TE-ESN: Time Encoding Echo State Network for Prediction
Based on Irregularly Sampled Time Series Data
Abstract
Prediction based on Irregularly Sampled Time Series (ISTS) is of wide concern in the real-world applications. For more accurate prediction, the methods had better grasp more data characteristics. Different from ordinary time series, ISTS is characterised with irregular time intervals of intra-series and different sampling rates of inter-series. However, existing methods have suboptimal predictions due to artificially introducing new dependencies in a time series and biasedly learning relations among time series when modeling these two characteristics. In this work, we propose a novel Time Encoding (TE) mechanism. TE can embed the time information as time vectors in the complex domain. It has the the properties of absolute distance and relative distance under different sampling rates, which helps to represent both two irregularities of ISTS. Meanwhile, we create a new model structure named Time Encoding Echo State Network (TE-ESN). It is the first ESNs-based model that can process ISTS data. Besides, TE-ESN can incorporate long short-term memories and series fusion to grasp horizontal and vertical relations. Experiments on one chaos system and three real-world datasets show that TE-ESN performs better than all baselines and has better reservoir property.
1 Introduction
Prediction based on Time Series (TS) widely exists in many scenarios, such as healthcare management and meteorological forecast Xing et al. (2010). Many methods, especially Recurrent Neural Networks (RNNs), have achieved state-of-the-art Fawaz et al. (2019). However, in the real-world applications, TS usually is Irregularly Sampled Time Series (ISTS) data. For example, the blood sample of a patient during hospitalization is not collected at a fixed time of day or week. This characteristic limits the performances of the most methods.
Basically, a comprehensive learning of the characteristics of ISTS contributes to the accuracy of final prediction Hao and Cao (2020). For example, the state of a patient is related to a variety of vital signs. ISTS has two characteristics of irregularity under the aspects of intra-series and inter-series:
-
•
Intra-series irregularity is the irregular time intervals between observations within a time series. For example, due to the change of patient’s health status, the relevant measurement requirements are also changing. For example, in Figure 1, the intervals between blood sample collections of a COVID-19 patient could be 1 hour or even 7 days. Uneven intervals will change the dynamic dependency between observations and large time intervals will add a time sparsity factor Jinsung et al. (2017).
-
•
Inter-series irregularity is the different sampling rates among time series. For example, in Figure 1, because vital signs have different rhythms and sensors have different sampling time, for a COVID-19 patient, heart rate is measured in seconds, while blood sample is collected in days. The difference of sampling rates is not conducive to data preprocessing and model design Karim et al. (2019).
However, grasping both two irregularities of ISTS is challenging. In the real-world applications, a model usually has multiple time series as input. If seeing the input as a multivariate time series, the data alignment with up/down-sampling and imputation occurs. But it will artificially introduce some new dependencies while omit some original dependencies, causing suboptimal prediction Sun et al. (2020a); If seeing the input as multiple separated time series and changing dependencies based on time intervals, the method will encounter the problem of bias, embedding stronger short-term dependency in high sampled time series due to smaller time intervals. This is not necessarily the case, however, for example, although the detection of blood pressure is not frequent than heart rate in clinical practice, its values have strong diurnal correlation Virk (2006).
In order to get rid of the above dilemmas and achieve more accurate prediction, modeling all irregularities of each ISTS without introducing new dependency is feasible. However, the premise is that ISTS can’t be interpolated, which makes the alignment impossible, leading to batch gradient descent for multivariate time series hard to implement, aggravating the non-converging and instability of error Back Propagation RNNs (BPRNNs), the basis of existing methods for ISTS Sun et al. (2020a). Echo State Networks (ESNs) is a simple type of RNNs and can avoid non-converging and computationally expensive by applying least square problem as the alternative training method Jaeger (2002). But ESNs can only process uniform TS by assuming time intervals are equal distributed, with no mechanism to model ISTS. For solving all the difficulties mentioned above, we design a new structure to enable ESNs to handle ISTS data, where a novel mechanism makes up for the disadvantage of no learning of irregularity.
The contributions are concluded as:
-
•
We introduce a novel mechanism named Time Encoding (TE) to learn both intra-series irregularity and inter-series irregularity of ISTS. TE represents time points as dense vectors and extends to complex domain for more options of representation. TE injects the absolute and relative distance properties based on time interval and sampling rate into time representations, which helps model two ISTS irregularities at the same time.
-
•
We design a mode named Time Encoding Encoding Echo State Network (TE-ESN). In addition to the ability of modeling both two ISTS irregularities, TE-ESN can learn the long short-term memories in a time series longitudinally and fuses the relations among time series horizontally.
-
•
We evaluate TE-ESN for two tasks, early prediction and one-step-ahead forecasting, on MG chaos system, SILSO sunspot dataset, USHCN meteorological dataset and COVID-19 medical dataset. TE-ESN outperforms state-of-the-art models and has better reservoir property.
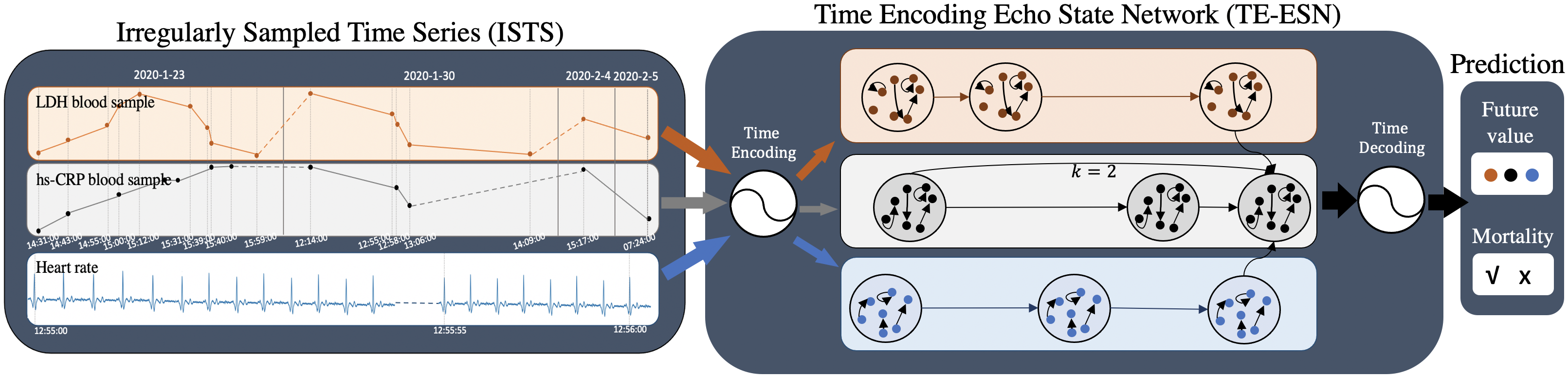
2 Related Work
Existing methods for ISTS can be divided into two categories:
The first is based on the perspective of missing data. It discretizes the time axis into non-overlapping intervals, points without data are considered as missing data points. Multi-directional RNN (M-RNN) Jinsung et al. (2017) handled missing data by operating time series forward and backward. Dated Recurrent Units-Decay (GRU-D) Che et al. (2018) used decay rate to weigh the correlation between missing data and other data. However, data imputation may artificially introduce not naturally occurred dependency beyond original relations and totally ignore to model ISTS irregularities.
The second is based on the perspective of raw data. It constructs models which can directly receive ISTS as input. Time-aware Long Short-Term Memory (T-LSTM) Baytas et al. (2017) used the elapsed time function for modeling irregular time intervals. Interpolation-Prediction Network Shukla and Marlin (2019) used three time perspectives for modeling different sampling rates. However, they just performed well in the univariate time series, for multiple time series, they had to apply alignment first, causing the data missing in some time points, back to the defects of the first category.
The adaption of the BPRNNs training requirements causes the above defects. ESNs with a strong theoretical ground, is practical and easy to implement, can avoid non-converging Gallicchio and Micheli (2017); Sun et al. (2020c). Many state-of-the-art ESNs designs can predict time series well. Jaeger et al. (2007) designed a classical reservoir structure using leaky integrator neurons (leaky-ESN) and mitigated noise problem in time series. Gallicchio et al. (2017) proposed a stacked reservoirs structure based on deep learning (DL) (DeepESN) to pursue conciseness of ESNs and effectiveness of DL. Zheng et al. (2020) proposed a long short-term reservoir structure (LS-ESN) by considering the relations of time series in different time spans. But there is no ESNs-based methods for ISTS.
3 Time Encoding Echo State Network
The widely used RNN-based methods, especially ESNs, only model the order relation of time series by assuming the time distribution is uniform. We design Time Encoding (TE) mechanism (Section 3.2) to embed the time information and help ESNs to learn the irregularities of ISTS (Section 3.3).
3.1 Definitions
First, we give two new definitions used in this paper.
Definition 1 (Irregularly Sampled Time Series ISTS).
A time series with sampling rate has several observations distributed with time . represents an observation of a time series with sampling rate in time .
ISTS has two irregularities: (1) Irregular time intervals of intra-series: . (2) Different sampling rate of inter-series: .
For prediction tasks, one-step-ahead forecasting is using the observed data to predict the value of , and continues over time; Early prediction is using the observed data () to predict the classes or values in time .
Definition 2 (Time Encoding TE).
Time encoding mechanism aims to design methods to embed and represent every time point information of a time line.
TE mechanism extends the idea of Positional Encoding (PE) in natural language processing. PE was first introduced to represent word positions in a sentence Gehring et al. (2017). Transformer Vaswani et al. (2017) model used a set of sinusoidal functions discretized by each relative input position, shown in Equation 1. Where indicates the position of a word, is the embedding dimension. Meanwhile, a recent study Wang et al. (2020) encoded word order in complex embeddings. An indexed word in the position is embeded as . , and denote amplitude, frequency and primary phase respectively. They are all the parameters that should to be learned using deep learning model.
| (1) |
3.2 Time encoding mechanism
First, we introduce how the Time Vector (TV) perceives irregular time intervals of a single ISTS with the fixed sampling rate. Then, we show how Time Encoding (TE) embeds time information of multiple ISTS with different sampling rates. The properties and proofs are summarized in the Appendix.
3.2.1 Time vector with fixed sampling rate
Now, let’s only consider one time series, whose irregularity is just reflected in the irregular time intervals. Inspired by Positional Encoding (PE) in Equation 1, we apply Time Vector (TV) to note the time codes. Thus, in a time series, each time point is tagged with a time vector:
| (2) | ||||
In Equation 2, each time vector has embedding dimensions. Each dimension corresponds to a sinusoidal. Each sinusoidal wave forms a geometric progression from to . is the biggest wavelength defined by the maximum number of input time points.
Without considering the different sampling rates of inter-series, for a single ISTS, TV can simulate the time intervals between two observations by its properties of absolute distance and relative distance.
Property 1 (Absolute Distance Property).
For two time points with distance , the time vector in time point is the linear combination of the time vector in time point .
| (3) | ||||
Property 2 (Relative Distance Property).
The product of time vectors of two time points and is negatively correlated with their distance . The larger the interval, the smaller the product, the smaller the correlation.
| (4) |
For a computing model, if its inputs have the time vectors of time points corresponding to each observation, then the calculation of addition and multiplication within the model will take the characteristics of different time intervals into account through the above two properties, improving the recognition of long term and short term dependencies of ISTS. Meanwhile, without imputing new data, natural relation and dependency within ISTS are more likely to be learned.
3.2.2 Time encoding with different sampling rates
When the input is multi-series, another irregularity of ISTS, different sampling rates, shows up. Using the above introduced time vector will encounter the problem of bias. It will embed more associations between observations with high sampling rate according to the Property 2, as they have smaller time intervals. But we can not simply conclude that the correlation between the values of time series with low sampling rate is weak.
Thus, we design an advanced version of time vector, noted Time Encoding (TE), to encode time within multiple ISTS. TE extends TV to complex-valued domain. For a time point in the -th ISTS with sampling rate, the time code is in Equation 5, where is the frequency.
| (5) |
Compared with TV, TE has two advantages:
The first is that TE not only keeps the property 1 and 2, but also incorporates the influence of frequency , making time codes consistent at different sampling rates.
reflects the sensitivity of observation to time, where a large leads to more frequent changes of time codes and more difference between the representations of adjacent time points. For relative distance property, a large makes the product large when distance is fixed.
Property 3 (Relative Distance Property with ).
The product of time encoding of two time points and is positive correlated with frequency .
| (6) |
In TE, we set . is the frequency parameter of -th sampling rate. TE fuses the sampling rate term to avoid the bias of time vector causing by only considering the effect of distance .
The second is that each time point can be embeded into dimensions with more options of frequencies by setting different in Equation 7.
| (7) | ||||
In TE, means the time vector in dimension has frequencies. But in Equation 2 of TV, the frequency of time vector in dimension is fixed with .
3.2.3 The relations between different mechanisms
Time encoding with different sampling rates is related to time vector with fixed sampling rate and a general complex expression Wang et al. (2020).
-
•
TV is a special case of TE. If we set , then .
-
•
TE is a special case of a fundamental complex expression . We set as we focus more on the relation between different time points than the value of the first point; We understand term as the representation of observations and leave it to learn by computing models. Besides, TE inherits the properties of position-free offset transformation and boundedness Wang et al. (2020).
3.3 Injecting time encoding mechanism into echo state network
Echo state network is a fast and efficient recurrent neural network. A typical ESN consists of an input layer , a recurrent layer, called reservoir , and an output layer . The connection weights of the input layer and the reservoir layer are fixed after initialization, and the output weights are trainable. , and denote the input value, reservoir state and output value at time , respectively. The state transition equation is:
| (8) | ||||
Before training, three are three main hyper-parameters of ESNs: Input scale ; Sparsity of reservoir weight ; Spectral radius of reservoir weight Jiang and Lai (2019).
However, existing ESNs-based methods cannot model the irregularities of ISTS. Thus, we make up for this by proposing Time Encoding Echo State Network (TE-ESN).
Time Encoding. TE-ESN has reservoirs, assigning each time series of input an independent reservoir. An observation is transferred trough input weight , time encoding , reservoir weight and output weight . The structure of TE-ESN is shown in Figure 1. The state transition equation is:
| (9) | |||
TE-ESN creates three highlights compared with other ESNs-based methods by changing the Reservoir state:
-
•
Time encoding mechanism (TE). TE-ESN integrates time information when modeling the dynamic dependencies of input, by changing recurrent states in reservoirs through TE term to Time encoding state.
-
•
Long short-term memory mechanism (LS). TE-ESN leans different temporal span dependencies, by incorporating not only short-term memories from state in last time, but also long-term memories from state in former time ( is the time skip) to Long short state.
-
•
Series fusion (SF). TE-ESN also considers the horizontal information between time series, by changing Reservoir state according to not only the former state in its time series but also the Neighbor state in other time series.
The coefficients and trade off the memory length in Long short state and the fusion intensity in Reservoir state.
Time Decoding. The states in reservoir of TE-ESN have time information as TE embeds time codes into the representations of model input. For final value prediction, it should decode the time information and get the real estimated value at time by Equation 10. Further, by changing the time , we can get different prediction results in different time points.
| (10) |
Equation 11 is the calculation formula of the readout weights when training to find a solution to the least squares problem with regularization parameter .
| (11) | ||||
Algorithm 1 shows the process of using TE-ESN for prediction. Line 1-11 obtains the solution of readout weights of TE-ESN by that using the training data. Line 12-18 shows the way to predict the value of test data. Assuming the reservoir size of TE-ESN is fixed by , The maximum time is , the input has time series, the complexity is:
| (12) |

| BPRNNs-based | ESNs-based | ||||||||
| M-RNN | T-LSTM | GRU-D | ESN | leaky-ESN | DeepESN | LS-ESN | TV-ESN | TE-ESN | |
| MGsystem | 0.232±0.005 | 0.216±0.0.003 | 0.223±0.005 | 0.229±0.001 | 0.213±0.0.001 | 0.197±0 | 0.198±0 | 0.204±0.001 | 0.195±0.001 |
| SILSO () | 2.95±0.74 | 2.93±0.81 | 2.99±0.69 | 3.07±0.63 | 2.95±0.59 | 2.80±0.73 | 2.54±0.69 | 2.54±0.79 | 2.39±0.78 |
| USHCN | 0.752±0.32 | 0.746±0.33 | 0.747±0.25 | 0.868±0.29 | 0.857±0.20 | 0.643±0.12 | 0.663±0.15 | 0.647±0.15 | 0.640±0.19 |
| COVID-19 | 0.959±0.004 | 0.963±0.003 | 0.963±0.004 | 0.941±0.003 | 0.942±0.003 | 0.948±0.003 | 0.949±0.003 | 0.958±0.002 | 0.965±0.002 |
| 0.098±0.0.005 | 0.096±0.007 | 0.100±0.005 | 0.136±0.006 | 0.135±0.007 | 0.129±0.006 | 0.120±0.007 | 0.115±0.005 | 0.093±0.005 |
4 Experiments
4.1 Datasets
-
•
MG system Mackey and Glass (1977). Mackey-Glass system is a classical chaotic system, often used to evaluate ESNs. . We initialized to , random increases with irregular time interval. The task is one-step-ahead-forecasting in first 1000 time.
-
•
SILSO Center (2016). SILSO provides an open-source monthly sunspot series from 1749 to 2020. It has irregular time intervals, from 1 to 6 month. The task is one-step-ahead forecasting from 1980 to 2019.
-
•
USHCN Menne and R. (2010). The dataset consists of daily meteorological data of 48 states from 1887 to 2014. We extracted the records of temperature, snowfall and precipitation from New York, Connecticut, New Jersey and Pennsylvania. Each TS has irregular time intervals, from 1 to 7 days. Sampling rates are different among TS, from 0.33 to 1 per day. The task is to early predict the temperature of New York in next 7 days.
-
•
COVID-19 Yan L (2020). The COVID-19 patients’ blood samples dataset were collected between 10 Jan. and 18 Feb. 2020 at Tongji Hospital, Wuhan, China, containing 80 features from 485 patients with 6877 records. Each TS has irregular time intervals, from 1 minus to 12 days. Sampling rates are different among TS, from 0 to 6 per day. The task is to early predict in-hospital mortality before 24 hours and one-step-ahead forecasting for each biomarkers.
4.2 Baselines
The code of 9 baselines with 3 categories is available at https://github.com/PaperCodeAnonymous/TE-ESN.
- •
- •
-
•
Our methods: We use TV-ESN with the time representation embedded by TV, we use TE-ESN with the time representation embedded by TE.
4.3 Experiment setting
We use Genetic Algorithms (GA) Zhong et al. (2017) to optimize hyper-parameters shown in Table 5. For TV-ESN, we set . For TE-ESN, We set , where and . Results are got by 5-fold cross validation. Method performances are evaluated by the Area Under Curve of Receiver Operating Characteristic (AUC-ROC) (higher is better) and the Mean Squared Error (MSE) (lower is better). Network property of ESNsis evaluated by Memory Capability (MC) (higher is better) Farkas et al. (2016) in Equation 13. where is the squared correlation coefficient.
| Parameters | Value range | Parameters | Value range |
|---|---|---|---|
| (13) |
4.4 Results
We show the results from five perspectives below. The conclusions drawn from the experimental results are shown in italics. More experiments are in Appendix.
4.4.1 Prediction results of methods
Shown in Table 1: (1) TE-ESN outperforms all baselines on four datasets. It means Learning two irregularities of ISTS helps for prediction and TE-ESN has this ability. (2) TE-ESN is better than TV-ESN in multivariable time series datasets (COVID-19, USHCN) shows the effect of Property 3 of TE; TE-ESN is better than TV-ESN in univariable time series datasets (SILSO, MG) shows the advantage of multiple frequencies options of TE. (3) ESNs-based methods perform better in USHCN, SILSO and MG, while BPRNNs-based method performs better in COVID-19. Which shows the characteristic of ESNs that they are good at modeling the consistent dynamic chaos system, such as astronomical, meteorological and physical. Figure 2 shows a case of forecasting lactic dehydrogenase (LDH), an important bio-marker of COVID-19 Yan L (2020); Sun et al. (2020b). TE-ESN has smallest difference between real and predicted LDH values.
4.4.2 Time encoding mechanism analysis
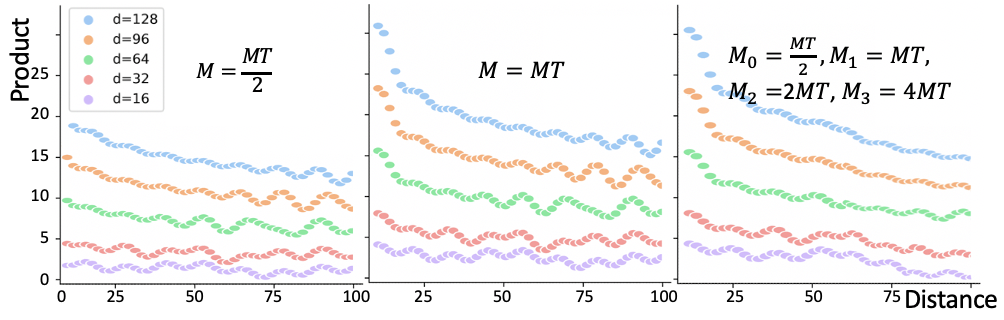
Dot product between two sinusoidal positional encoding decreases with increment of absolute value of distance Yan et al. (2019). (1) Figure 3 shows the relation of TE dot product and time distance, it shows that using multiple frequencies will enhance monotonous of negative correlation between dot product and distance. (2) Table 3 shows the prediction results in different TE settings, results shows that using multiple frequencies can improve the prediction accuracy.
| MGsystem | 0.226±0.0.001 | 0.204±0.001 | 0.210±0.001 | 0.193±0.001 |
| SILSO | 2.69±0.60 | 2.54±0.79 | 2.55±0.75 | 2.39±0.78 |
| USHCN | 0.681±0.18 | 0.670±0.20 | 0.673±0.17 | 0.640±0.19 |
| COVID-19 | 0.949±0.002 | 0.952±0.003 | 0.950±0.002 | 0.965±0.002 |
| 0.105±0.006 | 0.099±0.005 | 0.101±0.005 | 0.093±0.005 |
4.4.3 Ablation study of TE-ESN
We test the effect of TE, LS and SF, which are introduced in Section 3.3, by removing TE term, setting and setting . The results in Table 4 show that all theses three mechanisms of TE-ESN contribute to the final prediction tasks. TE has the greatest impact in COVID-19, the reason may be that the medical dataset has the strongest irregularity compared with other datasets. LS has the greatest impact in USHCN and SILSO, as there are many long time series, it is necessary to learn the dependence in different time spans. SF has a relatively small impact, the results have no change in SILSO and MG as they are univariate.
| w/o TE | w/o LS | w/o SF | TE-ESN | |
| MGsystem | 0.210±0.0.001 | 0.213±0.001 | 0.193±0.001 | 0.193±0.001 |
| SILSO | 2.79±0.63 | 2.93±0.69 | 2.39±0.78 | 2.39±0.78 |
| USHCN | 0.713±0.12 | 0.757±0.21 | 0.693±0.16 | 0.640±0.19 |
| COVID-19 | 0.943±0.003 | 0.949±0.003 | 0.956±0.003 | 0.965±0.002 |
| 0.135±0.006 | 0.130±0.006 | 0.125±0.007 | 0.093±0.005 |
4.4.4 Hyper-parameters analysis of TE-ESN
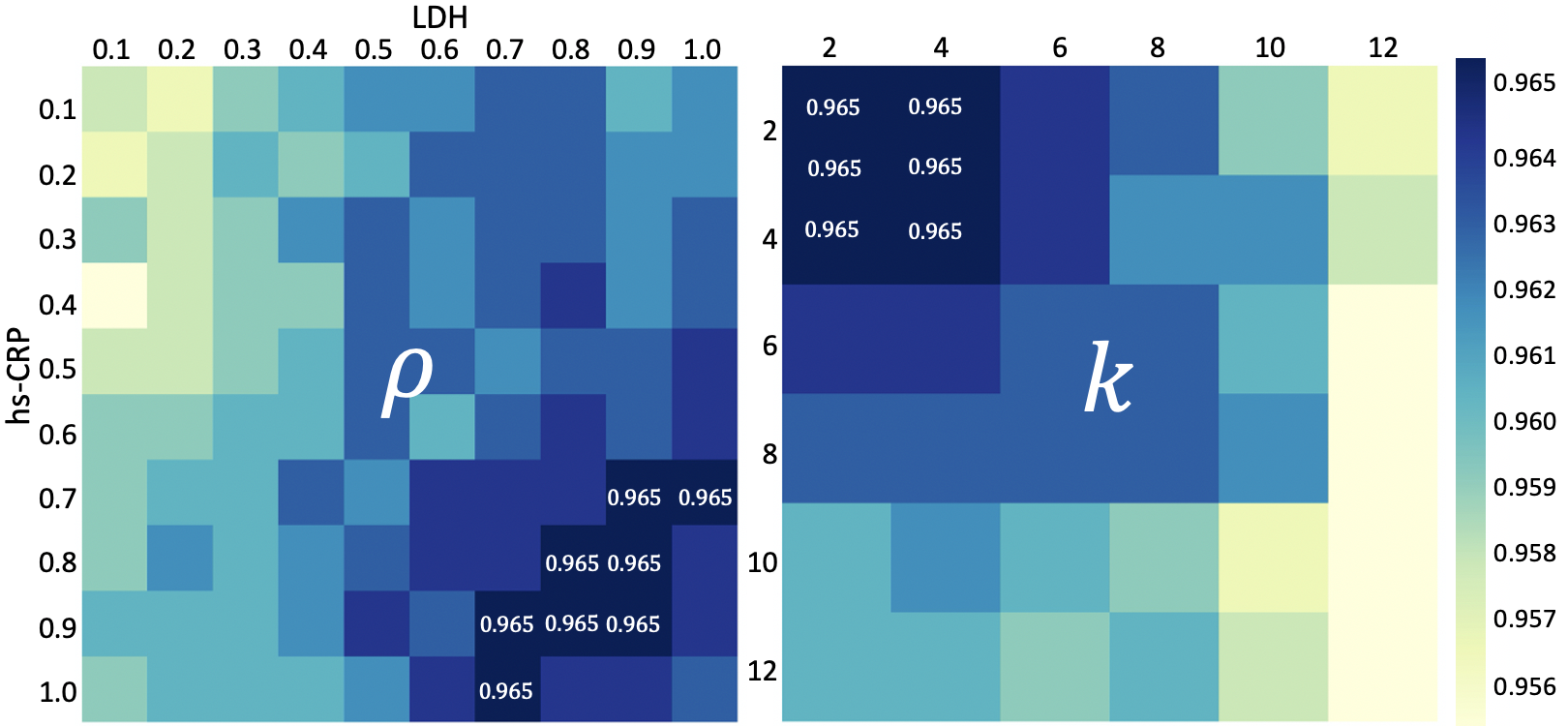
In TE-ESN, each time series has a reservoir, reservoirs setting can be different. Figure 4 shows COVID-19 mortality prediction results when changing spectral radius and time skip of LDH and hs-CRP. Setting uniform hyper-parameters or different hyper-parameters for each reservoir has little effect on the prediction results. Thus, we set all reservoirs with the same hyper-parameters for efficiency. Table 5 shows the best hyper-parameter settings.
| MGsystem | 1 | 0.1 | 0.7 | 0.8 | 6 | 1.0 | |
| SILSO | 1 | 0.1 | 0.6 | 0.8 | 10 | 1.0 | |
| USHCN | 1 | 0.1 | 0.7 | 0.8 | 12 | 0.8 | |
| COVID-19 | 1 | 0.3 | 0.9 | 0.7 | 4 | 0.9 | |
| 1 | 0.2 | 0.8 | 0.8 | 2 | 0.8 |
4.4.5 Memory capability analysis of TE-ESN
Memory capability (MC) can measure the short-term memory capacity of reservoir, an important property of ESNs Gallicchio et al. (2018). Table 6 shows that TE-ESN obtains the best MC, and TE mechanism can increase the memory capability.
| ESN | leaky-ESN | DeepESN | LS-ESN | TE-ESN (-TE) | TE-ESN |
| 35.05 | 39.65 | 42.98 | 46.05 | 40.46 | 47.83 |
5 Conclusions
In this paper, we propose a novel Time Encoding (TE) mechanism in complex domain to model the time information of Irregularly Sampled Time Series (ISTS). It can represent the irregularities of intra-series and inter-series. Meanwhile, we create a novel Time Encoding Echo State Network (TE-ESN), which is the first method to enable ESNs to handle ISTS. Besides, TE-ESN can model both longitudinal long short-term dependencies in time series and horizontal influences among time series. We evaluate the method and give several model related analysis in two prediction tasks on one chaos system and three real-world datasets. The results show that TE-ESN outperforms the existing state-of-the-art models and has good properties. Future works will focus more on the dynamic reservoir properties and hyper-parameters optimization of TE-ESN, and will incorporate deep structures to TE-ESN for better prediction accuracy.
References
- Baytas et al. [2017] Inci M. Baytas, Cao Xiao, Xi Zhang, Fei Wang, Anil K. Jain, and Jiayu Zhou. Patient subtyping via time-aware LSTM networks. In KDD 2017, pages 65–74, 2017.
- Center [2016] SILSO World Data Center. The international sunspot number, int. sunspot number monthly bull. online catalogue (1749-2016). [Online], 2016.
- Che et al. [2018] Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. Recurrent neural networks for multivariate time series with missing values. Sentific Reports, 8(1):6085, 2018.
- Farkas et al. [2016] Igor Farkas, Radomír Bosák, and Peter Gergel. Computational analysis of memory capacity in echo state networks. Neural Networks, 83:109–120, 2016.
- Fawaz et al. [2019] Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. Deep learning for time series classification: a review. Data Min. Knowl. Discov., 33(4):917–963, 2019.
- Gallicchio and Micheli [2017] Claudio Gallicchio and Alessio Micheli. Deep echo state network (deepesn): A brief survey. CoRR, abs/1712.04323, 2017.
- Gallicchio et al. [2017] Claudio Gallicchio, Alessio Micheli, and Luca Pedrelli. Deep reservoir computing: A critical experimental analysis. Neurocomputing, 268(dec.11):87–99, 2017.
- Gallicchio et al. [2018] Claudio Gallicchio, Alessio Micheli, and Luca Pedrelli. Design of deep echo state networks. Neural Networks, 108:33–47, 2018.
- Gehring et al. [2017] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. In ICML 2017, pages 1243–1252, 2017.
- Hao and Cao [2020] Yifan Hao and Huiping Cao. A new attention mechanism to classify multivariate time series. In IJCAI 2020, pages 1999–2005. ijcai.org, 2020.
- Jaeger et al. [2007] Herbert Jaeger, Mantas Luko?Evi?Ius, Dan Popovici, and Udo Siewert. Optimization and applications of echo state networks with leaky-integrator neurons. Neural Netw, 20(3):335–352, 2007.
- Jaeger [2002] Herbert Jaeger. Adaptive nonlinear system identification with echo state networks. In NIPS 2002, pages 593–600, 2002.
- Jiang and Lai [2019] Jun-Jie Jiang and Ying-Cheng Lai. Model-free prediction of spatiotemporal dynamical systems with recurrent neural networks: Role of network spectral radius. CoRR, abs/1910.04426, 2019.
- Jinsung et al. [2017] Yoon Jinsung, Zame William R., and Mihaelaå Van Der Schaar. Estimating missing data in temporal data streams using multi-directional recurrent neural networks. IEEE Transactions on Biomedical Engineering, PP:1–1, 2017.
- Karim et al. [2019] Fazle Karim, Somshubra Majumdar, and Houshang Darabi. Insights into LSTM fully convolutional networks for time series classification. IEEE Access, 7:67718–67725, 2019.
- Mackey and Glass [1977] M. Mackey and L Glass. Oscillation and chaos in physiological control systems. Science, 197(4300):287–289, 1977.
- Menne and R. [2010] Williams C. Menne, M. and Vose R. Long-term daily and monthly climate records from stations across the contiguous united states. [Online], 2010.
- Shukla and Marlin [2019] Satya Narayan Shukla and Benjamin M. Marlin. Interpolation-prediction networks for irregularly sampled time series. In ICLR, 2019.
- Sun et al. [2020a] Chenxi Sun, Shenda Hong, Moxian Song, and Hongyan Li. A review of deep learning methods for irregularly sampled medical time series data. CoRR, abs/2010.12493, 2020.
- Sun et al. [2020b] Chenxi Sun, Shenda Hong, Moxian Song, Hongyan Li, and Zhenjie Wang. Predicting covid-19 disease progression and patient outcomes based on temporal deep learning. BMC Medical Informatics and Decision Making, 2020.
- Sun et al. [2020c] Chenxi Sun, Moxian Song, Shenda Hong, and Hongyan Li. A review of designs and applications of echo state networks. CoRR, abs/2012.02974, 2020.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS 2017, pages 5998–6008, 2017.
- Virk [2006] Imran S. Virk. Diurnal blood pressure pattern and risk of congestive heart failure. Congestive Heart Failure, 12(6):350–351, 2006.
- Wang et al. [2020] Benyou Wang, Donghao Zhao, Christina Lioma, Qiuchi Li, Peng Zhang, and Jakob Grue Simonsen. Encoding word order in complex embeddings. In ICLR, 2020.
- Xing et al. [2010] Zhengzheng Xing, Jian Pei, and Eamonn J. Keogh. A brief survey on sequence classification. SIGKDD Explorations, 12(1):40–48, 2010.
- Yan et al. [2019] Hang Yan, Bocao Deng, Xiaonan Li, and Xipeng Qiu. TENER: adapting transformer encoder for named entity recognition. CoRR, abs/1911.04474, 2019.
- Yan L [2020] Goncalves J et al. Yan L, Zhang H T. An interpretable mortality prediction model for covid-19 patients. Nature, Machine intelligence, 2, 2020.
- Zheng et al. [2020] Kaihong Zheng, Bin Qian, Sen Li, Yong Xiao, Wanqing Zhuang, and Qianli Ma. Long-short term echo state network for time series prediction. IEEE Access, 8:91961–91974, 2020.
- Zhong et al. [2017] Shisheng Zhong, Xiaolong Xie, Lin Lin, and Fang Wang. Genetic algorithm optimized double-reservoir echo state network for multi-regime time series prediction. Neurocomputing, 238:191–204, 2017.