Statistical Taylor Expansion111
Abstract
Statistical Taylor expansion replaces the input precise variables in a conventional Taylor expansion with random variables each with known distribution, to calculate the result mean and deviation. It is based on the uncorrelated uncertainty assumption [1]: Each input variable is measured independently with fine enough statistical precision, so that their uncertainties are independent of each other. Statistical Taylor expansion reveals that the intermediate analytic expressions can no longer be regarded as independent of each other, and the result of analytic expression should be path independent. This conclusion differs fundamentally from the conventional common approach in applied mathematics to find the best execution path for a result. This paper also presents an implementation of statistical Taylor expansion called variance arithmetic, and the tests on variance arithmetic.
Keywords: computer arithmetic, error analysis, interval arithmetic, uncertainty, numerical algorithms.
AMS subject classifications: G.1.0
Copyright ©2024
1 Introduction
1.1 Measurement Uncertainty
Except for the simplest counting, scientific and engineering measurements never give completely precise results [2][3]. In scientific and engineering measurements, the uncertainty of a measurement usually is characterized by either the sample deviation or the uncertainty range [2][3].
-
•
If or , is a precise value.
-
•
Otherwise, is an imprecise value.
is defined as the statistical precision (or simply precision in this paper) of the measurement, in which is the value, and is the uncertainty deviation. A larger precision means a coarser measurement while a smaller precision means finer measurement. The precision of measured values ranges from an order-of-magnitude estimation of astronomical measurements to to of common measurements to of state-of-art measurements of basic physics constants [4].
How to calculate the analytic expression with imprecise values is the subject of this paper.
1.2 Extension to Existing Statistics
Instead of focusing on the result uncertainty distribution of a function [5], statistical Taylor expansion gives the result mean and variance for general analytic expressions.
- •
- •
1.3 Problem of the Related Numerical Arithmetics
Variance arithmetic implements statistical Taylor expansion. It exceeds all existing related numerical arithmetics.
1.3.1 Conventional Floating-Point Arithmetic
The conventional floating-point arithmetic [7][8][9] assumes the finest precision for each value all the time, and constantly generates artificial information to meet this assumption during the calculation [10]. For example, the following calculation is carried out precisely in integer format:
| (1.1) |
If Formula (1.1) is carried out using conventional floating-point arithmetic:
| (1.2) |
-
1.
The normalization of the input values pads zero tail bit values artificially, to make each value as precise as possible for the 64-bit IEEE floating-point representation, e.g., from to .
-
2.
The multiplication results exceed the maximal significance of the 64-bit IEEE floating-point representation, so that they are rounded off, generating rounding errors, e.g., from to .
- 3.
Because a rounding error from lower digits quickly propagates to higher digits, the significance of the 32-bit IEEE floating-point format [7][8][9] is usually not fine enough for calculations involving input data of to precision. For complicated calculations, even the significance of the 64-bit IEEE floating-point format [7][8][9] may not enough for inputs with to precision.
Self-censored rules are developed to avoid such rounding error propagation [13][14], such as avoiding subtracting results of large multiplication, as in Formula (1.2). However, these rules are not enforceable, and in many cases are difficult to follow, and even more difficult to quantify. So far, the study of rounding error propagation is concentrated on linear calculations [11][12][15], or on special cases [13][16][17], while the rounding errors are generally manifested as the mysterious and ubiquitous numerical instability [18].
The forward rounding error study [12] compares 1) the result with rounding error and 2) the ideal result without rounding error, such as comparing the result using 32-bit IEEE floating-point arithmetic and the corresponding result using 64-bit IEEE floating-point arithmetic [19]. The most recent such study gives an extremely optimistic view on numerical library errors as a fraction of the least significant bit of the significand of floating-point results [19]. However, such optimism does not seem to hold in the real statistical tests on the numerical library functions as presented in this paper. In contrast, the results of variance arithmetic agree well with all tests statistically.
The backward rounding error study [11][12][15] only estimates the result uncertainty due to rounding errors, so that it misses the bias caused by rounding errors on the result value. Such analysis is generally limited to very small uncertainty due to its usage of perturbation theory, and it is specific for each specific algorithm [11][12][15]. In contrast, statistical Taylor expansion is generic for any analytic function, for both result mean and deviation, and it can deal with input uncertainties of any magnitudes.
The conventional numerical approaches explore the path-dependency property of calculations based on conventional floating-point arithmetic, to find the best possible methods, such as in Gaussian elimination [12][13][14]. However, by showing that the analytic result of statistical input(s) should be path-independent, statistical Taylor expansion challenges this conventional wisdom.
1.3.2 Interval Arithmetic
Interval arithmetic [14][20][21][22][23][24] is currently a standard method to track calculation uncertainty. Its goal is to ensure that the value x is absolutely bounded within its bounding range throughout the calculation.
The bounding range used by interval arithmetic is not compatible with usual scientific and engineering measurements, which instead use the statistical mean and deviation to characterize uncertainty [2][3] 222 There is one attempt to connect intervals in interval arithmetic to confidence interval or the equivalent so-called p-box in statistics [25]. Because this attempt seems to rely heavily on 1) specific properties of the uncertainty distribution within the interval and/or 2) specific properties of the functions upon which the interval arithmetic is used, this attempt does not seem to be generic. If probability model is introduced to interval arithmetic to allow tiny bounding leakage, the bounding range is much less than the corresponding pure bounding range [15]. Anyway, these attempts seem to be outside the main course of interval arithmetic. .
Interval arithmetic only provides the worst case of uncertainty propagation. For instance, in addition, it gives the bounding range when the two input variables are +1 correlated [26]. However, if the two input variables are -1 correlated, the bounding range after addition reduces [27] 333 Such case is called the best case in random interval arithmetic. The vast overestimation of bounding ranges in these two worst cases prompts the development of affine arithmetic [26][28], which traces error sources using a first-order model. Being expensive in execution and depending on approximate modeling even for such basic operations as multiplication and division, affine arithmetic has not been widely used. In another approach, random interval arithmetic [27] randomly chooses between the best-case and the worst-case intervals, so that it can no longer guarantee bounding without leakage. Anyway, these attempts seem to be outside the main course of interval arithmetic. . Such worse assumption leads to overestimation of result uncertainties by order-of-magnitude [1].
The results of interval arithmetic may depend strongly on the actual expression of an analytic function . This is the dependence problem which is amplified in interval arithmetic [23] but also presented in conventional floating-point arithmetic [13].
Interval arithmetic lacks mechanism to reject a calculation, while a mathematical calculation always has a valid input range. For example, it forces branched results for or when , while a context-sensitive uncertainty bearing arithmetic should reject such calculation naturally.
In contrast, variance arithmetic provides statistical bounding range with a fixed bounding leakage of probability. It has no dependency problem. Its statistical context rejects certain input intervals mathematically, such as inversion and square root of a statistical bounding range containing zero.
1.3.3 Statistical Propagation of Uncertainty
If each input variable is a random variable, and the statistical correlation between the two input variables is known, statistical propagation of uncertainty gives the result mean and variance [29][30].
Statistical Taylor expansion has a different statistical assumption called uncorrelated uncertainty assumption [1]: Each input variable is measured independently with fine enough precision, so that their uncertainties are independent of each other, even though the input variables could be highly correlated. This assumption is in line with most error analysis [2][3].
1.3.4 Significance Arithmetic
Significance arithmetic [31] tries to track reliable bits in an imprecise value during the calculation. In the two early attempts [32][33], the implementations of significance arithmetic are based on simple operating rules upon reliable bit counts, rather than on formal statistical approaches. They both hold the reliable a bit count as an integer when applying their rules, while a reliable bit count could be a fractional number [34], so they both can cause artificial quantum reduction of significance. The significance arithmetic marketed by Mathematica [34] uses a linear error model that is consistent with a first-order approximation of interval arithmetic [14][22][23].
One problem of significance arithmetic is that itself can not properly specify the uncertainty [1]. For example, if the least significand bit of significand is used to specify uncertainty, then the representation has very coarse precision, such as [1]. Introducing limited bits calculated inside uncertainty cannot avoid this problem completely. Thus, the resolution of the conventional floating-point representation is desired. This is why variance arithmetic has abandoned the significance arithmetic nature of its predecessor [1].
1.3.5 Stochastic Arithmetic
Stochastic arithmetic [35][36] randomizes the least significant bits (LSB) of each of input floating-point values, repeats the same calculation multiple times, and then uses statistics to seek invariant digits among the calculation results as significant digits. This approach may require too much calculation since the number of necessary repeats for each input is specific to each algorithm, especially when the algorithm contains branches.
In contrast, statistical Taylor expansion provides a direct characterization of result mean and deviation without sampling.
1.4 An Overview of This Paper
This paper presents the theory for statistical Taylor expansion, the implementation as variance arithmetic, and the tests of variance arithmetic. Section 1 compares statistical Taylor expansion and variance arithmetic with each known uncertainty-bearing arithmetic. Section 2 presents the theoretical foundation for statistical Taylor expansion. Section 3 presents variance arithmetic. Section 4 discusses the standards and methods to validate variance arithmetic. Section 5 tests variance arithmetic for the most common math library functions. Section 6 applies variance arithmetic to adjugate matrix and matrix inversion. Section 7 applies variance arithmetic to process time-series data. Section 8 focuses on the effect of numerical library errors and shows that such library errors can be significant. Section 9 applies variance arithmetic to regression. Section 10 provides a summary and discussion for variance arithmetic.
2 Statistical Taylor Expansion
2.1 The Uncorrelated Uncertainty Assumption
The uncorrelated uncertainty assumption [1] states that the uncertainty of any input is statistically uncorrelated with any other input uncertainty. It is consistent with the common methods in processing experimental data [2][3], such as the common knowledge or belief that precision improves with the count as during averaging.
If two signals are independently measured so that their measurement noises are not correlated. Their measurement precision are and , respectively. Even these two signal has overall correlation , at the level of the average precision , the correlation is reduced to according to Formula (2.1) [1].
| (2.1) |
decreases fast with finer so that when is fine enough, at the level of uncertainty, the two signals are independent of each other [1].
2.2 Distributional Zero and Distributional Pole
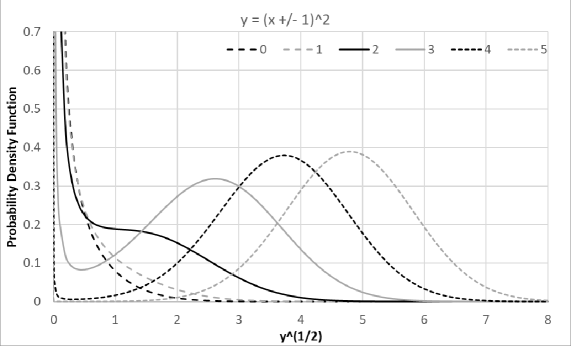
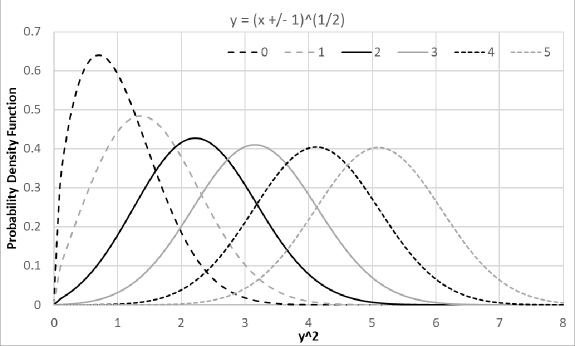
Let be the distribution density function of random variable with mean and deviation . Let be the normalized form of , in which , e.g., Normal distribution is the normalized form of Gaussian distribution.
Let be a strictly monotonic function, so that exists. Formula (2.2) is the distribution density function of [2][5]. In Formula (2.2), the same distribution can be expressed in either or or , which are different representations of the same underlying random variable. Using Formula (2.2), Formula (2.3) gives the for if is Gaussian.
| (2.2) | ||||
| (2.3) |
Viewed in the coordinate, is modulated by , in which is the first derivative of to . A distributional zero of the uncertainty distribution happens when , while a distributional pole happens when . Zeros and poles provides the strongest local modulation to :
- •
- •
- •
In both Figure 1 and 2, the result probability density function in the representation resembles the input distribution more when the mode of the distributions is further away from either distributional pole or distributional zero.
2.3 Statistical Taylor Expansion
Formula (2.2) gives the uncertainty distribution of an analytic function. However, normal scientific and engineering calculations usually do not care about the result distribution, but just few statistics of the result, such as the result mean and deviation [2][3]. Such simple statistics is the result of statistical Taylor expansion. The deviation in statistical Taylor expansion is also referred to as uncertainty, which may or may not be the measured statistical deviation.
An analytic function can be precisely calculated in a range by the Taylor series as shown in Formula (2.5). Formula (2.4) defines bounded momentum , in which are bounding factors. Using Formula (2.4), Formula (2.6) and (2.3) gives the mean and the variance for , respectively. is defined as the uncertainty bias which is the effect of the input uncertainty to the result value.
| (2.4) | ||||
| (2.5) | ||||
| (2.6) | ||||
| (2.7) |
Due to uncorrelated uncertainty assumption, Formula (2.9) and (2.3) calculate the mean and variance of Taylor expansion in Formula (2.8), in which and are the variance momenta for and , respectively:
| (2.8) | ||||
| (2.9) | ||||
| (2.10) |
Although Formula (2.3) is only for 2-dimensional, it can be extended easily to any dimensional.
2.4 Statistical Bounding
When the bounding factors and are limited, Formula (2.4) provides statistical bounding . The probability for is defined as bounding leakage.
2.5 Bounding Symmetry and Asymptote
A bounding is mean-preserving if , which has the same mean as the unbounded distribution. To achieve mean-preserving, determines . With mean-preserving bounding, Formula (2.11) and (2.12) give the result for , while Formula (2.13) and (2.14) give the result for :
| (2.11) | ||||
| (2.12) | ||||
| (2.13) | ||||
| (2.14) |
For any input distribution symmetric around its mean , any bounding has property , which simplifies statistical Taylor expansion further.
2.5.1 Uniform Input Uncertainty
For uniform distribution, the bounding factor is , and the bounding leakage . According to Formula (2.15), while .
| (2.15) |
2.5.2 Gaussian Input Uncertainty
The central limit theorem converges other distributions toward Gaussian [5] after addition and subtraction, and such convergence is fast [1]. In a digital computer, multiplication is implemented as a series of shifts and additions, division is implemented as a series of shifts and subtractions, and general function is calculated as addition of expansion terms [8][9]. This is why in general an uncertainty without bounds is assumed to be Gaussian distributed [2][3][5].
For Gaussian uncertainty input, .
2.5.3 An Input Uncertainty with Limited Range
Formula (2.20) shows a distribution density function with , whose bounding range satisfying . Formula (2.21) shows its mean-preserving equation. Formula (2.22) shows its bounded momentum. Formula (2.23) shows its asymptote. Formula (2.24) shows its bounding leakage.
| (2.20) | ||||
| (2.21) | ||||
| (2.22) | ||||
| (2.23) | ||||
| (2.24) |
2.6 One Dimensional Examples
The result variance in statistical Taylor expansion shows the nature of the calculation, such as , , , and .
2.7 Dependency Tracing
| (2.37) | ||||
| (2.38) | ||||
| (2.39) | ||||
| (2.40) |
When all the inputs obey the uncorrelated uncertainty assumption, statistical Taylor expansion traces dependency in the intermediate steps. For example:
- •
- •
-
•
Formula (2.39) shows , whose dependence tracing can be demonstrated by .
- •
Variance arithmetic uses dependency tracing to guarantee that the result mean and variance fit statistics. Dependency tracing comes with a price: variance calculation is generally more complex than value calculation, and it has narrow convergence range for the input variables. Dependency tracing also implies that the result of statistical Taylor expansion should not be path dependent.
2.8 Traditional Execution and Dependency Problem
Dependency tracing requires an analytic solution to apply Taylor expansion for the result mean and variance, such as using Formula (2.6), (2.3), (2.9), and (2.3). It conflicts with traditional numerical executions on analytic functions:
-
•
Traditionally, using intermediate variables is a widespread practice. But it upsets dependency tracing through variable usage.
-
•
Traditionally, conditional executions are used to optimize numerical executions and to minimize rounding errors, such as the Gaussian elimination to minimize floating-point rounding errors for matrix inversion [37]. Unless required by mathematics such as for the definition of identity matrix, conditional executions need to be removed for dependency tracing, e.g., Gaussian elimination needs to be replaced by direct matrix inversion as described in Section 6.
-
•
Traditionally, approximations on the result values are carried out during executions. Using statistical Taylor expansion, Formula (2.3) shows that the variance converges slower than that of the value in Taylor expansion, so that the target of approximation should be more on the variance. Section 6 provides an example of first order approximation on calculating matrix determinant.
-
•
Traditionally, results from math library functions are trusted blindly down to every bit. As shown in Section 8, statistical Taylor expansion can now illuminate the numerical errors in math library functions, and it demands these functions to be recalculated with uncertainty as part of the output.
-
•
Traditionally, an analytic expression can be broken down into simpler and independent arithmetic operations of negation, addition, multiplication, division, and etc 444Sometimes square root is also regarded as an arithmetic operation.. But such approach causes the dependency problem in both floating-point arithmetic and interval arithmetic. It also causes the dependency problem in statistical Taylor expansion also. For example, if is calculated as , , and , only gives the correct result, while the other two give wrong results for wrong independence assumptions between and , or between and , respectively.
-
•
Traditionally, a large calculation may be broken into sequential steps, such as calculating as . But this method no longer works in statistical Taylor expansion due to dependency tracing of inside , e.g., and . is path-dependent, e.g., and .
Dependency tracing gets rid of almost all freedoms in the traditional numerical executions, as well as the associated dependence problems. All traditional numerical algorithms need to be reexamined or reinvented for statistical Taylor expansion.
3 Variance Arithmetic
Variance arithmetic implements statistical Taylor expansion, by adding practical assumptions.
3.1 Choices of Bounding Factors
For discussion simplicity, only Gaussian input uncertainty will be considered in this paper. For Gaussian input uncertainty, when , according to Formula (2.19), which is small enough for most applications. is also a golden standard to assert a negative result [3]. Thus, in variance arithmetic for Gaussian input uncertainty.
3.2 Low-Order Approximation
3.3 Expansion Calculation
Due to digital limitation of conventional floating-point representation, can only be calculated to before becoming infinitive, Thus, variance arithmetic has different convergence rule from its counterpart of Taylor expansion of precise variable. In variance arithmetic, an infinitive expansion (including Taylor expansion) can fail for the following reasons: not monotonic, not stable, not positive, not finite, and not reliable.
3.3.1 Convergent
The necessary condition for the expansion to converge is that the absolute values of its terms decrease monotonically with increasing when is sufficiently large. To judge for the convergence of Formula (2.3) with limited expansion, the last terms of the expansion is required to be monotonically and absolutely decreasing, so that the chance of the expansion to absolutely increase is only . Otherwise, the result is invalidated as not monotonic.
According to Formula (3.3.1), the condition for Formula (2.30) for to converge is , which is confirmed numerically by as . Beyond the upper bound , the expansion is not monotonic. Variance arithmetic rejects the distributional zero of inside the range of statistically due to the divergence of Formula (2.30) mathematically, with as the connection of these two worlds.
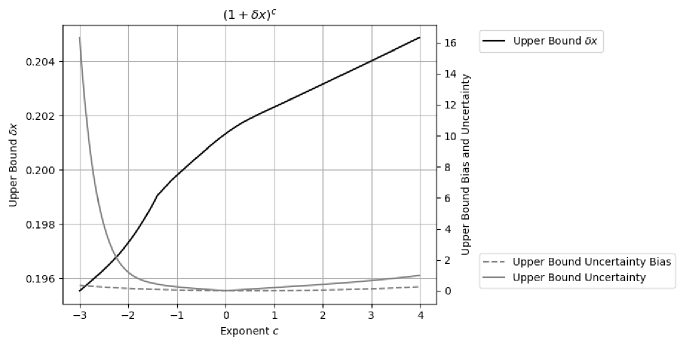
According to Formula (3.3.1), except when c is a nature number, Formula (2.33) for converges near , with the upper bound increasing with . This is confirmed approximately by Figure 3. Beyond the upper bound , the expansion is not monotonic. Qualitatively, converges slower than according to Formula (3.10) and (3.8).
for regardless of , while regardless of . Both are expected from the relation and , respectively, as shown by Formula (2.27) and (2.30).
| (3.11) | ||||
| (3.12) |
3.3.2 Stable
Conventional condition to terminate an infinitive series numerically is when the residual of an expansion is less than the unit in the last place of the result [13]. In practice, the last expansion term usually proxies for the expansion residual if either the residual is known to be less than the last expansion term, or if the residual is difficult to calculate [13]. This method no longer works in variance arithmetic because the expansion is limited to , and because the expansion result is no longer precise. The probability of an imprecie value not equal is indicated by its z-statistic [5]. If this probability is the bounding leakage , Formula (3.13) gives the corresponding upper bound for this z-statistic. Because variance arithmetic has already guaranteed that the expansion is absolutely and monotonically decreasing, if the absolute value of the last expansion term is more than -fold of the result uncertainty, the result is invalidated as not stable.
| (3.13) |
When the Taylor expansion is calculated without enough expansion terms, e.g., if is calculated with only -term expansion, the result will be not stable.
3.3.3 Valid
At any order, if the expansion variance becomes negative, the result is invalidated as not positive.
3.3.4 Finite
If the result of Taylor expansion is not finite, the expansion is invalidated as not finite. This usually happens when the expansion diverges so that it is usually not the reason to bound . For example has infinitive variance.
3.3.5 Reliable
While specifies the uncertainty of , the calculated itself can be imprecise. To guarantee to be precise enough, during expansion, if the value of the variance is less than the -fold of its uncertainty, the result is invalidated as not reliable.
Fortunately, being not reliable is rarely the reason to bound .
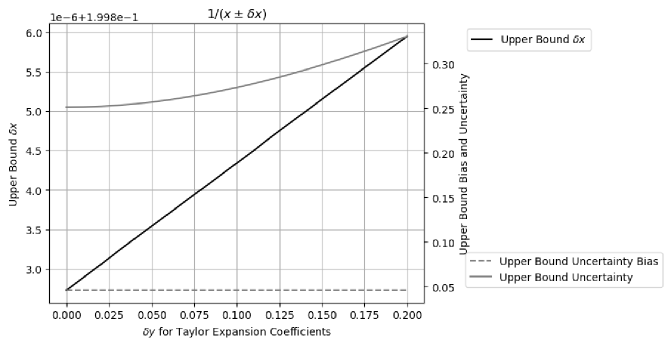
In Formula (2.5) for Taylor expansion, the coefficient can be imprecise, whose uncertainties also contributes to the result variance. Figure 5 shows the upper bound of for different uncertainty of Taylor expansion coefficients. It shows that the result upper bound uncertainty . In this example, such linear increase is extremely small. For discussion simplicity, the Taylor coefficient in Formula (2.5) is assumed to be precise in this paper.
3.3.6 Continuous
The result mean, variance and histogram of variance arithmetic are generally continuous in parameter space.
When is a nature number , Formula (2.33) has terms, so that has no upper bound for unless for not finite, such as Formula (3.6) for . The result mean, variance and histogram of are continuous around . Table 1 shows that the result of is very close to that of , even the former had upper bound for , while the latter has not.
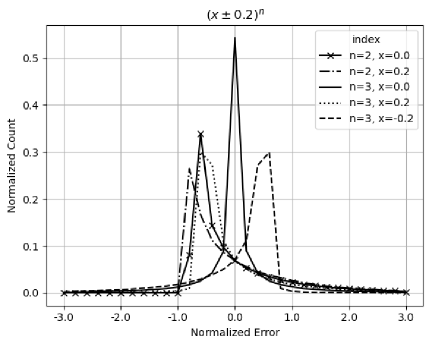
A statistical bounding range of variance arithmetic can include a distributional pole when an analytic function is defined around the distributional pole. The presence of such distributional poles does not cause any discontinuity of the result mean, variance, and histogram. Figure 7 shows the histograms of when and .
-
•
When the second derivative is zero, the resulted distribution is symmetric two-sided Delta-like, such as when .
-
•
When the second derivative is positive, the resulted distribution is right-sided Delta-like, such as the distribution when , or when , or when .
-
•
When the second derivative is negative, the resulted distribution is left-sided Delta-like, such as when , which is the mirror image of the distribution when .
-
•
In each case, the transition from to is continuous.
A statistical bounding range of variance arithmetic cannot include more than one distributional pole because the corresponding statistical Taylor expansion becomes not positive. One such example is in Figure 4.
A statistical bounding range of variance arithmetic cannot include any distributional zero because the underlying analytic function is not continuous when its first derivative becomes infinitive.
| Upper Bound | ||||
|---|---|---|---|---|
| Value | ||||
| Uncertainty |
3.4 Numerical Representation
Variance arithmetic uses a pair of 64-bit standard floating-point numbers to represent the value and the variance of an imprecise value .
The equivalent floating-point value of the least significant bit of significand of a floating-point value is defined as the least significant value 555The “least significant value” and “unit in the last place” are different in concept., which can be abbreviated as for simplicity.
When the uncertainty is not specified initially:
-
•
For a 64-bit standard floating-point value: If the least bits of its significand are all , the value is precise, representing a 2’s fractional with a possibility no less than ; Otherwise, it is imprecise with the uncertainty being -fold of , because pure rounding error of round-to-nearest is uniformly distributed within half bit of the significand of the floating-point value [1].
-
•
For an integer value: If it is within the range of 666Including a hidden bit, the significand in the standard IEEE 64-bit floating-point representation is 53-bit., it has 0 as its uncertainty; Otherwise, it is first converted to a conventional floating-point value before converted to an imprecise value.
3.5 Tracking Rounding Error
Variance arithmetic can track rounding errors effectively without requiring additional rules.
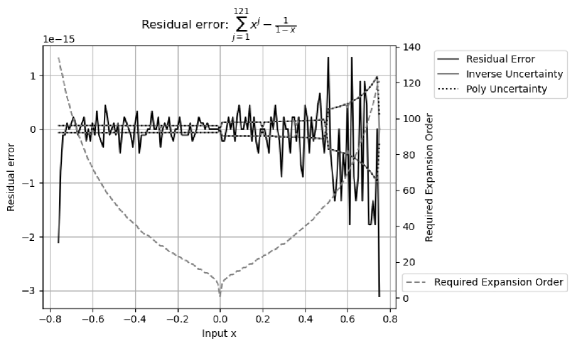
Figure 7 shows the residual error of , in which the polynomial is calculated using Formula (3.14), is calculated using Formula (2.31), and is initiated as a floating-point value. Because is limited to , Formula (3.14) for polynomial is limited to , so that has lower expansion order than that of . Figure 7 shows:
-
•
When , the required expansion order is no more than , so that the residual error is the calculation rounding error between and . Detailed analysis shows that the max residual error is -fold of the of . The calculated uncertainty bounds the residual error nicely for all .
-
•
When , such as when , the required expansion order is more than , so that the residual error is caused by insufficient expansion order of , and the residual error increases absolutely when , e.g., reaching when .
| (3.14) |
3.6 Comparison
Two imprecise values can be compared statistically using the z-statistic [5] of their difference.
When the value difference is zero, the two imprecise values are equal. In statistics, such two imprecise values have possibility to be less than or greater to each other but no chance to be equal to each other [5]. In variance arithmetic, these two imprecise values are neither less nor greater than each other, so they are equal. In reality, the probability of two imprecise values equal exactly to each other is very low.
Otherwise, the standard z-statistic method [5] is used to judge whether they are equal, or less or more than each other. For example, the difference between and is , so that the z-statistic for the difference is , and the probability for them to be not equal is , in which is the cumulative density function for Normal distribution [5]. If the threshold probability of not equality is , . Instead of using the threshold probability, the equivalent bounding range for z can be used, such as for the equal threshold probability of .
4 Verification of Statistical Taylor Expansion
4.1 Verification Methods and Standards
Verification of statistical Taylor expansion is done through the verification of variance arithmetic. Analytic functions or algorithms each with precisely known results are used to validate the result from variance arithmetic using the following statistical properties:
-
•
value error: as the difference between the numerical result and the corresponding known precise analytic result.
-
•
normalized error: as the ratio of a value error to the corresponding uncertainty.
-
•
error deviation: as the standard deviation of the normalized errors.
-
•
error distribution: as the histogram of the normalized errors.
-
•
uncertainty mean: as the mean of the result uncertainties.
-
•
uncertainty deviation: as the deviation of the result uncertainties.
-
•
error response: as the relation between the input uncertainties and the result uncertainties.
-
•
calculation response: as the relation between the amount of calculation and the result uncertainties.
One goal of calculation involving uncertainty is to precisely account for all input errors from all sources, to achieve ideal coverage. In the case of ideal coverage:
-
1.
The error deviation is exactly .
-
2.
The result error distribution should be Normal distribution when an imprecise value is expected, or Delta distribution when a precise value such as a true zero is expected.
-
3.
The error response fits the function, such as a linear error response is expected for a linear function.
-
4.
The calculation response fits the function, such as more calculations generally result in larger result uncertainties.
If the precise result is not known, according to Section 6, the result uncertainty distribution can be used to judge whether ideal coverage is achieved or not.
If instead, the input uncertainty is only correct for the input errors on the order of magnitude, the proper coverage is achieved when the error deviations are in the range of .
When an input contains unspecified errors, such as numerical errors of library functions, Gaussian or white noises of increasing deviations can be added to the input, until ideal coverage is reached. The needed minimal noise deviation gives a good estimation of the amount of unspecified input uncertainties. The existence of ideal coverage is a necessary verification if the application of Formula (2.3) or (2.3) has been applied correctly for the application. The input noise range for the idea coverage defines the ideal application range of input uncertainties.
Gaussian or white noises of specified deviations can also be added to the input to measure the error responses of a function.
4.2 Types of Uncertainties
There are five sources of result uncertainty for a calculation [1][2][13]:
-
•
input uncertainties,
-
•
rounding errors,
-
•
truncation errors,
-
•
external errors,
-
•
modeling errors.
The examples in this paper show that when the input uncertainty precision is or larger, variance arithmetic can provide ideal coverage for input uncertainties.
Empirically, variance arithmetic can provide proper coverage to rounding errors, with the error deviations in the range of .
Section 3 shows that variance arithmetic uses -based rule for truncation error.
The external errors are the value errors which are not specified by the input uncertainties, such as the numerical errors in the library math functions. Section 8 studies the effect of and numerical errors [13]. It demonstrates that when the external errors are large enough, neither ideal coverage nor proper coverage can be achieved. It shows that the library functions need to be recalculated to have corresponding uncertainty attached to each value.
The modelling errors arise when an approximate analytic solution is used, or when a real problem is simplified to obtain the solution. For example, the predecessor of variance arithmetic [1] demonstrates that the discrete Fourier transformation is only an approximation for the mathematically defined continuous Fourier transformation. Conceptually, modeling errors originate from mathematics, so they are outside the domain for variance arithmetic.
4.3 Types of Calculations to Verify
Algorithms of completely different nature with each representative for its category are needed to test the generic applicability of variance arithmetic [1]. An algorithm can be categorized by comparing the amount of its input and output data as [1]:
-
•
application,
-
•
transformation,
-
•
generation,
-
•
reduction.
An application algorithm calculates numerical values from an analytic formula. Through Taylor expansion, variance arithmetic is directly applicable to analytic problems.
A transformation algorithm has about equal amounts of input and output data. The information contained in the data remains about the same after transforming. For reversible transformations, a unique requirement for statistical Taylor expansion is to recover the original input uncertainties after a round-trip transformation which is a forward followed by a reverse transformation. Discrete Fourier Transformation is a typical reversible transforming algorithm, which contains the same amount of input and output data, and its output data can be transformed back to the input data using essentially the same algorithm. A test of variance arithmetic using FFT algorithms is provided in Section 8.
A generation algorithm has much more output data than input data. The generating algorithm codes mathematical knowledge into data, so there is an increase of information in the output data. Some generating algorithms are theoretical calculations which involve no imprecise input so that all result uncertainty is due to rounding errors. Section 9 demonstrates such an algorithm, which calculates a table of the sine function using trigonometric relations and two precise input data, and .
A reduction algorithm has much less output data than input data such as numerical integration and statistical characterization of a data set. Some information of the data is lost while other information is extracted during reducing. Conventional wisdom is that a reducing algorithm generally benefits from a larger input data set [5]. For example, discrete Fourier transformation was found to be unfaithful for continuous Fourier transformation [1].
5 Math Library Functions
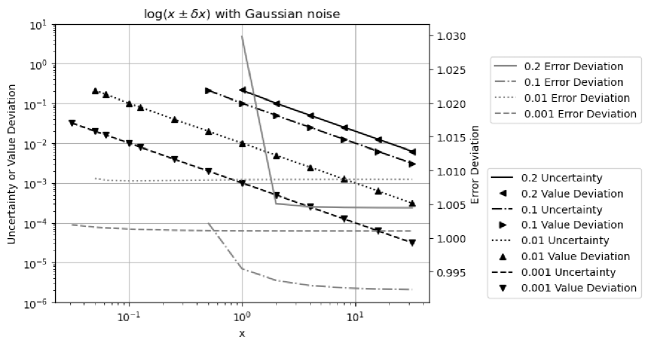
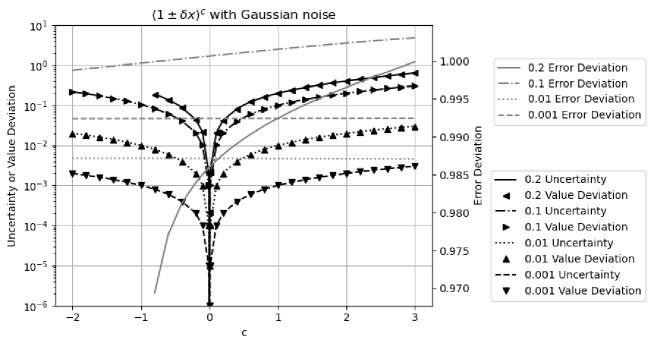
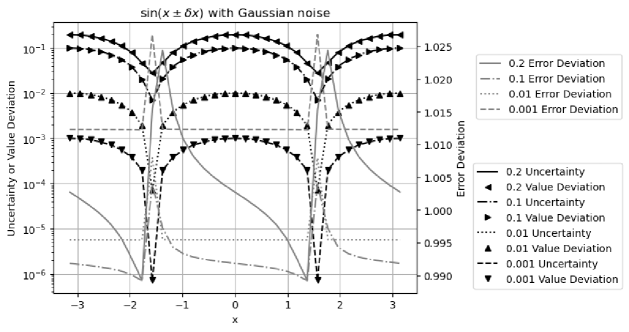
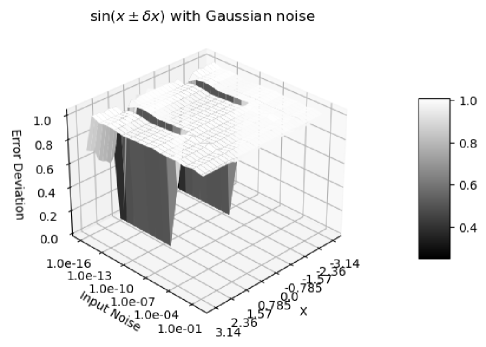
Formula (2.27), (2.30), (2.36), and (2.33) are tested by the corresponding math library functions exp, log, sin, and pow, respectively.
At each point for an input uncertainty , the result uncertainty is calculated by variance arithmetic. The corresponding error deviation is obtained by sampling:
-
1.
Take samples from either Gaussian noise or uniform distribution with as the deviation, and construct which is plus the sampled noise.
-
2.
For each , use the corresponding library function to calculate the value error as the difference between using and using as the input.
-
3.
The value error is divided by the result uncertainty, as the normalized error.
-
4.
The standard deviation of the normalized errors is the error deviation.
-
5.
In addition, for each of these tests, all value errors follow the same underlying distribution. The deviation of the value errors is defined as the value deviation, which the uncertainty should match.
5.1 Exponential
5.2 Logarithm
5.3 Power
5.4 Sine
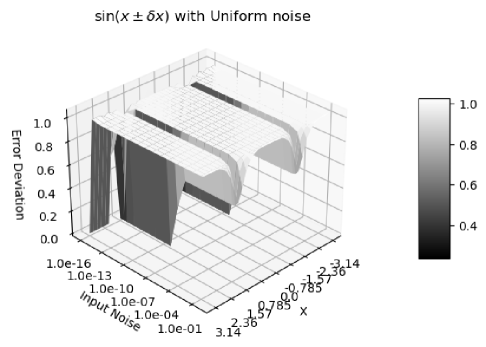
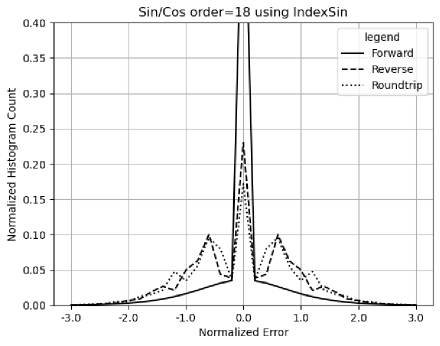
Figure 11 shows that the calculated uncertainties using Formula (2.36) agree very well with the measured value deviations for . It also shows that has the same periodicity as :
-
•
When , , so that .
-
•
When , , so that .
has distributional poles at . Figure 12 shows that the error deviation for is except when and , which agrees with the expected Delta distribution at . In other places, the error deviations are very close to .
Figure 12 and Figure 13 both show the result uncertainty of vs the input and the input uncertainty . In Figure 12, Gaussian noises are used, while in Figure 13, the input noises are uniformly distributed. The difference of Figure 12 and 13 shows that the uniform noise or white noise 777White noise is sampled from uniform distributed noise. is more local, while Gaussian noise has strong tail effect, so that the error deviation is much closer to for when . In both cases, there is a clear transition at , which is caused by numerical errors in library , as demonstrated in Section 8. For consistency, only Gaussian noises will be used for other analysis by default.
5.5 Numerical Errors for Library Functions
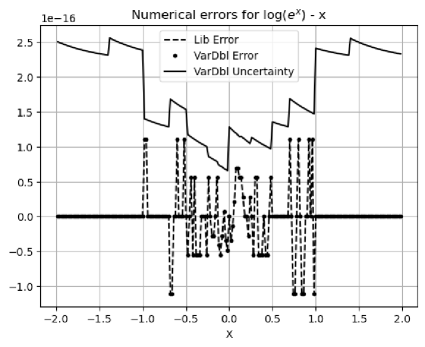
The combined numerical error of the library function and is calculated as . Figure 14 shows that using either variance arithmetic or the conventional floating-point library functions results in the same value errors. The uncertainties of variance arithmetic bound the value errors effectively, resulting in an error deviation about when . It looks suspicious when the value error is always in both calculations.
The numerical error of the library function is calculated as . Figure 15 shows that the normalized errors are not specific to either or , resulting in an error deviation .
The numerical errors of the library functions , , and will be studied in detail later in Section 8.
5.6 Summary
Formula (2.27), (2.30), (2.33), and (2.36) give effective uncertainties for the corresponding library functions. With added noise larger than , ideal coverage is achievable unless near a distributional pole where the deviation is . In non-ideal coverage cases, the error deviation is about so that proper coverage is achieved.
6 Matrix Inversion
6.1 Uncertainty Propagation in Matrix Determinant
Let vector denote a permutation of the vector [37]. Let denote the permutation sign of [37]. Formula (6.1) defines the determinant of a -by- square matrix with the element [37]. The sub-determinant at index is formed by deleting the row and column of , whose determinant is given by Formula (6.2) [37]. Formula (6.3) holds for the arbitrary row index or the arbitrary column index [37].
| (6.1) | ||||
| (6.2) | ||||
| (6.3) |
Assuming , let denote the length-2 unordered permutation which satisfies , and let denote the length-2 ordered permutation which satisfies , and let be an arbitrary ordered permutation 888An ordered permutation is a sorted combination.. Formula (6.3) can be applied to , as:
| (6.4) | ||||
| (6.5) |
The definition of a sub-determinant can be extended to Formula (6.6), in which . Formula (6.5) can be generalized as Formula (6.7), in which is an arbitrary ordered permutation. The -by- matrix in is obtained by deleting the rows in and the columns in . This leads to Formula (6.8) 999 in Formula (6.8) means absolute value of determinant..
| (6.6) | ||||
| (6.7) | ||||
| (6.8) |
Formula (6.9) give the Taylor expansion of , which leads to Formula (6.10) and (6.11) for mean and variance of matrix determinant, respectively.
| (6.9) | ||||
| (6.10) | ||||
| (6.11) |
Formula (6.10) and (6.11) assume that the uncertainties of matrix elements are independent of each other. In contrast, for the special matrix in Formula (6.12), after applying Formula (2.9) and (2.3), Formula (6.13) and (6.14) give the result mean and variance, respectively.
| (6.12) | ||||
| (6.13) | ||||
| (6.14) | ||||
6.2 Adjugate Matrix
The square matrix whose element is is defined as the adjugate matrix[37] to the original square matrix . Let be the identical matrix for . Formula (6.15) and (6.16) show the relation of and [37].
| (6.15) | ||||
| (6.16) |
To test Formula (6.11):
-
1.
A matrix is constructed using random integers uniformly distributed in the range of , which has a distribution deviation of . The integer arithmetic grantees that , , and are precise.
-
2.
Gaussian noises of predefined levels are added to , to construct a which contains imprecise values. Variance arithmetic is used to calculate , , and . For example, to construct a with input noise precision, the deviation of the Gaussian noise is .
- 3.
- 4.
- 5.
The existence of ideal coverage validates Formula (6.11).
6.3 Floating Point Rounding Errors
| Error Deviation | Input Noise Precision | |||
|---|---|---|---|---|
| Matrix Size | ||||
The significand of the conventional floating-point representation [9] has -bit resolution, which is equivalent to . Adding noise below this level will not change the value of a conventional floating-point value, so the result uncertainties are caused by the round errors in the floating-point calculations.
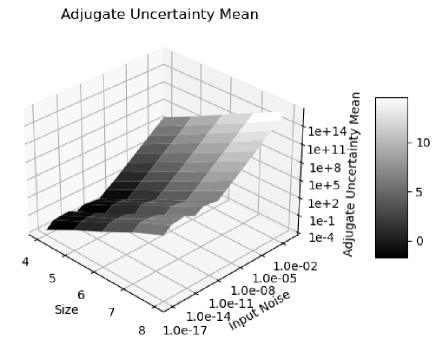
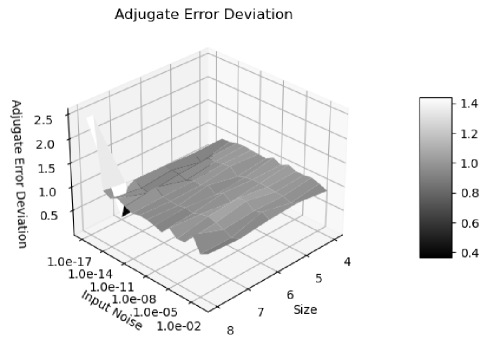
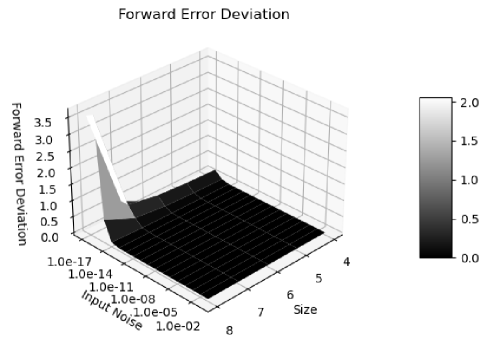
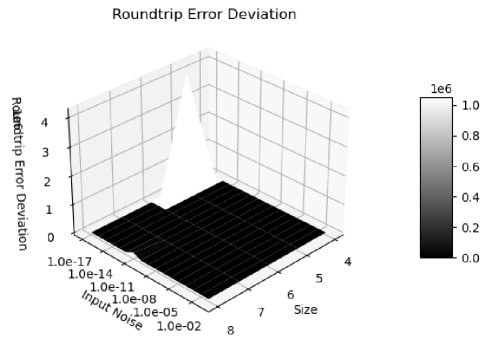
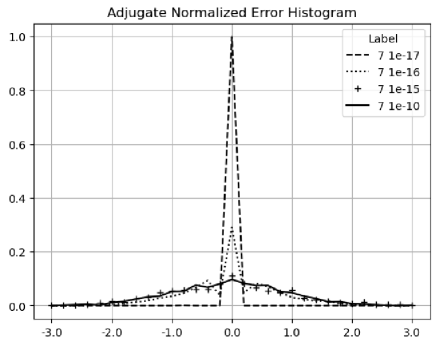
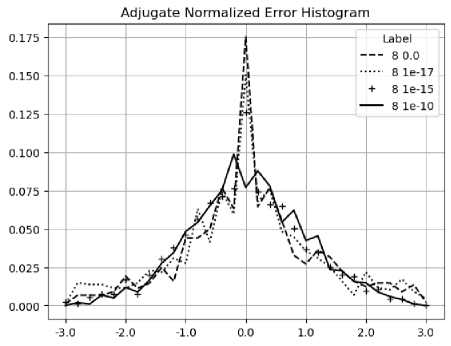
Figure 20 shows that the histograms of the normalized errors is Delta distributed for the input uncertainty , because the adjugate matrix calculation involves about significand bits for a matrix size . Such Delta distribution also holds when the matrix size is less than , or when the input is precise. When the matrix size is , significand bits are needed so rounding occurs. As a result, in Figure 21, the distribution becomes Gaussian with a hint of Delta distribution. Such delta-like distribution persists until the input noise precision reaches , which is also the transition of the two trends in Figure 16.
When the input noise precision increases from to , the distributions become less delta-like and more Gaussian, as shown in both Figure 20 and Figure 21. The non-ideal behaviors in Figure 17, 18, and 19 are all attributed to the rounding errors. Table 2 shows that variance arithmetic achieves proper coverage for the calculation rounding errors for adjugate matrix.
Figure 21 suggests that the histogram of normalized errors is more sensitive to rounding errors than the corresponding error deviation, due to averaging effect of the latter. Histograms of normalized errors can be used as a finger-print for the associated calculation. In case error deviation is not known, a nearly Normal-distributed histogram may be used to identify ideal coverage.
6.4 Matrix Inversion
A major usage of and is to define in Formula (6.17) which satisfies Formula (6.18). Formula (6.19) gives the Taylor expansion for the element . From it, and can be deduced, in the same way as how Formula (2.6) and (2.3) are deducted from Formula (2.5). Although the analytic expression for and is very complex on paper, the deduction is straight-forward in analytic programming such as using SymPy 101010The result of using SymPy for matrix inversion is demonstrated as part of an open source project at https://github.com/Chengpu0707/VarianceArithmetic..
| (6.17) | ||||
| (6.18) | ||||
| (6.19) | ||||
Formula (6.19) suggests that , and is much larger than , which agrees with the common practice to avoid using Formula (6.17) directly [13].
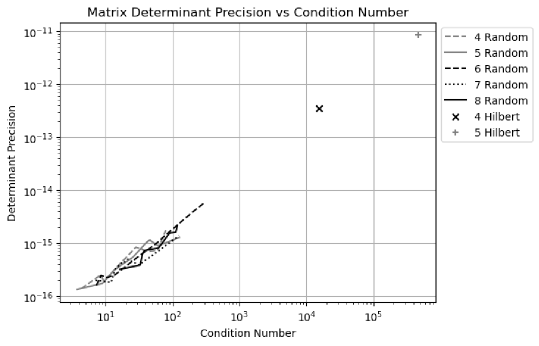
Traditionally, the error response of is quantified by matrix condition number [37]. In Formula (6.17), is dominated by , suggesting that the precision of is largely determined by the precision of . Variance arithmetic treats the to be imprecise, so it can use Formula (6.14) to calculate the determinant variance for a matrix containing floating-point elements, including a randomly generated matrix, or a Hilbert matrix [37] after it is converted to a floating-point matrix 111111Although Hilbert matrix is defined using fractional number, its condition number is also calculated using floating-point arithmetic in math libraries such as SciPy.. Figure 22 shows that there is a strong linear correlation between the conditional number and the determinant precision of matrices, so that the determinant precision can replace the condition number, which is more difficult to calculate 121212There are currently different definitions of matrix condition number, each based on a different definition of matrix norm..
In fact, condition number may not be the best tool to describe the error response of a matrix. Formula (6.20) shows an example matrix inversion using variance arithmetic representation. It clearly shows the overall precision dominance by the value of on the denominator, e.g., in the adjugate matrix becomes in the inverted matrix, while the direct calculation of has -fold better result precision. In Formula (6.20), even though the input matrix has element precision ranging from to , the inverted matrix has element precision all near except the worst one at , showing how dramatically the element precision gets worse in matrix inversion. Formula (6.19) suggests that the precision of inverted matrix deteriorates exponentially with matrix size.
| (6.20) | ||||
6.5 First Order Approximation
Formula (6.21) shows the first order approximation of leads to the first order approximation of . It states that when the input precision is much less than , the determinant of an imprecise matrix can be calculated in variance arithmetic using Formula (6.1) directly.
| (6.21) |
Figure 23 contains the result of applying Formula (6.21). It is very similar to Figure 17, validating Formula (6.21).
7 Moving-Window Linear Regression
7.1 Moving-Window Linear Regression Algorithm [1]
Formula (7.1) and (7.2) give the result of the least-square line-fit of between two set of data and , in which is an integer index to identify pairs in the sets [13].
| (7.1) | ||||
| (7.2) |
In many applications, data set is an input data stream collected with fixed rate in time, such as a data stream collected by an ADC (Analogue-to-Digital Converter) [38]. is called a time-series input, in which indicates time. A moving window algorithm [13] is performed in a small time-window around each . For each window of calculation, can be chosen to be integers in the range of in which is an integer constant specifying window’s half width so that , to reduce Formula (7.1) and (7.2) into Formula (7.3) and (7.4), respectively [1]:
| (7.3) | ||||
| (7.4) |
The calculation of can be obtained from the previous values of , to reduce the calculation of Formula (7.3) and (7.4) into a progressive moving-window calculation of Formula (7.5) and (7.6), respectively [1]
| (7.5) | ||||
| (7.6) |
7.2 Variance Adjustment
When the time series contains uncertainty, the direct application of Formula (7.5) and (7.6) will result in loss of precision, because both formulas use each input multiple times and accumulate the variance of the input once at each usage. Thus, the values for and should be calculated progressively using Formula (7.6) and (7.5), while the variance should be calculated using Formula (7.7) and (7.8), respectively. Formula (7.8) is no longer progressive.
| (7.7) | ||||
| (7.8) |
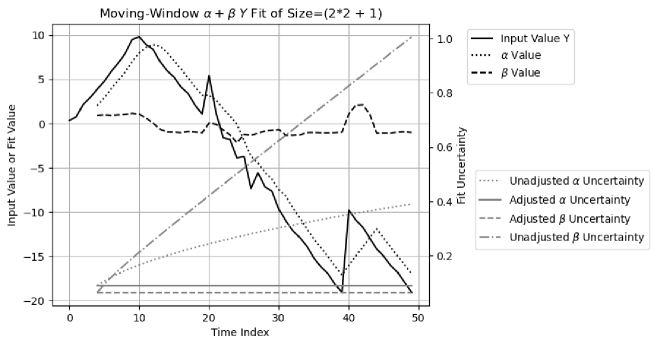
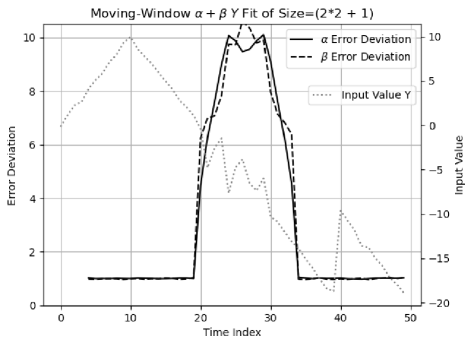
Figure 24 shows that the input signal is composed of:
-
1.
An increasing slope for .
-
2.
A decreasing slope for .
-
3.
A sudden jump with an intensity of at
-
4.
A decreasing slope for .
For each increase of , the increasing rate and the decreasing rate are and , respectively.
The specified input uncertainty is always . Normal noises of deviation are added to the slopes, except Normal noises of deviation are added to the slope for , during which the actual noises are -fold of the specified value.
Figure 24 also shows the result of moving window fitting of vs time index . The result values of and behave correctly with the expected delay in . When Formula (7.3) and (7.4) are used both for values and uncertainties for and , the result uncertainties of and both increase exponentially with the index time . When Formula (7.3) and (7.4) are used only for values, while Formula (7.7) and (7.8) are used for variance for and , the result uncertainty of is , and the result uncertainty of is , both of which are less than the input uncertainty , due to the averaging effect of the moving window.
7.3 Unspecified Input Error
To obtain the error deviation of and , the fitting is done on many time-series data, each with independent generated noises. Figure 25 shows the corresponding error deviation vs index time , which are except near for when the actual noise is -fold of the specified one. It shows that a larger than error deviation may probably indicate unspecified additional input errors other than rounding errors, such as the numerical errors from math libraries.
8 Fast Fourier Transformation
8.1 Discrete Fourier Transformation (DFT)
For each signal sequence , in which is a positive integer, the discrete Fourier transformation and its reverse transformation is given by Formula (8.1) and (8.2), respectively [13], in which is the index time and is the index frequency for the discrete Fourier transformation (DFT) 131313The index frequency and index time are not necessarily related to time unit. The naming is just a convenient way to distinguish the two opposite domains in the Fourier transformation: the waveform domain vs the frequency domain..
| (8.1) | ||||
| (8.2) |
8.2 FFT (Fast Fourier Transformation)
When , in which is a positive integer, the generalized Danielson-Lanczos lemma [13] can be applied to the discrete Fourier transformation as FFT [13].
- •
-
•
When is large, the large amount of input and output data enables high quality statistical analysis.
-
•
The amount of calculation is , because for each output, increasing by 1 results in one additional step of sum of multiplication.
-
•
Each step in the forward transformation thus increases the variance by -fold, so that the result uncertainty mean increases with the FFT order as . Because the reverse transformation divides the result by , the result uncertainty mean decreases with the FFT order as . The result uncertainty mean for the roundtrip transformations is thus .
-
•
Forward and reverse transformations are identical except for a sign, so they are essentially the same algorithm, and their difference is purely due to input data.
Forward and reverse FFT transforms have data difference in normal usage:
-
•
The forward transformation cancels real imprecise data of a Sin/Cos signal into a spectrum of mostly values, so that both its value errors and its result uncertainties are expected to grow faster.
-
•
The reverse transformation spread the spectrum of precise values of most to data of a Sin/Cos signal, so that both its value errors and its result uncertainties are expected to grow slower.
8.3 Testing Signals
To avoid unfaithfulness of discrete Fourier transformation to continuous transformation [1], only Formula (8.1) and (8.2) with integer and will be used.
The following signals are used for testing:
-
•
Sin: .
-
•
Cos: .
-
•
Linear: , whose discrete Fourier transformation is Formula (8.3).
(8.3)
Empirically:
-
•
The results from Sin and Cos signals are statistically indistinguishable from each other.
-
•
The results from Sin signals at different frequencies are statistically indistinguishable from each other.
Thus, the results for Sin and Cos signals at all frequencies are pooled together for the statistical analysis, as the Sin/Cos signals.
8.4 Library Errors
Formula (8.1) and (8.2) limit the use of and to . To minimize the numerical errors of and , indexed sine functions can be used instead of the library sine functions 141414The and library functions in Python, C++, Java all behave in the same way. The indexed sine functions are similar to and functions proposed in C++23 standard but not readily available excepted in few selected platforms such as for Apple.
-
1.
Instead of a floating-point value for and , the integer is used to specify the input to and , as and , to avoid the floating-point rounding error of .
-
2.
The values of and are extended from to using the symmetry of and .
-
3.
The values of and are extended from to the whole integer region using the periodicity of and .
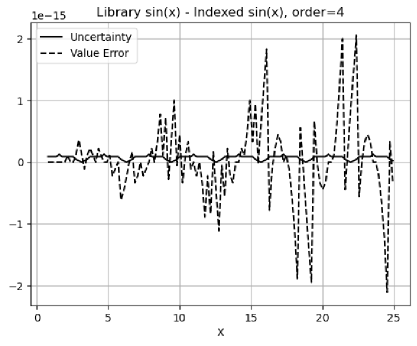
Figure 26 shows that the value difference between the library and the indexed increases with increasing . However, checked by , Figure 27 shows that the value errors are quite comparable between the indexed and library and functions. In Figure 27, the deviations of the value errors for the indexed sine function seem less stable statistically, because the deviations of the index sine function are calculated from much less samples: For the FFT order , the deviations for the indexed sine function contain data covering , while the deviations for the library sine function contain data covering . Figure 27 also shows that both functions have proper coverage in variance arithmetic. Thus, the difference is just caused by the rounding of in and library functions.
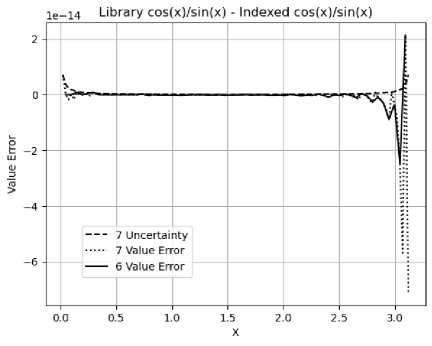
Figure 28 shows the value difference between the library and the indexed for . It covers all the integer inputs to the indexed cotan functions used for the Linear signal of FFT order and . The value errors near increase with the FFT order. It is likely that the rounding error of causes the numerical error when becomes very large near . According to Figure 29, the library function does not have proper coverage in variance arithmetic.
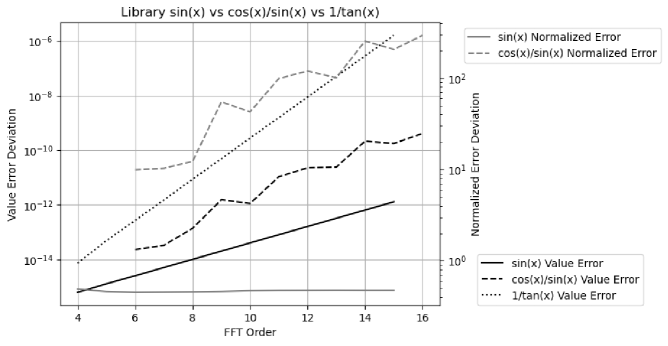
Figure 28 pin-points the deficit of the current and library functions: near . It also indicates the deficit of the current forward rounding error study [12]: near , and without mathematical relation test.
Using indexed as standard, Figure 29 compares the value errors of the library , , and for increasing FFT orders. It shows that the numerical errors of all these library functions grow exponentially with increasing FFT order. has the largest errors, and it will not be used for FFT. has larger errors than those of .
The difference between the indexed and library sine functions shows the inconsistency in the library sine functions, because the indexed sine functions is just the library sine functions in the range of , and should be related to other ranges according to precise mathematical relations. It is difficult to study the numerical errors of library functions using conventional floating-point arithmetic which has no concept of imprecise values. Having identified the nature and the strength of the numerical errors of the library and , variance arithmetic can show their effects using FFT.
8.5 Using the Indexed Sine Functions for Sin/Cos Signals
Using the indexed sine functions, for the waveform of in which is the index time:
-
•
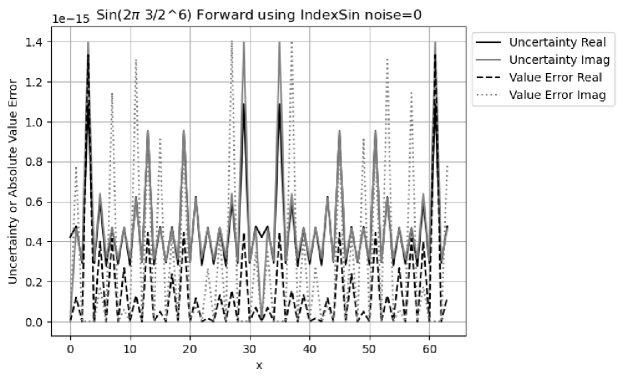
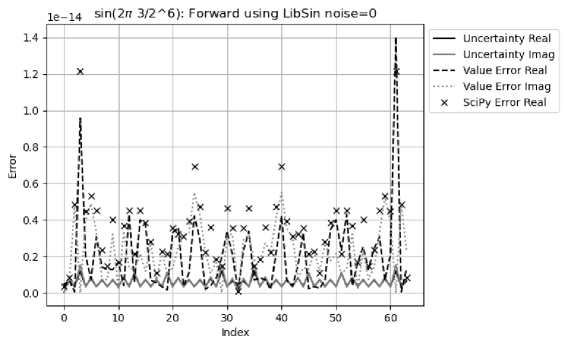
Figure 30 shows that for the forward transformation, the result value errors are comparable to the result uncertainties, with an error deviation of for the real part, and for the imaginary part. Both real and imaginary uncertainties peak at the expected index of , but only real value error peak at the frequency. Both real and imaginary uncertainties peak at the unexpected index of , and , as well as the value errors. The reason for the unexpected peaks is not clear. Overall, the uncertainty seems a smoothed version of the value error, and they are comparable in strength.
-
•
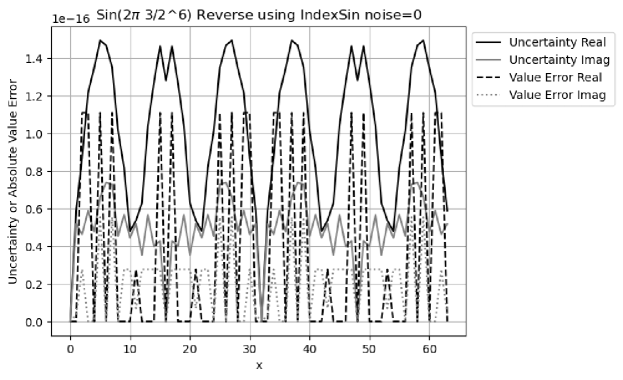
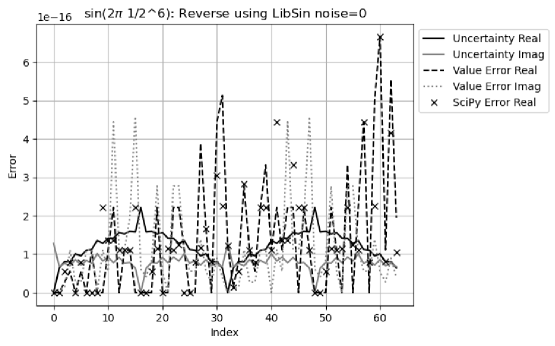
Figure 31 shows that for the reverse transformation, the result value errors are comparable to the result uncertainties, with an error deviation of for the real part, and for the imaginary part. The uncertainty captures the periodicity of the value error, as well as bigger strength of the real value error than that of the imaginary value error.
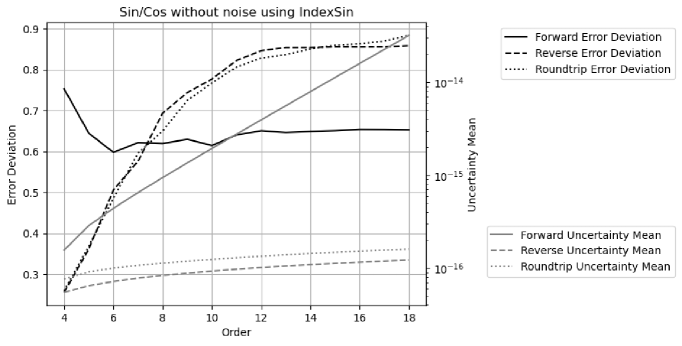
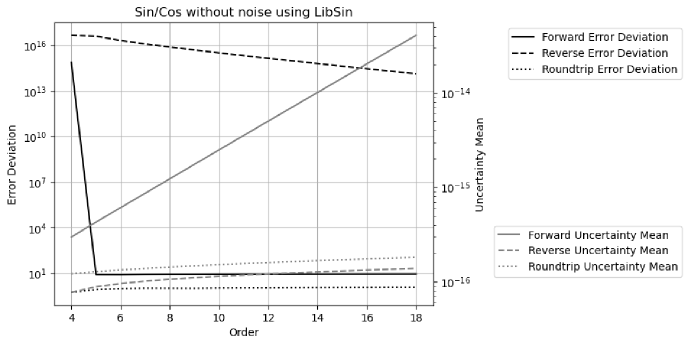
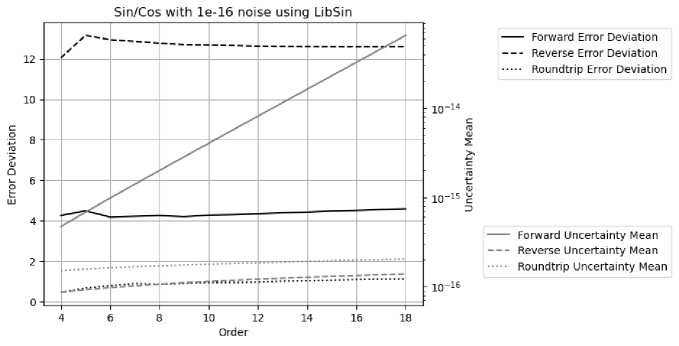
Figure 32 shows both the result uncertainty means and the error deviations vs. FFT order of DTF of Sin/Cos signals using the indexed sine functions. As expected, the uncertainties grow much faster with increasing FFT order for the forward transformation. The error deviations are a constant about for the forward transformation, while they increase with increasing FFT order from until reach a constant about when the FFT order is or more for the reverse and roundtrip transformation.
With increasing FFT order, all histograms become more Gaussian like, and the error deviations for the real and the imaginary parts become more equal in value. Figure 33 shows the corresponding histograms of the normalized errors at FFT order . The distribution of the forward transformation is a larger Delta distribution on top of a Gaussian distribution, while it is a structured distribution on top of a Gaussian distribution for the reverse transformation. The distribution of the roundtrip transformation is almost identical to that of the reverse transformation, suggesting that the presence of input uncertainty for the reverse transformation is not a major factor.
Proper coverage is achieved using the indexed sine functions for Sin/Cos signals.
8.6 Using the Library Sine Functions for Sin/Cos Signals
Because the least significant values are the only source of input uncertainties for variance arithmetic, the result uncertainties using either indexed or library sine functions are almost identical. The library sine functions have numerical calculation errors which are not specified by the input uncertainties of variance arithmetic. The question is whether variance arithmetic can track these numerical errors effectively or not.
Using the library sine functions, for the waveform of in which is the index time:
- •
-
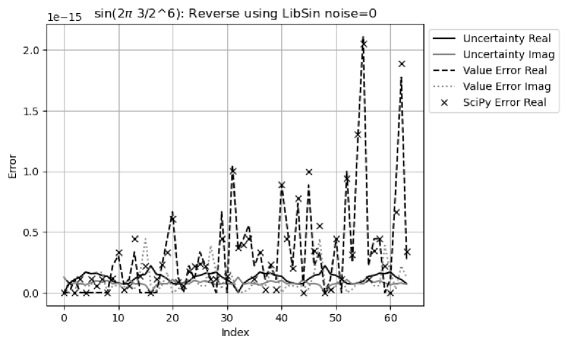
•
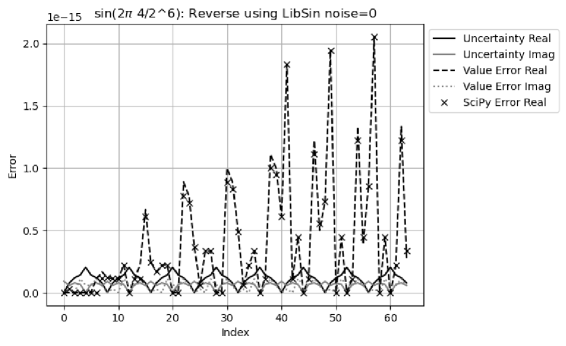
Figure 35 shows that for the reverse transformation, the result value errors are noticeably larger than the result uncertainties, with an error deviation of for the real part, and for the imaginary part. The surprisingly large imaginary error deviation is caused by the small uncertainty at the index time of where the value error is at a local maximum.
-
•
Because of the result of the huge error deviation, Figure 36 shows that the result of the reverse transformation no longer has proper coverage for all FFT orders. When a small noise with deviation of is added to the input, the result uncertainty of the reverse transformation at the index time of is no longer near , so that the result error deviations achieve proper coverage again, as show in Figure 37.
- •
Variance arithmetic reveals why to add small noises to the numerically generated input data, which is already a common practice [13]. It further reveals that the amount of noise needed is to achieve proper coverage.
In Figure 35, the value errors tend to increase with the index time, which is due to the periodic increase of the numerical errors of with as shown in Figure 26. When the signal frequency increases, the increase of the value errors with the index frequency in the reverse transformation becomes stronger, as shown in Figure 35, 38, and 39. In fact, Figure 38 suggests that the periodic numerical errors in Figure 26 resonate with the periodicity of the input signal. In contrast, Figure 31 shows no sign for such increase. It shows that the library numerical errors may have surprisingly large effect on the numerical results.
To validate the FFT implementation in variance arithmetic, the results are compared with the corresponding calculations using the python numerical library SciPy in Figure 34 and 35. The results are quite comparable, except that in SciPy, the data waveform is always real rather than complex. In Figure 34, the SciPy results have been made identical for the frequency indexes and , and the matching to the corresponding results of variance arithmetic is moderate. In Figure 35, the SciPy results match the corresponding results of variance arithmetic quite well. It shows that the effects of library numerical errors revealed by variance arithmetic exist in real applications.
8.7 Linear Signal
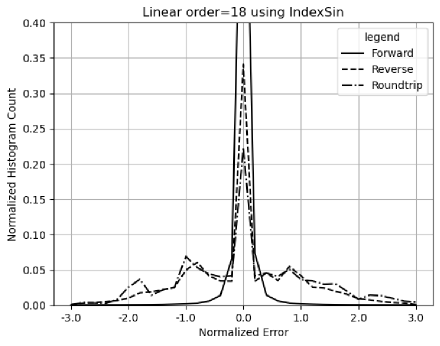
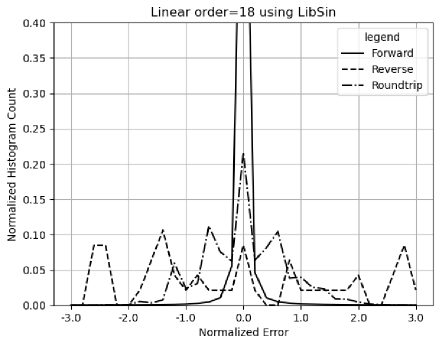
As shown in Figure 29, linear signals may introduce more numerical errors to the result through library . The question is whether variance arithmetic can track these additional numerical errors or not.
Using the indexed sine functions:
-
•
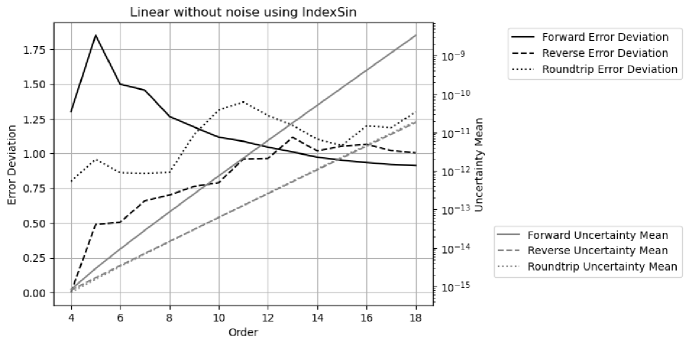
Figure 40 shows that the result uncertainty for each FFT transformation has much larger increase with the increasing FFT order than its counterpart in Figure 32. The much faster uncertainty increase of the forward transformation is attributed to the non-zero input uncertainties. Figure 40 shows that proper coverage can be achieved for all FFT for all FFT orders.
- •
Using the library sine functions:
-
•
Figure 42 shows that proper coverage cannot be achieved for all FFT for all FFT orders, because the value errors outpace the uncertainties with increasing FFT order, to result in worse error deviations for increasing FFT order.
- •
The result difference using variance arithmetic for library Sin/Cos signal vs library Linear signal suggests that variance arithmetic can break down when the input contains too much unspecified errors. The only solution seems to create a new sin library using variance arithmetic so that all numerical calculation errors are accounted for.
8.8 Ideal Coverage
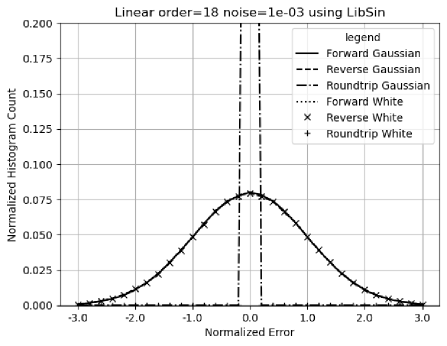
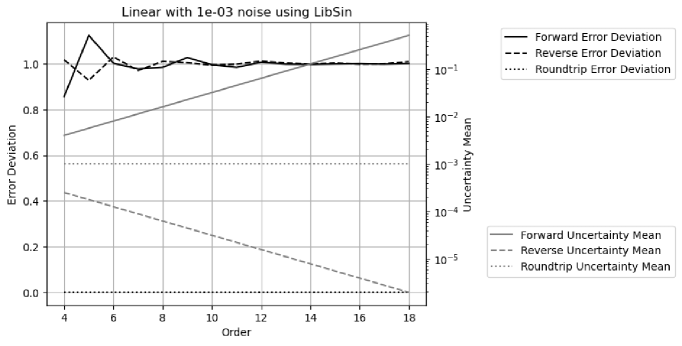
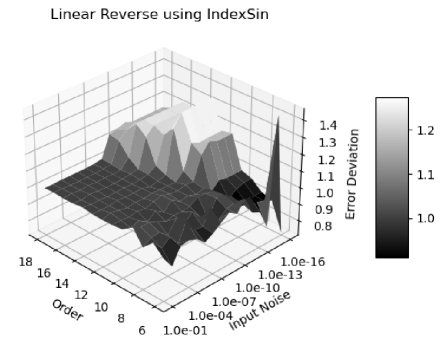
Adding enough noise to the input can overpower unspecified input errors, to achieve ideal coverage, such as input noise for Linear signal using the library sine functions.
-
•
Figure 44 shows the corresponding histogram. As expected, the normalized errors for the forward and the reverse transformations are Normal distributed. The normalized errors for the roundtrip transformations are Delta distributed at , meaning the input uncertainties are perfectly recovered.
-
•
Figure 45 show the corresponding error deviations and uncertainty means:
-
–
As expected, the result uncertainty means for the forward transformations increase with the FFT order as .
-
–
As expected, the result uncertainty means for the reverse transformations decrease with the FFT order as .
-
–
As expected, the result uncertainty means for the roundtrip transformations always equal the corresponding input uncertainties of .
-
–
As expected, the result error deviations for the forward and reverse transformations are constant , while the result error deviations for the roundtrip transformation approaches exponentially with increasing FFT order.
-
–
Also, the result uncertainty means for both the forward and the reverse transformations are linear to the input uncertainties, respectively, which is expected because FFT is linear.
The range of ideal coverage depends on how well the input uncertainty specifies the input noise. For Linear signals using library sine functions, Figure 46 and 47 show the error deviation vs. the added noise vs. FFT order for the forward and reverse transformations, respectively. The ideal coverage is shown as the regions where the error deviations are . In other regions, proper coverage is not achievable. Because the uncertainties grow slower in the reverse transformation than in the forward transformation, the reverse transformations have smaller ideal coverage region than that of the forward transformation. Because numerical errors increase with the amount of calculation, the input noise range for ideal coverage reduces with increasing FFT order. It is possible that ideal coverage is not achievable at all, e.g., visually, when the FFT order is larger than for the reverse transformation. As one of the most robust numerical algorithms that is very insensitive to input errors, FFT can breaks down due to the numerical errors in the library sine functions, and such deterioration of the calculation result is not easily detectable using the conventional floating-point calculation.
In contrast, for Linear signals using indexed sine functions, as shown by Figure 48 and 49 for the forward and reverse transformations, respectively, the ideal region is much larger, and proper coverage is achieved in other regions. Forward FFT transformation shows larger region of ideal coverage than that of Reverse FFT transformation.
As an comparison, because sin/cos has less numerical calculation errors, for Sin/Cos using either indexed sine functions or library sine functions, the ideal region is achieved when the added noise is large enough to cover the effect of rounding errors, almost independent of FFT orders. In both cases, forward transformation needs added noise, while reverse transformation needs added noise. The difference is that using indexed sine functions, in the proper coverage region, error deviations deviate from only slightly.
8.9 Summary
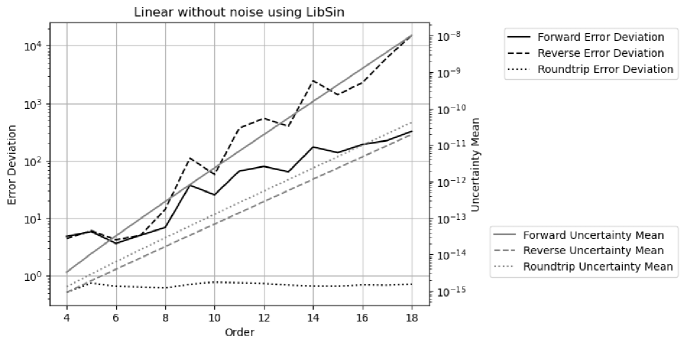
The library sine functions using conventional floating-point arithmetic have been shown to contain numerical errors as large as equivalently of input precision for FFT. The library errors increase periodically with , causing noticeable increase of the result errors with increasing index frequency in the reverse transformation, even in resonant fashion. The dependency of the result numerical errors on the amount of calculation and input data means that a small-scale test cannot properly qualify the result of a large-scale calculation. The effect of numerical errors inside math library has not been addressed seriously.
Variance arithmetic should be used, whose values largely reproduce the corresponding results using conventional floating-point arithmetic, whose uncertainties trace all input errors, and whose result error deviations qualify the calculation quality as either ideal, or proper, or suspicious. If the library functions also have proper coverage, the calculation result will probably have proper coverage as well.
9 Regressive Generation of Sin and Cos
Formula (9.2) and Formula (9.3) calculate repressively starting from Formula (9.1), .
| (9.1) | |||||
| (9.2) | |||||
| (9.3) |
When , the nominator in Formula (9.2) is the difference of two values both are very close to , to result in very coarse precision. Also, both value errors and uncertainties are accumulated in the regression. This regression is not suitable for calculating library and functions. It can be used to check the trigonometric relation for library and functions.
The number of regressions is defined as the order. For each order , and values are obtained, so that the result is more statistically stable with increasing .
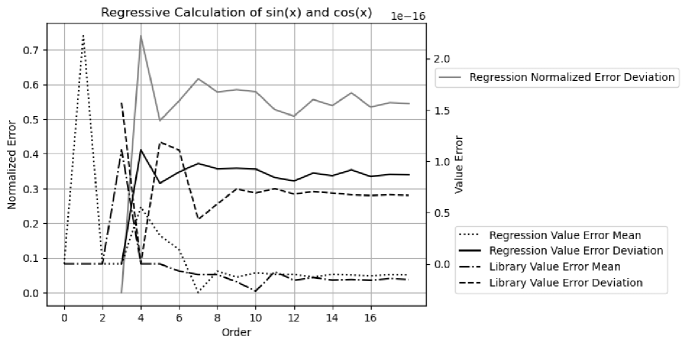
The value errors of and are checked by . Figure 50 shows that the value errors of the generated and is comparable to those of library and . It shows that the result error deviations are close to . Because floating-point rounding errors are the only source of errors in the regression, as expected, variance arithmetic provides proper coverage for this regression.
10 Conclusion and Discussion
10.1 Summary of Statistical Taylor Expansion
The starting point of statistical Taylor expansion is the uncorrelated uncertainty assumption of all input variables. It is a very reasonable statistical requirement on the input data [1]. Once the uncorrelated uncertainty assumption is satisfied, statistical Taylor expansion quantifies uncertainty as the deviation of the value errors. It can trace the variable dependency in the intermediate steps using standard statistics. It no longer has dependency problem, but demands a much more rigid process to obtain the result mean and deviation of an analytic expression.
Statistical Taylor Expansion suggests that a calculation result such as its convergence depends on input bounding factors, which may be another measurement of data quality.
10.2 Summary of Variance Arithmetic
Variance arithmetic simplifies statistical Taylor expansion by assuming that all input are Gaussian distributed. The statistical nature of variance arithmetic is reflected by the bounding leakage . Ill-formed problems can invalidate the result as: variance not convergent, value not stable, variance not positive, variance not finite, and variance not reliable.
The presence of ideal coverage is the necessary condition for a numerical algorithm in variance arithmetic to be correct. The ideal coverage also defines the ideal applicable range for the algorithm. In ideal coverage, the calculated uncertainty equals the value error deviation, and the result normalized errors is either Normal distributed or Delta distributed depending on the context. In variance arithmetic, the best-possible precision to achieve ideal coverage is , which is good enough for most applications.
Variance arithmetic can only provide proper coverage for floating-point rounding errors, with the empirical error deviations in the approximate range of . Table 3 shows the measured error deviations in different contexts.
Variance arithmetic has been showcased to be widely applicable, so as for analytic calculations, progressive calculation, regressive generalization, polynomial expansion, statistical sampling, and transformations.
The code and analysis for variance arithmetic are published as an open source project at https://github.com/Chengpu0707/VarianceArithmetic.
| Context | Error Deviation |
|---|---|
| Adjugate Matrix | |
| Forward FFT of Sin/Cos signal with indexed sine | |
| Reverse FFT of Sin/Cos signal with indexed sine | |
| Roundtrip FFT of Sin/Cos signal with indexed sine | |
| Forward FFT of Linear signal with indexed sine | |
| Reverse FFT of Linear signal with indexed sine | |
| Roundtrip FFT of Linear signal with indexed sine | |
| Regressive Calculation of sin and cos |
10.3 Improvement Needed
This paper just showcases variance arithmetic which is still in its infancy. Theoretically, some important questions remain:
-
•
Is there a way for variance arithmetic to provide ideal coverage to floating-point rounding errors? Many theoretical calculations have no input uncertainties, so that when the generation mechanism for rounding error is thoroughly understood, a special version of variance arithmetic for ideal coverage to floating-point rounding errors may be desirable.
- •
-
•
How to apply variance arithmetic when analytic solution is not available such as solving differential equation?
-
•
How to extend variance arithmetic to other input uncertainty distribution?
Traditional numerical approaches focus primarily on the result values, and they need to be reexamined or even reinvented in variance arithmetic. Most traditional numerical algorithms try to choose one of the best paths, while variance arithmetic rejects conceptually all path-dependent calculations. How to reconcile variance arithmetic and traditional numerical approaches could be a big challenge.
The calculation of the result mean and uncertainty contains a lot of sums of constant terms such as Formula (2.3) and (2.3), so that it is a excellent candidate for parallel processing. Because variance arithmetic has neither execution freedoms nor the associated dependency problems, it can be implemented either in software using GPU or directly in hardware.
In variance arithmetic, it is generally an order-of-magnitude more complicated to calculate the result uncertainties than the result values, such as Formula (6.19) for Taylor expansion of matrix inversion. However, modern software programs for analytic calculation such as SymPy can be a great help. Perhaps it is time to move from numerical programming to analytic programming for analytic problems.
10.4 Recalculating Library Math Functions
The library math functions need to be calculated using variance arithmetic, so that each output value has its corresponding uncertainty. Otherwise, the effect of the existing value errors in the library function can have unpredictable and large effects. For example, this paper shows that the periodic numerical errors in the sine library functions cause resonant-like large result value errors in a FFT reverse transformation.
10.5 Different Floating-Point Representation for Variance
In variance representation , is comparable in value with , but is calculated and stored. This limits the effective range for to be much smaller than the full range of the standard 64-bit floating-point representation. Ideally, should be calculated and stored in an unsigned 64-bit floating-point representation in which the sign bit reused for the exponent, so that has exactly the same range as the standard 64-bit floating-point representation.
10.6 Lower Order Approximation
Most practical calculations are neither pure analytic nor pure numerical, in which the analytic knowledge guides the numerical approaches, such as solving differential equations. In these cases, when input precision is fine enough, lower-order approximation of variance arithmetic may be a viable solution because these calculations may only have low-order derivatives for the result. This paper provides an example of first order approximation of variance arithmetic, as Formula (6.21) for . According to Section 3, the convergence and stability of the result has to be assumed for lower-order approximations. How to effectively apply variance arithmetic to practical calculations remains an open question.
10.7 Source Tracing
As an enhancement for dependency tracing, source tracing points out the contribution to the result uncertainty bias and uncertainty from each input. This gives clues to engineers on how to improve a measurement effectively.
10.8 Variable Variance Arithmetic
Variance arithmetic rejects a calculation if its distributional pole or distributional zero is within the input ranges. But there are many use cases in which such intrusion cannot be avoided, so variance arithmetic of smaller may be needed. It is even possible in another implementation of statistical Taylor expansion, is part of a variance representation, so that a calculation closer to a distributional zero can proceed but at the expense of reducing . The result for a calculation of imprecise inputs each with different is found statistically through the corresponding . Such approaches need theoretical foundation in both mathematics and statistics.
10.9 Acknowledgments
As an independent researcher without any academic association, the author of this paper feels indebted to encouragements and valuable discussions with Dr. Zhong Zhong from Brookhaven National Laboratory, Prof Weigang Qiu from Hunter College, the organizers of AMCS 2005, with Prof. Hamid R. Arabnia from University of Georgia in particular, and the organizers of NKS Mathematica Forum 2007, with Dr. Stephen Wolfram in particular. Prof Dongfeng Wu from Louisville University provides valuable guidance and discussions on statistical related topics. The author of this paper is very grateful for the editors and reviewers of Reliable Computing for their tremendous help in shaping and accepting the previous version of this paper from unusual source, with managing editor, Prof. Rolph Baker Kearfott in particular.
References
- [1] C. P. Wang. A new uncertainty-bearing floating-point arithmetic. Reliable Computing, 16:308–361, 2012.
- [2] Sylvain Ehrenfeld and Sebastian B. Littauer. Introduction to Statistical Methods. McGraw-Hill, 1965.
- [3] John R. Taylor. Introduction to Error Analysis: The Study of Output Precisions in Physical Measurements. University Science Books, 1997.
- [4] Jurgen Bortfeldt, editor. Fundamental Constants in Physics and Chemistry. Springer, 1992.
- [5] Michael J. Evans and Jeffrey S. Rosenthal. Probability and Statistics: The Science of Uncertainty. W. H. Freeman, 2003.
- [6] Fredrik Gustafsson and Gustaf Hendeby. Some relations between extended and unscented kalman filters. IEEE Transactions on Signal Processing, 60-2:545–555, 2012.
- [7] John P Hayes. Computer Architecture. McGraw-Hill, 1988.
- [8] David Goldberg. What every computer scientist should know about floating-point arithmetic. ACM Computing Surveys, March 1991.
- [9] Institute of Electrical and Electronics Engineers. ANSI/IEEE 754-2008 Standard for Binary Floating-Point Arithmetic, 2008.
- [10] U. Kulish and W.M. Miranker. The arithmetic of digital computers: A new approach. SIAM Rev., 28(1), 1986.
- [11] J. H. Wilkinson. Rounding Errors in Algebraic Processes. SIAM, 1961.
- [12] Nicholas J. Higham. Accuracy and Stability of Numerical Algorithms. SIAM, 2002.
- [13] William H. Press, Saul A Teukolsky, William T. Vetterling, and Brian P. Flannery. Numerical Recipes in C. Cambridge University Press, 1992.
- [14] Oliver Aberth. Precise Numerical Methods Using C++. Academic Press, 1998.
- [15] Nicholas J. Higham† and Theo Mary. A new approach to probabilistic rounding error analysis. SIAM Journal on Scientific Computing, 41(5):A2815–A2835, 2019.
- [16] B. Liu and T. Kaneko. Error analysis of digital filters realized with floating-point arithmetic. Proc. IEEE, 57:p1735–1747, 1969.
- [17] B. D. Rao. Floating-point arithmetic and digital filters. IEEE, Transations on Signal Processing, 40:85–95, 1992.
- [18] Gregory L. Baker and Jerry P. Gollub. Chaotic Dynamics: An Introduction. Cambridge University Press, 1990.
- [19] Brian Gladman, Vincenzo Innocente, John Mather, and Paul Zimmermann. Accuracy of mathematical functions in single, double, double extended, and quadruple precision. 2024.
- [20] R.E. Moore. Interval Analysis. Prentice Hall, 1966.
- [21] W. Kramer. A prior worst case error bounds for floating-point computations. IEEE Trans. Computers, 47:750–756, 1998.
- [22] G. Alefeld and G. Mayer. Interval analysis: Theory and applications. Journal of Computational and Applied Mathematics, 121:421–464, 2000.
- [23] W. Kramer. Generalized intervals and the dependency problem. Proceedings in Applied Mathematics and Mechanics, 6:685–686, 2006.
- [24] A. Neumaier S.M. Rump S.P. Shary B. Kearfott, M. T. Nakao and P. Van Hentenryck. Standardized notation in interval analysis. Computational Technologies, 15:7–13, 2010.
- [25] W. T. Tucker and S. Ferson. Probability bounds analysis in environmental risk assessments. Applied Biomathmetics, 100 North Country Road, Setauket, New York 11733, 2003.
- [26] J. Stolfi and L. H. de Figueiredo. An introduction to affine arithmetic. TEMA Tend. Mat. Apl. Comput., 4:297–312, 2003.
- [27] R. Alt and J.-L. Lamotte. Some experiments on the evaluation of functional ranges using a random interval arithmetic. Mathematics and Computers in Simulation, 56:17–34, 2001.
- [28] J. Stolfi and L. H. de Figueiredo. Self-validated numerical methods and applications. ftp:// ftp.tecgraf.puc-rio.br/pub/lhf/doc/cbm97.ps.gz, 1997.
- [29] Propagation of uncertainty. http://en.wikipedia.org/wiki/Propagation_of_uncertainty, 2011. wikipedia, the free encyclopedia.
- [30] S. Ferson H. M. Regan and D. Berleant. Equivalence of methods for uncertainty propagation of real-valued random variables. International Journal of Approximate Reasoning, 36:1–30, 2004.
- [31] Significance arithmetic. http://en.wikipedia.org/wiki/Significance_arithmetic, 2011. wikipedia, the free encyclopedia.
- [32] M. Goldstein. Significance arithmetic on a digital computer. Communications of the ACM, 6:111–117, 1963.
- [33] R. L. Ashenhurst and N. Metropolis. Unnormalized floating-point arithmetic. Journal of the ACM, 6:415–428, 1959.
- [34] G. Spaletta M. Sofroniou. Precise numerical computation. The Journal of Logic and Algebraic Programming, 65:113–134, 2005.
- [35] J. Vignes. A stochastic arithmetic for reliable scientific computation. Mathematics and Computers in Simulation, 35:233–261, 1993.
- [36] C. Denis N. S. Scott, F. Jezequel and J. M. Chesneaux. Numerical ’health’ check for scientific codes: the cadna approach. Computer Physics Communications, 176(8):501–527, 2007.
- [37] J. Hefferon. Linear algebra. http://joshua.smcvt.edu/linearalgebra/, 2011.
- [38] Paul Horowitz and Hill Winfield. Art of Electronics. Cambridge Univ Press, 1995.