Superpolynomial Lower Bounds for Learning One-Layer Neural Networks using Gradient Descent
Abstract
We prove the first superpolynomial lower bounds for learning one-layer neural networks with respect to the Gaussian distribution using gradient descent. We show that any classifier trained using gradient descent with respect to square-loss will fail to achieve small test error in polynomial time given access to samples labeled by a one-layer neural network. For classification, we give a stronger result, namely that any statistical query (SQ) algorithm (including gradient descent) will fail to achieve small test error in polynomial time. Prior work held only for gradient descent run with small batch sizes, required sharp activations, and applied to specific classes of queries. Our lower bounds hold for broad classes of activations including ReLU and sigmoid. The core of our result relies on a novel construction of a simple family of neural networks that are exactly orthogonal with respect to all spherically symmetric distributions.
1 Introduction
A major challenge in the theory of deep learning is to understand when gradient descent can efficiently learn simple families of neural networks. The associated optimization problem is nonconvex and well known to be computationally intractable in the worst case. For example, cyphertexts from public-key cryptosystems can be encoded into a training set labeled by simple neural networks [KS09], implying that the corresponding learning problem is as hard as breaking cryptographic primitives. These hardness results, however, rely on discrete representations and produce relatively unrealistic joint distributions.
Our Results.
In this paper we give the first superpolynomial lower bounds for learning neural networks using gradient descent in arguably the simplest possible setting: we assume the marginal distribution is a spherical Gaussian, the labels are noiseless and are exactly equal to the output of a one-layer neural network (a linear combination of say ReLU or sigmoid activations), and the goal is to output a classifier whose test error (measured by square-loss) is small. We prove—unconditionally—that gradient descent fails to produce a classifier with small square-loss if it is required to run in polynomial time in the dimension. Our lower bound depends only on the algorithm used (gradient descent) and not on the architecture of the underlying classifier. That is, our results imply that current popular heuristics such as running gradient descent on an overparameterized network (for example, working in the NTK regime [JHG18]) will require superpolynomial time to achieve small test error.
Statistical Queries.
We prove our lower bounds in the now well-studied statistical query (SQ) model of [Kea98] that captures most learning algorithms used in practice. For a loss function and a hypothesis parameterized by , the true population loss with respect to joint distribution on is given by , and the gradient with respect to is given by . In the SQ model, we specify a query function and receive an estimate of to within some tolerance parameter . An important special class of queries are correlational or inner-product queries, where the query function is defined only on and we receive an estimate of within some tolerance . It is not difficult to see that (1) the gradient of a population loss can be approximated to within using statistical queries of tolerance and (2) for square-loss only inner-product queries are required.
Since the convergence analysis of gradient descent holds given sufficiently strong approximations of the gradient, lower bounds for learning in the SQ model [Kea98, BFJ+94, Szö09, Fel12, Fel17] directly imply unconditional lower bounds on the running time for gradient descent to achieve small error. We give the first superpolynomial lower bounds for learning one-layer networks with respect to any Gaussian distribution for any SQ algorithm that uses inner product queries:
Theorem 1.1 (informal).
Let be a class of real-valued concepts defined by one-layer single-output neural networks with input dimension and hidden units (ReLU or sigmoid); i.e., functions of the form . Then learning under the standard Gaussian in the SQ model with inner-product queries requires queries for any tolerance .
In particular, this rules out any approach for learning one-layer neural networks in polynomial-time that performs gradient descent on any polynomial-size classifier with respect to square-loss or logistic loss. For classification, we obtain significantly stronger results and rule out general SQ algorithms that run in polynomial-time (e.g., gradient descent with respect to any polynomial-size classifier and any polynomial-time computable loss). In this setting, our labels are and correspond to the softmax of an unknown one-layer neural network. We prove the following:
Theorem 1.2 (informal).
Let be a class of real-valued concepts defined by a one-layer neural network in dimensions with hidden units (ReLU or sigmoid) feeding into any odd, real-valued output node with range . Let be a distribution on such that the marginal on is the standard Gaussian , and for some . For some and , outputting a classifier with requires statistical queries of tolerance
The above lower bound for classification rules out the commonly used approach of training a polynomial-size, real-valued neural network using gradient descent (with respect to any polynomial-time computable loss) and then taking the sign of the output of the resulting network.
Our techniques.
At the core of all SQ lower bounds is the construction of a family of functions that are pairwise approximately orthogonal with respect to the underlying marginal distribution. Typically, these constructions embed parity functions over the discrete hypercube . Since parity functions are perfectly orthogonal, the resulting lower bound can be quite strong. Here we wish to give lower bounds for more natural families of distributions, namely Gaussians, and it is unclear how to embed parity.
Instead, we use an alternate construction. For activation functions , define
Enumerating over every of size gives a family of functions of size . Here denotes the vector of for (typically we choose to produce a family of one-layer neural networks with hidden units). Each of the inner weight vectors are all of unit norm, and all of the outer weights have absolute value one. Note also that our construction uses activations with zero bias term.
We give a complete characterization of the class of nonlinear activations for which these functions are orthogonal. In particular, the family is orthogonal for any activation with a nonzero Hermite coefficient of degree or higher.
Apart from showing orthogonality, we must also prove that functions in these classes are nontrivial (i.e., are not exponentially close to the constant zero function). This reduces to proving certain lower bounds on the norms of one-layer neural networks. The analysis requires tools from Hermite and complex analysis.
SQ Lower Bounds for Real-Valued Functions.
Another major challenge is that our function family is real-valued as opposed to boolean. Given an orthogonal family of (deterministic) boolean functions, it is straightforward to apply known results and obtain general SQ lower bounds for learning with respect to loss. For the case of real-valued functions, the situation is considerably more complicated. For example, the class of orthogonal Hermite polynomials on variables of degree has size , yet there is an SQ algorithm due to [APVZ14] that learns this class with respect to the Gaussian distribution in time . More recent work due to [ADHV19] shows that Hermite polynomials can be learned by an SQ algorithm in time polynomial in and .
As such, it is impossible to rule out general polynomial-time SQ algorithms for learning real-valued functions based solely on orthogonal function families. Fortunately, it is not difficult to see that the SQ reductions due to [Szö09] hold in the real-valued setting as long as the learning algorithm uses only inner-product queries (and the norms of the functions are sufficiently large). Since performing gradient descent with respect to square-loss or logistic loss can be implemented using inner-product queries, we obtain our first set of desired results111The algorithms of [APVZ14] and [ADHV19] do not use inner-product queries..
Still, we would like rule out general SQ algorithms for learning simple classes of neural networks. To that end, we consider the classification problem for one-layer neural networks and output labels after performing a softmax on a one-layer network. Concretely, consider a distribution on where for some and (for example, could be tanh). We describe two goals. The first is to estimate the conditional mean function, i.e., output a classifier such that . The second is to directly minimize classification loss, i.e., output a boolean classifier such that
We give superpolynomial lower bounds for both of these problems in the general SQ model by making a new connection to probabilistic concepts, a learning model due to [KS94]. Our key theorem gives a superpolynomial SQ lower bound for the problem of distinguishing probabilistic concepts induced by our one-layer neural networks from truly random labels. A final complication we overcome is that we must prove orthogonality and norm bounds on one-layer neural networks that have been composed with a nonlinear activation (e.g., tanh).
SGD and Gradient Descent Plus Noise.
It is easy to see that our results also imply lower bounds for algorithms where the learner adds noise to the estimate of the gradient (e.g., Langevin dynamics). On the other hand, for technical reasons, it is known that SGD is not a statistical query algorithm (because it examines training points individually) and does not fall into our framework. That said, recent work by [AS20] shows that SGD is universal in the sense that it can encode all polynomial-time learners. This implies that proving unconditional lower bounds for SGD would give a proof that . Thus, we cannot hope to prove unconditional lower bounds on SGD (unless we can prove ).
Independent Work.
Independently, Diakonikolas et al. [DKKZ20] have given stronger correlational SQ lower bounds for the same class of functions with respect to the Gaussian distribution. Their bounds are exponential in the number of hidden units while ours is quasipolynomial. We can plug in their result and obtain exponential general SQ lower bounds for the associated probabilistic concept using our framework.
Related Work.
There is a large literature of results proving hardness results (or unconditional lower bounds in some cases) for learning various classes of neural networks [BR89, Vu98, KS09, LSSS14, GKKT17].
The most relevant prior work is due to [SVWX17], who addressed learning one-layer neural networks under logconcave distributions using Lipschitz queries. Specifically, let be the input dimension, and let be the number of hidden -Lipschitz sigmoid units. For , they construct a family of neural networks such that any learner using -Lipschitz queries with tolerance greater than needs at least queries.
Roughly speaking, their lower bounds hold for -Lipschitz queries due to the composition of their one-layer neural networks with a -function in order make the family more “boolean.” Because of their restriction on the tolerance parameter, they cannot rule out gradient descent with large batch sizes. Further, the slope of the activations they require in their constructions scales inversely with the Lipschitz and tolerance parameters.
To contrast with [SVWX17], note that our lower bounds hold for any inverse-polynomial tolerance parameter (i.e., will hold for polynomially-large batch sizes), do not require a Lipschitz constraint on the queries, and use only standard -Lipschitz ReLU and/or sigmoid activations (with zero bias) for the construction of the hard family. Our lower bounds are typically quasipolynomial in the number of hidden units; improving this to an exponential lower bound is an interesting open question. Both of our models capture square-loss and logistic loss.
In terms of techniques, [SVWX17] build an orthogonal function family using univariate, periodic “wave” functions. Our construction takes a different approach, adding and subtracting activation functions with respect to overlapping “masks.” Finally, aside from the (black-box) use of a theorem from complex analysis, our construction and analysis are considerably simpler than the proof in [SVWX17].
A follow-up work [VW19] gave SQ lower bounds for learning classes of degree orthogonal polynomials in variables with respect to the uniform distribution on the unit sphere (as opposed to Gaussians) using inner product queries of bounded tolerance (roughly ). To obtain superpolynomial lower bounds, each function in the family requires superpolynomial description length (their polynomials also take on very small values, , with high probability).
Shamir [Sha18] (see also the related work of [SSSS17]) proves hardness results (and lower bounds) for learning neural networks using gradient descent with respect to square-loss. His results are separated into two categories: (1) hardness for learning “natural” target families (one layer ReLU networks) or (2) lower bounds for “natural” input distributions (Gaussians). We achieve lower bounds for learning problems with both natural target families and natural input distributions. Additionally, our lower bounds hold for any nonlinear activations (as opposed to just ReLUs) and for broader classes of algorithms (SQ).
Recent work due to [GKK19] gives hardness results for learning a ReLU with respect to Gaussian distributions. Their results require the learner to output a single ReLU as its output hypothesis and require the learner to succeed in the agnostic model of learning. [KK14] prove hardness results for learning a threshold function with respect to Gaussian distributions, but they also require the learner to succeed in the agnostic model.
Very recent work due to Daniely and Vardi [DV20] gives hardness results for learning randomly chosen two-layer networks. The hard distributions in their case are not Gaussians, and they require a nonlinear clipping output activation.
Positive Results. Many recent works give algorithms for learning one-layer ReLU networks using gradient descent with respect to Gaussians under various assumptions [ZSJ+17, ZPS17, BG17, ZYWG19] or use tensor methods [JSA15, GLM18]. These results depend on the hidden weight vectors being sufficiently orthogonal, or the coefficients in the second layer being positive, or both. Our lower bounds explain why these types of assumptions are necessary.
2 Preliminaries
We use to denote the set , and to indicate that is a -element subset of . We denote euclidean inner products between vectors and by . We denote the element-wise product of vectors and by , that is, is the vector .
Let be an arbitrary domain, and let be a distribution on . Given two functions , we define their inner product with respect to to be . The corresponding norm is given by .
A real-valued concept on is a function . We denote the induced labeled distribution on , i.e. the distribution of for , by . A probabilistic concept, or -concept, on is a concept that maps each point to a random -valued label in such a way that for a fixed function , known as the conditional mean function. Given a distribution on the domain, we abuse to denote the induced labeled distribution on such that the marginal distribution on is and (equivalently the label is with probability and otherwise).
The SQ model
A statistical query is specified by a query function . The SQ model allows access to an SQ oracle that accepts a query of specified tolerance , and responds with a value in .222In the SQ literature, this is referred to as the STAT oracle. A variant called VSTAT is also sometimes used, known to be equivalent up to small polynomial factors [Fel17]. While it makes no substantive difference to our superpolynomial lower bounds, our arguments can be extended to VSTAT as well. To disallow arbitrary scaling, we will require that for each , the function has norm at most 1. In the real-valued setting, a query is called a correlational or inner product query if it is of the form for some function , so that . Here we assume when stating lower bounds, again to disallow arbitrary scaling.
Gradient descent with respect to squared loss is captured by inner product queries, since the gradient is given by
Here the first term can be estimated directly using knowledge of the distribution, while the latter is a vector each of whose elements is an inner product query.
We now formally define the learning problems we consider.
Definition 2.1 (SQ learning of real-valued concepts using inner product queries).
Let be a class of -concepts over a domain , and let be a distribution on . We say that a learner learns with respect to up to error using inner product quiers (equivalently squared loss ) if, given only SQ oracle access to for some unknown , and using only inner product queries, it is able to output such that .
For the classification setting, we consider two different notions of learning -concepts. One is learning the target up to small error, to be thought of as a strong form of learning. The other, weaker form, is achieving a nontrivial inner product (i.e. unnormalized correlation) with the target. We prove lower bounds on both in order to capture different learning goals.
Definition 2.2 (SQ learning of -concepts).
Let be a class of -concepts over a domain , and let be a distribution on . We say that a learner learns with respect to up to error if, given only SQ oracle access to for some unknown , and using arbitrary queries, it is able to output such that . We say that a learner weakly learns with respect to with advantage if it is able to output such that .
Note that the best achievable advantage is , achieved by . Note also that , and therefore a norm lower bound on functions in implies an upper bound on the achievable advantage.
Remark 2.3 (Learning with error implies weak learning).
If the functions in our class satisfy a norm lower bound, say , then a simple calculation shows that learning with error implies weak learning with advantage .
Our definition of weak learning also captures the standard boolean sense of weak learning, in which the learner is required to output a boolean hypothesis with 0/1 loss bounded away from . Indeed, by an easy calculation, the 0/1 loss of a function satisfies
The difficulty of learning a concept class in the SQ model is captured by a parameter known as the statistical dimension of the class.
Definition 2.4 (Statistical dimension).
Let be a concept class of either real-valued concepts or -concepts (i.e. their corresponding conditional mean functions) on a domain , and let be a distribution on . The (un-normalized) correlation of two concepts under is .333In the -concept setting, it is instructive to note that in the notation of [FGR+17], this correlation is precisely the distributional correlation of the induced labeled distributions and under the reference distribution . The average correlation of is defined to be
The statistical dimension on average at threshold , , is the largest such that for all with , .
Remark 2.5.
For any general and large concept class (such as all one-layer neural nets), we may consider a specific subclass and prove lower bounds on learning in terms of the SDA of . These lower bounds extend to because if it is hard to learn a subset, then it is hard to learn the whole class.
We will mainly be interested in the statistical dimension in a setting where bounds on pairwise correlations are known. In that case the following lemma holds.
Lemma 2.6 (adapted from [FGR+17], Lemma 3.10).
Suppose a concept class has pairwise correlation , i.e. for , and squared norm at most , i.e. for all . Then for any , . In particular, if is a class of orthogonal concepts (i.e. ) with squared norm bounded by , then .
Proof.
Let , and observe that for any subset satisfying ,
∎
3 Orthogonal Family of Neural Networks
We consider neural networks with one hidden layer with activation function , and with one output node that has some activation function . If we take the input dimension to be and the number of hidden nodes to be , then such a neural network is a function given by
where are the weights feeding into the hidden node, and are the weights feeding into the output node. If takes values in , we may also view as defining a -concept in terms of its conditional mean function.
For our construction, we need our functions to be orthogonal, and we need a lower bound on their norms. For the first property we only need the distribution on the domain to satisfy a relaxed kind of spherical symmetry that we term sign-symmetry, which says that the distribution must look identical on all orthants. To lower bound the norms, we need to assume that the distribution is Gaussian .
Assumption 3.1 (Sign-symmetry).
For any and , let denote . A distribution on is sign-symmetric if for any and drawn from , and have the same distribution .
Assumption 3.2 (Odd outer activation).
The outer activation is an odd, increasing function, i.e. .
Note that could be the identity function.
Assumption 3.3 (Inner activation).
The inner activation .
The construction of our orthogonal family of neural networks is simple and exploits sign-symmetry.
Definition 3.4 (Family of Orthogonal Neural Networks).
Let the domain be , let be any well-behaved activation function, and let be any odd function. For an index set , let denote the vector of for . Fix any . For any sign-pattern , let denote the parity . For any index set , define a one-layer neural network with hidden nodes,
Our orthogonal family is
Notice that the size of this family is (for appropriate ), which is in terms of . We will take , so that and thus the neural networks are -sized, and the size of the family is , i.e. quasipolynomial in .
We now prove that our functions are orthogonal under any sign-symmetric distribution.
Theorem 3.5.
Let the domain be , and let be a sign-symmetric distribution on . Fix any . Then for any two distinct .
Proof.
For the proof, the key property of our construction that we will use is the following: for any sign-pattern and any ,
| (1) |
where is the parity on of . Indeed, observe first that
| (replacing with ) | ||||
The property then follows since is odd and for any and .
Remark 3.6.
Our proof actually shows that any family of functions satisfying Eq. 1 is an orthogonal family under any sign-symmetric distribution.
We still need to establish that our functions are nonzero. For this we need to specialize to the Gaussian distribution, as well as consider specific activation functions (a similar analysis can in principle be carried out for other sign-symmetric distributions). For any and , it follows from Lemma A.1 that if the inner activation has a nonzero Hermite coefficient of degree or higher, then the functions in are nonzero. The sigmoid, ReLU and sign functions all satisfy this property.
Corollary 3.7.
Let the domain be , and let be any sign-symmetric distribution on . For any ,
Here we also assume that all are nonzero for our distribution .
Proof.
Follows from Theorem 3.5 and Lemma 2.6, using a loose upper bound of 1 on the squared norm. ∎
We also need to prove norm lower bounds on our functions for our notions of learning to be meaningful. In Appendix A, we prove the following.
Theorem 3.8.
Let the inner activation function be or sigmoid, and let the outer activation function be any odd, increasing, continuous function. Let the underlying distribution be . Then , where the hidden constants depend on and , for any .
With this in hand, we now state our main SQ lower bounds.
Theorem 3.9.
Let the input dimension be , and let the underlying distribution be . Consider instantiated with or sigmoid and any odd, increasing function (including the identity function), and let be the hidden layer size of each neural net. Let be an SQ learner using only inner product queries of tolerance . For any , there exists such that requires at least queries of tolerance to learn with advantage .
In particular, there exist and such that requires at least queries of tolerance to learn with advantage . In this case , so that each function in the family has polynomial size. This is our main superpolynomial lower bound.
Proof.
The proof amounts to careful choices of the parameters and in Corollary 3.7 and Corollary 4.6. Recall that . We pick appropriately such that is still . Theorem 3.8 gives us a norm lower bound of , allowing us to take and in Corollary 4.6. ∎
4 SQ Lower Bounds
SQ Lower Bounds for Real-valued Functions
Prior work [Szö09, Fel12] has already established the following fundamental result, which we phrase in terms of our definition of statistical dimension. For the reader’s convenience, we include a proof in Appendix B.
Theorem 4.1.
Let be a distribution on , and let be a real-valued concept class over a domain such that for all . Consider any SQ learner that is allowed to make only inner product queries to an SQ oracle for the labeled distribution for some unknown . Let . Then any such SQ learner needs at least queries of tolerance to learn up to error .
SQ Lower Bounds for p-concepts
It turns out to be fruitful to view our learning problem in terms of a decision problem over distributions. We define the problem of distinguishing a valid labeled distribution from a randomly labeled one, and show a lower bound for this problem. We then show that learning is at least as hard as distinguishing, thereby extending the lower bound to learning as well. Our analysis closely follows that of [FGR+17].
Definition 4.2 (Distinguishing between labeled and uniformly random distributions).
Let be a class of -concepts over a domain , and let be a distribution on . Let be the randomly labeled distribution . Suppose we are given SQ access either to a labeled distribution for some such that or to . The problem of distinguishing between labeled and uniformly random distributions is to decide which.
Remark 4.3.
Given access to for some truly boolean concept , it is easy to distinguish any other boolean function from since (which is information-theoretically optimal as a distinguishing criterion) can be computed using a single inner product query. However, if and are -concepts, and are not 1 in general and may be difficult to estimate. It is not obvious how best to distinguish the two, short of directly learning the target.
Considering the distinguishing problem is useful because if we can show that distinguishing itself is hard, then any reasonable notion of learning will be hard as well, including weak learning. We give simple reductions for both our notions of learning.
Lemma 4.4 (Learning is as hard as distinguishing).
Let be a distribution over the domain , and let be a -concept class over . Suppose there exists either
(a) a weak SQ learner capable of learning up to advantage using queries of tolerance , where ; or,
(b) an SQ learner capable of learning (assume for all ) up to error using queries of tolerance , where . Then there exists a distinguisher that is able to distinguish between an unknown and using at most queries of tolerance .
Proof.
(a) Run the weak learner to obtain . If , we know that , whereas if , then no matter what is. A single additional query () of tolerance distinguishes between the two cases.
(b) Run the learner to obtain . If , i.e. , we know that , so that by the triangle inequality, . But if , then . An additional query () of tolerance suffices to distinguish the two cases. ∎
We now prove the main lower bound on distinguishing.
Theorem 4.5.
Let be a distribution over the domain , and let be a -concept class over . Then any SQ algorithm needs at least queries of tolerance to distinguish between and for an unknown . (We will consider deterministic SQ algorithms that always succeed, for simplicity.)
Proof.
Consider any successful SQ algorithm . Consider the adversarial strategy where to every query of (with tolerance ), we respond with . We can pretend that this is a valid answer with respect to any such that . Our argument will be based on showing that each such query rules out fairly few distributions, so that the number of queries required in total is large.
Since we assumed that is a deterministic algorithm that always succeeds, it eventually correctly guesses that it is that it is getting answers from. Say it takes queries to do so. For the query , let be the set of concepts in that are ruled out by our response :
We’ll show that
(a) on the one hand, , so that ,
(b) while on the other, for every . Together, this will mean that .
For the first claim, suppose were not all of , and indeed say . This is a distribution that our answers were consistent with throughout, yet one that ’s solution () is incorrect for. But always succeeds, so for it not to have ruled out this is impossible.
For the second claim, suppose for the sake of contradiction that for some , . By Definition 2.4, this means we know that . One of the key insights in the proof of [Szö09] is that by expressing query expectations entirely in terms of inner products, we gain the ability to apply simple algebraic techniques. To this end, for any query function , let . Observe that for any -concept ,
the difference between the query expectations wrt and . Here we have expanded each using the fact that the label for is with probability and otherwise. Thus , where is the query, is greater than for any , since are precisely those concepts ruled out by our response. We will show contradictory upper and lower bounds on the following quantity:
Note that since every query satisfies for all , it follows by the triangle inequality that . So by Cauchy-Schwarz and our observation that ,
However since , we also have that Since , this contradicts our upper bound and in turn completes the proof of our second claim. And as noted earlier, the two claims together imply that . ∎
The final lower bounds on learning thus obtained are stated as a corollary for convenience. The proof follows directly from Lemma 4.4 and Theorem 4.5.
Corollary 4.6.
Let be a distribution over the domain , and let be a -concept class over . Let be such that . Let .
(a) Let be such that , and assume for all . Then any SQ learner learning up to error requires at least queries of tolerance .
(b) Let be such that . Then any weak SQ learner learning up to advantage requires at least queries of tolerance .
5 Experiments
We include experiments for both regression and classification. We train an overparameterized neural network on data from our function class, using gradient descent. We find that we are able to achieve close to zero training error, while test error remains high. This is consistent with our lower bound for these classes of functions.
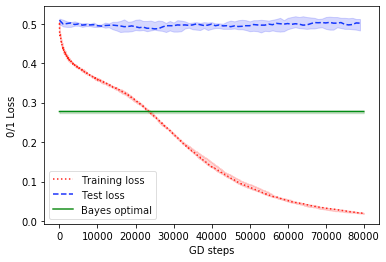
For classification, we use a training set of size of data corresponding to instantiated with and . We draw . For each , is picked randomly from in such a way that . Since the outer activation is , this can be thought of as applying a softmax to the network’s output, or as the Boolean label corresponding to a logit output. We train a sum of tanh network (i.e. a network in which the inner activation is and no outer activation is applied) on this data using gradient descent on squared loss, threshold the output, and plot the resulting 0/1 loss. See Fig. 1(a). This setup models a common way in which neural networks are trained for classification problems in practice.
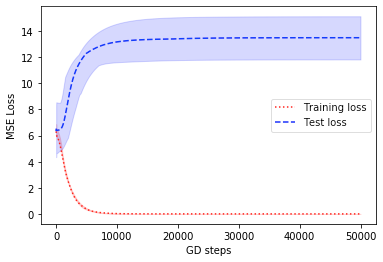
For regression, we use a training set of size of data corresponding to instantiated with and being the identity. We draw , and . We train a sum of tanh network on this data using gradient descent on squared loss, which we plot in Fig. 1(b). This setup models the natural way of using neural networks for regression problems.
In both cases, we train neural networks whose number of parameters considerably exceeds the amount of training data. In all our experiments, we plot the median over 10 trials and shade the inter-quartile range of the data.
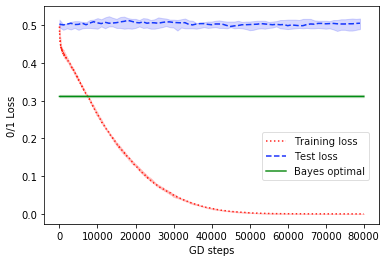
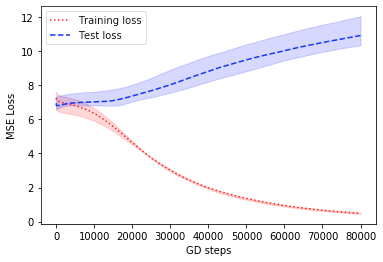
Similar results hold with the inner activation being instead of , and are shown in Fig. 2.
References
- [ADHV19] Alexandr Andoni, Rishabh Dudeja, Daniel Hsu, and Kiran Vodrahalli. Attribute-efficient learning of monomials over highly-correlated variables. In Thirtieth International Conference on Algorithmic Learning Theory, 2019.
- [APVZ14] Alexandr Andoni, Rina Panigrahy, Gregory Valiant, and Li Zhang. Learning sparse polynomial functions. In Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms, pages 500–510. SIAM, 2014.
- [AS20] Emmanuel Abbe and Colin Sandon. Poly-time universality and limitations of deep learning. arXiv preprint arXiv:2001.02992, 2020.
- [BFJ+94] Avrim Blum, Merrick Furst, Jeffrey Jackson, Michael Kearns, Yishay Mansour, and Steven Rudich. Weakly learning dnf and characterizing statistical query learning using fourier analysis. In Proceedings of the twenty-sixth annual ACM symposium on Theory of computing, pages 253–262, 1994.
- [BG17] Alon Brutzkus and Amir Globerson. Globally optimal gradient descent for a convnet with gaussian inputs. CoRR, abs/1702.07966, 2017.
- [Boy84] John P Boyd. Asymptotic coefficients of hermite function series. Journal of Computational Physics, 54(3):382–410, 1984.
- [BR89] Avrim Blum and Ronald L Rivest. Training a 3-node neural network is NP-complete. In Advances in neural information processing systems, pages 494–501, 1989.
- [DKKZ20] Ilias Diakonikolas, Daniel Kane, Vasilis Kontonis, and Nikos Zarifis. Algorithms and SQ Lower Bounds for PAC Learning One-Hidden-Layer ReLU Networks. In Conference on Learning Theory, 2020. To appear.
- [DV20] Amit Daniely and Gal Vardi. Hardness of learning neural networks with natural weights. arXiv preprint arXiv:2006.03177, 2020.
- [Fel12] Vitaly Feldman. A complete characterization of statistical query learning with applications to evolvability. Journal of Computer and System Sciences, 78(5):1444–1459, 2012.
- [Fel17] Vitaly Feldman. A general characterization of the statistical query complexity. In Conference on Learning Theory, pages 785–830, 2017.
- [FGR+17] Vitaly Feldman, Elena Grigorescu, Lev Reyzin, Santosh S Vempala, and Ying Xiao. Statistical algorithms and a lower bound for detecting planted cliques. Journal of the ACM (JACM), 64(2):8, 2017.
- [GKK19] Surbhi Goel, Sushrut Karmalkar, and Adam Klivans. Time/accuracy tradeoffs for learning a relu with respect to gaussian marginals. In Advances in Neural Information Processing Systems, pages 8582–8591, 2019.
- [GKKT17] Surbhi Goel, Varun Kanade, Adam R. Klivans, and Justin Thaler. Reliably learning the relu in polynomial time. In COLT, pages 1004–1042, 2017.
- [GLM18] Rong Ge, Jason D. Lee, and Tengyu Ma. Learning one-hidden-layer neural networks with landscape design. In ICLR. OpenReview.net, 2018.
- [JHG18] Arthur Jacot, Clément Hongler, and Franck Gabriel. Neural tangent kernel: Convergence and generalization in neural networks. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, editors, NeurIPS, pages 8580–8589, 2018.
- [JSA15] Majid Janzamin, Hanie Sedghi, and Anima Anandkumar. Beating the perils of non-convexity: Guaranteed training of neural networks using tensor methods. arXiv preprint arXiv:1506.08473, 2015.
- [Kea98] Michael Kearns. Efficient noise-tolerant learning from statistical queries. Journal of the ACM (JACM), 45(6):983–1006, 1998.
- [KK14] Adam R. Klivans and Pravesh Kothari. Embedding hard learning problems into gaussian space. In APPROX-RANDOM, volume 28 of LIPIcs, pages 793–809. Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik, 2014.
- [KS94] Michael J Kearns and Robert E Schapire. Efficient distribution-free learning of probabilistic concepts. Journal of Computer and System Sciences, 48(3):464–497, 1994.
- [KS09] Adam R Klivans and Alexander A Sherstov. Cryptographic hardness for learning intersections of halfspaces. Journal of Computer and System Sciences, 75(1):2–12, 2009.
- [LSSS14] Roi Livni, Shai Shalev-Shwartz, and Ohad Shamir. On the computational efficiency of training neural networks. In Advances in Neural Information Processing Systems, pages 855–863, 2014.
- [Sha18] Ohad Shamir. Distribution-specific hardness of learning neural networks. J. Mach. Learn. Res, 19:32:1–32:29, 2018.
- [SSSS17] Shai Shalev-Shwartz, Ohad Shamir, and Shaked Shammah. Failures of gradient-based deep learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3067–3075, 2017.
- [SVWX17] Le Song, Santosh Vempala, John Wilmes, and Bo Xie. On the complexity of learning neural networks. In Advances in Neural Information Processing Systems, pages 5514–5522, 2017.
- [Szö09] Balázs Szörényi. Characterizing statistical query learning: simplified notions and proofs. In International Conference on Algorithmic Learning Theory, pages 186–200. Springer, 2009.
- [Vu98] Van H Vu. On the infeasibility of training neural networks with small mean-squared error. IEEE Transactions on Information Theory, 44(7):2892–2900, 1998.
- [VW19] Santosh Vempala and John Wilmes. Gradient descent for one-hidden-layer neural networks: Polynomial convergence and sq lower bounds. In Conference on Learning Theory, pages 3115–3117, 2019.
- [ZPS17] Qiuyi Zhang, Rina Panigrahy, and Sushant Sachdeva. Electron-proton dynamics in deep learning. CoRR, abs/1702.00458, 2017.
- [ZSJ+17] Kai Zhong, Zhao Song, Prateek Jain, Peter L. Bartlett, and Inderjit S. Dhillon. Recovery guarantees for one-hidden-layer neural networks. In ICML, volume 70, pages 4140–4149. JMLR.org, 2017.
- [ZYWG19] Xiao Zhang, Yaodong Yu, Lingxiao Wang, and Quanquan Gu. Learning one-hidden-layer relu networks via gradient descent. In Kamalika Chaudhuri and Masashi Sugiyama, editors, The 22nd International Conference on Artificial Intelligence and Statistics, AISTATS 2019, 16-18 April 2019, Naha, Okinawa, Japan, volume 89 of Proceedings of Machine Learning Research, pages 1524–1534. PMLR, 2019.
Appendix A Bounding the function norms under the Gaussian
Our goal in this section will be to give lower bounds on the norms of the functions in , which is a technical requirement for our results to hold (see Lemma 4.4 and Corollary 4.6). Note that when learning with respect to error, such a lower bound is necessary if we wish to state SQ lower bounds, since if the target had small norm, say , then the zero function trivially achieves error .
All inner products and norms in this section will be with respect to the standard Gaussian, . Since we will fix throughout, for our purposes the only relevant part of the input is and so we drop the subscripts and let and , so that and are functions of . Our approach will be as follows. In order to prove a norm lower bound on , we will prove an anticoncentration result for . To this end we first calculate the second moment of in terms of the Hermite coefficients of .
Lemma A.1.
Under the distribution , let the Hermite representation of be , where is the normalized probabilists’ Hermite polynomial. Then
Proof.
We use in this proof instead of for simplicity. Then we have
Since , and are both standard Gaussian and have correlation , we then apply the following well-known property of the Hermite polynomials.
where is the Dirac delta function.
where and . Note that 3.3 implies that , the series above is absolute convergent. Then,
since we consider all distinct monomials in . Note that is always non-negative and is positive iff and . ∎
A.1 ReLU Activation
The goal of this section is to give a lower-bound of for under the standard Gaussian distribution . To this end, we prove an anti-concentration for . We first give a lower bound on based on the Hermite coefficients of . If were bounded, this alone would imply anti-concentration as in Section A.2. But since it is not, we first introduce , where all activations are truncated at some . We pick large enough that and behave almost identically over . We then show a lower bound on , translate that into an anticoncentration result for , and finally into one for .
Let be some constant to be determined later. Let
and
The following lemma from [GKK19] describes the Hermite coefficients of ReLU.
Lemma A.2.
where
In particular, .
We can now derive a lower bound on the norm of .
Lemma A.3.
When is even,
Proof.
Due to Lemma A.1,
The lemma then follows by the Stirling’s approximation,
and the bound on the Hermite coefficients,
∎
For the difference of and , we have
Lemma A.4.
Proof.
Let be shorthand for , and similarly . Observe that by the triangle inequality,
where the last equality holds because for any unit vector and , has the distribution . Now,
where is the probability density function of . Note that . We have
| (integration by parts) | |||
Thus,
∎
Lemma A.5.
Proof.
For any ,
The lemma follows by a union bound. ∎
Lemma A.6.
Proof.
The lower bound on now follows easily.
Corollary A.7.
Proof.
A.2 Sigmoid Activation
Here we consider and with . For the asymptotic bound of Hermite polynomial coefficients, we need the following theorem from [Boy84].
Theorem A.8.
For a function whose convergence is limited by simple poles at the roots of with residue , the non-zero expansion coefficients of as a series of normalized Hermite functions have magnitudes asymptotically given by
Here the normalized Hermite function is defined by
Applying this to and translating the Hermite coefficients for the series in terms of Hermite functions to those in terms of Hermite polynomials, we have
Lemma A.9.
where for and all non-zero odd terms satisfies
Corollary A.10.
There is an infinite increasing sequence such that ’s are all odd and
Proof.
It follows simply from the fact that is not a polynomial and there should be infinitely many non-zero terms in . ∎
Remark A.11.
Experimental evidence strongly indicates that in fact all odd Hermite coefficients of sigmoid are nonzero and decay as above, but this is laborious to formally establish. So we state our norm lower bound only for (and the associated , since we end up taking ). Since this is nevertheless an infinite sequence, it still establishes that no better asymptotic bound holds.
Similar to Lemma A.3, we can derive a lower bound of for some ’s.
Lemma A.12.
For ,
Proof.
Lemma A.13.
For ,
Proof.
Since ,
and so
The lemma then follows. ∎
Using the same argument as Corollary A.7, we have the following bound.
Corollary A.14.
A.3 General activations
It is not hard to see that the norm analysis of ReLU and sigmoid extends to any activation function for which a suitable lower bound on the Hermite coefficients holds, and which is either bounded or grows at a polynomial rate, so that under the standard Gaussian it behaves essentially identically to its truncated form. In particular, a lower bound of for any constant on the Hermite coefficient suffices to give , by the same argument as in Lemma A.3 and Lemma A.12. This then suffices to give , as above.
In fact, even a very weak lower bound on yields some superpolynomial bound on learning. Suppose we only had , for instance. Then we can take and have and still obtain a lower bound of (see Theorem 3.9). Any lower bound on will be a function only of , so a similar argument applies.
Appendix B SQ lower bound for real-valued functions proof
We give a self-contained variant of the elegant proof of [Szö09] for the reader’s convenience. For simplicity, we include the function in our class — this can only negligibly change the SDA, and it makes the core argument cleaner.
Theorem B.1.
Let be a distribution on , and let be a real-valued concept class over a domain such that , and for all . Consider any SQ learner that is allowed to make only inner product queries to an SQ oracle for the labeled distribution for some unknown . Let . Then any such SQ learner needs at least queries of tolerance to learn up to error .
Proof.
Consider the adversarial strategy where we respond to every query () with 0. This corresponds to the true expectation if the target were the 0 function. By the norm lower bound, outputting any other would then mean error greater than . Thus we must rule out all other .
Let . If is the query, let be the functions ruled out by our response of 0. (A similar argument will hold for .) Let . We claim that . Suppose not. Then by Definition 2.4, and
contradicting the fact that by definition of .
Similarly . Thus we rule out at most a fraction of functions with each query, and hence need at least queries to rule out all other possibilities. ∎