TCP D*: A Low Latency First Congestion Control Algorithm
Abstract
The choice of feedback mechanism between delay and packet loss has long been a point of contention in TCP congestion control. This has partly been resolved, as it has become increasingly evident that delay based methods are needed to facilitate modern interactive web applications. However, what has not been resolved is what control should be used, with the two candidates being the congestion window and the pacing rate. BBR is a new delay based congestion control algorithm that uses a pacing rate as its primary control and the congestion window as a secondary control. We propose that a congestion window first algorithm might give more desirable performance characteristics in situations where latency must be minimized even at the expense of some loss in throughput. To evaluate this hypothesis we introduce a new congestion control algorithm called TCP D*, which is a congestion window first algorithm that adopts BBR’s approach of maximizing delivery rate while minimizing latency. In this paper, we discuss the key features of this algorithm, discuss the differences and similarity to BBR, and present some preliminary results based on a real implementation.
1 Introduction
TCP congestion control has been a long studied problem in networking [1, 2, 3]. The first step in understanding this complex issue is to define and quantify what congestion is. Congestion can generally be understood as the degradation in network performance as packets are transmitted faster than the rate at which parts of the network (the bottlenecks) can process them. We quantify the congestion by considering the outstanding queues at these bottlenecks and we can equate the level of congestion to the number of packets in the queue. As congestion increases each packet must wait longer in the queue, increasing latency. Additionally, if the number of packets exceeds the maximum queue length, then they are dropped.
Obviously, dropped packets are bad because they need to be re-transmitted for TCP to achieve reliable delivery. Congestion also degrades the goodput of the network and increase latency, which poses other major issues. The first major issue is user experience. Many modern network applications such as AR/VR, online gaming, video conferencing, and remote systems administration are sensitive to latency change on the order of a few 10s of milliseconds [4, 5]. If latency degrades far enough, even web browsing is impacted. Empirical study shows that the QoE of web browsing can quickly deteriorate with delay greater than 2 seconds [6]. The second issue occurs when multiple flows from heterogeneous sources are present. Specifically if some sources are application limited, while others are not, then increased latency from congestion can cause the smaller flows to be starved of throughput. For example, if there is one flow that is downloading a large file (such as an hour long movie), then without limiting throughput to prevent congestion, smaller flows (like web page requests) can take much longer to download [7].
Now we understand why we want to reduce congestion, and preferably we will have no packets being queued. Additionally, it is important to ensure that the network links are fully utilized. Thus we can state the goal of congestion control as such, maximize throughput while minimizing latency. Ideally we would send data as fast as the bottleneck can process it, while at the same time maintaining an empty queue. This is known as Kleinrock’s optimal operating point [8]. This optimal operating point is achieved by maximizing power, which is the ratio of the throughput to the delay, thus achieving maximum throughput with the minimum delay.
The oldest and yet the most prevalent methods of congestion control use losses as the primary feedback of congestion [1, 2, 9]. This is far from ideal, as losses only occur when bottleneck queues are full and congestion is maximized. Things get even worse with deep buffers at the bottleneck links. In the worst case this can lead to large latencies, on the order of seconds in poorly configured networks. This effect has been termed bufferbloat [7]. One way to mitigate this is through active queue management (AQM) [10, 11, 12]. However, adoption of AQM on commodity devices has been slow.
A better alternative to loss based congestion control is delay based congestion control [13, 14, 15]. Delay based algorithms use the packet’s round-trip times (RTTs), to estimate latency. Since there is a direct relationship between congestion and RTT, delay based algorithms can operate much closer to Kleinrock’s optimal operating point. There are also congestion control algorithms that are hybrids in that they use both delay and loss as feedbacks. TCP Illinios [16] and TCP Compound [17] are two examples.
The next consideration in congestion control is how to control the rate at which packets are sent and how many packets are in queues. The most straightforward way to do this it to set a pacing rate, which is the rate at which a client transmits data. A pacing rate determined by the congestion control algorithm can be maintained using a qDisc such as FQ/pacing and HTB [18] or a scalable traffic shaping function implemented on a programmable NIC such as Carousel [19].
The other approach to control the rate at which packets are sent is to use a congestion window, which sets the maximum number of unacknowledged packets that a client may send. This is how most of the congestion algorithms such as TCP Reno [2], CUBIC [9], and HTCP [20] operate. As the tradeoffs between the methods are very important, we discuss them below.
When dealing with clients that send packets in bursts, a congestion window may let packets through all at once, overwhelming bottlenecks and leading to temporary congestion. By pacing the packets instead we can smooth out the sending of packets to a rate that bottlenecks can tolerate.
One advantage of the congestion window is that it has a linear relationship to the length of any outstanding queues, and thus to the degree of congestion. Briefly, the physical network links will be transmitting a number of packets equal to the network’s bandwidth-delay product (BDP). If the congestion window is greater than the BDP, than the excess packets must be stored in queues. The fact that the number of packets in queues is the difference of the BDP and congestion window is a core principal of many congestion control algorithms [1, 2, 9]. Conversely, the pacing rate does not have a linear relationship with how many packets are in queues. In fact, when operating close to the bottleneck rate, small changes can lead to large fluctuations in the number of queued packets [21, 1]. This means pacing rate based algorithms must react quickly and precisely to changes in the network to maintain optimal operation.
In this paper we discuss a newly developed TCP congestion control algorithm called TCP D*. It adopts BBR’s approach of maximizing delivery rate while minimizing latency [14]. However, TCP D* uses the congestion window as its primary control. We posit that this can result in a lower RTT, although potentially at the expense of throughput. With this paper, we hope to open up a discussion about the trade-offs of using a congestion window versus pacing packets. We found that generally the congestion window approach reduces latency potentially at the expense of some loss in throughput. On the other hand, a pacing rate approach maximizes throughput, potentially at the expense of increased latency.
2 Related Work
TCP D* is built upon earlier work in RTT based congestion control algorithms. One of the first, and simplest, such algorithms was TCP Vegas [13]. TCP Vegas extended TCP Reno [2] in order to react to RTT congestion signals. In essence, TCP Vegas used the difference between the base RTT and current RTT to estimate the number of packets at the bottleneck, and attempts to keep it in the range of 2-4 packets. This resulted in a lower RTT and better throughput than TCP Reno under good conditions. However, TCP Vegas performed poorly under changing network conditions, due to maintaining the same base RTT estimate for the entire lifetime of the flow. Similar algorithms that use variations of this technique include FAST TCP [22] and Compound TCP [17].
TIMELY [15] is a delay based algorithm that diverges significantly from TCP Vegas. TIMELY uses the delay gradient, or the derivative of the RTT, to control the pacing rate. In particular, it increases the rate on negative gradients, and decreases the rate on positive gradients. Delay gradient computation requires very accurate RTT values, which can only be realistically obtained using hardware support in the NIC. This makes TIMELY more suitable to data center use.
TCP LoLa [23] is another delay based algorithm that uses a congestion window. TCP LoLa’s goal is to set the RTT to a fixed amount over the base RTT, which hopefully allows it to fully utilize throughput while keeping latency at tolerable levels. To do this it cycles between a cubic gain cycle, a fair flow balancing cycle, and a holding cycle.
2.1 Relation to BBR
TCP D* is most closely related to BBR, and requires the most thorough comparison. The clearest way to do this is to compare their similarities and differences.
2.1.1 Similarities
-
•
Both try to operate near Kleinrock’s operating point that occurs when the ratio of the throughput to the RTT is maximized. This implies that throughput is set to the maximum bandwidth, while the RTT is set to the base RTT.
-
•
Both use packet delivery rate and RTT as primary feedback signals.
-
•
Both use modal operation. They transition between modes where they operate at Kleinrock’s optimal operating point and where they probe for more bandwidth or a lower base RTT.
2.1.2 Differences
-
•
TCP D* uses the send congestion window as it’s primary control, while BBR uses the pacing rate as the primary control, with the congestion window as a secondary control.
-
•
The gain in TCP D*’s control algorithm is based on the variance of the BDP estimate. On the other hand, BBR uses a constant multiple of its bottleneck rate estimate.
-
•
TCP D* sets the window to its estimated BDP, while BBR sets its window to twice its estimated BDP. This means that in the worst case, wherein BBR’s pacing rate control is not enough to prevent congestion, BBR may have an RTT twice that of TCP D*.
3 Implementation
TCP D* is implemented as a Linux kernel module. It consists of both a congestion avoidance and a slow start algorithm. Before discussing these algorithms in detail, it is important to understand the basic principles behind TCP D*.
3.1 First Principles
TCP D* uses the sending congestion window as its primary control. We use a windowed approach because there is a direct relationship between it and congestion. This relationship is that if the window is larger than the bandwidth-delay product (BDP), then the excess data must be stored in a buffer. The greater the amount of data stored in the buffer, the higher the round trip time (RTT), which serves as our main feedback. This relationship is linear and generally well behaved, which makes the congestion window and RTT combination ideal for congestion control.
To achieve an optimal control we need to model the network. There are four primary equations that relate the number of delivered bytes, RTT, BDP, and the delivery rate of data. The first defines the straight forward relationship for the delivery rate. For any flow indexed by , we have
| (1) |
The second equation defines the BDP for the flow as
| (2) |
The third equation simply states that the RTT must be at least its minimum value, or
| (3) |
The final and most important equation relates the RTT to all flows through a bottleneck, and is
| (4) |
To justify this consider a packet being sent through the network. The packet must at least experience the base RTT from propagation delay, giving the expression. Additionally, if the number of in-flight bytes is greater than the BDP, then the extra packets must be buffered. This buffer can only be emptied at the delivery rate and we get the rest of the equation. Also note that Eqs. (2), (3), and (4) imply that
| (5) |
This means that if the delivery rate is not restricted by a bottleneck, then it is determined by the number of in-flight bytes. When the two sides are unequal the additional in-flight bytes are no longer contributing to throughput, and is only increasing latency. Thus, our goal is to find the maximum such that , at which point the delivery rate is maximized and from Eq. (4).
3.2 Main Algorithm
The pseudocode for the main algorithm is given in Figure 1. There are four important modes the algorithm cycles between. In all of the following modes the pacing rate is unlimited, with the congestion window acting as the only control.
3.2.1 DRAIN
The first mode to be run after slow start is DRAIN. In normal operation it is run whenever has not been updated for at least 10 seconds. The purpose of this mode it to re-estimate the and thus adapt to changing network conditions. To achieve this goal we drain the pipe of all but the minimum number of packets necessary for feedback.
3.2.2 GAIN 1
The main purpose of GAIN 1 is to prep the network pipe for bandwidth estimation. From the results derived from Eq. (2), Eq. (3), and Eq. (4), we know that we want to set the congestion window equal to the maximum BDP. However, if we set it equal to the current BDP there is no way to detect unused throughput. We thus set the congestion window slightly above the BDP (with ) so that we can detect unused throughput. We then start tracking the number of delivered packets and enter GAIN 2.
3.2.3 GAIN 2
GAIN 2 computes the delivery rate given by Eq. (1) and uses it and the estimation to calculate the new BDP estimate given by Eq. (2). It also sets the gain_cwnd (see below). Note that the delivery rate is only tracked in GAIN 2, but not GAIN 1. This is done to allow time for the feedback to adjust when we change the congestion window. Immediately tracking delivery rate after such a change would result in under or over estimates, depending on if the window increased or decreased. At the end of the mode we enter DRAIN if a timeout has occurred, otherwise we fall back to GAIN 1.
3.2.4 gain_cwnd
The gain_cwnd determines how we increase snd_cwnd. Ideally, we want the gain_cwnd to be as small as possible at steady state to minimize overhead, but large enough so that under-utilized bandwidth is quickly reclaimed. While using a multiplicative increase (MI) could achieve these goals, we have found that this approach results in unfairness between flows. In order to maintain good fairness while in steady state, gain_cwnd must stay the same or decrease as the snd_cwnd increases. This rules out MI.
Using twice the absolute deviation of our BDP estimates was found to balance all of these requirements. When reclaiming bandwidth it results in exponential growth. This is because when we are gaining bandwidth the deviation in the BDP is equal to the last gain_cwnd, which ends up doubling the gain_cwnd every round. However, in steady state the gain_cwnd corresponds to the variance in the throughput, which is generally low relative to the overall throughput and roughly the same for all flows. Note that in the actual code we limit the gain_cwnd to the range . This is done to ensure that the algorithm continues probing at low variations, and does not over-react to large variations.
3.3 Slow Start
Another important part of the algorithm is its slow start routine. Slow start is entered on two occasions, those being when transmission starts and when the flow is restarted after a timeout [24]. The slow start routine is essentially the same as the main algorithm, with two major exceptions.
-
1.
It never enters DRAIN mode.
- 2.
These changes allow for rapid estimation of the BDP while keeping the core attributes intact. Slow start ends when either a loss or ECN congestion event (CE) occurs, or when the BDP estimate stops increasing. Note that a loss occurring is a worst case scenario. If there is at least one BDP of upstream buffering then Eq. (6) should guarantee that we do not send more data than can be buffered.
4 Results
The TCP D* Linux module has been tested under a wide variety of network conditions, both physical and simulated. These conditions include dedicated wide area networks (WANs), poorly tuned networks that are easily congested, and networks with different RTT flows. Except for cases where simulation was used, we also tested BBR [14], CUBIC [9], TCP Reno [1], and TCP Vegas [13]. The tests where conducted using Flent [25, 26], which is a wrapper around the Netperf and ping testing utilities.
4.1 Chameleon Testbed
For our first evaluation we used Chameleon which is a configurable experimental environment for large-scale cloud research [27]. The Chameleon setup consisted of two sites, University of Chicago and the Texas Advanced Computing Center (TACC), connected by a dedicated WAN. The defining characteristics of this case were low variance in throughput and RTT. It was also difficult to increase RTT by saturating the network with packets, possibly due to intermediate shaping or the availability of many routes for packets. A dedicated baremetal server running Linux at each location was used for this test.
Figure 2 compares the performance of the congestion algorithms with a single upload stream. TCP D* performs well in regards to RTT, but lags in throughput. This is unique to this test case. We believe the cause is a combination of TCP D*’s conservative window and that window increase is controlled by variance in our BDP estimates. For a network with low throughput variance, such as a dedicated WAN, resulting in the algorithm being unable to utilize the full bandwidth.
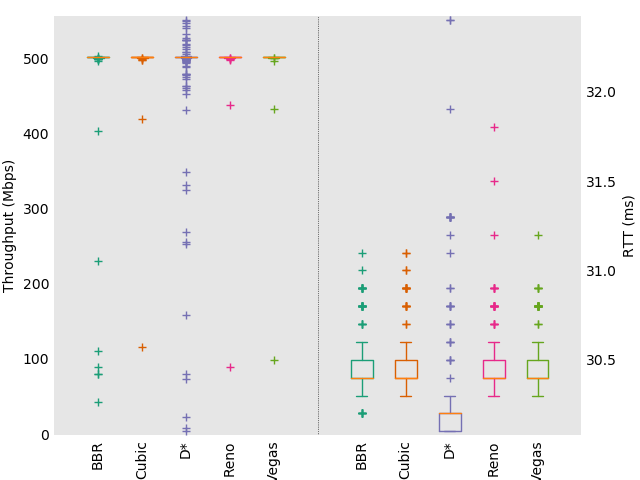
To compare how the algorithms operate under load we also tested running 128 streams in parallel. Figure 3 shows the results of these tests. All of the algorithms used the full bandwidth, and BBR and TCP D* performed significantly better in minimizing RTT than the other algorithms. Additionally, Table 1 compares how fair the competing flows were. It is evident that BBR and TCP D* performed much better in terms of stream fairness than the other algorithms, with near perfect indexes. This is a major advantage of using packet delivery rates as a feedback, as it allows quick convergence to fair usage.
| Algorithm | BBR | CUBIC | D* | Reno | Vegas |
| Jain Index | 0.9985 | 0.6237 | 0.9995 | 0.5557 | 0.7161 |
4.2 Network Emulation using NetEm
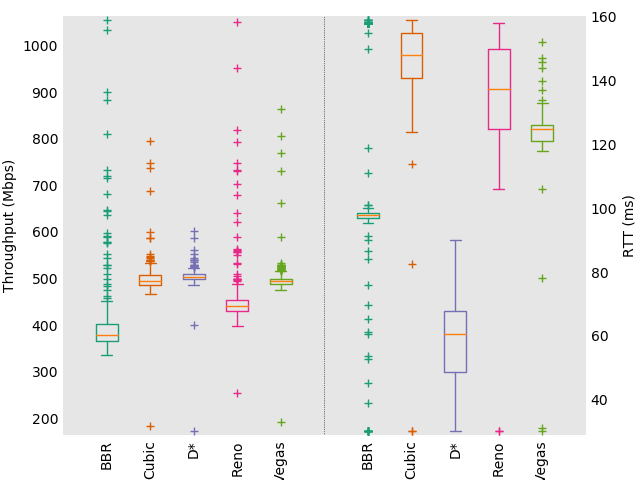
For the second test case we used NetEm [29] to emulate a 500 Mbps network with a 30 ms delay. The network consisted of two commodity hardware machines (a desktop and laptop) connected via a switch. The bottleneck link was setup on the laptop side with a buffer size equal to twice the BDP, half of which was used by NetEm to emulate network delays, and the rest used to emulate the bottleneck queue. The desktop was then used to run Flent. This network setup resulted in far more unpredictability and congestion than the WAN case, and is a good proxy for a poorly configured network.
Figure 4 shows the results for one upload stream. There is very little variation between the algorithms tested in this case. Figure 5 shows the results for 128 upload streams. The large number of streams resulted in serious congestion, and clear differences in performance between the algorithms. In this case TCP D* gives the lowest RTT, approximately half the next best (achieved by BBR), while using the full bandwidth. This is in part due to TCP D* keeping the margin for congestion very small, and its explicit modeling of congestion via the congestion window. It highlights TCP D*’s best use case, which is in networks with many competing flows, especially when the intermediate links are poorly configured.
4.3 Simulation
The last test case was an event based simulation of two streams with different RTTs and a common bottleneck. This was the only test where we could not test on a physical network, and it was thus performed using an event based simulation. Figure 6 shows the throughput for each stream, and Figure 7 shows their RTTs. The difference in throughput was roughly proportional to the difference in each flow’s base RTT. This is in part due to that fact that the snd_cwnd is set close to the estimated BDP, which in turn is the product of the delivery rate and base RTT. Thus, even with a similar delivery rate, the difference in base RTTs will result in the larger flow taking a greater share of the bandwidth. However, this partial sharing is still desirable, as an alternative is one flow being completely starved. Partial sharing thus guarantees that small flows get enough throughput to complete in an acceptable time frame.
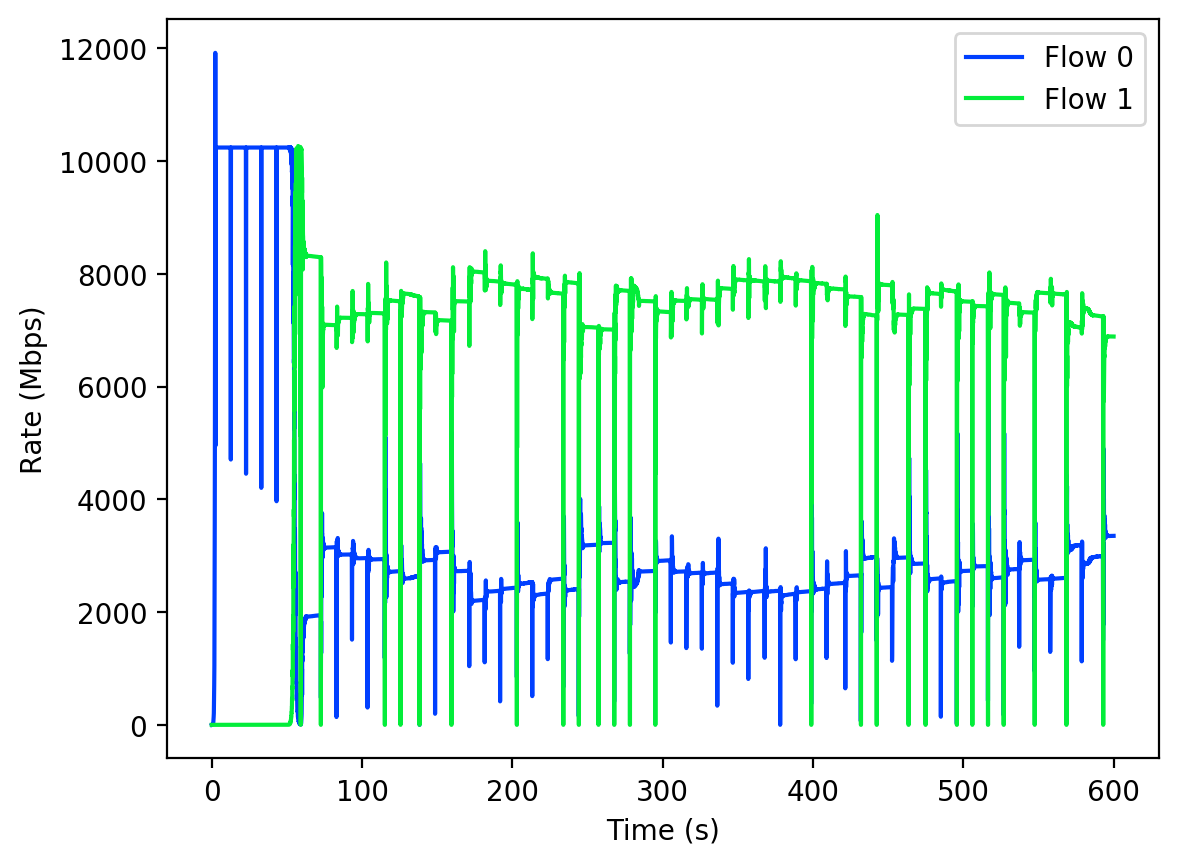
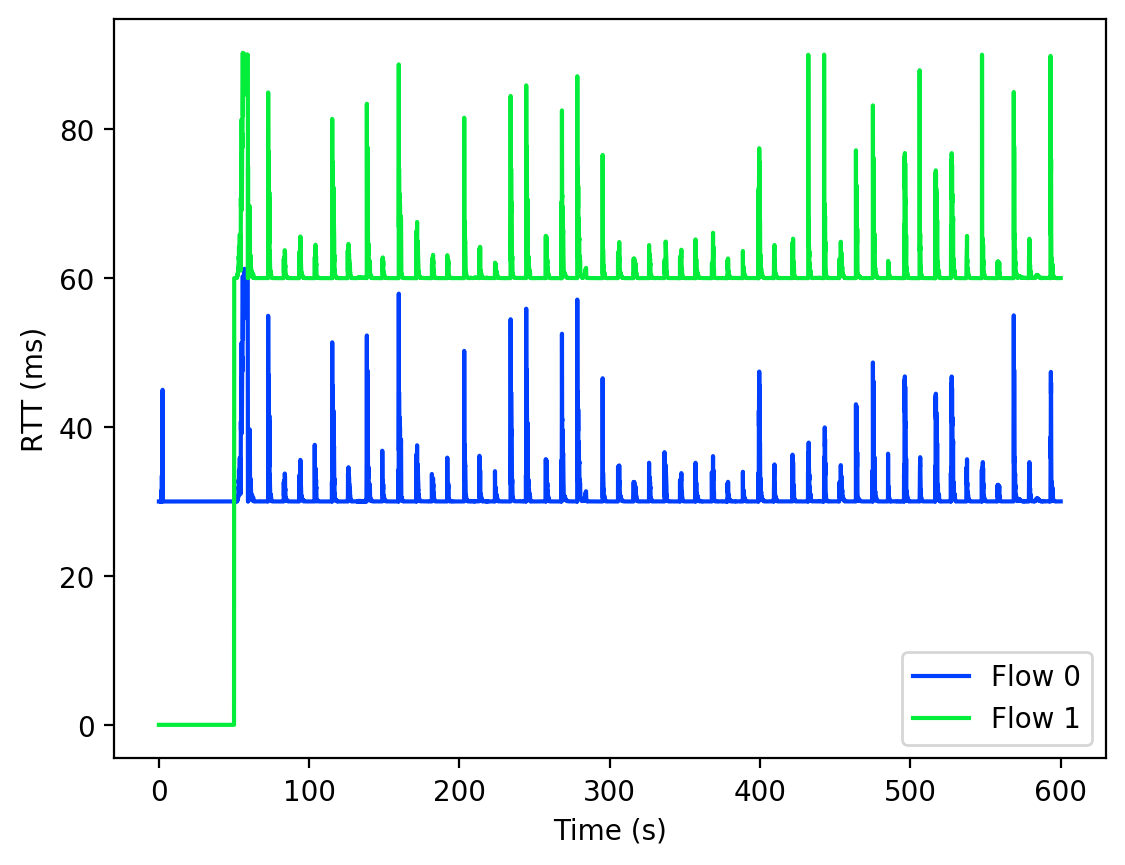
5 Conclusion
In this paper we have presented a new congestion control algorithm, called TCP D*, which is based off of concepts from BBR, but is driven by a congestion window first design. Our hope is to drive discussion about the advantages and disadvantages of using a congestion window versus a pacing rate for congestion control. Several questions remain to be investigated about the tradeoffs between these approaches. How do the two approaches perform in networks that have flows sending/receiving data at different rates? This is important as movie streaming and web page requests often occur on the same network and have very different speed requirements. How do these approaches affect performance in terms of shallow versus deep buffers? This would be relevant for data center networks.
There are also improvements for TCP D* and inquiries into its operation we wish to pursue in the future. The first is to improve D*’s performance with low variance dedicated WANs. We have already begun working on this, and have some promising solutions. We will also look into how TCP D* performs under different network conditions, specifically low-latency (sub-millisecond RTT) data center networks and networks with packet policing or shaping. Another improvement to consider is fairness when flows have different base RTTs. A possible course of investigation is whether this can be done with a knowledge of how many flows converge on a bottleneck, perhaps enabled by in-network telemetry.
Our goal with this paper is to open up new avenues of research on the problem of congestion control in new networking domains and for next generation distributed applications. We hope that others working on congestion control will consider the lessons learned and apply them to their own algorithms.
References
- [1] Van Jacobson “Congestion avoidance and control” In ACM SIGCOMM computer communication review 18.4 ACM New York, NY, USA, 1988, pp. 314–329
- [2] E Blanton and M Allman “RFC5681: TCP congestion control” September, 2009
- [3] James Kurose and Keith Ross “Computer networks: A top down approach featuring the internet” In Peorsoim Addison Wesley, 2010
- [4] Ashkan Nikravesh et al. “An in-depth understanding of multipath TCP on mobile devices: Measurement and system design” In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, 2016, pp. 189–201
- [5] Mohammed S Elbamby, Cristina Perfecto, Mehdi Bennis and Klaus Doppler “Toward low-latency and ultra-reliable virtual reality” In IEEE Network 32.2 IEEE, 2018, pp. 78–84
- [6] Xu Zhang et al. “E2E: embracing user heterogeneity to improve quality of experience on the web” In Proceedings of the ACM Special Interest Group on Data Communication, 2019, pp. 289–302
- [7] Jim Gettys and Kathleen Nichols “Bufferbloat: Dark buffers in the internet” In Queue 9.11 ACM New York, NY, USA, 2011, pp. 40–54
- [8] Leonard Kleinrock “Internet congestion control using the power metric: Keep the pipe just full, but no fuller” In Ad hoc networks 80 Elsevier, 2018, pp. 142–157
- [9] Shangtae Ha, Injong Rhee and Lisong Xu “CUBIC: A New TCP-Friendly High-Speed TCP variant” In Operating Systems Review 42, 2008, pp. 64–74
- [10] Kathleen Nichols and Van Jacobson “Controlling queue delay” In Communications of the ACM 55.7 ACM New York, NY, USA, 2012, pp. 42–50
- [11] R. Pan et al. “PIE: A lightweight control scheme to address the bufferbloat problem” In 2013 IEEE 14th International Conference on High Performance Switching and Routing (HPSR), 2013, pp. 148–155
- [12] Sally Floyd and Van Jacobson “Random early detection gateways for congestion avoidance” In IEEE/ACM Transactions on Networking (ToN) 1.4 IEEE Press, 1993, pp. 397–413
- [13] Lawrence S. Brakmo and Larry L. Peterson “TCP Vegas: End to end congestion avoidance on a global Internet” In IEEE Journal on selected Areas in communications 13.8 IEEE, 1995, pp. 1465–1480
- [14] Neal Cardwell “BBR: Congestion Based Congestion Control” In acmqueue 14 ACM, 2016, pp. 20–53
- [15] Radhika Mittal et al. “TIMELY: RTT-based Congestion Control for the Datacenter” In ACM SIGCOMM Computer Communication Review 45.4, 2015, pp. 537–550 ACM
- [16] Shao Liu, Tamer Başar and Ravi Srikant “TCP-Illinois: A loss-and delay-based congestion control algorithm for high-speed networks” In Performance Evaluation 65.6-7 Elsevier, 2008, pp. 417–440
- [17] K. Tan, J. Song, Q. Zhang and M. Sridharan “A Compound TCP Approach for High-Speed and Long Distance Networks” In Proceedings IEEE INFOCOM 2006. 25TH IEEE International Conference on Computer Communications, 2006, pp. 1–12
- [18] Doru Gabriel Balan and Dan Alin Potorac “Linux HTB queuing discipline implementations” In 2009 First International Conference on Networked Digital Technologies, 2009, pp. 122–126 IEEE
- [19] Ahmed Saeed et al. “Carousel: Scalable traffic shaping at end hosts” In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, 2017, pp. 404–417 ACM
- [20] Douglas Leith and Robert Shorten “H-TCP: TCP for high-speed and long-distance networks” In Proceedings of PFLDnet 2004, 2004
- [21] Leonard Kleinrock “Queueing Theory, volume I” Wiley, 1975
- [22] David X Wei, Cheng Jin, Steven H Low and Sanjay Hegde “FAST TCP: motivation, architecture, algorithms, performance” In IEEE/ACM transactions on Networking 14.6 IEEE, 2006, pp. 1246–1259
- [23] Mario Hock, Felix Neumeister, Martina Zitterbart and Roland Bless “TCP LoLa: Congestion control for low latencies and high throughput” In 2017 IEEE 42nd Conference on Local Computer Networks (LCN), 2017, pp. 215–218 IEEE
- [24] M. Handley, J. Padhye and S. Floyd “TCP Congestion Window Validation” RFC Editor, Internet Requests for Comments, 2000, pp. 1–11 URL: www.rfc-editor.org/rfc/rfc2861.txt
- [25] Toke Høiland-Jørgensen, Carlo Augusto Grazia, Per Hurtig and Anna Brunstrom “Flent: The flexible network tester” In Proceedings of the 11th EAI International Conference on Performance Evaluation Methodologies and Tools, 2017, pp. 120–125
- [26] Toke Høiland-Jørgensen “Flent” URL: flent.org
- [27] Kate Keahey et al. “Lessons Learned from the Chameleon Testbed” In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC ’20) USENIX Association, 2020
- [28] Raj Jain, Arjan Durresi and Gojko Babic “Throughput fairness index: An explanation” In ATM Forum contribution 99.45, 1999
- [29] Stephen Hemminger “Network emulation with NetEm” In Linux conf au, 2005, pp. 18–23