Statistical Uncertainty Principle in Stochastic Dynamics
Abstract
Maximum entropy principle identifies forces conjugated to observables and the thermodynamic relations between them, independent upon their underlying mechanistic details. For data about state distributions or transition statistics, the principle can be derived from limit theorems of infinite data sampling. This derivation reveals its empirical origin and clarify the meaning of applying it to large but finite data. We derive an uncertainty principle for the statistical variations of the observables and the inferred forces. We use a toy model for molecular motor as an example.
Thermodynamics has been the guiding empirical principle for statistical physicists to understand heat engines and condensed matters [1, 2]. Importantly, it identifies entropic forces conjugated to the observables of interest and dictates force-observable relations such as the equation of state and the Maxwell relations. However, textbook thermodynamics was limited to describing state distributions in large, mechanical systems at equilibrium. Extensions were thus needed for its application to nonequilibrium [3], small [4, 5], and dynamical [6, 7] systems.
The complexity of biological systems poses an additional challenge for formulating such a theory of forces. The “constituting individuals” of complex biological systems, e.g. a cell in a tissue or an organism in a ecosystem, are themselves high dimensional. When describing these complicated biological systems, it is often not practical to model its constituting individuals from classical or quantum mechanics. We consider these systems far from mechanics as the practical mathematical models that describe them are not Hamiltonian-based. To formulate a thermodynamic theory of forces for biological systems, we must formulate a theory that applies to not just nonequilibrium, small, dynamical systems, but also systems that are not modeled by mechanics [8, 9].
The formulation of such a theory, known as the Maximum Entropy principle (MaxEnt), has been summarized nicely by E. T. Jaynes [10, 6] and put into practices [7]. This paper mainly adds on two points. First, we revisit and advocate the empirical origin of MaxEnt based on limit theorems in the idealization of having infinite data. Second, closely following the logic of the first point, we derive and explain the uncertainty principle between the statistical variations of dynamical observables and the conjugated path entropic forces they infer.
We first argue that both of the two other mainstream derivations of MaxEnt implicitly assume the idealized limit of infinite data when MaxEnt is applied to real data. Specifically, both Jaynes’ “maximum-ignorance” argument [10] and Shore and Johnson’s axiomatic derivations [11] are formulated about the expected values of the observables. And, as true expected values are only available in the data infinitus limit, these formulations implicitly assumed data infinitum. Whenever one measures a sample average from large but finite data and consider the sample average a good approximation to the true expected value, it is plugged into MaxEnt as if the data were infinitely big.
With this, we advocate the empirical derivation of MaxEnt based solely on mathematical limit theorems of the data infinitus limit. This derivation has at least two advantages. On the one hand, it explicitly states the data infinitum assumption and clarifies how MaxEnt is used in finite but large data: MaxEnt applies to Big Data as a leading order approximation, as how textbook thermodynamics is applied to finite but large system. On the other hand, this derivation shows three equivalent interpretations of the MaxEnt posterior with clear connections to Bayesian conditioning. Further, it provides the entropy function a statistical meaning instead of treating it as an auxiliary function for inference.
We then revisit the limit theorem based derivation of the dynamic extension of MaxEnt [12, 13, 14], now commonly known as the maximum caliber principle (MaxCal) [6, 7]. We use it to derive the uncertainty principle of the statistical variations of observables and forces, which we shall call it the Statistical Uncertainty Principle (SUP) for stochastic dynamics. We will use a simple three-state toy model of molecular motor and the data it produces as an example. The SUP is different from the recently-celebrated thermodynamic uncertainty relation in stochastic thermodynamics [15, 16]. Our SUP is closer to the uncertainty principle in quantum mechanics as both of them are from invertible mathematical transforms: Legendre for SUP and Fourier for quantum.
Maximum Entropy Principle for Markov Processes
The empirical derivation of MaxEnt for state distribution data of independent and identically-distributed (i.i.d.) ensemble has been revisited by one of us [17, 18]. Here, we briefly revisit the data-driven derivation of its extension to correlated data about transitions [12, 13, 14].
Before we begin, let us first remark that applying MaxEnt to stochastic processes is conceptually straightforward from either Jaynes’ argument of least-bias [11] or Shore and Johnson’s axioms [11, 7]: one simply replaces state distribution with path distribution. Jaynes called this the Maximum Caliber principle (MaxCal) [6]. In this generalization, the stochastic process needs not to be Markovian or have a steady state. Once we know the expected values of some path observables, it can be used in MaxCal to provide an update on the our model of path probabilities. However, if one aims to get these expected values from data, one has to rely on the law of large number for convergence, i.e. the data about dynamics has to be either i.i.d. ensembles of paths or the large collections of Markov correlated transitions in a single long path. The former belongs to the formulation of i.i.d. ensembles and has been reviewed before. Here, we focus on the latter generalization where the data is Markov correlated about consequent transitions.
Let us begin by considering (a vector of) transition-based observables in a discrete-time Markov chain (DTMC) where and are in the state space . The steady-state expected value of is
| (1) |
where is the steady state distribution and is the underlying transition probability matrix of the DTMC from to . The ergodic theory for Markov chain tells us that the long-term empirical average of converges to the steady-state mean value :
| (2) |
The underlying mechanism of this convergence is the convergence of the joint empirical frequency of a transition pair in a length- path ,
| (3) |
to the steady-state pair probability in the long-term limit . These laws of large number for Markov chains are the direct extension from the i.i.d. sample of distribution to correlated-data produced by Markov processes.
Now, similar to the i.i.d. case [19, 18], a key to derive MaxEnt is that the frequency has an asymptotical distribution with an exponential form under a prior Markov chain model with probability [20]:
| (4) |
The matrix is our prior transition matrix that defines our prior probability , and the matrix is the empirical transition matrix calculated by . Then, we can consider three conceptually different posterior joint stationary probability [12], which are all mathematically equivalent in the long-term limit
a) the asymptotic conditional probability:
| (5) |
where the time label is a function of , chosen such that and are at the steady state of the process;
b) asymptotic conditional expectation of the empirical pair frequency:
| (6) |
where is taken w.r.t. the prior model ;
c) the most probable empirical frequency:
| (7) |
The three constraints in Eq. (7) are the empirical averages of data ad infinitum, the stationary constraint, and the normalization. The equivalency among the three are known as the Gibbs conditioning principle [21, 12].
We note that the “entropy” to be extremized in the Markov correlated data case here in Eq. (7) is not the Kullback-Leibler relative entropy of pair probabilities where is the stationary distribution of prior . The fundamental reason of this is because MaxCal is about the whole path , not just one step. This can be seen from the alternative MaxCal derivation of Eq. (7) shown in the Supplemental Material.
Since Eq. (7) is a less-known MaxEnt calculation, we briefly summarize the recipe of computing the posterior joint probability below. First, we construct a tilted matrix . Second, we compute its largest eigenvalue and the corresponding left and right eigenvectors, and (chosen such that ). The Perron-Forbenius theorem guarantees that is real and non-negative and can be found. Third, the posterior probability transition in terms of is then given by
| (8) |
with the stationary distribution given by and . Finally, we solve ( according to , which is a set of PDEs that can be solved systematically with optimization procedures described later in Eq. (12) and Eq. (13).
Thermodynamic structures emerge from limit theorems.
Statistical thermodynamics can be derived generally by MaxEnt [7, 18]. And, based on the data-driven empirical derivation of MaxEnt reviewed above, we can consider thermodynamics as emerged from the data infinitus limit, for both i.i.d. ensembles and Markov correlated transitions.
The origin of the thermodynamic structure is the convex duality between a pair of functions, known as entropy and free energy in classical thermodynamics. For i.i.d. data about the distribution of states, the “entropy” is the posterior relative entropy, , and the “free energy” is the generating function of the observable , . This is the textbook classical thermodynamics [17, 18]. For transition-based Markov correlated data, the “entropy” becomes the posterior path relative entropy,
| (9) |
and the “free energy” is the scaled generating function for the empirical sum
| (10) |
which becomes the logarithm of the largest eigenvalue computed by the tilted matrix. In both cases, the “free energy” is a generating function, and the entropy is the extremized value of a entropy function.
Convex duality between the entropy and the free energy emerges from limit theorems. On the one hand, the free energy is always the Legendre-Fenchel transform of the entropy .
| (11) |
This is a direct consequence of computing from its definition with the Laplace’s approximation in asymptotic analysis [22, 17]. On the other hand, the inverse of Eq. (11) requires the existence and differentiability of . This is known as the Gärtner-Ellis theorem [23, 24, 22]:
| (12) |
These Legendre-Fenchel-transform expressions of and tell us that both of them are convex functions [22]. With differentiable and , the two Legendre-Fenchel transforms above reduces to a single Legendre transform, which encodes derivative relations between the dual coordinates and of the system,
| (13) |
as well as the Maxwell’s relations associated with them. Importantly, Eq. (13) shows that the parameters are the entropy forces conjugated to the observables .
Statistical Uncertainty Principle (SUP)
We are now ready to discuss the dynamic extension of the uncertainty principle between the statistical variations of observables (e.g. energy) and of the inferred conjugated entropic forces (e.g. 1/temperature) in thermodynamics [1, 25, 26, 27]. We shall call it the statistical uncertainty principle (SUP) since it is an leading-order statistical result for large but finite data. Our contributions here are twofold: a) We extends SUP from state observables [1, 25, 26] to transition observables, from distribution to dynamics; b) SUP shows the physical meaning of a well-known mathematical relation in large deviation theory.
To illustrate, let’s consider the following scenario. Suppose Bob has transition-based data in the form of the empirical mean for a large but finite data of length . Note that is itself random: if Bob repeats the experiment, he can get different values of . Now, suppose Alice knows the true expected values of the transition observable either because she had data ad infinitum or due to other sources, she can then predict the asymptotic variation of Bob’s quantified by the covariance matrix of Bob’s to the leading order,
| (14) |
Bob can verify this by repeatedly measuring from i.i.d. copies of the length- process.
Each time Bob gets a , he can use it to infer the level of entropic forces . He computes by using the entropy function given by Eq. (9) and plug in the he measured. This inferred force fluctuates due to the stochasticity of . Alice can also derive the leading-order fluctuation of Bob’s , which becomes
| (15) |
See Supplemental Material for a derivation. Since and have a reciprocal curvature due to the Legendre transform [22], we then have the SUP for the fluctuations of and of the they infer:
| (16) |
While this mathematical relation is well-known to the large deviation theory community [22], to our knowledge this is the first time its statistical meaning is pointed out. It is worth noticing that Schlögl has derived an inequality version of SUP without taking data infinitus limit, which can be regarded as the mesoscopic origin of SUP [27].
A simple toy model of molecular motor as an example
To illustrate SUP, let us consider a simple three-state Markov chain as a toy model for a molecular motor monomer like myosin [28]. Our toy molecular motor is assumed to have three states with state space illustrated in Fig. 1.
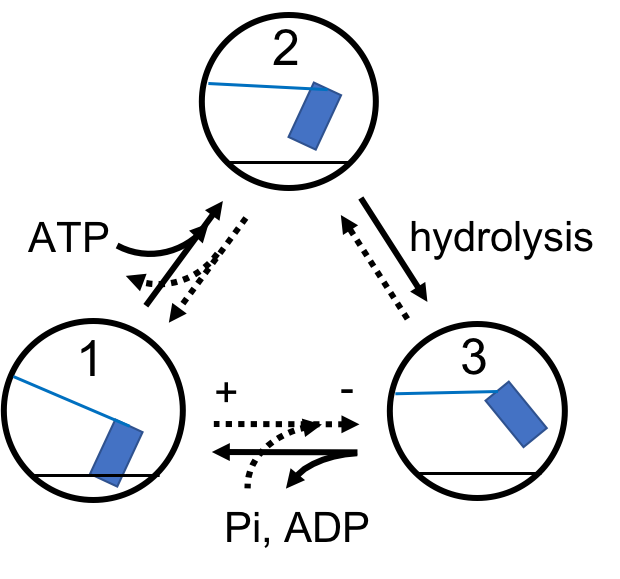
The motor at state 1 is bounded to the actin. Through coupling with an ATP, it detaches and becomes state 2. Then, hydrolysis of ATP leads to the mechanically deformed state 3. Through releasing ADP and Pi, the motor generates a power stroke (from - to +) and re-attach to the actin, back to state 1. The dynamics of this motor (in discrete time) is described by the transition probabilities from to , where .
With big data about a long trajectory of the motor’s state, we can use counting statistics to infer . Let us consider the following six linearly independent counting frequencies: the occurance frequency of two of the three states, say frequencies and , the symmetric flux (what Maes called traffic in [29]) over all edges measured by
| (17) |
where , and the net (antisymmetric) flux of the power stroke step, from state to , denoted by
| (18) |
Note that this is the net empirical velocity of the motor over a length trajectory.
Following the MaxEnt recipe mentioned above, we assume a uniform prior and construct the tilted matrix
| (19) |
with six parameters corresponding to the six observables . Then by Eq. (8), the posterior transition probabilities take the form of
| (20) |
where is the largest eigenvalue of and is the corresponding right eigenvector.
The set of observables we chose is holographic, i.e. it captures all degrees of freedom of the dynamics. When the trajectory becomes very long, the ergodic theorem of Markov chain guarantees that ,
| (21) |
and
| (22) |
With these six averages , one can uniquely compute the true underlying as a function of these six averages. Furthermore, since our observables are non-degenerate, simple relations between the six parameters and the transition probabilities can be derived 111One of us is writing a paper regarding the general version of this fact.:
| (23a) | ||||
| (23b) | ||||
| (23c) | ||||
| (23d) | ||||
where and . Notice that is (half of) the cycle affinity, an important term in stochastic thermodynamics [31].
Recall from Eq. (13) that the six parameters in Eqs. (23) are actually the entropic forces. In our example here, we plug in and
| (24) |
into the entropy form in Eq. (9) by using normalization and stationarity . One can easily check that
| (25) |
for and .
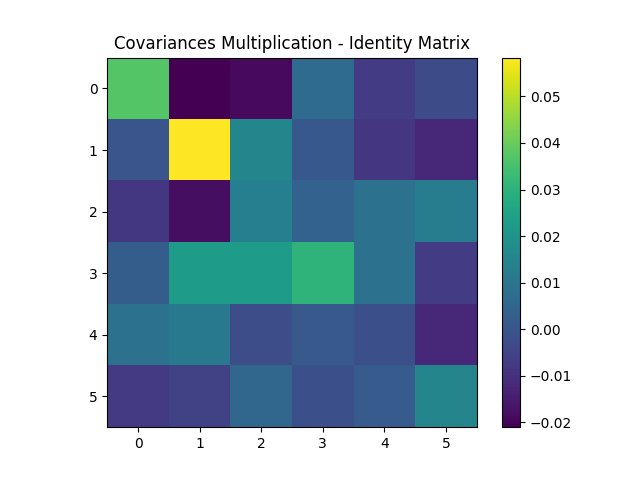
The SUP in Eq. (16) is an asymptotic relation between the covariance of the six frequency observables collected from a long but finite trajectory and the forces they inferred by computing By numerically produce a big ensemble of very long trajectories with length , we can play Bob’s role and check the SUP for the empirical scaled covariance of frequencies and that of the inferred forces . Their product is indeed very close to the identify matrix with vanishing difference to the identity matrix shown in Fig. (2).
Summary
In this paper, we revisit and advocate the empirical derivation of the Maximum Entropy principle of Markov correlated data [12, 13, 14], also known as the Maximum Caliber principle. We review how the principle can identify entropic forces, and lead to statistical thermodynamic conjugacy. From the empirical understanding and data-driven derivation that we revisited and advocated, we derived an uncertainty principle between the statistical variations of observables and the forces they infer from finite data. This theory is purely empirical and can thus be applied to trajectory data from small, nonequilibrium, dynamical biological systems that are far from mechanics.
In short, more is indeed different [32]. Maximum entropy principle and statistical thermodynamics emerge empirically and de-mechanically from the limit theorems of data ad infinitum, i.i.d. or Markov correlated. Akin to the uncertainty principle in quantum mechanics, there is an uncertainty principle about the statistical variations of dynamical observables and forces for Big Data.
Acknowledgements.
The authors thank Erin Angelini, Ken Dill, Charles Kocher, Zhiyue Lu, Jonny Patcher, Dalton Sakthivadivel, Dominic Skinner, David Sivak, Lowell Thompson, and Jin Wang for helpful feedback on our manuscript and for the stimulating discussions they had with the authors. H. Q. thanks the support from the Olga Jung Wan Endowed Professorship.References
- Landau and Lifshitz [1980] L. D. Landau and E. M. Lifshitz, Statistical Physics, Third Edition, Part 1: Volume 5, 3rd ed. (Butterworth-Heinemann, Amsterdam u.a, 1980).
- Huang [1987] K. Huang, Statistical Mechanics, 2nd Edition, 2nd ed. (Wiley, New York, 1987).
- Nicolis and Prigogine [1977] G. Nicolis and I. Prigogine, Self-Organization in Nonequilibrium Systems: From Dissipative Structures to Order through Fluctuations, 1st ed. (Wiley, New York, 1977).
- Hill [2013] T. L. Hill, Thermodynamics of Small Systems, Parts I & II (Dover Publications, Mineola, New York, 2013).
- Bedeaux et al. [2020] D. Bedeaux, S. Kjelstrup, and S. Schnell, Nanothermodynamics: General Theory (2020).
- Jaynes [1980] E. T. Jaynes, The Minimum Entropy Production Principle, Annual Review of Physical Chemistry 31, 579 (1980).
- Pressé et al. [2013] S. Pressé, K. Ghosh, J. Lee, and K. A. Dill, Principles of maximum entropy and maximum caliber in statistical physics, Rev. Mod. Phys. 85, 1115 (2013).
- Szilard [1929] L. Szilard, Uber die Ausdehnung der phanomenologischen Thermodynamik auf die Schewankungserscheinungen, Z. Phys. 32, 840 (1929).
- Mandelbrot [1964] B. Mandelbrot, On the Derivation of Statistical Thermodynamics from Purely Phenomenological Principles, J. Math. Phys. 5, 164 (1964).
- Jaynes [1957] E. T. Jaynes, Information Theory and Statistical Mechanics, Phys. Rev. 106, 620 (1957).
- Shore and Johnson [1980] J. Shore and R. Johnson, Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy, IEEE Trans. Inf. Theor. 26, 26 (1980).
- Csiszar et al. [1987] I. Csiszar, T. Cover, and Byoung-Seon Choi, Conditional limit theorems under Markov conditioning, IEEE Trans. Inform. Theory 33, 788 (1987).
- Chetrite and Touchette [2013] R. Chetrite and H. Touchette, Nonequilibrium Microcanonical and Canonical Ensembles and Their Equivalence, Phys. Rev. Lett. 111, 120601 (2013).
- Chetrite and Touchette [2015] R. Chetrite and H. Touchette, Nonequilibrium Markov Processes Conditioned on Large Deviations, Ann. Henri Poincaré 16, 2005 (2015).
- Barato and Seifert [2015] A. C. Barato and U. Seifert, Thermodynamic Uncertainty Relation for Biomolecular Processes, Phys. Rev. Lett. 114, 158101 (2015).
- Horowitz and Gingrich [2020] J. M. Horowitz and T. R. Gingrich, Thermodynamic uncertainty relations constrain non-equilibrium fluctuations, Nat Phys 16, 15 (2020).
- Qian and Cheng [2020] H. Qian and Y.-C. Cheng, Counting single cells and computing their heterogeneity: from phenotypic frequencies to mean value of a quantitative biomarker, Quant Biol 8, 172 (2020).
- Lu and Qian [2022] Z. Lu and H. Qian, Emergence and Breaking of Duality Symmetry in Generalized Fundamental Thermodynamic Relations, Phys. Rev. Lett. 128, 150603 (2022).
- Cheng et al. [2021] Y.-C. Cheng, H. Qian, and Y. Zhu, Asymptotic Behavior of a Sequence of Conditional Probability Distributions and the Canonical Ensemble, Ann. Henri Poincaré 22, 1561 (2021).
- Barato and Chetrite [2015] A. C. Barato and R. Chetrite, A Formal View on Level 2.5 Large Deviations and Fluctuation Relations, J Stat Phys 160, 1154 (2015).
- Dembo and Zeitouni [2009] A. Dembo and O. Zeitouni, Large Deviations Techniques and Applications, 2nd ed. (Springer, Berlin Heidelberg, 2009).
- Touchette [2009] H. Touchette, The large deviation approach to statistical mechanics, Physics Reports 478, 1 (2009).
- Gärtner [1977] J. Gärtner, On Large Deviations from the Invariant Measure, Theory Probab. Appl. 22, 24 (1977).
- Ellis [1984] R. S. Ellis, Large Deviations for a General Class of Random Vectors, The Annals of Probability 12, 1 (1984).
- Mandelbrot [1989] B. B. Mandelbrot, Temperature Fluctuation: A Well-Defined and Unavoidable Notion, Physics Today 42, 71 (1989), publication Title: Physics Today Publisher: American Institute of PhysicsAIP.
- Uffink and van Lith [1999] J. Uffink and J. van Lith, Thermodynamic Uncertainty Relations, Foundations of Physics 29, 655 (1999).
- Schlögl [1988] F. Schlögl, Thermodynamic uncertainty relation, Journal of Physics and Chemistry of Solids 49, 679 (1988).
- Qian [1997] H. Qian, A simple theory of motor protein kinetics and energetics, Biophysical Chemistry 67, 263 (1997).
- Maes [2020] C. Maes, Frenesy: Time-symmetric dynamical activity in nonequilibria, Physics Reports 850, 1 (2020).
- Note [1] One of us is writing a paper regarding the general version of this fact.
- Yang and Qian [2021] Y.-J. Yang and H. Qian, Bivectorial Nonequilibrium Thermodynamics: Cycle Affinity, Vorticity Potential, and Onsager’s Principle, J Stat Phys 182, 46 (2021).
- Anderson [1972] P. W. Anderson, More Is Different, Science 177, 393 (1972).