TARGETDROP: A TARGETED REGULARIZATION METHOD FOR
CONVOLUTIONAL NEURAL NETWORKS
Abstract
Dropout regularization has been widely used in deep learning but performs less effective for convolutional neural networks since the spatially correlated features allow dropped information to still flow through the networks. Some structured forms of dropout have been proposed to address this but prone to result in over or under regularization as features are dropped randomly. In this paper, we propose a targeted regularization method named TargetDrop which incorporates the attention mechanism to drop the discriminative feature units. Specifically, it masks out the target regions of the feature maps corresponding to the target channels. Experimental results compared with the other methods or applied for different networks demonstrate the regularization effect of our method.
Index Terms— Dropout, Attention, Targeted Regularization, Convolutional Neural Networks
1 Introduction
Convolutional neural networks are widely used in the field of computer vision and have achieved great success. Many excellent neural architectures have been designed successively such as ResNet [1], DenseNet [2] and SENet [3]. In order to solve the over-fitting problem caused by the increase in the number of parameters for convolutional neural networks, many regularization methods have been proposed, such as weight decay, data augmentation and dropout [4].
However, The effect of dropout for convolutional neural networks is not as significant as that for fully connected networks because the spatially correlated features allow dropped information to still flow through convolutional networks [5]. To address this problem, some structured forms of dropout have been proposed such as SpatialDropout [6], Cutout [7] and DropBlock [5]. But these methods prone to result in over or under regularization as features are dropped randomly.
Some methods attempt to combine structured dropout with attention mechanism such as AttentionDrop [8] and CorrDrop [9]. However, these methods only mask out the units with higher activation values or the regions with less discriminative information in the spatial dimension. They ignore the instructive information in the channel dimension which is proven to be meaningful in convolutional neural networks [3], even in dropout-based regularization methods[5].
In this paper, we propose a novel regularization method named TargetDrop, which drops the feature units with a clear target. Specifically, we choose the target channels and then drop the target regions in the corresponding feature maps. As is shown in Fig.1, compared with naive Dropout and DropBlock which may lead to unexpected results by dropping randomly, our TargetDrop prone to precisely mask out several effective features of the main object, thus forcing the network to learn more crucial information. Our experimental results demonstrate that TargetDrop can greatly improve the performance of convolutional neural networks and outperforms many other state-of-the-art methods on public datasets CIFAR-10 and CIFAR-100 which we attribute to our method.
Our contributions are summarized as follows:
We propose a targeted regularization method which incorporates attention mechanism to address the problem for unexpected results caused by dropping randomly.
We propose the rule of choosing target channels and target regions, and further analyse the regularization effect.
Our method achieves better regularization effect compared with the other state-of-the-art methods and is applicable to different architectures for image classification tasks.

2 Related Work
Since Dropout [4] was proposed to improve the performace of networks by avoiding overfitting the training data, a series of regularization variations have been proposed such as DropConnect [10], SpatialDropout [6], DropPath [11], DropBlock [5], AttentionDrop [8], CorrDrop[9] and DropFilterR [12]. In addition, several methods about attention processing are also related as our method incorporates the attention mechanism into the dropout-based regularization. Methods for computing the spatial or channel-wise attention have achieved a certain effect such as Squeeze-and-Excitation (SE) module [3], Convolutional Block Attention Module (CBAM) [13] and Selective Kernel (SK) unit [14]. Our method outperforms the dropout-based regularization counterparts by utilizing the attention mechanism to achieve the targeted dropout.
3 Methods
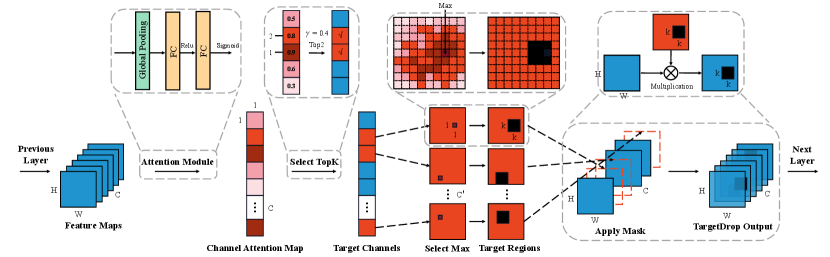
In this section, we propose our method TargetDrop which mainly contains seeking out the target channels and target regions. The pipeline of TargetDrop is shown in Fig. 2.
3.1 Target Channels
Given the output of the previous convolutional layer as , where and are the height and width of the feature map respectively, is the number of channels. As a first step, we are eager to figure out the importance of each channel. We aggregate the spatial information of each feature map into channel-wise vector by using global average pooling which has been proven to be effective [3, 13]. This vector can be regarded as the statistic generated by shrinking through spatial dimensions and this operation can be defined as:
| (1) |
where denotes the -th element of . To further capture channel-wise dependencies, the vector is then forwarded to a shared network to produce the channel attention map . The shared network is composed of two fully connected (FC) layers and two activation functions. Specifically, a dimensionality-reduction layer with parameters , a ReLU, a dimensionality-increasing layer with parameters and then a Sigmoid function are connected alternately. Here, is the reduction ratio to adjust the bottleneck. The map indicates the inter-channel relationships, and this operation can be defined as:
| (2) |
where and refer to the ReLU and Sigmoid, respectively.
Then, we sort all the values in and select the elements (tag ”1” means to be selected and ”0” if not) with top values as the target according to the drop probability . Specifically, the channels corresponding to those elements marked as tag ”1” in the vector are the target channels. Given the top -th value in as and this process can be described as:
| (3) |
where and denote the -th elements of and . Based on this, we further select the target regions of the original feature maps corresponding to the target channels which we will elaborate in the following subsection.
3.2 Target Regions
For each feature map corresponding to a target channel, we hope to further seek out a region with much discriminative information in convolution operation. Utilizing spatial attention mechanism like a convolution operation with the kernel size of 77 is not necessary and may lead to considerable additional computation. Considering the continuity of image pixel values [8], we can simply locate to a pixel with maximum value and the other top values distributed in the surrounding continuous regions are most likely to be certain crucial features of the main object. Hence the location with the maximum value will be selected and the region centered around it will be dropped. , , and represent the boundaries of the target region and the TargetDrop mask can be described as:
| (4) |
| (5) |
where and denote the -th elements of and . Given the final output as . Finally, we apply the mask and normalize the features:
| (6) |
where and denote the -th elements of and , counts the number of units in , counts the number of units where the value is ”1” and represents the point-wise multiplication operation.
3.3 TargetDrop
The pseudocode of our method is described in Algorithm 1.
4 Experiments
In this section, we introduce the implementation of experiments and report the performance of our method. We compare TargetDrop with the other state-of-the-art dropout-based methods on CIFAR-10 and CIFAR-100 [17] and apply it for different architectures. We further analyse the selection of hyper-parameters and visualize the class activation map.
4.1 Datasets
We use CIFAR-10 and CIFAR-100 [17] for image classification as basic datasets in our experiments. For preprocessing, we normalize the images using channel means and standard deviations and apply a standard data augmentation scheme: zero-padding the image with 4 pixels on each side, then cropping it to and flipping it horizontally at random.
4.2 Training Method
Networks using the official PyTorch implementation are trained on the full training dataset until convergence and we report the highest test accuracy following common practice. The hyper-parameters in our experiments are as follows: the batch size is 128, the optimizer is SGD with Nesterov’s momentum of 0.9, the initial learning rate is 0.1 and is decayed by the factor of 2e-1 at 0.4, 0.6, 0.8 ratio of total epochs. For Cutout [7], which is used in a few experiments, the cutout size is 1616 for CIFAR-10 and 88 for CIFAR-100.
4.3 Experiments for TargetDrop and Results
The experiments for TargetDrop we conducted mainly contain two parts: comparing the regularization effect with the other state-of-the-art dropout-based methods for ResNet-18 and show the performance for different architectures. We demonstrate the experiments and results in detail from these two aspects in the following two paragraphs. Specifically, in this part, the reduction ratio is 16, the drop probability and block size for TargetDrop are 0.15 and 5, respectively.
Comparison against the results of other methods. We compare the regularization effect with the other state-of-the-art dropout-based methods on ResNet-18. We apply our TargetDrop in the same way with the other methods that adding the regulation to the outputs of first two groups for a fair comparison. Specially, several methods we reproduced can not reach the reported results, so we refer to the data in the original paper [8] directly for these. As is shown in Table 1, the results of our method outperform the other methods on CIFAR-10 and CIFAR-100. Moreover, combined with Cutout [7], our method can achieve better regularization effect.
Regularization on different architectures. We further conduct experiments on CIFAR-10 with several classical convolutional neural networks to demonstrate that our method is applicable to different architectures. As is shown in Table 2, our method TargetDrop can improve the performances of different architectures. We can notice that Dropout [4] is not applicable for convolutional neural networks which is mentioned above and TargetDrop is an effective dropout-based regularization method for the networks on different scales.
The number of parameters added in our method is presented as follows. The additional parameters come from the channel attention mechanism, and the additional computation includes the simple selection of the maximum pixel besides this. The number of parameters in the training process only increase by about 0.02% and the amount of computation increase similarly. While in the test process, TargetDrop is closed like other methods, so the complexity will not change.
4.4 Analysis of the Hyper-parameters Selection
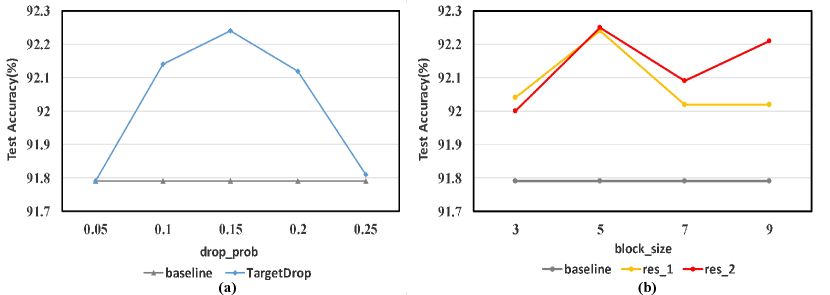
In this subsection, we further analyse the selection of hyper-parameters mentioned above: the drop probability and the block size . To analyse the former, we constrain the block size to 5 and TargetDrop is applied to the output of the first group (the size of the feature map is 3232). To analyse the latter, we constrain the drop probability to 0.15 and TargetDrop is applied to the outputs of the first two groups (the size of the feature map is 3232 for res_1 and 1616 for res_2). As is shown in Fig. 3, our method is suitable for more channels and insensitive to different hyper-parameters to a certain extent which may be due to the targeted dropout. The drop probability of 0.15 and the block size of 5 are slightly better.

4.5 Activation Visualization
In this subsection, we utilize the class activation mapping (CAM) [18] to visualize the activation units of ResNet-18 [1] on several images as shown in Fig. 4. We can notice that the activation map generated by model regularized with our method TargetDrop demonstrates strong competence in capturing the extensive and relevant features towards the main object. Compared with the other methods, the model regularized with TargetDrop tends to precisely focus on those discriminative regions for image classification which we attribute to targeting and masking out certain effective features corresponding to the crucial channels.
5 Conclusion
In this paper, we propose the novel regularization method TargetDrop for convolutional neural networks, which addresses the problem for unexpected results caused by the untargeted methods to some extent by considering the importance of the channels and regions of feature maps. Extensive experiments demonstrate the outstanding performance of TargetDrop by comparing it with the other methods and applying it for different architectures. Furthermore, we analyse the selection of hyper-parameters and visualize the activation map to prove the rationality of our method. In addition to image classification tasks, we believe that TargetDrop is suitable for more datasets and tasks in the field of computer vision.
References
- [1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, 2016, pp. 770–778.
- [2] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger, “Densely connected convolutional networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, 2017, pp. 2261–2269.
- [3] Jie Hu, Li Shen, and Gang Sun, “Squeeze-and-excitation networks,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, 2018, pp. 7132–7141.
- [4] Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014.
- [5] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V. Le, “Dropblock: A regularization method for convolutional networks,” in Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada., 2018, pp. 10750–10760.
- [6] Jonathan Tompson, Ross Goroshin, Arjun Jain, Yann LeCun, and Christoph Bregler, “Efficient object localization using convolutional networks,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015. 2015, pp. 648–656, IEEE Computer Society.
- [7] Terrance Devries and Graham W. Taylor, “Improved regularization of convolutional neural networks with cutout,” CoRR, vol. abs/1708.04552, 2017.
- [8] Zhihao Ouyang, Yan Feng, Zihao He, Tianbo Hao, Tao Dai, and Shu-Tao Xia, “Attentiondrop for convolutional neural networks,” in IEEE International Conference on Multimedia and Expo, ICME 2019, Shanghai, China, July 8-12, 2019. 2019, pp. 1342–1347, IEEE.
- [9] Yuyuan Zeng, Tao Dai, and Shu-Tao Xia, “Corrdrop: Correlation based dropout for convolutional neural networks,” in 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020. 2020, pp. 3742–3746, IEEE.
- [10] Li Wan, Matthew D. Zeiler, Sixin Zhang, Yann LeCun, and Rob Fergus, “Regularization of neural networks using dropconnect,” in Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16-21 June 2013. 2013, vol. 28 of JMLR Workshop and Conference Proceedings, pp. 1058–1066, JMLR.org.
- [11] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le, “Learning transferable architectures for scalable image recognition,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. 2018, pp. 8697–8710, IEEE Computer Society.
- [12] Hengyue Pan, Xin Niu, Rongchun Li, Siqi Shen, and Yong Dou, “Dropfilterr: A novel regularization method for learning convolutional neural networks,” Neural Process. Lett., vol. 51, no. 2, pp. 1285–1298, 2020.
- [13] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon, “CBAM: convolutional block attention module,” in Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VII, Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, Eds. 2018, vol. 11211 of Lecture Notes in Computer Science, pp. 3–19, Springer.
- [14] Xiang Li, Wenhai Wang, Xiaolin Hu, and Jian Yang, “Selective kernel networks,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. 2019, pp. 510–519, Computer Vision Foundation / IEEE.
- [15] Karen Simonyan and Andrew Zisserman, “Very deep convolutional networks for large-scale image recognition,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- [16] Sergey Zagoruyko and Nikos Komodakis, “Wide residual networks,” in Proceedings of the British Machine Vision Conference 2016, BMVC 2016, York, UK, September 19-22, 2016, 2016.
- [17] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Computer Science Department, University of Toronto, Tech. Rep, vol. 1, 01 2009.
- [18] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2921–2929.