Strategic Mitigation of Agent Inattention in Drivers with Open-Quantum Cognition Models
Abstract
State-of-the-art driver-assist systems have failed to effectively mitigate driver inattention and had minimal impacts on the ever-growing number of road mishaps (e.g. life loss, physical injuries due to accidents caused by various factors that lead to driver inattention). This is because traditional human-machine interaction settings are modeled in classical and behavioral game-theoretic domains which are technically appropriate to characterize strategic interaction between either two utility maximizing agents, or human decision makers. Therefore, in an attempt to improve the persuasive effectiveness of driver-assist systems, we develop a novel strategic and personalized driver-assist system which adapts to the driver’s mental state and choice behavior. First, we propose a novel equilibrium notion in human-system interaction games, where the system maximizes its expected utility and human decisions can be characterized using any general decision model. Then we use this novel equilibrium notion to investigate the strategic driver-vehicle interaction game where the car presents a persuasive recommendation to steer the driver towards safer driving decisions. We assume that the driver employs an open-quantum system cognition model, which captures complex aspects of human decision making such as violations to classical law of total probability and incompatibility of certain mental representations of information. We present closed-form expressions for players’ final responses to each other’s strategies so that we can numerically compute both pure and mixed equilibria. Numerical results are presented to illustrate both kinds of equilibria.
Index Terms:
Game theory, open quantum system model, mixed-strategy equilibrium, quantum cognition.I Introduction
Driver inattention is a dangerous phenomenon that can arise because of various reasons: distractions, drowsiness due to fatigue, less reaction time due to speeding, and intoxication. The consequences of inattentive driving can severely affect the driver’s safety even under normal road conditions, and can be devastating in terms of life-loss and/or long-lasting injuries. According to NHTSA’s latest revelations [1], in 2019, 3142 lives were claimed by distracted driving, 795 lives were claimed by drowsy driving, 9378 deaths were due to speeding, and 10,142 deaths were due to drunk driving, all in the United States alone. Therefore, several types of driver-assist systems have been developed and deployed in modern vehicles to mitigate inattentiveness. However, traditional driver-assist technologies are static and not personalized, which are insufficient to handle the situations in futuristic transportation systems with mostly connected and/or autonomous vehicles. For example, several deadly accidents have been reported where the Tesla driving assistants were working normally but the drivers were inattentive [2, 3]. As per SAE standard J3016 [4], the state-of-the-art vehicles mostly fall under Levels 2/3, which continue to demand significant driver attention (e.g. Tesla autopilot [5]), especially in uncertain road and weather conditions. Therefore, there is a strong need to design dynamic, data-driven driver-alert systems which present effective interventions in a strategic manner based on its estimates of the driver’s attention level and physical conditions.
However, the design of strategic interventions to mitigate the ill effects of driver inattention is quite challenging due to three fundamental reasons. Firstly, the driver may not follow the vehicle’s recommendations (i) if the driver is inattentive, (ii) if the driver does not trust the vehicle’s recommendations, and/or (iii) if the recommendation signal is not accurate enough to steer driver’s choices (e.g. the driver may not stop the vehicle because of a false alarm). Secondly, the persuasive effectiveness of vehicle’s recommendations is technically difficult to evaluate due to its complex/unknown relationship with the driver’s (i) attention level [6], (ii) own judgment/prior of road conditions [7], and (iii) trust on the vehicle’s recommendation system [8]. In addition, it is difficult to mathematically model and estimate these three terms [9, 10, 11]. Finally, there is strong evidence within the psychology literature that human decisions exhibit several anomalies to traditional decision theory. Examples include deviations from expected utility maximization such as Allais paradox [12], Ellsberg paradox [13], violations of transitivity and/or independence between alternatives [14]; and deviations from classical Kolmogorov probability theory such as conjunction fallacy [15], disjunction fallacy [16], and violation of sure thing principle [17].
There have been a few relevant efforts in the recent literature where both the driver and the driver-assist system interact in a game theoretic setting. These efforts can be broadly classified into two types: (i) the direct method where the system uses its on-board AI to directly control the vehicle, and (ii) the indirect method where the system indirectly controls the vehicle via relying on the driver to make decisions. On the one hand, Flad et al. proposed a direct method that models driver steering motion as a sequence of motion primitives so that the aims and steering actions of the driver can be predicted and then the optimal torque can be calculated [18]. Another example that proposes a direct method is by Na and Cole in [19], where four different paradigms were investigated: (i) decentralized, (ii) non-cooperative Nash, (iii) non-cooperative Stackelberg, and (iv) cooperative Pareto, to determine the most effective method to model driver reactions in collision avoidance systems. Although direct methods can mimic driver actions, they certainly do not consider the driver’s cognition state (in terms of preferences, biases and attention) and no intervention was designed/implemented to mitigate inattention. On the other hand, indirect methods have bridged this gap via considering driver’s cognition state into account. Lutes et al. modeled driver-vehicle interaction as a Bayesian Stackelberg game, where the on-board AI in the vehicle (leader) presents binary signals (no-alert/alert) based on which the driver (follower) makes a binary decision (continue/stop) regarding controlling the vehicle on a road [20]. This work and [20] share the same setting of unknown road condition and binary actions of two players, and also introduce a non-negative exponent parameter in the overall driver’s utility to capture his/her level of attention. The difference is that [20] still follows the traditional game theory framework of maximizing payoffs while this work extends the traditional framework in which the players do not necessarily maximize payoffs. Schwarting et al. integrated Social Value Orientation (SVO) into autonomous-vehicle decision making. Their model quantifies the degree of an agent’s selfishness or altruism in order to predict the social behavior of other drivers. They modeled interactions between agents as a best-response game wherein each agent negotiates to maximize their own utilities [21]. However, all the human players in the game of the above research are still assumed to be rational players maximizing utilities, even though the utilities are modified to capture attention level or social behavior, whether by a non-negative exponent parameter or by SVO. The present work bridges this gap by directly considering the driver as an agent who does not seek to maximize payoff, but instead uses a quantum-cognition based decision process to make decisions.
Note that most of the past literature focused on addressing each of these challenges independently. The main contribution of this paper is that we address all the three challenges jointly in our driver-vehicle interaction setting. In Section II, we propose a novel strategic driver-vehicle interaction framework where all the aforementioned challenges are simultaneously addressed in a novel game-theoretic setting. We assume that the vehicle constructs recommendations so as to balance a prescribed trade-off between information accuracy and persuasive effectiveness. On the other hand, we model driver decisions using an open quantum cognition model that considers driver attention as model parameter and incorporates the driver prior regarding road condition into the initial state. In Section III, we present a closed-form expression for the cognition matrix in the driver’s open quantum cognition model. Given that the agent rationalities are fundamentally different from each other (vehicle being a utility-maximizer, and driver following an open quantum cognition model), we also propose a novel equilibrium notion, inspired by Nash equilibrium, and compute both pure and mixed equilibrium strategies for the proposed driver-vehicle interaction game in Sections IV and V respectively. Finally, we analyze the impact of driver inattention on the equilibrium of the proposed game.
II Strategic Driver-Vehicle Interaction Model
In this section, we model the strategic interaction between a driver-assist system (car) and an inattentive driver as a one-shot Bayesian game. We assuming that the physical conditions of the road are classified into two states, namely, safe (denoted as ) and dangerous (denoted as ). The vehicle can choose one of the two signaling strategies: alert the driver (denoted as ), or no-alert (denoted as ) based on its belief about the road state. Meanwhile, based on the driver’s belief about the road state and his/her own mental state (which defines driver’s type), the driver chooses to either continue driving (denoted as ), or stop the vehicle (denoted as ). Note that although the letter is used to denote both road state being safe and driver decision being stop, the reader can easily decipher the notation’s true meaning from context.
Depending on the true road state, we assume that the vehicle (row player) and the driver (column player) obtain utilities as defined in Table I. When the road is dangerous, we expect the car to alert the driver. If the car does not alert, it will get a low payoff. Furthermore, we assume this low payoff depends on the driver’s action. If the driver stops, the payoff is only slightly low because no damage or injury is incurred. If the driver continues to drive, the payoff is very low because damage or injury is incurred. When the road is safe, the correct action for the car is not to alert. If the car does not alert, it will get a high payoff. This high payoff depends on the driver’s action. If the driver stops, the payoff is only slightly high because it does not help the driver and an unnecessary stop is waste of time and energy. If the driver continues to drive, the reward is very high because everything is fine.
|
|
In this paper, we assume that both the car and the driver does not know the true road state. While the car relies on its observations from on-board sensors and other extrinsic information sources (e.g. nearby vehicles, road-side infrastructure) and its on-board machine learning algorithm for road judgment to construct its belief regarding the road state being safe, we assume that the driver constructs a belief regarding the road state being safe based on what he/she sees and his/her prior experiences. Furthermore, as in the case of a traditional decision-theoretic agent, we assume that the car seeks to maximize its expected payoff. If is the probability with which the driver chooses , then the expected payoff for choosing and at the car are respectively given by
| (1) |
and
| (2) |
The calculation of is complicated by the fact that the driver exhibits bounded rationality. Fortunately, the bounded rationality can be characterized by the open quantum system cognition model, as described below.
II-A Driver’s Open Quantum Cognition Model
In this subsection, we present the basic elements of the open quantum system cognition model [22], and how it is applied to model driver behavior. The cognitive state of the agent is described by a mixed state or density matrix , which is a statistical mixture of pure states. Formally it is a Hermitian, non-negative operator, whose trace is equal to one. Under the Markov assumption (the evolution can be factorized as given a sequence of instants , , ), one can find the most general form of this time evolution based on a time local master equation , with a differential superoperator (it acts over operators) called Lindbladian, which is defined as follows.
Definition 1 ([23]).
The Lindblad-Kossakowski equation for any open quantum system is defined as
| (3) |
where
-
•
is the Hamiltonian of the system,
-
•
is the commutation operation between the Hamiltonian and the density operator ,
-
•
are entry of some positive semidefinite matrix (denoted as ),
-
•
is a set of linear operators,
-
•
denotes the anticommutator. The superscript represents the adjoint (transpose and complex conjugate) operation.
In this paper, we set
| (4) |
as defined in [22], where, for any , is a column vector whose th entry is 1 and the other entries are 0. Note that is obtained by transposing and then taking its complex conjugate. Thus is a row vector whose th entry is 1 and 0 otherwise.
The second term on the right side of Equation (3) contains the dissipative term responsible for the irreversibility in the decision-making process [22], weighted by the coefficient such that the parameter interpolates between the von Neumann evolution and the completely dissipative dynamics . Furthermore, the term is the -th entry in the cognitive matrix . This cognitive matrix is formalized as the linear combination of two matrices and , which are associated to the profitability comparison between alternatives and the formation of beliefs, respectively [22]:
| (5) |
where is a parameter assessing the relevance of the formation of beliefs during the decision-making process, is the transition matrix where -th entry is the probability that the decision maker switches from strategy to for a given state of the world , and matrix allows the driver to introduce a change of belief about the state of the world in the cognitive process by jumping from one connected component associated to a particular state of the world to the connected component associated to another one , while keeping the action fixed. The superscript denotes the transpose matrix. Finally, the dimension of the square matrix , i.e. , can be inferred from the detailed discussion given below.
| (6) |
At the driver, the world state primarily consists of two components: (i) the road condition, and (ii) the car’s action, i.e., the set of world states of the driver is where the first letter represents road condition and the second letter represents car action. The utilities of the driver for choosing a strategy at a world state are as follows:
We choose the basis of the road-car-driver system spanning the space of states to be
| (7) |
Next we define the transition matrix . If the utility of the decision maker by choosing strategy at the world state of is , the transition probability that the decision maker would switch to strategy at time step from strategy at time step is given in the spirit of Luce’s choice axiom [24, 25, 26]:
| (8) |
where the exponent measures the decision maker’s ability to discriminate the profitability among the different options. When , each strategy has the same probability of being chosen (), and when only the dominant alternative is chosen. There are two implications in this formulation of : (1) to avoid negative ; (2) only depends on the destination and does not depend on the starting point .
Below are the probabilities needed for the matrix:
where
-
•
is the probability that driver picks when he/she assumes that road state is and the car chooses ,
-
•
is the probability that driver will pick when he/she assumes that road state is and the car chooses ,
-
•
is the probability that driver will pick when he/she assumes that road state is and the car chooses ,
-
•
is the probability that driver will pick when he/she assumes that road state is and the car chooses .
Equation (6) puts all the terms together in a matrix form and demonstrates the physical meaning of the row and column labels in .
The matrix in Equation (3) is set as in [22]. When the elements of the is nonzero, the elements of in the same position is 1; Otherwise it is zero. Thus, the matrix is
| (9) |
In this paper, we set for the following two reasons: (1) Since the world state of the driver is mainly the action of the car and the action of the car is known when calculating the equilibrium, the driver does not need to form such a belief; (2) We are considering a one-shot game and we can assume the road condition does not change in one game, i.e., we are only considering short-time dynamic. The matrix is zeroed out and its content is not described here. Thus and we set in Equation (3).
II-B Pure and Mixed Strategy Equilibria
For the sake of simplicity, let us denote the car as Agent 1, and the driver as Agent 2 without any loss of generality. Since the car seeks to maximize its expected payoff given that the driver chooses a strategy , it is natural that the car’s final response is its best response that maximizes its expected payoff given in Equations (1) and (2), i.e.,
On the contrary, driver’s decisions are governed by the open quantum system model. If we denote the steady-state solution of Equation (3) as for a given car’s strategy , the final response of the driver is defined as
where and are driver’s model parameters in Equations (3) and (8) respectively. Then the (pure-strategy) equilibrium of this game is defined as follows.
Definition 2.
A strategy profile is a pure strategy equilibrium if and only if and .
On the contrary, the concept of mixed strategy equilibrium is actually more natural to the open-quantum-system model since the solution tells the probability of taking various actions instead of indicating a particular action. The open quantum system model directly gives a mixed strategy. Let the mixed strategy of the driver is denoted as where is the probability that the driver chooses to continue. Similarly, let the car’s mixed strategy be denoted as , where is the probability that the car chooses to alert. Then, a mixed strategy profile is denoted as . In such a mixed strategy setting, the car’s final response is its best mixed-strategy response, i.e.
Similarly, the final response of the driver is obtained from the steady-state solution of Eq. 3, i.e.
Then the mixed-strategy equilibrium of this game is defined as follows.
Definition 3.
A strategy profile is an mixed-strategy equilibrium if and only if and .
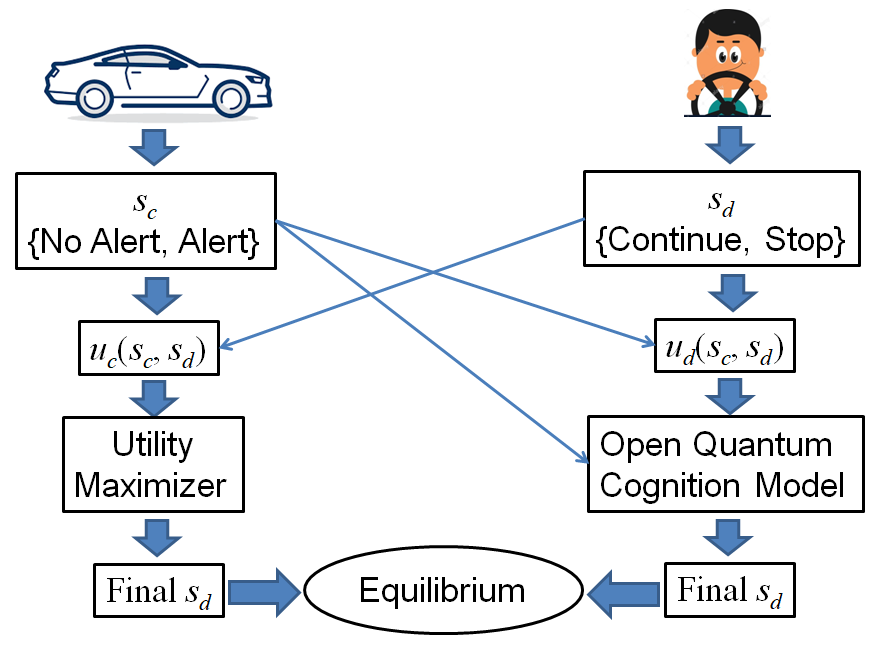
Note that the above equilibrium notions presented in Definitions 2 and 3 are novel and different from traditional equilibrium notions in game theory. This is because our game comprises of two different players: (i) the car modeled as an expected utility maximizer, and (ii) the driver modeled using open quantum cognition equation, as is illustrated in Figure 1. However, our equilibrium notions are both inspired from the traditional definition of Nash equilibrium, and are defined using players’ final responses as opposed to best responses in the Nash sense. By doing so, we can easily expand traditional equilibrium notions to any strategic setting where heterogeneous entities interact in a competitive manner.
III Driver’s Final Response
Note that the dependent variable in Equation (3) is a matrix. In order to obtain the analytical solution, we vectorize by stacking its columns one on another to obtain vector . Thus, the vectorized version of Definition 1 is as follows.
Definition 4.
The vectorized form for Lindblad-Kossakowski equation is given by
| (10) |
where is the identity matrix,
| (11) |
| (12) |
| (13) |
| (14) |
with the superscript * representing taking the complex conjugate of all entries.
In the driver-car game presented in Section II, note that we have basis states as stated in Equation (7). We will first derive the sparse structure of in Lemma 1.
Note that the symbol means direct-sum while the symbol means tensor-product. The following two simple examples show their difference.
Lemma 1.
If the Hamiltonian of the 8-dimensinoal Lindblad-Kossakowski equation is defined as
then its vectorized form is given by
| (15) |
where
with .
Proof.
By Equation (11), we only need to calculate and . Noting , we have
and
where
with 1 the matrix whose elements are all 1.
Subtracting from blockwise then leads to the claimed . ∎
Remark 1.
The condition of Lemma 1 is just setting the Hamiltonian of the Lindblad-Kossakowski equation as in Equation (9). is a sparse block diagonal matrix with four blocks, each being . is a sparse matrix consists of four blocks where the off-diagonal blocks are identity matrices and the diagonal matrices are again block diagonal matrices. Such a special structure results from stacking the columns of the all-one matrices.
Theorem 1 presents the special sparse structure of . To prove Theorem 1, Lemma 2 is needed. Lemma 2 gives the sparse structure of .
Lemma 2.
The entry of the matrix with is given by
| (16) |
The entry of the matrix with is given by
| (17) |
Proof.
is a real matrix, so and .
Since only the entry of is 1 and the others are 0, is a matrix with all entries zero except the entry, which is 1. Note that and range from 1 to 8.
Since the entry of is 1 and the other entries are 0, is a 6464 matrix whose entries are all zero except the th to the 8th diagonal entries (which are 1), and is a 6464 matrix whose entries are all zero except the entries (which are 1) with , for each fixed . Thus by Equation (14), is a 6464 matrix whose entries are all zero except the entries with or , for each fixed . The entries are 1/2 when and is 1 when .
By Equation (13), subtracting from leads to the claimed result: When , there is no cancellation of nonzero entries between and . When , only the entry of is nonzero (which is 1). The entry of also 1. Thus the resultant only has 14 nonzero entries. ∎
Remark 2.
Note that does not mean the entry of . is itself a matrix. There are 64 such matrices and they will be weighed by and summed. Then entry of depend on , , , and . is very sparse. The nonzero entries can only take and since the building blocks and only has 1 as nonzero entry value. Given and , the entries with or are special since either or takes nonzero values at these entries.
Theorem 1.
Let the coefficients in the 8-dimensinoal Lindblad-Kossakowski equation be the entries of the matrix (ref. to Equation (6))
where is of the form
Then, the entries of within the vectorized Lindblad-Kossakowski equation (ref. to Def. 4) with are given by
where and , and the entries of with are given by
Proof.
Interested readers may refer to Appendix A. ∎
Remark 3.
depends on and . The expression of must consist of entries of . Theorem 1 just reveals explicitly these relations. The entries of appearing in the expression of are and where or . Such relations arise due to vectorization (stacking columns). Dividing by 8 and mode 8 appear since each column to be stacked is 8-dimensional. Despite summation over all and , at most two entries of appear in since is itself sparse.
Next we will combine the obtained in Lemma 1 and the obtained in Theorem 1 to obtain in Corollary 1.
Corollary 1.
If the coefficients of the 8 dimensional Lindblad-Kossakowski equation is set as the entries of
where is a matrix in the form of
then
where
and are 1616 matrices. They both have only one nonzero entry. The nonzero entries are taken from the cognition matrix :
The ’s are 44 matrices:
for , , , where
Remark 4.
The Lindblad-Kossakowsi equation itself is not a cognition model since its coefficients are quite general. The open quantum cognition model is built by setting the as entry of the cognition matrix . The condition in Corollary 1 is just setting in Equation (5) and using the prescribed in Equation (6). This is exactly the scenario of the car-driver game.
Remark 5.
The vectorized operator of the vectorized Lindblad-Kossakowski equation is a block diagonal matrix with four blocks. The four blocks have very similar structures. Each block is actually quite sparse since each block is a block matrix with totally four sub-blocks and the two off-diagonal sub-blocks are almost identity matrix (only one entry is different).
IV Pure-strategy equilibrium
The diagonal elements of the steady-state solution of Equation (3) are just . Then we can calculate the probability for the driver to continue as
| (18) |
Let be the probability that the driver judges the road to be safe before knowing the car’s action and be the utility function of the driver. In this paper, we model driver’s pure strategy as the output of the open quantum cognition model parameters and taking the pure strategy of the car as input:
| (19) |
where is the parameter tuple of the open quantum model.
Remark 6.
In this paper, we use in two different ways to obtain pure and mixed strategy equilibria. We obtain a pure strategy at the driver by employing a hard threshold on (in our case, Continue if , Stop otherwise). By treating as the driver’s mixed strategy in Section V, we will obtain the mixed-strategy equilibrium.
We set the initial density matrix as , where
when the car action is A and
when the car action is N, with prescribed in Subsection II-A. The calculation of the generalized pure-strategy equilibrium is similar to that of the Nash equilibrium. We simply replace the best response with the final response. We loop over the car strategies. In the loop, the car strategy is the input of the open quantum model and a driver strategy is the output. If the car strategy is the best response with the outputted driver strategy, then the strategy profile is outputted as pure-strategy equilibrium. Algorithm 1 lists the procedures of calculating the pure-strategy equilibrium.
|
|||||||||
|
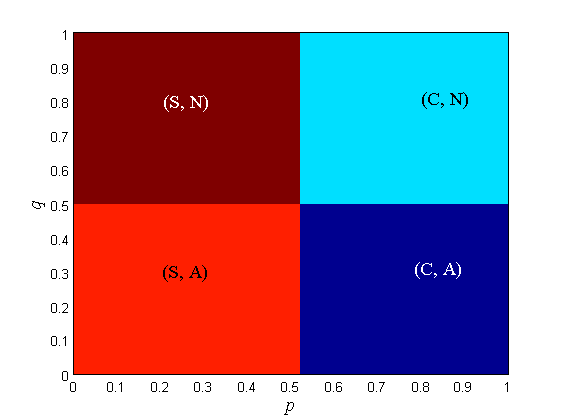
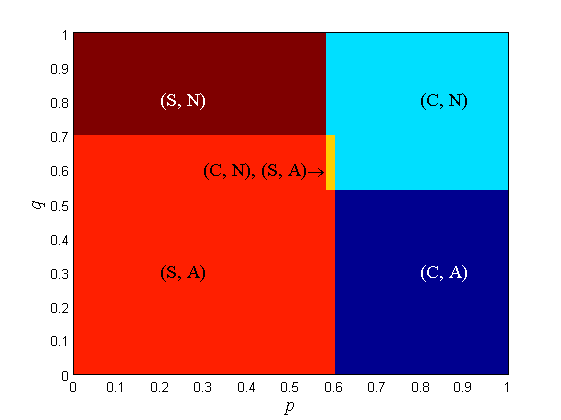
Furthermore, in our numerical evaluation, we assume the utilities at both the car and the driver as shown in Table II. In addition to the case of a driver-conscient car, we consider a benchmark case where the car does not care about the driver and makes decisions solely based on its prior, i.e., alert if and does not alert if . In this benchmark case, the final response of the car is independent of the driver’s strategy. The equilibrium points of the driver-car games with a driver-agnostic car and with a driver-conscient car (driver making decisions according to open quantum model with ) under various prior beliefs on road condition are shown in Fig. 2. When both the driver and car are sure of safety, the equilibrium is . When both the driver and car are sure of danger, the equilibrium is . When the driver is sure of safety but the car is sure of danger, the equilibrium is . When the driver is sure of danger but the car is sure of safety, the equilibrium is . The division line is not . (S, A) has the largest area. When the car is driver-agnostic, the border between Not Alert and Alert in the equilibrium plot is always regardless of the equilibrium strategy of the driver. When the car is driver-conscient, the border between Not Alert and Alert depends on the equilibrium strategy of the driver (or equivalently, road prior of the driver): the border is located close to when and the border is located close to when .
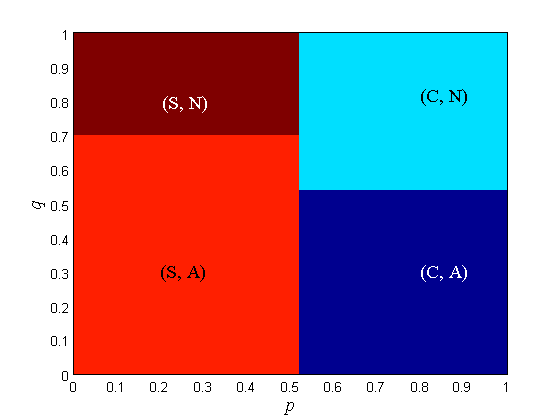
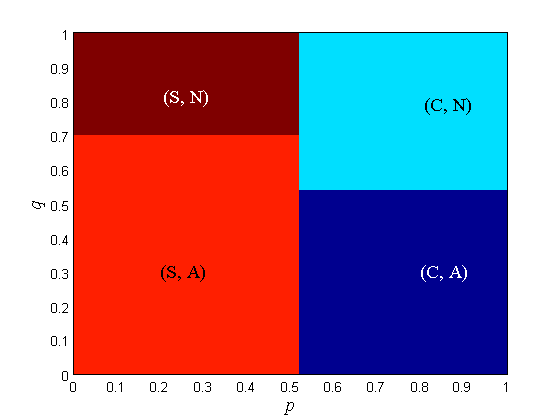
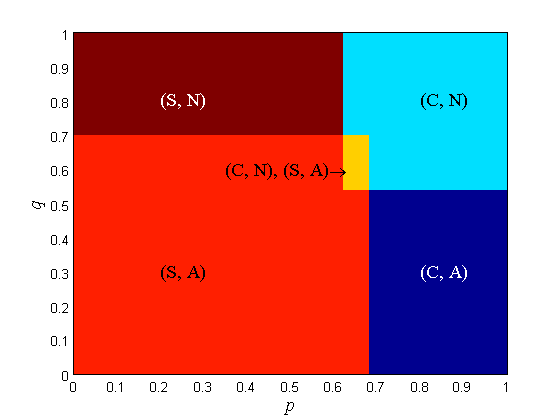
The equilibrium points of the driver-car game with = 0, 1, 2, 3, 4, 10 and = 0.8 under various prior beliefs on road condition are shown in Fig. 3 (C: Continues, S: Stop, A: Alert, N: Not Alert). When drops from 10 to 4, the border between S and C shifts from left to right. When drops from 4 to 3, the border between (S, A) and (C, A) shifts from left to right and a region with two equilibrium points appears inside the region of (C, N). The two equilibria are (C, N) and (S, A). When drops from 4 to 3 and from 3 to 2, the border between (S, A) and (C, A) shifts from left to right and the region with two equilibrium points enlarges with the border shift. When drops from 2 to 0, the driver can no longer distinguish the utilities. The region is merged into the region and the two-equilibrium region is merged into the region. The border between and shifts from left to right and a new no-equilibrium region appears inside the previous region.
Remark 7.
When , the driver cannot distinguish the utilities at all and is completely random, so the concept of final response does not apply. The type of pure-strategy equilibrium strongly aligns with the priors of the driver and the car. The desired equilibria are and , where the driver’s action is in harmony with car’s action.
Remark 8.
Since Fig. 2 and Fig. 3 are plotted over axes, we can find out which type of equilibrium is most common. With the prescribed utilities, the most common pure-strategy equilibrium is . This is the most favorable equilibrium, since following the car’s recommendation in the dangerous road can save life.
Remark 9.
As the driver’s ability to distinguish utilities weakens ( decreases), becomes more likely. This means that the driver follows the car’s advice diligently especially when he/she is incapable of making decisions on a dangerous road.
V Mixed-strategy equilibrium
When calculating the mixed-strategy equilibrium, and appear in the initial state of the open quantum model since the mixed-strategy of the car is completely determined by (ref. to Subsecion II-B). Theorem 2 will give a closed-form expression of by solving the vectorized Lindblad-Kossakowski equation (ref. to Definition 4).
Theorem 2.
Let the initial density matrix be given as where
The probability that the driver chooses to continue is
where , , and
Proof.
Interested readers may refer to Appendix B. ∎
Remark 10.
The output of the open quantum model, , presented in Theorem 2 consists of both transient and stationary parts. The transient part consists of sine and cosine multiplied with exponential decay. Thus, there always exists steady state when the exponential decay rate . When or , and the driver is completely random and absent-minded. Furthermore, a driver with a higher can make a decision faster. Thus also represents the brain power and attentiveness of the driver. On the other hand, the parameter appears only within the terms, which are linearly weighted by monomial terms of and . This is essentially prior probability multiplied with likelihood, or initial probability multiplied with transition probability. Viewing and as constants, the steady-state is a linear function of the driver’s prior .
For brevity, the mixed-strategy equilibrium is denoted as (). If the car knows that the driver will play , then its expected payoffs from playing alert and no alert must be equal, otherwise, it either chooses to alert only or chooses not to alert only and does not need to mix between them. Thus we have
| (20) |
Solving for , we obtain
| (21) |
where and .
For the sake of illustration, we consider the bi-matrix game presented in Table I. Upon substituting the utility values in Table II for this example in Equation (21), we obtain
| (22) |
Note that the above maybe outside [0, 1]. If so, there is no mixed-strategy equilibrium. In order for to lie within [0, 1] under the prescribed utilities, must lie within [10/19, 11/16]. This is a very narrow range of . Given , the car can assign any to A because A and N give the same payoff. Next we need to search the that produce . Such a is just the desired .
Since is completely determined by , it is more convenient to plot versus and . versus and with various s is shown in Fig. 4. The mixed-strategy equilibria only exist in a narrow band extending from a low--low- region to a high--high- region. There may not exist a mixed -strategy equilibrium for a given , but there always exists one for a given . When and increase, the band gets narrower. Within the band, the gradient of is perpendicular to the band, i.e., increases when increases and decreases simultaneously. When decreases, the band gets flatter and the band firstly widens and then narrows. As decreases, the band gets flatter and narrower.
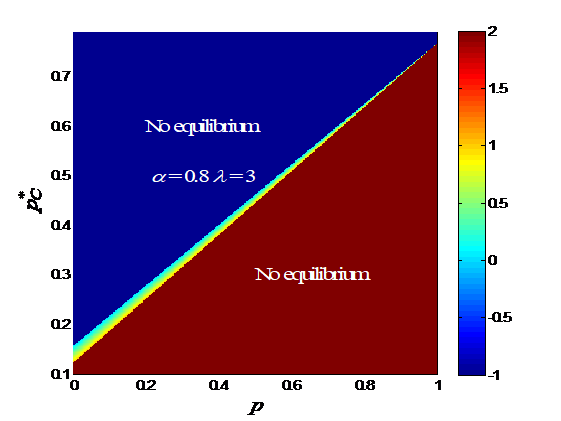
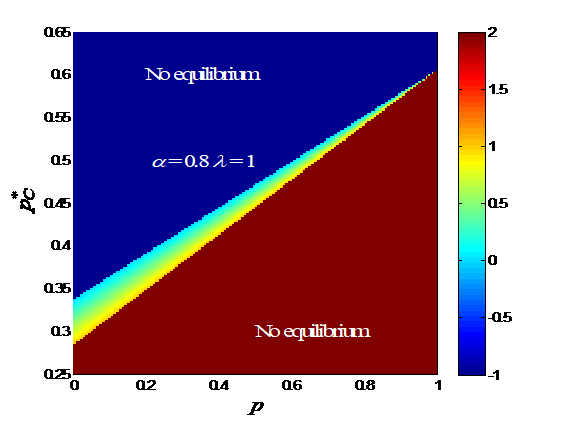
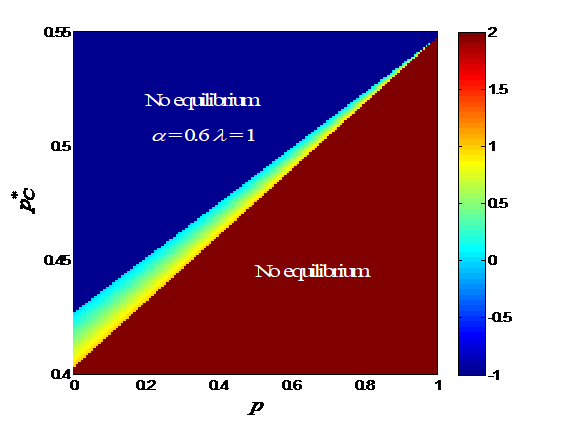
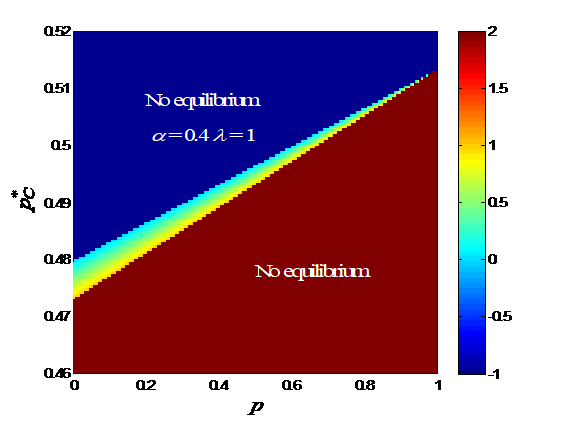
Remark 11.
In the case of mixed equilibria, when the driver is attentive, the equilibrium strategy is well aligned with her prior (higher , higher ) as shown in Figure 4. However, when the driver gradually loses her attention ( or decreases), steadily approaches to 0.5 regardless of . This means that the driver becomes uncertain to choose or at equilibrium, when she is inattentive.
VI Conclusion and Future Work
In this paper, we developed a strategic driver-assist system based on a novel vehicle-driver interaction game. While the car is modeled as an expected utility maximizer, the driver is characterized by open-quantum cognition model which models his/her attentiveness () as well as sensitivity to the utilities (). Based on a novel equilibrium concept proposed to solve any general human-system interaction game, we showed that both the car and the driver employ a threshold-based rule on their respective priors regarding the road state at equilibrium. Through numerical results, we also demonstrated how these thresholds vary under different settings based on road conditions and agent behavior. Specifically, in our proposed framework, we showed that an inattentive driver would stop the car in about 65% of all possible belief profile settings, and at least in 77% of belief profiles settings when the car alerts the driver. On the contrary, if there were no driver-assist system in the car, an inattentive driver would have stopped the car only in 50% of all possible belief profiles settings (the region where ), and in about 38.5% of all scenarios if the car were to alert the driver using our driver-assist system. At the same time, our proposed driver-assist system has improved persuasive ability by taking into account driver behavior, in addition to its inferences regarding the road state. This improvement in performance was demonstrated by the increase in threshold on a driver-conscient car’s belief, as opposed to that of a driver-agnostic car. Furthermore, we also proved that there always exists a mixed strategy equilibrium for any given driver’s prior, but only under a small range within car’s prior values. As the driver loses attention, we demonstrated that the mixed strategy of the driver at equilibrium drifts towards uniformly distributed probabilistic decisions. In the future, we will investigate repeated interaction games where the car can learn driver’s model parameters over multiple iterations. Furthermore, we will also incorporate matrix in the Lindblad model to account for the effects of mental deliberation in resolving conflicts between his/her own prior and the car’s signal.
VII Acknowledgment
Dr. S. N. Balakrishnan just passed away before this paper is ready to submit. However, Dr. Balakrishnan participated in every aspect through the research related to this paper. Therefore, we decided to still keep Dr. Balakrishnan as the co-author of this paper.
References
- [1] National Highway Traffic Safety Administration. Overview of Motor Vehicle Crashes in 2019 . https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/813060, 2020. [Online; accessed 26-February-2020].
- [2] BBC. Tesla Autopilot crash driver ’was playing video game’. https://www.bbc.com/news/technology-51645566, 2020. [Online; accessed 26-February-2020].
- [3] TOM KRISHER. NTSB: Autopilot flaw, driver inattention caused 2018 Tesla crash in Culver City’. https://www.ocregister.com/2019/09/04/ntsb-tesla-autopilot-let-driver-rely-too-much-on-automation/, 2019. [Online; accessed 04-September-2019].
- [4] Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. Standard, SAE International Surface Vehicle Recommended Practice, June 2018.
- [5] TOM KRISHER. 3 crashes, 3 deaths raise questions about Tesla’s Autopilot’. https://apnews.com/article/ca5e62255bb87bf1b151f9bf075aaadf, 2020. [Online; accessed 03-January-2020].
- [6] Philip Koopman and Michael Wagner. Autonomous vehicle safety: An interdisciplinary challenge. IEEE Intelligent Transportation Systems Magazine, 9(1):90–96, 2017.
- [7] Marcel Woide, Dina Stiegemeier, and Martin Baumann. A methodical approach to examine conflicts in context of driver-autonomous vehicle-interaction. 2019.
- [8] Jong Kyu Choi and Yong Gu Ji. Investigating the importance of trust on adopting an autonomous vehicle. International Journal of Human-Computer Interaction, 31(10):692–702, 2015.
- [9] Morimichi Nishigaki and Tetsuro Shirakata. Driver attention level estimation using driver model identification. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 3520–3525. IEEE, 2019.
- [10] Alex Zyner, Stewart Worrall, James Ward, and Eduardo Nebot. Long short term memory for driver intent prediction. In 2017 IEEE Intelligent Vehicles Symposium (IV), pages 1484–1489. IEEE, 2017.
- [11] Genya Abe and John Richardson. Alarm timing, trust and driver expectation for forward collision warning systems. Applied ergonomics, 37(5):577–586, 2006.
- [12] Amos Tversky and Daniel Kahneman. Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and uncertainty, 5(4):297–323, 1992.
- [13] Daniel Ellsberg. Risk, ambiguity, and the savage axioms. The quarterly journal of economics, pages 643–669, 1961.
- [14] Jerome R Busemeyer and James T Townsend. Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. Psychological review, 100(3):432, 1993.
- [15] Riccardo Franco. The conjunction fallacy and interference effects. Journal of Mathematical Psychology, 53(5):415–422, 2009.
- [16] Sean D Young, A David Nussbaum, and Benoît Monin. Potential moral stigma and reactions to sexually transmitted diseases: Evidence for a disjunction fallacy. Personality and Social Psychology Bulletin, 33(6):789–799, 2007.
- [17] Andrei Yu Khrennikov and Emmanuel Haven. Quantum mechanics and violations of the sure-thing principle: The use of probability interference and other concepts. Journal of Mathematical Psychology, 53(5):378–388, 2009.
- [18] M. Flad, L. Fröhlich, and S. Hohmann. Cooperative shared control driver assistance systems based on motion primitives and differential games. IEEE Transactions on Human-Machine Systems, 47(5):711–722, 2017.
- [19] Xiaoxiang Na and David J Cole. Game-theoretic modeling of the steering interaction between a human driver and a vehicle collision avoidance controller. IEEE Transactions on Human-Machine Systems, 45(1):25–38, 2014.
- [20] Nathan Lutes, Venkata Sriram Siddhardh Nadendla, and S. N. Balakrishnan. Perfect Bayesian Equilibrium in Strategic Interaction between Intelligent Vehicles and Inattentative Drivers. 2021. Working Paper.
- [21] Wilko Schwarting, Alyssa Pierson, Javier Alonso-Mora, Sertac Karaman, and Daniela Rus. Social behavior for autonomous vehicles. Proceedings of the National Academy of Sciences, 116(50):24972–24978, 2019.
- [22] Ismael Martínez-Martínez and Eduardo Sánchez-Burillo. Quantum stochastic walks on networks for decision-making. Scientific reports, 6:23812, 2016.
- [23] Angel Rivas and Susana F Huelga. Open quantum systems, volume 13. Springer, 2012.
- [24] R Duncan Luce. The choice axiom after twenty years. Journal of mathematical psychology, 15(3):215–233, 1977.
- [25] R Duncan Luce. Individual choice behavior: A theoretical analysis. Courier Corporation, 2012.
- [26] John I Yellott Jr. The relationship between luce’s choice axiom, thurstone’s theory of comparative judgment, and the double exponential distribution. Journal of Mathematical Psychology, 15(2):109–144, 1977.
Appendix A Proof of Theorem 1
There are totally 64 terms of to be summed in Equation (10) when . We only need to consider terms with . The nonzero entries of are: and when is odd, and when is even. There are only 16 nonzero terms.
Consider the terms. According to Lemma 2, has only 14 nonzero entries. They are all at the entries where or , , but and cannot be at the same time. Each entry of has exactly two ’s contributing to it: one with , and the other with . That is, the entry of is
where and . Note that when .
Next consider the terms. According to Lemma 2, has 16 nonzero entries. 14 of them are entries taking value where or , , but and cannot be at the same time. One of them is at the entry. The last one is at the entry. We only need to sum the terms when is odd and only need to sum the terms when is even. The entry of the sum of all terms is
where and .
Summing the terms and the terms of leads to the claimed result.
Appendix B Proof of Theorem 2
Let . The solution is in the form of .
By Corollary 1,
| (23) |
By Equation (18) and with the indices defined in Equation (6),
| (24) |
where is the ith element of vector .
Calculating only needs the first row of .
We will calculate from . Again only the first row of is needed. Given , to calculate the first row of = , still only the first row of is needed. Let the first row of be denoted as . Then . Denote the jth element of as . Then by Corollary 1,
| (25) |
| (26) |
where ,
and for .
Use Equation (27) from 1 to , we have
| (28) |
By Corollary 1,
where is a column vector. Plugging the initial values in Equation (28), we have
| (29) |
The other ’s with are all zero.
Similarly, calculating , , and only needs the 3rd row of , the 5th row of , the 7th row of , respectively. Denote the 3rd row of , the 5th row of , and the 7th row of as , , and , respectively. Then , , and . By Corollary 1,
Denote the jth elements of , , and as , , and , respectively. Then the nonzero elements can be calculated as
| (30) |
| (31) |
| (32) |
In Equation (29),
| (33) |
where
and
Thus it can be diagonalized as
| (34) |
where
and
with
and . Thus
| (35) |
The nonzero elements (the 1st, 2nd, 9th, 10th elements, denoted as , , , ) of the 1st row of are the 1st row of . The nonzero elements (the 3rd, 4th, 11th, 12th elements, denoted as , , , ) of the 3rd row of are the 1st row of . The nonzero elements (the 5th, 6th, 13th, 14th elements, denoted as , , , ) of the 5th row of are the 1st row of . The nonzero elements (the 7th, 8th, 15th, 16th elements, denoted as , , , ) of the 5th row of are the 1st row of . Thus
| (36) |
where . Similarly, we have
| (37) |
| (38) |
| (39) |
where
Summing up , , , and leads to the claimed .