SVT: Supertoken Video Transformer for Efficient Video Understanding
Abstract
Whether by processing videos with fixed resolution from start to end or incorporating pooling and down-scaling strategies, existing video transformers process the whole video content throughout the network without specially handling the large portions of redundant information. In this paper, we present a Supertoken Video Transformer (SVT) that incorporates a Semantic Pooling Module (SPM) to aggregate latent representations along the depth of visual transformer based on their semantics, and thus, reduces redundancy inherent in video inputs. Qualitative results show that our method can effectively reduce redundancy by merging latent representations with similar semantics and thus increase the proportion of salient information for downstream tasks. Quantitatively, our method improves the performance of both ViT and MViT while requiring significantly less computations on the Kinectics and Something-Something-V2 benchmarks. More specifically, with our SPM, we improve the accuracy of MAE-pretrained ViT-B and ViT-L by 1.5% with 33% less GFLOPs and by 0.2% with 55% less FLOPs, respectively, on the Kinectics-400 benchmark, and improve the accuracy of MViTv2-B by 0.2% and 0.3% with 22% less GFLOPs on Kinectics-400 and Something-Something-V2, respectively.
Index Terms:
Video understanding, vision transformer.I Introduction
Identifying actors or foreground objects in videos is important for the video understanding task due to high redundancy in videos caused by similar backgrounds covering large areas. Large computation requirement and longer training times also make the video-related tasks more challenging than images, especially more so for the computationally expensive vision transformers [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]. In this work, considering the redundancy and the large semantic overlap between video frames, we propose a Supertoken Video Transformer, referred to as the SVT, which can effectively reduce the redundancy at the semantic level, and thus, significantly decrease the complexity and memory requirement of transformer-based models. At the same time, our module also provides performance improvement over the state-of-the-art (SoTA) models on commonly used video datasets.
Previous video transformers [16, 3, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31] process the whole video content throughout the network without specially handling the redundant information. For instance, the Video Vision Transformer (ViViT) [3] primarily focuses on modeling global attention on the non-overlapping spatial-temporal video tokens. MViT [16, 32] produces multi-scale feature maps by creating a hierarchical architecture with multiple stages from high-resolution to low-resolution. Whether by processing videos with fixed resolution from start to end or incorporating pooling and downscaling strategies, mining features from entire videos, which have highly redundant content, can result in unnecessary computations. In addition, existing works on efficient transformers perform latent representation pooling uniformly according to the fixed space-time shape. In MViT [16, 32], the tensor is generated by a linear layer followed by a kernel group convolution layer applied on the space-time feature maps, and the size of the feature map is controlled by adjusting the stride of the convolution. Swin [33] reduces the size of feature maps by merging adjacent features based on the space-time location. Although this type of uniform downscaling strategies, based on spatio-temporal location, are effective and commonly used to pool features and build hierarchical architectures, they are not conducive to exploring various video semantics with uneven distribution and irregular shapes.
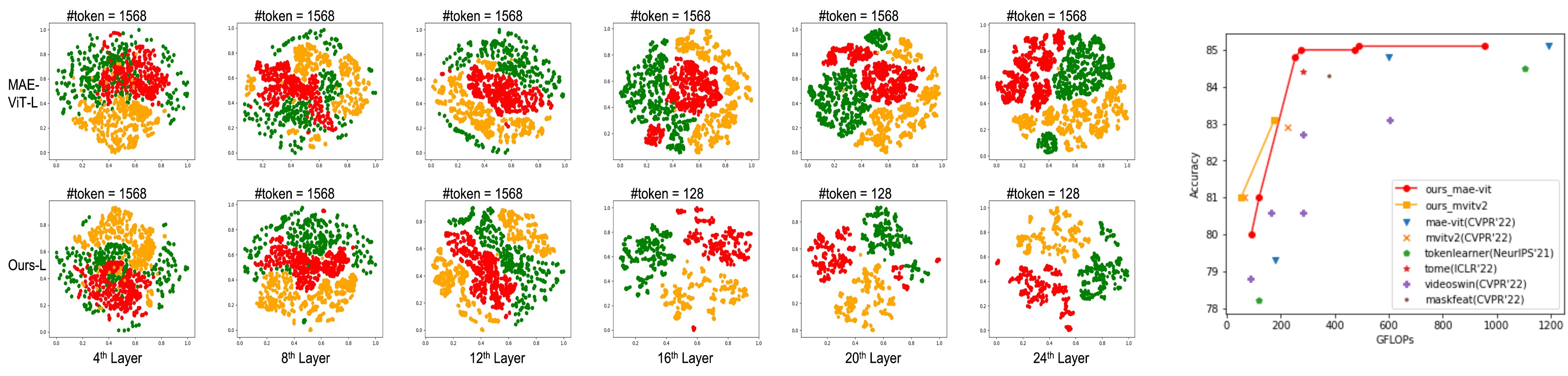
To address the aforementioned limitations of the existing video transformers, we present a Supertoken Video Transformer (SVT), which uses our proposed Semantic Pooling Module (SPM) to provide adaptability to uneven video information density or video content distribution and avoid unnecessary computation by reducing video redundancy. In the first line of Fig. 4, we visualize the token distributions of three examples from different classes at the , , , , , and layers of ViT [34]. The red, green and orange colors represent ‘swing dancing’, ‘baking cookie’ and ‘golf chipping’ classes, respectively. It can be observed that, in the shallow layers (, , ), the token distributions are relatively diffused, compared to deeper layers (, , ), where the token distribution is more concentrated, which indicates that the token representation learns connections from various low-level features to combined high-level semantics. As the number of tokens representing the similar high-level semantic meanings increases, many computations are unnecessarily performed producing repeated or redundant calculations. Because of such barriers, the three classes cannot be explicitly separated even in the last layer. Therefore, based on this observation, we propose to merge features by measuring their distances in multiple semantic spaces as the model goes deeper. Our goal is to effectively save memory space and reduce computations, by removing redundant information, while maintaining semantic diversity.
Contributions. The main contributions of this work include the following: (i) we present an effective technique, termed Semantic Pooling Module (SPM), to merge latent visual token representations, based on their distances in various learned semantic spaces, into several supertokens; (ii) we show that the SPM can be easily applied in both local/global, single/multi-scale video transformers, and achieves great performance-efficiency trade-off; (iii) we conduct extensive experiments and prove that by adding SPM to both ViT and MViT, comparable or even better performance can be achieved with less computation cost. Specifically, we improve MAE-ViT-L [34] by 0.2% with 55% less FLOPs and 0.3% with 18% less GFLOPs on the Kinetics-400 benchmark by applying SPM in a hierarchical way and single-pool way, respectively. We improve MViTv2 [16] by 0.2% and 0.3% with 22% less GFLOPs on Kinetics-400 and Something-Something-V2 datasets, respectively.
II Related Work
Video Transformers. The transformer proposed by Vaswani et al. [1] replaces the CNN or RNN layers with self-attention layers, and has been a big success in natural language processing. More recently, Dosovitskiy et al. [4] proposed a pure Vision Transformer (VIT) for the image classification. Many other works have focused on building vision transformer models with lower computational cost by using different strategies, such as using semantic visual tokens [35], layer-wise token to token transformation [36], adding distillation losses [37] and building a hierarchical structure with the shifted windows [33]. Video transformers [38, 3, 39, 17, 40, 41, 16, 32] have mirrored the advances in image understanding and SoTA performance on the major video recognition benchmarks [42, 43]. To reduce the computation and memory costs as well as provide locality inductive bias in the self-attention module, Liu et al. [17] strictly followed the hierarchy of the original Swin Transformer [33] for the image domain, and extended the scope of local attention computation from only the spatial domain to the spatiotemporal domain.
Computation-saving Techniques. Sevaral works have been presented for saving computations in transformers [44, 45, 46, 47]. AdaViT [44] is proposed to adaptively prune tokens throughout the transformer. A-ViT [45] is proposed to adaptively adjust the amount of token computations based on input complexity. Michael et al. [48] propose the tokenlearner for visual representation learning. Although it achieves the efficiency goal, pooling tokens globally with the learned weights from the tokenlearner module, the model cannot avoid redundancy and background noise when the core object only occupies a very small area and the obstruction signal is stronger in the video, like the examples in Fig. 5. In [49], TokenMerger (ToMe) is proposed to merge similar tokens based on the bipartite matching algorithm. In the merging process, the number of tokens in each merging group is added in the softmax of the proportional attention, which cannot handle the situation when there is a larger number of background tokens than the foreground tokens, which more frequently happens in video datasets. Although they provide efficiency benefits, both tokenlearner and ToMe cannot surpass the ViT baseline, and their usage is limited to the ViT-based models.
III Proposed Model
In this section, we present the details of our SVT. We first introduce the preliminaries and main baselines in Sec. III-A. Then, we present our SPM and the single-scale/multi-scale building architectures incorporating the SPM in Sec. III-B and Sec. III-C, respectively.
III-A Preliminaries
We use two latest SoTA models on video task, namely MAE-ViT [34] and MViTv2 [16], as our single-scale and multi-scale transformer baselines, respectively. In ViT, a 3D video input is segmented and flattened as a 1D sequence tensor of length and channel , . The model is constructed of several transformer blocks to perform self-attention and MLP on single-scale feature maps in a global manner without changing its size. In the self-attention module, LayerNorm is applied to stabilize the hidden state dynamics of the input tensor. Three linear layers are applied to generate a query,key,value tensor. Scaled matrix multiplication is performed between query and key to produce the attention map, which is normalized by the following SoftMax layer. Another linear layer is applied on the product of attention map and value tensor for output projection. Skip connection is applied to make the information stay local in the transformer layer stack. The MLP module is composed of an MLP layer, a LayerNorm layer, and skip connection. The whole process in a ViT transformer block can be formulated as in Eqs. (1) and (2):
| (1) | ||||
| (2) |
MViTv2 is the latest SoTA video transformer with hierarchical architecture for modeling both low- and high-level visual features. The main differences between MViTv2 and ViT are as follows: (i) In the attention mechanism of MViTv2, instead of using three separate single linear layers, three sets of pooling attention (a linear layer followed by a group convolution layer) are used to generate query-key-value tensors and reduce resolution, by enlarging the stride in group convolution layer at the first transformer block of each stage; (ii) the pooling attention allows computing attention on sparse key and value sequences, which helps reduce the computational cost; (iii) in contrast to ViT, where the channel dimension and sequence length remain fixed, MViTv2 progressively increases the channel dimension and reduces spatio-temporal resolution via pooling attention mechanism; (iv) MViTv2 incorporates decomposed relative position embedding and residual pooling connection with the (pooled) query tensor into the self-attention module to enhance the information flow. The procedure in a MViTv2 transformer block can be expressed as:
| (3) | ||||
| (4) | ||||
III-B Semantic Pooling
Suppose we have input tokens , where is the combination of the spatio-temporal axes of the video patches. Instead of investigating the pair-wise matching score among the input tokens, we initialize trainable embeddings, , as explicit semantic prototypes to be used for rating video tokens under different schemes. Then, the semantic matching degree among the input tokens is estimated by their dot products to these prototypes. The produced score map is then sent into an elitism function to select and cluster analogous individuals.
| (5) | ||||
In the elitism procedure, as expressed by Eq. (5), we apply a non-linear function to compress the affinity score into the range of , where and indicate the identity of the semantic space and input token, respectively. We set a fixed threshold as a filter to limit the interactions between input tokens and semantic spaces, i.e., if the compressed score is higher than the threshold , then its original value and the corresponding token are preserved in the semantic group, while other tokens and values with compressed scores lower than the threshold are muted. In our implementation, we use as the compression function. Therefore, each semantic group can consist of different numbers of active tokens. Many videos can have explicit bias to some semantic groups, and have less content belonging to other semantics. This may lead to semantic groups having no active tokens, which, in turn, causes the gradient vanishing problem during training. Considering this, we set all the tokens with their corresponding semantic scores as active states for such groups.
In order to enable hierarchical structure, we further split the tokens together with their semantic scores under each prototype into rough local groups. With window size of , the tokens and the semantic scores are segmented into the shapes of and , respectively, where indicates the number of windows. With various shapes of active semantic areas, the semantic scores are normalized by the function along the window axis. We then perform the weighted sum over the normalized score and the tokens window-wise. Hence, under -many semantics, the number of tokens with dimension is reduced to in each group, and the total number of output tokens is . We conduct ablation studies to investigate the trade-off between the number of semantics and the number of windows in Sec. IV-C.
III-C Model Architecture
We design different strategies for incorporating our proposed semantic pooling module (SPM) with single-scale transformer ViT and multi-scale transformer MViTv2.
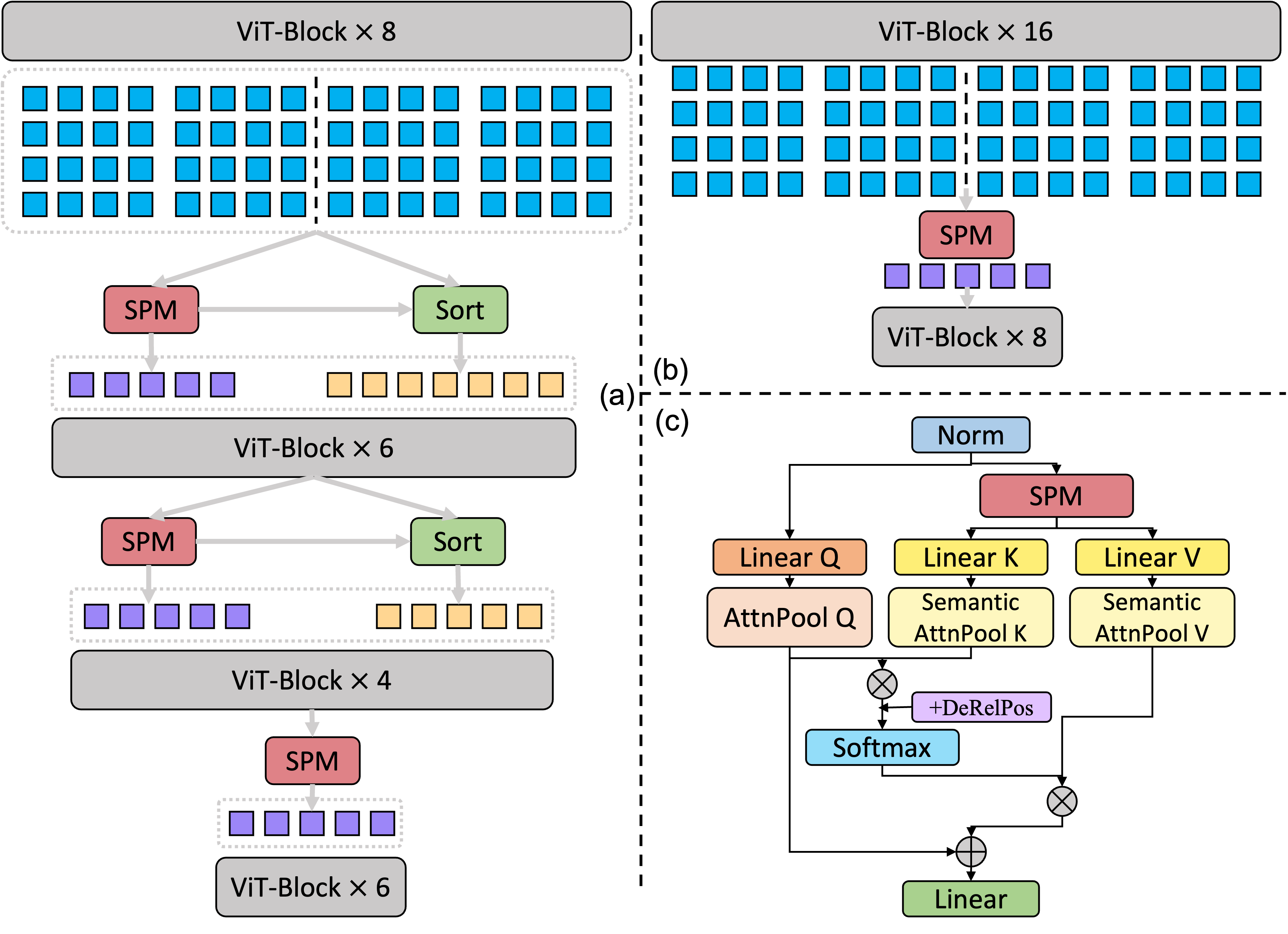
Semantic pooling with ViT. For the combination with ViT, we directly insert the SPM between transformer layers. We propose two different ways of integration as shown in Fig. 2(a)(b). In Fig. 2(a), we insert SPM in an hierarchical way to reduce the number of tokens progressively. As indicated in Sec. III-B, we extract a total of -many semantic tokens after SPM. To combine SPM with ViT in an hierarchical way, in each instance of SPM (except the last one), we keep the top original tokens based on their average semantic score. This is done to avoid losing details from the shallow layers of ViT. Hence, after SPM, the total number of tokens is reduced to . In our ablation studies in Sec.IV-C, we compare different ways of reducing the number of tokens to , more specifically, by using (i) only the semantic tokens, (ii) only the original tokens, and (iii) combination of semantic and original tokens. We show that the combination approach provides the best performance. In Fig. 2(b), the SPM is inserted as a single-pool layer to reduce the number of token to without keeping the original tokens. In this paper, we construct and investigate several variants for ViT-SPM, as provided in Tab. I, while the effective configurations are not necessarily limited to the examples shown in the table.
Model L MAE-ViT-B-SPM6 6 21414 432+0=128 MAE-ViT-B-SPM8 8 21414 432+0=128 MAE-ViT-L-SPM12 12 21414 432+0=128 MAE-ViT-L-SPM16 16 21414 432+0=128 MAE-ViT-L-SPM18 16 global 164+0=64 MAE-ViT-L-SPM8/12/16 8 21414 432+896=1024 12 global 1128+384=512 16 global 1128+0=128 MAE-ViT-L-SPM8/14/18 8 21414 432+896=1024 14 global 1128+384=512 18 global 1128+0=128
Semantic pooling with MViTv2. We design a semantic attention module for the multi-scale transformer MViTv2, as shown in Fig. 2(c). We replace the original multi-scale attention module with the semantic one for every 4 blocks in our experiments. For input , with shape , we apply SPM with window size of and -many semantic groups to generate semantic tokens . We apply two separate linear layers on to generate intermediate tensors for key and value. Then, each of them is sent into a group convolution with the number of group equal to and stride equal to 1 to produce the final key/value tensor as shown in Eq. (6). Hence, the key-value pairs are focusing on the semantic content, while the query is based on the spatial-temporal map. Then, each query will attend to the semantic spaces by computing the pair-wise attention with . The whole process of our semantic attention module can be expressed as follows:
| (6) | ||||
where is the attention map between and and is the final output tensor. Therefore, in the original multi-scale attention module in MViTv2, the stride in K/V attention pool can be larger than the kernel size causing middle patches to be ignored. In contrast, in our semantic attention module, all patches will contribute to K/V tensor via SPM, avoiding the risk of losing information. Also, with SPM, the number of K/V tokens can be reduced to a smaller number, making the module more efficient.
IV Experiments

We conduct extensive experiments on Kinetics and SSv2 datasets for video recognition to validate our model. We divide the experiments into two groups, wherein single-scale ViT and multi-scale MViTv2 are applied as baselines, respectively. In the first group, both ViT and our models adopt the same pre-trained weights from the MAE-ViT, while in the second group, both MViTv2 and our models are trained from scratch. We show and discuss the results of these two sets of experiments separately, and further provide the qualitative examples for comparison.
IV-A Video Recognition
Kinetics-Settings. Kinetics-400 (K400) is a large-scale video dataset including 400 human action classes, with at least 400 video clips for each action. We train the models following the recipes provided in [34, 16]. For ViT-based models, we adopt the same pre-trained weights from the MAE-ViT [34], while for MViTv2 based models, we train from scratch.
Kinetics-Results. Table II shows our results on K400. We show the results of MAE-ViT based models in the first three groups, and typical multi-scale transformers in the last two groups. For all the base, large, and huge versions of MAE-ViT, SPM not only helps improving the performance but also reduces the computation and memory requirements. The MAE-ViT-B-SPM6/SPM8 provides 0.6%/1.5% performance improvement, and 50%/33% decrease on the number of GFLOPs. MAE-ViT-L-SPM18/SPM8/14/18 provides 0.3%/0.2% performance improvement, and 55%/18% decrease on the number of GFLOPs. In addition, compared to other computation saving techniques MAE-ViT-Tokenlearner [48] and ToMe [49], ours-B-SPM6/SPM8 outperforms the Tokenlearner-B by 1.7%/2.6% accuracy increase with smaller computations; ours-L-SPM18/SPM8/14/18 surpasses the Tokenlearner-L by 0.6%/0.5% accuracy increase with 56%/75% less number of GFLOPs; and ours-L-SPM8/14/18 surpasses the ToMe-L by 0.6% accuracy with less computations. While other computation saving techniques can only be applied in ViT-based model, our SPM can also be applied in multi-scale transformers. As shown in Tab.II, for MViTv2-based models, ours-S-SPM can achieve comparable performance with 5 less GFLOPS than MViTv2-S, and ours-B-SPM outperforms the MViTv2-B by 0.2% accuracy with 22% less GFLOPs. Both results based on MAE-ViT and MViTv2 prove the effectiveness and efficiency of our proposed SPM.
| model | top-1 | top-5 | GFLOPs | #Params/M |
| MAE-ViT-B | 79.3 | 93.2 | 18037 | 87 |
| Tokenlearner-B | 78.2 | 93.2 | 12037 | 87 |
| ours-B-SPM6 | 79.9(+0.6) | 94.5 | 9137(50%) | 87 |
| ours-B-SPM8 | 80.8(+1.5) | 94.8 | 12037(33%) | 87 |
| MAE-ViT-L[34] | 84.8 | 96.2 | 59837 | 304 |
| TokenLearner-L[49] | 84.5 | - | 110543 | 383 |
| ToMe-MAE-ViT-L[49] | 83.2 | - | 184110 | 304 |
| ToMe-MAE-ViT-L[49] | 84.4 | - | 281110 | 304 |
| ours-L-SPM12 | 84.6 | 96.2 | 30237 | 304 |
| ours-L-SPM16 | 85.0(+0.2) | 96.6 | 47337(21%) | 304 |
| ours-L-SPM18 | 85.1(+0.3) | 96.5 | 49037(18%) | 304 |
| ours-L-SPM8/12/16 | 84.8 | 96.4 | 25437(58%) | 304 |
| ours-L-SPM8/14/18 | 85.0(+0.2) | 96.5 | 27537(55%) | 304 |
| MAE-ViT-H[34] | 85.1 | 96.6 | 119337 | 632 |
| ours-H-SPM22 | 85.1 | 96.7 | 95537(20%) | 632 |
| MViTv1, 16x4[32] | 78.4 | 93.5 | 7015 | 37 |
| Swin-S, (IN1K)[17] | 80.6 | 94.5 | 16643 | 50 |
| MViTv2-S, 16x4[16] | 81.0 | 94.6 | 6415 | 34 |
| ours-S-SPM, 16x4 | 80.9 | 94.6 | 5315(17%) | 34 |
| MViTv1, 32x3[32] | 80.2 | 94.4 | 17015 | 37 |
| Swin-B, (IN1K)[17] | 80.6 | 94.6 | 28243 | 88 |
| Swin-B, (IN21K)[17] | 82.7 | 95.5 | 28243 | 88 |
| MViTv2-B, 32x3[16] | 82.9 | 95.7 | 22515 | 51 |
| ours-B-SPM, 32x3 | 83.1(+0.2) | 95.6 | 17615(22%) | 51 |
SSV2-Settings. Something-Something-v2 (SSV2) is a collection of 220,847 labeled video clips covering 174 classes of humans performing actions with everyday objects. We train the models following the recipes provided in [34, 16]. For MViTv2-based models, we utilize the pre-trained weights from K400 task to initialize the corresponding models, while for ViT-based models, we utilize the same pre-trained weights as in K400 task.
SSV2-Results. We provide the video classification results for both MAE-ViT- and MViTv2-based models on SSV2 in Tab. III. It can be seen that, with fewer computations, each of our models achieve competitive if not better performance compared to the corresponding baseline model. Our SPM also shows superior feature exploring ability than other efficiency-oriented techniques, which invariably degrade model performance. This preeminence can be attributed to the following: with much redundancy in videos, while the baselines uniformly distribute tokens among the whole video content, our model can adjust the token distribution by increasing the portion of tokens representing the core object(s) and decreasing the portion of tokens representing the background and irrelevant objects (token distribution visualization details are provided in Sec. IV-B and Fig. 4). Proposed SPM, while improving the foreground ratio in the token pools, does not entirely wipe out the background information. This implies that it does not lose information while removing redundancy. Furthermore, SPM serves as a flexible aggregator that groups tokens in a data-driven way without fixing the number of tokens in each pooling group. Benefiting from the internal logic of pooling and adjusting the token distribution based on semantic meaning, our model can boost the performance and decrease computation and memory requirements at the same time.
Accuracy-efficiency tradeoff. We compared the accuracy-efficiency tradeoff of our SVT with other most-recently published SOTAs on K400 dataset in the Fig.4. We analyze the reasons for that our SVT achieves better accuracy-efficiency trade-off than other computation saving techniques are: (i) When reducing tokens, the Tokenlearner[48] captures global information in each token, while ours captures semantic information, including both global and local instances, which can better explore the interrelationship of the core objects in the video. Tokenlearner focuses on re-weighting the whole scene to generate tokens, while ours focuses on adjusting the ratio of foreground to background in the token pool, and gathering similar semantics to generate supertokens, which is a better way to explore the intrinsic features of the video as proved in our experiment results; (ii) In the bipartite matching process of ToMe [49], the number of foreground and background tokens is decreased simultaneously with equal proportions, while in our SPM, we improved the ratio of foreground tokens, as shown in Fig.3 and our supplement examples.
| model | top-1 | top-5 | GFLOPs | #Params/M |
|---|---|---|---|---|
| MAE-ViT-L[34] | 72.1 | 93.9 | 59831 | 304 |
| ours-L-SPM16 | 71.7 | 93.8 | 47331(21%) | 304 |
| ours-L-SPM18 | 71.9 | 94.0 | 49031(18%) | 304 |
| MAE-ViT-H[34] | 74.1 | 94.5 | 119331 | 632 |
| ours-H-SPM22 | 73.6 | 94.6 | 95531(20%) | 632 |
| MViTv1, 16x4[32] | 64.7 | 89.2 | 7115 | 37 |
| MViTv2-S, 16x4[16] | 68.2 | 91.4 | 6415 | 34 |
| ours-S-SPM, 16x4 | 68.0 | 91.0 | 5315(17%) | 34 |
| MViTv1, 64x3[32] | 67.7 | 90.9 | 45415 | 37 |
| MViTv2-B, 32x3[16] | 70.5 | 92.7 | 22515 | 51 |
| ours-B-SPM, 32x3 | 70.8(+0.3) | 93.0 | 17615(22%) | 51 |
IV-B Qualitative Results
In this section, we provide some visualization examples to better illustrate benefits of our proposed SPM. More visualizations are provided in the supplementary material.
Visualization of Attention. We provide examples for attention comparison between MAE-ViT-L (baseline) and MAE-ViT-L-SPM16 (ours) in Fig.3. In each video example, we show the raw video frames, the averaged attention score for each patch/token in the layer of the baseline, and the averaged semantic score for each patch/token in the layer of our approach (during SPM) in the first, second, and third rows, respectively. The redder the color, the higher attention is placed on it. From these examples, it can be clearly observed that significant attention is placed on the background tokens and only small parts of the core objects/actors are covered in red color by the baseline. In contrast, our approach can focus more on the core objects and properly mute some less important background patches, indicating that, after our proposed SPM, the ratio of foreground tokens is successfully improved and the unnecessary background information is properly deemphasized.

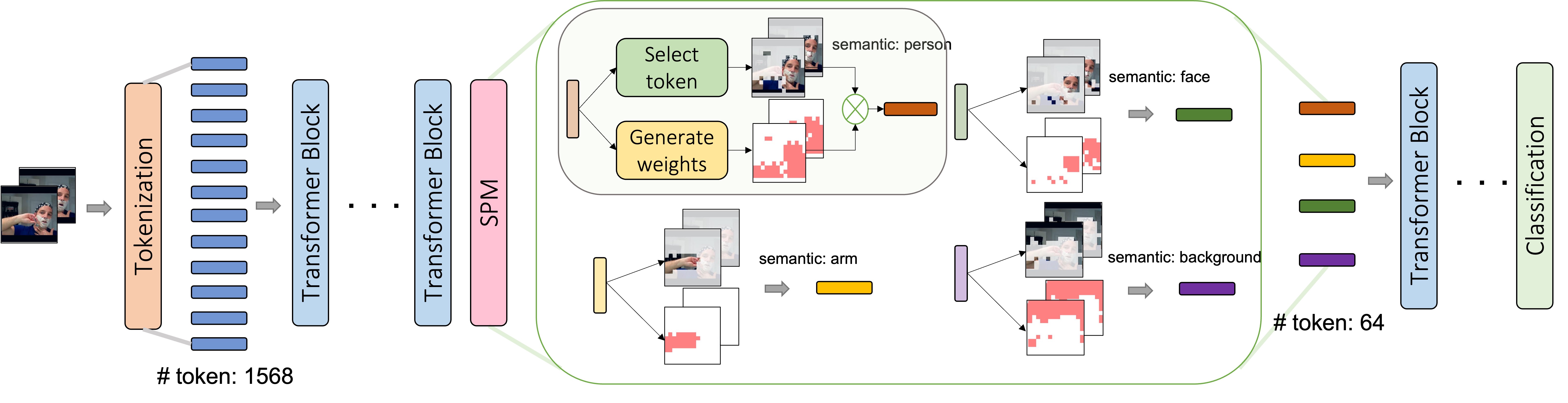
Visualization of Semantic Pooling. Fig. 5 provides visualization of semantic pooling in MAE-ViT-L-SPM16. In each example, the first row shows the raw video and the following rows show the token content in five different semantic pools (we provide all the semantic visualizations in the supplementary material). The tokens located in the white or gray areas are aggregated together with the assigned weights in each cluster (the whiter it is the larger attention is given to the corresponding token), while the tokens located in the black area are removed from each cluster. For ‘golf chipping’, the first and third pools collect the human information, the second pool collects the background tree information, the fourth pool collects the golf tokens, and the last pool captures the whole scene for the video and the golf-related parts are emphasized. For ‘Sanding floor’ class, the first three pools mainly collect the tokens representing the sander, which is the core active object, while the last two pools collect the background features. It is obvious that, before SPM, the core object occupies only a small portion of the whole video content, while after SPM, there are more semantic tokens describing the core objects and few representing the less important background. Therefore, these examples clearly illustrate that our proposed SPM properly mitigates the issues stated in Sec. LABEL:sec:Introduction, that is it can improve the token proportion of the core object and guide the model to focus more on the foreground part, which is helpful for understanding the video content. It also demonstrates that in our SPM, both foreground and background information are retained, meaning that it can adjust the token ratio without losing information.
Visualization of Token Distribution. We demonstrate the latent token representation distribution from the , , , , , and layers of the baseline (single-scale MAE-ViT-L) and our MAE-ViT-L-SPM16 in Fig. 4. The red, green and orange colors represent ‘swing dancing’, ‘baking cookie’ and ‘golf chipping’ classes, respectively. While the baseline processes a total of 1568 tokens throughout the entire network, we apply the SPM at the 16th layer in our model to reduce the number of tokens to 128 for all subsequent layers. With less color mixing area and larger margins between clusters with different classes in the shallow and deep layers, our model shows better representation ability than the baseline. In addition, such superiority is achieved with much less number of tokens, which implies that our model can effectively represent the video content in a more memory-efficient way.
IV-C Ablation Studies
In this section, we present part of our ablation studies on different configurations for integrating proposed SPM with MAE-ViT and MViTv2 in video recognition. For video recognition, we conduct all experiments with input size of and for MAE-ViT/MViTv2-S and MViT-B respectively.
Threshold. We investigate the thresholds in SPM, when integrated with MAE-ViT and MViTv2 on Kinetics-400. As shown in Tab. IV, 0.7 is the best value for MAE-ViT-L and 0.5 is the best value for MViTv2-S.
Window size. We investigated four window sizes while maintaining a constant 128 semantic tokens for SPM, when integrated with MAE-ViT-L and MViT-v2, on Kinetics-400 dataset. The results are shown in Tab. VI. For MAE-ViT-L, we incorporate SPM in a single-pool way, where the SPM is inserted at the layer. As can be seen, window sizes of and perform best for MAE-ViT-L and MViTv2-S, respectively.
Methods of building MAE-ViT-SPM in a hierarchical way. We progressively reduce the total number of tokens from 1568 to 1024, 512, 128 when incorporating SPM with MAE-ViT in a hierarchical way. To compare with the incorporation approach described in Sec. III-C and further prove the effectiveness of our module, we conduct experiments to progressively reduce the number of tokens with other strategies: (i) applying average/max pooling to keep only the original tokens; (ii) using SPM to keep only the semantic tokens; (iii) the combination method described in Sec. III-C. As shown in Tab. V, only the combination approach (Tokenori+sem) can surpass (85%) the MAE-ViT-L baseline (84.8%) on K400 dataset, illustrating the effectiveness of our strategy.
| model-dataset | 0.3 | 0.5 | 0.7 |
|---|---|---|---|
| MAE-ViT-L | 84.6 | 84.9 | 85.1 |
| MViTv2-S | 79.3 | 80.9 | 80.8 |
| model | top1 | top5 |
|---|---|---|
| AvgPool | 83.7 | 96.0 |
| MaxPool | 84.4 | 96.2 |
| Tokensem | 84.6 | 96.4 |
| Tokenori+sem | 85.0 | 96.5 |
| model | 477 | 11414 | 21414 | 81414 |
|---|---|---|---|---|
| MAE-ViT-L | 84.7 | 84.8 | 85.1 | 84.8 |
| MViTv2-S | 80.9 | 80.6 | 80.0 | 80.5 |
Additional ablations. To fully investigate the Semantic Pooling Module (SPM), we have conducted additional ablation studies on the following aspects with MAE-ViT-B on the K400 dataset: (i) We study two methods for grouping tokens representing similar semantics. The first one is grouping neighbouring tokens based on the semantic distances. We sort the tokens within each window based on the semantic scores under each prototype. Then, we split them into groups based on the sorting order, and apply softmax on the semantic scores within each group. The module will finally generate semantic tokens after performing weighted sum between the tokens and normalized scores in each group. The second one is the elitism filtering as described in Sec.3.2. (ii) We study the multi-head semantic pooling. When it is applied, we perform semantic pooling in parallel with multiple heads. (iii) We compare the performances of applying output project layer and not using output project layer in SPM. As can be seen from Tab. VII, the performances of elitism approach are better and more stable than the neighboring approach.
| model | top1 | top5 | #head | M | K | L | O | ||
|---|---|---|---|---|---|---|---|---|---|
| neighbor | 80.38 | 94.39 | 12M | 16S | 8K | 8,14,14 | 1W | 8l | N |
| neighbor | 80.16 | 94.42 | 12M | 8S | 8K | 4,14,14 | 2W | 8l | N |
| neighbor | 79.73 | 94.22 | 12M | 8S | 4K | 2,14,14 | 4W | 8l | N |
| neighbor | 79.66 | 94.27 | 12M | 4S | 4K | 1,14,14 | 8W | 8l | N |
| neighbor | 80.11 | 94.22 | 12M | 32S | 4K | 8,14,14 | 1W | 8l | N |
| neighbor | 79.66 | 93.87 | 12M | 8S | 2K | 1,14,14 | 8W | 8l | N |
| neighbor | 80.08 | 94.31 | 16M | 16S | 8K | 8,14,14 | 1W | 8l | N |
| neighbor | 80.54 | 94.32 | 8M | 16S | 8K | 8,14,14 | 1W | 8l | N |
| neighbor | 80.00 | 94.27 | 1M | 16S | 8K | 8,14,14 | 1W | 8l | N |
| neighbor | 77.10 | 92.8 | 12M | 16S | 8K | 8,14,14 | 1W | 6l | N |
| neighbor | 72.25 | 89.9 | 12M | 16S | 8K | 8,14,14 | 1W | 4l | N |
| neighbor | 79.50 | 94.00 | 12M | 16S | 8K | 8,14,14 | 1W | 8l | N |
| model | top1 | top5 | #head | M | th | L | O | ||
| elitism | 80.80 | 94.82 | 1M | 128S | 0.7 | 8,14,14 | 1W | 8l | N |
| elitism | 80.77 | 94.52 | 1M | 64S | 0.7 | 4,14,14 | 2W | 8l | N |
| elitism | 80.85 | 94.84 | 1M | 32S | 0.7 | 2,14,14 | 4W | 8l | N |
| elitism | 80.27 | 94.48 | 1M | 16S | 0.7 | 1,14,14 | 8W | 8l | N |
| elitism | 80.65 | 94.62 | 1M | 128S | 0.5 | 8,14,14 | 1W | 8l | N |
| elitism | 80.70 | 94.59 | 1M | 128S | 0.6 | 8,14,14 | 1W | 8l | N |
| elitism | 80.57 | 94.74 | 1M | 128S | 0.9 | 8,14,14 | 1W | 8l | N |
| elitism | 79.94 | 94.48 | 1M | 128S | 0.7 | 8,14,14 | 1W | 6l | N |
| elitism | 78.10 | 93.37 | 1M | 128S | 0.7 | 8,14,14 | 1W | 4l | N |
| elitism | 79.36 | 93.73 | 12M | 128S | 0.7 | 8,14,14 | 1W | 8l | N |
| elitism | 80.54 | 94.57 | 1M | 128S | 0.7 | 8,14,14 | 1W | 8l | Y |
| elitism | 80.73 | 94.74 | 1M | 128S | 0.7 | 8,14,14 | 1W | 8l | N |
V Conclusion
In this paper, we have presented a Supertoken Video Transformer, SVT, which employs our proposed semantic pooling module (SPM). SPM can be used with both single-scale and multi-scale transformers to reduce memory and computation requirements as well as improve the performance for video understanding. Thanks to adjusting the token proportion in the video pool and aggregating tokens based on semantics, our proposed module can reduce the video input redundancy without losing information, which has also been demonstrated via extensive experiments. With less computation and larger throughput, our model surpasses or provides comparable performance to both baselines and previous efficiency-oriented techniques on several datasets and vision tasks. In contrast to other computation/memory saving techniques, which can only be used by ViT and sacrifice performance, our module is applicable for both single-scale and multi-scale transformers without sacrificing performance, which also proves the superiority of our SPM. Since, in this work, our main target was video understanding, we will further investigate the SPM on images in our future work.
Acknowledgments
This work was done during an internship at Meta AI. Thanks to Chao-Yuan Wu and Christoph Feichtenhofer for helpful feedback.
References
- [1] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [2] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [3] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “Vivit: A video vision transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6836–6846.
- [4] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [5] K. Wu, J. Zhang, H. Peng, M. Liu, B. Xiao, J. Fu, and L. Yuan, “Tinyvit: Fast pretraining distillation for small vision transformers,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXI. Springer, 2022, pp. 68–85.
- [6] J. Cho, K. Youwang, and T.-H. Oh, “Cross-attention of disentangled modalities for 3d human mesh recovery with transformers,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part I. Springer, 2022, pp. 342–359.
- [7] S. Gao, C. Zhou, C. Ma, X. Wang, and J. Yuan, “Aiatrack: Attention in attention for transformer visual tracking,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII. Springer, 2022, pp. 146–164.
- [8] B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, “Joint feature learning and relation modeling for tracking: A one-stream framework,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII. Springer, 2022, pp. 341–357.
- [9] B. Yan, Y. Jiang, P. Sun, D. Wang, Z. Yuan, P. Luo, and H. Lu, “Towards grand unification of object tracking,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXI. Springer, 2022, pp. 733–751.
- [10] Z. Zhao, Z. Wu, Y. Zhuang, B. Li, and J. Jia, “Tracking objects as pixel-wise distributions,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII. Springer, 2022, pp. 76–94.
- [11] X. Dong, J. Bao, D. Chen, W. Zhang, N. Yu, L. Yuan, D. Chen, and B. Guo, “Cswin transformer: A general vision transformer backbone with cross-shaped windows,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 124–12 134.
- [12] M. Pu, Y. Huang, Y. Liu, Q. Guan, and H. Ling, “Edter: Edge detection with transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1402–1412.
- [13] Y. Wang, T. Ye, L. Cao, W. Huang, F. Sun, F. He, and D. Tao, “Bridged transformer for vision and point cloud 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 114–12 123.
- [14] D. Zhou, B. Kang, X. Jin, L. Yang, X. Lian, Z. Jiang, Q. Hou, and J. Feng, “Deepvit: Towards deeper vision transformer,” arXiv preprint arXiv:2103.11886, 2021.
- [15] B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for general video recognition,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IV. Springer, 2022, pp. 1–18.
- [16] Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision transformers for classification and detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4804–4814.
- [17] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” arXiv preprint arXiv:2106.13230, 2021.
- [18] D. Neimark, O. Bar, M. Zohar, and D. Asselmann, “Video transformer network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3163–3172.
- [19] R. Girdhar and K. Grauman, “Anticipative video transformer,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 505–13 515.
- [20] Y. Zhang, X. Li, C. Liu, B. Shuai, Y. Zhu, B. Brattoli, H. Chen, I. Marsic, and J. Tighe, “Vidtr: Video transformer without convolutions,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 577–13 587.
- [21] A. Bulat, J. M. Perez Rua, S. Sudhakaran, B. Martinez, and G. Tzimiropoulos, “Space-time mixing attention for video transformer,” Advances in Neural Information Processing Systems, vol. 34, pp. 19 594–19 607, 2021.
- [22] J. Liang, J. Cao, Y. Fan, K. Zhang, R. Ranjan, Y. Li, R. Timofte, and L. Van Gool, “Vrt: A video restoration transformer,” arXiv preprint arXiv:2201.12288, 2022.
- [23] K. Ranasinghe, M. Naseer, S. Khan, F. S. Khan, and M. S. Ryoo, “Self-supervised video transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2874–2884.
- [24] R. Wang, D. Chen, Z. Wu, Y. Chen, X. Dai, M. Liu, Y.-G. Jiang, L. Zhou, and L. Yuan, “Bevt: Bert pretraining of video transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 733–14 743.
- [25] H. Zhang, Y. Hao, and C.-W. Ngo, “Token shift transformer for video classification,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 917–925.
- [26] R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video action transformer network,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 244–253.
- [27] J. Wang and L. Torresani, “Deformable video transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 053–14 062.
- [28] D. Kim, J. Xie, H. Wang, S. Qiao, Q. Yu, H.-S. Kim, H. Adam, I. S. Kweon, and L.-C. Chen, “Tubeformer-deeplab: Video mask transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 914–13 924.
- [29] Z. Shi, X. Xu, X. Liu, J. Chen, and M.-H. Yang, “Video frame interpolation transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 482–17 491.
- [30] R. Herzig, E. Ben-Avraham, K. Mangalam, A. Bar, G. Chechik, A. Rohrbach, T. Darrell, and A. Globerson, “Object-region video transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3148–3159.
- [31] C. Liu, H. Yang, J. Fu, and X. Qian, “Learning trajectory-aware transformer for video super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5687–5696.
- [32] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, and C. Feichtenhofer, “Multiscale vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6824–6835.
- [33] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [34] C. Feichtenhofer, H. Fan, Y. Li, and K. He, “Masked autoencoders as spatiotemporal learners,” arXiv preprint arXiv:2205.09113, 2022.
- [35] J. Xie, R. Zeng, Q. Wang, Z. Zhou, and P. Li, “So-vit: Mind visual tokens for vision transformer,” arXiv preprint arXiv:2104.10935, 2021.
- [36] L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z.-H. Jiang, F. E. Tay, J. Feng, and S. Yan, “Tokens-to-token vit: Training vision transformers from scratch on imagenet,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 558–567.
- [37] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jegou, “Training data-efficient image transformers amp; distillation through attention,” in ICCV, 2021.
- [38] M. Z. Daniel Neimark, Omri Bar and D. Asselmann, “Video transformer network,” arXiv preprint arXiv:2102.00719, 2021.
- [39] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” arXiv preprint arXiv:2102.05095, 2021.
- [40] M. Patrick, D. Campbell, Y. M. Asano, I. M. F. Metze, C. Feichtenhofer, A. Vedaldi, J. Henriques et al., “Keeping your eye on the ball: Trajectory attention in video transformers,” arXiv preprint arXiv:2106.05392, 2021.
- [41] R. Herzig, E. Ben-Avraham, K. Mangalam, A. Bar, G. Chechik, A. Rohrbach, T. Darrell, and A. Globerson, “Object-region video transformers,” arXiv preprint arXiv:2110.06915, 2021.
- [42] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017.
- [43] R. Goyal, S. Ebrahimi Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag et al., “The” something something” video database for learning and evaluating visual common sense,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 5842–5850.
- [44] L. Meng, H. Li, B.-C. Chen, S. Lan, Z. Wu, Y.-G. Jiang, and S.-N. Lim, “Adavit: Adaptive vision transformers for efficient image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 309–12 318.
- [45] H. Yin, A. Vahdat, J. M. Alvarez, A. Mallya, J. Kautz, and P. Molchanov, “A-vit: Adaptive tokens for efficient vision transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 809–10 818.
- [46] Y. Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dynamicvit: Efficient vision transformers with dynamic token sparsification,” Advances in neural information processing systems, vol. 34, pp. 13 937–13 949, 2021.
- [47] Z. Kong, P. Dong, X. Ma, X. Meng, W. Niu, M. Sun, B. Ren, M. Qin, H. Tang, and Y. Wang, “Spvit: Enabling faster vision transformers via soft token pruning,” arXiv preprint arXiv:2112.13890, 2021.
- [48] M. S. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. Angelova, “Tokenlearner: What can 8 learned tokens do for images and videos?” arXiv preprint arXiv:2106.11297, 2021.
- [49] D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” arXiv preprint arXiv:2210.09461, 2022.