Technical Report for Trend Prediction Based Intelligent UAV Trajectory Planning for Large-scale Dynamic Scenarios
Abstract
The unmanned aerial vehicle (UAV)-enabled communication technology is regarded as an efficient and effective solution for some special application scenarios where existing terrestrial infrastructures are overloaded to provide reliable services. To maximize the utility of the UAV-enabled system while meeting the QoS and energy constraints, the UAV needs to plan its trajectory considering the dynamic characteristics of scenarios, which is formulated as the Markov Decision Process (MDP). To solve the above problem, a deep reinforcement learning (DRL)-based scheme is proposed here, which predicts the trend of the dynamic scenarios to provide a long-term view for the UAV trajectory planning. Simulation results validate that our proposed scheme converges more quickly and achieves the better performance in dynamic scenarios.
Index Terms:
unmanned aerial vehicle, dynamic scenario, trajectory planning, trend prediction, reinforcement learning.I Introduction
Unmanned Aerial Vehicles (UAVs) have been used in providing emergency communication services for some special scenarios that cannot be served satisfactorily with existing terrestrial infrastructures, such as some mass gathering events, like new year events, large conferences, etc. In these situations, the trajectory planning of the UAV involved can seriously affect system performances, e.g., data throughput[1], transmission delay[2], and user fairness[3].
For the practical applications, the classical optimization-based UAV trajectory planning strategies [15] may no longer be feasible, as most of them are designed to be operated in an iterative fashion with high computational complexity. In the light of the aforementioned, Reinforcement Learning (RL) [6] based strategies have been regarded as promising solutions for the UAV-enabled system owing to the great self-learning capability, which exhibits significant efficiency gains in static scenarios by optimizing the interaction process [4] and experience selection [5]. Furthermore, faced with realistic application scenarios with highly dynamic characteristics, more and more researches have studied on how to extract scene features by adding Deep Neural Networks to further enhance the capability of RL, so as to construct the Deep RL framework (DRL). To achieve above goals, [7, 10, 11, 9] construct the Artificial Neural Network (ANN) to mine the correlations between scene information (e.g. location [7, 10], energy state [10] and throughput [11, 9]). In order to avoid the uncertainty caused by manual feature extraction in ANN-based schemes, [6, 12, 13] construct the Convolutional Neural Network (CNN) and model the scene information as a tensor composed of multiple channels (e.g. communication range [6], location [12] and object tracking information [13]), which makes scene features more hierarchical. However, considering the dynamic characteristics of real scenarios, there are still two major research gaps in existing researches: 1) The number of GUs is related to the structure of the DRL framework***Assuming that each GU has features, then the input of the ANN-based model is a vector of dimension where denotes the number of GUs in the scenario. Apparently, a change of can lead to changes in the network structure. designed in existing studies [7, 10, 11, 9], the variation in the number of GUs in dynamic scenarios leads to the need for re-tuning and re-training for the proposed DRL models. 2) The scene information of GUs is not fully utilized in existing studies [6, 12, 13] where the whole dynamic process is usually processed as multiple independent frames, which lacks further exploration of their associations.
Therefore, the critical issue is how to bridge the above gaps by designing a DRL framework that is flexible enough and can fully exploit the dynamic characteristics of the scene, which motivates this work with the objective to maximizes the long-term performance of the UAV-enabled large-scale dynamic scenarios by optimizing the UAV’s movement action, subjected to the constraints of the communication QoS and energy. Therefore, we design a moving Trend Prediction (TP) based DRL framework for the UAV (served as an agent) to perceive the state of the current environment and predict the trend of the future state. Through continuous interaction with the environment, the agent optimizes its actions according to the received feedback (known as reward in DRL). Simulations have been used to verify and validate the performance of the proposed scheme.
II System Model and Problem Formulation
II-A System Model
Consider an area of interest (AoI) where the explosive growth of access requirements have already far outstripped the capacity of existing terrestrial base stations. One UAV with velocity is dispatched to provide the extra communication capacity for the GUs inside the AoI (denoted as a GU set ) with fixed flight altitude . In particular, the entire mission period of the UAV is discretized into multiple individual time slots and each with equal duration . Similarly, referring to [9], the AoI has been divided into equal grids, of which the centers are used as way-points of the UAV in each time slot. Thus, the location of the UAV (projected on the ground) and the -th mobile GU in time slot can be formulated as and , respectively. Following the model proposed in [9], the velocity and moving direction of the GU will be updated as
| (1) | ||||
| (2) |
where and denote average velocity and steering angle, respectively, and follows -greedy model†††In each time slot, the GU will keep the same moving direction with probability , otherwise the GU chooses one of the remaining directions randomly..
Since the terrestrial infrastructures cannot provide communication services, the GUs’ data will be temporarily stored in their on-board buffer and wait for the UAV to start the data upload process. Here, the GU-to-UAV channel is modeled as Rician models [1] that can capture the shadowing and small-scale fading effects due to multi-path propagation, in which the channel coefficient from the GU to the UAV in time slot can be expressed as
| (3) |
where and , , , and and denote the GU-to-UAV path loss component and Rician factor, respectively. denotes the channel power gain at the reference distance m.
By adopting OFDMA technology, the UAV can pre-divide communication resources into multiple equal and orthogonal resource blocks in advance, of which the bandwidth allocated to each communication GU is . In this way, the UAV using OFDMA technology can support concurrent data transmissions with surrounding GUs. Thus, the communication rate with respect to each GU is given by , where , , and denote the transmission power, bandwidth and noise power, respectively. In this way, the data uploaded throughput of the -th GU is obtained by , in which denotes the duration of the hovering time used for communications within one time slot, which is assumed as . Here we denote the data queue length of the GU in time slot as , which depends on both the newly generated data (i.e. ) and the data uploaded (i.e. ) to the UAV, which is given by .
In addition, the energy consumption of the UAV in time slot is associated with the flying distance of the UAV in the past time slot [9], which is formulated as
| (4) |
where denotes the UAV flying power.
II-B Problem Formulation
Regarding the dynamic scenarios considered in this work, the location, number, and data queue of GUs that change in real time greatly increases the feature dimension of the UAV-Ground communication scenario, which poses a severe challenge to build the efficient and reliable data links between GUs and the UAV. Therefore, our objective is to find a policy that helps the UAV make the optimal decision on trajectory planning, so that the utility of the UAV-enabled communication system over all the time slots is maximized, subjected to the coverage range, energy consumption, and the communication QoS. Thus, the UAV trajectory planning issue‡‡‡We summarize the notations used in this paper in section II of our technical report [Wang2021tech]. is formulated as
| s.t. | |||
where the system utility function depends on both the throughput and fairness during the data upload processes. Furthermore, C1 ensures that the communication link should meet the required QoS, namely the channel coefficient of each communication GU (see (3)) should not be smaller than the threshold . C2 limits the total energy consumption during the UAV flight process (see (4)) to within the portable energy under the premise that the communication energy consumption is negligible.
Furthermore, the utility function is defined here, , in which called as the Jain’s fairness index [3] is defined as
| (5) |
in which denotes the number of UAV-enabled communication services that GU has participated in. As a widely-used metric for fairness, the value of approaches when the total number of time slots that each GU is served are very close, which can be regarded as a measure of the fairness of UAV communication services in existing scenarios.
II-C MDP Model
In general, conventional methods normally would narrow down P0 for an individual time slot, namely , and solve it by classical convex optimization methods or heuristic algorithms, which may obtain the greedy-like performance due to lacking of a long-term target. To tackle above issue, we apply Markov Decision Process (MDP), defined as a tuple (, , , ), to model the UAV trajectory planning problem in large-scale dynamic scenarios, which are detailed as follows.
1) The contains the locations of the UAV and GUs as well as their real-time status, which is formulated as
| (6) |
2) The contains available actions of the UAV in each time slot, which is formulated as
| (7) | ||||
3) The represents the discounted accumulated reward from the state to the end of the task with the policy , which is formulated as
| (8) |
where denotes the immediate reward through executing action at the state , and denotes the end of the task. In particularly, the action adopted here is selected following the policy , i.e., . According to problem P0, is defined as
4) The represents the probability that the UAV reaches the next state while in the state , which is formulated as
where corresponds to the greedy coefficient during the action selection process.
Based on the formulated MDP model (, , , ), the UAV first observes the state in each time slot . Then, it takes an action following the policy , i.e., , and thus obtains the corresponding immediate reward . Then, the UAV moves to the next way-point and the updates to . Therefore, the problem P0 can be transformed into maximizing the discounted accumulated reward by optimizing the policy .
A table that summarizes all notations in this paper is given in Table. 1.
III -Step Mobile Trend Based DRL Scheme
III-A DRL Framework
It is well-known that the DRL algorithm is efficient and effective in solving MDP for the uncertain (i.e. ) and complex (i.e. ) system, in which the critical issue here is how to obtain the optimal policy for the action selection process.
To achieve that, we first rephrase into the form of state-action pairs as where means the action is selected at the state according to the policy . Here we call as the Q-function. Referring to [9], it is easy to draw the conclusion that the optimal policy can be derived by . In other words, once the UAV selects the action that can maximize the corresponding Q-function at each , the optimal policy can be realized. Then, the remaining issue is how to obtain with the given environment and action .
Based on above conclusions and (8), we have
| (9) |
where , thus the issue about searching the Q-function can be formulated as a regression problem, that is, through iteratively optimizing the parameters of the Q-function so that the left-hand side of the (9) is infinitely close to the right-hand side. Here, considering the high dimension of and in the scenario we studied, it is common to apply the neural networks (NN) to fit the Q-function mentioned above. To be specific, the NN can address the sophisticate mapping between the , and their corresponding Q-function value based on a large training data set. Accordingly, two individual deep neural networks are established here. One with parameters is utilized to construct the Evaluation network that models the function , and another one with parameters is used to construct the Target network for obtaining the target value (i.e., ) in the training process. Finally, the parameters of are updated by minimizing the loss function , which is formulated as
| (10) |
Finally, after the NN has been well trained, the UAV can make a decision at the state according to the obtained Q-function that is modeled as the NN, and then the UAV takes the action
III-B Design the Input Layer of Neural Network
In order to extract spatial features of the scenario, here we adopt Convolutional Neural Networks (CNNs) to achieve the Evaluation network , which sets a three-channel tensor with size as the input. Meanwhile, each channel of the tensor is modeled as a matrix with the size , corresponding to the scenario model that is divided into equal grids. (see the system model in Section. II-A). Here, two convolution layers are constructed to extract the features from the input, and two full connected layers are constructed to establish associations between them. The design of the three-channel tensor are given as follows.
III-B1 Channel 1
The Channel describes the effective communication range of the UAV with the location , which is formulated as a matrix . To meet the QoS during the Ground-to-UAV communication process, we substitute (3) into the constraint C1, namely
which indicates that the location of GUs that can establish reliable communication with the UAV must meet above condition. In this way, we can calculate whether the distance from GU to the location of the UAV satisfies the above condition. If so, we assign the corresponding element in matrix as the real-time channel coefficient obtained, otherwise set it as .
III-B2 Channel 2
The Channel describes the interaction information between GUs and the UAV, which is formulated as a matrix . In , we record the communication times between each GU and the UAV (i.e., ), and set the element of corresponding to the location of GU as , otherwise is .
III-B3 Channel 3
The Channel describes the predicted movement trend of GUs in the future time slots, which is formulated as a matrix . The design principle of is predicting the future movement situation of GUs by extracting their mobile features from historical records, which enables the UAV a future-oriented view during the trajectory planning to achieve the maximum accumulated reward from the current state until the end of the task. The specific steps for constructing the channel are as follows.
Step 1: The matrix is produced to record the buffer state of GUs in the scenario, in which the element is set as if GU is located in the corresponding grid (i.e. the -th row and the -th column) of the scenario, otherwise .
Step 2: The difference matrix is produced as here, showing the changes of between adjacent time slots.
Step 3: Four direction kernels , , , and are utilized here to detect the moving direction of GUs (corresponding to up, down, left and right respectively), which are given by
| (11) |
Step 4: The SAME convolution operation is performed on the difference matrix using the above four kernels, respectively. The corresponding outputs are four matrices , , and with the same size , which denotes the detection result of the movement direction of GUs in the past two time slots, respectively. Specifically, elements of above four matrices are obtained by
Step 5: Based on step , the trend prediction matrices of up, down, left and right directions are constructed respectively, which are denoted as , , and . Taking as an example, the specific steps are given in Algorithm. 1.
For , , , their elements are updated with the similar principle as in step of the Algorithm. 1, namely
Step 6: output the -step moving trend prediction matrix , and set it as the Channel of the CNN model.
III-C Joint Offline and Online Learning Framework
In order to enable the UAV to update the DRL model at the same time during executing the communication task, a training framework that combines online and offline manner is proposed, in which the UAV performs the task following the policy obtained at the offline stage, and then updates the its policy online in current episode.
The offline learning process is designed to learn the most valuable experiences from the past. Therefore, a large ”Replay Memory” (denoted as ) is constructed to store the experiences including , , and reward during the past episodes, of which seventy percent are with the largest reward and the remaining thirty percent are chosen randomly from the rest. In contrast, the online learning process aims to learn from the current experiences, resulting in the current best behavioral decisions. Therefore, it will generate a relative small ”Replay Memory” (denoted as ) to store the experiences sampled during the current communication task, of which eighty percent are with the largest reward from the current episode and the remaining twenty percent are picked randomly.
The combination of the above two training processes not only allows the UAV to take full advantage of past experiences, but also adjust its policy according to the current actual situation, and sum up all past experiences after the end.
III-D Computational Complexity
The computational complexity of our proposed moving Trend Prediction (TP) based DRL framework is mainly involved in two parts, namely the building process of the channel and the CNN calculation process. The former can be obtained as follows: step , and only involve simple calculations, step requires and step requires . Then, the computational complexity of the CNN calculation process is given by [14] in which = =, =3, =2 and =32 are the parameters of the model in our scheme.
IV NUMERICAL RESULTS
The simulation parameters of the scenario are set as , , , m/s, , W, , m, , and follows -greedy model with . The simulation parameters of the communication process are set as Mhz, s, s, , kJ, W , and bits/s. The Trend Prediction based model proposed in this work is called as TP here, in which the greedy coefficient . The results are shown in Fig. 1 and Fig. 2.
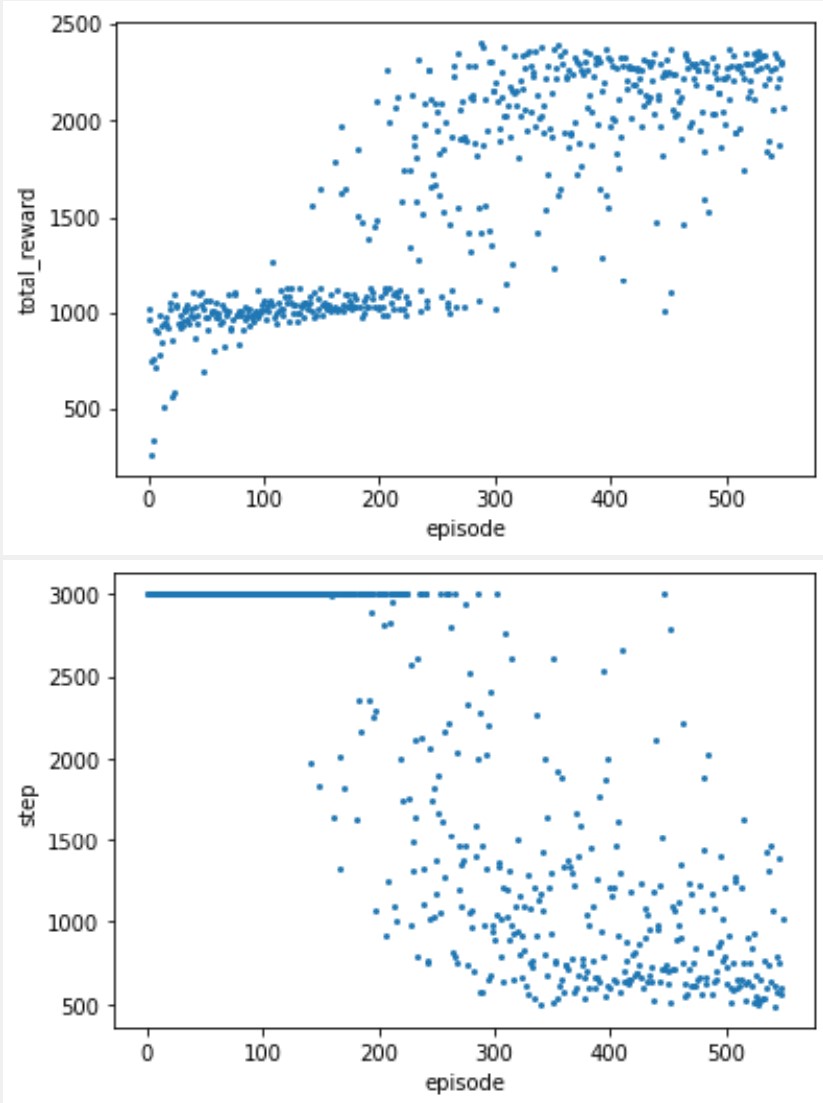
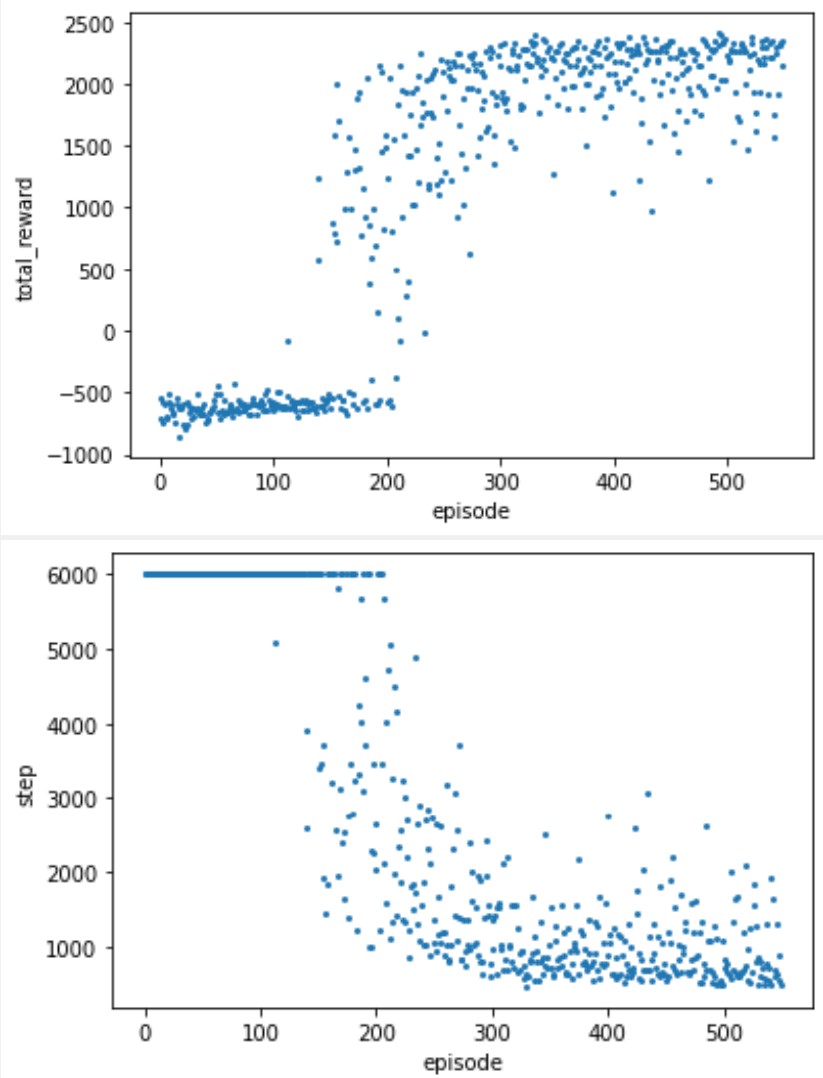
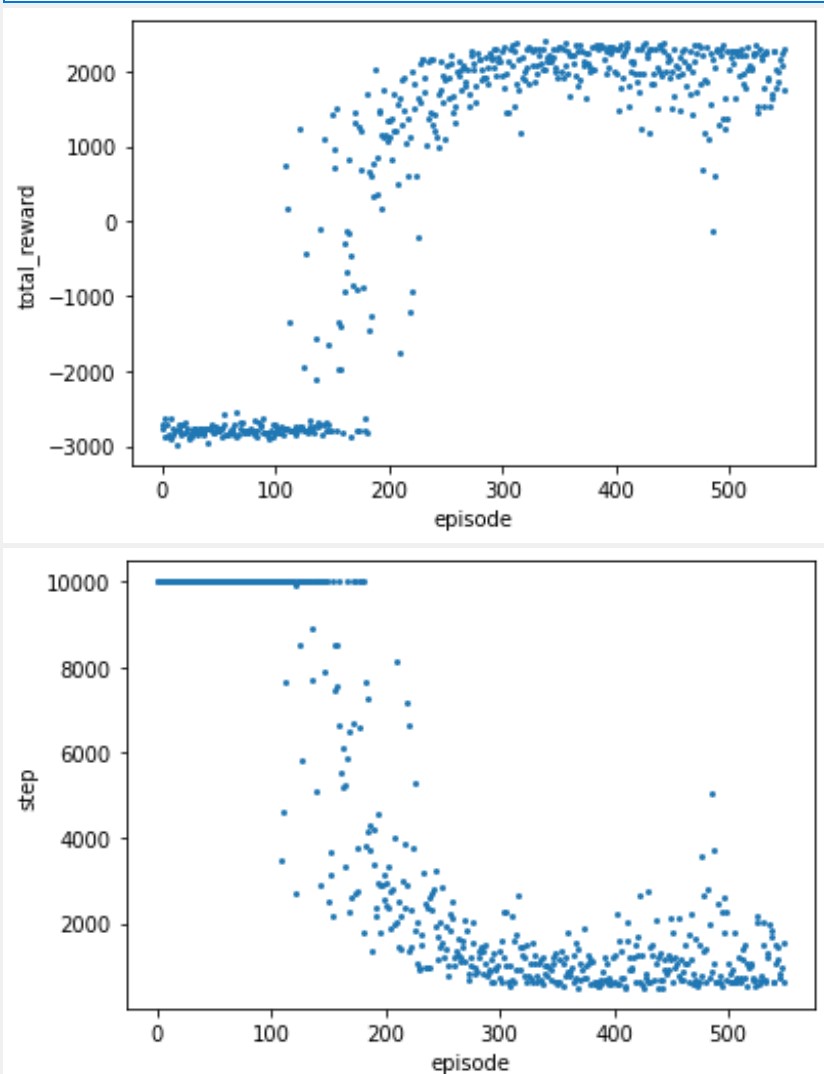
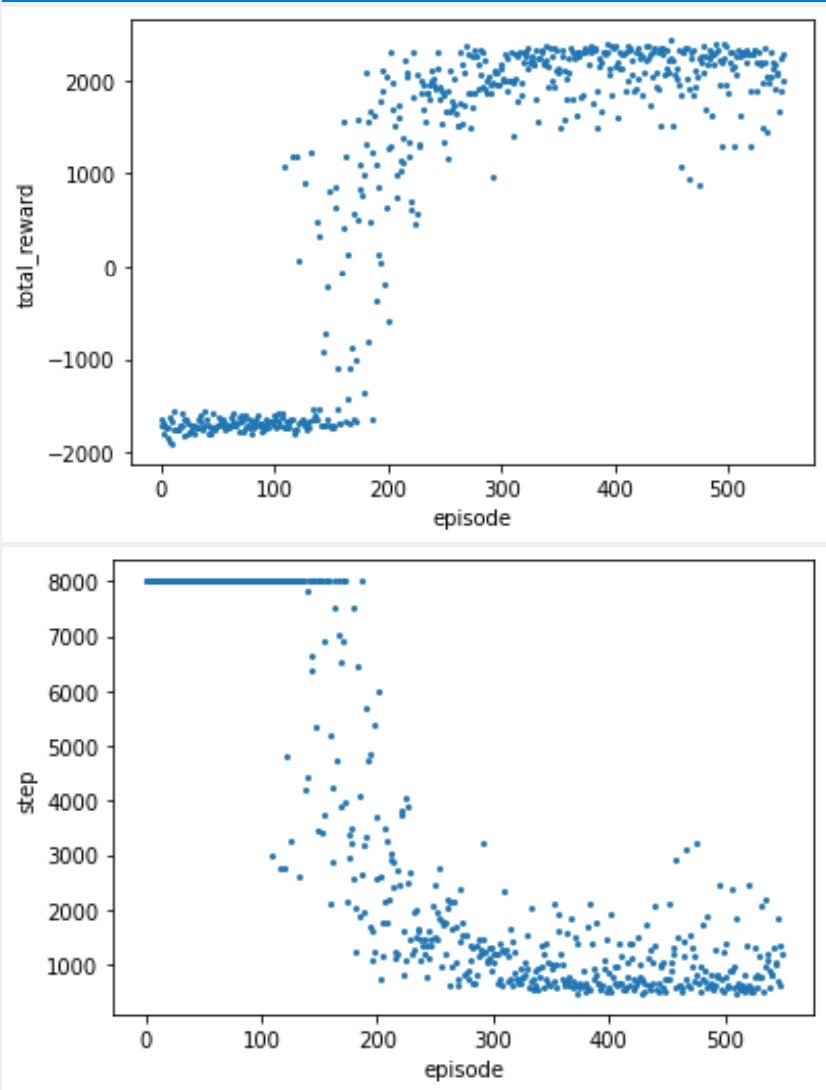
We tested the total reward and number of steps available under multiple training parameters in a scenario with GUs, where the total reward can be seen as the overall performance that combines fairness and throughput, while the number of steps reflects the efficiency of the UAV trajectory.
From the above results, even if the number of GUs is increased from to , the proposed solution can still obtain good performance. We didn’t compare the other two schemes because even in a -GU scenario, the other two were not only unable to converge but were also significantly at a performance disadvantage.
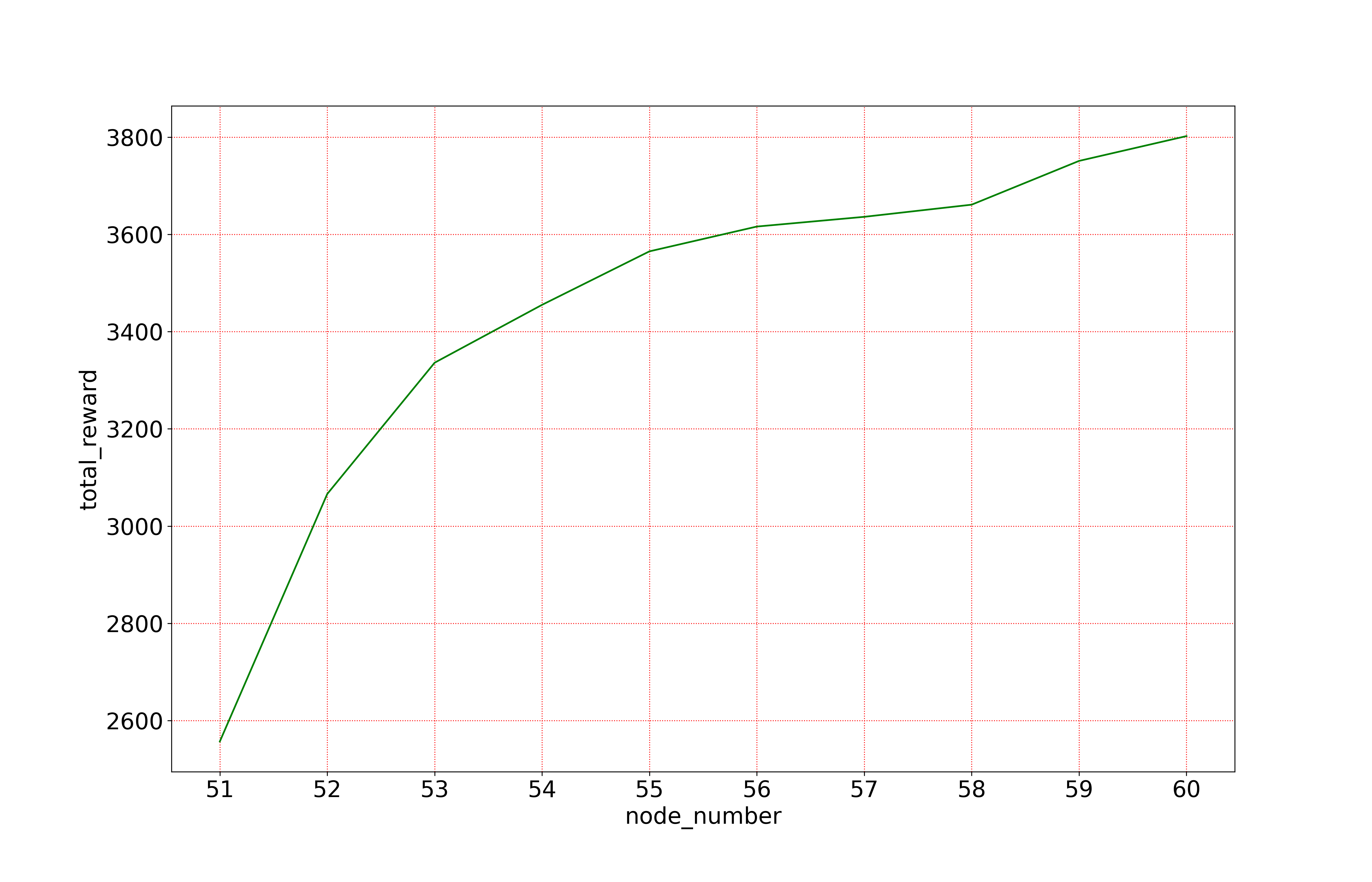
We further tested the performance of the proposed strategy when the number of GUs in the scene dynamically increased, in which only GUs are deployed in the base scene, and one new GU is deployed at the end of each training, the results are given in Fig. 3.
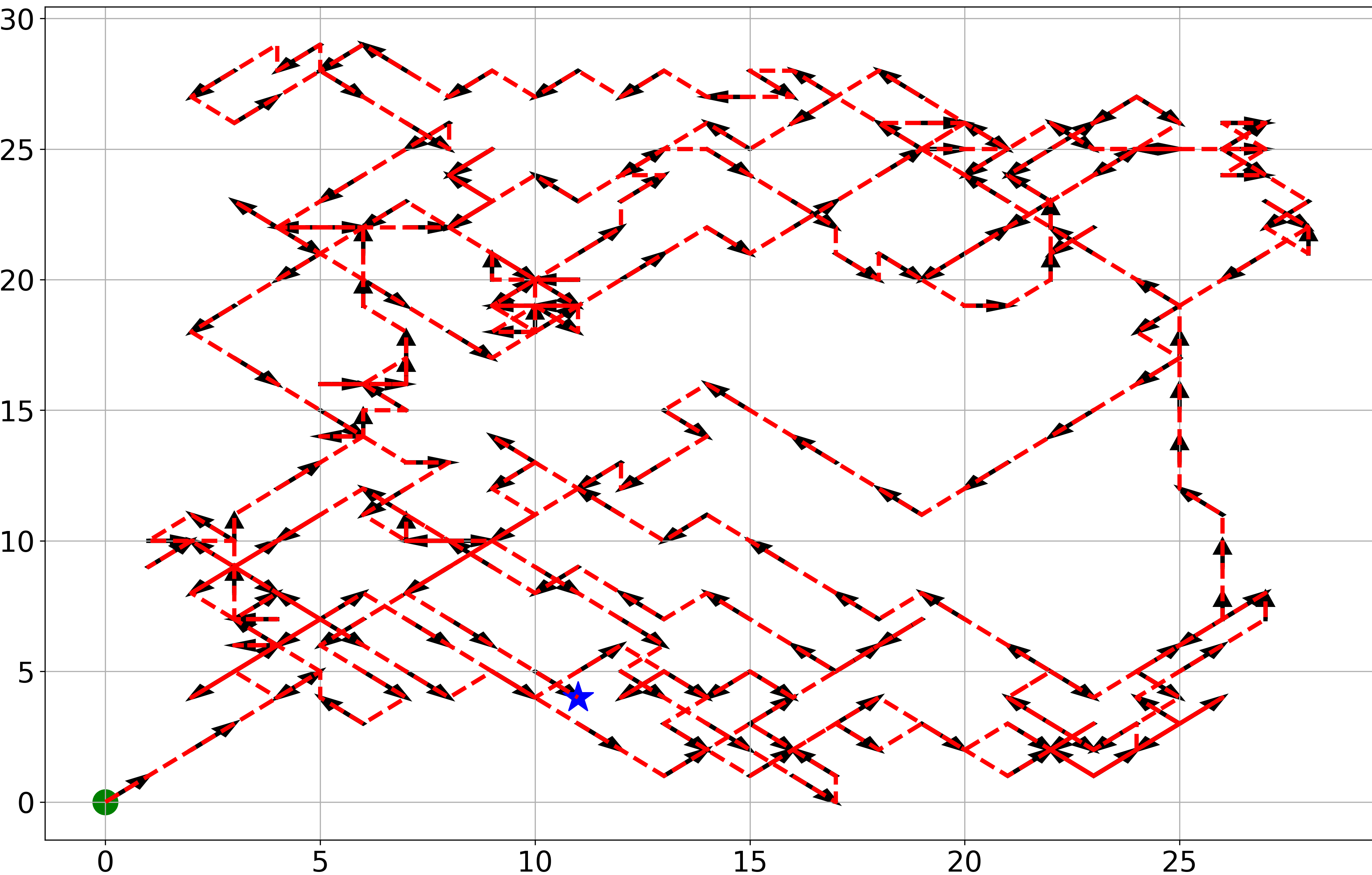
We further give the trajectory of the UAV in Fig. 4. The UAV starts at the green dot and ends at the blue pentagram. From the perspective of the entire trajectory, the UAV has a good effect on the coverage of the entire area, which indirectly shows that the UAV with the trend prediction function has a broader and long-term vision.
V Notation Table
A table that summarizes all notations in this paper is given in Table. 1.
| Notations | Meaning |
|---|---|
| The set of GUs in the scenario in time slot . | |
| The velocity of the GU in time slot . | |
| The velocity of the UAV. | |
| The moving direction of GU in time slot . | |
| The channel coefficient between GU and UAV in time slot . | |
| The location of the UAV in time slot . | |
| The location of GU in time slot . | |
| The fixed flight altitude of the UAV. | |
| The greedy coefficient in the selection of moving direction of GUs. | |
| The greedy coefficient in action selection of the UAV. | |
| The transmission power of the UAV. | |
| The -th channel of the input of CNN model. | |
| The duration of one time slot. | |
| The duration of the hovering time within each time slot. | |
| The data queue length of GU in time slot . | |
| The newly generated data of GU in time slot . | |
| The energy consumption of the UAV in time slot . | |
| The lower bound of the channel quality. | |
| The upper bound of the portable energy carried by the UAV. | |
| The Jain’s fairness index. | |
| The discounted accumulated reward from state to the end. | |
| The matrix used to record the buffer state of GUs in the scenario. |
References
- [1] Y. Sun, D. Xu, D. W. K. Ng, L. Dai and R. Schober, “Optimal 3D-Trajectory Design and Resource Allocation for Solar-Powered UAV Communication Systems,” IEEE Transactions on Communications, vol. 67, no. 6, pp. 4281-4298, 2019.
- [2] K. Meng, D. Li, X. He and M. Liu, “Space Pruning Based Time Minimization in Delay Constrained Multi-Task UAV-Based Sensing,” IEEE Transactions on Vehicular Technology, vol. 70, no. 3, pp. 2836-2849, 2021.
- [3] C. H. Liu, Z. Chen, J. Tang, J. Xu and C. Piao, “Energy-Efficient UAV Control for Effective and Fair Communication Coverage: A Deep Reinforcement Learning Approach,” IEEE Journal on Selected Areas in Communications, vol. 36, no. 9, pp. 2059-2070, 2018.
- [4] A. M. Seid, G. O. Boateng, B. Mareri, G. Sun and W. Jiang, “Multi-Agent DRL for Task Offloading and Resource Allocation in Multi-UAV Enabled IoT Edge Network,” IEEE Transactions on Network and Service Management, vol. 18, no. 4, pp. 4531-4547, 2021.
- [5] Y. Li, A. Hamid Aghvami and D. Dong, “Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay,” IEEE Transactions on Wireless Communications, 2022, early access.
- [6] C. H. Liu, Z. Dai, Y. Zhao, J. Crowcroft, D. Wu and K. K. Leung, “Distributed and Energy-Efficient Mobile Crowdsensing with Charging Stations by Deep Reinforcement Learning,” IEEE Transactions on Mobile Computing, vol. 20, no. 1, pp. 130-146, 2021.
- [7] O. S. Oubbati, M. Atiquzzaman, A. Baz, H. Alhakami and J. Ben-Othman, “Dispatch of UAVs for Urban Vehicular Networks: A Deep Reinforcement Learning Approach,” IEEE Transactions on Vehicular Technology, vol. 70, no. 12, pp. 13174-13189, 2021.
- [8] X. Wang, X. Liu, C. T. Cheng, L. Deng, X. Chen and F. Xiao, “A Joint User Scheduling and Trajectory Planning Data Collection Strategy for the UAV-Assisted WSN,” IEEE Communications Letters, vol. 25, no. 7, pp. 2333-2337, 2021.
- [9] Q. Liu, L. Shi, L. Sun, J. Li, M. Ding and F. Shu, “Path Planning for UAV-Mounted Mobile Edge Computing With Deep Reinforcement Learning,” IEEE Transactions on Vehicular Technology, vol. 69, no. 5, pp. 5723-5728, 2020.
- [10] P. Luong, F. Gagnon, L. -N. Tran and F. Labeau, “Deep Reinforcement Learning-Based Resource Allocation in Cooperative UAV-Assisted Wireless Networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 11, pp. 7610-7625, 2021
- [11] Z. Qin, Z. Liu, G. Han, C. Lin, L. Guo and L. Xie, “Distributed UAV-BSs Trajectory Optimization for User-Level Fair Communication Service With Multi-Agent Deep Reinforcement Learning,” IEEE Transactions on Vehicular Technology, vol. 70, no. 12, pp. 12290-12301, 2021.
- [12] H. Huang, Y. Yang, H. Wang, Z. Ding, H. Sari and F. Adachi, “Deep Reinforcement Learning for UAV Navigation Through Massive MIMO Technique,” IEEE Transactions on Vehicular Technology, vol. 69, no. 1, pp. 1117-1121, 2020.
- [13] W. Zhang, K. Song, X. Rong and Y. Li, “Coarse-to-Fine UAV Target Tracking With Deep Reinforcement Learning,” IEEE Transactions on Automation Science and Engineering, vol. 16, no. 4, pp. 1522-1530, 2019.
- [14] F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1800-1807.
- [15] X. Wang, X. Liu, C. T. Cheng, L. Deng, X. Chen and F. Xiao, “A Joint User Scheduling and Trajectory Planning Data Collection Strategy for the UAV-Assisted WSN,” IEEE Communications Letters, vol. 25, no. 7, pp. 2333-2337, 2021.