[ beforeskip=.05em plus .6pt,pagenumberformat=]toclinesection
Statistical Inference Under Constrained Selection Bias
Abstract
Large-scale datasets are increasingly being used to inform decision making. While this effort aims to ground policy in real-world evidence, challenges have arisen as selection bias and other forms of distribution shifts often plague observational data. Previous attempts to provide robust inference have given guarantees depending on a user-specified amount of possible distribution shift (e.g., the maximum KL divergence between the observed and target distributions). However, decision makers will often have additional knowledge about the target distribution which constrains the kind of possible shifts. To leverage such information, we propose a framework that enables statistical inference in the presence of selection bias which obeys user-specified constraints in the form of functions whose expectation is known under the target distribution. The output is high-probability bounds on the value of an estimand for the target distribution. Hence, our method leverages domain knowledge in order to partially identify a wide class of estimands. We analyze the computational and statistical properties of methods to estimate these bounds and show that our method can produce informative bounds on a variety of simulated and semisynthetic tasks, as well as in a real-world use case.
1 Introduction
Decision-makers in the public and private sectors increasingly seek to use machine learning or statistical models built on top of large-scale datasets in order to inform policy, operational decisions, individualized treatment rules, and more. However, these administrative datasets are typically purely observational, meaning that they are not carefully designed to sample from a true distribution of interest. Consequently, such efforts have been hindered by sampling biases and other distributional shifts between the observed data and the target distribution. Such selection biases have presented severe issues for past algorithmic systems [10, 14], policy analysis [18, 28], epidemiological studies [17, 25], among others.
As a motivating example, decision-makers in public health may wish to estimate the risk factors contributing to adverse outcomes related to COVID-19, e.g., hospitalizations, in order to target preventative interventions. Nevertheless, they usually only have data from people who engaged with some specific services in the past such as insurance claims or patients who visited the health system. This scenario poses the difficulty that some demographic groups will be underrepresented in the data, influenced by some latent factors (for instance, high healthcare costs) and the outcome itself. It is a known phenomenon that individuals with worse healthcare access will seek care primarily when facing severe diseases, thus increasing observed hospitalizations for this group. Hence, creating a problem akin to confounding when the relationship between these two quantities is estimated.
We consider the task of accurately estimating some functional of the ground-truth distribution using samples from an observed, potentially shifted, distribution. For instance, our goal might be to estimate the expectation of a measured covariate or the treatment effect from an intervention. In general, such inference is intractable without assumptions on the relationship between the observed and target distributions. The simplest setting is where we can directly observe some samples from the target distribution. However, we are interested in the scenarios where this is not the case, for example, the scenario introduced in the previous paragraph; given that the data is conditioned among other things on the outcome, it presents the insidious problem that it will never be representative of the population as whole. Absent target-distribution samples, other frameworks such as those related to distributionally robust optimization (DRO) [7, 16, 46, 39] or sensitivity analysis [12, 37, 43] allow users to specify the total magnitude of distribution shift allowed. Such magnitude is usually modeled by imposing a limit on the maximum distance (e.g., KL or divergence) between the target distribution and the observed one. However, since the target distribution (or samples of it) is unavailable, this assumption cannot be empirically verified, and often cannot even be set in an informed manner. Our goal is to provide provable guarantees without introducing untestable assumptions on the magnitude of shift, by using only observable quantities to set bounds on the possible difference in distributions.
Intuitively, this may be possible because decision makers often have aggregate knowledge about the target distribution. For instance, a policymaker may know, via census data, the distribution of demographic characteristics such as age, race, or income from the population as a whole. Moreover, in the public health setting, serosurveys may provide ground-truth estimates of exposure to infectious diseases in specific locations or population groups [19]. This aggregate information is typically not sufficient by itself for the original task because it fails to measure the key outcome or covariates of interest (e.g., knowing the demographic distribution of a population is by itself unhelpful for estimating a patient’s risk of hospitalization). However, it imposes constraints on the nature of the distribution shift between the observed distribution and the underlying population: any valid shift must respect these known quantities. Concretely, our contributions are as follows:
-
•
We introduce a framework that allows user-specified constraints on distribution shift via known expectations. Our framework incorporates such external information into an optimization program whose value gives valid max/min bounds on a statistic of interest using samples from an observed distribution. As a result, we are able to provide estimates by adding more observables in lieu of assumptions that are not empirically testable (e.g., the KL divergence between the target and sample distributions). We provide conditions under which this optimization problem is convex and hence, efficiently solvable.
-
•
We analyze the statistical properties of estimating these bounds using a sample average approximation for the optimization problem. We show that our estimators are asymptotically normal, allowing us to provide valid confidence intervals.
-
•
We extend our framework to accommodate estimands without a closed form (e.g., a regression coefficient or an estimated model parameter), provide statistical guarantees for this setting, and propose computational approaches to solve the resulting optimization problem.
-
•
We perform experiments on synthetic and semi-synthetic data to test our methods. The results empirically confirm that our framework provides valid bounds for the target estimand and allows effective use of domain knowledge: incorporation of more informative constraints produces tighter bounds, which can be strongly informative about the estimand of interest. All the code we used for our experiments is available at hidden.
-
•
We showcase a real-world case of study of assessing disparities in COVID-19 disease burden using a large-scale insurance claims dataset where our method allows us to produce policy-relevant results under the presence of selection bias.
Additional related work.
Our work is broadly related to the literature on partial identification, which spans statistics, economics, epidemiology, and computer science [20, 31, 33, 42]. Interest in partial identification has grown recently in the machine learning community, particularly in the causal inference setting. For example, [23, 4] consider partial identification of treatment effects for a known causal graph, extending the classic framework of [5] to incorporate generative models. [15] consider the setting where covariates are subject to a user-specified level of noise. Perhaps closest to our setting is [36], who consider methods for incorporating domain knowledge into partial identification problems. However, in their setting, domain knowledge takes the form of functional form restrictions for the treatment effect (e.g., smoothness or number of inflection points), rather than constraints on shift between observed and target distributions. Our work differs from the existing ML literature both in that we are concerned with inference problems broadly (not restricted to treatment effects), and in that we provide a means to impose externally-known constraints on shifts such as selection bias. Related issues have recently been considered in the epidemiology and biostatistics literature, motivated by the growing use of biobank-style datasets with known selection biases [22, 44]. Our work differs in that we explicitly consider the algorithmic properties of computing the resulting bounds, and in our analysis of estimators which themselves require fitting a model.
2 Problem formulation
Let be a random variable over a space , with distribution in a population of interest. Our goal is to estimate a real-valued functional . One prominent example is estimating the expectation for some function , but we will consider a range of examples for . If we observe iid samples from , estimating is a standard inference task. For instance, we may use the plug-in estimate , (where is the empirical distribution) or any number of other strategies. However, we consider a setting where we instead observe samples drawn iid from a different distribution . For illustration purposes, recall the example mentioned in the introduction: policymakers are interested in information relative to the population as a whole () but they only have access to observational data from the hospitals or insurance claims, i.e., a sample from .
We assume that both and have densities and , respectively, and that whenever . More formally, we require that is absolutely continuous with respect to so that the ground truth density ratio is well defined. Intuitively, inference on is impossible if some portions of the distribution can never be observed. Accordingly, similar overlap assumptions are near-universal in causal inference [24], domain adaptation [9], selection bias [38], distributionally robust optimization [35], etc. We expect this assumption to be satisfied in many application domains because selection bias is not strong enough to make some observations literally impossible. Our running COVID-19 example illustrates this: a patient with any covariates can in principle seek care (and some such patients do), even if they have worse access than patients with a different set of covariates .
With slight abuse of notation, for any , we let denote a distribution with density so that . If were known, estimating using samples from would be easily accomplished using standard importance sampling methods: in the case of estimating an expectation, we have that . However, our focus is on the setting where is not known, and we don’t have access to samples from from which to estimate it.
Without any information about the relationship between and this is a hopeless task. However, in many settings of importance some information is available, in the form of auxiliary functions whose true expectation under is known. In policy settings, this may come from census data, or well-design population surveys that estimate the ground-truth prevalence of specific health conditions (c.f. [26, 19, 34]). Concretely, we are able to observe for a collection of functions . Thus, we know that must satisfy
Let to be the set of density ratios which satisfy the above constraints, all of which are consistent with our observations. In general, will not be a singleton and so will not be point-identified. However, it is partially identified with the following bounds:
Proposition 1.
and these bounds are tight.
In the following, we provide computationally and statistically efficient methods for estimating these upper and lower bounds, each of which are defined via an optimization problem over . encapsulates the constraints on potential distribution shifts that are known in a particular domain, allowing an analyst to translate additional domain knowledge into tighter identification of the estimand. Intuitively, such identification will be close to point-wise when the constraints are informative enough about the behaviour of the estimand of interest under the true distribution. Our aim is to use the observed sample drawn iid from to estimate the value of the optimization problems defining our lower and upper bounds. Note that in order to do so, we have to tackle two different types of uncertainty. First, the uncertainty derived from partial identification where even the population level quantities do not exactly identify even if were known exactly. Second, finite-sample uncertainty from the estimation of the population level quantity using a sample : the statistical uncertainty from taking as an approximation of . We will provide confidence bounds for which account for both partial identification and finite-sample uncertainty in estimation. Throughout, we will assume for convenience that the optimization problems defining each side of the bound have a unique solution (if this is not satisfied, we could, e.g., modify the objective function to select a minimum-norm solution).
3 Methods
We now proceed to estimate the aforementioned bounds. Proposition 1 reduces the problem of computing such bounds to solving an optimization program. Throughout, we consider the problem of estimating the lower bound (i.e., solving the minimization problem), as the upper bound is symmetric. To start, we impose no restrictions on by representing as an arbitrary function. This yields the following optimization problem:
| (1) |
where the constraint ensures that is a valid density ratio. However, neither nor the population level restrictions can be observed directly. Nevertheless, having access to a sample from , it is only natural to use plug-in estimators to estimate the unavailable quantities from the previous program. This yields the sample optimization problem:
| (2) |
where is the empirical distribution of . We refer to the first problem (1) as the population optimization problem () and to the second one (2) as the plug-in approximation ().
Let be the optimal value of the population problem and the optimal value of the plug-in approximation problem. Suppose converges in distribution to a normally distributed random variable, such that, it has mean zero and variance that can be estimated from the data. If this is indeed the case, then the standard procedure to derive confidence intervals for can be applied. Furthermore, as corollary of Proposition 1, we can produce a high probability lower bound for . As the maximization problem is symmetric, we can use the same argument to upper bound .
We now turn to analyze several scenarios where this recipe can be applied. We use the theory of sample average approximation in optimization [40, 41] to describe the conditions to guarantee, both convergence and asymptotic normality, for the statistic . However, before developing this mathematical scaffolding, it is necessary to make one more assumption: we will assume a, differentiable, finite-dimensional parametrization of , denoted by , for some . This class is still quite expressive; e.g., a standard basis for smooth functions (e.g., a set of polynomial basis functions) allows us to represent any smooth function in this framework, or the analyst could use a highly expressive class such as neural networks [21].
3.1 Convex estimands
We start with the case where is a convex function of . The most prominent case where this holds is when is the expectation of some function , in which case is linear in and will be convex in when is convex. Another example is when is a conditional expectation, conditioned on some event . Then, we have
The plug-in approximation of is no longer linear in because determines both the numerator and the denominator. However, it can be reformulated as a linear function using the standard Charnes-Cooper transformation [47] and thus can be computed by the means of a linear program. It is worth pointing out that, being linear programs, the previous two examples can be efficiently computed.
When is a convex function of , we can use standard results in sample average approximation programs [41] to show asymptotic normality. Let be the dual variable associated with constraint , and be the optimal value of in the population problem. Similarly, let be the population-optimal value of . Then, we have
Proposition 2.
Let be convex in . Moreover, assume for compact and that the Slater’s condition holds. Then, and convergence is in distribution. In particular, if , then .
We can then produce confidence intervals by estimating this variance via the sample estimates and (see e.g. Schapiro et al. [41] Eqs. 5.183 and 5.172). In order to simplify estimation of this variance, it may be recommended to use a form of sample splitting (at the expense of a slower convergence rate), where disjoint sets of samples are used to estimate the objective function and each constraint in the sample problem. This eliminates the covariance terms in the expression for above. Alternatively, if computational power is not a constraint, it may be simpler in practice to estimate the variance using the bootstrap.
3.2 General estimands
When the estimand is a non-convex function of , obtaining provably optimal solutions for the plug-in approximation problem is in general not feasible. However, we can still obtain locally optimal solutions (as is common for other partial identification settings [36, 22, 23, 4]), although the statistical properties of the plug-in estimator may become more complex, as we illustrate in the two following examples.
Example 1: Average treatment effect estimation. Consider the setting where is a distribution over tuples , where is a covariate vector, is an outcome, and is a binary treatment indicator variable. For simplicity, we consider the case where the outcome is also binary. Researchers are often interested in estimating the average treatment effect. Under standard identifying assumptions (most prominently that ), this is done by the means of the estimand:
Now, consider the setting where we observe samples from a distribution different than , resulting in a density ratio . Computing the appropriate marginals and conditionals of , and substituting these for in the above expression, gives an objective that is non-convex in terms of , but which is nonetheless differentiable, enabling gradient-based optimization. However, we will still have to estimate the nuisance functions and the statistical properties of the resulting bounds will depend on how these are estimated.
Example 2: Coefficients of parametric models. Suppose that a researcher is interested in interpreting the estimated coefficient of a parametric model, e.g., linear or generalized linear models as commonly used in a variety of applied settings. For example, an applied researcher may estimate the odds ratio for an outcome given some exposure using a logistic model and wishes to obtain bounds on this parametric odds ratio under potential selection bias or other distribution shifts.
Bounding -estimators: To provide one way of addressing these (and other) examples, we consider the general challenge of partially identifying quantities produced by an -estimator. -estimators are those which estimate a parameter via minimizing the expected value of a function , i.e., , widely used across many areas of statistics and machine learning [45]. One prominent example is when is the negative log likelihood, resulting in a maximum likelihood estimate of . We are interested in producing bounds for some real-valued function of . For example, may be the value of a single coordinate of if we are interested in bounding a specific model coefficient that will be interpreted, or may be the treatment effect functional described above. This results in the optimization problems:
Since is not convex in general, Slater’s condition is not a strong enough regularity condition to guarantee asymptotic normality of the estimated optimal value. Therefore, we require to impose a more general constraint qualification. Specifically, we will assume the standard Mangasarian-Fromovitz Constraint Qualification [29] for the non-convex case. This regularity condition is sufficient to ensure that each minimizer of the population problem has a unique associated in the dual. Hence, under the MFCQ regularity condition and if is the covariance matrix of the -estimator at the optimal we prove the following asymptotic normality result:
Proposition 3.
Assume that is twice differentiable and locally convex in . Assume as well that , , . Then, if lies in a compact set , and are differentiable, then . Using sample splitting, the variance can be approximated by .
The proof of Proposition 3 requires tools from empirical process theory in order to study the asymptotic properties of the optimal value of the plug-in approximation problem. To sketch the main idea, let be the vector of functions for the plug-in approximation problem and for the population problem (where the first coordinate in each is the objective function and the rest are the constraints). Let be the function . If the empirical process converges in distribution to an object, then a functional version of the delta method can be applied to obtain our result. This strategy requires two conditions. First, that a limiting object exists (in distribution) for the random vector , which we accomplish by showing that the empirical process belongs to a Donsker class. Second, that such a limiting object, with specified variance, still exists after applying the function . We show this, subject to an appropriate constraint qualification, by applying a generalized version of the continuous mapping theorem (as in [40]). The whole proof and explicit expressions for can be found on the Appendix.
3.3 Computational approach
As long as has well defined subgradients, the plug-in approximation problem can be solved efficiently by projected gradient descent. Even for programs that include an -estimator, this is easily accomplished in autodifferentiation frameworks where we can use differentiable optimization [3, 1] or meta-learning style methods [6, 13, 30] to implement the defining in a manner which supports automatic backpropagation. In general, we can only obtain locally (instead of globally) optimal solutions for non-convex problems. However, we observe experimentally that the values obtained are nearly identical across many random restarts of the optimization, suggesting good empirical performance.
4 Experiments
We conduct experiments to show how our method allows users to specify domain knowledge in order to obtain informative bounds on the estimand of interest. We simulate inference for a range of different across various scenarios by testing our method with different choices of constraints and datasets. In addition, we present a real-world use case where we were able to produce policy-relevant conclusions using our method.
In each experiment, we start with samples from a ground truth distribution and then simulate the observed distribution using sampling probabilities which depend on the covariates (i.e., simulating selection bias). This ensures that the ground-truth value is known (to high precision), allowing us to verify if our bounds contain the true value. We consider two classes of estimands. First, estimating the conditional mean for an outcome and covariate . Second, estimating the coefficient of a linear regression model as an example of the -estimation setting from above.
We show how the amount of specified domain knowledge can result in tighter bounds along two axes. First, we vary the parametric form for , ranging from an arbitrary function of (i.e., a separate parameter for each discrete covariate stratum) to one that imposes specific assumptions (e.g., separability across specific groups of covariates, or that the covariates which the selection probabilities depend on are known). Second, we vary the number and informativeness of the constraints used to form the set ; modeling the ability of users to impose an increasing degree of constraints on possible distribution shifts. The Appendix shows experiments with additional kinds of constraints, e.g., on the sign of the covariance between pairs of variables.
The closest baselines to compare our methods against are sensitivity analyses based on distributionally robust optimization (DRO). However, DRO requires the distance between distributions under some divergence (the unobservable parameter ) as input. Conversely, our method requires observable aggregate data to provide partial identification, making a head-to-head comparison difficult. In order to provide baselines for comparison, we implement DRO on two artificial settings where the maximum distance is provided. The first baseline (omniscient) optimistically assumes that the divergence () between and is known. This gives an ”unfair advantage” to DRO because not only is a valid value of provided but, furthermore, it is the smallest of such feasible values (which is not actually observable when is unknown). Hence, we also propose a second scenario (observable) where the tightest possible value of is inferred from the same data used by our method. In this scenario is estimated by solving for . Thus, the solution of the program will be the radius of the smallest ball centered at that contains all distributions that satisfy all the observable constraints. Of course the previous program is not convex in ; hence we settle for the solution obtained from a saddle point obtained via gradient descent (which errs in favor of DRO by selecting a smaller value of than the one that may be justified by the data).
We now proceed to summarize how these experiments were instantiated in each setting, providing detailed information in the Appendix. Additionally, a guide on how to replicate each of these experiments is available in the code repository at hidden.
Synthetic data experiments. For the first set of experiments, we simulate a distribution over binary variables used to evaluate previous causal inference methods [27]. We add a selection bias scenario to this process by simulating an indicator variable . The observed distribution consists of those samples for which . In this domain, we consider the task of estimating bounds for setting restrictions on (i.e., is known). A total of six experiments were run. In the first three experiments, we vary the functional form for while leaving the constraints defining fixed. In the first experiment (unrestricted), is an arbitrary function of . In the second experiment (separable), we specify where is an arbitrary function of and is an arbitrary function of and . Finally, in the third experiment (targeted), we fix , i.e., is a function only of the variables which determine , thus simulating the scenario where the variables driving selection bias are known (even if the exact selection probabilities are not).
For experiments four to six, we vary instead by adding more informative constraints in each successive experiment. As our intention is to isolate the effect of adding more constraints, the parametric form of is set as flexible as possible, i.e., as an arbitrary function of (the unrestricted experiment above). In experiment four, we constrain two of the four parameters of the joint distribution of and via constraints on and . In experiment five, we add constraints on the remaining components of the joint distribution and . Experiment six, add constraints on the outcome () as well. Through out, we will refer to these experimental setups as (partial) race + income, (full) race + income and race + income + outcome respectively (the names were chosen to keep consistency with the semi-synthetic experiments).
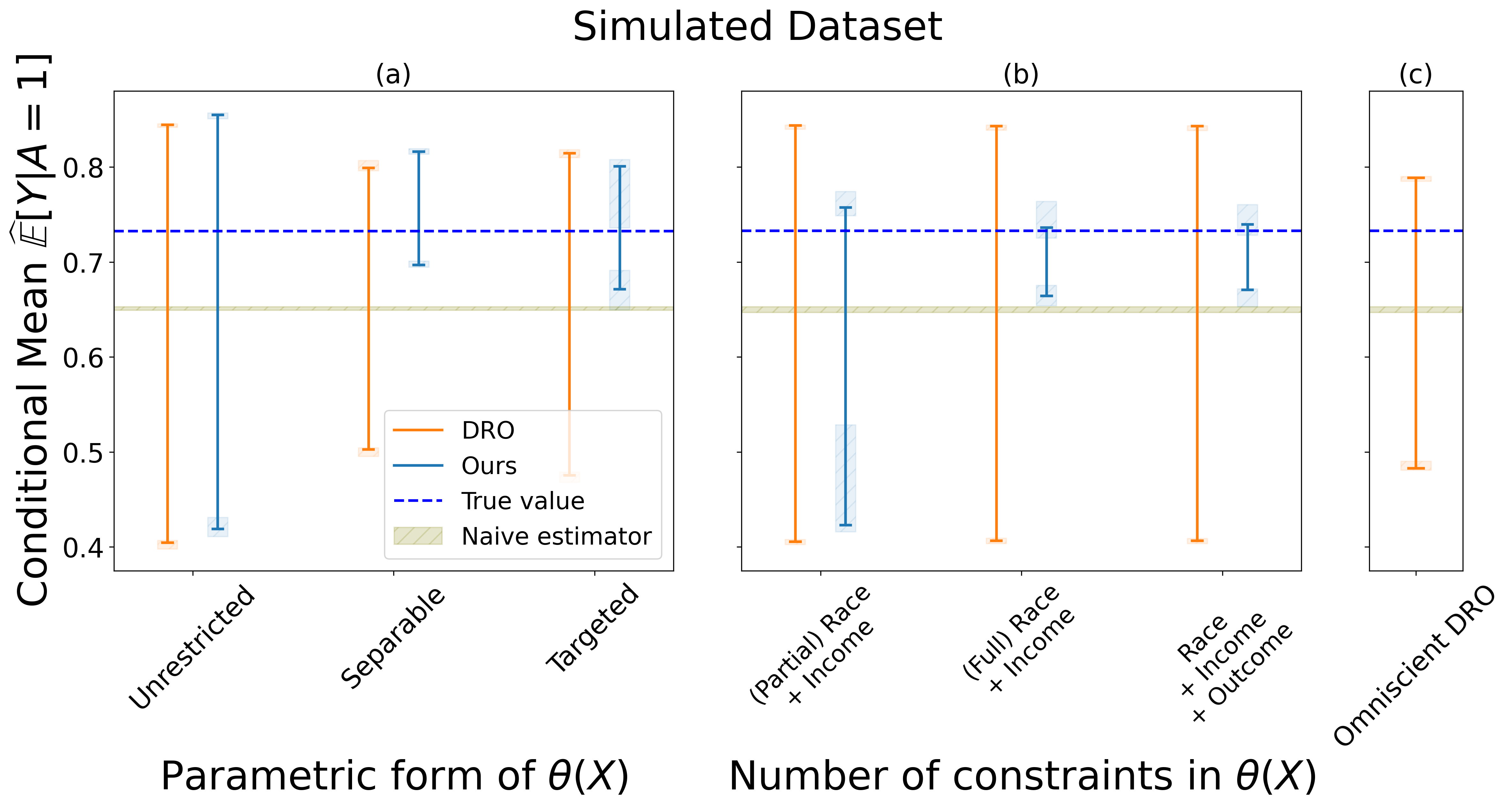
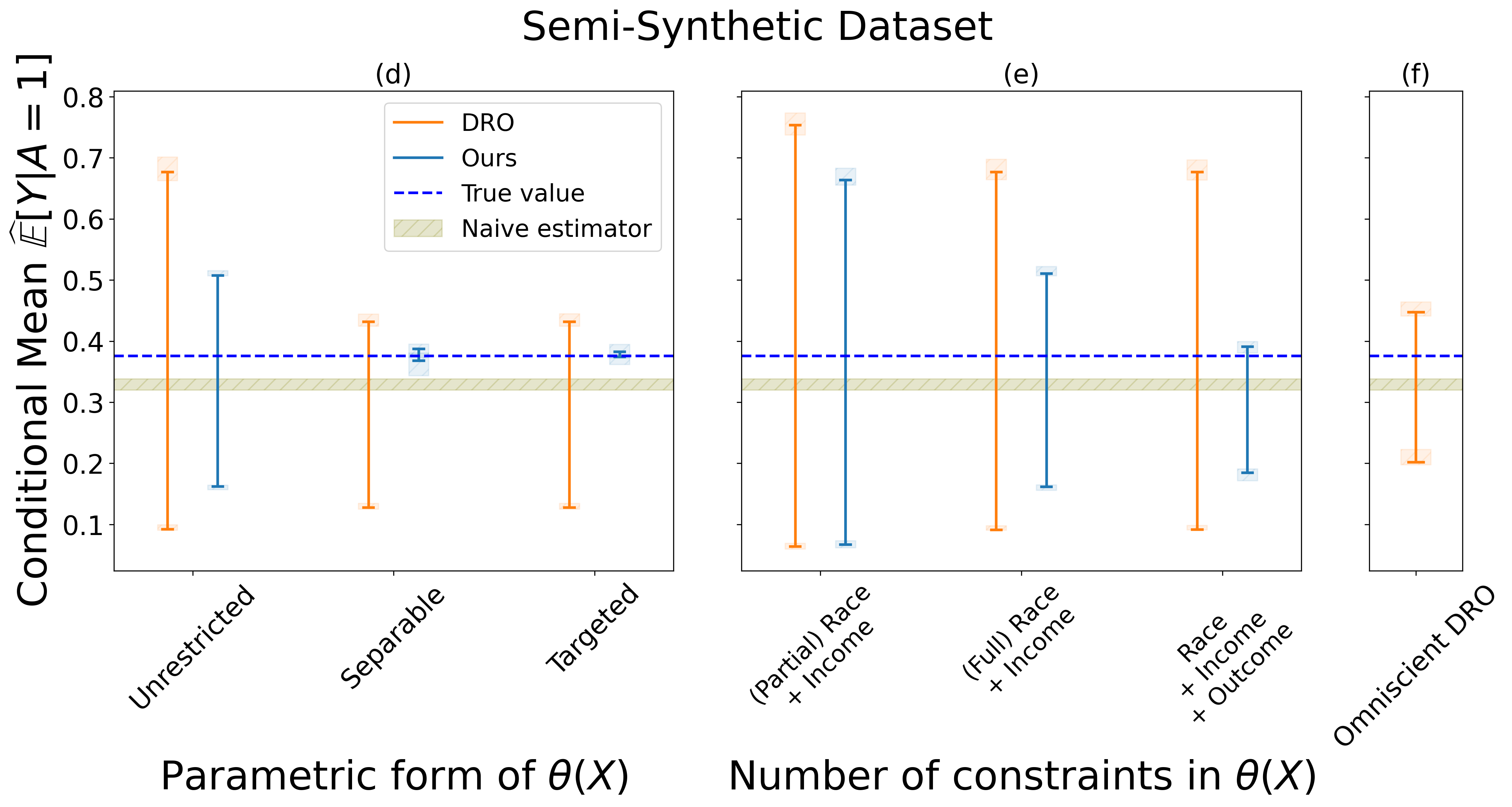
Semi-synthetic data experiments. We use the Folkstables dataset [11] which provides an interface for the data from the US Census American Community Survey from 2014 to 2019. Based on the ACSEmployment task suggested in [11], we consider a binary outcome variable indicating whether or not a person was employed at the time of the survey. We are interested in predicting the female unemployment rate (e.g., motivated by a policymaker who seeks to track or intervene on gender employment gaps [2] [32]). The variables driving the selection bias are citizenship and veteran status, as these variables can contribute to self-selection in a potential social services database.
We first consider estimating where indicates the sex of an individual. We conduct six experiments that exactly parallel the construction of the synthetic experiments, with the variable for income level playing the role of and race/ethnicity playing the role of (see Appendix for details). This simulates a setting where information about other outcomes correlated with the variables of interest is leveraged for partial identification. In the last experiment race + income + outcome, the additional constrain simulates a scenario where information on the outcome of interest is available with respect to a different demographic grouping than our desired estimand (race/ethnicity instead of gender).
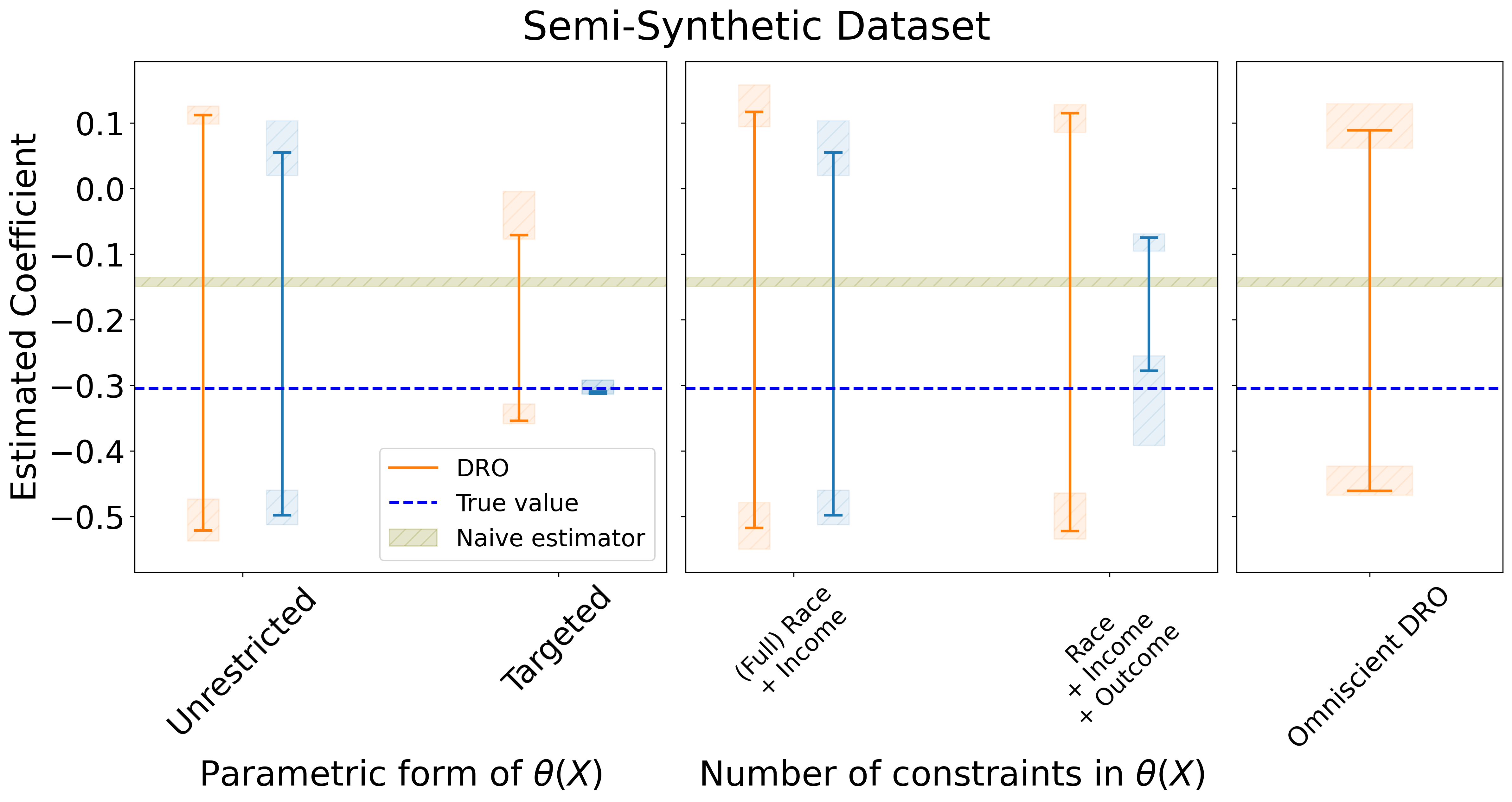
We then consider estimating the coefficient of the indicator variable in a linear regression model of on 7 covariates. This second setting is an example of the -estimator framework from above. We run the experiments (partial) race + income, (full) race + income and race + income + outcome using the settings of the case. Details for each experiment are shown in the Appendix.
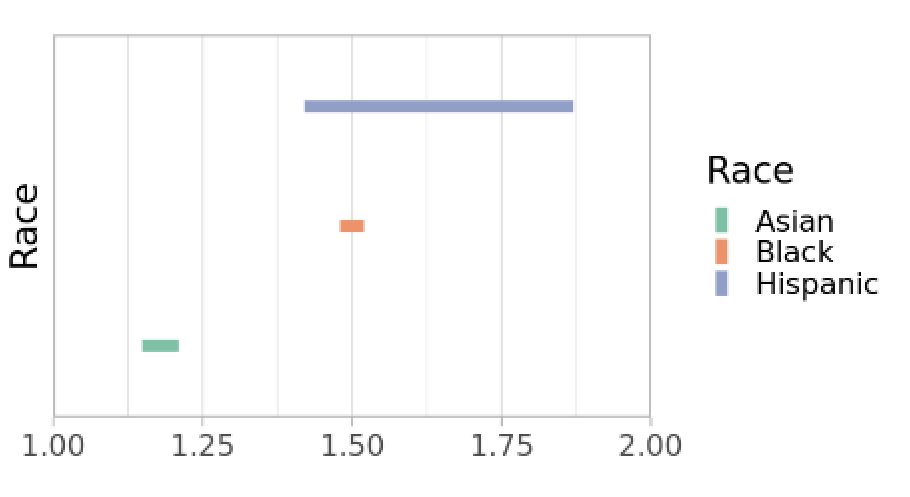
Real world case study. We apply our method to a dataset of over five million de-identified medical claims from COVID-19 patients. Medical claims provide the services that patients received, their diagnosis, and demographic attributes. We use this data to study disparities in hospitalization risk for US COVID-19 patients across race/ethnicity groups. We provide bounds for the relative excess risk of hospitalization for non-white patients after conditioning on clinically relevant covariates (a set of five comorbidities and age). Formally, our estimand is , where is whether a patient was hospitalized. As mentioned in the introduction, selection bias is particularly challenging for these data, because it may depend jointly on both the outcome and main covariate of interest. We model selection based on race, income, and hospitalization status to account for this potential interaction between disease severity and healthcare access in ascertainment. As constraints , we use the total hospitalizations per racial group reported by the CDC and the total number of estimated infections per group from CDC serology studies.
To further investigate the stability of our estimand, every experiment was run across 5 different random restarts of the projected gradient descent algorithm.
Results. Figures 1 and 2 show our main results. Each figure plots the bounds output by our method for each experiment described above. In each plot, we also show the true value of the estimand , the naive estimate using samples from (without any attempt to account for selection bias) and the bounds produced by the two DRO baselines. In each plot (1 and 2), accounting for the different results across multiple bootstrap replicates, there is a box plot at the endpoints of every bound as well as a band to represent .
The results of our experiments are consistent across all six scenarios, showing how the estimated bounds vary depending on the constraints imposed and on the functional form assumed for . Concordant with the theory, the bounds always contain the true value of the estimand. Additionally, as expected, when more external information is available the bounds become narrower. When additional constraints are added, it is possible to obtain narrow bounds for the estimand that rule out the naive estimates. Our method Pareto-improves over the observed-data DRO baseline across all settings. Interestingly, in the majority of settings, our method also produces tighter intervals than the omniscient DRO baseline. Thus, it can be highlighted the advantage of more nuanced descriptions of uncertainty: even in the case the true value of the divergence is known, moment constraints may provide a tighter bound than a divergence metric. We also find that in the targeted experiment where the variables driving selection bias are known, our method often provides close to point identification, indicating that this is a particularly powerful form of domain knowledge when available. These results demonstrate that our framework allows users to translate common forms of domain knowledge into robust and informative statistical inferences.
Figure 3 summarizes the results from the real-world case study. We find that Black, Asian, and Hispanic patients have a higher risk of hospitalization compared to white patients. Importantly, our method produces informative bounds for all groups, which are close to point identification for Black and Asian patients while highlighting greater sensitivity to potential selection biases for Hispanic patients. Since the true underlying target distribution is unknown, we cannot compare our results to the ‘ground truth’ in this domain; rather, this showcases that our methods produce informative and theoretically-guaranteed intervals for a policy-relevant question.
References
- Agrawal et al. [2019] Akshay Agrawal, Brandon Amos, Shane Barratt, Stephen Boyd, Steven Diamond, and J Zico Kolter. Differentiable convex optimization layers. Advances in neural information processing systems, 32, 2019.
- Albanesi and Şahin [2018] Stefania Albanesi and Ayşegül Şahin. The gender unemployment gap. Review of Economic Dynamics, 30:47–67, 2018.
- Amos and Kolter [2017] Brandon Amos and J Zico Kolter. Optnet: Differentiable optimization as a layer in neural networks. In International Conference on Machine Learning, pages 136–145. PMLR, 2017.
- Balazadeh Meresht et al. [2022] Vahid Balazadeh Meresht, Vasilis Syrgkanis, and Rahul G Krishnan. Partial identification of treatment effects with implicit generative models. Advances in Neural Information Processing Systems, 35:22816–22829, 2022.
- Balke and Pearl [1997] Alexander Balke and Judea Pearl. Bounds on treatment effects from studies with imperfect compliance. Journal of the American Statistical Association, 92(439):1171–1176, 1997.
- Bertinetto et al. [2019] Luca Bertinetto, Joao F Henriques, Philip Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. In International Conference on Learning Representations, 2019.
- Bertsimas et al. [2022] Dimitris Bertsimas, Kosuke Imai, and Michael Lingzhi Li. Distributionally robust causal inference with observational data. arXiv preprint arXiv:2210.08326, 2022.
- Billingsley [2013] Patrick Billingsley. Convergence of probability measures. John Wiley & Sons, 2013.
- Byrd and Lipton [2019] Jonathon Byrd and Zachary Lipton. What is the effect of importance weighting in deep learning? In International conference on machine learning, pages 872–881. PMLR, 2019.
- Chouldechova et al. [2018] Alexandra Chouldechova, Diana Benavides-Prado, Oleksandr Fialko, and Rhema Vaithianathan. A case study of algorithm-assisted decision making in child maltreatment hotline screening decisions. In Conference on Fairness, Accountability and Transparency, pages 134–148. PMLR, 2018.
- Ding et al. [2021] Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning. Advances in Neural Information Processing Systems, 34, 2021.
- Ding and VanderWeele [2016] Peng Ding and Tyler J VanderWeele. Sensitivity analysis without assumptions. Epidemiology (Cambridge, Mass.), 27(3):368, 2016.
- Finn et al. [2017] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, pages 1126–1135. PMLR, 2017.
- Gianfrancesco et al. [2018] Milena A Gianfrancesco, Suzanne Tamang, Jinoos Yazdany, and Gabriela Schmajuk. Potential biases in machine learning algorithms using electronic health record data. JAMA internal medicine, 178(11):1544–1547, 2018.
- Guo et al. [2022] Wenshuo Guo, Mingzhang Yin, Yixin Wang, and Michael Jordan. Partial identification with noisy covariates: A robust optimization approach. In Conference on Causal Learning and Reasoning, pages 318–335. PMLR, 2022.
- Gupta and Rothenhäusler [2021] Suyash Gupta and Dominik Rothenhäusler. The -value: evaluating stability with respect to distributional shifts. arXiv preprint arXiv:2105.03067, 2021.
- Haneuse and Daniels [2016] Sebastien Haneuse and Michael Daniels. A general framework for considering selection bias in ehr-based studies: what data are observed and why? EGEMs, 4(1), 2016.
- Harron et al. [2017] Katie Harron, Chris Dibben, James Boyd, Anders Hjern, Mahmoud Azimaee, Mauricio L Barreto, and Harvey Goldstein. Challenges in administrative data linkage for research. Big data & society, 4(2):2053951717745678, 2017.
- Havers et al. [2020] Fiona P Havers, Carrie Reed, Travis Lim, Joel M Montgomery, John D Klena, Aron J Hall, Alicia M Fry, Deborah L Cannon, Cheng-Feng Chiang, Aridth Gibbons, et al. Seroprevalence of antibodies to sars-cov-2 in 10 sites in the united states, march 23-may 12, 2020. JAMA internal medicine, 180(12):1576–1586, 2020.
- Ho and Rosen [2015] Kate Ho and Adam M Rosen. Partial identification in applied research: benefits and challenges. Technical report, National Bureau of Economic Research, 2015.
- Hornik et al. [1989] Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- Horowitz and Lee [2022] Joel L Horowitz and Sokbae Lee. Inference in a class of optimization problems: Confidence regions and finite sample bounds on errors in coverage probabilities. Journal of Business & Economic Statistics, pages 1–12, 2022.
- Hu et al. [2021] Yaowei Hu, Yongkai Wu, Lu Zhang, and Xintao Wu. A generative adversarial framework for bounding confounded causal effects. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 12104–12112, 2021.
- Imbens [2004] Guido W Imbens. Nonparametric estimation of average treatment effects under exogeneity: A review. Review of Economics and statistics, 86(1):4–29, 2004.
- Jensen et al. [2015] Elizabeth T Jensen, Suzanne F Cook, Jeffery K Allen, John Logie, Maurice Alan Brookhart, Michael D Kappelman, and Evan S Dellon. Enrollment factors and bias of disease prevalence estimates in administrative claims data. Annals of epidemiology, 25(7):519–525, 2015.
- Johnson et al. [2014] Clifford Leroy Johnson, Sylvia M Dohrmann, Vicki L Burt, and Leyla Kheradmand Mohadjer. National health and nutrition examination survey: sample design, 2011-2014. Number 2014. US Department of Health and Human Services, Centers for Disease Control and …, 2014.
- Kennedy et al. [2019] Edward H Kennedy, Shreya Kangovi, and Nandita Mitra. Estimating scaled treatment effects with multiple outcomes. Statistical methods in medical research, 28(4):1094–1104, 2019.
- Knox et al. [2020] Dean Knox, Will Lowe, and Jonathan Mummolo. Administrative records mask racially biased policing. American Political Science Review, 114(3):619–637, 2020.
- Kyparisis [1985] Jerzy Kyparisis. On uniqueness of kuhn-tucker multipliers in nonlinear programming. Mathematical Programming, 32:242–246, 1985.
- Lee et al. [2019] Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10657–10665, 2019.
- Manski [2003] Charles F Manski. Partial identification of probability distributions, volume 5. Springer, 2003.
- Mate et al. [2022] Aditya Mate, Lovish Madaan, Aparna Taneja, Neha Madhiwalla, Shresth Verma, Gargi Singh, Aparna Hegde, Pradeep Varakantham, and Milind Tambe. Field study in deploying restless multi-armed bandits: Assisting non-profits in improving maternal and child health. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 12017–12025, 2022.
- Molinari [2020] Francesca Molinari. Microeconometrics with partial identification. Handbook of econometrics, 7:355–486, 2020.
- Murray and Lopez [2013] Christopher JL Murray and Alan D Lopez. Measuring the global burden of disease. New England Journal of Medicine, 369(5):448–457, 2013.
- Namkoong and Duchi [2016] Hongseok Namkoong and John C Duchi. Stochastic gradient methods for distributionally robust optimization with f-divergences. Advances in neural information processing systems, 29, 2016.
- Padh et al. [2023] Kirtan Padh, Jakob Zeitler, David Watson, Matt Kusner, Ricardo Silva, and Niki Kilbertus. Stochastic causal programming for bounding treatment effects. Conference on Causal Learning and Reasoning, 2023.
- Robins et al. [2000] James M Robins, Andrea Rotnitzky, and Daniel O Scharfstein. Sensitivity analysis for selection bias and unmeasured confounding in missing data and causal inference models. IMA VOLUMES IN MATHEMATICS AND ITS APPLICATIONS, 116:1–94, 2000.
- Rosenbaum and Rubin [1983] Paul R Rosenbaum and Donald B Rubin. The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1):41–55, 1983.
- Rothenhäusler and Bühlmann [2022] Dominik Rothenhäusler and Peter Bühlmann. Distributionally robust and generalizable inference. arXiv preprint arXiv:2209.09352, 2022.
- Shapiro [1991] Alexander Shapiro. Asymptotic analysis of stochastic programs. Annals of Operations Research, 30:169–186, 1991.
- Shapiro et al. [2021] Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczynski. Lectures on stochastic programming: modeling and theory. SIAM, 2021.
- Tamer [2010] Elie Tamer. Partial identification in econometrics. Annu. Rev. Econ., 2(1):167–195, 2010.
- Tan [2006] Zhiqiang Tan. A distributional approach for causal inference using propensity scores. Journal of the American Statistical Association, 101(476):1619–1637, 2006.
- Tudball et al. [2019] Matthew Tudball, Rachael Hughes, Kate Tilling, Jack Bowden, and Qingyuan Zhao. Sample-constrained partial identification with application to selection bias. arXiv preprint arXiv:1906.10159, 2019.
- Van der Vaart [2000] Aad W Van der Vaart. Asymptotic statistics, volume 3. Cambridge university press, 2000.
- Yadlowsky et al. [2022] Steve Yadlowsky, Hongseok Namkoong, Sanjay Basu, John Duchi, and Lu Tian. Bounds on the conditional and average treatment effect with unobserved confounding factors. The Annals of Statistics, 50(5):2587–2615, 2022.
- Zionts [1968] Stanley Zionts. Programming with linear fractional functionals. Naval Research Logistics Quarterly, 15(3):449–451, 1968.
Appendix A Proofs
A.1 Proof proposition 1
This holds by construction since for some . To see that these bounds are tight, suppose wlog that we have a conjectured lower bound . Then, there would be some consistent with all the constraints in for which , implying that there is a target distribution consistent with all constraints for which is not a valid lower bound.
A.2 Proof proposition 2
This follows directly from Theorem 5.11 of [41], since the objective and constraints are convex and we have assumed that the population problem has a unique solution.
A.3 Proof proposition 3
We want to show that the empirical process converges to a Gaussian process when , where is the value of the plug-in approximation program estimated from a sample of size . To prove this, we will use the delta method in Theorem 2.1 of [40] following the Hadamard differentiability of the outer problem . The later condition is shown to hold by invoking Theorem 3.6 in [40]. However, to apply such theorem, the Mangasarian-Fromovitz Constraint Qualification has to hold, and the approximation vector has to have a limiting process in ; the first requirement is satisfied by assumption, and the second is shown in the following.
Assumption 1. has some finite dimensional parameterization .
Consider the function where
and is the distribution that the expectation is taken with respect to, e.g., the realized empirical distribution on a set of samples or the limiting distribution .
Assumption 2. The functions and are differentiable on .
Assumption 3. is always a strict local minimizer for any and realization so that the Hessian matrix is positive definite. In particular, we assume that the smallest eigenvalue satisfies for some which may depend on the realization of the randomness , but not on .
Step 1. Our goal will be to show that is Lipschitz as a function of for any fixed , which we will accomplish by showing that is bounded. We use for matrices to denote the spectral norm, or operator 2-norm, and for vectors to denote the Euclidean norm. We assume that , , and all satisfy bounds which in the case of the first two are allowed to depend on :
That is, they are each Lipschitz in their respective parameter for a fixed realization , but with Lipschitz constant which is allowed to depend on . While we present these assumptions in terms of the Euclidean norm for convenience, since we only aim to prove that the Lipschitz constant of is bounded (our results do not depend on its particular value), bounds on the gradients above in any norm suffice (using the equivalence of all norms in finite dimension).
In what follows we fix and drop it from the notation. We first apply the chain rule to obtain that where is the Jacobian of with respect to . To calculate this term, we apply the implicit function theorem to the first-order optimality condition
and obtain
where we remark that is guaranteed to be invertible by our assumption that it is positive definite in a neighborhood of and hence the implicit function theorem applies.
Next, note that
and
by Jensen’s inequality. Using the Lipschitz assumptions on and combined with the definition of the spectral norm we have that the outer product satisfies
and hence
Since has bounded minimum eigenvalue, has bounded spectral norm as well: . Finally, using the Lipschitz assumption on and again applying the sub-multiplicative property of the spectral norm, we have
Stepping back to re-introduce the random function , we have that the Lipschitz constant of with respect to is .
Step 2. Now we are going to proceed to prove that the restrictions are also Lipchitz. In order to do that, we are going to proceed using the same strategy as before and show that the restrictions also have bounded gradients. Let us denote the restrictions as . Note that
Thus it must be true that:
As is continuous in a compact set it must be bounded by a finite number . Then by hypothesis:
And again by Jensen’s inequality:
Step 3. Since and all are Lipschitz on a finite-dimensional parameter, this implies that they belong to a Donsker class [45] and so we are guaranteed to a limiting stochastic process for each and for marginally. Furthermore, as is separable, by theorem 3.2 of [8], the vector has a limiting process under the product measure.
Step 4. Thus, as and because of the constraint qualification assumed for the problem, we may apply Theorem 3.6 of [40] to guarantee Hadamard differentiability of the outer problem . Hence, the delta method in Theorem 2.1 of [40] can be applied to guarantee asymptotic normality and thus the result follows.
Step 5 In order to explicitly compute the variance of , let
and
Then, if , again by theorem 2.1 [40]
Where is the limiting object that we proved the empirical process has. As a consequence of theorem 3.6 of [40], if the set of minimizers is a singleton, . The term is normal as it is a M-estimator itself. Hence is the sum of Normally distributed random variables and therefore,
Using sample splitting and the delta method on , the variance can be approximated by , completing the proof.
Appendix B Experiments
B.1 Constraint derivation
In some cases, we may be able to replace the constrain with a tighter constraint. For example, consider the case of selection bias, where individual samples from select into based on . Formally, we model this via an indicator variable , which is 1 if a unit is observed in the sample and 0 otherwise. Then, , and via Bayes theorem we have . Since , we are guaranteed that . In many cases, the marginal is easily observable because we know the total size of the population that appears in our sample relative to the true population (e.g., a government may know the fraction of people in a city who are enrolled in a program). This allows us to replace the constraint with the tighter constraint . This was indeed the case in all the experiments presented in the article.
B.2 Synthetic data experiments details
Inspired by data models used in the causal inference literature [27], the distribution is given by the following model:
The observed distribution is given by simulating selection bias via an indicator variable:
Naturally, the sample from are all those samples for which . The set used in the experiments was:
-
•
Unrestricted, separable and Targeted : .
-
•
(partial) race + income :, was .
-
•
(full) race + income : was .
-
•
race + income + Outcome : was .
Each experiment was run 5 times over different bootstrap replicates of the sample of distribution . The experimental results are summarized in table 1.
| Lower bound | Upper bound | ||||
|---|---|---|---|---|---|
| mean | std | mean | std | ||
| Separable | DRO | 0.475 | 0.004 | 0.814 | 0.003 |
| Ours | 0.671 | 0.016 | 0.786 | 0.033 | |
| Targeted | DRO | 0.501 | 0.004 | 0.800 | 0.004 |
| Ours | 0.697 | 0.003 | 0.816 | 0.002 | |
| Unrestricted | DRO | 0.403 | 0.004 | 0.844 | 0.002 |
| Ours | 0.420 | 0.008 | 0.855 | 0.002 | |
| (Full) Race + Income | DRO | 0.406 | 0.002 | 0.842 | 0.002 |
| Ours | 0.665 | 0.009 | 0.743 | 0.016 | |
| (Partial) Race + Income | DRO | 0.405 | 0.002 | 0.843 | 0.002 |
| Ours | 0.449 | 0.052 | 0.761 | 0.011 | |
| Race + Income + Outcome | DRO | 0.406 | 0.002 | 0.842 | 0.002 |
| Ours | 0.665 | 0.008 | 0.744 | 0.014 | |
| DRO Omniscient | 0.484 | 0.004 | 0.788 | 0.002 | |
B.3 Semi-synthetic data
For the semi-synthetic experiments we used the Folkstables package [11] which provides an interface for curated US Census data. We use the ACSEmployment task, where is whether or not a person is employed, and the variable of interest is the sex of an individual. The rest of the covariates come from a one-hot encode of the features listed below. The last level of each variable is dropped to avoid an unidentifiable model, thus obtaining a 15-dimensional representation for every entry in the dataset.
-
1.
Citizenship status: 0: Born in the U.S, 1: Born in Puerto Rico, Guam, the U.S. Virgin Islands, or the Northern Marianas, 2: Born abroad of American parent(s), 3: U.S. citizen by naturalization, 4: Not a citizen of the U.S.
-
2.
Military service: 0: Is or was in active duty, 1: Never served in the military.
-
3.
Nativity: 0: Native, 1: Foreign-born.
-
4.
disability: 0: Not having any disability, 1: Having a Hearing, vision, or cognitive disability.
-
5.
Income: 0: Personal income over 50000 USD a year , 1: Personal income below 50000 USD a year.
-
6.
Race: 0:self-identifying as not white , 1:self-identifying as white
The observed distribution is given by simulating selection bias via an indicator variable:
Again, the sample from are all those samples for which .
Let be unemployment status, sex, income and be race. The set used in the first setting of experiments (estimating ) is:
-
•
Unrestricted, separable and Targeted : .
-
•
(partial) race + income : was .
-
•
(full) race + income : was .
-
•
race + income + Outcome : was .
Each experiment was run 5 times over different bootstrap replicates of the sample of distribution . The experimental results are summarized in table 2.
| Lower bound | Upper bound | ||||
|---|---|---|---|---|---|
| mean | std | mean | std | ||
| Unrestricted | DRO | 0.132 | 0.055 | 0.602 | 0.107 |
| Ours | 0.161 | 0.003 | 0.509 | 0.004 | |
| Separable | DRO | 0.129 | 0.004 | 0.433 | 0.008 |
| Ours | 0.371 | 0.007 | 0.383 | 0.009 | |
| Targeted | DRO | 0.129 | 0.004 | 0.433 | 0.008 |
| Ours | 0.366 | 0.015 | 0.385 | 0.010 | |
| (Partial) Race + Income | ours | 0.067 | 0.004 | 0.666 | 0.012 |
| DRO | 0.064 | 0.004 | 0.753 | 0.015 | |
| (Full) Race + Income | ours | 0.160 | 0.004 | 0.513 | 0.006 |
| DRO | 0.093 | 0.003 | 0.678 | 0.014 | |
| Race + Income + Outcome | ours | 0.184 | 0.008 | 0.389 | 0.007 |
| DRO | 0.093 | 0.003 | 0.677 | 0.013 | |
| DRO Omniscient | 0.208 | 0.012 | 0.451 | 0.01 | |
The set used in the second setting of experiments (estimating the coefficient of the indicator variable in a linear regression model) is:
-
•
Unrestricted and targeted: .
-
•
(Full) Race + income :, was .
-
•
Race + income + Outcome : was .
Each experiment was run 5 times over different bootstrap replicates of the sample of distribution . The experimental results are summarized in table 3.
| Lower bound | Upper bound | ||||
|---|---|---|---|---|---|
| mean | std | mean | std | ||
| Unrestricted | DRO | -0.513 | 0.026 | 0.112 | 0.011 |
| Ours | -0.492 | 0.022 | 0.062 | 0.036 | |
| Separable | DRO | -0.345 | 0.013 | -0.055 | 0.033 |
| Ours | -0.305 | 0.010 | -0.303 | 0.009 | |
| (Full) Race + Income | DRO | -0.492 | 0.022 | 0.062 | 0.036 |
| Ours | -0.515 | 0.028 | 0.123 | 0.025 | |
| Race + Income + Outcome | DRO | -0.509 | 0.029 | 0.110 | 0.017 |
| Ours | -0.304 | 0.057 | -0.079 | 0.011 | |
B.4 Logistic regression model
We run one additional experiment to estimate the coefficient of the indicator variable . However, instead of being the coefficient of a linear model, it is now the coefficient of a logistic regression. Only the unrestricted experiment was run. The experiment was run 5 times. The data reported is the average value and standard deviation for the 5 outputs obtained from the experiment. The results are summarized in figure 4 and table 4.
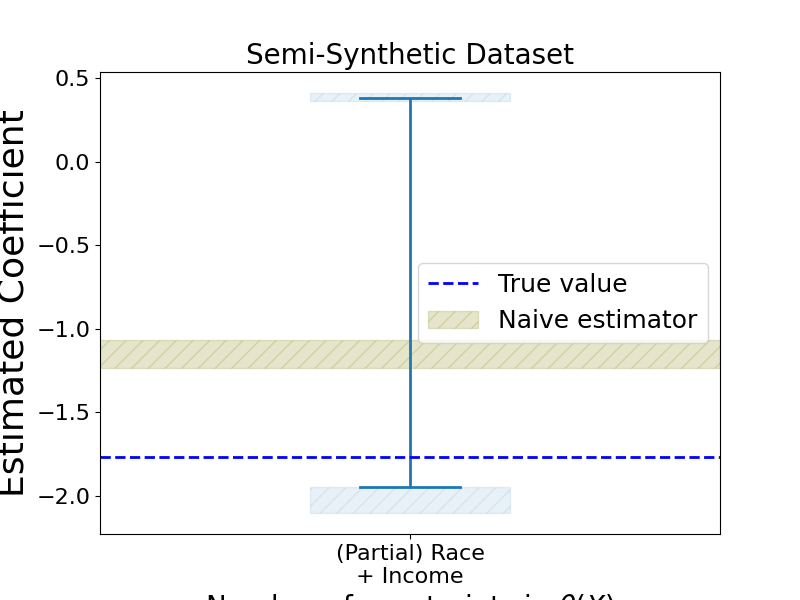
| Lower bound | Upper bound | |||
|---|---|---|---|---|
| mean | std | mean | std | |
| Unrestricted | -1.998 | 0.069 | 0.382 | 0.019 |
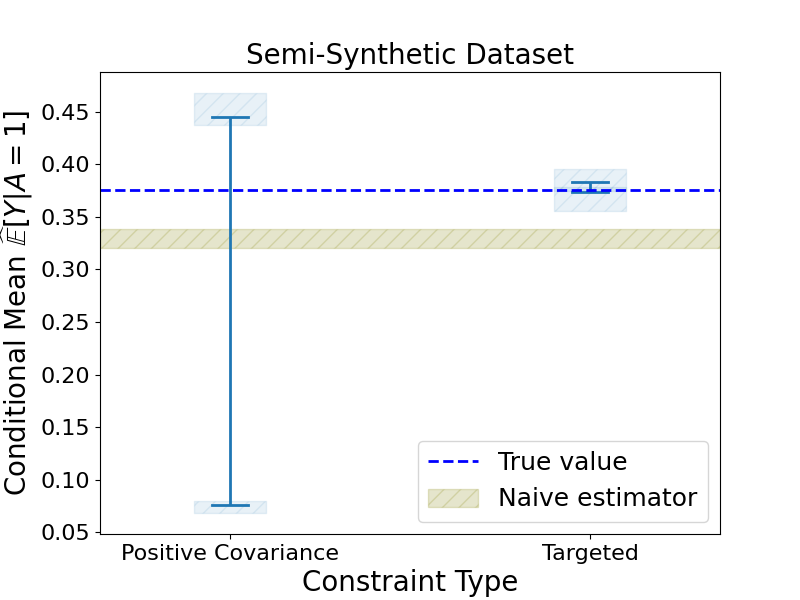
B.5 Covariance-like restrictions
We run one additional experiment to estimate the coefficient of the indicator variable . However, instead of being the coefficient of a linear model, it is now the coefficient of a logistic regression. The experiment was run 5 times. The data reported is the average value and standard deviation for the 5 outputs obtained from the experiment. The results are in figure 4 and table 4. For the results in figure 4 and table 4, we constrained the covariance for a set of variables to be positive. Specifically, we took the pair of variables with the largest positive covariance—being a US citizen and being a native—and restricted that covariance to positive during the optimization.
Overall, we experimented with two types of restrictions on the covariance: restricting the sign of the covariance or the exact covariance value. The two types of constraints had similar results. We also tested restricting on multiple feature pairs but didn’t see any significant differences in the bounds.
B.6 Guide to run the experiments
In the experiments_metadata folder are JSON files with the exact hyperparameters used in all the experiments presented in the paper. To execute a particular set of experiments related to the conditional mean, use the inference.py script. For example, the following command generates the bounds with different parametric forms for the simulated dataset:
To recreate the results of the experiments that involve regression models, use the inference_non_closed_form.py script:
We will provide a detailed table with the JSON files that generate the data of the plots we included.
Each successful run of the two commands will produce a folder containing a data frame with the results and several plots. The folder’s name is a timestamp denoting the experiment’s end time. To reproduce the plots from the paper, use the notebook in the folder named plotting.
The directory hierarchy is the following \dirtree.1 / (root). .2 README.md. .2 experiment_artifacts. .2 optimization. .3 experiments_metadata. .3 inference.py. .3 inference_non_closed_form.py. .2 plotting. .3 paper_plots.ipynb. .3 utils.py.