Stable and Accurate Orbital-Free DFT
Powered by Machine Learning
Abstract
Hohenberg and Kohn have proven that the electronic energy and the one-particle electron density can, in principle, be obtained by minimizing an energy functional with respect to the density. While decades of theoretical work have produced increasingly faithful approximations to this elusive exact energy functional, their accuracy is still insufficient for many applications, making it reasonable to try and learn it empirically. Using rotationally equivariant atomistic machine learning, we obtain for the first time a density functional that, when applied to the organic molecules in QM9, yields energies with chemical accuracy relative to the Kohn-Sham reference while also converging to meaningful electron densities. Augmenting the training data with densities obtained from perturbed potentials proved key to these advances. This work demonstrates that machine learning can play a crucial role in narrowing the gap between theory and the practical realization of Hohenberg and Kohn’s vision, paving the way for more efficient calculations in large molecular systems.
In a disarmingly simple proof, Hohenberg and Kohn showed [1] that the electron density alone is sufficient to determine the ground state energy of a molecular system. The proof marked a radical departure from most prior work, which had recurred to the Schrödinger equation acting on a multielectron wave function to describe a system of interacting electrons. Of note, for electrons, a general wave function lives (omitting spin for simplicity) in . Mean-field approximations such as Hartree-Fock reduce this to coupled one-electron wave functions, called orbitals, each living in . The electron density, on the other hand, is a single function in , teasing the possibility of a profound simplification of the description of multielectron quantum systems. This promise is reinforced by the second Hohenberg-Kohn theorem enunciating the existence of a variational principle: Not only is there an energy functional that assigns an energy to each density; but the ground state electron density is a minimizer of that functional.
Sadly, the proof of existence is non-constructive. That is, we know that a universal energy functional exists; but its exact form remains unknown except for simple special cases [2, 3, 4] that do not cover most chemistries of general interest.
This limitation led Kohn and Sham to re-introduce auxiliary one-electron wave functions for the sole reason that this representation would allow invoking the well-known quantum mechanical operator for the kinetic energy [5]. The enormous practical success of the resulting Kohn-Sham density functional theory, or KS-DFT for short, makes it the most widely used quantum chemical method today and arguably is what turned theoretical chemistry into a practically applied discipline. Its success also crowded out methods relying on the electron density alone, now called orbital-free density functional theory (OF-DFT).
Optimism that the latter can be made practical is founded on the “nearsightedness of electronic matter” which Kohn attributes to wave-mechanical destructive interference [6]. Admittedly, we are also emboldened by what may be called the “miracle of chemistry”: The empirical fact that chemists are able to make semi-quantitative predictions of stability and reactivity in their heads, even though the underlying systems are profoundly quantum mechanical. In other words, it is fair to assume some measure of locality and of well-behavedness of the unknown energy functional, at least for systems with a band gap.
The lure of a simple but complete description of molecular ground states in terms of their electron density alone has motivated an intense search for approximations with relatively few parameters [7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]. While remarkably successful considering the complex nature of the kinetic energy, these are not yet sufficiently accurate for the quantitative prediction of outcomes in typical laboratory chemistry.
This motivates the search for machine learned functionals whose significantly larger number of parameters promises greater expressivity [18, 19, 20]: While promising, initial forays [21, 22, 23, 24] were still limited regarding accuracy and/or transferability of the learned functionals. The equivariant KineticNet architecture [25] was the first to demonstrate chemical accuracy of a single learned functional across input densities and geometries of tiny molecules. This work was superseded by the milestone M-OFDFT pipeline [26]. Its representation of the density in terms of a linear combination of atomic basis functions [27, 28] is much more compact, compared to a grid. It first predicted molecular energies across the QM9 dataset [29, 30] of diverse organic molecules with up to nine second-period atoms with chemical accuracy with respect to the PBE/6-31G(2df,p) Kohn-Sham reference, a remarkable feat. Perhaps the biggest success of that work was its ability to extrapolate to larger molecules than trained on. One drawback was the model being fully non-local, i.e., each atom needs to exchange information with all others. While not a problem for molecules up to a few hundred atoms, this eventually becomes prohibitive for larger systems. Its foremost limitation, however, was that the learned functional did not afford variational density optimization: Following the energy gradient led to unphysical densities and energies, creating the need to engineer a method that picks an intermediate solution as the final prediction post hoc.
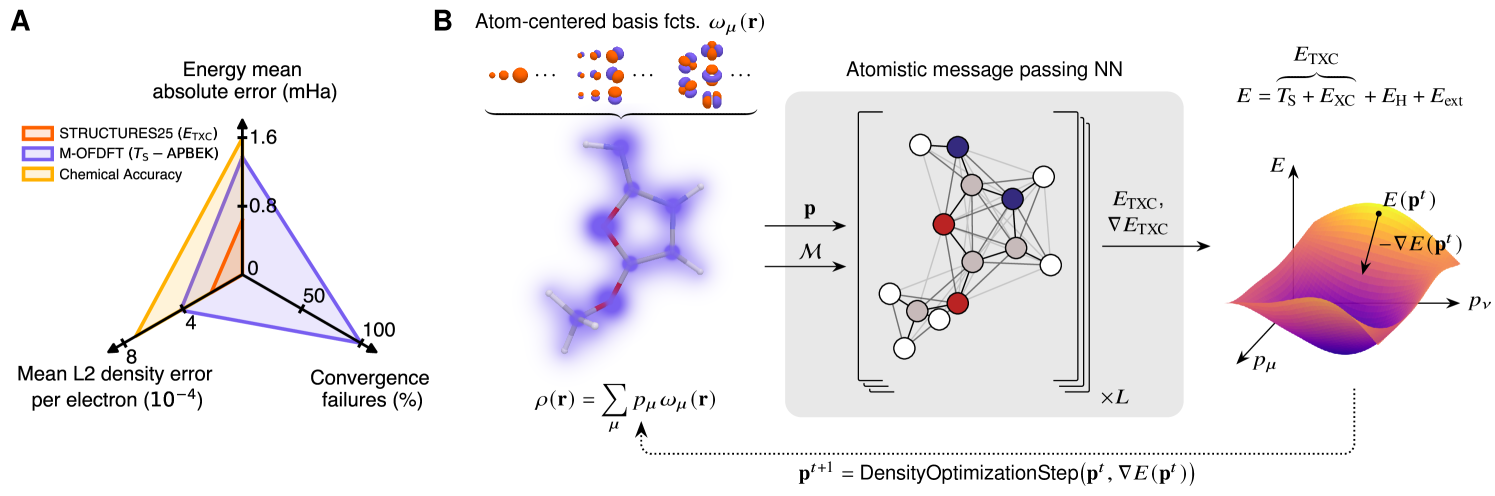
Learning a density functional which makes truly variational optimization possible has been our main objective, and below we describe how this objective is achieved (Fig. 1A) by letting the model learn from physically plausible, but more varied, and more evenly distributed training data. A secondary objective has been to address the scaling of computational cost with size. We demonstrate good extrapolation to larger systems with a guaranteed field of view that does not need to grow with the system of interest.
Variational density optimization
As illustrated in Fig. 1B, a suitable machine learning architecture can be used to map an electron density (here represented as a coefficient vector of atom-centered basis functions) for a given molecular constitution and geometry to an energy estimate . A “variational” density optimization then takes gradient descent steps on this energy surface to iteratively update the density coefficients.
Ensuring that the learned energy functional has a true minimum at the correct ground state electron density (or very nearby) is of paramount practical importance (Fig. 2A). Indeed, it enables convergent variational density optimization to meaningful densities (Fig. 2B). If no such minimum were present, following the gradient on such a misleading surface would result in unphysical densities, e.g., allowing electrons to collapse into a nucleus. Previously, such malformed energy surfaces required elaborate procedures to salvage a prediction from a diverging density optimization trajectory [26]. In addition, an estimated ground state density with vanishing gradients is vital for the calculation of valid nuclear gradients, which are required for robust geometry optimization but especially for faithful molecular dynamics.
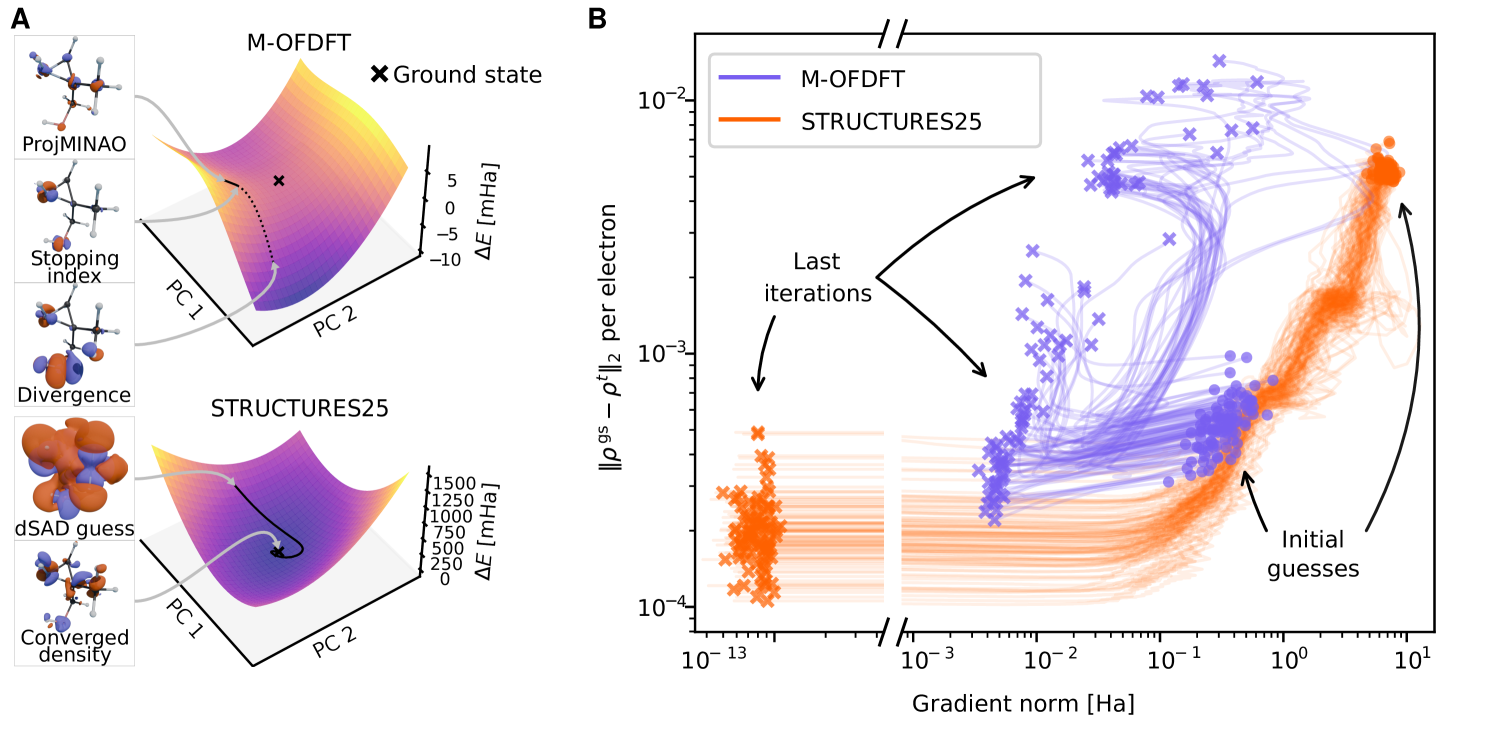
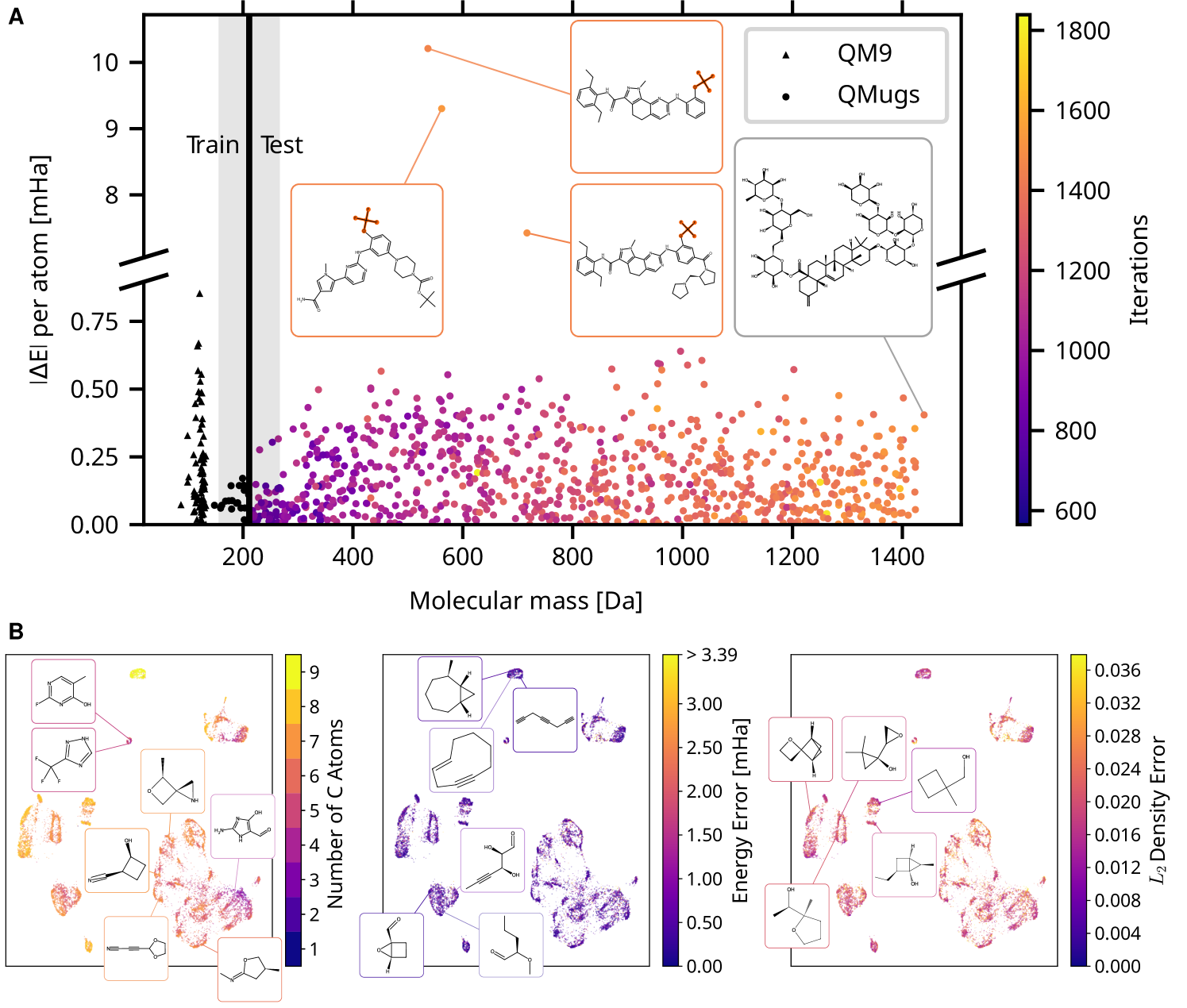
Improving upon the varied data generation pioneered in KineticNet [25] and combining it with a generalization [31] of the M-OFDFT architecture [26] finally affords a well-formed energy functional, which we call STRUCTURES25. Indeed, density optimization using this functional dramatically improves convergence on the QM9 [29, 30] test set while reducing energy and density errors at the same time.
An important side effect of these improvements are reduced demands on the quality, and hence cost, of the initial electron density for the OF-DFT calculation. In fact, the robustness of the new functional allows starting from our version of a simple but exceedingly fast data-driven superposition of atomic densities (dSAD) guess, see materials and methods.
In the following, we outline the changes to training data generation and architecture that made these improvements possible.
Generating diverse training data
Data efficiency in machine learning can be increased by using appropriate inductive biases, such as baking permutation or rotation equivariance into the architecture, or invoking prior knowledge such as scaling laws [32, 33], or more broadly learning an objective function rather than its minimizers. But even then, broad coverage of conceivable inputs in the training data is required.
Zhang et al. [26] have used the insight that each iteration of the self-consistent Kohn Sham DFT procedure [5]
| (1) |
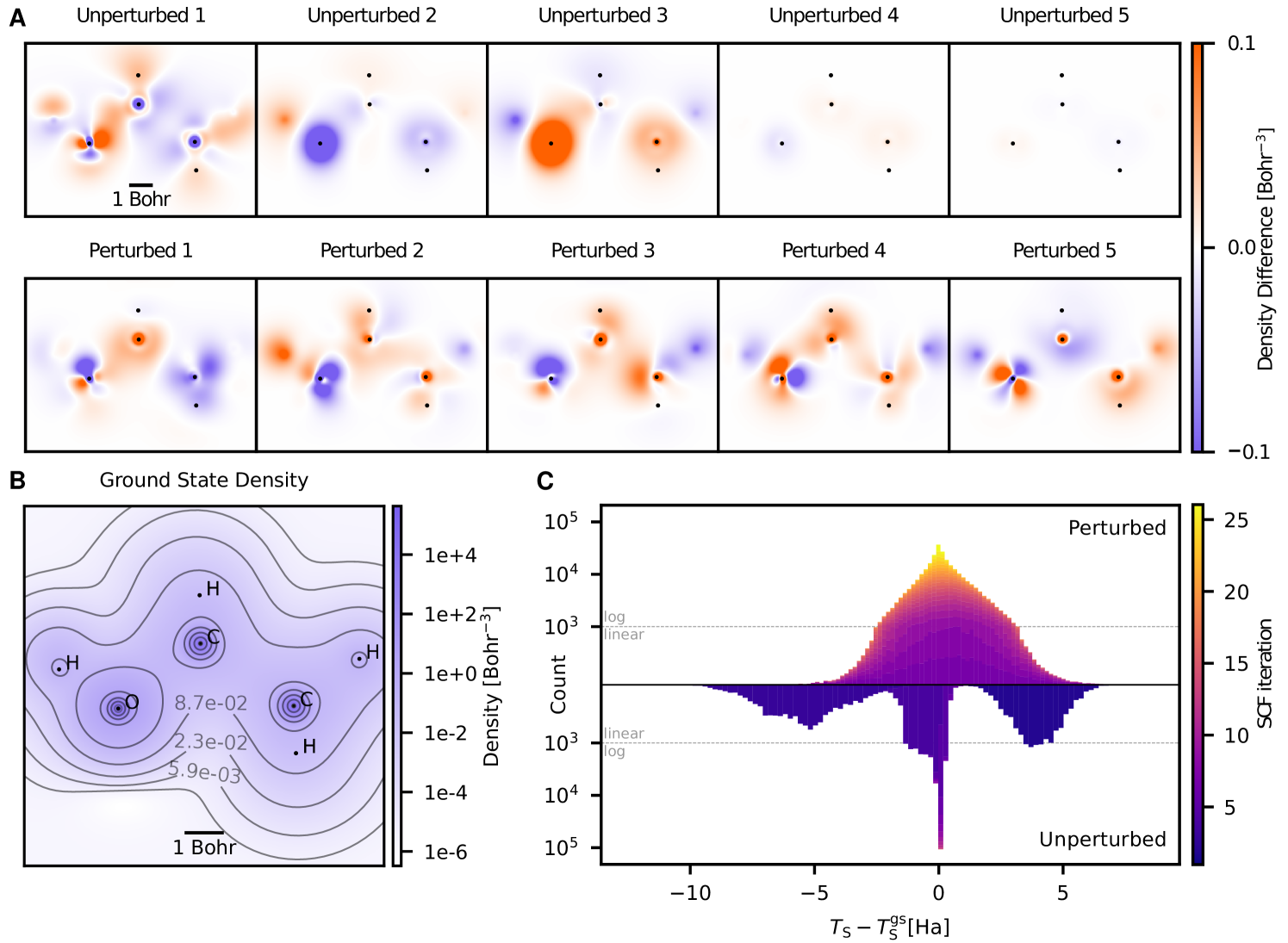
yields a consistent tuple of potential , orbitals and associated energies from which a training sample (density coefficients , energy , gradient ) can be obtained. The bottom of Fig. 3C characterizes the resulting high-dimensional training data in terms of a single axis, the energy difference between training and respective ground state electron densities. It is in the nature of self-consistent field (SCF) iterations that these quickly converge to the vicinity of the ground state, resulting in an uneven training distribution that is mostly concentrated in a spike around the ground state density.
We instead modify the potential in the above equation to read , where are randomly sampled perturbations. This approach results in more varied training labels (Figs. 3A and 3B) which in turn afford the training of much better-behaved functionals, see Fig. 2 and ablation experiments in supporting text S.10.
Training targets
The question of which target to train against is a highly interesting one. According to Hohenberg and Kohn [1], the total electronic energy can be decomposed into a universal (independent of the external potential) functional and a classical electrostatic interaction between the electron density and the external potential representing the atomic nuclei: . Following Levy and Lieb [32], it is customary to further decompose the universal functional into a “non-interacting kinetic energy” , a classical electrostatic electron-electron or “Hartree” interaction and an “exchange-correlation” term , which captures all quantum effects not accounted for elsewhere. The immense practical success of Kohn-Sham DFT is owing to the fact that reasonably good approximations to the true have been found [34, 35, 36], with active efforts [37] underway to further improve upon these using machine learning.
At first sight, learning a density functional form of just , the raison d’être of Kohn-Sham DFT, seems natural in the spirit of reductionism. As an example, the model from M-OFDFT [26] evaluated in Fig. 1A was trained on the difference of this non-interacting kinetic energy and the classical APBEK functional [12] in the fashion of “delta learning.”
Here we instead opt to learn the sum of kinetic and exchange correlation energies because that eliminates the need for a quadrature grid which is otherwise required for the evaluation of most exchange correlation functionals. This target, denoted in the following, aggregates all contributions that are not known analytically and gains further justification from the conjointness conjecture [12].
Finally, to obtain well-formed energy surfaces, it helps to use not only energies but also their functional derivatives as training targets. In the finite basis, the functional derivatives are gradients . Obtaining these is not trivial, and details can be found in the supporting information, section S.1.
Representation and Architecture
A compact representation of electron density can be obtained in terms of a linear combination [27, 28] of atom-centered basis functions ,
| (2) |
We use an even-tempered Gaussian basis [38] . While this representation does not guarantee positivity, regions of unphysical negative densities are no failure case that we encounter in practice, see Fig. S.5 in the supporting information.
The presently most successful class of architectures in molecular machine learning are atomistic message passing graph neural networks [39]. These iteratively exchange messages between atoms, along edges which are typically not defined by chemical bonds but rather by some distance cutoff or even by a fully connected graph. As desired, atomistic message passing predictions of molecular properties are invariant to the (mostly arbitrary) order in which the constituent atoms are presented. Similarly, as physical quantities transform equivariantly when the entire system is translated or rotated, so should the predictions. Scalar quantities, such as the energy, should be -invariant.
This equivariance with respect to rigid motions is commonly accomplished either by relying on the tensor product [40] as basic bilinear operation, or by “local canonicalization” [41, 42, 31]. The latter finds local coordinate systems, equivariant “local frames,” for each atom based on its few nearest neighbors.
Having experimented extensively with either class of architecture [43, 44, 45], we obtain broadly comparable results with representatives of both; but we currently find the best trade-off between cost and performance with a Graphormer [45, 46] type architecture. The latter profits from a self-attention mechanism, but is limited by the fact that it can only send scalar messages between nodes. In response, by invoking a recently proposed formalism [31], we generalize the architecture to allow sending tensorial messages between nodes.
The input to our model consists of the density coefficients from Eq. 2 as well as the molecular geometry given by atom positions and types . The model predicts the energy while its gradient is computed variationally using automated differentiation.
The atomic basis functions overlap and so the density coefficients are not independent. We follow M-OFDFT [26] in first transforming the coefficients into an orthonormal basis by means of a global “natural reparametrization” and then subjecting coefficients and energy gradients to dimension-wise rescaling and atomic reference modules, see [26] for details.
Importantly, for larger molecules, we use a distance cutoff in the definition of atomic adjacency, making for a message passing mechanism that scales gracefully with system size. For detailed model specifications, see the supporting text.
Evaluating STRUCTURES25
We concentrate here on equilibrium-geometry organic molecules with a mass of up to a few hundred Dalton. While they span only a tiny corner of the entire chemical space, this family is already estimated to comprise anywhere between and members [47, 48]. Needless to say, this number grows further when taking larger biopolymers such as peptides or nucleotide chains into account.
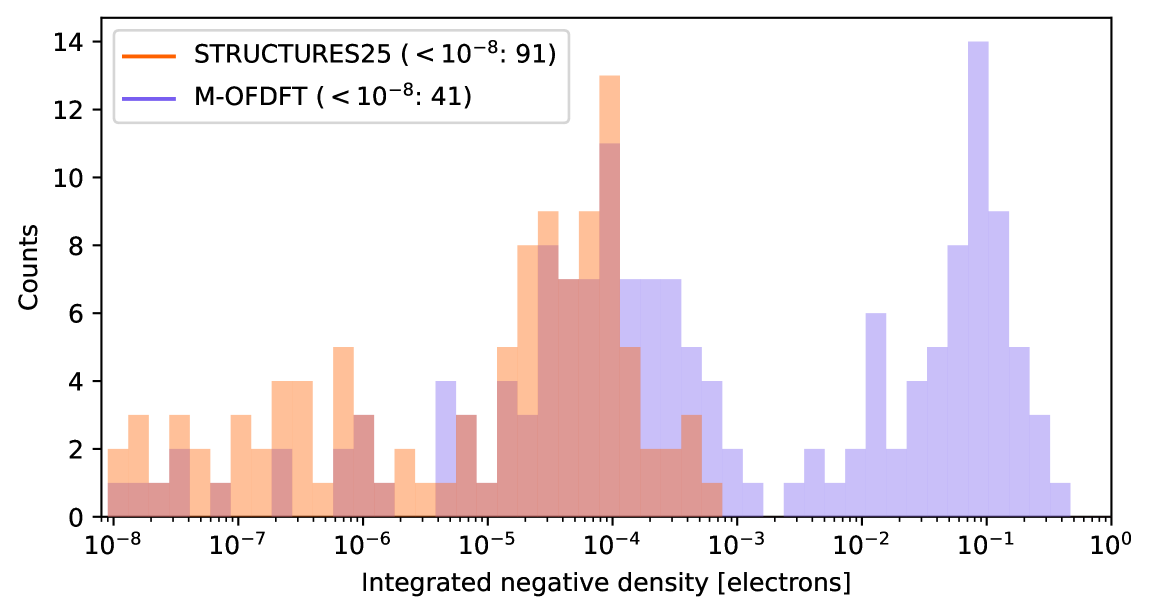
The QM9 database [30], while restricted to stable molecules and relaxed geometries, is already quite diverse when considering only small organic molecules, see Fig. 4B. Orbital-free DFT as implemented by the STRUCTURES25 functional now affords density optimization which fully converges for each and every of the ca. 13k QM9 test molecules; with the resulting densities deviating from Kohn-Sham ground truth by in the metric of the squared error integrated over space, normalized by the number of electrons. The biggest contribution to this deviation comes not from the machine learning model, but stems from the intrinsic error of density fitting (see Fig. S.2 in the supporting information), the process of expressing a Kohn-Sham density in the specific basis used to expand the orbital-free density in Eq. 2. Mean absolute energy errors of 0.64 mHa relative to the PBE/6-31G(2df,p) KS-DFT reference are well below the barrier of 1.6 mHa, a widely accepted definition of “chemical accuracy”.
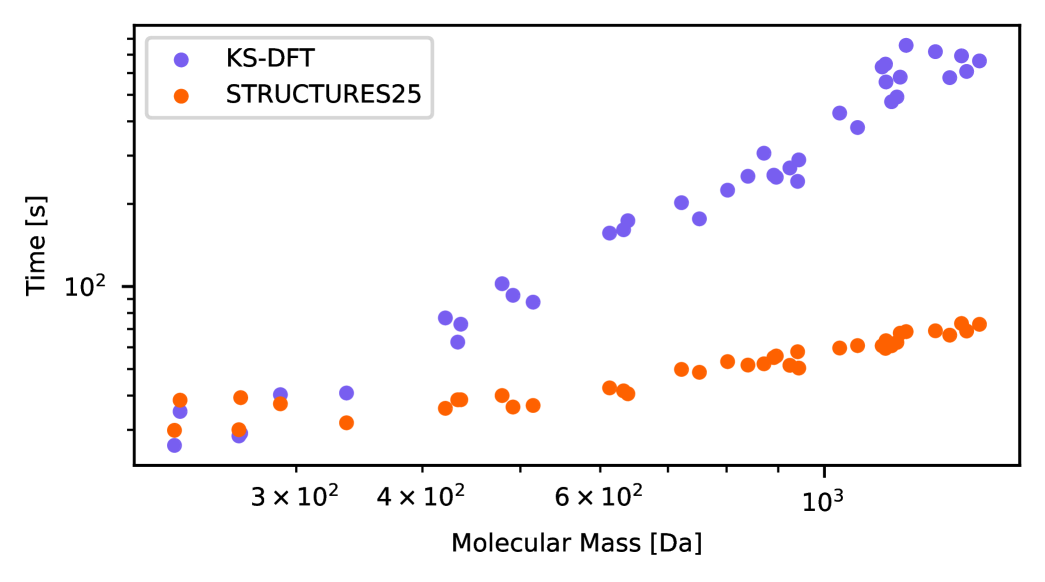
Reaching Kohn-Sham accuracy and fully convergent density optimization on the full chemistry embodied by the QM9 dataset is already most auspicious for orbital-free DFT. Yet, for future applications, reliable extrapolation to larger systems is essential: It is here that standard Kohn-Sham DFT becomes intractable. Following prior work [26], we evaluate extrapolation accuracy on the QMugs database [49] comprising substantially larger druglike molecules. To this end, we train on smaller molecules with a mass up to around 200 Da, and evaluate on a subset of 850 test molecules, with a mass up to around 1400 Da. On these, the STRUCTURES25 functional achieves fully convergent density optimization on all molecules, shown in Fig. 4. Remarkably, even though the STRUCTURES25 functional uses message passing only across local neighborhoods up to six Bohr in radius, the mean absolute error per atom is larger, but does not grow with the size of the molecule, across the QMugs database (Fig. 4A). The three largest energy errors were all associated with the trifluoromethoxy group, a moiety which turned out to be represented only in terms of a single molecule in the training data. Larger molecules in the QMugs database highlight the improved scaling of machine-learned OF-DFT in comparison to the Kohn-Sham reference calculations, resulting in nearly an order of magnitude speedup on identical hardware (section S.11 in the supporting information). While density optimization requires many more iterations than a typical Kohn-Sham SCF calculation, this is more than offset by the relative simplicity of each single iteration which does not require matrix diagonalization.
to a PBE/6-31G(2df,p) Kohn-Sham reference, and meaningful densities on QM9 and QMugs.
| Dataset | Functional | Locala | b | c | d | e | Runtimef |
| (mHa) | (mHa) | () | () | (s) | |||
| QM9 | Ours | 13 | |||||
| M-OFDFTg | 1.37 | 0.088 | 2.7 | 4.2 | 183 | ||
| QMugs | Ours | 40 | |||||
| M-OFDFT | 18 | 0.17 | 7.0 | 1.8 | 319 | ||
-
a
Indicates whether the model guarantees a finite field of view.
-
b, c
Mean absolute energy error, total and per atom.
-
d, e
Mean norm of the density difference, total and per electron.
-
f
Average time for density optimization for a single molecule on an Nvidia Quadro RTX 6000 GPU for QM9 and an Nvidia A100 GPU for QMUGS.
-
g
Trained on the target (all other models predict ).
Orbital-free DFT: Status quo, and where next
Building on a compact representation of the electron density [27, 28] (Eq. 2), state-of-the-art machine learning architectures [45, 31], automated differentiation [50], efficient training data generation and reparametrization [26] and a strategy to create more balanced training samples [25], orbital-free DFT is now emerging as a viable framework for accurate calculations grounded in the Hohenberg-Kohn theorems.
Still, important limitations persist. The present functional, trained on organic equilibrium-geometry molecules only, does not yet generalize to high-energy geometries (a prerequisite for successful geometry optimization), or across the periodic table. Also, the poor predictions of the trifluoromethoxy group illustrate that with the present size of training data, sufficient examples of chemical moietys must be seen during training. It will be fascinating to see to what extent future models, trained on more extensive data, will “grok” chemistry and generalize across more of chemical space. Indeed, we expect future machine-learned density functionals to work well in those regimes in which Kohn-Sham DFT does. In particular, the viable area should be significantly larger than the kind of chemistries typified by the QM9 and QMugs databases.
For the following discussion, we single out the question of scaling, one principal reason to study OF-DFT in the first place. To become an alternative to linear-scaling KS-DFT [51, 52, 53, 54], OF-DFT will not just need quasi-linear scaling, but also a small prefactor. Let us recall the computational complexity bottlenecks of OF-DFT, beginning with the initialization. While many classical OF-DFT functionals are sufficiently robust to start from cheap initial density guesses, the previous state of the art, the machine-learned M-OFDFT [26] was dependent on MINAO [55, 56] which has cubic complexity in the number of atoms . The robustness of STRUCTURES25 allows starting from our simple dSAD guess (see supporting text) which scales linearly. The next major step in the computational pipeline is natural reparametrization, which still has complexity. Finding cheaper alternatives has top priority. Next, message passing on completely connected graphs comes with complexity. Our local model operating on a radius graph reduces this to . The cost of the Hartree term scales quadratically with the number of basis functions when the representation in Eq. 2 is evoked. Approximations such as the fast multipole method can bring this cost down to linearithmic scaling.
Outside orbital-free DFT, direct property prediction using “foundation models” is progressing with great strides[57, 58, 59, 60]. When striving to make valid predictions across a broad range of chemical space, a key question is which approach will prevail: A transductive approach, as in foundation models for property prediction which directly map from molecular geometry to observable; or an inductive ansatz, as in orbital-free DFT, where a universal functional is learned and variational optimization yields the electron density and its energy, from which observables can be derived. We believe the inductive approach will generalize better, but are eager to learn whether this intuition stands the test of time.
References and Notes
- [1] P. Hohenberg, W. Kohn, Inhomogeneous electron gas. Phys. Rev. 136 (3B), B864 (1964).
- [2] C. v. Weizsäcker, Zur Theorie der Kernmassen. Z. Phys. 96 (7), 431–458 (1935).
- [3] L. H. Thomas, The calculation of atomic fields, in Mathematical proceedings of the Cambridge philosophical society (Cambridge University Press), vol. 23 (1927), pp. 542–548.
- [4] E. Fermi, Eine statistische Methode zur Bestimmung einiger Eigenschaften des Atoms und ihre Anwendung auf die Theorie des periodischen Systems der Elemente. Z. Phys. 48 (1), 73–79 (1928).
- [5] W. Kohn, L. J. Sham, Self-Consistent Equations Including Exchange and Correlation Effects. Phys. Rev. 140 (4A), A1133–A1138 (1965).
- [6] W. Kohn, Density functional and density matrix method scaling linearly with the number of atoms. Phys. Rev. Lett. 76 (17), 3168 (1996).
- [7] W. Yang, R. G. Parr, C. Lee, Various functionals for the kinetic energy density of an atom or molecule. Phys. Rev. A 34, 4586–4590 (1986), doi:10.1103/PhysRevA.34.4586, https://link.aps.org/doi/10.1103/PhysRevA.34.4586.
- [8] L.-W. Wang, M. P. Teter, Kinetic-energy functional of the electron density. Physical review. B, Condensed matter 45 (23), 13196–13220 (1992).
- [9] A. Lembarki, H. Chermette, Obtaining a gradient-corrected kinetic-energy functional from the Perdew-Wang exchange functional. Phys. Rev. A 50, 5328–5331 (1994), doi:10.1103/PhysRevA.50.5328, https://link.aps.org/doi/10.1103/PhysRevA.50.5328.
- [10] A. J. Thakkar, Comparison of kinetic-energy density functionals. Phys. Rev. A 46 (11), 6920 (1992).
- [11] Y. A. Wang, N. Govind, E. A. Carter, Orbital-free kinetic-energy density functionals with a density-dependent kernel. Phys. Rev. B 60 (24), 16350 (1999).
- [12] L. A. Constantin, E. Fabiano, S. Laricchia, F. Della Sala, Semiclassical neutral atom as a reference system in density functional theory. Phys. Rev. Lett. 106 (18), 186406 (2011).
- [13] V. V. Karasiev, D. Chakraborty, O. A. Shukruto, S. Trickey, Nonempirical generalized gradient approximation free-energy functional for orbital-free simulations. Physical Review B—Condensed Matter and Materials Physics 88 (16), 161108 (2013).
- [14] K. Luo, V. V. Karasiev, S. Trickey, A simple generalized gradient approximation for the noninteracting kinetic energy density functional. Physical Review B 98 (4), 041111 (2018).
- [15] W. C. Witt, B. G. del Rio, J. M. Dieterich, E. A. Carter, Orbital-free density functional theory for materials research. Journal of Materials Research 33 (7), 777–795 (2018), doi:10.1557/jmr.2017.462.
- [16] X. Shao, W. Mi, M. Pavanello, Revised Huang-Carter nonlocal kinetic energy functional for semiconductors and their surfaces. Physical Review B 104 (4), 045118 (2021).
- [17] W. Mi, K. Luo, S. Trickey, M. Pavanello, Orbital-free density functional theory: An attractive electronic structure method for large-scale first-principles simulations. Chem. Rev. 123 (21), 12039–12104 (2023).
- [18] J. C. Snyder, M. Rupp, K. Hansen, K.-R. Müller, K. Burke, Finding density functionals with machine learning. Phys. Rev. Lett. 108 (25), 253002 (2012).
- [19] H. J. Kulik, et al., Roadmap on machine learning in electronic structure. Electronic Structure 4 (2), 023004 (2022).
- [20] M. Bogojeski, L. Vogt-Maranto, M. E. Tuckerman, K.-R. Müller, K. Burke, Quantum chemical accuracy from density functional approximations via machine learning. Nature communications 11 (1), 5223 (2020).
- [21] K. Yao, J. Parkhill, Kinetic Energy of Hydrocarbons as a Function of Electron Density and Convolutional Neural Networks. J. Chem. Theory Comput. 12 (3), 1139–1147 (2016).
- [22] J. Seino, R. Kageyama, M. Fujinami, Y. Ikabata, H. Nakai, Semi-local machine-learned kinetic energy density functional with third-order gradients of electron density 148 (24), 241705.
- [23] M. Fujinami, R. Kageyama, J. Seino, Y. Ikabata, H. Nakai, Orbital-free density functional theory calculation applying semi-local machine-learned kinetic energy density functional and kinetic potential. Chem. Phys. Lett. 748, 137358 (2020).
- [24] K. Ryczko, S. J. Wetzel, R. G. Melko, I. Tamblyn, Toward Orbital-Free Density Functional Theory with Small Data Sets and Deep Learning 18 (2), 1122–1128 (2022), publisher: American Chemical Society.
- [25] R. Remme, T. Kaczun, M. Scheurer, A. Dreuw, F. A. Hamprecht, KineticNet: Deep learning a transferable kinetic energy functional for orbital-free density functional theory. J. Chem. Phys. 159 (14), 144113 (2023).
- [26] H. Zhang, et al., Overcoming the barrier of orbital-free density functional theory for molecular systems using deep learning. Nat. Comput. Sci. 4, 210–223 (2024).
- [27] A. Grisafi, et al., Transferable machine-learning model of the electron density. ACS Central Science 5 (1), 57–64 (2018).
- [28] U. A. Vergara-Beltran, J. I. Rodríguez, An efficient zero-order evolutionary method for solving the orbital-free density functional theory problem by direct minimization. J. Chem. Phys. 159 (12), 124102 (2023).
- [29] L. Ruddigkeit, R. Van Deursen, L. C. Blum, J.-L. Reymond, Enumeration of 166 billion organic small molecules in the chemical universe database GDB-17. J. Chem. Inf. Model. 52 (11), 2864–2875 (2012).
- [30] R. Ramakrishnan, P. O. Dral, M. Rupp, O. A. Von Lilienfeld, Quantum chemistry structures and properties of 134 kilo molecules. Sci. Data 1 (1), 140022 (2014).
- [31] P. Lippmann, G. Gerhartz, R. Remme, F. A. Hamprecht, Beyond Canonicalization: How Tensorial Messages Improve Equivariant Message Passing, in The Thirteenth International Conference on Learning Representations (2025).
- [32] R. Parr, W. Yang, Density-Functional Theory of Atoms and Molecules (Oxford University Press) (1989).
- [33] J. Hollingsworth, L. Li, T. E. Baker, K. Burke, Can exact conditions improve machine-learned density functionals? J. Chem. Phys. 148 (24), 241743 (2018).
- [34] C. Lee, W. Yang, R. G. Parr, Development of the Colle-Salvetti correlation-energy formula into a functional of the electron density. Phys. Rev. B 37 (2), 785 (1988).
- [35] A. D. Becke, Density‐functional thermochemistry. III. The role of exact exchange. J. Chem. Phys. 98 (7), 5648–5652 (1993).
- [36] J. W. Furness, A. D. Kaplan, J. Ning, J. P. Perdew, J. Sun, Accurate and Numerically Efficient r2SCAN Meta-Generalized Gradient Approximation. J. Phys. Chem. Lett. 11 (19), 8208–8215 (2020).
- [37] J. Kirkpatrick, et al., Pushing the frontiers of density functionals by solving the fractional electron problem. Science 374 (6573), 1385–1389 (2021).
- [38] R. D. Bardo, K. Ruedenberg, Even‐tempered atomic orbitals. VI. Optimal orbital exponents and optimal contractions of Gaussian primitives for hydrogen, carbon, and oxygen in molecules. J. Chem. Phys. 60 (3), 918–931 (1974).
- [39] A. Duval, et al., A Hitchhiker’s Guide to Geometric GNNs for 3D Atomic Systems. arXiv Preprint (2024), arXiv:2312.07511 [cs.LG].
- [40] N. Thomas, et al., Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds. arXiv Preprint (2018), arXiv:1802.08219 [cs.LG].
- [41] S. Luo, et al., Equivariant point cloud analysis via learning orientations for message passing, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022), pp. 18932–18941.
- [42] S.-O. Kaba, A. K. Mondal, Y. Zhang, Y. Bengio, S. Ravanbakhsh, Equivariance with learned canonicalization functions, in International Conference on Machine Learning (PMLR) (2023), pp. 15546–15566.
- [43] Y.-L. Liao, B. M. Wood, A. Das, T. Smidt, EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations, in The Twelfth International Conference on Learning Representations (2024).
- [44] G. Simeon, G. De Fabritiis, TensorNet: Cartesian Tensor Representations for Efficient Learning of Molecular Potentials, in Advances in Neural Information Processing Systems, vol. 36 (2023), pp. 37334–37353.
- [45] C. Ying, et al., Do transformers really perform badly for graph representation?, in Advances in neural information processing systems, vol. 34 (2021), pp. 28877–28888.
- [46] Y. Shi, et al., Benchmarking Graphormer on Large-Scale Molecular Modeling Datasets. arXiv Preprint (2023), arXiv:2203.04810 [cs.LG].
- [47] P. Ertl, Cheminformatics analysis of organic substituents: identification of the most common substituents, calculation of substituent properties, and automatic identification of drug-like bioisosteric groups. J. Chem. Inf. Comput. Sci. 43 (2), 374–380 (2003).
- [48] J.-L. Reymond, R. Van Deursen, L. C. Blum, L. Ruddigkeit, Chemical space as a source for new drugs. Med. Chem. Comm. 1 (1), 30–38 (2010).
- [49] C. Isert, K. Atz, J. Jiménez-Luna, G. Schneider, QMugs, quantum mechanical properties of drug-like molecules. Sci. Data 9 (1), 273 (2022).
- [50] A. Paszke, et al., Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32, 8024–8035 (2019).
- [51] J. M. Soler, et al., The SIESTA method for ab initio order-N materials simulation. J. Condens. Matter Phys. 14 (11), 2745 (2002).
- [52] J. Hutter, M. Iannuzzi, F. Schiffmann, J. VandeVondele, cp2k: atomistic simulations of condensed matter systems. Wiley Interdiscip. Rev. Comput. Mol. Sci. 4 (1), 15–25 (2014).
- [53] D. Bowler, R. Choudhury, M. Gillan, T. Miyazaki, Recent progress with large-scale ab initio calculations: the CONQUEST code. Phys. Status Solidi B 243 (5), 989–1000 (2006).
- [54] C.-K. Skylaris, P. D. Haynes, A. A. Mostofi, M. C. Payne, Introducing ONETEP: Linear-scaling density functional simulations on parallel computers. J. Chem. Phys. 122 (8), 084119 (2005).
- [55] J. Almlöf, K. Faegri, K. Korsell, Principles for a direct SCF approach to LICAO–MO ab‐initio calculations. J. Comput. Chem. 3 (3), 385–399 (1982).
- [56] J. H. Van Lenthe, R. Zwaans, H. J. J. Van Dam, M. F. Guest, Starting SCF calculations by superposition of atomic densities. J. Comput. Chem. 27 (8), 926–932 (2006).
- [57] I. Batatia, et al., A foundation model for atomistic materials chemistry. arXiv Preprint (2024), arXiv:2401.00096 [physics.chem-ph].
- [58] E. C. Y. Yuan, et al., Foundation Models for Atomistic Simulation of Chemistry and Materials. arXiv Preprint (2025), arXiv:2503.10538 [physics.chem-ph], https://arxiv.org/abs/2503.10538.
- [59] O. Isayev, D. Anstine, R. Zubaiuk, AIMNet2: a neural network potential to meet your neutral, charged, organic, and elemental-organic needs. Chemical Science 16, 10228–10244 (2025).
- [60] Facebook AI, Universal Multimodal Agent (UMA), https://huggingface.co/facebook/UMA (2025), accessed June 12, 2025.
- [61] G. K.-L. Chan, A. J. Cohen, N. C. Handy, Thomas–Fermi–Dirac–von Weizsäcker models in finite systems. J. Chem. Phys. 114 (2), 631–638 (2001).
- [62] Q. Sun, et al., Recent developments in the PySCF program package. J. Chem. Phys. 153 (2) (2020).
- [63] Q. Sun, et al., PySCF: the Python-based simulations of chemistry framework. Wiley Interdiscip. Rev. Comput. Mol. Sci. 8 (1), e1340 (2018).
- [64] Q. Sun, Libcint: An efficient general integral library for Gaussian basis functions. J. Comput. Chem. 36 (22), 1664–1671 (2015).
- [65] R. Krishnan, J. S. Binkley, R. Seeger, J. A. Pople, Self-consistent molecular orbital methods. XX. A basis set for correlated wave functions. J. Chem. Phys. 72, 650–654 (1980).
- [66] J. P. Perdew, K. Burke, M. Ernzerhof, Generalized Gradient Approximation Made Simple. Phys. Rev. Lett. 77 (18), 3865–3868 (1996).
- [67] P. Pulay, Improved SCF convergence acceleration. J. Comput. Chem. 3 (4), 556–560 (1982).
- [68] K. N. Kudin, G. E. Scuseria, E. Cancès, A black-box self-consistent field convergence algorithm: One step closer. J. Chem. Phys. 116 (19), 8255–8261 (2002).
- [69] J. L. Whitten, Coulombic potential energy integrals and approximations. J. Chem. Phys. 58 (10), 4496–4501 (1973).
- [70] B. I. Dunlap, J. Connolly, J. Sabin, On some approximations in applications of X theory. J. Chem. Phys. 71 (8), 3396–3402 (1979).
- [71] O. Vahtras, J. Almlöf, M. Feyereisen, Integral approximations for LCAO-SCF calculations. Chem. Phys. Lett. 213 (5-6), 514–518 (1993).
- [72] K. Ryczko, S. J. Wetzel, R. G. Melko, I. Tamblyn, Toward Orbital-Free Density Functional Theory with Small Data Sets and Deep Learning. J. Chem. Theory Comput. 18 (2), 1122–1128 (2022).
- [73] Y. Shi, A. Wasserman, Inverse Kohn–Sham Density Functional Theory: Progress and Challenges. J. Phys. Chem. Lett. 12 (22), 5308–5318 (2021).
- [74] I. Batatia, D. P. Kovacs, G. Simm, C. Ortner, G. Csanyi, MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields, in Advances in Neural Information Processing Systems, vol. 35 (2022), pp. 11423–11436.
- [75] P.-O. Löwdin, On the Non-Orthogonality Problem Connected with the Use of Atomic Wave Functions in the Theory of Molecules and Crystals. J. Chem. Phys. 18 (3), 365–375 (1950).
- [76] P.-O. Löwdin, On the Nonorthogonality Problem, in Advances in Quantum Chemistry (Elsevier), vol. 5, pp. 185–199 (1970).
- [77] J. G. Aiken, J. A. Erdos, J. A. Goldstein, On Löwdin orthogonalization. Int. J. Quant. Chem. 18 (4), 1101–1108 (1980).
- [78] J. G. Aiken, H. B. Jonassen, H. S. Aldrich, Löwdin Orthogonalization as a Minimum Energy Perturbation. J. Chem. Phys. 62 (7), 2745–2746 (1975).
- [79] I. Loshchilov, F. Hutter, SGDR: Stochastic Gradient Descent with Warm Restarts, arxiv:1608.03983 [cs.LG] (2017).
- [80] I. Loshchilov, F. Hutter, Decoupled Weight Decay Regularization, in International Conference on Learning Representations (2019).
- [81] S. Lehtola, Assessment of Initial Guesses for Self-Consistent Field Calculations. Superposition of Atomic Potentials: Simple yet Efficient. J. Chem. Theory Comput. 15 (3), 1593–1604 (2019).
- [82] F. Weigend, R. Ahlrichs, Balanced basis sets of split valence, triple zeta valence and quadruple zeta valence quality for H to Rn: Design and assessment of accuracy. Phys. Chem. Chem. Phys. 7, 3297 (2005).
- [83] J. Boroński, R. M. Nieminen, Accurate exchange and correlation potentials for the electron gas. Phys. Rev. B 72 (12), 125115 (2005).
- [84] A. D. Becke, Density-functional thermochemistry. V. Systematic optimization of exchange-correlation functionals. J. Chem. Phys. 107, 8554–8560 (1997).
- [85] C. Adamo, V. Barone, Toward reliable density functional methods without adjustable parameters: The PBE0 model. J. Chem. Phys. 110 (13), 6158–6170 (1999).
- [86] C. Lee, W. Yang, R. G. Parr, Development of the Colle-Salvetti correlation-energy formula into a functional of the electron density. Phys. Rev. B 37 (2), 785–789 (1988).
- [87] J. P. Perdew, Y. Wang, Accurate and simple analytic representation of the electron‐gas correlation energy. Phys. Rev. B 33, 8822–8824 (1986).
- [88] A. D. Becke, Density‐functional thermochemistry. IV. A new dynamical correlation functional and implications for exact exchange. J. Chem. Phys. 104 (7), 1040–1046 (1996).
- [89] R. Li, Q. Sun, X. Zhang, G. K.-L. Chan, Introducing GPU-acceleration into the Python-based Simulations of Chemistry Framework (2024), https://arxiv.org/abs/2407.09700.
- [90] X. Wu, et al., Enhancing GPU-acceleration in the Python-based Simulations of Chemistry Framework (2024), https://arxiv.org/abs/2404.09452.
Acknowledgments
The authors thank the STRUCTURES excellence cluster for nurturing a unique collaborative environment that made this work possible in the first place. The authors also thank Maurits Haverkort, Corinna Steffen, Virginia Lenk and Andreas Hermann for helpful discussions, chemical insight and analytics.
Funding:
This work is supported by Deutsche Forschungsgemeinschaft (DFG) under Germany’s Excellence Strategy EXC-2181/1–390900948 (the Heidelberg STRUCTURES Excellence Cluster). The authors acknowledge support by the state of Baden-Württemberg through bwHPC and the German Research Foundation (DFG) through grant INST 35/1597-1 FUGG. C.A.G. and M.V.K. were supported by the Konrad Zuse School of Excellence in Learning and Intelligent Systems (ELIZA) through the DAAD program Konrad Zuse Schools of Excellence in Artificial Intelligence, sponsored by the Federal Ministry of Education and Research. F.A.H. acknowledges partial support by the Royal Society – International Exchanges, IES\R2\242159. T.K. and A.D. acknowledge support by the German Research Foundation (DFG) through grant no INST40/575-1 FUGG (JUSTUS 2 cluster). The authors also acknowledge partial funding by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) Projektnummber 281029004 – SFB 1249 and Projektnummer 240245660 – SFB 1129. We also acknowledge partial support by the Klaus Tschira Stiftung gGmbH in the framework of the SIMPLAIX consortium, as well as by the Carl-Zeiss-Stiftung.
Author contributions:
Conceptualization: R.R., T.K., A.D., F.A.H.; Data Curation: R.R., T.K., M.K.I., M.V.K.; Funding acquisition: A.D., F.A.H.; Investigation: R.R., T.K., T.E., C.A.G., D.G., G.G., M.K.I., M.V.K., P.L., S.W., A.D., F.A.H.; Methodology: R.R., T.K., C.A.G., M.K.I., M.V.K., P.L., S.W., A.D., F.A.H.; Project Administration: R.R., F.A.H.; Software: R.R., T.K., T.E., C.A.G., D.G., G.G., M.K.I., M.V.K., P.L., J.S.S., S.W.; Supervision: A.D., F.A.H.; Visualization: R.R., T.K., T.E., C.A.G., D.G., G.G., M.K.I., M.V.K., J.S.S., F.A.H., Writing - original draft: R.R., T.K., T.E., C.A.G., D.G., M.K.I., M.V.K., P.L., S.W., F.A.H.; Writing – review & editing: R.R., T.K., T.E., C.A.G., D.G., M.K.I., M.V.K., P.L., S.W., A.D., F.A.H.
Competing interests:
There are no competing interests to declare.
Supplementary Materials for
Stable and Accurate Orbital-Free DFT
Powered by Machine Learning
S.1 Data generation details
S.1.1 Datasets
The QM9 dataset [29, 30] is a collection of 133885 molecules with relaxed geometries and stoichiometry CHNOF with and . We split the dataset randomly in an 80:10:10 ratio for training, validation and testing.
The extrapolation capabilities of STRUCTURES25 are tested on the QMugs dataset [49]. The latter contains more than 665k drug-like molecules from the ChEMBL database. We filter out sulfur, chlorine, bromine and iodine since these elements do not appear in the QM9 dataset. For comparison with M-OFDFT [26], we split the dataset into multiple bins according to size. The first bin comprises molecules with 10 to 15 heavy atoms and is used for training. The following bins have a width of 5 heavy atoms and contain 50 randomly sampled molecules each which are used in density optimization.
S.1.2 Kohn-Sham DFT settings
For the training and test label generation, KS-DFT calculations were carried out using the open source software package PySCF [62, 63, 64]. For ease of comparison with prior work M-OFDFT [26], we largely choose identical hyperparameters. Restricted-spin calculations employing the 6-31G(2df,p) basis set [65] were conducted using the established general gradient approximation (GGA) functional PBE [66] with a grid level of 3 for QM9 and a grid level of 2 for QMugs, respectively. For larger molecules with more than 30 atoms, density fitting with the def2-universal-jfit basis set was enabled. We set the convergence tolerance to the PySCF default of meV for QM9 and to 1 meV for QMugs. We use the commutator direct inversion of the iterative subspace (C-DIIS) [67, 68] method with a maximal subspace of eight iterations. Minimal atomic orbitals (MINAO) was used as initialization [55, 56]. The open source nature and python implementation of PySCF enabled us to insert callbacks in between the SCF steps of the KS-DFT computation. These serve two purposes: First, to extract density labels, energy labels, gradient labels and DIIS coefficients. Secondly and implicitly, to add perturbations to the Fock matrix, slowing down the convergence and leading to more varied training labels (see section S.1.3).
In KS-DFT, so-called Kohn-Sham orbitals are introduced. These orbitals describe non-interacting electrons in an effective potential such that the resulting ground state energy and density exactly match the interacting system. This approach leads to the well known Kohn-Sham equations [5]
| (S.1) |
which need to be solved iteratively, refining the orbitals and the effective potential they generate until self-consistency is achieved.
In molecules, the Kohn-Sham orbitals are expressed as a linear combination of atomic basis functions according to . In this representation, the Kohn-Sham equations at iteration are given by
| (S.2) |
where is the overlap matrix and the diagonal matrix of eigenvalues to . A naive implementation of two-electron integrals has a time complexity of with system size, which can be reduced to cubic scaling by employing density fitting [69, 70, 71]. Solving the generalized eigenvalue problem also comes with a time complexity of . This scaling impedes the application of Kohn-Sham DFT to larger systems.
In our linear orbital-free ansatz, we use a different basis set to directly represent the density as a linear combination
| (S.3) |
where are new coefficients that can be obtained from using density fitting as described in section S.1.4.
S.1.3 Perturbation of the effective potential
Our principal aim was to overcome a fundamental limitation of prior work [26, 72] and achieve convergent density optimization, an essential quality for application of the second Hohenberg-Kohn theorem. This work shows that a well-behaved functional can be obtained when training on more varied data. Previous work [26] has shown how to generate training data using Kohn-Sham DFT, where for each SCF iteration one electron density, together with its energy and gradient labels were extracted. This approach has a drawback: The resulting labels are poorly distributed around the ground state, to the point where there are gaps in the difference between sample and ground state kinetic energy where almost no samples are generated (see Fig. 3C in the main text). More successful training of a machine learning model depends on labeled electron densities well distributed around the ground state density. It is however not straightforward to generate energy and gradient labels for a given density directly. This would require using an inverse Kohn-Sham approach, which unfortunately is still a “numerical minefield” [73].
Our main contribution is to instead perturb the effective potential , which is used in each SCF iteration to generate the electron density of the next iteration (cf. Eqs. S.2 and S.4). This approach is simple and stable, and results in labeled data that is much more evenly distributed than densities generated naively from Kohn-Sham DFT. It also offers direct control of the strength of perturbation in the effective potential which in turn correlates with the strength of perturbation in electron densities and energies. This is illustrated in Fig. 3C, where the difference between the non-interacting kinetic energy and the corresponding value at the ground state is shown, using both perturbed and unperturbed . In both cases, samples are generated from all molecular geometries in the QM9 validation set, the higher total number of samples in the former case stems from the increased number of SCF iterations per molecule due to the perturbations.
The effective potential in Eq. S.1 is perturbed from the sixth up to the 26th SCF iteration, counting the initial guess as the zeroth iteration. Only these perturbed samples are used in training. The perturbed Kohn-Sham equations read , with the perturbation function , its coefficients are sampled from a normal distribution with a standard deviation decreasing linearly from to over the SCF iterations and then multiplied with the orbital-free basis functions . In the basis representation this amounts to
| (S.4) | ||||
| (S.5) |
Given that all Kohn-Sham DFT calculations are performed in this matrix representation one might wonder why we do not sample directly. This however could lead to inconsistent perturbed Fock matrices that cannot be generated by some operator of the form .
S.1.4 Label generation
To efficiently learn the energy functional, we create tuples of the molecular structure , the density coefficients , the target energy and the gradient of the target with respect to the coefficients .
To obtain density coefficients in the orbital-free ansatz (Eq. 2 in the main text), we employ density fitting. The resolution of identity method by Whitten[69] and Dunlap[70] can be used to fit the orbital-free density coefficients to a Kohn Sham density. Here, the discrepancy of the fit is measured by the residual Hartree energy
| (S.6) | ||||
| (S.7) |
Here , and are the overlap matrices between the basis functions under the kernel , where we define
| (S.8) |
The trace sums over the indices of the Kohn Sham basis as in . The density matrix is obtained by contracting the orbitals with the corresponding occupation number .
As Eq. S.7 is a quadratic form in , it can be minimized analytically. But in agreement with M-OFDFT[26], we found that also considering the residual external energy in the minimization yields better fitted external and exchange correlation energies, as using the residual Hartree energy alone only leads to a close fit for this energy. The residual external energy reads
| (S.9) | ||||
| (S.10) |
with and being the external energies of the individual basis functions and denoting the molecule geometry, comprising nuclear positions and corresponding charges . The objectives of and minimizing can be combined by differentiating Eq. S.7 with respect to and coupling with Eq. S.10, yielding an overdetermined linear system111 The M-OFDFT supplementary[26] suggests minimizing the loss (S.11) but the available code optimizes the least squares problem as we do. which is solved by minimizing
| (S.12) |
using a least squares solver.
To obtain labels for the energy targets, we write the total energy as the sum
| (S.13) |
where the nuclear repulsion energy only depends on the molecular structure . The Hartree energy as well as the external energy are known functionals of the density. There are many popular approximations of the exchange-correlation functional that are pure, meaning that they can also be computed from just the density. The non-interacting kinetic energy is only available in the Kohn-Sham setting via
| (S.14) |
Following prior work [26], we calculate the kinetic energy label for the orbital-free density such that the total energy remains constant, , yielding
| (S.15) |
which helps mitigate errors introduced during density fitting.
Finally, we need the gradients of the energy contributions as a training signal for the machine learning model. All contributions except for the kinetic energy can be simply differentiated with respect to the density coefficients to directly obtain the corresponding label. The gradient of the non-interacting kinetic energy can be calculated by using the fact that the resulting density of each individual SCF iteration is the ground state of the non-interacting system given by the Fock operator
| (S.16) |
where is the effective potential generated by the previous density . At the ground state of the non-interacting system, the functional derivative of the total energy with respect to the electron density, subject to the conservation of electron number, vanishes. The optimality condition leads to the identity
| (S.17) |
where the constant is the chemical potential, and where we include the perturbation function from above. Upon integrating over the density basis functions, we obtain
| (S.18) |
The unknown chemical potential can be set to zero, as this only yields a gradient contribution orthogonal to the manifold of normalized densities, which is projected out in density optimization (see section S.6). Instead of obtaining the effective potential function from the coefficients in the orbital basis, we follow M-OFDFT [26] and directly use the effective potential vector given by
| (S.19) |
Substituting , we obtain the gradient of the kinetic energy via
| (S.20) |
where is the overlap matrix of density basis functions.
In practice, the direct inversion of the iterative subspace (DIIS) is used to accelerate the convergence of the SCF iterations. Using DIIS, the new Fock matrix is a weighted sum of the previous Fock matrices,
| (S.21) |
Thus, the effective potential in iteration is given by
| (S.22) |
and we need to replace the effective potential vector above with
| (S.23) |
Taken together, the above equations describe how to obtain density, energy and gradient labels from perturbed KS-DFT SCF iterations.
S.2 Model overview
The model input consists of a molecular graph with atomic positions and atom types as well as the coefficients , representing the electron density in terms of atom-centered basis functions, cf. Eq. 2 in the main text. As is customary in local canonicalization, we compute an equivariant local coordinate system for each atom based on the relative position of adjacent non-hydrogen atoms. The basis functions are a product of a radial function and spherical harmonics. As a consequence, the density coefficients transform via Wigner-D matrices under 3D rotations. To achieve invariance w.r.t. the global orientation of the molecule, the coefficients are transformed into the respective local frame at each atom. As in M-OFDFT[26], the coefficients undergo a “natural reparametrization” into an orthonormal basis, that is specific to the molecule geometry (see section S.3 for details); and the coefficients are rescaled dimensionwise to standardize the model input and the desired gradient range of the model w.r.t. the input coefficients.
The preprocessed atom-wise coefficients are embedded as node features with a feature dimension of 768. To this end, they are first passed through a shrink gate module
| (S.24) |
with learnable parameters and subsequently through an MLP. Pairwise distances between nodes are embedded as edge features via a Gaussian basis function (GBF) module, given by
| (S.25) | |||
| (S.26) |
Here, are learnable scalars, which depend on the atom types of sending and receiving node, and are learnable mean and standard deviation of the -th Gaussian, respectively. We initialize to 1 and to 0, while and are drawn from a uniform distribution in the interval .
Further, an embedding of the atom number and an aggregation of edge features over neighboring nodes are added to the node features. These are then passed to a message-passing graph neural network. At the core of the architecture, we apply 4 (or 8 for QMugs) Graphormer blocks [45]. For experiments with local architectures, we propagate messages along a graph with a radial cutoff of 6 Bohr and otherwise use the fully connected graph. Before each attention block, we also apply a node-wise layer norm. Finally, we employ an energy MLP which produces an atom-specific energy contribution from the final node features. Combined with an atom-specific contribution (“atomic reference module”, see below) based on the statistics of the data, the individual energies of each molecule are aggregated by summation into the total energy prediction. For the QMugs model, we used a hierarchical energy readout (similar to prior work [74]), where, instead of a single energy MLP after the final layer, we employ an energy MLP after every second transformer block to predict atom-specific energy contributions. In the end, all energy contributions of the individual readouts are summed into the final atom-wise energies. Having readout MLPs also in intermediate layers, where the field of view is still small, enforces the prediction of more local energy contributions whereas MLPs after later layers are expected to capture increasingly non-local effects.
Tensorial messages
As stated in the main text, we use local frames not solely to canonicalize input density coefficients with respect to global rotations, but also adopt a recently introduced approach [31] to modify the Graphormer architecture. In this modification, the known relative orientation of local frames is additionally leveraged during message passing by transforming node features from one local frame to another, allowing for the exchange of “tensorial” messages. These enable the network to effectively communicate non-scalar geometric features – something that would not be possible without the frame-to-frame transition. The representations under which internal features, i.e., the queries, keys and values in the attention mechanism, transform are hyperparameters. We choose these features to consist of 513 scalars, which remain invariant under rotations, and 85 vectors. We modify the attention mechanism of the Graphormer in the following way: when updating the features of a given node , keys and values of any adjacent node are transformed into the local frame of node before computing the attention weights and aggregating the values:
| (S.27) | ||||
| (S.28) |
where is the neighborhood of node . is the group representation of the keys and queries w.r.t. -transformations (chosen to be the same). denotes the rotation from the global frame into the local frame of node . Our experiments indicate that incorporating tensorial messages, which enable direct communication of geometrical features, improves model performance (cf. Table S.1).
| Tensorial Messages | ||||
|---|---|---|---|---|
| (mHa) | (mHa) | () | ||
| 0.73 | 0.044 | 0.022 | 3.3 | |
| ✓ | 0.64 | 0.038 | 0.014 | 2.1 |
Radial cutoff
For our experiments on QMugs we construct the molecular graph using a radial cutoff instead of working with the fully connected graph. More specifically, we remove all edges between atoms with a pairwise Euclidean distance of . We choose as default value. The primary reason for introducing a cutoff is that message passing on the fully connected graph scales as whereas a radial cutoff reduces the complexity to . Additionally, we observe in our ablation study that training with cutoff leads to a better generalization of the model to larger molecules, see Table 1 in the main text. Further model hyperparameters are listed in Table S.2.
| Hyperparameter | Value |
|---|---|
| Number of layers | 8 |
| Attention heads | 32 |
| Node dimension | 768 |
| Irreps for keys and values | 513 scalars, |
| 85 vectors | |
| GBF dimension | 128 |
| (Shrink gate) | 10 |
| (Shrink gate) | 0.02 |
S.3 Enhancement modules
Proper normalization of model inputs and targets is critical for successful training of neural networks. In our pipeline, energy gradients with respect to density coefficients are predicted via back-propagation through our ML functional. This entails that the scales of input density coefficients and gradient labels are linked, as multiplying the former by some factor amounts to rescaling the latter by the inverse factor. Following M-OFDFT [26], we thus employ a number of enhancement modules to constrain energies, gradients and coefficients to favorable ranges.
Natural reparametrization enables the meaningful measurement of density and gradient differences. A difference in density coefficients in the LCAB ansatz (Eq. 2 in the main text) results in a residual density with an norm of
| (S.29) |
where is the density basis overlap matrix. Transforming coefficients by , where is a matrix square root of the overlap matrix, i.e. , leads to an expansion for the density difference in terms of coefficient differences only,
| (S.30) |
This implies that, after transformation, individual coefficient dimensions now equally and independently contribute to changes in the density. We can solve for by considering the eigendecomposition of the overlap matrix. The solution to has a rotational degree of freedom as any matrix , with an arbitrary orthogonal matrix , results in the overlap matrix upon squaring. We here shortly discuss the implications of choosing between two very distinct choices for . Natural reparametrization is not only carried out on the coefficients but also on all related quantities like gradients and basis functions. For the density to remain invariant under reparametrization, basis functions transform via As this transformation orthonormalizes the basis functions, , we stress the similarity to the non-orthogonality problem put forward by Löwdin [75, 76]. This seminal work suggests choosing and therefore , the symmetric orthogonalization – often simply called Löwdin orthogonalization [77, 78]. This flavor of reparametrization results in the orthogonalized basis set that is least distant to the original basis set, as measured by the -norm between basis functions. Furthermore, any rotation of the original basis set commutes with the orthogonalization; that is, the symmetrically reparametrized basis functions transform equivariantly under orthogonal transformations, which includes spatial rotations and permutation of basis functions. The latter property in particular motivates our choice to reparametrize coefficients by .
Zhang et al. [26] propose , i.e., in their supplementary. This transformation, called canonical orthogonalization by Löwdin [76], results in highly delocalized orbitals. That is, each individual basis function aims to summarize the information in all untransformed orbitals subject to orthogonality. In our experiments, this reparametrization performed significantly worse than the symmetric version described above. This is because this type of reparametrization not only nullifies any previous transformation into local frames, but also breaks permutation invariance, rendering the energy prediction dependent on the order of atoms in the molecule. However, the code provided by M-OFDFT [26] employs the symmetric reparametrization as we do.
The dimension-wise rescaling and atomic reference modules are implemented as in prior work [26]. Dimension-wise rescaling linearly transforms each density coefficient independently, trading off resulting coefficient and gradient scale for each component. The atomic reference module adds a simple linear fit to the learned part of our functional. It thereby reduces the dynamic range of the predicted energy and effectively centers the gradient labels.
S.4 Model training
For both QM9 and QMugs, we train the model for 90 epochs with a batch size of 128. Over the course of all epochs, the learning rate is reduced from to using a cosine annealing schedule [79]. As optimizer, we use AdamW [80] with , and a weight decay factor of . We do not use dropout. The training hyperparameters are summarized in Table S.3.
We apply a loss to both the energy and its gradient . For the energies, a simple loss is used to compare the output to the labels. The gradient needs further attention, since it is only known in the hyperplane of normalized densities. To compare the derivative of the predicted energy with the gradient label , we follow M-OFDFT [26] and apply an loss on the projected difference,
| (S.31) |
where is the vector of integrals over the density basis with components and the expression corresponds to a projection onto the hyperplane orthogonal to .
For direct comparison with prior work [26], we group the QMugs dataset by the number of heavy atoms into bins of width 5. The first bin contains molecules with heavy atoms and molecules with fewer heavy atoms are discarded from the set. When training on the QMugs dataset, we first combine the QM9 dataset with the first QMugs bin (10-15 heavy atoms) for the initial training set. Following this initial training on the combined dataset, we perform an additional fine-tuning step. This fine-tuning is conducted exclusively on the QMugs subset containing molecules with 10-15 heavy atoms (the first bin). The fine-tuning uses the same hyperparameters as the initial training, except for the learning rate and epoch count. We start with a learning rate of , which is also reduced to following a cosine annealing schedule over 30 epochs. All other training parameters, including the optimizer, loss function, and batch size, remain unchanged. Training on the QM9 dataset alone does not involve this fine-tuning step.
| Hyperparameter | Value |
|---|---|
| Number of epochs | 90 |
| Batch size | 128 |
| Learning rate | |
| Adam | |
| Adam | |
| Weight decay | |
S.5 Initial electron density guess: Data-driven sum of atomic densities (dSAD)
A multitude of established methods for generating initial guesses for the electron density in KS-DFT exist, such as the MINAO initialization [55, 56]. However, while it is cheap compared to the Kohn-Sham iterations because of the minimal basis that it uses, it still scales cubically with system size, and additionally requires density-fitting to transform the guess to the density basis (Eq. 2 in the main text).
A much simpler and linear scaling option is a superposition of atomic densities (SAD). We have datasets with ground state density coefficients at hand, as these are required for training. This allows us to determine average atomic densities with a data-driven approach: We take all instances of each atom type (i.e. chemical element) in the dataset, and take the average of the corresponding coefficients over all these instances. Averages for coefficients corresponding to basis functions with are set to zero. For a given molecule , concatenating these averages for all atom types in the molecule then yields , our data-driven SAD (dSAD). However, this superposition of atomic densities is not necessarily normalized to the correct electron number. Since the number of electrons stays invariant during density optimization (see section S.6), we need to normalize to generate a valid guess. One approach is to uniformly scale the coefficients linearly to the correct electron number , leading to
| (S.32) |
with the basis integrals , see section S.4. While simple, this has a major shortcoming: The largest part of the electron density lies close to the cores, and, for elements other than hydrogen, this core density varies only very little between different instances of the same atom type in neutral molecules. Thus, the SAD guess describes the core very precisely. The coefficients of the inner basis functions largely describe this core density and should hence be varied very little in the normalization. However, scaling all coefficients by the same factor to achieve normalization does not respect this. For example, the core density of atomic species with high electronegativity (whose corresponding coefficients, on average, describe a higher number of electrons than their atomic number indicates), would be scaled down and hence underestimated.
This is why we propose a heteroscedastic normalization procedure, which adapts to the variance of the coefficients over the dataset: Coefficients with high variance are scaled more than those with low variance, as they are more likely to be far from the mean. As the mean and variance of each coefficient are known, we can formulate this as an weighed least squares optimization problem with a linear constraint, where the weights of the squared deviations from are given by the inverse squares of the variances (see also Fig. S.1):
| (S.33) |
with , the difference between the desired electron number and the one corresponding to the mean coefficients. Introducing a Lagrange-multiplier , we get:
| (S.34) |
and can solve for and
| (S.35) |
to find
| (S.36) |
This result matches the intuition established above: The correction to each component of the average coefficients is proportional both to the variance of it over the dataset, and the weight of its corresponding basis function. An illustration of this method compared to simply scaling the guess is shown in Fig. S.1.
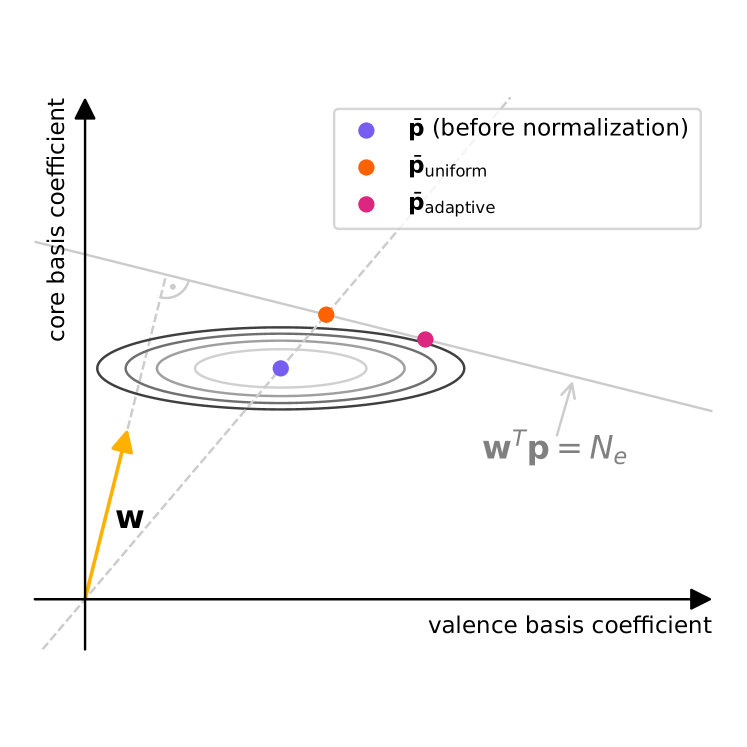
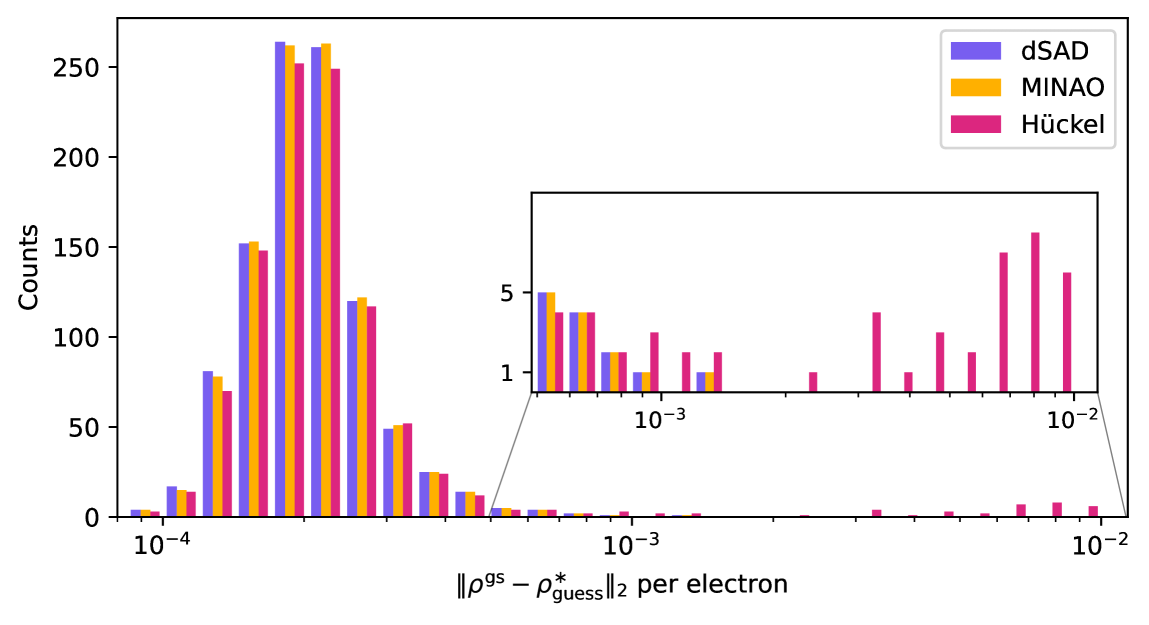
One could either apply this normalization per molecule, or per chemical element (in the latter case, denotes the number of electrons corresponding to the atom type). We choose the latter for simplicity, normalizing the electron number per element. The guess is computed before applying natural reparametrization. Comparing our dSAD guess to the MINAO guess on 1000 QM9 molecules in Table S.4, we find that it produces guesses which are slightly closer to the ground state.
| Initial guess | Computational complexity | |
|---|---|---|
| dSAD | 52 | |
| MINAO | 64 | |
| Hückel | 122 | |
S.6 Density optimization
After initialization of the electron density using our dSAD guess (section S.5), the learned energy functional enables its iterative optimization in order to find the ground state density and the corresponding energy. To conserve the number of electrons, we must not diverge from the hyperplane of normalized densities . We thus project the step of the optimizer onto the hyperplane such that the density coefficients are updated according to
| (S.37) |
We use gradient descent with momentum as our optimizer, with a learning rate of and a momentum of for QM9. For the QMugs dataset, we reduce the learning rate to . These parameters were tuned such that the density optimization shows a fast and robust convergence. The number of iterations is limited to 5000.
Note that while KS-DFT typically requires significantly fewer steps to converge, it relies on much more complex SCF iterations. While OF-DFT requires more steps, each is computationally inexpensive. This results in a significant net gain in efficiency, particularly for larger systems, see section S.11 for details.
The model is never trained on molecules from the test set, and density optimization is performed on the test set only. As Fig. 2B in the main text illustrates, density optimization on the STRUCTURES25 functional converges to gradient norms of Ha for smaller molecules. This level of convergence is more precise than our labels are, due to imperfect density fitting and a finite convergence tolerance in the Kohn Sham calculations of our ground truth, see section S.1.2. We thus stop density optimization when the gradient norm for an entire molecule falls below Ha.
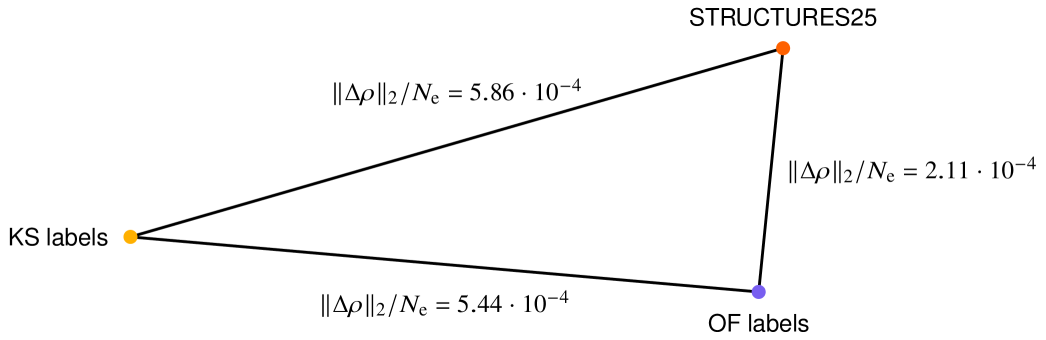
Regarding the definition of chemical accuracy, an error of 1 kcal mol-1 is a widely used threshold for acceptable energy errors. As there is no widely used definition for chemical accuracy of an electron density, we propose to compare the densities produced by different XC functionals using the same (def2-TZVP) basis set [82]. At the local density approximation (LDA) rung we use BN05[83]. Generalized gradient approximations (GGA) are represented by PBE and B97[84]. As Meta-GGA, incorporating the kinetic energy density, we use R2SCAN[36]. The highest accuracy levels are achieved by the hybrid-GGAs PBE0[85], B3LYP[86] or a meta-hybrid-GGA with PW86 exchange and B95 correlation [87, 88]. The ground state densities of 1000 randomly sampled molecules from QM9 were computed using our default Kohn Sham settings for each of the above functionals. We then measured the density difference between the XC functional PBE[66], which was used for data generation, and this assortment of functionals, with results shown in Table S.5. The density difference between PBE and methods at least at the GGA level is in the range of to electrons in the L2 norm, while the density difference to the less accurate LDA BN05 is around electrons. Given the above deviations from PBE densities, and given that the PBE functional has been used in more than 200 000 publications to date, we here define “chemically accurate densities” at the level of PBE as all those that come within electrons in the L2 norm on QM9-sized molecules.
| XC functional type | XC functional name | |
| LDA | BN05[83] | 41 |
| GGA | B97[84] | 13 |
| Meta-GGA | R2SCAN[36] | 8.7 |
| Hybrid-GGA | PBE0[85] | 7.2 |
| Hybrid-GGA | B3LYP[86] | 7.4 |
| Hybrid-Meta-GGA | PW86 B95[87, 88] | 11 |
S.7 QMugs trifluoromethoxy outliers
Fig. 4A in the main text, which shows the extrapolation accuracy from small to large organic molecules, reveals three outliers. It turned out that all three contained a trifluoromethoxy group, and that this chemical group was present only in the three conformers of a single molecule in the training set. We thus hypothesized that this group was responsible for the poor predictions. To investigate this hypothesis, we substituted the fluorine atoms of the trifluoromethoxy group by hydrogen, yielding their methoxy derivatives (see Fig. S.3). We re-optimized the geometry at the same level of theory as the original samples (GfN2-xtb using energy and gradient convergence criteria of Ha and Ha) [49]. Subsequent OF-DFT calculations employing the STRUCTURES25 functional (trained on QMugs) showed that the energy error per atom dropped from mHa to mHa, from mHa to mHa, and from mHa to mHa respectively, well within the range of the other QMugs test samples. This indicates it was indeed the trifluoromethoxy group which caused the outliers.
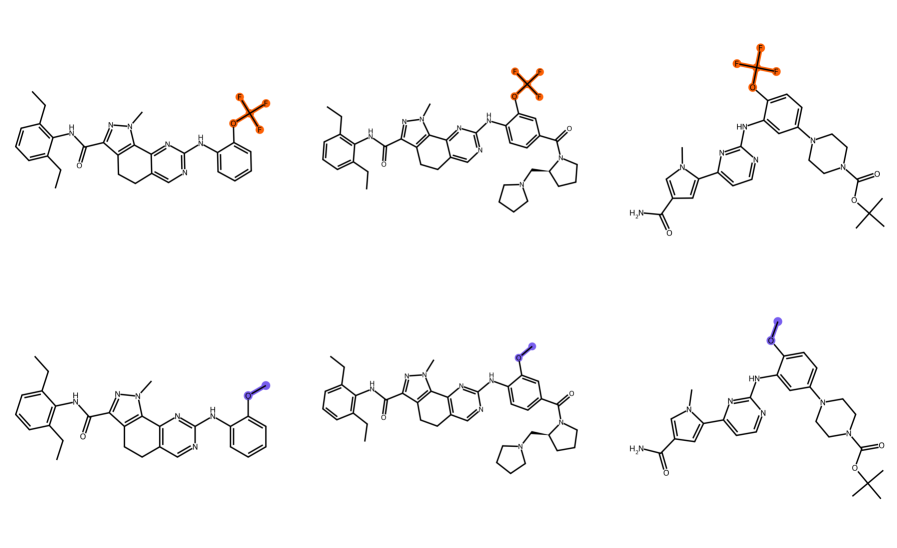
To further analyze the phenomenon, we evaluated the accuracy of STRUCTURES25 on smaller molecules containing a trifluoromethoxy group. These exhibited large errors as well, see Table S.6. Finally, the density error for a larger molecule containing the group is visualized in Figure S.4, demonstrating that the error is spatially localized around the group in question. Taken together, these observations support the hypothesis that the lack of sufficiently many training molecules including the trifluoromethoxy group is the root cause of this failure mode. Analyses of this type can help identify and close gaps in the training data.
| Molecule | [mHa] | substitute [mHa] |
|---|---|---|
| Trifluoro(methoxy)methane | 629.21 | 1.57 |
| (Trifluoromethoxy)benzene | 642.50 | 1.26 |
| 2-(Trifluoromethoxy)aniline | 639.28 | 1.81 |
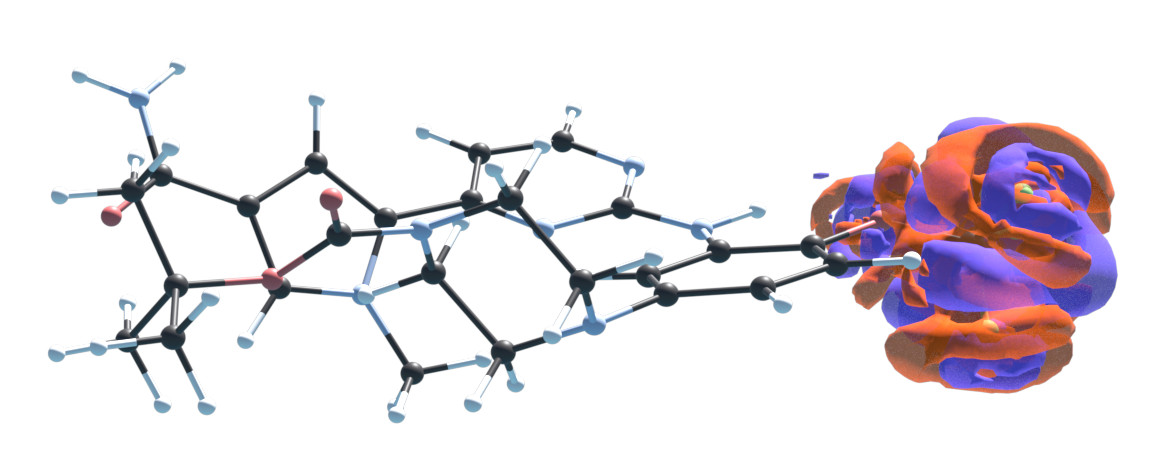
S.8 Negative densities
The representation of the density given in Eq. 2 in the main text in principle allows for regions of negative densities to occur. When using a trained model for density optimization this could lead to problems. Since negative densities are not physical and therefore no training data with negative densities exists, it is unclear if the model can make meaningful predictions for such non-physical densities.
In practice, we report that negative densities are no failure case for our models trained on the target. When starting from a reasonable initial guess such as dSAD (section S.5), the negative regions of the converged densities are insignificant. This is illustrated for our QM9 model and that of M-OFDFT [26] in Fig. S.5. If negative densities were to become a problem in the future, e.g. for larger molecules or when considering more elements, one could penalize negative densities directly in the density optimization. A penalization term of the form
| (S.38) |
can be added to the total energy, where is a hyperparameter. Using this penalization term does not significantly change our results, which is why we do not use it for the reported experiments. Such a penalization term has the significant downside of requiring a grid for evaluation, which we otherwise do not need for the target.
S.9 Robustness with respect to initialization
Zhang et al. [26] require a precise machine-learned guess, “ProjMINAO”, to produce their best results. Their results deteriorate by an order of magnitude when initializing with Hückel [81] densities and become worse still when initializing with a MINAO guess [26, 55, 56]. To gauge the robustness of the STRUCTURES25 functional, we compare density optimizations initialized with our data-driven superposition of atomic densities (dSAD, section S.5) as well as MINAO and Hückel densities. Unlike prior work [26] we refrain from training a model to improve on the initially guessed density.
For the following comparisons, we randomly sample 1000 molecules from our QM9 test set. As a point of reference for the various initial guesses, we report their density error with respect to the ground state in table S.4. Predicted ground state density errors, , from dSAD and MINAO are nearly identical while Hückel fares approximately an order of magnitude worse.
On the same set of molecules, we compare density optimization results starting from the different guesses in Table S.7 and Fig. S.6. Using the identical hyperparameter configuration, both dSAD and MINAO guesses lead to all molecules converging, i.e. achieving gradient norms below , within 5000 optimization steps. Hückel initialization is worse, with only 79% of molecules converging with default settings. Increasing the maximum number of iterations to 20k increases the convergence ratio to 85%. Tuning of the momentum to a value of 0.77 pushes the Hückel convergence ratio to 96.7% within 20k iterations. The ability to converge to good solutions for all molecules from both dSAD and MINAO guesses using the same model is a testament to the generality of the STRUCTURES25 functional, as these two initializations differ considerably (cf. Table S.4).
Starting from different guesses, density optimizations with STRUCTURES25 converges to very similar solutions. Specifically, the predictions on 953 of the 1000 tested molecules differ at least an order of magnitude less to predictions from other initializations than they differ to the ground state label. The remainder exhibit density differences that are of the same order as the distance from the ground truth density.
| Initial guess | Iterations | Converged | |
|---|---|---|---|
| median [min, max] | (%) | ||
| dSAD | 2.2 | 345 [226, 540] | 100 |
| MINAO | 2.2 | 500 [326, 635] | 100 |
| Hückel | 43.4 | 547 [323,–] | 79.0 |
| Hückel* | 5.7 | 1303 [839,–] | 96.7 |
S.10 Ablation experiments
The design of both the neural network architecture and the training procedure involves numerous choices. This section details our ablation studies, performed to systematically evaluate the impact of key parameters and justify our final model configuration. To minimize the influence of stochasticity, we report the best performance of three independent training runs (seeds) for each configuration, evaluating models based on the energy error unless otherwise specified.
Impact of perturbed training data:
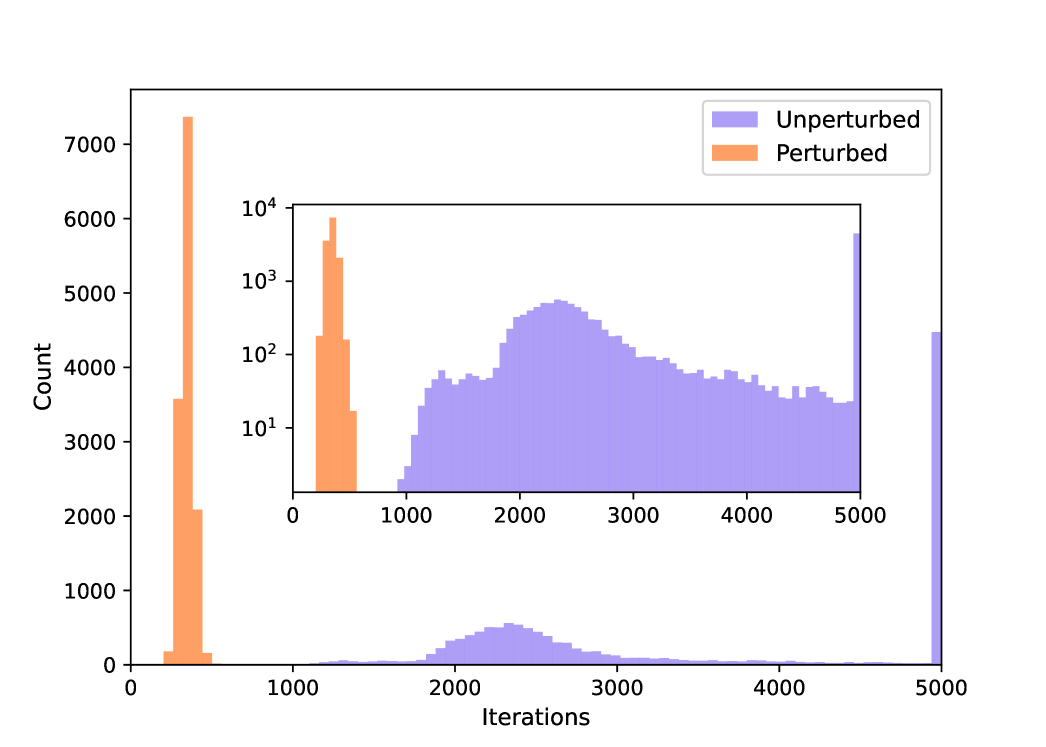
Our primary contribution lies in generating training data that is both more diverse and more evenly distributed across the energy landscape as shown in Fig. 3C. To quantify the benefit of this approach, we trained identical models on the QM9 dataset, once using only the standard Kohn-Sham SCF iterations (unperturbed) and once using our perturbed Fock matrix approach. Since the perturbed data has about 1.8 times the number of training labels, we increase the number of epochs for the non-perturbed model trainings to 161. Table S.8 and Fig. S.7 clearly demonstrate the advantages of perturbed data: the resulting model exhibits significantly improved convergence and achieves lower density errors.
| Perturbed Data | Convergence failures | ||||
| (mHa) | (mHa) | () | (%) | ||
| ✓ | 0.64 | 0.038 | 0.014 | 2.1 | 0 |
| 4.12 | 0.251 | 0.110 | 16.5 | 28 | |
Choice of energy target:
Several options exist for the training target, each with distinct characteristics. One approach, termed “delta learning,” involves training on the difference between the non-interacting kinetic energy () and the APBEK approximation (). This benefits from a smaller dynamic range in both energy and gradient values, which can simplify the learning process. Another possible target is , which combines the non-interacting kinetic energy and the exchange-correlation energy. A key advantage of this target is that it eliminates the need for numerical integration on a grid, significantly improving computational efficiency, particularly for larger molecules. Finally, we considered the total energy () as a target. Ideally, this would allow the model to fully capture the energy minimum and its surrounding landscape, benefiting from the small gradient norms near the ground state. However, accurately representing these small gradients proved challenging in practice.
Table S.9 summarizes the results of training with each target. The target, while viable, exhibits higher energy and density errors compared to the target. Furthermore, requires numerical integration on a grid for the evaluation of the APBEK functional and an XC functional, increasing the computational cost. Models trained on fail to converge to meaningful densities, highlighting the difficulty of directly learning the total energy. The superior performance and grid-free nature of made it our target of choice.
| Energy target | ||||
| (mHa) | (mHa) | () | ||
| 0.64 | 0.038 | 0.014 | 2.1 | |
| 2.94 | 0.178 | 0.037 | 5.7 | |
| 1183.88 | 62.314 | 1.858 | 279.2 | |
Tensorial vs. scalar messages:
We explore the impact of “tensorial” messages [31] in equivariant message passing based on local canonicalization, which allow the communication of non-scalar geometric information between nodes. We evaluate the performance of the standard Graphormer, which uses only scalar messages, against our modified version incorporating tensorial messages, as described in section S.2.
Table S.1 shows results for the QM9 dataset. The additional geometric information improves the model, with the energy error improving slightly and the density error significantly. Networks trained with tensorial messages also showed lower gradient loss during training.
Number of Graphormer layers:
The depth of the network, represented by the number of Graphormer layers, influences both the model’s capacity and its computational cost. We investigated the effect of varying the number of layers, with results presented in Table S.10. Performance initially improves as the number of layers increases, allowing the model to capture more complex relationships. However, when no cutoff is used, we observe a significant degradation in performance beyond 4 layers, likely due to higher instability of the gradient produced by the network. This led us to select 4 layers as the optimal balance between expressivity and training stability for QM9, and 8 layers for QMugs.
| #Layers | #Parameters | ||||
| () | (mHa) | (mHa) | () | ||
| 1 | 8.1 | 1.22 | 0.074 | 0.025 | 3.8 |
| 2 | 11.6 | 0.75 | 0.044 | 0.017 | 2.6 |
| 3 | 15.1 | 0.92 | 0.053 | 0.015 | 2.3 |
| 4 | 18.7 | 0.64 | 0.038 | 0.014 | 2.1 |
| 6 | 25.8 | 439.29 | 19.871 | 0.198 | 29.4 |
| 8 | 32.9 | 322.92 | 14.214 | 0.097 | 14.4 |
Fully connected vs. radial cutoff:
The Graphormer architecture [45] was originally designed for fully connected graphs. However, for scalability to larger systems, incorporating a radial cutoff is essential. In Table S.11 we show that introducing a cutoff not only lowers computational cost but also yields smaller prediction errors.
| local | ||||
|---|---|---|---|---|
| (mHa) | (mHa) | () | ||
| ✓ | 26 | 0.25 | 0.071 | 1.7 |
| 580 | 8.80 | 0.195 | 7.3 | |
S.11 Runtime comparison of KS-DFT and OF-DFT computations
Figure S.8 compares the runtimes of OF-DFT as embodied by STRUCTURES25 and KS-DFT as implemented in GPU4PySCF [89, 90], which can exploit the parallelism of the identical hardware. All computations were run on one Nvidia A100 GPU and 8 cores of an AMD EPYC 7452 processor. For the largest molecule of our QMUGS test set, STRUCTURES25 reaches a speedup of almost an order of magnitude. Importantly for future calculations on larger (e.g., biomolecular) systems, it shows favorable scaling with the size of the system.