Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework.††thanks: Supported by organization x.
Abstract
We study the challenging problem for inference tasks on large-scale graph datasets of Graph Neural Networks: huge time and memory consumption, and try to overcome it by reducing reliance on graph structure. Even though distilling graph knowledge to student MLP is an excellent idea, it faces two major problems of positional information loss and low generalization. To solve the problems, we propose a new three-stage multitask distillation framework. In detail, we use Positional Encoding to capture positional information. Also, we introduce Neural Heat Kernels responsible for graph data processing in GNN and utilize hidden layer outputs matching for better performance of student MLP’s hidden layers. To the best of our knowledge, it is the first work to include hidden layer distillation for student MLP on graphs and to combine graph Positional Encoding with MLP. We test its performance and robustness with several settings and draw the conclusion that our work can outperform well with good stability.
Keywords:
Knowledge distillation on graphs Positional encoding Hidden layer distillation.1 Introduction
Graph Neural Networks (GNNs)[3] have shown superior performance in learning structural information and are widely used in various fields, such as molecular biology, social networks, and recommendation systems[5, 6, 7]. With the continuous growth of applications and data scale, GNN tasks exhibit the characteristics of big models and big data. For instance, a frequently used Twitter-7 [8] dataset contains over seventeen million nodes and over four hundred million edges.
However, this trend poses a major drawback: the required computing resources are sharply increased. It is difficult to train conventional GNNs on large-scale datasets with limited resources and training time. Therefore, it is essential to propose efficient approaches for large-scale graph deep learning with acceptable performance.
A large number of efforts have been made to tackle this issue in both hardware-level and algorithm-level [11, 9]. For example, some studies optimize the cache and GPU usage, while others speed up and enhance graph data computation by sampling, clustering [12], quantization [13], and pruning [10]. Nevertheless, these methods still retain the graph aggregation process that consumes resources. Moreover, the prediction performance is poor on unseen classes. To address these issues, recent works have tried to use knowledge distillation on graphs [14, 15, 16]. Among them, GLNN [16] considers MLP, which is frequently used in the industrial area, as a student and transfers knowledge into it by matching its soft logits with the soft target distribution from the teacher. MLP serves as a simple, clear model and can perform well with only node features for inference.
Despite the efficiency of GLNN, there are problems with this type of knowledge distillation, which will restrict it to reach optimal prediction accuracy:
1) Positional information loss problem. Using student MLP as a classifier relies on the assumption that it is sufficient to perform classification with only node features. However, this is unsuitable for graph datasets where positional information is highly correlated with classification results. A simple MLP with raw node features as inputs cannot make use of this information. 2) Low generalization problem. GLNN uses soft logits from the teacher GNN to teach student MLP the mapping relationships between node features and labels. However, the relationships learned by MLP are usually too simple and direct, leading to low generalization probability.
In this paper, we propose a new multi-stage framework for knowledge distillation on graphs that efficiently solves the problems above. To address the positional information loss problem, we introduce a lightweight Laplacian Positional Encoding that captures the graph’s positional information and concatenates it with the initial node feature. This approach improves the performance and applicability of student MLP on different datasets. To enhance the generalization capability of the distillation, we draw inspiration from the GNN-level topology distillation [17, 18] and FitNet [19]. We teach the student the process of message propagation in the teacher GNN through a special hidden layer distillation. By mapping the student’s and teacher’s hidden layer outputs to the same space using kernel functions, we minimize the distance between the transformed results. This approach ensures that the student MLP captures the information responsible for the message-passing process, leading to better node representations of hidden layers and enhanced generalization. We validate our framework’s superiority experimentally and investigate its robustness. Our experiments demonstrate that the proposed framework outperforms existing state-of-the-art methods on various benchmark datasets.
The main contributions of this work are:
—Introducing Laplacian Positional Encoding as an initial feature for student MLP to capture the positional information of graphs and improve its performance and applicability on different datasets.
—Utilizing special hidden layer distillation to teach the student the process of message propagation in the teacher GNN and improve its generalization capability.
—Conducting experiments on both small and large scale data, showing that our approach significantly outperforms existing methods. We also have interesting cases to illustrate the robustness of our methods.
Overall, our framework provides a novel approach to knowledge distillation on graphs that is both efficient and effective.
2 Related Work
Graph Neural Networks. GNNs are primarily used to analyze and study data in non-Euclidean domains that can be represented as graphs . These models allow for the incorporation of two types of knowledge: node and structural information. Most commonly used GNNs, for instance, GCN [1], GAT [20] and GraphSAGE [21], are all based on message-passing neural networks (MPNN) represented as follows:
| (1) |
where means each node itself and means certain node from neighborhood node set. The process of aggregating and computing functions is highly dependent on the topology structure of the graph in order to achieve optimal performance.
Model-level GNN Acceleration. The field of GNN acceleration addresses two major challenges. The first challenge is that large-scale graph datasets used in real-world applications make GNN training and inference difficult to complete within a reasonable time frame. The second challenge arises from the development of more complex and deeper GNN models, such as DeeperGCN [22] and Graph Transformer [23], which require extensive training time that is almost impossible to complete without time-complexity optimization. To overcome these challenges, researchers have proposed model-level optimization techniques. GNN simplification methods, such as SGC [24] and LightGCN [25], aim to simplify the computational process in GNNs. On the other hand, GNN compression techniques, such as pruning, model quantization, and knowledge distillation, aim to replace cumbersome primitive models with lightweight models that require fewer parameters. By employing these techniques, researchers hope to reduce the time and computational resources required for GNN training and inference, making it feasible to apply GNNs to large-scale graph datasets and more complex models.
Knowledge Distillation for Graphs. Knowledge distillation methods have been proposed to transfer knowledge from complex teacher models to simpler student models. However, for graph-based models, the task is a bit challenging. Localized graph-based methods, such as LSP [26] and TinyGNN [27], focus on capturing local information of graphs. GraphAKD [28] proposes an adversarial framework for knowledge distillation that allows students to generate node embeddings and logits similar to their teachers’ output. All these methods highly rely on graphs for knowledge distillation. In contrast, GLNN, as mentioned above, aims to transfer knowledge into a simpler student MLP but does not utilize structural knowledge. It is effective at knowledge transferring to simpler models. However, a further optimization can be introduced.
3 Preliminaries
3.1 Motivation.
To improve knowledge transferring to student MLPs, it’s advisable to use distillation methods that go beyond just aligning soft label distributions. By defining the graph signal , we consider two species of knowledge: local node representation and global positional information. Here we introduce approach called Neural Heat Kernel(NHK) Based Distillation for effective node representation generation from student MLPs. Moreover, we study Positional Encoding (PE) for better global positional information transfer.
3.2 NHK Based Distillation
To introduce NHK as a teaching tool for MLPs, it’s essential to include the following definition:
Definition 1.
GNN from Riemannian manifold perspective. In this perspective, the graph data can be defined as a special kind of Riemannian manifold. When graph signal defined, a single-layer GNN is equivalent to solving the heat equation for a discrete value of some time interval . It can also be written with a kernel function :
| (2) |
where is the spatial signal, also graph structure we have. And is the temporal signal related to the number of GNN layers. denotes for the Laplace operator. Usually we consider kernel functions and distance measuring to approximate this operator. Kernel functions will be discussed in Sec. 4.
This transformation can facilitate the extraction of local structural features. We resort to the NHK to capture the influence exerted on the nodes by the message passing process during the graph convolution process, for the process of information exchange between two points on the manifold is similar to that of heat transform. Consequently, feature embedding of nodes after certain hidden layers is added with information from connected nodes with the mapping from kernel functions . This can be regarded as a prior knowledge also named Graph Smoothness [29]. Layer-to-layer kernel mapping are proposed as:
| (3) |
where node-level smoothness is passed between and , which are arbitrary nodes from graph. and are node representations after certain hidden layer. By characterizing fuzzy geometric information as a specific function, we adopt an easily comprehensible approach that simplifies local distillation, which will be discussed further below.
3.3 Positional Encoding for global distillation.
To improve the capturing of global information, we draw inspiration from graph transformer frameworks. Specially, Dwivedi et al. [32] utilize Laplacian Encoding as initial PE, calculated before training. By providing PE as prior knowledge to student model, its ability to perceive positional and structural information can be enhanced. In this work, we use Laplacian eigenvectors as PE. The eigenvectors are calculated by defining a Laplacian matrix:
| (4) |
where is the adjacency matrix, is the diagonal matrix for matrix standardization and , represents eigenvectors and eigenvalues of the Laplacian matrix. Then we choose k-smallest non-trivial eigenvectors in real space for n nodes as an extra input . A theorem related to Spectral Clustering [30] demonstrates benefits of PE for classification tasks:
Theorem 3.1.
(Effectiveness of Spectral Clustering). Suppose that whole graph consists of multiple graph partitions that are similar internally and differ significantly between partitions. Thus, we need to find such optimal partitions. Given a partition of the graph into k sets, we can define k indicator vectors by approximating Ratiocut or Ncut. We consider the problem of finding ideal indicator vectors transforming into the following Ncut minimizing problem:
| (5) |
It can be proven that clustering can provide structural information by providing similarities and Euclidean distances as prior knowledge. According to Perturbation theory, the eigenvectors of Laplacian matrices will be very similar to the ideal indicator vectors. Therefore, the first-k eigenvectors are often used in clustering.
3.4 KL-Divergence
To quantify the degree of difference in the soft target distribution between student and teacher models, we introduce Kullback-Leible Divergence [31] (KL divergence). Consider two random variables , , with discrete probability distributions(like the real situations) and , respectively. We have KL divergence from P to Q as:
| (6) |
The smaller the difference between the soft logits of the student and teacher models, the smaller the KL divergence will be. This shows that we can use minimizing KL divergence as a way to simplify the utilization of soft target information.
4 Methodology
To transfer graph information to MLP effectively, it’s necessary to consider both local and global perspect. Combining the above methods introduced, we propose a multi-task distillation framework Kernel-based Multilayer Perceptron with structural Processing (KMP) for better results of teaching student MLPs. The overall structure is shown in Fig. 1.
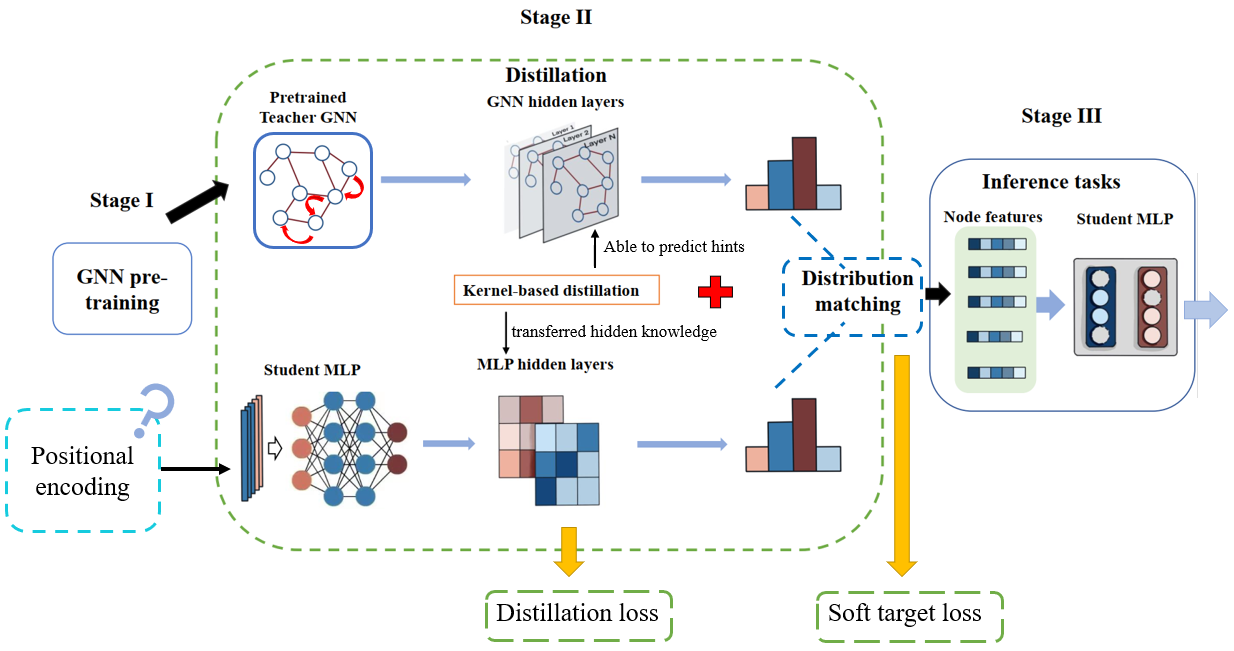
4.1 Three-Stage distillation
Our proposed distillation process consists of three stages: GNN pre-training stage, distillation stage and inference stage. During the first stage, we perform simple message-passing training and save the trained graph model and the soft target distribution of the model output.
During the second stage, we first add PE as a prior knowledge for student MLPs. Consider the -dimensional input feature of a certain node. We embed the -dimensional Laplacian PE into a feature vector with the same dimension as . Then we concatenate them or do a simple dot product between them. As the following equation shows:
| (7) |
| (8) |
In order to capture the , we make sure that nodes for training contain the same ones as being input towards teacher GNNs. Thus, the process of hidden mechanism control by Neural Heat Kernels can work. Our target is to make hidden layers of students able to predict the outputs of a guiding hidden layer of teachers [19]. Layer-to-layer mapping matrices as Sec. 3.2 on hidden outputs of training nodes are adopted as:
| (9) |
where denotes for operation to obtain mapping matrices. We select four non-linear kernel functions as to do the calculation:
| (10) |
where denotes for non-linear operations like , or , denotes for a linear transformation in Sigmod Kernel and denotes for a constant time interval in Gaussian Kernel. And is a randomized matrix whose vectors obey a Gaussian distribution in Randomized Kernel. We load the pre-trained in the first stage to generate teacher mapping matrices and aim to minimize the distance between those of teachers and students. A simple L2 Norm is used to measure distance as:
| (11) |
Also, we adopt a process of soft logits matching, which is defined in Section 4.2. During stage III, we do inference tasks on either the existing graph or unseen new in the same graph dataset. We will discuss this further in Sec. 5.5.
4.2 Distillation loss
During the entire training process, we consider two main parts of the distillation loss: the loss from model prediction matching and the loss from distance measurement between mapping matrices. Therefore, we can express the total multi-task distillation loss as:
| (12) |
where denotes for student prediction, and can be true labels or soft targets from teacher. is a constant to show the proportion of . And that is calculated by a K-layer matching process between and included above. It is noteworthy that we provide two kinds of training nodes: with true labels or with soft targets from teacher GNNs. The student predictions of them can be represented as and . So can be specified as:
| (13) |
where are true labels of selected labeled nodes while are soft target distributions from teacher outputs, as mentioned in Sec. 4.1. They are two parts of . By minimizing , we can get a well-trained MLP to do inference tasks.
4.3 Usage of trainable reverse kernel
Getting inspired by Variational Autoencoder (VAE) [40] and GNN-level topology distillation [18], We have tried to optimize the heat kernel itself. A trainable matrix is introduced for transformation whose parameters can be optimized and shared by both student and teacher. The trainable reverse kernel can be represented as:
| (14) |
Like VAE does, we also adopt reconstruction loss between original inputs() and outputs of the last hidden layer () and utilize it to optimize for data processing:
| (15) |
Consequently, we need to do a two-step optimization both on the student model and the kernel. That helps to explore proper kernels for distillation.
4.4 Discussion
Our proposed methodology is mainly for solving two major problems of MLP classifier: positional information loss low generalization. To address these issues, we utilize two efficient approaches: PE and NHK based distillation. These approaches enable the transfer of knowledge from non-Euclidean domains into simpler domains in a explainable manner. Overall, our methodology offers a promising solution to enhance the performance of MLP classifiers on graph datasets. Also, this transfer is done in a pretty explainable way.
5 Experiments
In this section, we introduce several groups of experiments to prove that our KMP framework can solve the problems of MLP classifier. Mainly, we focus on the following questions to design experiments: Q1: Does KMP perform better than student MLP without hidden layer distillation on most common node classification tasks?
Q2: Can KMP give better inference results on large-scale graph datasets?
Q3: Does trainable kernels work better?
Q4: How much can PE improve our model performance?
Q5: How is the robustness and sensitiveness of our framework? Before introducing our experiment results, we have the following preliminary statement: We study on question 1, 2 and 3 with a single KMP without PE, and adopt KMP+PE in question 4 and 5.
5.1 Dataset
In this part, we do our research on five typical datasets [33]. Three common benchmark datasets: Cora, Citeseer, Pubmed and two larger ones: Amazon photos, Amazon Computers. Also, we introduce two OGB datasets [34]: Arxiv and Products, to see if our model perform well on large-scale graphs. The details of the datasets are in Appendix. 7. For each dataset, we label 20 nodes per class and select 30 nodes randomly for validation. We adopt both true or soft labels here. Other nodes are provided for testing.
5.2 Baselines
We choose frequently used teacher models: SAGE, GCN and GAT. It’s easy for us to transfer knowledge from them into student MLPs. We use single MLP without distillation and GLNN as baseline model to check if our framework perform better.
5.3 Evaluation Metrics
In all experiments, we report accuracy()on test set. 10 experiments with random seeds are done, and mean value and standard deviation of test accuracy are reported.
5.4 Hyperparameters
During stage I and II, we set the max epochs during training to 1000, and an early stop is adopted when accuracy on validation set doesn’t increase for 50 epochs. We take 512 as our batch-size, as our optimizer and cuda as our training device. In order to report exact results, we follow the settings of teacher GNNs for 5 small datasets in Appendix. 0.A.2. A grid-research is also adopted to find the most proper hyperparameters for loss computing, as introduced in Appendix. 0.A.3.
5.5 Performance on most common node classification tasks
Transductive and inductive settings. We study two categories of node classification tasks. The most common setting for node classification is a transductive (trans) setting, where all nodes are split into training set, validation set and test set. Under this setting we can see the whole graph structure (adjacency matrix) while training. However, under real-life scenarios, an inductive (induc) setting is often more applicable, for we cannot always see all users and relations in real networks. Unobserved nodes are first taken out and all information of them can’t be seen during stage II. Then a train-valid-test split is adopted. Something to note while transductive or inductive distillation is as follows:
During stage II, we choose some of the training nodes to own true labels, and others to match teacher’s soft target distribution, as Sec. 4.2 shows.
During stage III, we use the structure-observed test set to do inference via our trained student MLP for transductive setting, while unobserved new nodes are used for inductive setting.
Results. Overall performance of the most common node classification task can be found in Table. 1 and Table. 2. For KMP, We report the best result among four categories of kernels as Sec. 4.1 mentions. Our comparison is among MLP without distillation, GLNN and our KMP (no Position Encoding here). It clearly demonstrates that our KMP outperform baseline GLNN well in nearly all cases with transductive settings. Moreover, test accuracy from KMP’s predictions clearly increases from GLNN’s with more discursive inductive settings on most occasions. We can safely draw the conclusion that our distillation method can improve student MLP’s performance with various teacher GNNs.
| Dataset | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cora | 79.701.90 | 79.581.01 | 81.411.15 | 58.662.34 | 78.991.90 | 79.481.48 | 79.430.82 | 80.031.19 | 79.891.44 | 80.441.13 |
| Citeseer | 70.532.16 | 70.092.23 | 71.761.54 | 58.010.96 | 71.232.13 | 71.962.25 | 71.242.98 | 72.182.23 | 72.441.63 | 72.721.18 |
| Pubmed | 75.532.39 | 77.962.96 | 78.302.44 | 67.723.34 | 76.322.67 | 76.802.01 | 77.942.95 | 78.481.90 | 76.442.28 | 76.862.40 |
| Amazon Photo | 90.261.14 | 87.184.05 | 91.610.94 | 78.391.71 | 92.040.91 | 92.230.85 | 89.973.08 | 90.482.55 | 93.010.94 | 93.190.78 |
| Amazon Computer | 83.231.49 | 80.195.18 | 83.032.30 | 69.013.27 | 84.411.51 | 84.751.10 | 78.424.26 | 78.964.27 | 83.522.17 | 82.942.00 |
| Dataset | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cora | 78.642.06 | 78.901.69 | 81.102.46 | 58.022.72 | 71.942.85 | 71.852.40 | 72.392.30 | 72.862.37 | 72.411.48 | 72.531.38 |
| Citeseer | 70.832.83 | 68.263.65 | 70.753.29 | 59.464.55 | 70.802.63 | 71.222.04 | 67.152.33 | 68.042.52 | 68.922.94 | 69.173.01 |
| Pubmed | 74.862.97 | 74.402.94 | 76.642.97 | 66.145.03 | 74.762.69 | 74.923.03 | 74.892.81 | 75.442.75 | 74.632.81 | 74.533.06 |
| Amazon Photo | 91.331.56 | 89.282.12 | 92.271.50 | 79.011.80 | 89.751.58 | 90.262.43 | 88.541.94 | 89.101.69 | 90.022.48 | 90.541.37 |
| Amazon Computer | 82.731.54 | 75.213.56 | 83.382.50 | 67.953.88 | 81.182.53 | 80.942.33 | 74.013.26 | 74.054.01 | 81.082.54 | 81.562.57 |
5.6 Study on large-scale graph datasets
We apply experiments to see performance of our framework on large-scale graphs on Arxiv and Products. Results are shown in Table. 3 and Table. 4.
Results. We can see that we improve baseline GLNN’s performance by about 0.5 to 1.5 in 7 of 10 total cases via our method, with transductive or inductive setting. It demonstrates that our method really works on large-scale graphs.
| Dataset | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OGBN-Arxiv | 71.540.47 | 69.840.41 | 73.450.29 | 54.122.97 | 64.481.29 | 64.310.50 | 60.070.18 | 60.961.11 | 63.454.06 | 65.022.23 |
| OGBN-Products | 78.070.06 | 75.020.23 | 78.350.14 | 60.880.17 | 67.440.60 | 68.010.52 | 66.920.41 | 66.070.64 | 67.530.33 | 68.200.69 |
| Dataset | Models | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OGBN-Arxiv | 70.530.58 | 69.790.41 | — | 54.462.75 | 58.830.33 | 59.310.22 | 58.940.71 | 60.011.02 | — | — |
| OGBN-Products | 77.250.22 | 74.930.15 | — | 61.050.36 | 65.240.39 | 65.930.53 | 64.370.13 | 63.950.17 | — | — |
5.7 Study on trainable reverse kernel
As mentioned in Sec. 4.3, we study trainable reverse kernel’s performance. We do our study on three benchmark datasets, Cora, Citeseer and Pubmed. Note that we use default hyperparameters for distillation, so we don’t really report the ’best’ results of our framework here but only a comparison. We show the results in Fig. 4 in Appendix. Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework.††thanks: Supported by organization x..
5.8 Study on Positional Encoding
Now we consider our KMP’s results when utilizing PE as an initial node feature. We test it on the seven datasets mentioned above. We only adopt Laplacian PE, for it’s easy to calculate and proved efficient [32]. Note that we also introduce a method SA-MLP [35] here. It tries to deal with problems of student MLP by simply mapping the adjacency matrix and node features to the same dimension and then concatenating them together. The complete source code of SA-MLP hasn’t been provided yet, so we reproduce a training process for it by ourselves. We provide results of SAGE as teacher GNN. Results are listed in Table. 5.
Results.
| Dataset | Models(SAGE teacher, trans) | Models(SAGE teacher, induc) | ||||
|---|---|---|---|---|---|---|
| Cora | 79.481.48 | 80.971.03 | 79.331.55 | 71.852.40 | 71.901.81 | 71.542.26 |
| Citeseer | 71.962.25 | 72.072.51 | 71.251.57 | 71.222.04 | 71.462.65 | 70.952.49 |
| Pubmed | 76.802.01 | 76.582.84 | 76.452.50 | 74.923.03 | 74.712.09 | 74.993.74 |
| Amazon Photo | 92.271.50 | 92.380.82 | 90.670.93 | 90.262.43 | 90.770.84 | 90.271.44 |
| Amazon Computer | 84.751.10 | 85.101.66 | 83.382.50 | 80.942.33 | 81.502.58 | 81.012.89 |
| OGBN-Arxiv | 64.310.50 | 65.320.46 | 65.030.89 | 59.310.22 | 59.470.27 | 59.260.24 |
| OGBN-Products | 68.010.52 | 68.840.49 | 67.930.37 | 65.930.53 | 65.410.14 | 66.670.30 |
Now we see that our framework can reach the best performance on all datasets with transductive setting. Moreover, it performs best with inductive setting on 5 datasets. The conclusion is that Positional Encoding can really help KMP work better with little extra consumption for doing calculations. Only a tiny linear layer projection is necessary for change PE into node features(much tinier than SA-MLP). It is a great guide to real-life inference tasks.
5.9 Robustness and Sensitiveness study
Dataset. We do our robustness and sensitiveness study on benchmark datasets: Cora, Citeseer, Pubmed. As they are easy for us to compute student predictions. This is an intuitive guide for large-scale graphs.
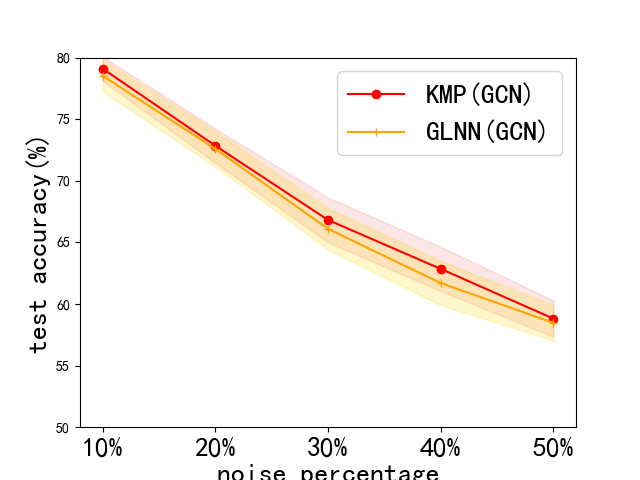
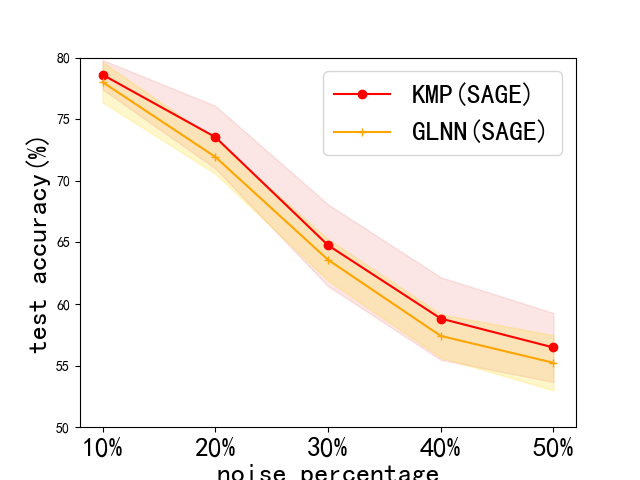
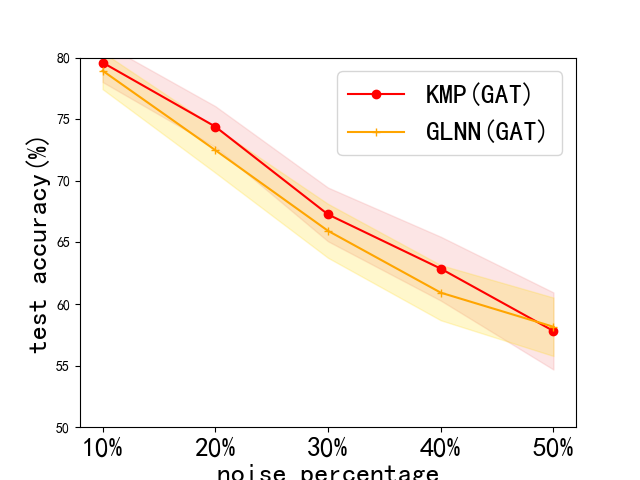
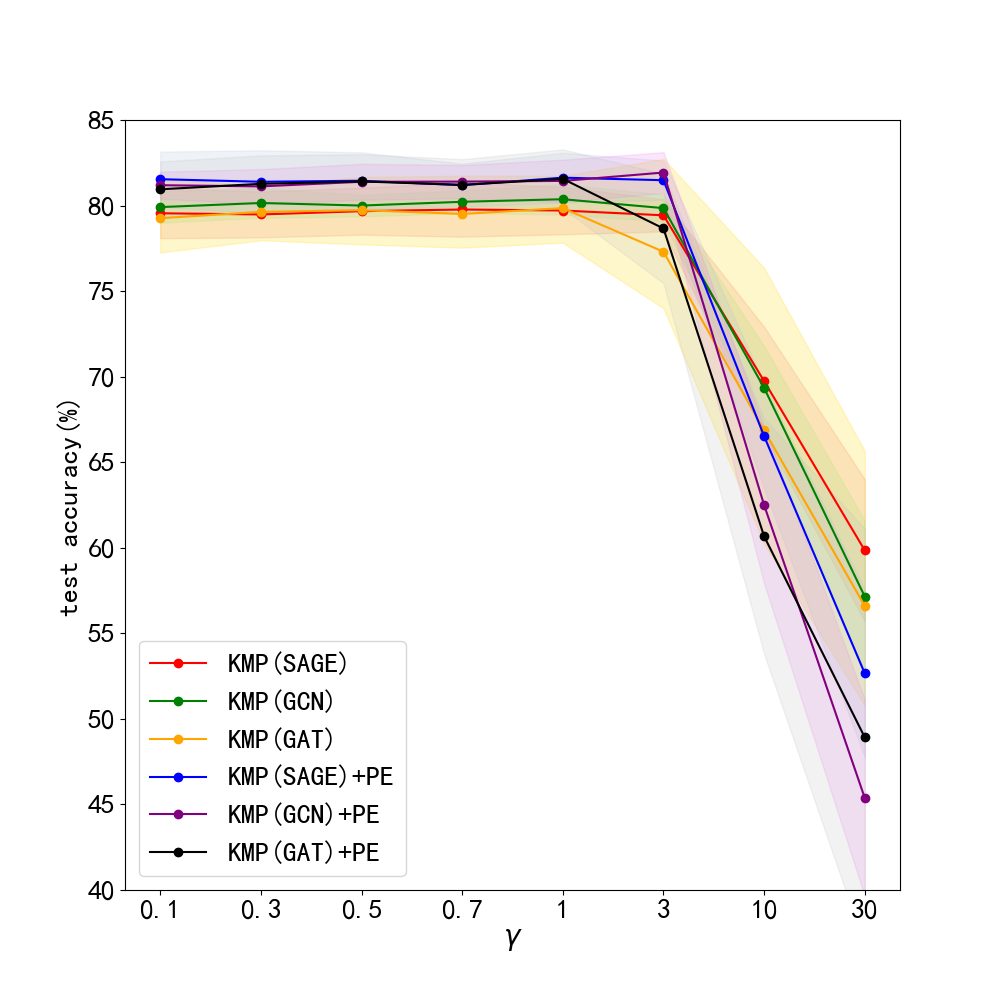
Problem definition. We test our framework’s robustness by adding noise attack to initial node features . Consider that a random matrix is added to by a certain percentage, and our doubt on robustness is whether KMP can work well with interference of noise features. We choose a percentage in . Note that we also provide GLNN’s performance for comparison. Next, we do sensitiveness test by modifying the constant , mentioned in Sec. 4.2, as our framework is much sensitive to only revealed by previous experiments. We choose . Note that we choose the default hyperparameters and try to get the test curve for comparison but not the best results.
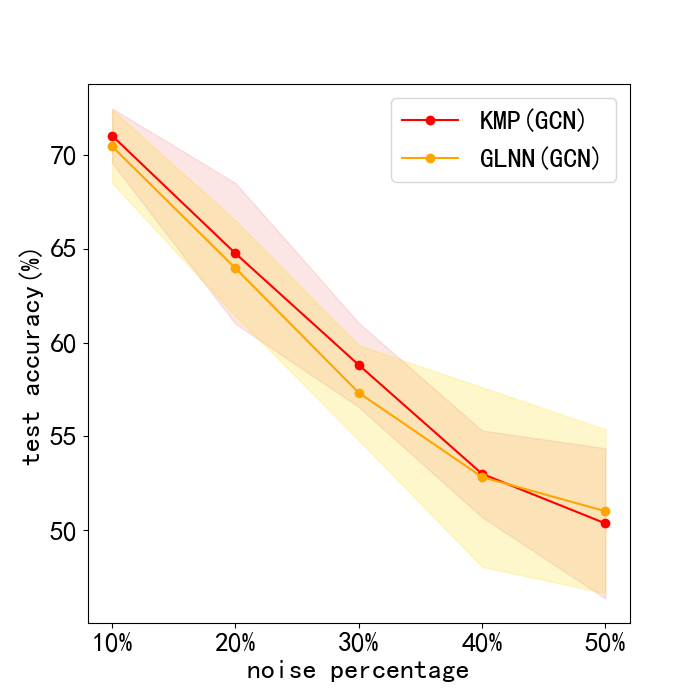
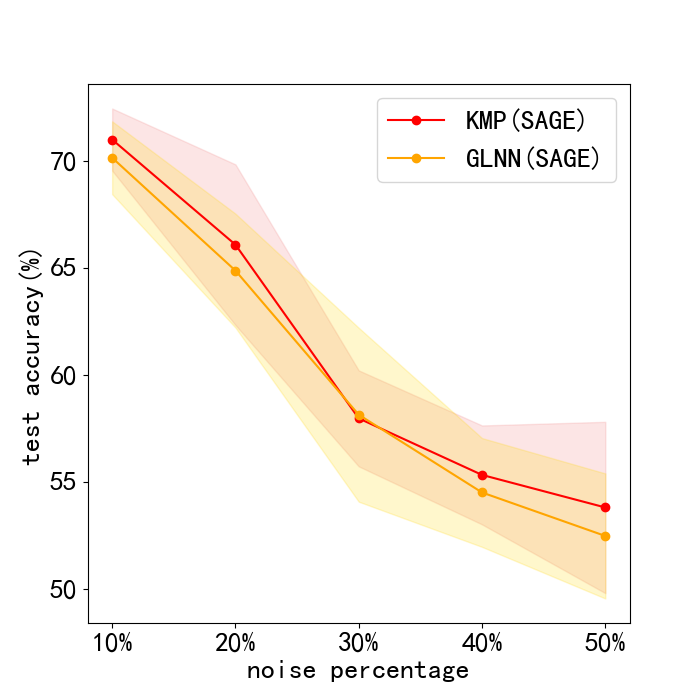
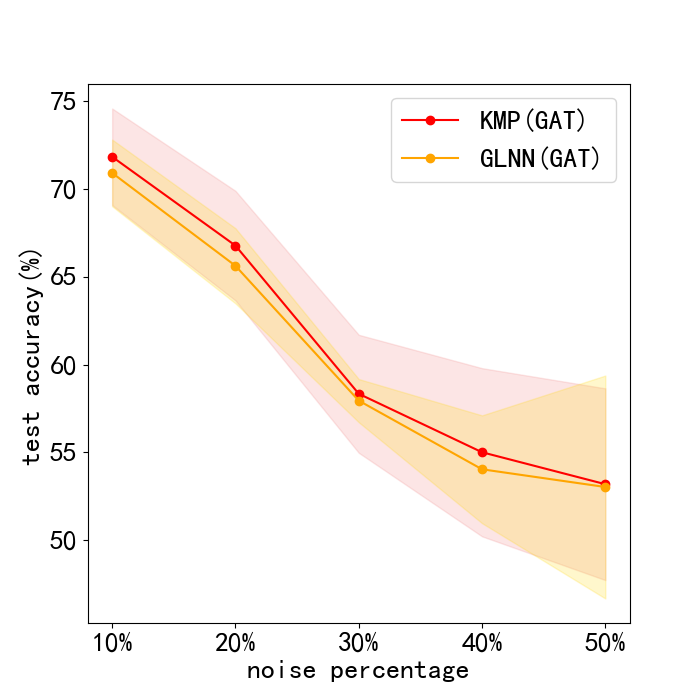
Results. The results of this robustness study is shown in Fig. 3. (We do not report results on Pubmed, for its test accuracy bitterly declined to very poor values with noise. This can be seen in Appendix. 0.A.5. Our frameworks ability to reduce harm of feature noise is stronger than baseline GLNN by about 2% in most cases. Next, we lay out results of sensitiveness study in Fig. 3. We discover the fact that our method works stably when is between 0 and 3, and a sharp decline in test accuracy occurs with larger than 3. Usually, we choose and our framework can work normally.
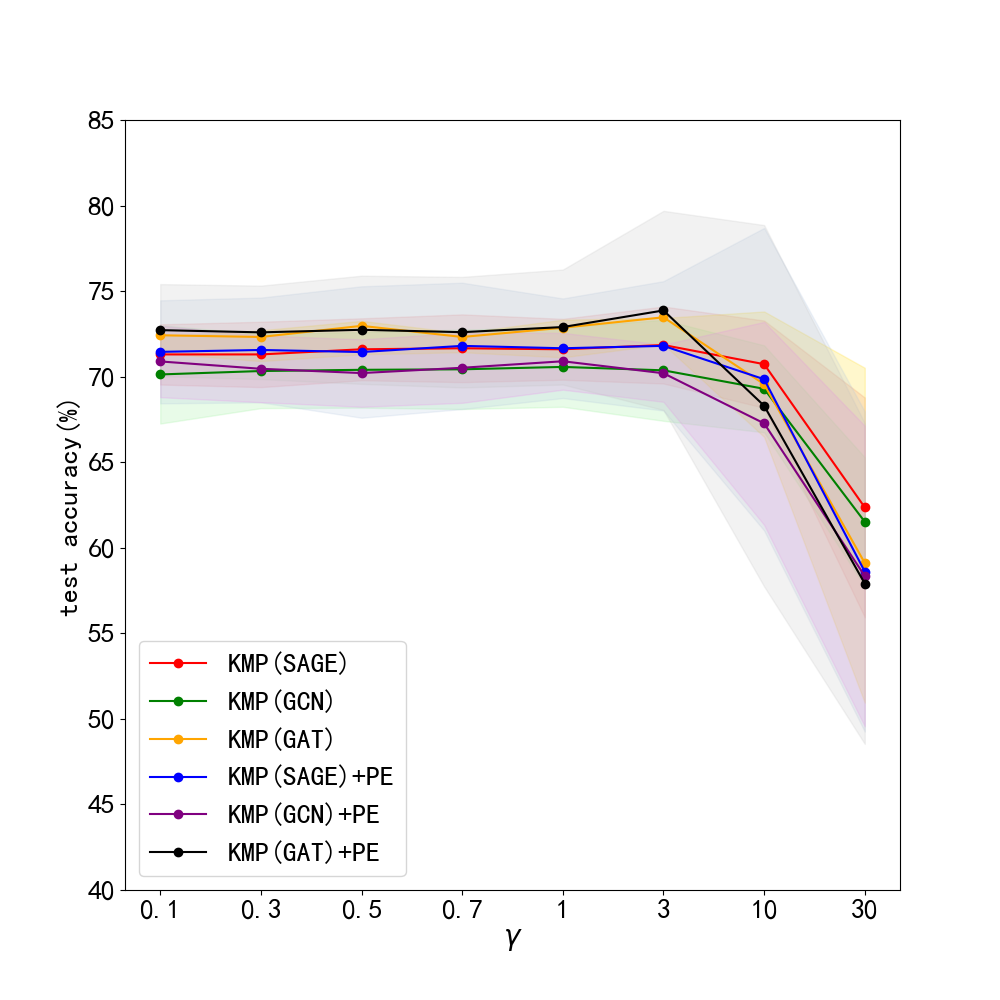
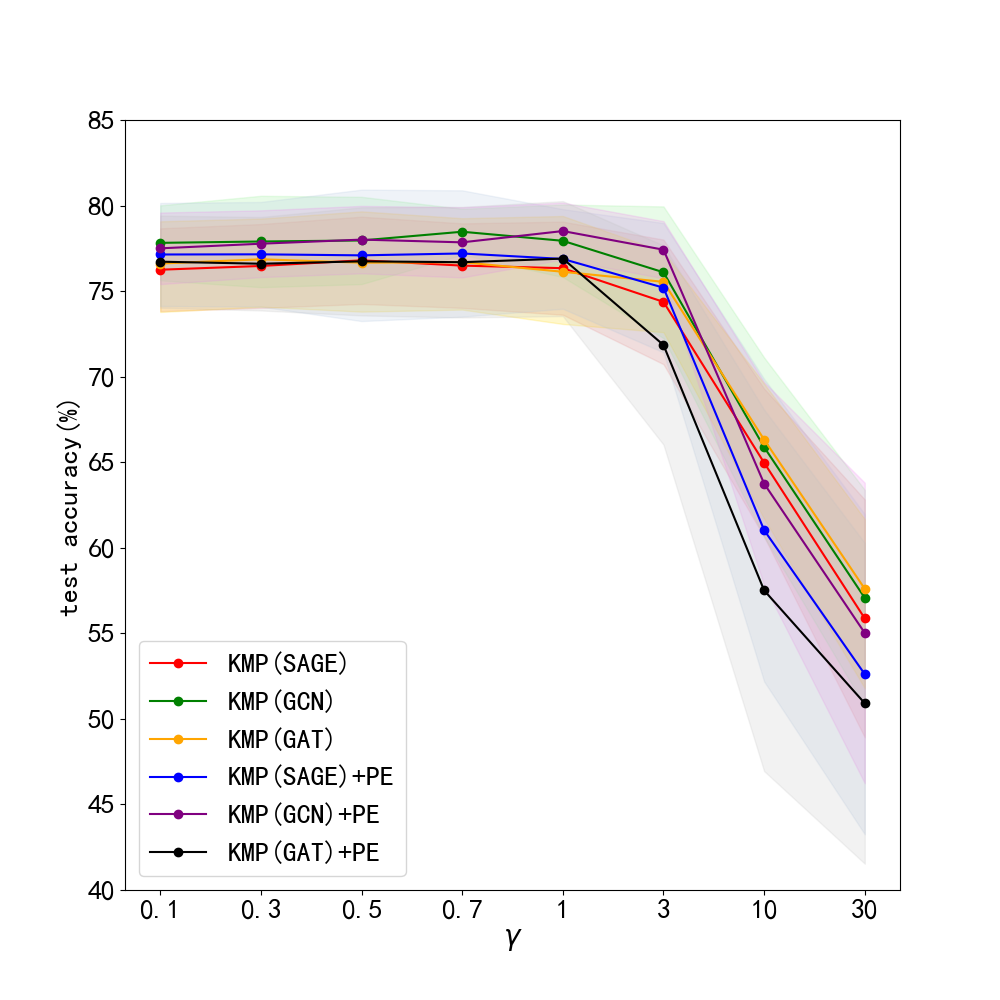
5.10 Additional study on graph classifaction tasks
Since our framework can achieve good results with inductive setting for node classification, we consider another inductive task: graph classification.
Dataset. We utilize MiniGC [36] for this additional study. It contains 8 kinds of graphs in total with variable number of nodes. Here we generate different graphs with 10-20 nodes, and choose 240 graphs for training, 60 for validation and 60 for testing. Our target is to train a student MLP excellent enough for classification.
Results. Our graph classification results are listed in Table. 6. We can see that our KMP increases test accuracy of GLNN by about 3.5. This means that our approach may also have positive results for larger graph classification datasets.
| Dataset | Models | |||
|---|---|---|---|---|
| MiniGC | 91.903.47 | 66.355.36 | 75.444.69 | 78.955.01 |
6 Conclusion and Future work
This paper formalizes the two main problems of transferring knowledge from teacher GNN to student MLP. Hence we propose a new framework for teaching student via knowledge distillation on graphs. In detail, we utilize postional encoding as additional initial node feature to solve the problem of structural information loss. What’s more, we introduce heat kernels in GNNs and use it for hidden layer distillation between GNNs and MLPs. Experiment results reveal us that our framework can reach the best result in almost all cases, and it obtains better robustness than baseline models.
We would like to point out several future directions: During training in our current work, the dimension of student MLP’s hidden layers must match that of teacher GNN’s hidden layers. It makes us hard to use a wider MLP as student without changing hidden layer dimensions of teacher model. Also, our current work can only introduce most frequently used GNNs as teachers, and they may perform badly in certain tasks. And that will cause to poor performance of student MLP. We will focus on more flexible methods for hidden layer distillation and adopt more sophisticated models as teachers, for example, Graph Transformer, etc.
7 Ethics
Our paper does not involve any ethical or moral issues. It is purely focused on proposing a methodology to solve two major problems of student MLP. Our experiments mainly aim to demonstrate the effectiveness and robustness of our proposed framework. Therefore, there is no need for ethical or moral considerations in our research. We ensure that our research is conducted in compliance with ethical guidelines and regulations.
References
- [1] Thomas N Kipf, F., Max Welling, S.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv: 1609.02907 (2016).
- [2] Zonghan Wu, F., Shirui Pan, S.: A Comprehensive Survey on Graph Neural Networks. arXiv preprint arXiv: 1901.00596. (2019).
- [3] Scarselli Franco, F.: The Graph Neural Network Model. IEEE Transactions on Neural Networks. 20(1), 61–80 (2008).
- [4] Zhou Jie, F.: Graph neural networks: A review of methods and applications. AI open 1, 57–81 (2020).
- [5] Kearnes Steven, F.: Molecular graph convolutions: moving beyond fingerprints. Journal of computer-aided molecular design 30, 595–608 (2016).
- [6] Fan Wenqi, F., Ma Yao, S.: Graph neural networks for social recommendation. In: The world wide web conference, pp. 417–426 (2019).
- [7] Wu Shiwen, F.: Graph neural networks in recommender systems: a survey. ACM Computing Surveys 55(5), 1–37 (2022).
- [8] Yang Jaewon, F., Leskovec Jure, S.: Patterns of temporal variation in online media. In: Proceedings of the fourth ACM international conference on Web search and data mining, pp. 177–186 (2011).
- [9] Liu Xin, F.: Survey on graph neural network acceleration: An algorithmic perspective. arXiv preprint arXiv: 2202.04822 (2022).
- [10] Zhou Hongkuan, F.: Accelerating large scale real-time GNN inference using channel pruning. arXiv preprint arXiv: 2105.04528 (2021).
- [11] Yu-Hsin Chen, F., Joel Emer, S.: A spatial architecture for energy-efficient dataflow for convolutional neural networks. In 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), pp. 367–379 (2016). doi: 10.1109/ISCA.2016.40.
- [12] Chiang Wei-Lin, F., Xuanqing Liu, S.: Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (2019).
- [13] Shyam Anil Tailor, F., Javier Fernandez-Marques, S.: Degree-quant: Quantization-aware training for graph neural networks. In International Conference on Learning Representations. In International Conference on Learning Representations (2021) https://openreview.net/forum?id=NSBrFgJAHg.
- [14] Cheng Yang, F., Liu Jiawei, S.: Extract the knowledge of graph neural networks and go beyond it: An effective knowledge distillation framework. In Proceedings of the web conference 2021 (2021).
- [15] Lee Seunghyun, F., Byung Cheol Song, S.: Graph-based knowledge distillation by multi-head attention network. arXiv preprint arXiv:1907.02226 (2019).
- [16] Zhang Shichang, F.: Graph-less neural networks: Teaching old mlps new tricks via distillation. arXiv preprint arXiv:2110.08727 (2021).
- [17] Lassance Carlos, F., Myrian Bontonou, S.: Deep geometric knowledge distillation with graphs. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8484–8488. IEEE (2020).
- [18] Yang Chenxiao, F.: Geometric Knowledge Distillation: Topology Compression for Graph Neural Networks. arXiv preprint arXiv:2210.13014 (2022).
- [19] Romero, Adriana, F.: Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550 (2014).
- [20] Velickovic Petar, F.: Graph attention networks. stat 1050(20), 10–48550 (2017).
- [21] Xu Keyulu, F.: How powerful are graph neural networks?. arXiv preprint arXiv:1810.00826 (2018).
- [22] Li Guohao, F.: Deepergcn: All you need to train deeper gcns. arXiv preprint arXiv:2006.07739 (2020).
- [23] Yun Seongjun, F.: Graph transformer networks. Advances in neural information processing systems 32 (2019).
- [24] Wu Felix, F. Amauri Souza, S.: Simplifying graph convolutional networks. In International conference on machine learning, pp. 6861–6871. PMLR (2019).
- [25] He, Xiangnan, F., Kuan Deng, S.: Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pp. 639–648 (2020).
- [26] Yang Yiding, F., Jiayan Qiu, S: Distilling knowledge from graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7074–7083 (2020).
- [27] Yan Bencheng, F., Chaokun Wang, S.: Tinygnn: Learning efficient graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1848–1856 (2020).
- [28] He Huarui, F., Jie Wang, S.: Compressing deep graph neural networks via adversarial knowledge distillation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 534–544 (2022).
- [29] Chepuri, F. Sundeep Prabhakar, S.: Learning sparse graphs under smoothness prior. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6508–6512. IEEE (2017).
- [30] Von Luxburg Ulrike, F.: A tutorial on spectral clustering. Statistics and computing 17, 395–416 (2007).
- [31] Joyce James M, F.: Kullback-leibler divergence. In International encyclopedia of statistical science, pp. 720–722. Springer, Berlin, Heidelberg (2011).
- [32] Dwivedi Vijay Prakash, F.: A generalization of transformer networks to graphs (2020).
- [33] Cheng Yang, F.: Extract the knowledge of graph neural networks and go beyond it: An effective knowledge distillation framework (2021a).
- [34] Hu Weihua, F., Matthias Fey, S.: Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems 33, 22118–22133 (2020).
- [35] Chen Jie, F.: SA-MLP: Distilling Graph Knowledge from GNNs into Structure-Aware MLP. arXiv preprint arXiv:2210.09609 (2022).
- [36] Dineen Jacob, F., ASM Ahsan-Ul Haque, S.: Reinforcement Learning for Data Poisoning on Graph Neural Networks. In Social, Cultural, and Behavioral Modeling: 14th International Conference, SBP-BRiMS 2021, Virtual Event, July 6–9, 2021, Proceedings 14, pp. 141–150. Springer International Publishing (2021).
- [37] Hu Yang, F.: Graph-mlp: Node classification without message passing in graph. arXiv preprint arXiv:2106.04051 (2021).
- [38] Wang Haorui, F.: Equivariant and stable positional encoding for more powerful graph neural networks. arXiv preprint arXiv:2203.00199 (2022).
- [39] Chen Yuzhao, F.: On self-distilling graph neural network. arXiv preprint arXiv:2011.02255 (2020).
- [40] An Jinwon, F.: Variational autoencoder based anomaly detection using reconstruction probability. Special lecture on IE 2(1), 1–18 (2015).
- [41] Ba Jimmy,F.: Do deep nets really need to be deep?. Advances in neural information processing systems 27 (2014).
- [42] Tang Raphael, F.: Distilling task-specific knowledge from bert into simple neural networks. arXiv preprint arXiv:1903.12136 (2019).
- [43] Xu Bingbing, F.: Graph convolutional networks using heat kernel for semi-supervised learning. arXiv preprint arXiv:2007.16002 (2020).
- [44] Joshi Chaitanya K., F.: On representation knowledge distillation for graph neural networks. IEEE Transactions on Neural Networks and Learning Systems (2022).
- [45] Hinton Geoffrey, F.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
Appendix 0.A Appendix
0.A.1 Dataset details
The seven used dataset for main experiments are listed here.
| Dataset | Nodes | Edges | Feature dim | Classes |
|---|---|---|---|---|
| Cora | 2708 | 5429 | 1433 | 7 |
| Citeseer | 3327 | 4732 | 3703 | 6 |
| Pubmed | 19717 | 44324 | 500 | 3 |
| Amazon Photo | 7487 | 119043 | 745 | 8 |
| Amazon Computer | 13381 | 245778 | 767 | 10 |
| OGBN-Arxiv | 169343 | 1166243 | 128 | 40 |
| OGBN-Products | 2449029 | 61859140 | 100 | 47 |
0.A.2 Settings mentioned in Sec. 5.4
We follows the settings for Cora, Citeseer, Pubmed, Amazon Photo and Amazon Computer as:
| GCN | SAGE | GAT | |
| number of layers | 2 | 2 | 2 |
| hidden layer dim | 64 | 128 | 128 |
| weight decay | 0.001 | 5e-4 | 0.01 |
| dropout ratio | 0.8 | 0 | 0.6 |
| attention dropout ratio | — | — | 0.6 |
| fan_out | — | 5,5 | — |
| number of heads | — | — | 3 |
| norm type(if used) | batch | batch | batch |
0.A.3 Grid search of hyperparameters.
We do grid search for the best hyperparameters for main experiments in Table. 9. We choose hyperparameters from the listed values. Note that influences student MLP’s performance most.
| 0.1,0.3,0.5,0.7,0.9,1,3,10,30 | |
|---|---|
| temperature() | 0.25,0.5,1,2,4,10 |
| (percentage of hard labels) | 0,0.2,0.4,0.6,0.8,1 |
| learning rate | 0.01,5e-3,1e-3,5e-4,1e-4 |
We also notice that a higher may bring better prediction results when making use of PE.
0.A.4 Results of trainable kernels
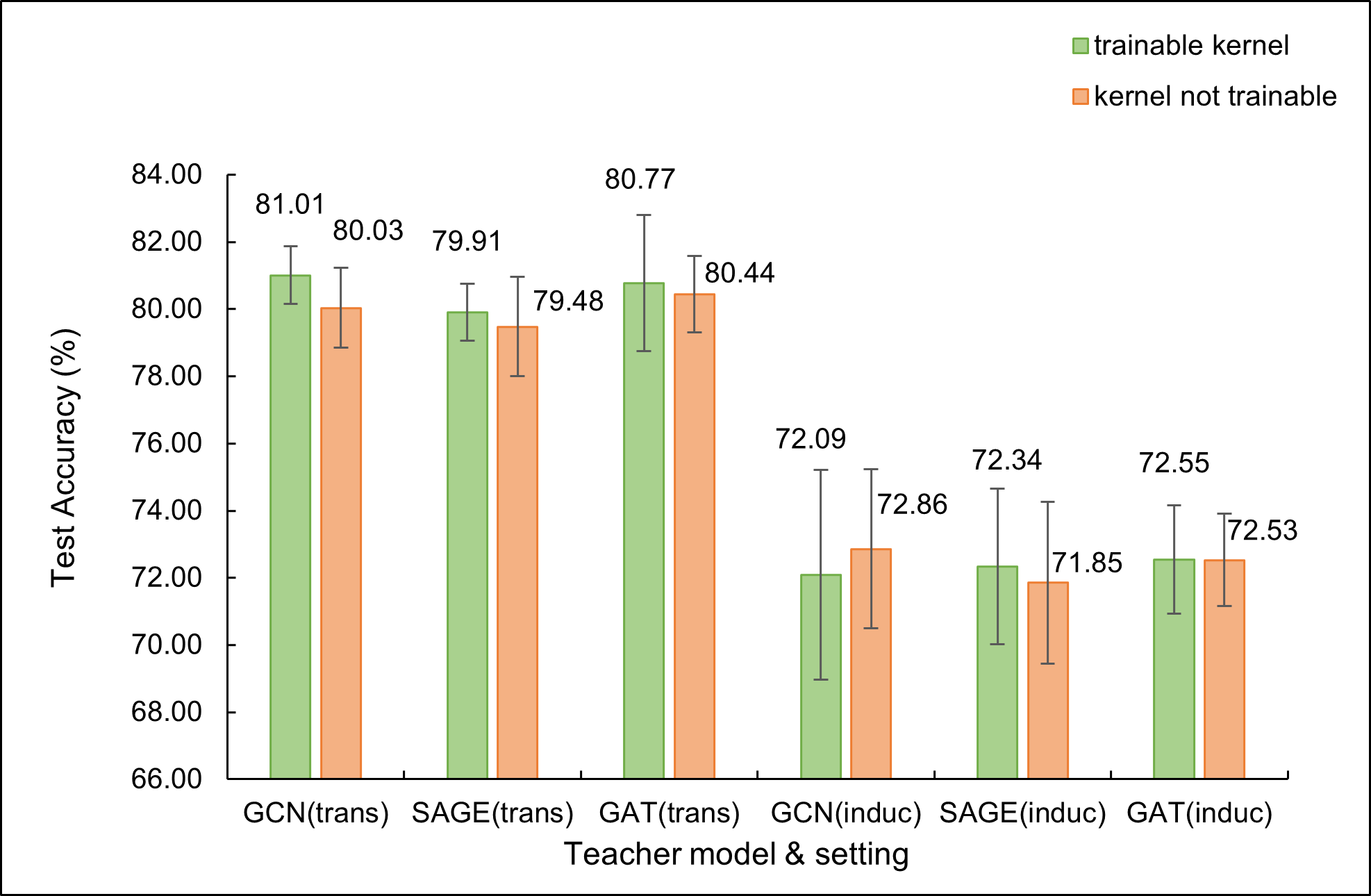
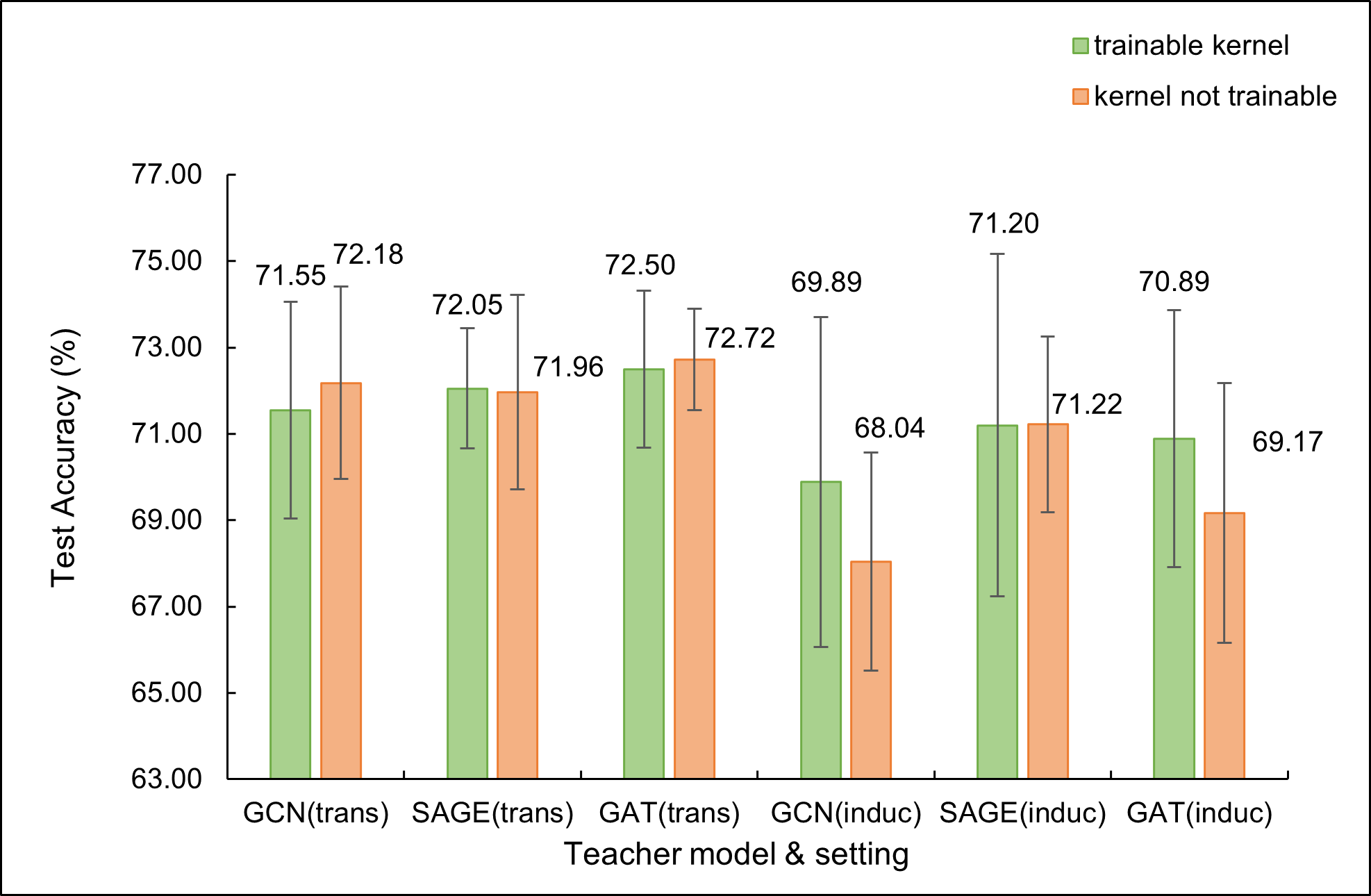
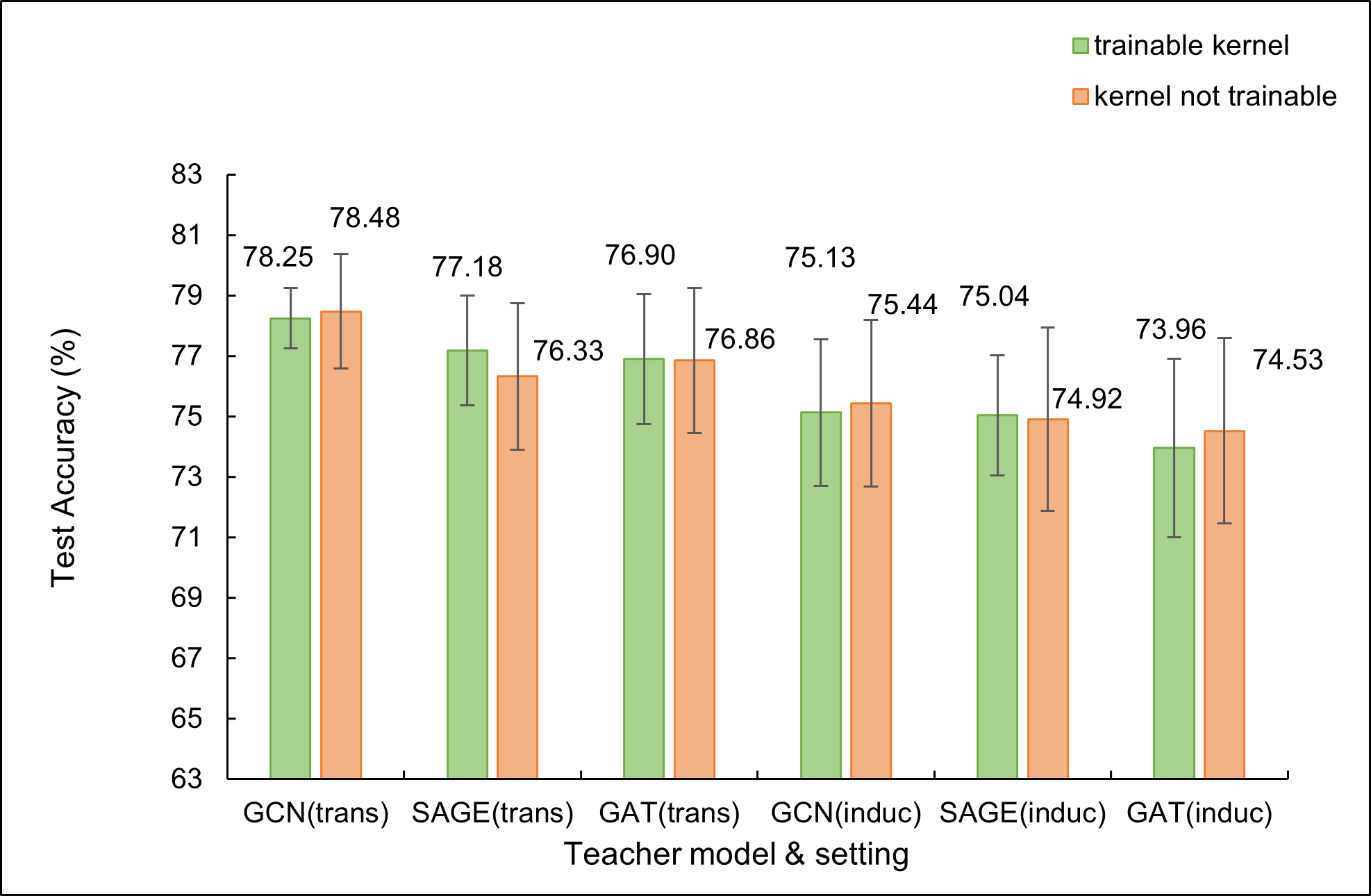
As shown in Fig. 4, trainable kernels can improve student MLP’s performance in many cases, especially GCN, GAT as teacher for Citeseer with inductive setting. Nevertheless, training student MLP together with kernel training can converge more slowly, for a two-stage optimization is introduced. Thus, it demonstrates us to choose trainable kernel in proper situations.
0.A.5 Perfomance on Pubmed with noise.
When adding noise to node features of the Pubmed dataset, we see a very poor performance as Table. 10 shows:
| Percentage of noise | GLNN(SAGE teacher) | KMP(SAGE teacher) |
|---|---|---|
| 10% | 47.702.91 | 48.912.44 |
| 20% | 40.752.29 | 41.602.47 |
| 30% | 37.083.96 | 37.414.65 |
| 40% | 33.965.23 | 33.165.88 |
| 50% | — | — |