Sublinear Maximum Inner Product Search using
Concomitants of Extreme Order Statistics
Abstract.
We propose a novel dimensionality reduction method for maximum inner product search (MIPS), named CEOs, based on the theory of concomitants of extreme order statistics. Utilizing the asymptotic behavior of these concomitants, we show that a few dimensions associated with the extreme values of the query signature are enough to estimate inner products. Since CEOs only uses the sign of a small subset of the query signature for estimation, we can precompute all inner product estimators accurately before querying. These properties yield a sublinear MIPS algorithm with an exponential indexing space complexity. We show that our exponential space is optimal for the -approximate MIPS in unit sphere. The search recall of CEOs can be theoretically guaranteed under a mild condition.
To deal with the exponential space complexity, we propose two practical variants, including sCEOs-TA and coCEOs, that use linear space for solving MIPS. sCEOs-TA exploits the threshold algorithm (TA) and provides superior search recalls to competitive MIPS solvers. coCEOs is a data and dimension co-reduction technique and outperforms sCEOs-TA on high recall requirements. Empirically, they are very simple to implement and achieve at least 100x speedup compared to the bruteforce search while returning top-10 MIPS with accuracy at least 90% on many large-scale data sets.
1. Introduction
Maximum inner product search (MIPS) is the task of, given a point set of size and a query point , finding the point such that,
MIPS and its variant top- MIPS, which finds the top- largest inner product points with a query, are central tasks in many real-world big data applications, for example recommender systems (KorenIEEE09, ; Linden03, ), similarity search in high dimensions (Glove, ; Sundaram13, ), multi-class learning (Dean13, ; ImageNet, ), and neural network (Covington16, ; Spring17, ).
Modern collaborative filtering based recommender systems, e.g. Xbox or Netflix, often deal with very large-scale data sets and require fast response (Xbox, ; Netflix, ). Such recommender systems present users as a query set and items as a data set. A large inner product value between the user and item vectors indicates that the item is relevant to the user preferences. When the context has been used (Adomavicius15, ), the learning (i.e. matrix factorization) phase cannot be done entirely offline (Xbox, ; YahooMusic, ). In other words, the items vectors are also computed online and hence a high cost of constructing the index structure for MIPS will significantly degrade the system performance.
Many MIPS applications arise on streaming data where both query and data points come with a rapid rate. For example, Twitter has to search with 400 million new tweets per day (Sundaram13, ). MIPS can also be used to reduce the computational cost of training and testing deep networks (Spring17, ). However, the very large index storage with high latency of updates will deteriorate the overall performance.
Motivated by the computational bottleneck of many MIPS applications in big data, this work addresses the following problem:
If we build a data structure for in 111Polylogarithmic factors, e.g. is absorbed in the -notation. time and space, can we have a fast MIPS solver that returns the best search recall?
Our main finding is that existing solutions, while highly efficient in general, cannot achieve effective search recall given that the index construction requires time and space complexity. We present novel solutions based on the concomitants of extreme order statistics. Our algorithms are very simple to implement (few lines of Python codes), run significantly faster, and yield higher search recall than competitive MIPS solvers.
Because Gaussian random projection is a building block of our approach, and because locality-sensitive hashing is our primary alternative for comparison, we review both briefly.
1.1. Gaussian random projections
Random projections (RP) refer to the technique of projecting data points in -dimensional spaces onto random -dimensional spaces () via a random matrix . In the reduced -dimensional space, the key data properties, e.g. pairwise Euclidean distances and inner product values, are preserved with high probability. Therefore, we can achieve a high quality approximation answer for MIPS in the reduced dimensional space.
Presenting the point set as a matrix , we generate a Gaussian random matrix whose elements are randomly sampled from the standard normal distribution . The signature (i.e. projected representation) of is computed by . Since we study MIPS, we only state the relative distortion bound of inner product values in the reduced space as follows:
Lemma 1.1.
Let be the angle between the vectors . Given , we have the following:
The proof of Lemma 1.1 can be found in (Kaban15, ). The constant of this bound on the inner product matches the Johnson-Lindenstrauss lemma bounds on the Euclidean distance (Dasgupta03, ; JL, ), which has been proven to be optimal for linear dimensionality reductions (Larsen17, ).
1.2. Locality-sensitive hashing
Locality-sensitive hashing (LSH) (Andoni08, ; Har12, ) is a key algorithmic primitive for similarity search in high dimensions due to the sublinear query time guarantee. Several approaches exploit LSH to obtain sublinear solutions for approximate MIPS (Huang18, ; RangeLSH, ; Shrivastava14, ; SimpleLSH, ). We will review solutions based on SimHash (SimHash, ) since we can use SimHash for both similarity estimation and sublinear search for MIPS.
SimHash. Given a Gaussian random vector whose elements are randomly drawn from the , a SimHash function of is . Denote by the angle between two vectors and , the seminal work of Goemans and Williamson (Goemans, ) and Charikar (SimHash, ) show that
Lemma 1.2.
Since is a monotonically decreasing function of when , SimHash is a LSH family for the inner product similarity on a unit sphere. Exploiting the binary representation of SimHash values, we can efficiently estimate the inner product with the fast Hamming distance computation using built-in functions of compilers. We note that SimHash binary code can be seen as a quantization of Gaussian RP since it keeps the sign of each projected value.
SimHash-based solutions for MIPS. Since the change of does not affect the result of MIPS, we can assume without loss of generality. Lemma 1.2 shows that the hash collision depends on both and . Therefore, by storing the 2-norm , we can use SimHash for estimating . However, the dependency on such 2-norms makes MIPS more challenging to guarantee a sublinear query time. Since inner product is not a metric, SimHash-based solutions have to convert MIPS to the nearest neighbor search by applying order preserving transformations to ensure that both data and query are on a unit sphere.
SimpleLSH (SimpleLSH, ) proposes asymmetric transformations : and where is the maximum 2-norm of all points in . Since the inner product order is preserved and , we can exploit SimHash for both similarity estimation and sublinear search for MIPS.
It is clear that the inner product values in the transformation space will be scaled down by a factor of . Furthermore, the top- inner product values are often very small compared to the vector norms in high dimensions. This means that the MIPS values and the distance gaps between “close” and “far apart” points in the transformation space are arbitrary small. Therefore, we need to use significantly large code length to achieve a reasonable search recall. In addition, the standard -parameterized (where is the number of concatenating hash functions and is number of hash tables) bucketing algorithm (Andoni08, ) demands a huge space usage (i.e. large ) to guarantee a sublinear query time. In other words, the LSH performance will be degraded in the transformation space.
RangeLSH (RangeLSH, ) handles this problem by partitioning the data into several partitions and applying SimpleLSH on each partition. While such distance gaps between “close” and “far apart” points in the LSH framework are slightly improved, the number of hash tables needs to be scaled proportional to the number of partitions to achieve a reasonable search recall. Nevertheless, the subquadratic time and space cost of building LSH tables in order to guarantee a sublinear query time will be a bottleneck on many big data applications.
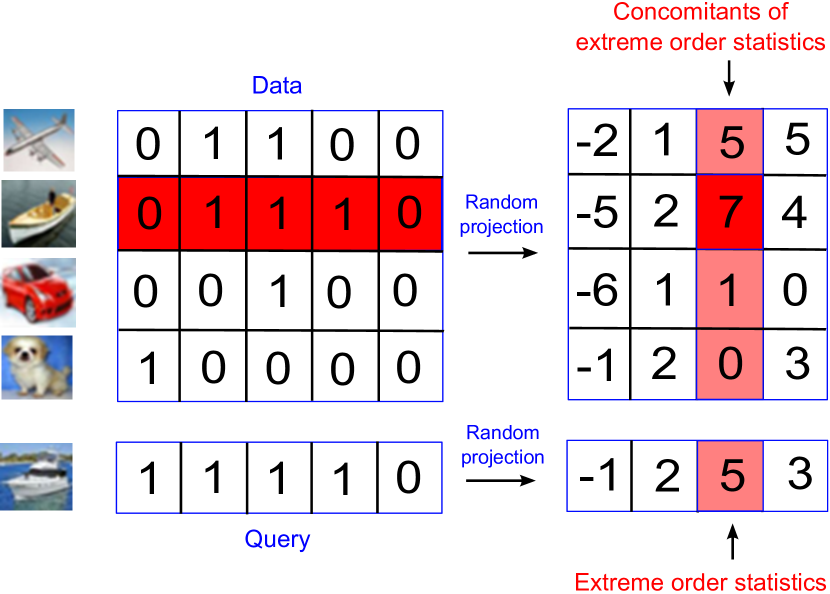
1.3. Our contribution
The paper introduces a specific dimensionality reduction, called CEOs, based the theory of concomitants of extreme order statistics. While we also construct signatures for both data and query points using Gaussian random projections, we only use a small subset of dimensions to estimate inner products. This subset of size corresponds to random projections associated with the extreme values (i.e. maximum or minimum) of the query signature.
The geometric intuition is that among Gaussian random projection vectors , the random projection associated with , the closest one to the query , will preserve the best inner product order. Since is the closest vector to , the value is maximum among signature values . Figure 1 shows a high level illustration of how CEOs works. We note that ones can also use the random projection associated with , the furthest one to due to the symmetry of Gaussian distribution.
The technical difficulty is to provide a good estimator for given a small subset of projected values associated with the random projection vectors closest and furthest to . We observe that this subset of size is the concomitants of extreme th normal order statistics associated with the query signature. Leveraging the theory of concomitants of extreme order statistics, we provide a surprisingly simple and asymptotically unbiased estimate for . That yields very fast and accurate MIPS solvers.
The key feature of CEOs is that we only need to use significantly small projected dimensions (often in our benchmark) among signature dimensions. Most importantly, in contrast to traditional dimensionality reductions, CEOs only uses the sign of a small subset of query signature (i.e. projections associated with maximum and minimum values) to estimate inner products. This means that we can precompute and rank inner product estimators of all data before querying to significantly reduce the query time. We show that this cost of constructing indexes matches the lower bound of the -approximate MIPS in unit sphere (Andoni06, ).
Under a mild condition, our theoretical analysis shows that we can achieve a sublinear query time for MIPS with search recall guarantees given an indexing space complexity. To deal with such exponential time and space complexity, we introduce several CEOs variants which require time and space for indexing and can answer top- MIPS with very high search recalls. A summary of our contributions is as follows:
-
(1)
We propose a novel dimensionality reduction method based on the theory of concomitants of extreme order statistics, named CEOs for top- MIPS. We theoretically and empirically show that CEOs provides better estimate accuracy and hence higher top- MIPS recall than SimHash (SimHash, ) and Gaussian random projections (Kaban15, ).
-
(2)
Inheriting from the asymptotic properties of concomitants of extreme th order statistics, CEOs yields a sublinear query time given time and space complexity for building the index. The search recall can be theoretically guaranteed under a mild condition, and the exponential space usage is optimal for MIPS on a unit sphere.
-
(3)
We propose practical CEOs variants, including sCEOs-TA and coCEOs, that build the index in time. sCEOs-TA exploits the threshold algorithm (TA, ) for solving MIPS. coCEOs is a data and dimension co-reduction technique and often outperforms sCEOs-TA on high search recall requirements. Especially, coCEOs can be viewed as a budgeted MIPS solver with a parameter that answers top- MIPS in time.
-
(4)
Our proposed algorithms are very simple to implement and require few lines of codes. Empirically, on the inferior choice that uses the concomitants of the maximum order statistics, CEOs requires sublinear index space and outperforms LSH bucket algorithms regarding both efficiency and accuracy. Both sCEOs-TA and coCEOs outperform competitive MIPS solvers on answering top-10 MIPS and achieve at least 100x speedup compared to the bruteforce search with the accuracy at least 90% on many real-world large-scale data sets.
2. Preliminaries
This section revises the background of bivariate normal distribution and concomitants of normal order statistics.
2.1. Bivariate distribution
Let be bivariate normal where is the correlation coefficient, and are the means and variances of and , respectively. Let be a bivariate normal sample, we can write
where and are mutually independent. Furthermore, is normal with .
(Bivariate_Book, , Section 4.7) shows that the conditional distribution of given is normal with the mean and variance as follows.
Lemma 2.1.
2.2. Concomitants of normal order statistics
Let be random samples from a bivariate normal distribution . We order these samples based on the -value. Given the th order statistic , the -value associated with is called concomitant of the th order statistic and denoted by . Let denote the specific associated with , we have the following equation:
The seminal work of David and Galambos (CEO_Paper, ) establishes the following properties of concomitants of normal order statistics.
Lemma 2.2.
In this work, we are interested in the concomitants of a few th and th order statistics where is small, for example and . The asymptotic distribution of these random variables with a sufficiently large has been studied in statistics during the last decades (CEO_Book, ; CEO_Paper, ) with a considerable use in survival analysis.
3. Theory of Concomitants of Extreme Order Statistics
Given two vectors and a random Gaussian vector whose coordinates are randomly sampled from the normal distribution , we let and . For simplicity, we assume that since it would not affect the efficiency and accuracy of our proposed MIPS solvers 222In practice, we do not need to normalize since all analysis will be scaled by a constant ..
It is well known that , . More importantly, and are normal bivariates from where (Li06, ; RP_Book, ).
Let be random samples from . We form the concomitants of normal order statistics by descendingly sorting these pairs based on -value. The theory of concomitants of extreme order statistics studies the asymptotic behavior of the concomitants when goes to infinity. In the following subsections, we will discuss how to leverage these asymptotic results to estimate inner products for MIPS.
3.1. Concomitant of the extreme
Let be the concomitant of the first (maximum) order statistic . Applying Lemma 2.2, we have the following properties of :
Lemma 3.1.
We note that is the largest variable among independent standard normal variables. When is sufficiently large, (maxGauss_Book, , Chapter 8) and (maxGauss, ) show that and , and the rate of convergence is . Using as a proxy for asymptotic results with a sufficiently large , we have
Lemma 3.2.
In order to use the concomitant of the first order statistics for estimating inner product value, we define . It is straightforward that and
| (1) |
We note that the behavior of is consistent with the result of Lemma 2.1 where are the extreme values of standard normal distribution, e.g. around . While the variance is stable, the expectation is scaled up by a factor of , which yields highly accurate estimates for MIPS. For notational simplicity, we name the method using for estimating inner products as CEOs.
Comparison with LSH: We now compare the inner product estimators provided by SimHash and CEOs. Define if ; otherwise 0. By the LSH property, we have and . Using the Taylor series with for , we have
Define , it is clear that and
| (2) |
Equations 1 and 2 show that SimHash needs to use approximately bits to achieve a similar accuracy as CEOs with a sufficiently large . As elaborated in Section 1.2, SimpleLSH applies SimHash for MIPS by scaling down all inner products with a normalization factor where is the maximum 2-norm of the data. This means that SimpleLSH needs to use approximately bits to have a similar accuracy as CEOs.
Comparison with Gaussian RP: We now bound the estimate error provided by and compare with the concentration bound provided by the Gaussian RP. We investigate the asymptotic behavior of concomitants of extreme order statistics. The theory of extreme order statistics (CEO_Paper, ) states that the distribution of the extreme case converges in probability to the normal distribution when . Recall that and hence .
We will use the following Chernoff bounds (Chernoff, ) to bound the relative estimate error induced by .
Lemma 3.3.
Let , for all we have
Applying the Chernoff bounds for the random variable , given any we have:
When is sufficiently large, the error probability will be arbitrarily small, and hence the estimate will be very accurate. Using the asymptotic distribution of , our concentration bound has the similar form of Lemma 1.1 with projections. While in the worst case where , Gaussian RP shares the similar bound as CEOs with . However for the case of , CEOs offers a much tighter bound than Gaussian RP due to .
MIPS algorithms: In general, compared to CEOs, SimHash and Gaussian RP can achieve similar performance for MIPS by using bits and random projections for constructing signatures, respectively. However, after constructing signatures, these approaches have to perform inner product estimation, which is clearly a computational bottleneck for MIPS. In contrast, CEOs does not need this costly estimation step since we can sort all the points based on their projection values in advance. At the query phase, after executing RP to compute the dimension index of , we can simply return point indexes corresponding to the top- concomitants associated with as an approximate top- MIPS. This key property makes CEOs more efficient than both Gaussian RP and LSH-based solutions on answering approximate MIPS.
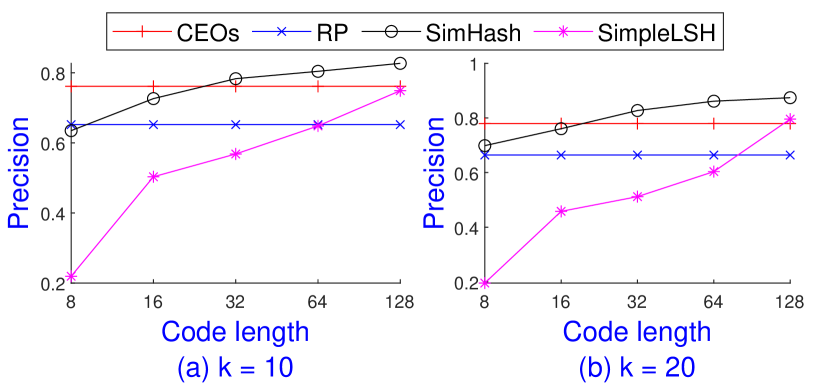
Theoretically, the theory of concomitants of extreme order statistics requires . However, we observe in practice that suffices for many real-world data sets. We present a brief experiment to compare the MIPS accuracy using called CEOs with , SimHash, SimpleLSH and Gaussian RP. We use the precision measure which computes the search recall of the top- answers provided by the estimation algorithms. Figure 2 shows the average measure and for and of these 4 methods on Nuswide over 100 queries. The result is consistent with our analysis. CEOs with outperforms Gaussian RP with , and achieves higher accuracy than SimpleLSH with and SimHash with bits code.
3.2. Concomitants of the extreme
We observe that the Gaussian distribution is symmetric. This means that we can use both and corresponding to the maximum and minimum order statistics for estimating . One natural question is: “Can we use more concomitants and are they independent so that we can boost the accuracy with the standard Chernoff bounds?”.
Indeed, we have a positive answer by investigating the asymptotic independence of concomitants of extreme order statistics. Let be a fixed positive integer and , the seminal work of David and Galambos (CEO_Paper, ) shows that the concomitants where are asymptotically independent and normal as follows:
By the symmetry of Gaussian distribution, we can use the concomitants and where to boost the accuracy of the estimator of . In other words, ones can view these concomitants as a specific dimension reduction since the sum of these values provides unbiased estimates of inner products.
By using the average of these concomitants to estimate , we achieve an asymptotic unbiased estimator with the variance decreased by a factor of . Hence, the concentration bound is tighter by a factor of .
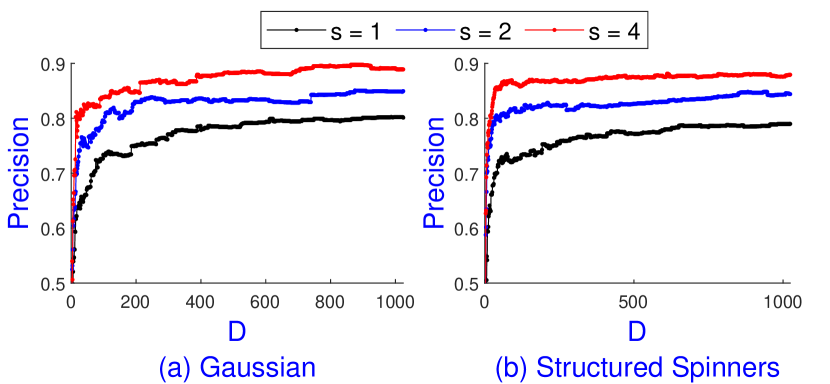
Figure 3 (a) confirms our results on Nuswide by showing the average precision of CEOs on top-10 MIPS when varying and . When fixing and is sufficiently large, e.g. , the precision marginally increases. However, increasing yields a substantial rise of precision. Especially, when and , is nearly 90%, which is higher than that of SimHash with 128 bits code shown in Figure 2 (a).
4. Efficient Algorithms for top- MIPS
As illustrated in Section 3.2, we can view the concomitants of extreme order statistics as a specific dimension reduction. The number of concomitants associated with the extreme th order statistics is the number of reduced dimensions. Though is often very small in practice, the linear time of estimating inner products will be the computational bottleneck of MIPS. This section will describe how to exploit key properties of concomitants of extreme th order statistics to achieve MIPS solvers.
We recall the notation that we have , , and a random Gaussian vector whose coordinates are sampled from . We let , , and . We have and are normal bivariates from where . and are normal bivariates from where .
Let and be the concomitants of the in random samples from the bivariate normal distribution and , respectively. We note that and are not independent due to the link to .
For simplicity, we only consider and and denote be the correlation between and . Let , and assume . By the asymptotic property of concomitants of extreme order statistics, we have
Let . Since the sum of two Gaussian variables is Gaussian, we have
Applying Lemma 3.3 for the Gaussian variable , we have
Since , we have . Therefore,
| (3) |
Let . When is not very small and is sufficiently large, for any . In order words, is ranked higher than with high probability in the sorted list associated with . This observation is the key property which makes CEOs more efficient than competitive MIPS solvers.
Due to the asymptotic independence and normal distribution of concomitants associated with and where , we can use the sum of these concomitants as an inner product estimate. Note that for , we have to reverse the sign due to the symmetry of normal distribution. Since the variance of the sum of independent random variables is decreased by a factor of , we have
| (4) |
Assume that is not very small, i.e. where . Given a sufficiently large , suffices for asymptotic properties of concomitants associated with the th order statistics. With , the probability in Equation 4 is bounded by . Applying the union bound, we state our main result as follows:
Theorem 4.1.
Assume is the top-1 MIPS given the query . Let for any . Given a sufficiently large and a constant , we assume that . By choosing , for all , we have:
Our result does not hold on the data sets where inner products between all data points and the query are almost similar. This is due to the fact that and the assumption does not hold. Nevertheless, real-world data sets rarely have such properties and our empirical results show that CEOs with works very efficiently, as shown in Figure 2 and 3.
4.1. Optimality for -MIPS on a unit sphere
This subsections discusses the optimality of CEOs on answering the -approximate MIPS on a unit sphere given a small . Given a point set of size and a query point on a unit sphere, it is clear that . Therefore, we investigate the result of theorem 4.1 for a decision version of the approximate nearest neighbor search over the Euclidean space on a unit sphere. The decision version is to build a data structure that answers -approximate near neighbor search as follows.
-
•
If there is such that , answer YES.
-
•
If there is no such that , answer NO.
Andoni et al. (Andoni06, ) analyze the lower bound of the decision problem given a constant query time (measured by the number of probes to the data structure) on the Euclidean space. In particular, any algorithm uses a constant number of probes to the data structure must use space. Since a high search recall demands very small , this result presents a fundamental difficulty for any practical data structures that can answer the nearest neighbor search very accurate and fast.
An upper bound for -nearest neighbor search over the Hamming space is proposed in (Kushilevitz00, ) that use . This work complements that result by showing a data structure which achieves a constant query time and uses over the Euclidean space on a unit sphere. We show it by deriving and bounding the value on Theorem 4.1 where and as follows.
Hence,
On a unit sphere and for a fixed distance , we have . From Equation 4, we have to use to answer the decision version of -approximate near neighbor search with high probability. This means that CEOs can precompute the results of -approximate near neighbor search for all queries using space and answer the query with a constant probes. This matches the lower bound on the space usage provided by (Andoni06, ).
4.2. MIPS using concomitants of
Consider that we have a small budget of inner product computations for post-processing to achieve higher MIPS accuracy. For each projected dimension, we only need to maintain top- largest concomitants among concomitants corresponding to points. For querying, we only use these concomitants associated with . Since any MIPS solver can use post-processing, we will consider to simplify the analysis. Algorithm 1 shows how CEOs with concomitants of , named 1CEOs, works.
Complexity: It is clear that building the index takes time. The index space is only since each of dimensions stores points, and the query time is . When , 1CEOs answers MIPS in both sublinear space and time.
Error analysis: Equation 3 indicates that, given a sufficiently large , corresponding to the top- MIPS tends to be ranked at the top positions on the list corresponding to . We note that by simply increasing inner products in post-processing, we can achieve higher accuracy of top- MIPS since we allow larger gap . While we cannot theoretically guarantee the performance of 1CEOs, our empirical results show that 1CEOs outperforms the sublinear LSH bucket algorithm regarding both space and time of indexing and querying for MIPS.
4.3. Sublinear MIPS using concomitants of
Since we can use concomitants associated with and where to boost the estimate accuracy, Theorem 4.1 shows that we can have a sublinear MIPS with guarantees.
Since the estimation does not use the values of query signatures (except the dimension order), we can precompute and sort all possible estimates before querying. For example, in order to use and for estimating , after executing random projections, we can precompute the difference of all pairs of dimensions and sort the data based on these difference values. We compute the difference because of the symmetry of normal bivariate distribution. Algorithm 2, named sCEOs, generalizes this observation to exploit concomitants of extreme th order statistics for MIPS.
Complexity and error analysis: Building the index takes time and space. This is because we have different sets and each of has different sets . sCEOs has query time as similar as 1CEOs. Setting for any , Theorem 4.1 states that sCEOs can have a sublinear query time given that the assumption holds for all . Furthermore, sCEOs returns exact top- MIPS with probability at least . Figure 3 (a) demonstrates that with , and , sCEOs can achieve nearly 90% search recall for top-10 MIPS on Nuswide even without post-processing.
Performance simulation: One of the nice features of sCEOs is that we can compute the sCEOs search recall by implementing it as a specific dimensionality reduction. We name this approach as sCEOs-Est since it estimates inner products by the sum of concomitants of extreme th order statistics of the query signature. While sCEOs-Est estimates inner products in time, it still runs significantly faster than both Gaussian RP and bruteforce search since addition operators are often much faster than multiply-add operators. More important, we can use sCEOs-Est to simulate the sublinear search performance of sCEOs before implementing it. This property makes sCEOs very useful in practice while LSH bucket algorithms do not have.
4.4. TA algorithm using concomitants of
While the querying time is sublinear, the space and time complexity for building the index of sCEOs blow up by a factor of , which will be the computational bottleneck of many big data applications. Therefore, we might need to use sCEOs-Est for large data sets.
We observe that sCEOs-Est estimates inner product values by the sum of positive concomitants and extracts top- indexes with the largest estimates for post-processing. Therefore, ones can speed up sCEOs-Est by using the well-known threshold algorithm (TA) (TA, ). Algorithm 3, named sCEOs-TA, shows how we can exploit the TA algorithm for speeding up sCEOs-Est.
Complexity: sCEOs-TA builds the index in time, which is slightly larger than time of sCEOs-Est, but uses the same space. Unfortunately, we could not state the query time complexity of sCEOs-TA. In practice, sCEOs-TA provides the same accuracy as sCEOs-Est due to the same computation of top- estimators for post-processing. However, our empirical results show that sCEOs-TA often runs 5 – 10 times faster than sCEOs-Est, especially when and are small. It is worth noting that sCEOs-TA can be used to speed up the index construction of sCEOs since it computes exactly top- inner product estimates for each set of dimensions.
4.5. Co-reduction using concomitants of
While sCEOs-TA can speed up sCEOs-Est given a similar time and space complexity for constructing the index, we could not bound its running time. From Equation 3, we observe that we do not need to keep the whole data in the sorted list associated with the dimension of for answering MIPS. By exploiting this property, we propose coCEOs, a co-reduction method that keeps a fraction of data in our index and uses a small number of dimensions for answering MIPS.
Since one dimension can associate with the maximum or minimum order statistics, we need to keep both top- point indexes with the largest and smallest values. Therefore, coCEOs can be seen as a compressed data structure that keeps the top- points on each dimension . When the query comes, we will choose the smallest or largest top- indexes depending on the rank of . We observe that the larger inner product the point has, the more frequent it should be listed on these top- points, and hence the larger estimate it has. We propose coCEOs to compute partial estimate of the inner products in sCEOs-based data structure, as shown in Algorithm 4 .
Complexity: While the space usage of our index is , the construction time is . By using a hash table to maintain the histogram of partial estimates, the query time of coCEOs is . Notable, coCEOs requires linear space but still runs in sublinear time when .
Practical setting: While sCEOs-Est sums the dimensions associated with for points, coCEOs computes partial estimates for the points that are likely to be the top- MIPS. Hence, coCEOs can exploit a larger number of extreme order statistics (i.e. larger number of dimensions) compared to sCEOs-Est. Let be the number of dimensions used by coCEOs. In order to govern the running time of coCEOs, we set a budget of samples and select points on each of dimensions associated with . Hence, coCEOs runs in time. Since we can govern the query time of coCEOs, we can use it on the budgeted MIPS setting (dWedge, ).
4.6. Make CEOs variants practical
For CEOs variants, both indexing and querying requires Gaussian RP, which takes time for one point. This cost is significant and often dominates the query time when is large. Fortunately, there are several approaches to simulate the Gaussian RP. We will use the Structured Spinners (Andoni15, ; Bojarski17, ; Choromanski17, ) that exploit the fast Hadamard transform to simulate Gaussian RP.
In particular, we generate 3 random diagonal matrices whose values are randomly chosen in . The Gaussian RP can be simulated by the mapping where is the Hadamard matrix. With the fast Hadamard transform, the Gaussian RP can be simulated in time, which will not dominate the query time of CEOs variants. Note that if is not a power of 2, we can simply add up additional zero coordinates. More important, we can use universal hash functions to generate random diagonal matrices . Hence, it takes extra space for storing Gaussian RP simulation. Furthermore, since both and are isometries, the inner products are preserved. Therefore, sCEOs-Est and sCEOs-TA can use these random rotated embeddings for computing inner products in post-processing, and hence do not need to keep the data set in the memory.
Figure 3 (b) shows that the Structured Spinners can simulate well the Gaussian RP with almost the same MIPS precision but run times faster. Even though we use the Eigen library333http://eigen.tuxfamily.org/index.php?title=Main_Page for the extremely fast C++ matrix-vector multiplication, Structured Spinners compute the signatures 4 times faster than the Gaussian RP on Nuswide with and . Since our benchmark data sets are high-dimensional, and since we need is a power of 2, we set in our experiments.
4.7. Potential applications of CEOs variants
In practice, we often need to run MIPS on large-scale data sets with a huge batch of queries in real-time at very high rates. This section will discuss potential applications of CEOs variants on answering MIPS on distributed environments to handle such scenarios.
sCEOs for distributed MIPS: Given concomitants and random projections, sCEOs answer query in time by computing inner products from the list . This key property makes sCEOs suitable for parallel computing.
-
(1)
The size of is small enough to keep in memory for fast query response.
-
(2)
Since we only assess one machine containing , sCEOs has almost no query broadcast overhead, and therefore yields large query throughput.
coCEOs for streaming MIPS: coCEOs uses samples for computing partial inner products. Such a small amount of information will significantly reduce the shuffling cost of the MapReduce implementations. Furthermore, the cost of updating the data structure for one point is due to the maintaining of sorted lists and where . Therefore, coCEOs is suitable for streaming MIPS over large-scale data sets where both queries and data arrive at very high rates.
CEOs variants on P2P MIPS: In P2P system, we can horizontally partition the data sets into several partitions and each node will store a partial of our data sets. In other scenario, different nodes can involve the search process by using their own data sets. In both cases, CEOs variants work efficiently. At the indexing phase, all nodes have to construct the data structure using the same random projections. Exploiting the fast Hadamard transform, we only need to send bits presenting for the matrix through the network. Regarding privacy preservation, the query node can send bits corresponding to dimensions of extreme order statistics. The query node will receive the largest estimates from all nodes and select the node with the largest estimate for the final MIPS evaluation.
5. Experiment
We implement CEOs variants 444https://drive.google.com/file/d/1cALMtc8u2027rRXc4XR14n4wBSsbrBSD and other competitors in C++ using -O3 optimization and conduct experiments on a 2.80 GHz core i5-8400 32GB of RAM with single CPU. We present empirical evaluations on top- MIPS to verify our claims, including:
-
(1)
CEOs provides very high MIPS recall using a small number of dimensions , which is consistent with the theory of concomitants of extreme order statistics.
-
(2)
On inferior choice that uses the concomitants of , sublinear sCEOs outperforms the LSH bucket algorithm on indexing and querying regarding both space and time.
-
(3)
Both sCEOs-TA and coCEOs outperform competitive top- MIPS solvers on many real-world data sets.
-
(4)
coCEOs outperforms sCEOs-TA when requiring high search recalls, e.g. 90%.
We use the speedup over the bruteforce search to measure the efficiency and to measure the search recall since we use post-processing with a small budget of inner product computations. We consider top-10 MIPS and hence when , we do not need post-processing. The measurements are defined as follows:
| P@b | |||
| Speedup |
| Cifar10 | Nuswide | Yahoo | Msong | Gist | Imagenet | Tiny5m | |
|---|---|---|---|---|---|---|---|
| 3072 | 500 | 300 | 420 | 960 | 150 | 384 | |
| 49K | 270K | 625K | 1M | 1M | 2.3M | 5M |
5.1. MIPS solvers and data sets
We implement CEOs variants, including (1) 1CEOs and sCEOs as sublinear MIPS solvers, (2) practical variants including sCEOs-Est, sCEOs-TA, and coCEOs which have index construction time and space. We implement recent LSH-based schemes, including SimpleLSH (SimpleLSH, ) and RangeLSH (RangeLSH, ), which exploit SimHash (SimHash, ) for top- MIPS. We also compare our solutions with dWedge (dWedge, ), a representative sampling approach for budgeted MIPS. We implement the bruteforce search and LSH hash evaluations with the Eigen-3.3.4 library for the extremely fast C++ matrix-vector multiplication.
We conduct experiments on standard real-world large-scale data sets, as shown in Table 1. We randomly extract 1000 points (e.g. 1000 user vectors for Yahoo) to form the query set. All randomized results are the average of 5 runs of the algorithms.
5.2. Search recall of sCEOs
This subsection shows the search recall of sCEOs on top-10 MIPS by implementing sCEOs-Est. We set to exploit the fast Structured Spinners. We observe that this setting satisfies on most of our high-dimensional data sets.
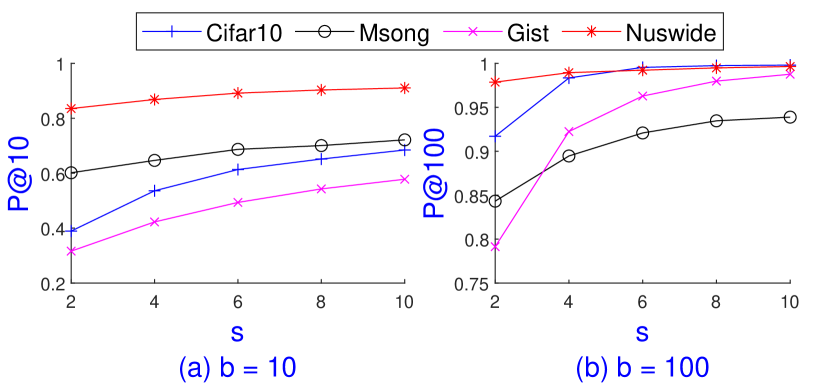
Figure 4 presents the accuracy of top-10 MIPS when varying on Cifar10, Msong, Gist, and Nuswide. It is clear that increasing leads to a substantial rise of the accuracy. When , sCEOs achieves over 90% accuracy on Msong and especially reaches nearly perfect recall on the other data sets. The results confirm the reliability of our theoretical analysis for the sublinear sCEOs since the settings are similar to the requirements of Theorem 4.1 where for any .
Given the above setting , sCEOs in practice uses space and time complexity for building the index and achieves nearly perfect recall with just 100 inner product computations on these data sets.
5.3. Comparison on sublinear algorithms
This subsection shows experiments comparing the performance between sublinear sCEOs and the -parameterized LSH bucket algorithms with SimpleLSH and RangeLSH instances. We note that both SimpleLSH and RangeLSH transform data and query into unit sphere in order to exploit SimHash.
While sCEOs can simply choose top- points with the largest inner product estimates in the list , it is impossible to tune LSH parameters to return the best candidates for each query. This is due to the fact that we do not know the collision probability between the query and data points. Given a fixed number of hash tables , the number of concatenating hash functions will control the number of collisions and therefore the candidate set size. The query complexity of LSH schemes are where the first term is from the hash computation and the second term comes from the post-processing phase.
For LSH parameter settings, we first fix as suggested in previous LSH-based MIPS solvers (SimpleLSH, ; Shrivastava14, ) and vary the parameter such that we achieve the highest search recall given candidates for each query. RangeLSH uses partitions and each partition has hash tables. We observe that increasing will decrease the performance. We use the Eigen library to speed up the hash computation. Regarding sCEOs, we only implement the inferior choices: 1CEOs with and 2CEOs with where we use concomitants of and . Due to the similar results, Figure 5 shows the representative results on Yahoo and Gist.
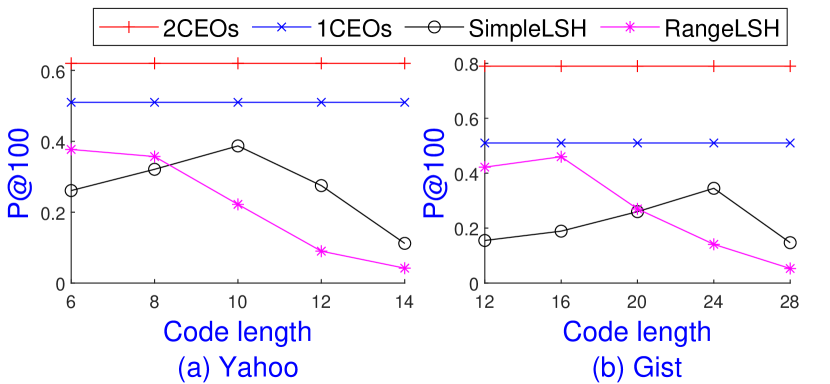
It is clear that CEOs schemes are superior to LSH schemes regarding search recall on these two data sets. We observe that RangeLSH reaches the highest search recall with smaller than SimpleLSH. Then, the accuracy of both schemes decreases when increasing on both data sets. A simple computation indicates that the average top-1 MIPS value after the SimpleLSH transformation is 0.24 on Yahoo. Hence, the total number of collisions is at most when , .
We observe that the average top-10 MIPS values are almost same even with partitions for RangeLSH. Hence there might be no advantages of increasing the distance gap between “close” and “far way” points. Since the top- MIPS points are often distributed on the same partition due to the similar large 2-norm values, RangeLSH reaches the highest search recall with smaller than SimpleLSH. Since each partition will have hash tables, increasing will decrease the accuracy of RangeLSH faster than SimpleLSH, as observed in Figure 5.
While 2CEOs gives higher search recalls than 1CEOs, its time and space complexity of building the index are also more significant. Table 2 shows a comparison of 1CEOs, 2CEOs, SimpleLSH 24 bits and RangeLSH 16 bits on indexing and querying on Gist.
| Algorithms | Index | Query | ||
|---|---|---|---|---|
| Time | Space | Speedup | ||
| 1CEOs | 1.5 mins | 0.8GB | 51% | 198 |
| 2CEOs | 1.2 hours | 8.4GB | 80% | 145 |
| SimpleLSH24 | 1.5 hours | 10GB | 35% | 62 |
| RangeLSH16 | 1.1 hours | 10GB | 46% | 52 |
It is clear that 1CEOs and 2CEOs outperform LSH schemes regarding both accuracy and efficiency on indexing and querying. Regarding the index, since the data set itself requires 8GB, 2CEOs uses only 0.4GB extra storage compared to 2GB of LSH schemes. Because 1CEOs only keeps points on each of dimensions, its index storage is just 10% of the data. Furthermore, the index construction time of 1CEOs is just some minutes compared to more than 1 hour of LSH schemes and 2CEOs.
Regarding querying, we observe that the hash computation time dominates the total time of LSH schemes with more than 70%, whereas more than 97% of total time of 1CEOs and 2CEOs are used for computing inner products. While 1CEOs provides lower search recall than 2CEOs, ones can simply increase inner product computations in post-processing to boost the accuracy. We observe that 1CEOs with achieves almost the same search recall of 2CEOs with just 40 speedup. Overall, 1CEOs is superior to LSH schemes regarding the indexing and querying.
We observe that the accuracy of 2CEOs is consistent with sCEOs-Est with , as shown in Figure 4 (b). In other words, ones can foresee the performance of sCEOs by implementing and testing sCEOs-Est in a few minutes. For example, sublinear sCEOs can achieve the performance of at least 85% accuracy for and at least 90% for with approximately 150 speedup on Cifar10, Msong and Nuswide. In contrast, we spent a day to find the best parameter settings for LSH schemes.
It is worth emphasizing that almost 100% of the search time of sCEOs are dedicated for computing inner products. Specifically, sCEOs runs on a single CPU and answers 1000 queries just only in 2 seconds on Gist. Ones can simply scale up the search process with multiple CPUs or distributed machines since sCEOs does not require any communication between CPUs or machines.
5.4. Comparison on estimation algorithms
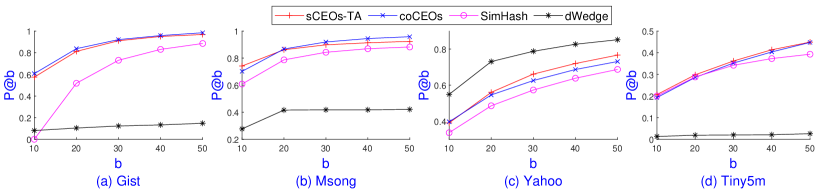
This subsection shows experiments comparing the performance between CEOs variants, including sCEOs-Est, sCEOs-TA, coCEOs, dWedge, and LSH code estimation schemes, including SimHash, SimpleLSH and RangeLSH on Gist, Msong, Yahoo, and Tiny5m. We note that Gaussian RP often suffers lower accuracy than these algorithms so we do not report it here.
Regarding parameter settings, sCEOs-Est and sCEOs-TA use , and they share the same accuracy. LSH schemes use the code length and use the _builtin_popcount function of compilers for Hamming distance computation. We observe that LSH with shares a similar speedup with sCEOs-Est.
While sCEOs-Est and LSH schemes require times for answering MIPS, sCEOs-TA often runs much faster. This is because sCEOs-TA might not have to estimate inner products. To show the sublinear running time, we will compare sCEOs-TA with coCEOs and dWedge using . dWedge shares a similar speedup with coCEOs due to the same mechanism: using samples to compute partial estimates of inner products. Note that we set for coCEOs since it can use a larger number of extreme order statistics.
Figure 6 shows the accuracy for a wide range of inner products in post-processing of sCEOs-TA, coCEOs, SimHash, dWedge on Gist, Msong, Yahoo, and Tiny5m. It is clear that CEOs variants consistently outperform SimHash on all 4 data sets while dWedge only shows advantages on the recommender system Yahoo. With , both sCEOs-TA and coCEOs achieve at least 90% accuracy on Gist and Msong whereas SimHash gives just above 80%. CEOs variants can provide 45% accuracy on Tiny5m whereas SimHash achieves approximately 35%. On Tiny5m, we can set and to increase of sCEOs-TA to at least 80% while SimHash still suffers from very low accuracy.
Table 3 shows a detailed comparison of three CEOs variants and three LSH variants on indexing and querying with on Gist. SimHash provides the highest search recall and similar speedup among LSH schemes given the same code length. It is reasonable since SimHash uses the norms directly to estimate inner products. While SimHash 256 bits and CEOs variants achieve similarly almost perfect recall, their speedups are very different. SimHash 256 bits are 3 times slower than sCEOs-Est and 15 times slower than sCEOs-TA and coCEOs. We observe that sCEOs-Est with shares the same speedup with LSH schemes of bits due to the fast addition operators supported by the Eigen library.
We note that the average inner products of top-10 MIPS on Gist is 0.68 and it does not change even with 1000 partitions on RangeLSH. Their Hamming distances are approximately 14 and 28 for 64 bits and 128 bits, respectively. This means that if you use a single hash table with multi-probing, you have to probe several thousands points for inner product computations, as illustrated in the experiment of RangeLSH. Such a large number of inner products will degrade the search performance, especially when data are located on disk. On the other hands, SimHash and CEOs variants only compute inner products and achieve more than 90% accuracy.
Though sCEOs-TA uses more time and space to construct the index, sCEOs-TA and coCEOs achieve almost the same search recall and speedup. Empirically, we observe that sCEOs-TA needs a few thousands of inner product estimates on all 4 data sets. This cost is nearly the same cost of computing partial inner products with of coCEOs and dWedge. Since we use the same in post-processing, coCEOs and sCEOs-TA achieve similar speedup on these data sets. For example, sCEOs-TA and coCEOs achieve more than 90% accuracy with at least 150 speedup on Msong and Nuswide, but we do not report in details here.
| Algorithms | Index | Query | ||
|---|---|---|---|---|
| Time | Space | Speedup | ||
| sCEOs-Est | 74s | 8.2GB | 97% | 45 |
| sCEOs-TA | 307s | 16.4GB | 97% | 166 |
| coCEOs | 172s | 8GB | 98% | 194 |
| SimHash256 | 60s | 8GB | 97% | 12 |
| SimHash128 | 30s | 8GB | 89% | 25 |
| SimpleLSH128 | 30s | 8GB | 73% | 37 |
| RangeLSH128 | 53s | 8GB | 76% | 27 |
Since sCEOs-TA extracts top- maximum inner product estimates, sCEOs-TA can be used to speed up the index construction of sublinear sCEOs. In particular, ones can run in parallel sCEOs-TA instances to construct the sCEOs index.
5.5. coCEOs vs. sCEOs-TA on high search recalls
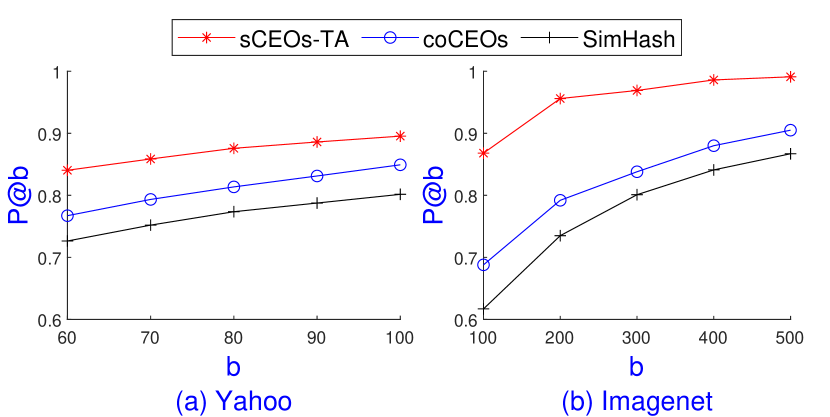
In the previous subsection, we observe that sCEOs-TA with achieves similar search recall and speedup with coCEOs with on all 4 data sets. However, to achieve significantly high search recalls, sCEOs-TA needs to use larger values of and . For example, Tiny5m requires , to achieve 90% recall. On these settings, sCEOs-TA’s performance is deteriorated and even outperformed by sCEOs-Est. This subsection demonstrates these findings on Yahoo, Tiny5m, and Imagenet, and shows that coCEOs is often superior to sCEOs-TA for a wide range of and .
We observe that sCEOs-TA requires , and , to achieve 90% accuracy on Yahoo and Imagenet, respectively. Since SimpleLSH and RangeLSH are outperformed by SimHash, we present only SimHash’s results with and bits code on Yahoo and Imagenet, respectively. coCEOs uses , on Yahoo and , on Imagenet. All methods use the same inner product computations in post-processing. Figure 7 shows a comparison of coCEOs, sCEOs-TA, and SimHash on Yahoo and Imagenet.
While coCEOs outperforms SimHash, providing 85% and 90% search recall on Yahoo and Imagenet, respectively, sCEOs-TA achieves the highest recall with at least 90% on both data sets. However, the running time of sCEOs-TA is deteriorated due to the large values of and . Table 4 shows a detailed comparison of these methods on the querying process on Yahoo.
| Algorithm | SimHash128 | sCEOs-Est | sCEOs-TA | coCEOs |
| Speedup | 116 | |||
| 80% | 90% | 90% | 85% |
It is clear that coCEOs runs orders of magnitude faster than sCEOs-TA, sCEOs-Est and SimHash 128 bits. We note that coCEOs with can boost the accuracy up to 90% and still offer at least 100 speedup.
On Imagenet, we observe that both sCEOs-TA and sCEOs-Est only provide marginal speedup due to the large reduced dimensions, i.e. and . However, coCEOs provides superior speedup to both sCEOs-TA and SimHash 512 bits while maintaining 90% accuracy since it uses . It achieves 7 speedup and 90% accuracy whereas SimHash 512 bits gives only 2 speedup and 87% accuracy with . We note that since all methods use the same inner product computations in post-processing, decreasing can significantly increase the speedup with the trade of accuracy.
On Tiny5m, sCEOs-TA also shows a slow query time with , . coCEOs with , can achieve 90% accuracy with at least 100 speedup whereas SimHash 128 bits gives only above 50% accuracy with just 16 speedup.
6. Related Work
Due to the “curse of dimensionality”, there is no known algorithms for solving exactly MIPS in truly sub-linear time. In fact, if there exists such an algorithm, the Strong Exponential Time Hypothesis (SETH) (SETH, ), a fundamental conjecture in computational complexity theory, is wrong (Rubinstein18, ; Williams14, ). Therefore, sequential scanning with pruning the search space techniques has been used to speed up MIPS and to return exact results (FEXIPRO, ; LEMP, ). However, these solutions run in time. In contrast, this work investigates algorithms that run in time and provide approximate top- MIPS. Our empirical evaluation on standard large-scale data sets shows that it is possible to achieve 90% search recall given query time.
An alternative efficient solution is applying sampling methods to estimate the vector-matrix multiplication derived by top- MIPS (Diamond, ; Wedge, ). The basic idea is to sample a point with probability proportional to the inner product . The larger inner product values the point has, the more occurrences of in the sample set. However, the number of required samples are often much larger than to guarantee high quality approximate MIPS.
It is worth noting that our investigated problem is similar to the budgeted MIPS, which has been recently studied in (dWedge, ; Yu17, ). These solutions also require to construct the index in time and space. We have demonstrated that our proposed solutions achieve significantly higher accuracy on many real-world data sets.
Recently, alternates to data-independent LSH are data-dependent schemes for approximate MIPS, including product quantization (Faiss, ; Guo16, ) and similarity graphs (Malkov20, ). Since these methods lack rigorous theoretical guarantees, we do not know when these schemes work or fail. Furthermore, these methods require significant data-dependent indexing time, and hence cannot be used on many applications, e.g. streaming search, scaling up machine learning models where both data and query distributions can change. In particular, quantization indexing runs as slowly as a -mean clustering and might converge to local minimum which degrades the performance. Building an exact Delauney graph is unfeasible due to the exponentially growing number of edges in high dimension (Malkov20, ). A popular approach is to build an approximation of Delaunay graph (Morozov18, ; Zhou19, ), which still requires time and does not offer any theoretical guarantee on search performance. In our work, we choose to compare with LSH (SimpleLSH, ; RangeLSH, ) due to the data-independent scheme with theoretical guarantees on query performance, and sub-quadratic (or linear) indexing time and space.
We note that CEOs shares some similar spirit with BOND (Vries02, ), a branch-and-bound search approach that selects a few of important data dimensions for execution. Since BOND is executed on the original data space, there is no theoretical guarantee on the search performance and it might run as slow as the sequential scanning. On the technical side, CEOs uses the maximum of Gaussian random variables for inner product estimation. This idea is similar to (Hadar19A, ; Hadar19B, ) which study the maximum of Gaussian variables for estimating the correlation of two parties’ variables in the distributed setting given a minimum number of exchanged bits. However, CEOs exploits the theory of concomitants of extreme order statistics to guarantee the search recall and optimality with the elementary Chernoff bounds.
7. Conclusions
The paper proposes CEOs, a novel dimension reduction for top- MIPS based on the theory of concomitants of extreme order statistics. Utilizing the asymptotic behavior of these concomitants, we show that CEOs provides a sublinear query time with an exponential space complexity. The search recall can be theoretically guaranteed under a mild condition of data and query distributions.
To deal with the exponential space and time complexity of indexing, we propose two variants, including sCEOs-TA and coCEOs, using linear space to solve top- MIPS. While sCEOs-TA outperforms competitive MIPS solvers regarding both efficiency and accuracy, coCEOs is even superior over a wide range of parameter settings. Empirically, they achieve more than 100 speedup compared to the bruteforce search while returning top-10 MIPS with accuracy at least 90% on many real-world large-scale data sets.
8. Acknowledgments
We thank Rasmus Pagh for pointing to the similar technique used in distributed statistical inference under communication constraints (Hadar19B, ).
References
- [1] G. Adomavicius and A. Tuzhilin. Context-aware recommender systems. In Recommender Systems Handbook, pages 191–226. Springer, 2015.
- [2] A. Andoni and P. Indyk. Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun. ACM, 2008.
- [3] A. Andoni, P. Indyk, T. Laarhoven, I. P. Razenshteyn, and L. Schmidt. Practical and optimal LSH for angular distance. In NIPS, pages 1225–1233, 2015.
- [4] A. Andoni, P. Indyk, and M. Pǎtraşcu. On the optimality of the dimensionality reduction method. In FOCS, pages 449–458, 2006.
- [5] Y. Bachrach, Y. Finkelstein, R. Gilad-Bachrach, L. Katzir, N. Koenigstein, N. Nice, and U. Paquet. Speeding up the Xbox recommender system using a euclidean transformation for inner-product spaces. In RecSys, pages 257–264, 2014.
- [6] G. Ballard, T. G. Kolda, A. Pinar, and C. Seshadhri. Diamond sampling for approximate maximum all-pairs dot-product (MAD) search. In ICDM, pages 11–20, 2015.
- [7] J. Bennett and S. Lanning. The Netflix prize, 2007.
- [8] D. P. Bertsekas and J. N. Tsitsiklis. Introduction to Probability. Athena Scientific, 2002.
- [9] M. Bojarski, A. Choromanska, K. Choromanski, F. Fagan, C. Gouy-Pailler, A. Morvan, N. Sakr, T. Sarlós, and J. Atif. Structured adaptive and random spinners for fast machine learning computations. In AISTATS, pages 1020–1029, 2017.
- [10] M. Charikar. Similarity estimation techniques from rounding algorithms. In STOC, pages 380–388, 2002.
- [11] K. M. Choromanski, M. Rowland, and A. Weller. The unreasonable effectiveness of structured random orthogonal embeddings. In NIPS, pages 219–228, 2017.
- [12] E. Cohen and D. D. Lewis. Approximating matrix multiplication for pattern recognition tasks. J. Algorithms, 30(2):211–252, 1999.
- [13] P. Covington, J. Adams, and E. Sargin. Deep neural networks for youtube recommendations. In RecSys, pages 191–198, 2016.
- [14] A. DasGupta. Asymptotic Theory of Statistics and Probability. Springer, 2008.
- [15] S. Dasgupta and A. Gupta. An elementary proof of a theorem of johnson and lindenstrauss. Random Struct. Algorithms, 22(1):60–65, 2003.
- [16] H. A. David. Concomitants of Extreme Order Statistics, pages 211–224. Springer US, 1994.
- [17] H. A. David and J. Galambos. The asymptotic theory of concomitants of order statistics. Journal of Applied Probability, 11(4):762–770, 1974.
- [18] A. P. de Vries, N. Mamoulis, N. Nes, and M. L. Kersten. Efficient k-nn search on vertically decomposed data. In SIGMOD, pages 322–333, 2002.
- [19] T. L. Dean, M. A. Ruzon, M. Segal, J. Shlens, S. Vijayanarasimhan, and J. Yagnik. Fast, accurate detection of 100, 000 object classes on a single machine. In CVPR, pages 1814–1821, 2013.
- [20] R. Fagin, A. Lotem, and M. Naor. Optimal aggregation algorithms for middleware. J. Comput. Syst. Sci., 66(4):614–656, 2003.
- [21] M. X. Goemans and D. P. Williamson. Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming. Journal of the ACM, 42(6), 1995.
- [22] R. Guo, S. Kumar, K. Choromanski, and D. Simcha. Quantization based fast inner product search. In AISTATS, pages 482–490, 2016.
- [23] U. Hadar, J. Liu, Y. Polyanskiy, and O. Shayevitz. Communication complexity of estimating correlations. In STOC, pages 792–803, 2019.
- [24] U. Hadar and O. Shayevitz. Distributed estimation of gaussian correlations. IEEE Trans. Inf. Theory, 65(9):5323–5338, 2019.
- [25] P. Hall. On the rate of convergence of normal extremes. Journal of Applied Probability, 16(2):433–439, 1979.
- [26] S. Har-Peled, P. Indyk, and R. Motwani. Approximate nearest neighbor: Towards removing the curse of dimensionality. Theory of Computing, 8(1):321–350, 2012.
- [27] Q. Huang, G. Ma, J. Feng, Q. Fang, and A. K. H. Tung. Accurate and fast asymmetric locality-sensitive hashing scheme for maximum inner product search. In KDD, pages 1561–1570, 2018.
- [28] R. Impagliazzo, R. Paturi, and F. Zane. Which problems have strongly exponential complexity? J. Comput. Syst. Sci., 63(4), 2001.
- [29] J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with gpus. arXiv preprint arXiv:1702.08734, 2017.
- [30] W. B. Johnson and J. Lindenstrauss. Extensions of Lipschitz mappings into a Hilbert space. Contemporary mathematics, 26(189-206):1, 1984.
- [31] A. Kabán. Improved bounds on the dot product under random projection and random sign projection. In SIGKDD, pages 487–496, 2015.
- [32] N. Koenigstein, G. Dror, and Y. Koren. Yahoo! music recommendations: modeling music ratings with temporal dynamics and item taxonomy. In RecSys, pages 165–172, 2011.
- [33] Y. Koren, R. M. Bell, and C. Volinsky. Matrix factorization techniques for recommender systems. IEEE Computer, 42(8):30–37, 2009.
- [34] E. Kushilevitz, R. Ostrovsky, and Y. Rabani. Efficient search for approximate nearest neighbor in high dimensional spaces. SIAM J. Comput., 30(2):457–474, 2000.
- [35] K. G. Larsen and J. Nelson. Optimality of the johnson-lindenstrauss lemma. In FOCS, pages 633–638, 2017.
- [36] H. Li, T. N. Chan, M. L. Yiu, and N. Mamoulis. FEXIPRO: fast and exact inner product retrieval in recommender systems. In SIGMOD, pages 835–850, 2017.
- [37] P. Li, T. Hastie, and K. W. Church. Very sparse random projections. In SIGKDD, pages 287–296, 2006.
- [38] G. Linden, B. Smith, and J. York. Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput., 7(1):76–80, 2003.
- [39] S. S. Lorenzen and N. Pham. Revisiting wedge sampling for budgeted maximum inner product search. In ECML/PKDD, 2020.
- [40] Y. A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Trans. Pattern Anal. Mach. Intell., 42(4):824–836, 2020.
- [41] S. Morozov and A. Babenko. Non-metric similarity graphs for maximum inner product search. In NeurIPS, pages 4726–4735, 2018.
- [42] B. Neyshabur and N. Srebro. On symmetric and asymmetric LSHs for inner product search. In ICML, pages 1926–1934, 2015.
- [43] J. Pennington, R. Socher, and C. D. Manning. GloVe: global vectors for word representation. In EMNLP, pages 1532–1543, 2014.
- [44] A. Rubinstein. Hardness of approximate nearest neighbor search. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, STOC 2018, Los Angeles, CA, USA, June 25-29, 2018, pages 1260–1268, 2018.
- [45] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and F. Li. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015.
- [46] A. Shrivastava and P. Li. Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS). In NIPS, pages 2321–2329, 2014.
- [47] R. Spring and A. Shrivastava. Scalable and sustainable deep learning via randomized hashing. In KDD, pages 445–454, 2017.
- [48] N. Sundaram, A. Turmukhametova, N. Satish, T. Mostak, P. Indyk, S. Madden, and P. Dubey. Streaming similarity search over one billion tweets using parallel locality-sensitive hashing. PVLDB, 6(14):1930–1941, 2013.
- [49] C. Teflioudi and R. Gemulla. Exact and approximate maximum inner product search with LEMP. TODS, 42(1):5:1–5:49, 2017.
- [50] S. S. Vempala. The Random Projection Method, volume 65 of DIMACS Series in Discrete Mathematics and Theoretical Computer Science. DIMACS/AMS, 2004.
- [51] M. J. Wainwright. Basic tail and concentration bounds, pages 21–57. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2019.
- [52] R. Williams and H. Yu. Finding orthogonal vectors in discrete structures. In SODA, pages 1867–1877, 2014.
- [53] X. Yan, J. Li, X. Dai, H. Chen, and J. Cheng. Norm-ranging LSH for maximum inner product search. In NeurIPS, pages 2956–2965, 2018.
- [54] H. Yu, C. Hsieh, Q. Lei, and I. S. Dhillon. A greedy approach for budgeted maximum inner product search. In NIPS, pages 5459–5468, 2017.
- [55] Z. Zhou, S. Tan, Z. Xu, and P. Li. Möbius transformation for fast inner product search on graph. In NeurIPS, pages 8216–8227, 2019.