Strictly Proper Kernel Scoring Rules and Divergences with an Application to Kernel Two-Sample Hypothesis Testing
Abstract
We study strictly proper scoring rules in the Reproducing Kernel Hilbert Space. We propose a general Kernel Scoring rule and associated Kernel Divergence. We consider conditions under which the Kernel Score is strictly proper. We then demonstrate that the Kernel Score includes the Maximum Mean Discrepancy as a special case. We also consider the connections between the Kernel Score and the minimum risk of a proper loss function. We show that the Kernel Score incorporates more information pertaining to the projected embedded distributions compared to the Maximum Mean Discrepancy. Finally, we show how to integrate the information provided from different Kernel Divergences, such as the proposed Bhattacharyya Kernel Divergence, using a one-class classifier for improved two-sample hypothesis testing results.
Keywords: strictly proper scoring rule, divergences, kernel scoring rule, minimum risk, projected risk, proper loss functions, probability elicitation, calibration, Bayes error bound, Bhattacharyya distance, feature selection, maximum mean discrepancy, kernel two-sample hypothesis testing, embedded distribution
1 Introduction
Strictly proper scoring rules Savage (1971); DeGroot (1979); Gneiting and Raftery (2007) are integral to a number of different applications namely, forecasting Gneiting et al. (2007); Brocker (2009), probability elicitation O’Hagan et al. (2006), classification Masnadi-Shirazi and Vasconcelos (2008, 2015), estimation Birg and Massart (1993), and finance Duffie and Pan (1997). Strictly proper scoring rules are closely related to entropy functions, divergence measures and bounds on the Bayes error that are important for applications such as feature selection Vasconcelos (2002); Vasconcelos and Vasconcelos (2009); Brown (2009); Peng et al. (2005), classification and regression Liu and Shum (2003); Lee et al. (2005); Friedman and Stuetzle (1981) and information theory Duchi and Wainwright (2013); Guntuboyina (2011); Cover and Thomas (2006); Brown and Liu. (1993).
Despite their vast applicability and having been extensively studied, strictly proper scoring rules have only recently been studied in Reproducing Kernel Hilbert Spaces. In Dawid (2007); Gneiting and Raftery (2007) a certain kernel score is defined and in Zawadzki and Lahaie (2015) its divergence is shown to be equivalent to the Maximum Mean Discrepancy. The Maximum Mean Discrepancy (MMD) Gretton et al. (2012) is defined as the squared difference between the embedded means of two distributions embedded in an inner product kernel space. It has been used in hypothesis testing where the null hypothesis is rejected if the MMD of two sample sets is above a certain threshold Gretton et al. (2007, 2012). Recent work pertaining to the MMD has concentrated on the kernel function Sriperumbudur et al. (2008, 2010, 2010a, 2011) or improved estimates of the mean embedding Muandet et al. (2016) or methods of improving its implementation Gretton et al. (2009) or incorporating the embedded covariance Harchaoui et al. (2007) among others.
In this paper we study the notion of strictly proper scoring rules in the Reproducing Kernel Hilbert Space. We introduce a general Kernel Scoring rule and associated Kernel Divergence that encompasses the MMD and the kernel score of Dawid (2007); Gneiting and Raftery (2007); Zawadzki and Lahaie (2015) as special cases. We then provide conditions under which the proposed Kernel Score is proven to be strictly proper. We show that being strictly proper is closely related to the injective property of the MMD.
The Kernel Score is shown to be dependent on the choice of an embedded projection vector and concave function . We consider a number of valid choices of such as the canonical vector, the normalized kernel Fisher discriminant projection vector and the normalized kernel SVM projection vector Vapnik (1998) that lead to strictly proper Kernel Scores and strictly proper Kernel Divergences.
We show that the proposed Kernel Score is related to the minimum risk and that the is related to the minimum conditional risk function. This connection is made possible by looking at risk minimization in terms of proper loss functions Buja et al. (2005); Masnadi-Shirazi and Vasconcelos (2008, 2015). This allows us to study the effect of choosing different functions and establish its relation to the Bayes error. We then provide a method for generating functions for Kernel Scores that are arbitrarily tight upper bounds on the Bayes error. This is especially important for applications that rely on tight bounds on the Bayes error such as classification, feature selection and feature extraction among others. In the experiment section we confirm that such tight bounds on the Bayes error lead to improved feature selection and classification results.
We show that strictly proper Kernel Scores and Kernel Divergences, such as the Bhattacharyya Kernel Divergence, include more information about the projected embedded distributions compared to the MMD. We provide practical formulations for calculating the Kernel Score and Kernel Divergence and show how to combine the information provided from different Kernel Divergences with the MMD using a one class classifier Tax (2001) for significantly improved hypothesis testing results.
The paper is organized as follows. In Section 2 we review the required background material. In Section 3 we introduce the Kernel Scoring Rule and Kernel Divergence and consider conditions under which they are strictly proper. In Section 4 we establish the connections between the Kernel Score and and MMD and show that the MMD is a special case of the Bhattacharyya Kernel Score. In Section 5 we show the connections between the Kernel Score and the minimum risk and explain how arbitrarily tighter bounds on the Bayes error are possible. In Section 6 we discuss practical consideration in computing the Kernel Score and Kernel Divergence given sample data. In Section 7 we propose a novel one-class classifier that can combine all the different Kernel Divergences into a powerful hypothesis test. Finally, in Section 8 we present extensive experimental results and apply the proposed ideas to feature selection and hypothesis testing on bench-mark gene data sets.
2 Background Material Review
In this section we provide a review of required background material on strictly proper scoring rules, proper loss functions and positive definite kernel embedding of probability distributions.
2.1 Strictly Proper Scoring Rules and Divergences
The concept of strictly proper scoring rules can be traced back to the seminal paper of Savage (1971). This idea was expanded upon by later papers such as DeGroot (1979); Dawid (1982) and has been most recently studied under a broader context O’Hagan et al. (2006); Gneiting and Raftery (2007). We provide a short review of the main ideas in this field.
Let be a general sample space and be a class of probability measures on . A scoring rule is a real valued function that assigns the score to a forecaster that quotes the measure and the event materializes. The expected score is written as and is the expectation of under
| (1) |
assuming that the integral exists. We say that a scoring rule is proper if
| (2) |
and we say that a scoring rule is strictly proper when if and only if . We define the divergence associated with a strictly proper scoring rule as
| (3) |
which is a non-negative function and has the property of
| (4) |
Presented less formally, the forecaster makes a prediction regarding an event in the form of a probability distribution . If the actual event materializes then the forecaster is assigned a score of . If the true distribution of events is then the expected score is . Obviously, we want to assign the maximum score to a skilled and trustworthy forecaster that predicts . A strictly proper score accomplishes this by assigning the maximum score if and only if .
If the distribution of the forecasters predictions is then the overall expected score of the forecaster is
| (5) |
The overall expected score is maximum when the expected score is maximum for each prediction , which happens when for all , assuming that the score is strictly proper.
2.2 Risk Minimization and the Classification Problem
Classifier design by risk minimization has been extensively studied in (Friedman et al., 2000; Zhang, 2004; Buja et al., 2005; Masnadi-Shirazi and Vasconcelos, 2008). In summary, a classifier is defined as a mapping from a feature vector to a class label . Class labels and feature vectors are sampled from the probability distributions and respectively. Classification is accomplished by taking the sign of the classifier predictor . This can be written as
| (6) |
The optimal predictor is found by minimizing the risk over a non-negative loss function and written as
| (7) |
This is equivalent to minimizing the conditional risk
for all . The predictor is decomposed and typically written as
where is called the link function and is the posterior probability function. The optimal predictor can now be learned by first analytically finding the optimal link and then estimating , assuming that is one-to-one.
If the zero-one loss
is used, then the associated conditional risk
| (11) |
is equal to the probability of error of the classifier of (6). The associated conditional zero-one risk is minimized by any such that
| (12) |
For example the two links of
can be used.
The resulting classifier is now the optimal Bayes decision rule. Plugging back into the conditional zero-one risk gives the minimum conditional zero-one risk
| (17) | |||||
The optimal classifier that is found using the zero-one loss has the smallest possible risk and is known as the Bayes error of the corresponding classification problem (Bartlett et al., 2006; Zhang, 2004; Devroye et al., 1997).
We can change the loss function and replace the zero-one loss with a so-called margin loss in the form of . Unlike the zero-one loss, margin losses allow for a non-zero loss on positive values of the margin . Such loss functions can be shown to produce classifiers that have better generalization (Vapnik, 1998). Also unlike the zero-one loss, margin losses are typically designed to be differentiable over their entire domain. The exponential loss and logistic loss used in the AdaBoost and LogitBoost Algorithms Friedman et al. (2000) and the hinge loss used in SVMs are some examples of margin losses Zhang (2004); Buja et al. (2005). The conditional risk of a margin loss can now be written as
| (18) |
This is minimized by the link
| (19) |
and so the minimum conditional risk function is
| (20) |
For most margin losses, the optimal link is unique and can be found analytically. Table 1 presents the exponential, logistic and hinge losses along with their respective link and minimum conditional risk functions.
| Algorithm | ||||
|---|---|---|---|---|
| AdaBoost | ||||
| LogitBoost | ||||
| SVM | NA |
2.2.1 Probability Elicitation and Proper Losses
Conditional risk minimization can be related to probability elicitation (Savage, 1971; DeGroot and Fienberg, 1983) and has been studied in (Buja et al., 2005; Masnadi-Shirazi and Vasconcelos, 2008; Reid and Williamson, 2010). In probability elicitation we find the probability estimator that maximizes the expected score
| (21) |
of a score function that assigns a score of to prediction when event holds and a score of to prediction when holds. The scoring function is said to be proper if and are such that the expected score is maximal when , in other words
| (22) |
with equality if and only if . This holds for the following theorem.
Theorem 1
| (23) |
Proper losses can now be related to probability elicitation by the following theorem which is most important for our purposes.
Theorem 2
It is shown in (Zhang, 2004) that is concave and that
| (24) | |||||
| (25) |
We also require that so that the minimum risk is zero when or .
In summary, for any continuously differentiable and invertible , the conditions of Theorem 2 are satisfied and so the loss will take the form of
| (26) |
and . In this case, the predictor of minimum risk is , the minimum risk is
| (27) |
and posterior probabilities can be found using
| (28) |
Finally, the loss is said to be proper and the predictor calibrated (DeGroot and Fienberg, 1983; Platt, 2000; Niculescu-Mizil and Caruana, 2005; Gneiting and Raftery, 2007).
In practice, an estimate of the optimal predictor is found by minimizing the empirical risk
| (29) |
over a training set . Estimates of the probabilities are now found from using
| (30) |
2.3 Positive Definite Kernel Embedding of Probability Distributions
In this section we review the notion of embedding probability measures into reproducing kernel Hilbert spaces Berlinet and Thomas-Agnan (2004); Fukumizu et al. (2004); Sriperumbudur et al. (2010b).
Let be a random variable defined on a topological space with associated probability measure . Also, let be a Reproducing Kernel Hilbert Space (RKHS) . Then there is a mapping such that
| (31) |
The mapping can be written as where is a positive definite kernel function parametrized by . A dot product representation of exists in the form of
| (32) |
where .
For a given Reproducing Kernel Hilbert Space , the mean embedding of the distribution exists under certain conditions and is defined as
| (33) |
In words, the mean embedding of the distribution is the expectation under of the mapping .
The maximum mean discrepancy (MMD) Gretton et al. (2012) is expressed as the squared difference between the embedded means and of the two embedded distributions and as
| (34) |
where is a unit ball in a universal RKHS which requires that be continuous among other things. It can be shown that the Reproducing Kernel Hilbert Spaces associated with the Gaussian and Laplace kernels are universal Steinwart (2002). Finally, an important property of the MMD is that it is injective which is formally stated by the following theorem.
Theorem 3
(Gretton et al., 2012) Let be a unit ball in a universal RKHS defined on the compact metric space with associated continuous kernel . if and only if .
3 Strictly Proper Kernel Scoring Rules and Divergences
In this section we define the Kernel Score and Kernel Divergence and show when the Kernel Score is strictly proper. To do this we need to define the projected embedded distribution.
Definition 1
Let be a random variable defined on a topological space with associated probability distribution . Also, let be a universal RKHS with associated positive definite kernel function . The projection of onto a fixed vector in is denoted by and found as
| (35) |
The univariate distribution associated with is defined as the projected embedded distribution of and denoted by . The mean and variance of are denoted by and .
The Kernel Score and Kernel Divergence are now defined as follows.
Definition 2
Let and be two distributions on . Also, let be a universal RKHS with associated positive definite kernel function where is a unit ball in . Finally, assume that is a fixed vector in . The Kernel Score between distributions and is defined as
| (36) |
and the Kernel Divergence between distributions and is defined as
| (37) | |||||
| (38) |
where is a continuously differentiable strictly concave symmetric function such that for all , , and and are the projected embedded distributions of and .
We can now present conditions under which a Kernel Score is strictly proper and Kernel Divergence has the important property of (4).
Theorem 4
The Kernel Score is strictly proper and the Kernel Divergence has the property of
| (39) |
if is chosen such that it is not in the orthogonal compliment of the set , where and are the mean embeddings of and respectively.
Proof 1
See supplementary material 10.
We denote Kernel Divergences that have the desired property of (39) as Strictly Proper Kernel Divergences. The canonical projection vector that is not in the orthogonal compliment of is to choose . The following lemma lists some valid choices.
Lemma 1
The Kernel Score and Kernel Divergence associated with the following choices of are strictly proper.
-
1.
.
-
2.
equal to the normalized kernel Fisher discriminant projection vector.
-
3.
equal to the normalized kernel SVM projection vector.
Proof 2
See supplementary material 11.
In what follows we consider the implications of choosing different projections and concave functions for the Strictly Proper Kernel Score and Kernel Divergence.
4 The Maximum Mean Discrepancy Connection
If we choose to be the concave function of and assume that the univariate projected embedded distributions and are Gaussian then, using the Bhattacharyya bound Choi and Lee (2003); Coleman and Andrews (1979), we can readily show that
| (40) | |||
| (41) | |||
| (42) |
where , , and are the means and variances of the projected embedded distributions and . We will refer to these as the Bhattacharyya Kernel Score and Bhattacharyya Kernel Divergence. Note that if then the above equation simplifies to . This leads to the following results.
Lemma 2
Let and be two distributions where and are the respective means of the projected embedded distributions and with projection vector . Then
| (43) |
Proof 3
See supplementary material 12.
With this new alternative outlook on the MMD, it can be seen as a special case of a strictly proper Kernel Score under certain assumptions outlined in the following theorem.
Theorem 5
Let be the concave function of and . Then
| (44) |
under the assumption that the projected embedded distributions and are Gaussian distributions of equal variance.
Proof 4
See supplementary material 13.
In other words, if we set and project onto this vector, the MMD is equal to the distance between the means of the projected embedded distributions squared. Note that while the MMD incorporates all the higher moments of the distribution of the data in the original space and determines a probability distribution uniquely Muandet et al. (2016), it completely disregards the higher moments of the projected embedded distributions. This suggests that by incorporating more information regarding the projected embedded distributions, such as its variance, we can arrive at measures such as the Bhattacharyya Kernel Divergence that are more versatile than the MMD in the finite sample setting. In the experimental section we apply these measures to the problem of kernel hypothesis testing and show that they outperform the MMD.
5 Connections to the Minimum Risk
In this section we establish the connection between the Kernel Score and the minimum risk associated with the projected embedded distributions. This will provide further insight towards the effect of choosing different concave functions and different projection vectors on the Kernel Score. First, we present a general formulation for the minimum risk of (7) for a proper loss function and show that we can partition any such risk into two terms akin to partitioning of the Brier score (DeGroot and Fienberg, 1983; Murphy, 1972).
Lemma 3
Let be a proper loss function in the form of (26) and an estimate of the optimal predictor . The risk can be partitioned into a term that is a measure of calibration plus a term that is the minimum risk in the form of
| (46) |
Furthermore the minimum risk term can be written as
| (47) |
Proof 5
See supplementary material 14.
The following theorem that writes the Kernel Score in terms of the minimum risk associated with the projected embedded distributions is now readily proven.
Theorem 6
Let and be two distributions and choose . Then
| (48) |
where is the minimum risk associated with the projected embedded distributions of and .
Proof 6
See supplementary material 15.
We conclude that the minimum risk associated with the projected embedded distributions term , and in turn the Kernel Score , are constants related to the distributions and (determined by the choice of ) and the choice of .
The effect of changing can now be studied in detail by noting the general result presented in the following theorem Hashlamoun et al. (1994); Avi-Itzhak and Diep (1996); Devroye et al. (1997).
Theorem 7
Let be a continuously differentiable concave symmetric function such that for all , and . Then and . Furthermore, for any such that there exists and where .
Proof 7
The above theorem, when especially applied to the projected embedded distributions, states that the minimum risk associated with the projected embedded distributions is an upper bound on the Bayes risk associated with the projected embedded distributions and as is made arbitrarily close to this upper bound is tight.
In summary, using different in the Kernel Score formulation, changes the projected embedded distributions of and and the Bayes risk associated with these projected embedded distributions . Using different changes the upper bound estimate of this Bayes risk .
5.0.1 Tighter Bounds on the Bayes Error
We can easily verify that, in general, the minimum risk is equal to the Bayes error when , leading to the smallest possible minimum risk for fixed data distributions. Unfortunately, is not continuously differentiable and so we consider other functions. For example when is used, the minimum risk simplifies to
| (49) |
which is equal to the asymptotic nearest neighbor bound Fukunaga (1990); Cover and Hart (1967) on the Bayes error. We have used the notation to make it clear that this is the minimum risk associated with the function.
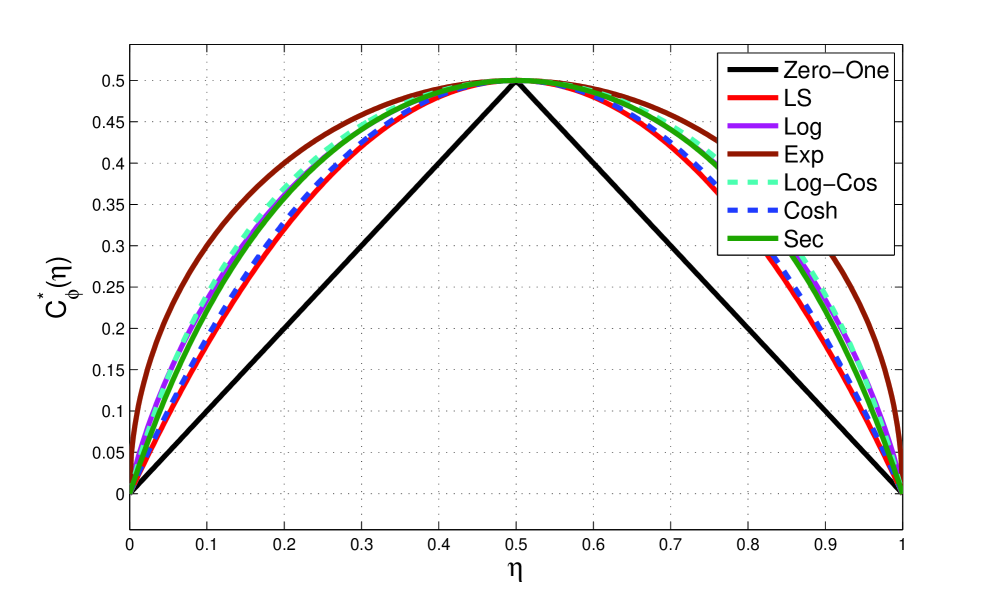
From Theorem 7 we know that when the minimum risk is computed under other functions, a list of which is presented in Table-2, an upper bound on the Bayes error is being computed. Also, the that are closer to result in minimum risk formulations that provide tighter bounds on the Bayes error. Figure-1 shows that , , , , and are in order the closest to and the corresponding minimum-risk formulations in Table-3 provide, in the same order, tighter bounds on the Bayes error. This can also be directly verified by noting that is equal to the Bhattacharyya bound Fukunaga (1990), is equal to the asymptotic nearest neighbor bound Fukunaga (1990); Cover and Hart (1967), is equal to the Jensen-Shannon divergence Lin (1991) and is similar to the bound in Avi-Itzhak and Diep (1996). These four formulations have been independently studied in the literature and the fact that they produce upper bounds on the Bayes error has been directly verified. Here we have rederived these four measures by resorting to the concept of minimum risk and proper loss functions which not only allows us to provide a unified approach to these different methods but has also led to a systematic method for deriving other novel bounds on the Bayes error, namely and .
| Method | |
|---|---|
| LS | |
| Log | |
| Exp | |
| Log-Cos | |
| Cosh | |
| Sec |
| Zero-One | Bayes Error |
|---|---|
| LS | |
| Exp | |
| Log | |
| Log-Cos | |
| Cosh | |
| Sec |
Next, we demonstrate a general procedure for deriving a class of polynomial functions that are increasingly and arbitrarily close to .
Theorem 8
Let
| (50) |
where
| (51) | |||
| (52) | |||
| (53) |
Then for all and converges to as .
Proof 8
See supplementary material 16.
As an example, we derive by following the above procedure
| (54) |
From this we have
| (55) |
Satisfying we find . Therefore,
| (56) |
Satisfying we find .
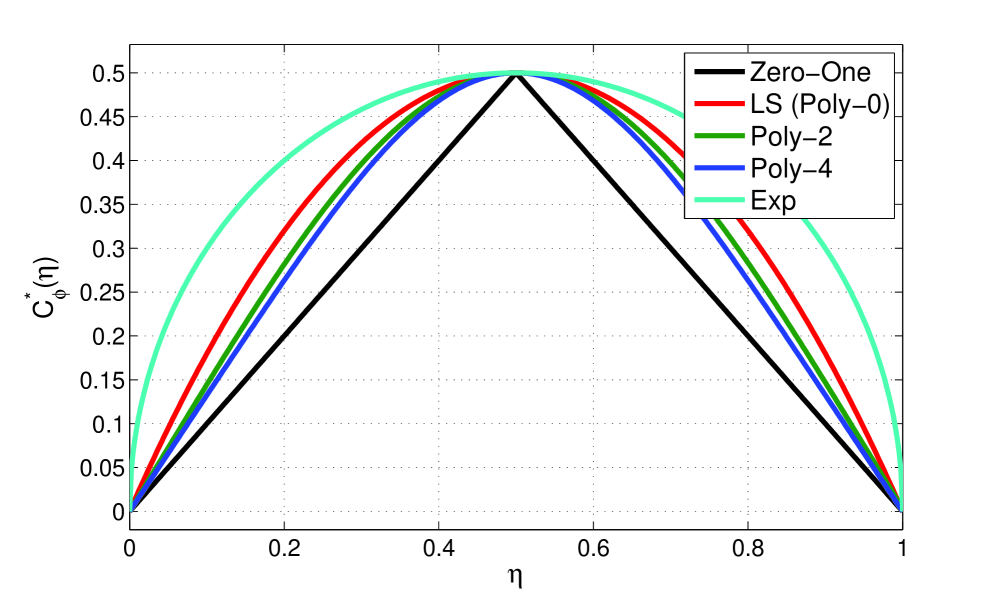
Figure-2 plots which shows that, as expected, it is a closer approximation to when compared to . Following the same steps, it is readily shown that , meaning that is derived from the special case of .
As we increase , we increase the order of the resulting polynomial which provides a tighter fit to . Figure-2 also plots
| (57) | |||
which is an even closer approximation to . Table-4 shows the corresponding minimum-risk for different functions, with providing the tightest bound on the Bayes error. Arbitrarily tighter bounds are possible by simply using with larger .
| Zero-One | Bayes Error |
|---|---|
| Poly-0 (LS) | |
| Poly-2 | |
| Poly-4 | |
Such arbitrarily tight bounds on the Bayes error are important in a number of applications such as in feature selection and extraction Vasconcelos (2002); Vasconcelos and Vasconcelos (2009); Brown (2009); Peng et al. (2005), information theory Duchi and Wainwright (2013); Guntuboyina (2011); Cover and Thomas (2006); Brown and Liu. (1993), classification and regression Liu and Shum (2003); Lee et al. (2005); Friedman and Stuetzle (1981), etc. In the experiments section we specifically show how using with tighter bounds on the Bayes error results in better performance on a feature selection and classification problem. We then consider the effect of using projection vectors that are more discriminative, such as the normalized kernel Fisher discriminant projection vector or normalized kernel SVM projection vector described in Lemma 1, rather than the canonical projection vector of . We show that these more discriminative projection vectors result in significantly improved performance on a set of kernel hypothesis testing experiments.
6 Computing The Kernel Score and Kernel Divergence in Practice
In most applications the distributions of and are not directly known and are solely represented through a set of sample points. We assume that the data points are sampled from and the data points are sampled from . Note that the Kernel Score can be written as
| (58) |
where the expectation is over the distribution defined by . The empirical Kernel Score and empirical Kernel Divergence can now be written as
| (59) | |||||
| (60) |
where and is the projection of onto .
Calculating in the above formulation using equation (35) is still not possible because we generally don’t know and . A similar problem exists for the MMD. Nevertheless the MMD Gretton et al. (2007) is estimated in practice as
| (61) | |||||
| (62) |
In view of Lemma 2 the MMD can be equivalently estimated as
| (63) |
where
| (64) |
| (65) |
and
| (66) |
It can easily be verified that equations (63)-(66) and equation (61) are equivalent. This equivalent method for calculating the MMD can be elaborated as projecting the two embedded sample sets onto , estimating the means and of the projected embedded sample sets and then finding the distance between these estimated means. This might seem like over complicating the original procedure. Yet, it serves to show that the MMD is solely measuring the distance between the means while disregarding all the other information available regarding the projected embedded distributions. Similarly, assuming that , can now be estimated as
| (69) | |||||
| (70) |
Once the are found for all using equation (70), estimating other statistics such as the variance is trivial. For example, the variances of the projected embedded distributions can now be estimated as
| (71) | |||
| (72) |
In light of this, the empirical Bhattacharyya Kernel Score and empirical Bhattacharyya Kernel Divergence can now be readily calculated in practice as
| (73) | |||
| (74) | |||
| (75) |
Finally, the empirical Kernel Score of equation (59) and the empirical Kernel Divergence of equation (60) can be calculated in practice after finding and using any one dimensional probability model.
Note that in the above formulations we used the canonical . A similar approach is possible for other valid choices of . Namely, the projection vector associated with the kernel Fisher discriminant can be found in the form of
| (76) |
using Algorithm 5.16 in Shawe-Taylor and Cristianini (2004). In this case can be found as
| (77) |
where
| (78) |
7 One-Class Classifier for Kernel Hypothesis Testing
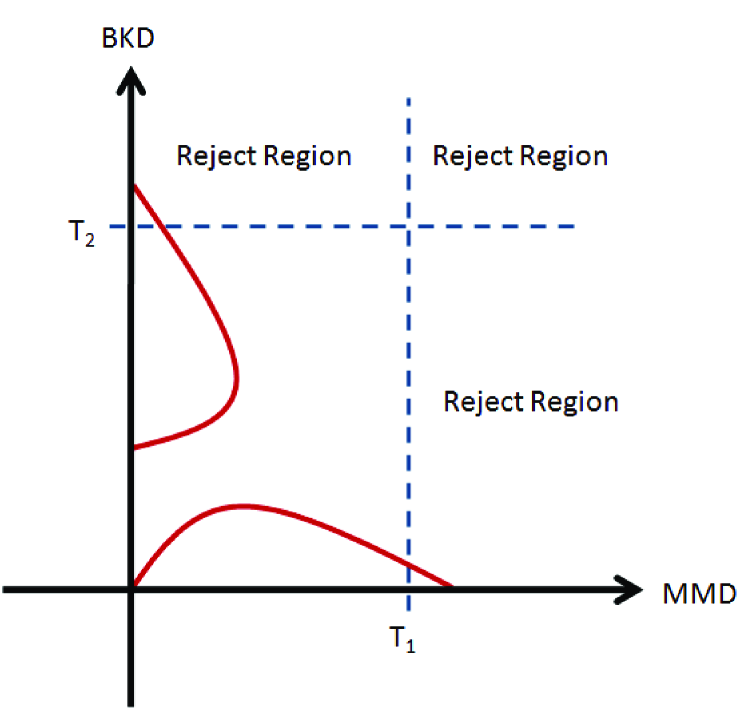
From Theorem 4 we conclude that the Kernel Divergence is injective similar to the MMD. This means that the Kernel Divergence can be directly thresholded and used in hypothesis testing. We showed that while the MMD simply measures the distance between the means of the projected embedded distributions, the Bhattacharyya Kernel Divergence (BKD) incorporates information about both the means and variances of the two projected embedded distributions. We also showed that in general the Kernel Divergence (KD) provides a measure related to the minimum risk of the two projected embedded distributions. Each one of these measures takes into account a different aspect of the two projected embedded distributions in relation to each other. We can integrate all of these measures into our hypothesis test by constructing a vector where each element is a different measure and learn a one-class classifier for this vector. In the hypothesis testing experiments of Section 8.2, we constructed the vectors [MMD, KD] and [MMD, BKD] and implemented a simple one-class nearest neighbor classifier with infinity norm (Tax, 2001) as depicted in Figure 3.
8 Experiments
In this section we include various experiments that confirm different theoretical aspects of the Kernel Score and Kernel Divergence.
8.1 Feature selection experiments
Different bounds on the Bayes error are used in feature selection and ranking algorithms Vasconcelos (2002); Vasconcelos and Vasconcelos (2009); Brown (2009); Peng et al. (2005); Duch et al. (2004). In this section we show that the tighter bounds we have derived, namely and , allow for improved feature selection and ranking. The experiments used ten binary UCI data sets of relatively small size: (#1) Habermanӳ survival,(#2) original Wisconsin breast cancer , (#3) tic-tac-toe , (#4) sonar, (#5) Pima-diabetes , (#6) liver disorder , (#7) Cleveland heart disease , (#8) echo-cardiogram , (#9) breast cancer prognostic, and (#10) breast cancer diagnostic.
Each data set was split into five folds, four of which were used for training and one for testing. This created five train-test pairs per data set, over which the results were averaged. The original data was augmented with noisy features. This was done by taking each feature and adding random scaled noise to a certain percentage of the data points. The scale parameters were and the percentage of data points that were randomly affected was . Specifically, for each feature, a percentage of the data points had scaled zero mean Gaussian noise added to that feature in the form of
| (80) |
where is the -th feature of the original data vector, is the Gaussian noise and is the scale parameter. The empirical minimum risk was then computed for each feature where was modeled as a bin histogram.
A greedy feature selection algorithm was implemented in which the features were ranked according to their empirical minimum risk and the highest ranked and of the features were selected. The selected features were then used to train and test a linear SVM classifier. If a certain minimum risk is a better bound on the Bayes error, we would expect it to choose better features and these better features should translate into a better SVM classifier with smaller error rate on the test data. Five different were considered namely , , , and and the error rate corresponding to each was computed and averaged over the five folds. The average error rates were then ranked such that a rank of was assigned to the with smallest error and a rank of assigned to the with largest error.
The rank over selected features was computed by averaging the ranks found by using both and of the highest ranked features. This process was repeated a total of times for each UCI data set and the over all average rank was found by averaging over the experiment runs. The over all average rank found for each UCI data set and each is reported in Table-5. The last two columns of this table are the total number of times each has had the best rank over the ten different data sets (#W) and a ranking of the over all average rank computed for each data set and then averaged across all data sets (Rank). It can be seen that which was designed to have the tightest bound on the Bayes error has the most number of wins of and smallest Rank of while which has the loosest bound on the Bayes error has the least number of wins of and worst Rank of . As expected, the Rank for each is in order of how tightly they approximate the Bayes error with in order , and at the top and and at the bottom. This is in accordance with the discussion of Section 5.0.1.
| #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 | #W | Rank | |
| 2.9 | 2.75 | 3.62 | 2.77 | 2.86 | 2.39 | 3.55 | 2.87 | 3.25 | 2.86 | 4 | 2.4 | |
| 2.82 | 2.88 | 3.37 | 2.62 | 2.87 | 2.74 | 3.27 | 2.9 | 3.46 | 2.98 | 2 | 2.7 | |
| 3.02 | 2.73 | 2.92 | 3.03 | 2.9 | 3.17 | 2.65 | 2.96 | 2.97 | 3.16 | 2 | 2.8 | |
| 3.16 | 3.32 | 2.5 | 3.44 | 3.0 | 3.2 | 2.78 | 3.08 | 2.62 | 2.88 | 2 | 3.35 | |
| 3.1 | 3.32 | 2.59 | 3.14 | 3.37 | 3.5 | 2.75 | 3.19 | 2.7 | 3.12 | 0 | 3.75 |
8.2 Kernel Hypothesis Testing Experiments
The first set of experiments comprised of hypothesis tests on Gaussian samples. Specifically, two hypothesis tests were considered. In the first test, we used samples for each dimensional Gaussian distribution and . Note that the means are equal and the variances are slightly different. In the second test, we used samples for each dimensional Gaussian distribution and . Note that the variances are equal and the means are slightly different. In both cases the reject thresholds were found from bootstrap iterations for a fixed type-I error of . We used the Gaussian kernel embedding for all experiments and the kernel parameter was found using the median heuristic of Gretton et al. (2007). Also, the Kernel Divergence (KD) used of equation (57) and one dimensional Gaussian distribution models. Unlike the classification problem described in the previous section, having a tight estimate of the Bayes error is not important for hypothesis testing experiments and so the actual concave function used is not crucial. The type-II error test results for repetitions are reported in Table 6 for the MMD, BKD, KD methods, where , along with the combined method described in Section 7 where a one-class nearest neighbor classifier with infinity norm is learned for [MMD, KD] and [MMD, BKD]. These results are typical and in general (a) the KD and BKD methods do better than the MMD when the means are equal and the variances are different, (b) the MMD does better than the KD and BKD when the variances are equal and the means are different and (c) The combined methods of [MMD, KD] and [MMD, BKD] do well for both cases. We usually don’t know which case we are dealing with in practice and so the combined methods of [MMD, KD] and [MMD, BKD] are preferred.
| Method | , | , |
| MMD | 46 | 25 |
| KD | 13 | 42 |
| BKD | 11 | 40 |
| [MMD, KD] | 13 | 25 |
| [MMD, BKD] | 12 | 24 |
8.2.1 Bench-Mark Gene Data Sets
Next we evaluated the proposed methods on a group of high dimensional bench-mark gene data sets. The data sets are detailed in Table 7 and are challenging given their small sample size and high dimensionality. The hypothesis testing involved splitting the positive samples in two and using the first half to learn the reject thresholds from bootstrap iterations for a fixed type-I error of . We used the Gaussian kernel embedding for all experiments and the kernel parameter was found using the median heuristic of Gretton et al. (2007). The Kernel Divergence (KD) used of equation (57) and one dimensional Gaussian distribution models. The type-II error test results for repetitions are reported in Table 8 for the MMD, BKD, KD, [MMD, KD] and [MMD, BKD] methods. Also, three projection directions are considered namely, MEANS where , FISHER where the associated with the kernel Fisher linear discriminant is used, and SVM where the associated with the kernel SVM is used.
We have reported the rank of each method among the five methods with the same projection direction under RANK1 and the overall rank among all fifteen methods under RANK2 in the last column. Note that the first row of Table 8 with MMD distance measure and MEANS projection direction is the only method previously proposed in the literature Gretton et al. (2012). We should also note that the KD with FISHER projection direction encountered numerical problems in the form of very small variance estimates, which resulted in poor performance. Nevertheless, we can see that in general the KD and BKD methods which incorporate more information regarding the projected distributions, outperform the MMD. Second, using more discriminant projection directions like the FISHER or SVM outperform simply projecting onto MEANS. Finally, the [MMD, KD] and [MMD, BKD] methods that combine the information provided by both the MMD and the KD or BKD have the lowest ranks. Specifically, the [MMD, KD] with SVM projection direction has the overall lowest rank among all fifteen methods.
| Number | Data Set | #Positives | #Negatives | #Dimensions |
|---|---|---|---|---|
| #1 | Lung Cancer Womenӳ Hospital | 31 | 150 | 12533 |
| #2 | Lukemia | 25 | 47 | 7129 |
| #3 | Lymphoma Harvard Outcome | 26 | 32 | 7129 |
| #4 | Lymphoma Harvard | 19 | 58 | 7129 |
| #5 | Central Nervous System Tumor | 21 | 39 | 7129 |
| #6 | Colon Tumor | 22 | 40 | 2000 |
| #7 | Breast Cancer ER | 25 | 24 | 7129 |
| Projection | Measure | #7 | #6 | #5 | #4 | #3 | #2 | #1 | Rank1 | Rank2 |
| MEANS | MMD | 24.3 | 27.4 | 95 | 31.2 | 90.8 | 11.7 | 6.3 | 3.42 | 9.14 |
| MEANS | KD | 9.8 | 58.5 | 83.8 | 53.1 | 79.2 | 64.7 | 7.7 | 3.71 | 10.14 |
| MEANS | BKD | 12 | 56.9 | 83.4 | 52.5 | 79.3 | 58.0 | 3.7 | 3.14 | 9.14 |
| MEANS | [MMD, KD] | 12.2 | 48 | 82.9 | 25.2 | 84.1 | 14.7 | 3.0 | 2.57 | 7.42 |
| MEANS | [MMD, BKD] | 13.2 | 47.3 | 81.9 | 24.3 | 83.6 | 14.0 | 3.2 | 2.14 | 6.42 |
| FISHER | MMD | 5.8 | 26.5 | 90.2 | 24.8 | 83.1 | 14.1 | 4.2 | 1.78 | 6.07 |
| FISHER | KD | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 5 | 15 |
| FISHER | BKD | 30.6 | 52.4 | 82.4 | 66.0 | 64.0 | 73.3 | 22.6 | 3.14 | 10.28 |
| FISHER | [MMD, KD] | 9.6 | 26.5 | 95.3 | 31.9 | 93.6 | 18.7 | 5.4 | 3.14 | 9.42 |
| FISHER | [MMD, BKD] | 6.2 | 26.4 | 82.8 | 31.0 | 74.9 | 18.6 | 5.4 | 1.92 | 5.21 |
| SVM | MMD | 22.8 | 29.9 | 95.1 | 26.2 | 89.2 | 10.0 | 2.1 | 3.85 | 8.00 |
| SVM | KD | 4.0 | 48.2 | 81.3 | 33.4 | 82.4 | 41.1 | 1.0 | 3.28 | 6.42 |
| SVM | BKD | 4.3 | 44.2 | 86.3 | 32.0 | 79.4 | 34.4 | 0.5 | 2.85 | 6.57 |
| SVM | [MMD, KD] | 6.3 | 28.1 | 88.4 | 20.5 | 86.4 | 13.7 | 0.4 | 2.28 | 5.14 |
| SVM | [MMD, BKD] | 6.6 | 28.2 | 89.0 | 20.5 | 84.9 | 13.8 | 0.4 | 2.71 | 5.57 |
9 Conclusion
While we have concentrated on the hypothesis testing problem in the experiments section, we envision many different applications for the Kernel Score and Kernel Divergence. We showed that the MMD is a special case of the Kernel Score and so the Kernel Score can now be used in all other applications based on the MMD, such as integrating biological data, imitation learning, etc. We also showed that the Kernel Score is related to the minimum risk of the projected embedded distributions and we showed how to derive tighter bounds on the Bayes error. Many applications that are based on risk minimization, bounds on the Bayes error or divergence measures such as classification, regression, feature selection, estimation, information theory etc, can now use the Kernel Score and Kernel Divergence to their benefit. We presented the Kernel Score as a general formulation for a score function in the Reproducing Kernel Hilbert Space and considered when it has the important property of being strictly proper. The Kernel Score is thus also directly applicable to probability elicitation, forecasting, finance and meteorology which rely on strictly proper scoring rules.
SUPPLEMENTARY MATERIAL
10 Proof of Theorem 4
If then
| (81) |
Next, we prove the converse. The proof is identical to Theorem 5 of Gretton et al. (2012) up to the point where we must prove that if then . To show this we write
| (82) |
or
| (83) |
Since is concave and has a maximum value of at then the above equation can only hold if
| (84) |
which means that
| (85) |
and so
| (86) |
From this we conclude that their associated means must be equal, namely
| (87) |
The above equation can be written as
| (88) |
or equivalently as
| (89) |
Since is not in the orthogonal compliment of then it must be that
| (90) |
The rest of the proof is again identical to Theorem 5 of Gretton et al. (2012) and the theorem is similarly proven.
To prove that the Kernel Score is strictly proper we note that if then and so . This means that we need to show that . This readily follows since is strictly concave with maximum at .
11 Proof of Lemma 1
is not in the orthogonal compliment of since
| (91) |
The equal to the kernel Fisher discriminant projection vector is not in the orthogonal compliment of because if it were then the kernel Fisher discriminant objective, which can be written as , would not be maximized and would instead be equal to zero.
The equal to the kernel SVM projection vector is not in the orthogonal compliment of since the kernel SVM is equivalent to the kernel Fisher discriminant computed on the set of support vectors Shashua (1999).
12 Proof of Lemma 2
We know that is the projection of onto so we can write
| (92) |
Similarly,
| (93) |
Hence,
| (94) | |||
| (95) |
13 Proof of Theorem 5
The result readily follows by setting and into equation (40).
14 Proof of Lemma 3
By adding and subtracting and considering equation (27), the risk can be written as
| (97) |
The first term denoted is obviously zero if we have a perfectly calibrated predictor such that for all and is thus a measure of calibration. Finally, using equation and Theorem 2, the minimum risk term can be written as
| (98) | |||||
| (99) | |||||
| (100) | |||||
| (101) | |||||
| (102) | |||||
| (103) | |||||
| (104) | |||||
| (105) |
15 Proof of Theorem 6
Assuming equal priors ,
| (107) |
and
| (108) |
We can now write the minimum risk as
| (109) |
Equation (48) readily follows by setting and , in which case is .
16 Proof of Theorem 8
The symmetry requirement of results in a similar requirement on the second derivative and concavity requires that the second derivative satisfy . The symmetry and concavity constraints can both be satisfied by considering
| (110) |
From this we write
| (111) |
Satisfying the constraint that , we find as
| (112) |
Finally, is
| (113) |
where
| (114) |
is a scaling factor such that . meets all the requirements of Theorem 7 so for all and .
Next, we need to prove that if we follow the above procedure for and find then . We accomplish this by showing that . Without loss of generality, let
| (115) |
and
| (116) |
then since . Also, since and then is a monotonically decreasing function and and so . From the mean value theorem
| (117) |
and
| (118) |
for any and some and . Since for all then and so
| (119) |
for all . A similar argument leads to
| (120) |
for all .
Since and then has a maximum at . Also, since is a polynomial of with no constant term, then and because of symmetry . From the mean value theorem
| (121) |
and
| (122) |
for any and some and . Since for all then and so
| (123) |
for all . A similar argument leads to
| (124) |
for all . Finally, since and are concave functions with maximum at , scaling these functions by and respectively, so that their maximum is equal to will not change the final result of
| (125) |
for all .
Finally, to show that converges to we need to show that converges to as . We can expand and write as
| (126) |
Assuming that then
| (127) |
where and . Since
| (128) |
then
| (129) |
So, we can write
| (130) |
A similar argument for completes the convergence proof.
References
- Avi-Itzhak and Diep (1996) Avi-Itzhak, H. and T. Diep (1996). Arbitrarily tight upper and lower bounds on the bayesian probability of error. Pattern Analysis and Machine Intelligence, IEEE Transactions on 18(1), 89–91.
- Bartlett et al. (2006) Bartlett, P., M. Jordan, and J. D. McAuliffe (2006). Convexity, classification, and risk bounds. JASA.
- Ben-Hur and Weston (2010) Ben-Hur, A. and J. Weston (2010). A user’s guide to support vector machines. Methods in Molecular Biology 609, 223–239.
- Berlinet and Thomas-Agnan (2004) Berlinet, A. and C. Thomas-Agnan (2004). Reproducing Kernel Hilbert Spaces in Probability and Statistics. Springer.
- Birg and Massart (1993) Birg , L. and P. Massart (1993). Rates of convergence for minimum contrast estimators. Probability Theory and Related Fields 97, 113–150.
- Bottou and Lin (2007) Bottou, L. and C.-J. Lin (2007). Support vector machine solvers. Large Scale Kernel Machines, 301–320.
- Brocker (2009) Brocker, J. (2009). Reliability, sufficiency, and the decomposition of proper scores. Quarterly Journal of the Royal Meteorological Society 135(643), 1512–1519.
- Brown (2009) Brown, G. (2009). A new perspective for information theoretic feature selection. In Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics (AISTATS-09), Volume 5, pp. 49–56.
- Brown and Liu. (1993) Brown, L. D. and R. C. Liu. (1993). Bounds on the bayes and minimax risk for signal parameter estimation. IEEE Transactions on Information Theory, 39(4), 1386–1394.
- Buja et al. (2005) Buja, A., W. Stuetzle, and Y. Shen (2005). Loss functions for binary class probability estimation and classification: Structure and applications. (Technical Report) University of Pennsylvania.
- Choi and Lee (2003) Choi, E. and C. Lee (2003). Feature extraction based on the bhattacharyya distance. Pattern Recognition 36(8), 1703–1709.
- Coleman and Andrews (1979) Coleman, G. and H. C. Andrews (1979). Image segmentation by clustering. Proceedings of the IEEE 67(5), 773–785.
- Cover and Hart (1967) Cover, T. and P. Hart (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory 13(1), 21–27.
- Cover and Thomas (2006) Cover, T. M. and J. A. Thomas (2006). Elements of Information Theory (2nd edition). John Wiley Sons Inc.
- Dawid (1982) Dawid, A. (1982). The well-calibrated bayesian. Journal of the American. Statistical Association 77, 605 –610.
- Dawid (2007) Dawid, A. P. (2007). The geometry of proper scoring rules. Annals of the Institute of Statistical Mathematics 59(1), 77–93.
- DeGroot (1979) DeGroot, M. (1979). Comments on lindley, et al. Journal of Royal Statistical Society (A) 142, 172–173.
- DeGroot and Fienberg (1983) DeGroot, M. H. and S. E. Fienberg (1983). The comparison and evaluation of forecasters. The Statistician 32, 14–22.
- Devroye et al. (1997) Devroye, L., L. Gy rfi, and G. Lugosi (1997). A Probabilistic Theory of Pattern Recognition. New York: Springer.
- Duch et al. (2004) Duch, W., T. Wieczorek, J. Biesiada, and M. Blachnik (2004). Comparison of feature ranking methods based on information entropy. In IEEE International Joint Conference on Neural Networks, Volume 2, pp. 1415–1419.
- Duchi and Wainwright (2013) Duchi, J. C. and M. J. Wainwright (2013). Distance-based and continuum fano inequalities with applications to statistical estimation. Technical report, UC Berkeley.
- Duffie and Pan (1997) Duffie, D. and J. Pan (1997). An overview of value at risk. Journal of Derivatives 4, 7–49.
- Friedman et al. (2000) Friedman, J., T. Hastie, and R. Tibshirani (2000). Additive logistic regression: A statistical view of boosting. Annals of Statistics 28, 337–407.
- Friedman and Stuetzle (1981) Friedman, J. and W. Stuetzle (1981). Projection pursuit regression. Journal of the American Statistical Association 76, 817–823.
- Fukumizu et al. (2004) Fukumizu, K., F. R. Bach, and M. I. Jordan (2004). Dimensionality reduction for supervised learning with reproducing kernel hilbert spaces. The Journal of Machine Learning Research 5, 73–99.
- Fukunaga (1990) Fukunaga, K. (1990). Introduction to Statistical Pattern Recognition, Second Edition. San Diego: Academic Press.
- Gneiting et al. (2007) Gneiting, T., F. Balabdaoui, and A. E. Raftery (2007). Probabilistic forecasts, calibration and sharpness. Journal of the Royal Statistical Society Series B, 243–268.
- Gneiting and Raftery (2007) Gneiting, T. and A. Raftery (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association 102, 359 –378.
- Gretton et al. (2007) Gretton, A., K. Borgwardt, M. Rasch, B. Sch olkopf, and A. Smola. (2007). A kernel method for the two-sample problem. In Advances in Neural Information Processing Systems, pp. 513–520.
- Gretton et al. (2012) Gretton, A., K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola (2012). A kernel two-sample test. The Journal of Machine Learning Research 13, 723–773.
- Gretton et al. (2009) Gretton, A., K. Fukumizu, Z. Harchaoui, and B. Sriperumbudur (2009). A fast, consistent kernel two-sample test. In In Advances in Neural Information Processing Systems, pp. 673–681.
- Guntuboyina (2011) Guntuboyina, A. (2011). Lower bounds for the minimax risk using f-divergences, and applications. IEEE Transactions on Information Theory 57, 2386–2399.
- Harchaoui et al. (2007) Harchaoui, Z., F. Bach, and E. Moulines (2007). Testing for homogeneity with kernel fisher discriminant analysis. In Proceedings of the International Conference on Neural Information Processing Systems, pp. 609–616.
- Hashlamoun et al. (1994) Hashlamoun, W. A., P. K. Varshney, and V. N. S. Samarasooriya (1994). A tight upper bound on the bayesian probability of error. IEEE Transactions on Pattern Analysis and Machine Intelligence 16(2), 220–224.
- Lee et al. (2005) Lee, E.-K., D. Cook, S. Klinke, and T. Lumley (2005). Projection pursuit for exploratory supervised classification, and applications. Journal of Computational and Graphical Statistics 14(4), 831–846.
- Lin (1991) Lin, J. (1991). Divergence measures based on the shannon entropy. IEEE Transactions on Information Theory 37, 145–151.
- Liu and Shum (2003) Liu, C. and H. Y. Shum (2003). Kullback-leibler boosting. In Computer Vision and Pattern Recognition, IEEE Conference on, pp. 587–594.
- Masnadi-Shirazi and Vasconcelos (2008) Masnadi-Shirazi, H. and N. Vasconcelos (2008). On the design of loss functions for classification: theory, robustness to outliers, and savageboost. In Advances in Neural Information Processing Systems, pp. 1049–1056. MIT Press.
- Masnadi-Shirazi and Vasconcelos (2015) Masnadi-Shirazi, H. and N. Vasconcelos (2015). A view of margin losses as regularizers of probability estimates. The Journal of Machine Learning Research 16, 2751–2795.
- Muandet et al. (2016) Muandet, K., K. Fukumizu, B. Sriperumbudur, and B. Schölkopf (2016, May). Kernel Mean Embedding of Distributions: A Review and Beyonds. ArXiv e-prints.
- Muandet et al. (2016) Muandet, K., B. Sriperumbudur, K. Fukumizu, A. Gretton, and B. Schölkopf (2016). Kernel mean shrinkage estimators. The Journal of Machine Learning Research 17(1), 1656–1696.
- Murphy (1972) Murphy, A. (1972). Scalar and vector partitions of the probability score: part i. two-state situation. Journal of applied Meteorology 11, 273–282.
- Niculescu-Mizil and Caruana (2005) Niculescu-Mizil, A. and R. Caruana (2005). Obtaining calibrated probabilities from boosting. In Uncertainty in Artificial Intelligence.
- O’Hagan et al. (2006) O’Hagan, A., C. E. Buck, A. Daneshkhah, J. R. Eiser, P. H. Garthwaite, D. J. Jenkinson, J. E. Oakley, and T. Rakow (2006). Uncertain judgements: Eliciting experts probabilities. John Wiley & Sons.
- Peng et al. (2005) Peng, H., F. Long, and C. Ding (2005). Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(8), 1226–1238.
- Platt (2000) Platt, J. (2000). Probabilistic outputs for support vector machines and comparison to regularized likelihood methods. In Adv. in Large Margin Classifiers, pp. 61–74.
- Reid and Williamson (2010) Reid, M. and R. Williamson (2010). Composite binary losses. The Journal of Machine Learning Research 11, 2387–2422.
- Savage (1971) Savage, L. J. (1971). The elicitation of personal probabilities and expectations. Journal of The American Statistical Association 66, 783–801.
- Shashua (1999) Shashua, A. (1999). On the equivalence between the support vector machine for classification and sparsified fisher s linear discriminant. Neural Processing Letters 9(2), 129–139.
- Shawe-Taylor and Cristianini (2004) Shawe-Taylor, J. and N. Cristianini (2004). Kernel Methods for Pattern Analysis. New York: Cambridge University Press.
- Sriperumbudur et al. (2010) Sriperumbudur, B., K. Fukumizu, and G. Lanckriet (2010). On the relation between universality, characteristic kernels and rkhs embedding of measures. The Journal of Machine Learning Research 9, 773–780.
- Sriperumbudur et al. (2011) Sriperumbudur, B. K., K. Fukumizu, and G. R. Lanckriet (2011). Universality, characteristic kernels and rkhs embedding of measures. The Journal of Machine Learning Research 12, 2389–2410.
- Sriperumbudur et al. (2008) Sriperumbudur, B. K., A. Gretton, K. Fukumizu, G. Lanckriet, and B. Sch lkopf (2008). Injective hilbert space embeddings of probability measures. In In Proceedings of the Annual Conference on Computational Learning Theory, pp. 111–122.
- Sriperumbudur et al. (2010a) Sriperumbudur, B. K., A. Gretton, K. Fukumizu, B. Schölkopf, and G. R. Lanckriet (2010a). Hilbert space embeddings and metrics on probability measures. The Journal of Machine Learning Research 11, 1517–1561.
- Sriperumbudur et al. (2010b) Sriperumbudur, B. K., A. Gretton, K. Fukumizu, B. Schölkopf, and G. R. Lanckriet (2010b). Hilbert space embeddings and metrics on probability measures. The Journal of Machine Learning Research 11, 1517–1561.
- Steinwart (2002) Steinwart, I. (2002). On the influence of the kernel on the consistency of support vector machines. The Journal of Machine Learning Research 2, 67–93.
- Tax (2001) Tax, D. (2001). One-class classification: Concept-learning in the absence of counter-examples. Ph. D. thesis, University of Delft, The Netherlands.
- Vapnik (1998) Vapnik, V. N. (1998). Statistical Learning Theory. John Wiley Sons Inc.
- Vasconcelos and Vasconcelos (2009) Vasconcelos, M. and N. Vasconcelos (2009). Natural image statistics and low-complexity feature selection. Pattern Analysis and Machine Intelligence, IEEE Transactions on 31, 228–244.
- Vasconcelos (2002) Vasconcelos, N. (2002). Feature selection by maximum marginal diversity. In Advances in Neural Information Processing Systems, pp. 1351–1358.
- Zawadzki and Lahaie (2015) Zawadzki, E. and S. Lahaie (2015). Nonparametric scoring rules. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, pp. 3635–3641.
- Zhang (2004) Zhang, T. (2004). Statistical behavior and consistency of classification methods based on convex risk minimization. Annals of Statistics 32, 56–85.