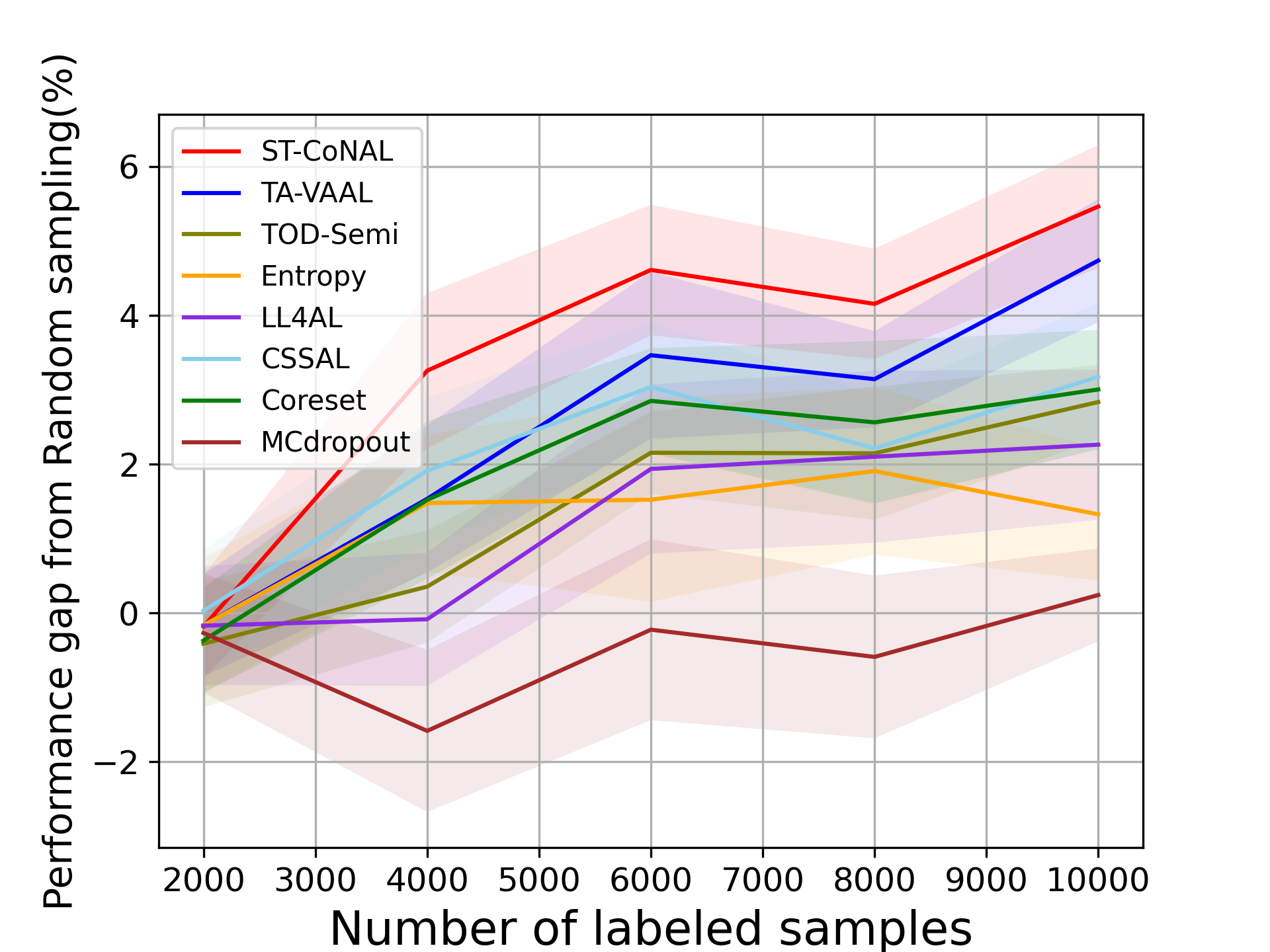
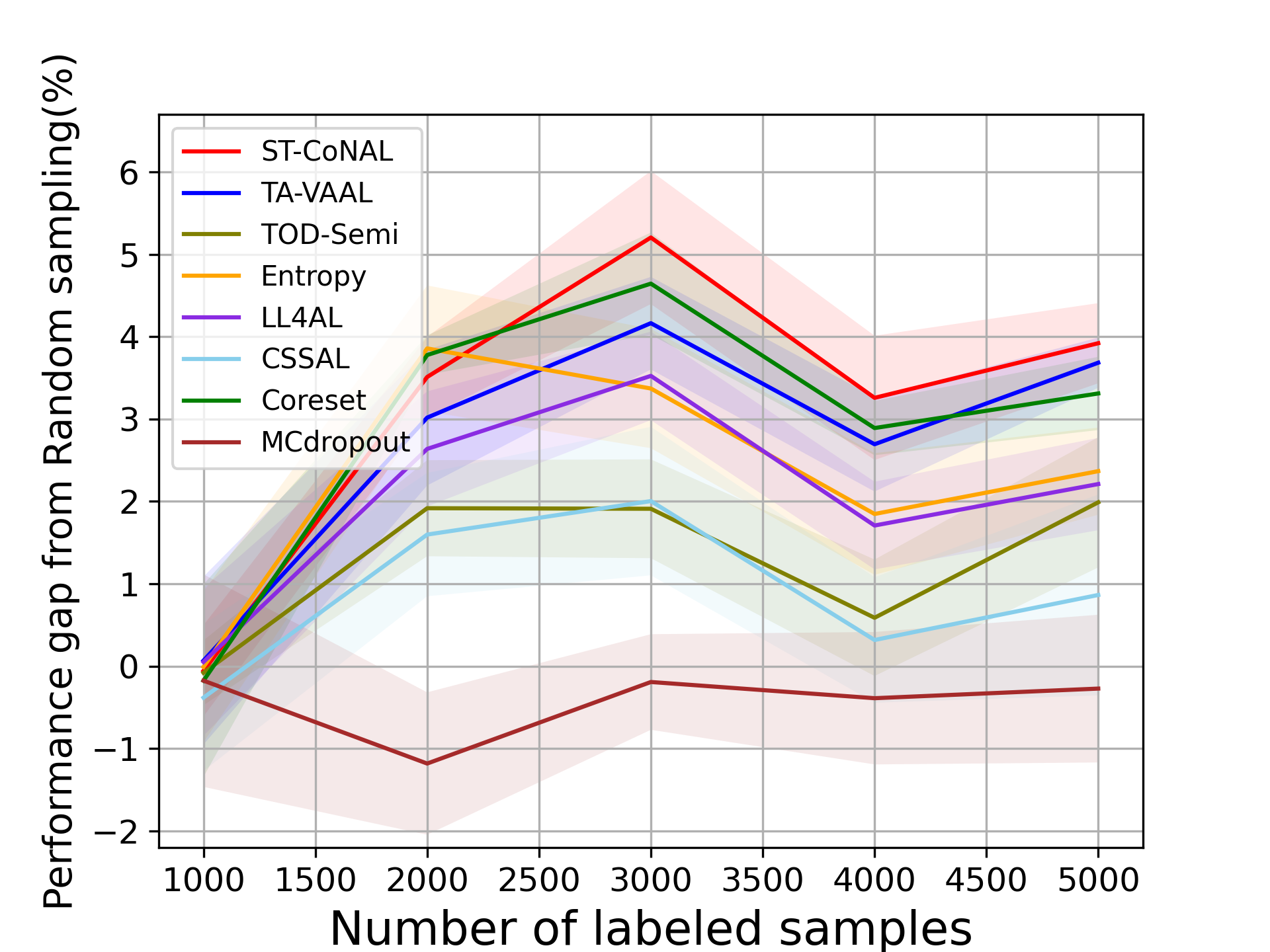
Baselines We compared our method with the existing AL methods including Core-set [34], MC-Dropout [9], LL4AL [46], Entropy [36], CSSAL [11] , TOD-Semi [16], TA-VAAL [20], and random sampling. We adopted the average classification accuracy as a performance metric. We report the mean and standard deviation of the classification accuracy measured 5 times with different random seeds. In our performance comparison, we kept the network optimization and inference methods the same and only changed the acquisition criterion. TOD-Semi, TA-VAAL and LL4AL are exceptions because we used the optimization and inference methods proposed in their original paper. In Fig. 2 to Fig. 5, the performance difference of the target method from the random sampling baseline was used as a performance indicator.
4.2 Performance Comparison
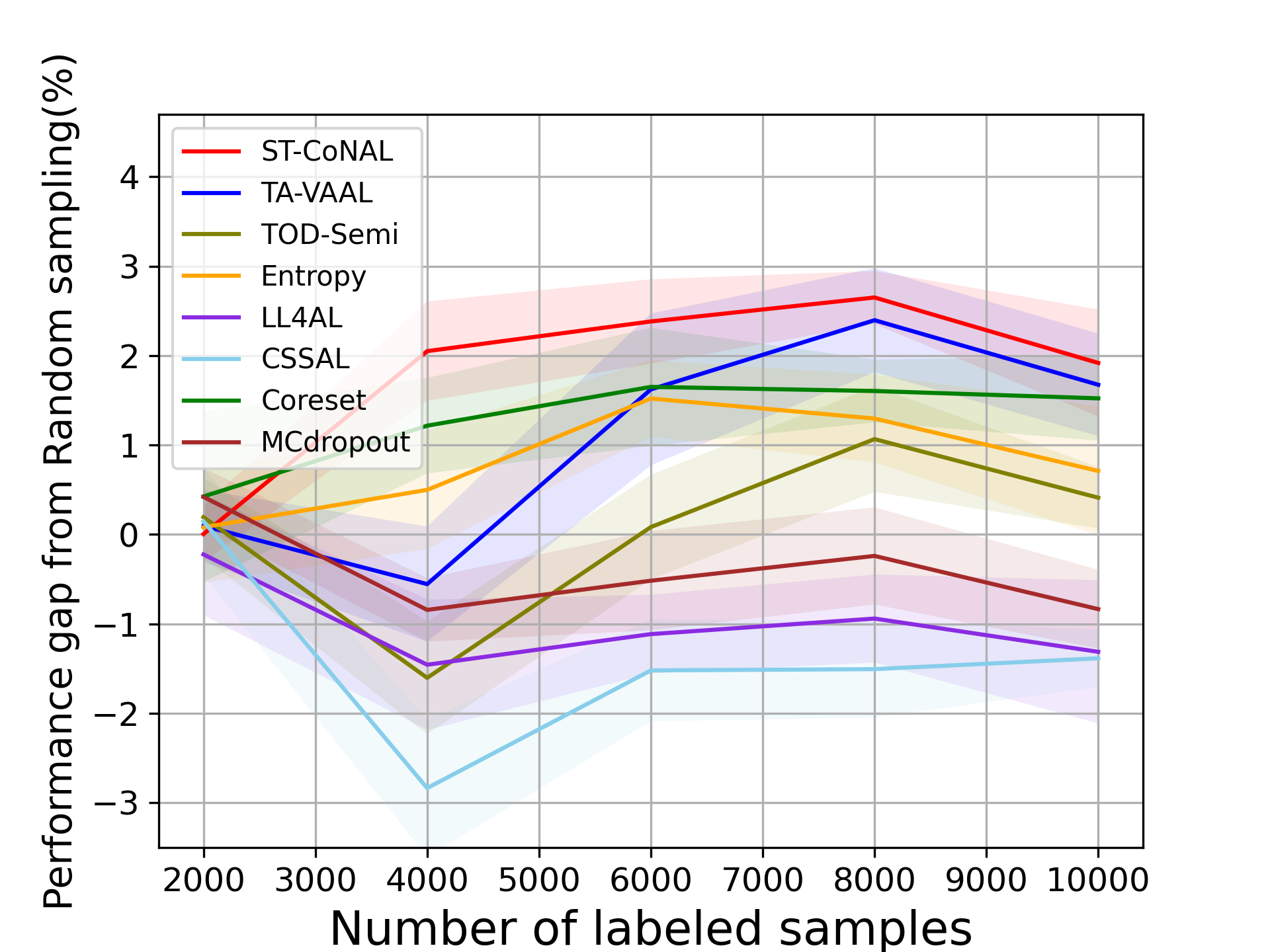
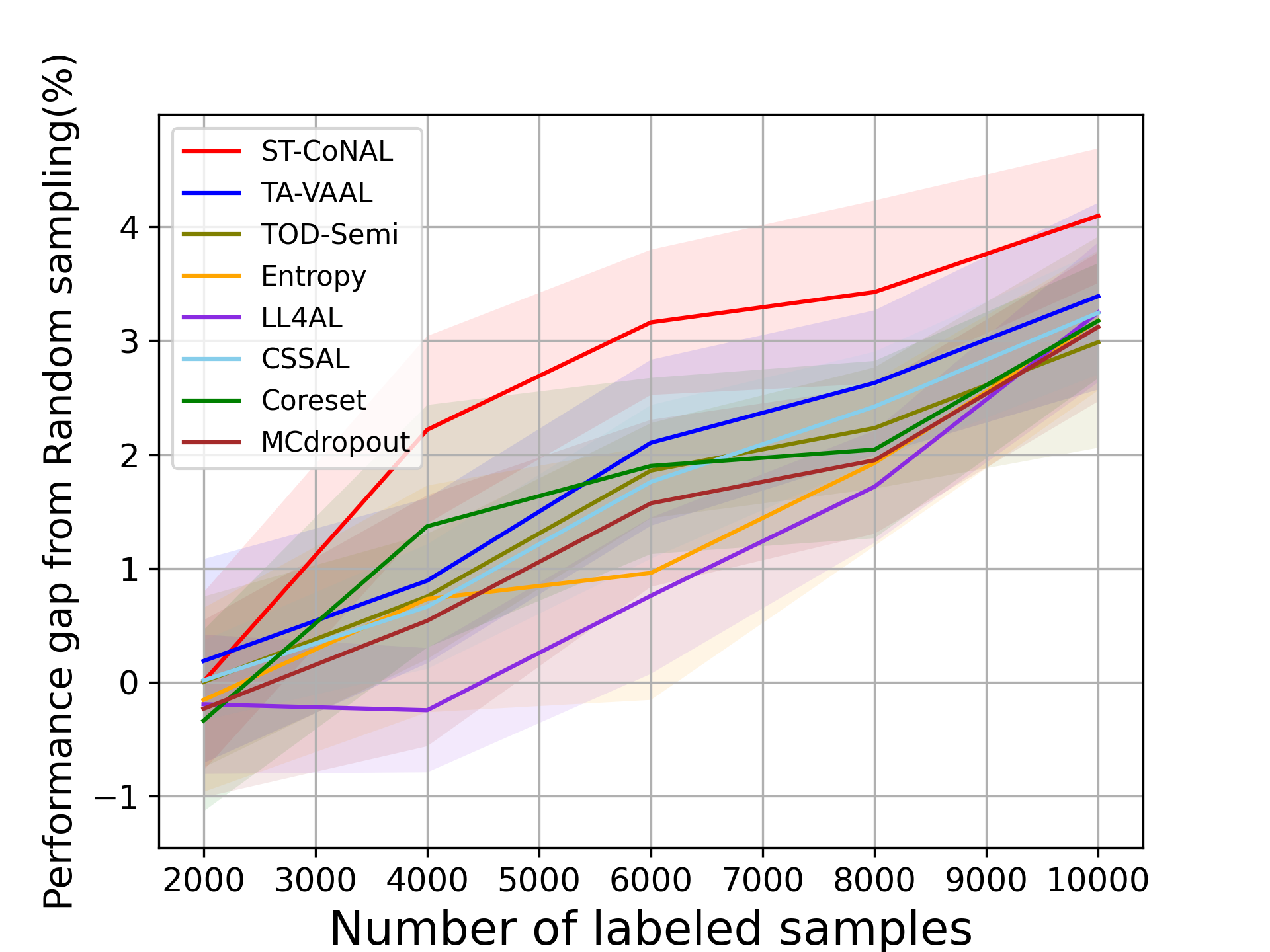
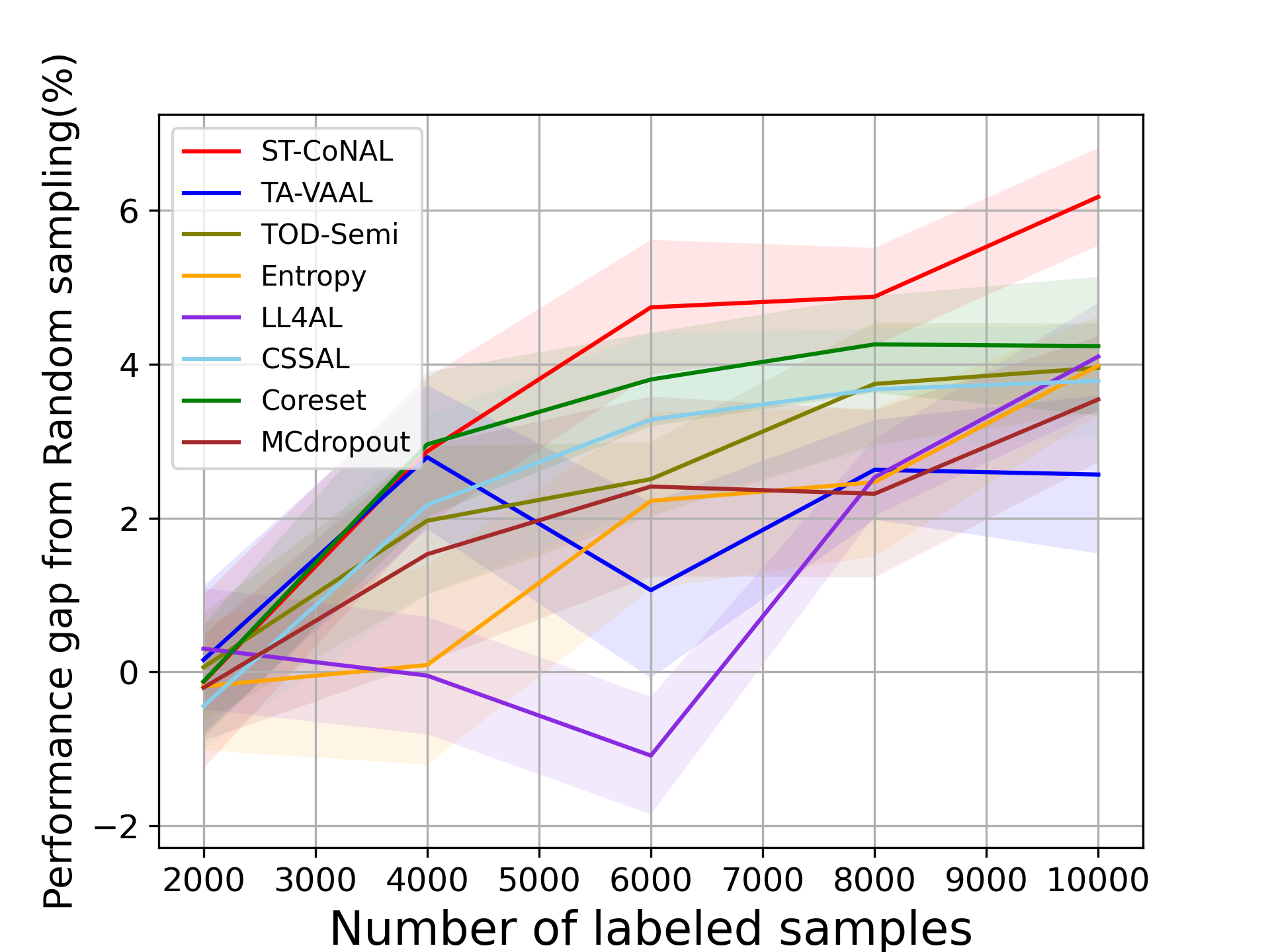
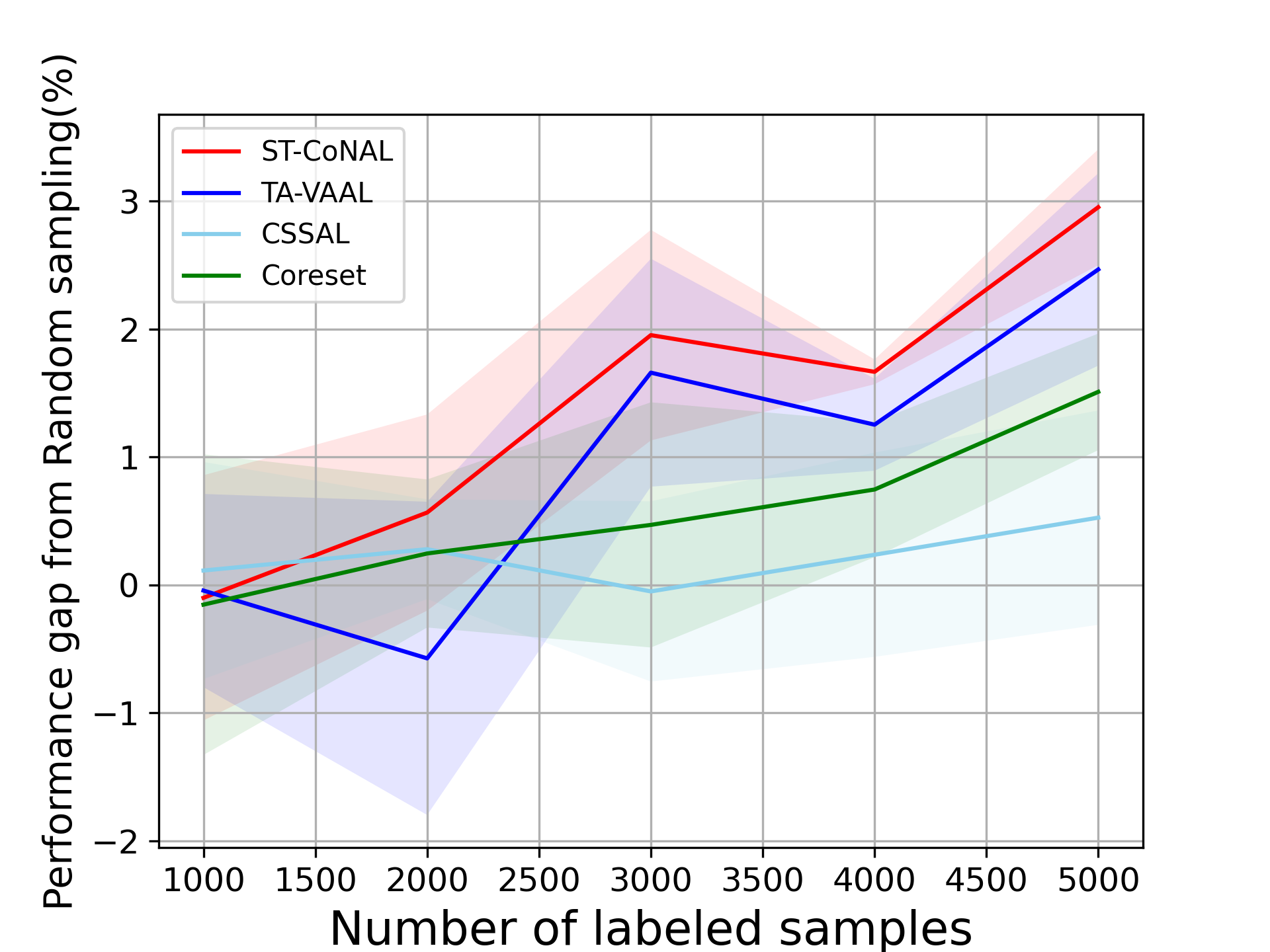
CIFAR-10 and CIFAR-100: Fig. 2 (a) and (b) show the performance of ST-CoNAL with respect to the number of labeled samples evaluated on CIFAR-10 and CIFAR-100 datasets, respectively. As mentioned earlier, we use the performance difference obtained compared to the classification accuracy of random sampling as a performance indicator. We observe that the proposed ST-CoNAL outperforms other AL methods on both CIFAR-10 and CIFAR-100. After the last acquisition step, our method achieves a performance improvement of 4.68% and 5.47% compared to the random sampling baseline on CIFAR-10 and CIFAR-100 datasets, respectively. It should be noted that ST-CoNAL achieves performance comparable to TA-VAAL, a state-of-the-art method that requires the addition of subnetworks and complex training optimization. Entropy shows a good performance at the beginning acquisition steps but the performance improves slowly as compared to other methods. After the last acquisition, ST-CoNAL achieves 1.37% and 4.15% higher accuracy than Entropy on CIFAR-10 and CIFAR-100, respectively. Our method outperforms CSSAL, another consistency-based AL method that only considers data uncertainty, not model uncertainty.
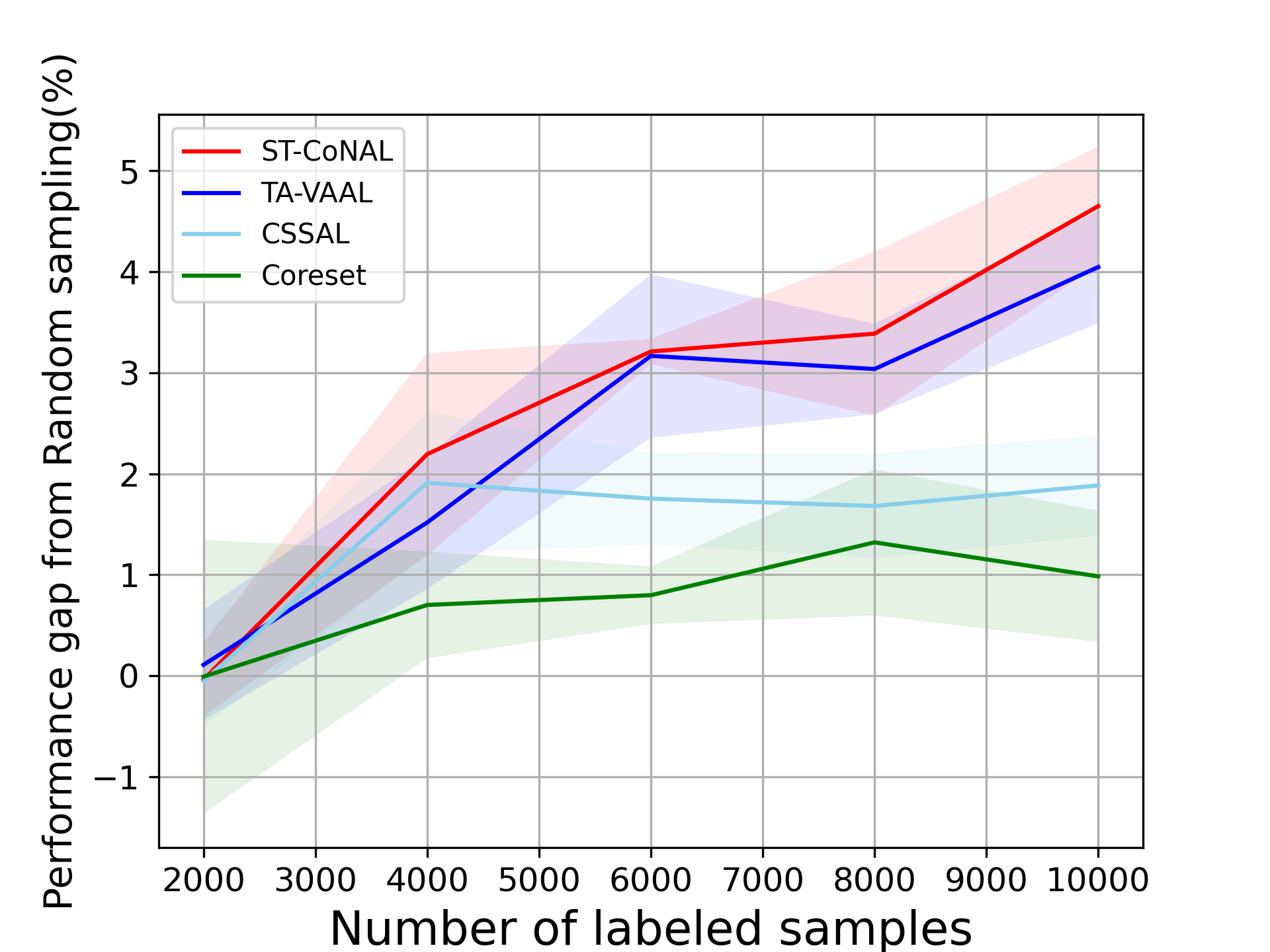
Caltech-256 and Tiny ImageNet: Fig. 3 (a) and (b) show the performance of several AL methods on Caltech-256 and Tiny ImageNet, respectively. The ST-CoNAL also achieves significant performance gain on these datasets. After the last acquisition step, ST-CoNAL achieves 3.92% higher accuracy than the random sampling baseline on Caltech-256 while it achieves 1.92% gain on Tiny-Imagenet dataset. Note that the proposed method far outperforms the CSSAL and performs comparable to more sophisticated representation-based methods, Coreset and TA-VAAL.
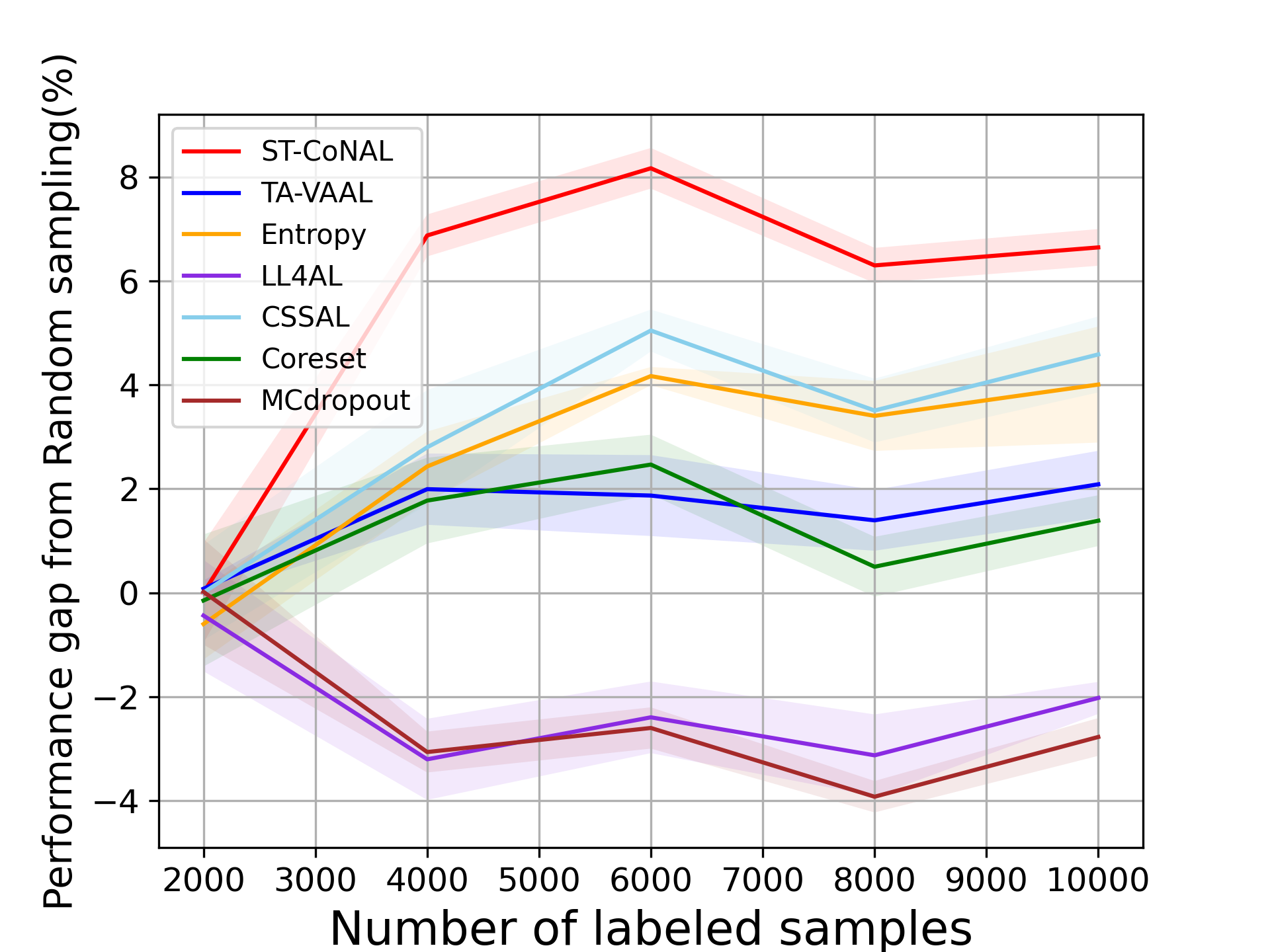
4.3 Performance Comparison on Other Setups
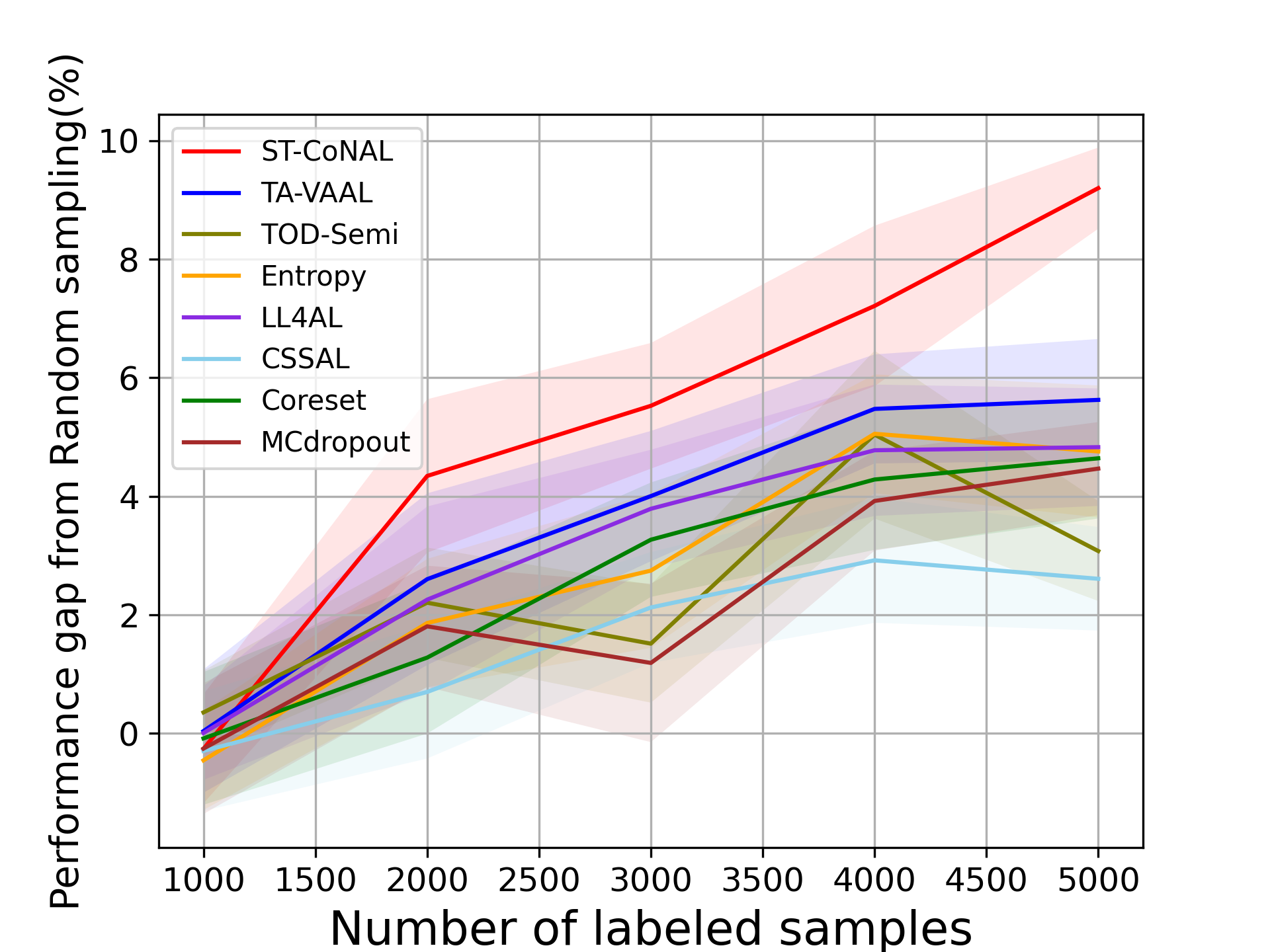
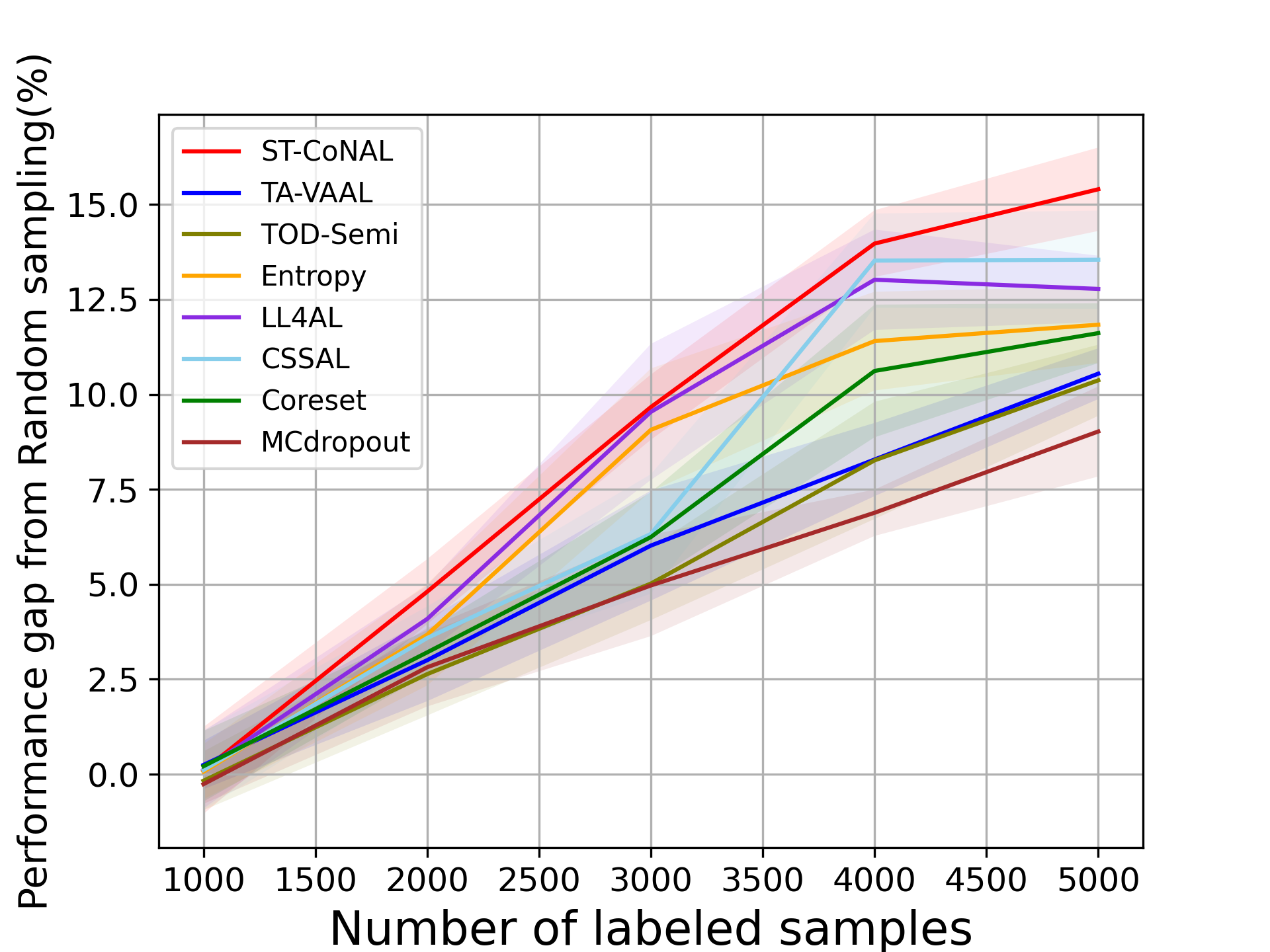
Class-Imbalanced Datasets. We also evaluate ST-CoNAL on class imbalanced datasets. Fig. 4 (a) and (b) present the performance of ST-CoNAL on (a) the step imbalanced CIFAR-10 [20] and (b) the long-tailed CIFAR-10 [5]. We see that ST-CoNAL achieves remarkable performance improvements compared to random sampling on the class imbalanced datasets. Specifically, after the last acquisition step, ST-CoNAL achieves a 9.2% performance improvement on the step-imbalanced CIFAR-10 and a 15.41% improvement on the long-tailed CIFAR-10. Furthermore, ST-CoNAL achieves larger performance gain over the current state-of-the-art, TA-VAAL. It achieves 3.58% and 4.86% performance gains over TA-VAAL on the step imbalanced CIFAR-10 and the long-tailed CIFAR-10, respectively. Note that the consistency-based method CSSAL does not perform well under this class-imbalanced setup.
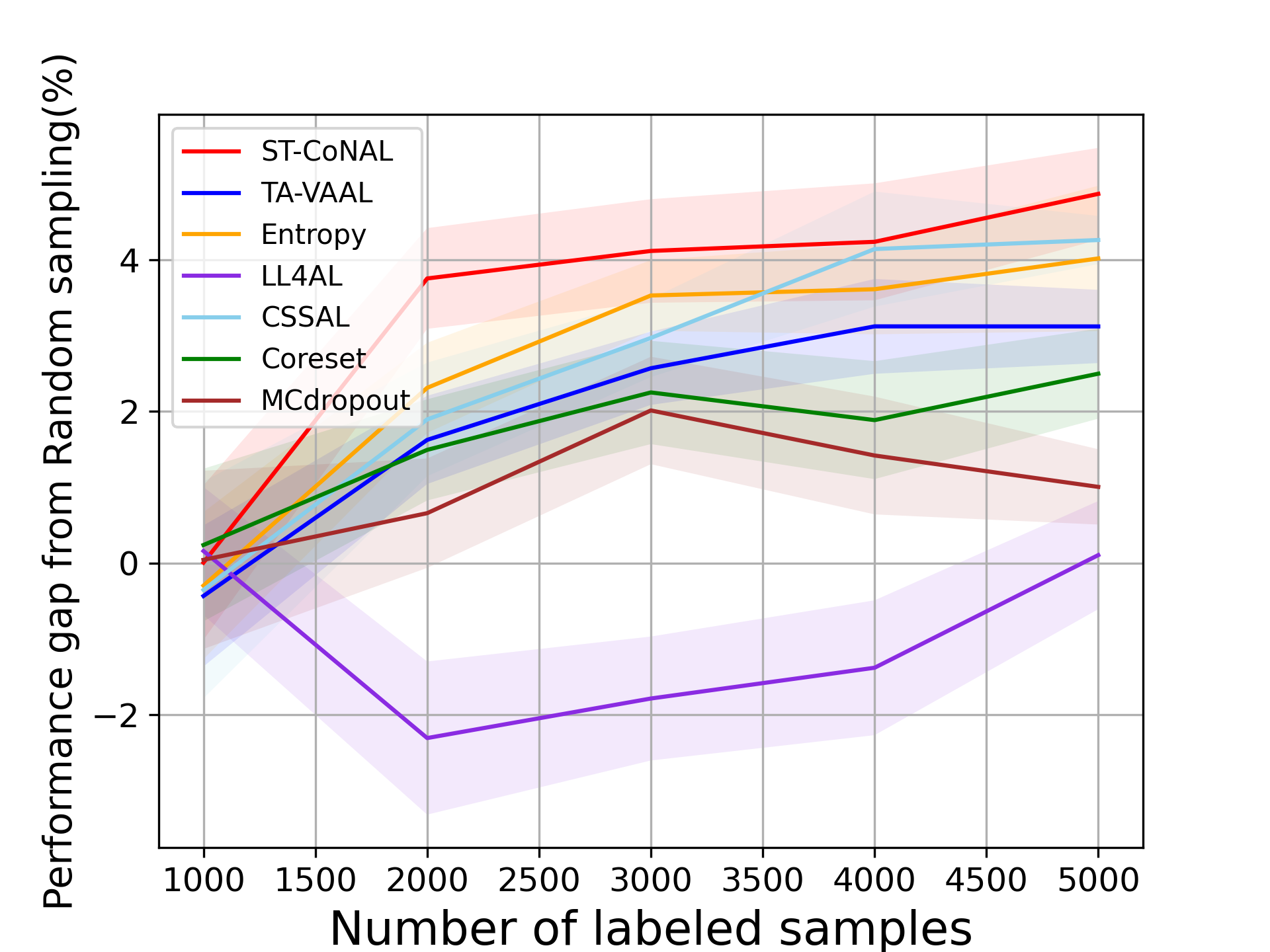
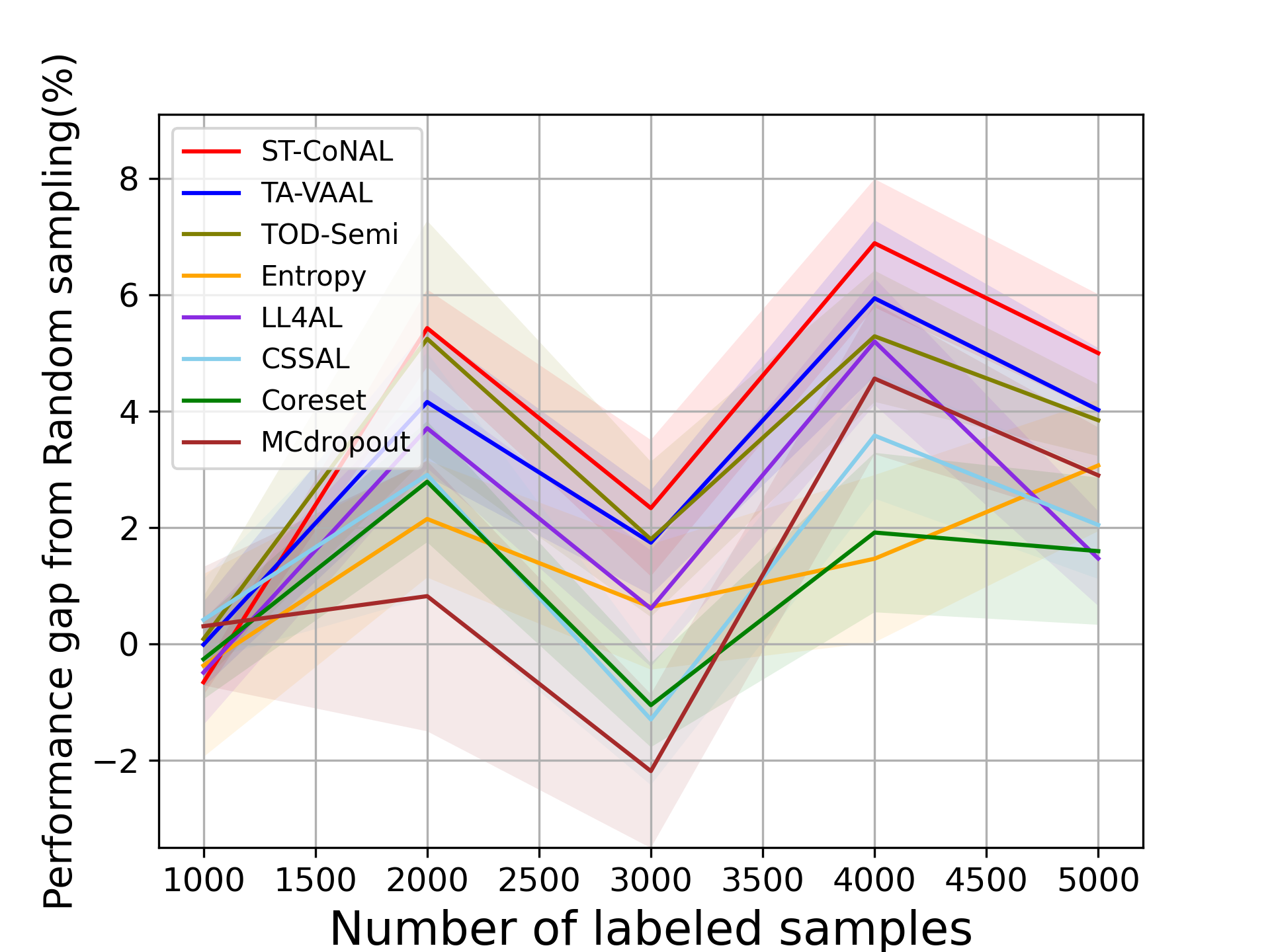
SSL Setups. Fig. 5 (a) and (b) show the performance evaluated on CIFAR-10 and CIFAR-100 datasets when ST-CoNAL is applied to SSL. ST-CoNAL maintains performance gains even in SSL settings and outperforms other AL methods by a larger margin than in supervised learning settings. After the last acquisition step, ST-CoNAL achieves the 4.87% and 6.66% performance gains over the random sampling baseline on CIFAR-10 and CIFAR-100, respectively. In particular, Fig. 5 (b) shows that ST-CoNAL achieves substantial performance gains over the existing methods in CIFAR-100.
4.4 Performance Analysis
In this subsection, we investigate the benefit of using self-ensemble for an acquisition criterion through some experiments.
4.4.1 Comparison Between Consistency Measure versus Uncertainty Measure.
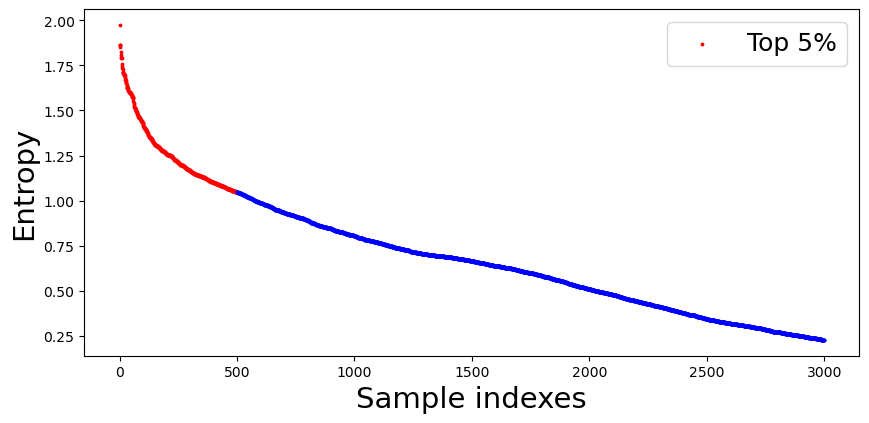
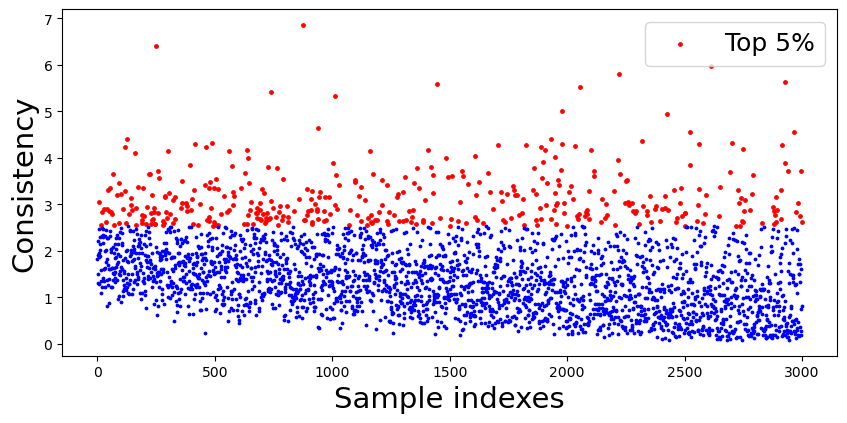
To understand the behavior of the proposed consistency measure, we compare it with the popularly used uncertainty measure, Entropy [36]. The sample acquisition process was conducted with the setup described in Experiment Setup section. We stopped the acquisition when samples are labeled. Then, we evaluated both the entropy measure and the consistency measure of ST-CoNAL with 10k samples randomly selected from the remaining unlabeled samples. The 10k samples were sorted in descending order according to entropy and sample indexes were assigned in order. Fig. 6 (a) shows the plot of entropy value versus the sample index. Obviously, due to sorting operation, the entropy value decreases with the sample index. Fig. 6 (b) presents the plot of the consistency measure over the samples sorted in the same order. The samples ranked in the top 5% by each measure are marked in red in each figure. We observe that quite different samples were identified in the top 5% according to two criteria. From this, we can conclude that the consistency measure offers the quite different standard for acquisition from the entropy measure.
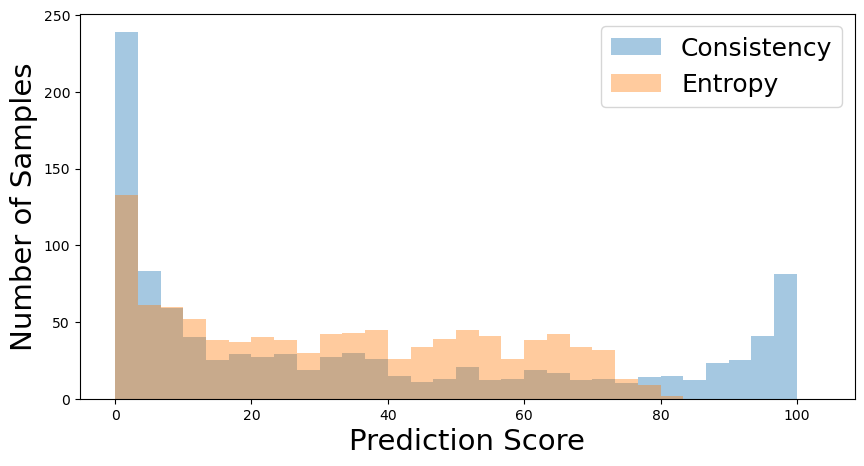
Fig. 7 shows the distribution of the prediction scores produced by the samples selected by the proposed acquisition criterion and the conventional entropy-based one [36]. We use a prediction score that corresponds to the true class index for the given sample. We used the same setup in Fig. 6. Obviously, the entropy-based criterion tends to select the samples with low confidence. It does not select the samples whose prediction score is above 80%. On the contrary, the proposed acquisition criterion selects samples with widely spread prediction scores. Note that it even selects samples for which predictions were made with near 100% confidence because they yielded the low consistency measure. The fact that the proposed method outperforms entropy-based acquisitions indicates that selecting samples with the lowest confidence is not necessarily the best strategy, and consistency-based acquisitions could promise a better solution by leveraging the advantage of various temporal self-ensemble models.
CIFAR-10 samples labeled samples labeled samples labeled samples labeled samples labeled EMA 46.36 60.73 69.10 77.49 81.51 Our EWA 47.13 61.48 71.85 79.61 83.05 CIFAR-100 samples labeled samples labeled samples labeled samples labeled samples labeled EMA 20.34 32.96 42.75 51.77 55.49 Our EWA 20.35 34.70 44.87 52.47 57.49
4.4.2 Comparison Between Equally-Weighted Average versus Exponential Moving Average.
Table 1 compares two acquisition functions that construct a teacher model using the equally-weighted average (EWA) of the proposed method versus the exponential moving average (EMA) of the MT method. For fair comparison, only the teacher models were differently constructed while all other configurations were set equally for both training and inference. Table 1 shows that EWA achieves higher performance gains over EWA as the acquisition step proceeds on both CIFAR-10 and CIFAR-100 datasets. This shows that the proposed method can construct more effective teacher model for sample acquisition than EMA.
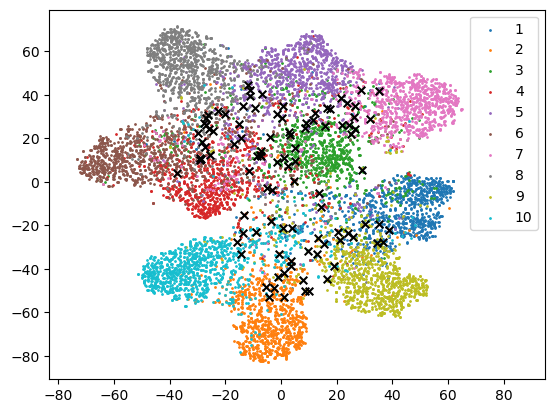
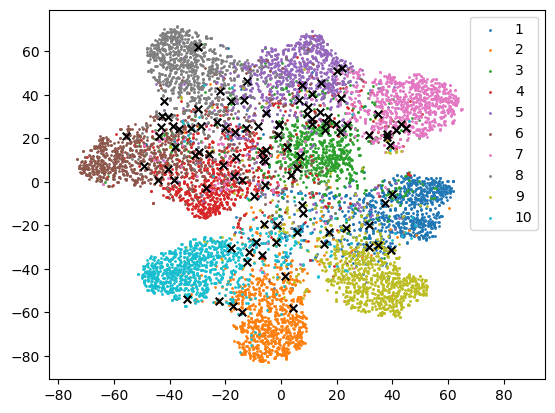
4.4.3 T-SNE Visualization.
We also visualize the samples acquired according to the entropy and the proposed consistency measure using T-SNE [28]. T-SNE projects the feature vectors onto the embedding space of lower dimension for visualization. The setup used in Fig. 6 was also used to perform T-SNE. In Fig. 8, the colored dots correspond to the unlabeled sample points projected in the embedding space. The samples selected by the entropy and by the consistency measure are marked by black cross in Fig. 8 (a) and (b), respectively. We observe from Fig. 8 that the samples selected by two acquisition criteria have different distribution, which is consistent with our finding in previous section. Samples selected by entropy tend to gather near the boundary, while samples selected by consistency measure tend to spread further. This shows that more diverse samples are selected according to consistency measure than entropy.
5 Conclusions
In this study, we proposed a new acquisition function for pool-based AL, which used the temporal self-ensemble generated during the SGD optimization. The proposed sample acquisition criterion measures the discrepancy between the predictions from the student model and the teacher model, where the student models are provided as the self-ensemble models and the teacher model is obtained through a weighted average of the student models. Using the consistency measure based on KL divergence, the proposed ST-CoNAL can acquire better samples for AL. We also showed that the sharpening operation applied to the logits of the teacher model can further improve the AL performance. The experiments conducted on CIFAR-10, CIFAR-100, Caltech-256 and Tiny ImageNet datasets demonstrated that ST-CoNAL achieved the significant performance gains over the existing AL methods. Furthermore, our numerical analysis indicated that our ST-CoNAL performs better than other AL baselines in class-imbalanced and semi-supervised learning scenarios.
References
- [1] Athiwaratkun, B., Finzi, M., Izmailov, P., Wilson, A.G.: There are many consistent explanations of unlabeled data: Why you should average. In: International Conference on Learning Representations (ICLR) (2019)
- [2] Beluch, W.H., Genewein, T., Nürnberger, A., Köhler, J.M.: The power of ensembles for active learning in image classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9368–9377 (2018)
- [3] Berthelot, D., Carlini, N., Cubuk, E.D., Kurakin, A., Sohn, K., Zhang, H., Raffel, C.: Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. In: International Conference on Learning Representations (ICLR) (2019)
- [4] Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., Raffel, C.A.: Mixmatch: A holistic approach to semi-supervised learning. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 5049–5059 (2019)
- [5] Cao, K., Wei, C., Gaidon, A., Arechiga, N., Ma, T.: Learning imbalanced datasets with label-distribution-aware margin loss. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 32 (2019)
- [6] Chen, C., Dong, S., Tian, Y., Cao, K., Liu, L., Guo, Y.: Temporal self-ensembling teacher for semi-supervised object detection. IEEE Transactions on Multimedia (2021)
- [7] Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9268–9277 (2019)
- [8] Drugman, T., Pylkkönen, J., Kneser, R.: Active and semi-supervised learning in ASR: Benefits on the acoustic and language models. In: Interspeech. pp. 2318–2322 (2016)
- [9] Gal, Y., Ghahramani, Z.: Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In: Proceedings of the International Conference on Machine Learning (ICML). pp. 1050–1059 (2016)
- [10] Gal, Y., Islam, R., Ghahramani, Z.: Deep Bayesian active learning with image data. In: Proceedings of the International Conference on Machine Learning (ICML). vol. 70, pp. 1183–1192 (2017)
- [11] Gao, M., Zhang, Z., Yu, G., Arık, S.Ö., Davis, L.S., Pfister, T.: Consistency-based semi-supervised active learning: Towards minimizing labeling cost. In: European Conference on Computer Vision (ECCV). pp. 510–526 (2020)
- [12] Grandvalet, Y., Bengio, Y.: Semi-supervised learning by entropy minimization. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 529–536 (2005)
- [13] Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset. In: California Institute of Technology (2007)
- [14] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778 (2016)
- [15] Houlsby, N., Ferenc, H., Zoubin, G., Lengyel, M.: Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745 (2011)
- [16] Huang, S., Wang, T., Xiong, H., Wen, B., Huan, J., Dou, D.: Temporal output discrepancy for loss estimation-based active learning. In: IEEE Transactions on Neural Networks and Learning Systems (2022)
- [17] Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., Wilson, A.G.: Averaging weights leads to wider optima and better generalization. In: Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence (UAI). pp. 876–885 (2018)
- [18] Johnson, E.H.: Elementary applied statistics: For students in behavioral science. Social Forces 44(3), 455–456 (1966)
- [19] Joshi, A.J., Porikli, F., Papanikolopoulos, N.: Multi-class active learning for image classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2372–2379 (2009)
- [20] Kim, K., Park, D., Kim, K.I., Chun, S.Y.: Task-aware variational adversarial active learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8166–8175 (2021)
- [21] Krizhevsky, A.: Learning multiple layers of features from tiny images. Technical report, Department of Computer Science, University of Toronto (2009)
- [22] Laine, S., Aila, T.: Temporal ensembling for semi-supervised learning. In: International Conference on Learning Representations (ICLR) (2017)
- [23] Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N 7(7), 3 (2015)
- [24] Lee, D.H.: Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In: Proceedings of the International Conference on Machine Learning Workshop on Challenges in Representation Learning. vol. 3, p. 2 (2013)
- [25] Lee, J., Chung, S.Y.: Robust training with ensemble consensus. In: International Conference on Learning Representations (ICLR) (2020)
- [26] Lewis, D.D., Gale, W.A.: A sequential algorithm for training text classifiers. In: SIGIR ’94. pp. 3–12. Springer (1994)
- [27] Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. In: International Conference on Learning Representations (ICLR) (2017)
- [28] Maaten, L.v.d., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research 9(Nov), 2579–2605 (2008)
- [29] Maddox, W.J., Izmailov, P., Garipov, T., Vetrov, D.P., Wilson, A.G.: A simple baseline for Bayesian uncertainty in deep learning. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 7026–7037 (2019)
- [30] Miyato, T., Maeda, S.i., Koyama, M., Ishii, S.: Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 1979–1993 (2018)
- [31] Oliver, A., Odena, A., Raffel, C.A., Cubuk, E.D., Goodfellow, I.: Realistic evaluation of deep semi-supervised learning algorithms. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 3235–3246 (2018)
- [32] Rhee, P., Erdenee, E., Shin, D.K., Ahmed, M., Jin, S.: Active and semi-supervised learning for object detection with imperfect data. Cognitive Systems Research 45, 109–123 (2017)
- [33] Sajjadi, M., Javanmardi, M., Tasdizen, T.: Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 1163–1171 (2016)
- [34] Sener, O., Savarese, S.: Active learning for convolutional neural networks: A core-set approach. In: International Conference on Learning Representations (ICLR) (2018)
- [35] Settles, B.: Active learning literature survey. Tech. rep., University of Wisconsin-Madison Department of Computer Sciences (2009)
- [36] Shannon, C.E.: A mathematical theory of communication. Bell system technical journal 27(3), 379–423 (1948)
- [37] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (ICLR) (2015)
- [38] Sinha, S., Ebrahimi, S., Darrell, T.: Variational adversarial active learning. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 5972–5981 (2019)
- [39] Sohn, K., Berthelot, D., Li, C.L., Zhang, Z., Carlini, N., Cubuk, E.D., Kurakin, A., Zhang, H., Raffel, C.: Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In: Advances in Neural Information Processing Systems (NeurIPS) (2020)
- [40] Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 1195–1204 (2017)
- [41] Tomanek, K., Hahn, U.: Semi-supervised active learning for sequence labeling. In: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. vol. 2, pp. 1039––1047. Association for Computational Linguistics (2009)
- [42] Tong, S., Koller, D.: Support vector machine active learning with applications to text classification. The Journal of Machine Learning Research 2, 45–66 (2001)
- [43] Verma, V., Lamb, A., Kannala, J., Bengio, Y., Lopez-Paz, D.: Interpolation consistency training for semi-supervised learning. In: Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI). pp. 3635–3641. IJCAI.org (2019)
- [44] Xie, Q., Dai, Z., Hovy, E., Luong, T., Le, Q.: Unsupervised data augmentation for consistency training. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 33, pp. 6256–6268 (2020)
- [45] Yang, G., Tianyi, C., Kirichenko, P., Wilson, A.G., De Sa, C.: Swalp: Stochastic weight averaging in low precision training. In: Proceedings of the International Conference on Machine Learning (ICML) (2019)
- [46] Yoo, D., Kweon, I.S.: Learning loss for active learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 93–102 (2019)
- [47] Zhang, B., Li, L., Yang, S., Wang, S., Zha, Z.J., Huang, Q.: State-relabeling adversarial active learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8756–8765 (2020)
- [48] Zhu, X., Lafferty, J.D., Ghahramani, Z.: Combining active learning and semi-supervised learning using gaussian fields and harmonic functions. In: Proceedings of the International Conference on Machine Learning Workshop on the Continuum from Labeled to Unlabeled Data. pp. 58–65 (2003)
Appendix
Appendix 0.A Experimental Setup
In this section, we provide the detailed experimental setups. The configuration parameters used for ST-CoNAL are provided in Table 2. As for SSL setup, we followed the configurations used in [40].
Dataset CIFAR-10 CIFAR-100 Caltech-256 Tiny ImageNet Initial learning rate 0.1 0.1 0.01 0.005 Nesterov momentum 0.9 0.9 0.9 0.9 Weight decay 0.0004 0.0004 0.001 - Batch size 128 128 128 128 Labeled batch size 32 32 32 32 Total epochs 200 200 200 100 Size of unlabeled subset 10k 20k 10k 20k Budget 1k 2k 1k 2k Size of initially labeled set 1k 2k 1k 2k Storing interval 10 10 10 10 Learning rate decay 1.0 0.5 0.3 0.5 Learning rate decay point 160 160 160 60
Appendix 0.B Experimental Results
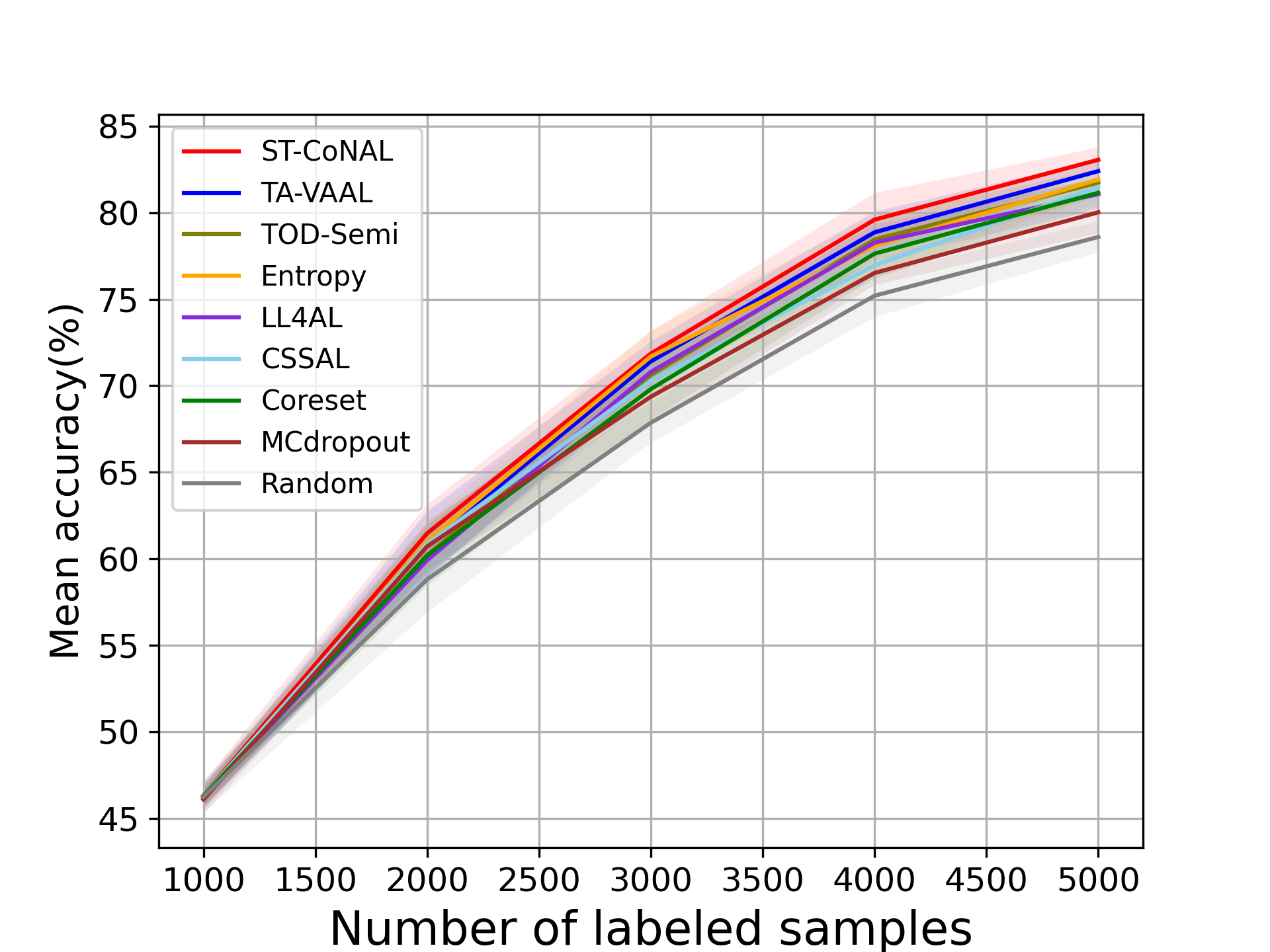
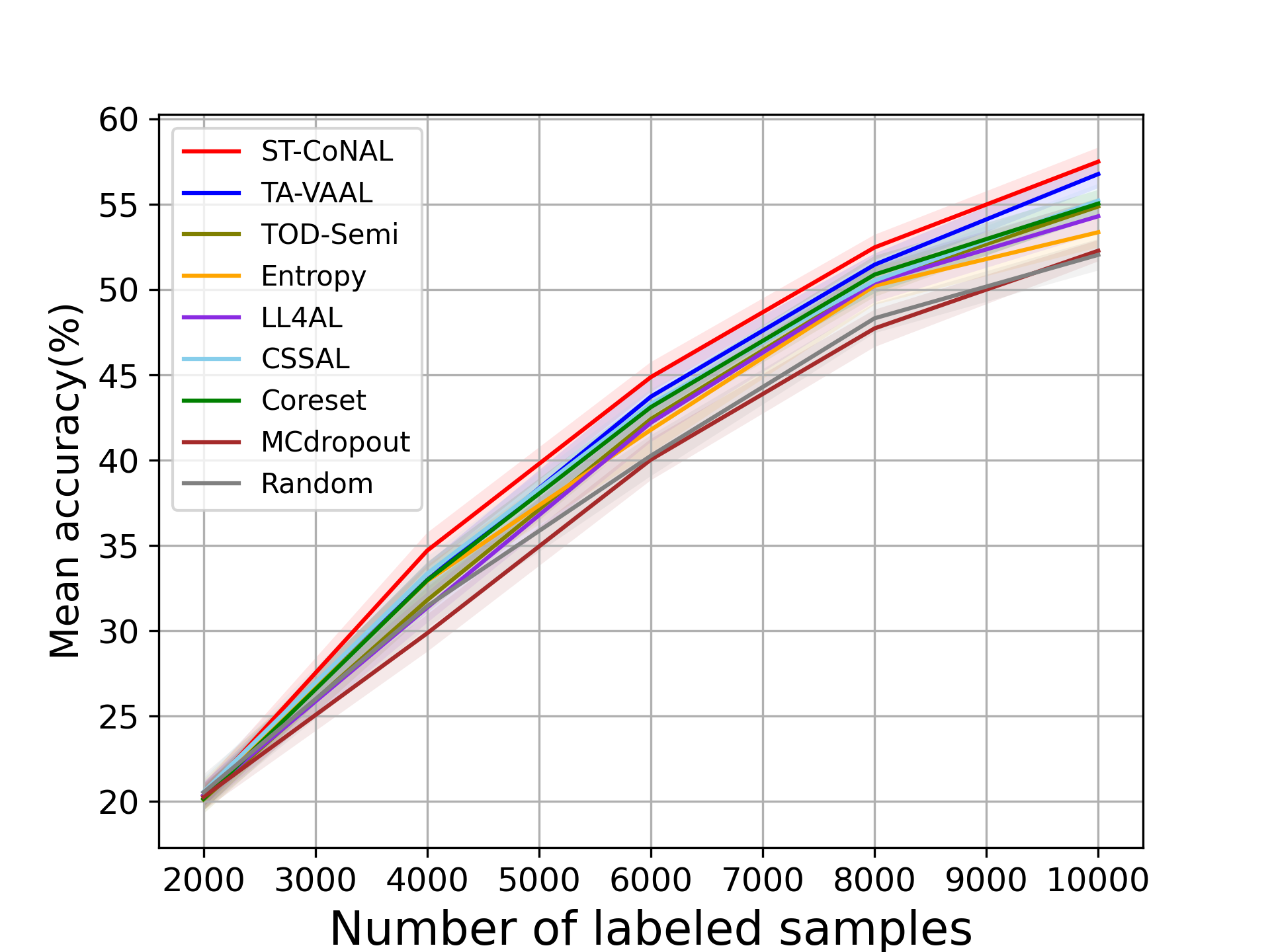
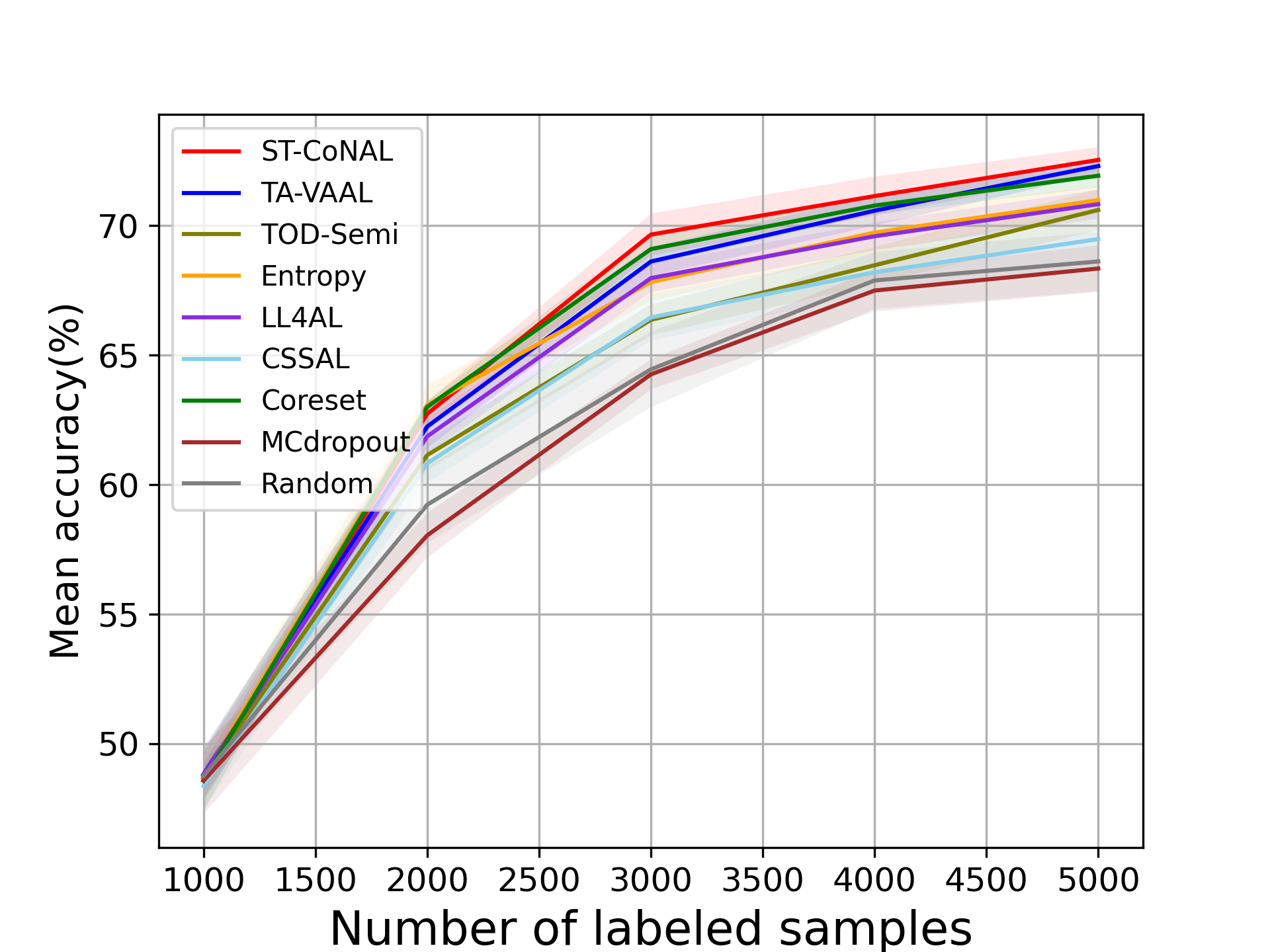
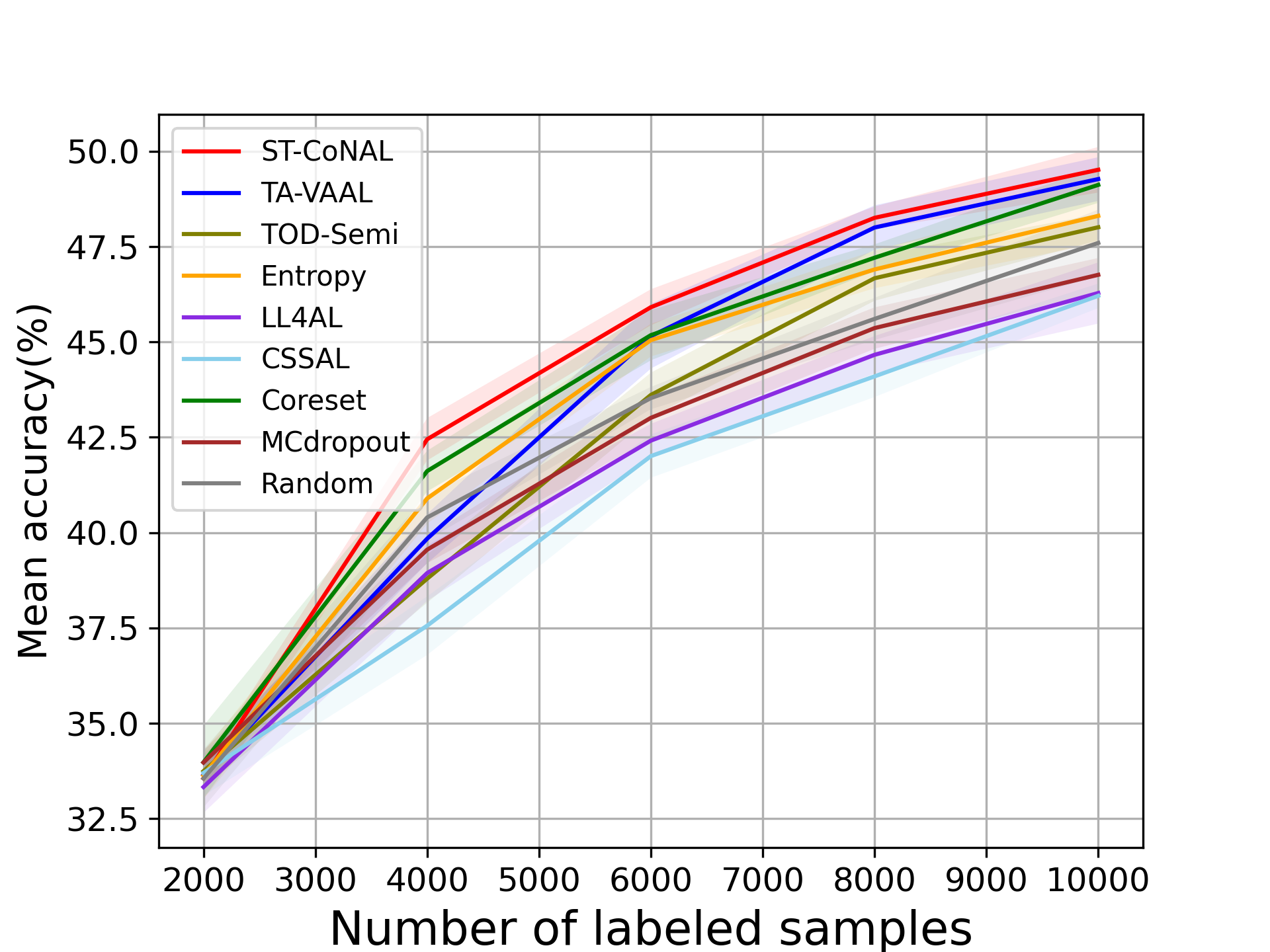
In the main manuscript, we used the performance gap from the random sampling baseline as a performance measure. To supplement this, we provide the absolute values of the average accuracy achieved by the AL methods. Fig. 9 (a) and (b) show the performance results evaluated on CIFAR-10 and CIFAR-100 datasets and Fig. 10 (a) and (b) represent those on Caltech-256 and Tiny ImageNet datasets.
Appendix 0.C Performance Comparison of AL Methods on Differently Imbalanced Datasets
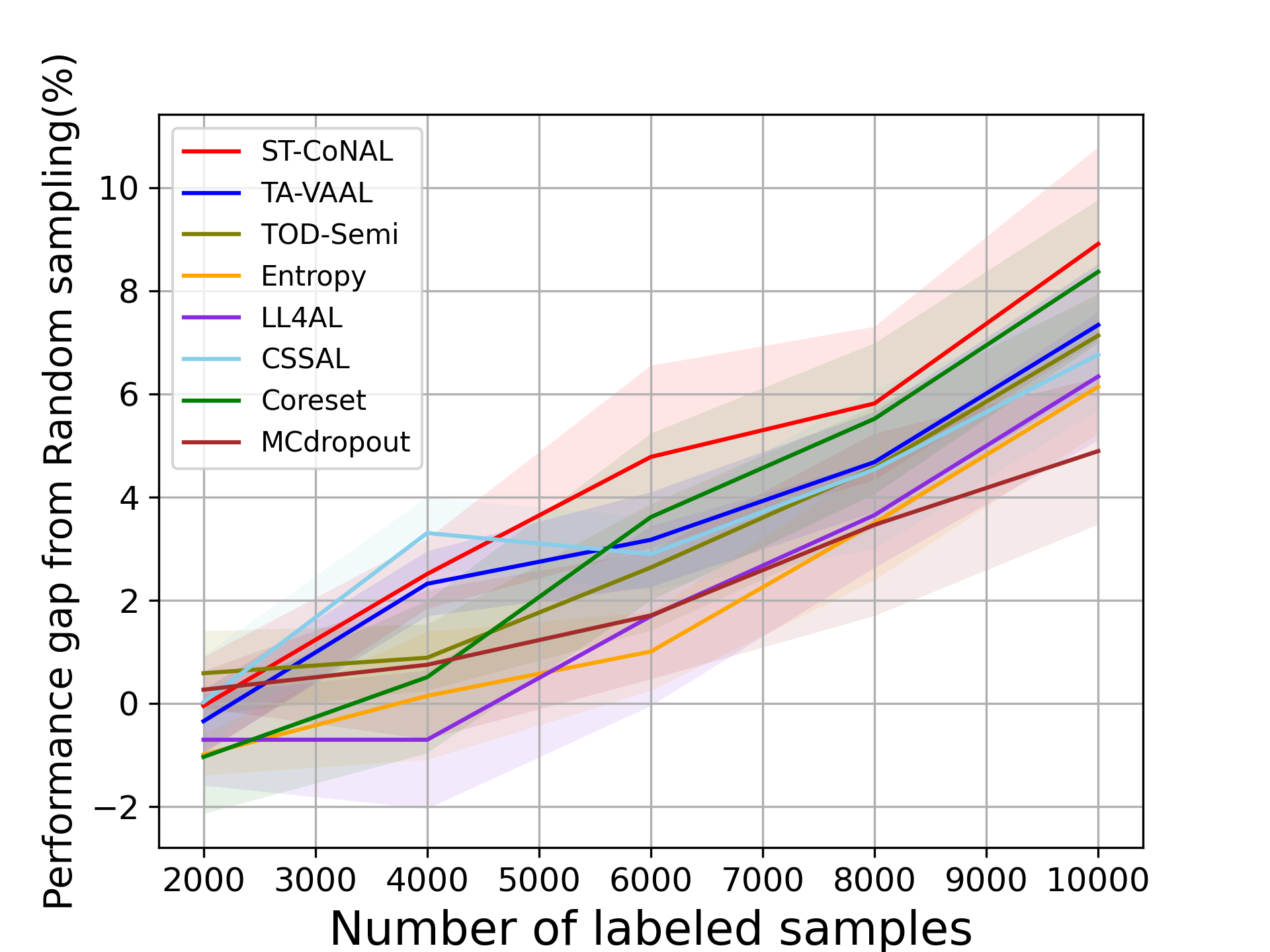
In the main manuscript, we reported the performance of ST-CoNAL obtained on two imbalanced versions of CIFAR-10. In this section, we evaluate the algorithms on two differently imbalanced CIFAR-100 datasets, the step-imbalanced CIFAR-100 [7] and long-tailed CIFAR-100 [5, 7]. The imbalance ratio was set to 100 for all cases. Fig. 11 (a) and (b) present the performance of ST-CoNAL on the step imbalanced CIFAR-100 [20] and the long-tailed CIFAR-100 [5], respectively. Even when different imbalance setups are used, ST-CoNAL consistently outperforms other AL methods. After the last acquisition step, ST-CoNAL achieves a performance improvement of 4.10% and 6.18% over the random sampling on the step-imbalanced CIFAR-100 and long-tailed CIFAR-100, respectively.
Appendix 0.D Performance Comparison of AL Methods With Different Backbones
In this section, we evaluate the performance of ST-CoNAL when VGG16 [37] and ResNet-50 [14] are used as a backbone network. Fig. 12 (a) and (b) show the performance of ST-CoNAL on CIFAR-10 and CIFAR-100 when VGG16 backbone is used. After the last acquisition step, ST-CoNAL achieves 2.95% and 4.65% performance gains over random sampling on CIFAR-10 and CIFAR-100, respectively. Fig. 13 presents the performance of ST-CoNAL when ResNet-50 backbone is used. ST-CoNAL achieves the performance improvement of 4.99% and 8.91% over random sampling on CIFAR-10 and CIFAR-100, respectively.
Appendix 0.E Performance Versus Other Parameters
We evaluate the performance of ST-CoNAL as a function of the budget sizes , the number of student models and temperature parameter on CIFAR-10. We try the different values of , , and . For the budget sizes , we compare our ST-CoNAL with three competitive methods, Entropy [36], and TA-VAAL [11]. Table 3 provides the classification accuracy as a function of the acquisition step for different values of labeling budget . The proposed ST-CoNAL maintains the performance gain over Entropy [36] and TA-VAAL [11] with different budget sizes. Additionally, we provide the performance of ST-CoNAL as a function of acquisition step versus the number of student models and temperature parameter . Table 4 shows that ST-CoNAL achieves good performance for different and values. For CIFAR-10 dataset, we set and to provide decent performance.
= samples labeled samples labeled samples labeled samples labeled samples labeled Entropy 46.83 59.29 68.33 76.10 81.16 TA-VAAL 47.26 60.71 69.71 76.35 82.27 ST-CoNAL 46.93 60.91 70.39 77.03 83.40 = samples labeled samples labeled samples labeled samples labeled samples labeled Entropy 46.96 61.00 71.69 78.09 81.92 TA-VAAL 46.94 60.79 71.40 78.87 82.40 ST-CoNAL 47.13 61.48 71.85 79.61 83.05 = samples labeled samples labeled samples labeled Entropy 47.19 71.00 81.29 TA-VAAL 47.18 71.22 81.40 ST-CoNAL 46.99 72.48 82.53
Q samples labeled samples labeled samples labeled samples labeled samples labeled 2 46.67 60.99 70.95 79.18 82.63 4 47.13 61.48 71.85 79.61 83.05 8 46.86 61.49 71.77 79.23 82.83 10 46.70 61.37 71.64 79.40 83.14 T samples labeled samples labeled samples labeled samples labeled samples labeled 0.3 47.00 60.66 70.62 78.03 82.57 0.5 47.23 60.91 70.82 78.51 82.35 0.7 47.13 61.48 71.85 79.61 83.05 1.0 46.87 60.91 71.41 79.78 82.96