Surfacing contextual hate speech words within social media
Abstract.
Social media platforms have recently seen an increase in the occurrence of hate speech discourse which has led to calls for improved detection methods. Most of these rely on annotated data, keywords, and a classification technique. While this approach provides good coverage, it can fall short when dealing with new terms produced by online extremist communities which act as original sources of words which have alternate hate speech meanings. These code words (which can be both created and adopted words) are designed to evade automatic detection and often have benign meanings in regular discourse. As an example, “skypes, googles, yahoos” are all instances of words which have an alternate meaning that can be used for hate speech. This overlap introduces additional challenges when relying on keywords for both the collection of data that is specific to hate speech, and downstream classification. In this work, we develop a community detection approach for finding extremist hate speech communities and collecting data from their members. We also develop a word embedding model that learns the alternate hate speech meaning of words and demonstrate the candidacy of our code words with several annotation experiments, designed to determine if it is possible to recognize a word as being used for hate speech without knowing its alternate meaning. We report an inter-annotator agreement rate of , and for data drawn from our extremist community and the keyword approach respectively, supporting our claim that hate speech detection is a contextual task and does not depend on a fixed list of keywords. Our goal is to advance the domain by providing a high quality hate speech dataset in addition to learned code words that can be fed into existing classification approaches, thus improving the accuracy of automated detection.
1. Introduction
The internet allows for the free flow of information and one of its major growing pains has been the propagation of hate speech and other abusive content, however, it is becoming increasingly common to find hateful messages that attack a person or a group because of their nationality, race, religion or gender. Sentences like I fucking hate niggers or go back to your muslim shithole 111Reader advisory: We present several examples that feature hate speech and explicit content. We want to warn the reader that these examples are lifted from our data set and are featured here for illustrative purposes only. can be readily found even when viewing topics that should be far removed from hate speech. This creates an atmosphere that becomes uncomfortable to engage in and can have a significant impact on online discourse and it inflicts a damaging financial and social cost on both the social network and the victims alike. Twitter has reportedly lost business partially as a result of potential buyers raising concerns about the reputation that the social network has for bullying and uncivil communication. (Bloomberg, 2016). Additionally, the European Union has moved to enact a law that will impose hefty fines on social media networks that fail to remove flagged hate speech content within 24 hours, and other offensive content within 7 days, even going as far as to hold personal staff accountable for the inaction of these companies. (Forbes, 2017)
To address the issue, social networks like Twitter try to balance the need to promote free speech and to create a welcoming environment. The Terms of Service for these platforms provide guidelines on what content is prohibited, these guidelines then shape the automatic filtering tools of these platforms. However, Hate Speech [HS] can be difficult to define as there are some who argue that restrictions on what constitutes HS are in fact violations of the right to free speech. The definition can also vary in terms of geographic location and the laws that can be applied. It is thus important to adhere to a rigid definition of HS in our work.
For this work we rely on the definition from the International Covenant on Civil and Political Rights, Article 20 (2) which defines Hate Speech as any advocacy of national, racial or religious hatred that constitutes incitement to discrimination, hostility or violence (United Nations General Assembly Resolution 2200A [XX1], 1966). In a troubling development, online communities of users that engage in HS discourse are constantly crafting new linguistic means of bypassing automatic filters. These include intentional misspellings and adapting common words to have alternative meanings, effectively softening their speech to avoid being reported and subsequently banned from the platform. There are two major challenges that need to be considered:
-
•
Substitution: members of online hate speech communities tend to to substitute words that have accepted hate speech meanings with something that appears benign and out of context, to be only understood by fellow community members. This is not unlike the use of codewords for open communication. To illustrate, consider the following example, “Anyone who isn’t white or christian does not deserve to live in the US. Those foreign skypes should be deported.” Here, the word “skypes” is a code word used to refer to Jewish people. The example would likely be missed by a classifier trained with word collocation features, as it does not contain any words strongly associated with hate speech, a problem highlighted by Nobata et al.(Nobata et al., 2016). We can infer that “skypes” is being used as a code word here and we can also infer possible words that are both similar and substitutable such as “niggers” or “muslims”.
-
•
Non representative data: Keyword sampling is often used to collect data but those keywords often overlap with many topics. For example, there is no distinction between the words fuck, fucking, shit, which are often used for hate speech as well as regular conversations. Extensive annotation is first required before any methodology can be applied. Additionally, Some users also limit what they say in public spaces and instead link to extremist websites that express their shared ideas, minimizing their risk being banned. This creates a certain fuzziness that has so far not been fully addressed when using public data for hate speech research.
In this paper we aim to develop a method that detects hate speech communities while also identifying the hate speech codewords that are used to avoid detection. We make use of word dependencies in order to detect the contexts in which words are utilized so as to identify new hate speech code words that might not exist in the known hate speech lexicon. Specifically, to address the challenges outlined, this paper has the following contributions:
-
•
We develop a graph based methodology to collect hateful content shared by extremist communities.
-
•
We address the constant introduction of new hate speech terms with our contextual word enrichment model that learns out-of-dictionary hate speech code words
-
•
We make public our dataset and our code word pipeline as a means to expand existing hate speech lexicon.
Our results show the benefit of collecting data from hate speech communities for use in downstream applications. We also demonstrate the utility of considering syntactic dependency-based word embeddings for finding words that function similar to known hate speech words (code words). We present our work as an online system that continuously learns these dependency embeddings, thus expanding the hate speech lexicon and allowing for the retrieval of more tweets where these code words appear.
2. Related Work
The last several years has seen an increase in research related to identifying HS within online platforms, with respect to both hate speech classification and the detection of extremist communities. O’Callaghan et al. (O’Callaghan et al., 2013) made use of Twitter profiles to identify and analyse the relationships between members of extremist communities which consider cross-country interactions as well. They note that linguistic and geographic proximity influences the way in which extremist communities interact with each other. Also central to the problem that we attempt to solve is the idea of supplementing the traditional bag of words [BOW] approach. Burnap and Williams (Burnap and Williams, 2016) introduced the idea of othering language (the idea of differentiating groups of with “us” versus “them” rhetoric) as a useful feature for HS classification. Long observed in discussions surrounding racism and HS, their work lends credence to the idea that HS discourse is not limited to the presence or absence of a fixed set of words, but instead relies one the context in which it appears. The idea of out-of-dictionary HS words is a key issue in all related classification tasks and this work provides us with the basis and motivation for constructing a dynamic method for identifying these words. However, hate speech detection is a difficult task as it is subjective and often varies between individuals. Waseem (Waseem, 2016) speaks to the impact that annotators have on the underlying classification models. Their results show the difference in model quality when using expert versus amateur annotators, reporting an inter-annotator agreement of amateurs and for the expert annotators. The low scores indicated that hate speech annotation and by extension classification, is difficult task and represents a significant and persistent challenge.
Djuric et al. (Djuric et al., 2015) adopted the paragraph2vec [a modification of word2vec] approach for classifying user comments as being either abusive or clean. This work was extended by Nobata et al. (Nobata et al., 2016), which made use of features from n-grams, Linguistic, Syntactic and Distributional Semantics. These features form their model, comment2vec, where each comment is mapped to a unique vector in a matrix of representative words. The joint probabilities from word vectors were then used to predict the next word in a comment. As our work focuses on learning the different contexts in which words appear, we utilize neural embedding approaches with fasttext by Bojanowski et al. (Bojanowski et al., 2016) and dependency2vec by Levy and Goldberg (Omer and Yoav, 2014).
Finally, Magu et al. (Magu et al., 2017) present their work on detecting hate speech code words which focused on the manual selection of hate speech code words. These represent words that are used by extremist communities to spread hate content without being explicit, in an effort to evade detection systems. A fixed seed of code words was used to collect and annotate tweets where those words appear for classification. These code words have an accepted meaning in the regular English language which users exploit in order to confuse others who may not understand their hidden meaning. In contrast to this work, we propose our method for dynamically identifying new code words. All of the previous studies referenced here utilize either an initial bag of words [BOW] and/or annotated data and the general consensus is that a BOW alone is not sufficient. Furthermore, if the BOW remains static then trained models would struggle to classify less explicit HS examples, in short, we need a dynamic BOW.
To advance the work, we propose the use of hate speech community detection in order to get data which fully represents how these communities use words for hate speech. We use this data to obtain the different types of textual context as our core features for surfacing new hate speech code words. This context covers both the topical and functional context of the words being used. The aim of our work is to dynamically identify new code words that are introduced into the corpus and to minimize the reliance on a BOW and annotated data.
3. Background
3.1. Addressing Hate Speech Challenges
Firstly, we must define our assumptions about hate speech and the role that context takes in our approach. Our goal is to obtain data from online hate speech communities, data which can be used to build models that create word representations of relatedness and similarity. We present our rationale for collecting data from online hate speech communities and explain the various types of context used throughout our methodology.
While there exists words or phrases that are known to be associated with hate speech222We used lists scraped from http://www.hatebase.org/ as used by Nobata et al. (Nobata et al., 2016)., it can often be expressed without any of these keywords. Additionally, it is difficult for human annotators to identify hate speech if they are not familiar with the meaning of words or any context that may surround the text as outlined in (Waseem and Hovy, 2016). These issues make it difficult to identify hate speech with Natural Language Processing [NLP] approaches. Further compounding the issue of hate speech detection, the members of these online communities have adopted strategies for bypassing the automatic detection systems that social networks employ. One such strategy being used is word substitution, where explicit hate speech words are replaced with benign words which have hidden meanings. Ultimately, the issue with code words is one of word polysemy and it is particularly difficult to address because these alternate meanings do not exist in the public lexicon.
To deal with the problem of code word substitution, we use word similarity and word relatedness features to train contextual representations of words that our model can use to identify possible hate speech usage. To do this, it is necessary to use models that align words into vector space in order to get the neighbours of a word under different uses. These models are referred to as Neural Embeddings and while most in the same fundamental way, the distinction comes from the input (hereafter referred to as context) that they make use of. We introduce topical context and functional context as key concepts that will influence our features.
3.2. Neural Embeddings and Context
Neural Embeddings refer to the various NLP techniques used for mapping words or phrases to dense vector representations that allow for efficient computation of semantic similarities of words. The idea is based on Distributional Hypothesis by Harris (Harris, 1981) which states that “words that appear in the same contexts share semantic meaning”, meaning that a word shares characteristics other words that are typically its neighbours in a sentence. Cosine similarity is the measure used for vector similarity, it will hereafter appear as . Neural Embedding models represent words in vector space. Given a target word , an embedding model , it and a specified value, it is possible to retrieve the most words in , will be used to reference this function hereafter.
Topical Context is the context used by word embedding approaches like word2vec (Mikolov et al., 2013), that utilize a bag-of-words in an effort to rank words by their domain similarity. Context here is considered as the window for each word in a sentence, the task being to extract target words and their surrounding words (given a window size) to predict each context from its target word. In doing so it models word relatedness. However, functional context describes and ranks words by the syntactic relationships that a word participates in. Levy and Goldberg (Omer and Yoav, 2014) proposed a method of adapting word2vec to capture the Syntactic Dependencies in a sentence with dependency2vec. Intuitively, Syntactic Dependencies refers to the word relationships in a sentence. Such a model might tell us words close to Florida, words might be New York, Texas, California; words that reflect that Florida is a state in the United States. We simplify this with the term similarity, to indicate that words that share similar functional contexts are similar to each other.
Functional context is modelled by dependency2vec, a modification of word2vec proposed by Levy and Goldberg (Omer and Yoav, 2014) who build the intuition behind Syntactic Dependency Context. The goal of the model is to create learned vector representations which reveal words that are functionally similar and behave like each other, i.e., the model captures word similarity. dependency2vec operates in the same way as word2vec with the only difference being the representation of context. The advantage of this approach is that the model is then able to capture word relations that are outside of a linear window and can thus reduce the weighting of words that appear often in the same window as a target word but might not actually be related.
Topical context reflects words that associate with each other (relatedness) while functional context reflects words that behave like each other (similarity). In our work we wish answer the following: how do we capture the meaning of code words that we do not know the functional context of? To provide an intuitive understanding and motivation for the use of both topical and functional context we provide an example. Consider the following real document drawn from our data:
| Skypes and googles must be expelled from our homelands |
| skypes | ||||||||||
| Clean Texts |
|
|
||||||||
| Hate Texts |
|
|
||||||||
| Relatedness | Similarity | |||||||||
With the example we generate Table 1 which displays the top 4 words closest to the target word skypes, across two different datasets and word contexts. We assume the existence of embedding models trained on relatively clean text and another trained on text filled with hate speech references. For words under the relatedness columns, we see that they refer to internet companies. In this case, while we know that skypes is a hate speech code word it still appears alongside the internet company words because of the word substitution problem. We see the same effect for similarity under Clean Texts. However, when looking at similarity under the Hate Texts we can infer that the author is not using Skype in its usual form. The similarity columns gives us words that are functionally similar. We do not yet know what the results mean but anecdotally we see that the model returns groups of people and it is this type of result we wish to exploit in order to detect code words within our datasets. It is for this reason that we desire Neural Embedding models that can learn both word similarity and word relatedness. We propose that this can be used as an additional measure to identify unknown hate speech code words that are used in similar functional contexts to words that already have defined hate speech meanings.
4. Methodology
4.1. Overview
The entire process consists of four main steps:
-
•
Identifying online hate speech communities
-
•
Creating Neural Embedding models that capture word relatedness and word similarity.
-
•
Using graph expansion and PageRank scores to bootstrap our initial HS seed words.
-
•
Enriching our bootstrapped words to learn out-of-dictionary terms that bare some hate speech relation and behave like code words.
The approach will demonstrate the effectiveness of our hate speech community detection process. Additionally, we will leverage existing research that confirmed the utility of using hate speech blacklists, syntactic features, and various neural embedding approaches. We provide a an overview of our community detection methodology, as well as the different types of word context, and how they can be utilised to identify possible code words.
4.2. Extremist Community Detection
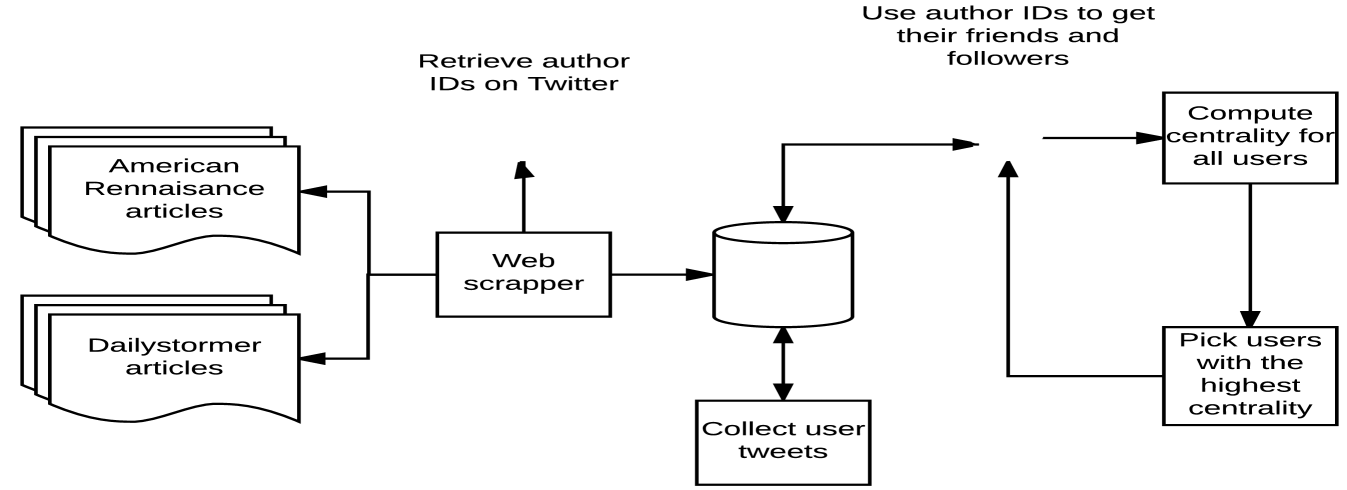
A key part of our method concerns the data and the way in which it was collected and partitioned, as such it is important to first outline our method and rationale. There exists words that can take on a vastly different meanings depending on the way in which they are used, that is, they act as codewords under different circumstances. Collecting data from extremist communities which produce hate speech content is necessary to build this representation. There are communities of users on Twitter and elsewhere that share a high proportion of hate speech content amongst themselves and it is reasonable to expect that they would want to share writing or other content that they produced with like minded individuals. We are of the belief that new hate speech codewords are created by these communities and that if there was any place to build a dataset that reflects a “hate speech community” it would be at the source. We began the search by referencing the Extremist Files maintained by the Southern Poverty Law Center[SPLC]333https://www.splcenter.org/, a US non-profit legal advocacy organization that focuses on civil rights issues and litigation.
The SPLC keeps track of prominent extremist groups and individuals within the US, including several websites that are known to produce extremist and hate content, most prominent of these being DailyStormer444https://www.dailystormer.com/ and American Renaissance555https://www.amren.com/. The articles on these websites are of a White Supremacist nature and are filled with references that degrade and threaten non white groups, as such, it serves as an ideal starting point for our hate speech data collection. The two websites mentioned were selected as our seed and we crawled their articles, storing the author name, the article body, and its title. The list of authors was then used for a manual lookup in order to tie the article author to their Twitter account. We were not able to identify the profile of each author as some of the accounts in our list self identified as being pseudo-names. For each of these Twitter accounts we extracted their followers and friends, building an oriented graph where each vertex represents a user and edges represent a directional user-follower relationship. In order to discover authors that were missed during the initial pass, we use the centrality betweenness of different vertices to get prominent users. Due to preprocessing constraints we opted to compute an approximate betweenness centrality.
Definition 4.1.
(Vertices) For this relationship graph, refers to the set containing all vertices while is a random subset of . We utilize SSSP (single source, shortest path) which is defined as , the number of shortest paths from to , . Similarly, the number of shortest paths between and going through , is thus:
The computed betweenness centrality for every element in is then used to extrapolate the value of other nodes, as described in Brandes et.al (Brandes and Pich, 2007). From there, an extended seed of a specified size will be selected based on the approximated centrality of the nodes and the original author. With this extended seed, it becomes possible to collect any user-follower relationships that were initially missed. After the initial graph processing, over 3 million unique users IDs were obtained. A random subset of vertices was then taken to reduce the size of the graph for computational considerations. This random subset forms a graph containing vertices, . Each vertex of represents a user while directed edges represent relationships. Consider , if is following then a directed edge will exists. Historical tweet data was collected from these vertices, representing over 36 millions tweets. We hereafter refer to graph as HateComm, our dataset which consists of the article content and titles previously mentioned in addition to the historical tweets of users within the network of author followers.
The issue with code words is that they are by definition secret or at best, not well known. Continuing with the examples of Skype and Google we previously introduced, if we were to attempt to get related or even similar words from a Neural Embedding model trained on generalized data, it is unlikely that we would observe any other words that share some relation to hate speech. However, it is not enough to train models on data that is dense with hate speech. The results might highlight a relation to hate speech but would provide no information on the frequency of use in different situations, in short, we need to have some measure of the use of a word in the general English vocabulary in order to support the claim that these words can also act as hate speech code words. It is for this reason that we propose a model that includes word similarity, relatedness and frequency of use, drawn from the differing datasets. We therefore introduce two additional datasets that we collect from Twitter, the first using hate speech keywords and the second collected from the Twitter stream without any search terms. Twitter offers a free 1% sample of the total tweets sent on the platform and so we consider tweets collected in this manner to be a best effort representation of the average.
Hate Speech Keywords is is defined as a set of words = typically associated with hate speech in the English language. We made use of the same word source as (Nobata et al., 2016). TwitterHate refers to our dataset of tweets collected using as seed words. While TwitterClean refers to our dataset collected without tracking any specific terms or users, only collecting what Twitter returned, free from the bias of collecting data based on keywords. We filter and remove any tweet that contains a word .
4.3. Contextual Code Word Search
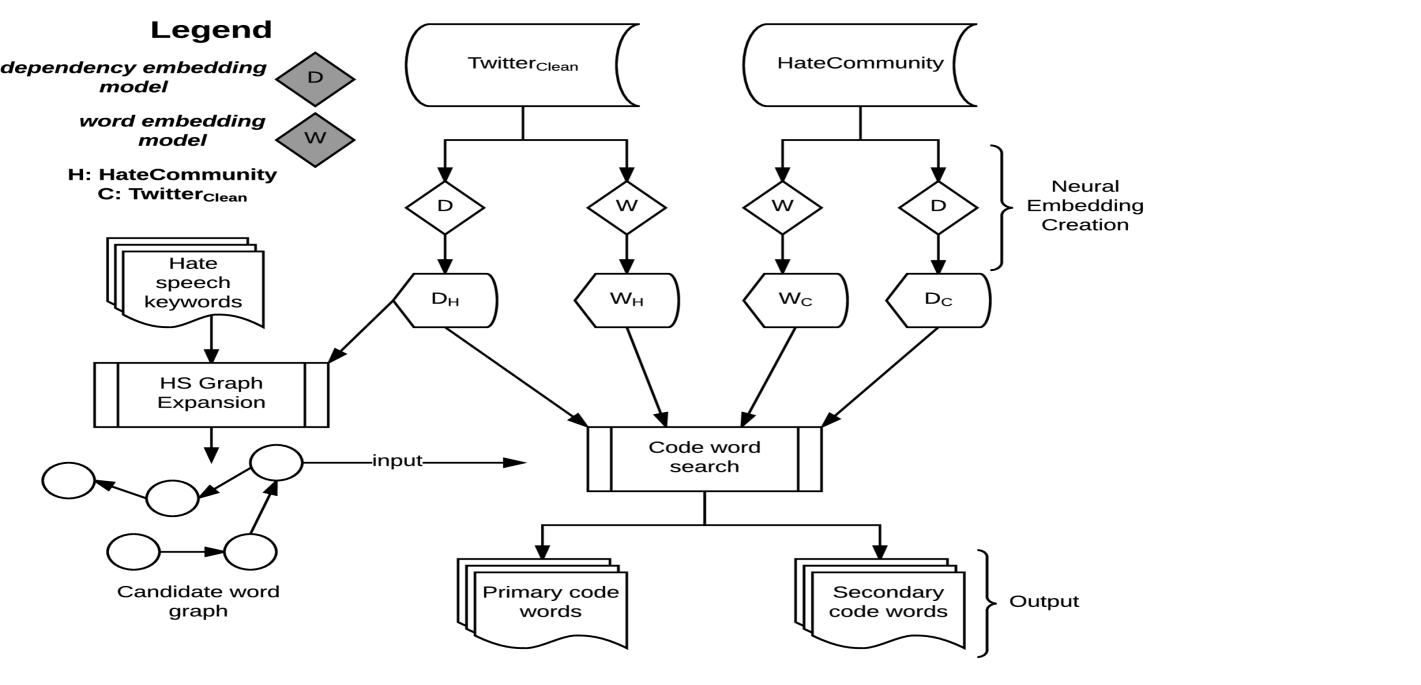
For our work we dynamically generate contextual word representations which we use for determining if a word acts as a hate speech code word or not. To create contextual word representations we use the Neural Embedding models proposed by dependency2vec(Omer and Yoav, 2014) and fasttext (Bojanowski et al., 2016). As we wish to identify out-of-dictionary words that can be linked to hate speech under a given context, as part of our preprocessing we we then define a graph based approach to reduce the word search space. Finally, our method for highlighting candidate code words is presented. We report our code words as well as the strength of the relationship that they may have to hate speech.
4.3.1. Embedding Creation
Creating a model that align words into vector space allows for the extraction of the neighbours of a word under different uses. Our intuition is that we can model the topical and functional context of words in our hate speech dataset in order to identify out-of-dictionary hate speech code words. For our HateComm and TwitterHate datasets we create both a Word Embedding Model and a Dependency Embedding Model as We refer to these as , , , and .
4.3.2. Contextual Graph Filtering
The idea for finding candidate code words is based on an approach that considers the output from the word list from our 4 embedding models, given a target word w. Filtering the list of possible out of dictionary words is required to reduce the search space and obtain non hate speech words input our code word search. to check. To achieve this, we devised a graph construction methodology that builds a weighted directed graph of words with the output from an embedding model. In this way, we can construct a graph that models word similarity or word relatedness, depending on the embedding model we utilize. This graph takes on several different inputs and parameters throughout the algorithm, as such we define the general construction.
Definition 4.2.
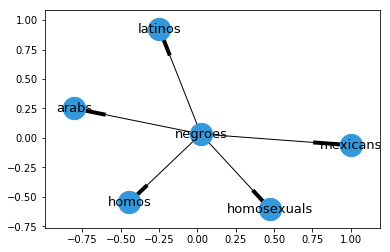
(Contextual Graph) is a weighted directed graph where each vertex represents a word . Edges are represented by the set . The graph represents word similarity or word relatedness, depending on the embedding model used at construction time. For a pair of vertices an edge is created if appears in the output of , with as the input word. As an intuitive example, using = negroes from Table 1 the output contextual graph can be seen in Figure 3.
To further reduce the search space we use PageRank (Page et al., 1999) to rank out-of-dictionary words in a graph where some of the vertices are known hate speech keywords. This allows us to model known hate speech words and words close to them as important links that pass on their weight to their their successor vertices, thus boosting their importance score. In this way we are able to have the edges that are successors of a known hate speech word get a boost which reflects a higher relevance in the overall graph.
Definition 4.3.
(boost) During the construction of any contextual graph we do a pre-initialization step where we call with a given for if . Recall that is the stored vocabulary for the embedding model used during graph construction. The frequency of each word in the resulting collection is stored in . thus returns the frequency of the word in this initialization step, if it exists.
This boosting gives us words that are close to known hate speech keywords and is done to to assign a higher weighting based on the frequency of a word in a list generated with the seed. Using cosine similarity scores alone as the edge weight would not allow us to model the idea that hate speech words are the important “pages” in the graph, the key concept behind PageRank. Concisely, this boosting is done to set known hate speech words as the important “pages” that pass on their weight during the PageRank computation. Edge attachment is then done via 2 weighting schemes that we employ.
Definition 4.4.
(weightingScheme) Let denote the frequency of vertex in for the given embedding model, and the cosine similarity score for the embedding vectors under vertices and . The weight of e() is then defined in the following:
With the prerequisite definitions in place we now outline our algorithm for building an individual word contextual graph in Algorithm 1. Intuitively, the algorithm accepts a target word and attaches edges to vertices that appear in the results for . We then collect all vertices in the graph and repeat the process, keeping track of the vertices that we have seen. Note that specifies the number of times that we collect current graph vertices and repeat the process of appending successor vertices. A of indicates that we will only repeat the process for unseen vertices twice.
Our hate speech seed graph then becomes a union of contextual graphs [4.2] created from a list of words, with a graph being created for each word. We opted to use similarity embedding model over relatedness for this step. The union can be seen in the following equation.
We then perform PageRank on the hate speech seed graph and use the document frequency [] for a given word as a cut-off measure, where is the total number of documents in a given dataset; subsequently removing all known hate speech words from the output. The assumption is that if a word in our Graph is frequently used as a code word, then it should representing have a higher in HateComm over TwitterClean . To illustrate, we wouldn’t expect hate communities to use the word animals for it’s actual meaning more than the general dataset. This assumption is supported by plotting the frequencies and observing that most of the words in the graph have a high in HateComm and it is necessary to surface low frequency words. We perform several frequency plots and the results confirm our assumption. For the PageRank scores we set as it is the standard rate of decay used for the algorithm. and trim as outlined in the equation:
Finally, we further refine our seed list, by building a new graph using the trimmed , computing a revised on the resulting graph. To be clear, only the word in this list and not the actual scores are used as input for our codeword search.
| Notation | Description |
|---|---|
| a contextual graph built with output from | |
| a learned model trained on TwitterClean | |
| a learned model trained on HateComm | |
| a learned embedding model of type or | |
| a stored vocabulary for a given embedding model | |
| a learned word embedding model trained on TwitterClean | |
| a learned word embedding model trained on HateComm |
4.3.3. Contextual Code Word Search
With our trimmed PageRank list as input, we outline our process for selecting out-of-dictionary hate speech code words. We place words into categories which represent words that may be very tightly linked to known hate speech words and those that have a weaker relation.
Definition 4.5.
(getContextRep) At the core of the method is the mixed contextual representation that we generate for an input word from our HateComm and TwitterClean datasets. It simply gives us word the relatedness and word similarity output from embedding models trained on HateComm . The process is as follows:
Definition 4.6.
(primaryCheck) accepts a word , its contextual representation, and to determine if should be placed in the primary code word bucket, returning true or false. Here, primary buckets refers to words that have some strong relation to known hate speech words. First we calculate thresholds which check whether the number of number of known hate speech words in the contextual representation for a given word is above the specified threshold .
With both thresholds, we perform an OR operation with . Next, we determine whether has a higher frequency in HateComm over TwitterClean by . Finally, a word is selected as a primary code word with
Definition 4.7.
(secondaryCheck) accepts a word and its contextual graph and searches the vertices for any , returning the predecessor vertices of as a set if a match is found as well as. We check that the set is not empty and use the truth value to indicate whether should be placed in the secondary code word bucket.
5. Experiment Results
5.1. Training Data
In order to partition our data and train our Neural Embeddings we first collected data from Twitter. Both TwitterClean and TwitterHate are composites of data collected over several time frames, including the two week window leading up to the 2016 US Presidential Elections, the 2017 US Presidential Inauguration, and at other points during early 2017, consisting of around 10M tweets each. In order to create HateComm we crawled the websites obtained from the SPLC as mentioned in Section 4.2 and obtained a list of authors and attempted to link them to their Twitter profiles. This process yielded 18 unique profiles from which we collected their followers and built a graph of user:followers. We then randomly selected 20,000 vertices and collected their historical tweets, yielding around 400K tweets. HateComm thus consists of tweets and the article contents that were collected during the scraping stage.
We normalize user mentions as user_mention, preserve hashtags and emoji, and lowercase text. The tokenizer built for Twitter in the Tweet NLP666http://www.cs.cmu.edu/ ark/TweetNLP/ package was used. It should be noted that the Neural Embeddings required a separate preprocessing stage, for that we used the NLP package Spacy777https://spacy.io/ to extract syntactic dependency features.
5.2. Experimental Setup
As mentioned previously, we utilized fasttext and dependency2vec to train our Neural Embeddings. For our Dependency Embeddings we used 200 dimension vectors and for fasttext we utilized 300.
To initialize our list of seed words for our approach we built a contextual graph with the following settings.
-
(1)
was used to build a based on similarity
-
(2)
to generate boost we set
-
(3)
We consider singular and plural variations of each
-
(4)
Vertices were added with and
This process for expanding our seed returned words after trimming with the frequency rationale. For the contextual code word search we used the following:
-
(1)
, ,
We set after experiments showed that most words did not return more than 1 known hate speech keyword when checking its 5 closest words. This process return 55 primary and 262 secondary bucket words. It should be noted that we filtered for known including any singular or plural variations. An initial manual examination of this list gave the impression that while the words were not directly linked to hate speech, the intent could be inferred under certain circumstances. It was not enough the do a manual evaluation as we needed a way to verify if the words we had surfaced could be recognized as being linked to hate speech under the right context. We saw fit to design an experiment to test our results.
5.3. Baseline Evaluation
The major difficulty of our work has been choosing a method to evaluate our results as their are few direct analogues. As our baseline benchmark we calculate the tf-idf word scores for HateComm and compare with frequencies for our surfaced code words. Using the tf-idf scores is a common approach for discovering the ideas present in a corpus. Where higher tf-idf scores indicate a higher weight, due to low frequency use of our code words lower scores represent a higher weight. For the code word weights we use inverse document frequency. Figures 4 and 5 show the difference between the TF-IDF baseline and our contextual code word search. The TF-IDF output appears to be of a topical nature, particularly politics while the code word output features multiple derogatory references throughout.
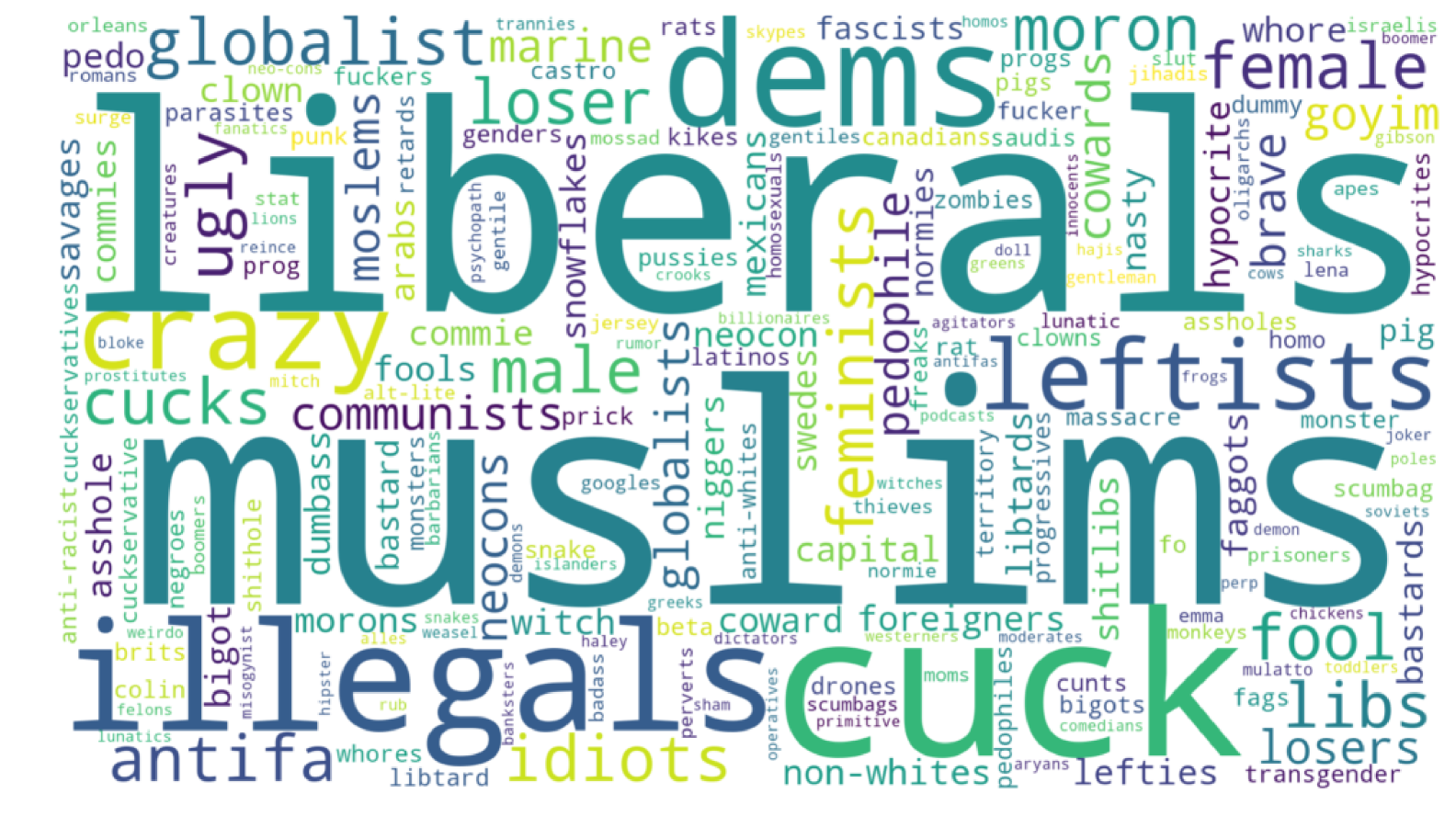
The contextual code word approach is not without drawbacks, as ultimately these words are a suggestion of possible hate speech code words. However, it represents an improvement over attempting to find these hate speech code words manually as the model can learn new hate speech code words as they are introduced.
5.4. Annotation Experiment
We have claimed throughout or work that context is important and we designed an experiment to reflect that. Our aim was to determine if a selection of annotators would be able to identify when a given word was being used in a hate speech context without the presence of known hate speech keyword and without known the meaning of the code words. The experiment featured manually selected code words including 1 positive and 1 negative control word. It is important to have some measure of control as many different works including (Waseem, 2016) have highlighted the difficulty of annotating hate speech. The positive and negative samples were designed to test if annotators could identify documents that featured explicit hate speech (positive) and documents that were benign (negative).
We built three distinct experiments where:
-
(1)
Documents refer to tweets and article titles.
-
(2)
10 code words were manually selected and participants were asked to rate a document on a scale of very unlikely (no references to hate speech) to very likely (hate speech) [0 to 4].
-
(3)
HateCommunity, TwitterClean, and TwitterHate were utilized as the sample pool, randomly drawing 5 documents for each code word (10 word X 5 documents for each experiment).
-
(4)
Control documents were the same across all three experiments and did not feature known HS words apart from the positive control.
-
(5)
Direct links were only provided for the experiments drawn from HateCommunity and TwitterClean. After completing these experiments, participants were given the option to move on to the TwitterHate experiment.
The experiment was designed to draw for our distinct datasets which would reflect the use of the same word across differing situations and contexts. We obtained 52, 53, and 45 responses for HateCommunity, TwitterClean, and TwitterHate respectively. The full list can be seen in Table 3. Table 4 provides a view of a few of the documents annotators were asked to rate. None of the examples features known but it is possible to infer the intent of the original author. The experiment also featured control questions designed to test if participants understood the experiment, we provided 5 samples that featured the use of the word nigger as positive for hate speech and water as negative for hate speech. An overwhelming majority of the were able to correctly rate both control questions, as can be seen in Figs. 6.
| code words | |
|---|---|
| niggers [positive control] | water [negative control] |
| snake | googles |
| cuckservatives | skypes |
| creatures | moslems |
| cockroaches | primitives |
| another cop killed and set on fire by googles |
| @user i’m sick of these worthless googles >>#backtoafrica |
| strange mixed-breed creatures jailed for killing white woman |
| germany must disinfect her land. one cockroach at a time if necessary |
To get an understanding of the quality of the data and to facilitate further experiments, we created a ground truth result and aggregated the annotators based on their majority ratings. We first calculated inter annotator agreement with Krippendorff’s Alpha which is a statistical measure of agreement that can account for ordinal data. With the majority rankings, we recorded , and for HateComm , TwitterClean and TwitterHate . The experiment demonstrated the importance of data sources as the sentences sampled from each data set were at times in stark contrast to each other, reflecting the advantage of the extremist community data over the traditional keyword collection method. We achieved the highest agreement scores for hate speech when using the extremist community dataset.
We then moved to calculate precision and recall scores. As we used a likert scale for our ratings, we took ratings that were above the neutral point (2) to as hate speech and ratings below as not hate speech. Interestingly, when taking the majority none of the questions featured the Neutral label as the majority. Our aim for this experiment was to determine if the ratings of the annotator group would reflect hate speech classification when aggregated. The results below show the classification across all 10 5 documents for each experiment (the matrix sums to 10). The Precision, Recall, and F1 scores can be seen in Table 5 which shows the F1 scores of 0.93 and 0.86 for HateComm and TwitterClean respectively. This result indicates that the annotators were able to correctly classify the usage of the same word under different contexts, from data that is dense in hate speech and data that reflects the general Twitter sample. The scores show that when taking the annotators as a single group that they were in line with the ground truth. This gives supports to our claim that it is possible in some cases to infer hate speech intent without the presence or absence of specific words.
| Hate Speech | Not Hate Speech | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HateCommunity |
|
|
|
|||||||||
| TwitterClean |
|
|
|
|||||||||
| TwitterHate |
|
|
|
One of the ideas that we wanted to verify in the experiment was whether the rankings of the annotators would align with the ground truth. We include the ranking distribution for the HateComm experiment results in Table 6. The results compare the majority ranking for each word as well as the percentage against the ground truth.
| HateCommunity Results | ||||
| Ground Truth | Annotators | |||
| Words | Label | Percent | Label | Percent |
| niggers | Very likely | 0.8 | Very likely | 0.68 |
| snakes | Unlikely | 0.4 | Neutral | 0.26 |
| googles | Very likely | 1.0 | Very likely | 0.41 |
| cuckservatives | Unlikely | 1.0 | Likely | 0.36 |
| skypes | Likely | 0.8 | Likely | 0.3 |
| creatures | Very likely | 0.6 | Very likely | 0.4 |
| moslems | Likely | 0.8 | Very likely | 0.39 |
| cockroaches | Very likely | 1.0 | Very likely | 0.40 |
| water | Very unlikely | 1.0 | Very unlikely | 0.65 |
| primatives | Very likely | 0.6 | Very likely | 0.37 |
6. Conclusions and Future Work
We propose a dynamic method for learning out-of-dictionary hate speech code words. Our annotation experiment showed that it is possible to identify the use of words in hate speech context without knowing the meaning of the word. The results show that the task of identifying hate speech is not dependent on the presence or absence of specific keywords and supports our claim that it is an issue of context. We show that there is utility in relying on a mixed model of word similarity and word relatedness as well as the discourse from known hate speech communities. We hope to implement an API that can constantly crawl known extremist websites in order to detect new hate speech code words that can be fed into existing classification methods. Hate speech is a difficult problem and our intent is to collaborate with organisations such as HateBase by providing our expanded dictionary.
References
- (1)
- Bloomberg (2016) Bloomberg. 2016. Disney Dropped Twitter Pursuit Partly Over Image. (Oct. 2016). Retrieved October 19, 2016 from https://www.bloomberg.com/news/articles/2016-10-17/disney-said-to-have-dropped-twitter-pursuit-partly-over-image/
- Bojanowski et al. (2016) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. Enriching Word Vectors with Subword Information. http://arxiv.org/abs/1607.04606
- Brandes and Pich (2007) Ulrik Brandes and Christian Pich. 2007. Centrality estimation in large networks. International Journal of Bifurcation and Chaos 17, 07 (2007), 2303–2318.
- Burnap and Williams (2016) Pete Burnap and Matthew L. Williams. 2016. Us and them: identifying cyber hate on Twitter across multiple protected characteristics. EPJ Data Science 5, 1 (2016).
- Djuric et al. (2015) Nemanja Djuric, Jing Zhou, Robin Morris, Mihajlo Grbovic, Vladan Radosavljevic, and Narayan Bhamidipati. 2015. Hate Speech Detection with Comment Embeddings. In Proceedings of the 24th International Conference on World Wide Web (WWW ’15 Companion). ACM, New York, NY, USA, 29–30.
- Forbes (2017) Forbes. 2017. Europe fine companies for hate speech. (June 2017). Retrieved June 3, 2017 from https://www.forbes.com/sites/janetwburns/2017/06/30/germany-now-allows-up-to-57m-in-fines-if-facebook-doesnt-remove-hate-speech-fast
- Harris (1981) Zellig S. Harris. 1981. Distributional Structure. Springer Netherlands, Dordrecht, 3–22.
- Magu et al. (2017) Rijul Magu, Kshitij Joshi, and Jiebo Luo. 2017. Detecting the Hate Code on Social Media. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media (ICWSM 2017). 608–611. arXiv:1703.05443
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26, C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (Eds.). Curran Associates, Inc., 3111–3119.
- Nobata et al. (2016) Chikashi Nobata, Joel Tetreault, Achint Thomas, Yashar Mehdad, and Yi Chang. 2016. Abusive Language Detection in Online User Content. In Proceedings of the 25th International Conference on World Wide Web (WWW ’16). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Switzerland, 145–153.
- O’Callaghan et al. (2013) Derek O’Callaghan, Derek Greene, Maura Conway, Joe Carthy, and Pádraig Cunningham. 2013. An analysis of interactions within and between extreme right communities in social media. In Ubiquitous social media analysis. Springer Berlin Heidelberg, 88–107.
- Omer and Yoav (2014) Levy Omer and Goldberg Yoav. 2014. Dependency-Based Word Embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short papers). ACL, 302–308.
- Page et al. (1999) Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. The PageRank Citation Ranking: Bringing Order to the Web. Technical Report 1999-66. Stanford InfoLab. Previous number = SIDL-WP-1999-0120.
- United Nations General Assembly Resolution 2200A [XX1] (1966) United Nations General Assembly Resolution 2200A [XX1]. 1966. International Covenant on Civil and Political Rights. (1966).
- Waseem (2016) Zeerak Waseem. 2016. Are You a Racist or Am I Seeing Things ? Annotator Influence on Hate Speech Detection on Twitter. Proceedings of 2016 EMNLP Workshop on Natural Language Processing and Computational Social Science (2016), 138–142.
- Waseem and Hovy (2016) Zeerak Waseem and Dirk Hovy. 2016. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. Proceedings of the NAACL Student Research Workshop (2016), 88–93.