StyleEDL: Style-Guided High-order Attention Network for Image Emotion Distribution Learning
Abstract.
Emotion distribution learning has gained increasing attention with the tendency to express emotions through images. As for emotion ambiguity arising from humans’ subjectivity, substantial previous methods generally focused on learning appropriate representations from the holistic or significant part of images. However, they rarely consider establishing connections with the stylistic information although it can lead to a better understanding of images. In this paper, we propose a style-guided high-order attention network for image emotion distribution learning termed StyleEDL, which interactively learns stylistic-aware representations of images by exploring the hierarchical stylistic information of visual contents. Specifically, we consider exploring the intra- and inter-layer correlations among GRAM-based stylistic representations, and meanwhile exploit an adversary-constrained high-order attention mechanism to capture potential interactions between subtle visual parts. In addition, we introduce a stylistic graph convolutional network to dynamically generate the content-dependent emotion representations to benefit the final emotion distribution learning. Extensive experiments conducted on several benchmark datasets demonstrate the effectiveness of our proposed StyleEDL compared to state-of-the-art methods. The implementation is released at: https://github.com/liuxianyi/StyleEDL.
1. Introduction
Image emotion analysis (Zhao et al., 2021) has gained significant research attention owing to its facility in conveying emotions and views of people. Currently, image emotion analysis has been applied in various scenarios, such as multimedia retrieval (Lu et al., 2019; Zhu et al., 2020, 2023; Qu et al., 2021; Nie et al., 2022), social network analysis (Serrat, 2017; Freeman, 2004; Wasserman and Faust, 1994; Jing et al., 6796), advertising recommendation (Yang et al., 2013; Holbrook and O’Shaughnessy, 1984; Mitchell, 1986).
In prior studies, the image emotion analysis tends to be formulated as a single-label classification task (Rao et al., 2020; Yang et al., 2018b, c; Zhang et al., 2019; Zhu et al., 2017), where each image is assigned a dominant label. However, one image may contain a mixture of multiple emotions with varying intensities, and an individual may have different emotional responses toward one image (i.e., ambiguity). As to this problem, the label distribution learning (LDL) paradigm (Yang et al., 2017a; Fan et al., 2018; Wang and Geng, 2021a; Gao et al., 2017) has been adopted to narrow the gap between visual features and affective states. Typically, (Yang et al., 2017a) intended to learn a more smooth label vector to represent the emotions of images, replacing the previous dominant emotion classification. (Fan et al., 2018) attempted to boost predicting performance by taking regions that represent emotions most into consideration. However, these methods failed to explicitly consider the correlations between emotions. For example, an image of a reunion of old friends may be more likely to evoke feelings of both excitement and happiness, without causing sadness. Fortunately, emotion correlations (Yang et al., 2021; He and Jin, 2019; Xiong et al., 2019; Xu and Wang, 2021) have been proven to be able to further improve the emotional distribution performance with prior knowledge.
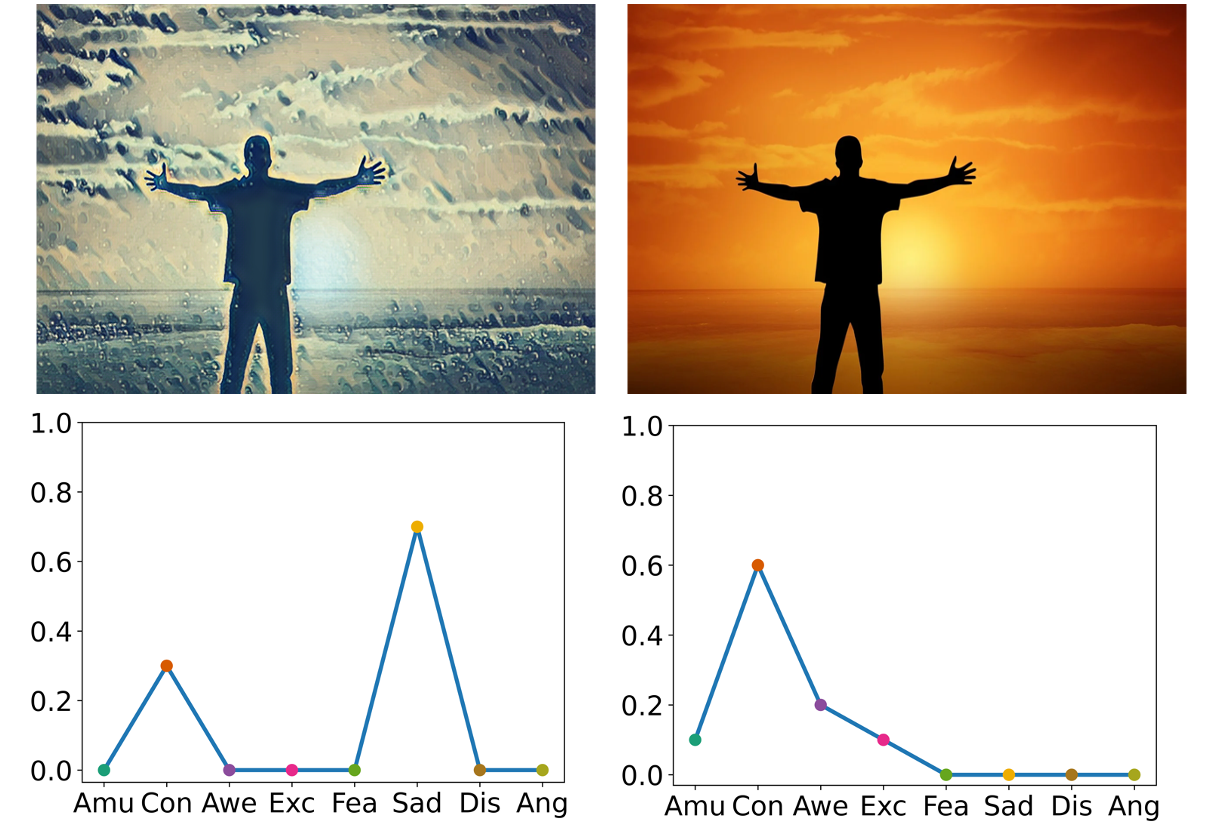
However, existing methods for emotion distribution learning usually suffer from two challenges that tightly hinder performance improvements. First, due to the subjectivity of human cognition, directly using visual representations extracted from convolutional neural networks (CNNs) may be insufficient to characterize emotions contained in images, especially for the emotion ambiguity problem. As an example, Figure 1 shows that the right side has more contentment, while the left side may evoke melancholic feelings among observers, despite depicting the same content. Different styles shown in these two pictures cause different emotions, but the existing methods rarely reveal this point from the perspective of stylistic representation learning. Second, the correlation among emotions is generally modeled by a static graph structure (He and Jin, 2019). Unfortunately, the adjacent relation of a static graph is usually manually defined according to the given dataset, and such relation generally models coarse dependencies, with limited versatility to mine fine latent relationships between emotions. As a result, these methods learn only coarse emotional correlations during iterations, which ultimately leads to unsatisfactory prediction performance.
To address the above issues, we propose a novel method termed style-guided high-order attention network for image emotion distribution learning (StyleEDL). The core idea behind our proposed StyleEDL is to leverage stylistic information to compensate for the deficiency of visual representations to resolve emotion ambiguity. To explore stylistic-aware information in datasets, we first use GRAM-based intra- and inter-layer correlations as emotional style representations. And then we intermix significant attention results of content information generated by an adversary-constrained high-order attention module to obtain stylistic-aware representations. To get more accurate emotions of images, we consider the intrinsic relationship upon stylistic-aware representations using a stylistic graph network. Taking the coarse information of static graph network learning as the prior information, the network adopts a dynamic graph structure to obtain the emotional-aware representations from the stylistic-aware representations in an adaptive way. Our main contributions are as follows:
-
•
We propose a novel emotion distribution learning method termed StyleEDL, which explores stylistic information as complementary information to refine the representations of images. To the best of our knowledge, this is the first work using a style-induced paradigm for IEDL.
-
•
We devise a stylistic-aware representation learning network that extracts attentive visual content representations and hierarchical stylistic representations. In addition, develop a stylistic GCN to capture the intrinsic correlation among stylistic-aware representations.
-
•
We conduct experiments on three public datasets, and the results show the superiority of the proposed method compared to state-of-the-art methods.
The remaining sections of the paper have been structured as follows: Section 2 expounds on the related research, Section 3 presents the proposed StyleEDL, Section 4 provides empirical evaluation and analysis, and Section 5 concludes the paper.
2. Related Work
2.1. Image Emotion Distribution Learning
Existing research on LDL can be borrowed to describe the emotions corresponding to an image. In particular, (Yang et al., 2017b) proposed two methods, conditional probability neural network with binary code (BCPNN) and augmented conditional probability neural network (ACPNN), based on conditional probability neural networks to address sentiment ambiguity with multiple emotions. (Gao et al., 2017) proposed the deep label distribution learning (DLDL) method, which effectively utilizes label ambiguity by minimizing the Kullback-Leibler divergence for the first time. (Yang et al., 2017a) developed a multi-task deep framework by jointly optimizing classification and distribution prediction. Later, polarity and relevance among emotions were also taken into account to explicitly model emotional correlation, making it effective to learn the distribution. (He and Jin, 2019) utilized graph neural networks as emotional predictors to capture the correlation among emotions. (Xiong et al., 2019) designed a combined loss based on the earth mover’s distance (EMD) and kullback-leibler divergence using structured labels in sentiment polarity. (Yang et al., 2021) designed a novel progressive circular (PC) loss based on an emotional circle to boost the learning process in an emotion-specific way. To explore emotional style representations in complicated images, our proposed method proposes stylistic-aware representation learning and emotional-aware enhanced representation learning, producing accurate emotion distribution in real-world datasets.
2.2. Image Style Recognition
Many recent works have indicated that the style of an image has a significant impact on the meaning it conveys. For example, (Lu et al., 2015) proposed a multi-patch aggregation network for extracting fine-grained features from images and showed that this approach achieves good performance in image style classification, aesthetic classification, and quality estimation tasks. (Matsuo and Yanai, 2016) used the GRAM matrix of feature maps to generate style vectors, which they applied to style image retrieval. (Lecoutre et al., 2017) demonstrated the effectiveness of deep residual networks in image style recognition. (Yang et al., 2018a) proposed a multi-factor distribution soft label and performed image style classification in a multi-task framework. (Chu and Wu, 2018) systematically explored the use of correlations between feature maps to characterize image style. (Laubrock and Dubray, 2019) confirmed that mid-level features corresponding to textures, shadows, etc., are particularly well-suited for illustration style classification. (Ghosal et al., 2019) proposed using geometry-sensitive style features based on image saliency for photographic image classification. However, those works have only focused on directly extracting feature maps from their models, which may not fully capture fine representations. In this paper, we propose a novel style-induced method that leverages attentive visual content representations and hierarchical stylistic representations to guide emotion distribution learning. This approach allows for more comprehensive emotional representations than previous methods.
3. The Proposed Method
Emotion distribution learning task can be defined as: given a labeled sample pair , which is used to learn a function:
| (1) |
where represents an input image, (, ) is the degree to which emotions are expressed in this image, and represents the corresponding emotional distribution learned. Our goal is to optimize the function with the help of supervised information , fitting the true emotional distribution of the image.
3.1. Framework Overview
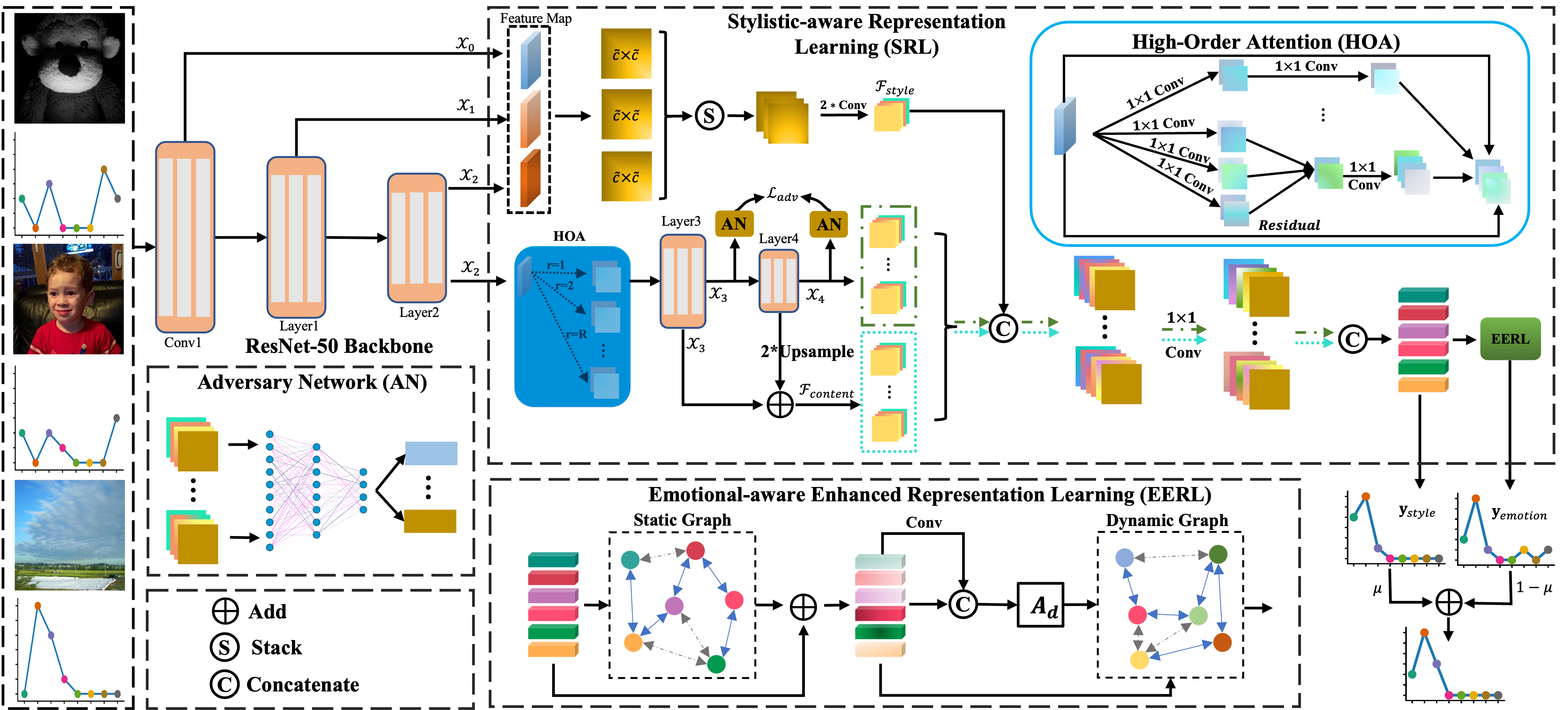
The representations of images can evoke different emotions depending on the aspects being considered. Different aspects can also contribute differently to the triggering of emotions. One way to construct different representations was to directly use shallow features extracted by CNN as emotional concepts. However, these concepts may not fully capture the emotional content of an image. Another way to represent emotions in different aspects is by using CNN with multiple convolutional layers. Even though a convolutional layer with small kernels may struggle to perceive everything in an image, a deeper architecture can increase the model’s receptive field. As a result, the early layers of the CNN tend to capture low-level features such as color and texture, while the later layers capture more complex and high-level features. Therefore, we use the characteristics of the CNN to construct a module for the stylistic-aware representation learning. In detail, we first use the GRAM matrix of low-level features as stylistic information. And then we combine it with visual content information from high-level features enhanced by a high-order attention module to obtain stylistic-aware representations. Moreover, recent studies (Mittal et al., 2021) have shown that the graph convolutional network (GCN) can improve the performance of emotion distribution learning due to its ability to capture emotion dependencies. However, traditional GCN only captures coarse emotion dependencies. And the stylistic-aware representations contain relatively comprehensive emotional representations from visual and stylistic information, but only parts of them play a role in improving performance. Therefore, we propose a stylistic GCN module for emotional-aware enhanced representation learning, which captures emotion relations of stylistic-aware representations in an adaptive way. Specifically, the module initializes coarse emotion dependencies from a static GCN and uses them to capture emotional-aware dependencies of stylistic-aware representations for each image. By integrating the stylistic-aware representations and emotional-aware dependencies, our proposed method can better capture the emotions present in images.
3.2. Stylistic-aware Representation Learning
In this module, we first learn the emotional style representations with image style by exploring intra-layer and inter-layer correlations in feature maps. Second, a high-order attention mechanism with adversary constraints is introduced to guide learning emotional content representations. Finally, we fuse the emotional style representations and emotional content representations and further explore the latent stylistic-aware representations of images.
3.2.1. GRAM-based Intra- and Inter-layer Correlation
Inspired by the work (Matsuo and Yanai, 2016), we use the GRAM matrix of each layer’s feature maps as the intra-layer emotional style representations. Because the features related to the emotional style of the image, such as texture and color, are typically captured in the low-dimensional feature maps, we first extract the input feature maps from the outputs of different layers of ResNet-50 to calculate the stylistic representation within each layer, as follows:
| (2) |
where represents the feature maps of the -th layer extracted from an image . For simplicity, in all the following layers, , and represent the number of channels, width and height of the feature maps or representations, respectively. We then convert feature maps into a vector ,, and concatenate them into a matrix .
| (3) |
Following the above transformation, we can obtain the GRAM matrix of each layer as the corresponding intra-layer correlation.
| (4) |
In , each element is the inner product between the transformed feature maps and in layer .
To capture the correlations between different layers of the network, we first use the GRAM matrix defined in Eq. (4) to obtain the emotional style representation for each layer. However, the shape of the GRAM matrix obtained from different layers may vary, so we next upsample them to the same shape and further stack them together along the channel dimension, denoted as
| (5) |
| (6) |
where is the stacked GRAM matrix by the operator .
To measure the inter-layer correlations in the image, we design an inter-layer correlation module that consists of two convolutional layers, each followed by a layer normalization (LN) and a ReLU activation. Unlike the commonly used instance normalization (IN) in image style transfer networks, the proposed module uses LN to normalize the input feature maps along the three dimensions of channel, width, and height. This increases the correlation between channels, and can be expressed as follows:
| (7) |
where is the emotional style representations, represents inter-layer correlation module.
3.2.2. Visual Attention Module
The visual content information of an image can be derived from the objects and scene information depicted in the image. Complex emotions are not easily acquired from those pieces of information. Inspired by (Chen et al., 2019) in solving person re-identification tasks, we propose a visual attention module that introduces high-order attention (HOA) and feature pyramid mechanisms. It captures the complex relations and subtle differences among visual parts to enhance the ability of emotion distribution learning. Specifically, given the feature maps obtained from the ‘Layer2’ layer, HOA is utilized to model the high-order attentive results among visual parts as follows:
| (8) |
| (9) |
| (10) |
where represents HOA, is the number of order, represents element-wise product operator. Specifically, Eq. (10) mines simple and coarse information from emotional perspectives using various convolution layers . The element-wise product operator that follows is used to capture the complex and high-order interactions of visual parts, as well as the subtle differences among emotional-aware regions caused by the objects present in the image. As shown in Figure 2, to generate the emotional content features under the guidance of high-order relationships, we use the ‘Layer3’ layer termed and ‘Layer4’ layer termed in ResNet-50 to encode the high-order attentive results to obtain multi-scale emotional content features and :
| (11) |
| (12) |
To effectively extract and describe visual content information, we construct a feature pyramid network (FPN) to improve the network’s multi-scale perception ability. This is done by upsampling the feature maps and convolving it with a convolution layer to match the number of channels in . The resulting feature maps are then added to to obtain the emotional content representations .
| (13) |
The HOA can explicitly capture diverse and complementary high-order information, which encourages the richness of the learned features. However, simply employing the HOA module causes partial/biased learning behavior, hindering the performance of our method. The variant labeled as ”noAN” aptly demonstrates this fact with great efficacy in Table 4. As mentioned in (Chen et al., 2019), we introduce an adversary constraint to suppress the problem of order collapse for the multi-scale emotional content features and , respectively:
| (14) | ||||
| (15) |
| (16) |
where is the adversary network (AN) which contains two fully-connected layers, means there are HOA modules (from first-order to -th order), is the multi-scale emotional content vector flattened from with and is the flattening operator. According to Eq. (14) , we get the adversarial loss .
3.2.3. Stylistic-aware Representation
Based on the emotional style and content representations learned above, we use a fusion operator to obtain the stylistic-aware distribution . The fusion operator is a convolution layer with concatenation, which produces an output with the same number of channels as the number of emotion categories.
Specifically, we first use the concatenation operator to combine the stylistic-content representation pairs and to obtain the intermediate representations and , respectively. On the condition, we set . We then concatenate these intermediate representations to obtain the stylistic-aware representations , where . Finally, we apply global average pooling and global max pooling to to generate the stylistic-aware distribution results .
| (17) |
| (18) |
where is the coefficient to control the trade-off between two types of pooling method, is the activation function to unify the element value in to .
3.3. Emotional-aware Enhanced Representation Learning
Different from other LDL tasks, emotions and their unique characteristics have intrinsic relationships, as demonstrated in psychological theories (Yang et al., 2021). Previous work (Yang et al., 2021; He and Jin, 2019; Xiong et al., 2019) has shown that exploiting the correlations between emotion labels can improve the prediction of the emotion distribution of images.
Inspired by (Ye et al., 2020), we introduce a stylistic GCN, which consists of a static GCN termed and a dynamic GCN termed , obtaining initialization representation and emotional-aware enhanced representations as follows:
| (19) |
where is the graph adjacency matrix constructed using the co-occurrence relationship between labels. is obtained by concatenating , where . represents -th order stylistic-aware representations. are learnable parameters. However, the static GCN is not very flexible and can not eliminate irrelevant information of stylistic-aware representations to capture fine emotional dependencies. Therefore, we use the adaptability of the dynamic graph network to better capture emotional-aware enhanced representations:
| (20) |
| (21) |
where enables the network structure to be dynamically adjusted for each image. and are learnable parameters. is obtained by concatenating and its global representations , is the sigmoid activation function.
3.4. Final Distribution and Optimization
Once we have these two predicted distributions and , we can simply combine them using the weighted sum defined above to obtain the final emotional distribution as follows:
| (22) |
where is the coefficient to control the trade-off between two different predicted results.
As with the previous method, the proposed method employs the KL loss (Gao et al., 2017) for the distribution learning. Our objective function consists of adversarial loss and prediction loss . For prediction loss, we consider intermediate supervision instead of directly optimizing the predicted results as follows:
| (23) |
Meanwhile, in order to balance the difference in the numerical scale of the two losses, we adopt an adaptive balance method:
| (24) |
where represents the truncated gradient operator, which calculates the adaptive balance coefficient of adversarial loss.
4. EXPERIMENT
4.1. Experimental Setup
4.1.1. Emotion Datasets
Flickr-LDL (Yang et al., 2017b) is a collection of images that has been annotated with emotional label distributions (i.e.anger, amusement, awe, contentment, disgust, excitement, fear and sadness). Per emotional category was created by selecting a subset of the Flickr dataset (Borth et al., 2013) using 1200 adjective-noun pairs, and then having 11 viewers annotate the images with one of eight common emotions. The final dataset contains 10700 images, with roughly equal numbers of images per emotion class. Twitter-LDL (Yang et al., 2017b) was created by using a variety of emotional keywords to search for images on Twitter and then the retrieved images were manually screened and annotated by 8 viewers. The final dataset contains 10045 images, with the annotations indicating the distribution of emotions present in each image. Emotion6 (Peng et al., 2015) contains 1980 images that were obtained from Flickr using seven categories of emotion keywords (i.e.anger, disgust, joy, fear, sadness, surprise and neutral), with 330 images in each category. And each image was annotated by 15 viewers.
| Measures | PT-Bayes | PT-SVM | AA-kNN | AA-BP | SA-BFGS | SA-CPNN | SSDL | LDL-LDM | DIEDL | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| KL | 1.31(8) | 1.65(9) | 3.89(10) | 1.19(6) | 1.19(6) | 0.85(5) | 0.51(3) | 0.53(4) | 0.47(2) | 0.42(1) |
| Chebyshev | 0.53(9) | 0.63(10) | 0.28(5) | 0.37(7) | 0.37(7) | 0.36(6) | 0.25(3) | 0.27(4) | 0.24(2) | 0.22(1) |
| Clark | 0.85(5) | 0.91(9) | 0.58(1) | 0.89(7) | 0.89(7) | 0.85(5) | 0.84(2) | 2.35(10) | 0.84(2) | 0.84(2) |
| Canberra | 0.77(3) | 0.88(9) | 0.41(1) | 0.84(7) | 0.84(7) | 0.78(6) | 0.76(2) | 6.05(10) | 0.77(3) | 0.77(3) |
| Cosine | 0.53(9) | 0.25(10) | 0.82(5) | 0.71(8) | 0.82(5) | 0.75(7) | 0.86(3) | 0.85(4) | 0.87(2) | 0.89(1) |
| Intersection | 0.40(9) | 0.21(10) | 0.66(5) | 0.59(6) | 0.57(7) | 0.56(8) | 0.69(2) | 0.67(3) | 0.67(4) | 0.73(1) |
| Average Rank | 7.17(9) | 9.50(10) | 4.50(4) | 6.83(7) | 6.50(6) | 6.17(8) | 2.50(2) | 5.83(5) | 2.50(2) | 1.50(1) |
| Measures | PT-Bayes | PT-SVM | AA-kNN | AA-BP | SA-BFGS | SA-CPNN | SSDL | LDL-LDM | DIEDL | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| KL | 2.32(10) | 1.07(8) | 0.85(7) | 0.63(6) | 1.16(9) | 0.56(5) | 0.40(2) | 0.44(4) | 0.40(2) | 0.36(1) |
| Chebyshev | 0.35(8) | 0.39(10) | 0.29(5) | 0.30(6) | 0.38(9) | 0.30(6) | 0.24(2) | 0.26(3) | 0.26(3) | 0.22(1) |
| Clark | 0.73(8) | 0.69(7) | 0.62(2) | 0.64(6) | 0.74(9) | 0.63(5) | 0.62(2) | 1.65(10) | 0.62(2) | 0.59(1) |
| Canberra | 0.66(8) | 0.62(7) | 0.51(2) | 0.54(5) | 0.67(9) | 0.54(5) | 0.51(2) | 3.64(10) | 0.52(4) | 0.47(1) |
| Cosine | 0.69(6) | 0.48(10) | 0.75(4) | 0.68(7) | 0.63(9) | 0.66(8) | 0.79(3) | 0.72(5) | 0.81(2) | 0.84(1) |
| Intersection | 0.56(8) | 0.42(10) | 0.62(5) | 0.59(7) | 0.52(9) | 0.60(6) | 0.66(2) | 0.65(4) | 0.66(2) | 0.70(1) |
| Average Rank | 8.00(8) | 8.67(9) | 4.17(4) | 4.17(4) | 9.00(10) | 5.83(6) | 2.17(2) | 6.00(7) | 2.50(3) | 1.00(1) |
| Measures | PT-Bayes | PT-SVM | AA-kNN | AA-BP | SA-BFGS | SA-CPNN | SSDL | LDL-LDM | DIEDL | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| KL | 1.88(9) | 1.69(8) | 3.28(10) | 0.82(5) | 1.06(6) | 1.06(6) | 0.46(3) | 0.49(2) | 0.46(3) | 0.39(1) |
| Chebyshev | 0.44(9) | 0.55(10) | 0.28(5) | 0.36(7) | 0.37(8) | 0.30(6) | 0.23(2) | 0.25(4) | 0.23(2) | 0.21(1) |
| Clark | 0.89(9) | 0.87(8) | 0.57(1) | 0.82(5) | 0.86(7) | 0.82(5) | 0.78(3) | 2.14(10) | 0.79(4) | 0.76(2) |
| Canberra | 0.85(9) | 0.83(8) | 0.41(1) | 0.75(6) | 0.82(7) | 0.74(5) | 0.69(3) | 5.26(10) | 0.70(4) | 0.66(2) |
| Cosine | 0.63(9) | 0.32(10) | 0.79 (5) | 0.72(6) | 0.70(7) | 0.70(7) | 0.85(3) | 0.84(4) | 0.86(2) | 0.88(1) |
| Intersection | 0.49(9) | 0.29(10) | 0.64(5) | 0.53(8) | 0.56(7) | 0.60(6) | 0.68(3) | 0.66(4) | 0.70(2) | 0.71(1) |
| Average Rank | 9.00(9) | 9.00(9) | 4.50(4) | 6.17(7) | 7.00(8) | 5.83(6) | 2.83(2) | 5.66(5) | 2.83(2) | 1.33(1) |
4.1.2. Evaluation Metrics
To evaluate the effectiveness of our proposed StyleEDL, four metrics are selected: Kullback-Leibler (KL) divergence, Chebyshev distance, Cosine coefficient, Intersection similarity, Clark distance and Canberra metric. Additionally, Average Rank is also adopted to indicate the total performance of each model.
4.1.3. Parameter and Evaluation Settings
We used a ResNet-50 model pre-trained on the ImageNet dataset as our backbone network and removed the last fully connected layer. We considered the outputs of the top convolutional layer and four groups of convolutional layers (‘Conv1’, ‘Layer1’, ‘Layer2’, ‘Layer3’, and ‘Layer4’) of the ResNet-50 model. All training images are resized to pixels and undergo random scaling and horizontal flipping for data augmentation. Our proposed method is implemented using the PyTorch deep learning framework and is trained on an NVIDIA GTX 1080Ti GPU. We used mini-batch stochastic gradient descent (SGD) with momentum and weight decay to optimize our proposed method. The mini-batch size is set to 8 and the learning rate is set to 0.01 for the first 10 epochs, then decreased 10-fold every 20 epochs until the total number of training epochs reaches 90.
4.2. Experimental Results
To evaluate the effectiveness of our proposed StyleEDL, we compared our proposed scheme with several existing state-of-the-art methods, which are grouped into four categories: problem transformation (PT-Bayes and PT-SVM (Geng, 2016)), algorithm adaptation (AA-kNN and AA-BP (Geng, 2016)), specialized algorithm (SA-BFGS (Geng, 2016) and SA-CPNN (Geng et al., 2013)) and CNN-based methods (SSDL (Xiong et al., 2019), LDL-LDM (Wang and Geng, 2021b) and DIEDL (Wu et al., 2023)). Table 1, 2 and 3 show the performances of these methods on three widely used datasets. The best results are highlighted in boldface. The down arrow next to the measure means a lower score is better, and the up arrow means that a higher one is better. From the table, we can make the following observations: 1) AA-kNN achieves insurmountable results in Clerk Distance and Canberra metric, affirming its superiority in addressing intersecting samples in visual emotion distributions. 2) CNN-based methods perform better than the other three types of algorithms, which suggests that CNNs have a stronger ability to capture emotional-related content information from visual parts. 3) Our method consistently outperforms the other methods by a clear margin, indicating that we can expect more accurate results by considering stylistic representations in emotion distribution learning tasks.
4.3. Ablation Study
To further investigate the influence of different components of the proposed method, several variants of our proposed method are configured and ablation experiments are conducted on the Twitter-LDL dataset for comparison. The variants of the model include: (a) B only, which adopts the backbone network. (b) B+G, which adds the GRAM-based intra- and inter-layer correlation based on the (a) model. (c) B+V, which employs the visual attention module based on the (a) model. (e) B+E, which adopts only backbone and emotional-aware enhanced representation learning. (d) B+G+V, which involves both GRAM-based intra- and inter-layer correlation and visual attention module based on the (a) model. (f) B+G+V+E⋆, which replaces our emotional-aware enhanced representation learning with a static GCN. (g) B+G⋆+V+E, which only considers the correlation between GRAM matrices, but not the correlation within the layers. (h) noAN, which discards adversarial constraint loss based on our proposed method.
| Method | KL | Chebyshev | Cosine | Intersection |
|---|---|---|---|---|
| B | 0.457 | 0.228 | 0.881 | 0.718 |
| B+G | 0.448 | 0.228 | 0.881 | 0.719 |
| B+V | 0.441 | 0.226 | 0.882 | 0.717 |
| B+E | 0.482 | 0.229 | 0.876 | 0.718 |
| B+G+V | 0.433 | 0.223 | 0.884 | 0.719 |
| B+G+V+E⋆ | 0.465 | 0.228 | 0.879 | 0.715 |
| B+G⋆+V+E | 0.434 | 0.224 | 0.884 | 0.719 |
| noAN | 0.446 | 0.223 | 0.882 | 0.723 |
| Ours | 0.420 | 0.218 | 0.889 | 0.726 |
The results are shown in Table 4. In this table, we selected six metrics mentioned in our paper to report the emotion distribution based on their predicted results. From the results, the following observations can be made: 1) Without style-induced information, B+V performs worse than B+G+V, indicating that the emotional style representations are beneficial for learning stylistic-aware representations. 2) B+G and B+V all take positive effects, which demonstrate that not only the learning of visual content information improves emotional distribution results, but also the style information plays an important role. 3) B+E yields inferior outcomes compared to B, suggesting that features extracted from ResNet-50 and directly applied to our stylistic GCN do not yield favorable results. 4) Our proposed StyleEDL consistently surpasses B+G+V, B+G+V+E⋆ and B+G⋆+V+E, which means our proposed method gains from the use of the intra- and inter-layer correlation and the stylistic GCN. Moreover, the outcomes further indicate that the flexible dynamic GCN can eliminate irrelevant information of stylistic-aware representations. Similar observations also can be found for the other two datasets.
4.4. Parameter Sensitivity Analysis
In our work, there are three essential parameters, which are the order of the HOA module and the balance coefficients and in stylistic-aware representation learning and emotional-aware enhanced representation learning, respectively. We conducted comprehensive experiments on two datasets: the Twitter-LDL and the Emotion6. Specifically, the KL divergence and Intersection coefficient metrics were used for the Twitter-LDL, while the KL divergence and Cosine coefficient metrics were used for the Emotion6.
| Order | ||||
|---|---|---|---|---|
| KL | 0.445 | 0.420 | 0.421 | 0.427 |
| Chebyshev | 0.225 | 0.218 | 0.221 | 0.219 |
| Cosine | 0.882 | 0.889 | 0.888 | 0.886 |
| Intersection | 0.721 | 0.726 | 0.720 | 0.724 |
| Order | ||||
|---|---|---|---|---|
| KL | 0.377 | 0.361 | 0.385 | 0.393 |
| Chebyshev | 0.227 | 0.222 | 0.231 | 0.235 |
| Cosine | 0.829 | 0.839 | 0.827 | 0.822 |
| Intersection | 0.694 | 0.698 | 0.689 | 0.687 |
4.4.1. Order of HOA module
Tables 5 and 6 show that our proposed method performs best when for both two datasets. When , our proposed method lacks the ability to further encode feature maps and fails to employ the attention mechanism to refine the visual content representations, while a large value of makes the model more susceptible to being influenced by noise.
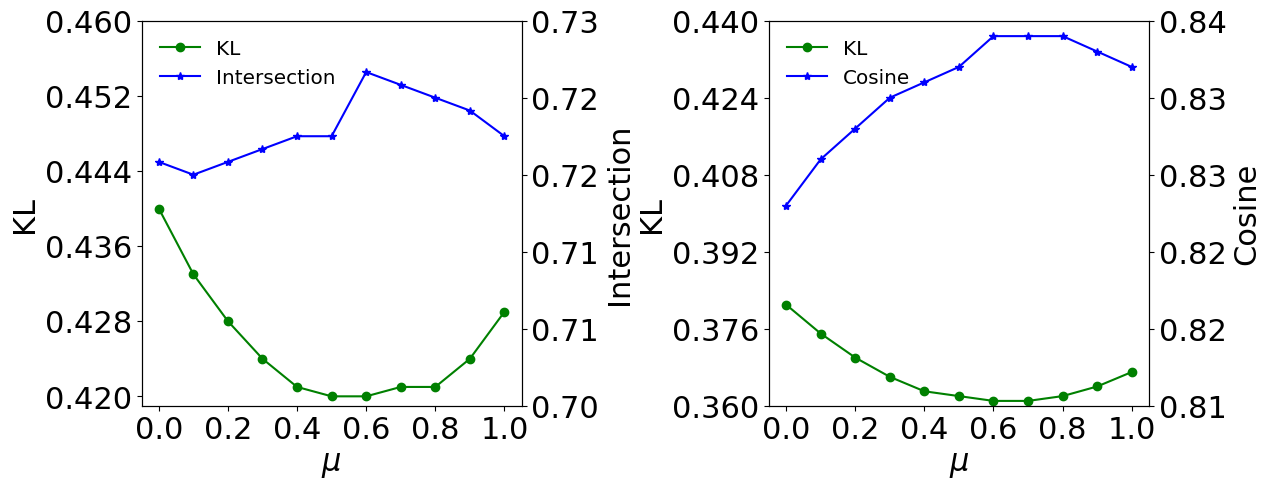
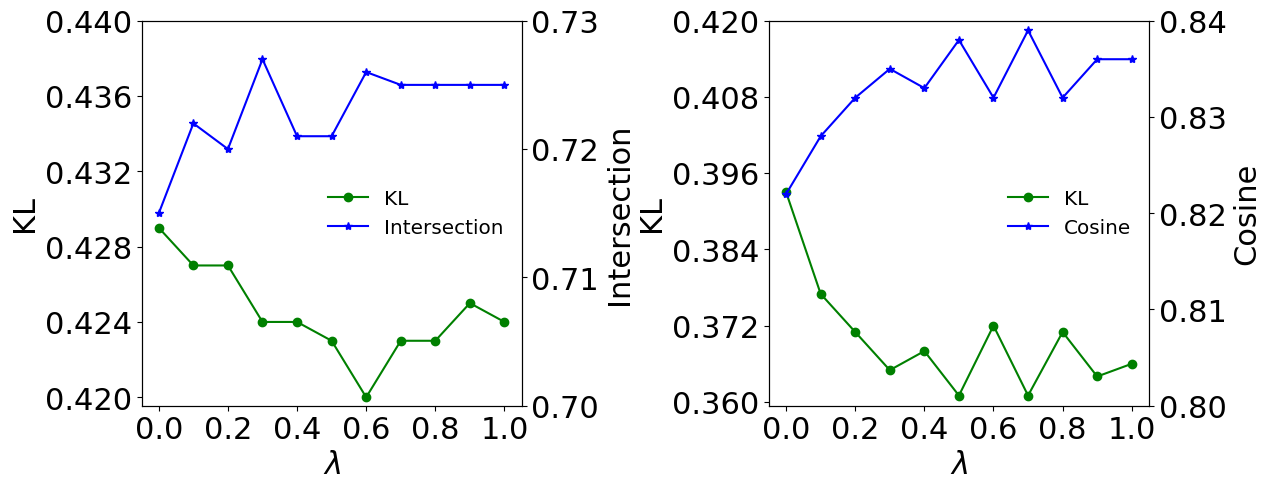
4.4.2. Balance coefficient
We investigated the influence of the balance coefficients and by varying their values from to . As shown in Figure 4, larger values of generally result in better performance than smaller values. A proper value of can enhance the stylistic-aware representations of images and improve the overall performance of the model. The coefficient plays an important role in balancing the importance between stylistic-aware distribution results and emotional-aware distribution results. From Figure 3, our proposed method steadily improves from to and reaches its best performance at . Intuitively, the performance can be enhanced by introducing emotional-aware enhanced representation learning. Moreover, all values of KL divergence on emotion6 are much lower than that on Twitter-LDL, which may be owing to the fact that the dataset size of emotion6 is much smaller than that of Twitter-LDL.
4.5. Computational Complexity
Table 7 reports the actual inference time with several recent state-of-the-art methods. As discerned from the table, our approach achieves superior performance than those methods at the cost of the high computational complexity of the HOA, which proffers us a glimpse into the future. In the future, we will explore light high-order solutions.
| SSDL | LDL-LDM | DIEDL | Ours | |
| Time (ms) | 5.853 | 1.27 | 7.659 | 16.272 |
Figure 5 presents a qualitative comparison of the predicted distributions on the Twitter-LDL dataset. The visualization encompasses two aspects: 1. different scenarios, such as human, animal, etc. 2. the impact of style on emotions. From the illustration, we could discern that our method has achieved decent prediction results. In particular, our model can identify well the changes in emotions induced by stylistic information. Taking the first and second images in Figure 5 as an example, the second one evokes a more melancholic state, and our method cannot solely rely on content perception alone to account for this difference, thereby substantiating the efficacy of incorporating style information.
5. CONCLUSION
In this paper, we propose a novel image emotion distribution learning method termed StyleEDL to learn emotional distribution in a style-induced manner. In StyleEDL, we sought stylistic-aware representations of images based on the hierarchical stylistic information of visual parts. In addition, emotional-aware enhanced representations are obtained and further exploited to explore correlations between emotions by the stylistic GCN. Comprehensive experiments on three well-known datasets demonstrate the superiority of our StyleEDL.
References
- (1)
- Borth et al. (2013) Damian Borth, Rongrong Ji, Tao Chen, Thomas Breuel, and Shih-Fu Chang. 2013. Large-scale visual sentiment ontology and detectors using adjective noun pairs. In Proceedings of the 21st ACM international conference on Multimedia. 223–232.
- Chen et al. (2019) Binghui Chen, Weihong Deng, and Jiani Hu. 2019. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE/CVF international conference on computer vision. 371–381.
- Chu and Wu (2018) Wei-Ta Chu and Yi-Ling Wu. 2018. Image style classification based on learnt deep correlation features. IEEE Transactions on Multimedia 20, 9 (2018), 2491–2502.
- Fan et al. (2018) Yangyu Fan, Hansen Yang, Zuhe Li, and Shu Liu. 2018. Predicting image emotion distribution by emotional region. In 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI). IEEE, 1–9.
- Freeman (2004) Linton Freeman. 2004. The development of social network analysis. A Study in the Sociology of Science 1, 687 (2004), 159–167.
- Gao et al. (2017) Bin-Bin Gao, Chao Xing, Chen-Wei Xie, Jianxin Wu, and Xin Geng. 2017. Deep label distribution learning with label ambiguity. IEEE Transactions on Image Processing 26, 6 (2017), 2825–2838.
- Geng (2016) Xin Geng. 2016. Label distribution learning. IEEE Transactions on Knowledge and Data Engineering 28, 7 (2016), 1734–1748.
- Geng et al. (2013) Xin Geng, Chao Yin, and Zhi-Hua Zhou. 2013. Facial age estimation by learning from label distributions. IEEE transactions on pattern analysis and machine intelligence 35, 10 (2013), 2401–2412.
- Ghosal et al. (2019) Koustav Ghosal, Mukta Prasad, and Aljosa Smolic. 2019. A geometry-sensitive approach for photographic style classification. arXiv preprint arXiv:1909.01040 (2019).
- He and Jin (2019) Tao He and Xiaoming Jin. 2019. Image emotion distribution learning with graph convolutional networks. In Proceedings of the 2019 on International Conference on Multimedia Retrieval. 382–390.
- Holbrook and O’Shaughnessy (1984) Morris B. Holbrook and John O’Shaughnessy. 1984. The role of emotion in advertising. Psychology & Marketing 1, 2 (1984), 45–64.
- Jing et al. (6796) Peiguang Jing, Kai Cui, Weili Guan, Liqiang Nie, and Yuting Su. 2023, DOI:10.1109/TMM.2023.3246796. Category-aware Multimodal Attention Network for Fashion Compatibility Modeling. IEEE Transactions on Multimedia (2023, DOI:10.1109/TMM.2023.3246796).
- Laubrock and Dubray (2019) Jochen Laubrock and David Dubray. 2019. CNN-based Classification of Illustrator Style in Graphic Novels: Which Features Contribute Most?. In International Conference on Multimedia Modeling. Springer, 684–695.
- Lecoutre et al. (2017) Adrian Lecoutre, Benjamin Negrevergne, and Florian Yger. 2017. Recognizing art style automatically in painting with deep learning. In Asian conference on machine learning. PMLR, 327–342.
- Lu et al. (2015) Xin Lu, Zhe Lin, Xiaohui Shen, Radomir Mech, and James Z Wang. 2015. Deep multi-patch aggregation network for image style, aesthetics, and quality estimation. In Proceedings of the IEEE international conference on computer vision. 990–998.
- Lu et al. (2019) Xu Lu, Lei Zhu, Zhiyong Cheng, Jingjing Li, Xiushan Nie, and Huaxiang Zhang. 2019. Flexible Online Multi-Modal Hashing for Large-Scale Multimedia Retrieval. In Proceedings of the 27th ACM International Conference on Multimedia (MM). 1129–1137.
- Matsuo and Yanai (2016) Shin Matsuo and Keiji Yanai. 2016. CNN-based style vector for style image retrieval. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval. 309–312.
- Mitchell (1986) Andrew A Mitchell. 1986. The effect of verbal and visual components of advertisements on brand attitudes and attitude toward the advertisement. Journal of consumer research 13, 1 (1986), 12–24.
- Mittal et al. (2021) Anshul Mittal, Noveen Sachdeva, Sheshansh Agrawal, Sumeet Agarwal, Purushottam Kar, and Manik Varma. 2021. ECLARE: Extreme classification with label graph correlations. In Proceedings of the Web Conference 2021. 3721–3732.
- Nie et al. (2022) Liqiang Nie, Leigang Qu, Dai Meng, Min Zhang, Qi Tian, and Alberto Del Bimbo. 2022. Search-oriented micro-video captioning. In Proceedings of the 30th ACM International Conference on Multimedia. 3234–3243.
- Peng et al. (2015) Kuan-Chuan Peng, Tsuhan Chen, Amir Sadovnik, and Andrew C Gallagher. 2015. A mixed bag of emotions: Model, predict, and transfer emotion distributions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 860–868.
- Qu et al. (2021) Leigang Qu, Meng Liu, Jianlong Wu, Zan Gao, and Liqiang Nie. 2021. Dynamic modality interaction modeling for image-text retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1104–1113.
- Rao et al. (2020) Tianrong Rao, Xiaoxu Li, and Min Xu. 2020. Learning multi-level deep representations for image emotion classification. Neural processing letters 51 (2020), 2043–2061.
- Serrat (2017) Olivier Serrat. 2017. Social network analysis. In Knowledge solutions. Springer, 39–43.
- Wang and Geng (2021a) Jing Wang and Xin Geng. 2021a. Label distribution learning by exploiting label distribution manifold. IEEE transactions on neural networks and learning systems (2021).
- Wang and Geng (2021b) Jing Wang and Xin Geng. 2021b. Label Distribution Learning by Exploiting Label Distribution Manifold. IEEE transactions on neural networks and learning systems PP (08 2021).
- Wasserman and Faust (1994) Stanley Wasserman and Katherine Faust. 1994. Social network analysis: Methods and applications. (1994).
- Wu et al. (2023) Huiyan Wu, Yonggang Huang, and Guoshun Nan. 2023. Doubled Coupling for Image Emotion Distribution Learning. Know.-Based Syst. 260, C (jan 2023), 11 pages.
- Xiong et al. (2019) Haitao Xiong, Hongfu Liu, Bineng Zhong, and Yun Fu. 2019. Structured and sparse annotations for image emotion distribution learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 363–370.
- Xu and Wang (2021) Zhiwei Xu and Shangfei Wang. 2021. Emotional attention detection and correlation exploration for image emotion distribution learning. IEEE Transactions on Affective Computing (2021).
- Yang et al. (2013) Byunghwa Yang, Youngchan Kim, and Changjo Yoo. 2013. The integrated mobile advertising model: The effects of technology-and emotion-based evaluations. Journal of Business Research 66, 9 (2013), 1345–1352.
- Yang et al. (2018a) Jufeng Yang, Liyi Chen, Le Zhang, Xiaoxiao Sun, Dongyu She, Shao-Ping Lu, and Ming-Ming Cheng. 2018a. Historical context-based style classification of painting images via label distribution learning. In Proceedings of the 26th ACM international conference on Multimedia. 1154–1162.
- Yang et al. (2021) Jingyuan Yang, Jie Li, Leida Li, Xiumei Wang, and Xinbo Gao. 2021. A circular-structured representation for visual emotion distribution learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4237–4246.
- Yang et al. (2018b) Jufeng Yang, Dongyu She, Yu-Kun Lai, Paul L Rosin, and Ming-Hsuan Yang. 2018b. Weakly supervised coupled networks for visual sentiment analysis. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7584–7592.
- Yang et al. (2017a) Jufeng Yang, Dongyu She, and Ming Sun. 2017a. Joint Image Emotion Classification and Distribution Learning via Deep Convolutional Neural Network.. In IJCAI. 3266–3272.
- Yang et al. (2018c) Jufeng Yang, Dongyu She, Ming Sun, Ming-Ming Cheng, Paul L Rosin, and Liang Wang. 2018c. Visual sentiment prediction based on automatic discovery of affective regions. IEEE Transactions on Multimedia 20, 9 (2018), 2513–2525.
- Yang et al. (2017b) Jufeng Yang, Ming Sun, and Xiaoxiao Sun. 2017b. Learning visual sentiment distributions via augmented conditional probability neural network. In Thirty-first AAAI conference on artificial intelligence.
- Ye et al. (2020) Jin Ye, Junjun He, Xiaojiang Peng, Wenhao Wu, and Yu Qiao. 2020. Attention-driven dynamic graph convolutional network for multi-label image recognition. In European Conference on Computer Vision. Springer, 649–665.
- Zhang et al. (2019) Wei Zhang, Xuanyu He, and Weizhi Lu. 2019. Exploring discriminative representations for image emotion recognition with CNNs. IEEE Transactions on Multimedia 22, 2 (2019), 515–523.
- Zhao et al. (2021) Sicheng Zhao, Xingxu Yao, Jufeng Yang, Guoli Jia, Guiguang Ding, Tat-Seng Chua, Bjoern W Schuller, and Kurt Keutzer. 2021. Affective image content analysis: Two decades review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021).
- Zhu et al. (2020) Lei Zhu, Xu Lu, Zhiyong Cheng, Jingjing Li, and Huaxiang Zhang. 2020. Deep Collaborative Multi-View Hashing for Large-Scale Image Search. IEEE Trans. Image Process. 29 (2020), 4643–4655.
- Zhu et al. (2023) Lei Zhu, Chaoqun Zheng, Weili Guan, Jingjing Li, Yang Yang, and Heng Tao Shen. 2023. Multi-modal Hashing for Efficient Multimedia Retrieval: A Survey. IEEE Transactions on Knowledge and Data Engineering (2023), 1–20. https://doi.org/10.1109/TKDE.2023.3282921
- Zhu et al. (2017) Xinge Zhu, Liang Li, Weigang Zhang, Tianrong Rao, Min Xu, Qingming Huang, and Dong Xu. 2017. Dependency Exploitation: A Unified CNN-RNN Approach for Visual Emotion Recognition.. In IJCAI. 3595–3601.