Strategy to select most efficient RCT samples based on observational data
Abstract
Randomized experiments can provide unbiased estimates of sample average treatment effects. However, estimates of population treatment effects can be biased when the experimental sample and the target population differ. In this case, the population average treatment effect can be identified by combining experimental and observational data. A good experiment design trumps all the analyses that come after. While most of the existing literature centers around improving analyses after RCTs, we instead focus on the design stage, fundamentally improving the efficiency of the combined causal estimator through the selection of experimental samples. We explore how the covariate distribution of RCT samples influences the estimation efficiency and derive the optimal covariate allocation that leads to the lowest variance. Our results show that the optimal allocation does not necessarily follow the exact distribution of the target cohort, but adjusted for the conditional variability of potential outcomes. We formulate a metric to compare and choose from candidate RCT sample compositions. We also develop variations of our main results to cater for practical scenarios with various cost constraints and precision requirements. The ultimate goal of this paper is to provide practitioners with a clear and actionable strategy to select RCT samples that will lead to efficient causal inference.
1 Introduction
1.1 Motivation
There is growing interest in combining observational and experimental data to draw causal conclusions (Hartman et al., 2015; Athey et al., 2020; Yang and Ding, 2020; Chen et al., 2021; Oberst et al., 2022; Rosenman et al., 2020). Experimental data from randomized controlled trials (RCTs) are considered the gold standard for causal inference and can provide unbiased estimates of average treatment effects. However, the scale of the experimental data is usually limited and the trial participants might not represent those in the target cohort. For example, the recruitment criteria for an RCT may prescribe that participants must be less than 65 years old and satisfy certain health criteria, whereas the target population considered for treatment may cover all age groups. This problem is known as the lack of transportability (Pearl and Bareinboim, 2011; Rudolph and van der Laan, 2017), generalizability (Cole and Stuart, 2010; Hernán and VanderWeele, 2011; Dahabreh and Hernán, 2019), representativeness (Campbell, 1957) and external validity (Rothwell, 2005; Westreich et al., 2019). By contrast, observational data usually has both the scale and the scope desired, but one can never prove that there is no hidden confounding. Any unmeasured confounding in the observational data may lead to a biased estimate of the causal effect. When it comes to estimating the causal effect in the target population, combining obervational and experimental data provides an avenue to exploit the benefits of both.
Existing literature has proposed several methods of integrating RCT and observational data to address the issue of the RCT population not being representative of the target cohort. Kallus et al. (2018), considered the case where the supports do not fully overlap, and proposed a linear correction term to approximate the difference between the causal estimates from observational data and experimental data caused by hidden confounding.
Sometimes even though the domain of observational data overlaps with the experimental data, sub-populations with certain traits may be over- or under-represented in the RCT compared to the target cohort. This difference can lead to a biased estimate of the average treatment effect, and as a result, the causal conclusion may not be generalizable to the target population. In this case, reweighting the RCT population to make it applicable to the target cohort is a common choice of remedy (Hartman et al., 2015; Andrews and Oster, 2017). In particular, Inverse Probability of Sampling Weighting (IPSW) has been a popular estimator for reweighting (Cole and Hernán, 2008; Cole and Stuart, 2010; Stuart et al., 2011). In this paper, we base our theoretical results on the IPSW estimator.
1.2 Design Trumps Analysis
Most of the existing literature, including those discussed above, focuses on the analysis stage after RCTs are completed, and propose methods to analyse the data as given. This means, the analysis methods, including reweighting through IPSW, are to passively deal with the RCT data as they are. However, the quality of the causal inference is largely predetermined by the data collected. ‘Design trumps analysis’ (Rubin, 2008); a carefully designed experiment benefits the causal inference by far more than the analysis that follows. Instead of marginally improving through analyses, we focus on developing a strategy for the design phase, specifically the selection of RCT participants with different characteristics , to fundamentally improve the causal inference.
When designing an RCT sample to draw causal conclusions on the target cohort, a heuristic strategy that practitioners tend to opt for is to construct the RCT sample that looks exactly like a miniature version of target cohort. For example, suppose that we want to examine the efficacy of a drug on a target population consisting women and men. If the budget allows us to recruit 100 RCT participants in total, then the intuition is to recruit exactly females and males. This intuition definitely works, yet, is it efficient? We refer to the efficiency of the reweighted causal estimator for the average treatment effect in the target population, and specifically, its variance 111We note that the efficiency of an unbiased estimator is formally defined as , that is, the ratio of its lowest possible variance over its actual variance. For our purpose, we do not discuss the behaviour of the Fisher information of the data but rather focus on reducing the variance of the estimators. With slight abuse of terminology, in this paper, when we say that one estimator is more efficient than another, we mean that the variance of the former is lower. Similarly, we say that an RCT sample is more efficient if it eventually leads to an estimator of lower variance..
In fact, we find that RCTs following the exact covariate distribution of the target cohort do not necessarily lead to the most efficient estimates after reweighting. Instead, our result suggests that the optimal covariate allocation of experiment samples is the target cohort distribution adjusted by the conditional variability of potential outcomes. Intuitively, this means that an optimal strategy is to sample more from the segments where the causal effect is more volatile or uncertain, even if they do not make up a large proportion of the target cohort.
1.3 Contributions
In this work, we focus on the common practice of generalizing the causal conclusions from an RCT to a target cohort. We aim at fundamentally improving the estimation efficiency by improving the selection of individuals into the trial, that is, the allocation of a certain number of places in the RCT to individuals of certain characteristics. We derive the optimal covariate allocation that minimizes the variance of the causal estimate of the target cohort. Practitioners can use this optimal allocation as a guide when they decide ‘who’ to recruit for the trial. We also formulate a deviation metric that quantifies how far a given RCT allocation is from optimal, and practitioners can use this metric to decide when they are presented with several candidate RCT allocations to choose from.
We develop variations of the main results to cater for various practical scenarios such as where the total number of participants in the trial is fixed, or the total recruitment cost is fixed while unit costs can differ, or with different precision requirements: best overall precision, equal segment precision or somewhere in between. In this paper, we provide practitioners with a clear strategy and versatile tools to select the most efficient RCT samples.
1.4 Outline
The remainder of this paper is organized at follows: In Section 2, we introduce the problem setting, notations, provide the main assumptions and provide more details on the IPSW estimator that we consider. In Section 3, we derive the optimal covariate allocation for RCT samples to improve estimation efficiency, propose a deviation metric to assess candidate experimental designs and illustrate how this metric influences estimation efficiency. Section 4 provides an estimate of the optimal covariate allocation and the corresponding assumptions to ensure consistency. Section 5 extends the main results and propose design strategies under other practical scenarios like heterogeneous unit cost and same precision requirement. In Section 6, we use two numerical studies, a synthetic simulation and a semi-synthetic simulation with real-word data, to corroborate our theoretical results.
2 Setup, Assumptions and Estimators
2.1 Problem Setup and Assumptions
In this paper, we based our notations and assumptions on the potential outcome framework (Rubin, 1974). We assume to have two datasets: a RCT and an observational data. We also make the assumption that the target cohort of interest is contained in the observational data.
Define as the sample indicator where indicates membership of the experimental data and the target cohort, where as the treatment indicator and indicates treatment and indicates control. Let denotes potential outcome for a unit assigned to data set and treatment . We define as a set of observable pre-treatment variables, which can consist discrete and/or continuous variables. Let , , denote the number of units in the target cohort, RCT, and the combined dataset, respectively. We use and to denote the distribution of in the RCT population and target cohort, respectively.
The causal quantity of interest here is the average treatment effect (ATE) on the target population, denoted by .
Definition 2.1.
(ATE on target cohort)
We also define the CATE on the trial population, denoted by .
Definition 2.2.
(CATE on trial population)
To ensure an unbiased estimator of the ATE on the target population after reweighting the estimates from the RCT, we need to make several standard assumptions.
Assumption 1.
(Identifiability of CATE in the RCT data) For all the observations in the RCT data, we assume the following conditions hold.
-
(i)
Consistency: when and ;
-
(ii)
Ignorability: ;
-
(iii)
Positivity: for all .
The ignorability condition assumes that the experimental data is unconfounded and the positivity condition is guaranteed to hold in conditionally randomized experiments.The igonrability and positivity assumptions combined is also referred to as strong ignorability. Under Assumption 1, the causal effect conditioned on in the experimental sample can be estimated without bias using:
where is the probability of treatment assignment in the experimental sample. This estimator is also known as the Horvitz-Thompson estimator (Horvitz and Thompson, 1952), which we will provide more details later in this section.
To make sure that we can ‘transport’ the effect from the experimental data to the target cohort, we make the following transportability assumption.
Assumption 2.
(Transportability) .
Assumption 2 can be interpreted from several perspectives, as elaborated in Hernán and Robins (2010). First, it assumes that all the effect modifiers are captured by the set of observable covariates . Second, it also ensures that the treatment for different data stays the same. If the assigned treatment differs between the study population and the target population, then the magnitude of the causal effect of treatment will differ too. Lastly, the transportability assumption prescribes that there is no interference across the two populations. That is, treating one individual in one population does not interfere with the outcome of individuals in the other population.
Furthermore, we require the trial population fully overlaps with the the target cohort, so that we can reweight the CATE in the experimental sample to estimate the ATE in the target cohort. That is, for each individual in the target cohort, we want to make sure that we can find a comparable counterpart in the experimental sample with the same characteristics.
Assumption 3.
(Positivity of trial participation) for all .
2.2 Estimators and related work
Inverse Propensity (IP) weighted estimators were proposed by Horvitz and Thompson (1952) for surveys in which subjects are sampled with unequal probabilities.
Definition 2.3.
(Horvitz-Thompson estimator)
where the probability of treatment is assumed to be known as we focus on the design phase of experiments. In practice, we can extend the Horvitz-Thompson estimator by replacing with an estimate , for example the Hajek estimator (Hájek, 1971) and the difference-in-means estimator.
Definition 2.4.
(Augmented Inverse Propensity Weighted estimator)
where denotes the average outcome of treatment given covariate , that is, , and is an estimate of (Robins, 1994).
The estimator is doubly robust: is consistent if either (1) is consistent or (2) is consistent.
Definition 2.5.
(Inverse Propensity Sample Weighted (IPSW) estimator)
We can see that the IPSW estimator extends the Horvitz-Thompson estimator by adding a weight , which is the ratio between the probably of observing an individual with characteristics in the trial population that in the target population (Stuart et al., 2011)222The definition of the weight differs slightly from that in Stuart et al. (2011), where is defined as . That is, the ratio of the distribution of being selected into the trail over being selected into the target cohort. This definition is based on the problem setting where there is a super population which the target cohort and trial cohort are sampled from. Our definition here agrees with that in Colnet et al. (2022).. We use an asterisk in the notation to denote that it is an oracle definition where we assume both and are known, which is probably unrealistic. The IPSW estimator of average treatment effect on target cohort is proven to be unbiased under Assumptions 1– 3.
A concurrent study of high relevance to our work by Colnet et al. (2022) investigated performance of IPSW estimators. In particular, they defined different versions of IPSW estimators, where and are either treated as known or estimated, and derived the expressions of asymptotic variance for each version. They concluded that the semi-oracle estimator, where is estimated and is treated as known, outperforms the other two versions giving the lowest asymptotic variance.
Definition 2.6.
(Semi-oracle IPSW estimator, Colnet et al. (2022))
The re-weighted ATE estimator we use in this paper, , coincides with their semi-oracle IPSW estimator defined above, where is estimated from the RCT data.
3 Main Results
In this section, we start with the case where the number of possible covariate values is finite and derive the optimal covariate allocation of RCT samples that minimizes the variance of the ATE estimate, . We then develop a deviation metric, , that quantifies how much a candidate RCT sample composition with covariate distribution deviates from the optimal allocation. We prove that this deviation metric, , is proportional to the variance of therefore it can be used as a metric for selection. Finally, we derive the above results in presence of continuous covariates.
3.1 Variance-Minimizing RCT Covariate Allocation
We first consider the more straight-forward case, where the number of possible covariate values is finite. Recall that denotes the propensity score, We assume that the exact value of is known for the RCT.
When units in the experimental dataset cover all the possible covariate values, for , recall the Horvitz-Thompson inverse-propensity weighted estimators (Horvitz and Thompson, 1952) of CATE:
Discrete covariates can be furthered divided into two types: ordinal, for example, test grade, and categorical such as blood type. For ordinal covariates, we can construct a smoother estimator by applying kernel-based local averaging:
where is kernel function and is the smoothing parameter. Conceptually, the kernel function measures how individuals with covariates in proximity to influence the estimation of . This kernel-based estimator works even if the observational data does not fully overlap with the experimental data. The estimator is inspired by Abrevaya et al. (2015), who used it to estimate the CATE. Specifically, if the covariate is ordinal and the sample size of a sub-population with a certain covariate value is small or even zero, we can consider , as it applies local averaging so that each CATE is informed by more data.
To study the variance of CATE estimates and , we define the following terms:
The random vector is the influence function of the AIPW estimator (Bang and Robins, 2005). Term measures the conditional variability of the difference in potential outcomes given covariate , and denotes the average outcome with treatment given covariate .
Assumption 4.
As goes to infinity, has a limit in .
Assumption 4 suggests that when we consider the asymptotic behavior of our estimators, sample sizes for both experimental data and observational data go to infinity, though usually there is more observational samples than experimental samples.
Theorem 1.
Theorem 1 shows the asymptotic distribution of the two CATE estimators for every possible covariate value. Complete randomization in experiments ensures that is unbiased. Based on the idea of IPSW estimator, we then construct the following two reweighted estimators for ATE:
It is easy to see that the above is the same as the semi-oracle IPSW estimator defined in Definition 2.6 once we substitute in the expression of .
Theorem 2.
Theorem 2 indicates that even if the covariate distribution of experimental data is exactly the same as that of the target cohort, it does not necessarily produce the most efficient estimator. The optimal RCT covariate distribution also depends on the conditional variability of potential outcomes. In fact, is essentially the target covariate distribution adjusted by the variability of conditional causal effects. This result suggests that we should sample relatively more individuals from sub-populations where the causal effect is more volatile, even if they do not take up a big proportion of the target cohort. Moreover, the two estimators, and , share the same optimal covariate weight no matter whether local averaging is applied.
In practice, if the total number of samples is fixed, experiment designers can select RCT samples with covariate allocation identical to to improve the efficiency of IPSW estimate.
3.2 Deviation Metric
Corollary 1.
where , and we define
as the deviation metric of experiment samples as it measures the difference between the optimal covariate distribution and the real covariate distribution . We have , and if and only if the real covariate distribution of experiment samples is identical to the optimal one, i.e. for .
Accoring to Corollary 1, the variance of depends on two parts: the first part depends on the true distribution of the target population, while the second part is a measure of the deviation of the RCT sample allocation compared to the optimal variability-adjusted allocation , and can thus reflect the representativeness of our RCT samples. As Corollary 1 shows, the variance of IPSW estimator for the population, , is proportional to .
The deviation metric equips us with a method to compare candidate experiment designs. To be specific, if experiment designers have several potential plans for RCT samples, they can choose one with the smallest deviation metric to maximize the estimation efficiency.
3.3 Including Continuous Covariates
For continuous covariates, for instance, body mass index (BMI), we apply stratification based on propensity score. By considering an appropriate partition of the support with finite , we can turn it into the discrete case above.
Assumption 5.
For , and , we have
-
(i)
;
-
(ii)
.
Assumption 5 assumes that units within each stratum share the same propensity score and CATE. This is a strong but reasonable condition if we make each stratum sufficiently small. Under Assumption 5, let , , , denote the causal effect estimate, causal effect estimate with kernel-based local averaging, variance of influence function, propensity score, that are conditioned on . Let and . We can then construct two IPSW estimators:
As shown in Corollary 2, we have similar results to Theorem 2, but instead of the optimal covariate distribution, we derive the optimal probability on each covariate set .
Corollary 2.
In the sections that follow, for simplicity, we illustrate our method in the scenario where the covariates are all discrete with finite possible values. The results can easily be extended to include continuous covariates following the same logic as descibed in this section.
4 Estimating Conditional Variability
The optimal covariate allocation derived above can benefit the planning of the composition of RCT samples. However, it’s difficult, or impossible, to estimate the conditional variability of potential outcomes prior to RCTs being carried out. In this section, we provide a practical strategy using information from the observational data to estimate the theoretical optimal covariate distribution, and derive conditions under which our strategy yields consistent results.
In completely randomized experiments, we can show that
To estimate by observational data, , let
We can then estimate the conditional variability of potential outcomes, the optimal covariate distribution and the deviation metric of RCT samples from observational data as follows
Assumption 6 below ensures the consistency of the estimated conditional variance of potential outcomes . The main problem of estimating from observational data is the possibility of unobserved confounding. Instead of assuming unconfoundedness, our Assumption 6 is weaker and requires that the expectation of estimate is proportional to the target conditional variability, which is a weaker condition.
Assumption 6.
For , suppose
where is an unknown constant.
The left-hand side of the equation above is the conditional variance of observed outcomes that can be estimated from the observational data, and the right-hand side is the theoretical conditional variance of potential outcomes that we want to approximate. Assumption 6 requires these two quantities to be proportional, rather than absolutely equal. Intuitively, the assumption supposes that the covariate segments in the observational data that exhibit high volatility in observed outcomes, also have high variance in their potential outcomes, although it is not required that the absolute levels of variance have to be the same.
Based on Thereom 3, we propose a novel strategy to select efficient RCT samples. Specifically, we select the candidate experimental design with covariate allocation that minimizes the estimate of deviation metric . By contrast, a naive strategy prefers the candidate experimental design with , which mimics exactly the covariate distribution in the target cohort. If the conditional variability of potential outcomes vary widely according to . Our strategy can lead to much more efficient treatment effect estimator compared to the naive strategy.
5 Practical Scenarios
5.1 Heterogeneous Unit Cost
We also consider the experimental design with a cost constraint and heterogeneous cost for different sub-populations. The goal is to find the optimal sample allocation for RCT that minimizes the variance of the proposed estimator subject to a cost constraint. For , let denote the cost to collect a sample in the sub-population with .
Theorem 4.
Under the cost constraint that
the optimal sample allocation that minimizes is
for . Here we use the superscript to denote the cost constraint.
Theorem 4 suggests that the optimal RCT covariate allocation under the given cost constraint is the covariate allocation of target cohort adjusted by both the heterogeneous costs for sub-populations and the conditional variability of potential outcomes. Intuitively, compared to the case without heterogeneous costs, we should include more RCT samples with lower unit cost.
5.2 Different Precision Requirements
Theorem 2 shows the optimal sample allocation to maximize the efficiency of average treatment effect estimator for the target cohort. If we require the same precision for estimators in each domain, we need the sample allocation as follows:
where we use the superscript s to denote the requirement of same precision for the CATE estimate in each segment.
Intuitively, to take both objectives into consideration, we propose a compromised allocation that falls between the two optimum allocations :
Corollary 3.
If for ,
we have for ,
The deviation metric for sample allocation under same precision strategy and compromise strategy are
respectively.
6 Numerical Study
6.1 Simulation
In this section, we conduct a simulation study to illustrate how representativeness of experiment samples influences the estimation efficiency of average treatment effect for a target cohort, and demonstrate how the representativeness metric can facilitate the selection from candidate RCT sample designs. We set the size of observational dataset and the size of experimental dataset . For the units in the observational data, we draw covariates from with probability 0.3, 0.2 and 0.5 respectively. We then set
where . We can then compute the conditional variability of potential outcomes and thus the optimal covariate distribution from the true population. Our model engenders distinctive conditional variability given different , making the optimal covariate distribution very different from the target covariate distribution .
For experimental data, we simulate 100 different candidate experimental sample designs. In each design, we randomly draw experiment samples from the target cohort with probability
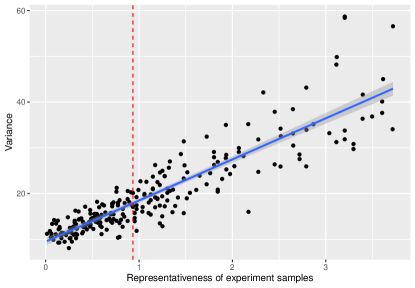
where are i.i.d. samples drawn from standard normal distribution. We can then compute the real covariate distribution and the repressiveness metric . To estimate the efficiency of average treatment effect estimator, we conduct 1000 experiments for each design. In each experiment, the treatment for each unit follows a Bernoulli distribution with probability 0.5. The simulation result is shown in Fig 1. The relationship between the variance and representativeness can be fit into a line, which is consistent with our result that . The red line shows the value for the naive strategy mimicking exactly the target cohort distribution, which is not zero, and we can see that it is not the optimal RCT sample and does not produce the most efficient causal estimator.
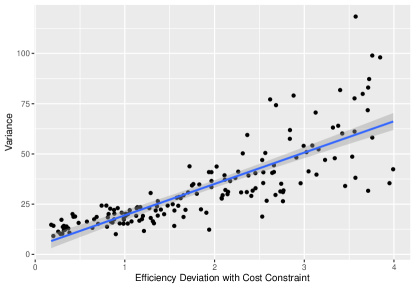
For the case with heterogeneous unit cost, we set the costs for sub-populations with covariate being 1, 2, 3 to be 20, 30, 40, respectively. The total capital available is 30000. Instead of randomly drawing experiment samples from the target cohort with a fixed number of total subjects, we randomly assign capitals for different sub-populations with a fixed amount of total cost. Given the budget assigned to each sub-population, we then draw subjects randomly from the sub-population, where the amount of subjects can be determined by the assigned budget. The simulation result is illustrated by Figure 2. We can see that under the cost constraint, experiment samples that follow a distribution closer to lead to causal estimator with better efficiency.
6.2 Real Data Illustration
We use the well-cited Tennessee Student/Teacher Achievement Ratio (STAR) experiment to assess how covariate distribution of experiment samples influences the estimation efficiency of average treatment effect for target cohort. STAR is a randomized experiment started in 1985 to measure the effect of class size on student outcomes, measured by standardized test scores. Similar to the exercise in Kallus et al. (2018), we focus a binary treatment: for small classes (13-17 pupils), and for regular classes (22-25 pupils). Since many students only started the study at first grade, we took as treatment their class-type at first grade. The outcome is the sum of the listening, reading, and math standardized test at the end of first grade. We use the following covariates for each student: student race () and school urbanicity (). We exclude units with missing covariates. The records of 4584 students remain, with 1733 assigned to treatment (small class, ), and 2413 to control (regular size class, ). Before analysis we fill the missing outcome by linear regression based on treatments and two covariates so that both two potential outcomes and for each student are known.
We simulate 500 candidate experiment sample allocations. For each allocations, we select experiment units from the dataset with probability
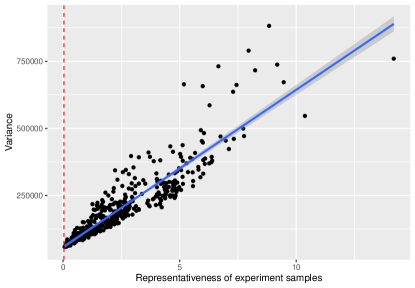
where are i.i.d. samples drawn from standard normal distribution. We can then compute the real covariate distribution and the repressiveness of the experiment samples . To estimate the efficiency of average treatment effect estimator, we conduct 200 experiments for each design. In each experiment, the treatment follows a Bernoulli distribution with probability . The simulation result is shown in Fig 3. The relationship between the variance and the deviation metric can be fit into a line, which is consistent with our result that .
7 Conclusion
In this paper, we examine the common procedure of generalizing causal inference from an RCT to a target cohort. We approach this as a problem where we can combine an RCT with an observational data. The observational data has two roles in the combination: one is to provide the exact covariate distribution of the target cohort, and the other role is to provide a means to estimate the conditional variability of the causal effect by covariate values.
We give the expression of the variance of Inverse Propensity Sampling Weights estimator as a function of covariate distribution in the RCT. We subsequently derive the variance-minimizing optimal covariate allocation in the RCT, under the constraint that the size of the trial population is fixed. Our result indicates that the optimal covariate distribution of the RCT does not necessarily follow the exact distribution of the target cohort, but is instead adjusted by the conditional variability of potential outcomes. Practitioners who are at the design phase of a trial can use the optimal allocation result to plan the group of participants to recruit into the trial.
We also formulate a deviation metric quantifying how far a given RCT allocation is from optimal. The advantage of this metric is that it is proportional to the variance of the final ATE estimate so that when presented with several candidate RCT cohorts, practitioners can compare and choose the most efficient RCT according to this metric.
The above results depend on the estimation of conditional variability of the causal effect by covariate values, which remains unknown. We propose to estimate it using the observational data and outline mild assumptions that needs to be met. In reality, practitioners usually have complex considerations when designing a trial, for instance cost constraints and precision requirements. We develop variants of our main results to apply in such practical scenarios. Finally, we use two numerical studies to corroborate our theoretical results.
References
- Abrevaya et al. (2015) J. Abrevaya, Y.-C. Hsu, and R. P. Lieli. Estimating conditional average treatment effects. Journal of Business & Economic Statistics, 33(4):485–505, 2015.
- Andrews and Oster (2017) I. Andrews and E. Oster. Weighting for external validity. National Bureau of Economic Research, 2017.
- Athey et al. (2020) S. Athey, R. Chetty, and G. Imbens. Combining experimental and observational data to estimate treatment effects on long term outcomes. arXiv preprint arXiv:2006.09676, 2020.
- Bang and Robins (2005) H. Bang and J. M. Robins. Doubly robust estimation in missing data and causal inference models. Biometrics, 61(4):962–973, 2005.
- Campbell (1957) D. T. Campbell. Factors relevant to the validity of experiments in social settings. Psychological bulletin, 54(4):297, 1957.
- Chen et al. (2021) S. Chen, B. Zhang, and T. Ye. Minimax rates and adaptivity in combining experimental and observational data. 9 2021. URL http://arxiv.org/abs/2109.10522.
- Cole and Hernán (2008) S. R. Cole and M. A. Hernán. Constructing inverse probability weights for marginal structural models. American journal of epidemiology, 168(6):656–664, 2008.
- Cole and Stuart (2010) S. R. Cole and E. A. Stuart. Generalizing evidence from randomized clinical trials to target populations: the actg 320 trial. American journal of epidemiology, 172(1):107–115, 2010.
- Colnet et al. (2022) B. Colnet, J. Josse, G. Varoquaux, and E. Scornet. Reweighting the rct for generalization: finite sample analysis and variable selection. arXiv preprint arXiv:2208.07614, 2022.
- Dahabreh and Hernán (2019) I. J. Dahabreh and M. A. Hernán. Extending inferences from a randomized trial to a target population. European Journal of Epidemiology, 34(8):719–722, 2019.
- Hájek (1971) J. Hájek. Comment on “an essay on the logical foundations of survey sampling, part one”. The foundations of survey sampling, 236, 1971.
- Hartman et al. (2015) E. Hartman, R. Grieve, R. Ramsahai, and J. S. Sekhon. From sate to patt: combining experimental with observational studies to estimate population treatment effects. JR Stat. Soc. Ser. A Stat. Soc.(forthcoming). doi, 10:1111, 2015.
- Hernán and Robins (2010) M. A. Hernán and J. M. Robins. Causal inference, 2010.
- Hernán and VanderWeele (2011) M. A. Hernán and T. J. VanderWeele. Compound treatments and transportability of causal inference. Epidemiology (Cambridge, Mass.), 22(3):368, 2011.
- Horvitz and Thompson (1952) D. G. Horvitz and D. J. Thompson. A generalization of sampling without replacement from a finite universe. Journal of the American statistical Association, 47(260):663–685, 1952.
- Kallus et al. (2018) N. Kallus, A. M. Puli, and U. Shalit. Removing hidden confounding by experimental grounding. Advances in neural information processing systems, 31, 2018.
- Oberst et al. (2022) M. Oberst, A. D’Amour, M. Chen, Y. Wang, D. Sontag, and S. Yadlowsky. Bias-robust integration of observational and experimental estimators. 5 2022. URL http://arxiv.org/abs/2205.10467.
- Pearl and Bareinboim (2011) J. Pearl and E. Bareinboim. Transportability of causal and statistical relations: A formal approach. In Twenty-fifth AAAI conference on artificial intelligence, 2011.
- Robins (1994) J. M. Robins. Correcting for non-compliance in randomized trials using structural nested mean models. Communications in Statistics-Theory and methods, 23(8):2379–2412, 1994.
- Rosenman et al. (2020) E. Rosenman, G. Basse, A. Owen, and M. Baiocchi. Combining observational and experimental datasets using shrinkage estimators. arXiv preprint arXiv:2002.06708, 2020.
- Rothwell (2005) P. M. Rothwell. External validity of randomised controlled trials:“to whom do the results of this trial apply?”. The Lancet, 365(9453):82–93, 2005.
- Rubin (1974) D. B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of educational Psychology, 66(5):688, 1974.
- Rubin (2008) D. B. Rubin. For objective causal inference, design trumps analysis. The annals of applied statistics, 2(3):808–840, 2008.
- Rudolph and van der Laan (2017) K. E. Rudolph and M. J. van der Laan. Robust estimation of encouragement design intervention effects transported across sites. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(5):1509–1525, 2017.
- Stuart et al. (2011) E. A. Stuart, S. R. Cole, C. P. Bradshaw, and P. J. Leaf. The use of propensity scores to assess the generalizability of results from randomized trials. Journal of the Royal Statistical Society: Series A (Statistics in Society), 174(2):369–386, 2011.
- Westreich et al. (2019) D. Westreich, J. K. Edwards, C. R. Lesko, S. R. Cole, and E. A. Stuart. Target validity and the hierarchy of study designs. American journal of epidemiology, 188(2):438–443, 2019.
- Yang and Ding (2020) S. Yang and P. Ding. Combining multiple observational data sources to estimate causal effects. Journal of the American Statistical Association, 115:1540–1554, 7 2020. ISSN 1537274X. doi: 10.1080/01621459.2019.1609973.
Appendix A Proof
To be continued.
Lemma 1.
Let , where and s.t. and . Function reaches its minimum when for .
Proof of Lemma 1.
Note that , for , we have
Given that is positive, by setting , we can get for . This, together with , ensures that reaches its minimum when for . ∎