Student Activity Recognition in Classroom Environments using Transfer Learning
Abstract
The recent advances in artificial intelligence and deep learning facilitate automation in various applications including home automation, smart surveillance systems, and healthcare among others. Human Activity Recognition is one of its emerging applications, which can be implemented in a classroom environment to enhance safety, efficiency, and overall educational quality. This paper proposes a system for detecting and recognizing the activities of students in a classroom environment. The dataset has been structured and recorded by the authors since a standard dataset for this task was not available at the time of this study. Transfer learning, a widely adopted method within the field of deep learning, has proven to be helpful in complex tasks like image and video processing. Pretrained models including VGG-16, ResNet-50, InceptionV3, and Xception are used for feature extraction and classification tasks. Xception achieved an accuracy of 93%, on the novel classroom dataset, outperforming the other three models in consideration. The system proposed in this study aims to introduce a safer and more productive learning environment for students and educators.
Index Terms:
human activity recognition, transfer learning, classroom, classification, xceptionI Introduction
Human Activity Recognition is a prominently emerging and dynamic field within artificial intelligence, which revolves around comprehending human gestures or movements and discerning the specific activities they represent. HAR can be useful in various areas like Human-Computer Interaction (HCI), entertainment, smart surveillance, Elderly Living, and autonomous driving systems [1, 2]. The two primary techniques to recognize human activities are handcrafted feature-based depiction and learning-based representation. Handcrafted representations encounter issues of subjectivity and bias due to their reliance on human intuition. They might lack the ability to generalize to unfamiliar data and face difficulties when dealing with complex tasks. Creating these representations can be a time-intensive process, and maintaining them could pose challenges. Deep learning representations excel at capturing intricate patterns in data while eliminating bias through automated feature extraction. They are good at generalizing to new data, adapting to shifting distributions, and facilitating efficient transfer learning. Although inherent feature hierarchies facilitate knowledge of complicated relationships, their interpretability may offer difficulties [3, 4]. Deep learning approaches like Convolutional Neural Networks (CNNs) [5], Long Short Term Memory (LSTMs)[6] and Deep Belief Networks (DBNs)[7] can be employed to perform HAR on large and complex datasets. However, the enormous amount of time, resources, and data needed for deep learning model training is a fundamental challenge [8].
Humans are capable of learning innumerable categories throughout their lives with only a small number of samples. It has been suggested that humans develop this skill through gathering information over a certain period and implementing it to learn new things[9]. Deep learning models can be trained on one classification task and used on another task, with some finetuning if necessary, by adhering to the Transfer Learning concept [10]. In transfer learning, there are two primary methods: one involves maintaining the pre-trained network while updating weights, and the other entails employing a pre-trained model for feature extraction and application of a classifier[11].
Human Activity Recognition can be used for recognizing student activities in the classroom to improve learning outcomes. Classroom activity detection provides insights into teaching methods, allowing for tailored learning, responding to levels of participation, assisting with data-driven decisions, and improving classroom management for a better learning environment. Classroom activity detection has been performed using audio sources as well as multimodal sources viz. vocal and language modalities [12, 13]. However, there is scope for further research into the use of videos to detect usual and unusual activities performed by students in a classroom. In this study, several pre-trained deep learning models have been explored for identifying classroom activities and utilized on the authors’ newly created and recorded classroom dataset.
II Related Work
This section will examine previous research in the domain of activity recognition and transfer learning. When used for human activity identification, handcrafted feature extraction methods such as SURF, HOG, and PCA integrated feature approaches paired with classifiers produce outstanding results. However, these time-consuming tasks need the use of skilled feature detectors as well as complex feature extraction and representation methodologies. Furthermore, they rely too heavily on the data in consideration and are not sufficiently robust[14, 15, 16].
Deep learning-based methods to recognize human activity have become popular because of their capacity to extract features from data automatically and identify intricate patterns. 2D Convolutional Neural Networks were used to recognize human behaviors such as fighting and non-fighting, and the results were noteworthy [17].CNNs were used to identify running, walking, activities on the assembly line, and activities in the kitchen by utilizing data from mobile sensors. While 2D CNNs yield impressive results, they are not able to simultaneously collect spatial and temporal features[18]. Spatial and temporal feature extraction is used by 3D CNNs to identify dynamic patterns and provide better context. Consequently, 3D CNNs produced remarkable results on recordings of surveillance from airports[19]. Simonayan et al. presented ConvNet, a two-stream convolution layer that demonstrated good performance in identifying human actions on a modest amount of training data[20]. Convolutional layers, in connection with Long Short Term Memory (LSTM) models, are suitable for processing temporal sequences and enhanced performance while avoiding complex feature extraction[21]. Sheikh et al. trained various deep models on PSRA6, a novel dataset with six action types, and achieved remarkable results in detecting suspicious human activities[22].
The problem with deep learning models is that as the task’s complexity increases, so do the resources, time, and data required for training. This challenge can be handled by employing Transfer Learning, which entails applying knowledge obtained in one task to another. Deep et al. applied transfer learning alongside CNNs for video-based activity recognition, achieving a remarkable accuracy on the Weizmann dataset[23]. Sargano et al. constructed an SVM-KNN classifier on the new data and extracted features using a pre-trained architecture. Outperforming state-of-the-art approaches, their proposed strategy produced impressive results on the Weizmann and KTH datasets[24]. This study centers on exploring the utilization of transfer learning for activity recognition within the newly created classroom dataset.
III Methodology
III-A Transfer Learning
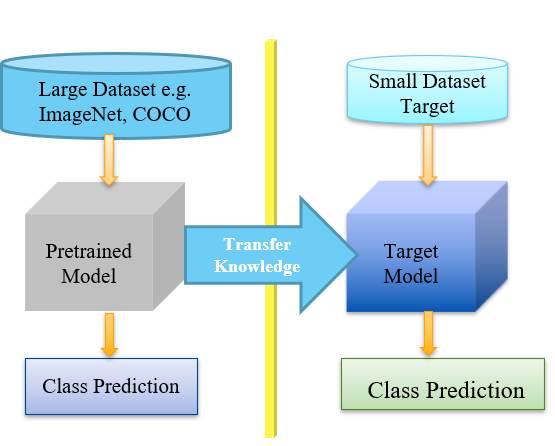
Deep Learning models require extensive resources, time, and data to be employed successfully on complex tasks. Figure 1 depicts the concept of transfer learning, which can be used to mitigate the problems associated with deep learning models. Four models were chosen from a variety of pre-trained models that were investigated for use on the classroom activity detection task: VGG-16 [25], ResNet-50[26], InceptionV3[27] and Xception[28].
III-B Models Used
VGG-16 is a pre-trained deep learning model that has applications in image classification and face recognition. To proliferate the number of layers and avoid having a large number of parameters, a small 3x3 convolution kernel is used in all layers. VGG takes an RBG image of size 244x244 as an input, which is the average RGB value of images in the training set. Fig. 2 shows the architecture of the VGG-16 model containing 16 layers with 5 sets of convolutional layers, followed by a MaxPool layer.
The winner of the COCO and ILSVRC 2015 competitions, Residual Network (ResNet), makes an effort to solve the difficulty of building very deep neural networks by utilizing residual connections, which helps to handle the vanishing gradient issues and permits the training of deeper models. Fig.3 depicts the architecture of the ResNet-50 model containing fifty layers, with convolutional, pooling, and fully connected layers. When compared to raw feature mappings, skip connections allow the network to understand residual mappings, which improves deep structure optimization. By utilizing a bottleneck residual block with 1x1 convolutions, ResNet can employ fewer parameters and fewer matrix multiplications.
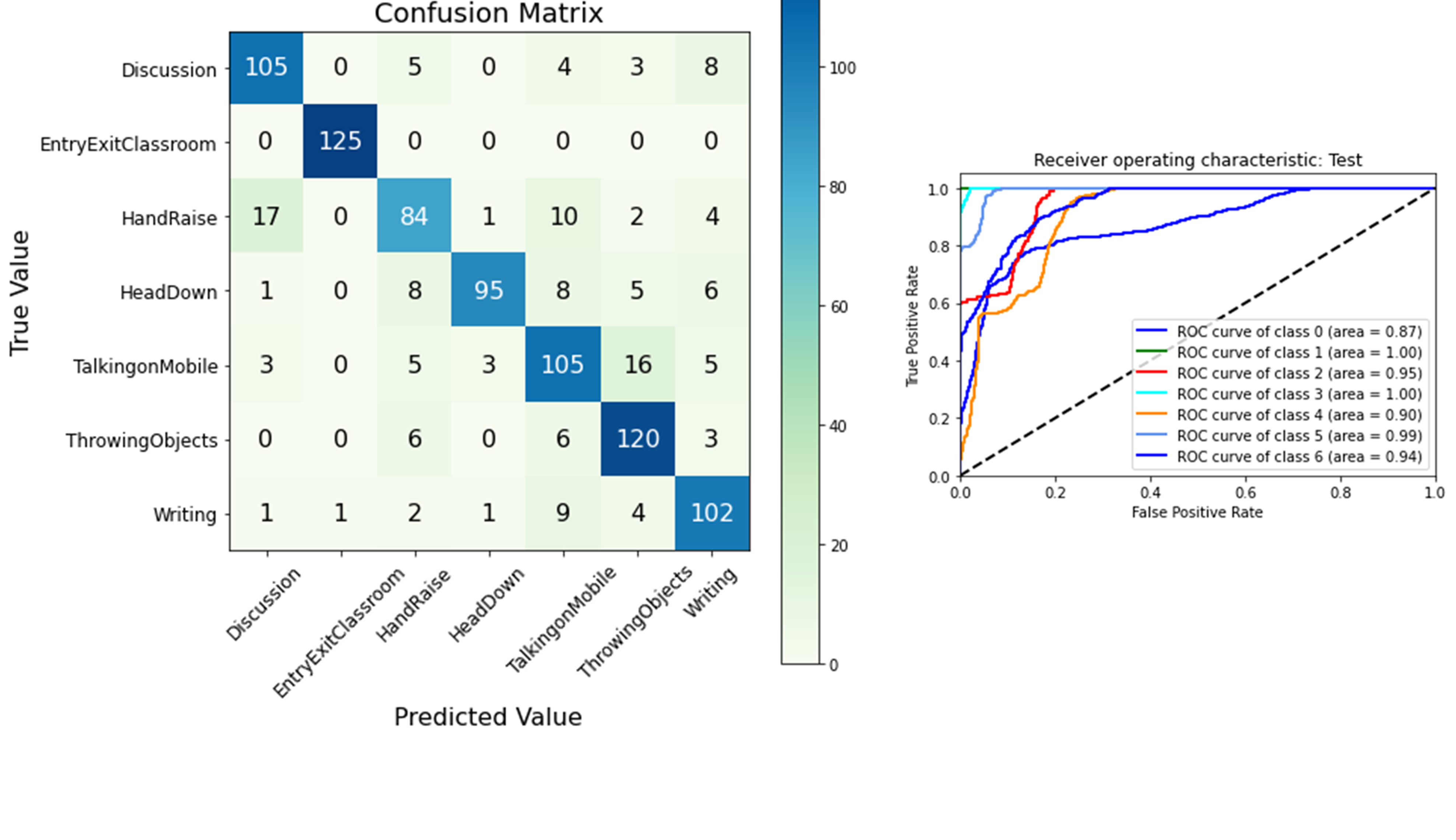
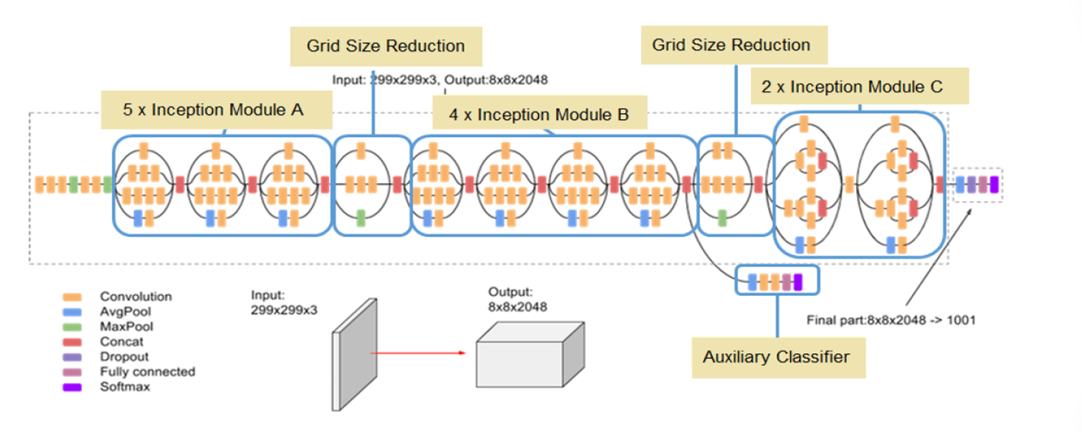
Fig. 4 shows the architecture of InceptionV3, a deep learning model from the Inception family that is an enhanced version of GoogleNet [30]. Convolutions and maximum pooling are calculated simultaneously, unlike other architectures like AlexNet [31] and VGG. To enable deeper networks, it has fewer parameters—under 25 million—than AlexNet, which has 60 million. InceptionV3 has 48 layers and uses 3x3 spatial convolutions.
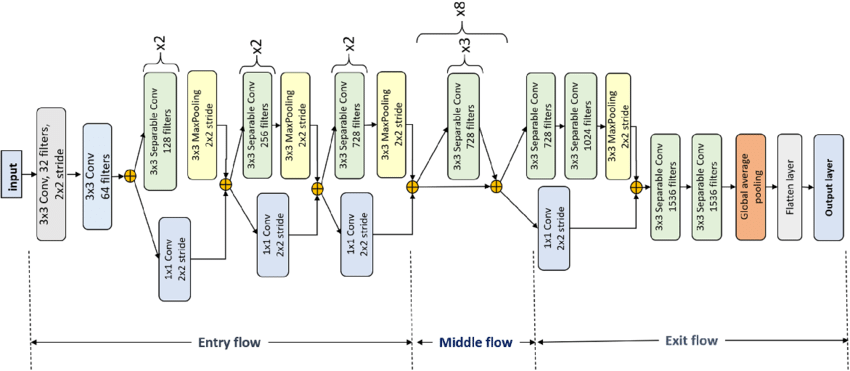
Xception model, as presented in Fig. 5, is a deep learning architecture that exclusively uses depthwise separable convolution layers. It has 36 convolutional layers and has a comparable parameter count to Inception V3 which lessens the space and time complexity. There is no intermediate ReLU non-linearity, and the order of operations differs from InceptionV3 — 1x1 convolution comes first, followed by spatial convolution.
IV Experimentation and Results
IV-A Dataset
The novel Classroom dataset, captured via a mobile phone camera, aims to identify student behavior in a classroom setting. It includes short 4-5 second video sequences in MP4 format, shot at 30 FPS, and RGB frames with a resolution of 640x480. The focus is on recognizing both usual and unusual student activities, which can be beneficial for enhancing the learning environment. The dataset requires up to 100MB of storage space. Existing video datasets, such as KTH[34] and Weizman[35], primarily consist of simple, usual actions like walking, jogging, and jumping. On the other hand, datasets like UCF101[36] offer a more complex representation of interactions, focusing on activities like sports or playing music. This novel classroom dataset contains usual and unusual activities observed predominantly in the classroom environment. Fig. 6 displays the activity classes present in the dataset. The activity classes in the dataset are Discussion, Entry/Exit, Hand Raise, Head Down, Talking on mobile, Throwing Objects, and Writing. Real-time recording challenges included dynamic backgrounds, variations in scale and illumination, changing camera views, and capturing multiple people in a single frame, among others.

IV-B Experimental Setup
This section covers the experimental setup, the process used for training, and the results of the four architectures mentioned previously. The models are tested on a novel classroom dataset recorded and created by the authors, which contains 7 activity classes. Each image has a frame size of 160x160, for a total of 4372 frames. Training, validation, and test data are divided in a ratio of 70:10:20. Adam optimizer having a learning rate of 0.0001 is used along with categorical_crossentropy loss, and accuracy is employed as an evaluation metric. With a batch size of 8, each model is iterated over 20 epochs.
The base convolution neural network model is generated by disabling the trainable parameters in pre-trained models like VGG16, ResNet50, InceptionV3, and Xception. The newly generated model is succeeded by the Global Average Pooling 2D layer, intended to lower the spatial dimension of data while retaining the essential features. Subsequently, a fully connected layer comprising seven output neurons is connected. The activation function employed here is the softmax function, which is commonly chosen for scenarios involving multi-class classification. Fig. 8 shows the sequential model diagrams and trainable parameters for the proposed model.
IV-C Performance Measures
Accuracy, Precision, Recall, and F1 Score are the four performance indicators used in this study, with Accuracy being the most relevant of the four. True positive is indicated by TP, false positive by FP, true negative by TN, and false negative by FN.
Accuracy is a metric that indicates the model’s fraction of exact predictions in relation to the overall number of predictions made.
| (1) |
The fraction of true positive predictions to total predicted positive samples is denoted as precision.
| (2) |
Recall is defined as the fraction of accurately predicted positive samples among all positive samples.
| (3) |
Finally, the F1 score is the combined value of precision and recall, calculated by taking the harmonic mean of precision and recall.
| (4) |
IV-D Results
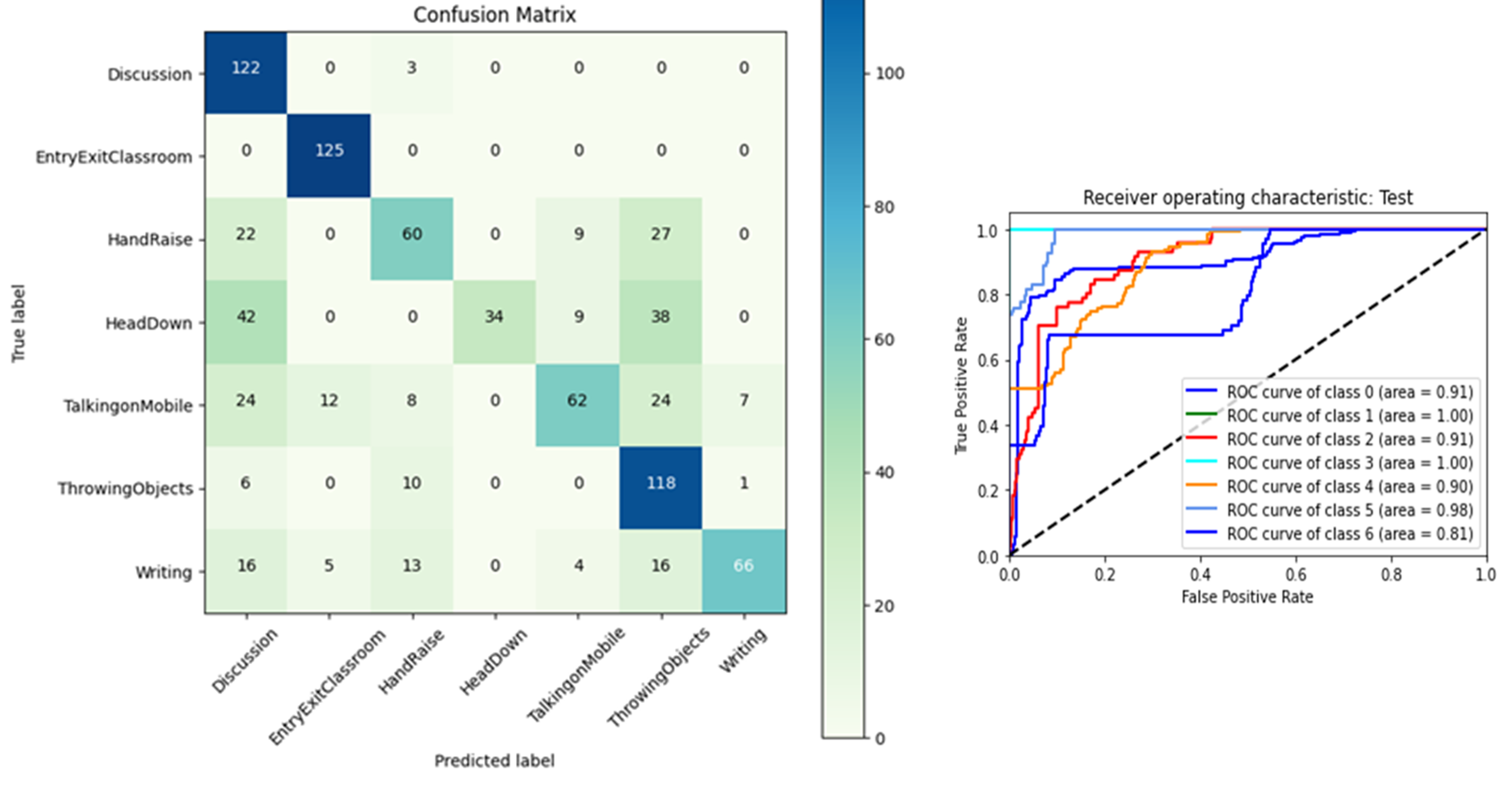
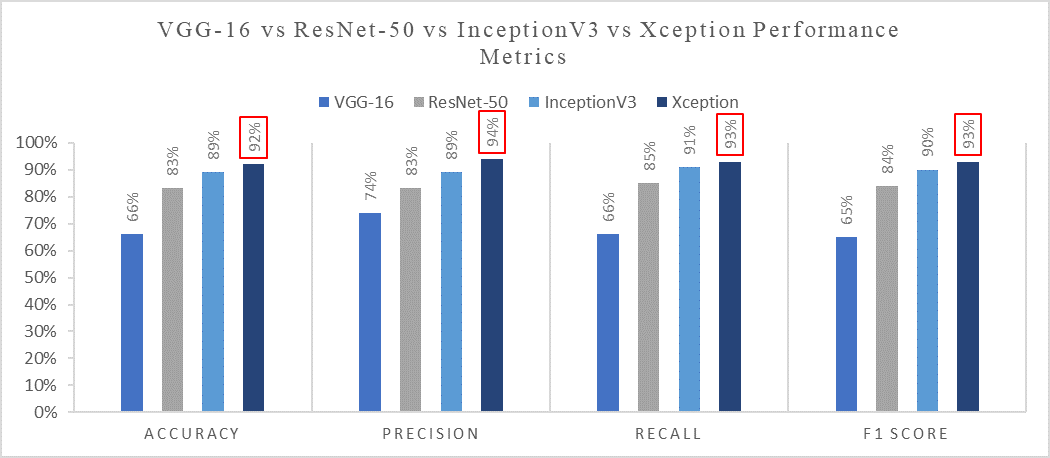
As stated previously, 70% of the dataset is dedicated to training, 20% to validation, and 10% is dedicated to testing the models. After employing the models on the testing dataset, a Collation of the four models in terms of output measuring parameters can be observed in Table 1. Xception outperformed the other three models, yielding a testing accuracy of 92%. Fig. 7 contains a graphical representation of the comparison of the selected models. This study’s findings are consistent with the fact that Xception is an improved version of Inception, yielding better results on the novel classroom dataset. The Xception model, due to a depth-wise separable convolutional layer with varied reduced filter dimensionality, improves the accuracy and computation cost.

| Model | Accuracy | Precision | Recall | F1 Score |
| VGG-16 | 66% | 74% | 66% | 65% |
| ResNet-50 | 83% | 83% | 85% | 84% |
| InceptionV3 | 89% | 89% | 89% | 90% |
| Xception | 92% | 94% | 93% | 93% |
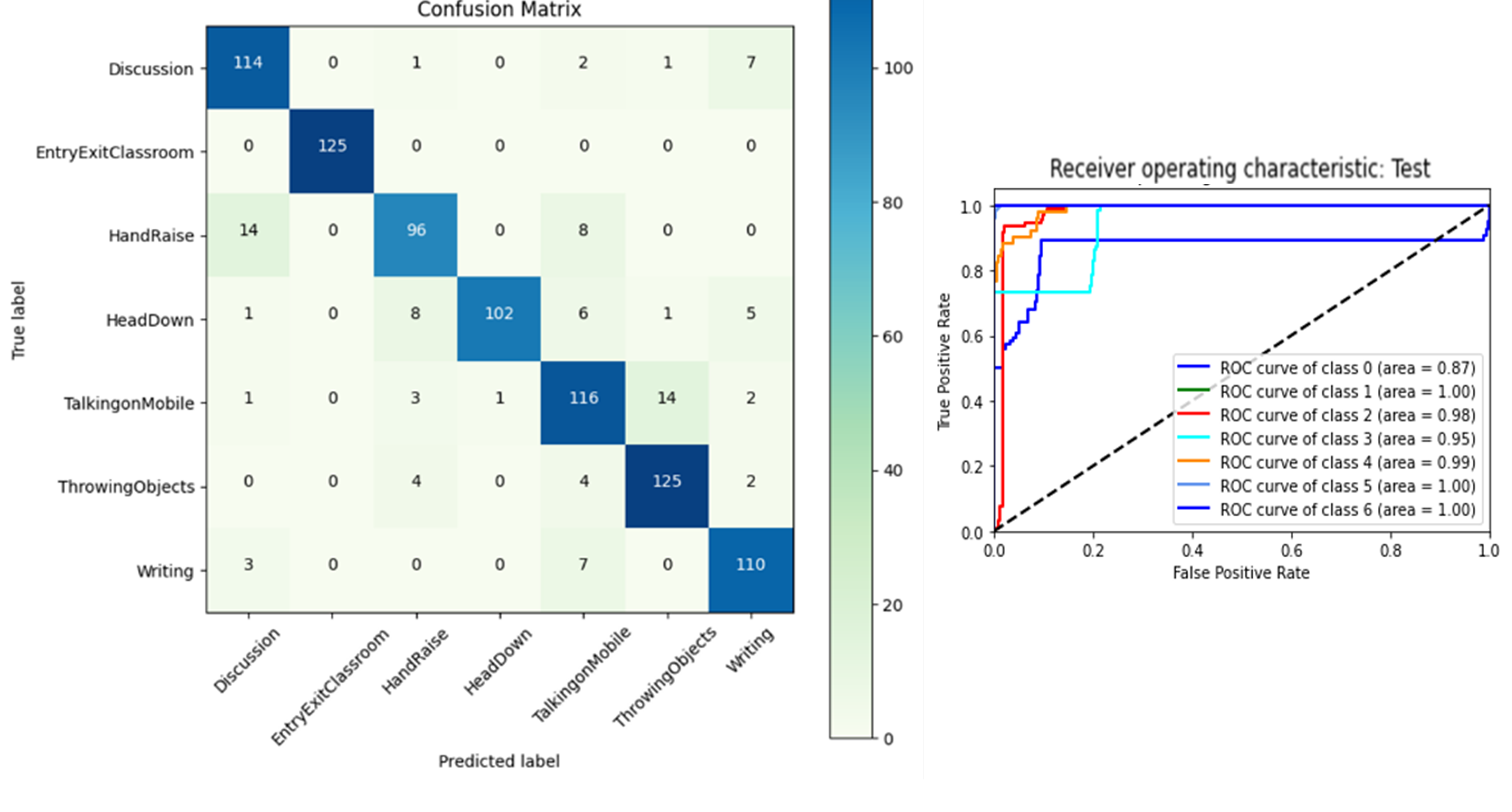
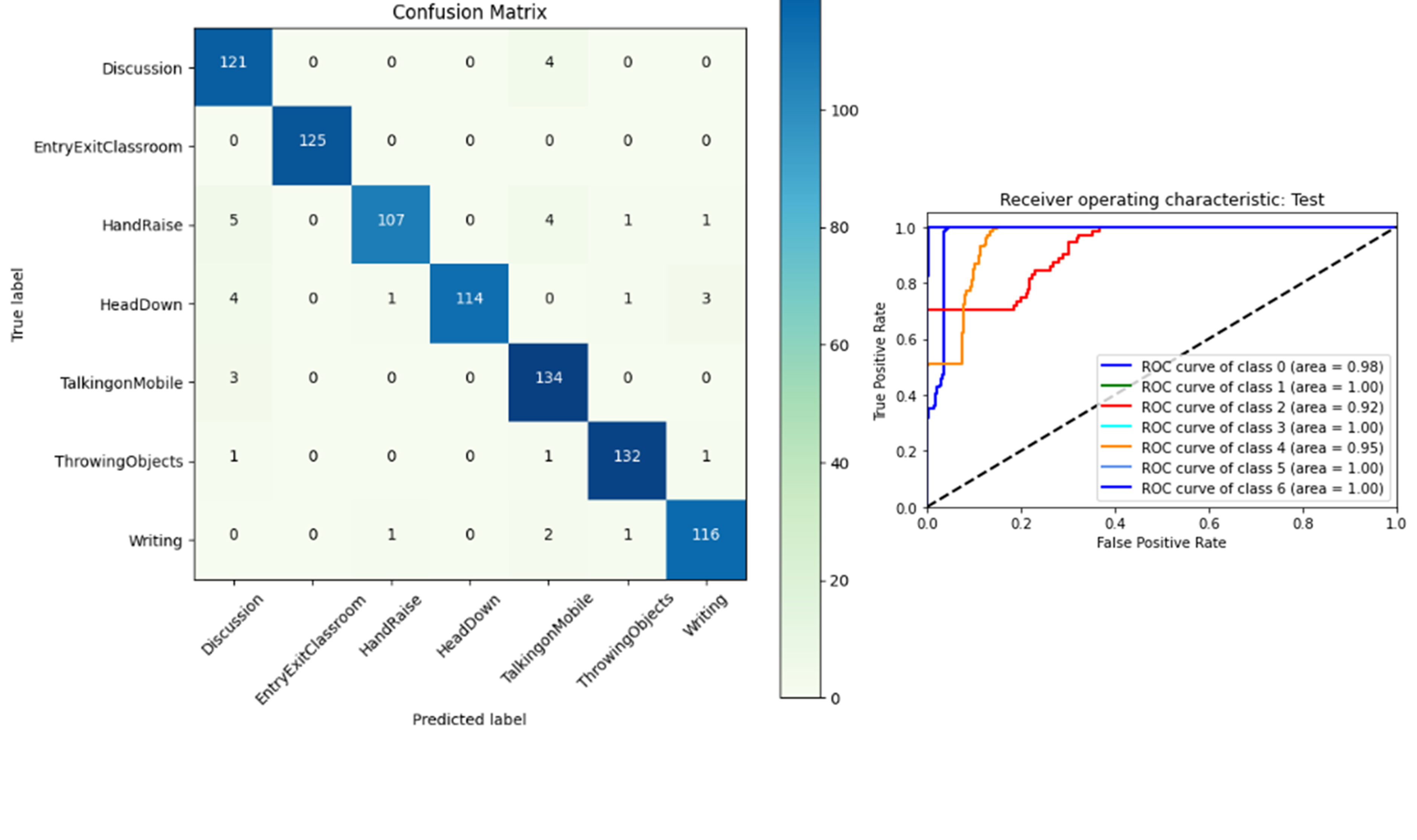
The confusion matrix is used to compare predicted and actual class labels to determine the performance of a model, while the Receiver Operating Characteristic (ROC) curve graphically depicts the balance between true positive rate and false positive rate, which aids in the evaluation and comparison of the classification model. The Area Under the Curve (AUC) is the measure of the ability of a classifier to distinguish between classes and is used as a summary of the ROC curve. The classifiers can distinguish well when each class is measured against the others (AUC), but not as well when the prediction probabilities are an output of the softmax function.
V Conclusion
In this paper, we present a Convolutional Neural Network based on transfer learning in solving the problem of student activity recognition using a time series dataset. The research is carried out on a novel classroom dataset comprising over 4,000 images split across 7 activity classes. The developed system is capable of distinguishing seven different student activities, Discussion, Entry/Exit, Hand Raise, Head Down, Talking on mobile, Throwing Objects, and Writing. Various pre-trained convolutional neural networks were studied and four were employed on the novel classroom dataset using the transfer learning approach. The confusion matrices and classification reports show an accuracy of 92% for the Xception model, followed by 89% for InceptionV3. The Xception-pertained model supports depthwise separable convolutions, isolates cross-channel and spatial correlations, and captures fine-grained spatial details, which helps in improving recognition accuracy. The ROC curves depict that classifiers are adept at differentiating various classes, but not as well in terms of prediction probabilities, which can be improved by applying superior classifiers. The future focus of this research will be employing the proposed system on a larger and more diverse dataset and the use of cutting-edge models like RNNs and LSTMs for the classification task along with the pre-trained networks.
References
- [1] Aggarwal, J.K. and M.S. Ryoo, Human activity analysis: A review. ACM Computing Surveys (CSUR), 2011. 43(3): p. 16.
- [2] S. Ali and M. Shah, “Human action recognition in videos using kinematic features and multiple instance learning.,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 2, pp. 288–303, Feb. 2010.
- [3] Zhu, F., Sha, L., Xie, J., and Fang, Y., From handcrafted to learned representations for human action recognition: A survey. Image and Vision Computing, 2016.
- [4] Sargano, A.B., P. Angelov, and Z. Habib, A comprehensive review on handcrafted and learning-based action representation approaches for human activity recognition. Applied Sciences, 2017. 7(1): p. 110.
- [5] LeCun, Y., Bottou, L., Bengio, Y., Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998. 86(11): p. 2278-2324.
- [6] S. Hochreiter and J. Schmidhuber, ”Long Short-Term Memory,” in Neural Computation, vol. 9, no. 8, pp. 1735-1780, 15 Nov. 1997, doi: 10.1162/neco.1997.9.8.1735.
- [7] Hinton, G.E., S. Osindero, and Y.-W. Teh, A fast learning algorithm for deep belief nets. Neural computation, 2006. 18(7): p. 1527-1554.
- [8] Cao, X., Wang, Z., Yan, P., Li, X., Transfer learning for pedestrian detection. Neurocomputing, 2013. 100: p. 51-57.
- [9] Fei-Fei, L. Knowledge transfer in learning to recognize visual objects classes. in Proceedings of the International Conference on Development and Learning (ICDL). 2006.
- [10] Azizpour, H., Razavian, S.A., Sullivan, J., From generic to specific deep representations for visual recognition. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2015.
- [11] Zeiler, M.D. and R. Fergus. Visualizing and understanding convolutional networks. in European Conference on Computer Vision. 2014. Springer
- [12] R. Cosbey, A. Wusterbarth and B. Hutchinson, ”Deep Learning for Classroom Activity Detection from Audio,” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 2019, pp. 3727-3731, doi: 10.1109/ICASSP.2019.8683365.
- [13] H. Li et al., ”Multimodal Learning for Classroom Activity Detection,” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 9234-9238, doi: 10.1109/ICASSP40776.2020.9054407.
- [14] Willems, G., T. Tuytelaars, and L. Van Gool. An efficient dense and scale-invariant spatio-temporal interest point detector. in European conference on computer vision. 2008. Springer.
- [15] Klaser, A., M. Marszaáek, and C. Schmid. A spatio-temporal descriptor based on 3d-gradients. in BMVC 2008-19th British Machine Vision Conference. 2008. British Machine Vision Association.
- [16] A. Deshpnande and K. K. Warhade, ”An Improved Model for Human Activity Recognition by Integrated feature Approach and Optimized SVM,” 2021 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 2021, pp. 571-576, doi: 10.1109/ESCI50559.2021.9396914.
- [17] I. Serrano, O. Deniz, J. L. Espinosa-Aranda and G. Bueno, ”Fight Recognition in Video Using Hough Forests and 2D Convolutional Neural Network,” in IEEE Transactions on Image Processing, vol. 27, no. 10, pp. 4787-4797, Oct. 2018, doi: 10.1109/TIP.2018.2845742.
- [18] M. Zeng et al., ”Convolutional Neural Networks for human activity recognition using mobile sensors,” 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 2014, pp. 197-205, doi: 10.4108/icst.mobicase.2014.257786.
- [19] S. Ji, W. Xu, M. Yang and K. Yu, ”3D Convolutional Neural Networks for Human Action Recognition,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 1, pp. 221-231, Jan. 2013, doi: 10.1109/TPAMI.2012.59.
- [20] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” in Advances in neural information processing systems, 2014, pp. 568–576.
- [21] K. Xia, J. Huang and H. Wang, ”LSTM-CNN Architecture for Human Activity Recognition,” in IEEE Access, vol. 8, pp. 56855-56866, 2020, doi: 10.1109/ACCESS.2020.2982225.
- [22] Sheikh RS, Patil SM, Dhanvijay MR. Framework for deep learning based model for human activity recognition (HAR) using adapted PSRA6 dataset . International Journal of Advanced Technology and Engineering Exploration. 2023; 10(98):37-66. DOI:10.19101/IJATEE.2021.876325.
- [23] S. Deep and X. Zheng, ”Leveraging CNN and Transfer Learning for Vision-based Human Activity Recognition,” 2019 29th International Telecommunication Networks and Applications Conference (ITNAC), Auckland, New Zealand, 2019, pp. 1-4, doi: 10.1109/ITNAC46935.2019.9078016.
- [24] A. B. Sargano, X. Wang, P. Angelov and Z. Habib, ”Human action recognition using transfer learning with deep representations,” 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 2017, pp. 463-469, doi: 10.1109/IJCNN.2017.7965890.
- [25] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014
- [26] K. He, X. Zhang, S. Ren and J. Sun, ”Deep Residual Learning for Image Recognition,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 770-778, doi: 10.1109/CVPR.2016.90.
- [27] C. Szegedy, V. Vanhoucke, S. Ioffe, et al., “Rethinking the inception architecture for computer vision,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818- 2826, 2016.
- [28] F. Chollet, ”Xception: Deep Learning with Depthwise Separable Convolutions,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 1800-1807, doi: 10.1109/CVPR.2017.195.
- [29] H. Qassim, A. Verma and D. Feinzimer, ”Compressed residual-VGG16 CNN model for big data places image recognition,” 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 2018, pp. 169-175, doi: 10.1109/CCWC.2018.8301729.
- [30] C. Szegedy et al., ”Going deeper with convolutions,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015, pp. 1-9, doi: 10.1109/CVPR.2015.7298594.
- [31] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, pp. 84-90, Jan. 2012.
- [32] Elleuch, M., Mezghani, A., Khemakhem, M., Kherallah, M. (2021). Clothing Classification Using Deep CNN Architecture Based on Transfer Learning. In: Abraham, A., Shandilya, S., Garcia-Hernandez, L., Varela, M. (eds) Hybrid Intelligent Systems. HIS 2019. Advances in Intelligent Systems and Computing, vol 1179. Springer, Cham. https://doi.org/10.1007/978-3-030-49336-3_24
- [33] F. Chollet, ”Xception: Deep Learning with Depthwise Separable Convolutions,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 1800-1807, doi: 10.1109/CVPR.2017.195
- [34] C. Schuldt, I. Laptev and B. Caputo, ”Recognizing human actions: a local SVM approach,” Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., Cambridge, UK, 2004, pp. 32-36 Vol.3, doi: 10.1109/ICPR.2004.1334462.
- [35] L. Gorelick, M. Blank, E. Shechtman, M. Irani, and R. Basri, ”Actions as Space-Time Shapes,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 12, pp. 2247-2253, Dec. 2007. [Online]. Available: www.wisdom.weizmann.ac.il/ vision/SpaceTimeActions.html
- [36] K. Soomro, A. R. Zamir, and M. Shah, ”UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild,” CRCV-TR-12-01, November 2012.