Sub-Aperture Feature Adaptation in Single Image Super-resolution Model for Light Field Imaging
Abstract
With the availability of commercial Light Field (LF) cameras, LF imaging has emerged as an up-and-coming technology in computational photography. However, the spatial resolution is significantly constrained in commercial micro-lens-based LF cameras because of the inherent multiplexing of spatial and angular information. Therefore, it becomes the main bottleneck for other applications of light field cameras. This paper proposes an adaptation module in a pre-trained Single Image Super-Resolution (SISR) network to leverage the powerful SISR model instead of using highly engineered light field imaging domain-specific Super Resolution models. The adaption module consists of a Sub-aperture Shift block and a fusion block. It is an adaptation in the SISR network to further exploit the spatial and angular information in LF images to improve the super-resolution performance. Experimental validation shows that the proposed method outperforms existing light field super-resolution algorithms. It also achieves PSNR gains of more than dB across all the datasets as compared to the same pre-trained SISR models for scale factor , and PSNR gains dB for scale factor .
Index Terms— Light field, sub-aperture feature, super-resolution
1 Introduction
A Light Field (LF) camera not only provides spatial information but also captures the angular information of the incoming light from a scene point. Therefore, it enables the LF camera to improve image processing performance in different applications such as depth estimation [1], image segmentation [2], image editing [3], and many more. These techniques can be further improved if we have an image of higher spatial resolution. In the case of an LF camera, multiplexing of angular and spatial information results in poor spatial resolution of Sub-Aperture (SA) images. For example, the Lytro Illum sensor resolution is MP, but a sub-aperture image’s spatial resolution is close to MP. Therefore it is necessary to achieve Super-Resolution (SR) in LF image by exploiting the additional angular information present in the LF data.
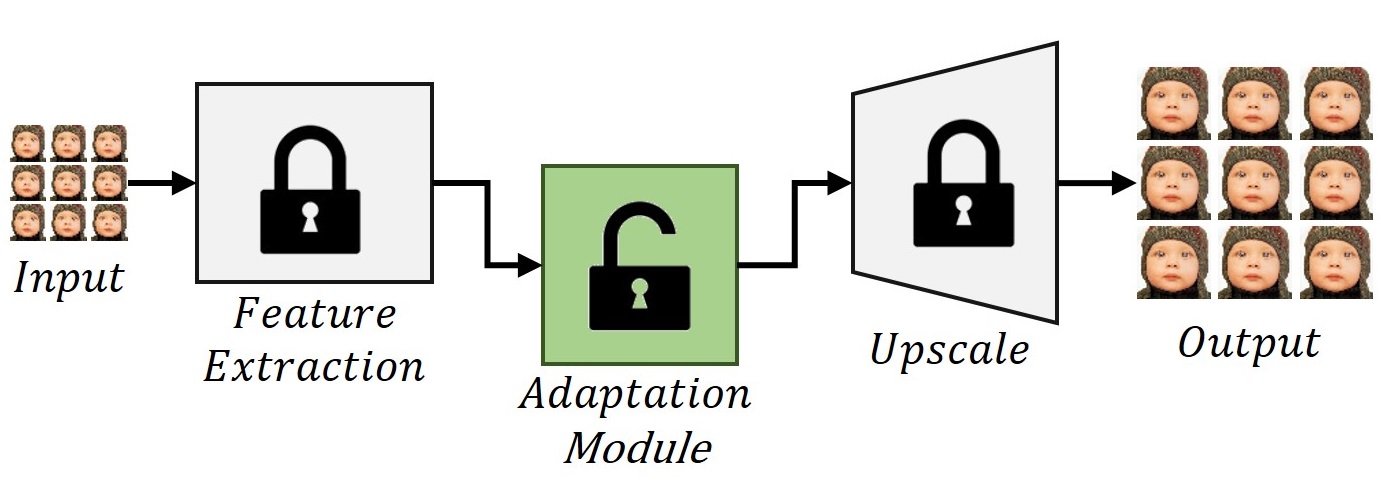
Recently, Light Field Super-Resolution (LFSR) has been an area of active research, and a considerable amount of work has been done in the last few years. The earlier works were mainly based on Bayesian or variational optimization frameworks with different priors such as variational model [4], Gaussian mixture model [5], and PCA analysis model [6]. These methods are inefficient in exploiting Spatio-angular information of the light field data. In contrast, learning-based methods have been proposed to achieve SR via cascaded convolutions and data-driven training. Single Image Super-Resolution (SISR) methods [7, 8, 9, 10] are becoming increasingly deep and complicated with improved capability in spatial information exploitation. However, the angular information of LF images remains unexploited in SISR networks, resulting in limited performance. Inspired by learning-based methods in SISR and in pursuit of exploiting the angular information, recent LFSR methods [11, 12, 13, 14] adopted deep Convolution Neural Networks (CNNs) to improve SR performance.
This paper proposes a novel Light Field Sub-Aperture Feature Adaptation (LFSAFA) module and puts it into a pre-trained single image super-resolution model for achieving LFSR. LFSAFA exploits the angular information present in the SA images of LF data to improve the performance of LFSR. The proposed module consists of Sub Aperture Shift (SAS) and feature fusion blocks. SAS blocks process the Sub-Aperture (SA) features, and the fusion block combines those features. The modulated SA features are then fed to the upscaling network to reconstruct high-resolution images. Our experimental validation shows that pre-trained SISR models with simple LF-specific modifications can perform better than highly engineered light field image-specific super-resolution models. To summarize, the contributions of this proposed work are as follows.
-
•
We propose a light-field domain adaptation module to achieve LFSR using SISR models. To the best of our knowledge, this is the first work in this direction.
-
•
We show that the proposed module can utilize angular information present in SA images to improve the performance, and ablation studies support our claims.
-
•
Our qualitative and quantitative analysis shows that the performance of our method is better than light-field domain-specific super-resolution solutions, and any SISR models can adopt our proposed modification to make it work for LFSR.
2 Related Work
Due to the advancement of deep learning architectures and algorithms, the LFSR domain has witnessed tremendous progress. C. Yoon et al. [15] super-resolved Sub-Aperture Images (SAIs) via CNN and then fine-tuned using angular information to enhance both spatial and angular resolutions. LF-DCNN [16] super-resolved each SAI via a more powerful SISR network and fine-tuned the initial results using an EPI-enhancement network. LFNet [17] proposed a bidirectional recurrent network by extending BRCNN [18]. Zhang et al. [11] proposed a multi-stream residual network (resLF) by stacking SAIs as inputs to super-resolve the center-view SAI. LFSSR [12] alternately shuffle LF features between SAI pattern and macro-pixel image pattern for convolution. Jin et al. [19] proposed an all-to-one geometric aware method using structural consistency regularization that preserves the parallax structure among reconstructed views. LF-InterNet [13] used spatial-angular information interaction for LFSR. LF-DFnet [14] performed feature alignment using an angular deformable alignment module (ADAM). MEG-Net [20] considered multiple epipolar geometry, and all views are simultaneously super-resolved through an end-to-end manner. DPT [21] used SAIs as a sequence and introduced a detail-preserving transformer to learn geometric dependencies among those sequences.
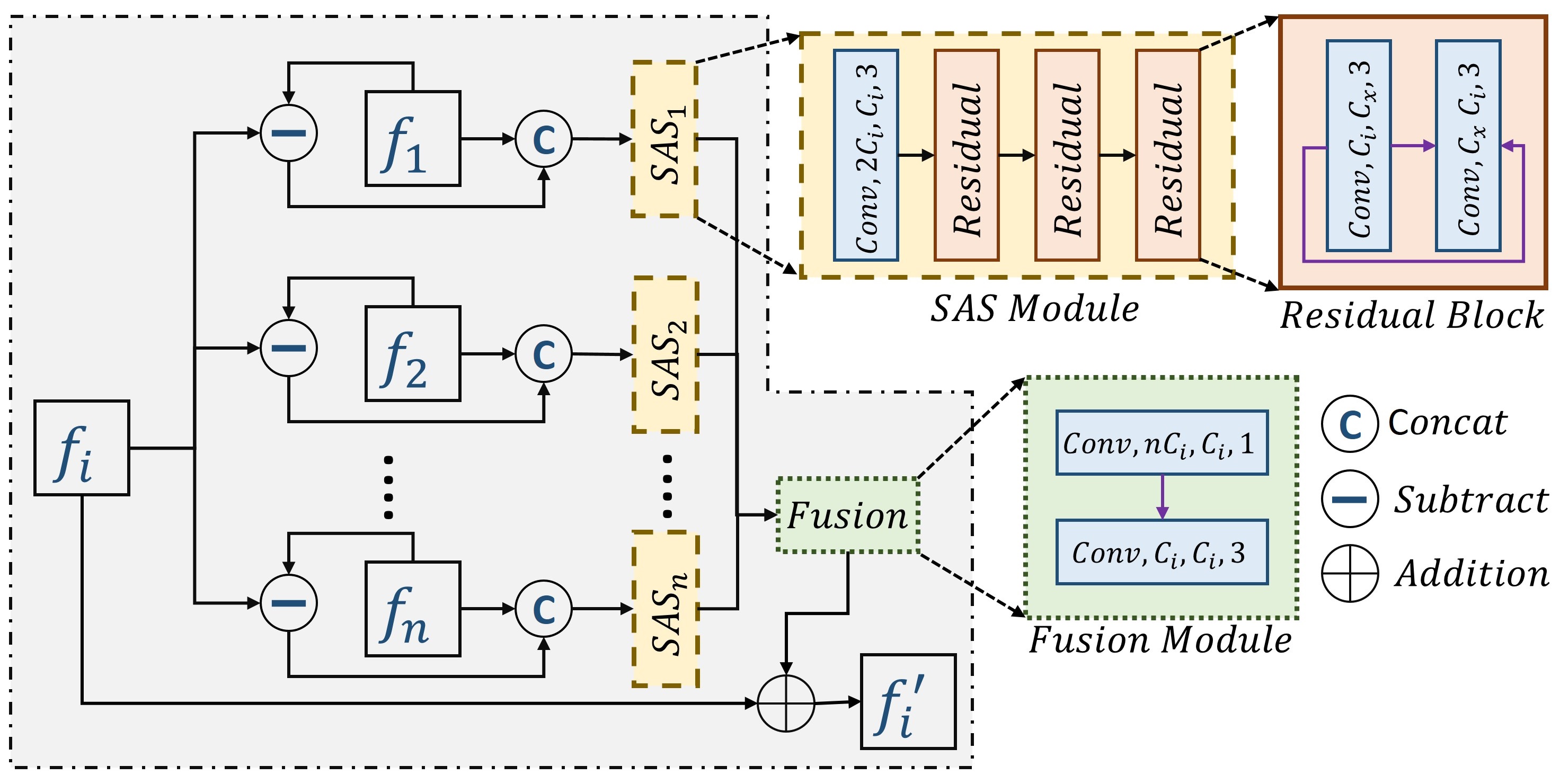
3 Methodology
3.1 Motivation and Problem Formulation
Well-developed research has been achieved in the single-image super-resolution domain, leading to extraordinary performance in a single image. Images captured by the LF camera can be up-scaled by pre-trained SISR models by considering each sub-aperture image as a single image. However, it fails to exploit the angular and disparity information present in multiple SAIs. Our main objective is to propose an LF domain-specific module on top of the SISR model to achieve LFSR. Recently developed SISR models, can be divided into two parts. One is feature extraction module , and another one is upscaling cum reconstruction module . extracts the salient features from a single image that is up-scaled by . Our main objective is to introduce a module that modulates the extracted features from by exploiting angular information across SAIs.
3.2 Light-field Sub-aperture Feature Adaptation Module
Using our proposed adaptation module, the pre-trained SISR model adapts the spatial and angular information present in LF images which eventually improves the super-resolution performance further, as shown in Fig. 1. The feature extraction and upscale module are from any pre-trained SISR model, and we place the adaptation module between them. Fig. 2 shows the proposed light-field domain information adaptation module. The light-field camera captures multiple SA images of the same scene. In this work, the rich information present in those angular SA images is utilized to enhance each SA image’s quality. is extracted feature set from a sub-aperture image using pre-trained feature extraction module of a SISR model. are extracted features from different sub-aperture images. Each sub-aperture feature set is processed through its corresponding Sub-Aperture Shift (SAS) module. Each SAS module is expected to process the features in such a way that it can improve the performance on the sub-aperture image task in hand. The term shift in SAS is used as it is desired that the SAS module is expected to align the features from different sub-aperture images in the direction of the SA image feature set in hand to improve the performance. Fusion block fuses the processed SA features and feeds the fused features into the upscale module. During training, the weights of the pre-trained feature extraction and upscale modules are not updated during gradient back-propagation. We only update the weights of the adaptation module, as shown in Fig. 1.
SAS Module: If we consider a light-field image of angular resolution, there will be number of SA images. Therefore, we have SAS modules for SA images. Each module takes its corresponding extracted SA features concatenated with a difference feature map. The difference feature map represents the difference between the SA feature set in hand and the SA feature set of that corresponding SAS module. The difference feature map helps to shift or modify a SA feature set in such a way that it will improve the performance of the SA feature set in hand. The difference map acts as a modulator that decides how much shift is required for a SA feature for pixel-wise mapping. The output of a SAS module can be mathematically represented as
| (1) |
is the extracted features of angular SA image, which will be super-resolved, and is the extracted features of angular SA image. Both and are concatenated before feeding into module. This module is expected shift features and align with using the difference map . All the SAS modules will align the features with and feed them into the fusion module.
Fusion Module: All the modulated SA features are fused together. It is mathematically expressed as
| (2) |
is the fusion module and is the sub-aperture informative fused feature of SA feature .
3.3 Architecture Details
Each SAS module consists of one convolution block and three consecutive residual blocks, as shown in Fig. 2. Fusion block contains two convolution layers. The first convolution layer blends all the SA features using convolution, and the second convolution layer processes the fused features. We consider the popular RDN [9] and EDSR [8] architecture of SISR for experimental purposes. In both cases, there are features in the feature set that are extracted from the feature extraction block. Therefore, we consider and in our experimental setup, as shown in Fig. 2.
| Method | Scale | Dataset | ||
| EPFL [22] | INRIA [23] | STFgantry [24] | ||
| Bicubic | 29.500.935 | 31.100.956 | 30.820.947 | |
| VDSR [7] | 32.500.960 | 34.430.974 | 35.540.979 | |
| RCAN [10] | 33.160.964 | 35.010.977 | 36.330.983 | |
| resLF [11] | 32.750.967 | 34.570.978 | 36.890.987 | |
| LFSSR [12] | 33.690.975 | 35.270.983 | 38.070.990 | |
| LF-InterNet [13] | 34.140.976 | 35.800.985 | 38.720.992 | |
| LF-DFnet [14] | 34.440.977 | 36.360.984 | 39.610.994 | |
| MEG-Net [20] | 34.310.977 | 36.100.985 | 38.770.992 | |
| DPT [21] | 34.490.976 | 36.410.984 | 39.430.993 | |
| LFSAFA-EDSR | 35.080.973 | 37.510.983 | 38.690.990 | |
| LFSAFA-RDN | 35.190.974 | 37.640.983 | 39.020.991 | |
| Bicubic | 25.140.831 | 26.820.886 | 25.930.843 | |
| VDSR [7] | 27.250.878 | 29.190.921 | 28.510.901 | |
| RCAN [10] | 27.880.886 | 29.760.927 | 28.900.911 | |
| resLF [11] | 27.460.890 | 29.640.934 | 28.990.921 | |
| LFSSR [12] | 28.270.908 | 30.310.945 | 30.150.939 | |
| LF-InterNet [13] | 28.670.914 | 30.640.949 | 30.530.943 | |
| LF-DFnet [14] | 28.770.917 | 30.830.950 | 31.150.949 | |
| MEG-Net [20] | 28.750.916 | 30.670.949 | 30.770.945 | |
| DPT [21] | 28.940.917 | 30.960.950 | 31.150.949 | |
| LFSAFA-EDSR | 29.470.909 | 31.880.945 | 30.410.937 | |
| LFSAFA-RDN | 29.620.911 | 32.060.947 | 30.800.941 | |
4 Experiments
4.1 Implementation Details
We used images from publicly available LF datasets, namely EPFL [22], HCInew [25], HCIold [26], INRIA [23], and STFgantry [24]. We follow the same train-test split as given by [14]. There are a total of training images in the dataset and consider standard angular resolution for benchmark analysis. For testing, we use real-world images from EPFL [22], INRIA [23], and STFgantry [24] datasets which consists of , , and test images, respectively. EDSR [8] and RDN [9] are the base SISR models, where we insert our proposed LFSAFA module to adapt these models for light-field imaging. Bicubic downsampling generates low-resolution (LR) images from its high-resolution (HR) counterpart. We extract random crop from LR images during training and augment the patch using random rotation with a random horizontal and vertical flip. We train the LFSAFA module for epochs, and each epoch consists of batch updates with a batch size of . Adam optimizer with a learning rate is used for updating the weights, and the learning rate is reduced by a factor of after every epochs. The mean absolute difference between output reconstruction and HR image is employed as a loss function. Peak signal-to-noise ratio (PSNR) and Structural Similarity Index (SSIM) are calculated on all the sub-aperture views for comparative performance analysis. Larger values on those metrics imply better reconstruction performance. Following the trend in the LFSR domain, PSNR and SSIM are calculated on the luminance channel Y of an image in YCbCr space. The code is available at https://aupendu.github.io/LFSAFA-SR.
4.2 Performance Analysis
We compare the performance of our proposed approach with state-of-the-art single image super-resolution and light field super-resolution models. VDSR [7], RCAN [10] are the SISR models, and the rest of the methods in Table 1 are the LFSR models. All the SISR models are trained on light field training images for a fair comparison. We can observe from Table 1 that both the SISR models with our proposed modification outperform all the existing techniques in terms of PSNR on EPFL and INRIA datasets. The proposed method cannot outperform other methods in the SSIM metric. However, the SSIM values are very close to the best. Fig. 3 shows the qualitative comparison of our proposed algorithm with existing LFSR approaches. We observe that our proposed algorithm achieves a more satisfactory reconstruction of numbers in the first-row image, excellently reconstructs the round holes in the second-row image, and adequately preserves the line structure, which is on the left side of the third-row image.







|
|
|
|
PSNR/ SSIM | |||||||||
| Ablation-1 | ✗ | ✗ | ✗ | 34.10/ 0.9662 | |||||||||
| Ablation-2 | ✓ | ✗ | ✓ | 34.17/ 0.9664 | |||||||||
| Ablation-3 | ✗ | ✓ | ✓ | 34.81/ 0.9711 | |||||||||
| Ablation-4 | ✓ | ✓ | ✓ | 34.86/ 0.9715 | |||||||||
| Ablation-5 | ✓ | ✓ | ✓ | 35.19/ 0.9737 |
4.3 Ablation Studies
Table 2 shows the model ablation studies of our proposed LFSAFA module. Along with the model ablation, a study on the effect of the angular resolution is given in that table. All the components are the same for both Ablation-4 and Ablation-5 except the angular resolution of the input LF image. We can observe from the table that the network’s performance in terms of PSNR and SSIM increases as we increase the angular resolution. The proposed module LFSAFA gets more angular information as we increase the angular resolution. Therefore, it leads to better performance. This phenomenon also supports our claim that our module has the potential to explore sub-aperture angular information. Other ablations show the effectiveness of three different parts of the LFSAFA module. The first one is the residual connection between the input and output, the second one is the inclusion of difference features into each SAS module, and the third one is the contribution of the whole proposed adaptation module, LFSAFA. The only difference between Ablation-3 and Ablation-4 is the residual connection, and it shows that performance improves slightly with that connection, and we also observe that the network converges faster. Ablation-1 is basically the SISR model without the LFSAFA module. The performance does not improve much even if we add the proposed adaptation module without the difference feature, as shown in Ablation-2. Therefore, the difference feature plays a key role, and we can observe that by comparing the Ablation-2 and Ablation-4. There is a significant jump in performance metrics. Therefore, we can say that the difference feature plays a crucial role in utilizing the sup-aperture information in a controlled manner. Table 3 shows the summarized main contribution of this paper. LFSAFA module helps both the SISR models to adopt the LF domain-specific extra angular information. We can observe a significant improvement in PSNR metric across all the datasets and models for SR, and improvement for SR.
| Scale | Dataset | RDN | LFSAFA-RDN | EDSR | LFSAFA-EDSR |
| EPFL | 34.140.966 | 35.190.974 | 34.060.966 | 35.080.973 | |
| INRIA | 36.420.978 | 37.640.983 | 36.280.978 | 37.510.983 | |
| STFgantry | 37.910.987 | 39.020.991 | 37.480.986 | 38.690.990 | |
| EPFL | 28.840.898 | 29.620.911 | 28.730.895 | 29.470.909 | |
| INRIA | 31.060.935 | 32.060.947 | 30.920.933 | 31.880.945 | |
| STFgantry | 30.180.932 | 30.800.941 | 29.750.926 | 30.410.937 |
5 Conclusion
In this work, we propose a module that will turn a SISR model into an LFSR model. The proposed module can be used in all the recently developed SISR models without architectural modifications. This paper presents a new research direction in the LFSR domain, which will drive the community to develop a better sub-aperture feature adaptation module. In the future, a more powerful sub-aperture feature adaptation module can improve the performance further.
References
- [1] Jiayong Peng, Zhiwei Xiong, Yicheng Wang, Yueyi Zhang, and Dong Liu, “Zero-shot depth estimation from light field using a convolutional neural network,” IEEE TCI, vol. 6, pp. 682–696, 2020.
- [2] Numair Khan, Qian Zhang, Lucas Kasser, Henry Stone, Min H Kim, and James Tompkin, “View-consistent 4d light field superpixel segmentation,” in ICCV, 2019, pp. 7811–7819.
- [3] Ki Won Shon, In Kyu Park, et al., “Spatio-angular consistent editing framework for 4d light field images,” Multimedia Tools and Applications, vol. 75, no. 23, pp. 16615–16631, 2016.
- [4] Sven Wanner and Bastian Goldluecke, “Variational light field analysis for disparity estimation and super-resolution,” IEEE TPAMI, vol. 36, no. 3, pp. 606–619, 2013.
- [5] Kaushik Mitra and Ashok Veeraraghavan, “Light field denoising, light field superresolution and stereo camera based refocussing using a gmm light field patch prior,” in CVPRW. IEEE, 2012, pp. 22–28.
- [6] Reuben A Farrugia, Christian Galea, and Christine Guillemot, “Super resolution of light field images using linear subspace projection of patch-volumes,” IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 7, pp. 1058–1071, 2017.
- [7] Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee, “Accurate image super-resolution using very deep convolutional networks,” in CVPR, 2016, pp. 1646–1654.
- [8] Bee Lim, Sanghyun Son, et al., “Enhanced deep residual networks for single image super-resolution,” in CVPRW, 2017, pp. 136–144.
- [9] Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu, “Residual dense network for image super-resolution,” in CVPR, 2018, pp. 2472–2481.
- [10] Yulun Zhang, Kunpeng Li, et al., “Image super-resolution using very deep residual channel attention networks,” in ECCV, 2018, pp. 286–301.
- [11] Shuo Zhang, Youfang Lin, and Hao Sheng, “Residual networks for light field image super-resolution,” in CVPR, 2019, pp. 11046–11055.
- [12] Henry Wing Fung Yeung, Junhui Hou, et al., “Light field spatial super-resolution using deep efficient spatial-angular separable convolution,” IEEE TIP, vol. 28, no. 5, pp. 2319–2330, 2018.
- [13] Yingqian Wang, Longguang Wang, et al., “Spatial-angular interaction for light field image super-resolution,” in ECCV, 2020.
- [14] Yingqian Wang, Jungang Yang, et al., “Light field image super-resolution using deformable convolution,” IEEE TIP, vol. 30, pp. 1057–1071, 2020.
- [15] Youngjin Yoon, Hae-Gon Jeon, et al., “Light-field image super-resolution using convolutional neural network,” IEEE SPL, vol. 24, no. 6, pp. 848–852, 2017.
- [16] Yan Yuan, Ziqi Cao, and Lijuan Su, “Light-field image superresolution using a combined deep cnn based on epi,” IEEE SPL, vol. 25, no. 9, pp. 1359–1363, 2018.
- [17] Yunlong Wang, Fei Liu, et al., “Lfnet: A novel bidirectional recurrent convolutional neural network for light-field image super-resolution,” IEEE TIP, vol. 27, no. 9, pp. 4274–4286, 2018.
- [18] Yan Huang, Wei Wang, and Liang Wang, “Bidirectional recurrent convolutional networks for multi-frame super-resolution,” in NeurIPS, 2015, pp. 235–243.
- [19] Jing Jin, Junhui Hou, Hui Yuan, and Sam Kwong, “Learning light field angular super-resolution via a geometry-aware network,” in AAAI, 2020.
- [20] Shuo Zhang, Song Chang, and Youfang Lin, “End-to-end light field spatial super-resolution network using multiple epipolar geometry,” IEEE TIP, vol. 30, pp. 5956–5968, 2021.
- [21] Shunzhou Wang, Tianfei Zhou, Yao Lu, and Huijun Di, “Detail-preserving transformer for light field image super-resolution,” in AAAI, 2022.
- [22] Martin Rerabek and Touradj Ebrahimi, “New light field image dataset,” in International Conference on Quality of Multimedia Experience (QoMEX), 2016.
- [23] Mikael Le Pendu, Xiaoran Jiang, and Christine Guillemot, “Light field inpainting propagation via low rank matrix completion,” IEEE TIP, vol. 27, no. 4, pp. 1981–1993, 2018.
- [24] Vaibhav Vaish and Andrew Adams, “The (new) stanford light field archive,” Computer Graphics Laboratory, Stanford University, vol. 6, no. 7, 2008.
- [25] Katrin Honauer, Ole Johannsen, Daniel Kondermann, and Bastian Goldluecke, “A dataset and evaluation methodology for depth estimation on 4d light fields,” in ACCV. Springer, 2016, pp. 19–34.
- [26] Sven Wanner, Stephan Meister, and Bastian Goldluecke, “Datasets and benchmarks for densely sampled 4d light fields.,” in Vision, Modelling and Visualization (VMV). Citeseer, 2013, vol. 13, pp. 225–226.