Subgraph Federated Learning with Missing Neighbor Generation
Abstract
Graphs have been widely used in data mining and machine learning due to their unique representation of real-world objects and their interactions. As graphs are getting bigger and bigger nowadays, it is common to see their subgraphs separately collected and stored in multiple local systems. Therefore, it is natural to consider the subgraph federated learning setting, where each local system holds a small subgraph that may be biased from the distribution of the whole graph. Hence, the subgraph federated learning aims to collaboratively train a powerful and generalizable graph mining model without directly sharing their graph data. In this work, towards the novel yet realistic setting of subgraph federated learning, we propose two major techniques: (1) FedSage, which trains a GraphSage model based on FedAvg to integrate node features, link structures, and task labels on multiple local subgraphs; (2) FedSage+, which trains a missing neighbor generator along FedSage to deal with missing links across local subgraphs. Empirical results on four real-world graph datasets with synthesized subgraph federated learning settings demonstrate the effectiveness and efficiency of our proposed techniques. At the same time, consistent theoretical implications are made towards their generalization ability on the global graphs.
1 Introduction
Graph mining leverages links among connected nodes in graphs to conduct inference. Recently, graph neural networks (GNNs) have gained applause with impressing performance and generalizability in many graph mining tasks [29, 11, 16, 20, 32]. Similar to machine learning tasks in other domains, attaining a well-performed GNN model requires its training data to not only be sufficient but also follow the similar distribution as general queries. While in reality, data owners often collect limited and biased graphs and cannot observe the global distribution. With heterogeneous subgraphs separately stored in local data owners, accomplishing a globally applicable GNN requires collaboration.
Federated learning (FL) [17, 35], targeting at training machine learning models with data distributed in multiple local systems to resolve the information-silo problem, has shown its advantage in enhancing the performance and generalizability of the collaboratively trained models without the need of sharing any actual data. For example, FL has been devised in computer vision (CV) and natural language processing (NLP) to allow the joint training of powerful and generalizable deep convolutional neural networks and language models on separately stored datasets of images and texts [19, 6, 18, 39, 13].
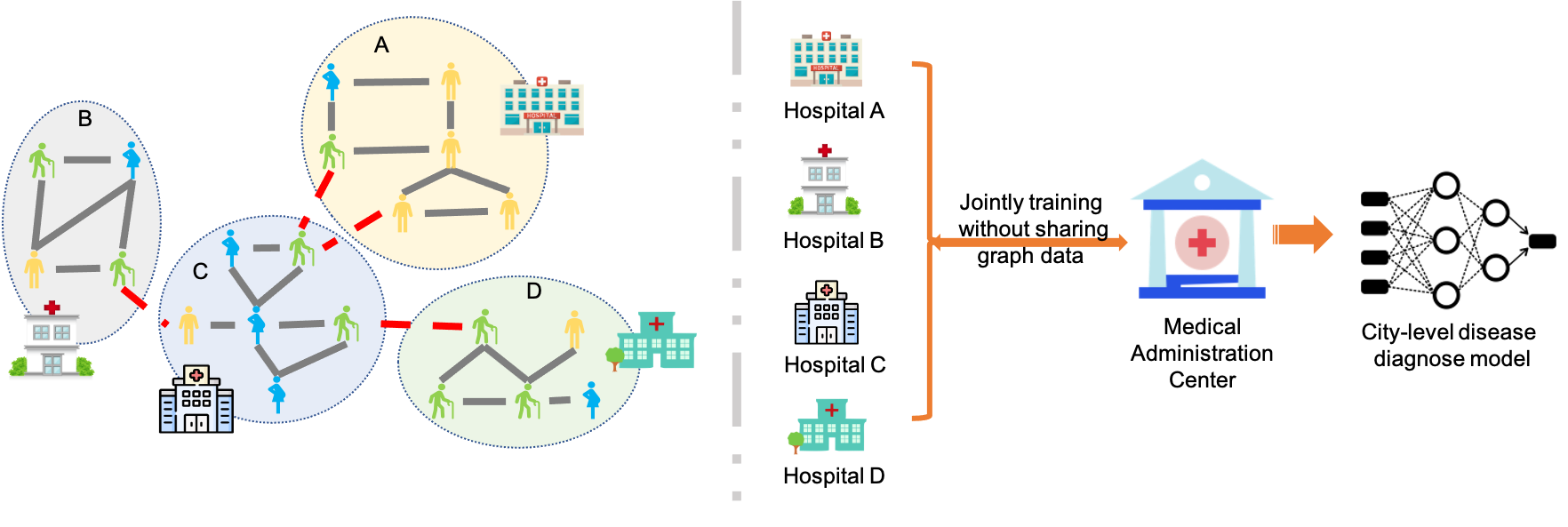
Motivating Scenario. Taking the healthcare system as an example, as shown in Fig. 1, residents of a city may go to different hospitals for various reasons. As a result, their healthcare data, such as demographics and living conditions, as well as patient interactions, such as co-staying in a sickroom and co-diagnosis of a disease, are stored only within the hospitals they visit. When any healthcare problem is to be studied in the whole city, e.g., the prediction of infections when a pandemic occurs, a single powerful graph mining model is needed to conduct effective inference over the entire global patient network, which contains all subgraphs from different hospitals. However, it is rather difficult to let all hospitals share their patient networks with others to train the graph mining model due to conflicts of interests.
In such scenarios, it is desirable to train a powerful and generalizable graph mining model over multiple distributed subgraphs without actual data sharing. However, this novel yet realistic setting brings two unique technical challenges, which have never been explored so far.
Challenge 1: How to jointly learn from multiple local subgraphs? In our considered scenario, the global graph is distributed into a set of small subgraphs with heterogeneous feature and structure distributions. Training a separate graph mining model on each subgraph may not capture the global data distribution and is also prone to overfitting. Moreover, it is unclear how to integrate multiple graph mining models into a universally applicable one that can handle any queries from the underlying global graph.
Solution 1: FedSage: Training GraphSage with FedAvg. To attain a powerful and generalizable graph mining model from small and biased subgraphs distributed in multiple local owners, we develop a framework of subgraph federated learning, specifically, with the vanilla mechanism of FedAvg [21]. As for the graph mining model, we resort to GraphSage [11], due to its advantages of inductiveness and scalability. We term this framework as FedSage.
Challenge 2: How to deal with missing links across local subgraphs? Unlike distributed systems in other domains such as CV and NLP, whose data samples of images and texts are isolated and independent, data samples in graphs are connected and correlated. Most importantly, in a subgraph federated learning system, data samples in each subgraph can potentially have connections to those in other subgraphs. These connections carrying important information of node neighborhoods and serving as bridges among the data owners, however, are never directly captured by any data owner.
Solution 2: FedSage+: Generating missing neighbors along FedSage. To deal with cross-subgraph missing links, we add a missing neighbor generator on top of FedSage and propose a novel FedSage+ model. Specifically, for each data owner, instead of training the GraphSage model on the original subgraph, it first mends the subgraph with generated cross-subgraph missing neighbors and then applies FedSage on the mended subgraph. To obtain the missing neighbor generator, each data owner impairs the subgraph by randomly holding out some nodes and related links and then trains the generator based on the held-out neighbors. Training the generator on an individual local subgraph enables it to generate potential missing links within the subgraph. Further training the generator in our subgraph FL setting allows it to generate missing neighbors across distributed subgraphs.
We conduct experiments on four real-world datasets with different numbers of data owners to better simulate the application scenarios. According to our results, both of our models outperform locally trained classifiers in all scenarios. Compared to FedSage, FedSage+ further promotes the performance of the outcome classifier. Further in-depth model analysis shows the convergence and generalization ability of our frameworks, which is corroborated by our theoretical analysis in the end.
2 Related works
Graph mining. Graph mining emerges its significance in analyzing the informative graph data, which range from social networks to gene interaction networks [31, 33, 34, 24]. One of the most frequently applied tasks on graph data is node classification. Recently, graph neural networks (GNNs), e.g., graph convolutional networks (GCN) [16] and GraphSage [11], improved the state-of-the-art in node classification with their elegant yet powerful designs. However, as GNNs leverage the homophily of nodes in both node features and link structures to conduct the inference, they are vulnerable to the perturbation on graphs [4, 40, 41]. Robust GNNs, aiming at reducing the degeneration in GNNs caused by graph perturbation, are gaining attention these days. Current robust GNNs focus on the sensitivity towards modifications on node features [3, 42, 15] or adding/removing edges on the graph [37]. However, neither of these two types recapitulates the missing neighbor problem, which affects both the feature distribution and structure distribution.
To obtain a node classifier with good generalizability, the development of domain adaptive GNN sheds light on adapting a GNN model trained on the source domain to the target domain by leveraging underlying structural consistency [38, 36, 28]. However, in the distributed system we consider, data owners have subgraphs with heterogeneous feature and structure distributions. Moreover, direct information exchanges among subgraphs, such as message passing, are fully blocked due to the missing cross-subgraph links. The violation of the domain adaptive GNNs’ assumptions on alignable nodes and cross-domain structural consistency denies their usage in the distributed subgraph system.
Federated learning. FL is proposed for cross-institutional collaborative learning without sharing raw data [17, 35, 21]. FedAvg [21] is an efficient and well-studied FL method. Similar to most FL methods, it is originally proposed for traditional machine learning problems [35] to allow collaborative training on silo data through local updating and global aggregation. The ecently proposed meta-learning framework [9, 23, 14] that exploits information from different data sources to obtain a general model attracts FL researchers [8]. However, meta-learning aims to learn general models that easily adapt to different local tasks, while we learn a generalizable model from diverse data owners to assist in solving a global task. In the distributed subgraph system, to obtain a globally applicable model without sharing local graph data, we borrow the idea of FL to collaboratively train GNNs.
Federated graph learning. Recent researchers have made some progress in federated graph learning. There are existing FL frameworks designed for the graph data learning task [12, 27, 30]. [12] design graph-level FL schemes with graph datasets dispersed over multiple data owners, which are inapplicable to our distributed subgraph system construction. [27] proposes an FL method for the recommendation problem with each data owner learning on a subgraph of the whole recommendation user-item graph. It considers a different scenario assuming subgraphs have overlapped items (nodes), and the user-item interactions (edges) are distributed but completely stored in the system, which ignores the possible cross-subgraph information lost in real-world scenarios. However, we study a more challenging yet realistic case in the distributed subgraph system, where cross-subgraph edges are totally missing.
In this work, we consider the commonly existing yet not studied scenario, i.e., distributed subgraph system with missing cross-subgraph edges. Under this scenario, we focus on obtaining a globally applicable node classifier through FL on distributed subgraphs.
3 FedSage
In this section, we first illustrate the definition of the distributed subgraph system derived from real-world application scenarios. Based on this system, we then formulate our novel subgraph FL framework and a vanilla solution called FedSage.
3.1 Subgraphs Distributed in Local Systems
Notation.
We denote a global graph as , where is the node set, is the respective node feature set, and is the edge set. In the FL system, we have the central server , and data owners with distributed subgraphs. is the subgraph owned by , for .
Problem setup.
For the whole system, we assume . To simulate the scenario with most missing links, we assume no overlapping nodes shared across data owners, namely for and . Note that the central server only maintains a graph mining model with no actual graph data stored. Any data owner cannot directly retrieve from another data owner . Therefore, for an edge , where and , , that is, might exist in reality but is not stored anywhere in the whole system.
For the global graph , every node has its features and one label for the downstream task, e.g., node classification. Note that for , ’s feature and respective label is a -dimensional one-hot vector. In a typical GNN, predicting a node’s label requires an ego-graph of the queried node. For a node from graph , we denote the queried ego-graph of as , and .
With subgraphs distributed in the system defined above, we formulate our goal as follows.
Goal.
The system exploits an FL framework to collaboratively learn on isolated subgraphs in all data owners, without raw graph data sharing, to obtain a global node classifier . The learnable weights in is optimized for queried ego-graphs following the distribution of ones drawn from the global graph . We formalize the problem as finding that minimizes the aggregated risk
where is the local empirical risk defined as
where is a task-specific loss function
3.2 Collaborative Learning on Isolated Subgraphs
To fulfill the system’s goal illustrated above, we leverage the simple and efficient FedAvg framework [21] and fix the node classifier as a GraphSage model. The inductiveness and scalability of the GraphSage model facilitate both the training on diverse subgraphs with heterogeneous query distributions and the later inference upon the global graph. We term the GraphSage model trained with the FedAvg framework as FedSage.
For a queried node , a globally shared -layer GraphSage classifier integrates and its -hop neighborhood on graph to conduct prediction with learnable parameters . Taking a subgraph as an example, for with features as , at each layer , computes ’s representation as
| (1) |
where is the set of ’s neighbors on graph , is the concatenation operation, is the aggregator (e.g., mean pooling) and is the activation function (e.g., ReLU).
With outputting the inference label for , the supervised loss function is defined as follows
| (2) |
where is the cross entropy function, is ’s K-hop ego-graph on , which contains the information of and its K-hop neighbors on .
In FedSage, the distributed subgraph system obtains a shared global node classifier parameterized by through epochs of training. During each epoch , every first locally computes , where contains the sampled training nodes for epoch , and is the learning rate; then the central server collects the latest ; next, through averaging over , sets as the averaged value; finally, broadcasts to data owners and finishes one round of training . After epochs, the entire system retrieves as the outcome global classifier, which is not limited to or biased towards the queries in any specific data owner.
Unlike FL on Euclidean data, nodes in the distributed subgraph system can have potential interactions with each other across subgraphs. However, as the cross-subgraph links cannot be captured by any data owner in the system, incomplete neighborhoods, compared to those on the global graph, commonly exist therein. Thus, directly aggregating incomplete queried ego-graph information through FedSage restricts the outcome from achieving the desideratum of capturing the global query distribution.
4 FedSage+
In this section, we propose a novel framework of FedSage+, i.e., subgraph FL with missing neighbor generation. We first design a missing neighbor generator (NeighGen) and its training schema via graph mending. Then, we describe the joint training of NeighGen and GraphSage to better achieve the goal in Section 3.1. Without loss of generality, in the following demonstration, we take NeighGeni, i.e., the missing neighbor generator of , as an example, where .
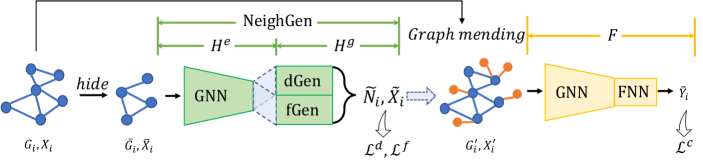
4.1 Missing Neighbor Generator (NeighGen)
Neural architecture of NeighGen.
As shown in Fig. 2, NeighGen consists of two modules, i.e., an encoder and a generator . We describe their designs in details in the following.
: A GNN model, i.e., a K-layer GraphSage encoder, with parameters . For node on the input graph , computes node embeddings according to Eq. (1) by substituting , with and .
: A generative model recovering missing neighbors for the input graph based on the node embedding. contains dGen and fGen, where dGen is a linear regression model parameterized by that predicts the numbers of missing neighbors , and fGen is a feature generator parameterized by that generates a set of feature vectors . Both dGen and fGen are constructed as fully connected neural networks (FNNs), while fGen is further equipped with a Gaussian noise generator that generates -dimensional noise vectors and a random sampler . For node , fGen is variational, which generates the missing neighbors’ features for after inserting noises into the embedding , while ensures fGen to output the features of a specific number of neighbors by sampling feature vectors from the feature generator’s output. Mathematically, we have
| (3) |
Graph mending simulation.
For each data owner in our system, we assume that only a particular set of nodes have cross-subgraph missing neighbors. The assumption is realistic yet non-trivial for it both seizing the quiddity of the distributed subgraph system, and allowing us to locally simulate the missing neighbor situation through a graph impairing and mending process. Specifically, to simulate a graph mending process during the training of NeighGen, in each local subgraph , we randomly hold out of its nodes and all links involving them , to form an impaired subgraph, denoted as . contains the impaired set of nodes , the corresponding nodes features and edges .
Accordingly, based on the ground-truth missing nodes and links , the training of NeighGen on the impaired graph boils down to jointly training dGen and fGen as below.
| (4) |
where is the smooth L1 distance [10] and is the -th predicted feature in . Note that, contains nodes that are ’s neighbors on missing into . , which can be retrieved from and , provides ground-truth for training NeighGen.
Neighbor Generation.
To retrieve from , data owner performs two steps, which are also shown in Fig. 2: 1) trains NeighGen on the impaired graph w.r.t. the ground-true hidden neighbors ; 2) exploits NeighGen to generate missing neighbors for nodes on and then mends into with generated neighbors. On the local graph alone, this process can be understood as a data augmentation that further generates potential missing neighbors within . However, the actual goal is to allow NeighGen to generate the cross-subgraph missing neighbors, which can be achieved via training NeighGen with FL and will be discussed in Section 4.3.
4.2 Local Joint Training of GraphSage and NeighGen
While NeighGen is designed to recover missing neighbors, the final goal of our system is to train a node classifier. Therefore, we design the joint training of GraphSage and NeighGen, which leverages neighbors generated by NeighGen to assist the node classification by GraphSage. We term the integration of GraphSage and NeighGen on the local graphs as LocSage+.
After NeighGen mends the graph into , the GraphSage classifier is applied on , according to Eq. (1) (with replaced by ). Thus, the joint training of NeighGen and GraphSage is done by optimizing the following loss function
| (5) |
where and are defined in Eq. (4), and is defined in Eq. (2) (with substituted by ).
The local joint training of GraphSage and NeighGen allows NeighGen to generate missing neighbors in the local graph that are helpful for the classifications made by GraphSage. However, like GraphSage, the information encoded in the local NeighGen is limited to and biased towards the local graph, which does not enable it to really generate neighbors belonging to other data owners connected by the missing cross-subgraph links. To this end, it is natural to train NeighGen with FL as well.
4.3 Federated Learning of GraphSage and NeighGen
Similarly to GraphSage alone, as described in Section 3.2, we can apply FedAvg to the joint training of GraphSage and NeighGen, by setting the loss function to and learnable parameters to . However, we observe that cooperation through directly averaging weights of NeighGen across the system can negatively affect its performance, i.e., averaging the weights of a single NeighGen model does not really allow it to generate diverse neighbors from different subgraphs. Recalling our goal of constructing NeighGen, which is to facilitate the training of a centralized GraphSage classifier by generating diverse missing neighbors in each subgraph, we do not necessarily need a centralized NeighGen. Therefore, instead of training a single centralized NeighGen, we train a local NeighGeni for each data owner . In order to allow each NeighGeni to generate diverse neighbors similar to those missed into other subgraphs , we add a cross-subgraph feature reconstruction loss into fGeni as follows:
| (6) |
where is picked as the closest node from other than to simulate the neighbor of missed into .
As shown above, to optimize Eq. (6), needs to pick the closest from . However, directly transmitting node features in to not only violates our subgraph FL system constraints on no direct data sharing but also is impractical in reality, as it requires each to hold the entire global graph’s node features throughout training NeighGeni. Therefore, to allow to update NeighGeni using Eq. (6) without direct access to , for , locally computes and sends the respective gradient back to .
During this process, for , to federated optimize Eq. (6), only , ’s input , and the ’s locally computed model gradients of loss term are transmitted among the system via the server . For data owner , the gradients received from are then weighted by and combined with the local gradients as in Eq. (6) to update the parameters of of NeighGeni In this way, achieves the federate training of NeighGeni without raw graph data sharing. Note that, due to NeighGen’s architecture of a concatenation of and , the locally preserved GNN can prevent other data owners from inferring by only seeing . Through Eq. (6), NeighGeni is expected to perceive diverse neighborhood information from all data owners, so as to generate more realistic cross-subgraph missing neighbors. The expectedly diverse and unbiased neighbors further assist the FedSage in training a globally applicable classifier that satisfies our goal in Section 3.1.
5 Experiments
We conduct experiments on four datasets to verify the effectiveness of FedSage and FedSage+ under different testing scenarios. We further conduct case studies to visualize how FedSage and FedSage+ assist local data owners in accommodating queries from the global distribution. Finally, we also provide more in-depth studies on the effectiveness of NeighGen in Appendix D.
5.1 Datasets and experimental settings
We synthesize the distributed subgraph system with four widely used real-world graph datasets, i.e., Cora [25], Citeseer [25], PubMed [22], and MSAcademic [26]. To synthesize the distributed subgraph system, we find hierarchical graph clusters on each dataset with the Louvain algorithm [2] and use the clustering results with 3, 5, and 10 clusters of similar sizes to obtain subgraphs for data owners. The statistics of these datasets are presented in Table 1.
| Data | Cora | Citeseer | PubMed | MSAcademic | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #C | 7 | 6 | 3 | 15 | ||||||||
| 2708 | 3312 | 19717 | 18333 | |||||||||
| 5429 | 4715 | 44338 | 81894 | |||||||||
| M | 3 | 5 | 10 | 3 | 5 | 10 | 3 | 5 | 10 | 3 | 5 | 10 |
| 903 | 542 | 271 | 1104 | 662 | 331 | 6572 | 3943 | 1972 | 6111 | 3667 | 1833 | |
| 1675 | 968 | 450 | 1518 | 902 | 442 | 12932 | 7630 | 3789 | 23584 | 13949 | 5915 | |
| 403 | 589 | 929 | 161 | 206 | 300 | 5543 | 6189 | 6445 | 11141 | 12151 | 22743 | |
We implement GraphSage with two layers using the mean aggregator [5]. The number of nodes sampled in each layer of GraphSage is 5. We use batch size 64 and set training epochs to 50. The training-validation-testing ratio is 60%-20%-20% due to limited sizes of local subgraphs. Based on our observations in hyper-parameter studies for and the graph impairing ratio , we set and =1. All s are simply set to 1. Optimization is done with Adam with a learning rate of 0.001. We implement FedSage and FedSage+ in Python and execute all experiments on a server with 8 NVIDIA GeForce GTX 1080 Ti GPUs.
Since we are the first to study the novel yet important setting of subgraph federated learning, there are no existing baselines. We conduct comprehensive ablation evaluation by comparing FedSage and FedSage+ with three models, i.e., 1) GlobSage: the GraphSage model trained on the original global graph without missing links (as an upper bound for FL framework with GraphSage model alone), 2) LocSage: one GraphSage model trained solely on each subgraph, 3) LocSage+: the GraphSage plus NeighGen model jointly trained solely on each subgraph.
The metric used in our experiments is the node classification accuracy on the queries sampled from the testing nodes on the global graph. For globally shared models of GlobSage, FedSage, and FedSage+, we report the average accuracy over five random repetitions, while for locally possessed models of LocSage and LocSage+, the scores are further averaged across local models.
5.2 Experimental results
| Cora | Citesser | |||||
| Model | M=3 | M=5 | M=10 | M=3 | M=5 | M=10 |
| LocSage | 0.5762 | 0.4431 | 0.2798 | 0.6789 | 0.5612 | 0.4240 |
| (0.0302) | (0.0847) | (0.0080) | (0.054) | () | () | |
| LocSage+ | 0.5644 | 0.4533 | 0.2851 | 0.6848 | 0.5676 | 0.4323 |
| () | (0.047) | (0.0080) | (0.0517) | (0.0714) | (0.0715) | |
| FedSage | 0.8656 | 0.8645 | 0.8626 | 0.7241 | 0.7226 | 0.7158 |
| () | (0.0050) | (0.0103) | (0.0022) | 0.0066) | (0.0053) | |
| FedSage+ | 0.8686 | 0.8648 | 0.8632 | 0.7454 | 0.7440 | 0.7392 |
| () | (0.0051) | (0.0034) | (0.0038) | (0.0025) | () | |
| GlobSage | 0.8701 (0.0042) | 0.7561 (0.0031) | ||||
| PubMed | MSAcademic | |||||
| Model | M=3 | M=5 | M=10 | M=3 | M=5 | M=10 |
| LocSage | 0.8447 | 0.8039 | 0.7148 | 0.8188 | 0.7426 | 0.5918 |
| () | () | (0.0951) | () | () | () | |
| LocSage+ | 0.8481 | 0.8046 | 0.7039 | 0.8393 | 0.7480 | 0.5927 |
| () | () | (0.0925) | (0.0330) | () | () | |
| FedSage | 0.8708 | 0.8696 | 0.8692 | 0.9327 | 0.9391 | 0.9262 |
| () | () | (0.0010) | (0.0005) | (0.0007) | (0.0009) | |
| FedSage+ | 0.8775 | 0.8755 | 0.8749 | 0.9359 | 0.9414 | 0.9314 |
| () | () | (0.0013) | (0.0005) | (0.0006) | (0.0009) | |
| GlobSage | 0.8776(0.0011) | 0.9681(0.0006) | ||||
Overall performance.
We conduct comprehensive ablation experiments to verify the significant promotion brought by FedSage and FedSage+ for local owners in global node classification, as shown in Table 2. The most important observation emerging from the results is that FedSage+ not only clearly outperforms LocSage by an average of 23.18%, but also distinctly overcomes the cross-subgraph missing neighbor problem by reducing the average accuracy drop from the 2.11% of FedSage to 1.28%, when compared with GlobSage (absolute accuracy difference).
The significant gaps between a locally obtained classifier, i.e., LocSage or LocSage+, and a federated trained classifier, i.e., FedSage or FedSage+, assay the benefits brought by the collaboration across data owners in our distributed subgraph system. Compared to FedSage, the further elevation brought by FedSage+ corroborates the assumed degeneration brought by missing cross-subgraph links and the effectiveness of our innovatively designed NeighGen module. Notably, when the graph is relatively sparse (e.g., see Citeseer in Table 1), FedSage+ significantly exhibits its robustness in resisting the cross-subgraph information loss compared to FedSage. Note that the gaps between LocSage and LocSage+ are comparatively smaller, indicating that our NeighGen serves more than a robust GNN trainer, but is rather uniquely crucial in the subgraph FL setting.
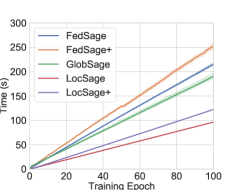
Hyper-parameter studies.
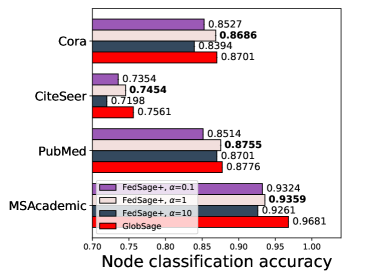
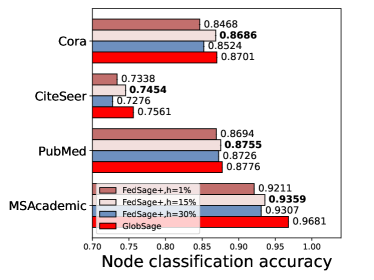
We compare the downstream task performance under different and values with three data owners. Results are shown in Fig. 3, where Fig. 3 (a) shows results when is fixed as 15%, and Fig. 3 (b) shows results under =1.
Fig. 3 (a) indicates that choosing a proper , which brings the information from other subgraphs in the system, can constantly elevate the final testing accuracy. Across different datasets, the optimal is constantly around 1, and the performance is not influenced much unless is set to extreme values like 0.1 or 10. Referring to Fig. 3 (b), we can observe that either a too-small (1%) or a too-large (30%) hiding portion can degrade the learning process. A too-small can not provide sufficient data for training NeighGen, while a too-large can result in sparse local subgraphs that harm the effective training of GraphSage. Referring back to the graph statistics in Table 1 in the paper, the portion of actual missing edges compared to the global graph is within the range of [3.4%, 27.8%], which explains why a value like 15% can mostly boost the performance of FedSage+.
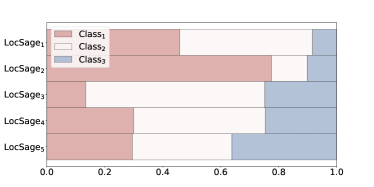
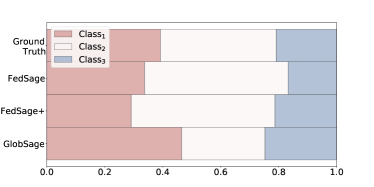
Case studies.
To further understand how FedSage and FedSage+ improve the global classifier over LocSage, we provide case study results on PubMed with five data owners in Fig. 4. For the studied scenario, each data owner only possesses about 20% of the nodes with rather biased label distributions, as shown in Fig. 4 (a). Such bias is due to the way we synthesize the distributed subgraph system with Louvain clustering, which is also realistic in real scenarios. Local bias essentially makes it hard for any local data owner with limited training samples to obtain a generalized classifier that is globally useful. Although with 13.9% of the links missing among the system, both FedSage and FedSage+ empower local data owners in predicting labels that closely follow the ground-true global label distribution as shown in Fig. 4 (b). The figure clearly evidences that our FL models exhibit their advantages in learning a more realistic label distribution as our goal in Section 3.1, which is consistent with the observed performances in Table 2 and our theoretical implications in Section 6.
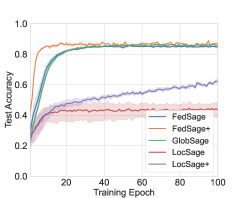
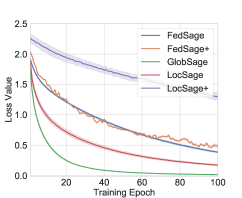
For Cora dataset with five data owners, we visualize testing accuracy, loss convergence, and runtime along 100 epochs in obtaining with FedSage, FedSage+, GlobSage, LocSage and LocSage+. The results are presented in Fig. 5. Both FedSage and FedSage+ can consistently achieve convergence with rapidly improved testing accuracy. Regarding runtime, even though the classifier from FedSage+ learns from distributed mended subgraphs, FedSage+ does not consume observable more training time compared to FedSage. Due to the additional communications and computations in subgraph FL, both FedSage and FedSage+ consume slightly more training time compared to GlobSage.
6 Implications on Generalization Bound
In this section, we provide a theoretical implication for the generalization error associated with number of training samples, i.e., nodes in the distributed subgraph system, following Graph Neural Tangent Kernel (GNTK) [7] on universal graph neural networks. Thus, we are motivated to promote the FedSage and FedSage+ algorithms that include more nodes in the global graph through collaborative training with FL.
Setting.
Our explanation builds on a generalized setting, where we assume a GNN with layer-wise aggregation operations and fully-connected layers with ReLU activation functions, which includes GraphSage as a special case. The weights of , , is i.i.d. sampled from a multivariate Gaussian distribution . For Graph , we define the kernel matrix of two nodes as follows. Here we consider is in the GNTK format.
Definition 6.1 (Informal version of GNTK on node classification (Definition B.2))
Considering in the overparameterized regime for an GNN , is trained using gradient descent with infinite small learning rate. Given nodes with corresponding labels as training samples, we denote as the the kernel matrix of GNTK. is defined as
Full expression of is shown in the Appendix B. The generalization ability in the GNTK regime depends on the kernel matrix . We present the generalization bound associated with the number of training samples in Theorem 6.2.
Theorem 6.2 (Generalization bound)
Given training samples of nodes drawn i.i.d. from the global graph , consider any loss function that is 1-Lipschitz in the first argument such that . With probability at least and constant , the generalization error of GNTK for node classification can be upper-bounded by
Implications.
We show the error bound of GNTK on node classification corresponding to the number of training samples. Under the assumptions in Definition 6.1, our theoretical result indicates that more training samples bring down the generalization error , which provides plausible support for our goal of building a globally useful classifier through FL in Eq. (3.1). Such implications are also consistent with our experimental findings in Fig. 4 where our FedSage and FedSage+ models can learn more generalizable classifiers that follow the label distributions of the global graph through involving more training nodes across different subgraphs.
7 Conclusion
This work aims at obtaining a generalized node classification model in a distributed subgraph system without direct data sharing. To tackle the realistic yet unexplored issue of missing cross-subgraph links, we design a novel missing neighbor generator NeighGen with the corresponding local and federated training processes. Experimental results evidence the distinguished elevation brought by our FedSage and FedSage+ frameworks , which is consistent with our theoretical implications.
Though FedSage manifests advantageous performance, it confronts additional communication cost and potential privacy concerns. As communications are vital for federated learning, properly reducing communication and rigorously guaranteeing privacy protection in the distributed subgraph system can both be promising future directions.
Acknowledgments and Disclosure of Funding
This work is partially supported by the internal funding and GPU servers provided by the Computer Science Department of Emory University. We thank Dr. Pan Li from Purdue University for the suggestions on the design of our NeighGen mechanism.
References
- [1] Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. JMLR, 3:463–482, 2002.
- [2] Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks. JSTAT, 2008(10):P10008, 2008.
- [3] Liang Chen, Jintang Li, Qibiao Peng, Yang Liu, Zibin Zheng, and Carl Yang. Understanding structural vulnerability in graph convolutional networks. In IJCAI, 2021.
- [4] Hanjun Dai, Hui Li, Tian Tian, Xin Huang, Lin Wang, Jun Zhu, and Le Song. Adversarial attack on graph structured data. In ICML, 2018.
- [5] CSIRO’s Data61. Stellargraph machine learning library. https://github.com/stellargraph/stellargraph, 2018.
- [6] Qi Dou, Tiffany Y So, Meirui Jiang, Quande Liu, Varut Vardhanabhuti, Georgios Kaissis, Zeju Li, Weixin Si, Heather HC Lee, Kevin Yu, et al. Federated deep learning for detecting covid-19 lung abnormalities in ct: a privacy-preserving multinational validation study. NPJ digital medicine, 4:1–11, 2021.
- [7] Simon S. Du, Kangcheng Hou, Ruslan Salakhutdinov, Barnabás Póczos, Ruosong Wang, and Keyulu Xu. Graph neural tangent kernel: Fusing graph neural networks with graph kernels. In NeurIPS, 2019.
- [8] Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. Personalized federated learning: A meta-learning approach. NeurIPS, 2020.
- [9] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML, 2017.
- [10] Ross Girshick. Fast r-cnn. In ICCV, 2015.
- [11] William L. Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NeurIPS, 2017.
- [12] Chaoyang He, Keshav Balasubramanian, Emir Ceyani, Carl Yang, Han Xie, Lichao Sun, Lifang He, Liangwei Yang, Philip S Yu, Yu Rong, Peilin Zhao, Junzhou Huang, Murali Annavaram, and Salman Avestimehr. Fedgraphnn: A federated learning system and benchmark for graph neural networks. arXiv preprint arXiv:2104.07145, 2021.
- [13] Chaoyang He, Shen Li, Mahdi Soltanolkotabi, and Salman Avestimehr. Pipetransformer: Automated elastic pipelining for distributed training of transformers. arXiv preprint arXiv:2102.03161, 2021.
- [14] Timothy M Hospedales, Antreas Antoniou, Paul Micaelli, and Amos J Storkey. Meta-learning in neural networks: A survey. TPAMI, 2021.
- [15] Wei Jin, Yao Ma, Xiaorui Liu, Xianfeng Tang, Suhang Wang, and Jiliang Tang. Graph structure learning for robust graph neural networks. In SIGKDD, 2020.
- [16] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2017.
- [17] Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions. IEEE SPM, 37:50–60, 2020.
- [18] Xinle Liang, Yang Liu, Tianjian Chen, Ming Liu, and Qiang Yang. Federated transfer reinforcement learning for autonomous driving. arXiv preprint arXiv:1910.06001, 2019.
- [19] Quande Liu, Cheng Chen, Jing Qin, Qi Dou, and Pheng-Ann Heng. Feddg: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space. arXiv preprint arXiv:2103.06030, 2021.
- [20] Gongxu Luo, Jianxin Li, Hao Peng, Carl Yang, Lichao Sun, Philip Yu, and Lifang He. Graph entropy guided node embedding dimension selection for graph neural networks. In IJCAI, 2021.
- [21] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In AISTATS, 2017.
- [22] Galileo Namata, Ben London, Lise Getoor, and Bert Huang. Query-driven active surveying for collective classification. In MLG workshop, 2012.
- [23] Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999, 2018.
- [24] Saif Ur Rehman, Asmat Ullah Khan, and Simon Fong. Graph mining: A survey of graph mining techniques. In ICDIM, 2012.
- [25] Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- [26] Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868, 2018.
- [27] Chuhan Wu, Fangzhao Wu, Yang Cao, Yongfeng Huang, and Xing Xie. Fedgnn: Federated graph neural network for privacy-preserving recommendation. arXiv preprint arXiv:2102.04925, 2021.
- [28] Man Wu, Shirui Pan, Chuan Zhou, Xiaojun Chang, and Xingquan Zhu. Unsupervised domain adaptive graph convolutional networks. In WWW, 2020.
- [29] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. TNNLS, 2020.
- [30] Han Xie, Jing Ma, Li Xiong, and Carl Yang. Federated graph classification over non-iid graphs. In NeurIPS, 2021.
- [31] Carl Yang, Haonan Wang, Ke Zhang, Liang Chen, and Lichao Sun. Secure deep graph generation with link differential privacy. In IJCAI, 2021.
- [32] Carl Yang, Yuxin Xiao, Yu Zhang, Yizhou Sun, and Jiawei Han. Heterogeneous network representation learning: A unified framework with survey and benchmark. In TKDE, 2020.
- [33] Carl Yang, Jieyu Zhang, and Jiawei Han. Co-embedding network nodes and hierarchical labels with taxonomy based generative adversarial nets. In ICDM, 2020.
- [34] Carl Yang, Peiye Zhuang, Wenhan Shi, Alan Luu, and Pan Li. Conditional structure generation through graph variational generative adversarial nets. In NeurIPS, 2019.
- [35] Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. Federated machine learning: Concept and applications. TIST, 10(2):1–19, 2019.
- [36] Yizhou Zhang, Guojie Song, Lun Du, Shuwen Yang, and Yilun Jin. DANE: domain adaptive network embedding. In IJCAI, 2019.
- [37] Dingyuan Zhu, Ziwei Zhang, Peng Cui, and Wenwu Zhu. Robust graph convolutional networks against adversarial attacks. In SIGKDD, 2019.
- [38] Qi Zhu, Yidan Xu, Haonan Wang, Chao Zhang, Jiawei Han, and Carl Yang. Transfer learning of graph neural networks with ego-graph information maximization. In NeurIPS, 2021.
- [39] Xinghua Zhu, Jianzong Wang, Zhenhou Hong, and Jing Xiao. Empirical studies of institutional federated learning for natural language processing. In EMNLP, 2020.
- [40] Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. Adversarial attacks on neural networks for graph data. In SIGKDD, 2018.
- [41] Daniel Zügner and Stephan Günnemann. Adversarial attacks on graph neural networks via meta learning. In ICLR, 2019.
- [42] Daniel Zügner and Stephan Günnemann. Certifiable robustness and robust training for graph convolutional networks. In SIGKDD, 2019.
Appendix A FedSage+ Algorithm
Referring to Section 4.3, FedSage+ includes two phases. Firstly, all data owners in the distributed subgraph system jointly train NeighGen models through sharing gradients. Next, after every local graph mended with synthetic neighbors generated by the respective NeighGen model, the system executes FedSage to obtain the generalized node classification model. Algorithm 1 shows the pseudo code for FedSage+.
Appendix B Full Version of Definition 6.1
Notation.
We denote the whole graph and . To perform node classification on , we consider a GNN with aggregation operations111In Graphsage, this is equivalent to having graph convectional layers. and each aggregation operation contains fully-connected layers. We describe the aggregation operation below.
Definition B.1 (Aggregation operation, ())
For , aggregates the information from the previous layer and performs times non-linear transformation. With denoting the initial feature vector for node as , for an with fully-connected layers, the can be written as:
where is a scaling factor related initialization, is a scaling factor associated with neighbor aggregation, is ReLU activation, and learnable parameter for as .
For notation simplicity, GNN here is considered in GNTK format. The weights of , is i.i.d. sampled from a multivariate Gaussian distribution . For node , we denote ’s computational graph as and . Let denote inner-product of vector and . We are going to define the kernel matrix of two nodes as follows.
Definition B.2 (GNTK for node classification)
Considering in the overparameterized regime for an GNN , is trained using gradient descent with infinite small learning rate. Given training samples of nodes with corresponding labels, we denote as the the kernel matrix of GNTK. For , is the entry of and defined as
In GNTK formulation, an B.1 needs to calculate 1) a covariance matrix ; and 2) the intermediate kernel values Now, we specify the pairwise value in and . For and , and indicate the corresponding covariance and intermediate kernel matrix for th transformation and th layers. Initially, we have , where are the input features of node and . Denote the scaling factor for node as . can be calculated recursively through the aggregation operation given in [7]. Specifically, we have the following two steps.
Step 1: Neighborhood Aggregation
As the we defined above, in GNTK, the aggregation step can be performed as:
Step 2: transformations
Now, we consider the ReLU fully-connected layers which perform non-linear transformations to the aggregated feature generated in step 1. The ReLU activation function ’s derivative is denoted as For , we define covariance matrix and its derivative as
where is an intermediate variable that
Thus, we have
can be viewed as kernel matrix of GNTK for node classification. The generalization ability in the NTK regime and depends on the kernel matrix.
Appendix C Missing Proofs for Theorem 6.2
In this section, we provide the detailed version and proof of Theorem 6.2.
Theorem C.1 (Full version of generalization bound Theorem 6.2)
Given training data samples drawn i.i.d from Graph , we consider any loss function that is 1-Lipschitz in the first argument such that . With a probability at least and a constant , the generalization error of GNTK for node classification can be upper-bounded by
To prove the generalization bound, we make the following assumptions about the labels.
Assumption C.2
For each , the labels satisfies
where , , and .
Lemma C.3 (Bound on )
Under the Assumption C.2, we have
Proof. Without loss of generality, we consider a simple GNN () in Section B and define the kernel matrix for on the computational graph node as
We denote as the feature map of the kernel at degree that . Following the proof in [7], we have
As is a positive semidefinite matrix, we have
We define and for each . Under Assumption C.2, label can be rewritten as
Then we have
When , we have
When , we have
Thus,
The bound of is simpler to prove.
Lemma C.4 (Bound on )
Let denote as the number of training samples. Then .
Appendix D Detailed ablation studies of NeighGen
In this section, we provide in-depth NeighGen studies to empirically explain its power in the cross-subgraph missing neighbor generation. Specifically, we first show the intermediate results of NeighGen by boiling down the generation process into the missing cross-subgraph link generation by dGen and the missing cross-subgraph neighbor feature generation by fGen. Next, we experimentally verify the necessity of training locally specialized NeighGen. Finally, we provide FL training hyper-parameter study on batch size and local epoch to emphasize the robustness of FedSage+.
D.1 Intermediate results of dGen and fGen.
In this section, we study the two generative components in NeighGen, i.e., dGen and fGen, to explore their expressiveness in reconstructing missing neighbors. Especially, we analyze the outputs from dGen and fGen separately to explain how NeighGen assists in the missing cross subgraph neighbor generation process.
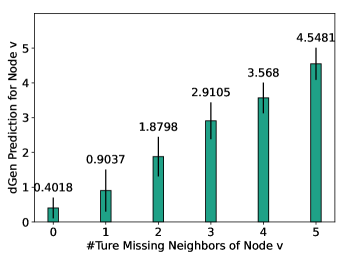
As described in Section 4, both dGen and fGen are constructed as fully connected neural networks (FNNs) whose depths can be varied according to the target dataset. In principle, due to the expressiveness of FNNs [29], dGen and fGen with even very few layers have the power to approximate complex functions. The node degree and feature distributions, on the other hand, are often highly relevant to the graph structure and less complex in nature. In Fig. 6 and Table 3, we provide intermediate results on how dGen and fGen are able to recover missing neighbor numbers and features, respectively.
Additional details for dGen.
Fig. 6 shows the break-down performance of dGen on the MSAcademic dataset with M=3, which clearly shows the effectiveness of dGen in recovering the true number of missing neighbors. Notably, though the original output of dGen is a float number, we simply apply the round function to retrieve the integer number of missing neighbors for reconstruction.
Additional details for fGen.
As described in Section 4.1, based on the number of missing neighbors generated by dGen, fGen further generates the feature of missing neighbors, thus recovering the incomplete neighborhoods resulting from the subgraph federated learning scenario. Regarding to our ultimate mission in missing neighbor generation as described in Section 4, i.e., locally modeling the original global graph during graph convolution, we evaluate fGen by comparing the NeighGen generated neihgbors with the neihgbors drawn from original whole graph and the ones from original subgraph. Specifically, we present the distance between the averaged feature distributions of neighborhoods from these three types of graphs to show how the NeighGen generated missing neighbors narrow the gap. For simplicity, we use , , and to represent the first-order neighbors of nodes drawn from the global graph , the original subgraph , and the mended subgraph respectively. Smaller values indicate the locally drawn neighbors ( or ) being more similar to the true neighbors from the global graph (). The results in Table 3 clearly show the effectiveness of fGen in recovering the true features of missing neighbors.
| M=3 | Cora | CiteSeer | PubMed | MSAcademic |
| std | 0.01240.0140 | 0.00740.0097 | 0.0034 0.0047 | 1.1457 1.580 |
| std | 0.01680.0182 | 0.01010.0131 | 0.0046 0.0053 | 1.86901.8387 |
| M=5 | Cora | CiteSeer | PubMed | MSAcademic |
| std | 0.02620.0885 | 0.00650.0083 | 0.00400.0054 | 1.1245 1.5801 |
| std | 0.0309 0.0897 | 0.00830.0115 | 0.00530.0060 | 1.88061.9695 |
| M=10 | Cora | CiteSeer | PubMed | MSAcademic |
| std | 0.06360.2100 | 0.15690.3310 | 0.00560.0170 | 2.7136 4.5595 |
| std | 0.06870.2093 | 0.1586 0.3307 | 0.00650.0171 | 3.29854.5686 |
D.2 Usage of local specialized NeighGens
To empirically explain why we need separate NeighGen functions, we contrast the downstream task performances between FedSage with a globally shared NeighGen, i.e., FedSage with NeighGen obtained with FedAvg, and FedSage with FL obtained local specialized NeighGens, i.e., FedSage+. We conduct ablation experiments on four datasets with =3, and the results are in Table 4. The results clearly assert our explanation in Section 4.3, i.e., directly averaging NeighGen weights across the system degenerates the downstream task performance, which indicates the insufficiency of FedAvg in assisting local data owners in the diverse neighbor generation.
| Model | Cora | CiteSeer | PubMed | MSAcademic |
|---|---|---|---|---|
| FedSage | 0.8656 | 0.7393 | 0.8708 | 0.9327 |
| (without NeighGen) | 0.0064) | (0.0034) | (0.0014) | (0.0005) |
| FedSage | 0.8619 | 0.7326 | 0.8721 | 0.9210 |
| with globally shared NeighGen | 0.0034) | (0.0055) | (0.0012) | (0.0016) |
| FedSage+ | 0.8686 | 0.7454 | 0.8775 | 0.9414 |
| (with local specialized NeighGens) | (0.0054) | (0.0038) | (0.0012) | (0.0006) |
D.3 Experiments on Local Epoch and Batch Size
For the proposed FedSage and FedSage+, we further explore the association between the outcome classifiers’ performances and different training hyper-parameters, i.e., batch size and local epoch number, which are often concerned in federated learning frameworks.
The experiments are conducted on the PubMed dataset with . To control the variance, we fix the model parameters’ updating times. Specifically, for subgraph FL methods, i.e., FedSage and FedSage+, we fix the communication round as 50, while for the centralized learning method, i.e., GlobSage, we train the model for 50 epochs. Under different scenarios, we train the GlobSage model with all utilized training samples in data owners. Test accuracy indicates how models perform on the same set of global test samples. Results are shown in Table 5 and 6. Every result is presented as Mean ( Std Deviation).
| Batch Size | FedSage | FedSage+ | GlobSage |
|---|---|---|---|
| 1 | 0.8682(0.0012) | 0.8782(0.0012) | 0.8751(0.001) |
| 16 | 0.8733(0.0018) | 0.8814(0.0023) | 0.8736(0.0013) |
| 64 | 0.8696(0.0035) | 0.8755(0.0047) | 0.8776(0.0011) |
| Local Epoch | FedSage | FedSage+ | GlobSage |
|---|---|---|---|
| 1 | 0.8696(0.0035) | 0.8755(0.0047) | |
| 3 | 0.8663() | 0.8740(0.0015) | 0.8776(0.0011) |
| 5 | 0.8591(0.0012) | 0.8740(0.0011) |
Table 5 and 6 both evidence the reliable, repeatable therapeutic effects that FedSage+ consistently further elevates FedSage in the global node classification task. Notably, in Table 5, when batch sizes are as small as 16 and 1, FedSage+ accomplishes even higher classification results compared to the centralized model GlobSage due to the employment of NeighGen.
Table 5 reveals the graph learning model can be affected by different batch sizes. As GlobSage is trained on a whole global graph, rather than a set of subgraphs, compared to FedSage and FedSage+, it suits a larger batch size, i.e., 64, than 1 or 16. Both FedSage and FedSage+, where every data owner samples on a limited subgraph, fit better in batch sizes 16. Remarkably, when the batch size equals 1, FedSage is prone to overfit to local biased distribution, while FedSage+ resists the overfitting problem under the NeighGen’s assistance, i.e., generating cross-subgraph missing neighbors.
Table 6 provides the relation between the local epoch number and the downstream task performance. For FedSage, more local epochs degenerate the outcome model with more biased aggregated local weights, while FedSage+ maintains a relatively more stable performance in the downstream task. Table 6 empirically evidences that the missing neighbor generator in FedSage+ provides further generalization and robustness in resisting rapid accuracy loss brought by higher local epochs.