Surface Reconstruction from Point Clouds via Grid-based Intersection Prediction
Abstract.
Surface reconstruction from point clouds is a crucial task in the fields of computer vision and computer graphics. SDF-based methods excel at reconstructing smooth meshes with minimal error and artefacts but struggle with representing open surfaces. On the other hand, UDF-based methods can effectively represent open surfaces but often introduce noise, leading to artefacts in the mesh. In this work, we propose a novel approach that directly predicts the intersection points between line segment of point pairs and implicit surfaces. To achieve it, we propose two modules named Relative Intersection Module and Sign Module respectively with the feature of point pair as input. To preserve the continuity of the surface, we also integrate symmetry into the two modules, which means the position of predicted intersection will not change even if the input order of the point pair changes. This method not only preserves the ability to represent open surfaces but also eliminates most artefacts on the mesh. Our approach demonstrates state-of-the-art performance on three datasets: ShapeNet, MGN, and ScanNet. The code will be made available upon acceptance.
1. Introduction
Surface reconstruction from point clouds is a long-standing and essential task that has been studied for many years. It plays a crucial role in various modern applications, including visual navigation and robotics. Numerous notable works (Li et al., 2022; Liu et al., 2021; Liao et al., 2018; Chibane et al., 2020b; Ma et al., 2020; Atzmon and Lipman, 2020a, b; Venkatesh et al., 2020; Wang et al., 2022a; Richa et al., [n. d.]; Zhenxing et al., 2020; Zhao et al., 2023) have significantly advanced this field. Among the traditional methods, Poisson Surface Reconstruction (Kazhdan et al., 2013), a well-known approach, has yielded good results. However, its performance may deteriorate in the absence of normals and faces with open-surface challenges. With the emergence of deep learning, many researchers have sought to enhance reconstruction results by leveraging the robust representation and predictive capabilities of deep neural networks. These methods can generally be categorized into SDF-based (Signed Distance Function) and UDF-based (Unsigned Distance Function) approaches in terms of geometry representation. UDF-based methods excel at representing open surfaces, whereas SDF-based methods struggle in this regard. Yet, predicting UDF values often introduces noise, despite the critical role these UDF values play in achieving high-quality surface reconstruction. In this study, a novel approach is proposed to enhance surface reconstruction by directly predicting the intersection points between surfaces and line segments. This method not only improves reconstruction quality but also maintains the capacity to represent open surfaces effectively.
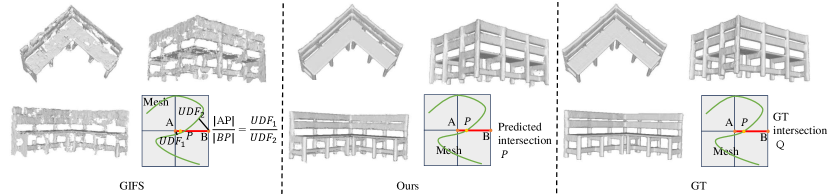
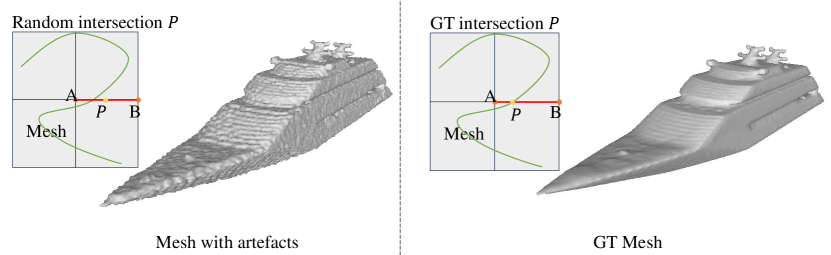
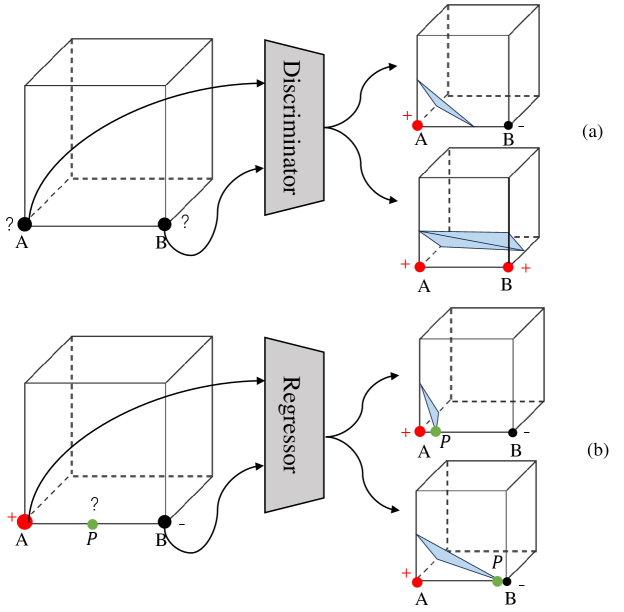
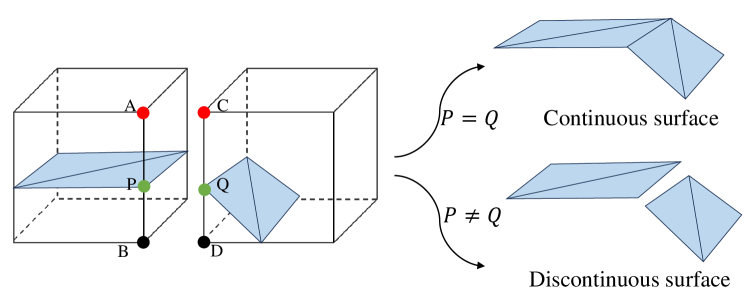
In particular, the motivation of our method comes from the following two aspects. First, Most methods for reconstructing surfaces from point clouds ultimately rely on Marching Cubes or its variants. Marching Cubes requires two key pieces of information to generate a triangle mesh. As depicted in Fig. 3 (a), the first piece is the sign of the vertices at the eight corners of the cube, while the second is the intersection points between the surface and the edges of the cube, as the exact position of point P after determining that P lies on line AB in Fig. 3 (b). Therefore, in order to achieve better surface reconstruction, it is crucial to enhance the accuracy of both the sign of the vertices at the eight corners of a cube and the exact intersection positions. While most researchers agree on the importance of the accuracy of the sign of the vertices at the eight corners of a cube, the significance of the exact intersection position is often overlooked. However, the second aspect is also very important. This can be illustrated through a simple comparison. As demonstrated in Fig. 2, the shape in the left column is reconstructed using Marching Cubes with ground-truth signs, and all intersection points are randomly chosen in , supposing the length of the cube edge is . On the other hand, the shape in the right column is reconstructed with ground-truth signs and ground-truth intersection positions. It is evident that the shape in the right column appears smoother, whereas the one in the left column exhibits numerous artefacts. These artefacts mainly stem from incorrect intersection positions when is disturbed by the random noise, where in Fig. 1. Therefore, the accuracy of intersection positions significantly impacts the quality of surface reconstruction.
Secondly, it is a common phenomenon that predicting the UDF in the vicinity of the surface tends to introduce noise. This noise arises from the discontinuity of the UDF gradient on the two side of the surface. When utilizing a neural network to represent the UDF, accurately predicting the sharp changes in the UDF gradient around the zero-level set becomes a challenging task. Furthermore, we provide a small yet compelling example to illustrate this point in Section 4.1. The CAP method (Zhou et al., 2022) also emphasizes this challenge. The presence of UDF noise can result in inaccurate intersection points between the cube edge and the surface, leading to artefacts in the reconstructed mesh. This discrepancy elucidates why SDF-based methods typically produce smoother results compared to UDF-based approaches. Building upon these insights, we aim to propose a method that can not only reconstruct the open surface but also mitigate the impact of UDF noise.
Therefore, we have chosen to avoid predicting UDF and instead focus on directly predicting the intersection points between surfaces and cube edges. Specifically, we have designed two modules: the Relative Sign Module and the Intersection Module.
In the Relative Sign module, we predict whether two points have the same sign and incorporate a symmetrical design in the module. The symmetry guarantees that the relative sign will not change when the input order of point pair changes. Once we confirm that the signs of the two points are different, we proceed to use the Intersection Module.
In the Intersection Module, we directly predict the intersection points between the cube edges and the surface, while also implementing a symmetrical design. The symmetry aims to achieve the following purpose. In the point pair with A as start point and B as end point, the intersection point will not change when A and B exchange their position. The symmetry of both the Intersection Module and the Relative Sign module ensures the continuity of the surface.
To demonstrate the superiority of our approach, we conducted evaluations using chamfer distance and normal consistency metrics across three diverse datasets: ShapeNet, MGN, and ScanNet, encompassing watertight shapes, open surfaces, and partially scanned scenes. Compared to state-of-the-art methods, our method consistently outperforms them, yielding the best results across all three datasets. Notably, our method excels on ShapeNet, demonstrating a remarkable 30% reduction of and a 1.8% enhancement of .
In summary, we can list our main innovative points,
-
•
Initially proposed to directly predict the intersection point between the cube edge and the surface, leading to enhanced accuracy in determining the intersection point.
-
•
Developed two specialized modules designed to predict these intersections while maintaining the surface’s continuity.
-
•
Successfully achieved high-quality reconstruction results on three datasets: ShapeNet, MGN, and ScanNet.
2. Related Works
Traditional point cloud reconstruction.
Point cloud reconstruction has been a persistent challenge in the fields of graphics and computer vision. Among the traditional methods, Poisson surface reconstruction (Kazhdan et al., 2013) and ball-pivoting reconstruction (Bernardini et al., 1999) stand out as the most significant. The Poisson surface reconstruction method categorizes the query points based on the Poisson indicator function, while the ball-pivoting method generates a continuous surface by simulating a ball rolling over the points. Although these approaches yield satisfactory surface reconstructions, there is still room for further enhancement in performance.
SDF-based implicit surface reconstruction.
Implicit surface reconstruction methods based on signed distance functions (SDF) utilize deep learning techniques to either classify the occupancy of query points or directly predict the SDF value. These methods can be categorized into global approaches, which leverage overall shape information to classify query points, and local approaches, which classify query points based on their neighboring points.
Early representative works include AtlasNet(Groueix et al., 2018), IF-Net(Chibane et al., 2020a), DeepSDF(Park et al., 2019) and BSP-Net(Chen et al., 2020), which extract shape features and reconstruct the surface from these features. Later, ConvOccNet(Peng et al., 2020), SSR-Net(Zhenxing et al., 2020), DeepMLS(Liu et al., 2021; Kolluri, 2008), and POCO(Boulch and Marlet, 2022), O-CNN(Wang et al., 2020) DeepCurrents(Palmer et al., [n. d.]), LP-DIF(Wang et al., 2023a) and Venkatesh(Venkatesh et al., 2021) develop this methods. ConvOccNet(Peng et al., 2020) converts point cloud features into voxels and enhances features through volume convolution. SSR-Net(Zhenxing et al., 2020) extracts point features, maps neighborhood point features to octants, and classifies them accordingly. DeepMLS(Liu et al., 2021; Kolluri, 2008) predicts normal and radius for each point and classifies query points based on the moving least-squares equation. ALTO(Wang et al., 2023b; Hu et al., 2020) dynamically adjusts the representation of local geometry. Dual Octree(Wang et al., 2022a) proposes a new graph convolution operator defined over a regular grid of features fused from irregular neighboring octree nodes at different levels, simultaneously improving the performance and reducing the cost. Li, T(Li et al., 2022) propose a dynamic code to represent the local geometry with dynamic resource adaptively. Points2Surf(Erler et al., 2020) aims to regress the absolute SDF value using local information and determine the sign using global information.
Other SDF-based implicit surface reconstruction methods include SAL(Atzmon and Lipman, 2020a), SALD(Atzmon and Lipman, 2020b), StEiK(Yang et al., 2023), SIREN(Sitzmann et al., 2020), DiGS(Ben-Shabat et al., [n. d.]) and On-Surface Prior(Ma et al., [n. d.]), which aim to transform explicit representations like point clouds and 3D triangle soups into implicit SDF representations. These methods require unique training processes and network parameters for each 3D model. SAL(Atzmon and Lipman, 2020a) employs MLP to predict shape SDFs with UDF-based metric supervision, while SALD(Atzmon and Lipman, 2020b) adds a derivative regularization term. On-Surface Prior(Ma et al., [n. d.]) utilizes a pre-trained UDF-based network to improve SDF predictions.
Differential Marching Cube methods is related to ours, including Deep Marching Cube(Liao et al., 2018) and Neural Marching Cube(Chen and Zhang, 2021). Both of them are based on SDF.
While SDF methods have shown significant advancements in point cloud reconstruction, they have limitations in representing open surfaces or partial scans. This is important in realistic application, because we usually cannot guarantee that the scan is watertight.
UDF-based implicit surface reconstruction.
UDF has been a focal point in the realm of surface representation due to its ability to capture more general surfaces, including open surfaces and partial scans. Various research efforts have delved into leveraging UDF for implicit surface reconstruction. For instance, NDF (Chibane et al., 2020b) utilizes UDF to encode surface information and introduces a method for up-sampling point clouds during mesh reconstruction, employing the Ball Pivoting (Bernardini et al., 1999) technique. On the other hand, DUDE (Venkatesh et al., 2020) adopts a volumetric UDF representation encoded within a neural network to describe shapes, leading to promising results in implicit surface reconstruction tasks. Nevertheless, a common challenge across these approaches is the reliance on 3D ground truth labels for training. Furthermore, a key unresolved issue pertains to the direct extraction of iso-surfaces from UDF. In a different approach, UWED (Richa et al., [n. d.]) leverages Moving Least Squares (MLS) to convert UDF into a dense point cloud, showcasing an alternative strategy for handling UDF representations in surface reconstruction tasks. MeshUDF(Guillard et al., 2021)vote the sign of local cube corner according the local geometry. HSDF(Wang et al., 2022b) adopts the hybrid SDF and UDF to represent open surface.
3. Methods
3.1. Overview
In this section, we will initially present the complete pipeline of our method. Subsequently, we will delve into the prediction of intersection points and the pair-based sampling technique. Following that, we will discuss the two distinct components: predicting the relative sign and the intersection point individually. Lastly, we will elucidate the training loss.
3.2. Architecture
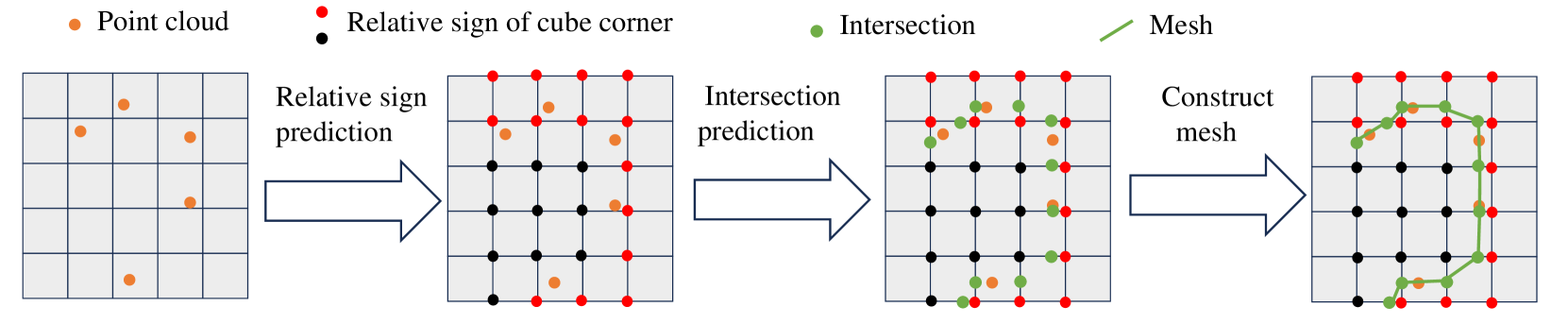
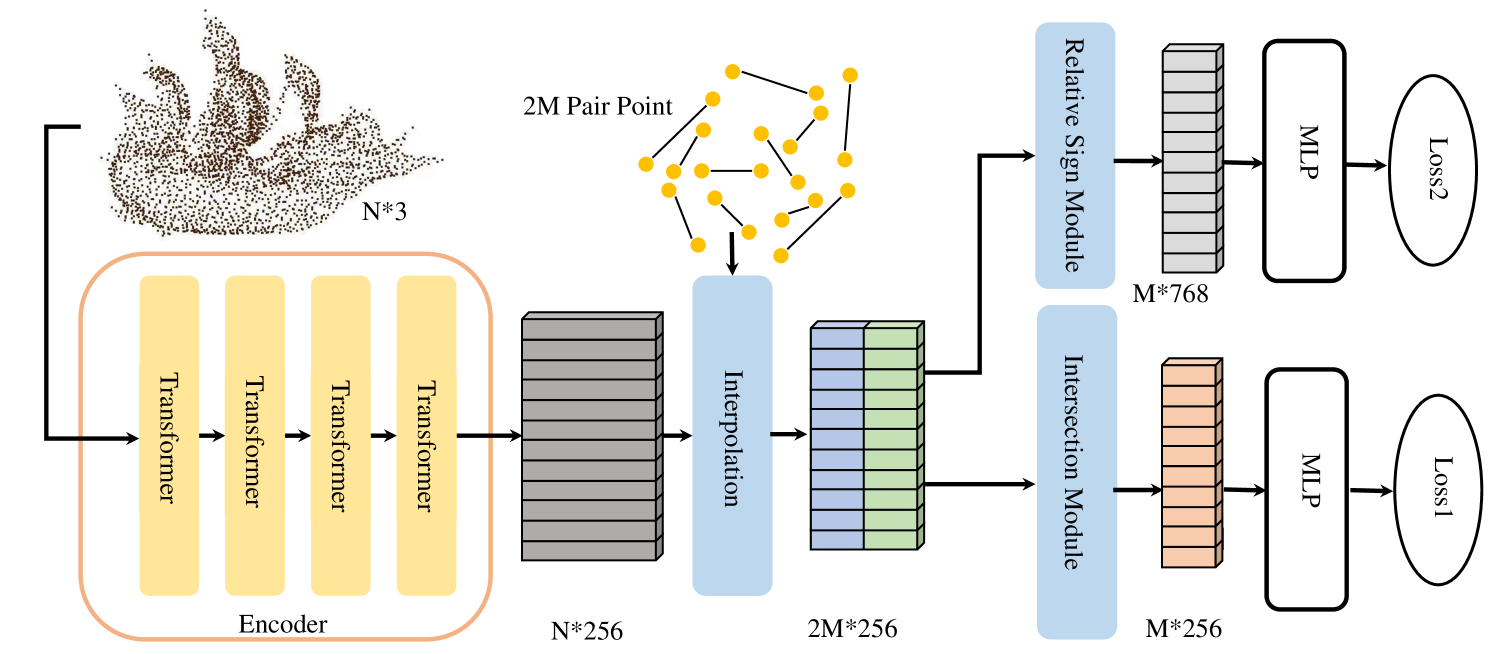
The total pipeline is shown in Fig. 4. The network architecture is depicted in a straightforward manner, as illustrated in Fig. 5. Initially, the input point cloud with a total of points is inputted into the encoder to extract features with a dimension of . The encoder comprises 4 transformer layers(Zhao et al., 2021, 2020), outputting dimensions of , , , and respectively. Following a similar approach to GIFS (Ye et al., 2022), we adopt a paired query point sampling method, generating a total of pairs. Subsequently, an interpolation layer is employed to derive the features of the query points. The network then diverges into two distinct paths. In the upper path, the focus is on predicting the relative sign of the two points. The feature of the point pair is fed into the Relative Sign Module to capture the relationship between the points. A multi-layer perceptron (MLP) is utilized to predict whether the two points exhibit the same sign, with a binary cross-entropy loss function applied. In the bottom path, the aim is to predict the position of the intersection point. The feature of the point pair is inputted into the Intersection Module, followed by the use of a MLP to predict the relative distance from the starting point to the intersection point. A simple regression loss is employed for this prediction. However, in cases where no intersection occurs between the cube edge and the surface, this term is disregarded in the loss calculation.
3.3. Pair Prediction
To sample point pairs for training and testing, we start by considering a point cloud . During training, we uniformly sample points around at varying scales and ratios. For each point , a query point is randomly sampled, where takes values of 0.005, 0.01, and 0.02, corresponding to sample ratios of 0.6, 0.3, and 0.1 respectively. Subsequently, a cube with an edge length of 1/256 and as the upper-left-front corner is generated, allowing us to sample 12 point pairs corresponding to the 12 edges of the cube. Following this, we determine the intersection point of each edge with the surface and assess whether the point pairs lie on the same side of the surface.
During testing, to reconstruct the entire surface within the given space, we begin by identifying the bounding box of the shape and dividing it into cube meshes with an edge length of 1/256. For each cube within the bounding box, we predict the relative sign of the cube’s corners and the intersection positions, where the reference point is the vertex at the upper-left-front corner of the cube. Utilizing the template matching method in Marching Cubes, we can then generate the triangle mesh. After sampling, we will elaborate on the specific predictions made by our network. Illustrated in Fig. 5, the lower pathway involves selecting a point pair AB, with point designated as the starting point and as the end point. The intersection point is denoted as , and our aim is to forecast the proportionate distance from to , expressed as . Furthermore, as depicted in Fig. 5, within the upper pathway, we predict whether the point pairs lie on the same or different sides of the surface. The Relative Sign Module’s name suggests that we solely predict the relationship between the corners of the cube and the upper-left-front corner within the cube. It is not the sign in the global view but a relative sign to the upper-left-front corner.
3.4. Relative Sign Module
In the Relative Sign Module, we formalize the problem as follows: given a start point and an end point with features and respectively, we denote the Relative Sign Module as . The Relative Sign Module is required to exhibit the following property: when the positions of and are exchanged, should vanish, i.e., . This is because the relationship between and remains unchanged when their positions are swapped. To maintain this property and enhance the expressive capacity of , we design the Relative Sign Module as follows:
| (1) |
where is the positional encoding(Tancik et al., 2020) of . Here, in order to keep the property , we abandon the traditional sin-cos positional encoding and adopt only cosine positional encoding. Specifically, , .
3.5. Intersection Module
In the Intersection Module, we aim to predict the position of the intersection point between point pair and , each associated with features and respectively. The position of is represented by , where . To ensure the continuity of the surface, we define the Intersection Module as , which should satisfy the property . This condition is crucial for maintaining surface continuity. The relationship can be intuitively understood by observing that . Based on this, we formulate the design of the Intersection Module as follows,
| (2) |
where is also the positional encoding of . However, in this part, in order to keep the property , we adopt only sine positional encoding. Specifically, , .
Next, we can delve into the explanation for why a surface may not exhibit continuity if . Referring to Fig. 6, the two cubes represent adjacent cubes in the Marching Cube algorithm. It is evident that is equivalent to and is equivalent to . Pints and must coincide; otherwise, the mesh will lack continuity. Therefore, the relationship must be upheld. This condition serves as both necessary and sufficient for ensuring and .
3.6. Losses
In this approach, we utilize two types of loss functions for training. For sign prediction, we employ a straightforward binary cross-entropy loss. For intersection prediction, we apply a regression loss to minimize the disparity between the predicted and the ground-truth , as illustrated below:
| (3) |
where means the predicted intersection position of point pair, means the ground-truth intersection position of point pair,
| (4) |
3.7. Details and Discussions
Training.
During training, we utilize 16,000 randomly sampled point pairs every iteration. The training epoch is 100. We employ the Adam optimizer (Kingma et al., 2014) and incorporate cosine learning rate adjustment (Loshchilov and Hutter, 2016). The initial learning rate is set to 0.001, and the batch size is 1.
Testing.
During testing, to assess the quality of the reconstructed mesh, we randomly sample 100,000 points with normals on both the reconstructed mesh and the ground-truth mesh. Subsequently, we calculate the Chamfer Distance () and Normal Consistency () between these point sets.
Training/Testing splitting.
During training, we sampled 1300 shapes for ShapeNet, 71 for MGN, and 100 for ScanNet, respectively. For testing, the same number of shapes was sampled. It is important to note that the shapes used for training and testing do not overlap.
Two prediction ways.
In fact, we have experimented with two methods for constructing the mesh. The first method involves first predicting the relative sign of the cube corners and then predicting the intersection point when the point pair is on different sides of the surface, with the intersection parameter . On the other hand, the second method directly predicts the intersection parameter without the need to predict the cube corner sign first. By observing that if , an intersection exists between the two points, while no intersection point exists for other values of , we found that the convergence of the second method was unsatisfactory in our experiments. Therefore, we have decided to adopt the first method for constructing the mesh.
Post-processing.
After generating the mesh, we design a method to remove the triangle soup which is obviously wrong. The idea is very simple. In short, if the normal of the triangle is far from its neighbors, we will remove this triangle. Specifically, we calculate the following indicator
| (5) |
where is number of k-nearest neighbor, is inner-product. is the normal of triangle, is the normal of its neighbor triangles. If , we will remove the triangle.
Similarities and differences between GIFS (Ye et al., 2022) and Ours.
Our approach shares a common point with GIFS in that both methods involve predicting the relative sign of a point pair, indicating whether the two points are on the same side or opposite sides of the surface. However, a key distinction between our method and GIFS lies in the approach to determining the intersection point: we directly predict the intersection between a segment and a surface, whereas GIFS utilizes to define point . Additionally, a minor difference is observed in the network architecture, as we employ a point transformer and interpolation layer to extract query point features, while GIFS utilizes 3D convolution for the same purpose.
Similarities and differences of Deep Marching Cube, Neural Marching Cube and Ours.
Deep Marching Cube (Liao et al., 2018) is a work closely related to ours, as both focus on the two key aspects: the sign of vertices at the corner of the cube and the position of intersection points. However, several differences distinguish our approaches. Firstly, our motivation differs. While our goal is to eliminate artefacts, Deep Marching Cube aims to differentiate the Marching Cube. Secondly, our method is UDF-based, allowing us to represent open surfaces, whereas Deep Marching Cube, based on SDF, can only represent watertight surfaces. Thirdly, we directly predict the relative sign of point pairs, while Deep Marching Cube employs a probabilistic model to represent vertex signs.
Neural Marching Cube (Chen and Zhang, 2021) seeks to enhance Marching Cube performance by intersecting additional vertices beyond those on the cube edges, aiming to generate a finer mesh without cube subdivision. Consequently, our approach and Neural Marching Cube employ different methods to address distinct problems, indicating a somewhat distant relationship between them.
4. Experiments
4.1. Tiny example to show the difficulty of learning UDF
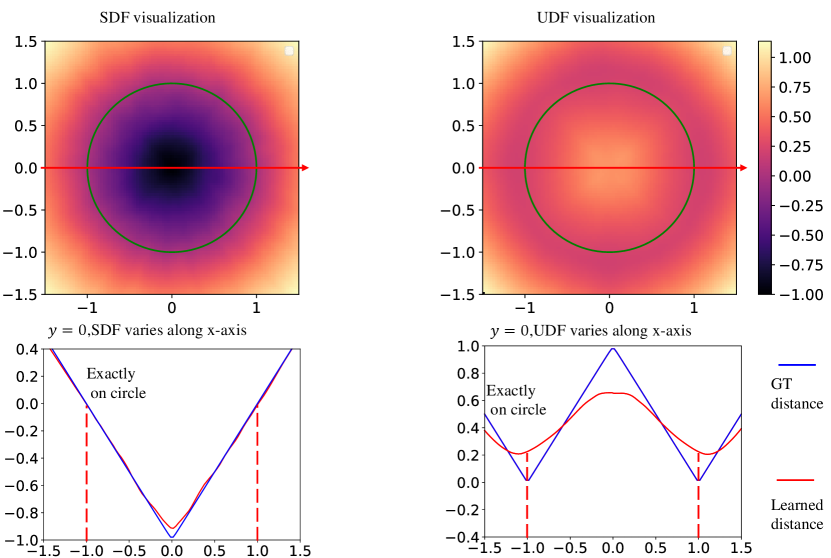
Compared to SDF, UDF does not require predicting signs, making it seem simpler than SDF. However, this is not the case. We designed a small experiment to demonstrate the difficulties of learning UDF, using a simple neural network to fit the circle function on a two-dimensional plane. Our goal is to learn the UDF and SDF of a circle on the plane, using a three-layer MLP (Multi-Layer Perception) to represent this sphere, with optimization done through gradient descent. We provide two three-layer MLP functions to represent the UDF field on the plane, and to represent the SDF field on the plane. The parameters of the experiment are as follows: the output dimensions of the three-layer MLP are respectively, the number of sampled points is , the initial learning rate is , and the optimizer used is Adam. The visualization of the learning results is shown in Fig. 7.
From the results of SDF and UDF in the first row, it can be seen that the neural network indeed learns the approximate distance field. When the distance field changes along the x-axis at the position of in the second row, we focus on the error between the GT distance field and the learned distance field to the circle as x changes. It can be observed that when learning SDF, the error between the two is almost zero, while when learning UDF, the error is significant. This is because near the surface of the curve, the gradient of the SDF remains unchanged, resulting in a continuous change in the distance field, while the gradient of the UDF rotates by , making the change in the distance field discontinuous. Specifically, when x approaches from the left side, the gradient of the SDF is
| (6) |
When x approaches -1 from the right, the gradient of the SDF is
| (7) |
They are same with each other in SDF. when x approaches from the left side, the gradient of the UDF is
| (8) |
When x approaches -1 from the right, the gradient of the UDF is
| (9) |
The two are exactly opposite. Although the Signed Distance Function (SDF) also has some errors at due to the collision of gradient directions, it is insignificant because it occurs at the center of the sphere, which is not important for surface reconstruction. Therefore, the error here can be ignored. However, the Unsigned Distance Function (UDF) has a discontinuity in the vicinity of the surface, and the distance field near the surface is particularly important for surface reconstruction. For regression methods, fitting a continuously changing function is relatively easy, while fitting a function with gradient discontinuities is very difficult. This is the difficulty of reconstruction based on UDF. The difficulty of reconstruction based on SDF is easier to understand, mainly in complex topological surfaces where it is difficult for neural networks to determine the sign information at a specific point.
4.2. Dataset and Experiment Settings
Our methodology is assessed on three prominent open-source datasets. Initially, we randomly select 1300 shapes from 13 distinct categories within the ShapeNet dataset (Chang et al., 2015), with each category comprising 100 shapes. The point number of each input point cloud is 3000. Subsequently, we employ the MGN dataset, encompassing both pants and shirts. The point number of each input point cloud is 3000. Finally, we include 100 scenes from the real-world ScanNet dataset (Dai et al., 2017), obtained through scanning technology, resulting in 10,000 input point clouds. To facilitate a comprehensive comparison with existing techniques, we utilize standard evaluation metrics commonly employed in surface reconstruction. One such metric is Chamfer- (), which measures the distance between two sets of points. Additionally, to demonstrate enhancements in artifact elimination, we utilize normal consistency () as a metric to evaluate the smoothness of the reconstructed surface.
When calculating , we follow O-Net(Mescheder et al., 2019) and randomly sample 100000 points on the reconstructed mesh and 100000 points on ground-truth mesh. equation is shown as the Eq.10
| (10) | ||||
is the points set sampled from ground-truth mesh. is the point set sampled from reconstructed mesh. means the nearest point to in reconstructed point set. means the nearest point to in ground-truth point set. means .
Normal consistency is closely related to , shown in Eq.11
| (11) | ||||
means the normal of point . means inner-product. Here, we calculate the absolute value of inner product, because our mesh is not orientated.
4.3. Watertight Surface Reconstruction
| Indicator | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Class | GIFS | CAP | PSR | SuperUDF | Ours | GIFS | CAP | PSR | SuperUDF | Ours |
| airplane | 0.0026 | 0.0031 | 0.0023 | 0.0022 | 0.0012 | 0.9322 | 0.9318 | 0.9435 | 0.9469 | 0.9716 |
| bench | 0.0058 | 0.0059 | 0.0037 | 0.0029 | 0.0019 | 0.8865 | 0.8874 | 0.9062 | 0.9234 | 0.9449 |
| cabinet | 0.0104 | 0.0048 | 0.0056 | 0.0039 | 0.0026 | 0.9370 | 0.9331 | 0.9357 | 0.9456 | 0.9700 |
| car | 0.0052 | 0.0054 | 0.0039 | 0.0029 | 0.0024 | 0.8825 | 0.8879 | 0.8975 | 0.9014 | 0.9133 |
| chair | 0.0041 | 0.0042 | 0.0053 | 0.0039 | 0.0024 | 0.9415 | 0.9447 | 0.9311 | 0.9498 | 0.9601 |
| display | 0.0055 | 0.0047 | 0.0043 | 0.0034 | 0.0021 | 0.9456 | 0.9513 | 0.9643 | 0.9712 | 0.9834 |
| lamp | 0.0078 | 0.0082 | 0.0036 | 0.0030 | 0.0018 | 0.9108 | 0.9025 | 0.9366 | 0.9334 | 0.9476 |
| speaker | 0.0081 | 0.0063 | 0.0050 | 0.0041 | 0.0026 | 0.9015 | 0.9243 | 0.9531 | 0.9589 | 0.9712 |
| rifle | 0.0029 | 0.0013 | 0.0012 | 0.0011 | 0.0009 | 0.9345 | 0.9533 | 0.9685 | 0.9668 | 0.9776 |
| sofa | 0.0069 | 0.0050 | 0.0038 | 0.0033 | 0.0022 | 0.9370 | 0.9413 | 0.9534 | 0.9520 | 0.9758 |
| table | 0.0065 | 0.0088 | 0.0043 | 0.0025 | 0.0023 | 0.9235 | 0.9109 | 0.9381 | 0.9428 | 0.9749 |
| phone | 0.0049 | 0.0024 | 0.0024 | 0.0021 | 0.0017 | 0.9537 | 0.9725 | 0.9790 | 0.9713 | 0.9869 |
| vessel | 0.0033 | 0.0025 | 0.0012 | 0.0021 | 0.0015 | 0.9167 | 0.9355 | 0.9464 | 0.9487 | 0.9625 |
| Mean | 0.0057 | 0.0048 | 0.0037 | 0.0028 | 0.0019 | 0.9239 | 0.9284 | 0.9423 | 0.9470 | 0.9648 |
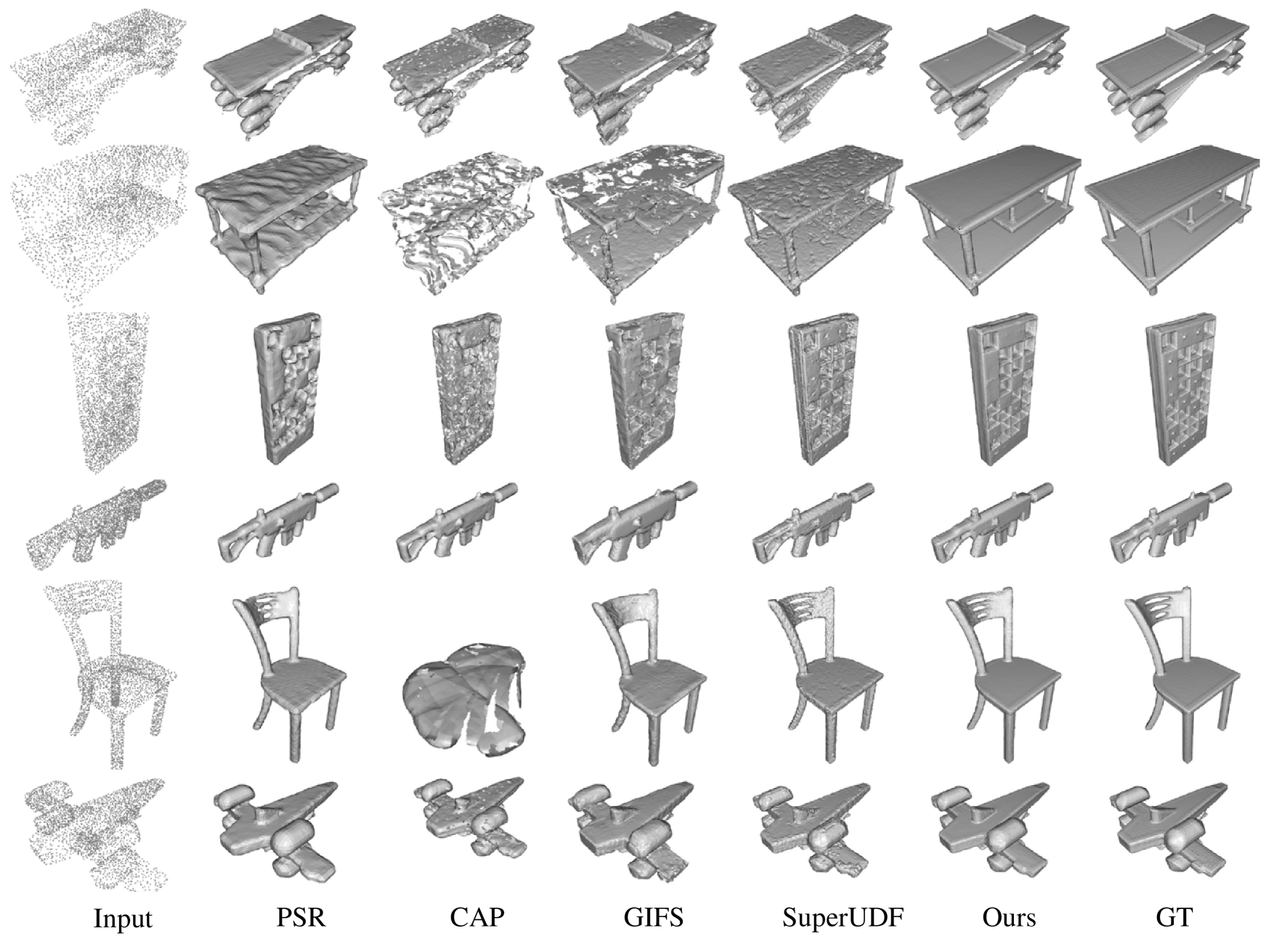
Several previous studies (Park et al., 2019; Peng et al., 2020; Mescheder et al., 2019; Chibane et al., 2020b) have commonly utilized the watertight surface reconstruction approach for implicit surface reconstruction, a key focus of this point cloud reconstruction research. In order to evaluate the effectiveness of our proposed method, we conducted a comprehensive analysis of watertight surface reconstruction using the ShapeNet dataset (Chang et al., 2015). Specifically, we uniformly sampled 3000 points from the watertight mesh to serve as input data. We compared our method against four well-known techniques, excluding PSR (Kazhdan et al., 2013), all of which are UDF-based methods. The methods included GIFS (Ye et al., 2022), CAP (Zhou et al., 2022), and SuperUDF (Tian et al., 2023). For the PSR (Kazhdan et al., 2013) method, we incorporated ground-truth normals as input data. The visualization results are presented in Fig. 8 and Fig. 9. Our method not only preserves more details but also produces smoother results. One of the reasons for the unsatisfactory performance of CAP (Zhou et al., 2022) is the insufficient number of input points in the point cloud. With only 3000 points available for training, CAP typically requires over 20000 points in the point cloud to achieve optimal results. Typically, methods such as ConvOccNet(Peng et al., 2020) and POCO(Boulch and Marlet, 2022) initially learn features from sparse point clouds and then decode the distance field of query points. Conversely, approaches like Neural Pull(Ma et al., 2020) and CAP(Zhou et al., 2022) train neural networks to approximate the distance field, often necessitating dense point clouds. Our method falls within the former category.
The quantitative evaluation results are summarized in Table 1. These results demonstrate that our method achieves excellent performance across all 13 classes with a significant margin, showcasing its state-of-the-art capabilities. Particularly noteworthy is the performance on the , indicating that our reconstructed surfaces are not only faithful to the ground truth but also exhibit smoothness.

4.4. Open Surface Reconstruction
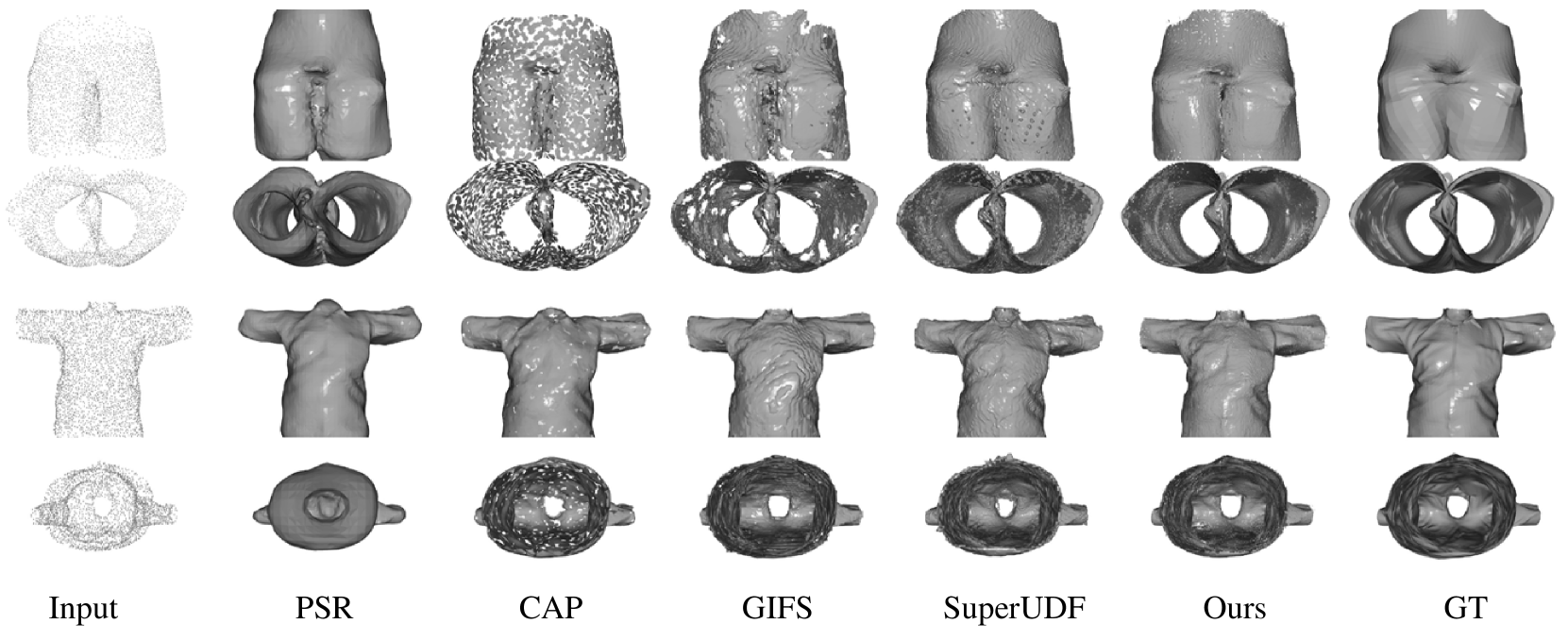
| CAP | PSR | GIFS | SuperUDF | Ours | |
|---|---|---|---|---|---|
| 0.0035 | 0.0045 | 0.0033 | 0.0024 | 0.0019 | |
| 0.9407 | 0.9356 | 0.9418 | 0.9645 | 0.9758 |
By leveraging a pair-point structure akin to GIFS for representing surfaces within our framework, we are able to proficiently reconstruct open surfaces. We achieve this by uniformly sampling 3000 points on each MGN mesh to reconstruct the implicit surface, a task that poses challenges for SDF-based methods given the characteristics of open surfaces. The comparative analysis presented in Table 2 illustrates the superior performance of our approach in comparison to various methods including PSR (Kazhdan et al., 2013), CAP (Zhou et al., 2022), GIFS (Ye et al., 2022), and SuperUDF (Tian et al., 2023). Moreover, the visual results depicted in Fig. 10 and Fig. 11. exhibit the faithfulness of our reconstructed mesh, capturing intricate details and closely mirroring the ground-truth.
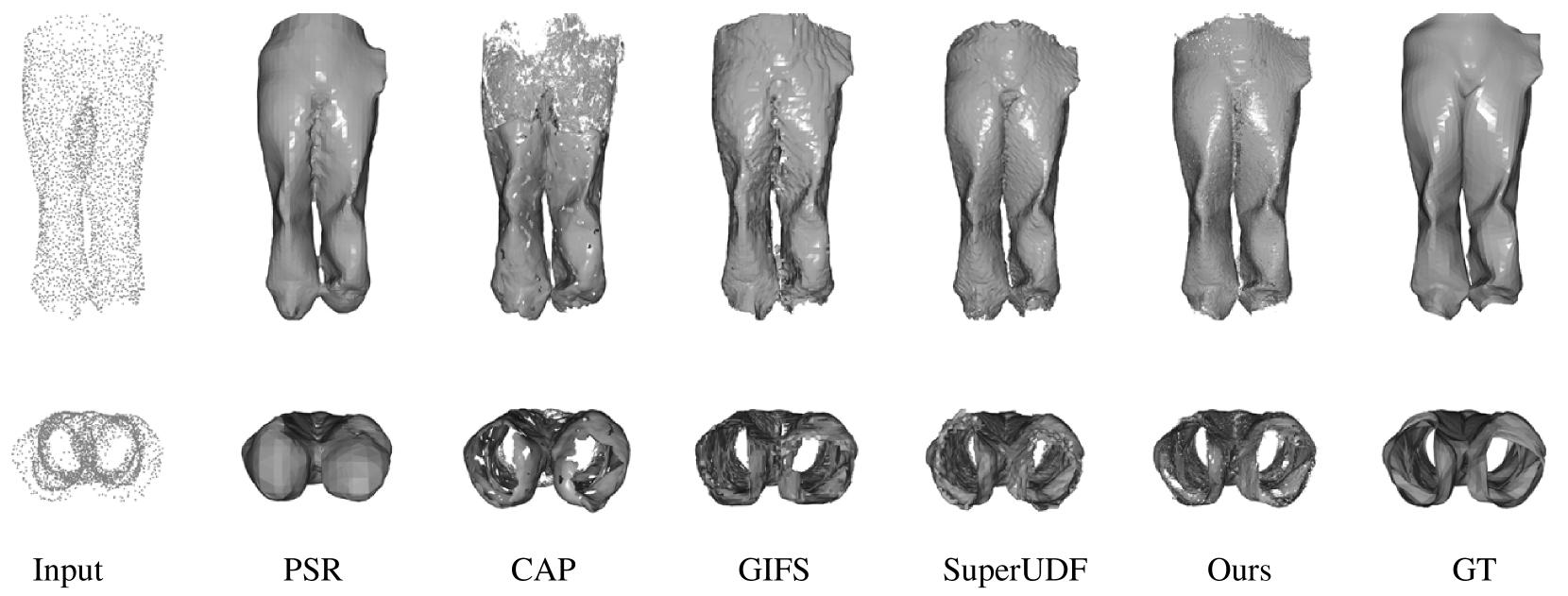
4.5. Scene Reconstruction
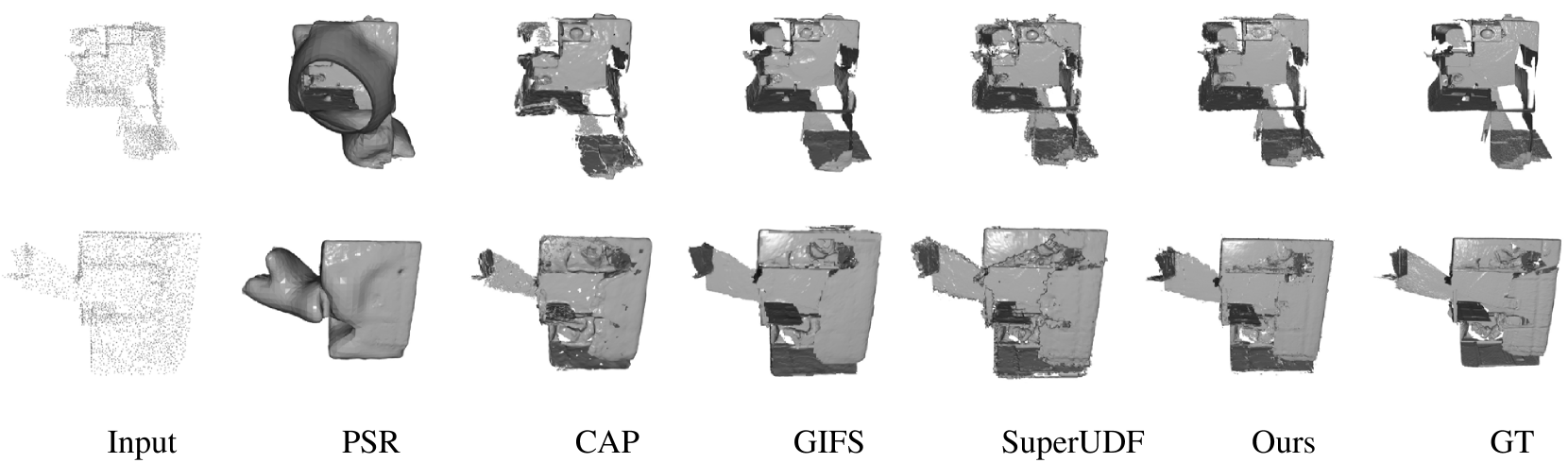
Real scene reconstruction is characterized by a heightened level of complexity, primarily due to the inherent openness and incompleteness of the input point cloud data. In this study, we meticulously selected 100 scenes from ScanNet and illustrated the visualization results in Fig. 13 and Fig. 12, along with the quantitative results in Table 3, in comparison with other methods.
Upon examining the visualization results, our reconstructed surface exhibits a notably smoother appearance compared to other methods. Furthermore, the quantitative analysis reveals that our approach outperforms other methods in terms of both and , underscoring the efficacy of our design in accurately predicting the intersection points between the surface and cube edges.

| CAP | PSR | GIFS | SuperUDF | Ours | |
|---|---|---|---|---|---|
| 0.0044 | 0.0240 | 0.0043 | 0.0039 | 0.0037 | |
| 0.8679 | 0.8420 | 0.8713 | 0.8722 | 0.8810 |
4.6. Ablation Study
Contribution of Relative Sign Module and Intersection Module.
To enhance the quality of surface reconstruction, it is essential to predict the sign of cube corners. This allows for the selection of appropriate triangle templates akin to the Marching Cube algorithm. Additionally, accurate intersection point prediction is crucial. By leveraging this information, adjustments can be made to the triangle positions, resulting in smoother surfaces with reduced artefacts. Our approach consists of two key components: the Relative Sign Module and the Intersection Module. Consequently, we aim to conduct experiments to evaluate the impact of each component on surface quality. In pursuit of this objective, we have devised 9 comparative experiments to demonstrate the contributions of each component, as presented in Table 4 and Table 5. Upon examining the results row-wise, it is evident that regardless of the chosen sign prediction method, our intersection results outperform those of GIFS (Ye et al., 2022). Furthermore, the disparity between our intersection prediction outcomes and ground truth (GT) predictions is minimal, indicating the enhanced accuracy of our Intersection Module. When analyzing the results column-wise, it is apparent that regardless of the chosen intersection prediction method, our sign prediction results surpass those of GIFS (Ye et al., 2022). Moreover, the difference between our sign prediction outcomes and GT sign predictions is negligible, highlighting the efficacy of our Relative Sign Module in improving sign prediction accuracy.
| GIFS Intersection | Our Intersection | GT Intersection | |
|---|---|---|---|
| GIFS Sign | 0.0057 | 0.0042 | 0.0037 |
| Our Sign | 0.0025 | 0.0019 | 0.0018 |
| GT Sign | 0.0023 | 0.0018 | 0.0017 |
| GIFS Intersection | Our Intersection | GT Intersection | |
|---|---|---|---|
| GIFS Sign | 0.9239 | 0.9312 | 0.9403 |
| Our Sign | 0.9435 | 0.9648 | 0.9703 |
| GT Sign | 0.9677 | 0.9801 | 0.9812 |
Accuracy of intersection point.
Except for the final metrics and on the mesh, we also present intermediate results to demonstrate the enhancements made to the Intersection Module. When reconstructing the mesh, both UDF-based methods and ours attempt to compute the intersection point of the surface and the cube edge. The key difference lies in the approach: the UDF-based method determines the intersection position by inversely considering the UDF value between two points, while our method directly predicts the intersection using a neural network. Specifically, we evaluate the distance between the predicted intersection point and the ground-truth intersection point generated by different methods in Table 6. To elaborate, we initially divide the space into cubes with a resolution of 256. Subsequently, for each cube edge intersecting with the implicit surface, we calculate the distance from the predicted intersection to the ground-truth intersection as . These results are obtained from the ShapeNet dataset. It is evident that our method significantly enhances the accuracy of the intersection point.
| Method | GIFS | SuperUDF | CAP | Ours |
|---|---|---|---|---|
| Distance | 0.0131 | 0.0127 | 0.0095 | 0.0084 |
| Method | ||
|---|---|---|
| 0.0023 | 0.9573 | |
| 0.0019 | 0.9648 |
| Method | ||
|---|---|---|
| 0.0024 | 0.9425 | |
| 0.0019 | 0.9648 |
Relative Sign Module Symmetry.
In our design, the Relative Sign Module remains symmetrical when the start point and end point exchange their positions, i.e., . Here, we aim to quantitatively evaluate the influence of this design feature. Therefore, we compare the reconstruction results when does not maintain this symmetry with the results when does maintain this symmetry. Specifically, when does not maintain the symmetry, we set
| (12) |
where is the standard positional encoding of both sine and cosine encoding. The quantitative result is in Table 7. We can see the symmetry works.
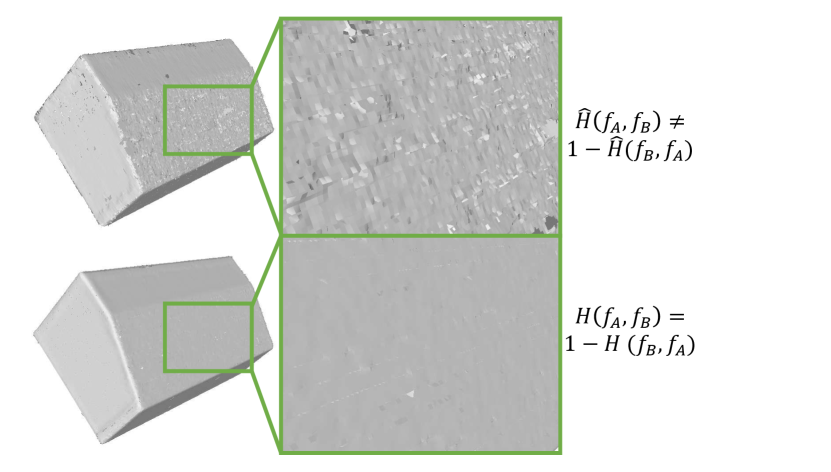
Intersection Module symmetry.
In our design, the Intersection Module exhibits the symmetry of the point pair, i.e., . This symmetry is ensured by the Sigmoid activation function and the unique design of positional encoding. Here, we seek to assess the influence of this symmetry. Therefore, we compare the results when the symmetry is absent versus when it is present. Specifically, we define the function as
| (13) |
The quantitative result is in Table 8 and visualization result is in Fig. 14, we can see that the discontinuity indeed appear when the symmetry is absent.
Efficiency Analysis
Here, we present the GPU memory usage and time required for mesh reconstruction in Table 9. The average reconstruction time was calculated across 1300 shapes from ShapeNet. The experiments were conducted using a Titan X 12GB GPU and an Intel(R) i9-9900k@3.60GHz CPU. It is evident that our approach achieves high reconstruction speed, albeit at the expense of increased GPU memory utilization.
5. Conclusion and Limitations
This study introduces a method that predicts the intersection between a line segment of a point pair and an implicit surface to effectively eliminate artefacts. Additionally, it proposes two novel modules that utilize neural networks to predict the relative sign of vertices at the corners of the cube and intersections between surface and line segment. This approach results in a more detailed surface reconstruction with fewer artefacts, leading to excellent outcomes on three datasets: ShapeNet, MGN, and ScanNet. However, there are some limitations to this method. For example, the method struggles to generate satisfactory meshes near the edges of open surfaces. This is problem will be addressed in the future works.
References
- (1)
- Atzmon and Lipman (2020a) Matan Atzmon and Yaron Lipman. 2020a. SAL: Sign Agnostic Learning of Shapes From Raw Data. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 2562–2571.
- Atzmon and Lipman (2020b) Matan Atzmon and Yaron Lipman. 2020b. SALD: Sign Agnostic Learning with Derivatives. arXiv:2006.05400 [cs]
- Ben-Shabat et al. ([n. d.]) Yizhak Ben-Shabat, Chamin Hewa Koneputugodage, and Stephen Gould. [n. d.]. DiGS: Divergence Guided Shape Implicit Neural Representation for Unoriented Point Clouds. ([n. d.]), 10.
- Bernardini et al. (1999) Bernardini, F., Mittleman, J., Rushmeier, H., Silva, C., Taubin, and G. 1999. The ball-pivoting algorithm for surface reconstruction. Visualization and Computer Graphics, IEEE Transactions on (1999).
- Boulch and Marlet (2022) A. Boulch and R. Marlet. 2022. POCO: Point Convolution for Surface Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Chang et al. (2015) Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. 2015. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015).
- Chen et al. (2020) Zhiqin Chen, Andrea Tagliasacchi, and Hao Zhang. 2020. Bsp-net: Generating compact meshes via binary space partitioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 45–54.
- Chen and Zhang (2021) Zhiqin Chen and Hao Zhang. 2021. Neural marching cubes. ACM Trans. Graph. 40, 6 (2021).
- Chibane et al. (2020a) Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. 2020a. Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE.
- Chibane et al. (2020b) J. Chibane, A. Mir, and G. Pons-Moll. 2020b. Neural Unsigned Distance Fields for Implicit Function Learning. (2020).
- Dai et al. (2017) Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. 2017. ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE.
- Erler et al. (2020) P. Erler, P. Guerrero, S. Ohrhallinger, M. Wimmer, and N. J. Mitra. 2020. Points2Surf: Learning Implicit Surfaces from Point Cloud Patches. (2020).
- Groueix et al. (2018) Thibault Groueix, Matthew Fisher, Vladimir G. Kim, Bryan C. Russell, and Mathieu Aubry. 2018. AtlasNet: A Papier-M\âch\’e Approach to Learning 3D Surface Generation. arXiv:1802.05384 [cs]
- Guillard et al. (2021) B. Guillard, F. Stella, and P. Fua. 2021. MeshUDF: Fast and Differentiable Meshing of Unsigned Distance Field Networks. arXiv e-prints (2021).
- Hu et al. (2020) Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, and Wen-Yang Zhou. 2020. Jittor: a novel deep learning framework with meta-operators and unified graph execution. Science China Information Sciences 63, 222103 (2020), 1–21.
- Kazhdan et al. (2013) M. Kazhdan, M. Bolitho, and H. Hoppe. 2013. Poisson surface reconstruction. The Japan Institute of Energy 67, 224 (2013), 1517–1531.
- Kingma et al. (2014) Kingma, Diederik P, and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kolluri (2008) Ravikrishna Kolluri. 2008. Provably good moving least squares. ACM Transactions on Algorithms (TALG) 4, 2 (2008), 1–25.
- Li et al. (2022) T. Li, X. Wen, Y. S. Liu, H. Su, and Z. Han. 2022. Learning Deep Implicit Functions for 3D Shapes with Dynamic Code Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Liao et al. (2018) Y. Liao, S Donné, and A. Geiger. 2018. Deep Marching Cubes: Learning Explicit Surface Representations. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Liu et al. (2021) Shi-Lin Liu, Hao-Xiang Guo, Hao Pan, Peng-Shuai Wang, Xin Tong, and Yang Liu. 2021. Deep Implicit Moving Least-Squares Functions for 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1788–1797.
- Loshchilov and Hutter (2016) I. Loshchilov and F. Hutter. 2016. SGDR: Stochastic Gradient Descent with Restarts. (2016).
- Ma et al. (2020) B. Ma, Z. Han, Y. S. Liu, and M. Zwicker. 2020. Neural-Pull: Learning Signed Distance Functions from Point Clouds by Learning to Pull Space onto Surfaces. (2020).
- Ma et al. ([n. d.]) Baorui Ma, Yu-Shen Liu, and Zhizhong Han. [n. d.]. Reconstructing Surfaces for Sparse Point Clouds With On-Surface Priors. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11.
- Mescheder et al. (2019) L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin, and A. Geiger. 2019. Occupancy Networks: Learning 3D Reconstruction in Function Space. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Palmer et al. ([n. d.]) David Palmer, Dmitriy Smirnov, Stephanie Wang, Albert Chern, and Justin Solomon. [n. d.]. DeepCurrents: Learning Implicit Representations of Shapes With Boundaries. ([n. d.]), 11.
- Park et al. (2019) JJ Park, P. Florence, J. Straub, R. Newcombe, and S. Lovegrove. 2019. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Peng et al. (2020) Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. 2020. Convolutional Occupancy Networks.
- Richa et al. ([n. d.]) Jean Pierre Richa, Jean-Emmanuel Deschaud, Francois Goulette, and Nicolas Dalmasso. [n. d.]. UWED: Unsigned Distance Field for Accurate 3D Scene Representation and Completion. ([n. d.]), 20.
- Sitzmann et al. (2020) Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. 2020. Implicit Neural Representations with Periodic Activation Functions. arXiv:2006.09661 [cs, eess]
- Tancik et al. (2020) M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. T. Barron, and R. Ng. 2020. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains.
- Tian et al. (2023) Hui Tian, Chenyang Zhui, Yifei Shi, and Kai Xu. 2023. SuperUDF: Self-supervised UDF Estimation for Surface Reconstruction. https://arxiv.org/abs/2308.14371 (2023).
- Venkatesh et al. (2021) Rahul Venkatesh, Tejan Karmali, Sarthak Sharma, Aurobrata Ghosh, R Venkatesh Babu, László A Jeni, and Maneesh Singh. 2021. Deep implicit surface point prediction networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 12653–12662.
- Venkatesh et al. (2020) Rahul Venkatesh, Sarthak Sharma, Aurobrata Ghosh, Laszlo Jeni, and Maneesh Singh. 2020. DUDE: Deep Unsigned Distance Embeddings for Hi-Fidelity Representation of Complex 3D Surfaces. arXiv:2011.02570 [cs]
- Wang et al. (2022b) Li Wang, Jie Yang, Wei-Kai Chen, Xiao-Xu Meng, Bo Yang, Jin-Tao Li, and Lin Gao. 2022b. HSDF: Hybrid Sign and Distance Field for Modeling Surfaces with Arbitrary Topologies. In Neural Information Processing Systems (NeurIPS).
- Wang et al. (2023a) Meng Wang, Yu-Shen Liu, Yue Gao, Kanle Shi, Yi Fang, and Zhizhong Han. 2023a. LP-DIF: Learning Local Pattern-Specific Deep Implicit Function for 3D Objects and Scenes. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, 21856–21865. https://doi.org/10.1109/CVPR52729.2023.02093
- Wang et al. (2020) Peng-Shuai Wang, Yang Liu, and Xin Tong. 2020. Deep Octree-based CNNs with Output-Guided Skip Connections for 3D Shape and Scene Completion. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
- Wang et al. (2022a) Peng-Shuai Wang, Yang Liu, and Xin Tong. 2022a. Dual Octree Graph Networks for Learning Adaptive Volumetric Shape Representations. In ACM Transactions on Graphics.
- Wang et al. (2023b) Zhen Wang, Shijie Zhou, Jeong Joon Park, Despoina Paschalidou, Suya You, Gordon Wetzstein, Leonidas Guibas, and Achuta Kadambi. 2023b. ALTO: Alternating Latent Topologies for Implicit 3D Reconstruction. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 259–270.
- Yang et al. (2023) Huizong Yang, Yuxin Sun, Ganesh Sundaramoorthi, and Anthony Yezzi. 2023. StEik: Stabilizing the Optimization of Neural Signed Distance Functions and Finer Shape Representation. arXiv:2305.18414 [cs.CV]
- Ye et al. (2022) Jianglong Ye, Yuntao Chen, Naiyan Wang, and Xiaolong Wang. 2022. GIFS: Neural Implicit Function for General Shape Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11.
- Zhao et al. (2020) Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. 2020. Exploring Self-attention for Image Recognition.
- Zhao et al. (2021) Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. 2021. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 16259–16268.
- Zhao et al. (2023) Tong Zhao, Laurent Busé, David Cohen-Steiner, Tamy Boubekeur, Jean-Marc Thiery, and Pierre Alliez. 2023. Variational Shape Reconstruction via Quadric Error Metrics. In ACM SIGGRAPH 2023 Conference Proceedings. Article 45, 10 pages.
- Zhenxing et al. (2020) Mi Zhenxing, Luo Yiming, and Tao Wenbing. 2020. SSRNet: Scalable 3D Surface Reconstruction Network. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Zhou et al. (2022) Junsheng Zhou, Baorui Ma, Liu Yu-Shen, Fang Yi, and Han Zhizhong. 2022. Learning Consistency-Aware Unsigned Distance Functions Progressively from Raw Point Clouds. In Advances in Neural Information Processing Systems (NeurIPS).