2021
1]Department of Statistics and Data Science, University of Pennsylvania, Philadelphia, USA
2]Department of Statistics, Rutgers University, Piscataway, USA
3]Department of Statistics and Data Science, Fudan University, Shanghai, China
Statistical Inference and Large-scale Multiple Testing for High-dimensional Regression Models
Abstract
This paper presents a selective survey of recent developments in statistical inference and multiple testing for high-dimensional regression models, including linear and logistic regression. We examine the construction of confidence intervals and hypothesis tests for various low-dimensional objectives such as regression coefficients and linear and quadratic functionals. The key technique is to generate debiased and desparsified estimators for the targeted low-dimensional objectives and estimate their uncertainty. In addition to covering the motivations for and intuitions behind these statistical methods, we also discuss their optimality and adaptivity in the context of high-dimensional inference. In addition, we review the recent development of statistical inference based on multiple regression models and the advancement of large-scale multiple testing for high-dimensional regression. The R package SIHR has implemented some of the high-dimensional inference methods discussed in this paper.
keywords:
confidence interval, debiasing, false discovery rate, hypothesis testing, linear functionals, quadratic functionals, simultaneous inference1 Introduction
High-dimensional data analysis has become a vital part of scientific research in many fields. While the abundance of high-dimensional data offers numerous opportunities for statistical analysis, it also presents significant technical challenges, as the number of variables can be much larger than the number of observations. In high-dimensional settings, most of the classical inferential procedures, such as the maximum likelihood, are no longer valid. In recent years, there has been significant progress in developing new theories and methods for parameter estimation, hypothesis testing, confidence interval construction, and large-scale simultaneous inference in the context of high-dimensional data analysis.
In this paper, we provide a selective survey of recent advances in statistical inference and multiple testing for high-dimensional regression models, commonly used in modern data analysis across various fields such as genetics, metabolomics, finance, health, and economics. Much progress has been made in estimation and prediction under the high-dimensional linear and generalized linear models (GLMs); see, for example, tibshirani1996regression ; candes2007dantzig ; zou2005regularization ; zou2006adaptive ; bickel2009simultaneous ; buhlmann2011statistics ; negahban2009unified ; van2009conditions ; huang2012estimation ; fan2001variable ; zhang2010nearly ; belloni2011square ; sun2012scaled ; bunea2008honest ; bach2010self ; meier2008group ; bellec2018slope ; friedman2010regularization ; efron2004least ; greenshtein2004persistence . Theoretical properties have been established in different settings, including the minimax estimation rate and the rate of convergence for the estimation and prediction errors of several penalized procedures.
Uncertainty quantification is at the heart of many critical scientific applications and is more challenging than point estimation. For high-dimensional regression models, although the Lasso and other penalized estimators have been shown to achieve the optimal rates of convergence for estimation, these estimators suffer from non-negligible bias that makes them unsuitable to be directly used for statistical inference, as noted in several studies (van2014asymptotically, ; javanmard2014confidence, ; zhang2014confidence, ). To overcome this issue, debiased inference methods have been developed in (van2014asymptotically, ; javanmard2014confidence, ; zhang2014confidence, ) that correct the bias of penalized estimators and allow for statistical inference based on the debiased estimators. The development of debiased inference methods has led to an increase in research on statistical inference for a wide range of low-dimensional objectives in different high-dimensional models; see, for example, guo2021inference ; guo2019optimal ; guo2021group ; cai2020semisupervised ; ma2022statistical ; cai2017confidence ; athey2018approximate ; cai2021statistical ; ning2017general ; ren2015asymptotic ; yu2018confidence ; fang2020test ; zhou2020estimation ; zhao2014general ; javanmard2020flexible ; chen2019inference ; zhu2018linear ; guo2018testing ; cai2018high ; eftekhari2021inference ; deshpande2018accurate ; fang2017testing ; neykov2018unified ; dezeure2015high . In particular, cai2017confidence studied the minimaxity and adaptivity of confidence intervals for general linear functionals of a high-dimensional regression vector and found significant differences between the cases of sparse and dense loading vectors. Another important inference tool, known as Neyman’s orthogonalization or double machine learning, has been proposed in econometrics to enable inference for low-dimensional objectives with high-dimensional nuisance parameters; see, for example, (belloni2014inference, ; chernozhukov2015valid, ; farrell2015robust, ; chernozhukov2018double, ; belloni2017program, ).
In the single regression model (one-sample) setting, we observe data , where and denote the outcome and the high-dimensional covariates respectively, generated independently from the high-dimensional GLM,
| (1) |
with and the high-dimensional regression vector . Throughout the paper, we use to denote the intercept and set . We assume that the high-dimensional covariates are centered and sub-gaussian and the matrix is well-conditioned. We focus on the linear and logistic regression models with the link function and respectively. The regression vector is assumed to be sparse, and its sparsity level is denoted by The high-dimensional covariates might come from a large number of measured covariates or the basis transformations of the baseline covariates. For the linear model, we further assume the error is sub-gaussian with homoscedastic regression error .
In addition to the one-sample setting, we examine the statistical inference methods for the two-sample high-dimensional regression models. For we assume that the data are i.i.d. generated, following
| (2) |
where and is the pre-specified link function.
Based on the models above, this paper first addresses the challenges of making statistical inferences for low-dimensional objectives (e.g., linear and quadratic functionals) in high-dimensional regression, both in one- and two-sample settings. Specifically, the following quantities are of particular interest.
-
1.
Linear functional with in one-sample setting. The linear functional includes as special cases the single regression coefficient (van2014asymptotically, ; javanmard2014confidence, ; zhang2014confidence, ; cai2017confidence, ) when is the canonical unit vector and the conditional mean of the outcome under (1) when is a future observation’s covariates. When denotes the average of the covariates observations for a group, is closely related to average treatment effect athey2018approximate . In logistic regression, the linear functional is closely related to the case probability guo2021inference .
-
2.
Quadratic functionals and with and in one-sample setting. For a subset , these quadratic functionals measure the total effect of variables in Statistical inference for quadratic functionals can be motivated from the group significance test, and the (local) genetic heritability estimation guo2019optimal ; guo2021group . The inference method can be generalized to handle heterogeneous effect tests, hierarchical testing, prediction loss evaluation, and confidence ball construction guo2021group ; cai2020semisupervised .
-
3.
Difference between linear functionals with in two-sample setting. This difference measures the discrepancy between the conditional means, which is closely related to individual treatment selection for the new observation cai2021optimal .
-
4.
Inner products of regression vectors and with the weighting matrix in two-sample setting. The inner product of regression vectors or its weighted version measures the similarity between the two regression vectors. In genetic studies, such inner products can be used as the genetic relatedness measure when the covariates are genetic variants, and outcome variables are different phenotypes guo2019optimal ; ma2022statistical .
We examine statistical inference procedures for linear and quadratic functionals from both methodological and theoretical perspectives. We also discuss the optimality results for the corresponding estimation and inference problems. A user-friendly R package SIHR rakshit2021sihr has been developed to implement the statistical inference methods for the low-dimensional objectives mentioned above. This package provides a convenient way to apply the discussed statistical inference methods.
Beyond the aforementioned inference for a single coordinate of the regression vector or other one-dimensional functionals, we also discuss the simultaneous inference of high-dimensional regression models. This includes using global methods with maximum-type statistics to test the entire regression coefficient vector (dezeure2017high, ; zhang2017simultaneous, ; ma2021global, ), as well as component-wise simultaneous inference methods that control the false discovery rate (FDR). Specifically, we examine the one-sample testing of high-dimensional linear regression coefficients liuluo2014 , the comparison of two high-dimensional linear regression models xia2018two , and the joint testing of regression coefficients across multiple responses xia2018joint . We also extend our discussion to logistic regression models. We discuss these large-scale multiple testing problems focusing on controlling the asymptotic FDR.
While error rate control is important for simultaneous inference, statistical power is also crucial. However, many existing testing methods for high-dimensional linear models do not consider auxiliary information, such as model sparsity and heteroscedasticity, that could improve statistical power. While there has been a significant amount of research on methods to enhance power in multiple testing in general (BenHoc97, ; storey2002direct, ; genovese2006false, ; Roeder2009, ; Ignatiadis2016, ; LeiFithian2018, ; Li2019, ; LAWS, ; fithian2022conditional, , among many others), recent efforts have also focused on simultaneous inference methods that incorporate auxiliary information to assist power improvement of high-dimensional regression analysis. For example, xia2018joint achieved power gains by leveraging similarities across multivariate responses; xia2020gap explored the sparsity information hidden in the data structures and improved the power through -value weighting mechanisms; liu2021integrative obtained power enhancement through integrating heterogeneous linear models. In the current paper, we primarily focus on power enhancement in a two-sample inference setting where the high-dimensional objects of interest are individually sparse. We will discuss methods for controlling FDR with and without power enhancement and the related theoretical aspects.
The rest of the paper is organized as follows. We finish this section by introducing the notation. Section 2 discusses the debiased inference idea for the regression coefficients, and Section 3 presents the debiased methods for linear and quadratic functionals in one- and two-sample settings. Section 4 focuses on simultaneous inference for high-dimensional regression models. We conclude the paper by discussing other related works in Section 5.
Notation. For an event , denote by its indicator function. For an index set and a vector , is the sub-vector of with indices in and is the sub-vector with indices in . For a set , denotes the cardinality of . For a vector , the norm of is defined as for with and . Denote by the canonical unit vector and the identity matrix. For a symmetric matrix , denote by and its maximum and minimum eigenvalues, respectively. For a matrix , and respectively denote the column and row of , denotes the entry of , denotes the row of with its entry removed, denotes the column of with its entry removed, denotes the row of with its and entries both removed and denotes the submatrix of with its row and column removed. We use and to denote generic positive constants that may vary from place to place. For two positive sequences and , means there exists a constant such that for all ; if and , and if . Let and respectively represent the sequences that grow in a smaller and equal/smaller rate of the sequence with probability approaching as .
2 Inference for Regression Coefficients
In this section, we begin with a discussion in Section 2.1 on several commonly used penalized estimators for the high-dimensional GLMs. We review in Section 2.2 the debiased methods for linear models introduced in zhang2014confidence ; van2014asymptotically ; javanmard2014confidence and discuss its extensions to high-dimensional logistic regression in Section 2.3. We also present the optimality of the confidence interval construction in both linear and logistic high-dimensional regression models.
2.1 Estimation in high-dimensional regression
For the high-dimensional linear model (1), a commonly used estimator of the regression vector is the Lasso estimator tibshirani1996regression , defined as
| (3) |
with the tuning parameter for some positive constant . In the penalized regression (3), we do not penalize the intercept . The tuning parameter is typically chosen by cross-validation, as implemented in the R package glmnet friedman2010regularization . With the Lasso estimator the variance can be estimated by
The tuning parameter in (3) depends on the noise level Alternative estimators have been proposed such that the tuning parameter does not depend on the unknown noise (sun2012scaled, ; belloni2011square, , e.g.). Particularly, sun2012scaled proposed the scaled Lasso estimator
| (4) |
with the tuning parameter for some positive constant Beyond the estimators mentioned above, a wide collection of estimators of high-dimensional regression vectors have been proposed (e.g., zou2005regularization, ; zou2006adaptive, ; buhlmann2011statistics, ; negahban2009unified, ; huang2012estimation, ; fan2001variable, ; zhang2010nearly, ; belloni2011square, ).
For the high-dimensional logistic model (1), the penalized methods have also been well developed to estimate (e.g., bunea2008honest, ; bach2010self, ; buhlmann2011statistics, ; meier2008group, ; negahban2009unified, ; huang2012estimation, ). In this paper, we use the penalized log-likelihood estimator in buhlmann2011statistics , defined as
| (5) |
with a positive tuning parameter .
2.2 Debiased or desparsified estimators in linear models
The penalized estimators introduced in Section 2.1 have been shown to achieve the optimal convergence rate and satisfy desirable variable selection properties meinshausen2006high ; bickel2009simultaneous ; zhao2006model ; wainwright2009sharp . However, (van2014asymptotically, ; javanmard2014confidence, ; zhang2014confidence, ) highlighted that the Lasso and other penalized estimators are not ready for statistical inference due to the non-negligible estimation bias. They further proposed correcting the penalized estimators’ bias and then making inferences based on the bias-corrected estimators.
In the following, we present the main idea of the bias correction method. To illustrate the main idea, we fix the parameter index and focus on the confidence interval construction for in the model (1). With denoting the Lasso estimator in (3), the main idea of the method proposed in zhang2014confidence ; javanmard2014confidence is to estimate the error of the plug-in estimator . The approximation of the error can be motivated by the following decomposition: for any vector ,
| (6) |
with . We explain how to construct the vector by balancing the two terms on the right-hand side of the decomposition in (6). The first term on the right-hand side of (6) has the conditional variance while the second term can be further upper-bounded by
| (7) |
An algorithmic method of constructing is to constrain the bias and minimize the variance. Particularly, zhang2014confidence ; javanmard2014confidence proposed the following construction of the projection direction,
| (8) |
with denoting a positive tuning parameter. The construction in (8) is designed to minimize the conditional variance of the “asymp normal” term and constrain , which further controls the “remaining bias” term as in (7).
With the projection direction in (8), zhang2014confidence ; javanmard2014confidence introduced the debiased estimator,
| (9) |
Following from (6), we obtain the following error decomposition of ,
| (10) |
The first term on the right-hand side of (10) is asymptotically normal with the asymptotic variance . Implied by (7), we show that the projection direction in (8) constrains the second term on the right-hand side of (10) by an upper bound with the tuning parameter specified in (8). This upper bound can be established to be of rate and the rate of convergence of the estimating error is which is shown to be the minimax optimal rate of estimating the regression coefficient ren2015asymptotic ; cai2021statistical . More importantly, zhang2014confidence ; javanmard2014confidence have shown that the debiased estimator in (9) is approximately unbiased and asymptotically normal when . Based on the asymptotic normality, zhang2014confidence ; javanmard2014confidence constructed the following confidence interval
| (11) |
where is the upper quantile for the standard normal distribution.
Remark 1.
In the low-dimensional setting, we may set as in (8) and obtain This choice of reduces the debiased estimator in (9) to the OLS estimator. The debiased estimator is also referred to as the “desparsified” estimator zhang2014confidence ; van2014asymptotically since is generally not zero even if the true is zero. Hence, even if is a sparse vector, the vector is dense. Consequently, the vector does not estimate well in general even though is an optimal estimator of for every
2.2.1 Optimality of statistical inference
In high-dimensional linear model, the paper cai2021statistical established the minimax expected length of the confidence interval over the parameter space
| (12) |
where and are positive constants. The space contains all regression vectors of less than non-zero elements. As established in cai2021statistical , the minimax expected length of confidence intervals over for the regime is When , the optimal length can be achieved by the confidence interval in (11). Over the regime , cai2021statistical proposed a confidence interval attaining the optimal rate , where the construction requires the prior knowledge of the sparsity level We illustrate the minimax expected length in Figure 1.
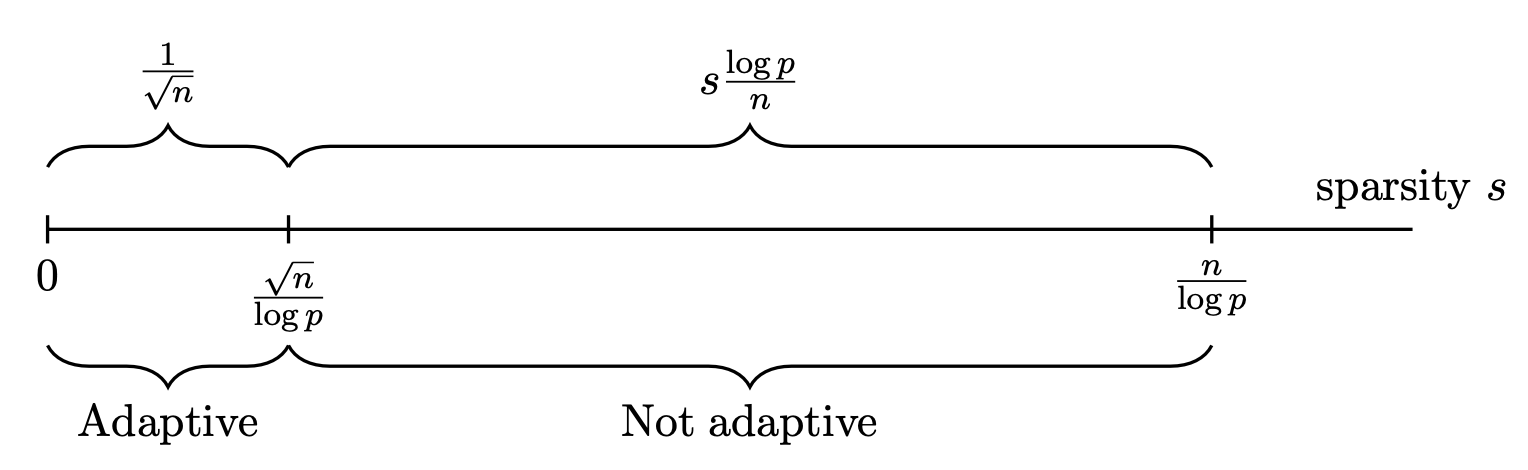
More importantly, cai2017confidence studied the possibility of constructing a rate-optimal adaptive confidence interval. Here, an adaptive confidence interval means that, even without knowing about the sparsity level , the length of the constructed confidence interval is automatically adapting to . Since the sparsity information of the regression vector is generally unknown, it is desirable to construct an adaptive confidence interval. The work cai2017confidence established the following adaptivity results: if the design covariance matrix is unknown, it is possible to construct an adaptive confidence interval only for the ultra-sparse regime . That is, if , it is impossible to construct a rate-optimal confidence interval that is adaptive to the sparsity level. This phase transition about the possibility of constructing adaptive confidence intervals is presented in Figure 1.
The information of is critical for constructing optimal confidence intervals. If is known, the minimax expected length is over the entire sparse regime ; see javanmard2018debiasing ; cai2017confidence for details. This contrasts sharply with the optimality results in Figure 1.
2.2.2 Another viewpoint: debiasing with decorrelation
In this subsection, we detour to introduce a slightly different view of debiased Lasso estimator proposed in zhang2014confidence ; van2014asymptotically , which is of the following form
| (13) |
where is a decorrelation vector to be specified. zhang2014confidence ; van2014asymptotically proposed to construct the vector as the residual , with the Lasso estimator where is a positive tuning parameter. The KKT condition ensures that the residual is nearly orthogonal to all columns of , via
To see the effectiveness of the estimator in (13), we examine its estimation error
| (14) |
In the above expression, the first term on the right-hand side can be shown to be asymptotically normal under regularity conditions, while the second term is constrained as
where the last inequality holds with a high probability for some positive constant With the above argument, zhang2014confidence ; van2014asymptotically have shown that the first term in the decomposition (14) is the dominating term for the ultra-sparse regime . This leads to the asymptotic normality of the estimator . zhang2014confidence ; van2014asymptotically further constructed the confidence interval based on asymptotic normality. In the current paper, we focus on methods generalizing the debiased estimator in (9), instead of the decorrelation form in (13). However, the decorrelation idea has been extended to handle other statistical inference problems, including high-dimensional generalized linear model ning2017general ; van2014asymptotically , gaussian graphical model ning2017general , high-dimensional confounding model guo2020doubly ; sun2022decorrelating , and high-dimensional additive model guo2019local .
2.3 Debiasing in binary outcome models
We generalize the debiased estimator in (9) to high-dimensional GLM with a binary outcome. Similarly to the Lasso estimator, the penalized logistic regression estimator in (5) suffers from the bias due to the penalty. The bias-corrected estimator is proposed as the following generic form,
| (15) |
where , for , are the weights to be specified and is the projection direction to be specified. We apply the Taylor expansion of the function and obtain
| (16) |
with the approximation error . We plug in the Taylor expansion (16) into the weighted bias-correction estimator in (15), leading to the error decomposition of as
| (17) | ||||
In the following, we describe two ways of specifying the weights .
-
1.
Linearization weighting. guo2021inference proposed to construct the weight . Then the “remaining bias” term in (17) is reduced to which is the same as the corresponding term in the linear regression. This enables us to directly adopt the projection direction constructed in (8). This connection reveals the advantage of the weight , that is, the bias-correction developed under the linear regression model can be directly extended to the logistic regression.
-
2.
Link-specific weighting. For a general link function , cai2021statistical constructed the weight . If is the logistic link, we have and obtain the constant weight . Such a link-specific weighting can be generalized to other binary outcome models (e.g., the probit model) with various link functions ; see details in cai2021statistical .
After specifying the weights, the projection direction can be constructed as
| (18) | ||||
| subject to |
with the positive tuning parameters and . The construction in (18) can be motivated from a similar view as (8). The constraint is imposed to constrain the “remaining bias” term in (17) and is imposed to constrain the “nonlinearity bias” in (17). For the linearization weighting, the conditional variance of is , which is of the same order as the objective function in (18) for a bounded So, instead of minimizing the exact variance, we minimize a scaled conditional variance in (18), which has the advantage of leading to almost the same optimization as in (8) for the linear model.
Theoretical properties of the debiased estimators (15) have been established for the logistic outcome model. With the weights for the linearization weighting, guo2021inference established the asymptotic normality of in (15). cai2021statistical established a similar theoretical property for in (15) with the weights for the link-specific weighting. The asymptotic normality results in both works require the ultra-sparse condition . The use of the weights in cai2021statistical leads to a smaller standard error than using the weights proposed in guo2021inference . The theoretical justification in cai2021statistical requires a sample splitting such that the initial estimator is constructed from an independent sample. Such sample splitting is not required in the analysis of guo2021inference , which is part of the benefit of linearization weighting.
Based on the asymptotic normality, we construct the confidence interval
| (19) |
where
The optimality of confidence interval construction in high-dimensional logistic regression was studied in cai2021statistical . The minimax expected length and the possible regime of constructing adaptive confidence intervals are similar to those in Figure 1, up to a polynomial order of ; see the results in cai2021statistical .
3 Linear and Quadratic Functionals Inference
We consider in this section statistical inference for linear and quadratic transformations of the regression vectors under high-dimensional linear and logistic regressions. We investigate both one- and two-sample regression models. In Section 3.7, we discuss the R package SIHR rakshit2021sihr that implements these methods.
3.1 Linear functionals for linear regression
For a given vector , we present the construction of the point estimator and confidence interval for under the high-dimensional linear model (1). Similar to inference for , the plug-in estimator suffers from the estimation bias by directly plugging in the Lasso estimator in (3). The work cai2021optimal proposed the following bias-corrected estimator,
| (20) |
with the projection direction defined as
| (21) | ||||
| (22) |
where and is a positive tuning parameter.
The debiased estimator in (20) satisfies the following error decomposition,
| (23) |
The construction in (21), without the additional constraint (22), can be viewed as a direct generalization of (8) by replacing with the general loading . Specifically, (21) minimizes the conditional variance of the “asymp normal” term in (23) and provides a control of the “remaining bias” term by the inequality Such a construction of the projection direction for linear functional has been proposed in cai2017confidence ; athey2018approximate . However, such a direct generalization is not universally effective for all loadings. As established in Proposition 2 in cai2021optimal , the projection direction, constructed without the additional constraint (22), does not correct the bias for a wide class of dense loading vectors.
We shall emphasize that the new constraint in (22) is crucial to ensuring the asymptotic normality of for any loading vector This constraint is imposed such that the variance of the “asymp normal” term in (23) always dominates the “remaining bias” term in (23). With this additional constraint, the projection direction constructed in (21) and (22) enables the effective bias correction for any loading vector , no matter it is sparse or dense. The work cai2021optimal established the asymptotic normality of the estimator in (20) for any loading vector Based on the asymptotic normality, we construct a confidence interval for as
| (24) |
3.2 Linear functionals for logistic regression
We now consider the high-dimensional logistic model and present the inference procedures for or proposed in guo2021inference . In particular, guo2021inference proposed the following debiased estimator,
| (25) |
where is defined in (5), for , and the projection direction is defined as
| (26) | ||||
| subject to | ||||
The bias-corrected estimator in (25) can be viewed as a generalization of those in (21) and (22) by incorporating the weighted bias-correction in (15).
It has been established in guo2021inference that in (25) is asymptotically unbiased and normal. Based on the asymptotic normality, we construct the following confidence interval
| (27) |
where . We estimate the case probability by and construct the confidence interval for as
| (28) |
3.3 Conditional average treatment effects
The inference methods proposed in Sections 3.1 and 3.2 can be generalized to make inferences for conditional average treatment effects, which can be expressed as the difference between two linear functionals. For let denote the treatment assignment for the observation, where and represent the subject receiving the control or the treatment assignment, respectively. Moreover, in the context of comparing the treatment effectiveness, , and may stand for the subject receiving the first or the second treatment assignment, respectively. As a special case of (2), we consider the following conditional outcome models and For an individual with , we define which measures the change of the conditional mean from being untreated to treated for individuals with the covariates .
By generalizing (20), we construct the debiased estimators and together with their corresponding variance estimators and . The paper cai2021optimal proposed to estimate by and construct the confidence interval for as
| (29) |
Regarding the hypothesis testing problem versus the paper cai2021optimal proposed the following test procedure,
| (30) |
As a direct generalization, we may consider the logistic version, and For an individual with , our inference target becomes The methods in Section 3.2 can be applied here to make inferences for
3.4 Quadratic functionals
We now focus on inference for the quadratic functionals and , where and denotes a pre-specified matrix. Without loss of generality, we set In the following, we mainly discuss the main idea under the high-dimensional linear regression, which can be generalized to the high-dimensional logistic regression. Let denote the Lasso estimator in (3).
We start with the error decomposition of the plug-in estimator ,
| (31) |
In consideration of high-dimensional linear models, guo2021group ; guo2019optimal proposed to construct the bias-corrected estimator through estimating the error component on the right-hand side of (31). Since can be expressed as with , the techniques of estimating the error component for the linear functional can be directly applied to approximate . Particularly, guo2021group ; guo2019optimal proposed the following estimator of ,
| (32) |
where denotes the solution of (21) and (22) with No bias correction is required for the last term on the right-hand side of (31) since it is a higher-order error term under regular conditions.
We now turn to the estimation of where the matrix has to be estimated from the data. With we decompose the estimation error of the plug-in estimator as
| (33) | ||||
By a similar approach as (32), guo2021group proposed the following estimator of ,
| (34) |
where denotes the solution of (21) and (22) with As a special case, cai2020semisupervised considered and constructed
The works guo2021group ; guo2019optimal established the asymptotic properties for a sample-splitting version of and , where the initial estimator is constructed from a subsample independent from the samples used in (32) and (34). Based on the asymptotic properties, guo2021group estimated the variance of by for some positive constant , where the term is introduced as an upper bound for the term in (31). guo2021group estimated the variance of by
and further constructed the following confidence intervals for and ,
| (35) | ||||
For a positive definite matrix , the significance test can be recast as or The following -level significance tests of and have been respectively proposed in guo2021group ,
| (36) |
The inference for and can be generalized to the high-dimensional logistic regression together with the weighted bias correction detailed in (26). The paper ma2022statistical studied how to construct the debiased estimators of under the high-dimensional logistic regression.
3.5 Semi-supervised inference
We summarize the optimal estimation of and in a general semi-supervised setting, with the labelled data and the unlabelled data , where the covariates are assumed to be identically distributed.
The work cai2020semisupervised proposed the following semi-supervised estimator of ,
| (37) |
The matrix estimator in (37) utilizes both the labeled and unlabelled data. The work cai2020semisupervised constructed the following confidence interval for in the semi-supervised setting,
where with and being a user-specific tuning parameter adjusting for the higher order estimation error. The above confidence interval construction demonstrates the usefulness of integrating the unlabelled data, significantly reducing the ratio and the interval length.
Define as a subspace of in (12) with the constraint on In the semi-supervised setting, it was established in cai2020semisupervised that the minimax rate for estimating over is
| (38) |
The estimator in (37) is shown to achieve the optimal rate in (38) for . When , then estimating by zero achieves the optimal rate in (38). The optimal convergence rate in (37) characterizes its dependence on the amount of unlabelled data. With a larger size of the unlabelled data, the convergence rate decreases. In the semi-supervised setting, the unlabelled data can also be used to construct a more accurate estimator of ; see Section 4 of cai2020semisupervised for details.
In the following, we consider the two extremes under semi-supervised learning: the supervised learning setting with and the other extreme setting of knowing , which can be viewed as a special case of the semi-supervised setting with In Table 1, we summarize the optimal convergence rate of estimating and over both and , where With leveraging the information of , Table 1 shows that the optimal rates of estimating and are reduced by and respectively. The improvement can be substantial when the parameter , characterizing the norm , is relatively large. The optimal rate of estimating was established in collier2017minimax under the sequence model When we know and focus on the regime for , the optimal rate of estimating in the high-dimensional linear model matches that in collier2017minimax . However, when is unknown, estimating is much harder in the high-dimensional linear model than in the sequence model.
| Target | Optimal Rate over | Optimal Rate over |
|---|---|---|
3.6 Inner products of regression vectors
We next consider the two-sample regression models in (2). When the high-dimensional covariates are genetic variants and the outcome variables measure different phenotypes, then the inner product can be interpreted as the genetic relatedness guo2019optimal , measuring the similarity between the two association vectors and . We present the debiased estimator of proposed in guo2019optimal . For let be the Lasso estimator of . Similar to the decomposition in (31), we decompose the error of the plug-in estimator
| (39) | ||||
The key is to estimate and separately in the above decomposition, which can be viewed as a projection of and respectively.
The work guo2019optimal proposed the following bias-corrected estimator of
| (40) | ||||
where the projection direction vectors are constructed as
with and for
For the estimator (40), the bias-correction terms and are constructed to estimate and respectively. The construction of the projection directions and can be viewed as extensions of that in (21) with and respectively. An additional constraint as in (22) is not needed here since both and are sufficiently sparse. The paper guo2019optimal has established the convergence rate of the debiased estimator proposed in (40). The analysis can be extended to establish the asymptotic normal distribution of under suitable conditions.
The quantity is another genetic relatedness measure if with for We can propose the debiased estimator , defined as The above results have been extended to the logistic regression models, where the quantity still captures an interpretation of genetic relatedness. The paper ma2022statistical has carefully investigated the confidence interval construction for in consideration of several high-dimensional logistic regression models. Moreover, we might need to estimate and make inferences for with denoting a general matrix. The idea in (40) can be generalized to make inference for The work guo2020inference applied such a generalized debiased estimator of in an intermediate step to determine the optimal aggregation weight of multiple regression models.
3.7 R package SIHR
The methods reviewed in Sections 2 and 3 have been implemented in the R package SIHR rakshit2021sihr , which is available from CRAN. The SIHR package contains the main functions: LF, QF, and CATE. The LF function implements the confidence interval for in (24) under the high-dimensional linear regression with specifying model="linear" and the confidence intervals for in (28) under the high-dimensional logistic regression with specifying model="logistic" or model="logisticalter", corresponding to the linearization weighting and link-specific weighting introduced in Section 2.3, respectively.
The QF function implements the confidence interval construction in (35) and hypothesis testing in (36) with different choices of the weighting matrix . The CATE function implements the confidence interval in (29) and hypothesis testing in (30). Both QF and CATE functions can be applied to the logistic regression setting by specifying model="logistic" or model="logisticalter". The detailed usage of the SIHR package can be found in the paper rakshit2021sihr .
4 Multiple Testing
In the previous sections, we have examined statistical inference for individual regression coefficients and related one-dimensional functionals. However, in many applications, such as genomics, it is necessary to perform simultaneous inference for multiple regression coefficients while controlling for the false discovery rate (FDR) and false discovery proportion (FDP). In this section, we will explore several large-scale multiple testing procedures for high-dimensional regression models. We start with the linear models in Section 4.1 and extend the discussion to logistic models in Section 4.2. The testing procedures are unified in Section 4.3 and the power enhancement methods are discussed next.
4.1 Simultaneous inference for linear regression
One-sample simultaneous inference for high-dimensional linear regression coefficients is closely related to the problem of variable selection. Common approaches for variable selection include regularization methods, such as Lasso tibshirani1996regression , SCAD fan2001variable , Adaptive Lasso zou2006adaptive and MCP zhang2010nearly , which simultaneously estimate parameters and select features, and stepwise feature selection techniques like LARS efron2004least and FoBa zhang2011adaptive , which prioritize variable selection. See the discussions in liuluo2014 and references therein. However, both of these approaches aim to find the model that is closest to the truth, which may not be achievable in practice. Alternatively, liuluo2014 approached the problem from a multiple testing perspective and focused on controlling false discoveries rather than achieving perfect selection results. Specifically, for the high-dimensional regression model (1) with link function , i.e., where , , , and , with being independent and identically distributed (i.i.d) random variables with mean zero and variance and independent of , , liuluo2014 considered the following multiple testing problem,
| (41) |
with the control of FDR and FDP.
In some fields, one-sample inference may not be sufficient, particularly for detecting interactions. For example, as demonstrated in hunter2005gene , many complex diseases are the result of interactions between genes and the environment. Therefore, it is important to thoroughly examine the effects of the environment and its interactions with genetic predispositions on disease phenotypes. When the environmental factor is a binary variable, such as smoking status or gender, interaction detection can be approached under a two-sample high-dimensional regression framework. Specifically, interactions can be identified by comparing two high-dimensional regression models as introduced in (2) with identity link function, i.e., for , and recovering the nonzero components of , where , , , and , with being i.i.d random variables with mean zero and variance and independent of , . Assume that and let . Then xia2018two investigated simultaneous testing of the hypotheses
| (42) |
with FDR and FDP control.
In genetic association studies, it is common to measure multiple correlated phenotypes on the same individuals. To detect associations between high-dimensional genetic variants and these phenotypes, one can individually assess the relationship between each response and each covariate, as in (41), and then adjust for multiplicity in the comparisons. However, as noted by Zhou2015 and Schifano2013 , jointly analyzing these phenotypic measurements may increase the power to detect causal genetic variants. Therefore, motivated by the potential to enhance power by leveraging the similarity across multivariate responses, xia2018joint used high-dimensional multivariate regression models to address applications in which correlated responses are measured on independent individuals:
| (43) |
where , with , denotes responses with fixed, and is the covariate matrix. In (43), , with , represents the regression coefficient matrix, where represents the regression coefficients of the covariate; , where , and are i.i.d random variables with mean zero and variance and independent of . To examine whether the covariate is associated with any of the responses, xia2018joint simultaneously tested
| (44) |
while controlling FDR and FDP. Because the effect of the variable on each of the responses may share strong similarities, namely, if , then the rest of the entries in this row are more likely to be nonzero, a row-wise testing method using the group-wise information is more favorable than testing the significance of the matrix column by column as in testing problem (41).
4.1.1 Bias corrections via inverse regression
In the multiple testing problems discussed in Section 4.1, our goal is to simultaneously infer the regression coefficients while controlling for error rates. Therefore, it is crucial to begin with an asymptotically unbiased estimator for each regression component. The debiasing techniques outlined in Section 2.2 can be used to attain nearly unbiased estimates, however, as noted in liuluo2014 , the constraints or tuning parameters utilized in debiasing can significantly affect test accuracy. Additionally, the asymptotic distribution of these debiased estimators is conditional, making it challenging to characterize the dependence structure among the test statistics, which is vital for error rate control in simultaneous inference. As an alternative, we will explore an inverse regression approach in this section, which establishes the unconditional asymptotic distribution of bias corrected statistics and allows for explicit characterization of the correlation structure. Alternatively, the debiasing method (13) in zhang2014confidence ; van2014asymptotically can be used as long as the decorrelation vectors ’s introduced in Section 2.2.2 are close enough to their population counterparts. This approach will be illustrated in Section 4.2.
Recall that . To achieve bias correction, by taking testing problem (42) as an example, we consider the inverse regression models obtained by regressing on , where , for :
where for , has mean zero and variance and is uncorrelated with , and the first component of satisfies
| (45) |
where with .
Note that, can be expressed as , hence we can approach the debiasing of through the debiasing of , and equivalently formulate the testing problem (42) as
The most straightforward way to estimate is to use the sample covariance between the error terms, . However, the error terms are unknown, so we first estimate them by
where and are respectively the estimators of and that satisfy
| (46) | |||||
| (47) |
for some and such that
| (48) |
As noted by (liuluo2014, ; xia2018two, ), estimators and that satisfy (46) and (48) can be obtained easily via standard methods such as the Lasso and Danzig selector. Following that, a natural estimator of can be constructed by However, the bias of exceeds the desired rate for the subsequent analysis. Hence, the difference of and is calculated, and it is equal to up to order under regularity conditions, where and are the sample variances. Hence, a bias-corrected estimator for is defined as
| (49) |
For the other two testing problems, the bias corrections can be performed almost exactly the same via the inverse regression technique above that translates the debiasing of regression coefficients to the debiasing of residual covariances. Note that, through such an inverse regression approach, one can appropriately deal with the dependency of the component-wise debiased statistics, which is important for the following adjustment of multiplicity and the goal of FDR control.
4.1.2 Construction of test statistics
We next construct test statistics for each of the three problems discussed in Section 4.1, using the bias-corrected statistics as a starting point.
For problem (41), because testing whether is equivalent as testing whether the residual covariance is equal to zero, the test statistics can be constructed directly based on the bias corrected (it can be obtained exactly the same as as shown in Section 4.1.1 where the superscript is dropped since there is only one sample). Then the test statistics that standardize ’s are obtained by
| (50) |
where and are again the sample variances by respectively dropping the superscript and subscript in the one-sample case. As shown in liuluo2014 , the statistics ’s are asymptotically normal under the null.
The above construction cannot be directly applied to the problem (42), because is not necessary equal to 0 under the two-sample null and is not equivalent to . Thus, it is necessary to construct testing procedures based directly on estimators of . By the bias correction in Section 4.1.1, xia2018two proposed an estimator of :
and tested (42) via the estimators . Due to the heteroscedasticity, xia2018two considered a standardized version of . Specifically, let
It was shown in xia2018two that is close to asymptotically under regularity conditions. Because it can be estimated by and the standardized statistics are defined by
| (51) |
which are asymptotically normal under the null as studied in xia2018two .
For the multivariate testing problem (44), by taking advantage of the similar effect of the variable on each of the responses, a group lasso penalty (yuan2006model, ) can be imposed to obtain an estimator of , such that
for some and satisfying (48). By lounici2011oracle , the above rates can be fulfilled if the row sparsity of satisfies . Then following the same bias correction strategy as described in Section 4.1.1, a debiased estimator for can be obtained via Then similarly as the aforementioned two problems, the standardized statistic can be constructed by
where and Finally, a sum-of-squares-type test statistic for testing the row of is proposed:
| (52) |
which is asymptotically distributed under the null as studied in xia2018joint .
4.2 Simultaneous inference for logistic regression
The principles of simultaneous inference for high-dimensional linear regression can also be applied to high-dimensional logistic regression models. In particular, ma2021global considered the regression model (1), i.e., , , with the link function , and studied the simultaneous testing problem (41) as described in Section 4.1, namely testing
with FDR control.
Based on the regularized estimator given in (5), ma2021global corrected the bias of via the Taylor expansion of at for and , and obtained that
| (53) |
where is the remainder term as specified in (16). Next, can be treated as the new response, as the new covariates, and as the new noise. Under such a formulation, testing can be translated into the simultaneous inference for the regression coefficients of an approximate linear model. ma2021global applied the decorrelation method (13) and constructed the following debiased estimator ,
| (54) |
where is determined by the scaled residual that regresses on through the linearization weighting introduced in Section 2.3; same strategy was also employed in (ren2016asymptotic, ; cai2019differential, ). As summarized in Section 4.1.1, for the subsequent FDR control analysis, the decorrelation vectors ’s were shown to be close to the true regression errors. Alternatively, the inverse regression technique in Section 4.1.1 can be similarly applied in the approximate linear model (53) for the bias correction.
Based on (54), ma2021global proposed the following standardized test statistic:
| (55) |
which is asymptotically normal under the null. Additionally, ma2021global extended the idea to the two-sample multiple testing (42). Similarly, multiple testing of (44) can also be approached in the logistic setting.
4.3 Multiple testing procedure
Using the test statistics in (50), (51), (52) and (55) as a foundation, we next examine a unified multiple testing procedure that guarantees error rates control.
Let , be the set of true null indices and be the set of true alternatives. We are interested in cases where most of the tests are nulls, that is, is relatively small compared to . Let be the asymptotic cumulative distribution function (cdf) of under the null and let be the standard normal cdf, then we develop a normal quantile transformation of by , which approximately has the same distribution as the absolute value of a standard normal random variable under the null . Let be the threshold level such that is rejected if . For any given , denote by and the total number of false positives and the total number of rejections, respectively. Then the FDP and FDR are defined as
An ideal choice of rejects as many true positives as possible while controlling the FDP at the pre-specified level , i.e.,
Since can be estimated by and is upper bounded by , we conservatively estimate it by . Therefore, the following multiple testing algorithm is proposed in (e.g., liuluo2014, ; xia2018two, ; xia2018joint, ; ma2021global, ).
- Step 1.
-
Obtain the transformed statistics from the test statistics , .
- Step 2.
- Step 3.
-
For , reject if .
As noted in xia2018multiple , the constraint in (56) is critical. When exceeds the upper bound, is not even a consistent estimate of . However, Benjamini-Hochberg (B-H) procedure (BenHoc95, ) used as an estimate of for all and hence may not be able to control the FDP. On the other hand, if is not attained in the range, it is important to threshold at , because thresholding at may cause too many false rejections. As a result, by applying the above multiple testing algorithm to each of the problems in Sections 4.1 and 4.2, under some regularity conditions as specified in (liuluo2014, ; xia2018two, ; xia2018joint, ; ma2021global, ), we reach both the FDP and FDR control at the pre-specified level asymptotically, i.e., for any and .
4.4 Power enhancement
In addition to controlling error rates, we consider strategies to improve the power of multiple testing procedures, focusing on enhancing the power for two-sample inference when the high-dimensional objects of interest are individually sparse. This is explored in xia2020gap with an extension to a more general framework in liang2022locally . It is worth noting that xia2020gap improved the performance of Algorithm 1 by utilizing unknown sparsity in two-sample multiple testing. Additionally, power enhancement for the simultaneous inference of GLMs can be achieved through data integration (e.g., cai2021individual, ; liu2021integrative, ) as well as other power boosting methods designed for general multiple testing problems as introduced in Section 1.
Recall that, in the two-sample problem studied in Section 4.1, we aim to make inference for , . Following Algorithm 1, we first summarize the data by a single vector of test statistics and then choose a significance threshold to control the multiplicity. However, such approach ignores the important feature that both objects and are individually sparse. Let denote the support of , , and the union support. Because the small cardinality of implies that both and are sparse, the information on can be potentially utilized to narrow down the alternatives via the logical relationship that implies that .
The goal of xia2020gap is to incorporate the sparsity information to improve the testing efficiency, and it is accomplished via the construction of an additional covariate sequence to capture the information on . Note that and have different roles: is the primary statistic to evaluate the significance of the test, while is the auxiliary one that captures the sparsity information to assist the inference. It is also important to note that should be asymptotically independent with so that the null distribution of would not be distorted by the incorporation of . For the two-sample problem in Section 4.1, such auxiliary statistics can be constructed by
| (57) |
Then based on the pairs of statistics , the proposal in xia2020gap operates in three steps: grouping, adjusting and pooling (GAP). The first step divides all tests into groups based on , which leads to heterogeneous groups with varied sparsity levels. The second step adjusts the -values to incorporate the sparsity information. The final step combines the adjusted -values and chooses a threshold to control the global FDR. Based on the -values obtained by the test statistics ’s, i.e., , the algorithm is summarized in Algorithm 2 and we refer to xia2020gap for its detailed implementations such as the choices of the number of groups and the grid sets.
- Step 1 (Grouping).
-
Divide hypotheses into groups: , for . The optimal choice of grouping will be determined in Step 2.
- Step 2 (Adjusting).
-
Define . Calculate adjusted -values if , , where and will be calculated as follows.
-
•
Initial adjusting. For a given grouping , let be the estimated proportion of non-nulls in . Compute the group-wise weights
(58) Define for .
-
•
Further refining. For each (allowed to be empty), let
(59) and reject the hypotheses corresponding to , where are the re-ordered -values. The weights are computed using (58) based on the optimal grouping that yields most rejections.
-
•
- Step 3 (Pooling).
-
Combine ’s computed from Step 2 based on the optimal grouping, apply (59) again and output the rejections.
In addition, xia2020gap provided some insights on why the GAP algorithm works. First, it adaptively chooses the group-wise FDR levels via adjusted -values and effectively incorporates group-wise information. Intuitively, Algorithm 2 increases the overall power by assigning higher FDR levels to groups where signals are more common. It does not assume known groups and searches for the optimal grouping to maximize the power. Moreover, the construction of the weights in Algorithm 2 ensures that after all groups are combined, the weights are always “proper” in the sense of genovese2006false . As a result, even inaccurate estimates of the non-null proportions would not affect the validity of overall FDR control.
Then, same as Algorithm 1, xia2020gap provided the asymptotic error rates control results for Algorithm 2, namely, we have for any and . Moreover, due to the informative weights (58) that effectively incorporate the sparsity information through , Algorithm 2 dominates Algorithm 1 in power asymptotically. Specifically, xia2020gap provided the rigorous theoretical comparison that as , where and represent the expectations of the proportions of correct rejections among all alternative hypotheses for Algorithms 1 and 2, respectively.
5 Discussion
In this expository paper, we provided a review of methods and theoretical results on statistical inference and multiple testing for high-dimensional regression models, including linear and logistic regression. Due to limited space, we were unable to discuss a number of related inference problems. In this section, we briefly mention a few of them.
Accuracy assessment. Accuracy assessment is a crucial part of high-dimensional uncertainty quantification. Its goal is to evaluate the estimation accuracy of an estimator . For linear regression, cai2018accuracy considered a collection of estimators and established the minimaxity and adaptivity of the point estimation and confidence interval for with Suppose that is independent of the data (which can be achieved by sample splitting, for example). Define the residue . The quadratic functional inference approach introduced in cai2020semisupervised can be applied to the data to make inference for both and ; see more details in Section 5.2 of cai2020semisupervised . nickl2013confidence used an estimator of to construct a confidence set for with denoting an accurate high-dimensional estimator. In the context of approximate message passing, donoho2011noise ; bayati2011lasso considered a different framework with and independent Gaussian design and established the asymptotic limit of for the Lasso estimator
Semi-supervised Inference. The semi-supervised inference is well motivated by a wide range of modern applications, such as Electronic Health Record data analysis. In addition to the labeled data, additional covariate observations exist in the semi-supervised setting. It is critical to leverage the information in the unlabelled data and improve the inference efficiency. As reviewed in Section 3.5, the additional unlabelled data improves the accuracy of various high-dimensional inference procedures by facilitating the estimation of or javanmard2018debiasing ; cai2020semisupervised . Moreover, in a different context where the linear outcome model might be misspecified, one active research direction in semi-supervised learning is to construct a more complicated imputation model (e.g., by applying the classical non-parametric or machine learning methods) and conduct a following-up bias correction after outcome imputation (e.g., zhang2019semi, ; chakrabortty2018efficient, ; zhang2021double, ; deng2020optimal, ; hou2021surrogate, ).
Applications of quadratic form inference. The statistical inference methods for quadratic functionals in Section 3.6 and inner products in Section 3.4 are useful in a wide range of statistical applications. Firstly, the group significance test of or forms an important basis for designing computationally efficient hierarchical testing approaches mandozzi2016hierarchical ; guo2021group . Secondly, consider the high-dimensional interaction model with denoting the variable of interest (e.g., the treatment) and denoting a large number of other variables. In this model, testing the existence of the interaction term can be reduced to the inference for Lastly, in the two-sample model (2), the methods proposed in Sections 3.6 and 3.4 have been applied in guo2023robust to calculating the difference , which has the expression of
Multiple heterogeneous regression models. It is essential to perform efficient integrative inference in various applications that combine multiple regression models. Examples include transfer learning, distributed learning, federated learning, and distributionally robust learning. Transfer learning provides a powerful tool for incorporating data from related studies to improve estimation and inference accuracy in a target study of direct interest. li2021transfer studied transfer learning for high-dimensional linear regression. Minimax optimal convergence rates were established, and data-driven adaptive algorithms were proposed. Li2021Transfer-GLM ; tian2022transfer explored transfer learning in high-dimensional GLMs and battey2018distributed ; lee2017communication considered distributed learning for high-dimensional regression. Additionally, liu2021integrative ; cai2021individual proposed integrative estimation and multiple testing procedures of cross-sites high-dimensional regression models that simultaneously accommodated between study heterogeneity and protected individual-level data. In a separate direction, meinshausen2015maximin proposed the maximin effect as a robust prediction model for the target distribution being generated as a mixture of multiple source populations. guo2020inference further established that the maximin effect is a group distributionally robust model and studied the statistical inference for the maximin effect in high dimensions. Many questions in multiple heterogeneous regression models are open and warrant future research.
Other simultaneous inference problems. The principles of multiple testing procedures reviewed in Section 4 are also widely applicable to a range of simultaneous inference problems, including graph learning (e.g., liu2013ggm, ; xia2017hypothesis, ; xia2018multiple, ; cai2019differential, ), differential network recovery (e.g., xia2015testing, ; xia2019matrix, ; kim2021two, ), as well as various structured regression analysis (e.g., zhang2020estimation, ; li2021inference, ; sun2022decorrelating, ). For example, through similar regression-based bias-correction techniques as reviewed in Section 4.1.1, liu2013ggm studied the estimation of Gaussian Graphical Models with FDR control; xia2018multiple focused on the recovery of sub-networks in Gaussian graphs; cai2019differential identified significant communities for compositional data. Additionally, xia2015testing ; xia2019matrix proposed multiple testing procedures for differential network detections of vector-valued and matrix-valued observations, respectively. Multiple testing of structured regression models such as mixed-effects models and confounded linear models has also been extensively studied in the literature (li2021inference, ; sun2022decorrelating, ).
Alternative multiple testing methods for regression models. Besides the bias-correction based multiple testing approaches reviewed in this article, there are a few alternative classes of methods that aim at finite sample FDR control for linear models. Examples include knockoff based methods, mirror statistics approaches and -value proposals. In particular, barber2015controlling constructed a set of knockoff variables and selected those predictors that have considerably higher importance scores than the knockoff counterparts; candes2018panning extended the work to a model-X knockoff framework that allowed unknown conditional distribution of the response. There are several generalizations along this line of research; see barber2020robust ; ren2021derandomizing and many references therein. Inspired by the knockoff idea, du2021false proposed a symmetrized data aggregation approach to build mirror statistics that incorporate data dependence structure; a general framework on mirror statistics of GLMs was studied in dai2023scale and the references therein. The -value based proposal (vovk2021values, ) is another useful tool for multiple testing in general. wang2020false proposed an e-BH procedure that achieved FDR control under arbitrary dependence among the -values, and the equivalence between the knockoffs and the e-BH was studied in ren2022derandomized .
References
- \bibcommenthead
- (1) Tibshirani, R.: Regression shrinkage and selection via the Lasso. J. R. Statist. Soc. B 58(1), 267–288 (1996)
- (2) Candes, E., Tao, T.: The dantzig selector: Statistical estimation when is much larger than . Ann. Statist. 35(6), 2313–2351 (2007)
- (3) Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Statist. Soc. B 67(2), 301–320 (2005)
- (4) Zou, H.: The adaptive Lasso and its oracle properties. J. Am. Statist. Assoc. 101(476), 1418–1429 (2006)
- (5) Bickel, P.J., Ritov, Y., Tsybakov, A.B.: Simultaneous analysis of Lasso and dantzig selector. Ann. Statist. 37(4), 1705–1732 (2009)
- (6) Bühlmann, P., van de Geer, S.: Statistics for High-dimensional Data: Methods, Theory and Applications. Springer, New York (2011)
- (7) Negahban, S., Yu, B., Wainwright, M.J., Ravikumar, P.K.: A unified framework for high-dimensional analysis of -estimators with decomposable regularizers. In: Adv. Neural Inf. Process. Syst., pp. 1348–1356 (2009)
- (8) van de Geer, S.A., Bühlmann, P.: On the conditions used to prove oracle results for the Lasso. Electron. J. Stat. 3, 1360–1392 (2009)
- (9) Huang, J., Zhang, C.-H.: Estimation and selection via absolute penalized convex minimization and its multistage adaptive applications. J. Mach. Learn. Res. 13(Jun), 1839–1864 (2012)
- (10) Fan, J., Li, R.: Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Statist. Assoc. 96(456), 1348–1360 (2001)
- (11) Zhang, C.-H.: Nearly unbiased variable selection under minimax concave penalty. Ann. Statist. 38(2), 894–942 (2010)
- (12) Belloni, A., Chernozhukov, V., Wang, L.: Square-root Lasso: pivotal recovery of sparse signals via conic programming. Biometrika 98(4), 791–806 (2011)
- (13) Sun, T., Zhang, C.-H.: Scaled sparse linear regression. Biometrika 101(2), 269–284 (2012)
- (14) Bunea, F.: Honest variable selection in linear and logistic regression models via and + penalization. Electron. J. Stat. 2, 1153–1194 (2008)
- (15) Bach, F.: Self-concordant analysis for logistic regression. Electron. J. Stat. 4, 384–414 (2010)
- (16) Meier, L., van de Geer, S., Bühlmann, P.: The group Lasso for logistic regression. J. R. Statist. Soc. B 70(1), 53–71 (2008)
- (17) Bellec, P.C., Lecué, G., Tsybakov, A.B.: Slope meets Lasso: improved oracle bounds and optimality. Ann. Statist. 46(6B), 3603–3642 (2018)
- (18) Friedman, J., Hastie, T., Tibshirani, R.: Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 33(1), 1 (2010)
- (19) Efron, B., Hastie, T., Johnstone, I., Tibshirani, R.: Least angle regression. Ann. Statist. 32(2), 407–499 (2004)
- (20) Greenshtein, E., Ritov, Y.: Persistence in high-dimensional linear predictor selection and the virtue of overparametrization. Bernoulli 10(6), 971–988 (2004)
- (21) van de Geer, S., Bühlmann, P., Ritov, Y., Dezeure, R.: On asymptotically optimal confidence regions and tests for high-dimensional models. Ann. Statist. 42(3), 1166–1202 (2014)
- (22) Javanmard, A., Montanari, A.: Confidence intervals and hypothesis testing for high-dimensional regression. J. Mach. Learn. Res. 15(1), 2869–2909 (2014)
- (23) Zhang, C.-H., Zhang, S.S.: Confidence intervals for low dimensional parameters in high dimensional linear models. J. R. Statist. Soc. B 76(1), 217–242 (2014)
- (24) Guo, Z., Rakshit, P., Herman, D.S., Chen, J.: Inference for the case probability in high-dimensional logistic regression. J. Mach. Learn. Res. 22(1), 11480–11533 (2021)
- (25) Guo, Z., Wang, W., Cai, T.T., Li, H.: Optimal estimation of genetic relatedness in high-dimensional linear models. J. Am. Statist. Assoc. 114(525), 358–369 (2019)
- (26) Guo, Z., Renaux, C., Bühlmann, P., Cai, T.T.: Group inference in high dimensions with applications to hierarchical testing. Electron. J. Stat. 15(2), 6633–6676 (2021)
- (27) Cai, T.T., Guo, Z.: Semisupervised inference for explained variance in high dimensional linear regression and its applications. J. R. Statist. Soc. B 82(2), 391–419 (2020)
- (28) Ma, R., Guo, Z., Cai, T.T., Li, H.: Statistical inference for genetic relatedness based on high-dimensional logistic regression. arXiv preprint arXiv:2202.10007 (2022)
- (29) Cai, T.T., Guo, Z.: Confidence intervals for high-dimensional linear regression: Minimax rates and adaptivity. Ann. Statist. 45(2), 615–646 (2017)
- (30) Athey, S., Imbens, G.W., Wager, S.: Approximate residual balancing: debiased inference of average treatment effects in high dimensions. J. R. Statist. Soc. B 80(4), 597–623 (2018)
- (31) Cai, T.T., Guo, Z., Ma, R.: Statistical inference for high-dimensional generalized linear models with binary outcomes. J. Am. Statist. Assoc. 116, 1–14 (2021)
- (32) Ning, Y., Liu, H.: A general theory of hypothesis tests and confidence regions for sparse high dimensional models. Ann. Statist. 45(1), 158–195 (2017)
- (33) Ren, Z., Sun, T., Zhang, C.-H., Zhou, H.H.: Asymptotic normality and optimalities in estimation of large gaussian graphical models. Ann. Statist. 43(3), 991–1026 (2015)
- (34) Yu, Y., Bradic, J., Samworth, R.J.: Confidence intervals for high-dimensional cox models. arXiv preprint arXiv:1803.01150 (2018)
- (35) Fang, E.X., Ning, Y., Li, R.: Test of significance for high-dimensional longitudinal data. Ann. Statist. 48(5), 2622 (2020)
- (36) Zhou, R.R., Wang, L., Zhao, S.D.: Estimation and inference for the indirect effect in high-dimensional linear mediation models. Biometrika 107(3), 573–589 (2020)
- (37) Zhao, T., Kolar, M., Liu, H.: A general framework for robust testing and confidence regions in high-dimensional quantile regression. arXiv preprint arXiv:1412.8724 (2014)
- (38) Javanmard, A., Lee, J.D.: A flexible framework for hypothesis testing in high dimensions. J. R. Statist. Soc. B 82(3), 685–718 (2020)
- (39) Chen, Y., Fan, J., Ma, C., Yan, Y.: Inference and uncertainty quantification for noisy matrix completion. Proc. Natl. Acad. Sci. 116(46), 22931–22937 (2019)
- (40) Zhu, Y., Bradic, J.: Linear hypothesis testing in dense high-dimensional linear models. J. Am. Statist. Assoc. 113(524), 1583–1600 (2018)
- (41) Guo, Z., Kang, H., Cai, T.T., Small, D.S.: Testing endogeneity with high dimensional covariates. J. Econom. 207(1), 175–187 (2018)
- (42) Cai, T.T., Zhang, L.: High-dimensional gaussian copula regression: Adaptive estimation and statistical inference. Stat. Sin., 963–993 (2018)
- (43) Eftekhari, H., Banerjee, M., Ritov, Y.: Inference in high-dimensional single-index models under symmetric designs. J. Mach. Learn. Res. 22, 27–1 (2021)
- (44) Deshpande, Y., Mackey, L., Syrgkanis, V., Taddy, M.: Accurate inference for adaptive linear models. In: International Conference on Machine Learning, pp. 1194–1203 (2018). PMLR
- (45) Fang, E.X., Ning, Y., Liu, H.: Testing and confidence intervals for high dimensional proportional hazards models. J. R. Statist. Soc. B 79(5), 1415–1437 (2017)
- (46) Neykov, M., Ning, Y., Liu, J.S., Liu, H.: A unified theory of confidence regions and testing for high-dimensional estimating equations. Stat. Sci. 33(3), 427–443 (2018)
- (47) Dezeure, R., Bühlmann, P., Meier, L., Meinshausen, N.: High-dimensional inference: confidence intervals, -values and R-software hdi. Stat. Sci., 533–558 (2015)
- (48) Belloni, A., Chernozhukov, V., Hansen, C.: Inference on treatment effects after selection among high-dimensional controls. Rev. Econ. Stud. 81(2), 608–650 (2014)
- (49) Chernozhukov, V., Hansen, C., Spindler, M.: Valid post-selection and post-regularization inference: An elementary, general approach. Annu. Rev. Econom. 7(1), 649–688 (2015)
- (50) Farrell, M.H.: Robust inference on average treatment effects with possibly more covariates than observations. J. Econom. 189(1), 1–23 (2015)
- (51) Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., Robins, J.: Double/debiased machine learning for treatment and structural parameters: Double/debiased machine learning. Econom. J. 21(1), 1–68 (2018)
- (52) Belloni, A., Chernozhukov, V., Fernández-Val, I., Hansen, C.: Program evaluation and causal inference with high-dimensional data. Econometrica 85(1), 233–298 (2017)
- (53) Cai, T., Tony Cai, T., Guo, Z.: Optimal statistical inference for individualized treatment effects in high-dimensional models. J. R. Statist. Soc. B 83(4), 669–719 (2021)
- (54) Rakshit, P., Cai, T.T., Guo, Z.: SIHR: An R package for statistical inference in high-dimensional linear and logistic regression models. arXiv preprint arXiv:2109.03365 (2021)
- (55) Dezeure, R., Bühlmann, P., Zhang, C.-H.: High-dimensional simultaneous inference with the bootstrap. Test 26(4), 685–719 (2017)
- (56) Zhang, X., Cheng, G.: Simultaneous inference for high-dimensional linear models. J. Am. Statist. Assoc. 112(518), 757–768 (2017)
- (57) Ma, R., Cai, T.T., Li, H.: Global and simultaneous hypothesis testing for high-dimensional logistic regression models. J. Am. Statist. Assoc. 116(534), 984–998 (2021)
- (58) Liu, W., Luo, S.: Hypothesis testing for high-dimensional regression models. Technical report (2014)
- (59) Xia, Y., Cai, T., Tony Cai, T.: Two-sample tests for high-dimensional linear regression with an application to detecting interactions. Stat. Sin. 28, 63–92 (2018)
- (60) Xia, Y., Cai, T.T., Li, H.: Joint testing and false discovery rate control in high-dimensional multivariate regression. Biometrika 105(2), 249–269 (2018)
- (61) Benjamini, Y., Hochberg, Y.: Multiple hypotheses testing with weights. Scand. J. Stat. 24(3), 407–418 (1997)
- (62) Storey, J.D.: A direct approach to false discovery rates. J. Roy. Statist. Soc. B 64(3), 479–498 (2002)
- (63) Genovese, C.R., Roeder, K., Wasserman, L.: False discovery control with -value weighting. Biometrika 93(3), 509–524 (2006)
- (64) Roeder, K., Wasserman, L.: Genome-wide significance levels and weighted hypothesis testing. Stat. Sci. 24(4), 398 (2009)
- (65) Ignatiadis, N., Klaus, B., Zaugg, J.B., Huber, W.: Data-driven hypothesis weighting increases detection power in genome-scale multiple testing. Nat. Methods 13(7), 577–580 (2016)
- (66) Lei, L., Fithian, W.: Adapt: an interactive procedure for multiple testing with side information. J. R. Statist. Soc. B 80(4), 649–679 (2018)
- (67) Li, A., Barber, R.F.: Multiple testing with the structure-adaptive Benjamini-Hochberg algorithm. J. R. Statist. Soc. B 81(1), 45–74 (2019)
- (68) Cai, T.T., Sun, W., Xia, Y.: LAWS: A locally adaptive weighting and screening approach to spatial multiple testing. J. Am. Statist. Assoc. 117, 1370–1383 (2022)
- (69) Fithian, W., Lei, L.: Conditional calibration for false discovery rate control under dependence. Ann. Statist. 50(6), 3091–3118 (2022)
- (70) Xia, Y., Cai, T.T., Sun, W.: GAP: A General Framework for Information Pooling in Two-Sample Sparse Inference. J. Am. Statist. Assoc. 115(531), 1236–1250 (2020)
- (71) Liu, M., Xia, Y., Cho, K., Cai, T.: Integrative high dimensional multiple testing with heterogeneity under data sharing constraints. J. Mach. Learn. Res. 22, 126–1 (2021)
- (72) Meinshausen, N., Bühlmann, P.: High-dimensional graphs and variable selection with the Lasso. Ann. Statist. 34(3), 1436–1462 (2006)
- (73) Zhao, P., Yu, B.: On model selection consistency of Lasso. J. Mach. Learn. Res. 7, 2541–2563 (2006)
- (74) Wainwright, M.J.: Sharp thresholds for high-dimensional and noisy sparsity recovery using -constrained quadratic programming (Lasso). IEEE Trans. Inf. Theory 55(5), 2183–2202 (2009)
- (75) Javanmard, A., Montanari, A.: Debiasing the Lasso: Optimal sample size for gaussian designs. Ann. Statist. 46(6A), 2593–2622 (2018)
- (76) Guo, Z., Ćevid, D., Bühlmann, P.: Doubly debiased Lasso: High-dimensional inference under hidden confounding. Ann. Statist. 50(3), 1320–1347 (2022)
- (77) Sun, Y., Ma, L., Xia, Y.: A decorrelating and debiasing approach to simultaneous inference for high-dimensional confounded models. arXiv preprint arXiv:2208.08754 (2022)
- (78) Guo, Z., Yuan, W., Zhang, C.-H.: Decorrelated local linear estimator: Inference for non-linear effects in high-dimensional additive models. arXiv preprint arXiv:1907.12732 (2019)
- (79) Collier, O., Comminges, L., Tsybakov, A.B.: Minimax estimation of linear and quadratic functionals on sparsity classes. Ann. Statist. 45(3), 923–958 (2017)
- (80) Guo, Z.: Inference for high-dimensional maximin effects in heterogeneous regression models using a sampling approach. arXiv preprint arXiv:2011.07568 (2020)
- (81) Zhang, T.: Adaptive forward-backward greedy algorithm for learning sparse representations. IEEE Trans. Inf. Theory 57(7), 4689–4708 (2011)
- (82) Hunter, D.J.: Gene–environment interactions in human diseases. Nat. Rev. Genet. 6(4), 287–298 (2005)
- (83) Zhou, J.J., Cho, M.H., Lange, C., Lutz, S., Silverman, E.K., Laird, N.M.: Integrating multiple correlated phenotypes for genetic association analysis by maximizing heritability. Hum. Hered. 79, 93–104 (2015)
- (84) Schifano, L. E.D. Li, Christiani, D.C., Lin, X.: Genome-wide association analysis for multiple continuous secondary phenotypes. Am J Hum Genet., 744–759 (2013)
- (85) Yuan, M., Lin, Y.: Model selection and estimation in regression with grouped variables. J. R. Statist. Soc. B 68(1), 49–67 (2006)
- (86) Lounici, K., Pontil, M., van de Geer, S., Tsybakov, A.B., et al.: Oracle inequalities and optimal inference under group sparsity. Ann. Statist. 39(4), 2164–2204 (2011)
- (87) Ren, Z., Zhang, C.-H., Zhou, H.: Asymptotic normality in estimation of large ising graphical model. Unpublished Manuscript (2016)
- (88) Cai, T.T., Li, H., Ma, J., Xia, Y.: Differential markov random field analysis with an application to detecting differential microbial community networks. Biometrika 106(2), 401–416 (2019)
- (89) Xia, Y., Cai, T., Tony Cai, T.: Multiple testing of submatrices of a precision matrix with applications to identification of between pathway interactions. J. Am. Statist. Assoc. 113(521), 328–339 (2018)
- (90) Benjamini, Y., Hochberg, Y.: Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. Roy. Statist. Soc. B 57, 289–300 (1995)
- (91) Liang, Z., Cai, T.T., Sun, W., Xia, Y.: Locally adaptive transfer learning algorithms for large-scale multiple testing. arXiv preprint arXiv:2203.11461 (2022)
- (92) Cai, T., Liu, M., Xia, Y.: Individual data protected integrative regression analysis of high-dimensional heterogeneous data. J. Am. Statist. Assoc. 116, 1–15 (2021)
- (93) Cai, T.T., Guo, Z.: Accuracy assessment for high-dimensional linear regression. Ann. Statist. 46(4), 1807–1836 (2018)
- (94) Nickl, R., van de Geer, S.: Confidence sets in sparse regression. Ann. Statist. 41(6), 2852–2876 (2013)
- (95) Donoho, D.L., Maleki, A., Montanari, A.: The noise-sensitivity phase transition in compressed sensing. IEEE Trans. Inf. Theory 57(10), 6920–6941 (2011)
- (96) Bayati, M., Montanari, A.: The Lasso risk for gaussian matrices. IEEE Trans. Inf. Theory 58(4), 1997–2017 (2011)
- (97) Zhang, A., Brown, L.D., Cai, T.T.: Semi-supervised inference: General theory and estimation of means. Ann. Statist. 47(5), 2538–2566 (2019)
- (98) Chakrabortty, A., Cai, T.: Efficient and adaptive linear regression in semi-supervised settings. Ann. Statist. 46(4), 1541–1572 (2018)
- (99) Zhang, Y., Chakrabortty, A., Bradic, J.: Double robust semi-supervised inference for the mean: Selection bias under mar labeling with decaying overlap. arXiv preprint arXiv:2104.06667 (2021)
- (100) Deng, S., Ning, Y., Zhao, J., Zhang, H.: Optimal semi-supervised estimation and inference for high-dimensional linear regression. arXiv preprint arXiv:2011.14185 (2020)
- (101) Hou, J., Guo, Z., Cai, T.: Surrogate assisted semi-supervised inference for high dimensional risk prediction. arXiv preprint arXiv:2105.01264 (2021)
- (102) Mandozzi, J., Bühlmann, P.: Hierarchical testing in the high-dimensional setting with correlated variables. J. Am. Statist. Assoc. 111(513), 331–343 (2016)
- (103) Guo, Z., Li, X., Han, L., Cai, T.: Robust inference for federated meta-learning. arXiv preprint arXiv:2301.00718 (2023)
- (104) Li, S., Cai, T.T., Li, H.: Transfer learning for high-dimensional linear regression: Prediction, estimation and minimax optimality. J. R. Statist. Soc. B 84(1), 149–173 (2021)
- (105) Li, S., Zhang, L., Cai, T.T., Li, H.: Estimation and inference for high-dimensional generalized linear models with knowledge transfer. Technical Report (2021)
- (106) Tian, Y., Feng, Y.: Transfer learning under high-dimensional generalized linear models. J. Am. Statist. Assoc. 117(just-accepted), 1–30 (2022)
- (107) Battey, H., Fan, J., Liu, H., Lu, J., Zhu, Z.: Distributed testing and estimation under sparse high dimensional models. Ann. Statist. 46(3), 1352 (2018)
- (108) Lee, J.D., Liu, Q., Sun, Y., Taylor, J.E.: Communication-efficient sparse regression. J. Mach. Learn. Res. 18(1), 115–144 (2017)
- (109) Meinshausen, N., Bühlmann, P.: Maximin effects in inhomogeneous large-scale data. Ann. Statist. 43(4), 1801–1830 (2015)
- (110) Liu, W.: Gaussian graphical model estimation with false discovery rate control. Ann. Statist. 41(6), 2948–2978 (2013)
- (111) Xia, Y., Li, L.: Hypothesis testing of matrix graph model with application to brain connectivity analysis. Biometrics 73(3), 780–791 (2017)
- (112) Xia, Y., Cai, T., Tony Cai, T.: Testing differential networks with applications to the detection of gene-gene interactions. Biometrika 102(2), 247–266 (2015)
- (113) Xia, Y., Li, L.: Matrix graph hypothesis testing and application in brain connectivity alternation detection. Stat. Sin. 29(1), 303–328 (2019)
- (114) Kim, B., Liu, S., Kolar, M.: Two-sample inference for high-dimensional markov networks. J. R. Statist. Soc. B (2021)
- (115) Zhang, L., Ma, R., Cai, T.T., Li, H.: Estimation, confidence intervals, and large-scale hypotheses testing for high-dimensional mixed linear regression. arXiv preprint arXiv:2011.03598 (2020)
- (116) Li, S., Cai, T.T., Li, H.: Inference for high-dimensional linear mixed-effects models: A quasi-likelihood approach. J. Am. Statist. Assoc. 116, 1–12 (2021)
- (117) Barber, R.F., Candès, E.J.: Controlling the false discovery rate via knockoffs. Ann. Statist. 43(5), 2055–2085 (2015)
- (118) Candes, E., Fan, Y., Janson, L., Lv, J.: Panning for gold:‘model-x’ knockoffs for high dimensional controlled variable selection. J. R. Statist. Soc. B 80(3), 551–577 (2018)
- (119) Barber, R.F., Candès, E.J., Samworth, R.J.: Robust inference with knockoffs. Ann. Statist. 48(3), 1409–1431 (2020)
- (120) Ren, Z., Wei, Y., Candès, E.: Derandomizing knockoffs. J. Am. Statist. Assoc. 116, 1–11 (2021)
- (121) Du, L., Guo, X., Sun, W., Zou, C.: False discovery rate control under general dependence by symmetrized data aggregation. J. Am. Statist. Assoc. 116, 1–15 (2021)
- (122) Dai, C., Lin, B., Xing, X., Liu, J.S.: A scale-free approach for false discovery rate control in generalized linear models. J. Am. Statist. Assoc. (just-accepted), 1–31 (2023)
- (123) Vovk, V., Wang, R.: E-values: Calibration, combination and applications. Ann. Statist. 49(3), 1736–1754 (2021)
- (124) Wang, R., Ramdas, A.: False discovery rate control with e-values. arXiv preprint arXiv:2009.02824 (2020)
- (125) Ren, Z., Barber, R.F.: Derandomized knockoffs: leveraging e-values for false discovery rate control. arXiv preprint arXiv:2205.15461 (2022)