STACKED CONVOLUTIONAL DEEP ENCODING NETWORK FOR VIDEO-TEXT RETRIEVAL
Abstract
Existing dominant approaches for cross-modal video-text retrieval task are to learn a joint embedding space to measure the cross-modal similarity. However, these methods rarely explore long-range dependency inside video frames or textual words leading to insufficient textual and visual details. In this paper, we propose a stacked convolutional deep encoding network for video-text retrieval task, which considers to simultaneously encode long-range and short-range dependency in the videos and texts. Specifically, a multi-scale dilated convolutional (MSDC) block within our approach is able to encode short-range temporal cues between video frames or text words by adopting different scales of kernel size and dilation size of convolutional layer. A stacked structure is designed to expand the receptive fields by repeatedly adopting the MSDC block, which further captures the long-range relations between these cues. Moreover, to obtain more robust textual representations, we fully utilize the powerful language model named Transformer in two stages: pretraining phrase and fine-tuning phrase. Extensive experiments on two different benchmark datasets (MSR-VTT, MSVD) show that our proposed method outperforms other state-of-the-art approaches.
Index Terms— cross-modal, retrieval, convolutional neural network, Transformer
1 Introduction
Cross-modal retrieval is a challenging area of research in the vision and language community. Giving one instance from either modality, it aims at identifying and retrieving corresponding correct instance from the other modality. While image-text retrieval has achieved much progress in recent years, video-text retrieval still remains further exploration. Compared with image, video contains richer and more complex information, leading to be difficult to represent these complex information due to the noise and irrelevant background. Meanwhile, just as Figure 1 shows, for the video-text retrieval, a video is composed of several small events in which the corresponding sentence focuses on different parts of these events. Thus, both short-range and long-range dependency are necessary to be considered, which provide various semantic cues for the matching calculation between video and text. Besides, while using the textual description to describe the same event in a video, the words in a sentence may be variable. Hence, it is also significant to explore the way to efficiently capture the reliance among words.

To address the above problems, our work mainly focuses on the temporal cues modeling for both video and text. Convolutional neural network (CNN) is capable of aggregating spatial context and producing discriminative representation, thus is widely used in many tasks, such as action recognition, visual segmentation and so on. Especially, dilated spatial pyramid convolution [1] is effectively used in image segmentation for the spatial context modeling. Inspired by this, we extend it to exploit temporal semantic cues and relation learning for both video and text to produce deep discriminative features for retrieval.
Second, to better learn the word embedding, we fully utilize the superiority of Transformer for language modeling, which conducts position encoding and multi-head attention mechanism. In the first stage, we train the sentences by BERT in a unsupervised way, which randomly masks out some of the words in the sentence. The objective of BERT is to predict the masked words based only on the context, and thus the contextual information between words are captured inside the word embedding, which is then fine-tuned by the Transformer encoder in the second stage by the retrieval loss.
In this paper, a stacked convolutional deep encoding network is proposed to boost the video-text retrieval performance. The main contributions of this paper are summarized as follows: (1) We generalize the dilated spatial pyramid convolution to multi-scale dilated temporal convolution (MSDC) for capturing short-range temporal cues at the multiple scales. A stacked structure is designed to expand receptive fields by repeatedly adopting the MSDC block, which further captures the long-range relations between these cues. The Stacked MSDC can finally produce deep discriminative semantic cues for both video and text. (2) Unlike previous works that use word2vec to embed word and then encoded by RNN, we explore to pretrain word embedding with BERT and fine-tune with Transformer, which are powerful for language modeling. (3) Extensive experiments on two benchmark datasets show the effectiveness of our proposed method compared with the state-of-the-art methods.
2 RELATED WORK
The problem of vision and text retrieval can be divided into two categories: image-text retrieval and video-text retrieval. Previous methods for image-text retrieval mainly focus on a basic procedure:(1) extracting features from static image via deep convolutional neural network, (2) embedding words through word2vec and then encoded by RNN, and (3) measuring their similarity in a joint embedding space with a ranking loss to determine whether the input image and text are matched. Recently, there are also other interesting ideas to improve the performance, such as cross-attention based models. The intuition is that different image-text pair may attend to each other in different local parts. [2] proposed to make attending between words and image regions symmetrically and exploit message-passing between two modalities. While cross-attention based methods are shown to be effective, but the computational overhead is because each query instance should be encoded with all the reference instance, which may be time-consuming in practical application especially for large-scale datasets.
Similar to image-text retrieval, most video-text retrieval also conduct joint space learning. The basic procedure of video-text retrieval is also similar except that video feature is captured frame by frame via deep convolutional neural network (CNN) and then aggregated by RNN. [3] also exploits to additionally use multi-modal video features for information complement, such as activity feature and audio feature, which are then fused into a single space or an extra space. [4] is the most related work to us, which proposed dual-encoding network with three level features for video-text retrieval. Our work focuses on the deep discriminative feature learning with temporal cues encoding and text embedding modeling and thus do not consider additional video features or require instance interaction. Recent work [5] and [6] also conduct discriminative feature learning for cross-modal tasks.
3 OUR APPROACH
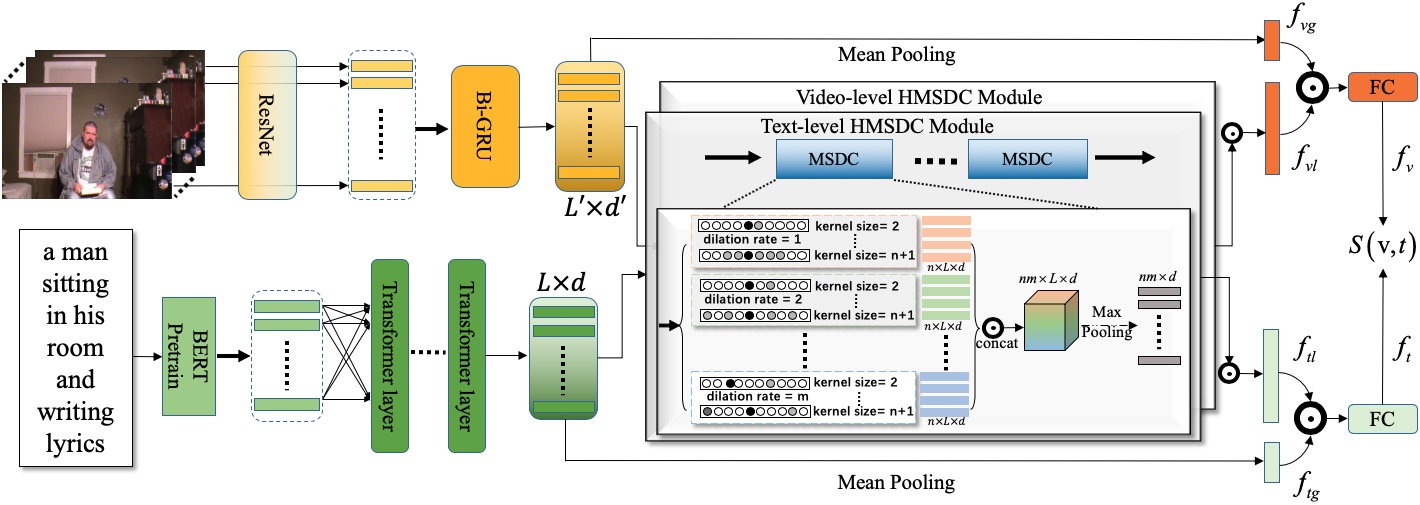
In this section, we firstly present the overall architecture of the proposed approach, and then introduce each component of this architecture in the following subsection. The framework of the proposed stacked convolutional deep encoding network is shown in Figure 2.
3.1 Video-side Encoder
Given a video, there are a large number of similar frames that contain redundant information. So we uniformly sample a sequence of frames with a interval of 0.5 second to represent the salient content of a video as follow [3] and [4]. And then a ResNet-152 [7] pretrained on ImageNet is adopted to extract the feature that represents each frame. In the end, each video is represented as with .
To capture the temporal information between video frames, we then feed into a single-layer bidirectional GRU (bi-GRU [8]) with 512-dimensional hidden states to process the whole video. For each frame, we concatenate the hidden states from the two directional GRU as the global temporal representation:
| (1) |
| (2) |
where denotes to the -th hidden state of bi-GRU.
Finally, we obtain a sequence of feature map from the bi-GRU, which refers to the representation of the each frame in the video. We then apply mean pooling operation on :
| (3) |
where denotes the global representation of the video.
3.2 Text-side Encoder
For text embedding, previous works [3, 4] usually embed a word by a traditional word2vec [9] model and then construct the contextual representation relaying on a single RNN. In this way, the textual representations are not discriminative enough. Recently, a great progress has been made in the field of natural language processing (NLP): a language representation model BERT [10] is proposed and has proven to be effective in many NLP tasks. Motivated by this, our textual data is pretrained by BERT. To be specific, the BERT is trained to predict masked words inside a sentence based only on the context in an unsupervised way. In this way, we can capture the discriminative contextual information between words. After pretraining, the word embedding is then fine-tuned by Transformer module [11] in retrieval task. It is more effective and efficient than RNN, because of its superiority in language modeling.
Given a sentence with length , we can obtain the fixed embeddings from the pretrained BERT. Specifically, we average the outputs of the last four layer from BERT as the embeddings. We enable to achieve the fixed embeddings with . After obtaining the embeddings of a sentence, we send them into Transformer module to extract the global encoding of words, which employ multi-head self-attention to capture the abundant contextual information. We formulate this as:
| (4) | |||
where is layer number of Transformer, refers to the length of a sentence and .
The global temporal feature map of a sentence is represented as . Same to video side, global representation of a sentence is produced by:
| (5) |
3.3 Stacked Multi-scale Dilated Convolution
In addition to global information, local cues are proved to be also necessary in the field of computer vision and natural language processing. So we need to design a module to simultaneously capture the global and local cues. In this paper, we propose a Stacked Multi-scale Dilated Convolutional (SMSDC) module which can be inserted into video or text processing model. This module consists of two steps: the first step is designed to capture the local temporal cues among consecutive frames and skipped frames, while the second step is designed to capture the complex long-range relations among these local temporal cues. Our intuition is that diverse and refined information of an instance can be derived in this way.
Spatial convolution is capable of modeling the spatial context within an image, which is widely used in many tasks such as Image Segmentation. Inspired by this, we implement a multi-scale dilated convolution (MSDC) which represents local temporal feature learning and relation learning both in videos and texts.
The MSDC takes global feature map (either of and ) as input and outputs a local feature vector ( for and for ). After obtaining this global feature map , we adopt the dilated convolution (DC) operation which is formulated as:
| (6) |
where denotes the parameters in the the dilated convolution, is the kernel size and is the dilated size.
is the collection of output features of DC. The dilated convolution adaptively fuses the local frames or words together for constituting the different local events. These events contain the different local temporal cues.
To capture more different semantic cues, we extend DC to a multi-scale dilated (MSDC) form with different kernel scale and dilation size, which can capture local temporal cues in terms of different receptive field. Defining be the kernel scale set and be the dilation size set. is the output of MSDC. To represent each input to a vector, we apply nonlinear activation and maxpooling along the time dimension:
| (7) |
We then stack another MSDC on to model the long-range relations among the different local semantic features, producing a discriminative feature representation .
To fuse the features into a single vector, we simply apply concatenation fusion to get the final local representation:
| (8) |
where refers to the output of our proposed SMSDC, which is used to calculate the similarity between video and text.
3.4 Model Learning
After encoding the video and text, we can obtain the global and local features of them, respectively. Then, we apply a concatenation operation to fuse them in order to provide more semantic cues for matching calculation between video and text.
| (9) |
In order to calculate the similarity between video and text, we embed them into a joint space, in which the embedding of the positive video-text pairs should be close to each other while the negative pairs should be far away.
Following [4], we use a Fully Connected (FC) layer following with a Batch Normalization(BN) layer as the final embedding layer, which can be formulated as:
| (10) | |||
where , , , are weights and biases.
With the final embedding of video and text as described above, the similarity of and , denoted as , can then be computed as the cosine of the angle between them. The similarity should be subject to the model parameters during the optimization. We utilize bidirectional max-margin hard ranking loss to optimize the model, which is the state-of-the art loss and widely used in vision and language matching task. The loss of this optimization problem can then be written as:
| (11) | |||
where is the margin constant and is set as a hyperparameter. During the training, hard negative sample is utilized within a batch to penalize the model: is the negative text for while is the negative video for .
The whole model is trained end-to-end to minimize except that the image feature and word embedding are respectively extracted by pretrained CNN and pretrained BERT, which are all fixed.
4 EXPERIMENTS
We first introduce our experiment setup and implementation details. Then, we present the experimental result and the comparison with previous work. After that, ablation study is shown.
4.1 Experimental Settings
Datasets. In this paper, we conduct experiments on two benchmark datasets: MSR-VTT [12] and MSVD [13] to evaluate the performance of our proposed framework. MSR-VTT and MSVD are two challenging datasets in the filed of video question answering, video captioning and video-text retrieval. MSR-VTT consists of 10000 video clips , each of which is annotated with 20-sentence descriptions. MSVD is a small dataset, which contains 1970 videos, while each of them has around 40 sentences. Note that, there are two kinds of sentence constructing strategies in the previous work: JMET [14] uses all the ground-truth sentences while LJRV [15] randomly samples 5 ground-truth sentences for each video. We follow the latter strategy. The splits of train, validation and test for the two datasets are consistent to previous work.
| Method | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||||||
| R@1 | R@5 | R@10 | MedR | mAP | R@1 | R@5 | R@10 | MedR | mAP | ||
| W2VV[16] | 1.8 | 7.0 | 10.9 | 193 | 0.052 | 9.2 | 25.4 | 25.4 | 24 | 0.050 | 90.3 |
| VSE[3] | 5.0 | 16.4 | 24.6 | 47 | - | 7.7 | 20.3 | 31.2 | 28 | - | 105.2 |
| VSE++[3] | 5.7 | 17.1 | 24.8 | 65 | - | 10.2 | 25.4 | 35.1 | 25 | _ | 118.3 |
| Mithun et al.[3] | 5.8 | 17.6 | 25.2 | 61 | - | 10.5 | 26.7 | 35.9 | 25 | - | 121.7 |
| W2VViml[4] | 6.1 | 18.7 | 27.5 | 45 | 0.131 | 11.8 | 28.9 | 39.1 | 21 | 0.058 | 132.1 |
| DualEncoding[4] | 7.7 | 22.0 | 31.8 | 32 | 0.155 | 13.0 | 30.8 | 43.3 | 15 | 0.065 | 148.6 |
| Ours | 8.8 | 25.5 | 36.5 | 22 | 0.174 | 14.0 | 33.1 | 44.9 | 14 | 0.076 | 162.8 |
| Method | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||||||
| R@1 | R@5 | R@10 | MedR | MeanR | R@1 | R@5 | R@10 | MedR | MeanR | ||
| ST[17] | 2.6 | 11.6 | 19.3 | 51 | 106 | 3.0 | 10.9 | 17.5 | 77.0 | 241.0 | 64.9 |
| LJRV[15] | 7.7 | 23.4 | 35 | 21 | 49.1 | 9.9 | 27.1 | 38.4 | 19.0 | 75.2 | 141.5 |
| W2VV-ResNet[3] | - | - | - | - | - | 17.9 | 39.6 | 51.3 | 11.0 | 57.6 | - |
| Mithun et al.[3] | 15.0 | 40.2 | 51.9 | 9.0 | 45.3 | 20.9 | 43.7 | 54.9 | 7.0 | 56.1 | 226.7 |
| Ours | 18.2 | 44.0 | 57.8 | 7.0 | 38.6 | 23.2 | 48.2 | 62.5 | 6.0 | 38.8 | 253.9 |
| Method | Text-to-Video Retrieval | Video-to-Text Retrieval | RSum | ||||||||
| R@1 | R@5 | R@10 | MedR | mAP | R@1 | R@5 | R@10 | MedR | mAP | ||
| baseline | 6.2 | 19.6 | 29.2 | 36 | 0.136 | 9.8 | 27.1 | 38.2 | 19 | 0.056 | 130.2 |
| +BERT | 7.0 | 21.6 | 31.8 | 29 | 0.151 | 11.6 | 30.3 | 41.0 | 17 | 0.064 | 143.3 |
| +Transformer | 7.4 | 22.5 | 33.0 | 27 | 0.156 | 12.3 | 30.5 | 41.2 | 17 | 0.069 | 146.9 |
| +MSDC | 8.5 | 24.9 | 35.6 | 23 | 0.173 | 13.6 | 32.4 | 43.8 | 14 | 0.075 | 158.7 |
| +SMSDC | 8.8 | 25.5 | 36.5 | 22 | 0.176 | 14.0 | 33.1 | 44.9 | 14 | 0.076 | 162.8 |
Evaluation Metric. Following prior work on vision-text matching task, we use the standard rank-based criteria: R@K (Recall at rank K, K=1, 5, 10), MedR (median Rank), MeanR (mean Rank) and mAP (mean Average Precision), to report our retireval performance. is calculated to compare the overall preformance. Note that, due to the missing result in prior work, we only report mAP for MSR-VTT and MeanR for MSVD.
Implementation Details. We set the margin in the rank loss and the dimension of the embedding space in equation is set to 2048. (n, m) pair in SMSDC is empirically set to (4, 2) for video and (3, 2) for text. The Transformer layer number K is set to 3. We keep the batch size to 64. Learning rate is initialized to and is decreased by a factor of 2 once the performance does not increase in three consecutive epochs. SGD with Adam is adopted as the optimizer. The maximal number of training epoch is set to 30. The best model is chosen by sum of recalls.
4.2 Compared with state-of-the-art
Table 1 and Table 2 show the experimental results and comparisons with previous methods on the two datasets respectively. All the results are cited from its original papers if available. We can see that our proposed method performs best and consistently outperforms state-of-the-art methods in both text-to-video and video-to-text retrieval. It verifies the effectiveness of our proposed method. The performance of video-to-text is higher than text-to-video because one video is paired with several sentence and we take the most similar one as the rank. Sum of recalls is increased from 148.6 to 162.7 on MSR-VTT dataset and 226.7 to 253.9 on MSVD dataset. Note that, we also use the source code and original settings of [4] to test on MSVD, the sum of recalls is around 241, which is still much lower than ours. The relative improvement is smaller on MSVD dataset compared with a same method, the reason may be that the length of videos are longer and the number of sentence is more and thus can provide more semantic information.
4.3 Ablation Study
We also conduct experiments on MSR-VTT dataset to evaluate the effectiveness of different components in the proposed method, including the text side embedding modeling and the proposed convolution module. The experimental results are shown in table 3, in which the baseline is both video feature and text feature encoding by Bi-GRU with word2vec embedding. Then the word embedding and Bi-GRU of text respectively replaced by BERT pretrained embedding and Transformer. Compared with baseline method, BERT pretraining with Transformer fine-tuning is effective. Then we add MSDC on both video and text, we can see the result is improved, which demonstrates the effectiveness of capturing dense temporal cues. SMSDC further improves the performance, which further captures the relation between temporal cues and result in a refined and discriminative feature.
5 CONCLUSION
In this paper, we have proposed a stacked convolutional deep encoding network to capture more discriminative semantic cues for video-text retrieval. A SMSDC module within our method is able to encode short-range temporal cues and long-range relations between them by adopting convolutions with different kernel size and dilation size. In addition, a more robust textual representation is obtained by fully utilizing the superiority of Transformer in language modeling. Through extensive experiments, we demonstrate that our method outperforms state-of-the-art video-text retrieval methods.
6 ACKNOWLEDGMENTS
This work was supported by the National Key R&D Program of China under Grant 2017YFB1300201, the National Natural Science Foundation of China (NSFC) under Grants 61622211, U19B2038 and 61620106009 as well as the Fundamental Research Funds for the Central Universities under Grant WK2100100030.
References
- [1] Fisher Yu and Vladlen Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint arXiv:1511.07122, 2015.
- [2] Zihao Wang, Xihui Liu, Hongsheng Li, Lu Sheng, Junjie Yan, Xiaogang Wang, and Jing Shao, “Camp: Cross-modal adaptive message passing for text-image retrieval,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5764–5773.
- [3] Niluthpol Chowdhury Mithun, Juncheng Li, Florian Metze, and Amit K Roy-Chowdhury, “Learning joint embedding with multimodal cues for cross-modal video-text retrieval,” in Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval. ACM, 2018, pp. 19–27.
- [4] Jianfeng Dong, Xirong Li, Chaoxi Xu, Shouling Ji, Yuan He, Gang Yang, and Xun Wang, “Dual encoding for zero-example video retrieval,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 9346–9355.
- [5] Zheng-Jun Zha, Jiawei Liu, Di Chen, and Feng Wu, “Adversarial attribute-text embedding for person search with natural language query,” IEEE Transactions on Multimedia, 2020.
- [6] Zheng-Jun Zha, Daqing Liu, Hanwang Zhang, Yongdong Zhang, and Feng Wu, “Context-aware visual policy network for fine-grained image captioning,” IEEE transactions on pattern analysis and machine intelligence, 2019.
- [7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [8] Mike Schuster and Kuldip K Paliwal, “Bidirectional recurrent neural networks,” IEEE Transactions on Signal Processing, vol. 45, no. 11, pp. 2673–2681, 1997.
- [9] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [11] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998–6008.
- [12] Jun Xu, Tao Mei, Ting Yao, and Yong Rui, “Msr-vtt: A large video description dataset for bridging video and language,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 5288–5296.
- [13] David L Chen and William B Dolan, “Collecting highly parallel data for paraphrase evaluation,” in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011, pp. 190–200.
- [14] Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, and Yong Rui, “Jointly modeling embedding and translation to bridge video and language,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4594–4602.
- [15] Mayu Otani, Yuta Nakashima, Esa Rahtu, Janne Heikkilä, and Naokazu Yokoya, “Learning joint representations of videos and sentences with web image search,” in European Conference on Computer Vision. Springer, 2016, pp. 651–667.
- [16] Jianfeng Dong, Xirong Li, and Cees GM Snoek, “Word2visualvec: Image and video to sentence matching by visual feature prediction,” arXiv preprint arXiv:1604.06838, 2016.
- [17] Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler, “Skip-thought vectors,” in Advances in Neural Information Processing Systems, 2015, pp. 3294–3302.