Stock price formation: useful insights from a multi-agent reinforcement learning model
Abstract
In the past, financial stock markets have been studied with previous generations of multi-agent systems (MAS) that relied on zero-intelligence agents, and often the necessity to implement so-called noise traders to sub-optimally emulate price formation processes. However recent advances in the fields of neuroscience and machine learning have overall brought the possibility for new tools to the bottom-up statistical inference of complex systems. Most importantly, such tools allows for studying new fields, such as agent learning, which in finance is central to information and stock price estimation. We present here the results of a new generation MAS stock market simulator, where each agent autonomously learns to do price forecasting and stock trading via model-free reinforcement learning, and where the collective behaviour of all agents decisions to trade feed a centralised double-auction limit order book, emulating price and volume microstructures. We study here what such agents learn in detail, and how heterogenous are the policies they develop over time. We also show how the agents learning rates, and their propensity to be chartist or fundamentalist impacts the overall market stability and agent individual performance. We conclude with a study on the impact of agent information via random trading.
I Introduction
Background: Multi-agent systems (MAS) or agent-based models (ABM) have had a long history of statistical inference in quantitative finance research. In particular, they have been used to study phenomena leading to price formation and hence general market microstructure, such as: the law of supply and demand Benzaquen and Bouchaud (2018), game theory Erev and E.Roth (2014), order books Huang et al. (2015), high-frequency trading Wah and Wellman (2013); Aloud (2014), cross-market structure Xu et al. (2014), quantitative easing Westerhoff (2008), market regulatory impact Boero et al. (2015), or other exogenous effects Gualdi et al. (2015). Remarkably, financial MAS have highlighted over the years certain specific patterns that are proper to virtually almost all asset classes and time scales, called stylised facts. These have since been an active topic of quantitative research Lipski and Kutner (2013); Barde (2015), and can be grouped in three main neighbouring categories: i- distributions of price returns are non-gaussian Cristelli (2014); Cont (2001); Potters and Bouchaud (2001) (they are asymmetric, negatively skewed, and platykurtic), ii- volatilities and volumes are clustered Lipski and Kutner (2013) (large jumps in prices and volumes are more likely to be followed by the same), iii- price auto-correlations decay Cont (2001, 2005) (there is a loss of arbitrage opportunity). In particular, the second stylised fact has long-range implications on the dynamics of meta-orders, and comprises the square-root impact law Bouchaud (2018a) (growth in square-root of orders impact with traded volumes). Implicit consequences of these stylised facts have fed numerous discussions pertaining to the validity of market memory Cont (2005); Cristelli (2014) and the extension of the efficient market hypothesis Fama (1970); Bera et al. (2015).
Epistemology: In the past, the epistemological pertinence of such models was sometimes put into question, because of the general conceptual challenge of framing realistic agents. Unlike other disciplines from hard science, financial MAS indeed had to justify their proper bottom-up approach to complex system inference Gao et al. (2011) in the light of a specific challenge of their field, namely the difficulty to realistically model and emulate human agents. Such critics especially carried greater weight by the fact that previous generations of financial MAS relied on so-called zero-intelligence agents (Gode and Sunder, 1993): these would trade according to specific and imbedded rules of trading, thereby overshadowing certain dynamics proper to game and decision theory that are crucial to real market activity. Yet, if compared with other famous types of models used in quantitative finance, like econometrics Greene (2017), MAS have two major advantages: i- they naturally display specific emergent phenomena proper to complex systems Bouchaud (2018b), and ii- they require fewer model assumptions (no gaussian distributions, no efficient market hypothesis Fama (1970); Bera et al. (2015), etc.). As for their shortcomings, we can mention specific conceptual challenges pertaining to: i- modelling complex system heterogeneity Chen et al. (2017), ii- discretionary framing of certain model parameters (e.g. number of agents) apart from possible empiricism Platt and Gebbie (2018).
Prospects: These general conceptual and epistemological considerations have been upset in the past few years, by the notable progress of two fields. The first, namely machine learning and especially multi-agent reinforcement learning Silver et al. (2018) (RL), has produced spectacular results that have far-reaching applications to other domains of interest to quantitative finance, like decision theory and game theory. The second, neuroscience and neurofinance especially, has benefitted from the wide use of brain-imaging devices Eickhoff et al. (2018) and peer data curation Smith and Nichols (2018). On both ends, some sort of technological emergence within these two fields is of special interest and relevance to financial MAS research, in that machine learning can imbed results from the latter Lefebvre et al. (2017); Palminteri et al. (2015), and vice-versa Duncan et al. (2018); Momennejad et al. (2017). Among other machine learning applications to finance (Hu and Lin, 2019; Neuneier, 1997; Deng et al., 2017), and in a way similar to what has been done for recent order book models (Spooner et al., 2018; Biondo, 2019; Sirignano and Cont, 2019), next-generation MAS stock market simulators can now be designed, and outstrip the former epistemological considerations pertaining to agent design, with a whole new degree of realism in market microstructure emulation. More importantly, these can address issues never computationally studied before, such as the crucial issues of agent information and learning, central to price formation Dodonova and Khoroshilov (2018); Naik et al. (2018) and hence to all market activity.
Our study: We have designed such a MAS stock market simulator, in which agents autonomously learn to do price forecasting and stock trading by reinforcement learning, via a centralised double-auction limit order book, and shown in a previous work Lussange et al. (2019) its calibration performances with respect to real market data from the London Stock Exchange daily quotes between and . We shall not review here its design in full details, but will recall its general architecture in Section II. Then our study will focus in Section III on agent learning: how can we gauge how heterogenous are the agent policies as compared to one another, and what are the trading characteristics of successful agents. Finally in Section IV, we will study the impact of such agent learning on the whole market at the mesoscale, and in particular with respect to herding or reflexivity effects when agents emulate the investments of the best (or worst) agent, and when increasing proportions of agents trade randomly as “noise traders.” As said, the greatest interest of financial MAS is to study and quantitatively gauge the impact of agent learning, which is at the heart of the price formation processes and hence of all market activity, and the motivation for multi-agent reinforcement learning for such a framework is motivated by the important parallels between reinforcement learning and decision processes in the brain Dayan and Daw (2008).
II Model
Architecture: We here briefly sketch the general architecture of our MAS simulator. Our model relies on a number of economic agents autonomously trading a number of stocks, over a number of simulation time steps, where we set as the number of annual trading days. All agents and their individual parameters are initialised at , with a portfolio made of specific stock holdings of value , where is the number of stocks of agent and the market price of stock , together with risk-free assets (e.g. a bank account) of value . Then all market prices are initialised at , and as in other models Franke and Westerhoff (2011); Chiarella et al. (2007), the simulation generates time series , which correspond to the fundamental values of the stocks. These are not fully known by the agents. Instead, each agent approximates the values of stock according to a proprietary rule (Murray, 1994) of cointegration . The time series are hence the approximation of the fundamental values of stock over time according to agent . Each agent thus relies on these two sources of information for its stock pricing strategy: one that is chartist, and one that is fundamental. At , the agent are agnostic with respect to trading. They are then allowed to learn over the course of time steps, after which their stock holdings and risk-free assets are reset back to their first value. The simulation and following results are hence applied to agents after this learning phase of time steps.
Initialisation: Let and denote the continuous and discrete uniform distributions, respectively. Each agent is then initialised with the following parameters: a drawdown limit (which is the maximum year-to-date loss in net asset value below which the agent is set as bankrupt), a reflexivity parameter (which gauges how fundamental or chartist the agent is via a weighted average of its price forecast), an investment horizon (which is the number of time steps after which the agent liquidates its position), a trading window (which assesses the optimal trading time for sending an order), a memory interval (which is the size of the past lag interval used by the agent for its learning process), a transaction gesture (which scales with bid-ask spread to set how far above or below the value of its own stock pricing the agent is willing to deal the transaction), and a reinforcement learning rate proper to both reinforcement learning algorithms and (see below).
Order book: At each time step, the agents may send transaction orders to the order book of each stock, whose function is to match these orders and process associated business transactions. More specifically, a number of order books are filled with all the agents’ trading limit orders for each stock at time step . All buy orders are there sorted by descending bid prices, all sell orders are sorted by ascending ask prices, each with their own associated number of stocks to trade. Then the order book clears these matching orders at same time step , with each transaction set at mid-price between buy and sell-side, starting from the top of the order book to the lowest level where the bid price still exceeds the ask price. Importantly, we then define the market price of stock at the next time step as that last and lowest level mid-price cleared by the order book. We also define the trading volume as the number of stocks traded during that same time . We also model the friction costs via broker fees (broker fees, ) applied to each transaction set at , an annual risk-free rate of applied to , and an annual stock dividend yield of according to (Div, ) applied to .
Agents: Each agent autonomously uses two distinct reinforcement learning algorithms to interact with the market. For a brief introductory sum up of reinforcement learning, we refer the reader to Lussange et al. (2019), and to Sutton and Barto (1998); Wiering and van Otterlo (2012); Szepesvari (2010) for a thorough study of the subject. A first algorithm learns the optimal econometric prediction function for the agent’s investment horizon, depending on specific local characteristics of the market microstructure and the agent’s fundamental valuation . It thus outputs this price forecast, which will in turn enter as input the second reinforcement learning algorithm . This second algorithm is in charge of sending an optimal limit order to a double auction order book (N and Larralde, 2016) at this same time step, based on this prediction and a few other market microstructure and agent portfolio indicators. Each reinforcement learning algorithm is individually ran by each agent following a direct policy search, for each stock , and at each time step . Each algorithm has and potential action-state pairs, respectively. We define the sets of states , actions , and returns of these two algorithms according to the following:
i- Forecasting: In the first algorithm , which is used for price forecasting, the agent continuously monitors the longer-term volatility of the stock prices , their shorter-term volatility , and the gap between its own present fundamental valuation and the present market price . This allows the agent to retrieve useful information on the microstructure and topology of the volatility, while avoiding dimensionality issues. Out of this state, it learns to optimise its price prediction at its investment horizon by selecting from a direct policy search three possible actions: choosing a simple forecasting econometric tool based on mean-reverting, averaging, or trend-following market prices , choosing the size of the historical lag interval for this forecast , and choosing the weight of its own fundamental stock pricing in an overall future price estimation, that is both fundamentalist and chartist . This is done in proportion to the agent reflexivity parameter . Via this action , the agent thus learns to gauge how fundamental or chartist it should be is in its price valuation, via a weighted average involving in the agent’s technical forecast of the market price and its fundamental pricing . At each time step, the rewards are defined according to percentiles in the distribution of the agent’s mismatches between past forecasts at time and their eventual price realisation at time . In parallel, an off-policy method computes the optimal action that was to be performed time steps ago, now that the market price is realised, and updates the agent policy accordingly.
ii- Trading: In the second algorithm , which is used for stock trading, the agent continuously monitors whether the stock prices are increasing or decreasing according to the output of the former algorithm , their volatility , its risk-free assets , its quantity of stock holdings , and the traded volumes of stock at former time step . Out of this state, it learns to optimise its investments by selecting two possible actions via a direct policy search: sending a transaction order to the order book as holding, buying, or selling a position in a given amount proportional to its risk-free assets and stock holdings , and at what price wrt. the law of supply and demand . The cashflow difference between the profit or loss consequent to the agent’s action, and that without action having been taken, are then computed time steps after each transaction. The rewards are defined according to percentiles in the distribution of these agent’s past cashflow differences. In parallel, an off-policy method computes the optimal action that was to be performed time steps ago, now that the market price is realised, and updates the agent policy according to it.
III Agent learning
III.1 Agent policy heterogeneity
We first want to measure the heterogeneity of the individual policies of these best and worse agents, not only as compared to one another as groups, but also to all other agents in the whole market population, and dynamically as a function of time. For this we compute matrices and of dimensions , where each matrix element and respectively, is computed as the average of the absolute differences between the probabilities and within the policy of agents and , for each policy and :
| (1) |
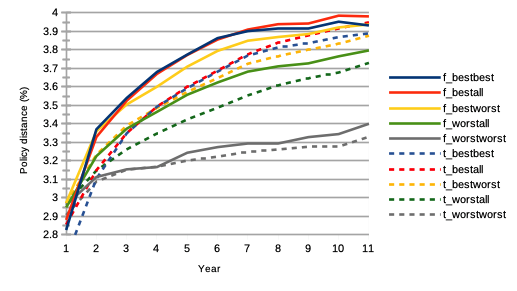
The results are shown on Fig. 1, where the values corresponding to were scaled to those corresponding to , in order to account for the different numbers of state-action pairs. For the first forecasting algorithm , we see that the best performing agents together converge to a pool of more diverse forecasting strategies, as compared to one another, but also to the worst performing agents and the rest of all market agents. Interestingly, the worst performing agents are less disparate in their policies among themselves, even more so than with regards to the rest of the market population. We see similar dynamics with the trading algorithm , with an even more pronounced heterogeneity among groups. One can say that as simulation time passes, worst performing agents have more in common among themselves, than best performing agents among themselves. This is a remarkable prediction under our model assumptions, because of its implication to trading strategies: there are more ways to succeed than to fail. From a regulation point of view, this also potentially implies that financial stock markets benefit in stability from the multitudes of available trading instruments, structured products, and a diversification of investment strategies. Finally, we also note that the curves corresponding to the forecasting algorithm are sorted like those of the trading algorithm , and nearly overlap one another. We posit this to be a consequence of the fact that each agent has identical reinforcement learning parameters (learning rate, rolling intervals, etc.) for both algorithms and .
III.2 Agent trading strategy
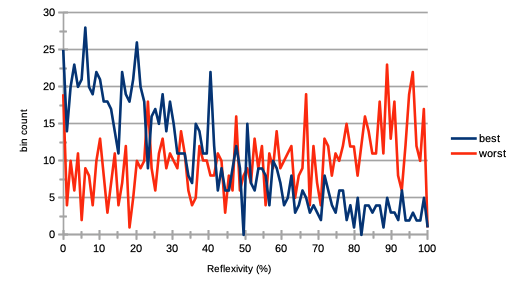
One of the first valuable statistical inference from the simulation is to gauge the agent propensity to engage in fundamentalist or chartist stock valuation for trading. At the mesoscale, this is one of the greatest known source of bubble formation and other so-called reflexivity effects Hardiman et al. (2013). Recall from Section II that each agent was initialised with a reflexivity parameter , reflecting how fundamental or chartist the agent is in its asset valuation. This reflexivity parameter works with a weighted average between the agent’s technical price forecast and its cointegrated estimation of the fundamental value of the stock. The agent learns to optimise this parameter through action , and hence learns to be more chartist or fundamentalist, depending on the market dynamics, represented by its states (longer-term volatility of the stock prices), (shorter-term volatility), and (gap between the agent’s own present fundamental valuation and present market price). We show the results on Fig. 2, where we can see at the end of the simulation a trend for the best agents to be fundamentalists and the worse agents to be chartists. We see that best performing agents have a tendency for being more fundamentalist, while the worst performing agents have for being more chartists. This can be linked with assumptions of the efficient market hypothesis of Fama (1970), if we would consider that all the information that is endogenous to the market is retrieved by the agents (in the sense that it is available to all), but that exogenous information would be less accessible, and hence a filter to screen agent trading performance.
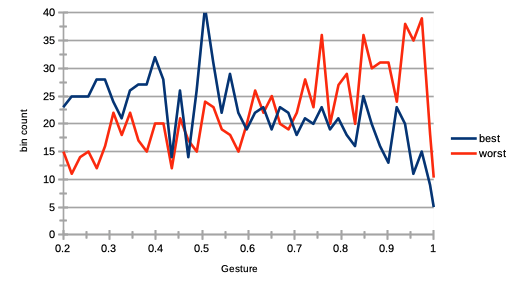
Another minor trait of reflexivity at the agent level is how much agents differ in their price estimation, and hence in the bid-ask spread formation. We can have a look into this spread and price formation process by checking the propensity for best performing agents to have a large gesture, as compared to worst performing ones. Such study has many parallels with market making and other strategies based on scalping the bid-ask spread. Recall each agent was initialised with a transaction gesture , reflecting how far above or below its own asset pricing the agent is willing to trade. The results are shown on Fig. 3, where we can see that best performing agents have a propensity for having a smaller transaction gesture (propensity to bid larger prices and ask smaller prices in transaction orders), while worst performing agents have a propensity for having a larger one (propensity to bid smaller prices and ask larger prices in transaction orders). Interestingly, such results indicate that “tougher” negotiators would thus statistically not be prone to better trading performance necessarily.
IV Market impact
IV.1 Agent learning rate
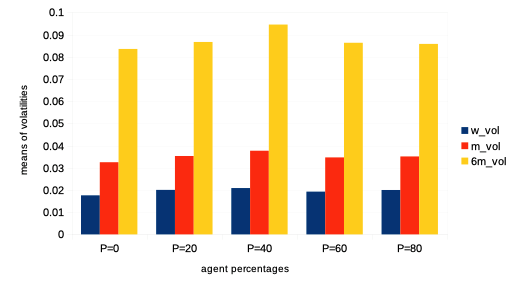
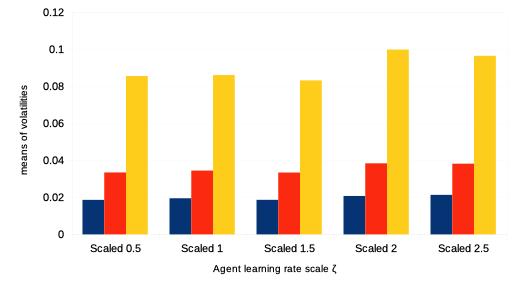
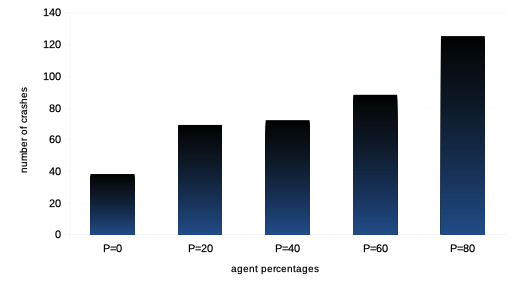
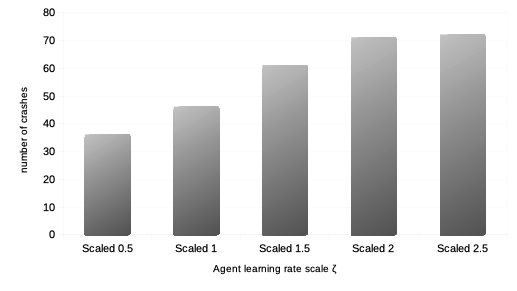
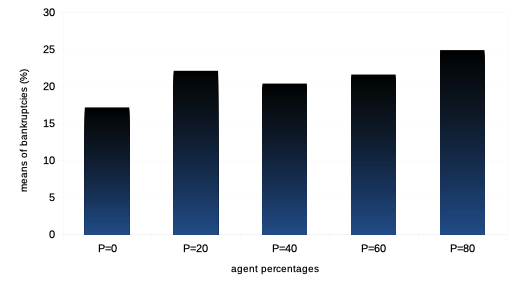
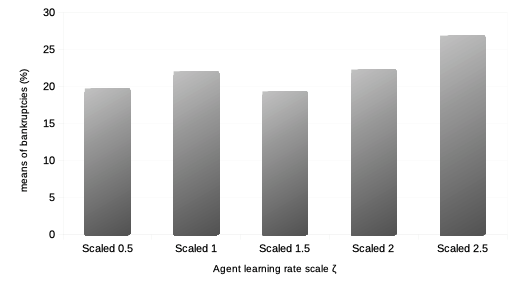
We then want to see the impact of the reinforcement learning rate on agent performance and overall market dynamics. Such study is related to the market impact over the years of ever higher frequency and lower latency strategies of trading. Recall each agent is initialised with a learning rate modelled by a parameter for both reinforcement algorithms and . In order to do this, we first vary the percentage of agents with such a learning rate multiplied by a scalar , so that it is statistically twice larger than that of the other agents.Then we study the impact of the learning rate when it is scaled by an increasing value of for the entire agent population. For both such variations in quantity and quality of agent learning rates, we can observe the following:
It is thus interesting to note that both types of variations in agent learning rates in our model do not affect general market volatility, except in tail events with statistically much greater numbers of market crashes. Means of agent bankruptcies are mildly affected.
IV.2 Impact of best agent herding
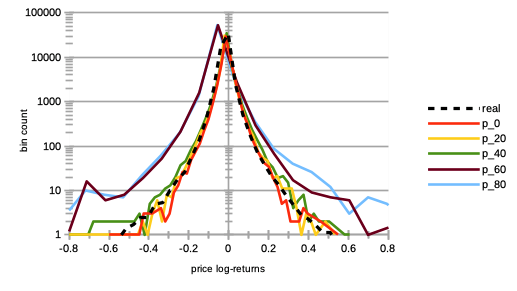
The importance of reflexivity in the agent proprietary price estimation and hence trading yield an open question, namely as to what or who is the source of the reflexivity trend endogenous to the market. A first natural and logical answer to this would be renown investors, traders, analysts, etc. that often publish investment recommendations or reviews. We thus can study the impact of agent reflexivity or herding on the market as a whole, as we introduce increasing percentages of agents sending (when possible) the same transaction order to the order book at time that was sent by the agent with best trading performance or track record at time . For the sake of simplicity, we consider this agent with best trading performance as the one with largest net asset value at time . Therefore, the rest of the herding agents may follow and emulate different agents over time (just as in real markets). In particular, for larger percentages of such best herding agents, we can mention the following:
-
–
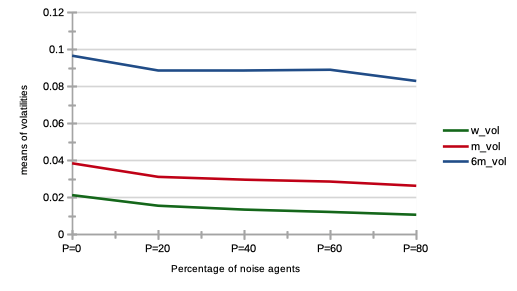
We see on Fig. 7 a strong increase in price volatilities, especially for higher percentages. Notice that this trend is almost imperceptible for .
-
–
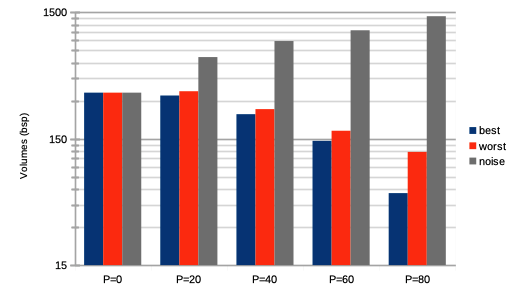
We see on Fig. 8 extremely decreasing trading volumes.
-
–
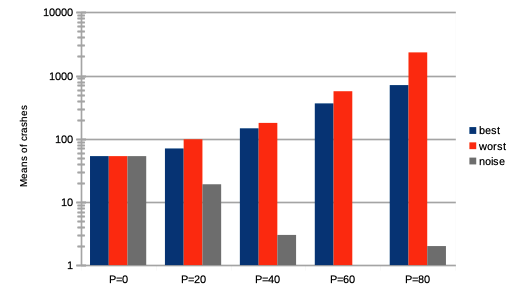
We see on Fig. 9 extremely increasing numbers of market crashes.
-
–
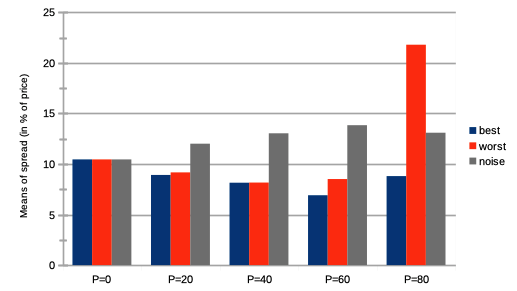
We see on Fig. 10 steadily decreasing market bid-ask spreads, until , after which they slightly increase again.
-
–
Remarkably, the rates of agent bankruptcy remain stable regardless of these varying percentages, with average means of for all values of .
This may be counter-intuitive, but following a renown investor according to this model is extremely averse to market stability.
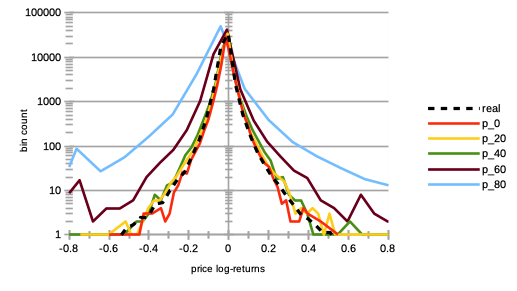
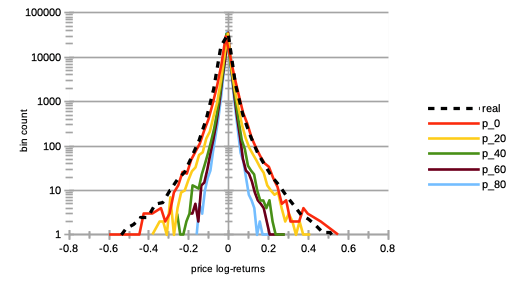
IV.3 Impact of worst agent herding
We then want to study the impact of agent reflexivity or herding on the whole market, as we introduce an increasing percentage of agents sending (when possible) the same transaction order to the order book at time that was sent by the agent with worst trading performance at time . The interest of this is to study how asymmetric market dynamics become to best agent herding. Here we consider this agent with worst trading performance as the one with lowest, non-bankrupt, net asset value at time . Therefore, the rest of the herding agents may follow and emulate different agents over time. In particular, for larger percentages of such worst herding agents, we can mention the following:
-
–
We see on Fig. 7 a very strong increase in price volatilities, especially for higher percentages. Notice that this trend is almost imperceptible for .
-
–
We see on Fig. 8 a very strong decrease in trading volumes.
-
–
We see on Fig. 9 an extreme increase in market crashes, especially for higher percentages.
-
–
We see on Fig. 10 steadily decreasing bid-ask spreads, except for a strong surge for higher percentages .
-
–
As one could expect, the rates of agent bankruptcy greatly increase with these varying percentages, staying above of agent bankruptcy for .
We conclude that market instability explodes with increasing proportions of such somewhat unrealistic agents, since no real investor will try and emulate the worst agent. Nevertheless, this shows and validate the previous observations with increasing percentages of agents following the best investor at time .
IV.4 Impact of noise traders
We then want to study the whole impact of agent learning on the market as we introduce an increasing percentage of “noise traders”, i. e. agents trading randomly Schmitt et al. (2012). A priori, an ever increasing number of noise agents should bring a certain financial stability to the whole market, by providing more liquidity and higher trading volumes in both bid and offer. In particular, for larger percentages of such “noise” agents, we can observe the following:
- –
-
–
We see on Fig. 8 a very strong increase in trading volumes.
-
–
We see on Fig. 9 a very sharp decrease in market crashes, which virtually almost vanish for .
-
–
We see on Fig. 10 a slow and steady increase in bid-ask spreads.
-
–
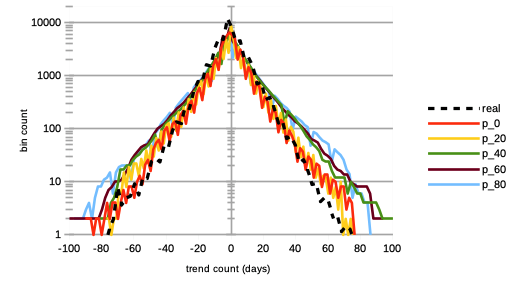
We see on Fig. 12 a steady increase in length of both bull and bear market regimes, especially the former.
-
–
Bankruptcy rates steadily decrease with such higher proportion of noise traders from means of for , to for . This is remarkable, as one could have posited that agent survival rates would decrease because of such random trading.
We conclude that counter-intuitively, larger numbers of agents trading randomly is beneficial to market stability and performance.
V Conclusion
Following calibration performances shown in a previous work Lussange et al. (2019), we have used a multi-agent reinforcement learning system to model stock market price microstructure. The advantage of such a framework is that it allows to gauge and quantify agent learning, which is at the source of the price formation process, itself at the foundation of all market activity. We first studied agent learning, and then its mesoscale impact on market stability and agent performance.
According to our results on policy learning, we posit that there are more trading strategies that yield successful portfolio performance, than unsuccessful.
We also found that best performing agents have a propensity for being fundamentalists rather than chartists in their approach to asset price valuation, and to be less stringent in their choices of transaction orders (i. e. willing to transact orders with larger bids or lower asks).
Next, we studied the impact on the market of agent learning rates, and found that market volatilities at all time-scales did not vary much (with more agents with larger learning rates, or when all agent collectively have larger learning rates), except for tail events, with average numbers of crashes greatly increasing. We also found that agent bankruptcy rates were not much impacted by such variations in reinforcement learning rates.
Then we studied the effect of herding or reflexivity, when increasing percentages of agents follow and emulate the investments of the best (and worst) performing agent at each simulation time step. As expected, we found that both such behaviours greatly increase market instability. Yet remarkably, bankruptcy rates of simulations with a best agent herding set up remain quite stable, regardless of the percentages of such agents, and regardless of the yet strongly increasing market volatilities and numbers of crashes.
Finally, we sought to explore the impact of agent trading information on the price formation process, with larger proportions of “noise traders” (i. e. agents trading randomly), and found a much greater market stability with increasing percentages of such agents, with a number of crashes virtually vanishing. We also found such markets to be more prone to display bull regimes, and that agents bankruptcy rates slightly diminished.
We trust such predictions under our model assumptions would be of interest not only to academia, but to industry practitioners and market regulators alike. A natural extension of our model would be to endow agents with a short selling ability (in order to account for specific microstructure effects in times of bubbles for instance). One could also add to each agent to capacity to perform proper portfolio diversification in the model’s multivariate framework. Finally, we graciously acknowledge this work was supported by the RFFI grant nr. 16-51-150007 and CNRS PRC nr. 151199.
References
- Benzaquen and Bouchaud (2018) M. Benzaquen and J.-P. Bouchaud, The European Physical Journal B 91(23) (2018).
- Erev and E.Roth (2014) I. Erev and A. E.Roth, PNAS 111, 10818 (2014).
- Huang et al. (2015) W. Huang, C.-A. Lehalle, and M. Rosenbaum, Journal of the American Statistical Association 110, 509 (2015).
- Wah and Wellman (2013) E. Wah and M. P. Wellman, Proceedings of the fourteenth ACM conference on Electronic commerce pp. 855–872 (2013).
- Aloud (2014) M. Aloud, Proceedings in Finance and Risk Perspectives ‘14 (2014).
- Xu et al. (2014) H.-C. Xu, W. Zhang, X. Xiong, and W.-X. Zhou, Mathematical Problems in Engineering 2014, 563912 (2014).
- Westerhoff (2008) F. H. Westerhoff, Jahrbucher Fur Nationalokonomie Und Statistik 228(2), 195 (2008).
- Boero et al. (2015) R. Boero, M. Morini, M. Sonnessa, and P. Terna, Agent-based models of the economy, from theories to applications (Palgrave Macmillan, 2015).
- Gualdi et al. (2015) S. Gualdi, M. Tarzia, F. Zamponi, and J.-P. Bouchaud, Journal of Economic Dynamics and Control 50, 29 (2015).
- Lipski and Kutner (2013) J. Lipski and R. Kutner, arXiv:1310.0762 (2013).
- Barde (2015) S. Barde, University of Kent, School of Economics Discussion Papers 04 (2015).
- Cristelli (2014) M. Cristelli, Complexity in Financial Markets (Springer, 2014).
- Cont (2001) R. Cont, Quantitative Finance 1, 223 (2001).
- Potters and Bouchaud (2001) M. Potters and J.-P. Bouchaud, Physica A 299, 60 (2001).
- Cont (2005) R. Cont, Volatility Clustering in Financial Markets: Empirical Facts and Agent-Based Models (A Kirman and G Teyssiere: Long memory in economics, Springer, 2005).
- Bouchaud (2018a) J.-P. Bouchaud, Handbook of Computational Economics 4 (2018a).
- Fama (1970) E. Fama, Journal of Finance 25, 383 (1970).
- Bera et al. (2015) A. K. Bera, S. Ivliev, and F. Lillo, Financial Econometrics and Empirical Market Microstructure (Springer, 2015).
- Gao et al. (2011) J. Gao, S. V. Buldyrev, H. E. Stanley, and S. Havlin, Nature physics 8, 40 (2011).
- Gode and Sunder (1993) D. Gode and S. Sunder, Journal of Political Economy 101(1) (1993).
- Greene (2017) W. H. Greene, Econometric Analysis (Pearson, 8th Edition, 2017).
- Bouchaud (2018b) J.-P. Bouchaud, arXiv:1901.03691 (2018b).
- Chen et al. (2017) T.-T. Chen, B. Zheng, Y. Li, and X.-F. Jiang, Front. Phys. 12(6), 128905 (2017).
- Platt and Gebbie (2018) D. Platt and T. Gebbie, Physica A: Statistical Mechanics and its Applications 503, 1092 (2018).
- Silver et al. (2018) D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, et al., Science 362, 1140 (2018), ISSN 0036-8075.
- Eickhoff et al. (2018) S. B. Eickhoff, B. T. T. Yeo, and S. Genon, Nature Reviews Neuroscience 19, 672 (2018).
- Smith and Nichols (2018) S. M. Smith and T. E. Nichols, Neuron 97(2), 263 (2018).
- Lefebvre et al. (2017) G. Lefebvre, M. Lebreton, F. Meyniel, S. Bourgeois-Gironde, and S. Palminteri, Nature Human Behaviour 1(4) (2017).
- Palminteri et al. (2015) S. Palminteri, M. Khamassi, M. Joffily, and G. Coricelli, Nature communications pp. 1–14 (2015).
- Duncan et al. (2018) K. Duncan, B. B. Doll, N. D. Daw, and D. Shohamy, Neuron 98, 645 (2018).
- Momennejad et al. (2017) I. Momennejad, E. Russek, J. Cheong, M. Botvinick, N. D. Daw, and S. J. Gershman, Nature Human Behavior 1, 680–692 (2017).
- Hu and Lin (2019) Y.-J. Hu and S.-J. Lin, 2019 Amity International Conference on Artificial Intelligence (2019).
- Neuneier (1997) R. Neuneier, Proc. of the 10th International Conference on Neural Information Processing Systems (1997).
- Deng et al. (2017) Y. Deng, F. Bao, Y. Kong, Z. Ren, and Q. Dai, IEEE Trans. on Neural Networks and Learning Systems 28(3) (2017).
- Spooner et al. (2018) T. Spooner, J. Fearnley, R. Savani, and A. Koukorinis, Proceedings of the 17th AAMAS (2018).
- Biondo (2019) A. E. Biondo, Journal of Economic Interaction and Coordination 14(3) (2019).
- Sirignano and Cont (2019) J. Sirignano and R. Cont, Quantitative Finance 19(9) (2019).
- Dodonova and Khoroshilov (2018) A. Dodonova and Y. Khoroshilov, Manag Decis Econ 39 (2018).
- Naik et al. (2018) P. K. Naik, R. Gupta, and P. Padhi, J Dev Areas 52(1) (2018).
- Lussange et al. (2019) J. Lussange, S. Bourgeois-Gironde, S. Palminteri, and B. Gutkin, arXiv:1909.07748 (2019).
- Dayan and Daw (2008) P. Dayan and N. D. Daw, Cognitive, Affective, and Behavioral Neuroscience 8(4), 429 (2008).
- Franke and Westerhoff (2011) R. Franke and F. Westerhoff, BERG Working Paper Series on Government and Growth 78 (2011).
- Chiarella et al. (2007) C. Chiarella, G. Iori, and J. Perell, arXiv:0711.3581 (2007).
- Murray (1994) M. P. Murray, The American Statistician 48(1), 37 (1994).
- (45) I. broker fees, https://www.ig.com/en/cfd-trading/charges-and-margins, accessed: 2019-05-21.
- (46) Dividend yield for stocks in the dow jones industrial average, accessed: 2019-05-17, URL http://indexarb.com/dividendYieldSorteddj.html.
- Sutton and Barto (1998) R. Sutton and A. Barto, Reinforcement Learning: An Introduction (MIT Press Cambridge MA, 1998).
- Wiering and van Otterlo (2012) M. Wiering and M. van Otterlo, Reinforcement Learning: State-of-the-Art (Springer, Berlin, Heidelberg, 2012).
- Szepesvari (2010) C. Szepesvari, Algorithms for Reinforcement Learning (Morgan and Claypool Publishers, 2010).
- N and Larralde (2016) R. M. N and H. Larralde, arXiv:1601.00229 (2016).
- Hardiman et al. (2013) S. J. Hardiman, N. Bercot, and J.-P. Bouchaud, arXiv:1302.1405 (2013).
- Schmitt et al. (2012) T. A. Schmitt, R. Schaefer, M. C. Muennix, and T. Guhr, Europhysics Letters 100 (2012).