Structural Credit Assignment with Coordinated Exploration
1 Overview
A biologically plausible method for training an Artificial Neural Network (ANN) involves treating each unit as a stochastic Reinforcement Learning (RL) agent, thereby considering the network as a team of agents. Consequently, all units can learn via REINFORCE, a local learning rule modulated by a global reward signal, which aligns more closely with biologically observed forms of synaptic plasticity [1, Chapter 15]. However, this learning method tends to be slow and does not scale well with the size of the network. This inefficiency arises from two factors impeding effective structural credit assignment: (i) all units independently explore the network, and (ii) a single reward is used to evaluate the actions of all units.
Accordingly, methods aimed at improving structural credit assignment can generally be classified into two categories. The first category includes algorithms that enable coordinated exploration among units, such as MAP propagation [2]. The second category encompasses algorithms that compute a more specific reward signal for each unit within the network, like Weight Maximization and its variants [3]. In this research report, our focus is on the first category. We propose the use of Boltzmann machines [4] or a recurrent network for coordinated exploration. We show that the negative phase, which is typically necessary to train Boltzmann machines, can be removed. The resulting learning rules are similar to the reward-modulated Hebbian learning rule [5]. Experimental results demonstrate that coordinated exploration significantly exceeds independent exploration in training speed for multiple stochastic and discrete units based on REINFORCE, even surpassing straight-through estimator (STE) backpropagation [6].
1.1 An Example: How should we vote?
Before we begin, let us consider an intuitive example of how coordinated exploration may help structural credit assignment. Suppose that you are in a town of 99 people. At the end of each year, all people in the town vote for a mayor next year and there are always two candidates in the election: John and Peter. The candidate with more votes wins and will influence the economy of the town next year. This is the first year, and people know nothing about the two candidates. Therefore, you and the others decide whom to vote by flipping coins. Suppose you voted for John, but Peter won, and Peter performed poorly as a mayor next year. The question is—whom should you vote for next year?
REINFORCE says that you should increase doing the action that leads to a positive reward and vice versa. In this case, you should vote more for Peter the next year because you got a negative reward (the economy was poor next year) after voting for John. Though it may not seems sensible, you can still learn the optimal candidate to vote for with this learning method in the long run—when there are 49 people voting for each person (this happens with the probability of , which decays to quickly when there are more people in the town) and you can determine the voting result, you can learn correctly with REINFORCE; other than that, you are only learning from noise as you have no influences over the election. This illustrates why REINFORCE does not scale well with the size of networks.
MAP propagation is similar to REINFORCE, but you ‘forgot’ the person you voted for and ‘believed’ that you have voted for the winning candidate. In this case, all people in the town, including you, believed that they had voted for Peter instead. The negative reward is therefore associated with the action of voting Peter, and all people learn to vote more for John the next year. This is like coordination in hindsight—all people believed that they had voted for the same candidate. However, there was actually no coordination between people when deciding whom to vote, since all people decided whom to vote by flipping their own coins.
Another form of coordinated exploration is through letting people in the town communicate with one another before voting. After flipping the coin, you were prepared to vote for John. But you observed that the majority was prepared to vote for Peter, and so you followed the majority by voting for Peter. The negative reward is therefore associated with the action of voting Peter, and you learn to vote more for John the next year.
This example suggests that coordinated exploration, whether in hindsight or not, may help with structural credit assignment. We will focus on the second case, i.e. coordinated exploration without hindsight, in this report.
2 Forms of Exploration
For simplicity, we consider an MDP with only immediate reward111The algorithms in this paper can be applied in general MDPs by replacing the reward with the sum of discounted reward (i.e. return) or TD error, and can be applied in supervised learning tasks by replacing the reward with the negative loss. defined by a tuple , where is the set of states, is the set of actions, is the reward function, and is the initial state distribution. Denoting the state, action, and reward by , , and respectively, and . We are interested in learning the policy such that selecting actions according to maximizes the expected reward .
2.1 Independent Exploration
Let us consider the case where the policy is computed by an ANN with one hidden layer of Bernoulli-logistic units: to sample action conditioned on , we first sample the vector of activation values of the hidden layer, denoted as , by:
| (1) |
where , is the weight matrix of the hidden layer, and is the bias vector of the hidden layer. Equivalently, all (we use subscript to denote entry in a vector, and subscript to denote entry in a matrix) are independent with each other conditioned on , and the conditional distribution is given by:
| (2) |
where and denotes the sigmoid function. After sampling , we sample from an appropriate distribution conditioned on . For example, if the set of actions , we can use an output layer of a single Bernoulli-logistic unit:
| (3) |
where , is the weight vector of the output layer, and is the scalar bias of the output layer. The parameters to be learned for this network are: .
Learning Rule – To derive a learning rule for , we first compute the gradient of the expected reward w.r.t. :
| (4) | ||||
| (5) | ||||
| (6) |
Therefore, to perform gradient ascent on the expected reward, we can use the following REINFORCE learning rule [7]:
| (7) |
where denotes the step size. Also note that .
The learning rule is intuitive: the expectation of is simply the covariance between and (conditioned on ); that is, . Hence if the covariance is positive, the learning rule makes unit to fire more, and vice versa.
Recall in statistics that the covariance between two random variables and equals:
| (8) |
and thus the following three estimators that estimate the covariance are all unbiased: (i) , (ii) , (iii) . We can further show that the first estimator has the lowest variance among the three. In other words, an estimator with two-sided centering gives a lower variance than an estimator with one-sided centering, and an estimator with one-sided centering is already an unbiased estimator of the covariance.
Noting that (7) only uses one-sided centering to estimate the covariance, an alternative learning rule with the same expected update is to use two-sided centering:
| (9) |
which is equivalent to REINFORCE with as baseline [7]. is generally unknown and so needs to be estimated by another network which is usually called a critic network.
Finally, we can also do one-sided centering on only, leading to the following learning rule that has the same expected update:
| (10) |
which has the property that the parameter of a unit is not updated if the unit does not fire—when , the above updates equal zero. This property may be desirable as biological learning rules such as reward-modulated spike-timing-dependent plasticity (R-STDP) [5] also require a neuron to fire to affect synaptic strength.
All three learning rules (7), (9) and (10) follow gradient ascent on in expectation. Among the three learning rules, learning rule (9) is associated with the lowest variance due to the use of two-sided centering. However, as we will see in the next section, learning rule (10) can be generalized more easily to incorporate coordinated exploration.
Note that a similar discussion applies to the bias , and the learning rules of are the same as above but with set to .
2.2 Coordinated Exploration with Boltzmann Machines
As discussed previously, independent exploration coupled with a uniform reward signal makes learning inefficient and scales poorly with the number of units in the network. In this section we consider how to generalize the above network to have coordinated exploration.
Let us consider the conditional distribution of given by (1), which says that hidden units are conditionally independent with one another. A natural way to allow interaction between hidden units is to add a cross term between hidden units:
| (11) |
where is a scalar hyperparameter that controls the strength of interaction between hidden units, and is a symmetric weight matrix with a zero diagonal that determines the interaction dynamics between hidden units. We call the recurrent weight and the feedforward weight to distinguish between these two weights. Note that we recover the case of independent exploration in (1) by setting . The distribution given by (11) can be viewed as a fully connected Boltzmann machine [4], with being the weight and being the bias of the Boltzmann machine.
We can then compute the distribution of conditioned on and S ( denotes all entries of except ):
| (12) |
To sample , we can perform Gibbs sampling: we first initialize to some values such as a zero vector (we use the subscript to denote time step as opposed to entry), then we randomly select one unit and replace its activation value by sampling from (12) to obtain . We continue this way to obtain , and it can be shown that the limiting distribution of as is the same as the distribution given by (11).
However, this asynchronous sampling method is computationally expensive222However, asynchronous computation should be closer to the dynamics of biological neurons as biological neurons do not fire at fixed intervals.. Therefore, we use synchronous sampling method instead, that is, we update the activation values of all hidden units on the same time step:
| (13) |
This allows easy sampling of conditioned on and . Then we let , where is a hyperparameter determining the number of steps for Gibbs sampling, and is passed to the next layer as input. See Figure 1 for an illustration.
Though the limiting distribution of as is not guaranteed to converge due to synchronous sampling, we found that it works well in experiments. We also found in experiments that works quite well.
Learning Rule – We now consider how to train a network when the distribution of is given by (11). Let us first compute , which will be useful when deriving learning rules later on:
| (14) | ||||
| (15) | ||||
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
This derivation is similar to the one used to derive the learning rule of Contrastive Divergence for Boltzmann machines. The term is called negative statistics and is usually estimated by drawing samples from the Boltzmann machine in the unclamped phase.
Similarly, we can show that:
| (20) | ||||
| (21) |
Now we are ready to compute the gradient of the expected reward w.r.t. the parameters. We first consider the gradient of the expected reward w.r.t. :
| (22) | ||||
| (23) |
The last line follows from (19). The gradient w.r.t other parameters are similar:
| (24) | ||||
| (25) |
Therefore, to perform gradient ascent on the expected reward, we can use the following learning rules:
| (26) | ||||
| (27) | ||||
| (28) |
Note that (27) is the same as (7), but the expected value has to be computed or estimated differently since the distributions of are not the same.
These learning rules require the computation or estimation of the negative statistics and . Both terms are intractable to compute directly, and so we have to resort to Monte Carlo estimation as in Boltzmann machines: we can perform multiple Gibbs samplings to obtain samples of conditioned on , and average these samples to estimate the negative statistics. But this is hardly biologically plausible and also computationally inefficient. Is it possible to remove the negative statistics from the learning rules while still performing gradient ascent?
Let us consider the terms in the learning rules. is estimating the covariance between and , and is estimating the covariance between and . Thus, the discussion in the previous section on different estimators for covariance can also be applied here. In particular, we can do one-sided centering on instead of to obtain the following learning rules with the same expected update:
| (29) | ||||
| (30) | ||||
| (31) |
These learning rules follow gradient ascent on in expectation. Again, we require a critic network to estimate , but this is considerably simpler than estimating the negative statistics. In fact, is simply TD error in a single-time-step MDP, and can be replaced with TD error in a multiple-time-step MDP, noting that TD error is also centered. In this way, we can get rid of the negative statistics in the learning rule.
It should be noted that we need at least one-side centering for learning to occur. Consider the learning rule with no centering: ; if the reward signals from the environment are all non-negative (e.g. Cartpole), then the weight can only be increased but not decreased, and learning cannot occur.
The learning rules are similar to reward-modulated Hebbian learning [5]—for example, (29) is the product between three terms: (i) TD error, (ii) the pre-synaptic activation value and (iii) the post-synaptic activation value . Furthermore, as long as is initialized to be symmetric, it will stay symmetric during training since the updates to and are the same, so we do not need additional mechanisms to ensure symmetric connections as in backprop.
The full algorithm is given in Algorithm 1. An illustration of the algorithm from the perspective of energy-based learning is shown in Figure 2. Note that if we set , the strength of recurrent connections, to zero, then we recover the case of independent exploration trained with REINFORCE (one-sided centering on ) given by the learning rule (10).
Experiments – To test the algorithm, we consider the -bit multiplexer task. The input is sampled from all possible values of a binary vector of size with equal probability. The action set is , and we give a reward of if the action equals the multiplexer’s output and otherwise. We consider here, so the dimension of the state space is 20 and there are possible states. We call a single interaction of the network from receiving the state to receiving the reward an episode; the series of episodes as the network’s performance increases during training is called a run.
The update step size for gradient ascent is chosen as , and the batch size is chosen as (i.e. we estimated the gradient for episodes and averaged them in the update). We used the Adam optimizer [8]. These hyperparameters are chosen prior to the experiments without any tuning. We use a one-hidden-layer ANN as the critic network and train it by backprop. These settings are the same for all our experiments.
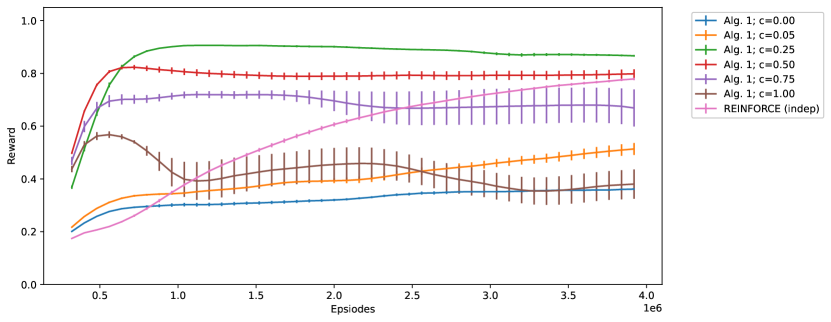
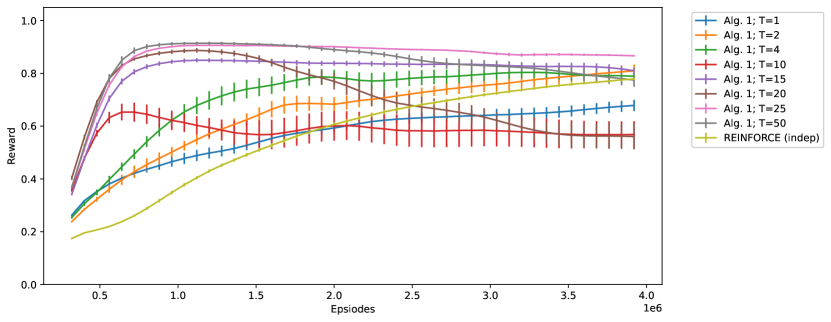
First, we tested Algorithm 1 with hidden units and sampling steps. The learning curve (i.e. the reward of each episode throughout a run) with varying (the strength of recurrent connection) is shown in Figure 3. The figure also shows the learning curve of a network with one hidden layer of Bernoulli-logistic units trained by REINFORCE with baseline (9), which we label ‘REINFORCE (indep)’. We observe that:
- •
-
•
However, as increases from to , the performance of Algorithm 1 improves due to the coordinated exploration, offsetting the reduced performance from one-sided centering.
-
•
The optimal is ; at , the learning curve, especially during the first episodes, is significantly better than ‘REINFORCE (indep)’, indicating that Algorithm 1 can improve learning speed significantly with a proper .
-
•
But as increases larger than , performance deteriorates since inputs from other hidden units instead of the state dominate the unit. In particular, the asymptotic performance is unstable for .
The experiment result suggests that coordinated exploration with Boltzmann machines can improve learning speed; the benefit from coordinated exploration offsets the reduced performance from one-sided centering. Also, , the strength of recurrent connection, is an important hyperparameter that needs to be carefully tuned. Simply setting can lead to reduced performance.
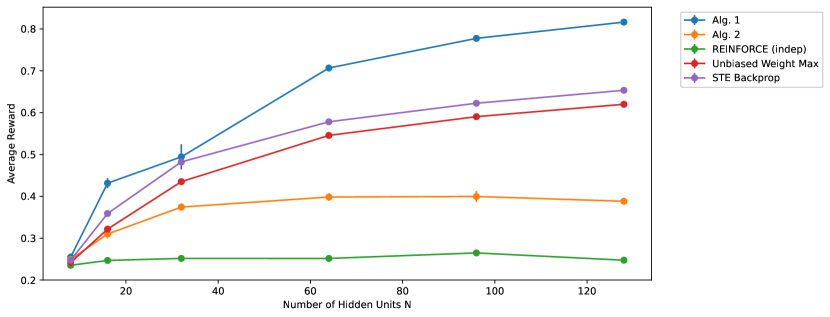
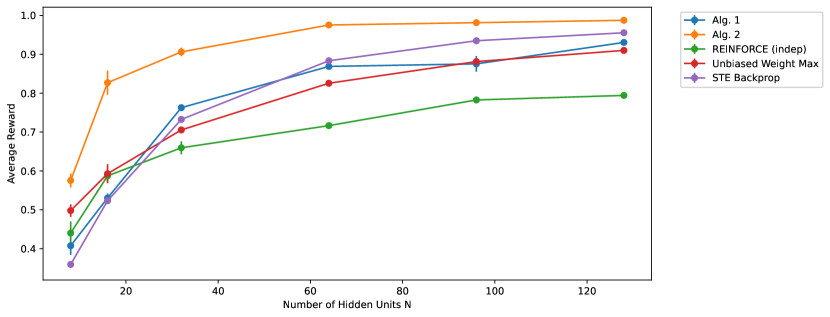
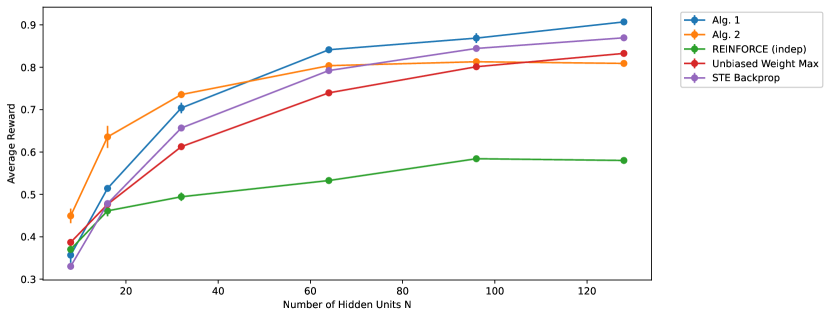
To understand how the different learning rules and networks scale with , the number of hidden units, we repeat the above experiments for . We used , and was tuned for each to maximize the average reward throughout all episodes. The average reward during the first 1e6 episodes (to evaluate the learning speed) and the last 1e6 episodes (to evaluate the asymptotic performance) for different is shown in Figure 4 and 5 respectively. For comparison, we also show the results from training a network with one hidden layer of Bernoulli-logistic units using REINFORCE with baseline (9), unbiased Weight Maximization, and STE backprop.
From Figure 4, we observe that Algorithm 1 has the best learning speed among all algorithms considered, and also scales well with the number of hidden units. It is worth noting that Algorithm 1 is faster than STE backprop at all tested. From Figure 5, we observe that the asymptotic performance of Algorithm 1 is similar to other algorithms considered except Algorithm 2, another algorithm that will be discussed in the next section. However, it should be noted that the computation cost of Algorithm 1 is more expensive than other algorithms considered. As we use , it means that we require times computational cost to sample compared to other algorithms.
Additional experiments, such as ablation analysis on and how the optimal changes with , can be found in Appendix A.1.
2.3 Coordinated Exploration with Recurrent Networks
Though symmetric recurrent weights arise naturally from Algorithm 1, symmetric connections between biological neurons are not commonly observed. Learning rules such as R-STDP is asymmetric instead of symmetric: if the post-synaptic spike arrives before the pre-synaptic spike arrives, then the synaptic strength is decreased instead of increased. Moreover, the use of one-sided centering increases variance and hurts performance. Is it possible to remove the requirement of symmetric connection in Algorithm 1 while using two-sided centering?
Let look at how is generated in Algorithm 1, as given by (13). One can also see this equation as a recurrent neural network, with being the common input at all time steps, as shown in Figure 1. From this perspective, we can simply apply REINFORCE on each time step to obtain an unbiased estimator of the gradient. For example, the gradient of the expected reward w.r.t. can be computed as:
| (32) | ||||
| (33) |
where . The first line follows by the fact that a recurrent ANN can be viewed as a multi-layer ANN with shared weights, and so we can apply REINFORCE on each layer.
The gradient w.r.t. and can be computed similarly:
| (34) | ||||
| (35) |
Note that these equations do not assume to be symmetric or to have zero diagonal. It also does not require to converge to any limiting distribution, so can be small. From these equations, we arrive at the following learning rules that follow gradient ascent on expected reward in expectation:
| (36) | ||||
| (37) | ||||
| (38) |
However, these learning rules suffer from a large variance as they can be viewed as REINFORCE applied to a multi-layer ANN with shared weights. To solve this issue, we borrow the idea of temporal credit assignment in RL. Consider that we use a very large , e.g. . It is unlikely that for a small can have influences on and also the reward . In other words, the dependency between and decreases as decreases from . Thus, instead of placing equal importance on every time step in the learning rule, we can multiply the terms in the learning rule with an exponentially decaying rate :
| (39) | ||||
| (40) | ||||
| (41) |
These learning rules can be easily implemented online by eligibility traces. For example, the learning rule for is equivalent to:
| (42) | ||||
| (43) | ||||
| (44) |
The full algorithm is given in Algorithm 2. We also adjust the reward by the expected reward from a critic network in the algorithm (though this is not necessary for learning to occur, as opposed to Algorithm 1). It should be noted that at and , the algorithm recovers REINFORCE with baseline (9) applied on a network with one hidden layer of Bernoulli-logistic units.
In addition, at (which works well in our experiments), that is, the hidden units only learn at the last time step, Algorithm 2 becomes the same as Algorithm 1, except: (i) Algorithm 2 uses two-sided centering as is subtracted from , which makes the learning rule no longer symmetric and so is the recurrent weight ; (ii) the pre-synaptic signal in the learning rule of the recurrent weight is in Algorithm 2 instead of in Algorithm 1. In other words, the pre-synaptic signal is one time step before the post-synaptic signal in the learning rule of in Algorithm 2, making it closer to R-STDP instead of reward-modulated Hebbian learning.
Though Algorithm 2 may seem similar to Algorithm 1 as is generated in the exact same way, the dynamics of these two algorithms are very different throughout learning. Algorithm 2 treats the hidden layer as a recurrent layer instead of a Boltzmann machine, so any already gives a good performance instead of in Algorithm 1. The asymmetric connection also makes not guaranteed to converge to any distributions as in Boltzmann machines. These different dynamics manifest in our experiments, which will be discussed in the following section.
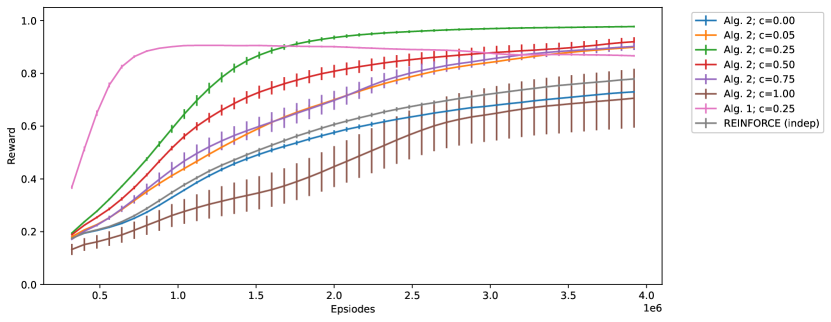
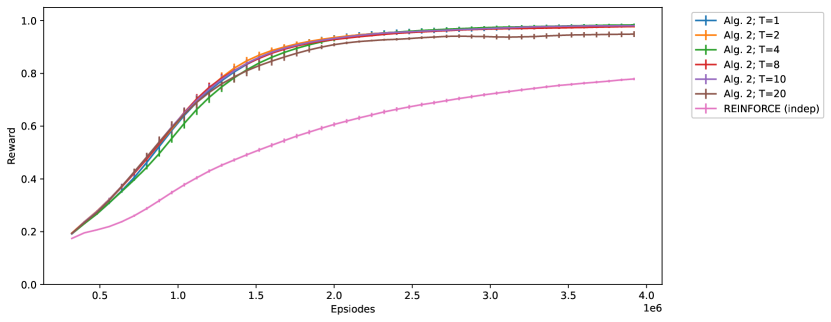
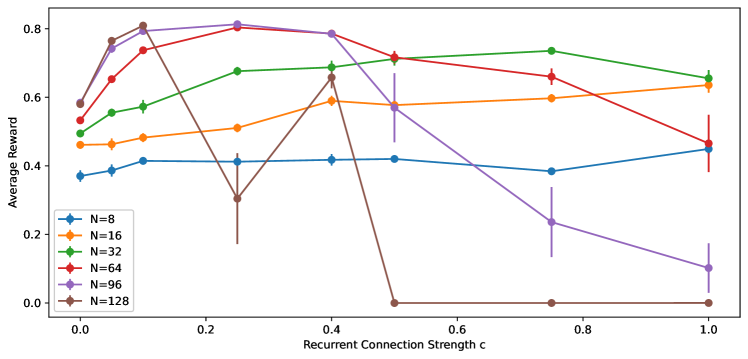
Experiments – To test the algorithm, we use the same setting as in Section 2.2; that is, we consider the task of -bit multiplexer tasks with the same set of hyperparameters. First, we tested Algorithm 2 with hidden units, sampling steps and trace decay rate. The learning curve with varying (the strength of recurrent connection) is shown in Figure 6. The figure also shows the learning curve of a network with one hidden layer of Bernoulli-logistic units trained by REINFORCE with baseline (9), which we label ‘REINFORCE (indep)’. The learning curve of Algorithm 1 with from Figure 3 is also shown here for comparison. We observe that:
-
•
Both ‘REINFORCE (indep)’ and ‘Alg. 2; c=0.00’ use independent exploration, and the former one is equivalent to Algorithm 2 with both and . Since ‘Alg. 2; c=0.00’ uses and there are no interaction between hidden units, the use of only adds noise to the parameter update and leads to a slightly worse performance.
-
•
However, as increases from to , the performance of Algorithm 2 improves due to the coordinated exploration.
-
•
The optimal is ; at , the learning curve is better than ‘REINFORCE (indep)’ in terms of both learning speed and asymptotic performance; compared to ‘Alg. 1; c=0.25’, the learning speed is lower, but the asymptotic performance is better.
-
•
But as increases larger than , performance deteriorates since inputs from other hidden units instead of the state dominate the unit.
-
•
The asymptotic performance is stable for all , unlike Algorithm 1.
The experiment result suggests that coordinated exploration with recurrent networks can improve learning speed. Again, , the strength of recurrent connection, is an important hyperparameter that needs to be carefully tuned. The dynamics of Algorithm 1 and 2 are also different; Algorithm 1 has a high learning speed while Algorithm 2 has a better and stable asymptotic performance. In addition, Algorithm 1 requires for good performance while the performance of Algorithm 2 remains stable for all .
To understand how the different learning rules and networks scale with , the number of hidden units, we repeat the above experiments for . We used , and was tuned for each to maximize the average reward throughout all episodes. The average reward during the first 1e6 episodes (to evaluate the learning speed) and the last 1e6 episodes (to evaluate the asymptotic performance) for different is shown in Figure 4 and 5 respectively.
From Figure 4, we observe that the learning speed of Algorithm 2 is moderately higher than ‘REINFORCE (indep)’ and also does not benefit much from increasing the network’s size. From Figure 5, however, we observe that the asymptotic performance of Algorithm 2 is the best among all algorithms considered at all .
The lower learning speed but better asymptotic performance can be explained by the assumption used in deriving the learning rules. In Algorithm 2, we view as the output of a recurrent layer, and we apply REINFORCE to the hidden units on the last few steps (due to eligibility traces). This is equivalent to training an ANN of hidden layers with shared weight by applying REINFORCE on the last few layers. Thus, the low learning speed of REINFORCE in training an ANN also manifests here; however, the deeper network increases the network’s capacity, thereby giving a better asymptotic performance.
Additional experiments, such as ablation analysis on and , and how the optimal changes with , can be found in Appendix A.2.
2.4 Discussion
In this report we propose and discuss two different algorithms to allow more efficient structural credit assignment by coordinated exploration. The first algorithm generalizes hidden layers of Bernoulli-logistic units to Boltzmann machines, while the second algorithm generalizes hidden layers to recurrent layers. It turns out that the activation values of hidden layers in these two algorithms can be sampled in the exact same way. However, the resulting learning rules are different and lead to different dynamics. Coordinated exploration with Boltzmann machines (Algorithm 1) increases learning speed significantly such that the learning speed is even higher than STE backprop, whereas coordinated exploration with recurrent networks (Algorithm 2) improves asymptotic performance. It remains to be seen whether we can combine the advantages of both algorithms in a single learning rule. Nonetheless, in either algorithm, we observe an improved learning speed compared to the baseline of training a network of Bernoulli-logistic units by REINFORCE, indicating that coordinated exploration can facilitate structural credit assignment.
In addition, coordinated exploration by Boltzmann machines or recurrent networks is arguably much more biologically plausible than backprop. Compared to a network of Bernoulli-logistic units trained by REINFORCE, which is argued to be close to biological learning [1, Chapter 15], coordinated exploration only requires adding recurrent connections between units on the same layer.
However, we only consider a one-hidden-layer ANN in this research report. Since the coordinated exploration of both Algorithm 1 and 2 is intra-layer instead of inter-layer, we expect that additional work is required to match the speed of STE backprop when applied in a multi-layer ANN. It may be possible to design a reward signal specific to each layer, with each layer being a Boltzmann machine or a recurrent layer that receives inputs from the previous layer. In this way, we have a vector reward signal with each reward signal targeting a subset of neurons, and the subset of neurons communicate with one another to generate a collective action such that a single reward is sufficient for assigning credit to the subset; this may be closer to the vector reward prediction errors observed in biological systems [9, 10].
Finally, further work can be done to understand how the long-term depression (LTD) in R-STDP can benefit learning, which is not included in the learning rules of both Algorithm 1 and 2. R-STDP states that if the pre-synaptic spike arrives after the post-synaptic spike, the synaptic strength is decreased instead of increased. This rule can be incorporated directly in the learning rules of Algorithm 1 or 2, but it remains to be seen whether it can benefit learning and what the theoretical basis is. Most studies on how R-STDP induces learning behavior [11, 12] focus on long-term potentiation (LTP) instead of LTD, and so how LTD can help learning is an important area for further work.
3 Acknowledgment
We would like to thank Andrew G. Barto, who inspired this research and provided valuable insights and comments.
Appendix A Additional Experiments
A.1 Coordinated Exploration with Boltzmann Machines
To see how the performance of Algorithm 1 scales with , the number of sampling step, we repeat the experiments shown in Figure 3 but with and . The results are shown in Figure 7. We observe that in terms of learning speed, works well; in terms of asymptotic performance, works the best. It is interesting to observe that the asymptotic performance of is slightly worse than . The reason for this remains to be understood.
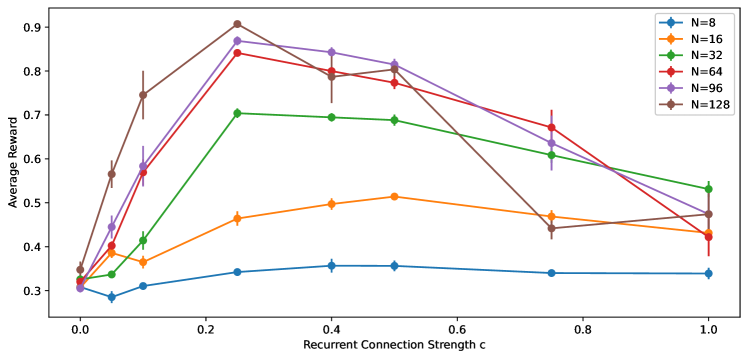
Finally, we consider how the optimal strength of recurrent connection changes with number of hidden units . The average reward throughout all episodes for Algorithm 1 with and is shown in Figure 8. We used here. We observe that the optimal scales inversely with . The optimal when is around while the optimal when is around .
A.2 Coordinated Exploration with Recurrent Networks
To see how the performance of Algorithm 2 scales with , the number of sampling step, we repeat the experiments shown in Figure 6 but with and . The results are shown in Figure 9. We observe that there are almost no differences in the learning curves for different .
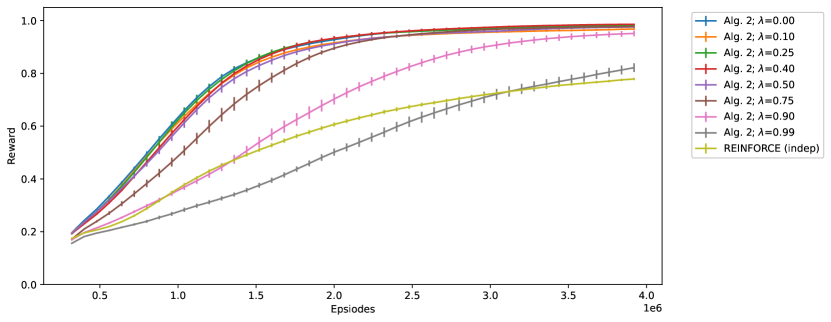
To see how the performance of Algorithm 2 scales with , the trace decay rate, we repeat the experiments shown in Figure 6 but with and . The results are shown in Figure 10. We observe that there are almost no differences in the learning curves for , indicating that we can apply REINFORCE on the last time step and the performance is still the same. However, performance deteriorates as grows larger than due to the increased noise.
Finally, we consider how the optimal strength of recurrent connection changes with the number of hidden units . The average reward throughout all episodes for Algorithm 2 with and is shown in Figure 11. We used and here. We observe that the optimal scales inversely with . The optimal for are respectively .
A.3 Miscellaneous
For completeness, we repeat Figure 4 and 5 here, but we show the average reward throughout all 4e6 episodes instead of only the first or the last 1e6 episodes. The results are shown in Figure 12.
References
- [1] Richard S Sutton and Andrew G Barto “Reinforcement learning: An introduction” MIT press, 2018
- [2] Stephen Chung “MAP Propagation Algorithm: Faster Learning with a Team of Reinforcement Learning Agents” In Advances in Neural Information Processing Systems 34, 2021
- [3] Stephen Chung “Learning by competition of self-interested reinforcement learning agents” In Proceedings of the AAAI Conference on Artificial Intelligence 36.6, 2022, pp. 6384–6393
- [4] David H Ackley, Geoffrey E Hinton and Terrence J Sejnowski “A learning algorithm for Boltzmann machines” In Cognitive science 9.1 Elsevier, 1985, pp. 147–169
- [5] Wulfram Gerstner, Werner M Kistler, Richard Naud and Liam Paninski “Neuronal dynamics: From single neurons to networks and models of cognition” Cambridge University Press, 2014
- [6] Yoshua Bengio, Nicholas Léonard and Aaron Courville “Estimating or propagating gradients through stochastic neurons for conditional computation” In arXiv preprint arXiv:1308.3432, 2013
- [7] Ronald J Williams “Simple statistical gradient-following algorithms for connectionist reinforcement learning” In Machine learning 8.3-4 Springer, 1992, pp. 229–256
- [8] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [9] Nathan F Parker et al. “Reward and choice encoding in terminals of midbrain dopamine neurons depends on striatal target” In Nature neuroscience 19.6 Nature Publishing Group, 2016, pp. 845–854
- [10] Rachel S Lee, Ben Engelhard, Ilana B Witten and Nathaniel D Daw “A vector reward prediction error model explains dopaminergic heterogeneity” In bioRxiv Cold Spring Harbor Laboratory, 2022
- [11] Răzvan V Florian “Reinforcement learning through modulation of spike-timing-dependent synaptic plasticity” In Neural Computation 19.6 MIT Press, 2007, pp. 1468–1502
- [12] Nicolas Frémaux, Henning Sprekeler and Wulfram Gerstner “Reinforcement learning using a continuous time actor-critic framework with spiking neurons” In PLoS computational biology 9.4 Public Library of Science, 2013