Sufficiently Accurate Model Learning for Planning
Abstract
Data driven models of dynamical systems help planners and controllers to provide more precise and accurate motions. Most model learning algorithms will try to minimize a loss function between the observed data and the model’s predictions. This can be improved using prior knowledge about the task at hand, which can be encoded in the form of constraints. This turns the unconstrained model learning problem into a constrained one. These constraints allow models with finite capacity to focus their expressive power on important aspects of the system. This can lead to models that are better suited for certain tasks. This paper introduces the constrained Sufficiently Accurate model learning approach, provides examples of such problems, and presents a theorem on how close some approximate solutions can be. The approximate solution quality will depend on the function parameterization, loss and constraint function smoothness, and the number of samples in model learning.
Index Terms:
Model Learning, Dynamics Model, Machine LearningI Introduction
Dynamics models play an essential role in many modern controllers and planners. This is for instance the case in Model Predictive Control (MPC) [1]. They can also be used to compute feedforward terms for feedback controllers [2], or be used with a planner to find a trajectory from which stabilizing controllers can be generated [3, 4]. While model-free Reinforcement Learning techniques can solve similar problems without the use of a dynamics model [5, 6, 7], they generally do not scale to new problems or changes in problem parameters. Model learning methods perform admirably when the models can approximate the dynamics of the system accurately. However, the performance of these controllers can be degraded with uncertainty in the model. While robust controllers can be designed to attempt to alleviate these issues [8], these methods typically perform conservatively due to having to cater to worst case approximations of the model. In addition, there may be effects that a robust controller designer may not be aware. For example, consider the problem of landing a quadrotor precisely at a target as shown in Figure 9. There are complex aerodynamic effects associated when nearby surfaces cause disturbances to the airflow. This may result in large torques when the quadrotor is hovering close to the ground and hamper precise landings. This is known as the “ground effect.” These aerodynamic effects can be hard to model from just prior knowledge and may show up as a highly correlated, state dependent, non-zero mean noise. A common method that has been suggested to model similar effects is to learn or adjust a dynamics model with real data taken from running the system.
For linear systems, this method of System Identification (SI) or Model Learning has many results [9, 10, 11, 12, 13, 14] —such as recoverability of linear system dynamics when the data contains sufficient excitation. System identification methods have been proposed for non-linear systems [15, 16, 17]. However, they suffer from issues such as the need for a large amount of data or the requirement of a special problem structure such as block-based systems.
While generic methods for non-linear systems do not provide the same theoretical guarantees, there has been some success in practice. In robotics, Gaussian Processes, Gaussian Mixture Models, or Neural Networks have been used to learn models of dynamics [18, 19, 20, 21]. A typical process for learning these models involves selecting a parameterized model, such as a neural network with a fixed number of layers and neurons, and choosing a loss function that penalizes the output of the model for not matching the data gathered from running the real system. Then, one optimizes the parameters by minimizing the empirical risk using, for instance, stochastic gradient descent like algorithms. This formulation assumes that all transitions are equally important, since it penalizes the mismatch between model and data uniformly on all portions of the state-action space. While this formulation has shown success in some applications, prior knowledge about the task and system can inform better learning objectives. A control designer may know that a certain part of the state space requires a certain accuracy for a robust controller to work well, or that some part of the state space is more important and should have hard constraints on the model accuracy. For example, to precisely land a quadrotor, a designer may note that the accuracy of modeling the complex ground effect forces is more important near the landing site. Incorporating this prior knowledge can lead to better performing models.
To address the problem of incorporating prior knowledge into model learning, we introduced the idea of Sufficiently Accurate Model Learning in [22]. This formulation is based on the inclusion of constraints in the optimization problem whose role is to introduce prior-knowledge about the importance of different state-control subsets. In the example of the quadrotor, notice that when the quadrotor is away from the surfaces, the ground effect is minor and thus, it is important to focus the learned model’s expressiveness in the region of the state-space that is most heavily affected. This can be easily captured by a constraint that the average error in the important state-space regions is smaller than a desired value. These constraints will allow models with finite expressiveness concentrate on modeling important aspects of a system. One point to note is that this constrained objective can be used orthogonally to many existing methods. For example, the constrained objective can replace the unconstrained objective in [20, 21], and all other aspects of the methods can remain the same. The data can be collected the same way. The idea of using extra sensors during training for [20] need not change. While not trivial, the idea of constraints can also be applied to Gaussian process models such as [18, 19].
In its most generic form, the problem of model learning is an infinite dimensional non-convex optimization problem that involves the computation of expectations with respect to an unknown distribution over the state-action space. In addition, the formulation proposed here introduces constraints which seems to make the learning process even more challenging. However, in this work we show that solving this problem accurately is not more challenging than solving an unconstrained parametric learning problem. To reach this conclusion we solve a relaxation of the problem of interest with three common modifications: (i) function parameterization, (ii) empirical approximation, and (iii) dual problem solving. Function parameterization turns the infinite dimensional problem into one over finite function parameters. Empirical approximation allows for efficient computation of approximate expectations, and solving the dual problem leads to a convex unconstrained optimization problem. The three approximations introduced however may not yield solutions that are good approximations of the original problem. To that end, we establish a bound on the difference of the value of these solutions. This gap between the original and approximate problem depends on the number of samples of data as well as the expressiveness of the function approximation (Theorem 1). In particular, the bound can be made arbitrarily small with sufficient number of samples and with the selection of a rich enough function approximator. This implies that solving the functional constrained problem is nearly equivalent to solving a sequence of unconstrained approximate problems using primal-dual methods.
This paper extends [22] to the case of empirical samples and presents Theorem 1 that relates number of samples, function approximation expressiveness, and loss function smoothness to approximation error. In addition, there is experimental validation of Theorem 1 as well as different examples to showcase the framework of Sufficiently Accurate model learning. This paper is organized as follows: Section II introduces the Sufficiently Accurate model learning framework, Section III presents in detail the three approximations introduced to solve the problem as well as a result that bounds the error on the approximate problem (Theorem 1). Section IV provides the proof for the main theorem. Section V presents a simple primal-dual method to solve the constrained problem, while experimental results are presented in Section VI on a double integrator system with friction, a ball bouncing task, and a quadrotor landing with ground effect in simulation. Theoretical results are experimentally tested for the double integrator system. Section VII presents the paper’s conclusions.
II Sufficiently Accurate Model Learning
In this paper we consider the problem of learning a discrete time dynamical system. Let us denote as the time index and let , be the state and input of the system at time . The dynamical system of interest is represented by a function that relates the state and input at time to the state at time
| (1) |
One approach to System Identification or Model Learning consists of fitting an estimated dynamical model, , to state transition data [18]. This state transition data consists of tuples of drawn from a distribution with the sample space . The estimated model belongs to a class of functions, , of which is an element. could be, for example, the space of all continuous functions. Then, the problem of model learning reduces to finding the function in the class that best fits the transition data. The figure of merit is a loss function . With these definitions, the problem of interest can be written as the following stochastic optimization problem
| (2) |
The loss function needs to be selected to encourage the model to match its output with the state transition data. An example of a loss function is the p-norm, . For , this reduces to a sum of absolute differences between each output dimension of and the true next state, . When , this is simply a euclidean loss. Other common losses can include the Huber loss and, in discrete state settings, a 0-1 loss.
Often times, one can derive, from first principles, a model of the dynamical system of interest. Depending on the complexity of the system of, these models may be inaccurate since they may ignore hard to model dynamics or higher order effects. For instance, one can derive a model for a quadrotor from rigid body dynamics where forces and torques are functions of each motor’s propeller speed. However, the accuracy of this model will depend on other effects that are harder to model such as aerodynamic forces near the ground. If these aerodynamic effects are ignored, it can result in a failure to control the system or in poor performance [23]. In these cases, the target model, denoted by , can decomposed as the sum of an analytic model and an error
| (3) |
The learning of the error term—or residual model—fits the framework described in (2). For instance, for the norm loss can be modified to take the form .
A characteristic of the classic model learning problem defined in (2) is that errors are uniformly weighted across the state-input space. In principle, one can craft the loss so to represent different properties on different subsets of the state-input space. However, this design is challenging, system dependent, and dependant on the transition data available. In contrast, our approach aims to exploit prior knowledge about the errors and how they impact the control performance. For instance, based on the analysis of robust controllers one can have bounds on the error required for successful control. This information can be used to formulate the Sufficiently Accurate model learning problem, where we introduce the prior information in the form of constraints. Formally, we encode the prior information by introducing functions . Define in addition, a collection of subsets of transition tuples where this prior information is relevant, and corresponding indicator functions taking the value one if and zero otherwise. With these definitions the sufficiently accurate model learning problem is defined as
| (4) | ||||
Note that the sets that define the indicator variables are not necessarily disjoint. In fact, in practice, they are often not. The sets can be arbitrary and have no relation to each other. Examples of how these sets are used are given in examples at the end of this section. Notice that the (4) is an infinite dimensional problem since the optimization variable is a function and it involves the computation of expectations with respect to a possibly unknown distribution. An approximation to this problem is presented in Section III. For technical reasons, the functions and should be expectation-wise Lipschitz continuous.
Assumption 1.
The functions and are -expectation-wise Lipschitz continuous in , i.e.,
| (5) |
Here, is the infinity norm for functions which is defined as .
The expectation-wise Lipschitz assumption is a weaker assumption than Lipschitz-continuity, as any Lipschitz-continuous function with a Lipschitz constant is also expectation-wise Lipschitz-continuous with a constant of . In particular, the loss functions in Example 1 and 2 are expectation-wise Lipschitz-continuous with some constant (cf., Appendix A). There is no assumption that the functions should be convex or continuous.
Before we proceed, we present two examples of Sufficiently Accurate model learning. For notational brevity, when an expectation does not have a subscript, it is always taken over .
Example 1.
Selective Accuracy
| (6) | ||||
This problem is a simple modification of (2). It has the same objective, but adds a constraint that a certain state-control subset, defined by a set , should be within accuracy. The indicator variable will be 1 when is in the set . Here, . This formulation allows you to trade off the accuracy in one part of the state-control space with everything else as it may be more important to a task. Another use case can be to provide an error bound for robust controllers. This is the formulation used in the quadrotor precise landing experiments detailed later in Section VI-C, where the set is defined to be all states close to the ground where the ground effect is more prominent. VI-C.
Example 2.
Normalized Objective
| (7) | ||||
where is the indicator variable for the subset , and is the complement of the set . This problem formulation looks at minimizing an objective such that the error term is normalized by the size of the next state. This can be useful in cases where the states can take values in a very large range. An error of 1 unit can be large if the true value is 0.1 units, but it is a small error if the true value is 100 units. The set contains all data samples where the true next state is large enough for this to be significant. This can reduce numerical issues when the denominator is small. For all small state values, the error is simply bounded by . From a practical point of view, sensors will always have noise. When the state is small, the “true” measurement of the state can be dominated by noise, and the model can be better off just bounding the error rather than focusing on fitting the noise. This is the formulation used in the ball bouncing experiment in Section VI-B, where the we would like the errors in velocity prediction to be scaled to the speed, and all errors below a small speed can be constrained with a simple constant.
III Problem Approximation
The unconstrained problem (2) and the constrained problem (4) are functional optimization problems. In general, these are infinite dimensional and usually intractable. Instead of optimizing over the entire function space , one may look at function spaces, , parameterized by a -dimensional vector . Examples of these classes of functions are linear functions of the form where is a vector of weights for the state and control input. More complex function approximators, such as neural networks, may be used to express a richer class of functions [21, 24]. Restricting the function space poses a problem in that the optimal solution to (4) may no longer exist in the set . The goal under these circumstances should be to find the closest solution in to the true optimal solution . Additionally, the expectations of the loss and constraint functions are in general intractable. The distributions can be unknown or hard to compute in closed form. In practice, the expectation is approximated with a finite number of data samples with . This yields the following empirical parameterized risk minimization problem
| (8) | ||||
While both function and empirical approximations are common ways to simplify the problem, the approximate problem introduced in (8) is still a constrained optimization problem and can be difficult to solve in general as it can be nonconvex in the parameters . This is the case for instance when the function approximator is a neural network. One approach to solve this problem is to solve the dual problem associated with (8). To aid in the definition of the dual problem, we first define the dual variables (also known as Lagrange multipliers), , along with the Lagrangian associated with (8)
| (9) |
Here, the symbol, , is defined as to condense the notation. Similarly, the bolded vector, is a vector where the entry is defined as . The dual problem is now defined as
| (10) |
Notice that (10) is similar to a regularized form of (8) where each constraint is penalized by a coefficient
| (11) |
Adding this type of regularization can weight certain state-action spaces more. In fact, if is chosen to be , solving (11) would be equivalent to solving (10). However, arbitrary choices of provide no guarantees on the constraint function values. By defining the constraint functions directly, constraint function values are determined independent of any tuning factor. For problems where strong guarantees are required or easier to define, the Sufficiently Accurate framework will satisfy them by design. An alternative interpretation is that (10) provides a principled way of selecting the regularization coefficients. In Section V, we discuss an implementation of a primal dual algorithm to do so.
The dual problem has two important properties that hold regardless of the structure of the optimization problem (8). For any that minimizes the Lagrangian , the resulting function—termed the dual function—is concave on the multipliers, since it is the point-wise minimum of linear functions (see e.g. [25]). Therefore, its maximization is tractable and it can be done efficiently for instance using stochastic gradient descent. In addition, the dual function is always a lower bound on the value and in that sense solving the dual problem (10) provides the tightest lower bound. In the case of convex problems (that fulfill Slater’s Condition), it is well known that the problems have zero duality gap, and therefore [25, Section 5.2.3]. However, the problem (8) is non-convex and a priori we do not have guarantees on how far the values of the primal and the dual are. Moreover, recall that the primal problem in (8) is an empirical approximation of the problem that we are actually interested in solving (4).
The previous discussion leads to the question about the quality of the solution (10) as an approximation to (4). The duality gap is defined as the difference between the primal and dual solutions of the same problem. Here, the gap is the difference between the primal and the dual of different but closely related problems. Hence, the quantity we are interested in bounding is the surrogate duality gap defined as
| (12) |
To provide specific bounds for the difference in the previous expression we consider the family of function classes termed -universal function approximators. We define this notion next.
Definition 1.
The function class is an -universal function approximator for if, for any , there exists a such that .
To provide some intuition on the definition consider the case where is the space of all continuous function, the above property is satisfied by some neural network architecture. That is, for any , there exists a class of neural network architectures, such that is an -universal approximator for the set of continuous functions [24, Corollary 2.1]. Thus, for any dynamical system with continuous dynamics, this assumption is mild. Other parameterizations, such as Reproducing Kernel Hilbert Spaces, are -universal as well [26]. Notice that the previous definition is an approximation on the total norm variation and hence it is a milder assumption than the universal approximation property that fully connected neural networks exhibit [24].
Next, we define an intermediate problem on which the surrogate duality gap depends: a perturbed version of problem (4) where the constraints are relaxed by where is the constant defined in Assumption 1 and the universal approximation constant in Definition 1
| (13) | ||||
is a vector of ones. The perturbation results in a problem whose constraints are tighter as compared to (4). The set of feasible solutions for the perturbed problem (13) is a subset of the feasible solutions for the unperturbed problem (4). The perturbed problem accounts for the approximation introduced by the parameterization. In the worst case scenario, if the problem (13) is infeasible, the parameterized approximation of (8) may turn infeasible as the number of samples increases.
Let be the solution to the dual of (13)
| (14) |
With these definitions, we can present the main theorem that bounds the surrogate duality gap.
Theorem 1.
Let be a compact class of functions over a compact space such that there exists for which (4) is feasible, and let be an -universal approximator of as in Definition 1. Let the space of Lagrange multipliers, , be a compact set as in [27]. In addition, let Assumption 1 hold and let satisfy the following property
| (15) |
where is the optimal dual variable for the problem (14), is the Lipschitz constant for the loss function, and is the random VC-entropy [28, section II.B]. Note that both arguments for must be positive. Then and , the values of (4) and (10) respectively, satisfy
| (16) |
where the probability is over independent samples drawn from the distribution as defined in problem (8).
Proof.
See Section IV ∎
The intuition behind the theorem is that given some acceptable surrogate duality gap, , there exists a neural network architecture, , and a number of samples, such that the probability that the solution to (10) is within to the solution to (4) is very high. The choice of neural network will influence the value of and . These in turn will decide the duality gap, , as the quantity must be positive. A larger neural network will correspond to a smaller which will also has an impact on the perturbed problem (13). A smoother function and smaller will lead to smaller perturbations. Smaller perturbations can lead to a smaller dual variable, . Thus, larger neural networks and smoother dynamic systems will have smaller duality gaps. If is large, then the perturbed problem may be infeasible. In theses cases, will be infinite. This corresponds to problems where the function approximation simply can not satisfy the original constraint functions. For example, using constant functions to approximate a complicated system may violate the constraint functions for all possible constant functions. Thus, no exists to bound the solution as the parameterized empirical problem (8) has no feasible solution. This theorem suggests that with a good enough function approximation and large enough , solving (10) is a good approximation to solving (4) with large probability.
There are some details to point out in Theorem 1. First, the function a complicated function that will usually scale with the size of the neural network. A larger neural network will lead to a smaller , but may require a larger number of samples to adequately converge to an acceptable solution. The assumption on the limiting behavior of is fufilled by some neural network architectures [29], but the general behavior of this function for all neural network architectures is still a topic of research. Additionally, we assume the space of Lagrange multipliers is a compact set. This will imply, along with compact state-action space, that is bounded. A finite Lagrange multiplier is a reasonable assumption as the problem (4) is required to be feasible [27].
The bound established in Theorem 1 depends on quantities that are in general difficult to estimate, These include , , , . Thus, while this theorem provides some insights on how these quantities influence the gap between solutions, it is mainly a statement of the existence of such values that can provide a desired result. In practice, this result can be achieved by choosing increasing the sizes of neural networks as well as data samples until the desired performance is reached. Note that the theorem follows our intuition that larger neural networks and more data will give us more accurate result. However, this theorem formalizes not only that it is more accurate, but that the error will tend to 0 as number of samples and number of parameters increase.
IV Proof of Theorem 1
To begin, we define an intermediate problem
| (17) | ||||
Note that this is the unperturbed version of (13). As a reminder, this problem uses a class of parameterized functions, but does not use data samples to approximate the expectation. Thus, it can be seen as a step in between (4) and (8). As with the dual problem to (8), we can define the Lagrangian associated with (17)
| (18) |
and the dual problem
| (19) |
Using this intermediate problem, we can break the bound into two components.
| (20) | ||||
As a reminder, is the solution to the problem we want to solve in (4), is the solution to the problem (10) we can feasibly solve, and is the solution to an intermediate problem (19). The first half of this bound, , is the error that arises from using a parameterized function and dual approximation. The second half of this bound, , is the error that arises from using empirical data samples. It can be seen as a kind of generalization error. The proof will now be split into two parts that will find a bound for each of these errors.
IV-A Function Approximation Error
We first look at the quantity . This can be further split as follows
| (21) | ||||
where is the solution to the dual problem associated with (4). This is defined with the Lagrangian
| (22) |
and the dual problem
| (23) |
We note that the quantity is actually 0 due to a result from [30, Theorem 1]. The theorem is reproduced here using the notation of this paper.
Theorem 2 ([30], Theorem 1).
While the problem defined in [30] is different from the sufficiently accurate problem defined in 4, there is an equivalent problem formulation (see Appendix B). Since Theorem 1 fulfills the assumptions of Theorem 2, we get .
For the second half of this approximation error, , has also been previously studied in [31, Theorem 1] in the context of a slightly different problem formulation. The following theorem adapts [31, Theorem 1] to the Sufficiently Accurate problem formulation (4).
Theorem 3.
Given the primal problem (4) and the dual problem (19), along with the following assumptions
-
1.
is an -universal function approximator for , and there exists a strictly feasible solution for (17).
-
2.
The loss and constraint functions are expectation-wise Lipschitz-continuous with constant .
-
3.
All assumptions of Theorem, 2
The dual value, is bounded by
| (24) |
where is the dual variable that achieves the optimal solution to (14).
Proof.
See Appendix C ∎
IV-B Empirical Error
We now look at the empirical error, . We first observe the following Lemma.
Lemma 1.
Let . Then under the assumption of Theorem 1 it follows that
| (26) |
Proof.
See Appendix D ∎
IV-C Probabilistic Bound
Substituting the parameterized bound (25) and the empirical bound (26) in (20) yields the following implication
| (27) |
Let be a probability over samples that are drawn to estimate the expectation in the primal problem (8). Using the implication (27) it follows that
| (28) | ||||
where the equality follows directly from the fact that for any event , . The assumptions of Theorem 1 allows us to use the following result from Statistical Learning Theory [28, (Section II.B)],
| (29) |
Note that this theorem requires bounded loss functions. The assumptions for a bounded dual variable, and compact state-action space in Theorem 1 satisfies this constraint.
Thus, this establishes that for any , we have This concludes the proof of the theorem.
V Constrained Solution Via Primal-Dual Method
Section III has shown that problem (10) can approximate (4) given a large enough neural network and enough samples. This section will discuss how to compute a solution (10). There are many primal-dual methods [32, 33, 34] in the literature to solve this exact problem, and Algorithm 1 is an example of a simple primal-dual algorithm. One way to approach this problem is to consider the optimal dual variable, . Given knowledge of , the problem reduces to the following unconstrained minimization
| (30) |
A possible solution method is to start with an estimate of , and solve the minimization problem. Then holding the primal variables fixed, update the dual variables by solving the outer maximization. This method can be seen as solving a sequence of unconstrained minimization problems. This method can be further approximated; instead of fully minimizing with respect to the primal variables, a gradient descent step can be taken. And instead of fully maximizing with respect to the dual variables, a gradient ascent step can be taken. This leads to Algorithm 1 where we iterate between the inner minimization step and the outer maximization step. At each iteration, dual variables are projected onto the positive orthant of , denoted by the projection operator, . This is to ensure non-negativity of the dual variables.
In many cases, the full gradient of and can be too expensive to compute. This is due to the possibly large number of samples . An alternative is to take stochastic gradient descent and ascent steps. The gradients can be approximated by taking random samples of the whole dataset . The samples will be denoted as where is an integer index into whole dataset . Using , we obtain
| (31) | ||||
The gradients and can be computed easily using backpropogation. Similarly, for ,
| (32) | ||||
The dual gradient can be estimated as simply the average of the constraint functions over the sampled dataset.
In the simplest form of the primal-dual algorithm, the variables are updated with simple gradient ascent/descent steps. These updates can be replaced with more complicated update schemes, such as using momentum [35] or adaptive learning rates [36]. Higher order optimization methods such as Newton’s method can be used to replace the gradient ascent and descent steps. For large neural networks, this can be unfeasible as it requires the computation of Hessians with respect to neural network weights. The memory complexity for the Hessian is quadratic with the number of neural network weights.
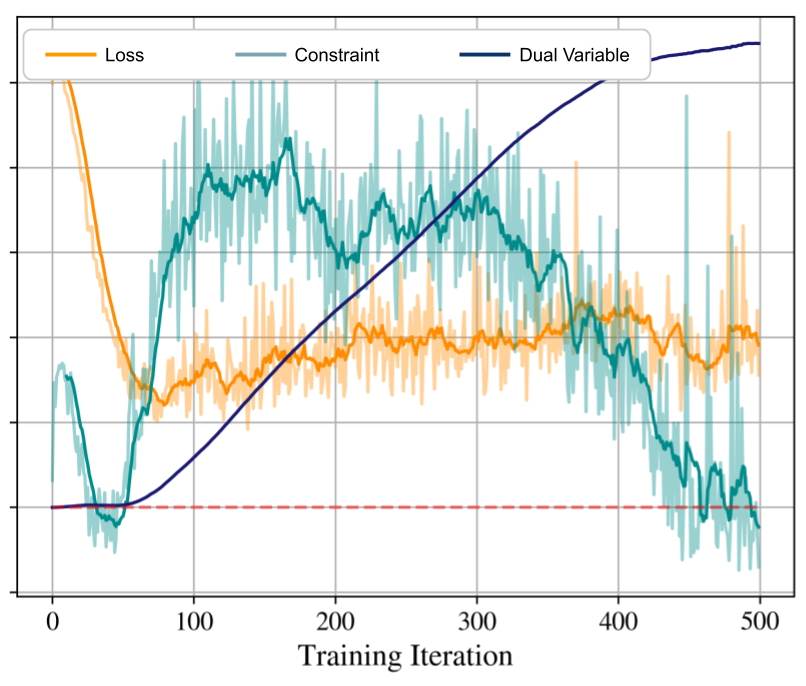
The primal-dual algorithm presented here is not guaranteed to converge to the global optimum. With proper choice of learning rate, it can converge to a local optimum or saddle point. This issue is present in unconstrained formulations like (2) as well. An example of the evolution of the loss and constraint functions is shown in Figure 1.
VI Experiments
This section shows examples of the Sufficiently Accurate model learning problem. First, experiments are performed using a simple double integrator experiencing unknown dynamic friction. The simplicity of this problem along with the small state space allows us to explore and visualize some of the properties of the approximated solution. Next, two more interesting examples are shown. One example learns how a ball bounces on a paddle with unknown paddle orientation and coefficient of restitution. The other example mitigates ground effects which can disturb the landing sequence of a quadrotor. The experiments will compare the sufficiently accurate problem (4) with the unconstrained problem (2) which will be denoted as the Uniformly Accurate problem. Each experimental subsection will be broken down into three parts, 1) System and Task introduction, 2) Experimental details, and 3) Results.
VI-A Double Integrator with Friction
VI-A1 Introduction
To analyze aspects of the Sufficiently Accurate model learning formulation, simple experiments are performed on a simple double integrator system with dynamic friction. When trying to control the system, a simple base model to use is that of a double integrator without any friction
| (33) |
where is the position of the system, is the velocity, is the control input, and is the sampling time. The state of the system is .The true model of the system that is unknown to the controller is
| (34) |
where a position varying kinetic friction. is a function that ensures that the friction cannot reverse the the direction of the speed (it is an artifact of the discrete time formulation)
| (35) |
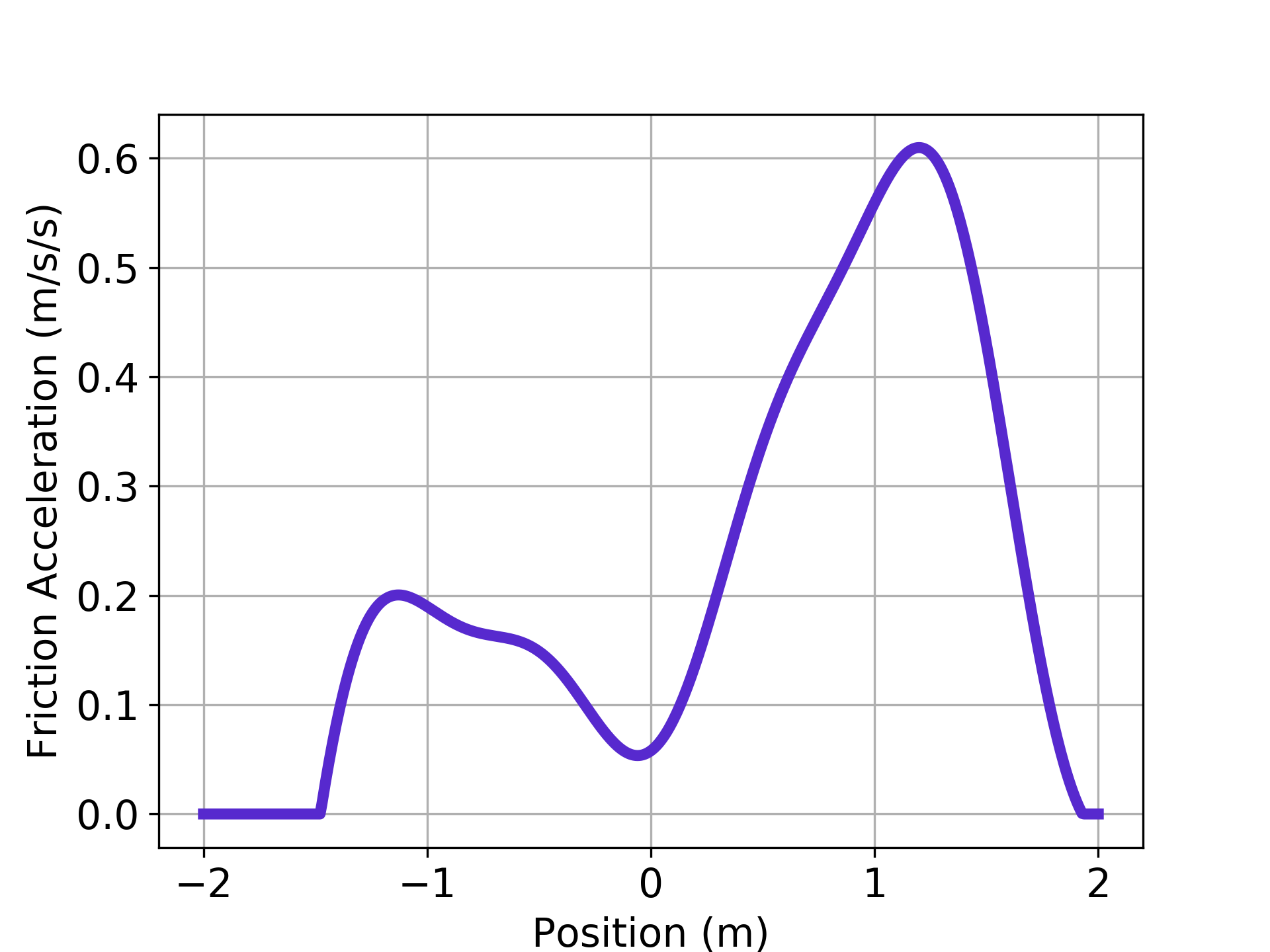
If within a single time step, the friction force will change the sign of the velocity, will set to be 0. Otherwise, will not modify the friction force in any way. The specific used is shown in Figure 3 and the sampling time is set to . The task is to drive the system to the origin .
VI-A2 Experimental Details
The goal of model learning in this experiment is to learn such that where is (34) and is (33). A Uniformly Accurate model will be learned using (2) along with a Sufficiently Accurate model using the problem defined in Example 1. In the scenario defined by (6), is active in the region and . The constraint, therefore, enforces a high accuracy in the state space near the origin.
The neural network, , used to approximate the residual dynamics has two hidden layers. The first hidden layer has four neurons, while the second has two. Both hidden layers use a parametric rectified linear (PReLU) activation [37]. The input into the network is a concatenated vector of . The output layer’s weights are initially set to zero so before learning the residual error, the network will output zero. The dataset used to train both the sufficiently and uniformly accurate models is generated by uniformly sampling positions from [-2, 2], velocities from [-2.5, 2.5], and control inputs from [-10, 10]. The real model (34) is then used to obtain the true next state. Instead of simple gradient descent/ascent, ADAM [36] is used as an update rule with and . Both models were trained in 200 epochs.
The models are then evaluated on how well it performs within a MPC controller defined in (36). This controller seeks to drive the system to the origin while obeying control constraints. The controller is solved using a Sequential Quadratic Programming solver [38] with a time horizon of . The models are evaluated in 200 different simulations where is drawn uniformly from .
| (36) | ||||
| s.t. | ||||

VI-A3 Results
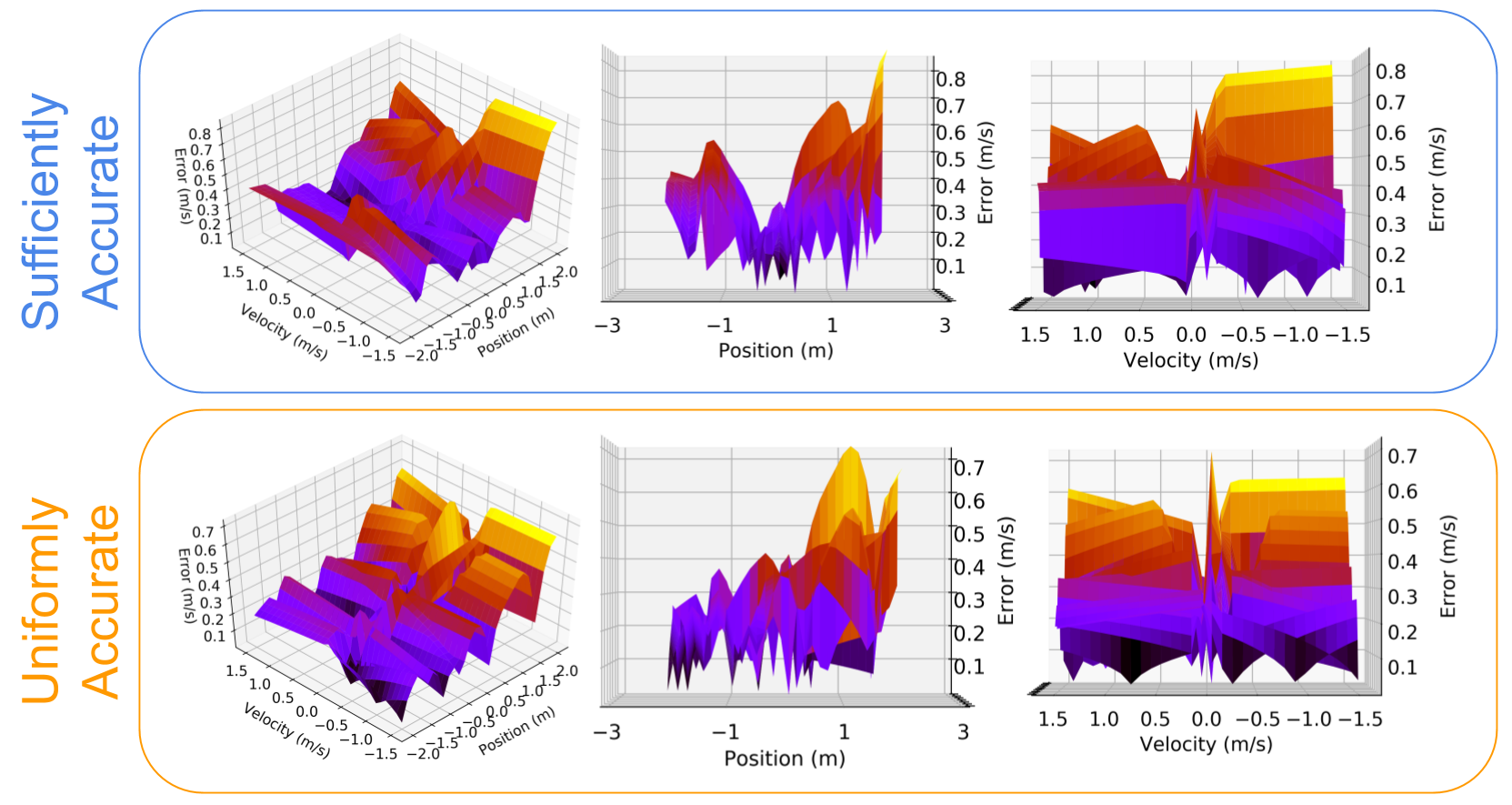
The sufficiently accurate formulation utilizes the prior knowledge that the model should be more accurate near the goal in order to stop efficiently. While the system is far from the origin, the control is simple, regardless of the friction; the controller only needs to know what direction to push in. A plot of the accuracy of both models is shown in Figure 2 and summarized in Table II. It is noticeable that the Sufficiently Accurate model has low average error near the origin, but suffers from higher average error outside of the region defined by . This is the expected behavior.
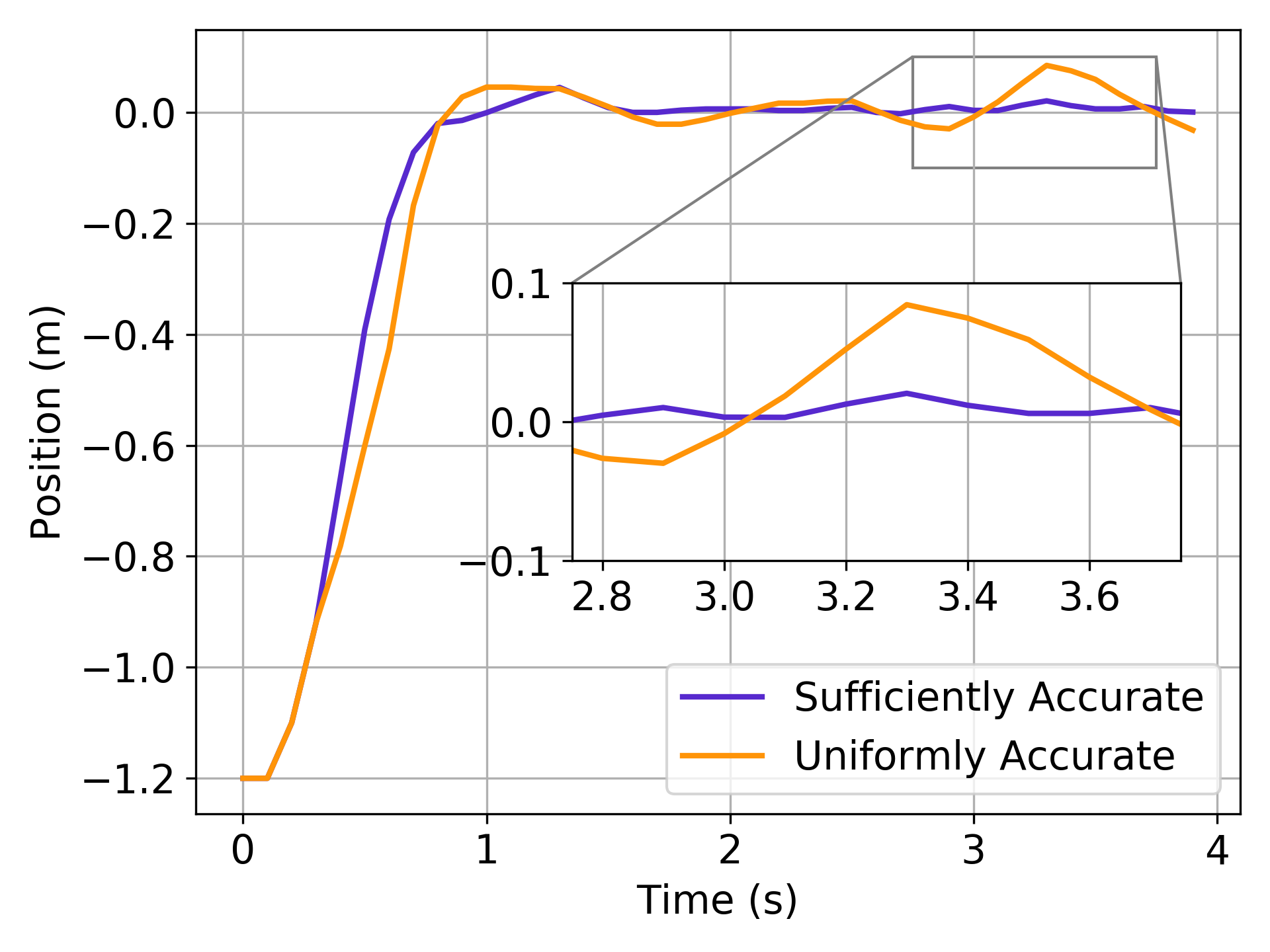
The performance of the controllers are summarized in Table I. Even though Sufficiently Accurate has higher error outside of the constraint region and lower error within, it leads to lower costs when controlling the double integrator. The reason is shown in Figure 5, where the sufficiently accurate model may get to steady state a bit slower but is able to control the overshoot better and not have oscillations near the origin. This is because the model is purposefully more accurate near the origin as it is more important for this task.
| Uniformly Accurate | ||
|---|---|---|
| Sufficiently Accurate |
| All state space | |||
| Uniform | |||
| Sufficient |
VI-A4 Convergence Experiments
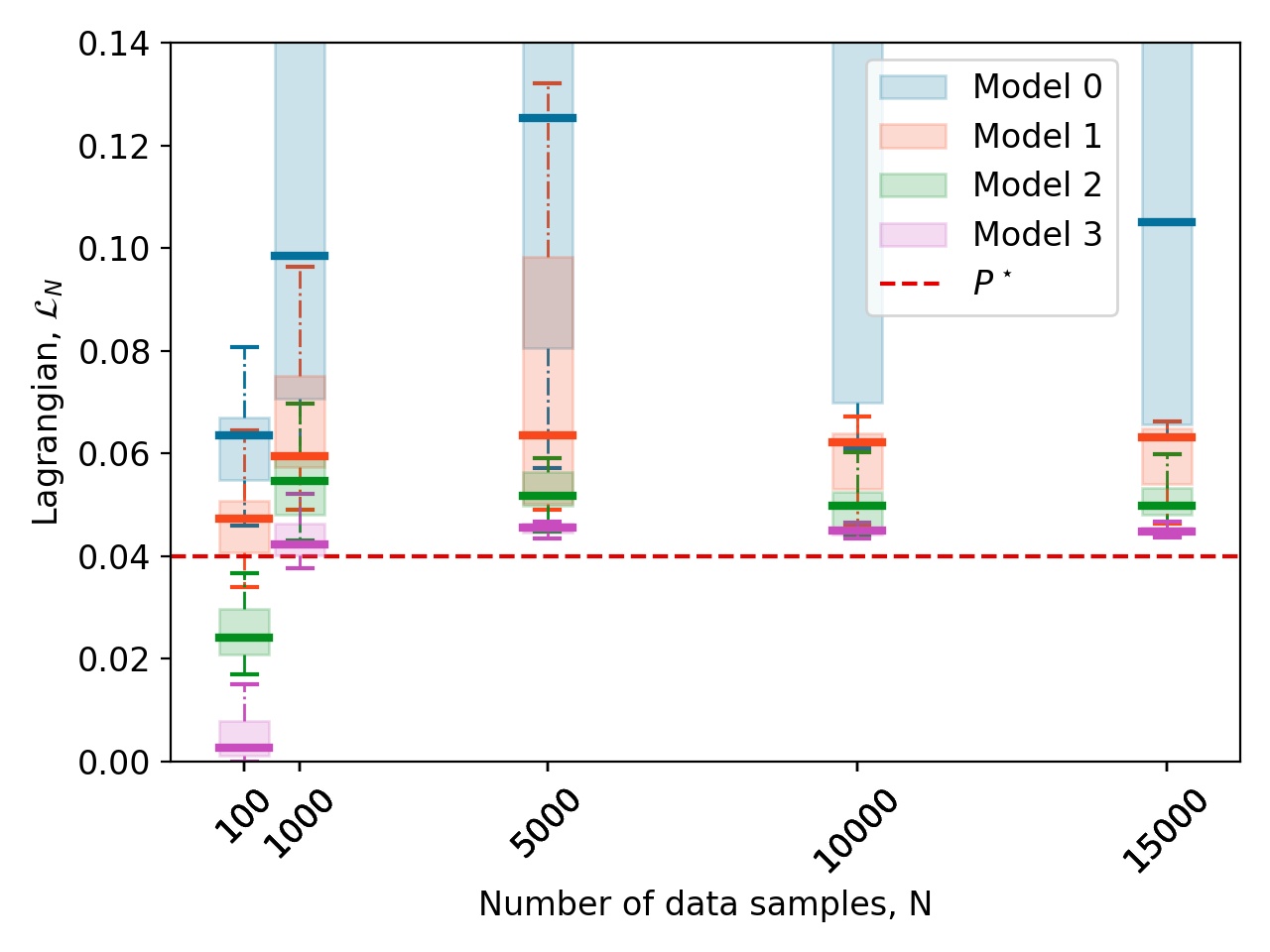
The double integrator is a simple system. This enables running more comprehensive tests to experimentally show some aspects of Theorem 1. For this particular system, we will run one more experiment where 4 different neural network architectures were used. Each network has two hidden layers with PReLU activation, where the only difference is in the number of neurons in each layer. Denoting a network as (number of neurons in first layer, number of neurons in second layer), the network sizes used are: (2, 1), (4, 2), (8, 4), (16, 8). A set of values of the number of samples, , are also chosen: . For each , 15 random datasets are sampled, and each neural network is trained with each dataset using the Sufficiently Accurate objective described in Section VI-A2. There is one minor difference in how the data is collected; a zero mean Gaussian noise with is added to . With noisy observations of velocity, the optimal model that can be learned for (4) will have an objective value of . The results of training each neural network model with each random dataset is shown in Figure 4. Each boxplot in the figure shows the distribution of the final value of the Lagrangian, , at the ending of training. This is an approximation of . The primal-dual algorithm may not be able to solve for the optimal , but the expectation is that for a simple problem like double integrator, the solution is somewhat close. In fact, Figure 4 shows that with increasing model sizes and larger , the distribution of the solutions appear to be converging to . Note that the figure shows the value of the Lagrangian with training data. Thus for small , networks can overfit and have a near zero Lagrangian value. When increasing , the networks have less of a chance to overfit to the training data.
VI-B Ball Bouncing
VI-B1 Introduction
This experiment involves bouncing a ball on a paddle as in Figure 6. The ball has the state space , where is the three-dimensional position of the ball, is the three-dimensional velocity of the ball. The control input is where is the velocity of the paddle at the moment of impact with the ball and is the normal vector of the paddle, representing its orientation. This control input is a high level action and is realized by lower level controllers that attempt to match the velocity and orientation desired for the paddle. A basic model of how the velocity of the ball changes during collision is
| (37) | ||||
where the superscript refers to quantities before the paddle-ball collision and the superscript refers to quantities after the paddle-ball collision (the paddle velocity and orientation are assumed to be unchanged during and directly after collision). is the coefficient of restitution. In this experiment, a neural network is tasked to learn the model of how the ball velocity changes, i.e. (37).
VI-B2 Experimental Details
First, a neural network is trained without knowledge of any base model of how the ball bounces. This will be denoted as learning a full model as opposed to a residual model. This network is trained two ways, with the Uniformly Accurate problem (2) as well as the Sufficiently Accurate problem realized in Example 2. The constants used in Example 2 are defined here as and .
A second neural network is trained for both the uniformly and sufficiently accurate formulations that utilizes the base model, given in (37) to learn a residual error. In the base model, the coefficient of restitution, , is wrong and the control has a constant bias where a rotation of 0.2 radians is applied to the y-axis. This is to simulate a robot arm picking up the paddle and not observing the rotation from the hand to the paddle correctly.
The neural network used for all models has 2 hidden layers with 128 neurons in each using the pReLU activation. The input into the network is the the state of the ball and the control input at time of collision, , and it outputs the ball velocity after the collision, . The network was trained using the ADAM optimizer with an initial learning rate of for both the primal and dual variables. The data used for all model training was gathered by simulating random ball bounces in MuJoCo for the equivalent of 42 minutes in real life.
All learned models are then evaluated with how well a controller utilizes them. The controller will attempt to bounce the ball at a specific location. This is represented through the following optimization problem that the controller solves
| (38) | ||||
where is a function that maps the velocity of the ball to the location it will be in when it falls back to its current height. and are both derived from the paddle normal . are parameters of the controller that can be chosen. The system and controller is then simulated in MuJoCo [39] using libraries from the DeepMind Control Suite [40].
Each model is evaluated 500 different times for varying controller parameters. is uniformly distributed in the region , uniformly sampled from the interval , and is selected to be above by between to .
VI-B3 Results
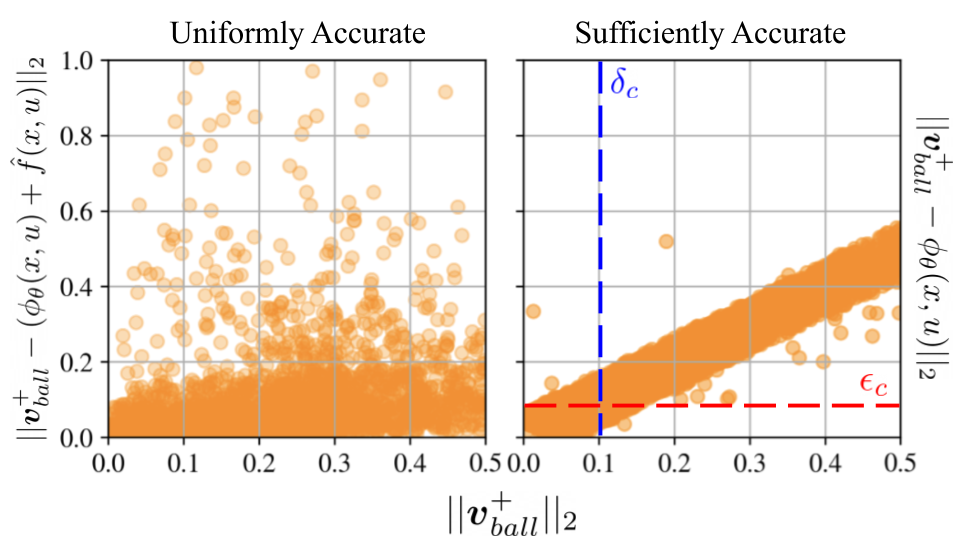
A plot of the model errors are shown in Figure 7. While the uniformly accurate model has errors that are distributed more or less uniformly across all magnitudes of ball velocity, the sufficiently accurate model has a clear linear relationship. This is expected from the normalized objective that is used which penalizes errors based on large the velocity of the ball is. Therefore, larger velocities can have larger errors with the same penalty as smaller velocities with small errors.
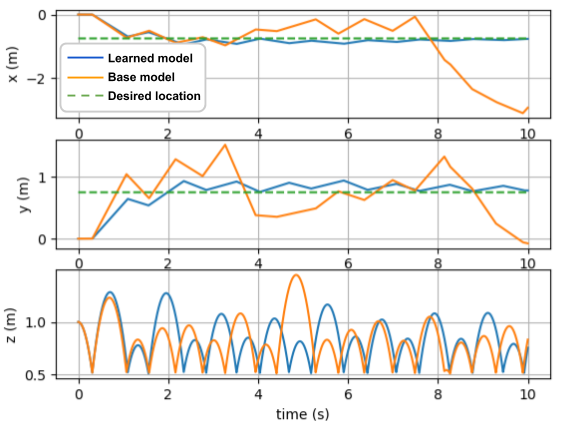
The results of running each model with the controller 500 times is shown in Table III. The error characteristics of the Sufficiently Accurate model (Figure 7) allow it to out perform its Uniformly Accurate counterpart with both a full model and a residual model. For the full model, the uniformly accurate problem yields a failure rate of over while the sufficiently accurate problem yields a failure rate of under . Here, failure means the paddle fails to keep the ball bouncing. For the residual model, neither model failed because the base model provides a decent guess (though the base model by itself is not good enough for control, see Figure 8). The sufficiently accurate model still provided better mean errors.
We hypothesize that the large errors spread randomly across the Uniform model leads to high variance estimates of the output given small changes in the input. For optimizers that use gradient information, this leads to a poor estimate of the gradient. For optimizers that are gradient free, this still causes problems due to the high variance of the values themselves.
| Uniform | Sufficient | ||
| Full Model | Failure | ||
| Mean error | 0.2124 | ||
| Residual Model | Failure | ||
| Mean error | 0.156 |
VI-C Quadrotor with ground effects
VI-C1 Introduction
The last experiment deals landing a quadrotor while undergoing disturbances from ground effect. This disturbance occurs when a quadrotor operates near surfaces which can change the airflow [23]. The state for the quadrotor model is a 12 degree of freedom model which consists of where is position of the center of mass, is the center of mass velocity, is a quaternion that represents the orientation the quadrotor, and is the angular velocity expressed in body frame. The control input is where is the force from the motor. The base model of the quadrotor, is as follows
| (39) | ||||
where is the total mass of the quadrotor (set to be 1kg for all experiments) and is inertia matrix around the principle axis (set to be identity for all experiments). The symbol represents cross product, and represents quaternion multiplication. When using between a vector and a quaternion, the vector components are treated as the imaginary components of a quaternion with a real component of 0. The discrete model normalizes the quaternion for each state update so that it remains a unit quaternion. The body frame of the quadrotor is such that the x axis aligns with one of the quadrotor arms, and the z axis points “up.”
The true model used in simulation adds disturbances to the force on each propeller, but is otherwise the same as the base model:
| (40) |
where is the ground effect model. In this experiment we provide a simplified model of ground effects where each motor has independence disturbances. The output of the ground effect model, is
| (41) | ||||
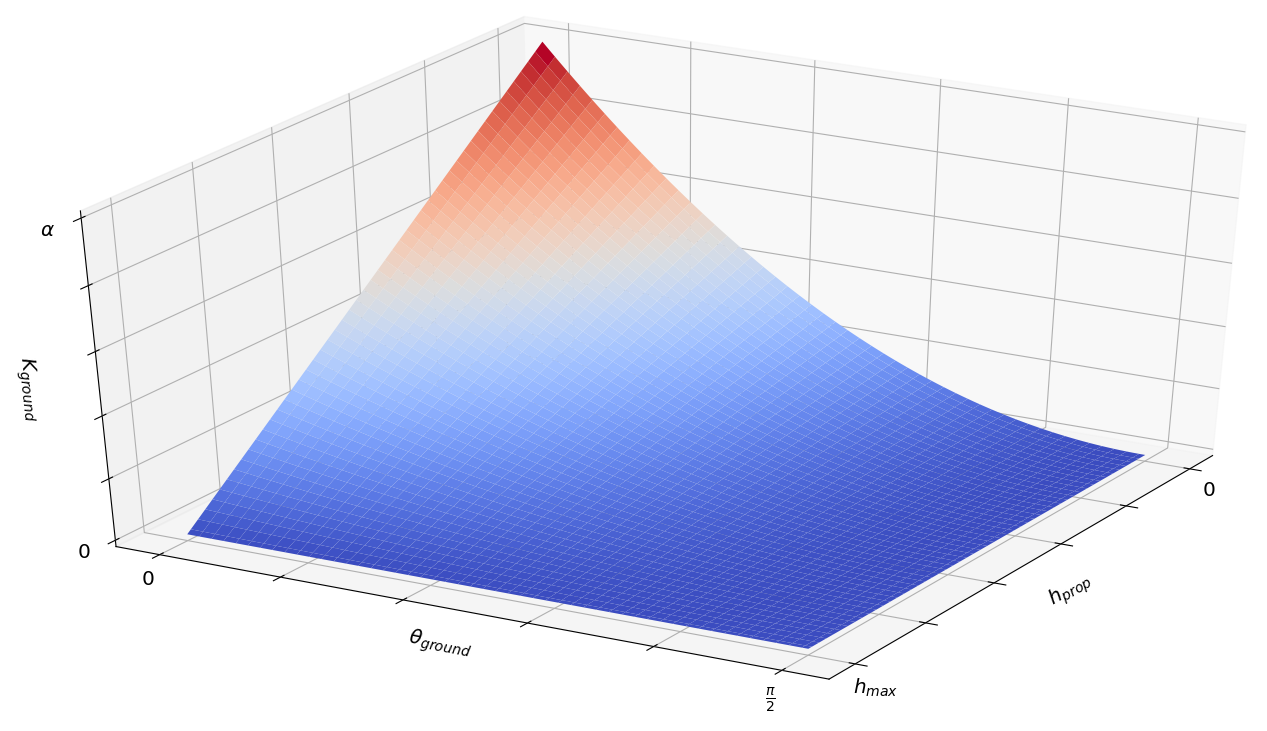
where is height of the propeller above the ground (not the height of the center of mass), is a constant that determines the height at which the ground effect is no longer in effect. is the angle between the unit vector aligned with the negative axis of the quadrotor and the unit vector . is a number in the set that represents the maximum fraction of the propeller’s generated force that can be added as a result of ground effect. As a reminder, the operator projects its arguments onto the positive orthant. A visualization of is shown in Figure 10. In the experiments, , .
VI-C2 Experimental Details
The Sufficiently Accurate model trained using the problem presented in Example 1, where and the indicator is active when the height of the quadrotor is less than . A Uniformly Accurate and Sufficiently Accurate model are trained to learn the residual error between and . Both models use a neural network with 2 hidden layers of 16 and 8 neurons each with pReLU activation. The update for primal and dual variables used ADAM with and , and both models trained using epochs. The training data consists of randomly sampled quadrotor states. The positions of the quadrotor were uniformly sampled from . The positions of the quadrotor were uniformly sampled from . Linear velocities components were uniformly sampled from . Angular velocities components were uniformly sampled from . Control inputs for each motor are sampled from . Quaternions are sampled by sampling random unit vectors along with a random angle in . This angle-axis rotation is transformed into a quaternion.
Both models are tested by sampling a random starting location and asking the quadrotor to land at the origin. The controller used for landing is an MPC controller that repeatedly solves the following problem
| (42) | ||||
where is the position of the quadrotor, is the height of the center of mass, and is the real component of the quaternion at the last time step. This problem encourages reaching a target, subject to control and dynamics constraint. It also has a constraint on the height of the quadrotor so it is always above a certain small altitude, and an orientation constraint on the last time step so it is mostly upright when it lands.
VI-C3 Results
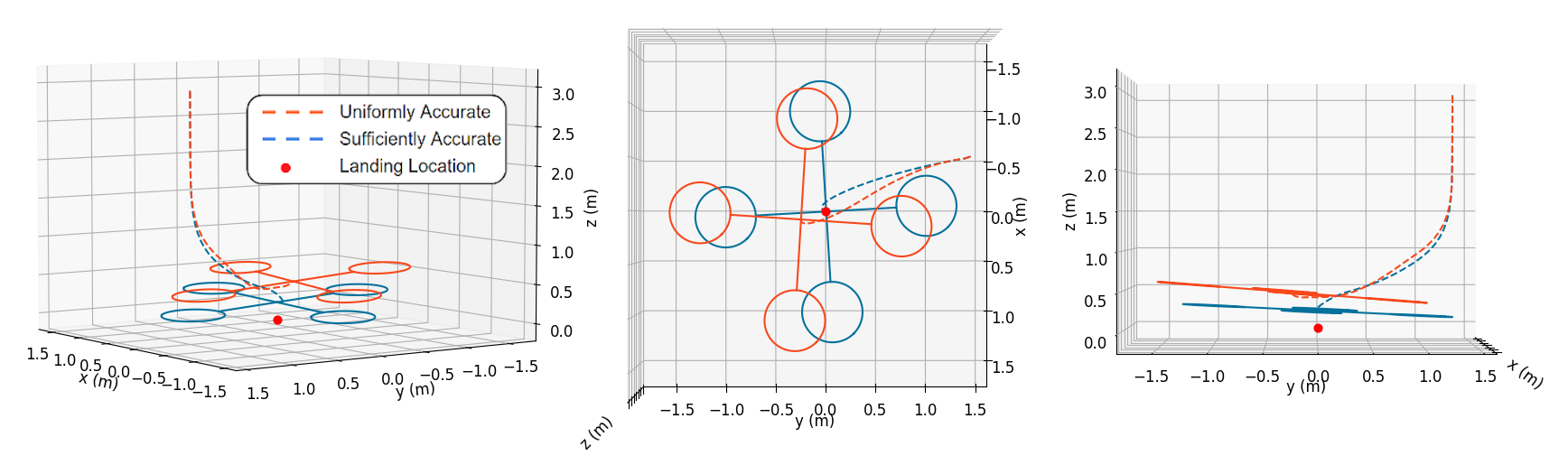
The results of running this controller over several different starting locations is shown in Table IV. Similar to previous experiments, the Sufficiently Accurate model has a higher loss overall, but better accuracy in the constrained area which is more important to the task. This allows the controller to utilize the higher accuracy to land the quadrotor precisely. An example of one of the landing trajectories is shown in Figure 9. It can be seen that the Sufficiently Accurate model can more precisely land at the origin . It also is able to reach the ground faster, as it can more accurately compensate for the extra force caused by the ground surface. The ground effect can also disturb roll and pitch maneuvers which can offset the center of mass as well.
| Sufficiently Accurate | Uniformly Accurate | |
| MPC cost | ||
VII Conclusion
This paper presents Sufficiently Accurate model learning as a way to incorporate prior information about a system in the form of constraints. In addition, it proves that this constrained learning formulation can have arbitrarily small duality gap. This means that existing methods like primal-dual algorithms can find decent solutions to the problem.
With good constraints, the model and learning method can focus on important aspects of the problem to improve the performance of the system even if the overall accuracy of the model is lower. These constraints can come from robust control formulations or from knowledge of sensor noise. Some important questions to consider when using this method is how to choose good constraints. For some systems and tasks, it can be simple while for others, it can be quite difficult. This objective is not useful for all tasks and systems but rather for a subset of tasks and systems where prior knowledge is more easily expressed as a constraint.
Acknowledgements
This material is based upon work supported by the National Science Foundation Graduate Research Fellowship Program under Grant No. DGE-1321851. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Appendix A Expectation-wise Lipschitz-Continuity of Loss functions
A-A
The loss function is expectation-wise Lipschitz-continuous in .
Using the reverse triangle inequality, we get
| (43) | ||||
By, the equivalence of norms, there exists such that , for all . Thus,
| (44) |
Since this is true for any , it is also true in expectation.
| (45) |
A-B
The loss function is also expectation-wise Lipschitz-continuous in . Following the same logic as for the euclidean norm, we get
| (46) |
This reduces to
| (47) |
when considering the case where . The largest that can be is over the smallest value of . If , both sides reduce to 0, as the indicator variable is 0. This leads to
| (48) | ||||
Appendix B Equivalent Problem Formulation
Using the notation in this paper, the problem defined in [30] is
| (49) | ||||
where , and are concave functions. is not necessarily convex with respect to . is a convex set and is compact. Note that , , , , and are not directly present in the Sufficiently Accurate problem.
To translate the problem, let us assume that is dimensional, where is the number of constraints in (4). Let the last element of be equal to , the negative of the objective function in the Sufficiently Accurate problem. Let the first element of be equal to , the negative of a constraint function in (4). Set the objective function to be , where is the element of . can be ignored by setting it to be the zero function. Under these assumptions, (49) is equivalent to the following
| (50) | ||||
Now, define the set , where is an arbitrary compact set in one dimension. This set of vectors, , is a set that is 0 in the first components, and is compact in the last component. This, will further simplify (50) to the following
| (51) | ||||
as long as takes on values in a compact set. Finally, flipping all the negatives in (51),
| (52) | ||||
Appendix C Proof of Theorem 3
This proof follows some of the steps of the proof for [31, Theorem 1]. Let be the primal and dual variables that attains the solution value of in problems (4) and (23). Similarly, let be the primal and dual variables that attain the solution value in problem (19). is the function that induces. Note that the optimal dual variables for (23), , are not necessarily the same as the optimal dual variables for (19), .
C-A Lower Bound
We first show the lower bound for . Writing out the dual problem (23), we obtain
| (53) |
Since is the optimal dual variable that achieves the maximal value for the maximization and minimization for the Lagrangian, it is true that
| (54) |
Thus for any ,
| (55) |
We now look at the parameterized dual problem (19).
| (56) |
This simply redefines in terms of as the only difference is that is only defined for a subset of the primal variables that is defined for. By definition, maximizes the minimization of over . That is to say for the dual solution , minimizes
| (57) | ||||
Thus, for all , it is the case that
| (58) |
Putting together (55) and (58), we obtain
| (59) |
C-B Upper Bound
Next, we show the upper bound for . We begin by writing the Lagrangian (18)
| (60) |
as previously written in (56). By adding and subtracting , we obtain
| (61) | ||||
where the last line comes from the fact that the absolute value of an expression is always at least as large as the original expression, i.e. . Looking just at the quantity , we can expand it as
| (62) | ||||
Using the triangle inequality, this is upper bounded as
| (63) | ||||
Using Hölder’s inequality, we can create a further upper bound
| (64) | ||||
where the infinity norm of the scalar value is the same as its absolute value. Using the fact that the infinity norm is convex and Jensen’s inequality, we can move the norm inside of the expectation.
| (65) | ||||
By expectation-wise Lipschitz-continuity of both the loss and constraint functions,
| (66) | ||||
Combining (61) with (66), we obtain
| (67) |
Since, is an -universal approximation for , we can write . This further reduces (67) to
| (68) |
Note that (68) is true for all . In particular it must be also true for the that minimizes the inner value, i.e.
| (69) | ||||
The second half of (69) is actually the solution to the dual problem (14). The primal problem is reproduced here for reference,
That is to say, . The primal problem (13) is a perturbed version of (4), where all the constraints are tighter by . There exists a relationship between the solution of (13) and (4) from [25, Eq. 5.57]. Treating (4) as the perturbed version of (13) (that tightens the constraints by ), the relationship between the two solutions is
| (70) |
Since both (4) and (13) have zero duality gap by Theorem 2, this is the same as
| (71) |
Combining (71) with the fact that , the following bound is obtained.
| (72) |
This gives us the desired upper bound.
Appendix D Proof of Lemma 1
We start by establishing an upper bound on the difference . By definition of the Dual Problems (19) and (10), it follows that and . Hence we have that
| (73) |
where the inequality follows from the fact that maximizes the function . Thus, any other , in particular results in a value that is less than or equal to . Let . Substituting by this definition and using the definition of minimum, (73) can be further upper bounded by
| (74) |
We set now to establish a similar lower bound. Analogous to the step for the upper bound, we can use the definition of the Dual problem to lower bound
References
- [1] M. Morari and J. H. Lee, “Model predictive control: past, present and future,” Computers & Chemical Engineering, vol. 23, no. 4-5, pp. 667–682, 1999.
- [2] K. J. Åström and R. M. Murray, Feedback systems: an introduction for scientists and engineers. Princeton university press, 2010.
- [3] G. Hoffmann, S. Waslander, and C. Tomlin, “Quadrotor helicopter trajectory tracking control,” in AIAA guidance, navigation and control conference and exhibit, p. 7410.
- [4] D. Mellinger and V. Kumar, “Minimum snap trajectory generation and control for quadrotors,” in 2011 IEEE International Conference on Robotics and Automation, 2011, pp. 2520–2525.
- [5] J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” in International conference on machine learning, 2015, pp. 1889–1897.
- [6] A. Khan, V. Kumar, and A. Ribeiro, “Learning sample-efficient target reaching for mobile robots,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3080–3087.
- [7] S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,” in 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 3389–3396.
- [8] I. R. Petersen, V. A. Ugrinovskii, and A. V. Savkin, Robust Control Design Using H-infinity Methods. Springer Science & Business Media, 2012.
- [9] S. J. Qin, “An overview of subspace identification,” Computers & chemical engineering, vol. 30, no. 10-12, pp. 1502–1513, 2006.
- [10] M. Viberg, “Subspace-based methods for the identification of linear time-invariant systems,” Automatica, vol. 31, no. 12, pp. 1835–1851, 1995.
- [11] G. Pillonetto and G. De Nicolao, “A new kernel-based approach for linear system identification,” Automatica, vol. 46, no. 1, pp. 81–93, 2010.
- [12] J. Bruls, C. T. Chou, B. Haverkamp, and M. Verhaegen, “Linear and non-linear system identification using separable least-squares.”
- [13] L. Ljung, “System identification,” Wiley encyclopedia of electrical and electronics engineering, pp. 1–19, 1999.
- [14] R. Pasquier and I. F. Smith, “Robust system identification and model predictions in the presence of systematic uncertainty,” Advanced Engineering Informatics, vol. 29, no. 4, pp. 1096–1109, 2015.
- [15] S. Ozer and H. Zorlu, “Identification of bilinear systems using differential evolution algorithm,” Sadhana, vol. 36, no. 3, pp. 281–292, 2011.
- [16] S. A. Billings, “Identification of nonlinear systems–a survey,” in IEE Proceedings D (Control Theory and Applications), vol. 127, no. 6. IET, 1980, pp. 272–285.
- [17] M. Schoukens and K. Tiels, “Identification of block-oriented nonlinear systems starting from linear approximations: A survey,” Automatica, vol. 85, pp. 272–292, 2017.
- [18] M. Deisenroth and C. E. Rasmussen, “Pilco: A model-based and data-efficient approach to policy search,” in Proceedings of the 28th International Conference on machine learning (ICML-11), 2011, pp. 465–472.
- [19] D. Nguyen-Tuong, J. R. Peters, and M. Seeger, “Local gaussian process regression for real time online model learning,” in Advances in neural information processing systems, 2009, pp. 1193–1200.
- [20] S. Levine and V. Koltun, “Guided policy search,” in International Conference on Machine Learning, 2013, pp. 1–9.
- [21] A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine, “Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 7559–7566.
- [22] C. Zhang, A. Khan, S. Paternain, and A. Ribeiro, “Learning sufficiently accurate models,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
- [23] P. Sanchez-Cuevas, G. Heredia, and A. Ollero, “Characterization of the aerodynamic ground effect and its influence in multirotor control,” International Journal of Aerospace Engineering, vol. 2017, 2017.
- [24] K. Hornik, M. Stinchcombe, H. White et al., “Multilayer feedforward networks are universal approximators.”
- [25] S. Boyd, S. P. Boyd, and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [26] B. Sriperumbudur, K. Fukumizu, and G. Lanckriet, “On the relation between universality, characteristic kernels and rkhs embedding of measures,” in Proceedings of the thirteenth international conference on artificial intelligence and statistics, 2010, pp. 773–780.
- [27] A. Nedić and A. Ozdaglar, “Subgradient methods for saddle-point problems,” Journal of optimization theory and applications, vol. 142, no. 1, pp. 205–228, 2009.
- [28] V. N. Vapnik, “An overview of statistical learning theory,” IEEE transactions on neural networks, vol. 10, no. 5, pp. 988–999, 1999.
- [29] P. L. Bartlett, D. J. Foster, and M. J. Telgarsky, “Spectrally-normalized margin bounds for neural networks,” in Advances in Neural Information Processing Systems, 2017, pp. 6240–6249.
- [30] A. Ribeiro, “Optimal resource allocation in wireless communication and networking,” EURASIP Journal on Wireless Communications and Networking, vol. 2012, no. 1, p. 272, 2012.
- [31] M. Eisen, C. Zhang, L. F. Chamon, D. D. Lee, and A. Ribeiro, “Learning optimal resource allocations in wireless systems,” arXiv preprint arXiv:1807.08088, 2018.
- [32] T. Goldstein, B. O’Donoghue, S. Setzer, and R. Baraniuk, “Fast alternating direction optimization methods,” SIAM Journal on Imaging Sciences, vol. 7, no. 3, pp. 1588–1623, 2014.
- [33] D. M. Gay, M. L. Overton, and M. H. Wright, “A primal-dual interior method for nonconvex nonlinear programming,” in Advances in nonlinear programming. Springer, 1998, pp. 31–56.
- [34] P. E. Gill and D. P. Robinson, “A primal-dual augmented lagrangian,” Computational Optimization and Applications, vol. 51, no. 1, pp. 1–25, 2012.
- [35] I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” in International conference on machine learning, 2013, pp. 1139–1147.
- [36] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [37] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034.
- [38] D. H. Kraft, “A software package for sequential quadratic programming,” 1988.
- [39] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 5026–5033.
- [40] Y. Tassa, Y. Doron, A. Muldal, T. Erez, Y. Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq et al., “Deepmind control suite,” arXiv preprint arXiv:1801.00690, 2018.