STC-IDS: Spatial-Temporal Correlation Feature Analyzing based Intrusion Detection System for Intelligent Connected Vehicles
Abstract
Intrusion detection is an important defensive measure for automotive communications security. Accurate frame detection models assist vehicles to avoid malicious attacks. Uncertainty and diversity regarding attack methods make this task challenging. However, the existing works have the limitation of only considering local features or the weak feature mapping of multi-features. To address these limitations, we present a novel model for automotive intrusion detection by spatial-temporal correlation features of in-vehicle communication traffic (STC-IDS). Specifically, the proposed model exploits an encoding-detection architecture. In the encoder part, spatial and temporal relations are encoded simultaneously. To strengthen the relationship between features, the attention-based convolutional network still captures spatial and channel features to increase the receptive field, while attention-LSTM builds meaningful relationships from previous time series or crucial bytes. The encoded information is then passed to detector for generating forceful spatial-temporal attention features and enabling anomaly classification. In particular, single-frame and multi-frame models are constructed to present different advantages respectively. Under automatic hyper-parameter selection based on Bayesian optimization, the model is trained to attain the best performance. Extensive empirical studies based on a real-world vehicle attack dataset demonstrate that STC-IDS has outperformed baseline methods and obtains fewer false-alarm rates while maintaining efficiency.
Index Terms:
In-vehicle networks (IVNs), Control area network (CAN), Intrusion detection system (IDS), Spatial-temporal features, Attention mechanismI Introduction
Nowadays, a large number of electronic control units (ECUs) have replaced the mechanical control units to manage the assorted functions of in-vehicle control systems. The ECUs are interconnected to exchange varied vehicle information with each other via networks referred to as in-vehicle networks (IVNs) such as controller area networks (CAN) [1]. Along with local interconnected network LIN and FlexRay, CAN is well-known and most employed as the de-factor standard for IVNs [2, 3]. It is noteworthy that CAN was developed as a broadcast-based communication protocol that supports the maximum baud rate up to 1Mb per-second. Furthermore, the fault-tolerant detection mechanism guarantees the stability of message transmission.
However, the CAN bus is potentially vulnerable to attacks owing to the lack of security mechanisms such as encryption, access control, and authentication [4, 5, 6]. Cyber security is becoming a major concern for IVNs systems as increasingly more security researchers demonstrate their ability to launch attacks on actual vehicles [7]. What can be investigated is various attacks have been threatening several significant components of IVNs [4, 8, 9]. For instance, 360 cyberattack Lab adopted electronic radio-frequency technology to successfully hack into Tesla in 2015 [10]. Miller et al. invaded the Jeep Cherokee’s IVNs system using an open Wi-Fi port and reprogrammed the firmware of ECU. They succeeded in taking control of a wide range of vehicle functions (e.g., disabling the brakes and stopping the engine), triggering a recall of 1.4 million vehicles [4]. Thereafter, the electric features lift, warning lights, airbag, and tire pressure monitoring system (TPMS) have also become the target of attack [11]. Incredibly, these attacks have multiple ways of being performed. As such, the study on the security of IVNs is attracting significant attention from security researchers [12, 13].
There are many available methods that have the ability to protect IVNs secure, where IDS as an effective defense method has attracted more attention from researchers [14, 15]. Currently, a host of IDS schemes are rule-based and statistical-based. Although accuracy and efficiency are excellent about some common attacks, the passive characteristic and the constant need for updates result in a certain restriction [16]. With the increase in vehicle computing power and the maturity in machine learning (ML) technology, they promote the further development of IDS [17]. Real-time, higher detection, and lower false-positive rates have been a fervent research problem for deep learning-based in-vehicle IDS. Simultaneously, inadequate feature extraction, complex network structure, and more parameters, also are pending breakthroughs [1, 18]. To address such limitations, variants of IDS based on deep learning have been proposed in recent years [1, 19, 20]. However, these variants merely consider the partial features, either time-series of CAN ID or CAN data field. Moreover, spatial-temporal correlation features have been shown to better capture the details of the message in anomaly detection [21, 22, 23], whereas how to create represent the relationship between spatial-temporal features becomes a vital concern to elevate detection performance in the automotive intrusion [24, 25].
Thus, the purpose of this paper is to provide STC-IDS (Spatial-Temporal Correlation Features Analyzing based-enhanced Intrusion Detection System). Based on an encoding-detection architecture, the intuition first trained a boosted convolutional LSTM parallel feature extraction model. Improved attention-based LSTM network (A-LSTM) captures the temporal features and builds important relationships from previous sequences or crucial bytes. Meanwhile, a reduced VGGNet network can learn the spatial features from CAN frames. Moreover, the attention convolutional block (A-Conv2D) enables attaining a broad perspective through multi-channel features to refine feature mapping.Unlike many previous methods, it can concentrate more on changes in crucial areas and ignore bytes that are regular and unchanging. Afterward, spatial-temporal correlations between features are established to feed into the detector as a two-class classification problem. Note that both single-frame and multi-frame models are considered in this paper to present different advantages respectively.
This paper makes the following contributions.
-
1.
Based on analyzing spatial-temporal correlation features of CAN messages in detail, we propose an enhanced convolutional LSTM spatial-temporal feature encoder with attention. The single-frame model automatically captures the important byte relationships of each CAN frame and uses convolutional components to find where key bytes are. Moreover, the multi-frame model captures significant relationships from previous time series, in which the attention convolutional block, assisted by spatial attention and channel attention, is able to snap changes in crucial areas.
-
2.
Further, the detector achieves anomaly detection for the constructed representative spatial-temporal correlation features after multi-view learning. We evaluated the detection performance of our scheme using a publicly available real vehicle CAN dataset. We also compare it with the baseline model and show a significant improvement in detection performance and a reduction in false-positive rates and error rates.
-
3.
By performing the injection attack in the same way, we calculated the detection efficiency of the model on real vehicles. The multi-frame model has sufficient ability to satisfy real-time detection. In addition, the single-frame model combined with database retrieval has the ability to trace anomalous ECUs.
The rest of this paper is organized as follows. Section II presents a discussion of related work on CAN-based IDS. Section III introduces the CAN bus protocol, vulnerability, and analyzes the CAN frame with spatial-temporal. Section IV proposes the parallel network model based on spatial-temporal features analysis. The experiment result of the proposed model on the public real-vehicle dataset is described in Section V. Finally, we conclude this study and look ahead at in-vehicle IDS potential perspectives.
II Related Work
In this section, we provide an in-depth discussion about the research situation in anomaly detection and intrusion detection for in-vehicle CAN communication systems. They are divided into four categories, namely specification-based, fingerprint-based, statistical-based and machine learning-based approaches, as summarized in Table I.
| Categories | Research work | Technique | Evaluation Data | Contribution | Limitation | ||||||||||
| Specification based | Studnia et al. [26] |
|
real |
|
|
||||||||||
| Dagan et al. [27] |
|
|
|
|
|||||||||||
| Olufowobi et al. [20] |
|
|
|
|
|||||||||||
| Fingerprint based | Cho and Shin [28] |
|
|
|
|
||||||||||
| Choi et al. [29] |
|
|
|
|
|||||||||||
| Statistics based | Song et al. [30] |
|
|
|
|
||||||||||
| Young et al. [31] |
|
real |
|
|
|||||||||||
| ML & DL based | Kang et al. [32] | deep belief network (DBN) | simulation |
|
|
||||||||||
| Yang et al. [33] |
|
real |
|
|
|||||||||||
| Tariq et al. [34] |
|
real |
|
|
|||||||||||
| Pawelec et al. [35] |
|
real |
|
|
|||||||||||
| Qin et al. [19] |
|
real |
|
|
|||||||||||
| Song et al. [36] | deep CNN | real |
|
|
|||||||||||
| STC-IDS (Ours) |
|
real |
|
|
II-A Intrusion detection model based on specification
The specification-based IDS focuses on defining system specifications, such as protocols and frame formats. When packets mismatch the system specification, an exception alarm is raised. In 2016, Dagan et al. [27] introduced an anti-spoofing system that detects malicious messages using each ECU, i.e., by detecting CAN message ID that was not sent by the ECU itself. Thereafter, the ECU informs the IDS, and then an interrupt pulse is sent to the CAN bus to overwrite the spoofed message. However, each ECU undertakes the IDS role, which increases a certain burden on communication.
In 2018, Studnia et al. [26] presented a signature-based IDS which utilize a list of signature derived from CAN dataset. However, this method is subject to the limitation that the length of the CAN bus words may not be known a priori. Recently, Olufowobi et al. [20] proposed a real-time IDS based on specification. The algorithm extracted the timing model to detect anomalies through observing CAN traffic rather than depending on predefined specifications, yet exhibited relatively poor performance in the real attack dataset.
II-B Intrusion detection model based on fingerprint
The fingerprint-based approaches are mainly based on profiles defined by ECU characteristics to implement anomaly detection. In 2016, Cho and Shin [28] proposed clock-based IDS to analyze ECUs periodic frequency. The method established the ECUs clock baseline through the recursive least squares algorithm (RLS) to detect intrusion. But it workable only to periodic messages excluding non-periodic messages.
Interestingly, Cho et al. [29] found a method to establish the electrical signal characteristics of each ECU using the physical layer data of CAN communication, and harness these signal characteristics as the fingerprint for each ECU. Regrettably, the electrical characteristics may change as the vehicle ages, and thus the IDS needs to keep updating.
II-C Intrusion detection model based on statistical
Unlike previous methods, the statistics-based approach implements anomaly detection by means of statistical information obtained from CAN traffic at the network level. Song et al. [30] introduced a lightweight IDS in 2016 that detected anomalies by monitoring the abnormally shortened intervals between messages. Although the proposed algorithm could have highly sensitive to common injection attacks and low computing cost, it cannot detect irregular incoming messages.
Furthermore, Young et al. [31] comprehensively analyzed the frequency characteristics of CAN messages in various driving modes, such as reverse, acceleration and hold speed, and then proposed a frequency-based intrusion detection system. In spite of the high detection accuracy, there is a high false alarm rate. Manifestly, an IDS based on conditional statistical relationship analysis to learn the normal behavior of the system can detect manipulations and incorrect payload values [37], but still does not satisfy the high detection rate and low latency required by present-day IVNs for anomalous traffic [38].
II-D Intrusion detection model based on deep learning
Machine learning (ML) and Deep learning (DL) based intrusion detection systems are an excellent option for extracting and learning normal or abnormal behavior, which provide models with detect and predict ability [39, 40]. Kang et al. [32] constructed a deep confidence network under unsupervised learning to detect if anomalies deviate from normal. However, inefficient and only validation of simulation data is not sufficient.
In 2019, Pawelec et al. [35] proposed a 3-layer LSTM neural network to predict the data payload for each CAN ID, which avoided reverse engineering proprietary encoding. Similarly, Qin et al. [19] also implemented anomaly detection for CAN bus based on timing features by LSTM and re-considered two data formats of CAN frames. Although these methods are implemented at the CAN bits level, they only consider timing characteristics and have relatively poor detection performance. Recently, convolutional neural network (CNN) have been implemented for traffic detection and praised for their high detection efficiency [41].
Song et al. [36] presented a reduced inception residual network to construct an IDS capable of detecting spoofing and denial of service (DoS) attacks in a continuous pattern of vehicular traffic. Since the assistance of spatial-temporal relation is not taken into account, there is still room for improvement in the false positive rate. In other studies, Tariq et al. [34] introduced a convolutional LSTM-based intrusion detection method. Although it displayed excellent detection performance in unknown attack than transfer learning, known attacks performance relatively worse that may be caused by the relevance of the CAN message features being discarded. Moreover, a multi-tiered hybrid IDS that incorporates a signature-based IDS and an anomaly-based IDS is proposed to detect both known and unknown attacks on vehicular networks by Yang et al. [33] in 2021. Their model has been proven that is effective for attacks on both in-vehicle and external networks. However, modeling with spatial-temporal features might take performance a step further.
However, these ML&DL-based methods have different in selecting the detection domain, typically the detection arbitration domain, the detection data domain, and the similar to our work that the spatial-temporal feature extraction. In a nutshell, traditional methods based on specification, fingerprint, and statistical, have limitations in terms of reliance on anomaly feature libraries, message frequency, message time domain, and fingerprint information. Instead, it is imperative in the ML&DL area to improve automotive IDS detection performance and reduce false positives by complementing spatial-temporal features in a limited message communication mode. Furthermore, the model trained with limited spatial-temporal features will not effectively improve the detection performance.
Considering the nature of attention mechanisms to capture essential features, the generation of spatial-temporal attention features is one of the potential ways to address the above problem [42]. Hence, modeling the normal behavior of CAN packets in combination with spatial-temporal attention features and then discovering the difference between anomalies and target traffic is still one of the ways to improve in-vehicle IDS.
III AN IN-DEPTH OVERVIEW OF CAN BUS DATASET
III-A Vulnerabilities of in-vehicle networks
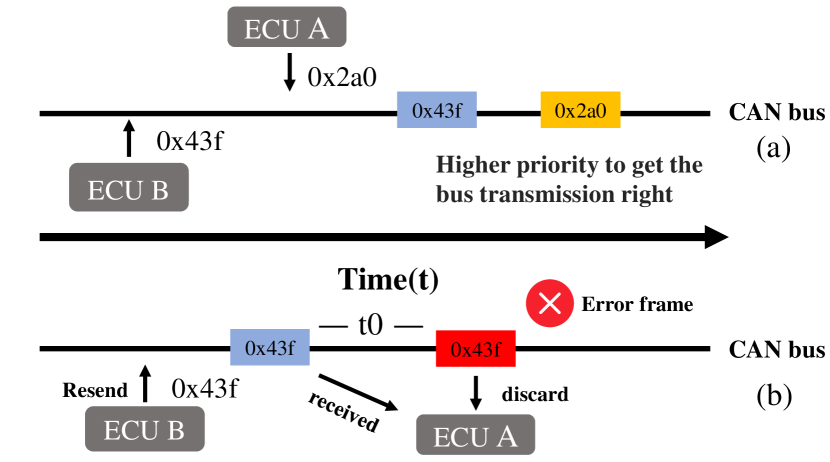
Intelligent Connected Vehicles (ICVs), integrating modern computing and communication technologies, is designed to improve user experience and driving safety. As the most significant communication medium, the CAN is the most prevalent bus topology network employed in contemporary vehicles owing to its low cost and complexity, high reliability, and fault-tolerance characteristics [43, 44]. All ECUs, connected to the CAN bus, are capable of exchanging messages in the form of data frames [45, 46]. Fig 1 presents the structure of a CAN message, consisting of seven fields [47]: 1) start of frame (1 bit); 2) arbitration field (12 bits for standard frames, 29 bits for extended frames); 3) control field (6 bits); 4) data field (Maximally 8 bytes); 5) cyclic redundancy code (CRC) field; 6) acknowledge (ACK) field; and 7) end of frame.

In the entire CAN frame, the most important is the arbitration field and the data field, as the arbitration field determines the priority of the message [48], shown in Fig 2(a); the data field contains the actual transmitted data that defines the node actions. Moreover, if an error is detected by CRC field, the receiving node will discard the received error message, while the sending node will only assume a transient fault on the bus and enter arbitration to resend the message frame [49, 50], shown in Fig 2(b). To guarantee the system consistency, the ECU broadcasts messages at regular intervals in spite of the data values have not changed. However, security problems were poor-needy thought out at the beginning of the CAN bus design [51], including its broadcast transmission strategy, lack of authentication and encryption, and unsecured priority scheme. Hence, many network traffic injection attacks are possible.
This directly motivates the adversary to attack in-vehicle networks in a variety of ways, as shown in Fig 3. Clearly, the adversary can not only through the OBD-II port for physical attacks but also implement a remote attack easily (e.g., Wi-Fi or Bluetooth) [10]. Types of such attacks include flooding the bus with messages designed to circumvent legitimate messages or using spoofed bus identifiers with invalid information [36]. Furthermore, there are more sophisticated and stealthy attacks [52]. These attacks appear to be legitimate traffic sequences that are tough to distinguish from normal messages [1].
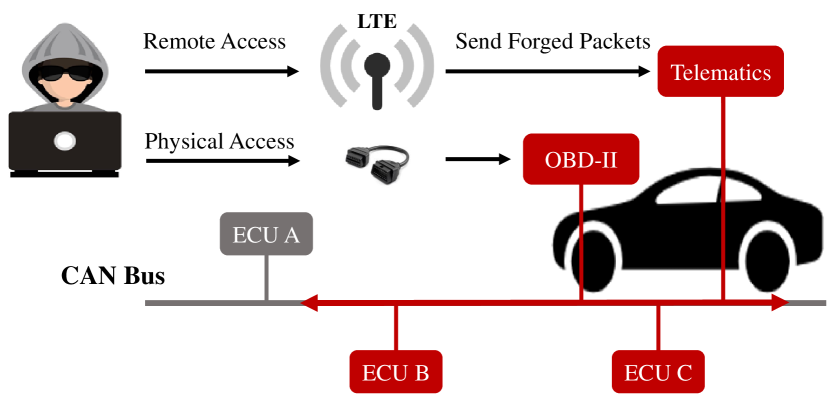
Once the attacker has successfully compromised, it has the opportunity to forge ECU nodes and take control of incumbent nodes to inject nefarious messages [53, 54]. In the CAN protocol, the connected nodes are synchronized with the current vehicle state by accepting the data field bits of the frame [36]. Consequently, in order to successfully deceive the ECU, the adversary must insert tampering messages in a high frequency and priority manner by following the target CAN ID message immediately after the message [55]. If the attacker injects a high-priority CAN frame, where the data field is populated with a status command to turn off the “wiper”, the driver loses judgment and even serious traffic accidents in rainy conditions while driving at high speed [56].
III-B Spatial-temporal correlation feature analyzing for CAN dataset
In this paper, we utilized car-hacking dataset which is published by Song et al. [52]. This data set is injected with four attacks, respectively DoS attack, fuzzy attack, spoofing attack including RPM and GEAR, as illustrated in Fig 4. The detailed injection rules are as follows.
-
1.
DoS attack: DoS attacks in the dataset are to inject a high priority message with a ‘0x000’ CAN ID every 0.3 milliseconds, with the data field populated with 0.
-
2.
Fuzzy attack: Fuzzy attacks in dataset are injected every 0.5 milliseconds with CAN messages where the CAN ID and DATA values are forged randomly.
-
3.
Spoofing attack: Spoofing attacks in dataset are injected messages every 1 millisecond with a specific CAN ID, e.g., related to RPM/Gear.
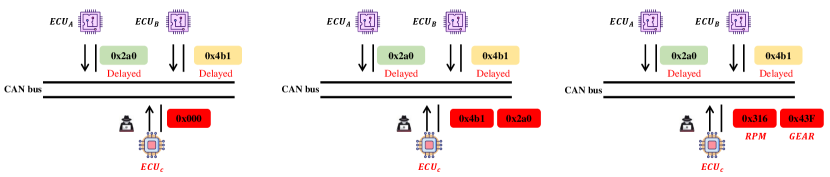
Table II indicates the number of normal and injected messages in each attack dataset. In order to summarize the spatial-temporal details of normal CAN bus traffic during the operation of a real vehicle, we first investigated the communication patterns of different CAN IDs. Since the dataset is not publicly available as to the receiving sender and receiver of the data, the paper analyzes the CAN protocol table of a brand from our laboratory. We find that an ECU has a fixed set of CAN IDs (e.g. EMS, containing 0x101, 0x278, 0x281) and that the recipients of the different CAN IDs are also fixed (e.g. 0x101, containing TCU, ESP, EPB, T-BOX). This is the initial purpose to design a single-frame detection model capable of tracking unauthorized ECUs and protecting non-attacked ECUs.
| Attack type | Normal messages | Injected messages |
|---|---|---|
| DoS attack | 3078250 | 587521 |
| Fuzzy attack | 3347013 | 491847 |
| RPM attack | 2766522 | 597252 |
| Gear attack | 2290185 | 654897 |
| ID | Transmitter | periods | Receiver |
|---|---|---|---|
| 0x101 | EMS | 10 | TCU, ESP, EPB, T-BOX |
| 0x278 | EMS | 10 | TCU, GSM, ABS, ESP, EPS, EPB, PEPS |
| 0x281 | EMS | 100 | TCU, AC, ICU, HUD, T-BOX |
| 0x1A0 | TCU | 10 | EMS, GSM, ESP, EPB, PEPS, DRC, PDC |
| 0x211 | ESP | 10 | TCU, ESP, EPB, T-BOX |
| … | … | … | … |
| 0x2EA | ABS | 20 | EMS, TCU, EPB, ICU, T-BOX, APA |
| 0x68A | NVS | 500 | HUD, PSW |
Additionally, the frequency of the different IDs is fixed by the vehicle manufacturer. It is worth noting that important automotive components have a higher priority. Hence, time-series features are reflected in the ID of the CAN messages. Despite the fact that there are some event-triggered messages with variable frequency, the set of commands is also fixed. The details are shown in Table III.
Spatial feature expression, especially the data field of the CAN frame, is most significant. Most new messages are generated at a steady rate over the period of data acquisition in the dataset. In this study, the spatial signature analysis was based on the data segment, and a single message often had a regular change in timing. We analyzed this and aggregated the messages of different periodic variation rules. Table IV displays some CAN message of different CAN IDs from the dataset, where the omissions represent same transferred bytes. We can observe that they have certain fixed byte constants (e.g., the first 7 bytes of ID=0x260), as well as fields that change more frequently (e.g., the third bytes of ID=0x316), but only in a certain range. There are distinct spatial characteristics of the data field, useful for modeling the normal behavior of the CAN packet, and also inspire the requirement to design attention convolutional blocks.
| ID | Transmitter | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 0x260 | N/A | 05 | 22 | 00 | 30 | FF | 99 | 63 | 38 |
| 0B | |||||||||
| 1A | |||||||||
| 29 | |||||||||
| 0x316 | RPM | 05 | 22 | 6A | 0B | 21 | 18 | 00 | 7F |
| 22 | 16 | 22 | |||||||
| 23 | 3A | 23 | |||||||
| 24 | 1A | 24 | |||||||
| 0x43F | GEAR | 10 | 50 | 60 | FF | 46 | 28 | 0A | 00 |
| 0C | |||||||||
| 10 | |||||||||
| F0 |
To more visually observe the byte change patterns, the data fields for each message are displayed in a heat map, as shown in Fig 5. In order to apparently visualize the differences in variation of the each byte, this paper presents 100 consecutive communication messages based on three important CAN IDs such as gear and speed. There is a certain period of color shade variation at ID = 0x260 and ID = 0x43F, while the messages sent by the RPM-specific IDs are clearly irregular, corresponding to the summary in Table IV.
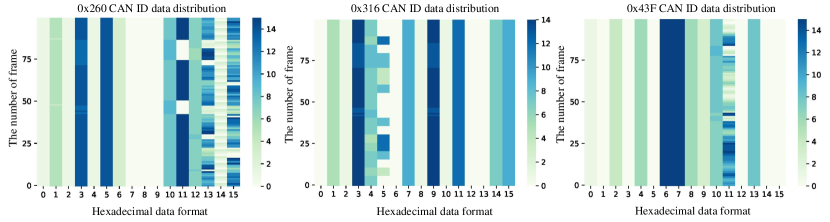
In conclusion, spatial-temporal details are useful for modeling the normal behavior of CAN packets, and attention also focuses on bytes that change frequently and time-series important relationships, thus helping the model to quickly detect violations and determine the targeted traffic.
IV IDS USING SPATIAL-TEMPORAL CORRELATION FEATURE
IV-A Dataset preprocessing
It is impractical to train an IDS based on the neural network on the original CAN dataset, so data pre-processing is a necessary part before model training. The payload field is 8 bytes as shown in Table IV, where each byte is represented by two numbers in hexadecimal format. In fact, the public source dataset was progressively judged and found to contain a large number of data frames that were inferior to 8 bytes or irregular. To ensure uniformity of model input, we filled in the missing data frames with ”00” in two scenarios: 1) where the data frame is less than 8 bytes; 2) where only the single digit ”0” is used to represent a byte. Afterward, we split and transformed the arbitration bits and data domain in the dataset into a trainable dataset containing 19 features, respectively 16 features in 8 bytes of the data domain. In particular, the CAN ID is partitioned into 3 bits in order to harmonize the operation with the split data field. On the one hands, the combination of hexadecimal features of the original multi-bit will not be too far removed from the data field features due to the introduction of temporal-frequency features; on the other hand, all messages provided by the public dataset have only 3 valid bits in hexadecimal.
In addition, the values of all features are converted to decimal from hexadecimal. After implementing missing data padding and decimal conversion to meet the basic inputs for the model, several additional data pre-processing steps still need to be completed. First, the CAN frame type is encoded using a label encoder, which is used to convert categorical features into numerical features owing to many ML&DL-based algorithms cannot directly support string features [33]. Thereafter, the network dataset is normalized by the Min-Max algorithm, as the features collected in network traffic data often have a wide range of differences that impose model deviations and emphasize only large-scale features. Furthermore, the ML&DL-based model is proven to perform more convergent easily on normalized dataset [57, 58]. Hence, the data normalization by the Min-Max method is calculated as:
| (1) |
The method implements equal scaling of the original data, where is the normalized data, is the original data, and and are the maximum and minimum values of the original dateset respectively. Table V presents the CAN data that is available as model input, where the former three columns are the CAN ID feature fields, the next eight columns in each message present 16 data domain fields, and the last column represents the label in digital form for each message. In addition, the first two rows represent the distribution for normal CAN data features, while the distribution for injection attacks is the third row. For multi-frame detection, encoder requires an additional image conversion step that splits the collected data set into 2-D images. After the normalization completing, in order to prevent the same attacks from appearing in both the test and the segmented attack data, dataset division is for 10-fold cross-validation via StratifiedKFold function in sklearn library.
| ID | DATA | Label | |||||||||
| ID1 | ID2 | ID3 | Byte1 | Byte2 | Byte3 | Byte4 | Byte5 | Byte6 | Byte7 | Byte8 | |
| 0.2 | 0.06 | 0.4 | 0 | 0.13 | 0.4 | 0 | 0.13 | 0.13 | 0 | 0.4 | 0 |
| 0.2 | 0.06 | 0.53 | 0.6 | 0.06 | 0.06 | 0 | 1 | ||||
| 0.06 | 0.53 | 1 | 1 | 0.33 | 0 | 0 | 0 | 0.2 | 0 | 0 | 0 |
| 0.93 | 0.73 | 0 | 0 | 0 | 0.8 | 0 | 0 | ||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||||
IV-B STC-IDS model design
The STC-IDS consists of two steps: encoding and detection, respectively. The encoder is an analysis of the spatial-temporal characteristics of the CAN messages, and capturing the important relationships based on attention to it; the detector achieves anomaly classification to the valuable spatial-temporal features.
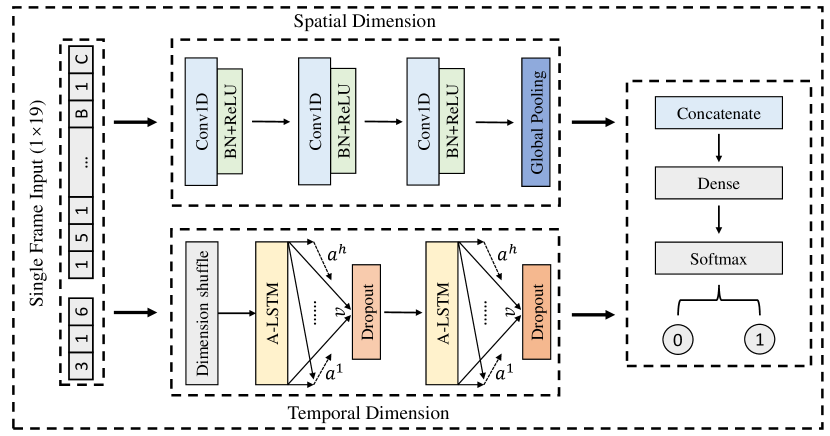
IV-B1 STC-IDS for single-frame detection
From the perspective of single-frame intrusion detection, our aim is to retrieve the illegally controlled source ECU in conjunction with the CAN ID (i.e., accurate identification of every abnormal traffic). In training phase, we extract spatial features at one-dimensional data by CNN. Since the input of the proposed model is defined as , the spatial component extracts valuable features only through three convolutional blocks and a global pooling layer in order to avoid invalidating features because of the deeper network. Each convolutional block consists of a 1-D convolutional layer, a batch-normalization layer, and an activation function ReLU. The batch-normalization allows the model to discard the learning of biases, and make the convolutional output of the model homogeneous particularly. The ReLU function makes the network realize nonlinear feature mapping, while the global pooling serves to assist the model in searching for where critical bytes are and reducing redundant information.
Attention actually mimics a visual mechanism of the human brain, seen as an automatic weighting scheme [42]. Hence, an improved LSTM structure with the attention mechanism (A-LSTM) is designed as a temporal component. We recognize the input as a multivariate time series with a single time step that is initially handled by the dimensional shuffling layer to increase the multivariate processing speed. When the features are fed into the A-LSTM blocks, it can mine significant temporal features. To prevent over-fitting, the discard layer plays a crucial role. Overall, the A-LSTM component could discover crucial byte changes, calculated as:
| (2) |
Where is the weight matrix, and means the implicit representation of the hidden state at computation feature bit . The is calculated as:
| (3) |
Where is the weight matrix and is the bias. Afterward, we attain the attention probability distribution value at each byte. Finally, the final feature vector is calculated as:
| (4) |
In Fig Fig.6, we present a parallel feature extraction classification model for single-frame detection. Both features are finally aggregated by the fully connected layers. We refer to it as the CAN valuable feature for spatial-temporal correlation under multi-view learning. Finally, it is fed into the final classification component, which specific elaboration in algorithm 1.
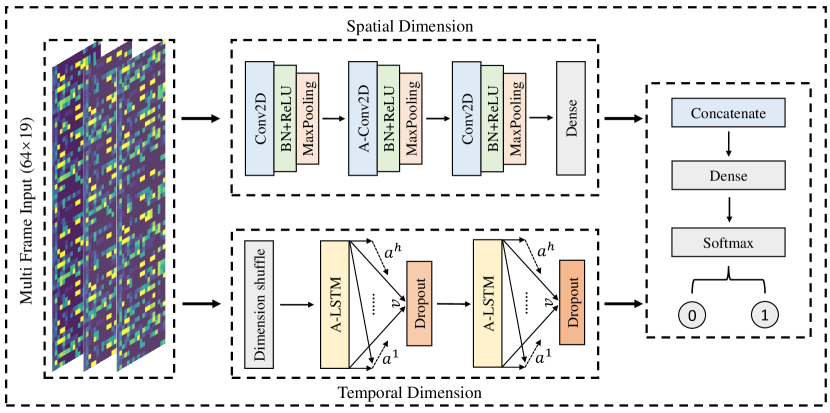
IV-B2 STC-IDS for multi-frame detection
To further elevate the efficiency, multi-frame based IDS is constructed. In other words, the model retrieves a continuous CAN 2-D matrix, aggregated from consecutive CAN messages during data pre-processing. The matrix height 64 represents the length of historical time series that the model could recall. For supervised learning, 2-D data frames that contain one or more injection messages are marked as attack CAN instance, while data frames that do not contain injection messages are marked as normal CAN instance.
As shown in Fig 7, the 2-D data frames are fed into the parallel networks. For the temporal feature extraction component, we remains the structure as same as the single-frame model, but the model input is a time series in 2-D so that A-LSTM can pay more attention to important relationships from previous time series. After the dimensional shuffling layer swap out the time dimension of the time series, the processed time-series are fed into the A-LSTM blocks. However, the three main parameters in the single-frame temporal attention model, i.e. ,,, need to be redefined as . indicates the implicit representation of the hidden state at computation time , while represents the final computed attention value.
Moreover, the spatial feature extraction component is inspired by the VGGNet model. we keep feature extraction capability of the model, but modify the number of convolutional layers and channel to adapt CAN dataset. It is composed of three convolutional blocks, where a convolutional module consists of a 2-D convolutional layer, a batch normalization layer, and a max-pooling layer.
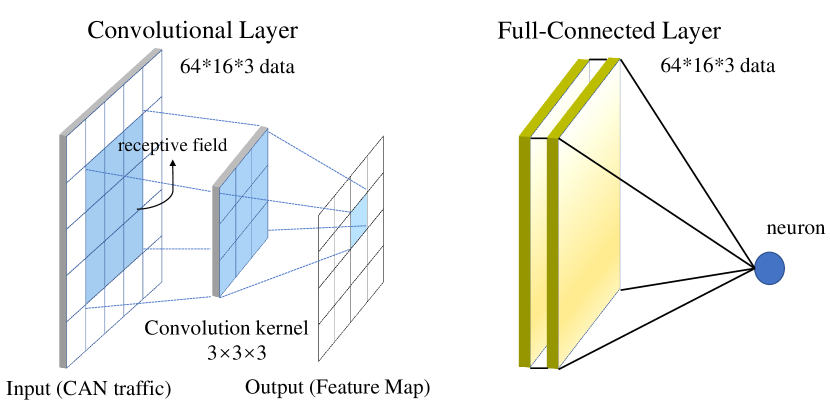
Since the convolutional layer has the feature of shared weight, the proposed model reduce the complexity and improve the inference efficiency. For instance, if a feature is mapped into a volume, the full-connected layer requires weights, while the convolutional layer via convolutional kernels only require weights. Fig 8 illustrates the difference between convolutional and fully connected layer computations. The multi-frame detection also has the capability to remove redundant information, and reduce the computational effort with the help of max-pooling layer. The convolutional block maps the raw data to the hidden feature space, thereby performing the task of feature engineering to improve the performance of the spatial component. The fully connected layer serves to map the learned ”distributed feature representation” to the sample markup space. Hence, spatial-temporal correlation features are extracted in a parallel network, and then aggregated by a fully connected layer to finish the classification task.
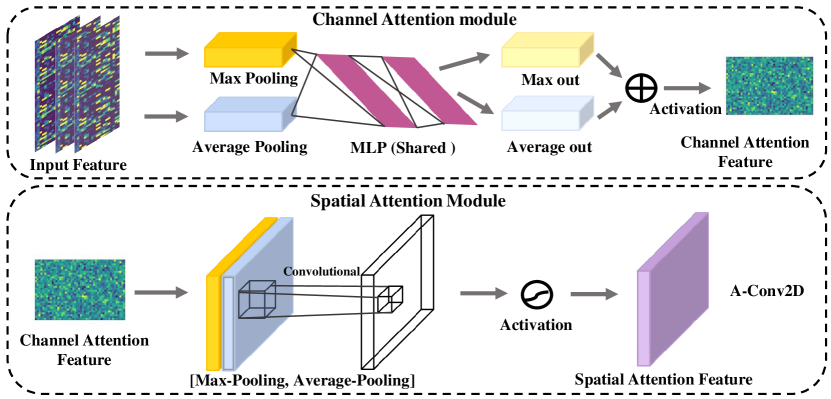
Most importantly, the second convolutional component is enhanced with visual attention mechanism, called A-Conv2D. The core idea of the component is to help the network extract and represent the information most relevant to the target. For instance, we usually focus on significant information when viewing a photograph, and summarize it. Observing Table II and the heat map in Fig 5, there are clearly crucial information changes in the bytes as a 2-D data frames. Recently, channel and spatial attention are mentioned in the CNN [59]. Inspired by the idea, the proposed structure integrates such ways, which can assist the model to find where the key information is and where the channel features are learned. The mode has the capability to self-select important features and eliminate the feature engineering step. Hence, convolutional branches of the intermediate layer can obtain a convolutional feature with spatial attention and channel attention. This additional structure is essentially cascaded over the original network with the purpose of better extracting valuable features. In summary, attention convolutional module features are calculated as follows:
| (5) | ||||
where is the aggregated feature. , are channel attention weight coefficients and spatial attention wight coefficients, respectively, while is the input feature and is the channel attention feature.
In Fig 9, the feature maps built by the first convolution block are extracted deep features and attention coefficients through the attention convolution component. Initially, the max-pooling and avg-pooling layers aggregate spatial attention information to generate two different spatial context descriptions. Immediately afterward, the two features are added together by the multi-layer perceptron (MLP). Note that the MLP is weight-sharing to realize information sharing. Finally, the weight coefficients are obtained through the sigmoid activation function, which is calculated as:
| (6) | ||||
After getting the weight coefficients , the channel attention features is calculated as follows:
| (7) |
where is the activation function, and are the weight matrices of the convergence layer.
The spatial attention module is a stable complement to channel attention information because of its ability to mine where the key features are. Similarly, given an feature , two channel descriptions are obtained by averaging pooling and max pooling in one channel dimension, respectively. Thereafter, the channel descriptions are stitched together based on the channel. Finally, a convolutional layer with sigmoid activation function is applied to obtain the weight coefficients , which calculated as follows:
| (8) | ||||
Where the represents convolutional computation, and represent two channel descriptions, respectively. Thus, the spatial-channel attention aggregation feature is obtained by multiplying the weight coefficients with the feature . The feature is continued calculated by the normal convolutional component, and then aggregated with the temporal feature to build the spatial-temporal features. The fully connected layer maps the spatial-temporal feature to sample markup space to finish the two-class classification task. Specifically, the multi-frame model is described in algorithm 2
IV-B3 Classification loss
For the intrusion detection based on classification, the loss value can be obtained according to the comparison between the prediction label and the actual label. Based on this loss message, the loss calculation method are used for the two data formats as discriminant mark for detection. Hence, the predict values are calculated as follows.
| (9) | ||||
Where is the combining features, and present the probability distribution over target classes zero and one. With the fusion of two structures, the model becomes more complex generating over-fit phenomena easily. For better generalization of the model, regularization is set in the network layer to limit the gradient. Besides, we need to continuously optimize by back propagation to reduce loss value, and fit the model to the best structure, in order to maximize the predicted probability . The loss function is calculated as follows.
| (10) | ||||
V Evaluation
We now validate that the spatial-temporal correlation feature can be used to detect anomaly frames, and evaluate the performance of a CAN bus prototype and real vehicles.
V-A Evaluation Metrics and Experiment Environment
In this paper, statistical metrics TP (true positive) and TN (true negative) are introduced to indicate the number of frames correctly classified as attack and normal, while metrics FP (false positive) and FN (false negative) are introduced to indicate the number of data frames that are misclassified as attack and normal. The model accuracy formula is as follows.
| (11) |
Precision (P) and recall (R) are considered as evaluation metrics to assess classification performance. Precision refers to the rate at which the actual data frame labels are detected correctly, while recall represents the proportion of all attack frame samples that end up in the attack frame class, which are calculated as follows.
| (12) |
and
| (13) |
The F1 score evaluation is also presented, which is a harmonic average based on the detection precision and completeness. Also, the F1 score is often used to measure classification performance when the data are unevenly distributed, which is calculated as follows.
| (14) |
Additionally, the false negative rate (FNR) and the error rate (ER) are one way of assessing classification performance. The FNR is the proportion of frames that are not detected as belonging to the attack frame and the ER is the proportion of frames that are incorrectly classified, calculated as follows.
| (15) |
and
| (16) |
The two models designed in this paper were trained offline based on the dataset, while the testing phase was based on real vehicles, injected with malicious frames of the same rules, to check the performance and efficiency of the models. The following is the experimental training and testing environment.
-
1.
Intel(R) Core (TM) i7-9500U CPU@3.6GHz
-
2.
RAM:64.0 GB
-
3.
GPU RTX 2080 Ti (Training environment)
-
4.
CAN Test, NVIDIA Jetson AGX Xavier (16GB) (Testing environment)
V-B Hyperparameter Selection and Optimization
The selection of hyperparameters is a crucial step in network performance and inference efficiency. Currently, automated hyperparametric optimization (HPO) services and tool-kits address the constant trial-and-error steps of deep learning developers [60]. In this paper, bayesian optimization (BO) automatic parametric tuning is used in order to quickly determine hyperparameters. It is a typical method applied to global optimization problems. Compared to grid search and stochastic search, BO is more computationally efficient and requires fewer attempts to find the optimal set of hyperparameters [57].
Based on the BO optimization library provided by Keras-tuner and on a 10-fold cross-validation dataset, we selected important hyperparameters such as learning rate (1e-2, 1e-3, 1e-4, 1e-5, 1e-6), optimizer (e.g., Adam, SGD, RMSprop), dropout rate, and filters. Afterward, we set the optimization goal to validate the accuracy (Val-Acc), a maximum number of trials of 10, and train the model 3 times per trial. Finally, the optimization results will present the set of top 3 hyperparameters for performance.
| Model type | Learning rate | Dropout rate | Filters | Dense | Optimizer | Val-Acc |
|---|---|---|---|---|---|---|
| Single Frame | 1e-6 | 0.4 | 16,32,128 | 64 | Adam | 0.9998 |
| 1e-6 | 0.4 | 8,96,32 | 48 | Adam | 0.9935 | |
| 1e-6 | 0.4 | 8,16,192 | 80 | Adam | 0.9869 | |
| Multi Frame | 1e-2 | 0.4 | 64,16,32 | 128 | Adam | 0.9996 |
| 1e-2 | 0 | 8,16,32 | 128 | Adam | 0.9993 | |
| 1e-2 | 0 | 24,80,96 | 256 | Adam | 0.9992 |
As shown in Table VI, the average accuracy on the cross-validation set reaches 99.98% in the single-frame model when setting the learning rate is 1e-6, the dropout rate is 0.4, the filters are 16, 32, 128, the dense layer is 64, and the optimizer is Adam. Similarly, the accuracy is achieved up to 99.96% to the multi-frame model under the optimal hyperparameters.
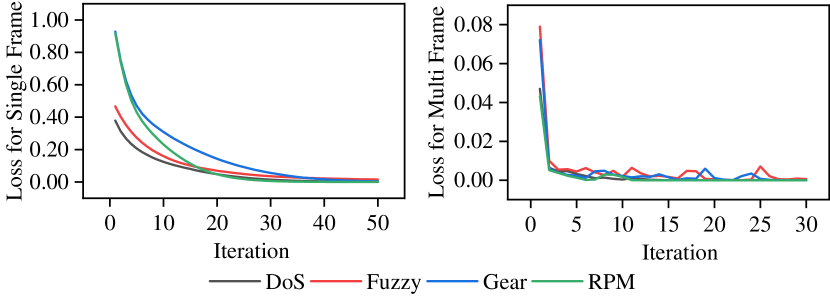
Interestingly, the inference speed of the model was significantly accelerated aided by the optimal hyperparameters. Despite the higher detection performance was obtained by the single-frame model, the inference speed is slower. Relative to multi-frame, it took 50 iterations to converge, whereas the multi-frame model only took 30 generations. Fig 10 shows the iterative training losses for each dataset. It can be observed that since the DoS attack disrupts the frequency of injection, both models learn the patterns and converge quickly. However, as the complexity of attack data increases, the fuzzy and spoofing attacks injected with random data converge slower in the single-frame model, while the training loss convergence fluctuates significantly in the multi-frame model.
V-C Detection Metrics Evaluation and Comparison
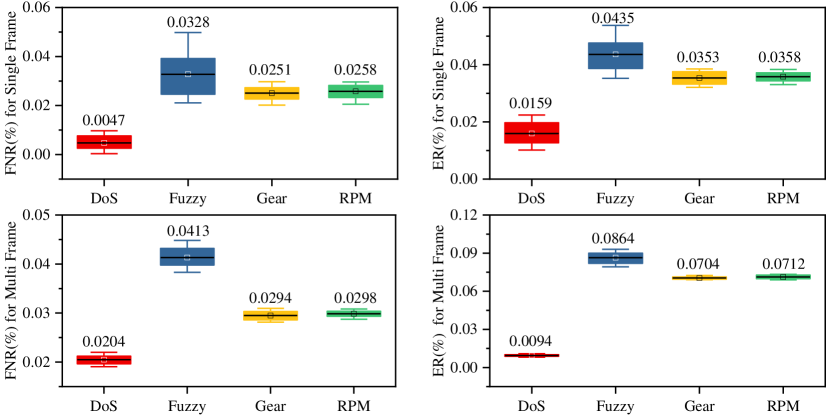
After training the best two models according to the set hyperparameters, Fig 11 shows the detection performance of the models in terms of ER and FNR for the four-attack testing sets in 30 repeated experiments. The two proposed models, both in terms of FNR, and ER, presents stable performance to detect DoS attacks with mean values of 0.0047%, 0.0204%, 0.0159% and 0.0094%, respectively. On the contrary, the fuzzy attacks shows greater fluctuations in detection performance. The complexity of fuzzy attack data seems to be significantly higher than the other injected data, necessitating more training iterations to construct a stable model. Hence, the ultimate mean values of FNR are still 0.0328% and 0.0413%, as well as ER get 0.0435% and 0.0864%.
Although FNR and ER on spoofing attacks are higher than DoS attacks, they achieve stable and better results compared to fuzzy attacks. The single-frame detector averages 0.0251% and 0.0353% for the Gear attack on both metrics, while the multi-frame detector obtains 0.0294% and 0.0704%. Similarly, the performance of both models is similar to Gear attacks when detecting RPM attacks. Notably, the single-frame detection model requires mining the characteristics of different CAN packets, thus exhibiting fluctuations in FNR and ER values that are greater than the multi-frame model. Despite the multi-frame model with better detection efficiency, it has a higher false alarm rate than the former.
To reflect the advantages of our model, Table VII lists the detection performance of STC-IDS when compared to those of the other machine-learning techniques, where the highest performance values are highlighted in bold, and ”-” only means that the scheme has not been tested on this metric. The results indicate clearly that the STC-IDS model outperforms the previous methods on all datasets. The false negative rate and error rate are significantly reduced. It can be seen that the model captures spatial-temporal details of network traffic remarkably well and enhances the anomaly detection ability satisfactorily.
| DoS | ER (%) | FNR (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| STC-IDS for Single Frame | 0.02 | 0.01 | 99.95 | 99.99 | 99.96 |
| STC-IDS for Multi Frame | 0.01 | 0.02 | 99.91 | 99.97 | 99.94 |
| 3-LSTM [35] | 0.07 | 0.22 | 1.0 | 99.78 | 99.88 |
| DCNN [36] | 0.03 | 0.10 | 1.0 | 99.89 | 99.95 |
| DAE [61] | - | 0.12 | 91.27 | 99.88 | 95.36 |
| OTIDS [62] | - | 26.2 | 99.90 | 73.80 | 84.88 |
| Fuzzy | ER (%) | FNR (%) | P (%) | R (%) | F1 (%) |
| STC-IDS for Single Frame | 0.05 | 0.04 | 99.97 | 99.95 | 99.96 |
| STC-IDS for Multi Frame | 0.09 | 0.07 | 99.90 | 99.92 | 99.91 |
| 3-LSTM [35] | 0.84 | 0.65 | 99.36 | 99.16 | 99.26 |
| DCNN [36] | 0.18 | 0.35 | 99.95 | 99.65 | 99.80 |
| DAE [61] | - | 3.74 | 90.05 | 96.26 | 93.05 |
| OTIDS [62] | - | 29.79 | 99.14 | 70.21 | 82.20 |
| Gear | ER (%) | FNR (%) | P (%) | R (%) | F1 (%) |
| STC-IDS for Single Frame | 0.04 | 0.03 | 99.97 | 99.96 | 99.97 |
| STC-IDS for Multi Frame | 0.07 | 0.03 | 99.94 | 99.96 | 99.95 |
| 3-LSTM [35] | 0.24 | 0.32 | 99.75 | 99.68 | 99.72 |
| DCNN [36] | 0.05 | 0.11 | 99.99 | 99.89 | 99.94 |
| DAE [61] | - | 18.2 | 94.63 | 81.80 | 87.75 |
| OTIDS [62] | - | 28.35 | 99.83 | 71.65 | 83.42 |
| RPM | ER (%) | FNR (%) | P (%) | R (%) | F1 (%) |
| STC-IDS for Single Frame | 0.04 | 0.03 | 99.98 | 99.96 | 99.97 |
| STC-IDS for Multi Frame | 0.07 | 0.03 | 99.95 | 99.96 | 99.96 |
| 3-LSTM [35] | 0.13 | 0.30 | 1 | 99.71 | 99.85 |
| DCNN [36] | 0.03 | 0.05 | 99.99 | 99.94 | 99.96 |
| DAE [61] | - | 4.27 | 95.73 | 95.73 | 92.10 |
| OTIDS [62] | - | 28.32 | 99.81 | 71.68 | 83.43 |
Evidently, we can observe that the STC-IDS for single-frame model achieves a stable precision (99.97%), a higher recall (99.96%), and an outstanding F1-score (99.96%) in average as compared to a threshold (OTIDS), classification (DCNN), prediction (3-LSTM), and clustering (DAE) based models. In contrast, the performance solely decreases by an average of 0.04% precision, 0.01% recall, and 0.03% in the F1-score while maintaining efficiency in the multi-frame model.
The 3-LSTM scheme shows high accuracy and unstable recall because of the unconsidered spatial correlation, resulting in a low F1 score and a large gap between FNR and ER with our scheme and DCNN. DCNN is currently one of the best models for in-vehicle intrusion detection, but the stacking of convolutions is ineffective in capturing the temporal relationships of the inputs. As a result, the single-frame model reduces the FNR and ER by 90% and 33% over the DCNN scheme for DoS attacks, while the multi-frame model reduces the FNR by 80% and the ER by 66%. More notably, for complex fuzzy attacks, only 0.04% FNR and 0.05% ER are achieved on the single-frame model. In addition, the FNR is slightly improved on the Gear and RPM dataset. Meanwhile, the ER gets approximate performance compared with the DCNN model.
Compared to the DAE model with a lack of labeling constraints, the proposed model has larger improvements in detection performance, while DAE only reaches 95.36% in F1-score on DoS attacks, and obtains lower performance on other attacks. Similarly, the OTIDS exhibited a high accuracy rate and extremely low recall, resulting in an FNR of over 25%, reflecting a relatively low F1-score. Thus, the robust spatial-temporal correlation feature demonstrates sufficient benefits in terms of improving detection performance and reducing the false alarm rate.
V-D Time Cost in Real Vehicle
This work first implemented single frame detection in terms of security considerations. Although the performance is improved over previous algorithms, the efficiency is not guaranteed. Besides, time and resources are the major limitations to applying deep learning models to real-world vehicle IDS. Therefore, STC-IDS based on multi-frames also was proposed. Obviously, significant improvements were made in terms of model convergence time as shown in subsection V-B. To test the efficiency of proposed model a resource-constrained in-vehicle network, the model was tested on an in-vehicle class device the NVIDIA Jetson AGX Xavier. Note that only 4GB of video memory was allocated for testing. The CAN Test software injected the attack traffic by connecting to the OBD-II port, as shown in Fig 12.

In Fig 13, we present that the proposed model has lower time (in milliseconds) cost on anomaly detection in case of different batches compared to previous algorithms. The average detection time for single-frame model remains under 0.7 ms. Although small-batch requires the highest time cost, the detection time is decreased based on the increasingly batch. For example, 256 batch shows 0.54 ms time cost, which is superior to DCNN [36] and MTH-IDS [33]. Moreover, this truly indicates that the model is constantly learning as it reasoned, thus making it easier to catch malicious features later on. However, it can be estimated that the model can detect 1851 messages in 1s at the fastest detection time cost, while CAN frames transmit approximately 2000 messages in 1s. One limitation of this method is that they do not usually satisfy real-time detection.
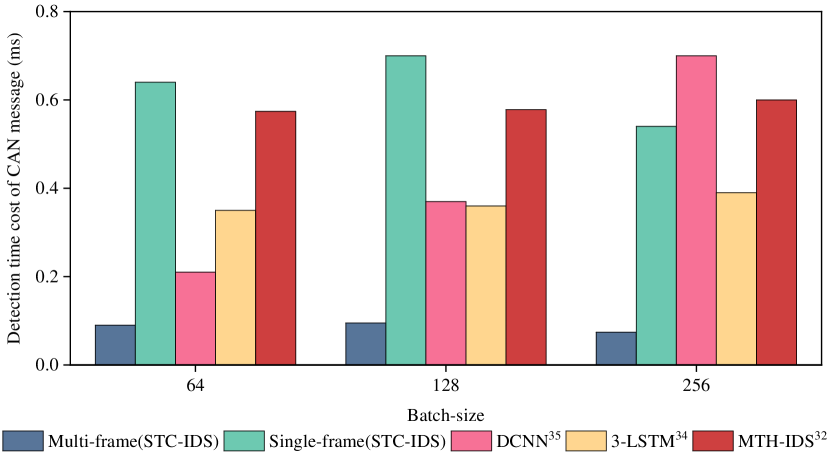
To overcome this limitation, the multi-frame model presents prominent advantages that just need the average time cost of 0.09 ms, 0.09 ms, and 0.074 ms for three batches, respectively. Compared testing time of the previous models as listed in Fig 13, the proposed model not only present outstanding performance, but also improves about 5 times in terms of efficiency. This means that the model can infer about five times the number of CAN transmission messages in 1s. Hence, the proposed model has the feasibility for real-time detection. Unlike the DCNN [36] model, a crucial phenomenon is that the proposed model does not depends on batch size. The same result reflects on 3-LSTM model [35] and MTH-IDS [33]. But even so, we also suggest a suitable batch size needs to be determined, as large batches may delay anomaly alert.
V-E Discussion and Limitations
The study presents two enhanced spatial-temporal features analyzing IDS for detecting single CAN messages and consecutive CAN frames based on open injection attack datasets. Experiments indicates that the single-frame model exhibits good detection performance. Similarly, the STC-IDS for multi-frame improves efficiency while ensuring performance.
Although the detection efficiency of the single-frame model is right limited, we believe that the model will be suitable for real-time detection when using higher-performance computing devices. In fact, it is necessary to track unauthorized ECUs in conjunction with CAN ID indexing in further in-vehicle security development based on single-frame detection. It is worth noting that the time-cost detection of proposed methods is based on in-vehicle edge computing and autonomous driving platform from our research group. Although it has satisfied the requirement for real-time intrusion detection when in a real environment, it has some impact when all tasks are performed simultaneously. Hence, more research still needs to develop in terms of practical implementation.
Clearly, the spatial-temporal feature modeling in this study is based on observing the CAN ID domain, data field, and communication protocol of the specific brand vehicles. The generality consequence of the proposed model is demonstrated due to the fixed time-interval, sender and receiver, despite different vehicle companies making distinct communication protocols. In other words, model transfer only needs to be re-trained on the new brand vehicle, which also can extract valuable spatial-temporal features, and obtains excellent detection performance.
Moreover, the division of CAN ID in the scheme is limited to public datasets. In order to accommodate more realistic in-vehicle messages, the division should be completed in practice by considering both standard frames (11 bits) and extended frames (29 bits). However, it is straightforward only to modify the dimensionality of the input for the proposed model. Most importantly, the model has a fundamental limitation in terms of detecting unlearned types of attacks as it is based on supervised learning. To address this challenge, more research is needed on unknown attack detection using models with generative functions such as adversarial training, or auto-encoder.
VI Conclusions
This work focuses on learning the temporal and spatial characteristics of in-vehicle network traffic in order to establish enhanced spatial-temporal correlation features, and then build an automotive intrusion detection model. The proposed model is implemented based on the encode-detection architecture. The encoding layer is constructed as a parallel network in both temporal and spatial terms base on LSTM and CNN. The introduction of A-LSTM and A-Conv2D helps the model uncover important relationships between keyword node variation and temporal order. Spatial-temporal correlation features are fed into the detection layer to complete anomaly detection.
Both models achieve optimal hyperparameter selection with Bayesian optimization, reducing the number of iterations and elevating accuracy. Compared to previous schemes, our model achieves a better performance on open source dataset, i.e., DoS, Fuzzy, Gear, and RPM, especially in the FNR and ER metrics.
Although this study achieves security protection of the CAN bus, there is still much room for improvement, especially unknown attack detection. In future work, we will consider how to express realistic unknown attack messages, improving model robustness and generalization capabilities. Data annotation also is a tedious task, but unsupervised algorithms are one of the solutions, which still need continuous research to improve performance.
References
- [1] H. M. Song and H. K. Kim, “Self-supervised anomaly detection for in-vehicle network using noised pseudo normal data,” IEEE Transactions on Vehicular Technology, vol. 70, no. 2, pp. 1098–1108, 2021.
- [2] S.-H. Kim, S.-H. Seo, J.-H. Kim, T.-M. Moon, C.-W. Son, S.-H. Hwang, and J. W. Jeon, “A gateway system for an automotive system: Lin, can, and flexray,” in 2008 6th IEEE International Conference on Industrial Informatics. IEEE, 2008, pp. 967–972.
- [3] T. Hoppe, S. Kiltz, and J. Dittmann, “Security threats to automotive can networks—practical examples and selected short-term countermeasures,” Reliability Engineering & System Safety, vol. 96, no. 1, pp. 11–25, 2011.
- [4] C. Miller and C. Valasek, “Remote exploitation of an unaltered passenger vehicle,” Black Hat USA, vol. 2015, no. S 91, 2015.
- [5] J. Li, H. Ye, T. Li, W. Wang, W. Lou, Y. T. Hou, J. Liu, and R. Lu, “Efficient and secure outsourcing of differentially private data publishing with multiple evaluators,” IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 1, pp. 67–76, 2022.
- [6] C. Gao, J. Li, S. Xia, K.-K. R. Choo, W. Lou, and C. Dong, “Mas-encryption and its applications in privacy-preserving classifiers,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [7] Z. Liu, Y. Huang, X. Song, B. Li, J. Li, Y. Yuan, and C. Dong, “Eurus: towards an efficient searchable symmetric encryption with size pattern protection,” IEEE Transactions on Dependable and Secure Computing, 2020.
- [8] S. Checkoway, D. McCoy, B. Kantor, D. Anderson, H. Shacham, S. Savage, K. Koscher, A. Czeskis, F. Roesner, and T. Kohno, “Comprehensive experimental analyses of automotive attack surfaces,” in 20th USENIX security symposium (USENIX Security 11), 2011.
- [9] J. Petit and S. E. Shladover, “Potential cyberattacks on automated vehicles,” IEEE Transactions on Intelligent transportation systems, vol. 16, no. 2, pp. 546–556, 2014.
- [10] E. Aliwa, O. Rana, C. Perera, and P. Burnap, “Cyberattacks and countermeasures for in-vehicle networks,” ACM Computing Surveys (CSUR), vol. 54, no. 1, pp. 1–37, 2021.
- [11] I. Rouf, R. Miller, H. Mustafa, T. Taylor, S. Oh, W. Xu, M. Gruteser, W. Trappe, and I. Seskar, “Security and privacy vulnerabilities of In-Car wireless networks: A tire pressure monitoring system case study,” in 19th USENIX Security Symposium (USENIX Security 10), 2010.
- [12] H. Yan, M. Chen, L. Hu, and C. Jia, “Secure video retrieval using image query on an untrusted cloud,” Applied Soft Computing, vol. 97, p. 106782, 2020.
- [13] C. Chen and T. Huang, “Camdar-adv: generating adversarial patches on 3d object,” International Journal of Intelligent Systems, vol. 36, no. 3, pp. 1441–1453, 2021.
- [14] W. Wu, R. Li, G. Xie, J. An, Y. Bai, J. Zhou, and K. Li, “A survey of intrusion detection for in-vehicle networks,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 3, pp. 919–933, 2019.
- [15] Z. Tianqing, W. Zhou, D. Ye, Z. Cheng, and J. Li, “Resource allocation in iot edge computing via concurrent federated reinforcement learning,” IEEE Internet of Things Journal, vol. 9, no. 2, pp. 1414–1426, 2021.
- [16] D. He, S. Chan, Y. Zhang, C. Wu, and B. Wang, “How effective are the prevailing attack-defense models for cybersecurity anyway?” IEEE Intelligent Systems, vol. 29, no. 5, pp. 14–21, 2013.
- [17] J. Cai, Q. Wang, J. Luo, Y. Liu, and L. Liao, “Capbad: Content-agnostic, payload-based anomaly detector for industrial control protocols,” IEEE Internet of Things Journal, 2021.
- [18] K. Mo, W. Tang, J. Li, and X. Yuan, “Attacking deep reinforcement learning with decoupled adversarial policy,” IEEE Transactions on Dependable and Secure Computing, 2022.
- [19] H. Qin, M. Yan, and H. Ji, “Application of controller area network (can) bus anomaly detection based on time series prediction,” Vehicular Communications, vol. 27, p. 100291, 2021.
- [20] H. Olufowobi, C. Young, J. Zambreno, and G. Bloom, “Saiducant: Specification-based automotive intrusion detection using controller area network (can) timing,” IEEE Transactions on Vehicular Technology, vol. 69, no. 2, pp. 1484–1494, 2019.
- [21] S. Tariq, S. Lee, Y. Shin, M. S. Lee, O. Jung, D. Chung, and S. S. Woo, “Detecting anomalies in space using multivariate convolutional lstm with mixtures of probabilistic pca,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 2123–2133.
- [22] C. Zhang, D. Song, Y. Chen, X. Feng, C. Lumezanu, W. Cheng, J. Ni, B. Zong, H. Chen, and N. V. Chawla, “A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 1409–1416.
- [23] H. Sun, M. Chen, J. Weng, Z. Liu, and G. Geng, “Anomaly detection for in-vehicle network using cnn-lstm with attention mechanism,” IEEE Transactions on Vehicular Technology, vol. 70, no. 10, pp. 10 880–10 893, 2021.
- [24] X. Kuang, M. Zhang, H. Li, G. Zhao, H. Cao, Z. Wu, and X. Wang, “Deepwaf: detecting web attacks based on cnn and lstm models,” in International Symposium on Cyberspace Safety and Security. Springer, 2019, pp. 121–136.
- [25] J. Cai, Z. Huang, L. Liao, J. Luo, and W.-X. Liu, “Appm: adaptive parallel processing mechanism for service function chains,” IEEE Transactions on Network and Service Management, vol. 18, no. 2, pp. 1540–1555, 2021.
- [26] I. Studnia, E. Alata, V. Nicomette, M. Kaâniche, and Y. Laarouchi, “A language-based intrusion detection approach for automotive embedded networks,” International Journal of Embedded Systems, vol. 10, no. 1, 2018.
- [27] T. Dagan and A. Wool, “Parrot, a software-only anti-spoofing defense system for the can bus,” ESCAR EUROPE, vol. 34, 2016.
- [28] K.-T. Cho and K. G. Shin, “Fingerprinting electronic control units for vehicle intrusion detection,” in 25th USENIX Security Symposium (USENIX Security 16), 2016, pp. 911–927.
- [29] W. Choi, K. Joo, H. J. Jo, M. C. Park, and D. H. Lee, “Voltageids: Low-level communication characteristics for automotive intrusion detection system,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 8, pp. 2114–2129, 2018.
- [30] H. M. Song, H. R. Kim, and H. K. Kim, “Intrusion detection system based on the analysis of time intervals of can messages for in-vehicle network,” in 2016 international conference on information networking (ICOIN). IEEE, 2016, pp. 63–68.
- [31] C. Young, J. Zambreno, H. Olufowobi, and G. Bloom, “Survey of automotive controller area network intrusion detection systems,” IEEE Design & Test, vol. 36, no. 6, pp. 48–55, 2019.
- [32] M.-J. Kang and J.-W. Kang, “Intrusion detection system using deep neural network for in-vehicle network security,” PloS one, vol. 11, no. 6, p. e0155781, 2016.
- [33] L. Yang, A. Moubayed, and A. Shami, “Mth-ids: a multitiered hybrid intrusion detection system for internet of vehicles,” IEEE Internet of Things Journal, vol. 9, no. 1, pp. 616–632, 2021.
- [34] S. Tariq, S. Lee, and S. S. Woo, “Cantransfer: Transfer learning based intrusion detection on a controller area network using convolutional lstm network,” in Proceedings of the 35th annual ACM symposium on applied computing, 2020, pp. 1048–1055.
- [35] K. Pawelec, R. A. Bridges, and F. L. Combs, “Towards a can ids based on a neural network data field predictor,” in Proceedings of the ACM Workshop on Automotive Cybersecurity, 2019, pp. 31–34.
- [36] H. M. Song, J. Woo, and H. K. Kim, “In-vehicle network intrusion detection using deep convolutional neural network,” Vehicular Communications, vol. 21, p. 100198, 2020.
- [37] A. Tomlinson, J. Bryans, and S. A. Shaikh, “Towards viable intrusion detection methods for the automotive controller area network,” in 2nd ACM Computer Science in Cars Symposium, 2018, pp. 1–9.
- [38] X. Zhang, Y. Wang, G. Geng, and J. Yu, “Delay-optimized multicast tree packing in software-defined networks,” IEEE Transactions on Services Computing, 2021.
- [39] S. Ai, A. S. V. Koe, and T. Huang, “Adversarial perturbation in remote sensing image recognition,” Applied Soft Computing, vol. 105, p. 107252, 2021.
- [40] L. Hu, H. Yan, L. Li, Z. Pan, X. Liu, and Z. Zhang, “Mhat: an efficient model-heterogenous aggregation training scheme for federated learning,” Information Sciences, vol. 560, pp. 493–503, 2021.
- [41] W. Wang, M. Zhu, X. Zeng, X. Ye, and Y. Sheng, “Malware traffic classification using convolutional neural network for representation learning,” in 2017 International conference on information networking (ICOIN). IEEE, 2017, pp. 712–717.
- [42] N. Jiang, W. Jie, J. Li, X. Liu, and D. Jin, “Gatrust: A multi-aspect graph attention network model for trust assessment in osns,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [43] L. Yang, A. Moubayed, I. Hamieh, and A. Shami, “Tree-based intelligent intrusion detection system in internet of vehicles,” in 2019 IEEE global communications conference (GLOBECOM). IEEE, 2019, pp. 1–6.
- [44] Z. Liu, J. Li, S. Lv, Y. Huang, L. Guo, Y. Yuan, and C. Dong, “Encodeore: reducing leakage and preserving practicality in order-revealing encryption,” IEEE Transactions on Dependable and Secure Computing, 2020.
- [45] A. U. Jadhav and N. Wagdarikar, “A review: control area network (can) based intelligent vehicle system for driver assistance using advanced risc machines (arm),” in 2015 International Conference on Pervasive Computing (ICPC). IEEE, 2015, pp. 1–3.
- [46] J. Cai, K. Qian, J. Luo, and K. Zhu, “Sarm: Service function chain active reconfiguration mechanism based on load and demand prediction,” International Journal of Intelligent Systems, 2022.
- [47] O. Y. Al-Jarrah, C. Maple, M. Dianati, D. Oxtoby, and A. Mouzakitis, “Intrusion detection systems for intra-vehicle networks: A review,” IEEE Access, vol. 7, pp. 21 266–21 289, 2019.
- [48] R. I. Davis, A. Burns, R. J. Bril, and J. J. Lukkien, “Controller area network (can) schedulability analysis: Refuted, revisited and revised,” Real-Time Systems, vol. 35, no. 3, pp. 239–272, 2007.
- [49] K. Tindell, A. Burns, and A. J. Wellings, “Calculating controller area network (can) message response times,” Control engineering practice, vol. 3, no. 8, pp. 1163–1169, 1995.
- [50] S. Punnekkat, H. Hansson, and C. Norstrom, “Response time analysis under errors for can,” in Proceedings Sixth IEEE Real-Time Technology and Applications Symposium. RTAS 2000. IEEE, 2000, pp. 258–265.
- [51] V. S. Barletta, D. Caivano, A. Nannavecchia, and M. Scalera, “Intrusion detection for in-vehicle communication networks: An unsupervised kohonen som approach,” Future Internet, vol. 12, no. 7, p. 119, 2020.
- [52] E. Seo, H. M. Song, and H. K. Kim, “Gids: Gan based intrusion detection system for in-vehicle network,” in 2018 16th Annual Conference on Privacy, Security and Trust (PST). IEEE, 2018, pp. 1–6.
- [53] J. Li, X. Hu, P. Xiong, W. Zhou et al., “The dynamic privacy-preserving mechanisms for online dynamic social networks,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [54] S. Ai, S. Hong, X. Zheng, Y. Wang, and X. Liu, “Csrt rumor spreading model based on complex network,” International Journal of Intelligent Systems, vol. 36, no. 5, pp. 1903–1913, 2021.
- [55] J. Cai, H. Fu, and Y. Liu, “Deep reinforcement learning-based multitask hybrid computing offloading for multiaccess edge computing,” International Journal of Intelligent Systems, 2022.
- [56] H. Yan, L. Hu, X. Xiang, Z. Liu, and X. Yuan, “Ppcl: Privacy-preserving collaborative learning for mitigating indirect information leakage,” Information Sciences, vol. 548, pp. 423–437, 2021.
- [57] L. Yang and A. Shami, “On hyperparameter optimization of machine learning algorithms: Theory and practice,” Neurocomputing, vol. 415, pp. 295–316, 2020.
- [58] F. Yuan, S. Chen, K. Liang, and L. Xu, Research on the coordination mechanism of traditional Chinese medicine medical record data standardization and characteristic protection under big data environment, 1st ed., ser. 1. No.517 Shungong Road, Shizhong District, Jinan, Shandong Province, China: Shandong:Shandong People’s Publishing House, 12 2021, vol. 1.
- [59] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 3–19.
- [60] T. Yu and H. Zhu, “Hyper-parameter optimization: A review of algorithms and applications,” arXiv preprint arXiv:2003.05689, 2020.
- [61] T. Amarbayasgalan, B. Jargalsaikhan, and K. H. Ryu, “Unsupervised novelty detection using deep autoencoders with density based clustering,” Applied Sciences, vol. 8, no. 9, p. 1468, 2018.
- [62] H. Lee, S. H. Jeong, and H. K. Kim, “Otids: A novel intrusion detection system for in-vehicle network by using remote frame,” in 2017 15th Annual Conference on Privacy, Security and Trust (PST). IEEE, 2017, pp. 57–5709.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3502429-606f-4955-bfbe-c3c703b78253/x14.jpg) |
Pengzhou Cheng received the M.S. Degree with the Department of Computer Science and Communication Engineering, Jiangsu University, Zhenjiang, China, in 2022. He is currently pursuing the Ph.D. Degree with the Department of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai, 201100, China. His primary research interests include cybersecurity, machine learning, time-series data analytic, intelligent transportation systems, and intrusion detection system. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3502429-606f-4955-bfbe-c3c703b78253/han.jpg) |
Mu Han (Member, IEEE) received the Ph.D.degree in Computer Science from Nanjing University of Science and Technology. She is an Associate Professor with the School of Computer Science and Communication Engineering, Jiangsu University. Her primary research interests are in the areas of Cryptography, Security and Communication in-vehicle networks, the design of security protocols for smart cars and Information Security. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3502429-606f-4955-bfbe-c3c703b78253/AoxueLi.jpg) |
Aoxue Li received the B.S., M.S., and Ph.D. degrees in vehicle engineering from Jiangsu University, Zhenjiang, China, in 2013, 2016, and 2020, respectively. From August 2018 to August 2019, he was a visiting scholar with the Department of Mechanical Engineering, Michigan State University, East Lansing, MI, USA. He is currently a lecturer with the School of Automotive and Traffic Engineering, Jiangsu University. His research interests include autonomous vehicle, intelligent transportation systems, and ADAS technologies. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c3502429-606f-4955-bfbe-c3c703b78253/zhang.jpg) |
Fengwei Zhang received the Ph.D.degree in Computer Science from George Mason University. He is an Associate Professor with Department of Computer Science and Engineering, Southern University of Science and Technology. He was an Assistant Professor and the Director of the COMPASS Lab with Department of Computer Science, Wayne State University. His primary research interests are in the areas of systems security, with a focus on trustworthy execution, hardware-supported security, transparent malware analysis, and plausible deniability encryption. |