Subspace based Federated Unlearning
Abstract
Federated learning (FL) enables multiple clients to train a machine learning model collaboratively without exchanging their local data. Federated unlearning is an inverse FL process that aims to remove a specified target client’s contribution in FL to satisfy the user’s right to be forgotten. Most existing federated unlearning algorithms require the server to store the history of the parameter updates, which is not applicable in scenarios where the server storage resource is constrained. In this paper, we propose a simple-yet-effective subspace based federated unlearning method, dubbed SFU, that lets the global model perform gradient ascent in the orthogonal space of input gradient spaces formed by other clients to eliminate the target client’s contribution without requiring additional storage. Specifically, the server first collects the gradients generated from the target client after performing gradient ascent, and the input representation matrix is computed locally by the remaining clients. We also design a differential privacy method to protect the privacy of the representation matrix. Then the server merges those representation matrices to get the input gradient subspace and updates the global model in the orthogonal subspace of the input gradient subspace to complete the forgetting task with minimal model performance degradation. Experiments on MNIST, CIFAR10, and CIFAR100 show that SFU outperforms several state-of-the-art (SOTA) federated unlearning algorithms by a large margin in various settings.
1 Introduction
The traditional training approach of deep learning usually brings together data from various participants. However, some data, e.g., medical records (Liu et al., 2017), cannot be moved from the hospital due to data privacy and personal-will concerns. Federated learning (FL) (McMahan et al., 2017) is one of the most popular decentralized machine learning methods to solve the above problems. It trains a global model by transmitting the model parameters between clients and the server, which obviates the need of transferring the underlying data (Li et al., 2022a, 2020a, 2020b).
Recent privacy legislations (Bussche, 2017; Pardau, 2018; Shastri et al., 2019) provide data owners the right to be forgotten. In the machine learning context, the right to be forgotten requires that (i) the user data is deleted from the entity storing it and (ii) the influence of the data on the model is removed (Halimi et al., 2022). Federated unlearning is the embodiment of the user’s right to be forgotten in the FL scenario, where the goal is to remove the contribution of specific clients’ data from the global model while maintaining the model’s accuracy. Three challenges in FL make the traditional machine unlearning approach unsuitable for federated unlearning: (1) Limited Access to the dataset: The server in FL cannot directly access all data and perform related operations, which makes forgetting techniques that rely on dataset segmentation cannot be applied to FL scenarios. (2) Model aggregation: The initial model of each client in each training round depends on the model aggregation of the clients that participated in the training in the previous round. Removing the contribution of a client will affect the model aggregation and affect the subsequent training of other clients (Nasr et al., 2018; Melis et al., 2019; Song et al., 2020). (3) Client selection: Since not all clients can participate in the training process in each round, the contribution of each client to the global model is not continuous, and the contribution can only be made when the client is selected.
There has been some current work on federated unlearning. To remove the contribution of a specific target client in the final global model, a naive idea is to retrain the model on the remaining clients after removing the target one (Bourtoule et al., 2021). However, some clients may only have limited storage, and they may delete data at any time after the training process. It will make even the most naive way of retraining the model from scratch impractical since the client may not have the same data as that used in the training time. Another idea in federated unlearning is to store the client’s historical updated gradient data in the server and use it to roll back the trained global model (Wu et al., 2022). The above unlearning methods all require the client or server to retain some additional data or gradient information, which is not possible in FL scenarios with limited storage resources.
In each FL training round, local training of each client is a process that reduces the empirical loss (Rumelhart et al., 1986). We argue that unlearning can be formulated as the inverse process of learning, in the sense that the gradient ascent on the target client can realize the forgetting of the client data. However, the loss is unbounded and we need to limit the gradient of training to ensure the quality of the model after unlearning (Chen & Wainwright, 2015). The whole process can be regarded as a constraint-solving problem to maximize the empirical loss of the target client within the constraints of the model performance. In this paper, we propose a Subspace-based Federated Unlearning method, dubbed SFU. SFU restricts the gradient of the target client’s gradient ascent to the orthogonal space of the input space of the remaining clients to remove the target client’s contribution from the final trained global model. In SFU, the server only needs the gradient information provided by the target client and the representation matrix information provided by other clients, without directly accessing the original data of each client. On the other hand, SFU can be used for models in any training phase without considering the specific details of model training and model aggregation. At the same time, SFU does not require the client or server to store additional historical gradient information or data.
Specifically, SFU participants can be divided into three kinds of roles: the target client to be forgotten, the remaining clients, and the server. In SFU, the target client performs gradient ascent locally based on the global model and sends the gradient to the server; each remaining client selects a certain amount of local data to build a representation matrix and send it to the server; the server receives the representation matrix from each client and merges it to obtain the input subspace with Singular Value Decomposition (SVD) (Hoecker & Kartvelishvili, 1996); the server finally projects the gradient of the target client into the orthogonal subspace of the input space and updates the global model with it. In addition, we design a differential privacy method to protect the privacy of clients in the process of sending the representation matrices (Li et al., 2021; Truex et al., 2019). It needs each client to add random perturbation factors to each vector of the representation matrix to prevent possible privacy leaks and those perturbation factors have no effect on the input space search and the final model. Empirical results show that SFU beats other SOTA baselines with 1%-10% improvement in test sets.
In the end, we summarize the main contributions as follows:
-
•
We first introduce subspace learning to federated unlearning and propose a new federated unlearning algorithm called SFU, which trains the global model by gradient ascent in an orthogonal subspace perpendicular to the input space of the remaining clients to achieve the forgetting goal without large performance loss and additional storage costs.
-
•
We design a differential privacy method to prevent the possible privacy leakage caused by the transmission of the client representation matrix during the process of unlearning. This method adds random perturbation factors to each vector of the representation matrix but does not affect the unlearning process.
-
•
We conduct extensive experiments to evaluate the effectiveness of SFU, which significantly outperforms several SOTA baselines on various datasets including MNIST, CIFAR10, and CIFAR100.
2 Related Work
Machine unlearning. The term “machine unlearning” is a process to forget a piece of training data completely which needs to revert the effects of the data on the extracted features and models. Machine unlearning is first proposed by Cao & Yang (2015), and they transform the statistical query learning into a summation form and achieve unlearning by updating a small part of the summation. However, this algorithm only works for those transformable traditional machine learning methods, machine unlearning for different ML models has been explored. Ginart et al. (2019) formulate the problem and the concept of effective data deletion in machine learning. They also propose two efficient deletion solutions for the K-means clustering algorithm. Izzo et al. (2021) focus on supervised linear regression and propose an approximate data deletion method called projective residual update (PRU) for linear and logistic models. The computational cost of PRU is linear in the feature dimension, but PRU is not applicable for more complex models such as neural networks. Baumhauer et al. (2022) introduce the more general framework SISA to reduce the computational overhead associated with forgetting. The main idea of SISA is to split the training data into several disjoint fragments, each of which trains a sub-model. To remove a specific sample, the algorithm simply retrains the sub-model that is learned from this sample. However, existing machine learning works focus on ML models in traditional centralized settings, where training data is assumed to be globally accessible, which is not suitable for learning in FL settings.
Federated unlearning. Compared with centralized learning, there are few works on unlearning in FL. Liu et al. (2021) first introduce unlearning into the field of FL and propose FedEraser. The main idea is to adjust the historical parameter updates of federated clients through the retraining process in FL and reconstruct the unlearning model. However, this process requires additional communication between the client and the server. Recently, Wu et al. (2022) develop a forgetting approach that removes historical parameter updates from the target client and recovers model performance through a knowledge distillation process. Both of these steps require the server to keep a history of all client updates. In addition, the knowledge distillation approach requires the server to have some additional unlabeled data. In some application scenarios, meeting these requirements may not be a matter of course. In contrast, our method does not need the server to store historical updates or additional unlabeled data and has better privacy. Our method mainly solves the case where a client (referred to as the target client) wants to remove its contribution from the global model. We let the global model perform gradient ascent in the orthogonal subspace of the input space of remaining clients to achieve federated unlearning. Different from these works (and the one we propose), Wang et al. (2022) propose a forgetting framework for forgetting a specific class or category in FL.
Our approach is closely related to the federated unlearning approach recently proposed by Halimi et al. (2022). They formulate the unlearning problem as a constrained maximization problem by restricting to an -norm ball around a suitably chosen reference model and allowed the target client to perform the unlearning by using the Projected Gradient Descent (PGD) algorithm (Thudi et al., 2022). However, -norm ball can not provide an effective guarantee for the performance of the model after unlearning. We add constraints on the performance of the unlearning model. Our method restricts the gradient ascent to a subspace orthogonal to the input space of other clients, and this constrained gradient update has minimal impact on the performance of the model on other clients. We will quantitatively show that our method has a performance guarantee.
3 Methodology
We propose a novel federated unlearning method, as shown in Algorithm 1, that can eliminate the client’s contribution and vastly reduce the unlearning cost in the FL system. This method does not require the server to keep the history of parameter updates from each client or additional training. The key idea is to use the restricted gradient information of the target client to modify the final trained model.
3.1 Problem Setup
Suppose that there are clients, denoted as , respectively. Client has a local dataset . The goal of traditional FL is to collaboratively learn a machine learning model over the dataset :
| (1) |
| (2) |
where is the empirical loss of and during federated training, each client minimizes their empirical risk , is the final model trained by the FL process.
Now we consider how to forget the contribution of the target client . A natural idea is to increase the empirical risk of the target client , which is equivalent to reversing the learning process. However, simply maximizing the loss can influence the effect of the model on other clients. Federated unlearning needs to forget the contribution of the target client while ensuring the overall model performance. Thus, the objective of federated unlearning is defined below:
| (3) | ||||
where is a small change in the empirical loss, is the empirical loss of the FL system after removing the target client.
| (4) |
where is the remaining data set after removing the target client.
3.2 Unlearning Metrics
Comparing the difference between the unlearned model and the retrained model is one of the criteria used to measure the effect of unlearning. Common dissimilarity metrics include model test accuracy difference (Bourtoule et al., 2021), -distance (Wu et al., 2020) or, and Kullback-Leibler (KL) divergence (Sekhari et al., 2021). However, in the FL scenario, it is difficult to intuitively indicate whether the contribution of a given client can be removed from the evaluation method based on model differences. Other metrics include privacy leakage in the differential privacy framework (Sekhari et al., 2021) and membership inference attacks (Graves et al., 2021; Baumhauer et al., 2022). In this paper, we use the backdoor triggers (Gu et al., 2017) as an effective way to evaluate the performance of unlearning methods, similar to Wu et al. (2022). In particular, the target client uses a dataset with a certain fraction of images that have a backdoor trigger inserted in them. Thus, the global FL model becomes susceptible to the backdoor trigger. Then, a successful unlearning process should produce a model that reduces the accuracy of the images with the backdoor trigger, while maintaining good performance on regular (clean) images. Note that we use the backdoor triggers as a way to evaluate the performance of unlearning methods; we do not consider any malicious client (Xie et al., 2020; Bagdasaryan et al., 2020; Fung et al., 2020)
3.3 Subspace-based Federated Unlearning (SFU)
We introduce a novel Subspace-based federated unlearning framework, named SFU. The main insight of the SFU is that we constrain the gradients generated by the target client’s gradient ascent to the input subspace of the other clients to remove the contribution of the target client from the global model. As shown in Fig. 1, SFU participants can be divided into three kinds of roles: the target client to be forgotten, the remaining clients, and the server. The target client performs gradient ascent to upload the gradient to the server. Other clients compute the local representation matrix and upload it to the server. The server is responsible for the computation of other client input Spaces and the unlearning update of the global model. Next, we will introduce the specific tasks of the three participants respectively.
3.3.1 Gradient ascent on the target client
To find a model with a large empirical loss in target client , we can simply make several local passes of (mini-batch stochastic) gradient ascent in client and add these gradient updates to the global model. In order to satisfy the constraints of Eq. (3), we need to consider a more reasonable way to add the updated gradient of client to the global model (Zhou et al., 2020; Qian et al., 2015).
Given a neural network and an input x we can obtain an output y:
| (5) |
When this model accepts a gradient update , the output becomes:
| (6) |
The difference between the two outputs is:
| (7) |
When is 0, the difference between the two outputs is minimized, which requires the updated gradient to be perpendicular to the original input gradient subspace x. Therefore, we can project the updated gradient of the target client into the orthogonal space of the gradient subspace of to minimize the degradation of the glob model performance (Farajtabar et al., 2020).
3.3.2 Computation of representation matrix
We first need to consider how to represent the input space in , the data of other clients. For an individual network, we construct the gradient subspace by the following two steps:
-
•
For each layer of the network, We first construct a representation matrix, concatenating representations along the column obtained from forward pass of random samples from the current training dataset through the network.
-
•
Next, we perform SVD on followed by its -rank approximation according to the following criteria for the given coefficient, :
(8) , spanned by the first vectors in as the space of significant representation at layer since it contains all the directions with highest singular values in the representation (Saha et al., 2021).
For FL scenarios, we need the data on each client to seek the gradient subspace of the . First, all clients excluding the target client select the same number of representations matrix of local samples for each layer and send them to the central server to construct the representation matrix.
To protect the privacy of the representation matrix, we design a differential privacy algorithm. We add random factors to the representation of layer from client to avoid leaking data information about the client data and it does not affect the search process of the subspace because of the nature of the orthogonal matrix.In Eq. (7), if
| (9) |
we have
| (10) |
The final set of representation matrix in the server is , and .
3.3.3 Update of the global model on the server
After several local passes of (mini-batch stochastic) gradient ascent, client sends the updated gradient to the server. The server performs the update of the global model after collecting the set of representation matrix and the gradient . The server first perform SVD (Rumelhart et al., 1986) on to get the set of input gradient subspace . To achieve the goal of Equation 3, we need to project onto and get projection . orthogonal to and the server update the global model with :
| (11) |
The updated model removes the contribution of the target client and maintains a similar performance to the original global model.
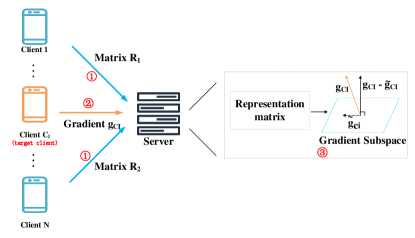
After a global model is trained, a complete SFU training process mainly includes three steps as shown in Fig.1:
-
•
Step 1. Besides target client , each client selects the same number of samples to calculate the representation matrix for each layer of the network and sends it to the server after adding random factors .
-
•
Step 2. The target client performs several local passes of gradient ascent locally and sends the updated gradient to the server.
-
•
Step 3. The server perform SVD on the set of representation to get the set of input gradient subspace , project onto and removes the contribution of the target client by updating the global model as Eq. 11.
In the end, we give several comments on the proposed SFU algorithm. Note that subspace learning has been commonly used to solve continual learning (Saha et al., 2021), meta learning (Jiang et al., 2022), adversarial training (Li et al., 2022c), and fast training of deep learning models (Li et al., 2022b). However, SFU is the first work to use the orthogonal space of input gradient space for federated unlearning. In addition, SFU needs to seek subspace from dispersed stored data and should consider the privacy leakage risk.
4 Experiments
| FedAvg | UL | GA | SFU | ||||||
| Dataset | network | test acc | atk acc | test acc | atk acc | test acc | atk acc | test acc | atk acc |
| MNIST | MLP | 97.73 | 93.26 | 77.19 | 0.0 | 96.80 | 0.0 | 97.66 | 0.15 |
| CNN | 99.31 | 91.29 | 42.36 | 0.0 | 92.33 | 19.28 | 99.29 | 0.21 | |
| CIFAR10 | MLP | 49.15 | 89.66 | 26.17 | 0.0 | 48.61 | 0.01 | 49.08 | 0.0 |
| CNN | 72.83 | 99.36 | 18.75 | 0.0 | 57.48 | 0.37 | 57.75 | 0.0 | |
| ResNet | 76.12 | 98.27 | 43.75 | 0.0 | 73.58 | 65.98 | 44.60 | 0.0 | |
| CIFAR100 | MLP | 18.86 | 9.93 | 2.24 | 0.0 | 13.42 | 0.00 | 18.70 | 0.0 |
| CNN | 37.47 | 97.77 | 2.51 | 0.0 | 20.12 | 1.41 | 36.31 | 0.0 | |
| ResNet | 39.68 | 90.38 | 7.38 | 0.0 | 37.63 | 6.73 | 26.84 | 0.0 | |
| Retraining | UL-Distillation | GA-retraining | SFU-retraining | ||||||
| Dataset | network | test acc | atk acc | test acc | atk acc | test acc | atk acc | test acc | atk acc |
| MNIST | MLP | 97.88 | 0.0 | 97.88 | 0.0 | 97.05 | 9.30 | 97.91 | 0.28 |
| CNN | 99.48 | 11.55 | 99.20 | 0.31 | 99.34 | 37.13 | 99.37 | 12.63 | |
| CIFAR10 | MLP | 48.77 | 0.00 | 47.83 | 0.0 | 48.09 | 20.36 | 48.81 | 0.10 |
| CNN | 74.86 | 0.00 | 72.33 | 0.51 | 72.43 | 26.47 | 72.87 | 2.18 | |
| ResNet | 76.95 | 7.23 | 77.47 | 9.68 | 77.19 | 81.06 | 76.84 | 3.12 | |
| CIFAR100 | MLP | 18.47 | 0.0 | 9.43 | 0.0 | 18.81 | 2.46 | 18.46 | 0.0 |
| CNN | 38.25 | 0.0 | 27.05 | 0.0 | 37.08 | 51.36 | 37.81 | 14.39 | |
| ResNet | 40.15 | 0.81 | 38.43 | 0.79 | 38.11 | 61.91 | 40.93 | 0.92 | |
In this section, we empirically evaluate the effectiveness of SFU using different model architectures on three datasets. We divide the unlearning process into two parts: the removal of specific client contributions and the recovery of model performance. The experimental results show that our unlearning strategies can effectively remove the contribution of the target client from the global model with low-performance loss and can quickly recover the accuracy of the model in a few rounds of training. We first introduce the experimental setup and then present the evaluation results.
4.1 Experimental Setup
Datasets: We evaluate SFU using three popular datasets: MNIST(Xiao et al., 2017), CIFAR10, and CIFAR100 (Krizhevsky et al., 2009) as described below:
-
•
MNIST: It is a dataset that contains a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image associated with a label from 10 classes.
-
•
CIFAR10: It consists of 60,000 32 × 32 color images in 10 classes, with 6000 images per class. There are 50,000 training images and 10,000 test images.
-
•
CIFAR100: It has 100 classes. Each class has 600 color images of size 32 × 32, of which 5000 are used as a training set, and 100 are used as a test set.
The training difficulty of the dataset is increasing from MNIST, CIFAR10 to CIFAR100. We adopt two data distribution Settings, including IID (Independent-Identically-Distributed) as well as Non-IID (Non Independent-Identically-Distributed). The Non-IID setting that we adopt is Dirichlet(): Label distribution on each device follows the Dirichlet distribution, where is a concentration parameter ().
Baselines. We chose three typical federated unlearning algorithms as our baseline:
(1) Retraining: This method retrains the entire FL system without the target client being forgotten, which is an effective but computationally and communicationally expensive algorithm;
(2) “UL” Wu et al. (2022): This method forgets the target client by subtracting historical parameter updates of the target client from the global model. Then, “UL” uses the knowledge distillation method to remedy the skew of the unlearning model caused by the subtraction without using any data from the target clients.
(3) “GA”: GA uses gradient ascent information on the target client to update the global model. Gradient ascent makes the loss of the model increase, which is the inverse process of learning and can achieve unlearning. However, the loss of gradient ascent is unbounded so we set the gradient clip norm when the global model is updated to reduce the probability of producing a random model.
Models. We employ three neural network architectures in our experiments.
-
•
MLP: This is a fully-connected neural network architecture with 2 hidden layers. The number of neurons in the layers is 200 and 100, respectively.
-
•
CNN: This network architecture consists of 2 convolutional layers with 64 5 × 5 filters followed by 2 fully connected layers with 800 and 500 neurons and a Relu layer.
-
•
ResNet: we use a smaller version of ResNet18 (He et al., 2016), with three times fewer feature maps across all layers.
We used two networks MLP and CNN for the MNIST dataset, while we used the above three network structures for the CIFAR10 and CIFAR100 datasets. We use PyTorch (Oord et al., 2018) to implement those models.
Evaluation metric. We use backdoor attacks in the target client’s updates to the global model as described before, so that we can intuitively investigate the unlearning effect based on the attack success rate of the unlearned global model. In Tab. 1 and Tab. 2, we record the attack success rate as “atk acc”. A lower “atk acc” represents a cleaner contribution removal from the target client. In our experiments, we implement the backdoor attack using a ”pixel pattern” trigger of size 2 × 2 and change the label to ”9”. Because of the prediction error of the model, We can consider an error rate of less than 10% as successful forgetting of the target client contribution. We also use the accuracy metric on the clean test data to measure the performance of the model after unlearning which is denoted “test acc” in Tab. 1 and Tab. 2. A high accuracy indicates that unlearning has little impact on the performance of the model. Current unlearning methods usually adopt certain methods to recover the model accuracy after unlearning, so we divide our evaluation of the unlearning approach into two respects: the removal of specific client contributions and the recovery of model performance.
Implementation details. We consider two scenarios: (i) We have ten clients with one target client, and all clients participate fully during each training round. (ii) We have 100 clients with one target client and only 10% of the clients participate during each training round. In the experiment of removal of specific client contributions, We conduct unlearning experiments on the FL model after 100 rounds of training; In the experiment of recovery of model performance, We start FL training with the stochastic model for full retraining. we start FL training on the unlearned local model without the involvement of the target client for SFU and GA. We use the knowledge of the public data on the server for distillation learning to recover the model accuracy for UL. Tab. 2 and Tab. 1 only show the results of scenario (i). Results of scenario (ii) and other implementation details are shown in Appendix A due to limited space.
4.2 Results of Contribution Removal
We conducted extensive experiments to determine the advantage of SFU in removing the contribution of a specific client in the global model. In addition, we demonstrate the robustness and superiority of SFU in different training degrees of the model and different data heterogeneity. All results are reported based on the global model after performing unlearning. The results show that SFU can effectively remove the contribution of target clients under the premise of ensuring model accuracy, and has strong robustness to data heterogeneity and the training degree of the model.
Efficient forgetting by SFU. Tab. 1 reports the unlearning effects of SFU and the other baselines on different IID datasets and model architectures. The results show that SFU can efficiently complete the contribution removal of target clients. We observe that SFU successfully eliminates the contribution of target customers and achieves low precision for backdoor data. For example, SFU can reduce the backdoor attack success rate to or close to 0% in all datasets. Other baselines also can achieve similar results. This shows that the current unlearning methods can effectively remove the contribution of the target client.
High model accuracy for SFU. The results in Tab. 1 also report the accuracy of the model on the clean test set data after unlearning for each baseline. The results show that SFU achieves the best results on various datasets and different model architectures. However, the UL method will cause great damage to the performance of the model, and the direct gradient ascent has a large probability of producing a low-accuracy model. For example, on the CNN architecture of the MNIST dataset, the accuracy of the UL model is only 42.76%, which is 56.55% lower than the accuracy of the original FL model 99.31%. The accuracy of the model generated by GA is 92.33%, which is 7% lower than the 99.29% accuracy of the model generated by SFU, which indicates that restricting the gradient in the orthogonal subspace of the input space can reduce the loss of the original model performance.
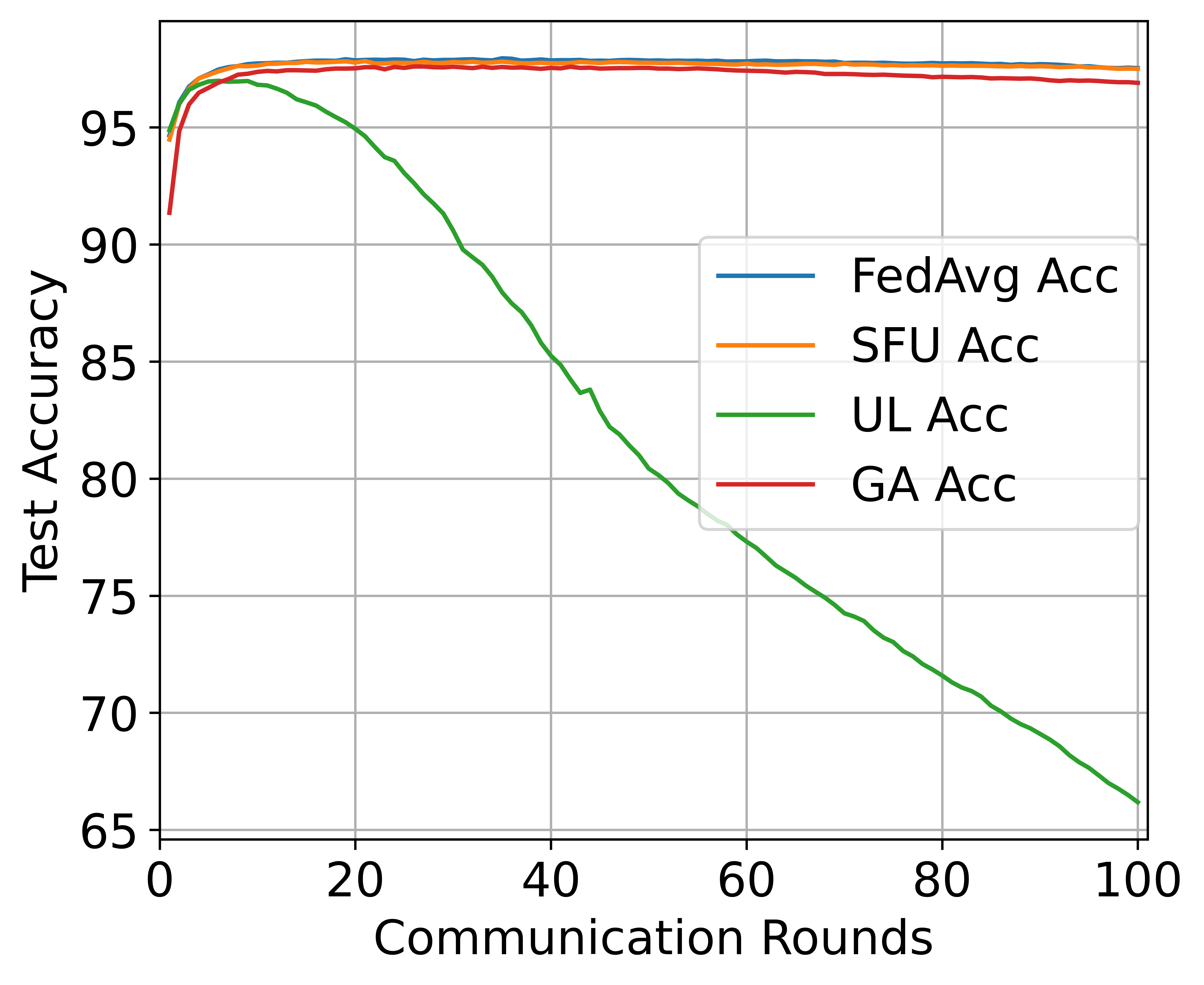
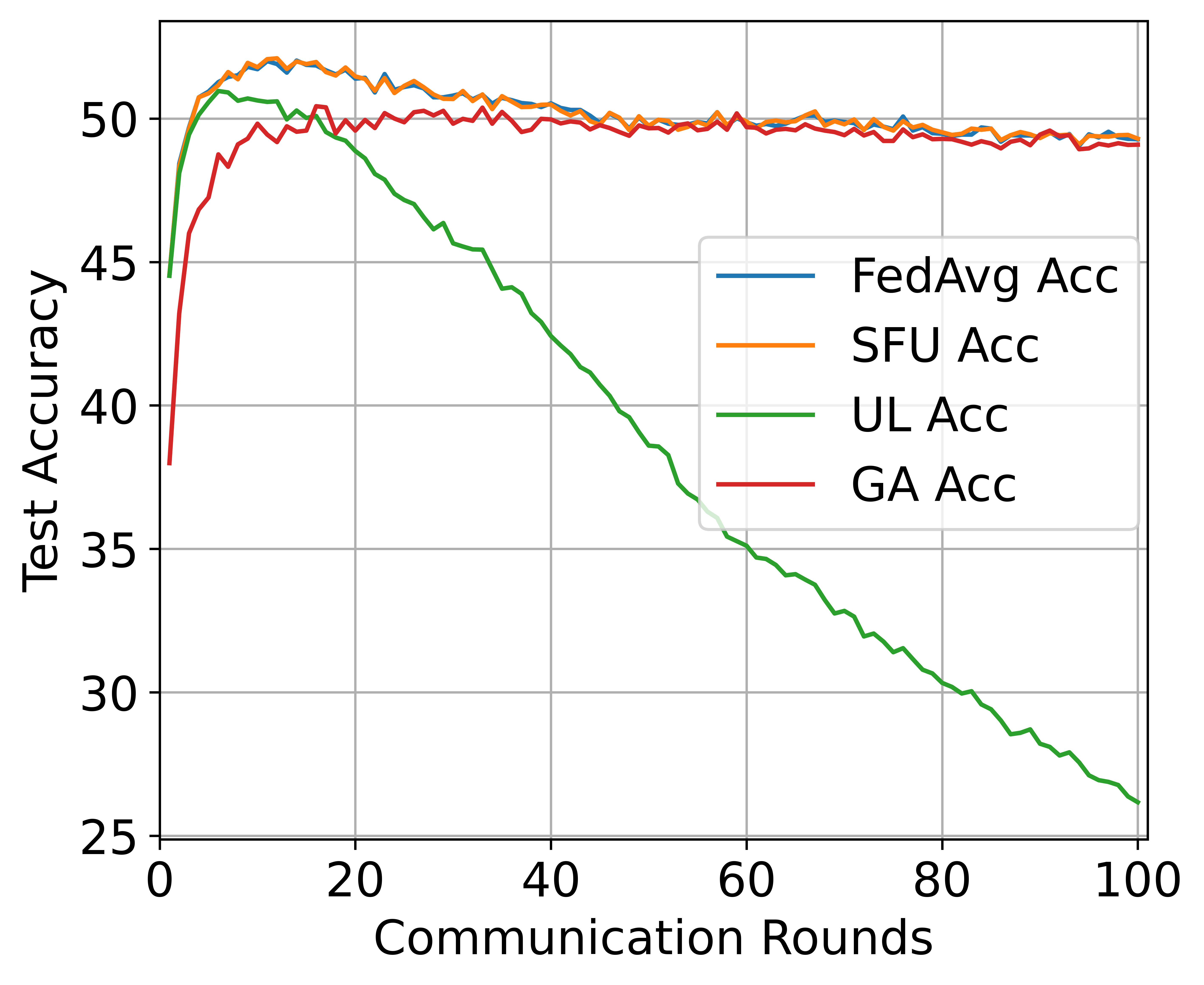
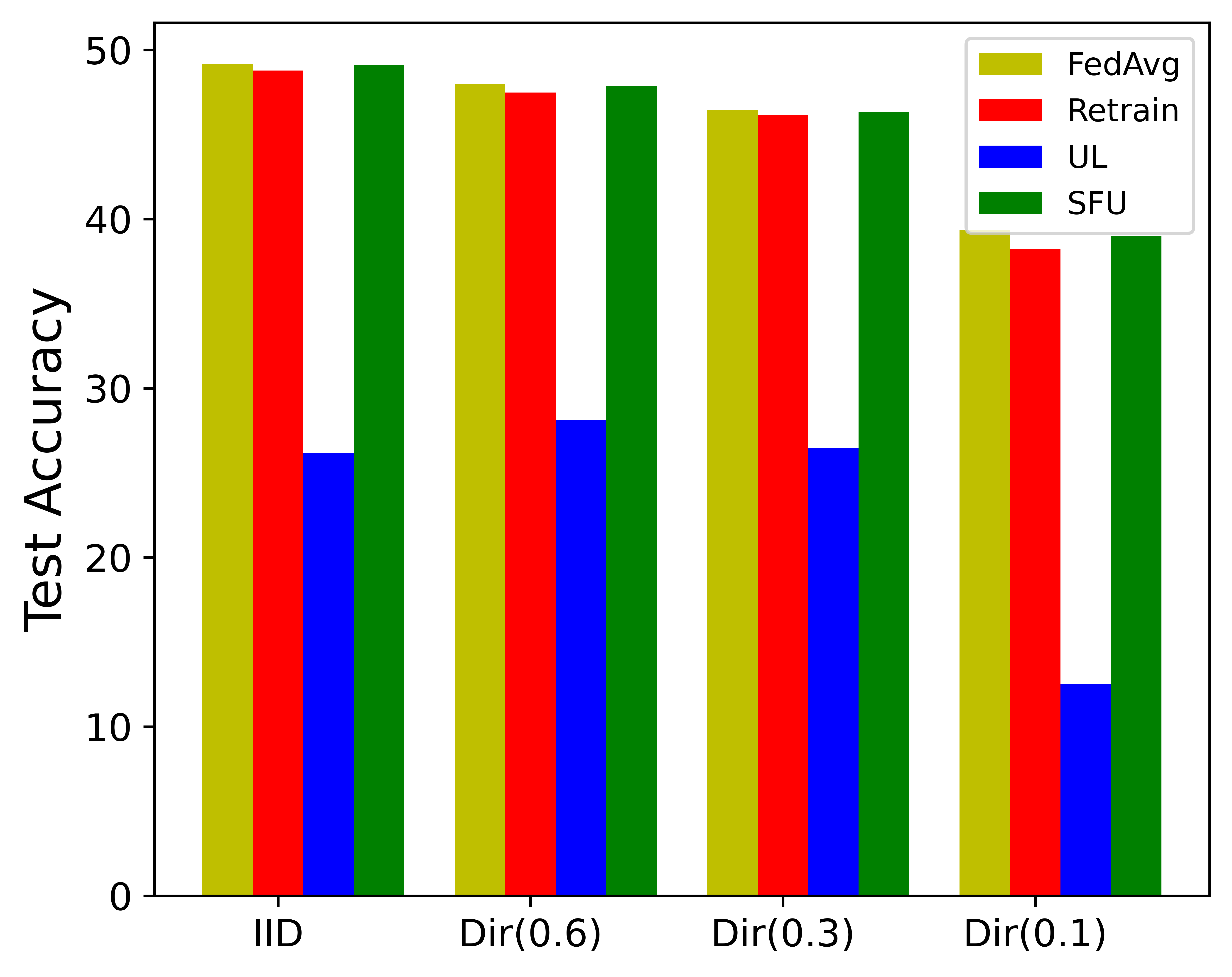
Robustness of the original model maturity. Federated unlearning can occur at any stage of FL, so it is possible that the model does not converge when federated unlearning is performed. We define the maturity of the model in terms of the number of rounds of model training, where the more rounds the model is trained, the more mature it is. Fig. 3 reports the effect of each baseline with unlearning at different rounds of the FL model training. The results show that SFU can ensure the performance of the model to the greatest extent at any round of model training, and the accuracy of SFU is similar to that of FL model training. UL is easy to remove in the early stage of model training. However, as the model continues to train, the integration degree of each client model increases, simply subtracting the historical weight of the client is easy to cause a significant decline in the accuracy of the model. For example, the UL accuracy in the MNIST dataset dropped from 97% to 66% as the model trained. GA has similar results to SFU, but still has lower accuracy than SFU, which indicates that SFU is robust to the original model maturity.
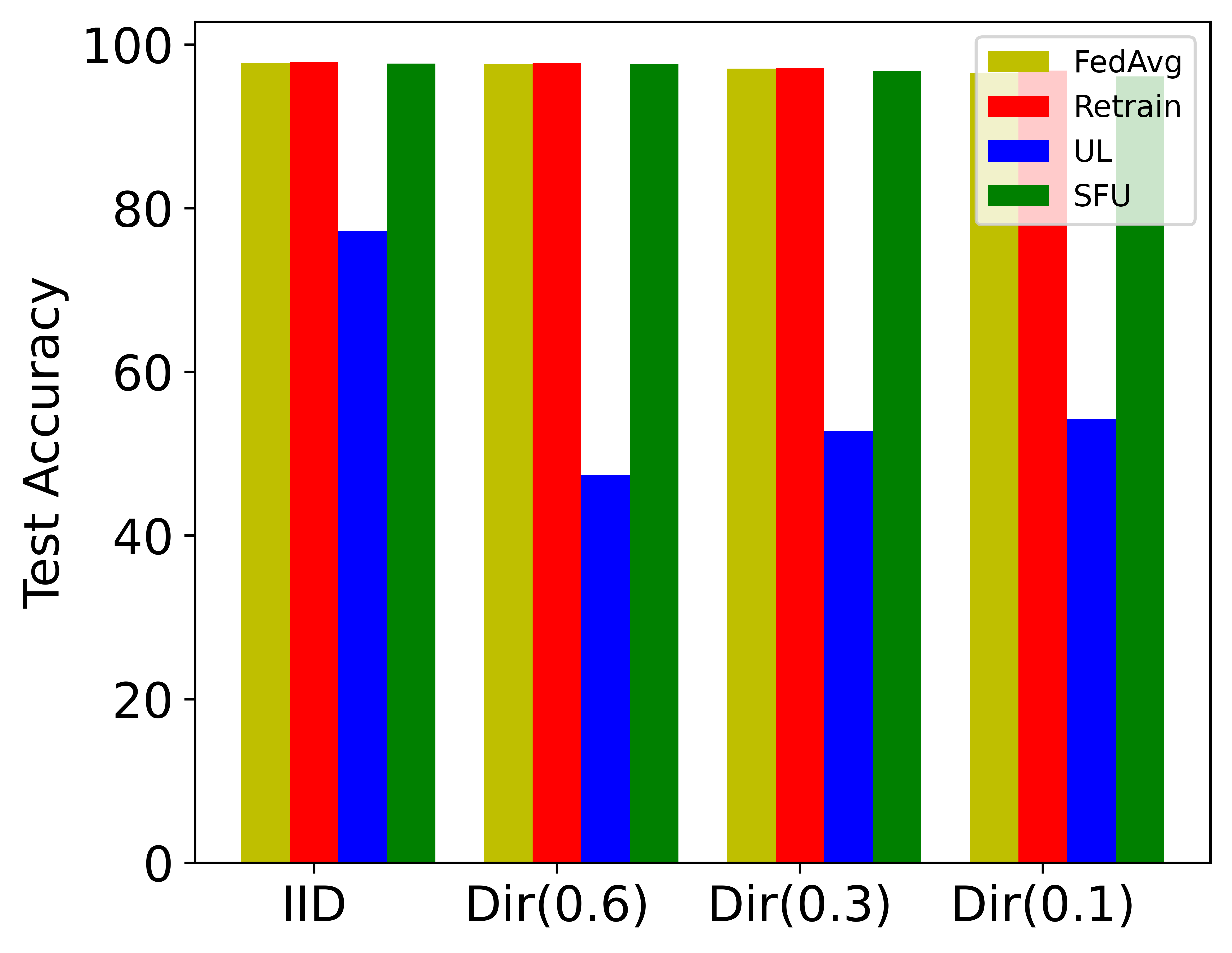
Robustness on heterogeneous data. We test different unlearning algorithms on MNIST datasets with different degrees of heterogeneity, and ten clients are selected to form the FL system. Fig. 3 shows that enhancing data distribution heterogeneity will reduce the effect of various unlearning algorithms. It is because the aggregation of the global model becomes more complex with the increase of model heterogeneity, which makes it more challenging to separate the contributions of specific clients under the premise of ensuring model accuracy. However, the accuracy of SFU is close to that of the original FL model and the retrained model in all Settings, which indicates that SFU is robust to data heterogeneity.
4.3 Results of Model Accuracy Recovery
Below, we report the accuracy of the final model and the recovery efficiency of different methods. All results are reported based on the global model after unlearning.
High final accuracy of the SFU. Tab. 2 reports the model performance of each algorithm after 10 rounds of accuracy recovery training and after 100 rounds of full retraining. We find that almost all methods can achieve a low success rate of backdoor attacks except for GA. The reason why GA has a high success rate of backdoor attacks is that the algorithm after unlearning is still near the original model, and it is easy to converge to the original model with high accuracy and a high success rate of backdoor attacks. The final accuracy of SFU is the highest among all the methods, and sometimes it can even exceed the accuracy of retraining, which proves that updating in the subspace will produce a better-initialized model to achieve higher accuracy.
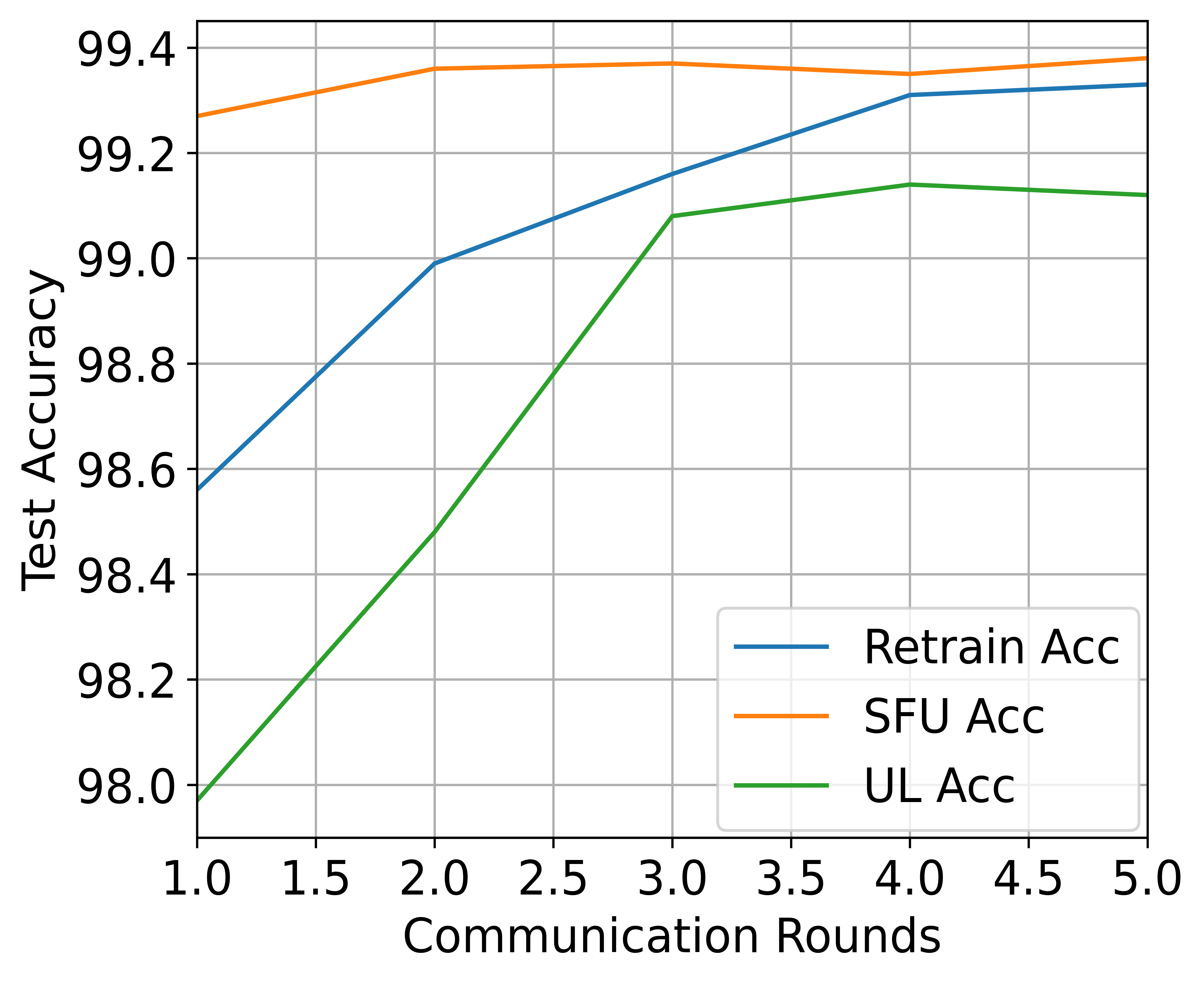
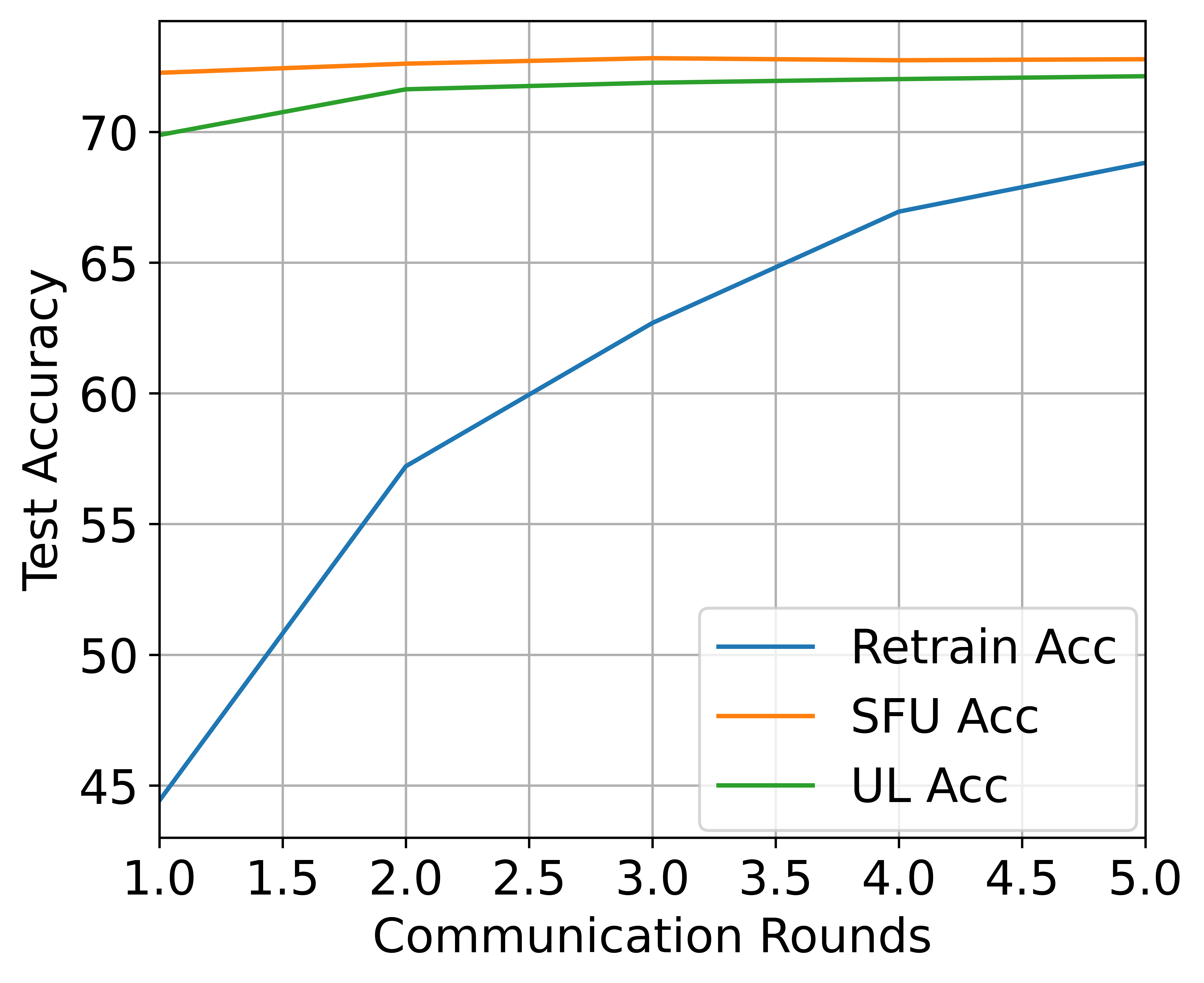
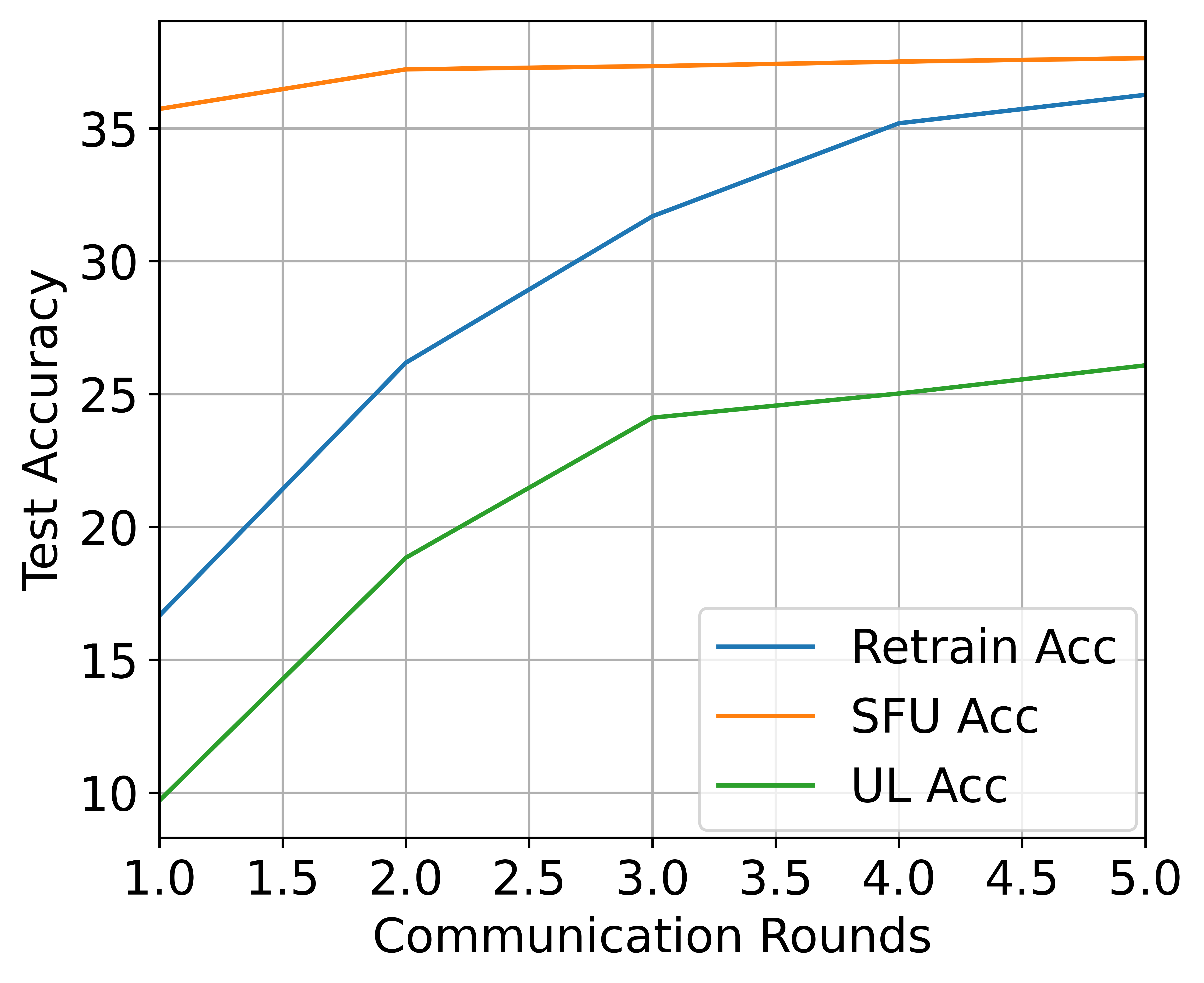
High-speed precision recovery for SFU. To compare the model accuracy recovery speed of SFU with each baseline, we calculate the accuracy and backdoor attack success rate of different methods in terms of the number of FL training rounds after unlearning, and the results are shown in Fig. 4. We observe that SFU is able to achieve high accuracy after one round of training, while other methods require 5 or even more rounds of training to achieve. SFU is more efficient in terms of computation and communication cost on the retained clients than the baseline of retraining while achieving comparable backdoor accuracy.
5 Conclusion
In this paper, we propose a novel federated unlearning approach that can successfully eliminate the contribution of a specified client to the global model, which also can minimize the model accuracy loss by performing a gradient ascent process within the subspace at any stage of model training. Our approach only relies on the target client to be forgotten from the federation without the server or any other client keeping track of its history of parameter updates. Our method also provides a differential privacy method to protect the representation matrix information during training. We have used a backdoor attack to effectively evaluate the performance of the proposed method. Our experimental results demonstrate the efficiency and effectiveness of SFU.
References
- Bagdasaryan et al. (2020) Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., and Shmatikov, V. How to backdoor federated learning. In International Conference on Artificial Intelligence and Statistics, pp. 2938–2948. PMLR, 2020.
- Baumhauer et al. (2022) Baumhauer, T., Schöttle, P., and Zeppelzauer, M. Machine unlearning: Linear filtration for logit-based classifiers. Machine Learning, 111(9):3203–3226, 2022.
- Bourtoule et al. (2021) Bourtoule, L., Chandrasekaran, V., Choquette-Choo, C. A., Jia, H., Travers, A., Zhang, B., Lie, D., and Papernot, N. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP), pp. 141–159. IEEE, 2021.
- Bussche (2017) Bussche, A. The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer, 2017.
- Cao & Yang (2015) Cao, Y. and Yang, J. Towards making systems forget with machine unlearning. In 2015 IEEE Symposium on Security and Privacy, pp. 463–480. IEEE, 2015.
- Chen & Wainwright (2015) Chen, Y. and Wainwright, M. J. Fast low-rank estimation by projected gradient descent: General statistical and algorithmic guarantees. arXiv preprint arXiv:1509.03025, 2015.
- Farajtabar et al. (2020) Farajtabar, M., Azizan, N., Mott, A., and Li, A. Orthogonal gradient descent for continual learning. In International Conference on Artificial Intelligence and Statistics, pp. 3762–3773. PMLR, 2020.
- Fung et al. (2020) Fung, C., Yoon, C. J., and Beschastnikh, I. The limitations of federated learning in sybil settings. In RAID, pp. 301–316, 2020.
- Ginart et al. (2019) Ginart, A., Guan, M., Valiant, G., and Zou, J. Y. Making ai forget you: Data deletion in machine learning. Advances in neural information processing systems, 32, 2019.
- Graves et al. (2021) Graves, L., Nagisetty, V., and Ganesh, V. Amnesiac machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 11516–11524, 2021.
- Gu et al. (2017) Gu, T., Dolan-Gavitt, B., and Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733, 2017.
- Halimi et al. (2022) Halimi, A., Kadhe, S., Rawat, A., and Baracaldo, N. Federated unlearning: How to efficiently erase a client in fl? arXiv preprint arXiv:2207.05521, 2022.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Hoecker & Kartvelishvili (1996) Hoecker, A. and Kartvelishvili, V. Svd approach to data unfolding. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 372(3):469–481, 1996.
- Izzo et al. (2021) Izzo, Z., Smart, M. A., Chaudhuri, K., and Zou, J. Approximate data deletion from machine learning models. In International Conference on Artificial Intelligence and Statistics, pp. 2008–2016. PMLR, 2021.
- Jiang et al. (2022) Jiang, W., Kwok, J., and Zhang, Y. Subspace learning for effective meta-learning. In International Conference on Machine Learning, pp. 10177–10194. PMLR, 2022.
- Krizhevsky et al. (2009) Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009.
- Li et al. (2022a) Li, G., Hu, Y., Zhang, M., Liu, J., Yin, Q., Peng, Y., and Dou, D. Fedhisyn: A hierarchical synchronous federated learning framework for resource and data heterogeneity. In Proceedings of the 51st International Conference on Parallel Processing, pp. 1–11, 2022a.
- Li et al. (2020a) Li, L., Fan, Y., Tse, M., and Lin, K.-Y. A review of applications in federated learning. Computers & Industrial Engineering, 149:106854, 2020a.
- Li et al. (2021) Li, Q., Wen, Z., Wu, Z., Hu, S., Wang, N., Li, Y., Liu, X., and He, B. A survey on federated learning systems: vision, hype and reality for data privacy and protection. IEEE Transactions on Knowledge and Data Engineering, 2021.
- Li et al. (2020b) Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. Federated learning: Challenges, methods, and future directions. IEEE signal processing magazine, 37(3):50–60, 2020b.
- Li et al. (2022b) Li, T., Tan, L., Huang, Z., Tao, Q., Liu, Y., and Huang, X. Low dimensional trajectory hypothesis is true: Dnns can be trained in tiny subspaces. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022b.
- Li et al. (2022c) Li, T., Wu, Y., Chen, S., Fang, K., and Huang, X. Subspace adversarial training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13409–13418, 2022c.
- Liu et al. (2021) Liu, G., Ma, X., Yang, Y., Wang, C., and Liu, J. Federaser: Enabling efficient client-level data removal from federated learning models. In 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), pp. 1–10. IEEE, 2021.
- Liu et al. (2017) Liu, Y., Gadepalli, K., Norouzi, M., Dahl, G. E., Kohlberger, T., Boyko, A., Venugopalan, S., Timofeev, A., Nelson, P. Q., Corrado, G. S., et al. Detecting cancer metastases on gigapixel pathology images. arXiv preprint arXiv:1703.02442, 2017.
- McMahan et al. (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pp. 1273–1282. PMLR, 2017.
- Melis et al. (2019) Melis, L., Song, C., De Cristofaro, E., and Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In 2019 IEEE symposium on security and privacy (SP), pp. 691–706. IEEE, 2019.
- Nasr et al. (2018) Nasr, M., Shokri, R., and Houmansadr, A. Comprehensive privacy analysis of deep learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), pp. 1–15, 2018.
- Oord et al. (2018) Oord, A. v. d., Li, Y., and Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Pardau (2018) Pardau, S. L. The california consumer privacy act: Towards a european-style privacy regime in the united states. J. Tech. L. & Pol’y, 23:68, 2018.
- Qian et al. (2015) Qian, Q., Jin, R., Yi, J., Zhang, L., and Zhu, S. Efficient distance metric learning by adaptive sampling and mini-batch stochastic gradient descent (sgd). Machine Learning, 99:353–372, 2015.
- Rumelhart et al. (1986) Rumelhart, D. E., Hinton, G. E., and Williams, R. J. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
- Saha et al. (2021) Saha, G., Garg, I., and Roy, K. Gradient projection memory for continual learning. arXiv preprint arXiv:2103.09762, 2021.
- Sekhari et al. (2021) Sekhari, A., Acharya, J., Kamath, G., and Suresh, A. T. Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34:18075–18086, 2021.
- Shastri et al. (2019) Shastri, S., Wasserman, M., and Chidambaram, V. The seven sins of Personal-Data processing systems under GDPR. In 11th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 19), 2019.
- Song et al. (2020) Song, M., Wang, Z., Zhang, Z., Song, Y., Wang, Q., Ren, J., and Qi, H. Analyzing user-level privacy attack against federated learning. IEEE Journal on Selected Areas in Communications, 38(10):2430–2444, 2020.
- Thudi et al. (2022) Thudi, A., Deza, G., Chandrasekaran, V., and Papernot, N. Unrolling sgd: Understanding factors influencing machine unlearning. In 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), pp. 303–319. IEEE, 2022.
- Truex et al. (2019) Truex, S., Baracaldo, N., Anwar, A., Steinke, T., Ludwig, H., Zhang, R., and Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM workshop on artificial intelligence and security, pp. 1–11, 2019.
- Wang et al. (2022) Wang, J., Guo, S., Xie, X., and Qi, H. Federated unlearning via class-discriminative pruning. In Proceedings of the ACM Web Conference 2022, pp. 622–632, 2022.
- Wu et al. (2022) Wu, C., Zhu, S., and Mitra, P. Federated unlearning with knowledge distillation. arXiv preprint arXiv:2201.09441, 2022.
- Wu et al. (2020) Wu, Y., Dobriban, E., and Davidson, S. Deltagrad: Rapid retraining of machine learning models. In International Conference on Machine Learning, pp. 10355–10366. PMLR, 2020.
- Xiao et al. (2017) Xiao, H., Rasul, K., and Vollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- Xie et al. (2020) Xie, C., Huang, K., Chen, P.-Y., and Li, B. Dba: Distributed backdoor attacks against federated learning. In International conference on learning representations, 2020.
- Zhou et al. (2020) Zhou, Y., Wu, Z. S., and Banerjee, A. Bypassing the ambient dimension: Private sgd with gradient subspace identification. arXiv preprint arXiv:2007.03813, 2020.
Appendix A Appendix: More Experiment Results
We run experiments on the true world datasets of including MNIST, CIFAR10, and CIFAR100. We consider two scenarios: (i) We have ten clients with one target client, and all clients participate fully during each training round. (ii) We have 100 clients with one target client and only 10% of the clients participate during each training round. We detailed describe the experiment settings and the experimental results of scenario (ii) in the following.
A.1 Setups
Dataset.
We adopt real-world datasets including MNIST, CIFAR10, and CIFAR100. MNIST(Xiao et al., 2017) dataset contains 60,000 training data and 10,000 test data in 10 classes. Each data sample is a 28×28 grayscale image. CIFAR10 dataset contains 50,000 training data and 10,000 test data in 10 classes. Each data sample is a 3×32×32 color image. CIFAR100 (Krizhevsky et al., 2009) includes 50,000 training data and 10,000 test data in 100 classes as 500 training samples per class, as shown in Table 3. For MNIST and CIFAR10/100, we normalize the pixel value within a specific mean and std value in our code, which are [0.5, 0.5, 0.5] for mean and [0.5, 0.5, 0.5] for std.
| Datasets | Training Data | Test Data | Class | Size |
|---|---|---|---|---|
| MNIST | 60000 | 10,000 | 10 | |
| CIFAR-10 | 50,000 | 10,000 | 10 | |
| CIFAR-100 | 50,000 | 10,000 | 100 |
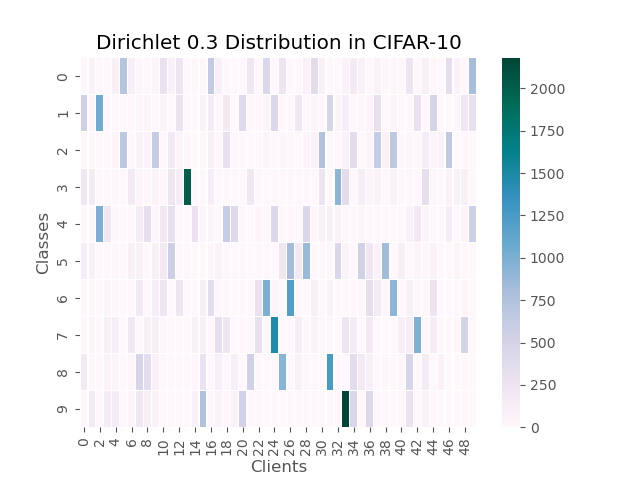
Dataset Partitions.
To fairly compare with the other baselines, we introduce the heterogeneity by splitting the total dataset by sampling the label ratios from the Dirichlet distribution. An additional parameter is used to control the level of heterogeneity of the entire data partition. In order to visualize the distribution of heterogeneous data, we make the heat maps of the label distribution in different datasets, as shown in Fig. 5. It could be seen that for heterogeneity weight equals to 0.3 in Dirichlet distribution, about 10% to 20% of the categories dominate on each client, which is the blue block in Fig. 3. The IID dataset is totally averaged in each client, which is the blue block in Fig. 3.
Baselines.
-
•
Retraining the entire FL system without the target client being forgotten;
-
•
Forgetting the target client based on the knowledge distillation Wu et al. (2022). This method subtracts historical parameter updates of the target client from the global model. Then, it uses the knowledge distillation method to remedy the skew of the unlearning model caused by the subtraction. We use “UL” to denote this kind of algorithm in our experiments;
-
•
The global model is updated using gradient ascent information on the target client. To reduce the probability of producing a random model, we set the gradient clip norm when the global model is updated. We refer to this approach as “GA” in our experiments.
Implementation Details.
In the experiment of removal of specific client contributions, We conduct unlearning experiments on the FL model after 100 rounds of training, where the hyperparameter Settings of each method are as follows: For SFU, we set the learning rate as 0.01, epoch as 1, and mini-batch size as 64 for gradient ascent on the target client, and each client selects 10 samples to solve the local expression matrix. The random factor in differential privacy is generated by sampling from a uniform distribution of. For SVD parameters we followed the setting of Saha et al. (2021). For UL and GA, we set the same learning rate and mini-batch as SFU, and the public data set of UL on the server is formed by randomly sampling one-tenth of the total data. In the experiment of recovery of model performance, We start FL training with the stochastic model for full retraining. we start FL training on the unlearned local model without the involvement of the target client for SFU and GA. We use the knowledge of the public data on the server for distillation learning to recover the model accuracy for UL.
A.2 Experimental results for scenario (ii).
| FedAvg | UL | GA | SFU | ||||||
| Dataset | network | test acc | atk acc | test acc | atk acc | test acc | atk acc | test acc | atk acc |
| MNIST | MLP | 94.41 | 0.02 | 94.41 | 0.02 | 94.38 | 0.02 | 94.51 | 0.0 |
| CNN | 98.47 | 0.0 | 98.47 | 0.0 | 98.26 | 0.0 | 98.44 | 0.0 | |
| CIFAR10 | MLP | 40.04 | 0.0 | 40.04 | 0.0 | 39.81 | 0.01 | 40.04 | 0.0 |
| CNN | 55.11 | 0.0 | 55.11 | 0.0 | 54.95 | 0.37 | 55.04 | 0.0 | |
| ResNet | 48.38 | 2.83 | 48.38 | 2.83 | 47.79 | 0.57 | 47.47 | 0.27 | |
| CIFAR100 | MLP | 13.5 | 0.0 | 13.5 | 0.0 | 13.47 | 0.0 | 13.51 | 0.0 |
| CNN | 16.59 | 0.0 | 16.59 | 0.0 | 16.57 | 0.0 | 16.62 | 0.0 | |
| ResNet | 15.05 | 0.25 | 15.05 | 0.25 | 15.32 | 0.0 | 14.93 | 0.0 | |
| Retraining | UL-Distillation | GA-retraining | SFU-retraining | ||||||
| Dataset | network | test acc | atk acc | test acc | atk acc | test acc | atk acc | test acc | atk acc |
| MNIST | MLP | 94.44 | 0.02 | 94.44 | 0.02 | 94.43 | 0.02 | 94.98 | 0.0 |
| CNN | 98.45 | 0.0 | 98.41 | 0.0 | 98.43 | 0.0 | 98.44 | 12.63 | |
| CIFAR10 | MLP | 40.13 | 0.0 | 40.13 | 0.0 | 39.95 | 20.36 | 41.49 | 0.10 |
| CNN | 55.11 | 0.00 | 55.27 | 0.0 | 55.36 | 0.0 | 56.13 | 0.0 | |
| ResNet | 47.33 | 3.51 | 50.93 | 2.52 | 48.36 | 1.63 | 49.93 | 0.94 | |
| CIFAR100 | MLP | 13.14 | 0.0 | 13.42 | 0.0 | 13.17 | 0.0 | 13.30 | 0.0 |
| CNN | 16.97 | 0.0 | 16.57 | 0.0 | 16.57 | 0.0 | 17.51 | 0.0 | |
| ResNet | 15.39 | 0.12 | 15.01 | 0.25 | 14.92 | 0.14 | 16.09 | 0.09 | |
We compare the performance of SFU and other baselines on the setting of scenario (ii).Tab. 4 and Tab. 5 show that the success rate of backdoor attacks in scenario (ii) are lower than it in Tab. 1 and Tab. 2. When the client has a certain probability of being selected in the FL system, the target client has little contribution to the final model. However, the discussion about forgetting accuracy is still consistent with the interpretation in Sec. 4.2 and Sec. 4.3.