omm
SZ Sequences: Binary-Based -Sequences
Abstract.
Low-discrepancy sequences have seen widespread adoption in computer graphics thanks to the superior rates of convergence that they provide. Because rendering integrals often are comprised of products of lower-dimensional integrals, recent work has focused on developing sequences that are also well-distributed in lower-dimensional projections. To this end, we introduce a novel construction of binary-based -sequences; that is, progressive fully multi-stratified sequences of 4D points, and extend the idea to higher power-of-two dimensions. We further show that not only it is possible to nest lower-dimensional sequences in higher-dimensional ones—for example, embedding a -sequence within our -sequence—but that we can ensemble two -sequences into a -sequence, four -sequences into a -sequence, and so on. Such sequences can provide excellent rates of convergence when integrals include lower-dimensional integration problems in 2, 4, 16, dimensions. Our construction is based on using 22 block matrices as symbols to construct larger matrices that potentially generate a sequence with the target -sequence in base property. We describe how to search for suitable alphabets and identify two distinct, cross-related alphabets of block symbols, which we call and , hence SZ for the resulting family of sequences. Given the alphabets, we construct candidate generator matrices and search for valid sets of matrices. We then infer a simple recurrence formula to construct full-resolution (64-bit) matrices. Because our generator matrices are binary, they allow highly-efficient implementation using bitwise operations and can be used as a drop-in replacement for Sobol matrices in existing applications. We compare SZ sequences to state-of-the-art low discrepancy sequences, and demonstrate mean relative squared error improvements up to in common rendering applications.

1. Introduction
Sampling is a fundamental process in computer graphics (CG), underlying multiple areas including halftoning and stippling, geometry processing, machine learning, and most notably rendering, where pixels are computed by Monte-Carlo integration of complex light-transport paths. Even though these paths are inherently high-dimensional, they are mostly built from from 2D surface interactions, in addition to some 1D constituents; from here emerged the idea of similarly building the high-dimensional samples by pairing 2D and 1D samples over these constituents (Cook et al., 1984; Glassner, 1994). The research focus therefore went to optimizing 2D distributions, and it was long believed that optimizing over the high-dimensional space is “at best a secondary concern” (Pharr and Humphreys, 2004). Even when the inherently high-dimensional low-discrepancy (LD) sequences were brought to CG, generally only the first two dimensions were used and similarly “padded” to build high-dimensional samples (Kollig and Keller, 2002).
While LD sequences could be used to sample the image plane directly (Mitchell, 1992), doing so with parallel rendering based on screen-space decomposition was challenging since consecutive image samples end up at far-away pixels. A milestone came with Grünschloß et. al. (2012) showing how to invert LD sequences, making it possible to determine which sample in the sequence corresponds to a given sample index in a pixel. This inversion greatly facilitated global LD sampling, where a single high-dimensional LD sequence is used to generate all samples for all pixels in all dimensions. Despite noticeable artifacts before convergence, the undeniably superior performance of this sampling strategy clearly indicated that high-dimensional uniformity, in fact, does matter. It is worth noting that the employed Sobol sequences are already optimized for improved 2D projections by Joe and Kuo (2008), hence it is actually a combination of two- and high-dimensional uniformity that accounts for this success. Soon after, pbrt and Mitsuba, the common research rendering engines, both adopted global Sobol sampling for their defaults, and most of subsequent sampling research in CG was devoted to LD constructions, with a primary goal of imposing more control on these distributions, especially their lower-dimensional projections.
In this paper, we make a major advancement in this research direction of controlling LD distributions. Rather than adapting one of the few known sequences, we present a novel construction of a complete family of LD sequences, built entirely from first principles. We use binary matrices to construct (0, 4)-sequences in base 4, as defined in Section 2 below. We then show how to extend this sequence to additional dimensions, achieving -sequences in each pair of dimensions, -sequences in each quad, -sequences in each set of 16 dimensions, and so on. Our sequences thus give superior integration performance in many cases where lower-dimensional projections are important. Because our generator matrices are binary, they can be used as a drop-in replacement in systems that currently use Sobol samples; no algorithmic changes are necessary, and performance is unaffected with their substitution.
2. Technical Background and Related Work
Our work belongs to the research area on uniform distribution of points (Kuipers and Niederreiter, 1974), aiming at obtaining point distributions that uniformly cover a domain better than random (white noise) distributions. The -dimensional sampled domain is usually scaled to a half-open unit hypercube . In this section, we furnish a basic technical background needed to understand our proposed method, and briefly review the most closely-related work.
2.1. Discrepancy
The term “discrepancy” refers to the error of using a point set to estimate the volume of region by counting the ratio of points falling inside. Star discrepancy, commonly notated as , refers to the maximum discrepancy measured over all axis-aligned hyper-rectangles in the concerned domain, and gives a reliable measure of the performance of the point set in numerical integration. A point set is considered a low-discrepancy (LD) set if it attains discrepancy for points in -dimensions. A low-discrepancy sequence is an infinite sequence of points that provides an LD set for certain contiguous blocks of points of certain sizes, and attains discrepancy for all contiguous blocks.
2.2. Radix-Based Constructions
A significant construction of a one-dimensional LD sequence was presented by van der Corput (1935). If
| (1) |
denotes the binary encoding of the sample index , then the th sample is computed by mirroring the bits of at the fraction point:
| (2) |
This approach can be generalized to higher dimensions by generating the th component/dimension of the sample using a distinct linear mapping
| (3) |
where is a vector representing the th digit-reversed van-der-Corput-like sample in some base , is a vector representing the same-base fractional digits of the final sample location along the th axis, and is a matrix in Galois Field (GF) , known as a generator matrix, that linearly maps reversed digits of the sample index to digits of the computed sample, hence the name “digital” to collectively describe these methods. Next we briefly outline the three most established digital construction approaches to LD sequences.
The first known higher-dimensional extension to van der Corput sequences in due to Halton (1960), and simply uses a different prime base for encoding the index along each axis. Identity matrices may be used for in Eq. (3), but more complex scrambling matrices have been proposed to improve the pairwise 2D projections.
A very different approach was taken by Sobol (1967), who stuck to a binary-base encoding, and constructed a different generator matrix for each dimension, using a recurrence operation to compute each column of the matrix from the preceding columns, taking the coefficients from an irreducible polynomial. These polynomials, in a sense, replace the role of different bases in Halton’s construction. We skip the details and only highlight the most relevant one here that the first two irreducible polynomials lead to the pair
| (4) |
that constitutes the first two, invariant, and most well-known dimensions of Sobol’s construction, where
| (5) |
happens to be the Pascal matrix in GF(2), where / are row/column indices, indexed from 0. Please note that we hereinafter adopt the convention of showing binary matrices as arrays of (0) gray and (1) black dots for better visibility, and also occasionally using dots instead of zeros for the same purpose.
These first two dimensions of Sobol inspired a third construction by Faure (1982) that uses powers of a Pascal matrices
| (6) |
in a prime base , and generates a -dimensional LD sequence analogous to the 2D Sobol sequence, in a sense explained in the following subsection. Niederreiter (1987) extended Faure construction to power-of-prime bases using symbolic matrices and arithmetic over the GF().
Thus, we have three well-established constructions approaches to high-dimensional LD sequences:
-
(1)
Halton, using different prime bases.
-
(2)
Sobol and variants, using binary-polynomial-based matrices.
-
(3)
Faure and Niederreiter extension, using Pascal matrices over fields.
Among the three, two factors made Sobol the most adopted one in computer graphics: a) the binary base, leading to extremely fast computation, and b) that higher distribution quality is obtained for lower dimensions, as will be explained in the following subsection. Halton comes next, sharing the second but not the first property of Sobol. Because the prime bases are known at compile-time, the cost of integer divisions and modulus operations can be reduced (Warren, 2012), bringing the digit reversal of Halton to within tolerable limits; this has led to making Halton sequences being used in common rendering platforms like pbrt (Pharr et al., 2016).
In contrast, we are unaware of any mention of Faure sequences and their derivatives in CG, and we may attribute this primarily to the large base used for all dimensions, requiring a considerably large number of points to attain the advertised uniformity. The lookup-based arithmetic of Niederreiter’s extension exacerbate this by adding considerable computational overhead.
While our work is developed from first principles, the resulting construction may be considered as an extension to Faure’s, specifically Niederreiter’s extension, that addresses both limitations: we ensemble higher-dimensional sequences from lower-dimensional ones, and use GF(2) matrices like Sobol’s. Thus, our construction effectively introduces the third category of LD sequences to CG.
2.3. -Nets and -Sequences
Niederreiter (1987) also established a complete theoretical framework for developing and studying a large class of LD constructions, including the radix-based ones listed above. At the heart of this theory is so-called -Nets in base , which refers to a multi-stratified distribution of points in an -dimensional hypercube such that, for all possible stratification (slicing) ways of the domain into similar rectangular strata (cells), we find exactly points in each stratum. An illustration of the essence of a -net in base 4, for example, is shown in Fig. 1. Then come -sequences in base , which are infinite sequences of -dimensional points such that, for all integer , the first and all subsequent blocks of points comprise a -net in base . While these definitions are independent of the construction method, the model possibly existed thanks to the existence of algebraic recipes for construction. Specifically, the definition of -nets translates directly into a simple condition on digital: if we build a hybrid matrix
| (7) |
|
by combining the first rows of the th generator matrix in Eq. (3), with s summing to , then each such a hybrid matrix multiplied by computes the allocation of the points to strata in a specific stratification. The -net condition, for example, then corresponds to requiring that each hybrid matrix is invertible, ensuring a one-to-one correspondence of points to strata. A -sequence requires a set of generator matrices that maintains this hybrid matrix condition progressively over their top-left corners.
These definitions suggest that it is desirable to keep both the base and the parameter small, though different needs might call for different configurations. To give some examples, the van der Corput construction is a (0, 1)-sequence in base 2. Faure sequences are -sequences in their respective prime bases, while Niederreiter’s extension to Faure creates -sequences in power-of-prime bases . The first two dimensions of Sobol sequence comprise a -sequence in base 2, but the value increases as we take more dimensions, which makes lower dimensions attain better quality, as we mentioned in Sec. 2.2. Halton sequences, in contrast, do not readily fit within the -sequences model, unless we adapt it to accept different bases. They still exhibit a multistratified structure, though. Hence, the common ground of all the three families of constructions is that they attain optimal quality at powers of the base, or product of bases in case of Halton, and here we can see the reason of superiority of Sobol and Halton over Faure for graphics applications where lower dimensions are usually more important.
In this paper we develop a novel construction of -sequences using binary GF(2) matrices. Technically speaking, we are breaking two traditional rules of nets and sequences: that a composite number cannot directly be used as a base, and that one can not obtain a -sequence with a base . We achieve this result, however, by combining the two violations: instead of using a base-4 directly, for example, we use binary matrices as building blocks to emulate base-4 matrices. Please note that is implied in the following if no base is mentioned.
2.4. Scrambling and Shuffling of LD Constructions
Beyond the algebraic recipes for constructing LD sets and sequences, the design space is greatly enriched by scrambling techniques that can derived new valid nets/sequences from given ones. Tezuka (1994) showed that multiplying arbitrary lower-triangular matrices from left by the generator matrices produces valid generators, since doing so preserves that ranks of all hybrid matrices. Owen (1995), in contrast, introduced a post-processing technique, “Owen scrambling”, that preserves the net/sequence structure. In contrast to scrambling that applies to sample locations, the term shuffling refers to reordering (permuting) the sample indices (Faure and Tezuka, 2002). As -sequences, all these are applicable to our sequences, and we will use them in our development.
2.5. LD Sampling in Computer Graphics
The interest in LD construction has grown in the graphics community over the past decade, mostly devoted to finding handles to impose control over these distributions as commonly needed in graphics applications. Ahmed et al. (2016) presented an original 2D low-discrepancy construction that enables imposing a blue noise spectrum, then Perreir et al. (2018) imposed a blue noise spectrum onto selected pairs of dimensions of a Sobol sequence. While both methods compromised the discrepancy of the underlying distribution, they presented a proof of concept that encouraged further research.
In a different path, Christensen et al. (2018) tried searching for dyadic (i.e., base-2) -sequences sequences with good spatial and spectral properties, and Pharr (2019) presented a more efficient search, but Ahmed and Wonka then presented a theorem ([)Theorem 4.2]Ahmed2021Optimizing implying that the search space is actually confined to Owen-scrambled 2D Sobol, and soon the first group of authors, lead by Helmer (2021), developed an extremely fast implementation of Owen scrambling. We take this as an excellent example of the fast-paced learning cycles of the community to analyze and manipulate the inherently difficult-to-understand LD construction. In this paper we present an almost complete cycle from experimentation to elements of a theory.
In more recent years, the research on LD in CG reached the state of enriching the quasi-Monte-Carlo (QMC) literature with significant findings and novel constructions, including an efficient algorithm that spans the whole space of dyadic -nets (Ahmed and Wonka, 2021), a cascade of dyadic -nets over successive pairs of dimensions (Paulin et al., 2021), a family of self-similar dyadic -sequences (Ahmed et al., 2023), a gradient-decent optimization of discrete Owen scrambling (Doignies et al., 2024), and a base-3 analog to Sobol sequences (Ostromoukhov et al., 2024). Our current work is partially inspired by this last work of Ostromoukhov et al., where we thought of using base 4 instead to gain the advantage of binary computation.
3. Exploration
In this section we report our pilot search for binary matrices that generate -sequences, starting from experimental exploration and gradually developing an analytical framework distilled from empirical findings. Starting with four dimensions, our initial goal is to construct a -sequence by searching for a working set of generator matrices that linearly map a reverse-ordered vector of digits of the sample index into vectors of digits representing coordinates along the four axes, as in Eq. (3). It is already established and well known that plain matrices and straightforward arithmetic in a composite base like 4 would not serve the purpose. An intuition of this deficiency may be obtained by noting that a factor of the base, like 2 in base 4, would not preserve all the ranks of a multiplied sequence number digit modulo base, which drastically limits the opportunity of finding a working set of matrices. Rather than using GF(4) symbolic arithmetic like Niederreiter (1987), our idea is to use plain GF(2) matrices and vectors, interpreting blocks of the generator matrices and pairs of bits of the multiplied vector as base-4 digits. Our first key insight is that the set of invertible binary matrix blocks is capable of resolving all the 6 permutations of the list of non-zero numbers in a base-4 digit. While this does not prove that building matrices from such blocks would yield a -sequence, it is at least encouraging to explore.
We start with an exhaustive search over a small range to validate the concept. Without loss of generality, we may assume the identity matrix for the first dimension, since it can be factored out from the right of the four matrices to permute the sequence number. Our plan, then, is to progressively search for three binary square matrices that expand at a pace of 2 rows and columns and fulfill the hybrid-matrices condition (Eq. (7)) in each step. That is, in each step, and for each dimension, we expand each matrix
| (8) |
by adding an column , a row , and a corner block . We will drop the suffix hereinafter where not deemed ambiguous. We may always assume zeros for by factoring a lower-triangular Tezuka-scrambling matrix:
| (9) |
where is an appropriately sized identity matrix. Then we use the factoring
| (10) |
to reveal that must be invertible. This reduces the set for corner extension matrices from 16 to the following six:
| (11) |
We may further exclude the third and fifth by factoring out a lower-triangular Tezuka-scrambling matrix, reducing the set to only four:
| (12) |
which is more favorable as a power of 2.
We built an efficient exhaustive search algorithm by placing a whole matrix compactly in a 64-bit word, allowing for fast bit manipulation and for building lookup tables of invertible matrices. This enabled searching up to matrices, i.e., four extension steps. The search confirmed the existence of multiple working sets of matrices, which encouraged us to conduct two important experiments. We first considered nesting a (0, 2)-sequence, namely 2D Sobol, in our (0, 4) set. Towards that end, we enforced the extension of the second-dimension matrix to reproduce the Pascal matrix, and search for a complementing pair of matrices. This successfully worked all the way to 88 matrices, with multiple choices in each extension. Next, we considered ensembling two (0, 2)-sequences into a (0, 4)-sequence. To achieve this, we used the formula recently exposed by Ahmed et al. (2023), telling that for any pair of upper-triangular generator matrices to make a (0, 2)-sequence, they have to satisfy
| (13) |
Thus, we conducted the search as with nesting, and in each extension filtered the results that satisfy this condition. Once again, the experiment worked successfully all the way to the matrices.
3.1. Initial Findings
For all combinations of valid initial 22 blocks of the three matrices, we consistently obtained 768 distinct valid sets for the first extension to 44, and 384 distinct valid extension on each branch for subsequent extension to 66 and 88, which suggests an analytical construction model. The fixed number of alternatives in each extension step indicates that the degrees of freedom are possibly limited to the top and bottom blocks of the extension columns. Following this hint, we note that the corner extension block in Eq. (8) is not involved in any of the hybrid matrices, hence comprises, for each of the three matrices, a free choice among the four options in Eq. (12). This accounts for a factor of , and we verified that fixing the extension corner blocks to identity reduces the list to 12/6 sets in the first/subsequent extension steps. This leaves us with the degrees of freedom in the top row, which we analyze next.
Let
| (14) |
denote the first block-row in one matrix of the three upon the th extension, where each is a 22 block matrix. By constructing a hybrid matrix comprising rows of the first identity matrix and this row of , we find that
| (15) |
leading to the conclusion that, for each of the three matrices, all blocks of the first block row have to be invertible.
Now consider taking a hybrid of the first rows of with the first row of each of two other matrices and , then we get
| (16) |
Since all four elements are invertible by virtue of Eq. (15), we can use our earlier “” reduction of Eq. (9) to get
| (17) |
or
| (18) |
Let us define a symbol
| (19) |
to designate the product of the inverse of the st by the th entry in the first row of block-matrix . Then Eq (18), rewritten as
| (20) |
says that the sum of corresponding symbols in the first row of each pair of generator matrices must be invertible, which also implies that the symbols at corresponding slots must be distinct for the three matrices. Thus, for each slot in the first block row, the inserted block-matrix symbols must be
-
(1)
Invertible.
-
(2)
Distinct for each matrix.
-
(3)
Have invertible sums.
The population of six invertible 22 matrices comprises two disjoint sets,
| (21) |
that satisfy these requirements, each comprising two diagonally-mirrored triangular elements, and a counter diagonal element that switches between them via addition, hence we call them (think ) and (think ) to make it easier to recall which is which. Hence comes the name SZ for these sequences. We will also stick hereinafter to this “S/Z” convention in discriminating left/right-hand elements and operations, respectively.
We conclude this subsection by noting that these three simple rules comprise all the requirements for satisfying the hybrid matrix condition for the first block matrices. Further, they analogously extend to other powers of 2. Thus, constructing binary matrices for generating a “-net in base ” reduces to finding an alphabet of -block matrices satisfying these rules. This name in Niederreiter’s notation just means a set of points in dimensions that is stratified in all pairs of 2D projections; cf. Jarosz et. al. (2019). Next, we show how to extend the matrices to arbitrary sizes for -sequences in base .
3.2. Refinement
Instead of defining the symbols in Eq. (19) in terms of adjacent entries, it would be more constructive to populate the matrices directly with symbols. Realizing that all first-row blocks must be invertible helps us to achieve this via this subtle factoring
| (22) |
The common (left-hand-side) factor represents a Tezuka scambling, hence may be dropped. Thus, without loss of generality, we may populate all blocks in the first row of the second-dimension (first of the three) matrix with identity matrix blocks. Once we implement this last factoring, the exhaustive search reduces to this one-and-only quadruple of generator matrices:
| (23) |
here shown to 32-bit depth. As per our exhaustive search, this quadruple represents the template of all binary-matrix-based (0, 4)-sequences, and all other possible variants may be derived by plugging back the degrees of freedom factored earlier, as we will discuss later.
Upon careful inspection of these matrices, the first important observation is that they are built exclusively from the block symbols in Eq. (21), plus empty (0) blocks. Further inspection, guided by a preliminary assumption that these sequences bear some relation to Faure’s, reveals that these are actually Pascal matrices
| (24) |
constructed from these four block symbols.
4. SZ Sequences
Based on our exhaustive search for binary -sequence generators and similar partial searches for and sequences, we find that what characterizes the set of block symbols, compared to the complementing set in Eq. (21), is that it is not only closed under addition, but also multiplication, and hence constitutes a finite field, as dictated by Wedderburn’s little theorem, stating that “every finite division ring is a field”. In a nutshell, finite fields are sets of elements over which are defined analogous operations to addition and multiplication, and the set is closed under these two operations, with associated neutral elements analogous to 0 and 1, and with analogous definitions of additive and multiplicative inverses. The only missing element in our alphabets to make a field is a zero, but in fact, this element has existed and been used all the way in our development: it is the symbol that is used to build the identity matrix in our set! This could be slightly confusing, since we have a “grand” identity matrix for the final set of generator matrices, built from the 0 symbol, and a “Pascal-ed” identity symbol used to build the second-dimension generator matrix.
Once we arrive at this conclusion for 4D, we may readily envision analogous constructions for higher power-of-2 dimensions, as summarized in Algorithm 1.
Using this algorithm, we constructed SZ sequences for different values of , and empirically verified their -sequence property by building and validating all the sets of hybrid matrices. It is worth noting here that, as a special case of our model, the conventional Pascal matrix in 2D Sobol/Faure constructions is the Pascal matrix of the identity of a 2D alphabet comprising granular 0 and 1 as their block matrices. Thus, we hereinafter consider an all-zero block matrix as an intrinsic symbol in our alphabets.
Thus, while we did not proactively choose to use fields, they automatically emerged, bringing us closer to Faure’s sequences and their Niederreiter’s extension. Let us briefly abstract our empirical search results in Section 3 to understand what happened: We constructed the following four base-4 matrices:
| (25) |
These are exactly the ones in Eq. (23), just encoding each distinct block as a base-4 digit, namely indexed after 0 and the three symbols in Eq. (21). When multiplied by a base-4 column vector representation of a sequence number, these specific matrices generate a (0, 4)-sequence in base 4, i.e., a sequence of 4D points that is fully multi-stratified for powers-of-4 number of points. However, multiplication is not the standard arithmetic modulo-4 one, but uses a special table
| (26) |
that is built to amend the degenerate multiplication table modulo 4, preparing it for Faure construction. Here refers to the left multiplicand digit from the matrix and to the right one from the vector. Finally, this arithmetic table is not built arbitrarily, nor looked up, but is intrinsic to the matrix-block alphabet, and is evaluated automatically via GF(2) matrix-vector multiplication:
| (27) |
Please mind the bit-reversed ordering: top row is least significant bit, so \binaryMatrix[-1.4]11. is 1 and \binaryMatrix[-1.4]1.1 is 2.
Even though we have arrived at this construction experimentally and independently, as detailed in the preceding Section 3, once abstracted this way, we may see a close similarity to the analytically developed construction of Niederreiter (1987; 1992) that extends Faure’s sequences to power-of-prime bases. Further, the uniqueness of finite fields makes us strongly believe that our construction does actually coincide with Niederrieter’s. This remains a hypothesis, though, awaiting for analytical validation, since the multiple degrees of freedom in both constructions makes them produce different realizations, which makes empirical verification difficult. In all cases, both constructions span the same universe of -sequences in base . It is the emphasized text in the preceding description, however, that is the essential difference between our construction and Niederrieter’s: instead of using symbolic GF() arithmetic with lookup tables, as in the standard implementation of Niederreiter sequences (Bratley et al., 1992), our field elements are embedded as block matrices in GF(2) generator matrices that handle both the field arithmetic and the bijections operators in Niederreiter’s construction. This makes our binary-based construction far more efficient and scalable. Another important advantage is that our experimental approach lead us to discover nesting and ensembling, which makes a significant difference in graphics applications, as we will see later in Section 5.2.
4.1. Alphabets
Identifying alphabets as finite fields brings with many insights and implications. For example, it implies commutativity of matrix multiplication over the set, which we will use later for randomization. The most relevant property for our construction, however, is that in fields like our alphabets there exists a symbol, in fact many, that multiplicatively cycles through all other non-zero symbols; that is, it can generate all the non-zero elements as its powers. Such a symbol is called a “primitive” and commonly designated as . Then the alphabet may be written as
| (28) |
Aside from analytical insights and proofs, alpha elements prove quite helpful in practice. The first facility they can offer is a straightforward search plan for alphabets, as summarized in Algorithm 2, replacing complex and time-consuming stack-based searches we implemented in our exploration phase.
Secondly, noting that an alpha element can belong to a unique alphabet, the search algorithm can easily be modified to enumerate all alphabets, dividing the number of alpha elements in the universe of invertible matrices by the number of alphas in a single alphabet. We performed such a search over the feasible range, and obtained
| (29) |
A brief Internet search identified this with OEISA258745 (2015), described as “Order of general affine group AGL(n,2) (=A028365(n)) divided by (n+1)”. This gives a hint for the possibility of building alphabets algorithmically, which we leave for future research.
4.2. Randomization
With the template set of generator matrices built up exclusively of alphabet building blocks, we may now randomize the set by plugging back the degrees of freedom we factored earlier. The extension rows we removed in Eq. (9), along with the diagonal blocks we factored later, exactly identify with the Tezuka’s (1994) scrambling mentioned in Section 2.4. Beyond that, our model readily supports Owen’s (1995) scrambling and Faure-Tezuka (2002) shuffling in both and bases; as well as Xor-scrambling (Kollig and Keller, 2002).
4.3. Nesting
The key idea of nesting, introduced in the exploration phase, is to find an alphabet over that embeds in its symbols the symbols of a given alphabet over , in such a way that the generators of the nested sequence may be reproduced using sequence-preserving manipulations of the corresponding generators of the nesting sequence. Toward that end, we start by extracting symbols of the nesting alphabet from generators of the nested sequence. We note that 22 blocks of the nested generator tile a single block of the nesting generator. The symbol of the nesting alphabet is found in the second block of the first row of the Pascal matrix, but we first have to factor out the first block, leaving only an identity; hence
| (30) |
where denotes a symbol of the nesting alphabet embedding symbol of the nested sequence alphabet. We then search for a alphabet that contains this subset. A brute-force approach to such a search is far more difficult than before, since we seek quite specific alphabets. We therefore generated and analyzed all nesting alphabets in a feasible range, and luckily managed to find a pattern that all nesting alphabets are built exclusively from the nested alphabet symbols. This reduces the search space dramatically from to , which makes it feasible to reach 64K dimensions. This reduction not only enables us to find working alphabets, but to uniformly sample them.
Once the alphabet is found, the generator matrices are built as per Algorithm 1, then the generator matrices of embedded symbols are multiplied by a factor
| (31) |
to restore the original matrices, which provably works by expanding the multiplication by the block entry
| (32) |
which match the entries in , then the coefficients
| (33) |
are matched using Lucas’ Theorem. Note that for the nesting set, this multiplication represents a Tezuka scrambling, hence preserves the structure of the sequence.
We conclude this section by making a remark that nesting, as described above, works only by doubling , i.e., squaring the dimension in each upsampling step of the sequence space, not by doubling the dimension as we would hope.
4.4. Ensembling
Ensembling is less obvious than nesting, since it depends on a non-obvious property. We start with a nested sequence, and the key idea is to try to make subsequent bands of dimensions of the nesting sequence, with respect to each other, look identical to their counterparts in the nested band. This starts by arranging the symbols in a suitable order, as outlined in Algorithm 3,
which arranges the symbols in a literally nested algebraic structure of bands
| (34) |
This idea is based on an interesting property
| (35) |
of Pascal matrices that summing the symbols is equivalent to multiplying the corresponding Pascal matrices. A sketch of a proof starts by noting that each entry
| (36) |
of on the right-hand side embodies a binomial expansion with the same range of powers as the corresponding row-column product on the left-hand side, and it then remains to equate the binomial coefficients. Applying this property to the nested structure in Eq. (34), we note that adding a symbol to each subset is equivalent to multiplying its generator matrix by those of the subset, with a net effect of reordering the points in the subset while preserving their geometry. That is, the sub-sequence of each band is just a reordering of the sequence of the reference band, hence can be turned into a nested sequence by the same restoration in Eq. (31), actually the identical sequence, but in a different order. This can be observed in Fig. 1(b), where all (0, 2) components look identical.
Ensembling, as described above, imposes substantial correlation between corresponding dimensions in different bands, which might cause undesirable effects in some applications. To mitigate this, we may shuffle the points in different bands, as done when pairing independent 2D sequences (Burley, 2020), but that would break the high-dimensional structure in our case. Fortunately, we may take advantage of the commutative multiplication property of alphabets mentioned in Section 4.1: if we multiply any of the Pascal generator matrices from left by any symbol from the alphabet, it is multiplied by all blocks, then the multiplication order can be exchanged, and the symbol can be factored on the right. The operation on the left is a Tezuka scrambling, hence preserves the structure of the sequence, but it is effectively equivalent to a Faure–Tezuka shuffling (see Section 2.4) that reorders the coordinates in the concerned dimension. To use this idea with ensembling, we use 4D symbols to shuffle 2D bands, 16D symbols to shuffle 4D bands, and so on. More details are in our supplementary code.
5. Results and Applications
To evaluate the performance of SZ-sequences, we have evaluated them both for the numerical integration of synthetic functions as well as for rendering. We further include empirical measurements of discrepancy as well as analysis of their power spectra. Our implementation is included in the supplemental material.
| Linear () | ||||
| Gaussian () |
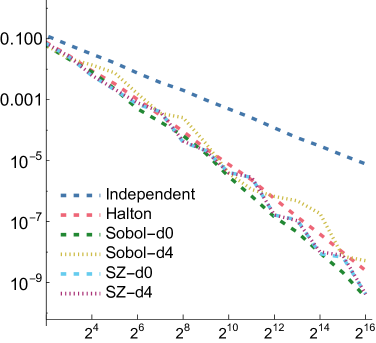
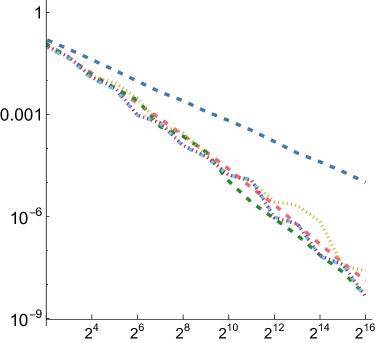
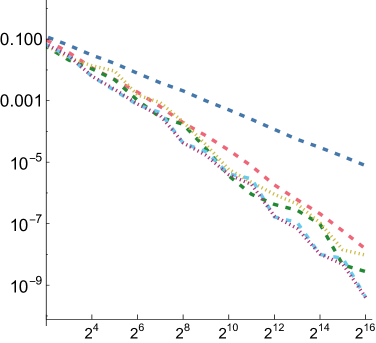
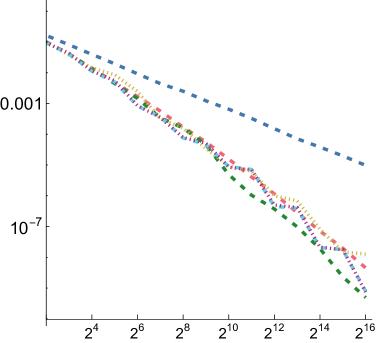
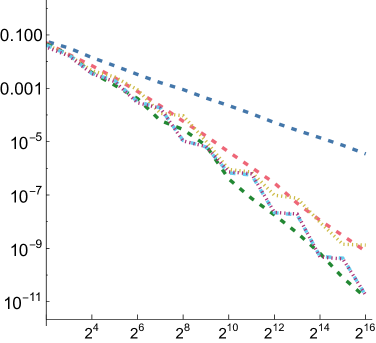
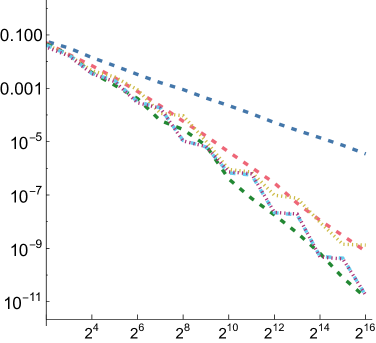
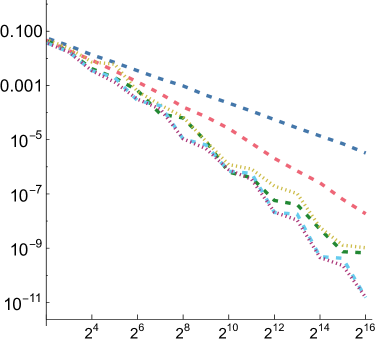
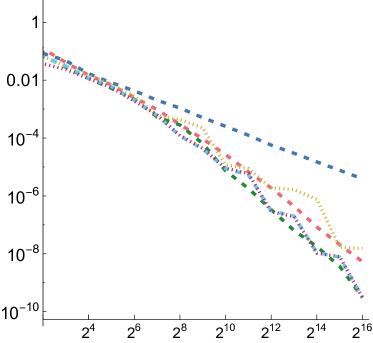
5.1. Numerical Integration
In order to compare the performance of SZ points to other point sets for integration, we measured mean relative squared error (MRSE) when integrating a variety of simple analytic functions. We follow the approach developed by Jarosz et al. ([)Section 5.2]Jarosz19Orthogonal, which we summarize here. Three 1D functions are used as building blocks
| (37) | ||||
| (38) | ||||
| (39) |
with , , and . Projection of an -dimensional point to a set of dimensions is denoted by
| (40) |
-dimensional functions are then defined by taking the vector norm of projected points
| (41) |
These are plots of associated 2D functions:



We used four forms of functions for our tests:
-
•
: the product of two 2D functions.
-
•
: a fully 4D function.
-
•
: the sum of the product of two 2D functions.
-
•
: the product of functions of all 2D projections of a 4D point.
For each of these and for each of the three functions defined above, we computed a reference value and then ran 1,024 independent trials, each taking up to samples. Owen scrambling was used to randomize the low-discrepancy sequences. In addition to our SZ sequence and the Sobol sequence, we also measured results with independent uniform random numbers and with the Halton sequence. For SZ and Sobol, we also measured results using samples starting at the 4th dimension, to reflect the case in rendering where such integrands might be encountered after a few dimensions of the sequence had already been consumed. We will use “SZ-d0” and “SZ-d4” to distinguish these, and similarly for Sobol. We measured MRSE at all power-of-two number of samples
 |
 |
 |
 |
 |
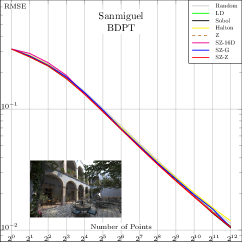 |
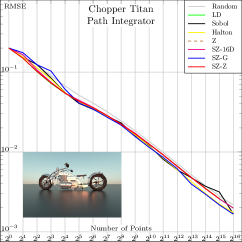
| (a) Complex Lighting | (b) Depth of Field | (c) Complex Light Transport | (d) Environment Map | (e) Glossy Surfaces | (f) Bidirectional Path Tracing |
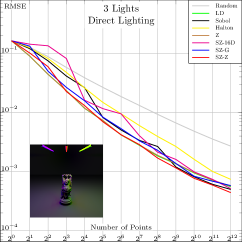
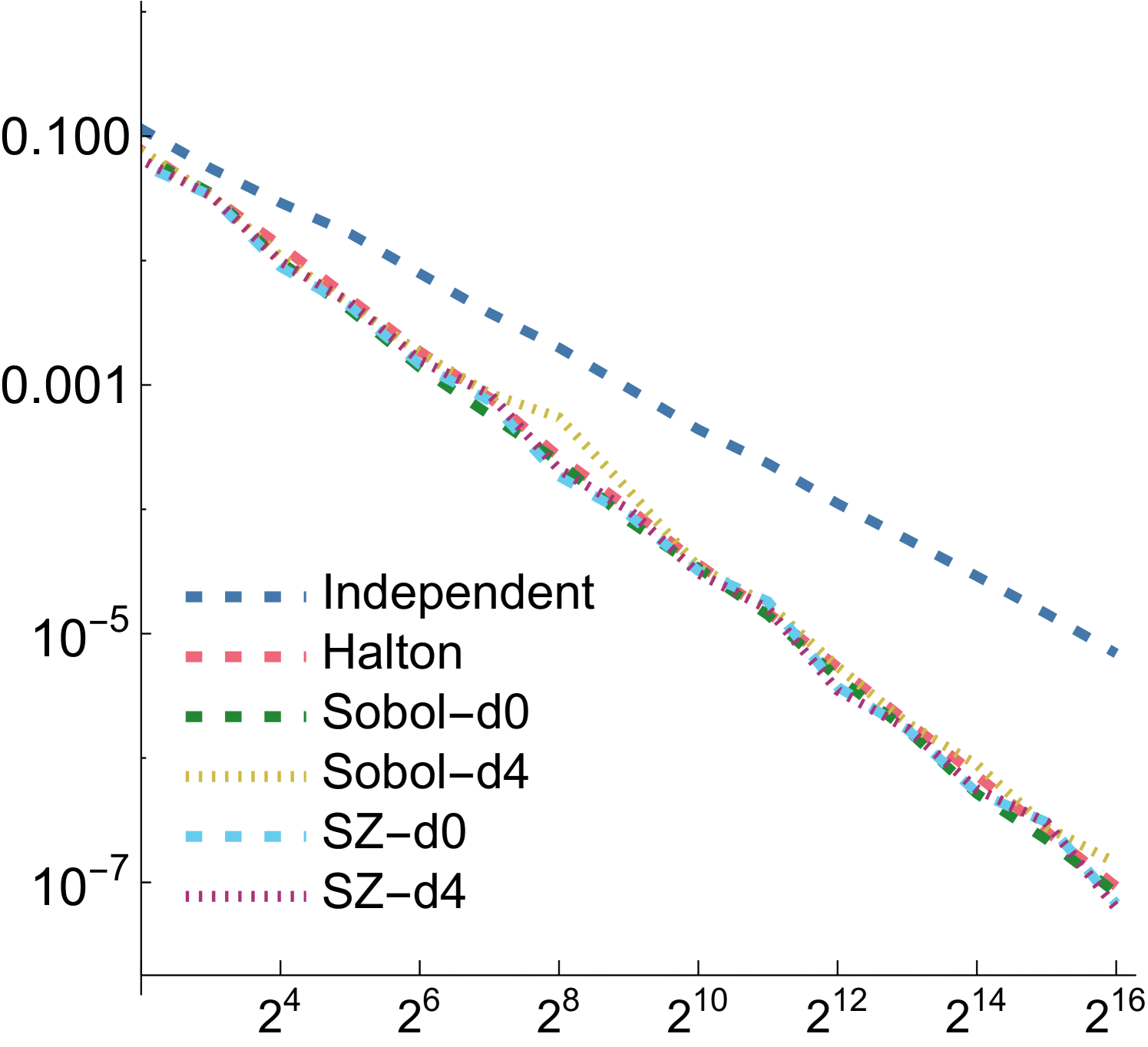
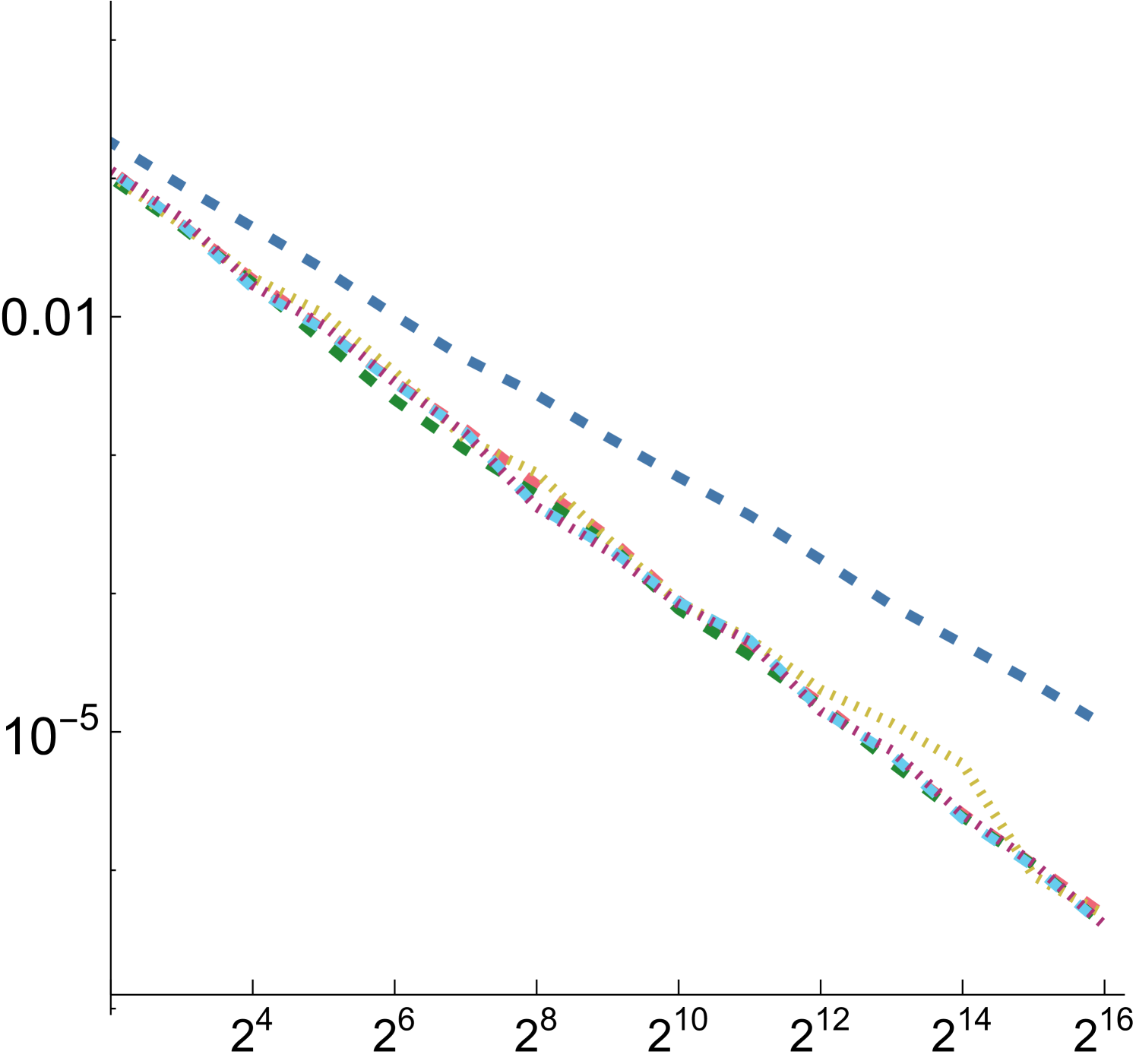
For all functions, performance of all samplers other than independent is similar for , so we will focus on and in the following. Error plots for and are shown in Fig. 2; the plot for can be seen in Fig. 8 in our supplemental. For both the first and second function forms, SZ-d0 matches Sobol-d0’s performance at power-of-4 sample counts, though it has higher error at intermediate powers of two. However, SZ-d4 delivers equally good error to SZ-d0, while Sobol-d4 is significantly worse. We would expect this trend to continue at higher dimensions, as SZ maintains its - and -sequences, while the quality of lower-dimensional projections of Sobol points worsens. For the third function form, the sum of the product of two 2D functions, both SZ-d0 and SZ-d4 significantly outperform the Sobol sampler. We believe that this is due both to it providing -sequences for each of the constituent 2D functions but also proving -sequences for each term. Finally, in the product of all of the 2D projections of a 4D point,we again see SZ-d0 and SZ-d4 matching Sobol at power-of-4 sample counts, and SZ-d4 having much lower error than Sobol-d4.
5.2. Rendering
To evaluate the effectiveness of SZ sequences for rendering, we first implemented a Sampler in pbrt (Pharr et al., 2016), using the global sampling strategy, where the first two dimensions are used for the image plane, and another using Z-Sampling (Ahmed and Wonka, 2020), where a shuffled Z-sequence of the pixels is used to index the samples. We modified the later, however, to sample all dimensions at once using SZ sequences.
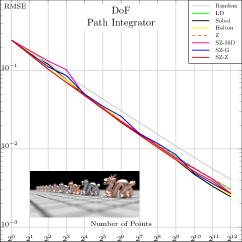
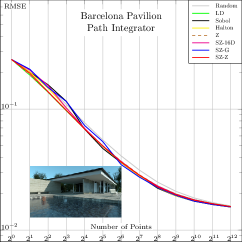
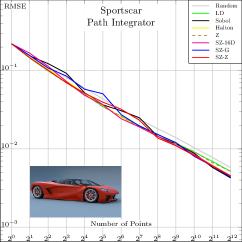
In Fig. 4, we compare these SZ-based samplers to state-of-the-art samplers for various common test scenes. We also included a raw (non-nested) 16D Z-indexed SZ sampler to give a rough idea about the expected performance of a randomly taken Niederreiter’s (0, 16) and Faure’s (0, 17) sequences. The plots suggest that the baseline performance of SZ is generally superior to Halton, Faure, and Niederreiter, thanks to finer granularity, and is in the same range as Sobol. We also note that the Z-indexed SZ sampler offers a decent aliasing/noise reduction compromise at low/high sampling rates, respectively. That is, it outperforms global samplers at low sampling rates and the original Z sampler at higher rates.

F








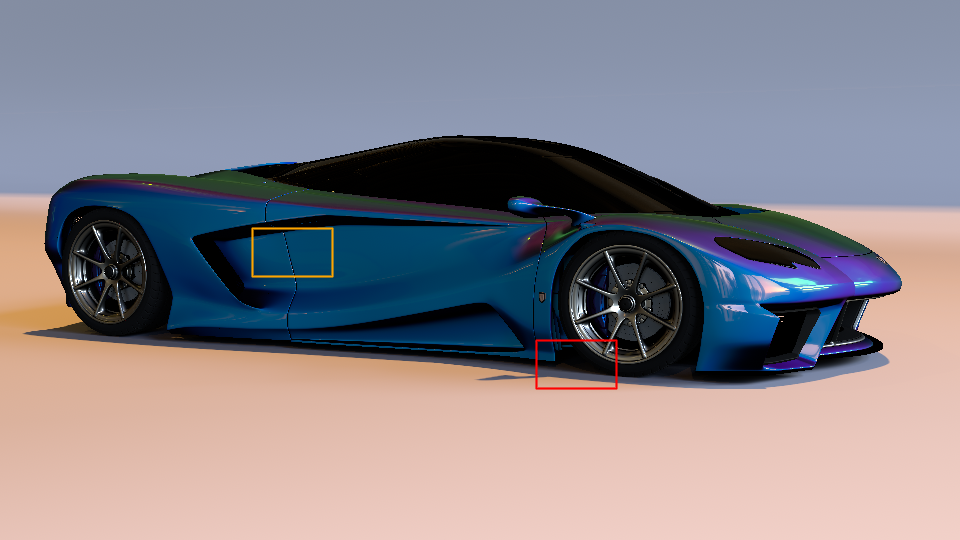
Beyond these baseline tests, we implemented a more detailed test in which we evaluated Sobol and SZ points for rendering direct illumination from an environment map, using two error metrics: MRSE and the perceptually-based F LIP metric (Andersson et al., 2020, 2021). For this evaluation, however, we modified pbrt so that the first two dimensions of the sequence are used to select a point inside each pixel area, the next two are used to select a point on the lens, the next two to importance-sample a direction from the environment map’s distribution, and then two more are used to sample the BSDF. Note that this differs from pbrt’s default assignment of dimensions for integration which does not consider the possibility of -sequences and so consumes additional 1D samples such as for time and sampling which light source to sample from early dimensions of samplers. We chose the Sportscar scene for the evaluation since it includes a variety of complex measured BSDFs, ranging from nearly diffuse to highly specular.
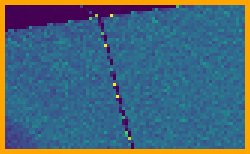
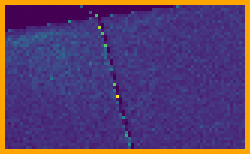
Fig. 5 shows results with a high-dynamic range environment map, including crops of representative parts of the image rendered at 64spp. The SZ sampler provides a meaningful reduction of for MRSE; this error reduction is visually evident in images. In this case, we can see that SZ does not suffer from the characteristic checkerboard pattern of unconverged Sobol sampling. See Section A for additional results with this scene, including a variety of different environment maps, visualizations of error across entire images, and error measurements at additional sampling rates.
5.3. Discrepancy
The essence of Niederreiter’s framework ([)Chapter 4]Niederreiter92Random is that identifying a sequence like SZ as -sequences in base is sufficient to qualify it as a low discrepancy sequence. We nontheless ran a test in the feasible range to empirically validate our model, and obtained the results in Fig. 6, confirming the theoretical model. Please note that we skipped the first two dimensions, as they are identical to Sobol, Faure, and Niederreter.
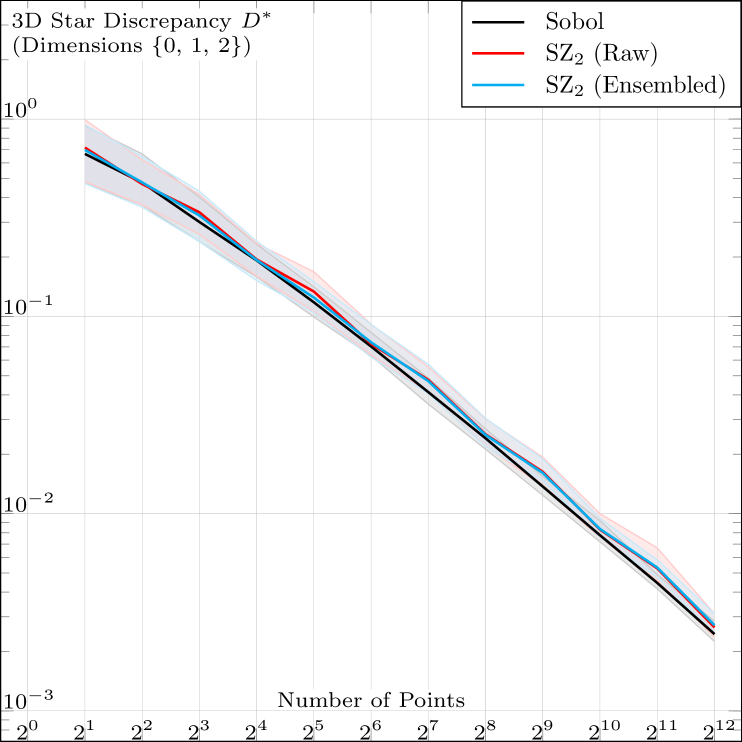 |
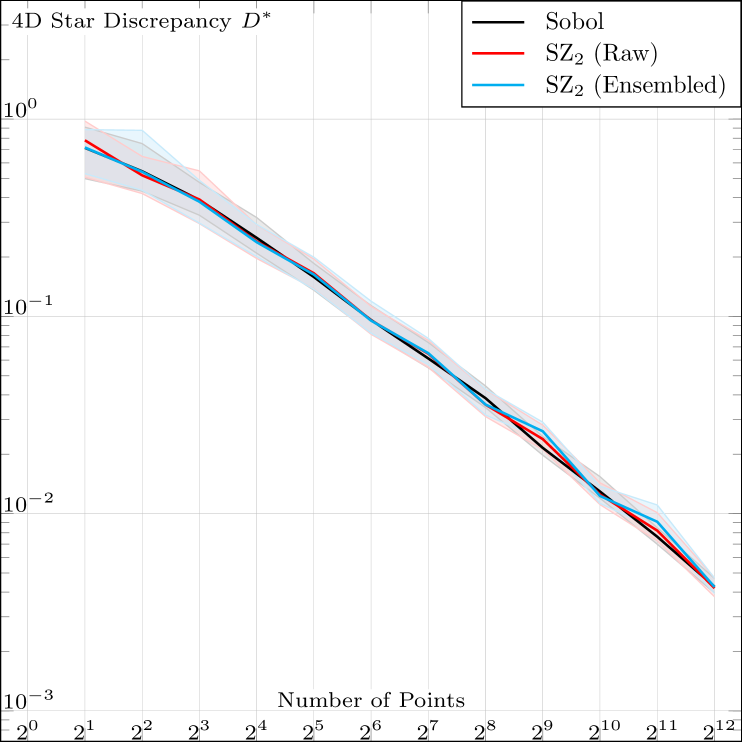 |
| (a) | (b) |
5.4. Frequency Spectra
In Fig. 1 we see a comparison between frequency spectra of corresponding pairs of dimensions between SZ and Sobol sequences. Our construction evidently admits better pairwise projections at powers of octaves, though the discrepancy plots in Fig. 6 suggest that Sobol behaves better at a more granular powers-of-2 octaves. Further, the fact that all consecutive pairs of dimensions of ensembled SZ sequences are dyadic -sequences makes them ripe for different optimizations of such sequences like those suggested by Ahmed et al. (2023; 2024) or Doignies et. al. (2024). In the supplementary materials we provide more detailed spectral plots, as well as a tool to produce more.
5.5. Time and Space Complexity
As a binary-matrix-based construction, the baseline for time and space complexity is that of Sobol sequences, and migrating from Sobol in existing systems is as simple as replacing the matrices. Notably, the matrices are identical for the the first two dimensions, hence preserving any special code for inversions (Grünschloß et al., 2012) or fast execution (Ahmed, 2024).
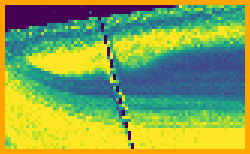
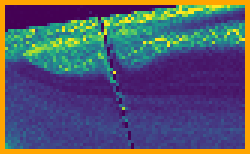
Understanding the anatomy of SZ matrices, however, offers multiple ways to optimize the space and/or time complexity. For a non-trivial example, in the code listing of Fig. 7(a), we exploit the alpha property to generate a complete set of 256 pair-wise stratified points in 16D, as visualized in Fig. 7(b).
 |
 |
| (a) Code | (b) plots of generated points |
In this example, the space complexity is reduced to a single integer 0x13A5 representing the alpha symbol of the alphabet in Fig. 1(b), while other symbols are evaluated implicitly by computing subsequent dimensions from preceding ones. Combined with Owen/Xor scrambling, this could represent a viable GPU-friendly sampling solutions for some applications, or a self-contained sample generator for hardware integration and/or in embedded systems. The mentioned example is limited to two octaves and without nesting, but similar specialized solution might be tailored for more advanced requirements.
Apart from such specialized hacks and tricks, SZ sequences admit a generic optimization via this “S-P-Z decomposition”:
| (42) |
The middle Pascal factor may be evaluated using the fast diagonal factoring introduced by Ahmed (2024), while the block-diagonal factors are simply treated as a sum of diagonal matrices that translate similarly to bit shift-n-mask operations. This reduces the time and space complexity from for -bit precision to for the middle factor and for the and factors, independent of numeric precision, which is especially significant for 64-bit computations. We actually obtained 11/23% memory saving and 20/15 speedup for the first 16/256 dimensions, respectively. An implementation is available in our supplementary materials.
5.6. Coding Complexity
Even though ending up in only a few lines of code, implementing low-discrepancy construction to compute generator matrices is relatively difficult and quite prone to mistakes, and SZ sequences are no exception. Acknowledging this, we will make our code publicly available, and aim at maintaining libraries for C, Python, etc., to encourage the adoption of these sequences. That said, we still encourage the readers to try to implement the sequences themselves, as it can potentially improve understanding of their properties.
6. Conclusion
In this paper, we enriched the sampling library with a novel construction of binary-based low-discrepancy sequences that scale flexibly with dimension, offering multiple degrees of freedom and control to enable sampling solution architects to build sequences tailored to their needs. Started experimentally, our empirical-based modeling led us close to the very well-established constructions of Faure and Niederreiter, with the primary difference that we replace elementary fields over (power-of-) prime bases by synthetic fields built over binary matrices, which enables very efficient computation. More importantly, our model uniquely offers the capability of ensembling a high-dimensional LD sequence from low-dimensional sub-sequences, which is desirable in graphics applications like rendering, where the integration domain is mostly made of 2D surfaces.
Our sequences are evidently superior to Halton’s for CG applications, and through multiple abstract and rendering tests, we demonstrated that they benchmark competitively with respect to the well-established Sobol sequences, offering a promising alternative to break their monopoly. Sobol seems to lead in some measures like discrepancy, while SZ excels in others like spectral control and speed performance. We believe, however, that a deeper analysis of the integrator-sampler interaction is needed before arriving at a final conclusion about the performance of these sequences. We therefore expect this work to spark future research aiming at analyzing, improving, and utilizing these sequences.
References
- (1)
- Ahmed (2024) Abdalla G. M. Ahmed. 2024. An Implementation Algorithm of 2D Sobol Sequence Fast, Elegant, and Compact. In Eurographics Symposium on Rendering, Eric Haines and Elena Garces (Eds.). The Eurographics Association. https://doi.org/10.2312/sr.20241147
- Ahmed et al. (2016) Abdalla G. M. Ahmed, Hélène Perrier, David Coeurjolly, Victor Ostromoukhov, Jianwei Guo, Dong-Ming Yan, Hui Huang, and Oliver Deussen. 2016. Low-Discrepancy Blue-Noise Sampling. ACM Trans. Graph. 35, 6, Article 247 (Nov. 2016), 13 pages. https://doi.org/10.1145/2980179.2980218
- Ahmed et al. (2023) Abdalla G. M. Ahmed, Mikhail Skopenkov, Markus Hadwiger, and Peter Wonka. 2023. Analysis and Synthesis of Digital Dyadic Sequences. ACM Trans. Graph. 42, 6, Article 218 (Dec. 2023), 17 pages. https://doi.org/10.1145/3618308
- Ahmed and Wonka (2020) Abdalla G. M. Ahmed and Peter Wonka. 2020. Screen-space blue-noise diffusion of monte carlo sampling error via hierarchical ordering of pixels. ACM Trans. Graph. 39, 6, Article 244 (Nov. 2020), 15 pages. https://doi.org/10.1145/3414685.3417881
- Ahmed and Wonka (2021) Abdalla G. M. Ahmed and Peter Wonka. 2021. Optimizing Dyadic Nets. ACM Trans. Graph. 40, 4, Article 141 (jul 2021), 17 pages. https://doi.org/10.1145/3450626.3459880
-
Andersson et al. (2020)
Pontus Andersson, Jim
Nilsson, Tomas Akenine-Möller,
Magnus Oskarsson, Kalle Åström,
and Mark D. Fairchild. 2020.
LIP: A Difference Evaluator for Alternating Images. Proceedings of the ACM on Computer Graphics and Interactive Techniques 3, 2 (2020), 15:1–15:23. https://doi.org/10.1145/3406183
F
- Andersson et al. (2021) Pontus Andersson, Jim Nilsson, Peter Shirley, and Tomas Akenine-Möller. 2021. Visualizing Errors in Rendered High Dynamic Range Images. In Eurographics Short Papers. https://doi.org/10.2312/egs.20211015
- Bratley et al. (1992) Paul Bratley, Bennett L. Fox, and Harald Niederreiter. 1992. Implementation and Tests of Low-Discrepancy Sequences. ACM Trans. Model. Comput. Simul. 2, 3 (July 1992), 195–213. https://doi.org/10.1145/146382.146385
- Burley (2020) Brent Burley. 2020. Practical Hash-based Owen Scrambling. Journal of Computer Graphics Techniques (JCGT) 10, 4 (29 December 2020), 1–20. http://jcgt.org/published/0009/04/01/
- Christensen et al. (2018) Per Christensen, Andrew Kensler, and Charlie Kilpatrick. 2018. Progressive Multi-Jittered Sample Sequences. In Computer Graphics Forum, Vol. 37. Wiley Online Library, 21–33.
- Cook et al. (1984) Robert L. Cook, Thomas Porter, and Loren Carpenter. 1984. Distributed Ray Tracing. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’84). Association for Computing Machinery, New York, NY, USA, 137–145. https://doi.org/10.1145/800031.808590
- Doignies et al. (2024) Bastien Doignies, David Coeurjolly, Nicolas Bonneel, Julie Digne, Jean-Claude Iehl, and Victor Ostromoukhov. 2024. Differentiable Owen Scrambling. ACM Trans. Graph. 43, 6, Article 255 (Nov. 2024), 12 pages. https://doi.org/10.1145/3687764
- Faure (1982) Henri Faure. 1982. Discrépance de Suites Associées à un Système de Numération (en Dimension s). Acta Arithmetica 41, 4 (1982), 337–351. http://eudml.org/doc/205851
- Faure and Tezuka (2002) Henri Faure and Shu Tezuka. 2002. Another Random Scrambling of Digital (t,s)-Sequences. In Monte Carlo and Quasi-Monte Carlo Methods 2000, Kai-Tai Fang, Harald Niederreiter, and Fred J. Hickernell (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 242–256.
- Glassner (1994) Andrew S. Glassner. 1994. Principles of Digital Image Synthesis. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.
- Grünschloß et al. (2012) Leonhard Grünschloß, Matthias Raab, and Alexander Keller. 2012. Enumerating Quasi-Monte Carlo Point Sequences in Elementary Intervals. In Monte Carlo and Quasi-Monte Carlo Methods 2010, Leszek Plaskota and Henryk Woźniakowski (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 399–408.
- Halton (1960) John H Halton. 1960. On The Efficiency Of Certain Quasi-Random Sequences Of Points In Evaluating Multi-Dimensional Integrals. Numer. Math. 2 (1960), 84–90.
- Helmer et al. (2021) Andrew Helmer, Per Christensen, and Andrew Kensler. 2021. Stochastic Generation of (t, s) Sample Sequences. In Eurographics Symposium on Rendering - DL-only Track, Adrien Bousseau and Morgan McGuire (Eds.). The Eurographics Association. https://doi.org/10.2312/sr.20211287
- Hošek and Wilkie (2012) Lukáš Hošek and Alexander Wilkie. 2012. An Analytic Model for Full Spectral Sky-Dome Radiance. ACM Transactions on Graphics 31, 4, Article 95 (July 2012), 9 pages. https://doi.org/10.1145/2185520.2185591
- Hošek and Wilkie (2013) Lukáš Hošek and Alexander Wilkie. 2013. Adding a Solar-Radiance Function to the Hošek-Wilkie Skylight Model. IEEE Computer Graphics and Applications 33, 3 (2013), 44–52. https://doi.org/10.1109/MCG.2013.18
- Inc. (2015) OEIS Foundation Inc. 2015. Sequence A258745: Order of the general affine group AGL(n,2). The Online Encyclopedia of Integer Sequences. https://oeis.org/A258745 Accessed: 2025-01-18.
- Jarosz et al. (2019) Wojciech Jarosz, Afnan Enayet, Andrew Kensler, Charlie Kilpatrick, and Per Christensen. 2019. Orthogonal Array Sampling for Monte Carlo Rendering. In Computer Graphics Forum, Vol. 38. Wiley Online Library, 135–147.
- Joe and Kuo (2008) Stephen Joe and Frances Y. Kuo. 2008. Constructing Sobol Sequences with Better Two-Dimensional Projections. SIAM J. Sci. Comput. 30, 5 (Aug. 2008), 2635–2654. https://doi.org/10.1137/070709359
- Kollig and Keller (2002) Thomas Kollig and Alexander Keller. 2002. Efficient Multidimensional Sampling. In Computer Graphics Forum, Vol. 21. 557–563.
- Kuipers and Niederreiter (1974) Lauwerens Kuipers and Harald Niederreiter. 1974. Uniform Distribution of Sequences. John Wiley & Sons, New York. http://opac.inria.fr/record=b1083239 A Wiley-Interscience publication..
- Mitchell (1992) Don Mitchell. 1992. Ray Tracing and Irregularities of Distribution. In Third Eurographics Workshop on Rendering Proceedings. 61–69.
- Niederreiter (1987) Harald Niederreiter. 1987. Point Sets and Sequences with Small Discrepancy. Monatshefte für Mathematik 104, 4 (1987), 273–337.
- Niederreiter (1992) Harald Niederreiter. 1992. Random Number Generation and Quasi-Monte Carlo Methods. SIAM.
- Ostromoukhov et al. (2024) Victor Ostromoukhov, Nicolas Bonneel, David Coeurjolly, and Jean-Claude Iehl. 2024. Quad-Optimized Low-Discrepancy Sequences. In ACM SIGGRAPH 2024 Conference Papers (Denver, CO, USA) (SIGGRAPH ’24). Association for Computing Machinery, New York, NY, USA, Article 72, 9 pages. https://doi.org/10.1145/3641519.3657431
- Owen (1995) Art B. Owen. 1995. Randomly Permuted (t,m,s)-Nets and (t, s)-Sequences. In Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing, Harald Niederreiter and Peter Jau-Shyong Shiue (Eds.). Springer New York, New York, NY, 299–317.
- Paulin et al. (2021) Loïs Paulin, David Coeurjolly, Jean-Claude Iehl, Nicolas Bonneel, Alexander Keller, and Victor Ostromoukhov. 2021. Cascaded Sobol’ Sampling. ACM Trans. Graph. 40, 6, Article 275 (dec 2021), 13 pages. https://doi.org/10.1145/3478513.3480482
- Perrier et al. (2018) Hélène Perrier, David Coeurjolly, Feng Xie, Matt Pharr, Pat Hanrahan, and Victor Ostromoukhov. 2018. Sequences with Low-Discrepancy Blue-Noise 2-D Projections. Computer Graphics Forum (Proceedings of Eurographics) 37, 2 (2018), 339–353.
- Pharr (2019) Matt Pharr. 2019. Efficient Generation of Points that Satisfy Two-Dimensional Elementary Intervals. Journal of Computer Graphics Techniques (JCGT) 8, 1 (27 February 2019), 56–68. http://jcgt.org/published/0008/01/04/
- Pharr and Humphreys (2004) Matt Pharr and Greg Humphreys. 2004. Physically-Based Rendering: from Theory to Implementation (1st ed.). Morgan Kaufmann Publishers Inc.
- Pharr et al. (2016) Matt Pharr, Wenzel Jakob, and Greg Humphreys. 2016. Physically Based Rendering: From Theory to Implementation (3rd ed.). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.
- Pharr et al. (2023) Matt Pharr, Wenzel Jakob, and Greg Humphreys. 2023. Physically Based Rendering: From Theory to Implementation (4th ed.). MIT Press.
- Sobol’ (1967) Il’ya Meerovich Sobol’. 1967. On the Distribution of Points in a Cube and the Approximate Evaluation of Integrals. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi Fiziki 7, 4 (1967), 784–802.
- Tezuka (1994) Shu Tezuka. 1994. A Generalization of Faure Sequences and its Efficient Implementation. Technical Report, IBM Research, Tokyo Research Laboratory (1994). https://doi.org/10.13140/RG.2.2.16748.16003
- van der Corput (1935) J.G. van der Corput. 1935. Verteilungsfunktionen. Proceedings of the Nederlandse Akademie van Wetenschappen 38 (1935), 813–821.
- Warren (2012) Henry S. Warren. 2012. Hacker’s Delight (2nd ed.). Addison-Wesley Professional.
Appendix A Additional Results
A.1. Numerical Integration
Fig. 8 presents MRSE measurements for four synthetic functions using the function from Sec. 5.1. Note that unlike with the and functions, all considered LD sampling patterns have similar error with the step function, though all still are substantially better than independent sampling.

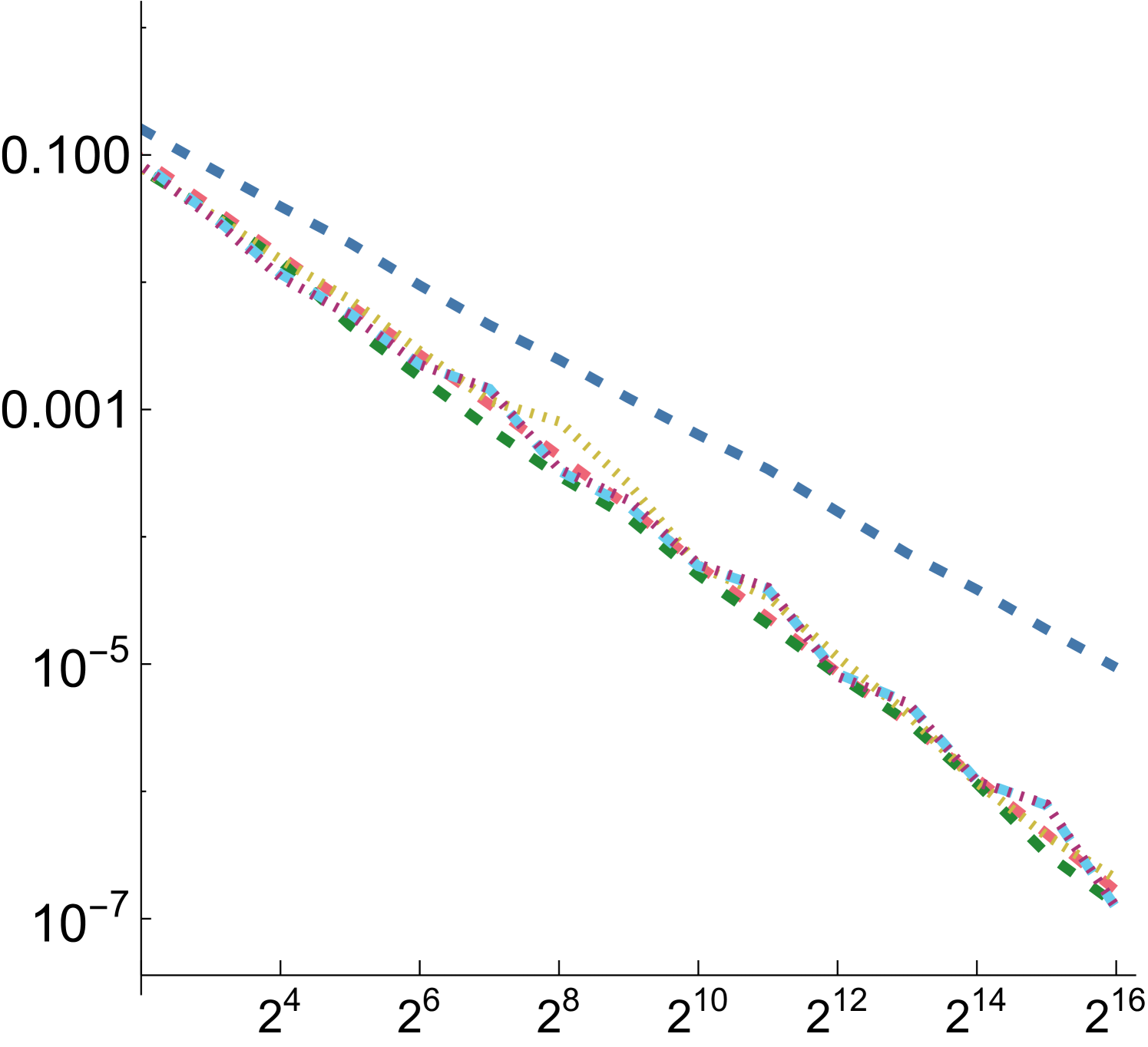
A.2. Rendering
Fig. 9 presents additional results for the Sportscar scene with additional environment maps to supplement Fig. 5. Together, we have the following environment maps, spanning a range of illumination:
-
•
Empty Warehouse: the interior of a large warehouse, primarily lit by fluorescent lights but with a small window allowing some daylight. (Fig. 5).
-
•
Cayley Interior: the interior of a house, mostly illuminated with daylight through the doors of a balcony.
-
•
Hangar Interior: the interior of an airplane hangar, lit by daylight both through skylights and a large open door.
- •
For all of these (and for Fig. 5), we report the average error over 50 images rendered with different random seeds to average out small variations in error across independent runs. Reference images were rendered with 32,768 samples per pixel (spp).
For the first two additional environment maps, SZ also reduces error compared to Sobol sampling; Sky has slightly higher error with SZ than with Sobol samples, though error for both is low. In general, the greatest improvement seems to come with the most complex environment maps. Given both a complex BSDF and complex illumination, sampling their full 4D product well is important for accurate rendering. We hypothesize that the scenes with more complex environments see more improvement thanks to SZ providing a -sequence for those dimensions.
| Cayley Interior | ||||||
| Empty Warehouse | ||||||
| Sky |
F









F











F










MRSE visualizations for the entire images with both samplers are shown in Figure 10. We can see that the error reduction is greatest with the complex glossy specular BSDF of the car’s paint, though for some scenes there is also some benefit for the near-diffuse ground plane and background.
Error at different numbers of samples per pixel is reported in Tables 1 and 2. SZ has lower MRSE than Sobol over a range of power-of-4 sampling rates and also has lower F LIP error at low sampling rates. At higher sampling rates, both have very low F LIP error. It is interesting to note that the relative performance of SZ and Sobol can be quite different at different sampling rates, even for the same scene. This is somewhat unexpected, as we generally expect MRSE to decrease at a constant rate with increasing sampling rate. We also see that with Sky, SZ does extremely well at 16 and 256spp—both even powers of 4 samples. At those rates, SZ has nearly lower error than Sobol sampling.
We have also measured performance of our sampler on a 32-core AMD 3970X CPU and an NVIDIA A6000 GPU. We find that there is no meaningful performance difference when using the SobolSampler or our SZSampler; the time spent generating sample points is less than 3% of total rendering time.
| SZ Sobol |








| Hangar Interior | Cayley Interior | Empty Warehouse | Sky | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| spp | Sobol | SZ | Ratio | Sobol | SZ | Ratio | Sobol | SZ | Ratio | Sobol | SZ | Ratio |
| 16 | ||||||||||||
| 64 | ||||||||||||
| 256 | ||||||||||||
| 1024 | ||||||||||||
| Hangar Interior | Cayley Interior | Empty Warehouse | Sky | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| spp | Sobol | SZ | Diff. | Sobol | SZ | Diff. | Sobol | SZ | Diff. | Sobol | SZ | Diff. |
| 16 | ||||||||||||
| 64 | ||||||||||||
| 256 | ||||||||||||
| 1024 | ||||||||||||
F