Start from Video-Music Retrieval: An Inter-Intra Modal Loss for Cross Modal Retrieval
Abstract
The burgeoning short video industry has accelerated the advancement of video-music retrieval technology, assisting content creators in selecting appropriate music for their videos. In self-supervised training for video-to-music retrieval, the video and music samples in the dataset are separated from the same video work, so they are all one-to-one matches. This does not match the real situation. In reality, a video can use different music as background music, and a music can be used as background music for different videos. Many videos and music that are not in a pair may be compatible, leading to false negative noise in the dataset. A novel inter-intra modal (II) loss is proposed as a solution. By reducing the variation of feature distribution within the two modalities before and after the encoder, II loss can reduce the model’s overfitting to such noise without removing it in a costly and laborious way. The video-music retrieval framework, II-CLVM (Contrastive Learning for Video-Music Retrieval), incorporating the II Loss, achieves state-of-the-art performance on the YouTube8M dataset. The framework II-CLVTM shows better performance when retrieving music using multi-modal video information (such as text in videos). Experiments are designed to show that II loss can effectively alleviate the problem of false negative noise in retrieval tasks. Experiments also show that II loss improves various self-supervised and supervised uni-modal and cross-modal retrieval tasks, and can obtain good retrieval models with a small amount of training samples.
Index Terms:
inter-intra modal loss, video-music retrieval, cross-modal retrieval, contrastive learning.I Introduction
With the increasing content demands in the short video industry, AI-assisted video editing has greatly increased the efficiency in video production. To choose a piece of good background music (BGM) for a video by AI is our main research point. Some supervised learning based algorithms select music by the matching scores of tags [1] [2] or the feature distance in the emotional space [3] [4] [5]. In recent works [6] [7] [8], music selection becomes a cross-modal retrieval task based on contrastive learning. Video and audio encoders learn various of video-music matching factors in a self-supervised training way. The cosine distance of the encoded cross-modal features is used to assess the suitability of media candidates.
This paper focuses on solving the problem of training with noisy data in self-supervised cross-modal retrieval. In self-supervised learning, a pair of video-music samples come from the same video work, so the dataset has only one-to-one matches. This obviously does not accurately reflect the real situation. In fact, a piece of music can be used as the background music for different videos, and a video can also be paired with different background music. In this case, there are many suitable videos and music that are not in the same pair, resulting in many false negative noisy samples. The cross-modal training objective is to minimize the distance between positive samples and maximize the distance between negative samples. When the model is overfitted to the noise, the distance between many false negative sample pairs is maximized, leading to a decrease in the model’s generalization ability. To tackle this challenge, a novel inter-intra modal loss (II Loss) is specifically designed to handle this type of noise. The II Loss addresses the issue by using the intra loss component to minimize drastic variations in the feature distributions within each modality during training. This approach effectively mitigates overfitting on the noisy data and allows for more accurate retrieval of relevant matches without requiring complex noise removal techniques. The proposed framework Inter-Intra Contrastive Learning for Video-Music Retrieval (II-CLVM) based on inter-intra modal loss achieves the state-of-the-art on video-music retrieval on Youtube8M and performs better when retrieving music using multi-modal video information (such as text). II loss is also performs well for other cross-modal retrieval tasks.
Our contributions are as follows:
-
•
This paper proposes inter-intra modal loss (II loss), which enables the retrieval models trained on noisy data to have better generalization ability. II loss alleviates the model’s overfitting to false negative noise by minimizing the drastic changes in feature distribution within each modality. II loss works well in various self-supervised and supervised uni-modal and cross-modal retrieval tasks.
-
•
The II-CLVM video-music retrieval framework is developed. It incorporates II Loss and achieves state-of-the-art performance on the YouTube8M dataset. Additionally, the framework employs Global Sparse (GS) sampling which allows music retrieval to be based on the content of the complete video, rather than on fixed-duration video clips. The framework can also easily integrate multi-modal video information (such as images and text) to achieve better performance.
II Related Work
In recent works, background music selection for video is a cross-modal retrieval task based on pretrained features. Contrastive learning enables the model to learn rich matching rules in large-scale video-music datasets and reduce the feature distance between matched video-music pairs.
II-A Contrastive learning and cross-modal retrieval
Due to the pervasively existed video music pairs online, retrieving a music for a video is usually treated as a cross-modal contrastive learning task. Early works such as [8] performed binary classification for pairwise cross-modal samples. Ranking/triplet loss ordered the similarity score of samples when the query was given (e.g. [7],[8],[9]). The distance or similarity of hash codes [10] [11][12], the canonical correlation analysis (CCA) [13] and the relational network (RN) [14] were also applied to model the cross-modal distance. In recent works, CLIP (Contrastive Language–Image Pre-training)[15] used a large number of image-text pairs to self-supervise the pre-training of two encoders for image-text retrieval tasks. During pre-training, the distance between cross-modal feature pairs of each mini-batch was processed by a simple cross entropy loss function. CLIP was then extended to various types of cross-modal retrieval and pre-training tasks such as video-text (CLIP4clip[16]) and audio-text (AudioCLIP[17]). In addition to matching and retrieval tasks, some recent works (e.g. BLIP[18]) explored different pre-training methods that enable encoders to migrate well to caption and QA tasks.
There are also many works that try to optimize the cross modal retrieval task by redesigning of loss function. Some works [6] [19] integrated the label classification loss into the inter-modal similarity loss. In order to prevent intra-modal structure collapse during cross-modal training, [7] and [20] added intra-modal loss to triplet loss. [21] designed a three-part loss for robust cross-modal retrieval.
II-B BGM Selection for videos
To find an appropriate BGM from a music library based on the contents of both music and the given video, early works were more likely to choose music by matching labels. Emotion was always regarded as a critical factor in music-video retrieval [3] [5]. In addition, some works also incorporated factors such as location ([1] [4]), style and genre ([22]), comments and lyrics text ([23]), and user personality ([4]). In recent works, algorithms [6] [7] [19] [8] are trained by self-supervised contrastive learning methods and capable to learn the rich factors and preferences of video creators to choose BGM automatically. There are also some works ([24] [25]) generated new BGM for videos.
II-C Pretrained visual and audio feature extractors
In video-music retrieval task, most works retrieved music based on the distance between the pretrained visual and audio features. The performance of pretrained feature extractors also becomes a key factor restricting retrieval performance. These pretrained feature extractors are pre-trained on large-scale datasets, and all parameters are frozen during fine-tuning. When extracting video embeddings, multiple frames can be sampled and the frame-level features such as ResNet-50 [26], Inception-V3 [27], ViT [28], or CLIP-Vision[15] can be extracted. Also, video-level features like I3D[29], SlowFast[30], and Video Swin Transformer[31] can be extracted. As for audio, frame-level features VGGish [32] or PANNs [33] can be extracted.
III The proposed framework
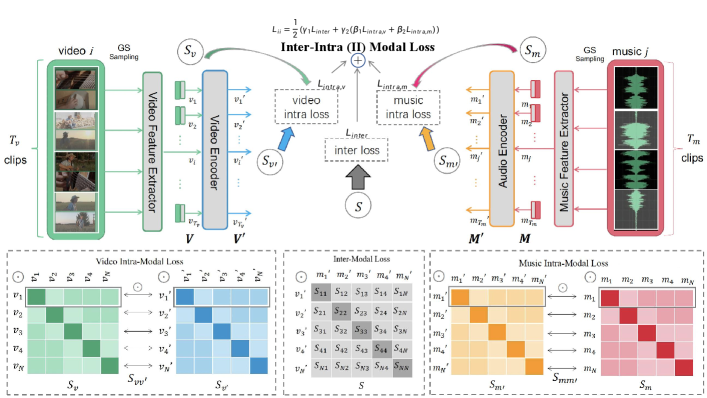
Fig 1 shows the architecture of the framework II-CLVM (Inter-Intra Contrastive Learning for Video-Music Retrieval) with the proposed inter-intra modal loss. During the model training, there are video-music pairs in each mini-batch. Firstly, global sparse (GS) sampling is performed on both video and music, and extract the pretrained feature sequences for video and for music. Then, the video embeddings and music embeddings are obtained by separate sequence encoders. The inter-intra (II) modal loss is proposed to measure the distance between the encoded video embeddings and music embeddings. The detail of each module of II-CLVM is introduced below.
III-A Global sparse sampling
Existing video-music retrieval usually takes one continuous fixed-duration (FD) clip from the original media to represent the whole sequence, e.g. cutting 30 around the center of both video and music as in [7]. Those methods ignore the rest parts of video and music, so that the retrieved music may only be partially related to the video. To extract features of the entire video and the whole music, the global sparse (GS) sampling [34] is applied. For video , it is split evenly into clips and the video feature sequence is obtained where is the dimension of the feature. Similarly, the audio feature sequence is obtained for music . Note that the purpose of extracting feature sequences of fixed length for video and music of different durations is to eliminate duration information and enable the model to retrieve based on content.
III-B Sequence encoders
To extract the temporal information from the frame-level video and music feature sequences, V and M are fed into two sequence encoders (biLSTM, transformer encoder, etc), respectively. After encoding, the encoded video feature and music feature are obtained, where is the fixed hidden dimension of the sequence encoders for both video and music modalities.
III-C The inter-intra (II) modal loss
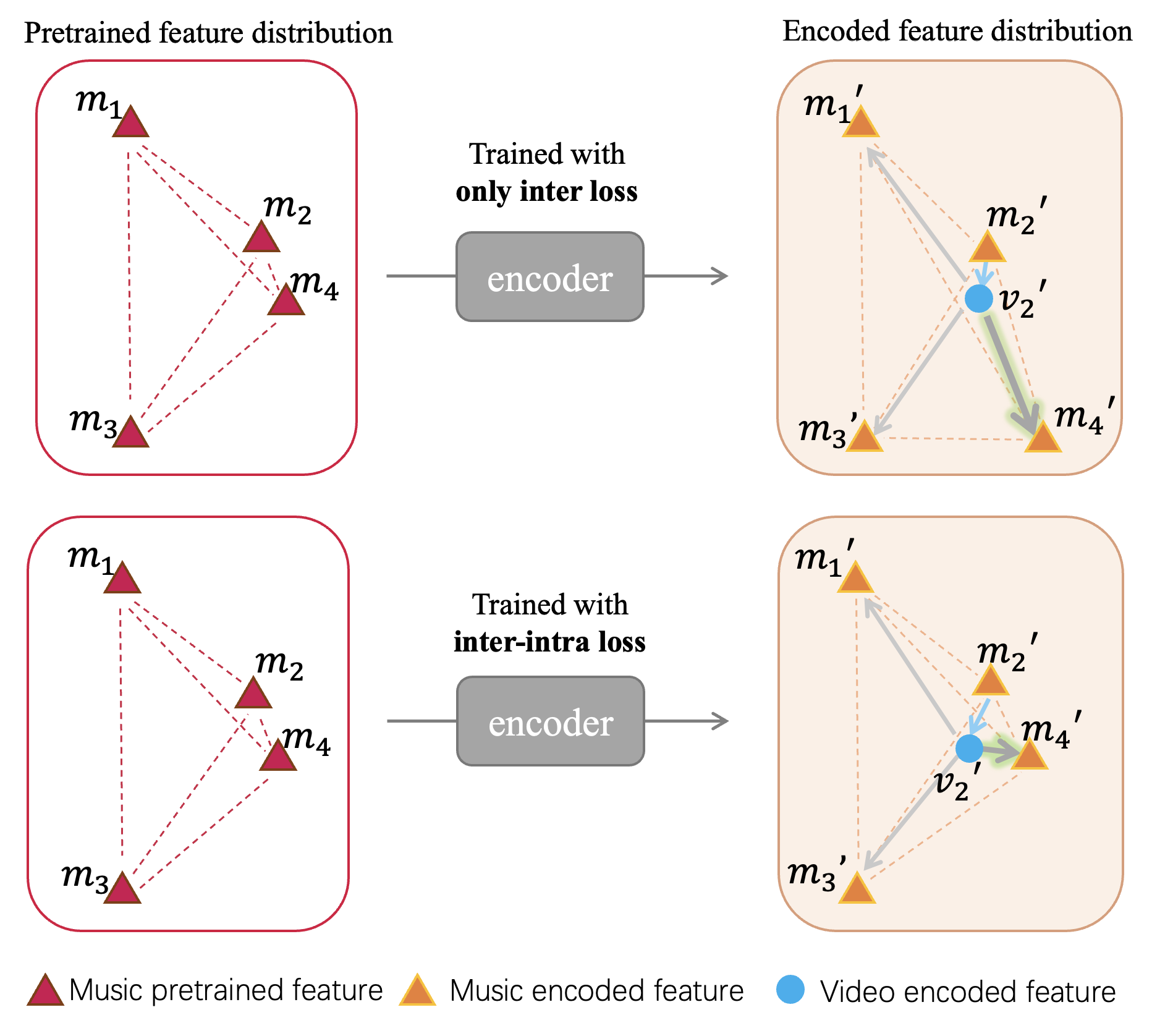
As illustrated in Fig 2, we consider an example of a batch with a size of 4. The video and the music constitute a pair of positive samples. Due to the similarity between music and , can also be effectively utilized as background music (BGM) for video . During cross-modal training, if solely relying on the conventional inter-modal loss, the distance between the features output by the encoder and would decrease, while the distance between the features and would increase, which is an undesired outcome. As depicted in Fig 2, the proposed intra loss aims to preserve the relative feature distribution of the four music samples in the encoder output, as close as possible to their pre-encoder state, thereby preventing from moving away from .
In II-CLVM, a mini-batch consists of matched video-music pairs. In each batch, the loss is a weighted sum of the inter-modal similarity loss and the intra-modal features distance distribution loss as shown in Fig 1.
III-C1 Inter-modal loss
As shown in equation (2), the inter-modal loss is calculated based on the cosine similarity matrix . Each element of is calculated as follows:
| (1) |
where is defined as the cosine similarity between two vectors.
| (2) | |||
In , is the th row, and is the th column. is a learnable temperature parameter and controls the range of the logits in the Softmax function. is an -order identity matrix. is the cross entropy loss, and means the Softmax function. and are adjustable parameters. The inter-modal loss increases values on the diagonal of and decreases those in other positions.
III-C2 Intra-modal loss
For the video modality, two intra-modal similarity matrices and are calculated as shown in Fig 1. In a mini-batch, and describe the similarity of different video features before and after the encoder, respectively. Here, each element of and is calculated as follows:
| (3) |
| (4) |
where is the temporal average of . To achieve the invariance of feature distribution before and after encoding, and should be similar. The vectors and are calculated to describe the row similarity and column similarity between and , respectively. The calculation is as follows:
| (5) |
| (6) |
Then, the intra-modal loss is calculated as follows:
| (7) | |||
where and are the weight parameters. Here, , , so is equivalent to , denoted as . The intra-modal loss can be simplified to:
| (8) |
The music modality is processed in the same way. The total intra-modal loss is computed as equation (9), where and are the weights of intra loss of the two modalities respectively. The inter-intra modal loss is a weighted sum of inter-modal loss and intra-modal loss as shown in equation (10). could work with various feature extractors and both of the above sampling methods.
| (9) |
| (10) |
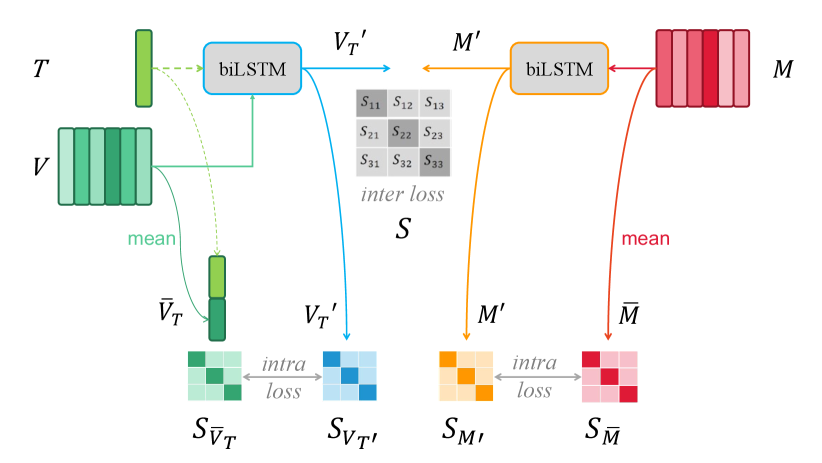
III-D II-CLVTM
When choosing a background music (BGM) for a video, the video creator may also provide some text information, such as the video’s description, title or keywords. Our framework can easily incorporate these text inputs. We use the Inter-Intra Contrastive Learning for VideoText-to-Music Retrieval (II-CLVTM) model, as shown in Fig 3, to fuse and encode the raw video feature sequences and text feature vectors with biLSTM. The text feature vector is used as the initial hidden vector for biLSTM. As Fig 3 shows, when the query is multi-modal, we compute the intra-modal loss based on the similarity matrix of the features before and after the cross-modal encoder. We also note that the uncoded feature is obtained by concatenating the raw text feature and the average video feature.
IV Experiments and results
The experiments in this section consist of three parts. Section IV-A mainly introduces the experiments of II-CLVM on the video-music retrieval task on the YouTube8M dataset. Section IV-B verifies the generality of II loss on various other cross-modal retrieval tasks. Section IV-C designs two experiments to verify that II loss can effectively alleviate the problem of false negative noise in the retrieval datasets.
IV-A Experiments on YouTube8M
In this section, the performance of each module in II-CLVM is tested on video-music retrieval task of official YouTube8M dataset[35]. What’s more, a subjective evaluation is conducted to check the BGM selection performance of II-CLVM on YouTube8M.
In YouTube8M [35], there are 149,213 video samples labeled as Music Video, in which 116,098 videos are for training and 33,115 videos are for testing. Three testing sets with 1024, and 1000 pairs are randomly generated from the test data. YouTube8M provides the official video features (Inception-v3 [27], 1024-d per second after whitening PCA) and music features (VGGish [32], 128-d per second). In the following experiments, these features are used as the raw pretrained features.
All experiments are conducted in a 32G Tesla V100 GPU accelerated environment. The model is built with PyTorch. In II-CLVM, , , and . The initial value of is 0.07. When the encoder is biLSTM encoder, the initial value of is also 0.07. When GS sampling method is applied, . Since YouTube8M provides second-level pretrained feature sequences, GS sampling is directly applied on the feature. Each model is trained for 30 epochs on the training dataset and the () metric is measured on three testing sets , respectively. is the most common evaluation metric in all kinds of retrieval tasks and is the abbreviation for recall at -th in the ranking list, defined as the proportion of correct matchings in top- retrieved results. Specifically, in video-to-music retrieval, refers to the probability that the correct music is included in the top retrieved music results. Apart from , and are also noteworthy due to the fuzziness of video-music retrieval rule.
| Group | |||
| biLSTM(CLVM)(FD) | 5.8 | 31.0 | 46.7 |
| biLSTM(II-CLVM)(FD) | 7.5 | 31.6 | 49.8 |
| biLSTM(CLVM)(GS) | 18.4 | 54.0 | 70.2 |
| biLSTM(II-CLVM)(GS) | 22.1 | 55.1 | 70.4 |
| Group | ||||||
| from 1024 | from 1000 | |||||
| CME[6] | 10.2 | 40.3 | - | - | - | - |
| CBVMR[7] | - | - | - | 8.2 | 23.3 | 35.7 |
| FC(CLVM) | 7.7 | 31.7 | 48.4 | 6.9 | 31.5 | 49.3 |
| FC(II-CLVM) | 7.8 | 31.6 | 49.2 | 8.2 | 32.8 | 49.9 |
| GCN(CLVM) | 5.4 | 24.8 | 39.5 | 3.2 | 21.9 | 41.3 |
| GCN(II-CLVM) | 5.6 | 26.1 | 42.7 | 4.8 | 24.4 | 40.9 |
| Att(CLVM) | 4.0 | 26.4 | 43.2 | 5.5 | 27.3 | 46.6 |
| Att(II-CLVM) | 10.4 | 28.6 | 56.0 | 11.4 | 42.5 | 58.8 |
| biLSTM(CLVM) | 18.4 | 52.3 | 69.2 | 18.4 | 54.0 | 70.2 |
| biLSTM(II-CLVM) | 20.5 | 56.1 | 69.6 | 22.1 | 55.1 | 70.4 |
IV-A1 GS sampling
Taking biLSTM as an example of the encoder, the FD (fixed-duration) and GS (global sparse) sampling methods are tested on video-to-music retrieval task on testing set . The results of Table I show that GS sampling significantly improves the retrieval performance, and the increases from 7.5 to 22.1. The FD method can only retrieve music by fixed-duration video clips, and the performance is not as good as the GS sampling method that retrieves by the complete video.
IV-A2 The sequence encoder
In this subsection, different types of encoders are compared on video-to-music retrieval task. The GS sampling method is applied in all experimental groups. The results in Table II(b) show that FC (Fully Connected) layer and GCN have relatively poor performance on the video-music retrieval task which involves two modalities that are both time series, because they do not consider temporal information. On the other hand, sequence models such as self-attention(Att) and biLSTM have much better retrieval performance. For example, in the FROM 1024 retrieval, the two sequence models increase the of video-to-music retrieval to 10.4 and 20.5, respectively.
IV-A3 II loss in II-CLVM
In this subsection, the impact of the II loss is evaluated. As shown in Table I, the II-CLVM framework achieves an improvement of 0.5 to 3 compared to CLVM across various sampling methods. With respect to different encoders, as presented in Table II(b)(a), the groups incorporating II loss consistently exhibit superior performance in the video-to-music retrieval task. Although our primary objective is to select music for videos, music-to-video retrieval results are also presented in Table II(b)(b). In both retrieval tasks, the proposed framework II-CLVM significantly outperforms previous works [6] [7], achieving state-of-the-art results.
IV-A4 Subjective evaluation of video-to-music retrieval
A subjective evaluation is necessary for the video music retrieval task. This experiment is conducted similar to [7]. Each set of samples consists of one video and two pieces of music. A subject needs to choose a better music from the two candidates for the given video. These materials are all from 642 randomly selected videos from the test data. For each video as query, its , , and music are choosen in different ways. (Ground Truth) is the video’s original music. (Select) is the top1 music retrieved by the model biLSTM(II-CLVM) in Table II(b)(a). (Random) is a randomly selected piece of music. For each video, three sets of testing music sample pairs are constructed. For set , (the probability of being selected) is calculated. Similarly, is calculated for set and for set .
To ensure the credibility of the subjective evaluation results, each set of samples is evaluated by three subjects. Each video is randomly chopped off at the beginning and end to prevent subjects from evaluating by the duration and to make them focus on the global match of video and music. Besides, the file names are all encrypted to prevent subjects from judging by video IDs.
| 88.52 | 57.27 | 82.07 |
From Table III, the result of shows that the video and music from the same video ID match very closely. It is feasible to train the matching model by recalling video ID. close to 50 indicates that subjects confuse how well and match the video. The result of set shows that the BGM selected by the model matches the video better than a random piece of music. In general, our matching model acts great on BGM selection.
IV-A5 II-CLVTM
| Group | |||
| CLTM(keyword) | 5.7 | 17.9 | 25.8 |
| II-CLTM(keyword) | 6.7 | 18.2 | 26.6 |
| CLTM(title) | 6.9 | 18.8 | 27.6 |
| II-CLTM(title) | 7.0 | 18.9 | 26.9 |
| CLVM | 16.6 | 49.0 | 65.4 |
| II-CLVM | 20.0 | 51.1 | 66.1 |
| CLVTM(keyword) | 19.2 | 52.9 | 68.6 |
| II-CLVTM(keyword) | 22.2 | 56.6 | 74.0 |
| CLVTM(title) | 18.7 | 54.5 | 70.6 |
| II-CLVTM(title) | 23.1 | 60.4 | 75.8 |
This subsection evaluates the performance of the II-CLVTM framework. We create a subset of YouTube8M music videos that have both titles and keywords. The subset contains 119,191 video samples, of which 92,604 are for training and 26,587 are for testing. Besides using the official video and music features from YouTube8M, we also extract Clip-text [15] feature vectors for titles and keywords. We randomly generate a test set with 1000 sample pairs from the test data. In Table IV, we compare the of II-CLTM(Inter-Intra Contrastive Learning for Text-to-Music Retrieval), II-CLVM, II-CLVTM with CLTM, CLVM, and CLVTM. The results show that using video and text together for music retrieval achieves higher than using video or text alone, regardless of whether the text information is the title or the keyword. Therefore, it is better to select BGM based on multi-modal features rather than a single modality. Moreover, II Loss performs well under all query conditions, especially when multi-modal information is used as the query.
IV-B II loss on other retrieval tasks
| Dataset | training data | testing data | NOTE |
| Audio-Text | |||
| CLOTHO[36] | development (2,981) | evaluation(1,000) | 5 |
| Image-Text | |||
| MSCOCO [37] | train2017(113,287) | val2017(5,000) | 5 |
| Flickr30K [38] | train(29,783) | test(1,000) | 20 |
| Video-Text | |||
| MSVD [39] | train(1,200) | test(670) | 40 |
| MSRVTT [40] | train9k(9,000) | JSFusion(1,000) | 20 |
| VATEX [41] | train-release(25,991) | test-public(6,000) | 10 |
This section evaluates the generality of II loss on different cross-modal retrieval tasks using the audio-text dataset Clotho, the image-text datasets MSCOCO and Flickr30K, and the video-text datasets MSVD, MSRVTT and VATEX. The details of each dataset are shown in Table V. In these supervised retrieval tasks, each image, video or audio has multiple corresponding texts(The number of texts is given in the NOTE column of Table V). But the training data still contains noise. For instance, in the MSCOCO training set, images with IDs 226419, 166798, 303404 etc. depict planes in the blue sky, and images with IDs 368402, 505728, 509149 etc. portray women in the kitchen. These image-text pairs with similar contents can introduce noise to training.
The experimental environment and training parameters are the same as IV-A. BiLSTM is used as the encoder for video and audio feature sequences. For text features, FC layer is used as the encoder. is calculated to test each group of models. It is worth mentioning that In each epoch, only one text is randomly selected from the multiple texts associated with each image, video or audio sample to form a positive pair for training.
Table 4(a), 4(c), 4(f) shows the results of these cross-modal retrieval task. Results for all experimental groups are measured at the steady state of each model after 30 epochs of training. Although there is no longer just one-to-one matches in the datasets of these cross-modal tasks, the noise of false negatives still exists. On CLOTHO dataset, II Loss significantly improves from 2 to 4. On the two datasets of image-text retrieval, II Loss improves from 1 to 2. On MSVD dataset of video-text retrieval, II Loss improves greater than 5. And on other datasets of video-text retrieval, II Loss also improves from 0.5 to 2. In the meantime, II loss works when different pretrained features are used.
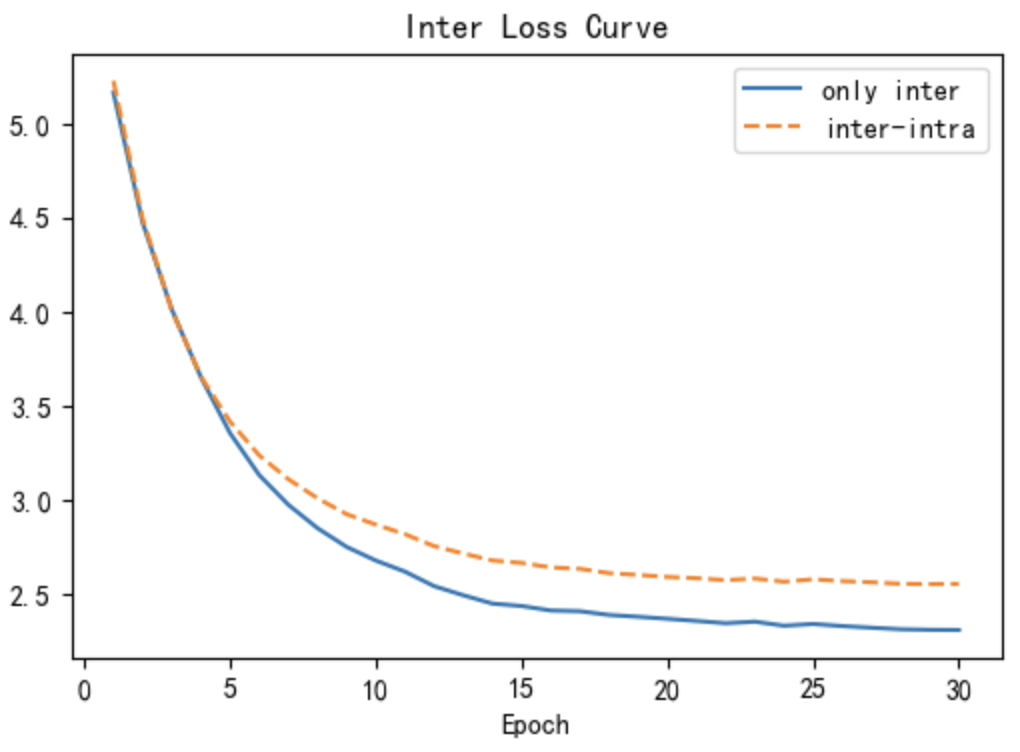
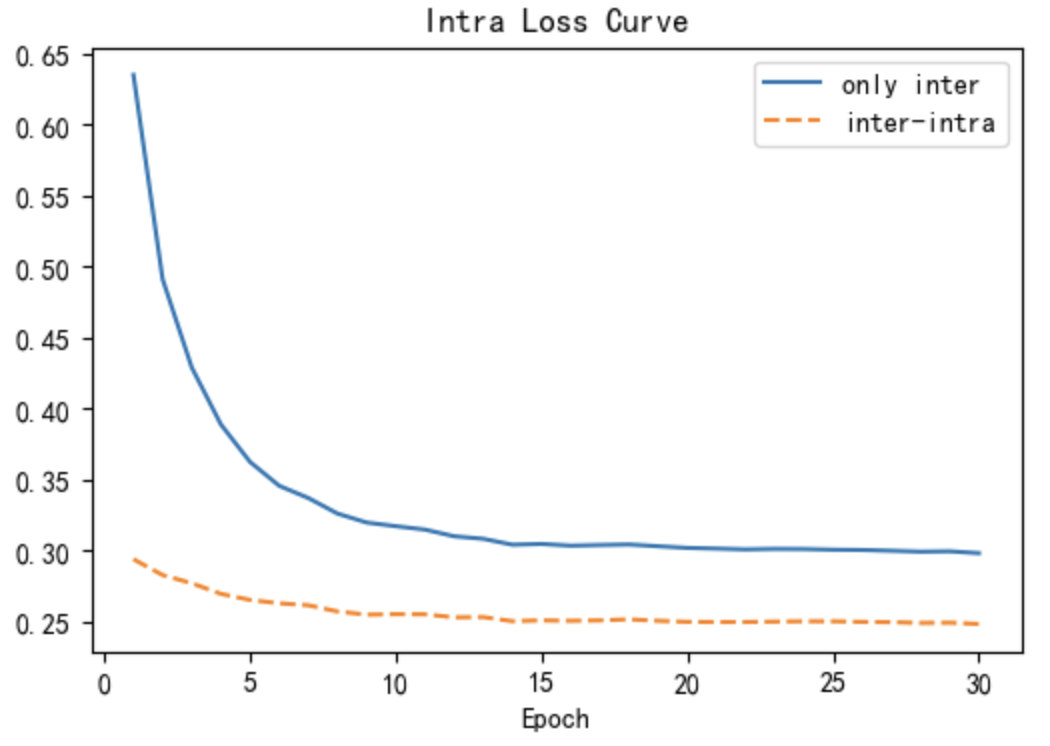
Using the MSVD dataset as an example, the three line charts in Fig 5 show the inter loss (5(a)) and intra loss (5(b)) during training, and the (5(c)) during testing as a function of the training epoch. The blue solid line represents the group that only uses inter loss, and the orange dashed line represents the group that uses inter-intra (II) loss. Note that in the only-inter group, the intra loss is calculated and plotted in the line chart 5(b), but not back-propagated. As shown in Fig 5(a), compared with the only-inter group, the inter-intra group reached a platform where it could not continue to decrease at a higher inter loss value, suggesting that intra loss can prevent inter loss from overfitting to the noisy training set. In Fig 5(b), Although the intra loss of the inter-intra group is always lower than that of the only-inter group, it does not decrease to a very low value. This is caused by the interaction between inter loss and intra loss. Fig 5(c) demonstrates that the score on the testing set for each epoch is higher in the inter-intra group than in the only-inter group.

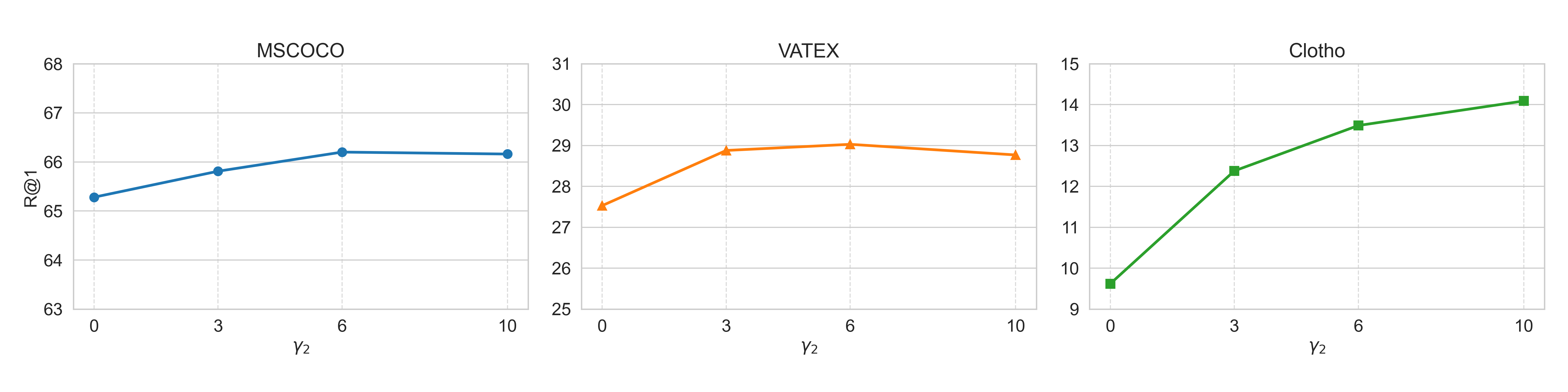
The three line charts in Fig 4 show the trend of indicator on three datasets: MSCOCO, VATEX, and Clotho, as the inter loss weight () takes the value of 1 and the intra loss weight () takes values of 0, 3, 6, and 10. It is obvious that the impact of the II loss is more pronounced in downstream tasks with smaller data volumes. For example, in the Clotho dataset, the values increase from 9.62 to 14.09 as goes from 0 to 10. It is also worth noting that has a noticeable effect on the model’s performance. As takes on values of 0, 3, 6, and 10, the indicator generally exhibits an upward trend. The trend slows down gradually and reaches a peak. For smaller datasets (such as clotho), the peak comes later. This is because on small datasets, the model tends to overfit to noisy sample pairs, which gives II loss more room for improvement. This distinctive characteristic of the II loss allows retrieval tasks to achieve satisfactory training results with only a limited number of cross-modal samples collected. To determine the optimal value, a limited number of experiments should be conducted. By analyzing these experiments and the specific values, researchers can select the best intra loss weight to maximize the performance of the model on various datasets and tasks.
IV-C The effect of II loss against false negative noise interference
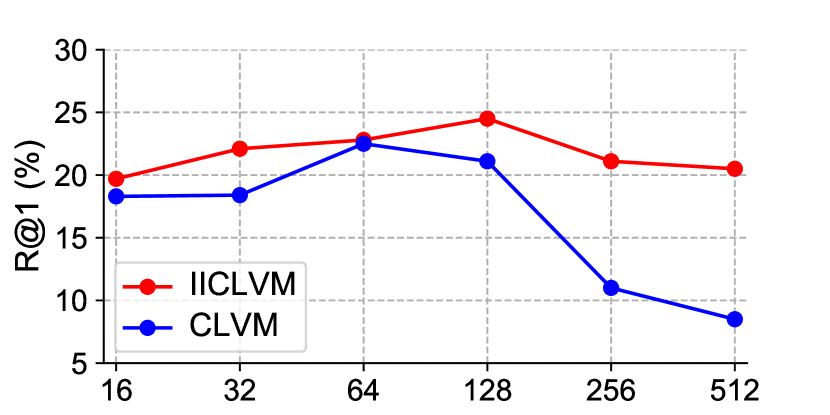
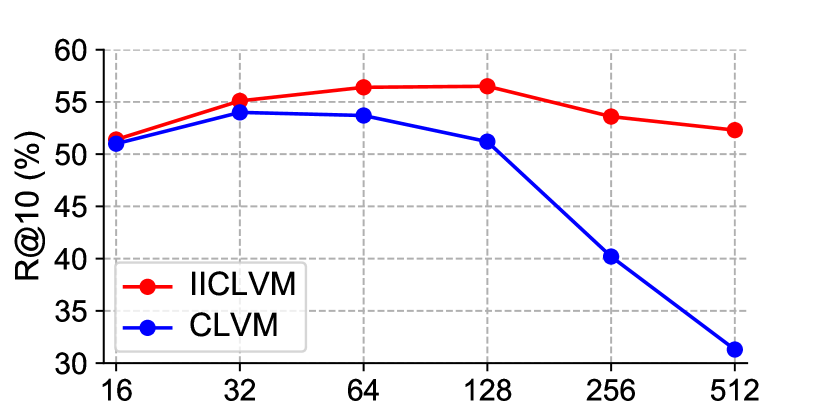
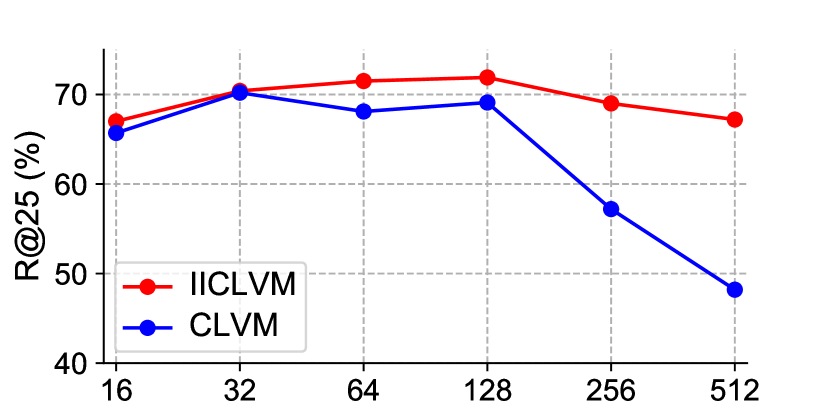
This section presents two experiments that focus on examining whether II loss can effectively resist the noise that exists in self-supervised retrieval tasks. The first experiment was performed on the YouTube8M dataset. Based on all the other experimental settings of the group biLSTM(II-CLVM) in section 4.1, this experiment changed the proportion of noise matching pairs by changing the batch size of training, and thus checked the different optimization effects of II loss under different amounts of noise. In Fig 6, the metric fluctuates as the batch size changes within the YouTube8m dataset. Initially, the value increases with the growing batch size due to more sufficient contrastive learning. However, as the batch size becomes larger, the number of noisy matching pairs increases exponentially, thereby negatively impacting training and leading to a decline in the value. The effectiveness of II loss in dealing with noise is demonstrated when comparing the II-CLVM group to the CLVM group; the former experiences a considerably slower decrease in , suggesting that the II loss is effective in mitigating the adverse effects of noise, and ultimately achieves the highest with a batch size of 128.
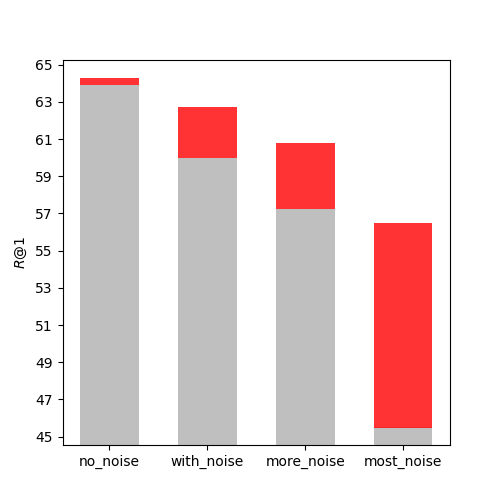
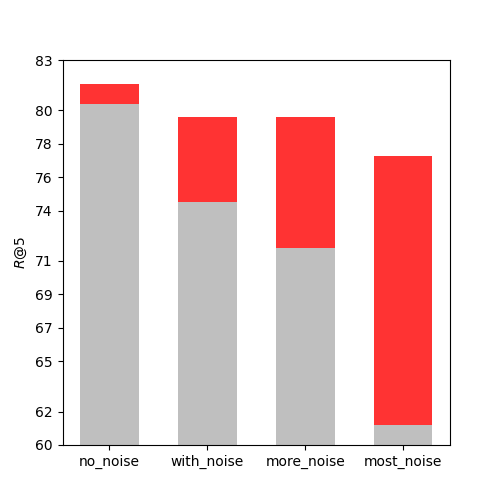
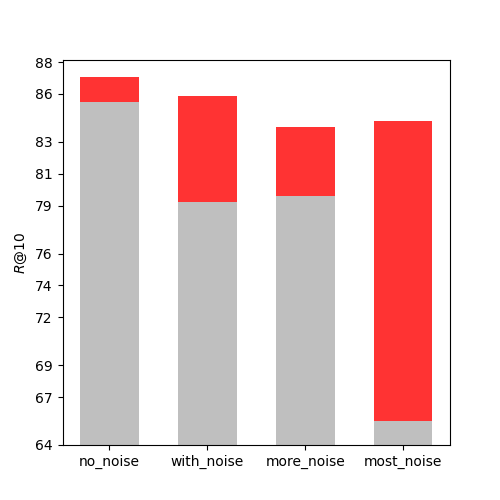
To test the effect of II loss on resisting different levels of noise interference in training, another experiment was conducted on an image classification dataset Caltech-256 [43] by manually adjusting the noise amount in training batches. The Caltech-256 dataset contains 256 categories of images, with about 100 images per category. The image retrieval task on Caltech-256 was defined as follows: given a query image, the aim was to retrieve another image from the same category as the query image, and was used to measure the retrieval performance. We randomly chose two images from each of the 256 categories as a positive sample pair for the testing set, and used the rest of the images as training data. During training, each pair of positive samples was randomly selected from the same category of training data. We also arranged multiple pairs of samples from the same category in each training batch to simulate different levels of noise. Four different experiments were performed: no_noise, with_noise, more_noise, and most_noise, with increasing amounts of noise. N represented the batch size of training. In the no_noise group, the N pairs of positive samples were selected from N different categories. In the with_noise group, we picked one pair from each of different categories and two pairs from each of another different categories. In the more_noise group, we picked two pairs from each of classes. In the most_noise group, we picked four pairs from each of classes. In this experiment, and . As shown in Fig 7, when there was almost no noise in the no_noise group, II loss had very little effect on R@k, and even decreased it. As the noise increased, II loss group showed more and more improvement compared to non-II loss group. In real-world self-supervised retrieval datasets, all sample pairs are unlabeled, so there is a high chance that a batch contains similar positive sample pairs. These similar positive sample pairs can produce false negative pairs as mentioned above, which can lower the model’s retrieval performance. II loss is an effective method to enhance the model’s generalization ability under such circumstances.
V Conclusion
The paper emphasizes the II loss as a key innovation in the new framework II-CLVM designed specifically for video-music retrieval. This innovative loss function improves the model’s generalization capabilities by maintaining pretrained feature distribution within the two modalities during training on noisy cross-modal datasets. The II-CLVM framework, which incorporates the II loss, has shown promising results in video-music retrieval tasks. The state-of-the-art results achieved on the youtube8m dataset for video-music retrieval tasks demonstrate the effectiveness of the II loss. The II-CLVTM framework with added multi-modal video information input (such as text) has better music retrieval performance in applications. Subjective evaluations also support the framework’s strong performance in music selection.
Beyond its application in the II-CLVM framework for video-music retrieval, the II loss has proven to be valuable for other cross-modal retrieval tasks as well, such as image-text, audio-text, and video-text retrieval. This showcases the adaptability and versatility of the II loss in different contexts and applications. Moreover, II loss is found to obtain good retrieval models with a small number of training samples.
Although the current findings are encouraging, the authors acknowledge there is potential for further enhancement, particularly in areas such as retrieval performance on tasks involving large datasets and the development of noise-resistant methods for end-to-end retrieval models. By addressing these challenges, the II loss has the potential to become an even more effective and versatile tool in the field of cross-modal retrieval.
References
- [1] Y. Yu, Z. Shen, and R. Zimmermann, “Automatic music soundtrack generation for outdoor videos from contextual sensor information,” in Proceedings of the 20th ACM international conference on Multimedia, 2012, pp. 1377–1378.
- [2] X. Wu, Y. Qiao, X. Wang, and X. Tang, “Bridging music and image via cross-modal ranking analysis,” IEEE Transactions on Multimedia, vol. 18, no. 7, pp. 1305–1318, 2016.
- [3] J.-C. Wang, Y.-H. Yang, H.-M. Wang, and S.-K. Jeng, “The acoustic emotion gaussians model for emotion-based music annotation and retrieval,” in Proceedings of the 20th ACM international conference on Multimedia, 2012, pp. 89–98.
- [4] R. R. Shah, Y. Yu, and R. Zimmermann, “Advisor: Personalized video soundtrack recommendation by late fusion with heuristic rankings,” in Proceedings of the 22nd ACM international conference on Multimedia, 2014, pp. 607–616.
- [5] J.-C. Lin, W.-L. Wei, and H.-M. Wang, “Emv-matchmaker: emotional temporal course modeling and matching for automatic music video generation,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 899–902.
- [6] D. Surís, A. Duarte, A. Salvador, J. Torres, and X. Giró-i Nieto, “Cross-modal embeddings for video and audio retrieval,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0.
- [7] S. Hong, W. Im, and H. S. Yang, “Cbvmr: content-based video-music retrieval using soft intra-modal structure constraint,” in Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, 2018, pp. 353–361.
- [8] L. Pretet, G. Richard, and G. Peeters, “Cross-modal music-video recommendation: A study of design choices,” arXiv preprint arXiv:2104.14799, 2021.
- [9] X. Mei, X. Liu, J. Sun, M. D. Plumbley, and W. Wang, “On metric learning for audio-text cross-modal retrieval,” arXiv preprint arXiv:2203.15537, 2022.
- [10] V. E. Liong, J. Lu, Y.-P. Tan, and J. Zhou, “Deep video hashing,” IEEE Transactions on Multimedia, vol. 19, no. 6, pp. 1209–1219, 2016.
- [11] X. Nie, B. Wang, J. Li, F. Hao, M. Jian, and Y. Yin, “Deep multiscale fusion hashing for cross-modal retrieval,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 1, pp. 401–410, 2020.
- [12] P.-F. Zhang, Y. Li, Z. Huang, and X.-S. Xu, “Aggregation-based graph convolutional hashing for unsupervised cross-modal retrieval,” IEEE Transactions on Multimedia, vol. 24, pp. 466–479, 2021.
- [13] D. Zeng, Y. Yu, and K. Oyama, “Audio-visual embedding for cross-modal music video retrieval through supervised deep cca,” in 2018 IEEE International Symposium on Multimedia (ISM). IEEE, 2018, pp. 143–150.
- [14] X. Wang, P. Hu, L. Zhen, and D. Peng, “Drsl: Deep relational similarity learning for cross-modal retrieval,” Information Sciences, vol. 546, pp. 298–311, 2021.
- [15] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” arXiv preprint arXiv:2103.00020, 2021.
- [16] H. Luo, L. Ji, M. Zhong, Y. Chen, W. Lei, N. Duan, and T. Li, “Clip4clip: An empirical study of clip for end to end video clip retrieval,” arXiv preprint arXiv:2104.08860, 2021.
- [17] A. Guzhov, F. Raue, J. Hees, and A. Dengel, “Audioclip: Extending clip to image, text and audio,” arXiv preprint arXiv:2106.13043, 2021.
- [18] J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” arXiv preprint arXiv:2201.12086, 2022.
- [19] B. Li and A. Kumar, “Query by video: Cross-modal music retrieval.” in ISMIR, 2019, pp. 604–611.
- [20] L. Wang, Y. Li, and S. Lazebnik, “Learning deep structure-preserving image-text embeddings,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5005–5013.
- [21] L. Zhen, P. Hu, X. Wang, and D. Peng, “Deep supervised cross-modal retrieval,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 394–10 403.
- [22] J.-C. Lin, W.-L. Wei, J. Yang, H.-M. Wang, and H.-Y. M. Liao, “Automatic music video generation based on simultaneous soundtrack recommendation and video editing,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 519–527.
- [23] S. Nemati and A. R. Naghsh-Nilchi, “Exploiting evidential theory in the fusion of textual, audio, and visual modalities for affective music video retrieval,” in 2017 3rd International Conference on Pattern Recognition and Image Analysis (IPRIA). IEEE, 2017, pp. 222–228.
- [24] C. Gan, D. Huang, P. Chen, J. B. Tenenbaum, and A. Torralba, “Foley music: Learning to generate music from videos,” in European Conference on Computer Vision. Springer, 2020, pp. 758–775.
- [25] Y. Zhu, K. Olszewski, Y. Wu, P. Achlioptas, M. Chai, Y. Yan, and S. Tulyakov, “Quantized gan for complex music generation from dance videos,” arXiv preprint arXiv:2204.00604, 2022.
- [26] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [27] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- [28] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [29] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308.
- [30] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6202–6211.
- [31] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” arXiv preprint arXiv:2106.13230, 2021.
- [32] J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780.
- [33] Q. Kong, Y. Cao, T. Iqbal, Y. Wang, W. Wang, and M. D. Plumbley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020.
- [34] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal segment networks: Towards good practices for deep action recognition,” in European conference on computer vision. Springer, 2016, pp. 20–36.
- [35] S. Abu-El-Haija, N. Kothari, J. Lee, P. Natsev, G. Toderici, B. Varadarajan, and S. Vijayanarasimhan, “Youtube-8m: A large-scale video classification benchmark,” arXiv preprint arXiv:1609.08675, 2016.
- [36] K. Drossos, S. Lipping, and T. Virtanen, “Clotho: An audio captioning dataset,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 736–740.
- [37] X. Chen, H. Fang, T.-Y. Lin, R. Vedantam, S. Gupta, P. Dollár, and C. L. Zitnick, “Microsoft coco captions: Data collection and evaluation server,” arXiv preprint arXiv:1504.00325, 2015.
- [38] B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2641–2649.
- [39] D. Chen and W. B. Dolan, “Collecting highly parallel data for paraphrase evaluation,” in Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, 2011, pp. 190–200.
- [40] J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video description dataset for bridging video and language,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5288–5296.
- [41] X. Wang, J. Wu, J. Chen, L. Li, Y.-F. Wang, and W. Y. Wang, “Vatex: A large-scale, high-quality multilingual dataset for video-and-language research,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 4581–4591.
- [42] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [43] G. Griffin, A. Holub, and P. Perona, “Caltech-256 object category dataset,” 2007.